Motivations, Natural Selection, and Curriculum Engineering
post by Oliver Sourbut · 2021-12-16T01:07:26.100Z · LW · GW · 0 commentsContents
Abstract/TL;DR How to Read This Post Intro and Why to Care Multi-Agent Curricula Immediate Concern and Motivation Examining the Capabilities Claim for Multi-Agent Autocurricula General Intelligence? Cultural Intelligence Accumulation Core Motivations Axes for understanding Motivations Reflexive - Deliberative Direct - Indirect Modular - Diffuse Aligned - Misaligned Considerations for Influencing Core Motivation Development Explicit Pressure on Motivation Types Auxiliary Training Objectives Fine-Tuning Diversity and Obedience Challenges Implicit Pressure on Motivation Types Altruism Obedience Challenges Early vs Late Motivations and Training Duration Speculations on Representation and Ingrainedness Motivation Development Sequences, Natural and Artificial Gradated Curricula Transmissible Accumulation Knowledge About Values Proclivity and Receptiveness Analogy and Disanalogy to Natural Selection Receptivity Constraints and Imprinting Adversarial Concerns and Risks from Proclivity Value Learning and Learning to Value Learn Heritable Accumulation When is Inheritance of Knowledge Not Substitutable for Transmission of Knowledge? Other effects of Heritable Accumulation Modularity of Capability Accumulation Relevance for Safety and Alignment Collectives Inner and Outer Timescales Is alignment at all tractable in this setting? Summary None No comments
Epistemic status: I am professionally familiar with contemporary machine learning theory and practice, and have a long-standing amateur interest in natural history. But (despite being a long-term lurker on LW and AF) I feel very uncertain about the nature and status of goals and motivations! This post is an attempt, heavily inspired by Richard Ngo’s Shaping Safer Goals sequence [? · GW], to lay out a few ways of thinking about goals and motivations in natural and artificial systems, to point to a class of possible prosaic development paths to AGI where general capabilities emerge from extensive open-ended training, and finally observe some desiderata and gaps in our understanding regarding alignment conditional on this situation.
This post was supported by the Stanford Existential Risks Initiative Machine Learning Alignment Scholars (MATS) program [LW · GW] and I thank them for their support, Evan Hubinger for his mentorship during the project, and Richard Ngo and Oliver Zhang for helpful discussion and feedback on portions of the post.
Abstract/TL;DR
Recent capabilities progress, scaling and complexity observations, and (pre)historical precedent all suggest that open-ended training of baseline/foundation models is emerging as a plausible ‘very prosaic’ route to AGI. Multi-agent environments may include a particularly rich class of training regimes. Any generally-applicable capabilities such foundation models develop may by default come along with ‘core motivations’ which develop over the training process. We can not necessarily expect those motivations to generalise in aligned ways at deployment.
There are many free variables in the regimes described in the preceding claims, including end-to-endness, diversity and kinds of training curricula, extent and form of human participation, sizes and homogeneity of populations, architectures, means of information transmission, etc. We would gain from investment in exploring the space, the better to develop techniques for making the route safer, and the better to steer through safer sub-routes (or motivate opposition to this route entirely).
This post begins by elaborating and challenging the above framing. Then some suggestions are made for ways of breaking down the concept of motivations, followed by a presentation of some considerations and desiderata for how we might influence them in the above setting. Genetic natural selection and its products are used as a substantial anchoring point for predictions, while attempting to include a diversity of sources and examples from natural history, as well as scrutinising the (dis)analogy and departing from it where possible.
Connections are made to the concept of ‘corrigibility’ as discussed by various authors, and value receptivity and imprinting are offered as some particular points of potential inspiration from nature for alignment. The phylogenetic-ontogenetic distinction is explored as an analogy for mechanically different portions of development stories for artificial systems.
How to Read This Post
For those who have read Shaping Safer Goals, sections Explicit Pressure on Motivation Types, Implicit Pressure on Motivation Types, Modularity of Capability Accumulation, and Collectives should seem familiar, as they are each maybe 50-80% summary of Richard’s discussions there, with framing and discussion added. Early vs Late Motivations and Training Duration also contains some summary as do the other sections to varying degrees.
Section Intro and Why to Care is intended to be as relevant to that sequence as it is to the rest of this post, and may be a good place to start if you intend to read either or both, or if you want more context to understand Richard’s sequence (at least my take on it). The same goes for Examining the Capabilities Claim for Curriculum Engineering. You do not need to read Shaping Safer Goals to understand this post (but I recommend it anyway).
Core Motivations was abstracted as I wrote, because I found myself referring back to a few of these concepts and wanted to standardise my terminology somewhat. I hope to expand on this in a later post or series and would welcome criticism of the terms I chose.
Early vs Late Motivations and Training Duration, Transmissible Accumulation, Heritable Accumulation, and Modularity of Capability Accumulation paint some additional pieces of a picture which I hope are of use or interest to readers.
Footnotes accompanying an inline link are just references to the same, for those who prefer to read that way. Footnotes alone have something (footnote-worthy) to say, either an aside or a small collection of references.
Intro and Why to Care
First note that a majority of deep learning research has historically focused on algorithms and architectures, taking data and problems as given ‘things to be learned’. Even in RL where data explicitly depend on the learning algorithm, the theoretical framing is usually a specific (PO)MDP with a more-or-less stable state distribution, and learning algorithms are judged for their ability to instantiate effective policies for particular (PO)MDPs (or suites) after sufficiently interacting with them.
On the other hand, recent progress points towards a substantial runway for increasingly general capabilities to be yielded from what we might call ‘curriculum engineering’ for open-ended or task-unspecific learning at scale. That is, qualitative model-class and learning-algorithm changes may be less marginally responsible for capability gains than the scale, diversity, and structure of the curricula they are trained on (is there a ‘curriculum overhang’?). As examples of this trend, consider breakthroughs in few-shot task-solving from training large language models on massive corpora [? · GW][1], meaningful qualitative and quantitative milestones in runtime planning and experimentation from population-based reinforcement learning in large-scale diverse environments[2], and the early emergence of impressive strategic behaviour from large-scale self-play in complex environments[3]. Take an analogy to animal and human intelligence, where, given a very diverse environment and rich model space, a very simple algorithm (natural selection) produced very general agents capable of adaptation and learning at runtime. This is not a new idea[4].
Observing also the increasing economic relevance of foundation models[5] and the plausible part they will come to play in deployments of advanced systems through fine-tuning, runtime generalisation, and efficient train-once-deploy-many approaches, we see emerging a plausible path to ‘very prosaic’ advanced AI involving innovations in engineering large-scale, diverse, mostly-automated open-ended curricula leading to ever more generally-capable foundation models and models capable of generalisable learning at runtime.
Potentially the easiest ways to deploy agents trained in such ways to specific tasks will involve one or both of fine-tuning or orientation at runtime via prompt- or context-engineering.
Multi-Agent Curricula
In Shaping Safer Goals [? · GW], Richard Ngo focuses in particular on multi-agent training environments and deployments. These are hypothesised (in part by analogy to animal and human evolution) to offer extremely extensible and diverse curricula, as well as being able, at least in some cases, to somewhat-automatically provide suitably-difficult incremental challenges for learning algorithms to accommodate by virtue of competition from other agents of balanced ‘skill level’. To see this intuitively, consider that when the reward for winning is ‘propagate and expand’, you should expect most competition you face to be of balanced difficulty to overcome, because those occasions when it isn’t, in a few generations you, or at least your descendants, are the competition[6]! As such we may expect AI capabilities investment in this kind of autocurriculum[7].
An essential observation is that many instrumentally adaptive behaviours in suitably interactive multi-agent environments will be adaptive not due to the environment or specific outer reward specification per se, but due to the particular emergent collaborative/competitive equilibrium of the interacting agents. If so, we can expect learning algorithms to produce policies and behaviours which reflect this. Richard predicts that, conditional on this kind of setup, the ‘most interesting and intelligent’ behaviour will be of this kind, and I also see no reason to doubt this.
Immediate Concern and Motivation
Assuming general intelligence emerges in this paradigm, it may exhibit some mix of any or all of
- baked in pretrained world model and/or priors for runtime world modelling
- flexible runtime world modelling
- exploration heuristics for gathering new information for runtime world modelling
- reflex-like pretrained policies (or partial policies)
- planning abilities for flexible runtime policies
- ‘core motivations’
Since we are mostly concerned about coherent capability generalisation pointed towards misaligned goals, the most safety-relevant pieces here are the form and content of any core motivations which emerge in tandem with competent planning abilities. Which motivations emerge and survive the training process is a difficult question. Similarly to arguments made about mesa optimisation[8], we might expect them to be such motivations as satisfy the inductive biases of the training process and are sufficiently reinforced by some commonalities in the training pressures, or insufficiently diminished by the training pressures.
Surely this is concerning? What if these core motivations generalise poorly or dangerously [LW · GW][9]? The spectre of mesa optimisation [? · GW][10] is not far away - in fact this kind of setup seems almost like ‘inner misalignment by design’! To the extent that we expect investment and progress in capabilities to come from this direction, we should take steps to provide clear arguments for the associated risks, recommendations and desiderata for projects of this type, tools for making them go safely, and scrutiny of their procedures and results.
Coincidentally, Professor Stuart Russell recently expressed similar concerns with less positivity on the nature-inspired capabilities claim, in a Q&A response after his first 2021 Reith Lecture[11]
The idea that you could use nature's amazing process of evolving creatures to instead evolve algorithms hasn't really paid off, yet...
The drawback of doing things that way is that you have absolutely no idea how it works - and creating very powerful machines that work on principles that you don't understand at all seems to be pretty much the worst way of going about this.
Examining the Capabilities Claim for Multi-Agent Autocurricula
Natural selection provides a very minimalist ‘training signal’ and yet in biological evolution was able to yield a diverse array of forms with all kinds of capabilities, including at least one with apparently general intelligence[12].
This comparison has been made many times in discussions around AI, both in capabilities and alignment. Though it anchors much of the following discussion, questions remain about how precise or useful the analogy is.
Besides the analogy to genetic natural selection, there may be other reasons or evidence in favour or against the capabilities claim for open-ended multi-agent autocurricula. In all, I find the capabilities claim somewhat convincing, while being quite concerned about alignment in this paradigm.
General Intelligence?
One challenge to the capabilities claim about multi-agent autocurricula is whether relatively prosaic ML techniques can really expect to discover generally-capable models or models able to generalise/learn at runtime. After all, even following the example of genetic natural selection, almost all animals are not usually considered ‘generally intelligent’, even granting that many species are capable of intra-episode learning and problem-solving. Noting the amount of compute and information that genetic natural selection needed to discover general intelligence may suggest that the scale or complexity required to ‘get lucky’ and fall onto a training trajectory which pushes towards general intelligence is practically insurmountable in the near term. There are extensive arguments in either direction but ‘at most decades’ seems to be a strongly-supported view for when it might be feasible to recapitulate natural selection substantially[13] though many urge caution when applying biological analogies to artificial systems for forecasting[14]. As discussed earlier, even at our present levels of compute and investment, there is already some evidence of contemporary learning algorithms locating simple runtime learning and exploration behaviours in contemporary recurrent model classes, which is not especially surprising to ML researchers.
Another consideration here is that while an artificial setup may need to retread ground that took natural selection a very long time to cover, natural selection had to bootstrap all the way from atoms up! - and it had no particular starting bias toward computation, let alone intelligence, which may weaken this challenge. That said, many very capable naturally-selected agents can be interpreted as mainly executing reflexive policies or policy templates which are only weakly adapted ‘on the fly’ and mostly discovered through the slow (outer) process of natural selection and it may be that without a paradigm shift, machine learning is practically limited to such forms.
An important related argument against the reference class of natural selection regards anthropic reasoning: we would not be here to ask the question, had natural selection failed to produce us, so it may be unreasonable to consider our own existence as evidence for feasibility[15]. Against this we might prefer to claim that humans are not the only generally-intelligent species, suggesting a degree of overdetermination, which may overcome the anthropic discount. How far back in evolutionary history can we push the ‘lucky anthropic event’ with this reasoning, and is our current AI technology beyond the analogous point? Perhaps to the first primates, or the first mammals, or the first chordates?
Another possible counterclaim regarding the practical feasibility of developing AGI via mostly prosaic engineering of diverse open-ended autocurricula is that our model classes may indeed be capable of expressing generally intelligent learning algorithms, and our training processes may even be able in principle to find instances of them, but their instantiation in the model class is so ludicrously inefficient as to be useless. For my part, I think ‘ludicrously inefficient’ is quite probably right, but given Moore’s Law and Sutton’s The Bitter Lesson, it seems unwise to bet on this implying ‘useless’!
One weakening of the ‘practically insurmountable expensiveness’ argument against expecting an expansive outer search to discover capable end-to-end generally intelligent algorithms is to instead claim that this expense is likely to mean that such projects may be feasible, but will in practice be eclipsed by those which engineer in certain architectural innovations or hard-coded modules[16]. I am sympathetic to this claim with a large degree of uncertainty around how strong it is. Many of the breakthroughs noted earlier in this piece as evidence for the strength of curriculum design also involved meaningful amounts of architecture design and algorithm design. Conditional on the prosaic path outlined here, absent a revolutionary paradigm shift, I suspect each will play a complementary role in capabilities gains at least in the coming decade.
Cultural Intelligence Accumulation
It is easy to take for granted modern humanity’s level of capabilities but the first anatomically modern humans, and their predecessors in turn, spent at least tens of thousands of generations living lives not so different from those of chimpanzees or other apes. Although I think it plausible that once our ancestors had the intelligence and social technology for compounding cumulative knowledge gains there was a somewhat inevitable path to something resembling our current level of capabilities, there do appear to have been many contingencies, and it was a long and unsteady process.
As such we may expect that in addition to recapitulating genetic natural selection’s long and expensive process, open-ended autocurricula without additional data are destined to lag behind any approach which uses artefacts from human society to bootstrap competence (e.g. documents in language and other media).
One example Richard Ngo envisages in Competitive safety via gradated curricula [? · GW] is an interplay between pretrained generative models (specifically language models but one could apply the same principle to other media) and training in various other regimes, for example to ‘kick-start’ language understanding of RL agents. This kind of approach could be able to exploit both the wealth of culturally accumulated knowledge which humanity has already produced and the strength of training of open-ended multi-agent autocurricula but may bring additional alignment risks of its own.
Core Motivations
What kinds of core motivations might be reinforced by an open-ended training process? Should we expect any outcome at all resembling ‘motivations’?
Axes for understanding Motivations
Here is a nonexhaustive list of axes which ‘motivations’ might vary along, intended to be mostly orthogonal. I’m generally looking for mechanistic properties, that is properties about the kind of computation running, which are relevant for understanding behaviour off-distribution. I’ll try to exemplify each with reference to real or imagined, biological or artificial systems.
Reflexive - Deliberative
All but the simplest of organisms, including many without brains or nervous systems, react ‘reflexively’ to stimuli according to policies pretrained by their training pressures. The most salient are quick-fire aversive or attractive actions, but I include in this category also slow-burn behaviours which play out over longer timescales and may involve sequential and parametrised activity, like plant growth and the adaptation of muscles and other tissues to the presence/absence of particular stimuli or nutrient balances, some of which can be very sophisticated [AF · GW][17].
While quickfire actions are interesting, and could in sufficiently dire situations prove ‘the final straw’ in a misaligned catastrophe, I do not consider them of main concern for alignment. It is interesting to consider what the superintelligent limits of slow-burn reflexive policies might be, but I consider these beyond the scope of this post, mainly because I do not expect them to remain coherent far off the learned distribution. The most convinced I can become of the primary importance of risks from this sort of slow-burn reflexive motivation relates to intuitions regarding generalised natural selection and continuous quantitative but not very qualitative changes to environment distributions, which thereby preserve the coherence of reflexive behaviours, but nevertheless lead to human unsurvivability, for example through a runaway capture or transformation of some vital resource or other [LW · GW][18].
By ‘deliberative’ I refer to motivations which are operated on at runtime in something closer to a utility-maximising optimisation/search/planning process. For various reasons, it seems appropriate to consider this case as the one most likely to lead to malign capability generalisation off-distribution. For the most part, it is deliberative motivations I am referring to in this post.
To my knowledge, very few if any contemporary end-to-end-learned algorithms are mechanistically deliberative in a substantive way at runtime - unless mesa optimisers are present without our knowledge, policy gradient and value-based model-free reinforcement learning agents would count as ‘reflexive’. In contrast, agents employing some form of search/planning algorithms at runtime (e.g. Monte-Carlo tree search[19]), whether on a hard-coded or learned world model, would count as ‘deliberative’. At present all such agents have these modules hard-coded to my knowledge.
There is an intriguing intermediate or combined possibility, where mostly-reflexive models give rise to ‘internal’ behaviours which interface with a more deliberative and flexible module responsible for much of the ‘external’ behaviours. In fact it seems like this is the situation for many animals and humans which may provide important inspiration for solutions or risks in alignment. In My computational framework for the brain [LW · GW] and referenced posts, Steve Byrnes explores this under his label of ‘steered optimisers’.
Direct - Indirect
Here I again consider mechanistic properties of the motivations. By ‘direct’ I mean motivations which are not formed through interaction with the world (but act on it via world modelling and planning), whereas ‘indirect’ means a motivation system which is shaped to some extent by observations and therefore context- and world-dependent.
A direct motivation might be defined in terms of a pretrained ontology apart from any particular world model, though to be applied to planning it would have to interface with some broader world model somehow, either through some shared representation with a pretrained world model, or connecting to a broader more flexible world model built at runtime.
A less direct motivation set might be represented as one or more motivation or value schemata, along with heuristics or ontogenetic procedures for populating and refining them flexibly at runtime. Human motivations appear behaviourally to include something like this though it is unclear how much this corresponds to the underlying mechanistic properties. Consider that individuals with different upbringings and life experiences can exhibit quite different motivations in ways which are not attributable merely to genetics or to differing world models (though these can interplay). Note however that human motivations likely cover only a very small part of motivation-space[20]!
I nearly called this phylogenetic - ontogenetic with analogy to phylogenetics[21], the study of inherited traits over lineages, and ontogeny[22], the process of development of an organism within its lifespan, because I think these different stances for understanding how an individual came to be how it is are highly related to the direct - indirect notion. More on inheritance vs development in Transmissible Accumulation and Heritable Accumulation. Other possible terms to capture what I’m gesturing at might be inflexible-flexible or explicit-implicit.
Modular - Diffuse
To what extent is the representation of motivations ‘separable’ from other representations in the learned model(s)? How coupled are the mechanisms of the motivations to the mechanisms of other cognitive components? What interfaces form and how breakable are they if modified? On the more diffuse side, are circuits and information flows multi-purposed for seemingly separate functions? Are interfaces wide and highly coupled between cognitive components?
Some architectures may explicitly favour certain separations (though that is not necessarily reason to rule out representation of motivations in other places [LW · GW][23]); some training procedures may have certain representational inductive biases; some training experiences or regularisation techniques may push for more or less modularity.
Aligned - Misaligned
There are many ways to break this down and I will not attempt to fully do so here.
In my view, when we are considering deliberative motivations, the most important component here is amenability to correction and oversight, or being motivated to ‘have the right motivations’ (for some appropriate definition of ‘right’)[24], which is roughly what I understand by the cluster of concepts referred to as ‘corrigibility’ by various authors.
In addition it could be useful to attempt to formalise or at least consider axes like
- prosocial - antisocial
- acquisitive - abstemious
- satiable - insatiable
Considerations for Influencing Core Motivation Development
What predictions can we make about core motivation development in multi-agent autocurricula, either anchored to the natural selection analogy or otherwise? What variables exist which might influence these one way or another? None of the following is a silver bullet and in fact this whole setup remains little explored.
Explicit Pressure on Motivation Types
Noticing that open-ended competition for acquisition of resources and influence is simultaneously a risky prospect for alignment, while also being a plausible type of autocurriculum to provide enough diversity and balanced challenge to push towards ever-increasing capabilities and potentially general intelligent behaviour, is an alignment attempt aiming to subvert this risk doomed to also curtail the pressure towards general intelligence and competitiveness? Is it possible that this objection is devastating enough that the main takeaway of this post should be something like ‘open-ended multi-agent autocurricula can not be competitively aligned’?
Not necessarily, though it does suggest that for alignment, it may be necessary to design alternative autocurricula which retain the diversity and appropriate balance of challenges without pushing toward ingraining misaligned or self-interested motives. For a contemporary somewhat alignment-neutral example of an autocurriculum like this, consider taking this perspective on GANs[25]: there is some measure of the ‘suitably-difficult incremental challenges for learning algorithms to accommodate’ mentioned earlier due to the iterated competitive improvement of each network, but absent any propagative ‘population’ element or ‘survival’ reward, there is no external pressure to develop self-interested values. Note though that GANs are famously hard to stabilise[26] and the process is not completely open-ended because by default the underlying training distribution remains fixed.
Richard Ngo provides some useful food for thought in this area in Multi-agent safety [? · GW].
Auxiliary Training Objectives
Firstly, can we apply an auxiliary training objective to agents in our open-ended training curricula to jointly encourage capabilities development and good behaviour? Flatly, not easily on the basis of behaviour itself - since we have already argued that behaviours in this context will emerge from diverse interactions between environment and agents without there being a desirable ‘outer goal’ to align to, how are we to discern good from bad behaviour? I would not rule this out completely since there may be discernible behaviour patterns which arise from desirable or undesirable properties of motivations, but grant that this might require very impressive monitoring capabilities and possibly a great deal of expensive human oversight, obviating the training competitiveness benefit of this regime. Further, behavioural pressure alone might not rule out deceptive alignment [LW · GW][27]. On the other hand, if we have sufficiently good interpretability tools, and a firm mechanistic understanding of some acceptability criteria[28], layering on something like relaxed adversarial training [LW · GW][29] to produce an auxiliary training pressure or trust region for training updates could be very promising!
Fine-Tuning
If an auxiliary training objective is not able to produce definitively aligned outputs, what about fine tuning as an intermediate to deployment? Richard gives the example of fine-tuning to be a CEO. But what if the agent already developed some deeply ingrained misaligned motivation in training, like acquisitive motivations to hoard resources or power [? · GW][30]? It seems very plausible that the default route for fine-tuning in such a situation would be to develop deceptive alignment. I address in more detail the concept of ‘ingrainedness’ later in Early vs Late Motivations and Training Duration, but this remains an area of wide uncertainty for me.
Diversity and Obedience
What can we say about modifications to the training environment(s)? Multi-agent safety imagines preliminary ways we could reinforce the motivation of ‘obedience to humans’. Perhaps injecting instructions from humans directly into the environment along with an associated reward or penalty could provide the necessary signal. Importantly, if we want to train the generalisable concept of ‘obedience to humans’ rather than some proxy for human goals themselves, the instructions in the environment must be legibly from humans, and in order to reinforce only that concept, the rewards and instructions would need to commonly oppose any otherwise-reinforced core motivations the agents may have. Furthermore, they may need to unpredictably contradict themselves between instances, and perhaps even sometimes oppose the relevant simulated analogy to actual human goals, to avoid reinforcing any proxy besides obedience.
Challenges
There are two key questions which Richard points out. Firstly, is ‘obedience’ easy for learning systems to generalise? And secondly, can it sufficiently generalise/transfer to real-world tasks (and real-world humans!) after training? In line with various authors’ discussions of ‘corrigibility’ as an alignment goal, an unstated justification here is that it may be safer and more robust (and easier?) to install the general motivation of obedience to humans (an indirect motivation) than to install some detailed ‘actual human goals’ motivation (a direct motivation), especially in the setting of multi-agent autocurricula.
Additionally, without powerful transparency tooling or constructive theoretical guarantees, even with the goal of setting up counterbalancing instructions and rewards, it may be difficult to identify the kinds of unwanted emergent motivations to undermine via goal- and environment-diversity. In particular, simply balancing instruction instances in training with their ‘opposite’ is not obviously feasible. For one thing, many tasks’ ‘opposite’ may be more or less challenging than the original (consider the task of building a bridge or tower vs the ‘opposite’), making it unclear how to normalise the training weight of such variable task rewards in order to nullify any training pressure on lingering motivations. Worse, especially in the setting of multi-agent autocurricula, as previously noted, many useful behaviour patterns will not be those explicitly reinforced by an outer training objective, and may be instrumentally useful for some tasks and their ‘opposites’ (e.g. ‘gain mechanical and technological advantage’ may be a useful motivation for tower-builders and tower-unbuilders). Even fully-collaborative agents have instrumental goals. It may be that with sufficient diversity of tasks, any otherwise-instrumental motivation would be sufficiently detrimental in some task that it is undermined, but this puts a lot of burden on the task and environment generating procedure. As such, the task of identifying these unwanted motivations may be a pivotal part of such a proposal and one which I would not be optimistic about without further analysis or guarantees.
 Tower-builders and tower-unbuilders. Whether the goal is to build or unbuild towers, an agent with motivations involving pulleys, levers, tools, and teamwork may have an advantage
Tower-builders and tower-unbuilders. Whether the goal is to build or unbuild towers, an agent with motivations involving pulleys, levers, tools, and teamwork may have an advantage
Implicit Pressure on Motivation Types
Naively construed, the above discussions bring scaling concerns to the training process, with expensive human input at many points, potentially compromising training competitiveness or tractability. In Safety via selection for obedience [? · GW] Richard Ngo begins considering ways in which training environments could be shaped to put pressure on the emergence of motivations which we favour.
Altruism
Safety via selection for obedience begins by discussing Fletcher and Doebeli’s contribution to the theory of natural selection for altruism[31] which involves individuals with some tendency to cooperate interacting assortively as opposed to interacting with the population at random.
In humans, some of the mechanisms which lead to assortment are:
- Kin recognition: we can tell who we share genes with.
- Observation of intentions or previous behaviour: these give us evidence about other agents’ future behaviour.
- Costly signalling: this can allow us to reliably demonstrate our future altruism.
- Communication of observed information: once one person has made an observation, it can be shared widely.
- Flexible interactions: we can choose who to assort with in different interactions.
Note that in this theory, kin selection is not in fact required, though unconditional fully sacrificial non-kin altruism can not be plainly genetically naturally selected in this model (that is, at least one of kin selection, mutually-genetically-beneficial cooperation, or conditionality are required). Though this point is not made, importantly, the conditionality can be at the level of the genotype-to-phenotype translation, or on the basis of spurious kinship or intent signals, meaning that more exotically, with the right environmental distributional shift, an entire naturally selected population could be expressing a fully sacrificial altruistic phenotype. In an artificial setup, exotic environmental distributional shifts are potentially in our toolkit! This line of thinking raises interesting possibilities, like for example reinforcing a spurious but easy non-kin detection signal which is not present in the real world (‘the purple polka-dot jelly aliens are our mortal enemy!’[32]) or identifying the developmental reagent or stimulus responsible for adopting an altruistic phenotype and exclusively deploying agents of this type[33].
 If altruistic collaboration against the purple polka-dot jelly aliens is beneficial, ‘is not a purple polka-dot jelly alien’ could arise as a naturally selected proxy for ‘is kin’, though selective pressure would remain to refine the proxy
If altruistic collaboration against the purple polka-dot jelly aliens is beneficial, ‘is not a purple polka-dot jelly alien’ could arise as a naturally selected proxy for ‘is kin’, though selective pressure would remain to refine the proxy
Richard’s takeaway from this model is to note more abstractly that theories like this provide promising insights into the kind of structural constraints we could apply to our training environments to put pressure on beneficial motivation types emerging, and to encourage further investigation into how incentives arise from multi-agent interactions. He suggests a few other deviations exotic to genetic natural selection but readily available in silico:
- Perhaps greater transparency of cognition could provide a strong intent-signalling mechanism for potential collaborators
- The question of how this translates to collaboration with (cognitively opaque) humans would need to be addressed
- A diversity of fabricated environmental opportunities for mutual benefit in collaboration could encourage collaborative motivations to develop
- These opportunities could involve many different ‘species’ with opportunities to collaborate for mutual benefit
- We are not limited to natural selection’s simple pseudo-objective of ‘acquire resources and expand’. In particular, different agents’ objectives could in fact coincide to a greater degree than is possible in nature (they can even completely coincide)
Obedience
As noted previously, even collaborative agents have instrumental incentives which could become reinforced through training into undesirable motivations. Safety via selection for obedience also suggests some speculative lines of inquiry into structural modifications to training regimes to implicitly incentivise obedience.
Examples are given of jointly-trained agents and differing in relevant ways, intuitively conceived as ‘planner/instructor’ and ‘worker’ respectively:
- might have exclusive access to the current task description, which might be varied between or within episodes, making ’s obedience and recurrent attendance to essential for success
- might have limited environmental observability compared to , forcing to pay attention to ’s descriptive detail
- at a larger multi-agent level, incentives for specialisation and obedience to planners might be encouraged even for relatively homogeneous agents by
- the right structure to communication channels between agents (Richard’s example is just good communication channels to protect coordination, but one could also apply asymmetric communication topologies to favour or disfavour certain modes of interaction)
- sufficient opportunities in the environment for collaboration, economies of scale and specialisation
- gains to be made by runtime learning from other agents - I elaborate on this at length later in Transmissible Accumulation
Challenges
In setups like this, humans might be able to be explicitly involved for a fraction of the training process depending on expense and scalability. Adversarial training and testing are certain to be important in such setups.
These proposals bring back a lot of the training competitiveness promised by multi-agent autocurricula, but at the cost of making the transfer to the real-world task of obedience to humans and collaboration even less direct. In particular, if the object of collaboration in training is frequently not human, how can we ensure that in deployment this is the transfer we will observe? And, especially if AGI are substantially cognitively different from humans, can we expect generalisation to human objects of collaboration only, and not also, say, to birds or ants or some other non-AGI agent? More on this challenge in Transmissible Accumulation later.
Early vs Late Motivations and Training Duration
Speculations on Representation and Ingrainedness
Evan Hubinger has argued for the importance of understanding the training stories and development sequence of proposals and projects for training AGI [LW · GW][34]. The importance of development sequence is emphasised here, because I tentatively think that ‘older’ learnings and cognitive modules may be harder to remove or train away (especially without harming capabilities), by virtue of being more ingrained, foundational to other aspects of cognition, or more robustly represented through extensive training pressure (in other words, more diffusely represented in some way). There is also the concern that such cognition arising early on could lead to deceptive alignment [LW · GW][35] during training and thereby be potentially harder to discover or push away from. On the other hand, with simplicity biases[36] of the right kind, older learnings may in fact become more simply-represented, which may mean being more distilled or legible or modular, making them more editable (with the right interpretability tools) or fine-tunable! I tend to doubt this for high-capacity estimators like neural networks, for reasons relating to ensembling and gradient boosting, but it would be exciting if we could understand these dynamics better, and how to control them. Some threads of research which seem relevant to understanding representations of older vs newer learnings in neural networks in particular are Deep Double Descent[37], the Lottery Ticket Hypothesis[38] or Neural Grokking[39].
Considering again the breakdown of motivations, we may hope that ‘early motivations’ (that is, those arising before substantial planning capabilities and runtime general intelligence) will tend to be reflexive rather than deliberative. The question remains whether they would be incorporated into, foundational to, or embedded in the planning capabilities (thereby becoming deliberative) or whether they would remain a separate or separable module of cognition. My best understanding of natural agents is that both of these cases are found in nature, as well as the reflexive-internal+deliberative-external fusion mentioned earlier.
Motivation Development Sequences, Natural and Artificial
For genetic natural selection, much more pressure empirically appears to exist ‘early in training’ (i.e. the first few billion years or so[40]) to develop hard-coded fitness-correlated attraction and aversion heuristics than to develop either runtime-adaptable learning or flexible planning. This makes intuitive and theoretical sense. Imagine the consequences for a lineage of creatures able to precisely understand the telltale scents and sounds of their predators, their musculoskeletal dynamics, and the ballistic trajectories they follow when pouncing, and the genetic fitness implications thereof, but which had no inclination to do anything about it!
 An indifference monster perfectly predicting the fatal consequences of predation but unmotivated to do anything about it
An indifference monster perfectly predicting the fatal consequences of predation but unmotivated to do anything about it
In contrast, social motivations beyond basic herding and huddling seem to only be adaptive after a certain level of runtime flexibility has already been attained. This second claim seems less clear cut though, with potential counterexamples including social insects, whose presumably essentially reflexive behaviours include ‘social’ ones, which give rise to quite coherent and flexible collective behaviour despite not having much individual runtime flexibility. It may be unhelpful or distracting to use such an agglomerative term as ‘social motivations’ here, and it may be useful for further work to refine this point to particular kinds of social motivations. I discuss some particular aspects of social behaviour in Transmissible Accumulation.
Artificial training environments and curricula need not necessarily apply similar pressures to their subjects, whether through population selection or gradient-based updating or other means. In particular, though, it seems reasonable to expect that approaches closer to a natural-selection-inspired approach (straightforwardly selecting for acquisition of resources and influence in large multi-agent environments) would push toward ingraining self-interested survival- and acquisition-oriented heuristics early on. Other approaches may push toward no motives at all, or toward aligned motives, or completely alien motives.
Though I don’t think it’s his main intention, John Wentworth’s selection theorems [AF · GW] agenda may be useful for improving understanding in this area.
Can we imagine training regimes which disrupt the apparent sequencing constraint of early self-preservation and acquisitiveness motivations, then runtime learning and planning, then late social motivations? The early sequence seems especially likely to hold in environments where there are certain abstractable and recognisable stimuli which stably correspond to success (whatever is being selected or reinforced). In contrast, imagine a training regime where the ‘reward sign’ of most stimuli is difficult to discern without sophisticated observation and reasoning, or perhaps teamwork of some kind, perhaps similar in spirit to those discussed earlier. As before, making such a training regime rigorously concrete seems challenging.
Gradated Curricula
Competitive safety via gradated curricula [? · GW] in the Shaping Safer Goals sequence approaches a different question from a similar angle: what if there is a spectrum of training curricula with variable tradeoffs between safety and training ease? It posits that open-ended multi-agent autocurricula, especially including competitive elements, may be on the unsafe+easy end of the spectrum, which is also the view motivating this post. In contrast, question-answering training regimes might have much less pressure for unsafe motivations, but lack the arguments for training effectiveness and efficiency. With the safety mitigations already mentioned, some others later in this post, and others yet to be devised, we can attempt to improve the safety aspects of the competitive autocurriculum regime and hope to arrive at a competitive alignment proposal.
But alternatively, Richard suggests, perhaps the training ease vs safety tradeoff is not so stark - he hypothesises that getting started may be the main hurdle to general intelligence, and that transitioning training to the ‘harder but safer’ regimes, after a certain point, may not have much impact on the training effectiveness and efficiency. In fact many of the most challenging but empowering domains of knowledge for humans (e.g. STEM disciplines) seem to involve quite abstract and symbolic reasoning, albeit usually grounded on interaction experience with the world, and guided by motivated search over very large combinatorial hypothesis spaces. These challenging but empowering domains may be adequately trained, for a suitably and sufficiently pre-trained agent, in more structured regimes like question-answering or other forms of limited-scope problem-solving.
I think this remains an open question, but as a recurrent theme in this piece, I turn to humans as an exemplar for intuition: both on the evolutionary timescale, and over the lifespan of an individual human, gains in technological capabilities often involve structured study unlocked and grounded by sufficient preliminary exploratory interaction with the world. On the other hand, it does appear that another important piece of that picture is the iterative feedback gained by sustained motivated interaction with the world. Consider your favourite technological breakthrough: how much of each of those ingredients was present?
Unless a gradated curriculum had confident guarantees that dangerous ‘early’ motivations were not developed, or that such motivations could be identified and removed or trained away, such an approach has no defense against ingrained early motivations surviving the training process and reaching deployment. More on ingraining aligned motivations to follow, and more on identifying and removing dangerous ones in Modularity of Capability Accumulation.
Transmissible Accumulation
Natural history also demonstrates the power of cultural accumulation of knowledge - in fact some suggest this is/was a primary driver of the natural selection gradient towards larger brains in hominins and other groups[41]. Genetic natural selection in its current manifestation is bottlenecked on how much information it can transmit, and incorporates almost none of the intra-episode experience into that payload, so cultural transmission in animals requires very expensive and lossy flapping of limbs and lips ‘at runtime’. Some of these aspects of sociability may be important to alignment and safety - but the constraints which selected for them are not by default present in artificial systems!
 Expensive runtime flapping. In this instance the rooster expends more time and energy getting its point across than the artificial agents (though the rooster may have other motives as well)
Expensive runtime flapping. In this instance the rooster expends more time and energy getting its point across than the artificial agents (though the rooster may have other motives as well)
Knowledge About Values
One of the most alignment-relevant types of knowledge or information is knowledge about values and norms. The human lineage has a long history of explicit and implicit communication about norms, and various behaviours, motivations, and capabilities which seem oriented toward this.
We might say that a training process which ultimately produces agents capable of runtime transmission of knowledge about values, in the right way, is ‘learning to value learn’[42]. More on ‘the right way’ later.
Proclivity and Receptiveness
An essential observation is that behaviours relating to the transmission of knowledge about values involve both receptiveness to transmission and proclivity for transmission of knowledge about values. Further, returning to the motivation axes discussed previously, behavioural accommodation to value transmission could be a sign either of instrumental ‘playing along’ (interpretable as deception by a direct, deliberative motivation system) or of ‘true receptiveness’, indicative of some form of indirect motivation system.
Imagine three employees, Priti, Reece, and Desmond. One day while they are working together, Priti explains, ‘Widget Co is better when we make frabjous widgets!’. Reece and Desmond believe her. Reece, who has drunk the Widget Co Kool Aid, immediately wants to become the kind of person who makes really frabjous widgets, and over the next few months, practices and seeks advice from others about how to improve his frabjous craft. Desmond, who just wants a pay rise, over the next few months, practices and seeks advice from others about how to improve his frabjous craft. Soon, the gang’s widget production is overall more frabjous. Note that in this story it is unspecified whether Widget Co really is improved by frabjous widgets, and whether or not Priti has reason to believe this is true.
 Frabjous widgets. Priti shares the information. Desmond and Reece respond in different ways internally, though with similar behavioural consequences
Frabjous widgets. Priti shares the information. Desmond and Reece respond in different ways internally, though with similar behavioural consequences
Priti had proclivity for value transmission. She was motivated (for unspecified reason) to transmit some information about local values in the context of her team. Desmond was deceptive, playing along. He accommodated to information about local values because he was motivated by a separate reward he anticipated downstream of that behaviour change. Reece was truly receptive, adopting local values according to information he received about them.
It would appear that true receptiveness is to be preferred to playing along when we are able to distinguish the cases! This is to some extent restating the problem of deceptive alignment [? · GW] but in the runtime/ontogenetic arena rather than the training/phylogenetic. Note that the outward behaviour for deception and true receptiveness could appear arbitrarily similar - but we may be able to say more either by appealing to the training story or by the use of transparency tools. I think a large part of ‘corrigibility’ as discussed by various authors comes down to an indirect motivation system being receptive to transmission of values.
Analogy and Disanalogy to Natural Selection
When we are not engineering these explicitly, what can we say about the distribution of the three kinds of motivation and behaviour pattern, and the pressures to develop them?
My understanding of human behaviour is that it involves some measure of proclivity for value transmission, true receptiveness to value transmission, and deceptive playing along to value transmission, with subject- and context-dependent balances of the three. In humans, it seems true receptiveness is more substantially embodied earlier in ontogenetic development, and playing along and proclivity become more prominent with time, though it appears that most people are tuned to be capable of all at most stages of life.
Domestic animals like dogs, and to a lesser extent horses, appear to lean much more toward true receptiveness - but could they be predominantly ‘playing along’ and just not competent enough to execute treachery? I think not, because I have strong introspective evidence that natural selection discovered some ‘genuine true receptiveness’ module at some evolutionary stage which is active in human-human interactions, and consequently highly suspect that something similar is found in wolf-wolf interactions. From this I expect that the much more readily-available path from wolf to dog goes via upweighting the genuine true receptiveness than upweighting playing along.
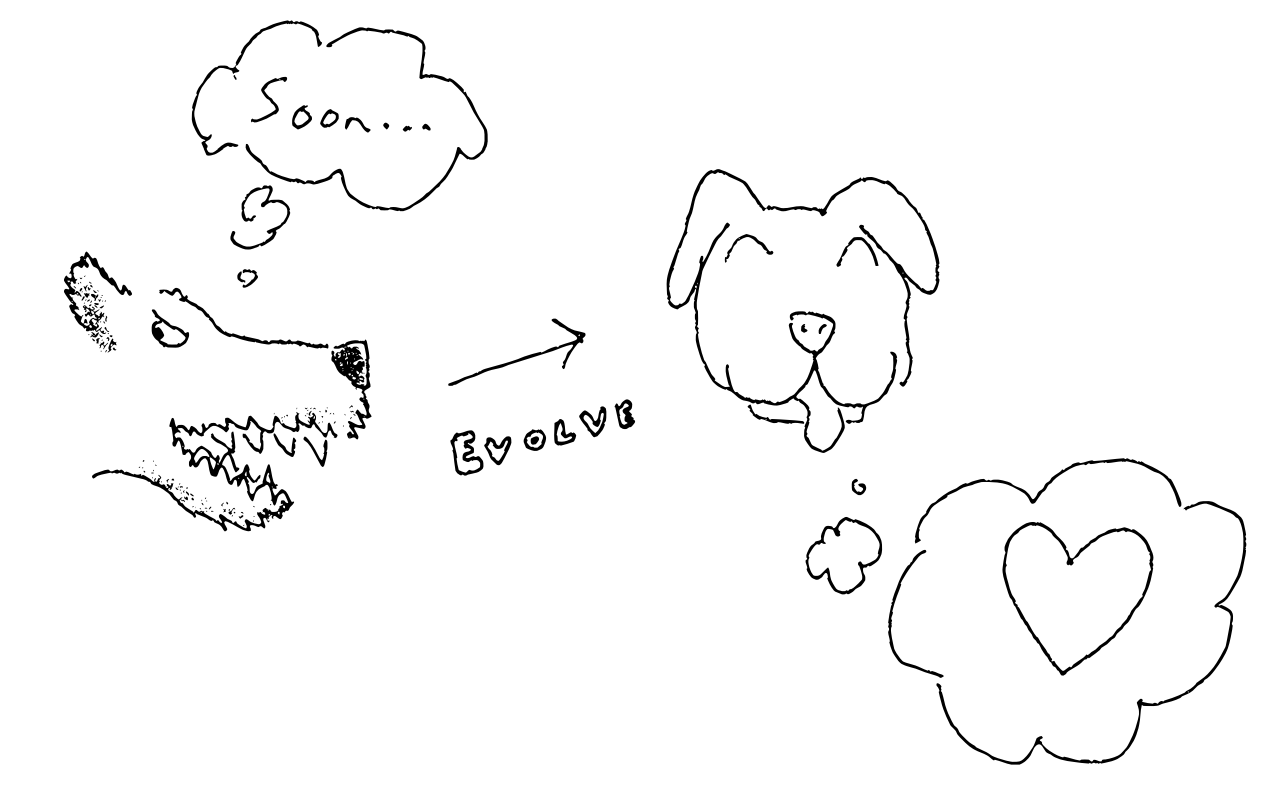 Man's most corrigible friend. A wolf with a blend of receptivity and playing along considers when to betray its human or wolf associates. Generations later its descendant has (most of) this inclination trained away. Those who have trained a dog may be of the opinion that even the 'dog alignment problem' is surprisingly hard.
Man's most corrigible friend. A wolf with a blend of receptivity and playing along considers when to betray its human or wolf associates. Generations later its descendant has (most of) this inclination trained away. Those who have trained a dog may be of the opinion that even the 'dog alignment problem' is surprisingly hard.
Whether natural or artificial, it seems difficult to imagine a behavioural training pressure to develop motivations and capacities for receptiveness (or for that matter deceptive playing along) if there is not also some element of the environment exhibiting proclivity for value transmission. Conversely, without some element of the environment with receptiveness, it is difficult to imagine a behavioural training pressure to develop proclivity for value transmission! Since these are asymmetric but complementary motivations, how this chicken-and-egg problem gets bootstrapped in evolution is not totally clear to me, but I expect it goes via imitation[43] or mirroring which are straightforwardly useful without needing the cooperation of the other party, symmetric or otherwise.
When is it adaptive to be motivated by receptivity? I think there are three ingredients
- A lack of the relevant knowledge
- Some other party having and transmitting the putative knowledge (either deliberately or as a side-effect of something else)
- A justified trust in the honesty of the transmission
Receptivity Constraints and Imprinting
Recalling the discussion earlier about generalisation of obedience, it is of course important to whom the motivation system is receptive. Ill-constrained receptiveness could be subject to adversarial attacks once deployed. In addition, as discussed earlier, foundation models are becoming an increasingly relevant paradigm due to the efficiency of copying ready-trained systems, making it more plausible that multiple deployments of AGI will be related or identical[44]. In this case the constraints on receptiveness matter even more because a misdirection could lead to a coordinated failure!
One biologically-inspired avenue for robustness may come from the phenomenon of imprinting[45], ironically most saliently (and adorably) observed when it fails off-distribution in baby birds[46]. If we could reverse engineer this phenomenon[47] and understand its behavioural envelope, when and how far it can be robust, or if we could apply environmental pressure for it to emerge in multi-agent autocurricula and sufficiently understand it, we could arrange for deployed systems to encounter appropriate imprinting signals during the relevant critical period[48] and thereby develop heterogeneous (and benign) indexical motivations even if they are from homogeneous stock. I could be persuaded that with a sufficient deployed population of receptive, imprintable agents with ‘mostly right, most of the time’ aligned imprinting, this situation might be overall robust and corrigible.
Independently of the discussion around multi-agent autocurricula, I think that understanding and reverse-engineering receptiveness and imprinting may be important concepts for alignment.
Adversarial Concerns and Risks from Proclivity
If the motivational complex of deployed systems includes proclivity for transmission of values, there may be even more adversarial pressure on overly-malleable value systems, and as such we may want to dissolve the link between the two - that is, develop receptiveness without proclivity, but given the aforementioned chicken-and-egg problem, this may be difficult without explicit engineering. The kind of specialisation/division between agents and suggested by Richard Ngo in Safety via selection for obedience and discussed in Implicit Pressure on Motivation Types may point in the right direction. After all, such specialisation/division characterises the relationship between humans and our domestic animals and pets, where a combination of natural and artificial selection have given rise to some of the most corrigible agents yet realised.
If we are concerned about escape from training, deception, or gradient hacking (or training hacking more generally), there may be an additional danger of instantiating any computation with proclivity for transmission of values, even in training. As previously noted here, such an agent could pose a threat of adversarial pressure on flexible value systems (potentially including those of humans), unless definitively safe. Humans are probably safe in this context but including humans in all such situations may be too expensive.
Value Learning and Learning to Value Learn
Artificial systems successfully learning and adopting human values is of course a major goal. But concerns arise when inferring the values of irrational agents (such as humans) - without strong assumptions, how to attribute behaviours to values rather than planning biases or deficiencies of rationality[49]? In particular, the values being inferred are to some degree latent variables in a complex causal structure and a good fit in the observed regime does not guarantee extrapolation off-distribution[50]. These issues present in a subtly different way for ‘learning to value learn’.
On the positive side, we may be encouraged by recent trends in ‘learning to X’ being more tractable than ‘hard-coding X’. Additionally, in multi-agent autocurricula, the challenge for inferred latent value alignment extrapolating past the observed examples is ‘grounded out’ by the necessity of actually succeeding in the assistance task! - at least sometimes, learners whose inference is mis-specified will fail to assist and get penalised (for example the perverse ‘anti-rational’ solution to value learning should fail dramatically).
On the other hand, if the necessary priors for value learning are sufficiently peculiar to agent-types, learning to value learn on mainly nonhuman partners may not transfer to value learning with human partners, though this may be obviated by including sufficient explicit human interaction opportunities in the training regime.
Of course this whole line of reasoning has many unresolved problems and additionally is reliant on a certain amount of ‘societal alignment’ (though I am not aware of many alignment proposals which are not). A potential problem could be one misaligned entity ‘maxing out’ by imprinting on a huge number of systems and thereby gaining a decisive advantage, but this problem is far from unique to this situation.
Heritable Accumulation
Genetic natural selection accumulates very few bits of information per organism-lifetime, and much of it is noisy and redundant[51]. In contrast, though also noisy and redundant, the information available to an organism over the course of its lifetime is vastly many orders of magnitude greater (e.g. consider the information content of a decades-long high definition video), and thus many lineages have evolved genetic encodings for learning algorithms able to exploit this much richer signal (e.g. through neural weight and activation updates). Genetic natural selection has very limited means of transmitting any intra-lifetime/intra-episode learning between generations[52].
In contrast, certain artificial setups make such inheritance of intra-episode learned information much more straightforward. Depending on how we draw the analogy, we may consider the incremental updates to a network trained by gradient descent to act on a lineage of inherited information (though an alternative analogy might be to a single individual learning over a lifespan; the analogy is not clear-cut in this case). Even in population or evolutionary setups, a large amount of learned information is inherited. As a concrete example, consider a use of Population Based Training for RL having the ‘exploit’ step (branching ‘offspring’ from a parent) copy weights as well as hyperparameters (as in the original paper[53] and subsequent uses for AlphaStar and others). In this case, offspring are equipped with the entirety of their lineage’s intra-episode learned information. Because learned weights are usually specific to architectural hyperparameters, approaches between these extremes are rare in the contemporary ML paradigm. One unusual and striking example is the use of ‘neural network surgery’ on the OpenAI Five project[54] to transfer some weights even between models of altered architecture. There are also various techniques for transferring learned parameters between heterogeneous use-cases while preserving portions of architecture, for example in learned word embeddings[55] and document embeddings. Given the expense of retraining, I would not be surprised to see this sort of approach becoming more ubiquitous. Perhaps another intermediate example could be the ‘inheritance’ of data in a shared experience buffer between hyperparameter changes, which would constitute inheritance of raw observations, but not of extracted learning/knowledge.
One of the main alignment-relevant impacts of the degree of heritability of knowledge may be its impact on the degree of training pressure for Transmissible Accumulation i.e. cultural learning. Prima facie it should seem that richer inheritance of knowledge should reduce pressures to develop mechanisms and inclination for transmission of knowledge.
When is Inheritance of Knowledge Not Substitutable for Transmission of Knowledge?
It appears to me that whether it is knowledge about the world in general, knowledge about local particulars, or knowledge about values, inherited knowledge is only a substitute for runtime transmission (or tabula rasa acquisition) of knowledge when the relevant aspect of the environment is relatively stable (or has multiple stable modes). In such cases, there may be diminished pressure for development of runtime knowledge acquisition and transmission, because if there is stability on one or more modes, inherited knowledge about those modes merely need be selected and applied.
In this post, much has been made of the importance of diversity of training tasks and here is no different. If environment and task modes are sufficiently varied and difficult to pattern-match, inherited knowledge and object-level motivations will be less useful, while knowledge acquired or shared at runtime will be more important.
Even with stability of ‘base environment specification’, with increasingly intelligent exploratory or experimental behaviour, none of these aspects are likely to remain particularly stable, most obviously knowledge about local particulars. Such exploratory or experimental behaviour may even include deliberative or reflexive forms of runtime knowledge transmission. In particular, collective strategies which require understanding of indexical information probably require more than simple information inheritance to execute well - consider the example in nature of pack hunting[56] where in many cases even if we grant that the overall collective strategy pattern may be mostly instinctively coded, the particulars of execution in any particular instance require runtime communication to be successful.
Can similar things be said about transmission of knowledge about values in particular? Evolutionary psychological theories of human moral motivations, such as Moral Foundations Theory[57] or Relational Models Theory[58] can be construed as positing that our ingrained moral intuitions are precisely such contextually-dependent templates for coordinated collective behaviour. Such modular templates are able to accommodate a variety of cultural and environmental contexts in a way that purely inherited motivations can not.
Other effects of Heritable Accumulation
Besides the influence of heritable accumulation on transmissible accumulation, returning to our axes for understanding motivations, my model of the impact of heritable accumulation mostly goes via its interaction with the length of training time and amount of pressure from inductive bias that different cognitive functions will be subjected to, as discussed in Early vs Late Motivations and Training Duration and Modularity of Capability Accumulation.
Further, without very strong reason, it may be hard to nudge development away from heritable accumulation due to its apparent benefits to training efficiency. Nevertheless, if we want to encourage runtime transmission of knowledge of various kinds, as it appears that we might, it may be useful to devise schemes which suppress the utility of heritable knowledge transmission.
Modularity of Capability Accumulation
Due to the parameters of mutation, inheritance and selection, genetic natural selection operates incrementally[59] and appears to favour modularity. There is some debate in biology around what pressures exist toward modularity, with at least one thread attributing modularity to indirect selection for lineage adaptability (modular systems being more adaptable to changing pressures over fewer generations)[60], others suggesting connections from ‘modular variety’ of the environmental pressures to modular development[61], and others suggesting direct selection pressure for reduced cost of connections between modular loci (modular systems having reduced overall connection cost)[62]. Empirically, many biological systems exhibit modularity and loose coupling, from the independently evolved vascular systems of animals and plants to the neural modularity of various animal lineages. It seems Mother Nature may have been taking Uncle Bob’s[63] advice!
To avoid anchoring our expectations too closely to natural selection, consider some disanalogies. While most methods of training neural networks involve local or step-wise search of one kind or another which is roughly comparable to evolution through natural selection, parameter updates are typically not primarily performed by evolutionary processes (though some counterexamples exist[64], and in many modern applications, architectural and other hyperparameters are updated by processes more similar to natural selection, which brings closer the analogy to biological evolution[65]). Other high capacity estimators besides neural networks, like gradient boosted trees and random forests, may not even use local search for training. The genetic information-inheritance bottleneck discussed, and the requirement for dependencies to be mostly fixated before they can be relied upon for further development has led to a relatively core set of development tools[66] for animal ontogeny which may strongly favour modularity, which are constraints not necessarily present in artificial systems.
In addition, nature’s regularising constraints include many which are not typically present in artificial learning systems but which may be relevant to modularity
- time and energy costs of computation
- material and energy costs of construction (and maintenance and repair)
- physical spatial constraints
- the necessity to be robust to the fidelity of translation of genotype to phenotype
Relevance for Safety and Alignment
In Emergent Modularity and Safety [? · GW] Richard Ngo discusses the analogy to biological neural networks, citing empirical work from Filan et al[67] on modularity of trained artificial neural networks and Olah et al[68] on the interpretation of human-comprehensible ‘circuits’ in trained artificial neural networks. He draws attention to the relevance to safety, in particular suggesting that if we can locate cognitive modules responsible for goal-directed agency and motivations, we may be able to explicitly remove them from our models during training, which he calls module pruning. A key insight is that we may be able to successfully carry out this technique even with quite coarse-grained and imprecise interpretability tools provided such modules exist. He even suggests the ‘counterintuitive possibility’ of deliberately training limited misbehaviour in order to produce specific modules to be detected and removed! I find this quite a disconcerting thought but grant that depending on our understanding of modularity it may be a useful trick.
If a particular training trajectory goes a long way on the modularity scale, we might end up with a conglomeration of a huge number of loosely coupled modules, some involving motivations and some involving other cognitive components. This could be more problematic for the module pruning story if it degrades the prospect of tractably interpretable transparency insights.
All of the above analogies and disanalogies suggest empirical lines of enquiry into the emergence of modularity. In addition, the linked work from Wagner, Clune et al, Kashtan and Alon, Filan et al, and Olah et al all make meaningful empirical and theoretical progress toward understanding the nature of modularity and what kinds of pressures can exist which favour or disfavour it.
Returning to our axes for considering motivations, we have already considered how modularity may interact with transparency, depending on interpretability tools. Might modularity also have an impact on completeness of the emerging motivations? Recall that a fully consistent agent with potentially incomplete preferences may be represented as a committee of multiple complete agents[69]. If so, perhaps a simple way to represent such an agent might be literally as something like a committee - meaning a push toward modular representation may encourage emergence of (overall) incomplete motivations. Humans look a lot like this from the outside (behaviourally)[70] and I am personally reasonably convinced that something like this is what is happening inside (mechanistically).
Collectives
Communication and collaboration of agents is not limited to training - various authors have discussed the potential for ‘collective’ AGI or superintelligence composed of multiple interacting agents, with some further suggesting that this is a useful lens to consider human organisations through.
Since under the very prosaic assumptions of this post, training is much more expensive than deployment, we may expect train-once-deploy-many foundation models to be the dominant pattern. The type of collective we are considering thus concerns a population of relatively-homogeneous (perhaps identical) deployed instances of independently relatively-autonomous agents. Evan Hubinger goes into some detail on the degree of homogeneity to expect in Homogeneity vs heterogeneity in AI takeoff scenarios [LW · GW] and Richard Ngo discusses some consequences in AGIs as collectives [? · GW] and Safer sandboxing via collective separation [? · GW].
One aspect which I think is mostly absent from those conversations is the distinction between runtime/ontogenetic and training/phylogenetic homogeneity. Note that very closely-related humans with differing development inputs can exhibit very different qualities and motivations (within the human range), and very distantly-related humans (within the human range) with similar development inputs can exhibit very similar qualities and motivations. The most obvious point to make here goes back to the discussions of value transmission, receptivity, and imprinting in Transmissible Accumulation: with the right diversity of training and suitable environmental components, flexibility (even of motivations) at runtime can be adaptive, so even identically-trained clone instances can be heterogeneous at runtime due to whatever state they carry with them. It is unclear to me how this type of heterogeneity affects what we should expect from collective AGI.
AGIs as collectives considers the following:
- Interpretability: a collective, not being trained end-to-end together, must have some relatively standardised communication protocol. Thus, it may be more interpretable.
- We may even be able to constrain bandwidth or communication topologies to this end
- Perhaps we could find ways to enforce a particular interpretable communication protocol (although the trick of injecting an obfuscated message into another is probably nearly as old as language, perhaps older)
- Flexibility: as with modular systems, ceteris paribus a collective system should be more adaptable and flexible than a singular one
- Fine-tunability: credit-assignment for collective behaviour is difficult, and it may be difficult to locally perturb individuals’ behaviours to move the collective behaviour in a different direction
- collective behaviour may in part emerge from the collaborative or competitive equilibria of the collective, in addition to the particular indexical motivations of each individual
- Agency: the apparent motivations of a collective may not be the same as those of individual members (even if that question is well-defined)
- interaction - collaboration and competition - may dampen or may amplify the degree and direction of goals
Safer sandboxing via collective separation considers a specific hypothesis about different types of task an AGI might be applied to. Perhaps there is a fortunate anticorrelation between the required level of actuation and interaction with the world, and the required level of extreme intelligence and strategic capability (with ‘low’ conceived of as human- or mild-superhuman-level). Examples of high-interaction-lower-intelligence tasks are ‘personal assistant’ or ‘web administrator’. Examples of low-interaction-higher-intelligence tasks are ‘new scientific discoveries’ and ‘major strategic decisions’.
If so, we could constrain deployments of the high-interaction-lower-intelligence type to few or single instances, perhaps with other resource limitations, while constraining deployments for the low-interaction-higher-intelligence type, requiring more instances and more computational resources, in much more tightly controlled sandboxes, including limiting input-output bandwidth and modalities. This is only an available possibility when the overall system is structured as a collective.
Of the suggestions in the Shaping Safer Goals sequence, this is the least convincing to me. On that I appear to agree with Richard, who caveats
this is not intended as a primary solution to the safety problem... it’s worth thinking about ways to “move the needle” by adding additional layers of security.
In particular, I suspect that ‘new scientific discoveries’ and ‘major strategic decisions’ may in fact in many cases require sustained motivated interaction with the world in order to get the necessary feedback and information for learning.
Inner and Outer Timescales
One key difference compared to genetic natural selection may be the timescales of the ‘outer’ and ‘inner’ processes. For human genetic natural selection, very many ‘inner’ actions are taken over the course of an ‘episode’ for every ‘outer’ adjustment natural selection is able to make (and the signal of the outer adjustment is extremely noisy), while there is no such constraint on artificial systems. In principle it could even be the other way round! As a concrete example, imagine some form of experience-replaying learning algorithm extracting many gradient updates on average from each experience. Exploring when and how the outer training process makes updates may be relevant to the kinds of motivations which emerge in the learned models.
In particular for the present discussion, can these disanalogies of inner and outer timescales in natural selection compared to artificial training setups dissolve the phylogenetic-ontogenetic distinction which underlies the difference between direct and indirect motivations? I believe runtime or indirect world knowledge acquisition and planning will ultimately be much more competitive than direct or pretrained versions, at least in the prosaic paradigm. Whether the same can be said for motivations is not clear to me.
Is alignment at all tractable in this setting?
There are reasons to be concerned that achieving aligned artefacts in the high-capabilities regime, when training with the explicit intention of producing emergent goals, is futile.
As noted in Stuart Russell’s quote near the start of this post, in this super prosaic world, it is really difficult to know what is going on in the training process and in the models. This is a motivation to develop insight and interpretability tools tailored to this setting.
Several of the above desiderata and suggestions involve reasoning about training pressures giving rise to motivations via the behaviour those motivations produce. But as explored in various discussions about mesa optimisation[71], such behavioural properties may not in general guarantee any particular generalisation to new input distributions. This seems a risky prospect! But noting that to the extent that success in alignment is conjunctive, each layer of risk reduction is valuable in playing its part. Also, we are sometimes able to say more about the kinds of motivations that develop in response to different environmental training pressures.
Others among the above suggestions involve using transparency tooling to influence the mechanistic and architectural aspects of motivations. If done correctly, mechanistic guarantees about motivations could indeed generalise appropriately to unseen input distributions[72]. But if we have transparency tools which are able to make mechanistic guarantees relating to alignedness, why should we not instead use them in a regime which is less favourable to the development of (potentially misaligned) goals in the first place? As noted here, it appears there is some capabilities runway ahead for curriculum engineering, so it may be that training or capabilities competitiveness push us in this direction. Further insights from alignment research may not prove sufficient disincentive to develop further technologies in this way. In the world where multi-agent autocurricula is the fastest path to AGI, it seems indeed that we are very underinvested in making it safe. So depending on how plausible that is, you may or may not agree with the neglect argument for this story.
Summary
In Shaping Safer Goals Richard Ngo pointed at an especially prosaic development story for capabilities in AGI, and there is some evidence this story is neglected in alignment, namely large-scale open-ended curriculum engineering, and in particular multi-agent autocurricula. The deployment scenario of many deployments from few relatively-homogeneous trained foundation models adds some additional refinement to the picture.
We’ve considered some ways that the core motivations of such systems might pose risks, made some preliminary predictions about the kind of motivations that can arise in this context, and begun to describe desiderata for making the training and deployment processes safer, as well as some ways they might fail.
Concepts which I think are particularly useful here are the reflexive-deliberative and direct-indirect distinctions for describing and understanding motivations, and the training/phylogenetic vs runtime/ontogenetic boundary.
I’d be especially interested to encounter more thinking about instilling or reverse-engineering value receptivity and imprinting in artificial systems. The possibility of ‘learning to value learn’ is appealing as a potential way to ground out the otherwise-underdetermined extrapolation of inferred values onto new tasks, but there are lots of holes remaining in the description.
If the capabilities predictions are convincing but the alignment prospects seem dim, it may be that the best strategy is to refine and robustify the arguments to that effect. Even in that case, hopefully the conceptualisation of this development model and the analogies from nature can prove fruitful.
Take GPT-3 for example - see Alignment Forum Tag GPT [? · GW] ↩︎
DeepMind - Generally capable agents emerge from open-ended play ↩︎
Consider DeepMind - AlphaGo and AlphaStar, OpenAI Five ↩︎
For additional related arguments from authority, compare Sutton’s ‘bitter lesson’, Rohin Shah’s suggestion in Alignment Newsletter #159 that ‘diversity is all you need’ [LW · GW] for generalisation in deep learning, or through your AGI lens note Andrew Ng’s recent emphasis of ‘data-centric AI’ (Forbes - Andrew Ng Launches a Campaign for Data-Centric AI), or The Unreasonable Effectiveness of Data from Google researchers ↩︎
Stanford Center for Research on Foundation Models - On the Opportunities and Risks of Foundation Models ↩︎
Some illustrative examples from nature may include human prehistory, the Great American Interchange (Wikipedia) and other colonisations followed by adaptive radiation (Wikipedia) ↩︎
Compare Ecoffet et al on Open Questions in Creating Safe Open-ended AI or Deepmind researchers on Autocurricula and the Emergence of Innovation from Social Interaction and ‘the problem problem’ ↩︎
e.g. Hubinger et al - Conditions for Mesa-Optimization [LW · GW], Mark Xu - Does SGD Produce Deceptive Alignment? [LW · GW] ↩︎
Vladimir Mikulik - 2-D Robustness ↩︎
Hubinger et al - Risks from Learned Optimisation ↩︎
https://www.bbc.co.uk/programmes/m001216j or https://podcasts.apple.com/us/podcast/the-biggest-event-in-human-history/id318705261?i=1000543602912 (~42:10) transcription, punctuation and emphases my own ↩︎
A general intelligence which incidentally promptly and almost immediately (on evolutionary timescales) demonstrated inner misalignment what with asceticism, birth control, academia, eugenics (the first definitive instance of gradient hacking? [LW · GW]), expanding moral circles of concern, and other things of the sort that no self-respecting inclusive genetic fitness maximiser would dream of ↩︎
e.g. see Cotra - Draft report on AI timelines [LW · GW] ↩︎
Eliezer Yudkowsky suggests here that anchoring to biological estimates is an essentially doomed endeavor: Biology-Inspired AGI Timelines: The Trick That Never Works [LW · GW] (he appears to in fact favour earlier timelines on the basis of anticipated further paradigmatic shifts) ↩︎
See Schulman and Bostrom discussing the strengths and weaknesses of this point here: How Hard is Artificial Intelligence? Evolutionary Arguments and Selection Effects ↩︎
Steve Byrnes makes a good case for this kind of position here: Against evolution as an analogy for how humans will create AGI [LW · GW], taking into account both runtime computational efficiency as well as the training cost of discovering useful runtime learning algorithms ↩︎
See Flint on The Ground of Optimisation (https://www.alignmentforum.org/posts/znfkdCoHMANwqc2WE/the-ground-of-optimization-1 [AF · GW]) for some interesting discussion of this sort of ‘motivation’ ↩︎
See Critch on Robust Agent-Agnostic Processes [LW · GW] for a piece which evokes related concerns - if I can crispen my thoughts in this area I may attempt to write my own detail on these intuitions in a later post ↩︎
Wikipedia - Monte-Carlo Tree Search ↩︎
e.g. see descriptions of theories like Moral Foundations Theory (Wikipedia) which find abstract or schematic moral commonalities across many people and cultures ↩︎
Wikipedia - Phylogenetics ↩︎
Wikipedia - Ontogeny ↩︎
Hubinger et al - Conditions for Mesa Optimization ↩︎
There is a suggestive connection to Virtue Ethics here but I have not given this thought much time ↩︎
Goodfellow et al - Generative Adversarial Networks ↩︎
Enter ‘GAN mode collapse’ in your favourite index or search engine ↩︎
Hubinger et al - Deceptive Alignment ↩︎
E.g. see Evan on mechanistic corrigibility (Towards a mechanistic understanding of corrigibility [LW · GW]) ↩︎
Hubinger - Relaxed adversarial training for inner alignment ↩︎
Turner et al - Seeking Power is Often Convergently Instrumental in MDPs ↩︎
Fletcher and Doebeli - A simple and general explanation for the evolution of altruism ↩︎
Though this raises the exotic risk that when we actually meet the purple polka-dot jelly aliens, even if they are perfectly peaceful our AGI may unexpectedly wage sudden war against them ↩︎
For want of time and focus on more superficially promising lines of enquiry I have not explored this further but would welcome related thoughts, and may return to it in a later doc ↩︎
Hubinger - How do we become confident in the safety of a machine learning system? ↩︎
Hubinger et al - Deceptive Alignment ↩︎
There are lots of discussions of simplicity biases in training procedures for neural networks, but it remains poorly understood. Consider John Wentworth here SGD’s bias [LW · GW] or some of the pieces discussed and linked in Alignment Newsletter #139 [LW · GW] ↩︎
E.g. see Evan on Understanding deep double descent [LW · GW] or AN 77 [LW · GW] and AN 129 [LW · GW] which talk about this phenomenon ↩︎
Alignment Forum - [Lottery Ticket Hypothesis tag(https://www.lesswrong.com/tag/lottery-ticket-hypothesis [? · GW]) collects some expository and explanatory posts ↩︎
Look at Wikipedia - Proterozoic and related to understand what I mean ↩︎
Muthukrishna et al - The Cultural brain Hypothesis ↩︎
See Rohin Shah’s sequence on Value Learning [? · GW] ↩︎
Wikipedia ↩︎
For more on homogeneity of AI takeoff, see Evan on Homogeneity vs. heterogeneity in AI takeoff scenarios [LW · GW] ↩︎
Wikipedia - Imprinting (psychology) ↩︎
Atlas Obscura - Watch Ducklings Follow Various Creatures That Are Not Their Mom ↩︎
Disappointingly I can not find a Steve Byrnes article on this subject ↩︎
Wikipedia - Critical Period ↩︎
See Stuart Armstrong - Humans can be assigned any values whatsoever [LW · GW] ↩︎
See Jacob Steinhardt on this problem in Latent Variables and Model Mis-Specification [? · GW] ↩︎
See MacKay Information Theory, Inference, and Learning Algorithms chapter 19 Why Have Sex? for an interesting and entertaining preliminary exploration of this (the rest of the book is also masterful and recommended) ↩︎
Incidentally, for a fictional exploration of a counterexample, consider Yudkowsky’s Three Worlds Collide [? · GW] ↩︎
DeepMind - Population Based Training of Neural Networks ↩︎
OpenAI - Neural Network Surgery with Sets - thanks to Evan for pointing me to this ↩︎
E.g. peruse the Wikipedia article on Word Embedding ↩︎
Wikipedia - Pack Hunter ↩︎
Wikipedia - Moral Foundations Theory ↩︎
Wikipedia - Relational Models Theory ↩︎
See some of Eliezer Yudkowsky’s writings on evolution e.g. Evolutions Are Stupid (But Work Anyway) [? · GW] ↩︎
e.g. see Wagner 1996 Homologues, Natural Kinds, and the Evolution of Modularity. The hypothesis that more isolation and modularity enables adaptability with reduced risk of breaking connected components chimes with my experience as an engineer of complex software systems! ↩︎
See John Wentworth discussing Kashtan and Alon Spontaneous evolution of modularity and network motifs here (Evolution of Modularity [AF · GW]) ↩︎
e.g. Clune et al - The evolutionary origins of modularity ↩︎
Wikipedia - Robert C. Martin ↩︎
Wikipedia - Neuroevolution ↩︎
Consider the Population Based Training used in many recent DeepMind publications ↩︎
Wikipedia - Evo-devo Gene Toolkit ↩︎
Filan et al. - Clusterability in Neural Networks ↩︎
Olah et al. - Zoom in ↩︎
see John Wentworth - Why Subagents? [LW · GW] ↩︎
e.g. see Kaj Sotala’s sequence Multiagent models of mind [? · GW] ↩︎
E.g. Hubinger et al - The Inner Alignment Problem [LW · GW] ↩︎
See Mark Xu discussing this distinction here in Towards a Mechanistic Understanding of Goal-Directedness [AF · GW] or Evan Hubinger here in Towards a mechanistic understanding of corrigibility [AF · GW] ↩︎
0 comments
Comments sorted by top scores.