Transformers Represent Belief State Geometry in their Residual Stream
post by Adam Shai (adam-shai) · 2024-04-16T21:16:11.377Z · LW · GW · 100 commentsContents
Introduction Theoretical Framework Do Transformers Learn a Model of the World? The Structure of Belief State Updating The Mixed-State Presentation Experiment and Results Experimental Design The Data-Generating Process and MSP The Results! Limitations and Next Steps Limitations Next Steps None 100 comments
Produced while being an affiliate at PIBBSS[1]. The work was done initially with funding from a Lightspeed Grant, and then continued while at PIBBSS. Work done in collaboration with @Paul Riechers [LW · GW], @Lucas Teixeira [LW · GW], @Alexander Gietelink Oldenziel [LW · GW], and Sarah Marzen. Paul was a MATS scholar during some portion of this work. Thanks to Paul, Lucas, Alexander, Sarah, and @Guillaume Corlouer [LW · GW] for suggestions on this writeup.
Update May 24, 2024: See our manuscript based on this work
Introduction
What computational structure are we building into LLMs when we train them on next-token prediction? In this post we present evidence that this structure is given by the meta-dynamics of belief updating over hidden states of the data-generating process. We'll explain exactly what this means in the post. We are excited by these results because
- We have a formalism that relates training data to internal structures in LLMs.
- Conceptually, our results mean that LLMs synchronize to their internal world model as they move through the context window.
- The computation associated with synchronization can be formalized with a framework called Computational Mechanics. In the parlance of Computational Mechanics, we say that LLMs represent the Mixed-State Presentation of the data generating process.
- The structure of synchronization is, in general, richer than the world model itself. In this sense, LLMs learn more than a world model.
- We have increased hope that Computational Mechanics can be leveraged for interpretability and AI Safety more generally.
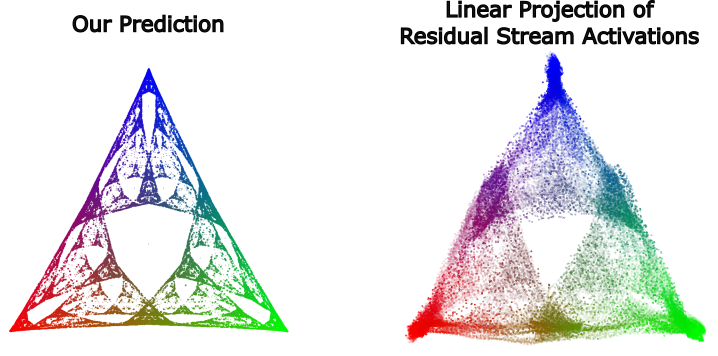
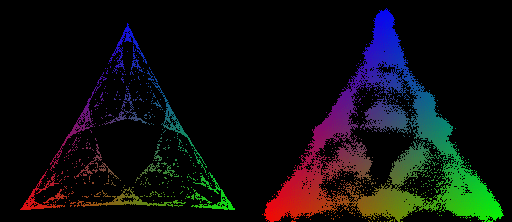
- There's just something inherently cool about making a non-trivial prediction - in this case that the transformer will represent a specific fractal structure - and then verifying that the prediction is true. Concretely, we are able to use Computational Mechanics to make an a priori and specific theoretical prediction about the geometry of residual stream activations (below on the left), and then show that this prediction holds true empirically (below on the right).
Theoretical Framework
In this post we will operationalize training data as being generated by a Hidden Markov Model (HMM)[2]. An HMM has a set of hidden states and transitions between them. The transitions are labeled with a probability and a token that it emits. Here are some example HMMs and data they generate.
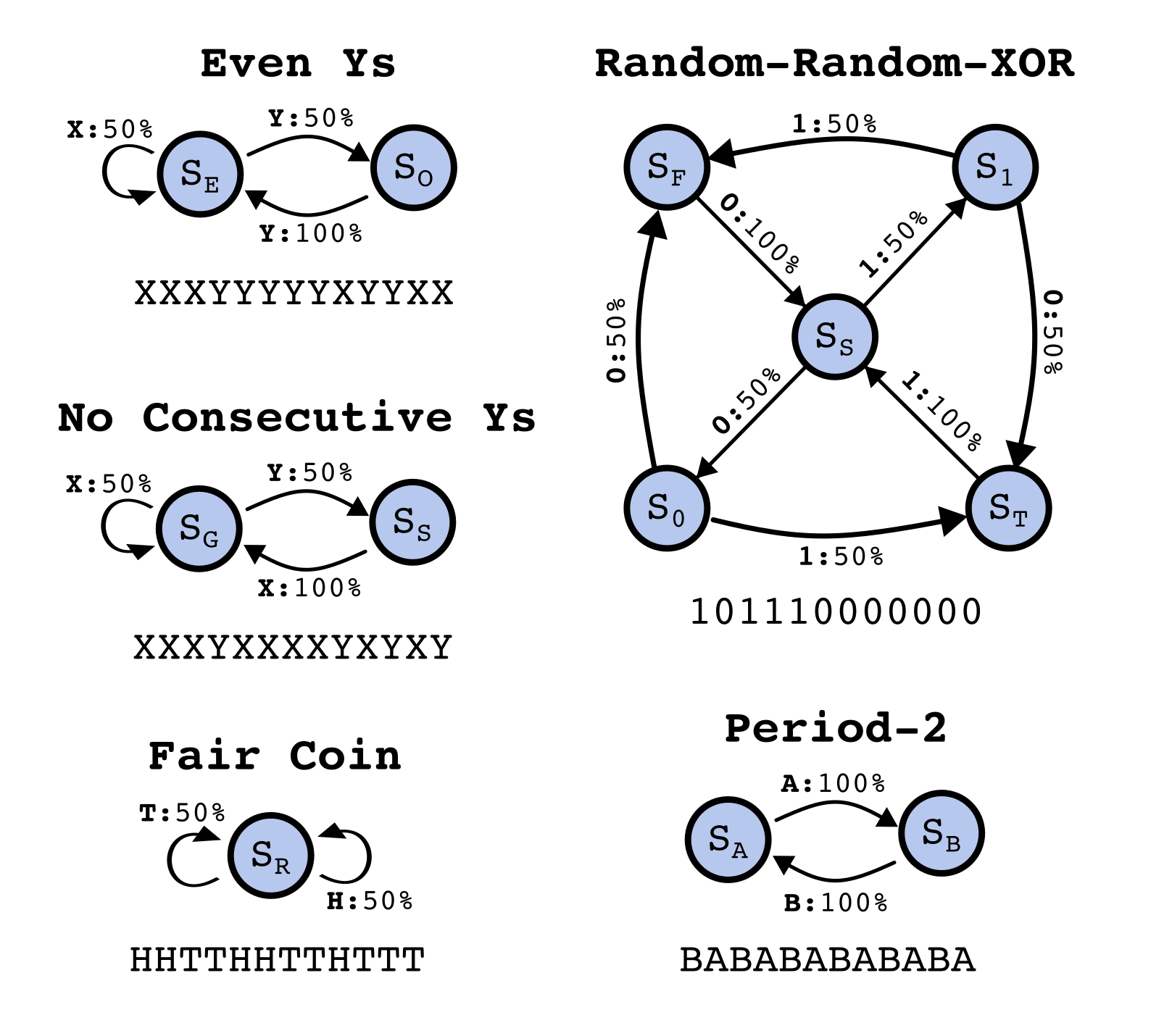
Consider the relation a transformer has to an HMM that produced the data it was trained on. This is general - any dataset consisting of sequences of tokens can be represented as having been generated from an HMM. Through the discussion of the theoretical framework, let's assume a simple HMM with the following structure, which we will call the Z1R process[3] (for "zero one random").
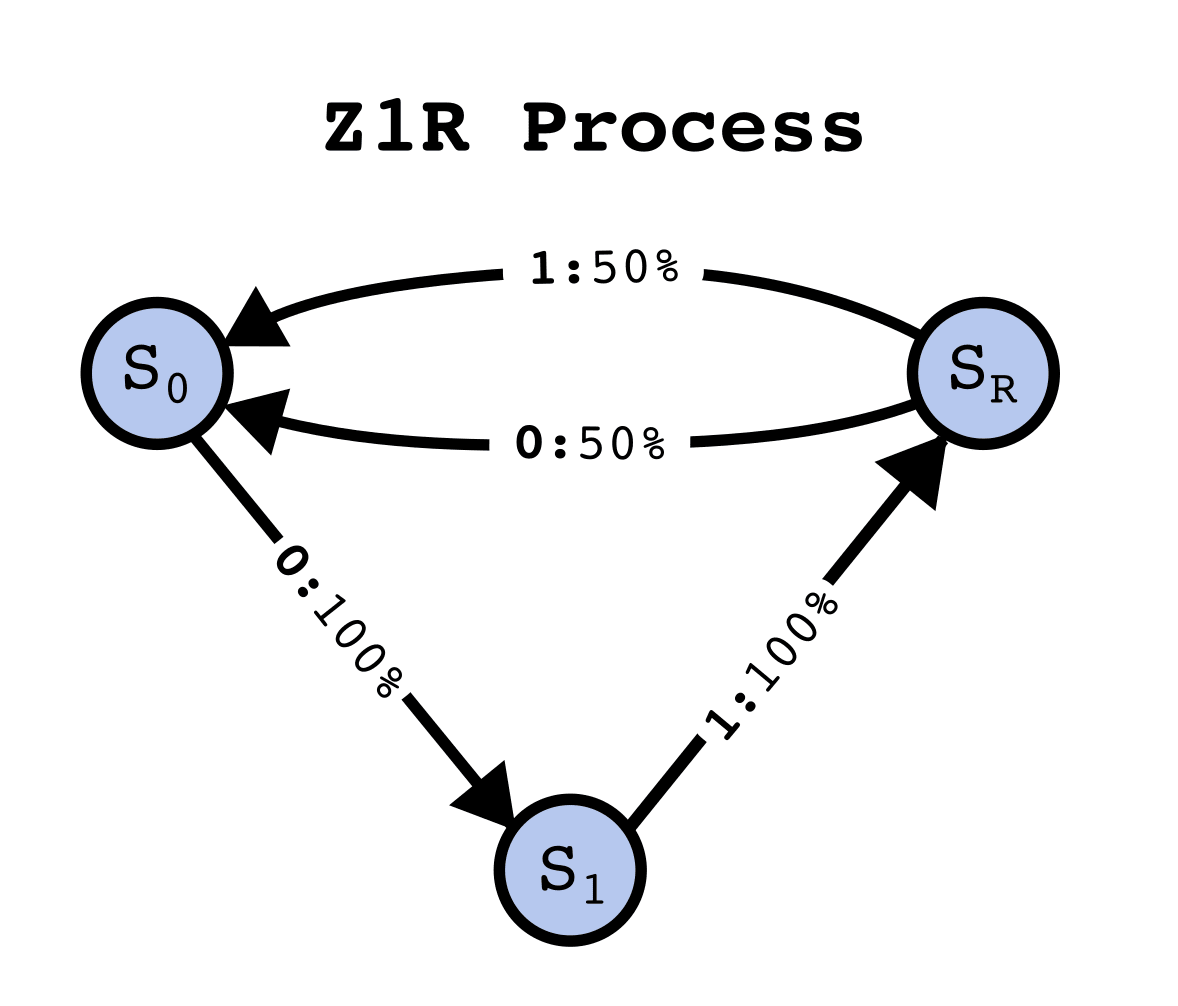
The Z1R process has 3 hidden states, and . Arrows of the form denote , that the probability of moving to state and emitting the token , given that the process is in state , is . In this way, taking transitions between the states stochastically generates binary strings of the form ...01R01R... where R is a random 50/50 sample from {0, 1}.
The HMM structure is not directly given by the data it produces. Think of the difference between the list of strings this HMM emits (along with their probabilities) and the hidden structure itself[4]. Since the transformer only has access to the strings of emissions from this HMM, and not any information about the hidden states directly, if the transformer learns anything to do with the hidden structure, then it has to do the work of inferring it from the training data.
What we will show is that when they predict the next token well, transformers are doing even more computational work than inferring the hidden data generating process!
Do Transformers Learn a Model of the World?
One natural intuition would be that the transformer must represent the hidden structure of the data-generating process (ie the "world"[2]). In this case, this would mean the three hidden states and the transition probabilities between them.
This intuition often comes up (and is argued about) in discussions about what LLM's "really understand." For instance, Ilya Sutskever has said:
Because if you think about it, what does it mean to predict the next token well enough? It's actually a much deeper question than it seems. Predicting the next token well means that you understand the underlying reality that led to the creation of that token. It's not statistics. Like it is statistics but what is statistics? In order to understand those statistics to compress them, you need to understand what is it about the world that creates this set of statistics.
This type of intuition is natural, but it is not formal. Computational Mechanics is a formalism that was developed in order to study the limits of prediction in chaotic and other hard-to-predict systems, and has since expanded to a deep and rigorous theory of computational structure for any process. One of its many contributions is in providing a rigorous answer to what structures are necessary to perform optimal prediction. Interestingly, Computational Mechanics shows that prediction is substantially more complicated than generation. What this means is that we should expect a transformer trained to predict the next token well should have more structure than the data generating process!
The Structure of Belief State Updating
But what is that structure exactly?
Imagine you know, exactly, the structure of the HMM that produces ...01R... data. You go to sleep, you wake up, and you see that the HMM has emitted a 1. What state is the HMM in now? It is possible to generate a 1 both from taking the deterministic transition or from taking the stochastic transition . Since the deterministic transition is twice as likely as the 50% one, the best you can do is to have some belief distribution over the current states of the HMM, in the case [5].
| 1 | 1 | 0 | 1... | |
| P() | |||||
| P() | |||||
| P() |
If now you see another 1 emitted, so that in total you've seen 11, you can now use your previous belief about the HMM state (read: prior), and your knowledge of the HMM structure alongside the emission you just saw (read: likelihood), in order to generate a new belief state (read: posterior). An exercise for the reader: What is the equation for updating your belief state given a previous belief state, an observed token, and the transition matrix of the ground-truth HMM?[6] In this case, there is only one way for the HMM to generate 11, , so you know for certain that the HMM is now in state . From now on, whenever you see a new symbol, you will know exactly what state the HMM is in, and we say that you have synchronized to the HMM.
In general, as you observe increasing amounts of data generated from the HMM, you can continually update your belief about the HMM state. Even in this simple example there is non-trivial structure in these belief updates. For instance, it is not always the case that seeing 2 emissions is enough to synchronize to the HMM. If instead of 11... you saw 10... you still wouldn't be synchronized, since there are two different paths through the HMM that generate 10.
The structure of belief-state updating is given by the Mixed-State Presentation.
The Mixed-State Presentation
Notice that just as the data-generating structure is an HMM - at a given moment the process is in a hidden state, then, given an emission, the process move to another hidden state - so to is your belief updating! You are in some belief state, then given an emission that you observe, you move to some other belief state.
| Data Generating Process | Belief State Process | |
|---|---|---|
| States belong to | The data generating mechanism | The observer of the outputs of the data generating process |
| States are | Sets of sequences that constrain the future in particular ways | The observer's beliefs over the states of the data generating process |
| Sequences of hidden states emit | Valid sequences of data | Valid sequences of data |
| Interpretation of emissions | The observables/tokens the data generating process emits | What the observer sees from the data generating process |
The meta-dynamics of belief state updating are formally another HMM, where the hidden states are your belief states. This meta-structure is called the Mixed-State Presentation (MSP) in Computational Mechanics.
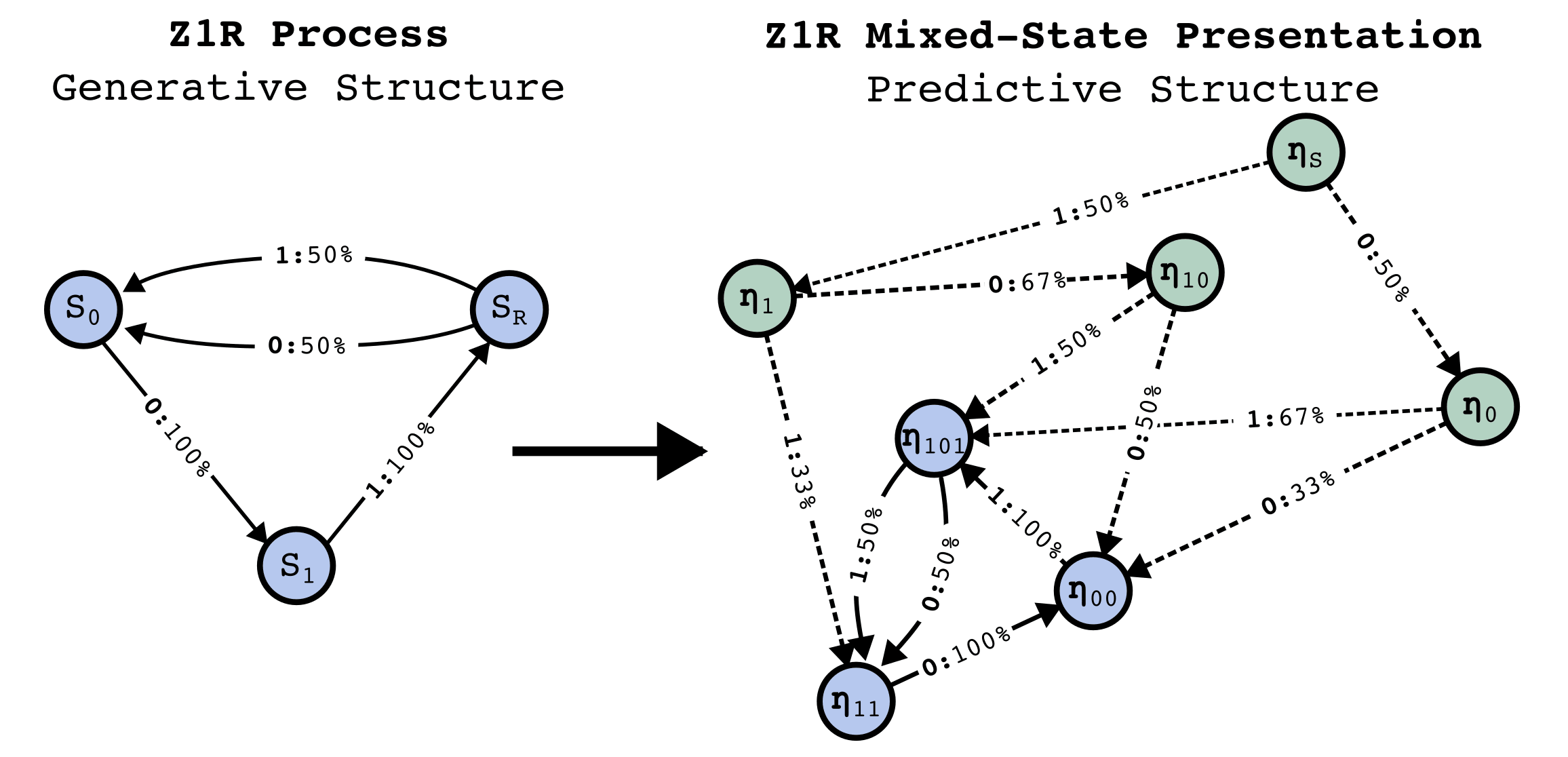
Note that the MSP has transitory states (in green above) that lead to a recurrent set of belief states that are isomorphic to the data-generating process - this always happens, though there might be infinite transitory states. Synchronization is the process of moving through the transitory states towards convergence to the data-generating process.
A lesson from Computational Mechanics is that in order to perform optimal prediction of the next token based on observing a finite-length history of tokens, one must implement the Mixed-State Presentation (MSP). That is to say, to predict the next token well one should know what state the data-generating process is in as best as possible, and to know what state the data-generating process is in, implement the MSP.
The MSP has a geometry associated with it, given by plotting the belief-state values on a simplex. In general, if our data generating process has N states, then probability distributions over those states will have degrees of freedom, and since all probabilities must be between 0 and 1, all possible belief distributions lie on an simplex. In the case of Z1R, that means a 2-simplex (i.e. a triangle). We can plot each of our possible belief states in this 2-simplex, as shown on the right below.
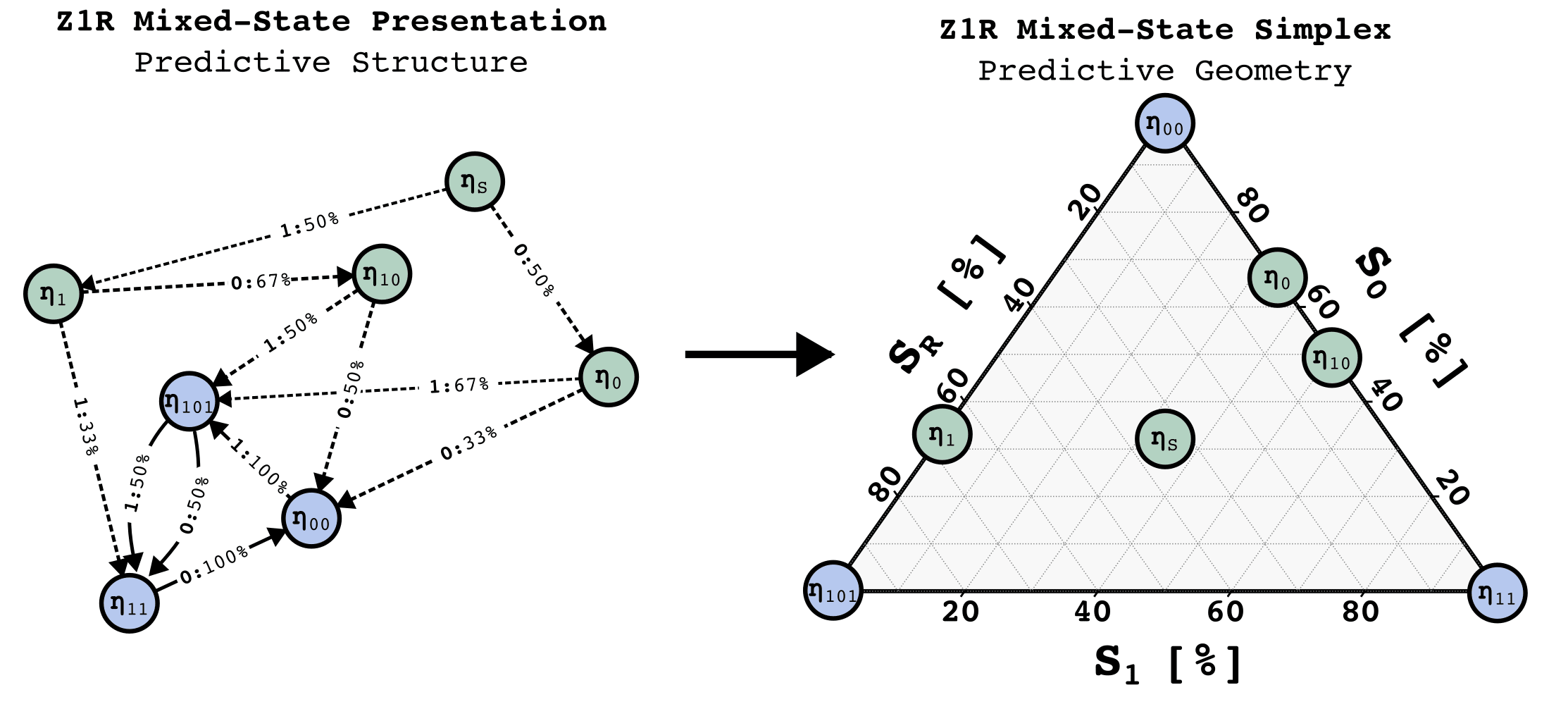
What we show in this post is that when we train a transformer to do next token prediction on data generated from the 3-state HMM, we can find a linear representation of the MSP geometry in the residual stream. This is surprising! Note that the points on the simplex, the belief states, are not the next token probabilities. In fact, multiple points here have literally the same next token predictions. In particular, in this case, , , and , all have the same optimal next token predictions.
Another way to think about this claim is that transformers keep track of distinctions in anticipated distribution over the entire future, beyond distinctions in next token predictions, even though the transformer is only trained explicitly on next token prediction! That means the transformer is keeping track of extra information than what is necessary just for the local next token prediction.
Another way to think about our claim is that transformers perform two types of inference: one to infer the structure of the data-generating process, and another meta-inference to update it's internal beliefs over which state the data-generating process is in, given some history of finite data (ie the context window). This second type of inference can be thought of as the algorithmic or computational structure of synchronizing to the hidden structure of the data-generating process.
A final theoretical note about Computational Mechanics and the theory presented here: because Computational Mechanics is not contingent on the specifics of transformer architectures and is a well-developed first-principles framework, we can apply this framework to any optimal predictor, not just transformers[7].
Experiment and Results
Experimental Design
To repeat the question we are trying to answer:
What computational structure are we building into LLMs when we train them on next-token prediction?
To test our theoretical predictions, we designed an experiment with the following steps:
- Generate training data from a known HMM structure, specifically the 3-state HMM described in the "Data-Generating Process and MSP" section below.
- Train a transformer on this data to perform next-token prediction. In the experiments shown here we use a 4-layer transformer with 64 dimensional residual stream, and 4 attention heads per layer.
- Analyze the final layer of the transformer's residual stream to look for a linear subspace with a geometry matching the predicted fractal structure of the Mixed-State Presentation (MSP).
By controlling the structure of the training data using an HMM, we can make concrete, falsifiable predictions about the computational structure the transformer should implement during inference. Computational Mechanics, as presented in the "Theoretical Framework" section above, provides the framework for making these predictions based on the HMM's structure.
The specific HMM we chose has an MSP with an infinite fractal geometry, serving as a highly non-trivial prediction about what we should find in the transformer's residual stream activations if our theory is correct.
The Data-Generating Process and MSP
For this experiment we trained a transformer on data generated by a simple HMM, called the Mess3 Process, that has just 3 hidden states[8]. Moving between the 3 hidden states according to the emission probabilities on the edges generates strings over a 3-token vocabulary: {A, B, C}. The HMM for this data-generating process is given on the left of the figure below.
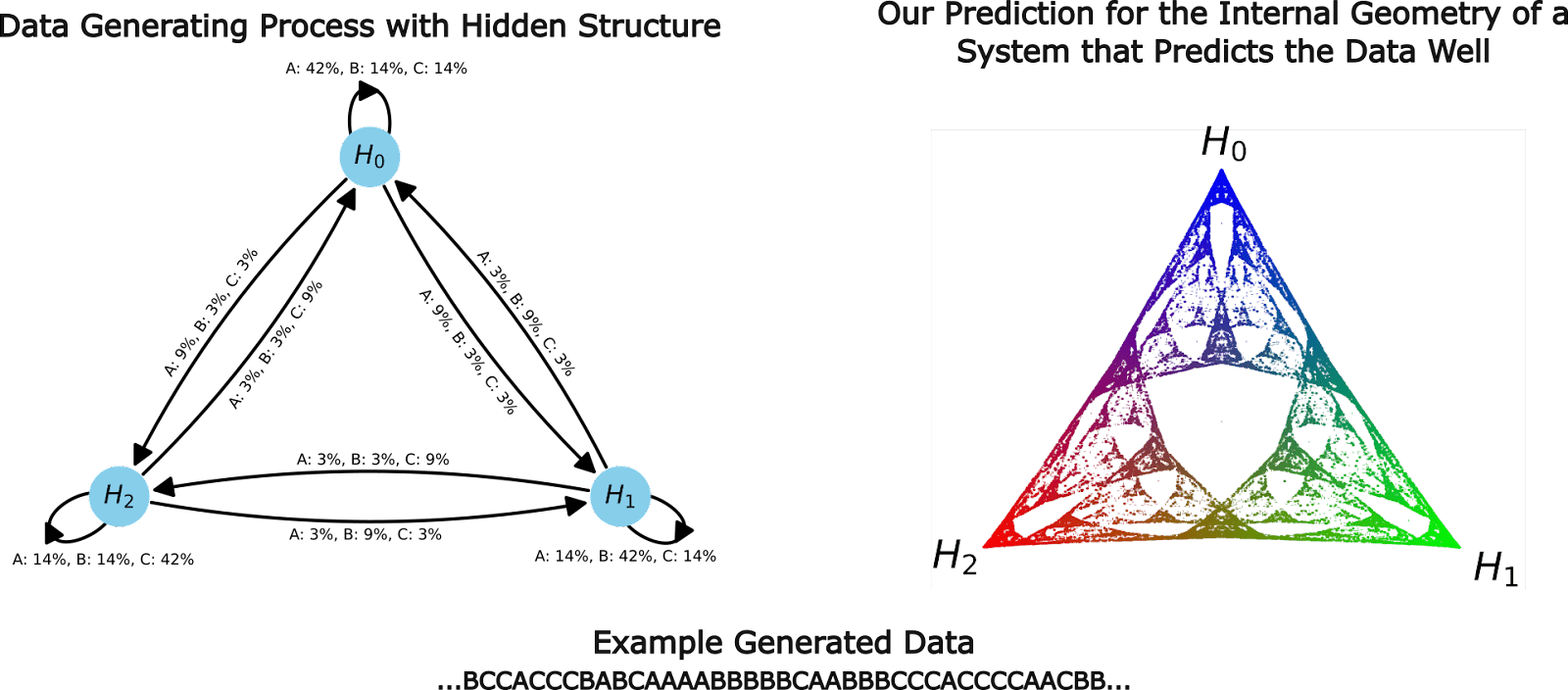
Our approach allows us to make rigorous and testable predictions about the internal structures of transformers. In the case of this HMM, the theory (outlined above) says that transformers trained on this data should instantiate the computational structure associated with the fractal geometry shown on the right of the figure above. Every colored point in the simplex on the above right panel is a distinct belief state.
We chose the Mess3 HMM because it's MSP has an infinite fractal structure, and thus acts as a highly-nontrivial prediction about what geometry we should find in the residual stream.
The Results!
We train a transformer on data generated by the Mess3 HMM. We look in the final layer of the residual stream and find a linear 2D subspace where activations have a structure remarkably similar to that of our predicted fractal. We do this by performing standard linear regression from the residual stream activations (64 dimensional vectors) to the belief distributions (3 dimensional vectors) which associated with them in the MSP.
We can also look at how this structure emerges over training, which shows (1) that the structure we find is not trivial[9] since it doesn’t exist in detail early in training, and (2) the step-wise refinement of the transformers activations to the fractal structure we predict.
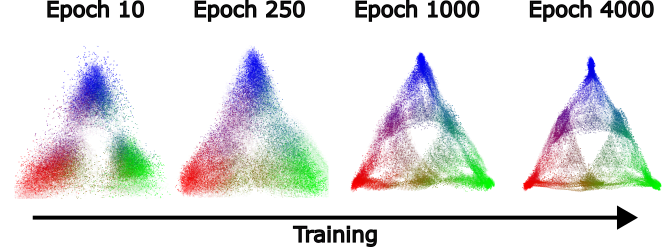
A movie of this process is shown below. Because we used Stochastic Gradient Descent for training, the 2D projection of the activations wiggles, even after training has converged. In this wiggling you can see that fractal structures remain intact.
Limitations and Next Steps
Limitations
- Presented here was one simple data structure given by an HMM with 3 states, with a vocab size of 3. In practice, the LLMs that currently exist are much larger, have vocab sizes of >50,000, and natural language has infinite Markov order. Though we've tested this theory on other HMMs and everything continues to work, all tests so far have been on similarly small examples. How this relates to larger, more complicated, and more realistic settings is unknown (but we have ideas!).
- Though we haven't focused on it in this post, the MSP is an input-driven dynamical system. For each possible input in the system, we have dynamics that determine where in the belief simplex one should move to given the current belief. We have not explicitly tested that the LLM instantiates these dynamics, and instead have only tested that the belief states and their geometry is represented in the transformer.
- Computational Mechanics is primarily a story about optimal prediction. LLMs in practice won't be literally optimal. A number of papers exist studying near-optimality, non-optimality, and rate-distortion phenomenon from the point of view of Computational Mechanics, but applying that to LLMs has not been done.
- We have focused on ergodic and stationary processes in the work presented here. Computational Mechanics can relax those assumptions, but again, we have not applied those (very interesting!) extensions of Computational Mechanics to LLMs. Non-ergodicity, in particular, is likely at the heart of in-context learning.
- In the experiment presented in this post we focussed on the final layer of the residual stream, right before the unembedding. In other experiments we've run (not presented here), the MSP is not well-represented in the final layer but is instead spread out amongst earlier layers. We think this occurs because in general there are groups of belief states that are degenerate in the sense that they have the same next-token distribution. In that case, the formalism presented in this post says that even though the distinction between those states must be represented in the transformers internal, the transformer is able to lose those distinctions for the purpose of predicting the next token (in the local sense), which occurs most directly right before the unembedding.
Next Steps
- We are hopeful that the framing presented in this post provides a formal handle on data structure, internal network structure, and network behavior.
- There are many open questions about how this work relates to other technical AI Safety work. I'll list a few ideas very quickly, and expand on these and more in future posts. In particular:
- What is the relationship between features and circuits, as studied in Mechanistic Interpretability, and the Mixed-State Geometry?
- Is there a story about superposition and compression of the MSP in cases where the residual stream is too small to "fit" the MSP.
- Can we relate the development of MSP geometric structure over training to phenomenon in SLT? see Towards Developmental Interpretability [LW · GW]
- Can we use our formalism to operationalize particular capabilities (in-context learning, out-of-distribution generalization, situational awareness, sleeper agents, etc.) and study them in toy models from our framework?
- Can we use our formalism to understand task structure and how distinct tasks relate to each other? see A starting point for making sense of task structure (in machine learning) [LW · GW]
- As mentioned in the Limitations section, how MSP structures in transformers divide across the layers of the transformer, and how the functional form of the attention mechanism relates to that is an obvious next step.
- We will be releasing a python library soon to be able to perform these types of experiments. Here is the github repo.
- Computational Mechanics is a well-developed framework, and this post has only focused on one small section of it. In the future we hope to bring other aspects of it to bear on neural networks and safety issues, and also to expand Computational Mechanics and combine it with other methods and frameworks.
- If you're interested in learning more about Computational Mechanics, we recommend starting with these papers: Shalizi and Crutchfield (2000), Riechers and Crutchfield (2018a), and Riechers and Crutchfield (2018b)
- We (Paul and Adam) have received funding to start a new AI Safety research org, called Simplex! Presented here was one small facet of the type of work we hope to do, and very much only the beginning. Stay tuned for posts that outline our broader vision in the future.
- In about a month we will be teaming up with Apart to run a Hackathon! We will post about that soon as well, alongside an open problems post, and some more resources to run experiments.
- There's a lot of work to do going forward! This research plan has many parts that span the highly mathematical/theoretical to experimental. If you are interested in being a part of this please have a low threshold for reaching out!
- ^
PIBBSS is hiring [LW · GW]! I wholeheartedly recommend them as an organization.
- ^
One way to conceptualize this is to think of "the world" as having some hidden structure (initially unknown to you), that emits observables. Our task is then to take sequences of observables and infer the hidden structure of the world - maybe in the service of optimal future prediction, but also maybe just because figuring out how the world works is inherently interesting. Inside of us, we have a "world model" that serves as the internal structure that let's us "understand" the hidden structure of the world. The term world model is contentious and nothing in this post depends on that concept much. However, one motivation for this work is to formalize and make concrete statements about peoples intuitions and arguments regarding neural networks and world models - which are often handwavy and ill-defined.
- ^
Technically speaking, the term process refers to a probability distribution over infinite strings of tokens, while a presentation refers to a particular HMM that produces strings according to the probability distribution. A process has an infinite number of presentations.
- ^
Any HMM defines a probability distribution over infinite sequences of the emissions.
- ^
Our initial belief distribution, in this particular case, is the uniform distribution over the 3 states of the data generating process. However this is not always the case. In general the initial belief distribution is given by the stationary distribution of the data generating HMM.
- ^
You can find the answer in section IV of this paper by @Paul Riechers [LW · GW].
- ^
There is work in Computational Mechanics that studies non-optimal or near-optimal prediction, and the tradeoffs one incurs when relaxing optimality. This is likely relevant to neural networks in practice. See Marzen and Crutchfield 2021 and Marzen and Crutchfield 2014.
- ^
This process is called the mess3 process, and was defined in a paper by Sarah Marzen and James Crutchfield. In the work presented we use x=0.05, alpha=0.85.
- ^
We've also run another control where we retain the ground truth fractal structure but shuffle which inputs corresponds to which points in the simplex (you can think of this as shuffling the colors in the ground truth plot). In this case when we run our regression we get that every residual stream activation is mapped to the center point of the simplex, which is the center of mass of all the points.
100 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2024-04-19T07:59:33.163Z · LW(p) · GW(p)
Is it accurate to summarize the headline result as follows?
- Train a Transformer to predict next tokens on a distribution generated from an HMM.
- One optimal predictor for this data would be to maintain a belief over which of the three HMM states we are in, and perform Bayesian updating on each new token. That is, it maintains .
- Key result: A linear probe on the residual stream is able to reconstruct .
(I don't know what Computational Mechanics or MSPs are so this could be totally off.)
EDIT: Looks like yes. From this post [LW · GW]:
Replies from: adam-shai, eggsyntaxPart of what this all illustrates is that the fractal shape is kinda… baked into any Bayesian-ish system tracking the hidden state of the Markov model. So in some sense, it’s not very surprising to find it linearly embedded in activations of a residual stream; all that really means is that the probabilities for each hidden state are linearly represented in the residual stream.
↑ comment by Adam Shai (adam-shai) · 2024-04-19T17:08:13.076Z · LW(p) · GW(p)
That is a fair summary.
comment by Chris_Leong · 2024-04-17T00:55:30.502Z · LW(p) · GW(p)
"The structure of synchronization is, in general, richer than the world model itself. In this sense, LLMs learn more than a world model" given that I expect this is the statement that will catch a lot of people's attention.
Just in case this claim caught anyone else's attention, what they mean by this is that it contains:
• A model of the world
• A model of the agent's process for updating its belief about which state the world is in
↑ comment by snewman · 2024-05-01T21:54:39.944Z · LW(p) · GW(p)
I am trying to wrap my head around the high-level implications of this statement. I can come up with two interpretations:
- What LLMs are doing is similar to what people do as they go about their day. When I walk down the street, I am simultaneously using visual and other input to assess the state of the world around me ("that looks like a car"), running a world model based on that assessment ("the car is coming this way"), and then using some other internal mechanism to decide what to do ("I'd better move to the sidewalk").
- What LLMs are doing is harder than what people do. When I converse with someone, I have some internal state, and I run some process in my head – based on that state – to generate my side of the conversation. When an LLM converses with someone, instead of maintaining internal state, needs to maintain a probability distribution over possible states, make next-token predictions according to that distribution, and simultaneously update the distribution.
(2) seems more technically correct, but my intuition dislikes the conclusion, for reasons I am struggling to articulate. ...aha, I think this may be what is bothering me: I have glossed over the distinction between input and output tokens. When an LLM is processing input tokens, it is working to synchronize its state to the state of the generator. Once it switches to output mode, there is no functional benefit to continuing to synchronize state (what is it synchronizing to?), so ideally we'd move to a simpler neural net that does not carry the weight of needing to maintain and update a probability distribution of possible states. (Glossing over the fact that LLMs as used in practice sometimes need to repeatedly transition between input and output modes.) LLMs need the capability to ease themselves into any conversation without knowing the complete history of the participant they are emulating, while people have (in principle) access to their own complete history and so don't need to be able to jump into a random point in their life and synchronize state on the fly.
So the implication is that the computational task faced by an LLM which can emulate Einstein is harder than the computational task of being Einstein... is that right? If so, that in turn leads to the question of whether there are alternative modalities for AI which have the advantages of LLMs (lots of high-quality training data) but don't impose this extra burden. It also raises the question of how substantial this burden is in practice, in particular for leading-edge models.
Replies from: penguinagen↑ comment by AlbertGarde (penguinagen) · 2024-05-13T17:59:37.941Z · LW(p) · GW(p)
You are drawing a distinction between agents that maintain a probability distribution over possible states and those that don't and you're putting humans in the latter category. It seems clear to me that all agents are always doing what you describe in (2), which I think clears up what you don't like about it.
It also seems like humans spend varying amounts of energy on updating probability distributions vs. predicting within a specific model, but I would guess that LLMs can learn to do the same on their own.
Replies from: snewman↑ comment by snewman · 2024-05-13T18:05:52.986Z · LW(p) · GW(p)
As I go about my day, I need to maintain a probability distribution over states of the world. If an LLM tries to imitate me (i.e. repeatedly predict my next output token), it needs to maintain a probability distribution, not just over states of the world, but also over my internal state (i.e. the state of the agent whose outputs it is predicting). I don't need to keep track of multiple states that I myself might be in, but the LLM does. Seems like that makes its task more difficult?
Or to put an entirely different frame on the the whole thing: the job of a traditional agent, such as you or me, is to make intelligent decisions. An LLM's job is to make the exact same intelligent decision that a certain specific actor being imitated would make. Seems harder?
Replies from: Brent↑ comment by Brent · 2024-05-23T21:05:15.874Z · LW(p) · GW(p)
I agree with you that the LLM's job is harder, but I think that has a lot to do with the task being given to the human vs. LLM being different in kind. The internal states of a human (thoughts, memories, emotions, etc) can be treated as inputs in the same way vision and sound are. A lot of the difficulty will come from the LLM being given less information, similar to how a human who is blindfolded will have a harder time performing a task where vision would inform what state they are in. I would expect if an LLM was given direct access to the same memories, physical senations, emotions, etc of a human (making the task more equivalent) it could have a much easier time emulating them.
Another analogy for what I'm trying to articulate, imagine a set of twins swapping jobs for the day, they would have a much harder time trying to imitate the other than imitate themselves. Similarly, a human will have a harder time trying to make the same decisions an LLM would make, than the LLM just being itself. The extra modelling of missing information will always make things harder. Going back to your Einstein example, this has the interesting implication that the computational task of an LLM emulating Einstein may be a harder task than an LLM just being a more intelligent agent than Einstein.
Replies from: snewman↑ comment by snewman · 2024-05-24T00:19:11.365Z · LW(p) · GW(p)
I think we're saying the same thing? "The LLM being given less information [about the internal state of the actor it is imitating]" and "the LLM needs to maintain a probability distribution over possible internal states of the actor it is imitating" seem pretty equivalent.
comment by Jett Janiak (jett) · 2024-05-17T10:08:29.713Z · LW(p) · GW(p)
This is such a cool result! I tried to reproduce it in this notebook
comment by johnswentworth · 2024-04-17T01:35:03.240Z · LW(p) · GW(p)
[EDIT: I no longer endorse this response, see thread.]
(This comment is mainly for people other than the authors.)
If your reaction to this post is "hot damn, look at that graph", then I think you should probably dial back your excitement somewhat. IIUC the fractal structure is largely an artifact of how the data is visualized, which means the results visually look more striking than they really are.
It is still a cool piece of work, and the visuals are beautiful. The correct amount of excitement is greater than zero.
Replies from: Vladimir_Nesov, adam-shai↑ comment by Vladimir_Nesov · 2024-04-17T16:14:19.766Z · LW(p) · GW(p)
To me the consequences of this response were more valuable than the-post-without-this-response, since it led to the clarification [LW(p) · GW(p)] by the post's author on a crucial point that wasn't clear in the post and reframed it substantially. And once that clarification arrived, this thread ceased being highly upvoted, which seems the opposite of the right thing to happen.
I no longer endorse this response
(So it's a case where value of content in hindsight disagrees with value of the consequences of its existence. Doesn't even imply there was originally an error, without the benefit of hindsight.)
↑ comment by Adam Shai (adam-shai) · 2024-04-17T01:42:42.672Z · LW(p) · GW(p)
Can you elaborate on how the fractal is an artifact of how the data is visualized?
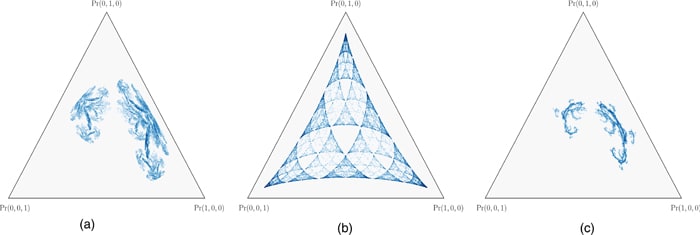
From my perspective, the fractal is there because we chose this data generating structure precisely because it has this fractal pattern as it's Mixed State Presentation (ie. we chose it because then the ground truth would be a fractal, which felt like highly nontrivial structure to us, and thus a good falsifiable test that this framework is at all relevant for transformers. Also, yes, it is pretty :) ). The fractal is a natural consequence of that choice of data generating structure - it is what Computational Mechanics says is the geometric structure of synchronization for the HMM. That there is a linear 2d plane in the residual stream that when you project onto it you get that same fractal seems highly non-artifactual, and is what we were testing.
Though it should be said that an HMM with a fractal MSP is a quite generic choice. It's remarkably easy to get such fractal structures. If you randomly chose an HMM from the space of HMMs for a given number of states and vocab size, you will often get synchronizations structures with infinite transient states and fractals.
This isn't a proof of that previous claim, but here are some examples of fractal MSPs from https://arxiv.org/abs/2102.10487:
↑ comment by johnswentworth · 2024-04-17T02:18:30.450Z · LW(p) · GW(p)
Can you elaborate on how the fractal is an artifact of how the data is visualized?
I don't know the details of the MSP, but my current understanding is that it's a general way of representing stochastic processes, and the MSP representation typically looks quite fractal. If we take two approximately-the-same stochastic processes, then they'll produce visually-similar fractals.
But the "fractal-ness" is mostly an artifact of the MSP as a representation-method IIUC; the stochastic process itself is not especially "naturally fractal".
(As I said I don't know the details of the MSP very well; my intuition here is instead coming from some background knowledge of where fractals which look like those often come from, specifically chaos games.)
That there is a linear 2d plane in the residual stream that when you project onto it you get that same fractal seems highly non-artifactual, and is what we were testing.
A thing which is highly cruxy for me here, which I did not fully understand from the post: what exactly is the function which produces the fractal visual from the residual activations? My best guess from reading the post was that the activations are linearly regressed onto some kind of distribution, and then the distributions are represented in a particular way which makes smooth sets of distributions look fractal. If there's literally a linear projection of the residual stream into two dimensions which directly produces that fractal, with no further processing/transformation in between "linear projection" and "fractal", then I would change my mind about the fractal structure being mostly an artifact of the visualization method.
Replies from: adam-shai↑ comment by Adam Shai (adam-shai) · 2024-04-17T02:54:55.810Z · LW(p) · GW(p)
Responding in reverse order:
If there's literally a linear projection of the residual stream into two dimensions which directly produces that fractal, with no further processing/transformation in between "linear projection" and "fractal", then I would change my mind about the fractal structure being mostly an artifact of the visualization method.
There is literally a linear projection (well, we allow a constant offset actually, so affine) of the residual stream into two dimensions which directly produces that fractal. There's no distributions in the middle or anything. I suspect the offset is not necessary but I haven't checked ::adding to to-do list::
edit: the offset isn't necessary. There is literally a linear projection of the residual stream into 2D which directly produces the fractal.
But the "fractal-ness" is mostly an artifact of the MSP as a representation-method IIUC; the stochastic process itself is not especially "naturally fractal".
(As I said I don't know the details of the MSP very well; my intuition here is instead coming from some background knowledge of where fractals which look like those often come from, specifically chaos games.)
I'm not sure I'm following, but the MSP is naturally fractal (in this case), at least in my mind. The MSP is a stochastic process, but it's a very particular one - it's the stochastic process of how an optimal observer's beliefs (about which state an HMM is in) change upon seeing emissions from that HMM. The set of optimal beliefs themselves are fractal in nature (for this particular case).
Chaos games look very cool, thanks for that pointer!
comment by johnswentworth · 2024-04-17T21:04:59.638Z · LW(p) · GW(p)
We're now working through understanding all the pieces of this, and we've calculated an MSP which doesn't quite look like the one in the post:
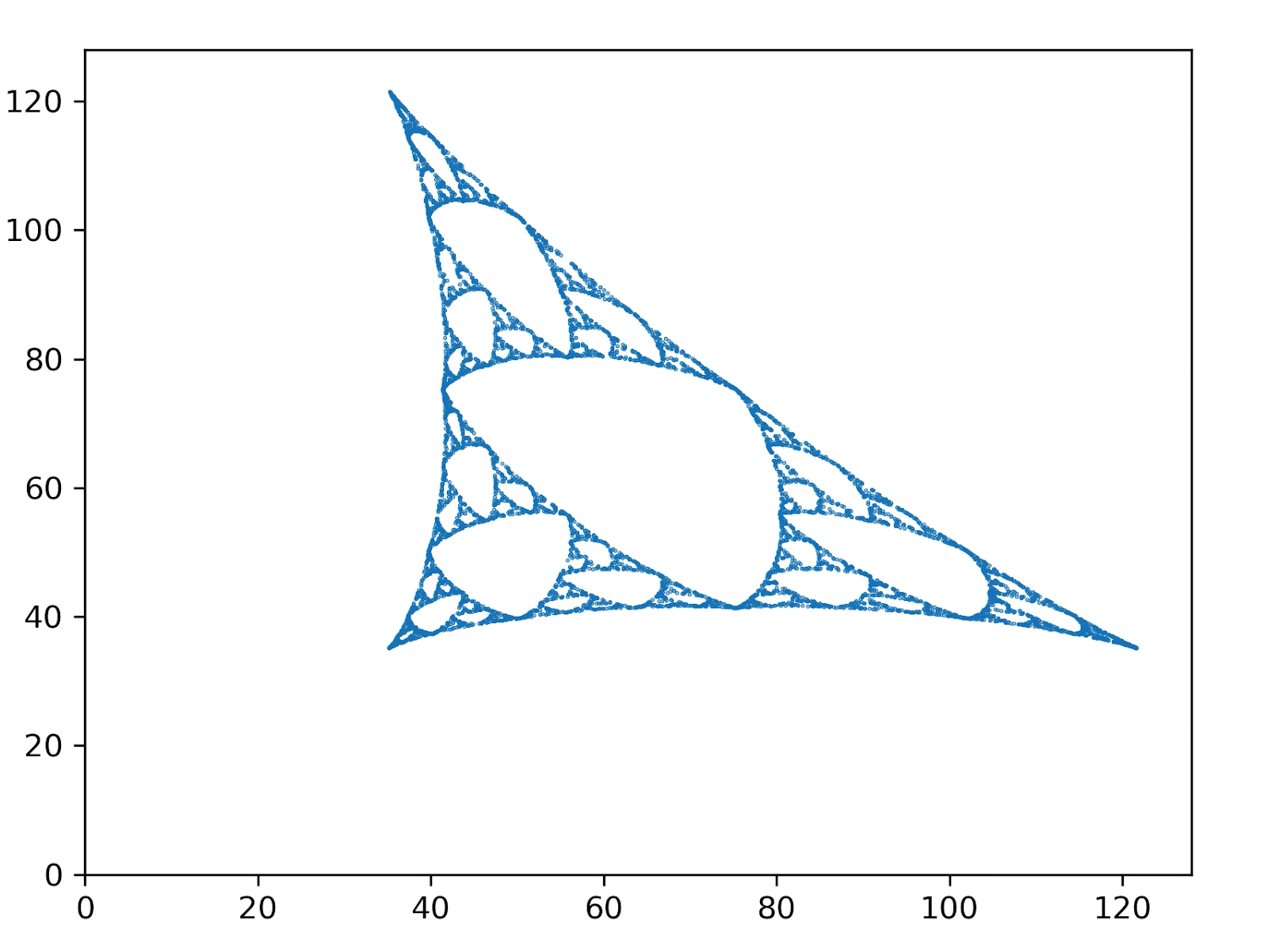
(Ignore the skew, David's still fiddling with the projection into 2D. The important noticeable part is the absence of "overlap" between the three copies of the main shape, compared to the fractal from the post.)
Specifically, each point in that visual corresponds to a distribution for some value of the observed symbols . The image itself is of the points on the probability simplex. From looking at a couple of Crutchfield papers, it sounds like that's what the MSP is supposed to be.
The update equations are:
with given by the transition probabilities, given by the observation probabilities, and a normalizer. We generate the image above by running initializing some random distribution , then iterating the equations and plotting each point.
Off the top of your head, any idea what might account for the mismatch (other than a bug in our code, which we're already checking)? Are we calculating the right thing, i.e. values of ? Are the transition and observation probabilities from the graphic in the post the same parameters used to generate the fractal? Is there some thing which people always forget to account for when calculating these things?
Replies from: adam-shai, adam-shai↑ comment by Adam Shai (adam-shai) · 2024-04-17T22:03:21.123Z · LW(p) · GW(p)
Everything looks right to me! This is the annoying problem that people forget to write the actual parameters they used in their work (sorry).
Try x=0.05, alpha=0.85. I've edited the footnote with this info as well.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-04-17T22:25:12.060Z · LW(p) · GW(p)
Yup, that was it, thankyou!
↑ comment by Adam Shai (adam-shai) · 2024-04-17T22:13:09.078Z · LW(p) · GW(p)
Oh wait one thing that looks not quite right is the initial distribution. Instead of starting randomly we begin with the optimal initial distribution, which is the steady-state distribution. Can be computed by finding the eigenvector of the transition matrix that has an eigenvalue of 1. Maybe in practice that doesn't matter that much for mess3, but in general it could.
Replies from: jett↑ comment by Jett Janiak (jett) · 2024-05-17T09:47:28.554Z · LW(p) · GW(p)
For the two sets of mess3 parameters I checked the stationary distribution was uniform.
comment by ChrisCundy · 2024-04-17T06:10:09.669Z · LW(p) · GW(p)
The figures remind me of figures 3 and 4 from Meta-learning of Sequential Strategies, Ortega et al 2019, which also study how autoregressive models (RNNs) infer underlying structure. Could be a good reference to check out!
.
↑ comment by Adam Shai (adam-shai) · 2024-04-17T15:39:13.118Z · LW(p) · GW(p)
this looks highly relevant! thanks!
Replies from: ran-wei↑ comment by Ran W (ran-wei) · 2024-04-18T15:53:24.655Z · LW(p) · GW(p)
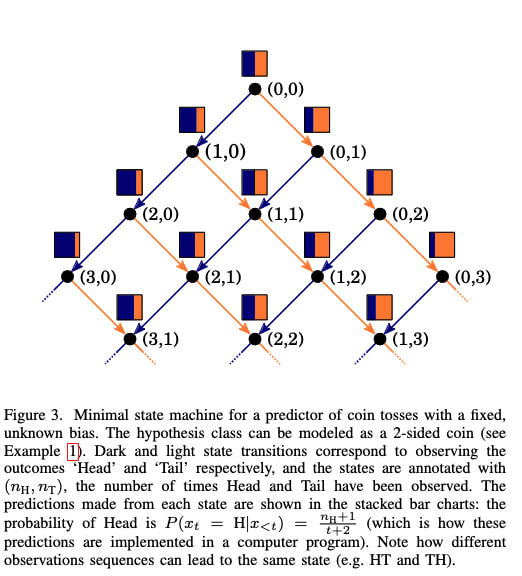
This reminds me of the paper Chris linked as well. I think there's very solid evidence on the relationship between the kind of meta learning Transformers go through and Bayesian inference (e.g., see this, this, and this). The main question I have been thinking about is what is a state for language and how that can be useful if so discovered in this way? For state-based RL/control tasks this seems relatively straightforward (e.g., see this and this), but this is much less clear for more abstract tasks. It'd be great to hear your thoughts!
Replies from: gwern↑ comment by gwern · 2024-05-09T01:59:04.185Z · LW(p) · GW(p)
My earlier comment on meta-learning and Bayesian RL/inference for background: https://www.lesswrong.com/posts/TiBsZ9beNqDHEvXt4/how-we-picture-bayesian-agents?commentId=yhmoEbztTunQMRzJx [LW(p) · GW(p)]
The main question I have been thinking about is what is a state for language and how that can be useful if so discovered in this way?
The way I would put it is that 'state' is misleading you here. It makes you think that it must be some sort of little Turing machine or clockwork, where it has a 'state', like the current state of the Turing machine tape or the rotations of each gear in a clockwork gadget, where the goal is to infer that. This is misleading, and it is a coincidence in these simple toy problems, which are so simple that there is nothing to know beyond the actual state.
As Ortega et al highlights in those graphs, what you are really trying to define is the sufficient statistics: the summary of the data (history) which is 100% adequate for decision making, and where additionally knowing the original raw data doesn't help you.
In the coin flip case, the sufficient statistics are simply the 2-tuple (heads,tails), and you define a very simple decision over all of the possible observed 2-tuples. Note that the sufficient statistic is less information than the original raw "the history", because you throw out the ordering. (A 2-tuple like '(3,1)' is simpler than all of the histories it summarizes, like '[1,1,1,0]', '[0,1,1,1]'. '[1,0,1,1]', etc.) From the point of view of decision making, these all yield the same posterior distribution over the coin flip probability parameter, which is all you need for decision making (optimal action: 'bet on the side with the higher probability'), and so that's the sufficient statistic. If I tell you the history as a list instead of a 2-tuple, you cannot make better decisions. It just doesn't matter if you got a tails first and then all heads, or all heads first then tails, etc.
It is not obvious that this is true: a priori, maybe that ordering was hugely important, and those correspond to different games. But the RNN there has learned that the differences are not important, and in fact, they are all the same.
And the 2-tuple here doesn't correspond to any particular environment 'state'. The environment doesn't need to store that anywhere. The environment is just a RNG operating according to the coin flip probability, independently every turn of the game, with no memory. There is nowhere which is counting heads & tails in a 2-tuple. That exists solely in the RNN's hidden state as it accumulates evidence over turns, and optimally updates priors to posteriors every observed coin flip, and possibly switches its bet.
So, in language tasks like LLMs, they are the same thing, but on a vastly grander scale, and still highly incomplete. They are (trying to) infer sufficient statistics of whatever language-games they have been trained on, and then predicting accordingly.
What are those sufficient statistics in LLMs? Hard to say. In that coinflip example, it is so simple that we can easily derive by hand the conjugate statistics and know it is just a binomial and so we only need to track heads/tails as the one and only sufficient statistic, and we can then look in the hidden state to find where that is encoded in a converged optimal agent. In LLMs... not so much. There's a lot going on.
Based on interpretability research and studies of how well they simulate people as well as just all of the anecdotal experience with the base models, we can point to a few latents like honesty, calibration, demographics, and so on. (See Janus's "Simulator Theory" for a more poetic take, less focused on agency than the straight Bayesian meta-imitation learning take I'm giving here.) Meanwhile, there are tons of things about the inputs that the model wants to throw away, irrelevant details like the exact mispellings of words in the prompt (while recording that there were mispellings, as grist for the inference mill about the environment generating the mispelled text).
So conceptually, the sufficient statistics when you or I punch in a prompt to GPT-3 might look like some extremely long list of variables like, "English speaker, Millennial, American, telling the truth, reliable, above-average intelligence, Common Crawl-like text not corrupted by WET processing, shortform, Markdown formatting, only 1 common typo or misspelling total, ..." and it will then tailor responses accordingly and maximize its utility by predicting the next token accurately (because the 'coin flip' there is simply betting on the logits with the highest likelihood etc). Like the coinflip 2-tuple, most of these do not correspond to any real-world 'state': if you or I put in a prompt, there is no atom or set of atoms which corresponds to many of these variables. But they have consequences: if we ask about Tienanmen Square, for example, we'll get a different answer than if we had asked in Mandarin, because the sufficient statistics there are inferred to be very different and yield a different array of latents which cause different outputs.
And that's what "state" is for language: it is the model's best attempt to infer a useful set of latent variables which collectively are sufficient statistics for whatever language-game or task or environment or agent-history or whatever the context/prompt encodes, which then supports optimal decision-making.
comment by aysja · 2024-04-18T05:17:57.197Z · LW(p) · GW(p)
This is very cool! I’m excited to see where it goes :)
A couple questions (mostly me grappling with what the implications of this work might be):
- Given a dataset of sequences of tokens, how do you find the HMM that could have generated it, and can this be done automatically? Also, is the mapping from dataset to HMM unique?
- This question is possibly more confused on my end, sorry if so. I’m trying to get at something like “how interpretable will these simplexes be with much larger models?” Like, if I’m imagining that each state is a single token, and the HMM is capable of generating the totality of data the model sees, then I’m imagining something quite unwieldy, i.e., something with about the amount of complexity and interpretability as, e.g., the signaling cascade networks in a cell. Is this imagination wrong? Or is it more like, you start with this unwieldy structure (but which has some nice properties nonetheless), and then from there you try to make the initial structure more parse-able? Maybe a more straightforward way to ask: you say you’re interested in formalizing things like situational awareness with these tools—how might that work?
↑ comment by Adam Shai (adam-shai) · 2024-04-18T21:55:59.382Z · LW(p) · GW(p)
Thanks!
- one way to construct an HMM is by finding all past histories of tokens that condition the future tokens with the same probablity distribution, and make that equivalence class a hidden state in your HMM. Then the conditional distributions determine the arrows coming out of your state and which state you go to next. This is called the "epsilon machine" in Comp Mech, and it is unique. It is one presentation of the data generating process, but in general there are an infinite number of HMM presntations that would generate the same data. The epsilon machine is a particular type of HMM presentation - it is the smallest one where the hidden states are the minimal sufficient statistics for predicting the future based on the past. The epsilon machine is one of the most fundamental things in Comp Mech but I didn't talk about it in this post. In the future we plan to make a more generic Comp Mech primer that will go through these and other concepts.
- The interpretability of these simplexes is an issue that's in my mind a lot these days. The short answer is I'm still wrestling with it. We have a rough experimental plan to go about studying this issue but for now, here are some related questions I have in my mind:
- What is the relationship between the belief states in the simplex and what mech interp people call "features"?
- What are the information theoretic aspects of natural language (or coding databases or some other interesting training data) that we can instantiate in toy models and then use our understanding of these toy systems to test if similar findings apply to real systems.
For something like situational awareness, I have the beginnings of a story in my head but it's too handwavy to share right now. For something slightly more mundane like out-of-distribution generaliztion or transfer learning or abstraction, the idea would be to use our ability to formalize data-generating structure as HMMs, and then do theory and experiments on what it would mean for a transformer to understand that e.g. two HMMs have similar hidden/abstract structure but different vocabs.

Hopefully we'll have a lot more to say about this kind of thing soon!
Replies from: lillybaeum↑ comment by lillybaeum · 2024-04-22T11:01:33.958Z · LW(p) · GW(p)
The following is text from Claude Opus 3. I generally find people just dumping answers from LLMs to be kind of cringe, but in this case, as I was using it to try to understand the post and your comments better, I came across some really genuinely insightful-feeling stuff and felt as though Claude's input might be helpful to you in some way, and that it would be remiss not to share it. I'm sorry if it's nonsensical, I'm not informed enough on the topic to know.
"Regarding the relationship between belief states and "features", I think there are a few important connections:
-
Belief states can be thought of as the "true features" that optimally compress the information needed for prediction. In the simplex visualizations, each point corresponds to a unique belief state - a particular probabilistic weighting of the possible hidden states of the generator at that point in the sequence. These belief states are the most parsimonious representation of the relevant information for predicting the future.
-
The "features" often discussed in mech interp (e.g. as visualized in attribution maps or extracted by probing classifiers) can be seen as approximations or projections of these true belief states. When we probe an LM's activations and find that certain neurons or directions correspond to interpretable features like "noun-ness" or "sentiment", we're effectively discovering linear projections that approximate some aspect of the true belief state.
-
The topology and geometry of the belief state simplex can give us intuitions about the structure of these feature spaces. For example, the fact that belief states are constrained to a simplex (rather than an unbounded space) suggests that there may be inherent trade-offs or dependencies between different features. The trajectories of belief states through the simplex as a sequence evolves could also inform us about the dynamics of how features interact and compose.
So in a sense, belief states provide a principled foundation for thinking about what the "ideal features" for a given predictive task would be, and mech interp techniques can be seen as ways to approximate or probe these ideal features in real models.
Regarding toy models and information-theoretic aspects, some elements that could bridge between formal systems and natural language are:
-
Temporal dependencies and long-range correlations: Natural language exhibits complex temporal structure at multiple scales (e.g. within sentences, across paragraphs, across documents). Toy sequence models with tunable temporal correlations could help us understand how belief states track and compress these dependencies.
-
Compositionality and recursion: Language exhibits rich compositional structure, where smaller units (morphemes, words, phrases) combine in systematic ways to produce complex meanings. Toy generative grammars or rule systems could help us study how belief states navigate these combinatorial spaces.
-
Stochasticity and entropy: Language is inherently stochastic and exhibits varying levels of predictability (e.g. some words are much more predictable from context than others). Toy models with tunable entropy could help us understand how belief states adapt to different levels of predictability and how this impacts the geometry of the feature space.
-
Hierarchical structure: Language operates at multiple levels of abstraction (e.g. phonology, morphology, syntax, semantics, pragmatics). Toy models with explicit hierarchical structure could illuminate how belief states at different levels interact and compose.
The key idea would be to start with minimally complex toy systems that capture some core information-theoretic property of language, fully characterize the optimal belief states in that system, and then test whether the key signatures (e.g. the topology of the belief state space, the trajectory of dynamics) can be found in real language models trained on natural data.
This could provide a roadmap for building up more and more realistic models while maintaining a principled understanding of the underlying information-theoretic structures. The goal would be to eventually bridge the gap between our understanding of toy systems and the much more complex but often qualitatively similar structures found in real language models.
Of course, this is a highly ambitious research program and there are many challenges to contend with. But I believe this kind of cross-pollination between formal methods like Computational Mechanics and more empirical mech interp work could be very fruitful."
Replies from: alexander-gietelink-oldenziel↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-04-22T11:22:11.309Z · LW(p) · GW(p)
Not at all cringe! This is the age of AI. We either channel its immense power or ignore it at our own peril.
There is no human alive today that is utilizing even last-generation's LLMs at their full potential. We should all be copying, delegating and cyborging much more from, to and with LLM - not less.
comment by habryka (habryka4) · 2024-05-01T18:09:01.638Z · LW(p) · GW(p)
Promoted to curated: Formalizing what it means for transformers to learn "the underlying world model" when engaging in next-token prediction tasks seems pretty useful, in that it's an abstraction that I see used all the time when discussing risks from models where the vast majority of the compute was spent in pre-training, where the details usually get handwaived. It seems useful to understand what exactly we mean by that in more detail.
I have not done a thorough review of this kind of work, but it seems to me that also others thought the basic ideas in the work hold up, and I thought reading this post gave me crisper abstractions to talk about this kind of stuff in the future.
comment by Aprillion · 2024-04-17T07:35:25.472Z · LW(p) · GW(p)
transformer is only trained explicitly on next token prediction!
I find myself understanding language/multimodal transformer capabilities better when I think about the whole document (up to context length) as a mini-batch for calculating the gradient in transformer (pre-)training, so I imagine it is minimizing the document-global prediction error, it wasn't trained to optimize for just a single-next token accuracy...
Replies from: D0TheMath, adam-shai↑ comment by Garrett Baker (D0TheMath) · 2024-04-17T19:04:31.665Z · LW(p) · GW(p)
There is evidence that transformers are not in fact even implicitly, internally, optimized for reducing global prediction error (except insofar as comp-mech says they must in order to do well on the task they are optimized for).
Replies from: ejenner, caffeinumDo transformers "think ahead" during inference at a given position? It is known transformers prepare information in the hidden states of the forward pass at t that is then used in future forward passes t+τ. We posit two explanations for this phenomenon: pre-caching, in which off-diagonal gradient terms present in training result in the model computing features at t irrelevant to the present inference task but useful for the future, and breadcrumbs, in which features most relevant to time step t are already the same as those that would most benefit inference at time t+τ. We test these hypotheses by training language models without propagating gradients to past timesteps, a scheme we formalize as myopic training. In a synthetic data setting, we find clear evidence for pre-caching. In the autoregressive language modeling setting, our experiments are more suggestive of the breadcrumbs hypothesis.
↑ comment by Erik Jenner (ejenner) · 2024-04-18T01:57:01.291Z · LW(p) · GW(p)
I think that paper is some evidence that there's typically no huge effect from internal activations being optimized for predicting future tokens (on natural language). But I don't think it's much (if any) evidence that this doesn't happen to some small extent or that it couldn't be a huge effect on certain other natural language tasks.
(In fact, I think the myopia gap is probably the more relevant number than the local myopia bonus, in which case I'd argue the paper actually shows a pretty non-trivial effect, kind of contrary to how the authors interpret it. But I haven't read the paper super closely.)
Also, sounds like you're aware of this, but I'd want to highlight more that the paper does demonstrate internal activations being optimized for predicting future tokens on synthetic data where this is necessary. So, arguably, the main question is to what extent natural language data incentivizes this rather than being specifically about what transformers can/tend to do.
In that sense, thinking of transformer internals as "trying to" minimize the loss on an entire document might be exactly the right intuition empirically (and the question is mainly how different that is from being myopic on a given dataset). Given that the internal states are optimized for this, that would also make sense theoretically IMO.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-04-18T03:02:08.677Z · LW(p) · GW(p)
+1 to this comment, also I expect the importance of activations being optimized for predicting future tokens to increase considerably with scale. (E.g., GPT-4 level compute maybe just gets you a GPT-3 level model if you enforce no such optimization with a stop grad.)
↑ comment by Aleksey Bykhun (caffeinum) · 2024-04-23T03:10:44.081Z · LW(p) · GW(p)
I have tried to play with Claude – I would ask it to think of a number, drop the hint, and only then print the number. It should have test the ability to have "hidden memory" that's outside the text.
I expected it to be able to do that, but the hints to be too obvious. Instead, actually it failed multiple times in a row!
Sharing cause I liked the experiment but wasn't sure if I executed it properly. There might be a way to do more of this.
P.S. I have also tried "print hash, and then preimage" – but this turned out to be even harder for him
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2024-04-23T03:22:15.095Z · LW(p) · GW(p)
Post the chat logs?
↑ comment by Adam Shai (adam-shai) · 2024-04-17T18:42:32.194Z · LW(p) · GW(p)
That's an interesting framing. From my perspective that is still just local next-token accuracy (cross-entropy more precisely), but averaged over all subsets of the data up to the context length. That is distinct from e.g. an objective function that explicitly mentioned not just next-token prediction, but multiple future tokens in what was needed to minimize loss. Does that distinction make sense?
One conceptual point I'd like to get across is that even though the equation for the predictive cross-entropy loss only has the next token at a given context window position in it, the states internal to the transformer have the information for predictions into the infinite future.
This is a slightly different issue than how one averages over training data, I think.
Replies from: Aprillion↑ comment by Aprillion · 2024-04-18T14:12:57.483Z · LW(p) · GW(p)
To me as a programmer and not a mathematitian, the distinction doesn't make practical intuitive sense.
If we can create 3 functions f, g, h so that they "do the same thing" like f(a, b, c) == g(a)(b)(c) == average(h(a), h(b), h(c)), it seems to me that cross-entropy can "do the same thing" as some particular objective function that would explicitly mention multiple future tokens.
My intuition is that cross-entropy-powered "local accuracy" can approximate "global accuracy" well enough in practice that I should expect better global reasoning from larger model sizes, faster compute, algorithmic improvements, and better data.
Implications of this intuition might be:
- myopia is a quantity not a quality, a model can be incentivized to be more or less myopic, but I don't expect it will be proven possible to enforce it "in the limit"
- instruct training on longer conversations outght to produce "better" overall conversations if the model simulates that it's "in the middle" of a conversation and follow-up questions are better compared to giving a final answer "when close to the end of this kind of conversation"
What nuance should I consider to understand the distinction better?
comment by cousin_it · 2024-04-20T09:46:38.108Z · LW(p) · GW(p)
I have maybe a naive question. What information is needed to find the MSP image within the neural network? Do we have to know the HMM to begin with? Or could it be feasible someday to inspect a neural network, find something that looks like an MSP image, and infer the HMM from it?
comment by Leon Lang (leon-lang) · 2024-04-17T17:17:47.891Z · LW(p) · GW(p)
I really enjoyed reading this post! It's quite well-written. Thanks for writing it.
The only critique is that I would have appreciated more details on how the linear regression parameters are trained and what exactly the projection is doing. John's thread is a bit clarifying on this.
One question: If you optimize the representation in the residual stream such that it corresponds to a particular chosen belief state, does the transformer than predict the next token as if in that belief state? I.e., does the transformer use the belief state for making predictions?
Replies from: adam-shai↑ comment by Adam Shai (adam-shai) · 2024-04-17T18:26:48.089Z · LW(p) · GW(p)
Thanks! I appreciate the critique. From this comment and from John's it seems correct and I'll keep it in mind for the future.
On the question, by optimize the representation do you mean causally intervene on the residual stream during inference (e.g. a patching experiment)? Or do you mean something else that involves backprop? If the first, then we haven't tried, but definitely want to! It could be something someone does at the Hackathon, if interested ;)
Replies from: leon-lang↑ comment by Leon Lang (leon-lang) · 2024-04-17T20:46:26.981Z · LW(p) · GW(p)
Yes the first! Thanks for the link!
comment by eggsyntax · 2024-04-19T23:52:22.530Z · LW(p) · GW(p)
I struggled with the notation on the figures; this comment tries to clarify a few points for anyone else who may be confused by it.
- There are three main diagrams to pay attention to in order to understand what's going on here:
- The Z1R Process (this is a straightforward Hidden Markov Model diagram, look them up if it's unclear).
- The Z1R Mixed-State Presentation, representing the belief states of a model as it learns the underlying structure.
- The Z1R Mixed-State Simplex. Importantly, unlike the other two this is a graph and spatial placement is meaningful.
- It's better to ignore the numeric labels on the green nodes of the Mixed-State Presentation, at least until you're clear about the rest. These labels are not uniquely determined, so the relationship between the subscripts can be very confusing. Just treat them as arbitrarily labeled distinct nodes whose only importance is the arrows leading in and out of them. Once you understand the rest you can go back and understand the subscripts if you want[1].
- However, it's important to note that the blue nodes are isomorphic to the Z1R Process diagram (n_101 = SR, n_11 = S0, n_00 = S1. Once the model has entered the correct blue node, it will thereafter be properly synchronized to the model. The green nodes are transient belief states that the model passes through on its way to fully learning the model.
- On the Mixed-State Simplex: I found the position on the diagram quite confusing at first. The important thing to remember is that the three corners represent certainty that the underlying process is in the equivalent state (eg the top corner is n_00 = S1). So for example if you look at the position of n_0, it indicates that the model is confident that the underlying process is definitely not in n_101 (SR), since it's as far as possible from that corner. And the model believes that the process is more likely to be in n_00 (S1) than in n_11 (S0). Notice how this corresponds to the arrows leaving n_0 & their probabilities in the Mixed-State Presentation (67% chance of transitioning to n_101, 33% chance of transitioning to n_00).
- Some more detail on n_0 if it isn't clear after the previous paragraph:
- Looking at the mixed-state presentation, if we're in n_0, we've just seen a 0.
- That means that there's a 2/3 chance we're currently in S1, and a 1/3 chance we're currently in S0. And, of course, a 0 chance that we're currently in SR.
- Therefore the point on which n_0 should lie should be maximally far from the SR corner (n_101), and closer to the S1 corner (n_00) than to the S0 corner (n_11). Which is what we in fact see.
@Adam Shai [LW · GW] please correct me if I got any of that wrong!
If anyone else is still confused about how the diagrams work after reading this, please comment! I'm happy to help, and it'll show me what parts of this explanation are inadequate.
- ^
Here's the details if you still want them after you've understood the rest. Each node label represents some path that could be taken to that node (& not to other nodes), but there can be multiple such paths. For example, n_11 could also be labeled as n_010, because those are both sequences that could have left us in that state. So as we take some path through the Mixed-State Presentation, we build up a path. If we start at n_s and follow the 1 path, we get to n_1. If we then follow the 0 path, we reach n_10. If we then follow the 0 path, the next node could be called n_100, reflecting the path we've taken. But in fact any path that ends with 00 will reach that node, so it's just labeled n_00. So initially it seems as though we can just append the symbol emitted by whichever path we take, but often there's some step where that breaks down and you get what initially seems like a totally random different label.
↑ comment by Adam Shai (adam-shai) · 2024-04-20T01:47:05.424Z · LW(p) · GW(p)
This all looks correct to me! Thanks for this.
comment by ChosunOne · 2024-04-17T16:46:40.803Z · LW(p) · GW(p)
I'm curious how much space is left after learning the MSP in the network. Does representing the MSP take up the full bandwidth of the model (even if it is represented inefficiently)? Could you maintain performance of the model by subtracting out the contributions of anything else that isn't part of the MSP?
Replies from: adam-shai↑ comment by Adam Shai (adam-shai) · 2024-04-17T18:24:27.366Z · LW(p) · GW(p)
Cool question. This is one of the things we'd like to explore more going forward. We are pretty sure this is pretty nuanced and has to do with the relationship between the (minimal) state of the generative model, the token vocab size, and the residual stream dimensionality.
One your last question, I believe so but one would have to do the experiment! It totally should be done. check out the Hackathon if you are interested ;)
comment by Nina Panickssery (NinaR) · 2024-04-19T02:13:53.282Z · LW(p) · GW(p)
This is really cool work!!
In other experiments we've run (not presented here), the MSP is not well-represented in the final layer but is instead spread out amongst earlier layers. We think this occurs because in general there are groups of belief states that are degenerate in the sense that they have the same next-token distribution. In that case, the formalism presented in this post says that even though the distinction between those states must be represented in the transformers internal, the transformer is able to lose those distinctions for the purpose of predicting the next token (in the local sense), which occurs most directly right before the unembedding.
Would be interested to see analyses where you show how an MSP is spread out amongst earlier layers.
Presumably, if the model does not discard intermediate results, something like concatenating residual stream vectors from different layers and then linearly correlating with the ground truth belief-state-over-HMM-states vector extracts the same kind of structure you see when looking at the final layer. Maybe even with the same model you analyze, the structure will be crisper if you project the full concatenated-over-layers resid stream, if there is noise in the final layer and the same features are represented more cleanly in earlier layers?
In cases where redundant information is discarded at some point, this is a harder problem of course.
↑ comment by Adam Shai (adam-shai) · 2024-04-19T23:39:02.362Z · LW(p) · GW(p)
Thanks! I'll have more thorough results to share about layer-wise reprsentations of the MSP soon. I've already run some of the analysis concatenating over all layers residual streams with RRXOR process and it is quite interesting. It seems there's a lot more to explore with the relationship between number of states in the generative model, number of layers in the transformer, residual stream dimension, and token vocab size. All of these (I think) play some role in how the MSP is represented in the transformer. For RRXOR it is the case that things look crisper when concatenating.
Even for cases where redundant info is discarded, we should be able to see the distinctions somewhere in the transformer. One thing I'm keen on really exploring is such a case, where we can very concretely follow the path/circuit through which redundant info is first distinguished and then is collapsed.
comment by Sandi · 2024-04-17T20:41:50.970Z · LW(p) · GW(p)
We do this by performing standard linear regression from the residual stream activations (64 dimensional vectors) to the belief distributions (3 dimensional vectors) which associated with them in the MSP.
I don't understand how we go from this to the fractal. The linear probe gives us a single 2D point for every forward pass of the transformer, correct? How do we get the picture with many points in it? Is it by sampling from the transformer while reading the probe after every token and then putting all the points from that on one graph?
Is this result equivalent to saying "a transformer trained on an HMM's output learns a linear representation of the probability distribution over the HMM's states"?
↑ comment by Adam Shai (adam-shai) · 2024-04-17T22:10:34.911Z · LW(p) · GW(p)
I should have explained this better in my post.
For every input into the transformer (of every length up to the context window length), we know the ground truth belief state that comp mech says an observer should have over the HMM states. In this case, this is 3 numbers. So for each input we have a 3d ground truth vector. Also, for each input we have the residual stream activation (in this case a 64D vector). To find the projection we just use standard Linear Regression (as implemented in sklearn) between the 64D residual stream vectors and the 3D (really 2D) ground truth vectors. Does that make sense?
Replies from: dr_s, Sandicomment by Fiora Sunshine (Fiora from Rosebloom) · 2024-05-04T02:31:23.956Z · LW(p) · GW(p)
We look in the final layer of the residual stream and find a linear 2D subspace where activations have a structure remarkably similar to that of our predicted fractal. We do this by performing standard linear regression from the residual stream activations (64 dimensional vectors) to the belief distributions (3 dimensional vectors) which associated with them in the MSP.
Naive technical question, but can I ask for a more detailed description of how you go from the activations in the residual stream to the map you have here? Or like, can someone point me in the direction of the resources I'd need to undestand? I know that the activations in any given layer of an NN can be interpreted as a vector in a space the same number of dimensions as there are neurons in that layer, but I don't know how you map that onto a 2D space, esp. in a way that maps belief states onto this kind of three-pole system you've got with the triangles here.
comment by Sodium · 2024-05-25T13:12:29.378Z · LW(p) · GW(p)
I thought that the part about models needing to keep track of a more complicated mix-state presentation as opposed to just the world model is one of those technical insights that's blindingly obvious once someone points it out to you (i.e., the best type of insight :)). I love how the post starts out by describing the simple ZIR example to help us get a sense of what these mixed state presentations are like. Bravo!
Replies from: adam-shai↑ comment by Adam Shai (adam-shai) · 2024-05-26T03:39:39.422Z · LW(p) · GW(p)
Thanks! In my experience Computational Mechanics has many of those types of technical insights. My background is in neuroscience and in that context it really helped me think about computation in brains, and design experiments. Now I'm excited to use Comp Mech in a more concrete and deeper way to understand how artificial neural network internal structures relate to their behavior. Hopefully this is just the start!
comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-05-03T23:13:27.667Z · LW(p) · GW(p)
Non exhaustive list of reasons one could be interested in computational mechanics: https://www.lesswrong.com/posts/GG2NFdgtxxjEssyiE/dalcy-s-shortform?commentId=DdnaLZmJwusPkGn96 [LW(p) · GW(p)]
comment by Moughees Ahmed (moughees-ahmed) · 2024-05-02T19:49:15.807Z · LW(p) · GW(p)
This might be an adjacent question but assuming this is true and comprehensively explains the belief updating process. What does it say, if anything, about whether transformers can produce new (undiscovered) knowledge/states? If they can't observe a novel state - something that doesn't exist in the data - can they never discover new knowledge on their own?
Replies from: adam-shai↑ comment by Adam Shai (adam-shai) · 2024-05-03T01:31:50.937Z · LW(p) · GW(p)
This is a great question, and one of the things I'm most excited about using this framework to study in the future! I have a few ideas but nothing to report yet.
But I will say that I think we should be able to formalize exactly what it would mean for a transformer to create/discover new knowledge, and also to apply the structure from one dataset and apply it to another, or to mix two abstract structures together, etc. I want to have an entire theory of cognitive abilities and the geometric internal structures that support them.
Replies from: moughees-ahmed↑ comment by Moughees Ahmed (moughees-ahmed) · 2024-05-03T15:03:09.574Z · LW(p) · GW(p)
Excited to see what you come up with!
Plausibly, one could think that if a model, trained on the entirety of human output, should be able to decipher more hidden states - ones that are not obvious to us - but might be obvious in latent space. It could mean that models might be super good at augmenting our existing understanding of fields but might not create new ones from scratch.
comment by Review Bot · 2024-05-01T17:50:59.273Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Exa Watson (exa-watson) · 2024-04-20T15:35:13.295Z · LW(p) · GW(p)
If I understand this right, you train a transformer on data generated from a hidden markov process, of the form {0,1,R} and find that there is a mechanism for tracking when R occurs in the residual stream, as well as that the transformer learns the hidden markov process. is that correct?
Replies from: keenan-pepper↑ comment by Keenan Pepper (keenan-pepper) · 2024-04-20T23:50:32.543Z · LW(p) · GW(p)
No, the actual hidden Markov process used to generate the awesome triangle fractal image is not the {0,1,random} model but a different one, which is called "Mess3" and has a symmetry between the 3 hidden states.
Also, they're not claiming the transformer learns merely the hidden states of the HMM, but a more complicated thing called the "mixed state presentation", which is not the states that the HMM can be in but the (usually much larger number of) belief states which an ideal prediction process trying to "sync" to it might go thru.
comment by Nisan · 2024-04-18T16:07:03.871Z · LW(p) · GW(p)
If I understand correctly, the next-token prediction of Mess3 is related to the current-state prediction by a nonsingular linear transformation. So a linear probe showing "the meta-structure of an observer's belief updates over the hidden states of the generating structure" is equivalent to one showing "the structure of the next-token predictions", no?
Replies from: Nisancomment by p.b. · 2024-04-17T20:52:07.930Z · LW(p) · GW(p)
This reminds me a lot of a toy project I have in the back of my mind but will probably never get around to:
Which is to train a transformer on the sequences generated by the logic models from the apperception engine paper (which in the paper are inferred by the apperception engine from the sequences) with the aim of predicting the logic model.
Replies from: adam-shai↑ comment by Adam Shai (adam-shai) · 2024-04-17T20:53:40.104Z · LW(p) · GW(p)
That sounds interesting. Do you have a link to the apperception paper?
Replies from: p.b., MondSemmel↑ comment by p.b. · 2024-04-18T17:36:27.989Z · LW(p) · GW(p)
https://www.sciencedirect.com/science/article/pii/S0004370220301855#se0050
https://www.sciencedirect.com/science/article/pii/S0004370221000722
↑ comment by MondSemmel · 2024-04-18T06:53:12.429Z · LW(p) · GW(p)
This book chapter and this paper, maybe?
Replies from: p.b.comment by Vladimir_Nesov · 2024-04-17T18:18:26.562Z · LW(p) · GW(p)
This is interesting as commentary on superposition, where activation vectors with N dimensions can be used to represent many more concepts, since the N-dimensional space/sphere can be partitioned into many more regions than N, each with its own meaning. If similar fractal structure substantially occurs in the original activation bases (such as the Vs of attention, as in the V part of KV-cache) and not just after having been projected to dramatically fewer dimensions, this gives a story for role of nuance that improves with scale that's different from it being about minute distinctions in meaning of concepts.
Instead, the smaller distinctions would track meanings of future ideas, modeling sequences of simpler meanings of possible ideas at future time steps rather than individual nuanced meanings of the current idea at the current time step. Advancing to the future would involve unpacking these distinctions by cutting out a region and scaling it up. That is, there should be circuits that pick up past activations with attention and then reposition them without substantial reshaping, to obtain activations that in broad strokes indicate directions relevant for a future sequence-step, which in the original activations were present with smaller scale and off-center.
comment by Aprillion · 2024-04-17T07:02:35.196Z · LW(p) · GW(p)
Can you help me understand a minor labeling convention that puzzles me? I can see how we can label from the Z1R process as in MSP because we observe 11 to get there, but why is labeled as after observing either 100 or 00, please?
Replies from: adam-shai↑ comment by Adam Shai (adam-shai) · 2024-04-17T07:10:35.249Z · LW(p) · GW(p)
Good catch! That should be eta_00, thanks! I'll change it tomorrow.
comment by Dalcy (Darcy) · 2024-04-17T02:19:49.662Z · LW(p) · GW(p)
What is the shape predicted by compmech under a generation setting, and do you expect it instead of the fractal shape to show up under, say, a GAN loss? If so, and if their shapes are sufficiently distinct from the controls that are run to make sure the fractals aren't just a visualization artifact, that would be further evidence in favor of the applicability of compmech in this setup.
Replies from: adam-shai↑ comment by Adam Shai (adam-shai) · 2024-04-17T03:26:06.510Z · LW(p) · GW(p)
Cool idea! I don't know enough about GANs and their loss so I don't have a prediction to report right now. If it is the case that GAN loss should really give generative and not predictive structure, this would be a super cool experiment.
The structure of generation for this particular process has just 3 points equidistant from eachother, no fractal. But in general the shape of generation is a pretty nuanced issue because it's nontrivial to know for sure that you have the minimal structure of generation. There's a lot more to say about this but @Paul Riechers [LW · GW] knows these nuances more than I do so I will leave it to him!
comment by Laurence Aitchison (laurence_ai) · 2024-06-05T07:23:43.826Z · LW(p) · GW(p)
One nice little prediction from this approach: you'd expect the first few tokens to have denser (as in SAE) features, as there is less context, so the "HMM" could be in a broad range of states. Whereas once you've seen more tokens, you have much more information so the state is pinned down more precisely and you'd expect to be denser.
There's also a big literature from computational neuroscience about how you represent probabilities. This is suggesting a "mean parameter code", where the LLM activations are a function of E[z| data]. But lots of other possibilities are available, e.g. see:
http://www.gatsby.ucl.ac.uk/teaching/courses/tn1-2021/slides/uncert-slides.pdf
comment by Joel Ye (joel-ye) · 2024-05-22T12:26:05.271Z · LW(p) · GW(p)
Thanks for the post, it's neat to see the fields and terms existing for these questions.
I have two questions for hope of using this type of analysis in my work to analyze a lack of transfer between two distinct datasets A and B. (I see this is in your future work?)
1. Where does OOD data project, or data that is implausible for the model?
2. For more complex data, might we expect this MSP to most clearly show in places other than the final layer?
re: transfer, my hypothesis is that we might be able to see, having trained on A and B, that during inference, the heldout data from A rapidly becomes easily identifiable as A, and thus stands to reason that there's less to benefit from any of B's features. Alternatively, a more optimistic test for whether we might see transfer between A and B prior to training on B, is if we could tell that a sample from B is extremely unlikely or OOD, via raw likelihood or misbehaving MSP?
comment by Steve Kommrusch (steve-kommrusch) · 2024-05-16T22:06:03.314Z · LW(p) · GW(p)
This is very interesting work, showing the fractal graph is a good way to visualize the predictive model being learned. I've had many conversations with folks who struggle with the idea 'the model is just predicting the next token, how can it be doing anything interesting'?. My standard response had been that conceptually the transformer model matches up tokens at the first layer (using the key and query vectors), then matches up sentences a few layers up, and then paragraphs a few layers above that; hence the model, when presented with an input, was not just responding with 'the next most likely token', but more accurately 'the best token to use to start the best sentence to start the best paragraph to answer the question'. Which usually helped get the complexity across; but I like the learned fractal of the belief state and will see how well I can use that in the future.
For future work, I think it would be interesting to tease out how the system learns 2 interacting state machines (this may give hints regarding its ability to generalize different actors in the world). For example, consider another 3-state HMM with the same transition probabilities but behaving independent of the 1st HMM. Then have the probability of outputting A,B, or C be the average of the arcs taken on the 2 HMMs each step. For example, if the 1st HMM is in H0 and stays in H0 it gives a 60% chance of generating A and a 20% chance for B and C, while if the 2nd HMM is in H2 and stays in H2, it gives 20% for A and B and 60% for C, so the overall output probability is 40% A, 20% B, 40%C for my example. Now certainly this is a 9 state HMM (3x3), but it's more simply represented as two 3-state HMMs, what would the neural network learn? What if you combined 3 HMMs this way, so the single HMM is 3x3x3=27 states, but the simpler representation is 3+3+3=9? Again, my goal here would be to understand how the system might model multiple agents in the world given limited visibility to the agents directly. Perhaps there is a cleaner way to explore the same question.
comment by PoignardAzur · 2024-05-15T09:09:30.995Z · LW(p) · GW(p)
We think this occurs because in general there are groups of belief states that are degenerate in the sense that they have the same next-token distribution. In that case, the formalism presented in this post says that even though the distinction between those states must be represented in the transformers internal, the transformer is able to lose those distinctions for the purpose of predicting the next token (in the local sense), which occurs most directly right before the unembedding.
I wonder if you could force the Mixed-State Presentation to be "conserved" in later layers by training the model with different objectives. For instance, training on next-token prediction and next-token-after-that prediction might force the model to be a lot more "rigorous" about its MSP.
Papers from Google have shown that you can get more predictable results from LLMs if you train then on both next-token prediction and "fill-the-blanks" tasks where random tokens are removed from the middle of a text. I suspect it would also apply here.
comment by Daniel Munro · 2024-05-06T05:54:45.406Z · LW(p) · GW(p)
Fascinating. But are these diagrams really showing HMMs? I thought each state in an HMM had a set of transition probabilities and another set of emission probabilities, which at each step are sampled independently. In these diagrams, the two processes are coupled. If "Even Ys" were a conventional HMM, would sometimes emit X and transition to , which would result in some even and some odd runs of Y. Are these a special variant of HMM, or some other type of state machine? And would these results apply to conventional HMMs with separate transition and emission probabilities?
comment by Oliver Sourbut · 2024-05-02T18:06:59.679Z · LW(p) · GW(p)
Nice explanation of MSP and good visuals.
This is surprising!
Were you in fact surprised? If so, why? (This is a straightforward consequence of the good regulator theorem[1].)
In general I'd encourage you to carefully track claims about transformers, HMM-predictors, and LLMs, and to distinguish between trained NNs and the training process. In this writeup, all of these are quite blended.
↑ comment by kave · 2024-05-02T22:32:23.921Z · LW(p) · GW(p)
This is a straightforward consequence of the good regulator theorem
IIUC, the good regulator theorem doesn't say anything about how the model of the system should be represented in the activations of the residual stream. I think the potentially surprising part is that the model is recoverable with a linear probe.
↑ comment by Adam Shai (adam-shai) · 2024-05-03T01:25:45.484Z · LW(p) · GW(p)
It's surprising for a few reasons:
- The structure of the points in the simplex is NOT
- The next token prediction probabilities (ie. the thing we explicitly train the transformer to do)
- The structure of the data generating model (ie. the thing the good regulator theorem talks about, if I understand the good regulator theorem, which I might not)
The first would be not surprising because it's literally what our loss function asks for, and the second might not be that surprising since this is the intuitive thing people often think about when we say "model of the world." But the MSP structure is neither of those things. It's the structure of inference over the model of the world, which is quite a different beast than the model of the world.
Others might not find it as surprising as I did - everyone is working off their own intuitions.
edit: also I agree with what Kave said about the linear representation.
Replies from: Oliver Sourbut↑ comment by Oliver Sourbut · 2024-05-03T10:50:26.729Z · LW(p) · GW(p)
I guess my question would be 'how else did you think a well-generalising sequence model would achieve this?' Like, what is a sufficient world model but a posterior over HMM states in this case? This is what GR theorem asks. (Of course, a poorly-fit model might track extraneous detail or have a bad posterior.)
From your preamble and your experiment design, it looks like you correctly anticipated the result, so this should not have been a surprise (to you). In general I object to being sold something as surprising which isn't (it strikes me as a lesser-noticed and perhaps oft-inadvertent rhetorical dark art and I see it on the rise on LW, which is sad).
That said, since I'm the only one objecting here, you appear to be more right about the surprisingness of this!
The linear probe is new news (but not surprising?) on top of GR, I agree. But the OP presents the other aspects as the surprises, and not this.
Replies from: alexander-gietelink-oldenziel↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-05-03T14:30:24.648Z · LW(p) · GW(p)
I agree with you that the new/surprising thing is the linearity of the probe. Also I agree that not entirely clear how surprising & new linearity of the probe is.
If you understand how the causal states construction & the MSP works in computational mechanics the experimental results isn't surprising. Indeed, it can't be any other way! That's exactly the magic of the definition of causal states.
What one person might find surprising or new another thinks trivial. The subtle magic of the right theoretical framework is that it makes the complex simple, surprising phenomena apparent.
Before learning about causal states I would have not even considered that there is a unique (!) optimal minimal predictor canonical constructible from the data. Nor that the geometry of synchronizing belief states is generically a fractal. Of course, once one has properly internalized the definitions this is almost immediate. Pretty pictures can be helpful in building that intuition !
Adam and I (and many others) have been preaching the gospel of computational mechanics for a while now. Most of it has fallen on deaf ears before. Like you I have been (positively!) surprised and amused by the sudden outpouring of interest. No doubt it's in part a the testimony to the Power of the Visual! Never look a gift horse in the mouth ! _
I would say the parts of computational mechanics I am really excited are a little deeper - downstream of causal states & the MSP. This is just a taster.
I'm confused & intrigued by your insistence that this is follows from the good regulator theorem. Like Adam I don't understand it. It is my understanding is that the original 'theorem' was wordcelled nonsense but that John has been able to formulate a nontrivial version of the theorem. My experience is that it the theorem is often invoked in a handwavey way that leaves me no less confused than before. No doubt due to my own ignorance !
I would be curious to hear a *precise * statement why the result here follows from the Good Regular Theorem.
Replies from: Oliver Sourbut↑ comment by Oliver Sourbut · 2024-05-06T09:18:30.200Z · LW(p) · GW(p)
the original 'theorem' was wordcelled nonsense
Lol! I guess if there was a more precise theorem statement in the vicinity gestured, it wasn't nonsense? But in any case, I agree the original presentation is dreadful. John's is much better.
I would be curious to hear a *precise * statement why the result here follows from the Good Regular Theorem.
A quick go at it, might have typos.
Suppose we have
- (hidden) state
- output/observation
and a predictor
- (predictor) state
- predictor output
- the reward or goal or what have you (some way of scoring 'was right?')
with structure
Then GR trivially says (predictor state) should model the posterior .
Now if these are all instead processes (time-indexed), we have HMM
- (hidden) states
- observations
and predictor process
- (predictor) states
- predictions
- rewards
with structure
Drawing together as the 'goal', we have a GR motif
so must model ; by induction that is .
comment by JoNeedsSleep (joanna-j-1) · 2024-05-02T03:03:00.427Z · LW(p) · GW(p)
Thank you for the insightful post! You mentioned that:
Consider the relation a transformer has to an HMM that produced the data it was trained on. This is general - any dataset consisting of sequences of tokens can be represented as having been generated from an HMM.
and the linear projection consists of:
Linear regression from the residual stream activations (64 dimensional vectors) to the belief distributions (3 dimensional vectors).
Given any natural language dataset, if we didn't have the ground truth belief distribution, is it possible to reverse engineer (data model) a HMM and extract the topology of the residual stream activation?
I've been running task salient representation experiments on larger models and am very interested in replicating and possibly extending your result to more noisy settings.
Replies from: adam-shai↑ comment by Adam Shai (adam-shai) · 2024-05-03T01:28:23.738Z · LW(p) · GW(p)
If I'm understanding your question correctly, then the answer is yes, though in practice it might be difficult (I'm actually unsure how computationally intensive it would be, haven't tried anything along these lines yet). This is definitely something to look into in the future!
comment by Niclas Kupper (niclas-kupper) · 2024-04-24T12:09:26.869Z · LW(p) · GW(p)
Is there some theoretical result along the lines of "A sufficiently large transformer can learn any HMM"?
Replies from: alexander-gietelink-oldenziel↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-04-24T12:29:08.471Z · LW(p) · GW(p)
Depending on what one means by 'learn' this is provably impossible. The reason has nothing to do with the transformer architecture (which one shouldn't think of as a canonical architecture in the grand scheme of things anyway).
There is a 2-state generative HMM such that the optimal predictor of the output of said generative model provably requires an infinite number of states. This is for any model of computation, any architecture.
Of course, that's maybe not what you intend by 'learn'. If you mean by 'learn' express the underlying function of an HMM then the answer is yes by the Universal Approximation Theorem (a very fancy name for a trivial application of the Stone-Weierstrass theorem).
Hope this helped. 😄
Replies from: jarviniemi, niclas-kupper↑ comment by Olli Järviniemi (jarviniemi) · 2024-06-05T14:15:42.307Z · LW(p) · GW(p)
There is a 2-state generative HMM such that the optimal predictor of the output of said generative model provably requires an infinite number of states. This is for any model of computation, any architecture.
Huh, either I'm misunderstanding or this is wrong.
If you have Hidden Markov Models like in this post (so you have a finite number of states, fixed transition probabilities between them and outputs depending on the transitions), then the optimal predictor is simple: do Bayesian updates on the current hidden state based on the observations. For each new observation, you only need to do O(states) computations. Furthermore, this is very parallelizable, requiring only O(1) serial steps per observation.
Replies from: alexander-gietelink-oldenziel, alexander-gietelink-oldenziel↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-06-09T17:56:19.864Z · LW(p) · GW(p)
You are absolutely right and I am of course absolutely and embarrasingly wrong.
The minimal optimal predictor as a Hidden Markov Model of the simple nonunfilar is indeed infinite. This implies that any other architecture must be capable of expressing infinitely many states - but this is quite a weak statement - it's very easy for a machine to dynamically express finitely many states with finite memory. In particular, a transformer should absolutely be able to learn the MSP of the epsilon machine of the simple nonunifilar source - indeed it can even be solved analytically.
This was an embarrasing mistake I should not have made. I regret my rash overconfidence - I should have taken a moment to think it through since the statement was obviously wrong. Thank you for pointing it out.
↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-06-05T16:41:47.521Z · LW(p) · GW(p)
Behold

↑ comment by Niclas Kupper (niclas-kupper) · 2024-04-28T08:24:08.390Z · LW(p) · GW(p)
Where can I read about this 2-state HMM? By learn I just mean approximate via an algorithm. The UAT is not sufficient as it talks about learning a known function. Baum-Welch is such an algorithm, but as a far as I am aware it gives no guarantees on anything really.
comment by ProgramCrafter (programcrafter) · 2024-04-22T14:57:16.349Z · LW(p) · GW(p)
Speaking of next steps, I'd love to see a transformer that was trained to manipulate those states (given target state and interactor's tokens, would emit its own tokens for interleaving)! I believe this would look even cooler, and may be useful in detecting if AI starts to manipulate someone.
comment by Keenan Pepper (keenan-pepper) · 2024-04-20T21:29:09.471Z · LW(p) · GW(p)
Can you share the hyperparameters used to make this figure?
Replies from: keenan-pepper↑ comment by Keenan Pepper (keenan-pepper) · 2024-04-20T23:51:59.187Z · LW(p) · GW(p)
Ah, never mind, I believe I found the relevant hyperparameters here: https://github.com/adamimos/epsilon-transformers/blob/main/examples/msp_analysis.ipynb
In particular, the stuff I needed was that it has only a single attention head per layer, and 4 layers.
Replies from: keenan-pepper↑ comment by Keenan Pepper (keenan-pepper) · 2024-04-23T00:21:39.887Z · LW(p) · GW(p)
Actually I would still really appreciate the training hyperparameters like batch size, learning rate schedule...
Replies from: tropea@gwu.edu↑ comment by tropea@gwu.edu · 2024-05-01T22:34:37.830Z · LW(p) · GW(p)
A simple suggestion on word usage: from "belief state" to "interpretive state." This would align your comments better with disciplines more concerned with behavior than cognition. JL Tropea.
↑ comment by Keenan Pepper (keenan-pepper) · 2024-05-13T10:24:01.861Z · LW(p) · GW(p)
I think you may have meant this as a top-level comment rather than a reply to my comment?