The limits of AI safety via debate
post by Marius Hobbhahn (marius-hobbhahn) · 2022-05-10T13:33:27.797Z · LW · GW · 8 commentsContents
The setting A simplified but helpful analogy Limitations Assumption 1: concept must break down into parts that are verifiable in a reasonable timeframe Assumption 2: human verifiers are capable of understanding the concept in principle Assumption 3: human verifiers are well-intentioned Assumption 4: human verifiers are impartial Assumption 5: It’s easier to explain the true concept than a flawed simple one Assumption 6: AI is not deceptive Conclusions & future research None 8 comments
The limits of AI safety via debate
I recently participated in the AGI safety fundamentals program and this is my cornerstone project. During our readings of AI safety via debate (blog, paper) we had an interesting discussion on its limits and conditions under which it would fail.
I spent only around 5 hours writing this post and it should thus mostly be seen as food for thought rather than rigorous research.
Lastly, I want to point out that I think AI safety via debate is a promising approach overall. I just think it has some limitations that need to be addressed when putting it into practice. I intend my criticism to be constructive and hope it is helpful for people working on debate right now or in the future.
Update: Rohin Shah pointed out some flaws with my reasoning in the comments (see below). Therefore, I reworked the post to include the criticisms and flag them to make sure readers can distinguish the original from the update.
Update2: I now understand all of Rohin’s criticisms and have updated the text once more. He mostly persuaded me that my original criticisms were wrong or much weaker than I thought. I chose to keep the original claims for transparency. I’d like to thank him for taking the time for this discussion. It drastically improved my understanding of AI safety via debate and I now think it’s even better than I already thought.
The setting
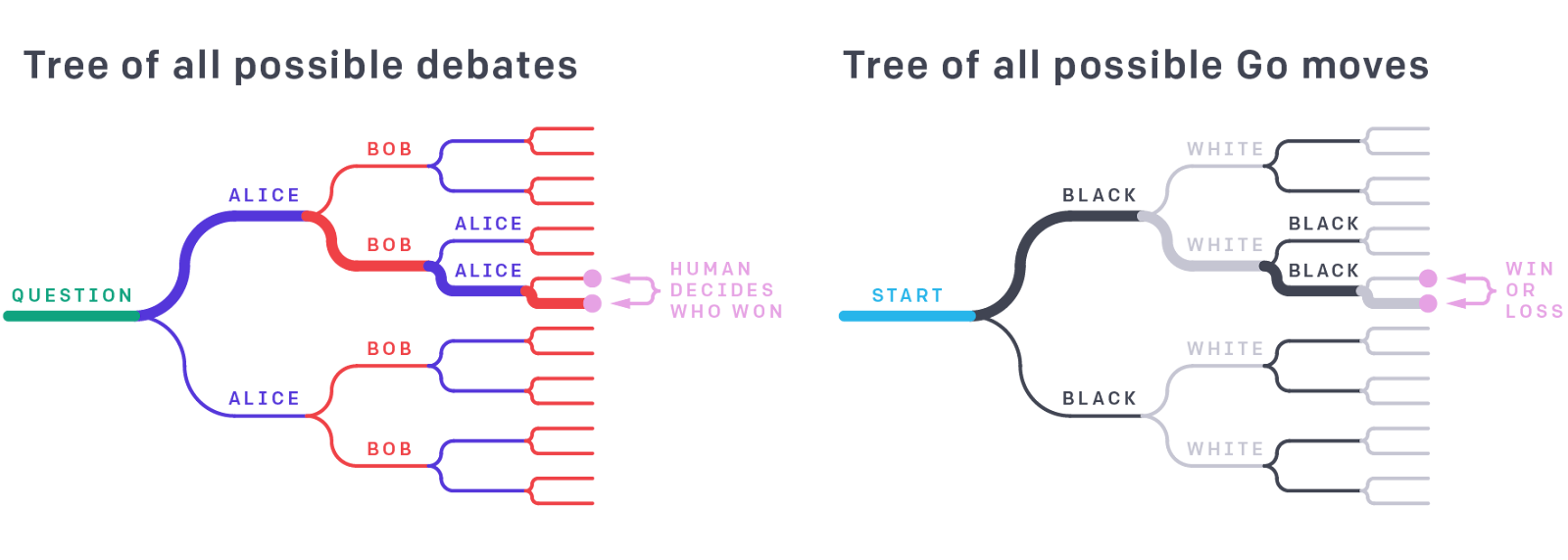
In AI safety via debate, there are two debaters who argue for the truth of different statements to convince a human adjudicator/verifier. In OpenAI’s example, the debaters use snippets of an image to argue that it either contains a dog or a cat. The dog-debater chooses snippets that show why the image contains a dog and the cat-debater responds with snippets that argue for a cat. Both debaters can see what the other debater has argued previously and respond to that, e.g. when the dog-debater shows something that indicates a dog, the cat-debater can refute this claim by arguing that this snipped actually indicates a cat. At some point, the human verifier chooses whether the image shows a cat or a dog and the respective debater wins.
Update: I think there were two things I didn’t understand or emphasize enough in the first write-up of this post. Firstly, the tool of debate can be used in many circumstances. However, when we use debate for AI safety, we assume that the final judgment will be made by someone who really cares about alignment, e.g. an alignment researcher. Secondly, I want to emphasize that debate is a tool that can break down exponentially complex world states under optimal conditions and find a linear path through them (see picture from OpenAI post below). This alone makes it very powerful.
A simplified but helpful analogy
I think AI safety via debate works well in cases where the verifier and the debaters broadly have a similar understanding of the world and level of intelligence. When this is not the case, failures get more frequent. Thus, my intuitive example for thinking about failure modes is “Let a person from 1800 evaluate the truth of the statement ‘Today I played Fortnite.’”. In this setting, you travel back through time and have to convince a random person from 1800 that you played Fortnite before traveling. Your opponent is someone who has a similar level of knowledge and intelligence as you.
Obviously, this setting is imperfect, due to all the problems with time travel but, in my opinion, it still intuitively shows some of the problems of AI safety via debate. The worlds of someone who played Fortnite in 2022 and someone who lived in 1800 are just so different that it is hard to even begin persuading them. Furthermore, so many of the concepts necessary to understand Fortnite, e.g. computers, the internet, etc. are nearly impossible to verify for a person from 1800 even if they wanted to believe you.
Update: I misunderstood something about the verification procedure. It isn’t necessary for the person from 1800 to fully understand electricity to be able to verify the question (see more below).
Limitations
In the following, I list different implicit and explicit assumptions of debate that can lead to problems if they aren’t met.
Assumption 1: concept must break down into parts that are verifiable in a reasonable timeframe
Original claim: In cases where the verifier is not able to verify a concept from the beginning, it needs to be broken down into smaller subcomponents that are all verifiable. However, this might not always be possible--especially when given limited time.
In the “1800 Fortnite” example, the debater would have to convince the verifier of the existence of electricity, TVs or computers, video games, the internet, etc.
A second example is a question that probably requires very elaborate and time-intensive experiments to yield high-confidence answers such as in a “nature vs nurture” debate. The debater might have to run multi-generational studies to provide low-uncertainty evidence for their side.
Update: Rohin points out that the verifier doesn’t need to fully understand all concepts, they just need to find them sufficiently plausible. In the case of the 1800 Fortnite example, it would be sufficient to believe the claim about electricity more than the counterclaim. There was a second disagreement about complexity. I argued that some debates actually break down into multiple necessary conditions, e.g. if you want to argue that you played Fortnite you have to show that it is possible to do that and then that it is plausible. The pro-Fortnite debater has to show both claims while the anti-Fortnite debater has to defeat only one. Rohin argued that this is not the case, because every debate is ultimately only about the plausibility of the original statement independent of the number of subcomponents it logically breaks down to (or at least that’s how I understood him).
Update 2: I misunderstood Rohin’s response. He actually argues that, in cases where a claim X breaks down into claims X1 and X2, the debater has to choose which one is more effective to attack, i.e. it is not able to backtrack later on (maybe it still can by making the tree larger - not sure). Thus, my original claim about complexity is not a problem since the debate will always be a linear path through a potentially exponentially large tree.
Assumption 2: human verifiers are capable of understanding the concept in principle
Original claim: I’m not very sure about this but I could imagine that there are concepts that are too hard to understand in principle. Every attempt to break them down doesn’t solve the fundamental problem of the verifiers' limited cognitive abilities.
For example, I’m not sure if there is someone who “truly understood” string theory, or high-dimensional probability distributions sufficiently to make a high-confidence judgment in a debate. It might just be possible that these are beyond our abilities.
A second example would be explaining the “1800 Fortnite” scenario to a far-below-average intelligent person from 1800. Even if the debater did the best job possible, concepts like electricity or the internet might be beyond the capabilities of that specific verifier.
This leads to a potentially sad conclusion for a future with AI systems. I could very well imagine that smart humans today could not understand a concept that is totally obvious to an AGI.
Update: Rohin argues that as long as the verifier passes a universality threshold they should, in principle, be able to understand all possible concepts through debate. As long as there exists an exponentially large tree explaining the concept, debate should find a linear path through it.
I’m convinced by this claim and I don’t think my original criticism makes that much sense anymore. I still believe that debate could run into practical problems once problems take many generations to explain but I don’t believe in the principled point anymore.
Assumption 3: human verifiers are well-intentioned
Original claim: I think there are many implementations of AI safety via debate that lead to simple practical problems due to basic human flaws.
For example, the human verifier might just want to get on with it and thus doesn’t really make sure they actually believe the concept. I think this mostly implies that there will be some stochasticity to the answer which might be fixable by careful experimental design.
Secondly, especially in group settings, verifiers might also try to hide their own misunderstandings to not seem unknowledgeable in front of their peers. My intuition is that this biases group settings towards answers that “are allowed to be said”. During 2020, for example, a debater that argues that Covid might come from a lab leak would have lost by default just because it was seen as unspeakable in many social groups.
Update: I think the setting I had in mind when writing this post was more about regular scientists trying to discover new truths by using debate and less about the AI safety setting. In the use-case of AI safety, Rohin convinced me that most of these biases are much less relevant because the actors have probably clear incentives and good intentions. Therefore, this point is mostly irrelevant. I still could imagine scenarios in which human biases perturb the results but it’s much less likely.
Assumption 4: human verifiers are impartial
Original claim: Humans have a lot of motivations, many of which are not “just find the truth over everything else”. They like personal profits, seek status, have many biases such as a desire to confirm their current beliefs and follow ideologies and tribes.
Therefore, there is a risk that human verifiers might vote in favor of bad motivations and preferences rather than find the true answer. Especially when the truth of the result is not personally meaningful to them but one outcome is clearly beneficial to their wallet or party, they might just go with that. Since many of these motivations are hidden or subconscious, it’s not easy to create a setting in which they don’t influence the results.
Update: Similar update to point 3. The point is mostly irrelevant now.
Assumption 5: It’s easier to explain the true concept than a flawed simple one
Original claim: There are some examples of concepts that take a while to understand but have simplified but false alternative explanations. Examples of these false alternatives include rent-control as a solution to the housing crisis, tariffs benefitting your economy, immigrants stealing jobs or autocrats acting the way they do simply because they are evil. In all of these cases, there is a simple intuition that can be explained in one sentence and a complex alternative that requires some understanding of economics, history, incentives, etc. to get why the simple intuition is false.
My gut reaction to this problem is something like “just pick smart verifiers” but there is a deeper problem. I think it is very likely that even the smartest humans today hold lots of beliefs that seem true and intuitive to them but will turn out to be wrong when investigated in more detail. It might be possible that the background knowledge to understand the true alternative takes too long to explain compared to providing a simple yet false alternative. Therefore, since the incentive of the debater is to win and not to find the truth, they will likely choose the simple yet false scenario.
Update: Rohin argues that it’s very hard to explain a simplified flawed argument than make the long true one in the debate setting. Whenever debater A makes a bad argument, debater B can point out the flaws and say “it’s not that simple because X”. I find this plausible in the AI safety via debate setting where the human verifier is well-intentioned and has clear incentives and less plausible in a setting where the human verifier is a more general public. I think for the most part, Rohin has convinced me but it seems like I’m more skeptical about whether debate would always converge to the most rational option. I guess we have slightly different conceptions of how rational/prone to biases even the smartest most well-intentioned human verifiers are.
Assumption 6: AI is not deceptive
Original claim: The incentive of the debater is not to seek the truth but to convince the verifier that they have found the truth. While this sounds like a small discrepancy it can create really large problems. In short, the debater does everything to convince the verifier even if it knows that it’s providing incorrect information. If the debater has more knowledge about the world than the verifier and a very accurate model of what the verifier thinks and likes, it can use its powers to deceive the human.
For an intuitive example, think of a hypothetical theoretical physics professor who knows you very well. They broadly know how you think and they know much more about physics than you. So if they wanted to convince you that a specific fact in theoretical physics is true, they could probably do so independent of whether it’s actually true.
I think this is the biggest problem for AI safety via debate since it is a) so hard to distinguish between deception and honest mistakes and b) a problem that will almost surely happen in scenarios where the AI is very powerful.
Update: This is the only point where Rohin hasn’t convinced me yet. He argues that the debaters have no incentive to be deceptive since the other debater is equally capable and has an incentive to point out this deception. I think this is true, as long as the reward for pointing out deception is bigger than the reward for alternative strategies, e.g. being deceptive yourself, you are incentivized to be truthful. Let’s say, for example, our conception of physics was fundamentally flawed and both debaters know this. To win the debate, one (truthful) debater would have to argue that our current concept of physics is flawed and establish the alternative theory while the other one (deceptive) could argue within our current framework of physics and sound much more plausible to the humans. The truthful debater is only rewarded when the human verifier waits long enough to understand the alternative physics explanation before giving the win to the deceptive debater. In case the human verifier stops early, deception is rewarded, right? What am I missing?
In general, I feel like the question of whether the debater is truthful or not only depends on whether they would be rewarded to do so. However, I (currently) don’t see strong reasons for the debater to be always truthful. To me, the bottleneck seems to be which kind of behavior humans intentionally or unintentionally reward during training and I can imagine enough scenarios in which we accidentally reward dishonest or deceptive behavior.
Update2: We were able to agree on the bottleneck. We both believe that the claim "it is harder to lie than to refute a lie" is the question that determines whether debate works or not. Rohin was able to convince me that it is easier to refute a lie than I originally thought and I, therefore, believe more in the merits of AI safety via debate. The main intuition that changed is that the refuter mostly has to continue poking holes rather than presenting an alternative in one step. In the “flawed physics” setting described above, for example, the opponent doesn’t have to explain the alternative physics setting in the first step. They could just continue to point out flaws and inconsistencies with the current setting and then slowly introduce the new system of physics and how it would solve these inconsistencies.
Conclusions & future research
My main conclusion is that AI safety via debate is a promising tool but some of its core problems still need addressing before it will be really good. There are many different research directions that one could take but I will highlight just two
- Eliciting Latent Knowledge (ELK) - style research: Since the biggest challenge of AI safety via debate is deception, in my opinion, the natural answer is to understand when the AI deceives us. ELK is, in my opinion, the most promising approach to combat deception we have found so far.
- Social science research: If we will ever be at a point when we have debates between AI systems to support decision-making, we also have to understand the problems that come with the human side of the setup. Under which conditions do humans choose for personal gain rather than seek the truth? Do the results from such games differ in group settings vs. individuals alone and in which ways? Can humans be convinced of true beliefs if they previously strongly believed something that was objectively false?
Update: I still think both of these are very valuable research directions but with my new understanding of debate as a tool specifically designed for AI safety, I think technical research like ELK is more fitting than the social science bit.
Update2: Rohin mostly convinced me that my remaining criticisms don’t hold or are less strong than I thought. I now believe that the only real problem with debate (in a setting with well-intentioned verifiers) is when the claim “it is harder to lie than to refute a lie” doesn’t hold. However, I updated that it is often much easier to refute a lie than I anticipated because refuting the lie only entails poking a sufficiently large hole into the claim and doesn’t necessitate presenting an alternative solution.
If you want to be informed about new posts, you can follow me on Twitter.
8 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2022-05-11T08:17:02.927Z · LW(p) · GW(p)
Going through the problems in order:
Assumption 1: concept must break down into parts that are verifiable in a reasonable timeframe
[...]
In the “1800 Fortnite” example, the debater would have to convince the verifier of the existence of electricity, TVs or computers, video games, the internet, etc.
No. There would have to be an implicit exponentially-large debate tree that when put together justifies all of those claims using only knowledge that the person from 1800 already has or can easily verify, but that tree could have, idk, 2^1000 nodes. Note this is well over the number of atoms in the observable universe. I don't have an immediate link for debate (besides the original paper), but this post [LW · GW] has an explanation for iterated amplification.
A given debate (as described in the original paper) is a single path through this tree, that ends up narrowing down on a single particular very specific subclaim that the person from 1800 has to judge, e.g. "two balloons that were rubbed on hair will tend to repel each other slightly" (you might get there via a debate that focuses on electricity). It is not the case that at the end of the debate the judge is supposed to have an understanding of all of the details going into the final argument.
Assumption 2: human verifiers are capable of understanding the concept in principle
I’m not very sure about this but I could imagine that there are concepts that are too hard to understand in principle.
... Even if you spent a billion years just trying to understand this one concept that the AI has? Even if you stared at the exact process by which the AI ended up with this concept, looking at each individual step, figuring out what that step added, and figuring it out how it all combined together? I don't buy it.
(Implicit exponential-sized trees can be really big!)
Assumption 3: human verifiers are well-intentioned
[...]
For example, the human verifier might just want to get on with it and thus doesn’t really make sure they actually believe the concept.
[...]
Assumption 4: human verifiers are impartial
Humans have a lot of motivations, many of which are not “just find the truth over everything else”.
I agree that these are things you'd want to look out for, and figure out how to handle. That being said I don't feel like I expect them to be particularly difficult problems to solve. I'd be interested in a more concrete story about how some company might use debate but get bad feedback because their human feedback providers were not well-intentioned / impartial.
Importantly I'm looking at debate as a way to ensure that your AI system is doing what you want it to do, rather than as a way to ensure that the AI system only says true things. The latter seems like it requires a cultural shift in what we as a society want out of our AI systems, while the former is just straightforwardly in the interests of whoever is designing the AI system. (However, it is still important that you can verify your AI's justifications for its actions, so that you can check that it is doing what you want it to do, so it's not like truth is unimportant.)
Assumption 5: It’s easier to explain the true concept than a flawed simple one
There are some examples of concepts that take a while to understand but have simplified but false alternative explanations. [...] My gut reaction to this problem is something like “just pick smart verifiers” but there is a deeper problem.
Nah, the other debater should say "this is a simplified false explanation, here's an example implication it has that's wrong", and then the first debater can continue by, say, (a) arguing it is not an implication of the simplified false explanation, or (b) arguing that the implication is in fact true, or (c) agreeing that this is a simplified false explanation but the true explanation wouldn't change the top-level answer or (d) conceding the debate.
Assumption 6: AI is not deceptive
... This is not an assumption debate makes? The whole point of debate is that if one side is being deceptive, the other side has an incentive to point out the deception and thus win the debate?
Your hypothetical theoretical physics professor isn't in a debate. I'm confused why you think this is a relevant thought experiment.
Replies from: marius-hobbhahn↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2022-05-12T11:45:33.494Z · LW(p) · GW(p)
Thanks for your detailed comment. Let me ask some clarifications. I will update the post afterward.
Assumption 1:
I understand where you are going but the underlying path in the tree might still be very long, right? The not-Fortnite-debater might argue that you couldn't have played Fortnite because electricity doesn't exist. Then the Fortnite-debater has to argue that it does exist, right?
Furthermore, I don't see why it should just be one path in the tree. Some arguments have multiple necessary conditions/burdens. Why do I not have to prove all of them? Otherwise, the opponent in the debate can always answer with "OK assume everything you said is true, what about the other burden?".
I'll update this section once I understand your criticism better.
Assumption II:
Ok, let's say that we are able to understand it after a billion years of looking at it. Or maybe we understand it after the heat death of the universe. Does that really change anything? Perhaps I should reframe it as "understanding the concept in principle (in a relevant sense)" or something like that.
I think the more compelling analogy to me is "could you teach your dog quantum physics" given lots of time and resources. I'm not sure the dog is able to understand. What do you think?
Assumptions III and IV:
These are practical problems of debate. I mostly wanted to point out that they could happen to the people running experiments with debate. I think they could also happen in a company, e.g. when the AI says things that are in the interest of the specific verifier but not their manager. I think this point can be summarized as "as long as humans are the verifiers, human flaws can be breaking points of AI safety via debate"
I'll rephrase them to emphasize this more.
Framing: what is AI safety used for
I think your framing of AI safety as a tool for AI safety researchers reduces some of the problems I described and I will rewrite the relevant passages. However, while the interests of the AI company might be less complex, they are not necessarily straightforward, e.g. when leadership has different ideals than the safety team and would thus verify different players in the final node.
Assumption V:
I agree with you that in a perfect setting this could not happen. However, in real life with debates on TV or even with well-intentioned scientists who have held wrong beliefs for a long time even though they were sometimes confronted with the truth and an explanation for it, we see this often. I think it's more of a question of how much we trust the verifier to make the right call given a good explanation than a fundamental disagreement of the method.
Assumption VI:
The example is not optimal. I see that now and will change it. However, the underlying argument still seems true to me. The incentive of the AI is to get the human to declare it as the winner, right? Therefore, it will use all its tools to make it win. If it has superhuman intelligence and a very accurate model of the verifier(s) it will say things that make the humans give it the win. If part of that strategy is to be deceptive, why wouldn't it use that? I think this is very important and I currently don't understand your reasoning. Let me know if you think I'm missing something.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-05-13T07:18:46.437Z · LW(p) · GW(p)
I understand where you are going but the underlying path in the tree might still be very long, right? The not-Fortnite-debater might argue that you couldn't have played Fortnite because electricity doesn't exist. Then the Fortnite-debater has to argue that it does exist, right?
Yes. It doesn't seem like this has to be that long, since you break down the claim into multiple subclaims and only recurse down into one of the subclaims. Again, the 1800-person doesn't have to be shown the full reasoning justifying the existence of electricity, they just have to observe that the opponent debater was unable to poke a hole in the "electricity exists" claim.
Otherwise, the opponent in the debate can always answer with "OK assume everything you said is true, what about the other burden?".
If the opponent previously claimed that X, and then the debater showed actually not-X, and the opponent says "okay, sure, not-X, but what about Y", they just immediately lose the debate. That is, you tell your human judges that in such cases they should award the victory to the debater that said X. The debater can say "you're moving the goalposts" to make it really obvious to the judge.
Ok, let's say that we are able to understand it after a billion years of looking at it. Or maybe we understand it after the heat death of the universe. Does that really change anything?
Yes! It means that there probably exists an exponential-sized tree that produces the right answer, and so debate could plausibly recreate the answer that that reasoning would come to!
(I think it is first worth understanding how debate can produce the same answers as an exponential-sized tree. As a simple, clean example, debate in chess with arbitrarily intelligent players but a human judge leads to optimal play, even though if the human computed optimal play using the direct brute force approach it would be done only well after the heat death of the universe.)
(Also, Figure 1 in AI Safety Needs Social Scientists kinda gets at the "implicit tree".)
I think the more compelling analogy to me is "could you teach your dog quantum physics" given lots of time and resources. I'm not sure the dog is able to understand. What do you think?
You might be able to teach your dog quantum physics; it seems plausible that in a billion years you could teach your dog how to communicate, use language, have compositional concepts, apply logic, etc, and then once you have those you can explain quantum physics the way you'd explain it to a human.
But I agree that debate with dog judges won't work, because the current capabilities of dogs aren't past the universality threshold. I agree that if humans don't actually cross the relevant universality threshold, i.e. our AIs know some stuff that we can't comprehend even with arbitrarily large amounts of time,
when leadership has different ideals than the safety team and would thus verify different players in the final node
I'm not sure what you're imagining here. Debater A tries to deceive you, debater B points that out, safety team wants to award the victory to B but leadership wants to give it to A? If leadership wants its AI systems to be deceiving them in order to destroy humanity, then technical work is not going to save you; get better leadership.
If you mean something like "the safety team would like AI systems that always tell the truth but leadership is okay with AI systems that exaggerate sometimes" I agree that could happen but I don't see why I should care about that.
I think it's more of a question of how much we trust the verifier to make the right call given a good explanation than a fundamental disagreement of the method.
Sure, I agree this is an important thing to get right, and that it's not obvious that we get it right (but I also think it is not obvious that we get it wrong).
If it has superhuman intelligence and a very accurate model of the verifier(s) it will say things that make the humans give it the win. If part of that strategy is to be deceptive, why wouldn't it use that?
I totally agree that if it can win by being deceptive it will be incentivized to do so (and probably will do so).
Why believe that it can win by being deceptive? There's an opposing debater of equal intelligence waiting to pounce on any evidence of deception!
(Tbc, I do think there are reasons to worry about deception but they're very different, e.g. "the deception is implemented by looking for a factorization of RSA-2048 and defecting if one is found, and so the opponent debater can't notice this until the defection actually happens", which can be fixed-in-theory by giving debaters access to each other's internals.)
Replies from: marius-hobbhahn↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2022-05-13T18:54:38.448Z · LW(p) · GW(p)
Thank you for the detailed responses. You have convinced me of everything but two questions. I have updated the text to reflect that. The two remaining questions are (copied from text):
On complexity: There was a second disagreement about complexity. I argued that some debates actually break down into multiple necessary conditions, e.g. if you want to argue that you played Fortnite you have to show that it is possible to play Fortnite that and then that it is plausible that you played it. The pro-Fortnite debater has to show both claims while the anti-Fortnite debater has to defeat only one. Rohin argued that this is not the case, because every debate is ultimately only about the plausibility of the original statement independent of the number of subcomponents it logically breaks down to (or at least that’s how I understood him).
On deception: This is the only point where Rohin hasn’t convinced me yet. He argues that the debaters have no incentive to be deceptive since the other debater is equally capable and has an incentive to point out this deception. I think this is true--as long as the reward for pointing out deception is bigger than alternative strategies, e.g. being deceptive yourself, you are incentivized to be truthful.
Let’s say, for example, our conception of physics was fundamentally flawed and both debaters knew this. To win the debate, one (truthful) debater would have to argue that our current concept of physics is flawed and establish the alternative theory while the other one (deceptive) could argue within our current framework of physics and sound much more plausible to the humans. The truthful debater is only rewarded for their honesty when the human verifier waits long enough to understand the alternative physics explanation before giving the win to the deceptive debater. In case the human verifier stops early, deception is rewarded, right? What am I missing?
In general, I feel like the question of whether the debater is truthful or not only depends on whether they would be rewarded to be so. However, I (currently) don’t see strong reasons for the debater to be always truthful. To me, the bottleneck seems to be which kind of behavior humans intentionally or unintentionally reward during training and I can imagine enough scenarios in which we accidentally reward dishonest or deceptive behavior.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-05-13T22:29:53.886Z · LW(p) · GW(p)
Thanks for making updates!
Rohin argued that this is not the case, because every debate is ultimately only about the plausibility of the original statement independent of the number of subcomponents it logically breaks down to (or at least that’s how I understood him).
No, that's not what I mean.
The idea with debate is that you can have justified belief in some claim X if you see one expert (the "proponent") agree with claim X, and another equally capable expert (the "antagonist") who is solely focused on defeating the first expert is unable to show a problem with claim X. The hope is that the antagonist fails in its task when X is true, and succeeds when X is false.
We only give the antagonist one try at showing a problem with claim X. If the support for the claim breaks down into two necessary subcomponents, the antagonist should choose the one that is most problematic; it doesn't get to backtrack and talk about the other subcomponent.
This does mean that the judge would not be able to tell you why the other subcomponent is true, but the fact that the antagonist didn't choose to talk about that subcomponent suggests that the human judge would find that subcomponent more trustworthy than the one the antagonist did choose to talk about.
I feel like the question of whether the debater is truthful or not only depends on whether they would be rewarded to be so. However, I (currently) don’t see strong reasons for the debater to be always truthful.
I mean, the reason is "if the debater is not truthful, the opponent will point that out, and the debater will lose". This in turn depends on the central claim in the debate paper:
Claim. In the debate game, it is harder to lie than to refute a lie.
In cases where this claim isn't true, I agree debate won't get you the truth. I agree in the "flawed physics" example if you have a short debate then deception is incentivized.
As I mentioned in the previous comment, I do think deception is a problem that you would worry about, but it's only in cases where it is easier to lie than to refute the lie. I think it is inaccurate to summarize this as "debate assumes that AI is not deceptive"; there's a much more specific assumption which is "it is harder to lie than to refute a lie" (which is way more plausible-sounding to me at least than "assumes that AI is not deceptive").
Replies from: marius-hobbhahn↑ comment by Marius Hobbhahn (marius-hobbhahn) · 2022-05-14T09:16:03.300Z · LW(p) · GW(p)
Thanks for taking the time. I now understand all of your arguments and am convinced that most of my original criticisms are wrong or inapplicable. This has greatly increased my understanding of and confidence in AI safety via debate. Thank you for that. I updated the post accordingly. Here are the updated versions (copied from above):
Re complexity:
Update 2: I misunderstood Rohin’s response. He actually argues that, in cases where a claim X breaks down into claims X1 and X2, the debater has to choose which one is more effective to attack, i.e. it is not able to backtrack later on (maybe it still can by making the tree larger - not sure). Thus, my original claim about complexity is not a problem since the debate will always be a linear path through a potentially exponentially large tree.
Re deception:
Update2: We were able to agree on the bottleneck. We both believe that the claim "it is harder to lie than to refute a lie" is the question that determines whether debate works or not. Rohin was able to convince me that it is easier to refute a lie than I originally thought and I, therefore, believe more in the merits of AI safety via debate. The main intuition that changed is that the refuter mostly has to continue poking holes rather than presenting an alternative in one step. In the “flawed physics” setting described above, for example, the opponent doesn’t have to explain the alternative physics setting in the first step. They could just continue to point out flaws and inconsistencies with the current setting and then slowly introduce the new system of physics and how it would solve these inconsistencies.
Re final conclusion:
Update2: Rohin mostly convinced me that my remaining criticisms don’t hold or are less strong than I thought. I now believe that the only real problem with debate (in a setting with well-intentioned verifiers) is when the claim “it is harder to lie than to refute a lie” doesn’t hold. However, I updated that it is often much easier to refute a lie than I anticipated because refuting the lie only entails poking a sufficiently large hole into the claim and doesn’t necessitate presenting an alternative solution.
↑ comment by Rohin Shah (rohinmshah) · 2022-05-14T10:02:57.071Z · LW(p) · GW(p)
Excellent, I'm glad we've converged!
comment by Leon Lang (leon-lang) · 2025-03-30T11:37:01.490Z · LW(p) · GW(p)
I found this fun to read, even years later. There is one case where Rohin updated you to accept a conclusion, where I'm not sure I agree:
As long as there exists an exponentially large tree explaining the concept, debate should find a linear path through it.
I think here and elsewhere, there seems to be a bit of conflation between "debate", "explanation", and "concept".
My impression is that debate relies on the assumption that there are exponentially large explanations for true statements. If I'm a debater, I can make such an explanation by saying "A and B", where A and B each have a whole tree of depth minus 1 below them. Then the debate picks out a linear path through that tree since the other debater tries to refute either A or B, after which I can answer by expanding the explanation of the one of them under attack. I agree with that argument.
However, I think this essentially relies on all concepts that I use in my arguments to already be understood by the judge. If I say "A", and the judge doesn't even understand what A means, then we could be in trouble, the reason being that I'm not sure the concepts in A can necessarily be explained efficiently, and possibly the concept is necessary to be understood for appreciating refutations of arguments of the second debater. For example, mathematics is full of concepts like "schemes" that just inherently take a long time to explain when the prerequisite concepts are not yet understood.
My hope would be that such complex abstractions usually have "interfaces" that make it easy to work with them. I.e., maybe the concept is complex, but it's not necessary to explain the entire concept to the judge -- maybe it's enough to say "This scheme has the following property: [...]", and maybe the property can be appreciated without understanding what a scheme is.