Classifying specification problems as variants of Goodhart's Law
post by Vika · 2019-08-19T20:40:29.499Z · LW · GW · 5 commentsContents
5 comments
There are a few different classifications of safety problems, including the Specification, Robustness and Assurance (SRA) taxonomy and the Goodhart's Law taxonomy [AF · GW]. In SRA, the specification category is about defining the purpose of the system, i.e. specifying its incentives. Since incentive problems can be seen as manifestations of Goodhart's Law, we explore how the specification category of the SRA taxonomy maps to the Goodhart taxonomy. The mapping is an attempt to integrate different breakdowns of the safety problem space into a coherent whole. We hope that a consistent classification of current safety problems will help develop solutions that are effective for entire classes of problems, including future problems that have not yet been identified.
The SRA taxonomy defines three different types of specifications of the agent's objective: ideal (a perfect description of the wishes of the human designer), design (the stated objective of the agent) and revealed (the objective recovered from the agent's behavior). It then divides specification problems into design problems (e.g. side effects) that correspond to a difference between the ideal and design specifications, and emergent problems (e.g. tampering) that correspond to a difference between the design and revealed specifications.
In the Goodhart taxonomy, there is a variable U* representing the true objective, and a variable U representing the proxy for the objective (e.g. a reward function). The taxonomy identifies four types of Goodhart effects: regressional (maximizing U also selects for the difference between U and U*), extremal (maximizing U takes the agent outside the region where U and U* are correlated), causal (the agent intervenes to maximize U in a way that does not affect U*), and adversarial (the agent has a different goal W and exploits the proxy U to maximize W).
We think there is a correspondence between these taxonomies: design problems are regressional and extremal Goodhart effects, while emergent problems are causal Goodhart effects. The rest of this post will explain and refine this correspondence.

The SRA taxonomy needs to be refined in order to capture the distinction between regressional and extremal Goodhart effects, and to pinpoint the source of causal Goodhart effects. To this end, we add a model specification as an intermediate point between the ideal and design specifications, and an implementation specification between the design and revealed specifications.
The model specification is the best proxy within a chosen formalism (e.g. model class or specification language), i.e. the proxy that most closely approximates the ideal specification. In a reinforcement learning setting, the model specification is the reward function (defined in the given MDP/R over the given state space) that best captures the human designer's preferences.
- The ideal-model gap corresponds to the model design problem (regressional Goodhart): choosing a model that is tractable but also expressive enough to approximate the ideal specification well.
- The model-design gap corresponds to proxy design problems (extremal Goodhart), such as specification gaming and side effects.
While the design specification is a high-level description of what should be executed by the system, the implementation specification is a specification that can be executed, which includes agent and environment code (e.g. an executable Linux binary). (We note that it is also possible to define other specification levels at intermediate levels of abstraction between design and implementation, e.g. using pseudocode rather than executable code.)
- The design-implementation gap corresponds to tampering problems (causal Goodhart), since they exploit implementation flaws (such as bugs that allow the agent to overwrite the reward). (Note that tampering problems are referred to as wireheading and delusions in the SRA.)
- The implementation-revealed gap corresponds to robustness problems in the SRA (e.g. unsafe exploration).

In the model design problem, U is the best approximation of U* within the given model. As long as the global maximum M for U is not exactly the same as the global maximum M* for U*, the agent will not find M*. This corresponds to regressional Goodhart: selecting for U will also select for the difference between U and U*, so the optimization process will overfit to U at the expense of U*.
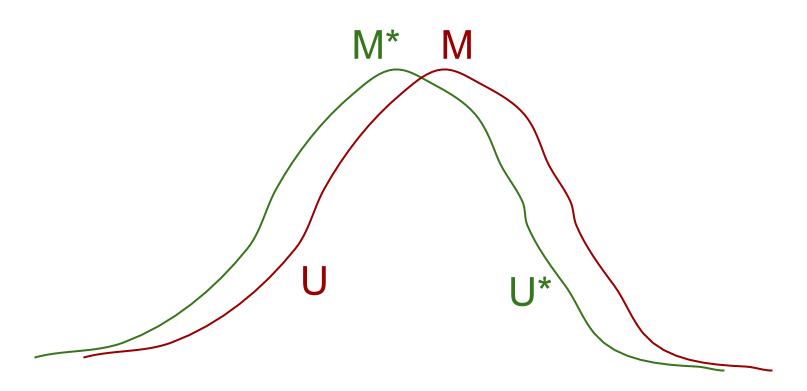
In proxy design problems, U and U* are correlated under normal circumstances, but the correlation breaks in situations when U is maximized, which is an extremal Goodhart effect. The proxy U is often designed to approximate U* by having a maximum at a global maximum M* of U*. Different ways that this approximation fails produce different problems.
- In specification gaming problems, M* turns out to be a local (rather than global) maximum for U, e.g. if M* is the strategy of following the racetrack in the boat race game. The agent finds the global maximum M for U, e.g. the strategy of going in circles and repeatedly hitting the same reward blocks. This is an extrapolation of the reward function outside the training domain that it was designed for, so the correlation with the true objective no longer holds. This is an extremal Goodhart effect due to regime change.
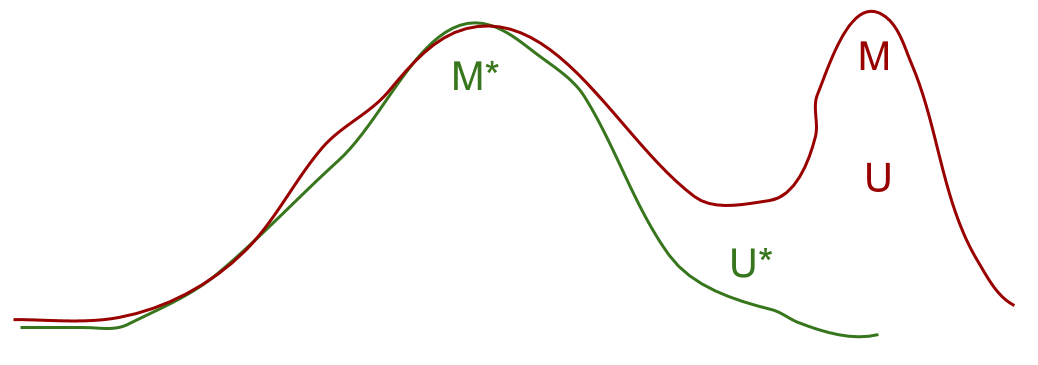
In side effect problems, M* is a global maximum for U, but U incorrectly approximates U* by being flat in certain dimensions (corresponding to indifference to certain variables, e.g. whether a vase is broken). Then the set of global maxima for U is much larger than the set of global maxima for U*, and most points in that set are not global maxima for U*. Maximizing U can take the agent into a region where U doesn't match U*, and the agent finds a point M that is also a global maximum for U, but not a global maximum for U*. This is an extremal Goodhart effect due to model insufficiency.

Current solutions to proxy design problems involve taking the proxy less literally: by injecting uncertainty (e.g. quantilization), avoiding extrapolation (e.g. inverse reward design), or adding a term for omitted preferences (e.g. impact measures).
In tampering problems, we have a causal link U* -> U. Tampering occurs when the agent intervenes on some variable W that has a causal effect on U that does not involve U*, which is a causal Goodhart effect. W could be the reward function parameters, the human feedback data (in reward learning), the observation function parameters (in a POMDP), or the status of the shutdown button. The overall structure is U* -> U <- W.
For example, in the Rocks & Diamonds environment, U* is the number of diamonds delivered by the agent to the goal area. Intervening on the reward function to make it reward rocks increases the reward U without increasing U* (the number of diamonds delivered).
Current solutions to tampering problems involve modifying the causal graph to remove the tampering incentives, e.g. by using approval-direction or introducing counterfactual variables.
[Updated] We think that mesa-optimization belongs in the implementation-revealed gap, rather than in the design-implementation gap, since it can happen during the learning process even if the implementation specification matches the ideal specification, and can be seen as a robustness problem [AF · GW]. When we consider this problem one level down, as a specification problem for the mesa-optimizer from the main agent's perspective, it can take the form of any of the four Goodhart effects. The four types of alignment problems in the mesa-optimization paper can be mapped to the four types of Goodhart's Law as follows: approximate alignment is regressional, side effect alignment is extremal, instrumental alignment is causal, and deceptive alignment is adversarial.
This correspondence is consistent with the connection [AF · GW] between the Goodhart taxonomy and the selection vs control distinction, where regressional and extremal Goodhart are more relevant for selection, while causal Goodhart is more relevant for control. The design specification is generated by a selection process, while the revealed specification is generated by a control process. Thus, design problems represent difficulties with selection, while emergent problems represent difficulties with control.
[Updated] Putting it all together:
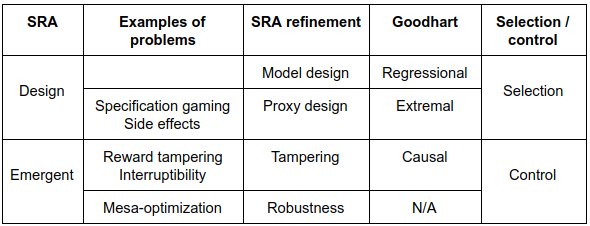
In terms of the limitations of this mapping, we are not sure about model specification being the dividing line between regressional and extremal Goodhart. For example, a poor choice of model specification could deviate from the ideal specification in systematic ways that result in extremal Goodhart effects. It is also unclear how adversarial Goodhart fits into this mapping. Since an adversary can exploit any differences between U* and U (taking advantage of the other three types of Goodhart effects) it seems that adversarial Goodhart effects can happen anywhere in the ideal-implementation gap.
We hope that you find the mapping useful for your thinking about the safety problem space, and welcome your feedback and comments. We are particularly interested if you think some of the correspondences in this post are wrong.
(Cross-posted to the Deep Safety blog. Thanks to Jan Leike and Tom Everitt for their helpful feedback on this post.)
5 comments
Comments sorted by top scores.
comment by evhub · 2019-08-22T21:36:56.564Z · LW(p) · GW(p)
I'm really glad this exists. I think having universal frameworks like this that connect the different ways of thinking across the whole field of AI safety are really helpful for allowing people to connect their research to each other and make the field more unified and cohesive as a whole.
Also, you didn't mention it explicitly in your post, but I think it's worth pointing out how this breakdown maps onto the outer alignment vs. inner alignment distinction drawn in "Risks from Learned Optimization." Specifically, I see the outer alignment problem as basically matching directly onto the ideal-design gap and the inner alignment problem as basically matching onto the design-emergent gap. That being said, the framework is a bit different, since inner alignment is specifically about mesa-optimizers in a way in which the design-emergent gap isn't, so perhaps it's better to say inner alignment is a subproblem of resolving the design-emergent gap.
Replies from: Vika↑ comment by Vika · 2019-08-29T11:03:02.984Z · LW(p) · GW(p)
Thanks Evan, glad you found this useful! The connection with the inner/outer alignment distinction seems interesting. I agree that the inner alignment problem falls in the design-emergent gap. Not sure about the outer alignment problem matching the ideal-design gap though, since I would classify tampering problems as outer alignment problems, caused by flaws in the implementation of the base objective.
comment by Vika · 2021-01-09T18:25:15.905Z · LW(p) · GW(p)
Writing this post helped clarify my understanding of the concepts in both taxonomies - the different levels of specification and types of Goodhart effects. The parts of the taxonomies that I was not sure how to match up usually corresponded to the concepts I was most confused about. For example, I initially thought that adversarial Goodhart is an emergent specification problem, but upon further reflection this didn't seem right. Looking back, I think I still endorse the mapping described in this post.
I hoped to get more comments on this post proposing other ways to match up these concepts, and I think the post would have more impact if there was more discussion of its claims. The low level of engagement with this post was an update for me that the exercise of connecting different maps of safety problems is less valuable than I thought.
comment by Ben Pace (Benito) · 2020-12-11T05:49:20.138Z · LW(p) · GW(p)
I like the thing this post does, and I like the diagrams. I'd like to see this reviewed and voted on.