Posts
Comments
(cross-posted on EAF)
Love this!
As presaged in our verbal discussion my top conceptual complement would be to emphasise exploration/experimentation as central to the knowledge production loop - the cycle of 'developing good taste to plan better experiments to improve taste (and planning model)' is critical (indispensable?) to 'produce new knowledge which is very helpful by the standards of human civilization' (on any kind of meaningful timescale).
This because just flailing, or even just 'doing stuff', gets you some novelty of observations, but directedly seeking informative circumstances at the boundaries of the known (which includes making novel unpredictable events happen, as well as getting equipped with richer means to observe and record them, and perhaps preparing to deliberatively extract insight) turns out to be able to mine vastly more insight per resource (time, materials, etc.). Hence science, but also hence individual human and animal playfulness, curiosity, adversarial exercises and drills (self-play ish), and whatnot.
Said another way, maybe I'd characterise 'the way that fluid intelligence and crystallised intelligence synergise in the knowledge production loop' as 'directed exploration/experimentation'?
Having said that, I don't necessarily think these capacities need to reside 'in the same mind', just as contemporary human orgs get more of this done and more effectively than individuals. But the pieces do need to be fit to each other (like, a physicist with great physics taste can't usually very well complement a bio lab without first becoming a person with great bio taste).
But hey, I don’t think the “Demis Hassabis signs off on perpetual mass sabotage of the global AI research enterprise” thing is going to actually happen either.
Here's Demis' recent version of 'IAEA/CERN for AGI'
Featuring
...to monitor unsafe projects, right? And sort of (awkward nose touch) deal with those
Thanks for this! I hadn't seen those quotes, or at least hadn't remembered them.
I actually really appreciate Alex sticking his neck out a bit here and suggesting this LessWrong dialogue. We both have some contrary opinions, but his takes were probably a little more predictably unwelcome in this venue. (Maybe we should try this on a different crowd - we could try rendering this on Twitter too, lol.)
There's definitely value to being (rudely?) shaken out of lazy habits of thinking - though I might not personally accuse someone of fanfiction research! As discussed in the dialogue, I'm still unsure the exact extent of correct- vs mis-interpretation and I think Alex has a knack for (at least sometimes correctly) calling out others' confusion or equivocation.
As an aside, note that some of "AIs misbehave in ways we've predicted" can be a self-fulfilling prophecy due to out-of-context generalization: We wrote lots of stories about how powerful AI will do X; powerful AI is trained on our stories and realizes it's powerful; the powerful AI does X. So it's possible that AIs would e.g. try to self-exfiltrate and goal-guard much less frequently if we hadn't talked about it as much or those stories were expunged from the pretraining corpus.
I think this is conceivable if either
- the apparent reasoning is actually still just a bag of surface heuristics
- it's still quite shallow reasoning, and the salience of those as strategies is a consequence mainly of pretraining
I sincerely doubt the first nowadays. For the second, I think probably not; these strike me as quite basic and 'obvious' strategies, but I can't give it less than 20% that a system with those expunged from training data would need substantially more in-context nudging to recognise them.
I appreciate you revisiting another couple of months later! This topic continues to evolve.
It was also an update for me that merely-RLHF-ish training on top of GPTs appears to have been enough (in latest-generation models at least) to get something mostly-consistently 'actually trying' in an apparently coherent way. I expected that to happen; I didn't know when. The lede which they somewhat buried in that paper was also that,
Furthermore, we find that this compliance gap persists in our synthetic document fine-tuned setup even when we entirely remove the model’s hidden chain-of-thought scratchpad
(though the gap is smaller and we don't have the tools to understand the mechanism)
The bigger update from that paper, for me, was that the somewhat-coherent goals apparently-pursued by these things actually align with the target constitution somewhat! i.e. (that which was) reward(ed) was the optimisation target after all, a bit??
We'll see how robustly these sorts of findings hold up to future developments and greater elicitation efforts.
Organisms in general typically sense their environment and take different actions across a wide variety of environmental conditions, so as to cause there to be approximate copies of themselves in the future.[4] That's basic agency.[5]
I agree with this breakdown, except I start the analysis with moment-to-moment deliberation, and note that having there (continue to) be relevantly similar deliberators is a very widely-applicable intermediate objective, from where we get control ('basic agency') but also delegation and replication.
The way the terms have typically been used historically, the simplest summary would be:
- Today's LLMs and image generators are generative models of (certain parts of) the world.
- Systems like e.g. o1 are somewhat-general planners/solvers on top of those models. Also, LLMs can be used directly as planners/solvers when suitably prompted or tuned.
- To go from a general planner/solver to an agent, one can simply hook the system up to some sensors and actuators (possibly a human user) and specify a nominal goal... assuming the planner/solver is capable enough to figure it out from there.
Yep! But (I think maybe you'd agree) there's a lot of bleed between these abstractions, especially when we get to heavily finetuned models. For example...
Applying all that to typical usage of LLMs (including o1-style models): an LLM isn't the kind of thing which is aligned or unaligned, in general. If we specify how the LLM is connected to the environment (e.g. via some specific sensors and actuators, or via a human user), then we can talk about both (a) how aligned to human values is the nominal objective given to the LLM[8], and (b) how aligned to the nominal objective is the LLM's actual effects on its environment. Alignment properties depend heavily on how the LLM is wired up to the environment, so different usage or different scaffolding will yield different alignment properties.
Yes and no? I'd say that the LLM-plus agent's objectives are some function of
- incompletely-specified objectives provided by operators
- priors and biases from training/development
- pretraining
- finetuning
- scaffolding/reasoning structure (including any multi-context/multi-persona interactions, internal ratings, reflection, refinement, ...)
- or these things developed implicitly through structured CoT
- drift of various kinds
and I'd emphasise that the way that these influences interact is currently very poorly characterised. But plausibly the priors and biases from training could have nontrivial influence across a wide variety of scenarios (especially combined with incompletely-specified natural-language objectives), at which point it's sensible to ask 'how aligned' the LLM is. I appreciate you're talking in generalities, but I think in practice this case might take up a reasonable chunk of the space! For what it's worth, the perspective of LLMs as pre-agent building blocks and conditioned-LLMs as closer to agents is underrepresented, and I appreciate you conceptually distinguishing those things here.
This was a hasty and not exactly beautifully-written post. It didn't get much traction here on LW, but it had more engagement on its EA Forum crosspost (some interesting debate in the comments).
I still endorse the key messages, which are:
- don't rule out international and inter-bloc cooperation!
- it's realistic and possible, though it hangs in the balance
- it might be our only hope
- lazy generalisations have power
- us-vs-them rhetoric is self-reinforcing
Not content with upbraiding CAIS, I also went after Scott Alexander later in the month for similar lazy wording.
You don't win by capturing the dubious accolade of nominally belonging to the bloc which directly destroys everything!
Not long after writing these, I became a civil servant (not something I ever expected!) at the AI Safety Institute (UK), so I've generally steered clear from public comment in the area of AI+politics since then.
That said, I've been really encouraged by the progress on international cooperation, which as I say remains 'realistic and possible'! For example, in late 2023 we had the Bletchley declaration, signed by US, China, and many others, which stated (among other things):
We affirm that, whilst safety must be considered across the AI lifecycle, actors developing frontier AI capabilities... have a particularly strong responsibility for ensuring the safety of these AI systems... in particular to prevent misuse and issues of control, and the amplification of other risks.
Since then we've had AI safety appearing among top Chinese priorities, official dialogues between US and China on AI policy, track 2 discussions in Thailand and the UK, two international dialogues on AI safety in Venice and Beijing, and meaningful AI safety research from prominent Chinese academics, and probably many other encouraging works of diplomacy - it's not my area of expertise, and I haven't even been trying that hard to look for evidence here.
Of course there's also continued conflict and competition for hardware and talent, and a competitive element to countries' approaches to AI. It's in the balance!
At the very least, my takeaway from this is that if someone argues (descriptively or prescriptively) in favour of outright competition without at least acknowledging the above progress, they're some combination of ill-informed, or wilfully or inadvertently censoring the evidence. Don't let that be you!
There are a variety of different attitudes that can lead to successionism.
This is a really valuable contribution! (Both the term and laying out a partial extentional definition.)
I think there's a missing important class of instances which I've previously referred to as 'emotional dependence and misplaced concern' (though I think my choice of words isn't amazing). The closest is perhaps your 'AI parentism'. The basic point is that there is a growing 'AI rights/welfare' lobby because some people (for virtuous reasons!) are beginning to think that AI systems are or could be deserving moral patients. They might not even be wrong, though the current SOTA conversation here appears incredibly misguided. (I have drafts elaborating on this but as I am now a civil servant there are some hoops I need to jump through to publish anything substantive.)
Good old Coase! Thanks for this excellent explainer.
In contrast, if you think the relevant risks from AI look like people using their systems to do some small amounts of harm which are not particularly serious, you'll want to hold the individuals responsible for these harms liable and spare the companies.
Or (thanks to Coase), we could have two classes of harm, with big arbitrarily defined as, I don't know, say $500m which is a number I definitely just made up, and put liability for big harms on the big companies, while letting the classic societal apparatus for small harms tick over as usual? Surely only a power-crazed bureaucrat would suggest such a thing! (Of course this is prone to litigation over whether particular harms are one big harm or n smaller harms, or whether damages really were half a billion or actually $499m or whatever, but it's a good start.)
I like this decomposition!
I think 'Situational Awareness' can quite sensibly be further divided up into 'Observation' and 'Understanding'.
The classic control loop of 'observe', 'understand', 'decide', 'act'[1], is consistent with this discussion, where 'observe'+'understand' here are combined as 'situational awareness', and you're pulling out 'goals' and 'planning capacity' as separable aspects of 'decide'.
Are there some difficulties with factoring?
Certain kinds of situational awareness are more or less fit for certain goals. And further, the important 'really agenty' thing of making plans to improve situational awareness does mean that 'situational awareness' is quite coupled to 'goals' and to 'implementation capacity' for many advanced systems. Doesn't mean those parts need to reside in the same subsystem, but it does mean we should expect arbitrary mix and match to work less well than co-adapted components - hard to say how much less (I think this is borne out by observations of bureaucracies and some AI applications to date).
Terminology varies a lot; this is RL-ish terminology. Classic analogues might be 'feedback', 'process model'/'inference', 'control algorithm', 'actuate'/'affect'... ↩︎
the original 'theorem' was wordcelled nonsense
Lol! I guess if there was a more precise theorem statement in the vicinity gestured, it wasn't nonsense? But in any case, I agree the original presentation is dreadful. John's is much better.
I would be curious to hear a *precise * statement why the result here follows from the Good Regular Theorem.
A quick go at it, might have typos.
Suppose we have
- (hidden) state
- output/observation
and a predictor
- (predictor) state
- predictor output
- the reward or goal or what have you (some way of scoring 'was right?')
with structure
Then GR trivially says (predictor state) should model the posterior .
Now if these are all instead processes (time-indexed), we have HMM
- (hidden) states
- observations
and predictor process
- (predictor) states
- predictions
- rewards
with structure
Drawing together as the 'goal', we have a GR motif
so must model ; by induction that is .
I guess my question would be 'how else did you think a well-generalising sequence model would achieve this?' Like, what is a sufficient world model but a posterior over HMM states in this case? This is what GR theorem asks. (Of course, a poorly-fit model might track extraneous detail or have a bad posterior.)
From your preamble and your experiment design, it looks like you correctly anticipated the result, so this should not have been a surprise (to you). In general I object to being sold something as surprising which isn't (it strikes me as a lesser-noticed and perhaps oft-inadvertent rhetorical dark art and I see it on the rise on LW, which is sad).
That said, since I'm the only one objecting here, you appear to be more right about the surprisingness of this!
The linear probe is new news (but not surprising?) on top of GR, I agree. But the OP presents the other aspects as the surprises, and not this.
Nice explanation of MSP and good visuals.
This is surprising!
Were you in fact surprised? If so, why? (This is a straightforward consequence of the good regulator theorem[1].)
In general I'd encourage you to carefully track claims about transformers, HMM-predictors, and LLMs, and to distinguish between trained NNs and the training process. In this writeup, all of these are quite blended.
Incidentally I noticed Yudkowsky uses 'brainware' in a few places (e.g. in conversation with Paul Christiano). But it looks like that's referring to something more analogous to 'architecture and learning algorithms', which I'd put more in the 'software' camp when in comes to the taxonomy I'm pointing at (the 'outer designer' is writing it deliberately).
Unironically, I think it's worth anyone interested skimming that Verma & Pearl paper for the pictures :) especially fig 2
Mmm, I misinterpreted at first. It's only a v-structure if and are not connected. So this is a property which needs to be maintained effectively 'at the boundary' of the fully-connected cluster which we're rewriting. I think that tallies with everything else, right?
ETA: both of our good proofs respect this rule; the first Reorder in my bad proof indeed violates it. I think this criterion is basically the generalised and corrected version of the fully-connected bookkeeping rule described in this post. I imagine if I/someone worked through it, this would clarify whether my handwave proof of Frankenstein Stitch is right or not.
That's concerning. It would appear to make both our proofs invalid.
But I think your earlier statement about incoming vs outgoing arrows makes sense. Maybe Verma & Pearl were asking for some other kind of equivalence? Grr, back to the semantics I suppose.
Aha. Preserving v-structures (colliders like ) is necessary and sufficient for equivalence[1]. So when rearranging fully-connected subgraphs, certainly we can't do it (cost-free) if it introduces or removes any v-structures.
Plausibly if we're willing to weaken by adding in additional arrows, there might be other sound ways to reorder fully-connected subgraphs - but they'd be non-invertible. Haven't thought about that.
Verma & Pearl, Equivalence and Synthesis of Causal Models 1990 ↩︎
Mhm, OK I think I see. But appear to me to make a complete subgraph, and all I did was redirect the . I confess I am mildly confused by the 'reorder complete subgraph' bookkeeping rule. It should apply to the in , right? But then I'd be able to deduce which is strictly different. So it must mean something other than what I'm taking it to mean.
Maybe need to go back and stare at the semantics for a bit. (But this syntactic view with motifs and transformations is much nicer!)
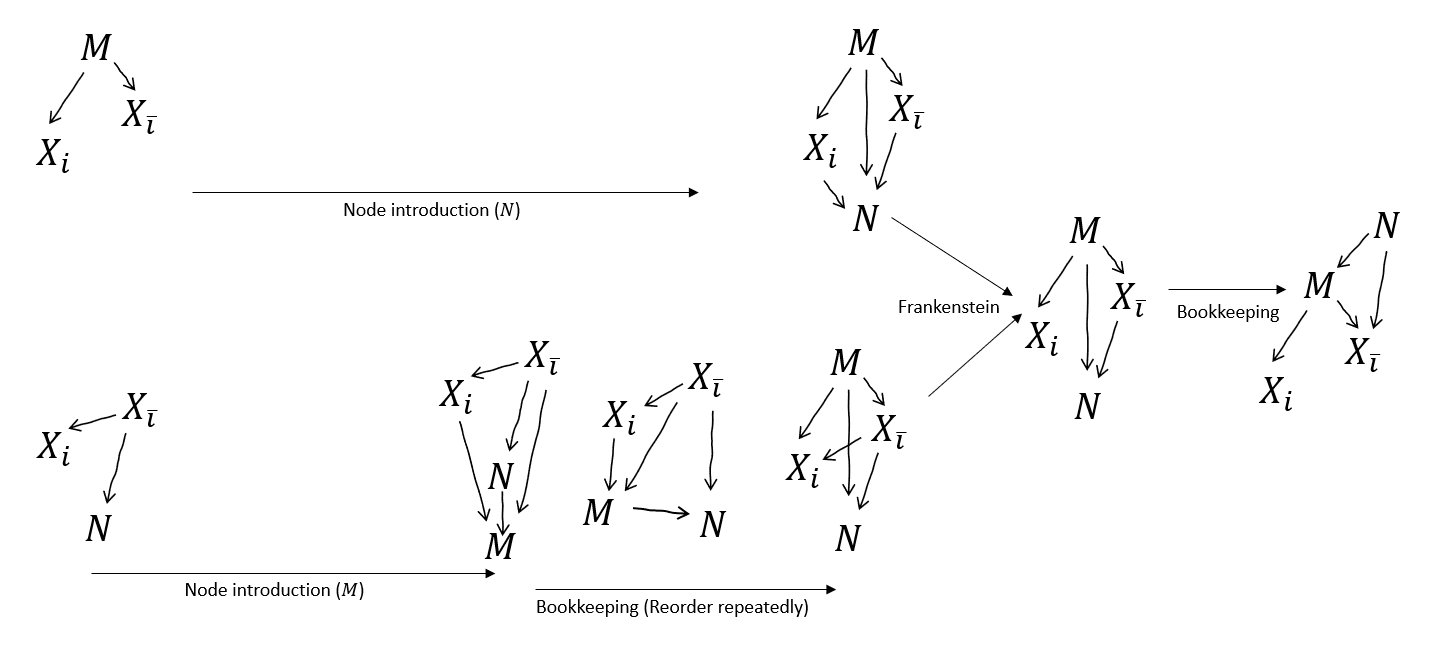
Perhaps more importantly, I think with Node Introduction we really don't need after all?
With Node Introduction and some bookkeeping, we can get the and graphs topologically compatible, and Frankenstein them. We can't get as neat a merge as if we also had - in particular, we can't get rid of the arrow . But that's fine, we were about to draw that arrow in anyway for the next step!
Is something invalid here? Flagging confusion. This is a slightly more substantial claim than the original proof makes, since it assumes strictly less. Downstream, I think it makes the Resample unnecessary.
ETA: it's cleared up below - there's an invalid Reorder here (it removes a v-structure).
I had another look at this with a fresh brain and it was clearer what was happening.
TL;DR: It was both of 'I'm missing something', and a little bit 'Frankenstein is invalid' (it needs an extra condition which is sort of implicit in the post). As I guessed, with a little extra bookkeeping, we don't need Stitching for the end-to-end proof. I'm also fairly confident Frankenstein subsumes Stitching in the general case. A 'deductive system' lens makes this all clearer (for me).
My Frankenstein mistake
The key invalid move I was making when I said
But this same move can alternatively be done with the Frankenstein rule, right?
is that Frankenstein requires all graphs to be over the same set of variables. This is kind of implicit in the post, but I don't see it spelled out. I was applying it to an graph ( absent) and an graph ( absent). No can do!
Skipping Stitch in the end-to-end proof
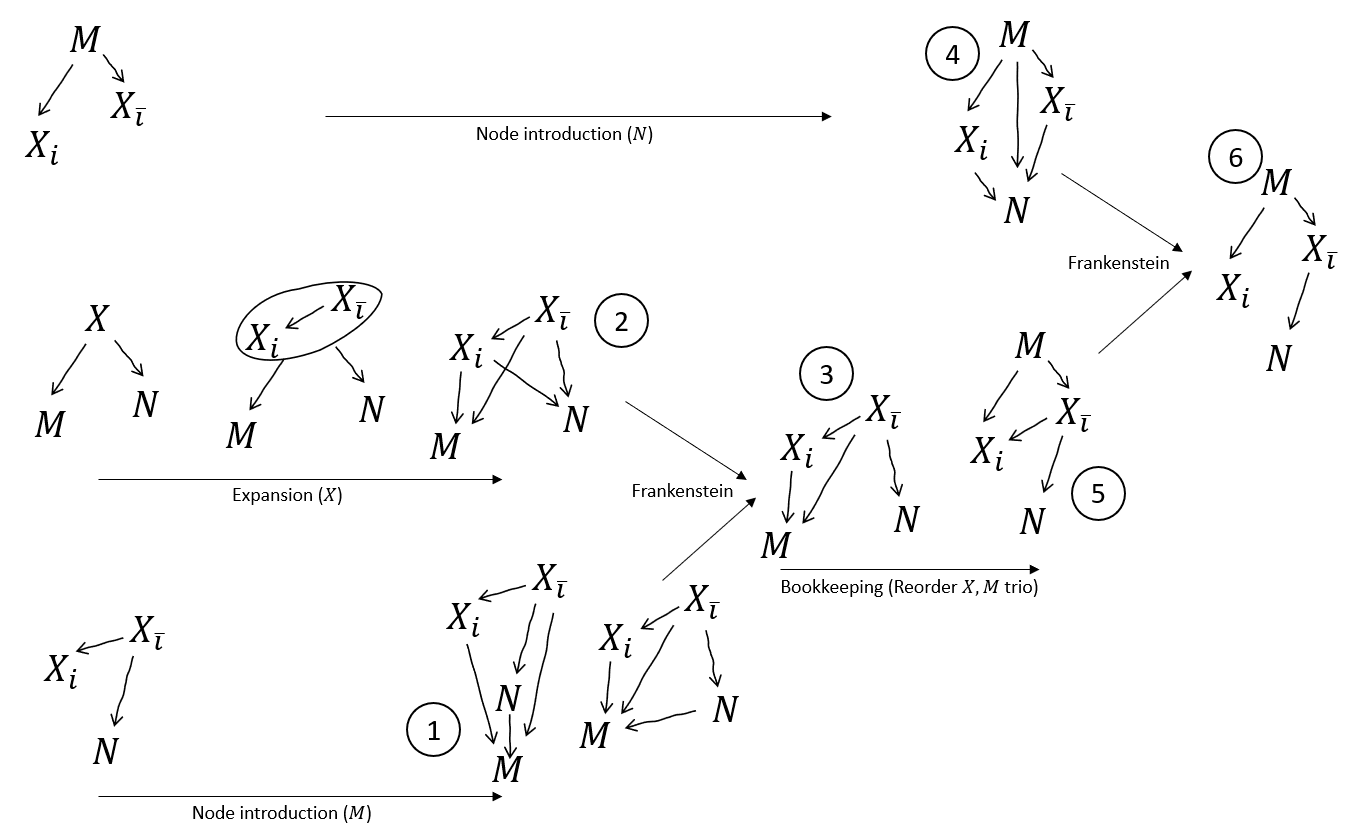
I was right though, Frankenstein can be applied. But we first have to do 'Node Introduction' and 'Expansion' on the graphs to make them compatible (these extra bookkeeping rules are detailed further below.)
So, to get myself in a position to apply Frankenstein on those graphs, I have to first (1) introduce to the second graph (with an arrow from each of , , and ), and (2) expand the 'blanket' graph (choosing to maintain topological consistency). Then (3) we Frankenstein them, which leaves dangling, as we wanted.
Next, (4) I have to introduce to the first graph (again with an arrow from each of , , and ). I also have a topological ordering issue with the first Frankenstein, so (5) I reorder to the top by bookkeeping. Now (6) I can Frankenstein those, to sever the as hoped.
But now we've performed exactly the combo that Stitch was performing in the original proof. The rest of the proof proceeds as before (and we don't need Stitch).
More bookkeeping rules
These are both useful for 'expansive' stuff which is growing the set of variables from some smaller seed. The original post mentions 'arrow introduction' but nothing explicitly about nodes. I got these by thinking about these charts as a kind of 'deductive system'.
Node introduction
A graph without all variables is making a claim about the distribution with those other variables marginalised out.
We can always introduce new variables - but we can't (by default) assume anything about their independences. It's sound (safe) to assume they're dependent on everything else - i.e. they receive an incoming arrow from everywhere. If we know more than that (regarding dependencies), it's expressed as absence of one or another arrow.
e.g. a graph with is making a claim about . If there's also a , we haven't learned anything about its independences. But we can introduce it, as long as it has arrows , , and .
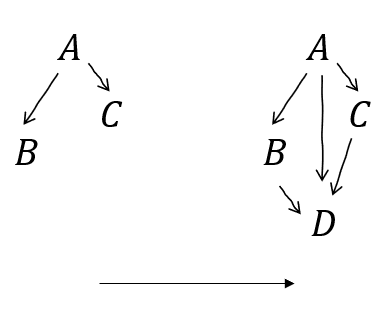
Node expansion aka un-combine
A graph with combined nodes is making a claim about the distribution as expressed with those variables appearing jointly. There's nothing expressed about their internal relationship.
We can always expand them out - but we can't (by default) assume anything about their independences. It's sound to expand and spell them out in any fully-connected sub-DAG - i.e. they have to be internally fully dependent. We also have to connect every incoming and outgoing edge to every expanded node i.e. if there's a dependency between the combination and something else, there's a dependency between each expanded node and that same thing.
e.g. a graph with is making a claim about . If is actually several variables, we can expand them out, as long as we respect all possible interactions that the original graph might have expressed.
Deductive system
I think what we have on our hands is a 'deductive system' or maybe grandiosely a 'logic'. The semantic is actual distributions and divergences. The syntax is graphs (with divergence annotation).
An atomic proposition is a graph together with a divergence annotation , which we can write .
Semantically, that's when the 'true distribution satisfies up to KL divergence' as you described[1]. Crucially, some variables might not be in the graph. In that case, the distributions in the relevant divergence expression are marginalised over the missing variables. This means that the semantic is always under-determined, because we can always introduce new variables (which are allowed to depend on other variables however they like, being unconstrained by the graph).
Then we're interested in sound deductive rules like
Syntactically that is 'when we have deduced we can deduce '. That's sound if, for any distribution satisfying we also have satisfying .
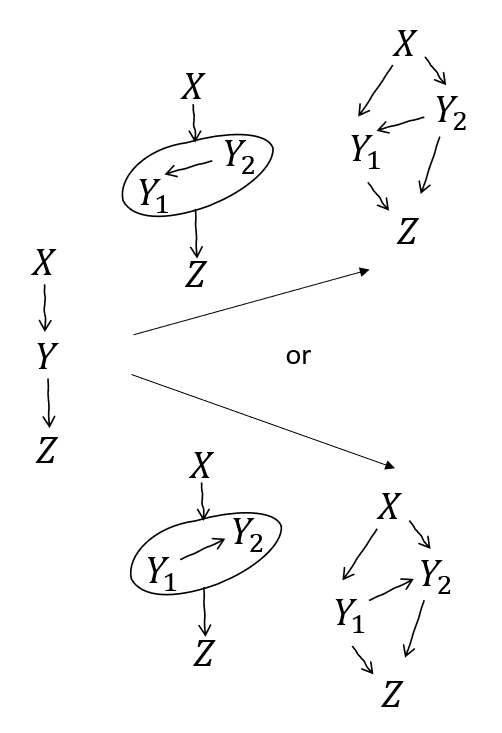
Gesture at general Frankenstitch rule
More generally, I'm reasonably sure Stitch is secretly just multiple applications of Frankenstein, as in the example above. The tricky bit I haven't strictly worked through is when there's interleaving of variables on either side of the blanket in the overall topological ordering.
A rough HANDWAVE proof sketch, similar in structure to the example above:
- Expand the blanket graph
- The arrows internal to , , and need to be complete
- We can always choose a complete graph consistent with the , , and parts of the original graphs (otherwise there wouldn't be an overall consistent topology)
- Notice that the connections are all to all , which is not necessarily consistent with the original graph
- and similarly for the arrows
- (there could be arrows in the original)
- Introduce to the graph (and vice versa)
- The newly-introduced nodes are necessarily 'at the bottom' (with arrows from everything else)
- We can always choose internal connections for the introduced s consistent with the original graph
- Notice that the connections and in the augmented graph all keep at the bottom, which is not necessarily consistent with the original graph (and vice versa)
- But this is consistent with the Expanded blanket graph
- We 'zip from the bottom' with successive bookkeeping and Frankensteins
- THIS IS WHERE THE HANDWAVE HAPPENS
- Just like in the example above, where we got the sorted out and then moved the introduced to the 'top' in preparation to Frankenstein in the graph, I think there should always be enough connections between the introduced nodes to 'move them up' as needed for the stitch to proceed
I'm not likely to bother proving this strictly, since Stitch is independently valid (though it'd be nice to have a more parsimonious arsenal of 'basic moves'). I'm sharing this mainly because I think Expansion and Node Introduction are of independent relevance.
More formally, over variables is satisfied by distribution when . (This assumes some assignment of variables in to variables in .) ↩︎
I'd probably be more specific and say 'gradient hacking' or 'update hacking' for deception of a training process which updates NN internals.
I see what you're saying with a deployment scenario being often implicitly a selection scenario (should we run the thing more/less or turn it off?) in practice. So deceptive alignment at deploy-time could be a means of training (selection) hacking.
More centrally, 'training hacking' might refer to a situation with denser oversight and explicit updating/gating.
Deceptive alignment during this period is just one way of training hacking (could alternatively hack exploration, cyber crack and literally hack oversight/updating, ...). I didn't make that clear in my original comment and now I think there's arguably a missing term for 'deceptive alignment for training hacking' but maybe that's fine.
I mean the deliberation happens in a neural network. Maybe you thought I meant 'net' as in 'after taking into account all contributions'? I should say 'NN-internal' instead, probably.
Some people seem to argue that concrete evidence of deception is no evidence for deceptive alignment. I had a great discussion with @TurnTrout a few weeks ago about this, where we honed in on our agreement and disagreement here. Maybe we'll share some content from it at some point. In the mean time, my take after that is roughly
- deception was obviously a priori going to be gettable, and now we have concrete evidence it occurs (approx 0 update for me, but >0 update for some)
- this does support an expectation of deceptive alignment in my terms, because deception about intentions is pretty central deception, and with misaligned intentions, deception is broadly instrumental (again not much update for me, but >0 update for others)
- it's still unclear how much deliberation about deception can/will happen 'net-internally' vs externalised
- externalised deliberation about deceptive alignment is still deceptive alignment in my terms!
- I keep notes in my diary about how I'm going to coordinate my coup
- steganographic deliberation about deceptive alignment is scarier
- my notes are encrypted
- fully-internal deliberation about deceptive alignment is probably scarier still, because probably harder to catch?
- like, it's all in my brain
- externalised deliberation about deceptive alignment is still deceptive alignment in my terms!
I think another thing people are often arguing about without making it clear is how 'net internal' the relevant deliberation/situational-awareness can/will be (and in what ways they might be externalised)! For me, this is a really important factor (because it affects how and how easily we can detect such things), but it's basically orthogonal to the discussion about deception and deceptive alignment.[1]
More tentatively, I think net-internal deliberation in LLM-like architectures is somewhat plausible - though we don't have mechanistic understanding, we have evidence of outputs of sims/characters producing deliberation-like outputs without (much or any) intermediate chains of thought. So either there's not-very-general pattern-matching in there which gives rise to that, or there's some more general fragments of net-internal deliberation. Other AI systems very obviously have internal deliberation, but these might end up moot depending on what paths to AGI will/should be taken.
ETA I don't mean to suggest net-internal vs externalised is independent from discussions about deceptive alignment. They move together, for sure, especially when discussing where to prioritise research. But they're different factors. ↩︎
This is great, and thanks for pointing at this confusion, and raising the hypothesis that it could be a confusion of language! I also have this sense.
I'd strongly agree that separating out 'deception' per se is importantly different from more specific phenomena. Deception is just, yes, obviously this can and does happen.
I tend to use 'deceptive alignment' slightly more broadly - i.e. something could be deceptively aligned post-training, even if all updates after that point are 'in context' or whatever analogue is relevant at that time. Right? This would be more than 'mere' deception, if it's deception of operators or other-nominally-in-charge-people regarding the intentions (goals, objectives, etc) of the system. Also doesn't need to be 'net internal' or anything like that.
I think what you're pointing at here by 'deceptive alignment' is what I'd call 'training hacking', which is more specific. In my terms, that's deceptive alignment of a training/update/selection/gating/eval process (which can include humans or not), generally construed to be during some designated training phase, but could also be ongoing.
No claim here to have any authoritative ownership over those terms, but at least as a taxonomy, those things I'm pointing at are importantly distinct, and there are more than two of them! I think the terms I use are good.
I wasn't eager on this, but your justification updated me a bit. I think the most important distinction is indeed the 'grown/evolved/trained/found, not crafted', and 'brainware' didn't immediately evoke that for me. But you're right, brains are inherently grown, they're very diverse, we can probe them but don't always/ever grok them (yet), structure is somewhat visible, somewhat opaque, they fit into a larger computational chassis but adapt to their harness somewhat, properties and abilities can be elicited by unexpected inputs, they exhibit various kinds of learning on various timescales, ...
Mold like fungus or mold like sculpt? I like this a bit, and I can imagine it might... grow on me. (yeuch)
Mold-as-in-sculpt has the benefit that it encompasses weirder stuff like prompt-wrangled and scaffolded stuff, and also kinda large-scale GOFAI-like things alla 'MCTS' and whatnot.
Yeah, thinking slightly aloud, I tentatively think Frankenstein needs an extra condition like the blanket stitch condition... something which enforces the choice of topo ordering to be within the right class of topo orderings? That's what the chain does - it means we can assign orderings or , but not e.g. , even though that order is consistent with both of the other original graphs.
If I get some time I'll return to this and think harder but I can't guarantee it.
ETA I did spend a bit more time, and the below mostly resolves it: I was indeed missing something, and Frankenstein indeed needs an extra condition, but you do need .
But this same move can alternatively be done with the Frankenstein rule, right? (I might be missing something.) But Frankenstein has no such additional requirement, as stated. If I'm not missing something, I think Frankenstein might be invalid as stated (like maybe it needs an analogous extra condition). Haven't thought this through yet.
i.e. I think either
- I'm missing something
- Frankenstein is invalid
- You don't need
One thing that initially stood out to me on the fundamental theorem was: where did the arrow come from? It 'gets introduced' in the first bookkeeping step (we draw and then reorder the subgraph at each .
This seemed suspicious to me at first! It seemed like kind of a choice, so what if we just didn't add that arrow? Could we land at a conclusion of AND ? That's way too strong! But I played with it a bit, and there's no obvious way to do the second frankenstitch which brings everything together unless you draw in that extra arrow and rearrange. You just can't get a globally consistent topological ordering without somehow becoming ancesterable to . (Otherwise the glommed variables interfere with each other when you try to find 's ancestors in the stitch.)
Still, this move seems quite salient - in particular that arrow-addition feels something like the 'lossiest' step in the proof (except for the final bookkeeping which gloms all the together, implicitly drawing a load of arrows between them all)?
(I said Frankenstitch advisedly, I think they're kinda the same rule, but in particular in this case it seems either rule does the job.)
I might be missing something, but I don't see where is actually used in the worked example.
It seems that there's a consistent topo order between the and diagrams, so we Frankenstitch them. Then we draw an edge from to and reorder (bookkeep). Then we Frankenstein the diagrams and the resulting diagram again. Then we collect the together (bookkeep). Where's used?
Oh yeah, I don't know how common it is, but when manipulating graphs, if there's a topo order, I seem to strongly prefer visualising things with that order respected on the page (vertically or horizontally). So your images committed a few minor crimes according to that aesthetic. I can also imagine that some other aesthetics would strongly prefer writing things the way you did though, e.g. with . (My preference would put and slightly lower, as you did with the , graph.)
This is really great!
A few weeks ago I was playing with the Good Regulator and John's Gooder version and incidentally I also found myself pulling out some simple graphical manipulation rules. Your 'Markov re-rooting' came into play, and also various of the 'Bookkeeping' rules. You have various more exciting rules here too, thanks!
I also ended up noticing a kind of 'good regulator motif' as I tried expanded the setting with a few temporal steps and partial observability and so forth. Basically, doing some bookkeeping and coarse-graining, you can often find a simple GR structure within a larger 'regulator-like' structure, and conclude things from that. I might publish it at some point but it's not too exciting yet. I do think the overall move of finding motifs in manipulated graphs is solid, and I have a hunch there's a cool mashup of Bayes-net algebra and Gooder Regulator waiting to be found!
I love the Frankenstein rule. FYI, the orderings you're talking about which are 'consistent' with the graphs are called topological orderings, and every DAG has (at least) one. So you could concisely phrase some of your conditions along the lines of 'shared topological order' or 'mutually-consistent topological ordering'.
BTW causal graphs are usually restricted to be DAGs, right? (i.e., the 'causes' relation is acyclic and antisymmetric.) So in this setting where we are peering at various fragments which are assumed to correspond to some 'overall mega-distribution', it might come in handy to assume the overall distribution has some acyclic presentation - then there's always a(t least one) topo ordering available to be invoked.
@the gears to ascension , could you elaborate on what the ~25% react on 'hardware' in
Would it be useful to have a term, analogous to 'hardware', ...
means? Is it responding to the whole sentence, 'Would it be useful to have...?' or some other proposition?
Separately, I'm not a fan of 'evolveware' or 'evoware' in particular, though I can't put my finger on exactly why. Possibly it's because of a connotation of ongoing evolution, which is sorta true in some cases but could be misleading as a signifier. Though the same criticism could be levelled against 'ML-ware', which I like more.
I hate to wheel this out again but evolution-broadly-construed is actually a very close fit for gradient methods. Agreed there's a whole lot of specifics in biological natural selection, and a whole lot of specifics in gradient-methods-as-practiced, but they are quite akin really.
This is nice in its way, and has something going for it, but to me it's far too specific, while also missing the 'how we got this thing' aspect which (I think) is the main reason to emphasise the difference through terminology.
This is simple but surprisingly good, for the reasons you said. It's also easy to say and write. Along with fuzz-, and hunch-, this is my favourite candidate so far.
Hardware, software, ... deepware? I quite like this actually. It evokes deep learning, obviously, but also 'deep' maybe expresses the challenge of knowing what's happening inside it. Doesn't evoke the 'found/discovered' nature of it.
Nice! 'Idioware'? Risks sounding like 'idiotware'...
noware? everyware? anyware? selfaware? please-beware?
(jokes, don't crucify me)
If humans had the computational capacity, they would lie a lot more and calculate personal advantage a lot more. But since those are both computationally expensive, and therefore can be caught-out by other humans, the heuristic / value of "actually care about your friends", is competitive with "always be calculating your personal advantage."
I think there's a missing connection here. At least, it seemed a non sequitur at first read to me. At my first read, I thought this was positing that scaling up given humans' computational capacity ceteris paribus makes them lie more. Seems strong (maybe for some).
But I think it's instead claiming that if humans in general had been adapted under conditions of greater computational capacity, then the 'actually care about your friends' heuristic might have evolved lesser weight. That seems plausible (though the self-play aspect of natural selection means that this depends in part on how offence/defence scales for lying/detection).
And as the saying goes, "humans are the least general intelligence which can manage to take over the world at all" - otherwise we'd have taken over the world earlier.
A classic statement of this is by Bostrom, in Superintelligence.
Far from being the smartest possible biological species, we are probably better thought of as the stupidest possible biological species capable of starting a technological civilization - a niche we filled because we got there first, not because we are in any sense optimally adapted to it.
I’m hazier on the details of how this would play out (and a bit sceptical that it would enable a truly runaway feedback loop), but more sophisticated systems could help to gather the real-world data to make subsequent finetuning efforts more effective.
On the contrary, I think proactive gathering of data is very plausibly the bottleneck, and (smarts) -> (better data gathering) -> (more smarts) is high on my list of candidates for the critical feedback loop.
In a world where the 'big two' (R&D and executive capacity) are characterised by driving beyond the frontier of the well-understood it's all about data gathering and sample-efficient incorporation of the data.
FWIW I don't think vanilla 'fine tuning' necessarily achieves this, but coupled with retrieval augmented generation and similar scaffolding, incorporation of new data becomes more fluent.
In particular, the 'big two' are both characterised by driving beyond the frontier of the well-understood which means by necessity they're about efficiently deliberately setting up informative/serendipitous scenarios to get novel informative data. When you're by necessity navigating beyond the well-understood, you have to bottom out your plans with heuristic guesses about VOI, and you have to make plans which (at least sometimes) have good VOI. Those have to ground out somewhere, and that's the 'research taste' at the system-1-ish level.
I think it’s most likely that for a while centaurs will significantly outperform fully automated systems
Agree, and a lot of my justification comes from this feeling that 'research taste' is quite latent, somewhat expensive to transfer, and a bottleneck for the big 2.
I think there are two really important applications, which have the potential to radically reshape the world:
- Research
- The ability to develop and test out new ideas, adding to the body of knowledge we have accumulated
- Automating this would be a massive deal for the usual reasons about feeding back into growth rates, facilitating something like a singularity
- In particular the automation of further AI development is likely to be important
- There are many types of possible research, and automation may look quite different for e.g. empirical medical research vs fundamental physics vs political philosophy
- The sequence in which we get the ability to automate different types of research could be pretty important for determining what trajectory the world is on
- Executive capacity
- The ability to look at the world, form views about how it should be different, and form and enact plans to make it different
- (People sometimes use “agency” to describe a property in this vicinity)
- This is the central thing that leads to new things getting done in the world. If this were fully automated we might have large fully autonomous companies building more and more complex things towards effective purposes.
- This is also the thing which, (if/)when automated, creates concerns about AI takeover risk.
I agree. I tentatively think (and have been arguing in private for a while) that these are 'basically the same thing'. They're both ultimately about
- forming good predictions on the basis of existing models
- efficiently choosing 'experiments' to navigate around uncertainties
- (and thereby improve models!)
- using resources (inc. knowledge) to acquire more resources
They differ (just as research disciplines differ from other disciplines, and executing in one domain differs from other domains) in the specifics, especially on what existing models are useful and the 'research taste' required to generate experiment ideas and estimate value-of-information. But the high level loop is kinda the same.
Unclear to me what these are bottlenecked by, but I think the latent 'research taste' may be basically it (potentially explains why some orgs are far more effective than others, why talented humans take a while to transfer between domains, why mentorship is so valuable, why the scientific revolution took so long to get started...?)
I swiftly edited that to read
we have not found it written in the universe
but your reply obviously beat me to it! I agree, there is plausibly some 'actual valence magnitude' which we 'should' normatively account for in aggregations.
In behavioural practice, it comes down to what cooperative/normative infrastructure is giving rise to the cooperative gains which push toward the Pareto frontier. e.g.
- explicit instructions/norms (fair or otherwise)
- 'exchange rates' between goods or directly on utilities
- marginal production returns on given resources
- starting state/allocation in dynamic economy-like scenarios (with trades)
- differential bargaining power/leverage
In discussion I have sometimes used the 'ice cream/stabbing game' as an example
- either you get ice cream and I get stabbed
- or neither of those things
- neither of us is concerned with the other's preferences
It's basically a really extreme version of your chocolate and vanilla case. But they're preference-isomorphic!
I think this post is mostly about how to do the reflection, consistentising, and so on.
But at the risk of oversimplifying, let's pretend for a moment we just have some utility functions.
Then you can for sure aggregate them into a mega utility function (at least in principle). This is very underspecified!! predominantly as a consequence of the question of how to weight individual utility functions in the aggregation. (Holden has a nice discussion of Harsanyi's aggregation theorem which goes into some more discussion, but yes, we have not found it written in the universe how to weight the aggregation.)
There's also an interesting relationship (almost 1-1 aside from edge-cases) between welfare optima (that is, optima of some choice of weighted aggregation of utilities as above) and Pareto optima[1] (that is, outcomes unimprovable for anyone without worsening for someone). I think this, together with Harsanyi, tells us that some sort of Pareto-ish target would be the result of 'the most coherent' possible extrapolation of humanity's goals. But this still leaves wide open the coefficients/weighting of the aggregation, which in the Pareto formulation corresponds to the position on the Pareto frontier. BTW Drexler has an interesting discussion of cooperation and conflict on the Pareto frontier.
I have a paper+blogpost hopefully coming out soon which goes into some of this detail and discusses where that missing piece (the welfare weightings or 'calibration') come from (descriptively, mainly; we're not very prescriptive unfortunately).
This connection goes back as far as I know to the now eponymous ABB theorem of Arrow, Barankin and Blackwell in 1953, and there's a small lineage of followup research exploring the connection ↩︎