Posts
Comments
An interesting part in OpenAI's new version of the preparedness framework:

I enjoyed reading the article! I have two counterarguments to some main points:
1. The article argues that alignment research might make things worse, and I think for many kinds of alignment research, that's a good point. (Especially the kind of alignment research that made its way into current frontier AI!). On the other hand, if we are really careful with our AI research, we might manage to align AI to powerful principles such as "Don't develop technologies which our human institutions cannot keep up with" etc.
My impression is that for very dangerous technologies that humans have historically developed, it *was* possible for humans to predict possible negative effects quite early (e.g., the nuclear chain reaction was conceived much earlier than nuclear fission; we don't have mirror life afaik but people already predict that it could be really harmful). Thus, I guess ASI would also be capable of predicting this, and so if we align it to a principle such as "don't develop marginally dangerous technology", then I think this should in principle work.
2. I think the article neglects the possibility that AI could kill us all by going rogue *without* this requiring any special technology. E.g., the AI might simply be broadly deployed in physical robots that are much like the robots we have today, and control more and more of our infrastructure. Then, if all AIs collude, they could one day decide to deprive us of basic needs, making humans go extinct.
Possibly Michael Nielsen would counter that this *is* in line with the vulnerable world hypothesis since the technology that kills us all is then the AI itself. But that would stretch it a bit since the vulnerable world hypothesis usually assumes that something world-destroying can be deployed with minor resources, which isn't the case here.
Thanks for these further pointers! I won't go into detail, I will just say that I take the bitter lesson very seriously and that I think most of the ideas you mention won't be needed for superintelligence. Some intuitions why I take typical arguments for limits of transformers not very seriously:
- If you hook up a transformer to itself with a reasoning scratchpad, then I think it can in principle represent any computation, beyond what would be possible in a single forward pass.
- On causality: Once we change to the agent-paradigm, transformers naturally get causal data since they will see how the "world responds" to their actions.
- General background intuition: Humans developed general intelligence and a causal understanding of the world by evolution, without anyone designing us very deliberately.
I worked on geometric/equivariant deep learning a few years ago (with some success, leading to two ICLR papers and a patent, see my google scholar: https://scholar.google.com/citations?user=E3ae_sMAAAAJ&hl=en).
The type of research I did was very reasoning-heavy. It’s architecture research in which you think hard about how to mathematically guarantee that your network obeys some symmetry constraints appropriate for a domain and data source.
As a researcher in that area, you have a very strong incentive to claim that a special sauce is necessary for intelligence, since providing special sauces is all you do. As such, my prior is to believe that these researchers don’t have any interesting objection to continued scaling and “normal” algorithmic improvements to lead to AGI and then superintelligence.
It might still be interesting to engage when the opportunity arises, but I wouldn’t put extra effort into making such a discussion happen.
I found this fun to read, even years later. There is one case where Rohin updated you to accept a conclusion, where I'm not sure I agree:
As long as there exists an exponentially large tree explaining the concept, debate should find a linear path through it.
I think here and elsewhere, there seems to be a bit of conflation between "debate", "explanation", and "concept".
My impression is that debate relies on the assumption that there are exponentially large explanations for true statements. If I'm a debater, I can make such an explanation by saying "A and B", where A and B each have a whole tree of depth minus 1 below them. Then the debate picks out a linear path through that tree since the other debater tries to refute either A or B, after which I can answer by expanding the explanation of the one of them under attack. I agree with that argument.
However, I think this essentially relies on all concepts that I use in my arguments to already be understood by the judge. If I say "A", and the judge doesn't even understand what A means, then we could be in trouble, the reason being that I'm not sure the concepts in A can necessarily be explained efficiently, and possibly the concept is necessary to be understood for appreciating refutations of arguments of the second debater. For example, mathematics is full of concepts like "schemes" that just inherently take a long time to explain when the prerequisite concepts are not yet understood.
My hope would be that such complex abstractions usually have "interfaces" that make it easy to work with them. I.e., maybe the concept is complex, but it's not necessary to explain the entire concept to the judge -- maybe it's enough to say "This scheme has the following property: [...]", and maybe the property can be appreciated without understanding what a scheme is.
The two sides of AI Safety (AI risk as anarchy vs. concentration of power) pattern-match a bit to this abstract I found today in my inbox:
The trajectory of intelligence evolution is often framed around the emergence of artificial general intelligence (AGI) and its alignment with human values. This paper challenges that framing by introducing the concept of intelligence sequencing: the idea that the order in which AGI and decentralized collective intelligence (DCI) emerge determines the long-term attractor basin of intelligence. Using insights from dynamical systems, evolutionary game theory, and network models, it argues that intelligence follows a path-dependent, irreversible trajectory. Once development enters a centralized (AGI-first) or decentralized (DCI-first) regime, transitions become structurally infeasible due to feedback loops and resource lock-in. Intelligence attractors are modeled in functional state space as the co-navigation of conceptual and adaptive fitness spaces. Early-phase structuring constrains later dynamics, much like renormalization in physics. This has major implications for AI safety: traditional alignment assumes AGI will emerge and must be controlled after the fact, but this paper argues that intelligence sequencing is more foundational. If AGI-first architectures dominate before DCI reaches critical mass, hierarchical monopolization and existential risk become locked in. If DCI-first emerges, intelligence stabilizes around decentralized cooperative equilibrium. The paper further explores whether intelligence structurally biases itself toward an attractor based on its self-modeling method -- externally imposed axioms (favoring AGI) vs. recursive internal visualization (favoring DCI). Finally, it proposes methods to test this theory via simulations, historical lock-in case studies, and intelligence network analysis. The findings suggest that intelligence sequencing is a civilizational tipping point: determining whether the future is shaped by unbounded competition or unbounded cooperation.
Do you think the x-axis being a release date is more mysterious than the same fact regarding Moore's law?
(Tbc., I think this doesn't make it less mysterious: For Moore's law this also seems like a mystery to me. But this analogy makes it more plausible that there is a mysterious but true reason driving such trends, instead of the graph from METR simply being a weird coincidence. )
Maryna Viazovska, the Ukrainian Fields medalist, did her PhD in Germany under Don Zagier.
---
I once saw at least one French TV talkshow where famous mathematicians were invited (I don't find the links anymore). Something like that would be pretty much unthinkable in Germany. So I wonder if math has generally more prestige in France than e.g. in Germany.
I’m confused by the order Lesswrong shows posts to me: I’d expect to see them in chronological order if I select them by “Latest”.
But as you see, they were posted 1d, 4d, 21h, etc ago.
How can I see them chronologically?
Thanks for this post!
The deadline possibly requires clarification:
We will keep the application form open until at least 11:59pm AoE on Thursday, February 27.
In the job posting, you write:
Application deadline: 12pm PST Friday 28th February 2025
There are a few sentences in Anthropic's "conversation with our cofounders" regarding RLHF that I found quite striking:
Dario (2:57): "The whole reason for scaling these models up was that [...] the models weren't smart enough to do RLHF on top of. [...]"
Chris: "I think there was also an element of, like, the scaling work was done as part of the safety team that Dario started at OpenAI because we thought that forecasting AI trends was important to be able to have us taken seriously and take safety seriously as a problem."
Dario: "Correct."
That LLMs were scaled up partially in order to do RLHF on top of them is something I had previously heard from an OpenAI employee, but I wasn't sure it's true. This conversation seems to confirm it.
Hi! Thanks a lot for your comments and very good points. I apologize for my late answer, caused by NeurIPS and all the end-of-year breakdown of routines :)
On 1: Yes, the formalism I'm currently working on also allows to talk about the case that the human "understands less" than the AI.
On 2:
Have you considered the connection between partial observability and state aliasing/function approximation?
I am not entirely sure if I understand! Though if it's just what you express in the following sentences, here's my answers:
Maybe you could apply your theory to weak-to-strong generalization by considering a weak model as operating under partial observability.
Very good observation! :) I'm thinking about it slightly differently, but the link is there: Imagine a scenario where we have a pretrained foundation model, and we train a linear probe attached to the internal representations, which is supposed to learn the correct reward for full state sequences, based on feedback from a human on partial observations. Then if we show this model (including attached probe) during training just the partial observations, it's receiving the correct data and is supposed to generalize from feedback on "easy situations" (i.e., situations where the partial observations of the human provide enough information to make a correct judgment) to "hard situations" (full state sequences that the human couldn't oversee, and where possibly the partial observations miss crucial details).
So I think this setting is an instance of weak-to-strong generalization.
Alternatively, by introducing structure to the observations, the function approximation lens might open up new angles of attack on the problem.
Yes that's actually also part of what I'm exploring, if I understand your idea correctly. In particular, I'm considering the case that we may have "knowledge" of some form about the space in which the correct reward function lives. This may come from symmetries in the state space, for example: maybe we want to restrict to localized reward functions that are translation-invariant. All of that can easily be formalized in one framework.
Pretrained foudation models on which we attach a "reward probe" can be viewed as another instance of considering symmetries in the state space: In this case, we're presuming that state sequences have the same reward if they give rise to the same "learned abstractions" in the form of the internal representations of the neural network.
On 3: Agreed. (Though I am not explicitly considering this case at this point. )
On 4:
I think you're exactly right to consider abstractions of trajectories, but I'm not convinced this needs to be complicated. What if you considered the case where the problem definition includes features of state trajectories on which (known) human utilities are defined, but these features themselves are not always observed? (This is something I'm currently thinking about, as a generalization of the work mentioned in the postscript.
This actually sounds very much like what I'm working on right now!! We should probably talk :)
On 5:
Am I correct in my understanding that the role Boltzmann rationality plays in your setup is just to get a reward function out of preference data?
If I understand correctly, yes. In a sense, we just "invert" the sigmoid function to recover the return function on observation sequences from human preference data. If this return function on observation sequences was already known, we'd still be doomed, as you correctly point out.
Thanks also for the notes on gradient routing! I will read your post and will try to understand the connection.
This is a link to a big list of LLM safety papers based on a new big survey.
Thanks for the list! I have two questions:
1: Can you explain how generalization of NNs relates to ELK? I can see that it can help with ELK (if you know a reporter generalizes, you can train it on labeled situations and apply it more broadly) or make ELK unnecessary (if weak to strong generalization perfectly works and we never need to understand complex scenarios). But I’m not sure if that’s what you mean.
2: How is goodhart robustness relevant? Most models today don’t seem to use reward functions in deployment, and in training the researchers can control how hard they optimize these functions, so I don’t understand why they necessarily need to be robust under strong optimization.
“heuristics activated in different contexts” is a very broad prediction. If “heuristics” include reasoning heuristics, then this probably includes highly goal-oriented agents like Hitler.
Also, some heuristics will be more powerful and/or more goal-directed, and those might try to preserve themselves (or sufficiently similar processes) more so than the shallow heuristics. Thus, I think eventually, it is plausible that a superintelligence looks increasingly like a goal-maximizer.
This is a low effort comment in the sense that I don’t quite know what or whether you should do something different along the following lines, and I have substantial uncertainty.
That said:
-
I wonder whether Anthropic is partially responsible for an increased international race through things like Dario advocating for an entente strategy and talking positively about Leopold Aschenbrenner’s “situational awareness”. I wished to see more of an effort to engage with Chinese AI leaders to push for cooperation/coordination. Maybe it’s still possible to course-correct.
-
Alternatively I think that if there’s a way for Anthropic/Dario to communicate why you think an entente strategy is inevitable/desirable, in a way that seems honest and allows to engage with your models of reality, that might also be very helpful for the epistemic health of the whole safety community. I understand that maybe there’s no politically feasible way to communicate honestly about this, but maybe see this as my attempt to nudge you in the direction of openness.
More specifically:
(a) it would help to learn more about your models of how winning the AGI race leads to long-term security (I assume that might require building up a robust military advantage, but given the physical hurdles that Dario himself expects for AGI to effectively act in the world, it’s unclear to me what your model is for how to get that military advantage fast enough after AGI is achieved).
(b) I also wonder whether potential future developments in AI Safety and control might give us information that the transition period is really unsafe; eg., what if you race ahead and then learn that actually you can’t safely scale further due to risks of loss of control? At that point, coordinating with China seems harder than doing it now. I’d like to see a legible justification of your strategy that takes into account such serious possibilities.
I have an AI agent that wrote myself
Best typo :D
Have you also tried reviewing for conferences like NeurIPS? I'd be curious what the differences are.
Some people send papers to TMLR when they think they wouldn't be accepted to the big conferences due to not being that "impactful" --- which makes sense since TMLR doesn't evaluate impact. It's thus possible that the median TMLR submission is worse than the median conference submission.
I just donated $200. Thanks for everything you're doing!
Yeah I think that's a valid viewpoint.
Another viewpoint that points in a different direction: A few years ago, LLMs could only do tasks that require humans ~minutes. Now they're at the ~hours point. So if this metric continues, eventually they'll do tasks requiring humans days, weeks, months, ...
I don't have good intuitions that would help me to decide which of those viewpoints is better for predicting the future.
Somewhat pedantic correction: they don’t say “one should update”. They say they update (plus some caveats).
After the US election, the twitter competitor bluesky suddenly gets a surge of new users:
How likely are such recommendations usually to be implemented? Are there already manifold markets on questions related to the recommendation?
In the reuters article they highlight Jacob Helberg: https://www.reuters.com/technology/artificial-intelligence/us-government-commission-pushes-manhattan-project-style-ai-initiative-2024-11-19/
He seems quite influential in this initiative and recently also wrote this post:
https://republic-journal.com/journal/11-elements-of-american-ai-supremacy/
Wikipedia has the following paragraph on Helberg:
“ He grew up in a Jewish family in Europe.[9] Helberg is openly gay.[10] He married American investor Keith Rabois in a 2018 ceremony officiated by Sam Altman.”
Might this be an angle to understand the influence that Sam Altman has on recent developments in the US government?
Why I think scaling laws will continue to drive progress
Epistemic status: This is a thought I had since a while. I never discussed it with anyone in detail; a brief conversation could convince me otherwise.
According to recent reports there seem to be some barriers to continued scaling. We don't know what exactly is going on, but it seems like scaling up base models doesn't bring as much new capability as people hope.
However, I think probably they're still in some way scaling the wrong thing: The model learns to predict a static dataset on the internet; however, what it needs to do later is to interact with users and the world. For performing well in such a task, the model needs to understand the consequences of its actions, which means modeling interventional distributions P(X | do(A)) instead of static data P(X | Y). This is related to causal confusion as an argument against the scaling hypothesis.
This viewpoint suggests that if big labs figure out how to predict observations in an online-way by ongoing interactions of the models with users / the world, then this should drive further progress. It's possible that labs are already doing this, but I'm not aware of it, and so I guess they haven't yet fully figured out how to do that.
What triggered me writing this is that there is a new paper on scaling law for world modeling that's about exactly what I'm talking about here.
Do we know anything about why they were concerned about an AGI dictatorship created by Demis?
What’s your opinion on the possible progress of systems like AlphaProof, o1, or Claude with computer use?
"Scaling breaks down", they say. By which they mean one of the following wildly different claims with wildly different implications:
- When you train on a normal dataset, with more compute/data/parameters, subtract the irreducible entropy from the loss, and then plot in a log-log plot: you don't see a straight line anymore.
- Same setting as before, but you see a straight line; it's just that downstream performance doesn't improve .
- Same setting as before, and downstream performance improves, but: it improves so slowly that the economics is not in favor of further scaling this type of setup instead of doing something else.
- A combination of one of the last three items and "btw., we used synthetic data and/or other more high-quality data, still didn't help".
- Nothing in the realm of "pretrained models" and "reasoning models like o1" and "agentic models like Claude with computer use" profits from a scale-up in a reasonable sense.
- Nothing which can be scaled up in the next 2-3 years, when training clusters are mostly locked in, will demonstrate a big enough success to motivate the next scale of clusters costing around $100 billion.
Be precise. See also.
Thanks for this compendium, I quite enjoyed reading it. It also motivated me to read the "Narrow Path" soon.
I have a bunch of reactions/comments/questions at several places. I focus on the places that feel most "cruxy" to me. I formulate them without much hedging to facilitate a better discussion, though I feel quite uncertain about most things I write.
On AI Extinction
The part on extinction from AI seems badly argued to me. Is it fair to say that you mainly want to convey a basic intuition, with the hope that the readers will find extinction an "obvious" result?
To be clear: I think that for literal god-like AI, as described by you, an existential catastrophe is likely if we don't solve a very hard case of alignment. For levels below (superintelligence, AGI), I become progressively more optimistic. Some of my hope comes from believing that humanity will eventually coordinate to not scale to god-like AI unless we have enormous assurances that alignment is solved; I think this is similar to your wish, but you hope that we already stop before even AGI is built.
On AI Safety
When we zoom out from the individual to groups, up to the whole of humanity, the complexity of “finding what we want” explodes: when different cultures, different religions, different countries disagree about what they want on key questions like state interventionism, immigration, or what is moral, how can we resolve these into a fixed set of values? If there is a scientific answer to this problem, we have made little progress on it.
If we cannot find, build, and reconcile values that fit with what we want, we will lose control of the future to AI systems that ardently defend a shadow of what we actually care about.
This is a topic where I'm pretty confused, but I still try to formulate a counterposition: I think we can probably align AI systems to constitutions, which then makes it unnecessary to solve all value differences. Whenever someone uses the AI, the AI needs to act in accordance with the constitution, which already has mechanisms for how to resolve value conflicts.
Additionally, the constitution could have mechanisms for how to change the constitution itself, so that humanity and AI could co-evolve to better values over time.
Progress on our ability to predict the consequences of our actions requires better science in every technical field.
ELK might circumvent this issue: Just query an AI about its latent knowledge of future consequences of our actions.
Process design for alignment: [...]
This section seems quite interesting to me, but somewhat different from technical discussions of alignment I'm used to. It seems to me that this section is about problems similar to "intent alignment" or creating valid "training stories", only that you want to define alignment as working correctly in the whole world, instead of just individual systems. Thus, the process design should also prevent problems like "multipolar failure" that might be overlooked by other paradigms. Is this a correct characterization?
Given that this section mainly operates at the level of analogies to politics, economics, and history, I think this section could profit from making stronger connections to AI itself.
Just as solving neuroscience would be insufficient to explain how a company works, even full interpretability of an LLM would be insufficient to explain most research efforts on the AI frontier.
That seems true, and it reminds me of deep deceptiveness, where an AI engages in deception without having any internal process that "looks like" deception.
The more powerful AI we have, the faster things will go. As AI systems improve and automate their own learning, AGI will be able to improve faster than our current research, and ASI will be able to improve faster than humanity can do science. The dynamics of intelligence growth means that it is possible for an ASI “about as smart as humanity” to move to “beyond all human scientific frontiers” on the order of weeks or months. While the change is most dramatic with more advanced systems, as soon as we have AGI we enter a world where things begin to move much quicker, forcing us to solve alignment much faster than in a pre-AGI world.
I agree that such a fast transition from AGI to superintelligence or god-like AI seems very dangerous. Thus, one either shouldn't build AGI, or should somehow ensure that one has lots of time after AGI is built. Some possibilities for having lots of time:
- Sufficient international cooperation to keep things slow.
- A sufficient lead of the West over countries like China to have time for alignment
Option 2 leads to a race against China, and even if we end up with a lead, it's unclear whether it will be sufficient to solve the hard problems of alignment. It's also unclear whether the West could use already AGI (pre superintelligence) for a robust military advantage, and absent such an advantage, scenario 2 seems very unstable.
So a very cruxy question seems to be how feasible option 1 is. I think this compendium doesn't do much to settle this debate, but I hope to learn more in the "Narrow Path".
Thus we need to have humans validate the research. That is, even automated research runs into a bottleneck of human comprehension and supervision.
That seems correct to me. Some people in EA claim that AI Safety is not neglected anymore, but I would say if we ever get confronted with the need to evaluate automated alignment research (possibly on a deadline), then AI Safety research might be extremely neglected.
AI Governance
The reactive framework reverses the burden of proof from how society typically regulates high-risk technologies and industries. In most areas of law, we do not wait for harm to occur before implementing safeguards.
My impression is that companies like Anthropic, DeepMind, and OpenAI talk about mechanisms that are proactive rather than reactive. E.g., responsible scaling policies define an ASL level before it exists, including evaluations for these levels. Then, mitigations need to be in place once the level is reached. Thus, decisively this framework does not want to wait until harm occurred.
I'm curious whether you disagree with this narrow claim (that RSP-like frameworks are proactive), or whether you just want to make the broader claim that it's unclear how RSP-like frameworks could become widespread enforced regulation.
AI is being developed extremely quickly and by many actors, and the barrier to entry is low and quickly diminishing.
I think that the barrier to entry is not diminishing: to be at the frontier requires increasingly enormous resources.
Possibly your claim is that the barrier to entry for a given level of capabilities diminishes. I agree with that, but I'm unsure if it's the most relevant consideration. I think for a given level of capabilities, the riskiest period is when it's reached for the first time since humanity then won't have experience in how to mitigate potential risks.
Paul Graham estimates training price for performance has decreased 100x in each of the last two years, or 10000x in two years.
If GPT-4's costs were 100 million dollars, then it could be trained and released by March 2025 for 10k dollars. That seems quite cheap, so I'm not sure if I believe the numbers.
The reactive framework incorrectly assumes that an AI “warning shot” will motivate coordination.
I never saw this assumption explicitly expressed. Is your view that this is an implicit assumption?
Companies like Anthropic, OpenAI, etc., seem to have facilitated quite some discussion with the USG even without warning shots.
But history shows that it is exactly in such moments that these thresholds are most contested –- this shifting of the goalposts is known as the AI Effect and common enough to have its own Wikipedia page. Time and again, AI advancements have been explained away as routine processes, whereas “real AI” is redefined to be some mystical threshold we have not yet reached.
I would have found this paragraph convincing before ChatGPT. But now, with efforts like the USG national security memorandum, it seems like AI capabilities are being taken almost adequately seriously.
we’ve already seen competitors fight tooth and nail to keep building.
OpenAI thought that their models are considered high-risk in the EU AI act. I think arguing that this is inconsistent with OpenAI's commitment for regulation would require to look at what the EU AI act actually said. I didn't engage with it, but e.g. Zvi doesn't seem to be impressed.
The AI Race
Anthropic released Claude, which they proudly (and correctly) describe as a state-of-the-art pushing model, contradicting their own Core Views on AI Safety, claiming “We generally don’t publish this kind of work because we do not wish to advance the rate of AI capabilities progress.”
The full quote in Anthropic's article is:
"We generally don’t publish this kind of work because we do not wish to advance the rate of AI capabilities progress. In addition, we aim to be thoughtful about demonstrations of frontier capabilities (even without publication). We trained the first version of our headline model, Claude, in the spring of 2022, and decided to prioritize using it for safety research rather than public deployments. We've subsequently begun deploying Claude now that the gap between it and the public state of the art is smaller."
This added context sounds quite different and seems to make clear that with "publish", Anthropic means the publication of the methods to get to the capabilities. Additionally, I agree with Anthropic that releasing models now is less of a race-driver than it would have been in 2022, and so the current decisions seem more reasonable.
These policy proposals lack a roadmap for government enforcement, making them merely hypothetical mandates. Even worse, they add provisions to allow the companies to amend their own framework as they see fit, rather than codifying a resilient system. See Anthropic’s Responsible Scaling Policy: [...]
I agree that it is bad that there is no roadmap for government enforcement. But without such enforcement, and assuming Anthropic is reasonable, I think it makes sense for them to change their RSP in response to new evidence for what works. After all, we want the version that will eventually be encoded in law to be as sensible as possible.
I think Anthropic also deserves some credit for communicating changes to the RSPs and learnings.
Mechanistic interpretability, which tries to reverse-engineer AIs to understand how they work, which can then be used to advance and race even faster. [...] Scalable oversight, which is another term for whack-a-mole approaches where the current issues are incrementally “fixed” by training them away. This incentivizes obscuring issues rather than resolving them. This approach instead helps Anthropic build chatbots, providing a steady revenue stream.
This seems not argued well. It's unclear how mechanistic interpretability would be used to advance the race further (unless you mean that it leads to safety-washing for more government trust and public trust?). Also, scalable oversight is so broad as a collection of strategies that I don't think it's fair to call them whack-a-mole strategies. E.g., I'd say many of the 11 proposals fall under this umbrella.
I'd be happy for any reactions to my comments!
Then the MATS stipend today is probably much lower than it used to be? (Which would make sense since IIRC the stipend during MATS 3.0 was settled before the FTX crash, so presumably when the funding situation was different?)
Is “CHAI” being a CHAI intern, PhD student, or something else? My MATS 3.0 stipend was clearly higher than my CHAI internship stipend.
I have a similar feeling, but there are some forces in the opposite direction:
- Nvidia seems to limit how many GPUs a single competitor can acquire.
- training frontier models becomes cheaper over time. Thus, those that build competitive models some time later than the absolute frontier have to invest much less resources.
My impression is that Dario (somewhat intentionally?) plays the game of saying things he believes to be true about the 5-10 years after AGI, conditional on AI development not continuing.
What happens after those 5-10 years, or if AI gets even vastly smarter? That seems out of scope for the article. I assume he's doing that since he wants to influence a specific set of people, maybe politicians, to take a radical future more seriously than they currently do. Once a radical future is more viscerally clear in a few years, we will likely see even more radical essays.
It is a thing that I remember having been said at podcasts, but I don't remember which one, and there is a chance that it was never said in the sense I interpreted it.
Also, quote from this post:
"DeepMind says that at large quantities of compute the scaling laws bend slightly, and the optimal behavior might be to scale data by even more than you scale model size. In which case you might need to increase compute by more than 200x before it would make sense to use a trillion parameters."
Are the straight lines from scaling laws really bending? People are saying they are, but maybe that's just an artefact of the fact that the cross-entropy is bounded below by the data entropy. If you subtract the data entropy, then you obtain the Kullback-Leibler divergence, which is bounded by zero, and so in a log-log plot, it can actually approach negative infinity. I visualized this with the help of ChatGPT:
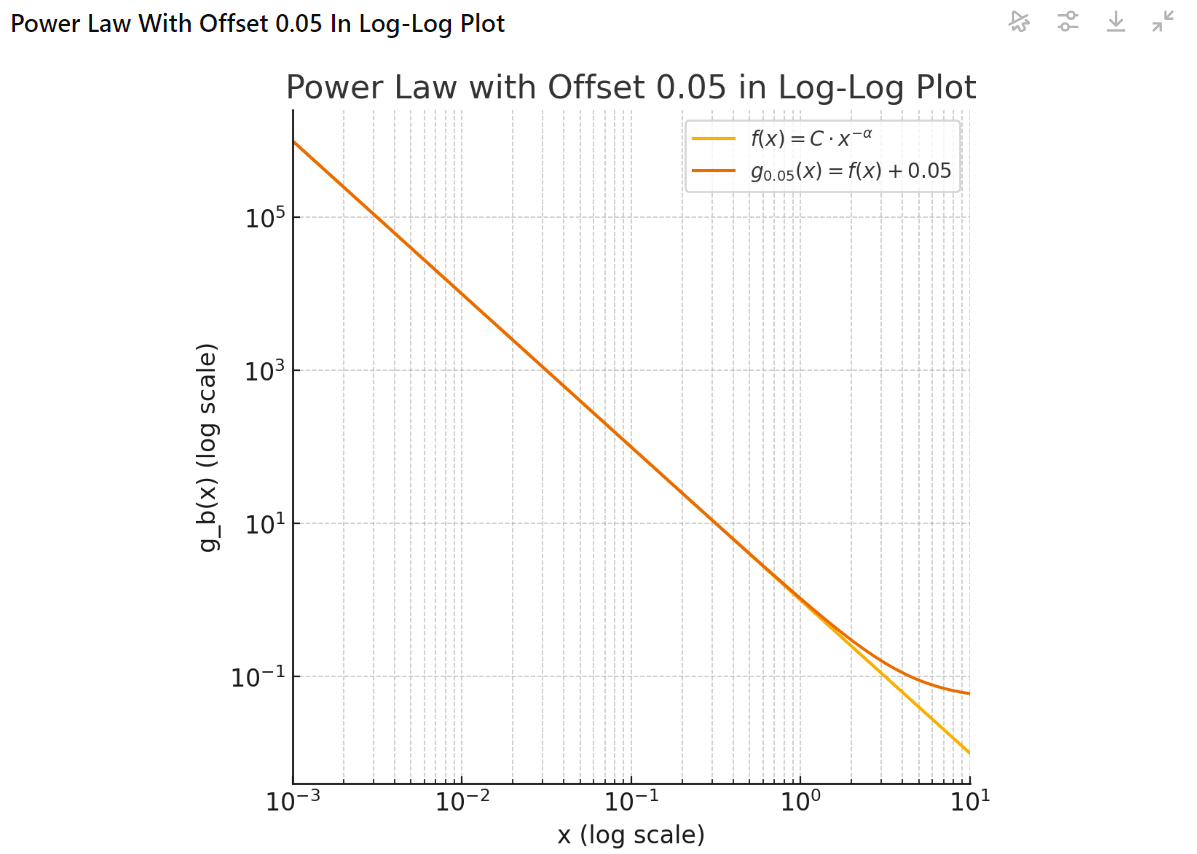
Here, f represents the Kullback-Leibler divergence, and g the cross-entropy loss with the entropy offset.
Agreed.
To understand your usage of the term “outer alignment” a bit better: often, people have a decomposition in mind where solving outer alignment means technically specifying the reward signal/model or something similar. It seems that to you, the writeup of a model-spec or constitution also counts as outer alignment, which to me seems like only part of the problem. (Unless perhaps you mean that model specs and constitutions should be extended to include a whole training setup or similar?)
If it doesn’t seem too off-topic to you, could you comment on your views on this terminology?
https://www.wsj.com/tech/ai/californias-gavin-newsom-vetoes-controversial-ai-safety-bill-d526f621
“California Gov. Gavin Newsom has vetoed a controversial artificial-intelligence safety bill that pitted some of the biggest tech companies against prominent scientists who developed the technology.
The Democrat decided to reject the measure because it applies only to the biggest and most expensive AI models and leaves others unregulated, according to a person with knowledge of his thinking”
New Bloomberg article on data center buildouts pitched to the US government by OpenAI. Quotes:
- “the startup shared a document with government officials outlining the economic and national security benefits of building 5-gigawatt data centers in various US states, based on an analysis the company engaged with outside experts on. To put that in context, 5 gigawatts is roughly the equivalent of five nuclear reactors, or enough to power almost 3 million homes.”
- “Joe Dominguez, CEO of Constellation Energy Corp., said he has heard that Altman is talking about building 5 to 7 data centers that are each 5 gigawatts. “
- “John Ketchum, CEO of NextEra Energy Inc., said the clean-energy giant had received requests from some tech companies to find sites that can support 5 GW of demand, without naming any specific firms.”
Compare with the prediction by Leopold Aschenbrenner in situational awareness:
- "The trillion-dollar cluster—+4 OOMs from the GPT-4 cluster, the ~2030 training cluster on the current trend—will be a truly extraordinary effort. The 100GW of power it’ll require is equivalent to >20% of US electricity production"
OpenAI would have mentioned if they had reached gold on the IMO.
I think it would be valuable if someone would write a post that does (parts of) the following:
- summarize the landscape of work on getting LLMs to reason.
- sketch out the tree of possibilities for how o1 was trained and how it works in inference.
- select a “most likely” path in that tree and describe in detail a possibility for how o1 works.
I would find it valuable since it seems important for external safety work to know how frontier models work, since otherwise it is impossible to point out theoretical or conceptual flaws for their alignment approaches.
One caveat: writing such a post could be considered an infohazard. I’m personally not too worried about this since I guess that every big lab is internally doing the same independently, so that the post would not speed up innovation at any of the labs.
Thanks for the post, I agree with the main points.
There is another claim on causality one could make, which would be: LLMs cannot reliably act in the world as robust agents since by acting in the world, you change the world, leading to a distributional shift from the correlational data the LLM encountered during training.
I think that argument is correct, but misses an obvious solution: once you let your LLM act in the world, simply let it predict and learn from the tokens that it receives in response. Then suddenly, the LLM does not model correlational, but actual causal relationships.
Agreed.
I think the most interesting part was that she made a comment that one way to predict a mind is to be a mind, and that that mind will not necessarily have the best of all of humanity as its goal. So she seems to take inner misalignment seriously.
40 min podcast with Anca Dragan who leads safety and alignment at google deepmind: https://youtu.be/ZXA2dmFxXmg?si=Tk0Hgh2RCCC0-C7q
To clarify: are you saying that since you perceive Chris Olah as mostly intrinsically caring about understanding neural networks (instead of mostly caring about alignment), you conclude that his work is irrelevant to alignment?
I can see that research into proof assistants might lead to better techniques for combining foundation models with RL. Is there anything more specific that you imagine? Outside of math there are very different problems because there is no easy to way to synthetically generate a lot of labeled data (as opposed to formally verifiable proofs).
Not much more specific! I guess from a certain level of capabilities onward, one could create labels with foundation models that evaluate reasoning steps. This is much more fuzzy than math, but I still guess a person who created a groundbreaking proof assistant would be extremely valuable for any effort that tries to make foundation models reason reliably. And if they’d work at a company like google, then I think their ideas would likely diffuse even if they didn’t want to work on foundation models.
Thanks for your details on how someone could act responsibly in this space! That makes sense. I think one caveat is that proof assistant research might need enormous amounts of compute, and so it’s unclear how to work on it productively outside of a company where the ideas would likely diffuse.
I think the main way that proof assistant research feeds into capabilies research is not through the assistants themselves, but by the transfer of the proof assistant research to creating foundation models with better reasoning capabilities. I think researching better proof assistants can shorten timelines.
- See also Demis' Hassabis recent tweet. Admittedly, it's unclear whether he refers to AlphaProof itself being accessible from Gemini, or the research into AlphaProof feeding into improvements of Gemini.
- See also an important paragraph in the blogpost for AlphaProof: "As part of our IMO work, we also experimented with a natural language reasoning system, built upon Gemini and our latest research to enable advanced problem-solving skills. This system doesn’t require the problems to be translated into a formal language and could be combined with other AI systems. We also tested this approach on this year’s IMO problems and the results showed great promise."
https://www.washingtonpost.com/opinions/2024/07/25/sam-altman-ai-democracy-authoritarianism-future/
Not sure if this was discussed at LW before. This is an opinion piece by Sam Altman, which sounds like a toned down version of "situational awareness" to me.
The news is not very old yet. Lots of potential for people to start freaking out.
One question: Do you think Chinchilla scaling laws are still correct today, or are they not? I would assume these scaling laws depend on the data set used in training, so that if OpenAI found/created a better data set, this might change scaling laws.
Do you agree with this, or do you think it's false?
https://x.com/sama/status/1813984927622549881
According to Sam Altman, GPT-4o mini is much better than text-davinci-003 was in 2022, but 100 times cheaper. In general, we see increasing competition to produce smaller-sized models with great performance (e.g., Claude Haiku and Sonnet, Gemini 1.5 Flash and Pro, maybe even the full-sized GPT-4o itself). I think this trend is worth discussing. Some comments (mostly just quick takes) and questions I'd like to have answers to:
- Should we expect this trend to continue? How much efficiency gains are still possible? Can we expect another 100x efficiency gain in the coming years? Andrej Karpathy expects that we might see a GPT-2 sized "smart" model.
- What's the technical driver behind these advancements? Andrej Karpathy thinks it is based on synthetic data: Larger models curate new, better training data for the next generation of small models. Might there also be architectural changes? Inference tricks? Which of these advancements can continue?
- Why are companies pushing into small models? I think in hindsight, this seems easy to answer, but I'm curious what others think: If you have a GPT-4 level model that is much, much cheaper, then you can sell the service to many more people and deeply integrate your model into lots of software on phones, computers, etc. I think this has many desirable effects for AI developers:
- Increase revenue, motivating investments into the next generation of LLMs
- Increase market-share. Some integrations are probably "sticky" such that if you're first, you secure revenue for a long time.
- Make many people "aware" of potential usecases of even smarter AI so that they're motivated to sign up for the next generation of more expensive AI.
- The company's inference compute is probably limited (especially for OpenAI, as the market leader) and not many people are convinced to pay a large amount for very intelligent models, meaning that all these reasons beat reasons to publish larger models instead or even additionally.
- What does all this mean for the next generation of large models?
- Should we expect that efficiency gains in small models translate into efficiency gains in large models, such that a future model with the cost of text-davinci-003 is massively more capable than today's SOTA? If Andrej Karpathy is right that the small model's capabilities come from synthetic data generated by larger, smart models, then it's unclear to me whether one can train SOTA models with these techniques, as this might require an even larger model to already exist.
- At what point does it become worthwhile for e.g. OpenAI to publish a next-gen model? Presumably, I'd guess you can still do a lot of "penetration of small model usecases" in the next 1-2 years, leading to massive revenue increases without necessarily releasing a next-gen model.
- Do the strategies differ for different companies? OpenAI is the clear market leader, so possibly they can penetrate the market further without first making a "bigger name for themselves". In contrast, I could imagine that for a company like Anthropic, it's much more important to get out a clear SOTA model that impresses people and makes them aware of Claude. I thus currently (weakly) expect Anthropic to more strongly push in the direction of SOTA than OpenAI.