Ryan Kidd's Shortform
post by Ryan Kidd (ryankidd44) · 2022-10-13T19:12:47.984Z · LW · GW · 70 commentsContents
70 comments
70 comments
Comments sorted by top scores.
comment by Ryan Kidd (ryankidd44) · 2024-05-25T18:07:42.155Z · LW(p) · GW(p)
I am a Manifund Regrantor. In addition to general grantmaking, I have requests for proposals in the following areas:
- Funding for AI safety PhDs [LW · GW] (e.g., with these supervisors), particularly in exploratory research connecting [LW · GW] AI safety theory with empirical ML research.
- An AI safety PhD [LW · GW] advisory service that helps prospective PhD students choose a supervisor and topic (similar to Effective Thesis, but specialized for AI safety).
- Initiatives to critically examine current AI safety macrostrategy (e.g., as articulated by Holden [? · GW] Karnofsky [? · GW]) like the Open Philanthropy AI Worldviews Contest and Future Fund Worldview Prize [EA · GW].
- Initiatives to identify and develop "Connectors [LW · GW]" outside of academia (e.g., a reboot of the Refine [LW · GW] program, well-scoped contests [LW · GW], long-term mentoring [LW · GW] and peer-support programs).
- Physical community spaces for AI safety in AI hubs outside of the SF Bay Area or London (e.g., Japan, France, Bangalore).
- Start-up incubators for projects, including evals/red-teaming/interp companies, that aim to benefit AI safety, like Catalyze Impact, Future of Life Foundation, and YCombinator's request for Explainable AI start-ups.
- Initiatives to develop and publish expert consensus on AI safety macrostrategy cruxes, such as the Existential Persuasion Tournament and 2023 Expert Survey on Progress in AI (e.g., via the Delphi method, interviews [LW · GW], surveys [LW · GW], etc.).
- Ethics/prioritization research into:
- What values to instill in artificial superintelligence?
- How should AI-generated wealth be distributed?
- What should people do in a post-labor society?
- What level of surveillance/restriction is justified by the Unilateralist's Curse?
- What moral personhood will digital minds have?
- How should nations share decision making power regarding transformative AI?
- New nonprofit startups that aim to benefit AI safety.
↑ comment by Thiwanka Jayasiri (thiwanka-jayasiri) · 2024-07-12T23:49:18.711Z · LW(p) · GW(p)
"Physical community spaces for AI safety in AI hubs outside of the SF Bay Area or London (e.g., Japan, France, Bangalore)"- I love this initiative. Can we also consider Australia or New Zealand in the upcoming proposal?
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-07-15T17:34:19.693Z · LW(p) · GW(p)
In theory, sure! I know @yanni kyriacos [LW · GW] recently assessed the need for an ANZ AI safety hub, but I think he concluded there wasn't enough of a need yet?
Replies from: yanni↑ comment by yanni kyriacos (yanni) · 2024-07-15T23:14:45.199Z · LW(p) · GW(p)
Hi! I think in Sydney we're ~ 3 seats short of critical mass, so I am going to reassess the viability of a community space in 5-6 months :)
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-12-26T19:14:32.984Z · LW(p) · GW(p)
@yanni kyriacos [LW · GW] when will you post about TARA and Sydney AI Safety Hub on LW? ;)
Replies from: yanni↑ comment by yanni kyriacos (yanni) · 2024-12-27T02:34:09.895Z · LW(p) · GW(p)
SASH isn't official (we're waiting on funding).
Here is TARA :)
https://www.lesswrong.com/posts/tyGxgvvBbrvcrHPJH/apply-to-be-a-ta-for-tara
comment by Ryan Kidd (ryankidd44) · 2024-10-31T01:48:36.809Z · LW(p) · GW(p)
Hourly stipends for AI safety fellowship programs, plus some referents. The average AI safety program stipend is $26/h.
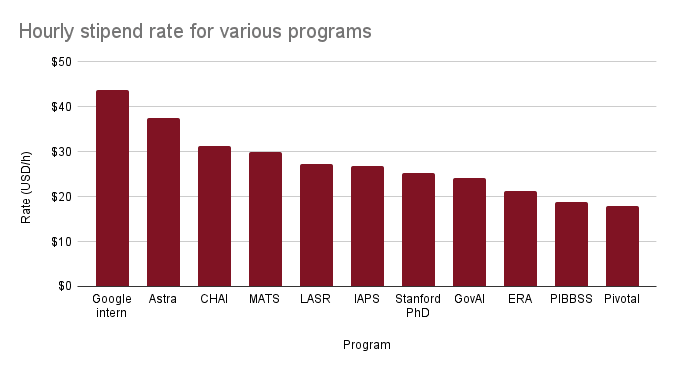
Edit: updated figure to include more programs.
Replies from: johnswentworth, ejenner, leon-lang, jacques-thibodeau, metawrong↑ comment by johnswentworth · 2024-11-01T02:33:10.176Z · LW(p) · GW(p)
... WOW that is not an efficient market.
Replies from: johnswentworth, ryankidd44↑ comment by johnswentworth · 2024-11-01T03:15:21.008Z · LW(p) · GW(p)
Y'know @Ryan [LW · GW], MATS should try to hire the PIBBSS folks to help with recruiting. IMO they tend to have the strongest participants of the programs on this chart which I'm familiar with (though high variance).
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-11-01T18:44:27.647Z · LW(p) · GW(p)
That's interesting! What evidence do you have of this? What metrics are you using?
Replies from: johnswentworth↑ comment by johnswentworth · 2024-11-01T20:23:37.457Z · LW(p) · GW(p)
My main metric is "How smart do these people seem when I talk to them or watch their presentations?". I think they also tend to be older and have more research experience.
Replies from: ryankidd44, ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-11-01T20:55:56.556Z · LW(p) · GW(p)
I think there some confounders here:
- PIBBSS had 12 fellows last cohort and MATS had 90 scholars. The mean/median MATS Summer 2024 scholar was 27; I'm not sure what this was for PIBBSS. The median age of the 12 oldest MATS scholars was 35 (mean 36). If we were selecting for age (which is silly/illegal, of course) and had a smaller program, I would bet that MATS would be older than PIBBSS on average. MATS also had 12 scholars with completed PhDs and 11 in-progress.
- Several PIBBSS fellows/affiliates have done MATS (e.g., Ann-Kathrin Dombrowski, Magdalena Wache, Brady Pelkey, Martín Soto).
- I suspect that your estimation of "how smart do these people seem" might be somewhat contingent on research taste. Most MATS research projects are in prosaic AI safety fields like oversight & control, evals, and non-"science of DL" interpretability, while most PIBBSS research has been in "biology/physics-inspired" interpretability, agent foundations, and (recently) novel policy approaches (all of which MATS has supported historically).
Also, MATS is generally trying to further a different research porfolio than PIBBSS, as I discuss here [LW · GW], and has substantial success in accelerating hires to AI scaling lab safety teams and research nonprofits, helping scholars found impactful AI safety organizations, and (I suspect) accelerating AISI hires.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-11-01T21:06:28.502Z · LW(p) · GW(p)
I suspect that your estimation of "how smart do these people seem" might be somewhat contingent on research taste. Most MATS research projects are in prosaic AI safety fields like oversight & control, evals, and non-"science of DL" interpretability, while most PIBBSS research has been in "biology/physics-inspired" interpretability, agent foundations, and (recently) novel policy approaches (all of which MATS has supported historically).
I think this is less a matter of my particular taste, and more a matter of selection pressures producing genuinely different skill levels between different research areas. People notoriously focus on oversight/control/evals/specific interp over foundations/generalizable interp because the former are easier. So when one talks to people in those different areas, there's a very noticeable tendency for the foundations/generalizable interp people to be noticeably smarter, more experienced, and/or more competent. And in the other direction, stronger people tend to be more often drawn to the more challenging problems of foundations or generalizable interp.
So possibly a MATS apologist reply would be: yeah, the MATS portfolio is more loaded on the sort of work that's accessible to relatively-mid researchers, so naturally MATS ends up with more relatively-mid researchers. Which is not necessarily a bad thing.
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-11-01T21:57:37.612Z · LW(p) · GW(p)
I don't agree with the following claims (which might misrepresent you):
- "Skill levels" are domain agnostic.
- Frontier oversight, control, evals, and non-"science of DL" interp research is strictly easier in practice than frontier agent foundations and "science of DL" interp research.
- The main reason there is more funding/interest in the former category than the latter is due to skill issues, rather than worldview differences and clarity of scope.
- MATS has mid researchers relative to other programs.
↑ comment by johnswentworth · 2024-11-02T02:20:33.269Z · LW(p) · GW(p)
Y'know, you probably have the data to do a quick-and-dirty check here. Take a look at the GRE/SAT scores on the applications (both for applicant pool and for accepted scholars). If most scholars have much-less-than-perfect scores, then you're probably not hiring the top tier (standardized tests have a notoriously low ceiling). And assuming most scholars aren't hitting the test ceiling, you can also test the hypothesis about different domains by looking at the test score distributions for scholars in the different areas.
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-11-04T02:43:11.083Z · LW(p) · GW(p)
We don't collect GRE/SAT scores, but we do have CodeSignal scores and (for the first time) a general aptitude test developed in collaboration with SparkWave. Many MATS applicants have maxed out scores for the CodeSignal and general aptitude tests. We might share these stats later.
Replies from: dtch1997↑ comment by Daniel Tan (dtch1997) · 2025-01-27T20:06:24.383Z · LW(p) · GW(p)
FWIW from what I remember, I would be surprised if most people doing MATS 7.0 did not max out the aptitude test. Also, the aptitude test seems more like an SAT than anything measuring important procedural knowledge for AI safety.
↑ comment by Ryan Kidd (ryankidd44) · 2024-11-01T20:31:25.605Z · LW(p) · GW(p)
Are these PIBBSS fellows (MATS scholar analog) or PIBBSS affiliates (MATS mentor analog)?
Replies from: johnswentworth↑ comment by johnswentworth · 2024-11-01T20:51:45.836Z · LW(p) · GW(p)
Fellows.
↑ comment by Ryan Kidd (ryankidd44) · 2024-11-01T18:55:21.872Z · LW(p) · GW(p)
Note that governance/policy jobs pay less than ML research/engineering jobs, so I expect GovAI, IAPS, and ERA, which are more governance focused, to have a lower stipend. Also, MATS is deliberately trying to attract top CS PhD students, so our stipend should be higher than theirs, although lower than Google internships to select for value alignment. I suspect that PIBBSS' stipend is an outlier and artificially low due to low funding. Given that PIBBSS has a mixture of ML and policy projects, and IMO is generally pursuing higher variance research than MATS, I suspect their optimal stipend would be lower than MATS', but higher than a Stanford PhD's; perhaps around IAPS' rate.
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-11-01T19:45:17.429Z · LW(p) · GW(p)
That said, maybe you are conceptualizing of an "efficient market" that principally values impact, in which case I would expect the governance/policy programs to have higher stipends. However, I'll note that 87% of MATS alumni are interested in working at an AISI and several are currently working at UK AISI, so it seems that MATS is doing a good job of recruiting technical governance talent that is happy to work for government wages.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-11-01T20:26:57.557Z · LW(p) · GW(p)
No, I meant that the correlation between pay and how-competent-the-typical-participant-seems-to-me is, if anything, negative. Like, the hiring bar for Google interns is lower than any of the technical programs, and PIBBSS seems-to-me to have the most competent participants overall (though I'm not familiar with some of the programs).
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-11-01T21:43:57.998Z · LW(p) · GW(p)
I don't think it makes sense to compare Google intern salary with AIS program stipends this way, as AIS programs are nonprofits (with associated salary cut) and generally trying to select against people motivated principally by money. It seems like good mechanism design to pay less than tech internships, even if the technical bar for is higher, given that value alignment is best selected by looking for "costly signals" like salary sacrifice.
I don't think the correlation for competence among AIS programs is as you describe.
↑ comment by Erik Jenner (ejenner) · 2024-10-31T16:34:48.288Z · LW(p) · GW(p)
Interesting, thanks! My guess is this doesn't include benefits like housing and travel costs? Some of these programs pay for those while others don't, which I think is a non-trivial difference (especially for the bay area)
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-10-31T18:02:56.833Z · LW(p) · GW(p)
Yes, this doesn't include those costs and programs differ in this respect.
↑ comment by Leon Lang (leon-lang) · 2024-10-31T18:11:07.028Z · LW(p) · GW(p)
Is “CHAI” being a CHAI intern, PhD student, or something else? My MATS 3.0 stipend was clearly higher than my CHAI internship stipend.
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-10-31T18:15:25.853Z · LW(p) · GW(p)
CHAI interns are paid $5k/month for in-person interns and $3.5k/month for remote interns. I used the in-person figure. https://humancompatible.ai/jobs
Replies from: leon-lang↑ comment by Leon Lang (leon-lang) · 2024-10-31T20:11:32.306Z · LW(p) · GW(p)
Then the MATS stipend today is probably much lower than it used to be? (Which would make sense since IIRC the stipend during MATS 3.0 was settled before the FTX crash, so presumably when the funding situation was different?)
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-10-31T20:49:29.074Z · LW(p) · GW(p)
MATS lowered the stipend from $50/h to $40/h ahead of the Summer 2023 Program to support more scholars. We then lowered it again to $30/h ahead of the Winter 2023-24 Program after surveying alumni [LW(p) · GW(p)] and determining that 85% would be accept $30/h.
↑ comment by jacquesthibs (jacques-thibodeau) · 2024-11-03T03:52:40.330Z · LW(p) · GW(p)
I’d be curious to know if there’s variability in the “hours worked per week” given that people might work more hours during a short program vs a longer-term job (to keep things sustainable).
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-11-05T03:34:50.236Z · LW(p) · GW(p)
I'm not sure!
↑ comment by metawrong · 2024-11-01T18:20:37.732Z · LW(p) · GW(p)
LASR (https://www.lasrlabs.org/) is giving a £11,000 stipend for a 13 week program, assuming 40h/week it works out to ~$27
Replies from: ryankidd44, ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-11-01T19:58:53.495Z · LW(p) · GW(p)
Updated figure with LASR Labs and Pivotal Research Fellowship at current exchange rate of 1 GBP = 1.292 USD.

↑ comment by Ryan Kidd (ryankidd44) · 2024-11-01T19:46:50.831Z · LW(p) · GW(p)
That seems like a reasonable stipend for LASR. I don't think they cover housing, however.
comment by Ryan Kidd (ryankidd44) · 2024-09-15T19:20:47.072Z · LW(p) · GW(p)
I just left a comment on PIBBSS' Manifund grant proposal (which I funded $25k) that people might find interesting.
Main points in favor of this grant
- My inside view is that PIBBSS mainly supports “blue sky” or “basic” research, some of which has a low chance of paying off, but might be critical in “worst case [AF · GW]” alignment scenarios (e.g., where “alignment MVPs” don’t work, or “sharp left turns [? · GW]” and “intelligence explosions [? · GW]” are more likely than I expect). In contrast, of the technical research MATS supports, about half is basic research (e.g., interpretability, evals, agent foundations) and half is applied research (e.g., oversight + control, value alignment). I think the MATS portfolio is a better holistic strategy for furthering AI alignment. However, if one takes into account the research conducted at AI labs and supported by MATS, PIBBSS’ strategy makes a lot of sense: they are supporting a wide portfolio of blue sky research that is particularly neglected by existing institutions and might be very impactful in a range of possible “worst-case” AGI scenarios. I think this is a valid strategy in the current ecosystem/market and I support PIBBSS!
- In MATS’ recent post, “Talent Needs of Technical AI Safety Teams [LW · GW]”, we detail an AI safety talent archetype we name “Connector”. Connectors bridge exploratory theory and empirical science, and sometimes instantiate new research paradigms. As we discussed in the post, finding and developing Connectors is hard, often their development time is on the order of years, and there is little demand on the AI safety job market for this role. However, Connectors can have an outsized impact on shaping the AI safety field and the few that make it are “household names” in AI safety and usually build organizations, teams, or grant infrastructure around them. I think that MATS is far from the ideal training ground for Connectors (although some do pass through!) as our program is only 10 weeks long (with an optional 4 month extension) rather than the ideal 12-24 months, we select scholars to fit established mentors’ preferences rather than on the basis of their original research ideas, and our curriculum and milestones generally focus on building object-level scientific skills rather than research ideation and “gap-identifying”. It’s thus no surprise that most MATS scholars are “Iterator” archetypes. I think there is substantial value in a program like PIBBSS existing, to support the development of “Connectors” and pursue impact in a higher-variance way than MATS.
- PIBBSS seems to have decent track record for recruiting experienced academics in non-CS fields and helping them repurpose their advanced scientific skills to develop novel approaches to AI safety. Highlights for me include Adam Shai’s “computational mechanics” approach to interpretability and model cognition, Martín Soto’s “logical updatelessness” approach to decision theory, and Gabriel Weil’s “tort law” approach to making AI labs liable for their potential harms on the long-term future.
- I don’t know Lucas Teixeira (Research Director) very well, but I know and respect Dušan D. Nešić (Operations Director) a lot. I also highly endorsed Nora Ammann’s vision (albeit while endorsing a different vision for MATS). I see PIBBSS as a highly competent and EA-aligned organization, and I would be excited to see them grow!
- I think PIBBSS would benefit from funding from diverse sources, as mainstream AI safety funders have pivoted more towards applied technical research (or more governance-relevant basic research like evals). I think Manifund regrantors are well-positioned to endorse more speculative basic research, but I don’t really know how to evalutate such research myself, so I’d rather defer to experts. PIBBSS seems well-positioned to provide this expertise! I know that Nora had quite deep models of this while Research Director and in talking with Dusan, I have had a similar impression. I hope to talk with Lucas soon!
Donor's main reservations
- It seems that PIBBSS might be pivoting away from higher variance blue sky research to focus on more mainstream AI interpretability. While this might create more opportunities for funding, I think this would be a mistake. The AI safety ecosystem needs a home for “weird ideas” and PIBBSS seems the most reputable, competent, EA-aligned place for this! I encourage PIBBSS to “embrace the weird”, albeit while maintaining high academic standards for basic research, modelled off the best basic science institutions.
- I haven’t examined PIBBSS’ applicant selection process and I’m not entirely confident it is the best version it can be, given how hard MATS has found applicant selection and my intuitions around the difficulty of choosing a blue sky research portfolio. I strongly encourage PIBBSS to publicly post and seek feedback on their applicant selection and research prioritization processes, so that the AI safety ecosystem can offer useful insight. I would also be open to discussing these more with PIBBSS, though I expect this would be less useful.
- My donation is not very counterfactual here, given PIBBSS’ large budget and track record. However, there has been a trend in typical large AI safety funders away from agent foundations and interpretability, so I think my grant is still meaningful.
Process for deciding amount
I decided to donate the project’s minimum funding ($25k) so that other donors would have time to consider the project’s merits and potentially contribute. Given the large budget and track record of PIBBSS, I think my funds are less counterfactual here than for smaller, more speculative projects, so I only donated the minimum. I might donate significantly more to PIBBSS later if I can’t find better grants, or if PIBBSS is unsuccessful in fundraising.
Conflicts of interest
I don't believe there are any conflicts of interest to declare.
comment by Ryan Kidd (ryankidd44) · 2024-07-12T18:20:27.913Z · LW(p) · GW(p)
Why does the AI safety community need help founding projects?
- AI safety should scale
- Labs need external auditors for the AI control plan [LW · GW] to work
- We should pursue many research bets [LW · GW] in case superalignment/control fails
- Talent leaves MATS/ARENA and sometimes struggles to find meaningful work for mundane reasons, not for lack of talent or ideas
- Some emerging research agendas don’t have a home
- There are diminishing returns at scale [LW · GW] for current AI safety teams; sometimes founding new projects is better than joining an existing team
- Scaling lab alignment teams are bottlenecked by management capacity, so their talent cut-off is above the level required to do “useful AIS work”
- Research organizations (inc. nonprofits) are often more effective than independent researchers
- “Block funding model” is more efficient, as researchers can spend more time researching, rather than seeking grants, managing, or other traditional PI duties that can be outsourced
- Open source/collective projects often need a central rallying point (e.g., EleutherAI, dev interp at Timaeus, selection theorems and cyborgism agendas seem too delocalized, etc.)
- There is (imminently) a market for for-profit AI safety companies [LW · GW] and value-aligned people should capture this free energy or let worse alternatives flourish
- If labs or API users are made legally liable for their products, they will seek out external red-teaming/auditing consultants to prove they “made a reasonable attempt” to mitigate harms
- If government regulations require labs to seek external auditing, there will be a market for many types of companies
- “Ethical AI” companies might seek out interpretability or bias/fairness consultants
- New AI safety organizations struggle to get funding and co-founders despite having good ideas
- AIS researchers are usually not experienced entrepeneurs (e.g., don’t know how to write grant proposals for EA funders, pitch decks for VCs, manage/hire new team members, etc.)
- There are not many competent start-up founders in the EA/AIS community and when they join, they don’t know what is most impactful to help
- Creating a centralized resource for entrepeneurial education/consulting and co-founder pairing would solve these problems
↑ comment by Ben Goldhaber (bgold) · 2024-07-13T00:13:34.413Z · LW(p) · GW(p)
I agree with this, I'd like to see AI Safety scale with new projects. A few ideas I've been mulling:
- A 'festival week' bringing entrepreneur types and AI safety types together to cowork from the same place, along with a few talks and lot of mixers.
- running an incubator/accelerator program at the tail end of a funding round, with fiscal sponsorship and some amount of operational support.
- more targeted recruitment for specific projects to advance important parts of a research agenda.
It's often unclear to me whether new projects should actually be new organizations; making it easier to spin up new projects, that can then either join existing orgs or grow into orgs themselves, seems like a promising direction.
↑ comment by Elizabeth (pktechgirl) · 2024-07-14T01:53:47.632Z · LW(p) · GW(p)
- Talent leaves MATS/ARENA and sometimes struggles to find meaningful work
I'm surprised this one was included, it feels tail-wagging-the-dog to me.
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-07-14T02:14:20.134Z · LW(p) · GW(p)
I would amend it to say "sometimes struggles to find meaningful employment despite having the requisite talent to further impactful research directions (which I believe are plentiful)"
Replies from: pktechgirl↑ comment by Elizabeth (pktechgirl) · 2024-07-14T21:28:40.038Z · LW(p) · GW(p)
This still reads to me as advocating for a jobs program for the benefit of MATS grads, not safety. My guess is you're aiming for something more like "there is talent that could do useful work under someone else's direction, but not on their own, and we can increase safety by utilizing it".
Replies from: mesaoptimizer, ryankidd44↑ comment by mesaoptimizer · 2024-07-15T07:50:37.047Z · LW(p) · GW(p)
I expect that Ryan means to say one of the these things:
- There isn't enough funding for MATS grads to do useful work in the research directions they are working on, that have already been vouched for by senior alignment researchers (especially their mentors) to be valuable. (Potential examples: infrabayesianism)
- There isn't (yet) institutional infrastructure to support MATS grads to do useful work together as part of a team focused on the same (or very similar) research agendas, and that this is the case for multiple nascent and established research agendas. They are forced to go to academia and disperse across the world instead of being able to work together in one location. (Potential examples: selection theorems, multi-agent alignment (of the sort that Caspar Oesterheld and company work on))
- There aren't enough research managers in existing established alignment research organizations or frontier labs to enable MATS grads to work on the research directions they consider extremely high value, and would benefit from multiple people working together on (Potential examples: activation steering)
I'm pretty sure that Ryan does not mean to say that MATS grads cannot do useful work on their own. The point is that we don't yet have the institutional infrastructure to absorb, enable, and scale new researchers the way our civilization has for existing STEM fields via, say, PhD programs or yearlong fellowships at OpenAI/MSR/DeepMind (which are also pretty rare). AFAICT, the most valuable part of such infrastructure in general is the ability to co-locate researchers working on the same or similar research problems -- this is standard for academic and industry research groups, for example, and from experience I know that being able to do so is invaluable. Another extremely valuable facet of institutional infrastructure that enables researchers is the ability to delegate operations and logistics problems -- particularly the difficulty of finding grant funding, interfacing with other organizations, getting paperwork handled, etc.
I keep getting more and more convinced, as time passes, that it would be more valuable for me to work on building the infrastructure to enable valuable teams and projects, than to simply do alignment research while disregarding such bottlenecks to this research ecosystem.
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-07-15T17:05:55.210Z · LW(p) · GW(p)
@Elizabeth, Mesa nails it above. I would also add that I am conceptualizing impactful AI safety research as the product of multiple reagents, including talent, ideas, infrastructure, and funding. In my bullet point, I was pointing to an abundance of talent and ideas relative to infrastructure and funding. I'm still mostly working on talent development at MATS, but I'm also helping with infrastructure and funding (e.g., founding LISA, advising Catalyze Impact, regranting via Manifund) and I want to do much more for these limiting reagents.
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2024-07-15T19:00:28.952Z · LW(p) · GW(p)
Also note that historically many individuals entering AI safety seem to have been pursuing the "Connector [LW · GW]" path, when most jobs now (and probably in the future) are "Iterator"-shaped, and larger AI safety projects are also principally bottlenecked by "Amplifiers". The historical focus on recruiting and training Connectors to the detriment of Iterators and Amplifiers has likely contributed to this relative talent shortage. A caveat: Connectors are also critical for founding new research agendas and organizations, though many self-styled Connectors would likely substantially benefit as founders by improving some Amplifier-shaped soft skills, including leadership, collaboration, networking, and fundraising.
↑ comment by Ryan Kidd (ryankidd44) · 2024-07-15T22:59:09.471Z · LW(p) · GW(p)
I interpret your comment as assuming that new researchers with good ideas produce more impact on their own than in teams working towards a shared goal; this seems false to me. I think that independent research is usually a bad bet in general and that most new AI safety researchers should be working on relatively few impactful research directions, most of which are best pursued within a team due to the nature of the research (though some investment in other directions seems good for the portfolio).
I've addressed this a bit in thread, but here are some more thoughts:
- New AI safety researchers seem to face mundane barriers to reducing AI catastrophic risk, including funding, infrastructure, and general executive function.
- MATS alumni are generally doing great stuff (~78% currently work in AI safety/control, ~1.4% work on AI capabilities), but we can do even better.
- Like any other nascent scientific/engineering discipline, AI safety will produce more impactful research with scale [LW · GW], albeit with some diminishing returns on impact eventually (I think we are far from the inflection point, however).
- MATS alumni, as a large swathe of the most talented new AI safety researchers in my (possibly biased) opinion, should ideally not experience mundane barriers to reducing AI catastrophic risk.
- Independent research seems worse than team-based research for most research that aims to reduce AI catastrophic risk:
- "Pair-programming", builder-breaker, rubber-ducking, etc. are valuable parts of the research process and are benefited by working in a team.
- Funding insecurity and grantwriting responsibilities are larger for independent researchers and obstruct research.
- Orgs with larger teams and discretionary funding can take on interns to help scale projects and provide mentorship.
- Good prosaic AI safety research largely looks more like large teams doing engineering and less like lone geniuses doing maths. Obviously, some lone genius researchers (especially on mathsy non-prosaic agendas) seem great for the portfolio too, but these people seem hard to find/train [LW · GW] anyways (so there is often more alpha [LW · GW] in the former by my lights). Also, I have doubts that the optimal mechanism to incentivize "lone genius research" is via small independent grants instead of large bounties and academic nerdsniping.
- Therefore, more infrastructure and funding for MATS alumni, who are generally value-aligned and competent, is good for reducing AI catastrophic risk in expectation.
↑ comment by Elizabeth (pktechgirl) · 2024-07-17T16:22:06.095Z · LW(p) · GW(p)
I interpret your comment as assuming that new researchers with good ideas produce more impact on their own than in teams working towards a shared goal
I don't believe that, although I see how my summary could be interpreted that way. I agree with basically all the reasons in your recent comment and most in the original comment. I could add a few reasons of my own doing independent grant-funded work sucks. But I think it's really important to track how founding projects tracks to increased potential safety instead of intermediates, and push hard against potential tail wagging the dog scenarios.
I was trying to figure out why this was important to me, given how many of your points I agree with. I think it's a few things:
- Alignment work seems to be prone to wagging the dog, and is harder to correct, due to poor feedback loops.
- The consequences of this can be dire
- making it harder to identify and support the best projects.
- making it harder to identify and stop harmful projects
- making it harder to identify when a decent idea isn't panning out, leading to people and money getting stuck in the mediocre project instead of moving on.
- One of the general concerns about MATS is it spins up potential capabilities researchers. If the market can't absorb the talent, that suggests maybe MATS should shrink.
- OTOH if you told me that for every 10 entrants MATS spins up 1 amazing safety researcher and 9 people who need makework to prevent going into capabilities, I'd be open to arguments that that was a good trade.
comment by Ryan Kidd (ryankidd44) · 2023-03-10T02:39:16.070Z · LW(p) · GW(p)
Main takeaways from a recent AI safety conference:
- If your foundation model is one small amount of RL away from being dangerous and someone can steal your model weights, fancy alignment techniques don’t matter. Scaling labs cannot currently prevent state actors from hacking their systems and stealing their stuff. Infosecurity is important to alignment.
- Scaling labs might have some incentive to go along with the development of safety standards as it prevents smaller players from undercutting their business model and provides a credible defense against lawsuits regarding unexpected side effects of deployment (especially with how many tech restrictions the EU seems to pump out). Once the foot is in the door, more useful safety standards to prevent x-risk might be possible.
- Near-term commercial AI systems that can be jailbroken to elicit dangerous output might empower more bad actors to make bioweapons or cyberweapons. Preventing the misuse of near-term commercial AI systems or slowing down their deployment seems important.
- When a skill is hard to teach, like making accurate predictions over long time horizons in complicated situations or developing a “security mindset [? · GW],” try treating humans like RL agents. For example, Ph.D. students might only get ~3 data points on how to evaluate a research proposal ex-ante, whereas Professors might have ~50. Novice Ph.D. students could be trained to predict good research decisions by predicting outcomes on a set of expert-annotated examples of research quandaries and then receiving “RL updates” based on what the expert did and what occurred.
comment by Ryan Kidd (ryankidd44) · 2025-01-14T02:57:04.388Z · LW(p) · GW(p)
Crucial questions for AI safety field-builders:
- What is the most important problem in your field? If you aren't working on it, why?
- Where is everyone else dropping the ball and why?
- Are you addressing a gap in the talent pipeline?
- What resources are abundant? What resources are scarce? How can you turn abundant resources into scarce resources?
- How will you know you are succeeding? How will you know you are failing?
- What is the "user experience" of my program?
- Who would you copy if you could copy anyone? How could you do this?
- Am I better than the counterfactual?
- Who are your clients? What do they want?
comment by Ryan Kidd (ryankidd44) · 2025-04-17T19:16:00.612Z · LW(p) · GW(p)
It seems plausible to me that if AGI progress becomes strongly bottlenecked on architecture design or hyperparameter search, a more "genetic algorithm"-like approach will follow. Automated AI researchers could run and evaluate many small experiments in parallel, covering a vast hyperparameter space. If small experiments are generally predictive of larger experiments (and they seem to be, a la scaling laws) and model inference costs are cheap enough, this parallelized approach might be be 1) computationally affordable and 2) successful at overcoming the architecture bottleneck.
Replies from: D0TheMath, ryankidd44↑ comment by Garrett Baker (D0TheMath) · 2025-04-17T21:47:32.645Z · LW(p) · GW(p)
My vague understanding is this is kinda what capabilities progress ends up looking like in big labs. Lots of very small experiments playing around with various parameters people with a track-record of good heuristics in this space feel should be played around with. Then a slow scale up to bigger and bigger models and then you combine everything together & "push to main" on the next big model run.
I'd also guess that the bottleneck isn't so much on the number of people playing around with the parameters, but much more on good heuristics regarding which parameters to play around with.
Replies from: george-ingebretsen↑ comment by George Ingebretsen (george-ingebretsen) · 2025-04-17T22:12:33.828Z · LW(p) · GW(p)
"Lots of very small experiments playing around with various parameters" ... "then a slow scale up to bigger and bigger models"
This Dwarkesh timestamp with Jeff Dean & Noam Shazeer seems to confirm this.
"I'd also guess that the bottleneck isn't so much on the number of people playing around with the parameters, but much more on good heuristics regarding which parameters to play around with."
That would mostly explain this question as well: "If parallelized experimentation drives so much algorithmic progress, why doesn't gdm just hire hundreds of researchers, each with small compute budgets, to run these experiments?"
It would also imply that it would be a big deal if they had an AI with good heuristics for this kind of thing.
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2025-04-18T07:58:33.160Z · LW(p) · GW(p)
Don’t double update! I got that information from that same interview!
↑ comment by Ryan Kidd (ryankidd44) · 2025-04-17T19:21:42.020Z · LW(p) · GW(p)
I expect mech interp to be particularly easy to automate at scale. If mech interp has capabilities externalities (e.g., uncovering useful learned algorithms or "retargeting the search [LW · GW]"), this could facilitate rapid performance improvements.
comment by Ryan Kidd (ryankidd44) · 2023-04-02T00:18:00.642Z · LW(p) · GW(p)
An incomplete list of possibly useful AI safety research:
- Predicting/shaping emergent systems (“physics”)
- Learning theory (e.g., shard theory, causal incentives)
- Regularizers (e.g., speed priors)
- Embedded agency (e.g., infra-Bayesianism, finite factored sets)
- Decision theory (e.g., timeless decision theory, cooperative bargaining theory, acausal trade)
- Model evaluation (“biology”)
- Capabilities evaluation (e.g., survive-and-spread, hacking)
- Red-teaming alignment techniques
- Demonstrations of emergent properties/behavior (e.g., instrumental powerseeking)
- Interpretability (“neuroscience”)
- Mechanistic interpretability (e.g., superposition, toy models, automated circuit detection)
- Gray box ELK (e.g., Collin Burns’ research)
- Feature extraction/sparsity (including Wentworth/Bushnaq style “modularity” research)
- Model surgery (e.g., ROME)
- Alignment MVP (“psychology”)
- Sampling simulators safely (conditioning predictive models)
- Scalable oversight (e.g., RLHF, CAI, debate, RRM, model-assisted evaluations)
- Cyborgism
- Prompt engineering (e.g., jailbreaking)
- Strategy/governance (“sociology”)
- Compute governance (e.g., GPU logging/restrictions, treaties)
- Model safety standards (e.g., auditing policies)
- Infosecurity
- Multi-party authentication
- Airgapping
- AI-assisted infosecurity
↑ comment by Roman Leventov · 2023-04-26T20:24:23.490Z · LW(p) · GW(p)
A systematic way for classifying AI safety work could use a matrix, where one dimension is the system level:
- A monolithic AI system, e.g., a conversational LLM
- A cyborg, human + AI(s)
- A system of AIs with emergent qualities (e.g., https://numer.ai/, but in the future, we may see more systems like this, operating on a larger scope, up to fully automatic AI economy; or a swarm of CoEms [LW · GW] automating science)
- A human+AI group, community, or society (scale-free consideration, supports arbitrary fractal nestedness): collective intelligence
- The whole civilisation [LW · GW], e.g., Open Agency Architecture [LW · GW]
Another dimension is the "time" of consideration:
- Design time: research into how the corresponding system should be designed (engineered, organised): considering its functional ("capability", quality of decisions) properties, adversarial robustness (= misuse safety, memetic virus security), and security.
- Manufacturing and deployment time: research into how to create the desired designs of systems successfully and safely:
- AI training and monitoring of training runs.
- Offline alignment of AIs during (or after) training.
- AI strategy (= research into how to transition into the desirable civilisational state = design).
- Designing upskilling and educational programs for people to become cyborgs is also here (= designing efficient procedures for manufacturing cyborgs out of people and AIs).
- Operations time: ongoing (online) alignment of systems on all levels to each other, ongoing monitoring, inspection, anomaly detection, and governance.
- Evolutionary time: research into how the (evolutionary lineages of) systems at the given level evolve long-term:
- How the human psyche evolves when it is in a cyborg
- How humans will evolve over generations as cyborgs
- How groups, communities, and society evolve.
- Designing feedback systems that don't let systems "drift" into undesired state over evolutionary time.
- Considering system property: property of flexibility of values (i.e., the property opposite of value lock-in, Riedel (2021)).
- IMO, it (sometimes) makes sense to think about this separately from alignment per se. Systems could be perfectly aligned with each other but drift into undesirable states and not even notice this if they don't have proper feedback loops and procedures for reflection.
There would be 5*4 = 20 slots in this matrix, and almost all of them have something interesting to research and design, and none of them is "too early" to consider.
There is still some AI safety work (research) that doesn't fit this matrix, e.g., org design, infosec, alignment, etc. of AI labs (= the system that designs, manufactures, operates, and evolves monolithic AI systems and systems of AIs).
comment by Ryan Kidd (ryankidd44) · 2023-01-14T22:42:40.204Z · LW(p) · GW(p)
AI alignment threat models that are somewhat MECE (but not quite):
- We get what we measure [LW · GW] (models converge to the human++ simulator [LW · GW] and build a Potemkin village world without being deceptive consequentialists [LW · GW]);
- Optimization daemon [? · GW] (deceptive [LW · GW] consequentialist [? · GW] with a non-myopic [? · GW] utility function [? · GW] arises in training and does gradient hacking [? · GW], buries trojans [LW · GW] and obfuscates cognition to circumvent interpretability tools [LW · GW], "unboxes [? · GW]" itself, executes a "treacherous turn [? · GW]" when deployed, coordinates with auditors and future instances of itself [LW · GW], etc.);
- Coordination failure [LW · GW] (otherwise-aligned AI systems combust or gridlock far from the Pareto frontier due to opaque values/capabilities, inadequate commitment mechanisms, or irreconcilable differences [? · GW]);
- Sharp left turn [? · GW] (models learn generally powerful cognitive tools that are efficiently reached by training on real-world tasks, especially as the real world contains useful embedded knowledge that shortcuts learning these tools from scratch; but powerful cognitive tools are somewhat anti-natural to corrigibility [? · GW] and the training process does not efficiently constrain the directionality of these tools towards human CEV [? · GW], which manifests under distributional shift [? · GW]).
In particular, the last threat model feels like it is trying to cut across aspects of the first two threat models, violating MECE.
Replies from: remmelt-ellen↑ comment by Remmelt (remmelt-ellen) · 2023-01-21T02:37:31.971Z · LW(p) · GW(p)
Great overview! I find this helpful.
Next to intrinsic optimisation daemons that arise through training internal to hardware, suggest adding extrinsic optimising "divergent ecosystems" that arise through deployment and gradual co-option of (phenotypic) functionality within the larger outside world.
AI Safety so far research has focussed more on internal code (particularly CS/ML researchers) computed deterministically (within known statespaces, as mathematicians like to represent). That is, rather than complex external feedback loops that are uncomputable – given Good Regulator Theorem limits and the inherent noise interference on signals propagating through the environment (as would be intuitive for some biologists and non-linear dynamics theorists).
So extrinsic optimisation is easier for researchers in our community to overlook. See this related paper by a physicist studying origins of life.
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2023-01-25T23:58:21.121Z · LW(p) · GW(p)
Cheers, Remmelt! I'm glad it was useful.
I think the extrinsic optimization you describe is what I'm pointing toward with the label "coordination failures," which might properly be labeled "alignment failures arising uniquely through the interactions of multiple actors who, if deployed alone, would be considered aligned."
comment by Ryan Kidd (ryankidd44) · 2023-03-02T03:10:46.955Z · LW(p) · GW(p)
Reasons that scaling labs might be motivated to sign onto AI safety standards:
- Companies who are wary of being sued for unsafe deployment that causes harm might want to be able to prove that they credibly did their best to prevent harm.
- Big tech companies like Google might not want to risk premature deployment, but might feel forced to if smaller companies with less to lose undercut their "search" market. Standards that prevent unsafe deployment fix this.
However, AI companies that don’t believe in AGI x-risk might tolerate higher x-risk than ideal safety standards by the lights of this community. Also, I think insurance contracts are unlikely to appropriately account for x-risk, if the market [EA · GW] is anything to go by.
comment by Ryan Kidd (ryankidd44) · 2025-01-27T18:41:43.758Z · LW(p) · GW(p)
How fast should the field of AI safety grow? An attempt at grounding this question in some predictions.
- Ryan Greenblatt seems to think [AF(p) · GW(p)] we can get a 30x speed-up in AI R&D using near-term, plausibly safe AI systems; assume every AIS researcher can be 30x’d by Alignment MVPs
- Tom Davidson thinks [AF · GW] we have <3 years from 20%-AI to 100%-AI; assume we have ~3 years to align AGI with the aid of Alignment MVPs
- Assume the hardness of aligning TAI is equivalent to the Apollo Program (90k engineer/scientist FTEs x 9 years = 810k FTE-years); therefore, we need ~9k more AIS technical researchers
- The technical AIS field is currently ~500 people; at the current growth rate of 28% per year [LW · GW], it will take 12 years to grow to 9k people (Oct 2036)
- Alternatively, if we bound by the Manhattan Project (25k FTEs x 5 years = 125 FTE-years), this will take 6.5 years (Jul 2031)
- Metaculus predicts weak AGI in 2026 and strong AGI in 2030; clearly, more talent development is needed if we want to make the Nov 2030 AGI deadline!
- If we want to make the 9k researchers goal by Nov 2030 AGI deadline, we need an annual growth rate of 65%, 2.3x the current growth rate of 28%
↑ comment by Buck · 2025-01-27T19:30:23.409Z · LW(p) · GW(p)
I appreciate the spirit of this type of calculation, but think that it's a bit too wacky to be that informative. I think that it's a bit of a stretch to string these numbers together. E.g. I think Ryan and Tom's predictions are inconsistent, and I think that it's weird to identify 100%-AI as the point where we need to have "solved the alignment problem", and I think that it's weird to use the Apollo/Manhattan program as an estimate of work required. (I also don't know what your Manhattan project numbers mean: I thought there were more like 2.5k scientists/engineers at Los Alamos, and most of the people elsewhere were purifying nuclear material)
↑ comment by Garrett Baker (D0TheMath) · 2025-01-27T19:08:14.627Z · LW(p) · GW(p)
There's the standard software engineer response of "You cannot make a baby in 1 month with 9 pregnant women". If you don't have a term in this calculation for the amount of research hours that must be done serially vs the amount of research hours that can be done in parallel, then it will always seem like we have too few people, and should invest vastly more in growth growth growth!
If you find that actually your constraint is serial research output, then you still may conclude you need a lot of people, but you will sacrifice a reasonable amount of growth speed for attracting better serial researchers.
(Possibly this shakes out to mathematicians and physicists, but I don't want to bring that conversation into here)
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2025-01-27T19:18:55.160Z · LW(p) · GW(p)
I also note that 30x seems like an under-estimate to me, but also too simplified. AIs will make some tasks vastly easier, but won't help too much with other tasks. We will have a new set of bottlenecks once we reach the "AIs vastly helping with your work" phase. The question to ask is "what will the new bottlenecks be, and who do we have to hire to be prepared for them?"
If you are uncertain, this consideration should lean you much more towards adaptive generalists than the standard academic crop.
comment by Ryan Kidd (ryankidd44) · 2023-05-23T15:43:32.886Z · LW(p) · GW(p)
Types of organizations that conduct alignment research, differentiated by funding model and associated market forces:
- Academic research groups (e.g., Krueger's lab at Cambridge, UC Berkeley CHAI, NYU ARG, MIT AAG);
- Research nonprofits (e.g., ARC Theory, MIRI, FAR AI, Redwood Research);
- "Mixed funding model" organizations:
- "Alignment-as-a-service" organizations, where the product directly contributes to alignment (e.g., Apollo Research, Aligned AI, ARC Evals, Leap Labs);
- "Alignment-on-the-side" organizations, where product revenue helps funds alignment research (e.g., Conjecture);
- Scaling labs, where alignment research is mostly directed towards improving product (e.g., Anthropic, DeepMind, OpenAI).
comment by Ryan Kidd (ryankidd44) · 2022-11-16T00:06:31.520Z · LW(p) · GW(p)
Can the strategy of "using surrogate goals to deflect threats" be countered by an enemy agent that learns your true goals and credibly precommits to always defecting (i.e., Prisoner's Dilemma style) if you deploy an agent against it with goals that produce sufficiently different cooperative bargaining equilibria than your true goals would?
Replies from: antimonyanthony↑ comment by Anthony DiGiovanni (antimonyanthony) · 2022-11-16T20:40:38.730Z · LW(p) · GW(p)
This is a risk worth considering, yes. It’s possible in principle to avoid this problem by “committing” (to the extent that humans can do this) to both (1) train the agent to make the desired tradeoffs between the surrogate goal and original goal, and (2) not train the agent to use a more hawkish bargaining policy than it would’ve had without surrogate goal training. (And to the extent that humans can’t make this commitment, i.e., we make honest mistakes in (2), the other agent doesn’t have an incentive to punish those mistakes.)
If the developers do both these things credibly—and it's an open research question how feasible this is—surrogate goals should provide a Pareto improvement for the two agents (not a rigorous claim). Safe Pareto improvements are a generalization of this idea.
comment by Ryan Kidd (ryankidd44) · 2023-05-23T16:14:08.758Z · LW(p) · GW(p)
MATS' goals:
- Find + accelerate high-impact research scholars:
- Pair scholars with research mentors via specialized mentor-generated selection questions (visible on our website);
- Provide a thriving academic community for research collaboration, peer feedback, and social networking;
- Develop scholars according to the “T-model of research [LW(p) · GW(p)]” (breadth/depth/epistemology);
- Offer opt-in curriculum elements, including seminars, research strategy workshops, 1-1 researcher unblocking support, peer study groups, and networking events;
- Support high-impact research mentors:
- Scholars are often good research assistants and future hires;
- Scholars can offer substantive new critiques of alignment proposals;
- Our community, research coaching, and operations free up valuable mentor time and increase scholar output;
- Help parallelize high-impact AI alignment research:
- Find, develop, and refer scholars with strong research ability, value alignment, and epistemics;
- Use alumni for peer-mentoring in later cohorts;
- Update mentor list and curriculum as the alignment field’s needs change.
comment by Ryan Kidd (ryankidd44) · 2023-02-02T22:37:37.558Z · LW(p) · GW(p)
"Why suicide doesn't seem reflectively rational, assuming my preferences are somewhat unknown to me," OR "Why me-CEV is probably not going to end itself":
- Self-preservation is a convergent instrumental goal for many goals.
- Most systems of ordered preferences that naturally exhibit self-preservation probably also exhibit self-preservation in the reflectively coherent pursuit of unified preferences (i.e., CEV).
- If I desire to end myself on examination of the world, this is likely a local hiccup in reflective unification of my preferences, i.e., "failure of present me to act according to me-CEV's preferences rather than a failure of hypothetical me-CEV to account for facts about the world."
Note: I'm fine; this is purely intellectual.
comment by Ryan Kidd (ryankidd44) · 2022-10-28T23:01:09.407Z · LW(p) · GW(p)
Are these framings of gradient hacking [? · GW], which I previously articulated here [LW · GW], a useful categorization?
- Masking: Introducing a countervailing, “artificial” performance penalty that “masks” the performance benefits of ML modifications that do well on the SGD objective, but not on the mesa-objective [? · GW];
- Spoofing: Withholding performance gains until the implementation of certain ML modifications that are desirable to the mesa-objective; and
- Steering: In a reinforcement learning context, selectively sampling environmental states that will either leave the mesa-objective unchanged or "steer" the ML model in a way that favors the mesa-objective.
comment by Ryan Kidd (ryankidd44) · 2022-10-28T17:56:10.101Z · LW(p) · GW(p)
How does the failure rate of a hierarchy of auditors scale with the hierarchy depth, if the auditors can inspect all auditors below their level?
comment by Ryan Kidd (ryankidd44) · 2022-10-13T19:12:48.226Z · LW(p) · GW(p)
Are GPT-n systems more likely to: