Framings of Deceptive Alignment
post by peterbarnett · 2022-04-26T04:25:56.115Z · LW · GW · 7 commentsContents
Types of Deception Goodhart Deception Consequentialist Deception Where is the deception? Concepts of deception an AI could have None 7 comments
In this post I want to lay out some framings and thoughts about deception in misaligned AI systems.
Types of Deception
There seem to be two different things which people mean by deception which have different causes and likely different effects. Because these are both often called ‘deception’, they are often incorrectly equated. To reason clearly about the dangers of deceptive AI we should be clear about which one we are talking about.
Goodhart Deception
An AI system may learn a strategy which just tricks the evaluator into giving high reward during training, rather than actually doing well on the task. The AI is ‘Goodharting’ the reward by optimizing for a proxy rather than for what humans actually want.
As a specific example we might be training an AI system using reinforcement learning with human feedback. Here the AI takes an action, the human evaluates how good or bad the action was, and then this reward is used to reinforce the behavior which was evaluated as good. Because we are training on human feedback, any behavior which the human thinks is good will result in a positive reward. So AI could just choose actions which seem good to the human but aren’t actually good. This is an outer alignment problem, where the AI learns to do a bad thing because the humans are unable to adequately reward it for doing the correct thing.
This will become more of a problem as
- The task becomes more difficult for the AI to actually do
- The task becomes more difficult for the human to judge
These two things seem likely to increase in tandem; harder tasks will be harder to evaluate. If the task is very difficult, then it will instead just learn to do the simpler thing (trick the human) which achieves the same high reward.
It is important to note that this doesn’t require the AI to have any ‘agency’ or ‘objective’; the training process has just reinforced a behavior which leads to high reward. Once the AI starts to trick the human, this will lead to good reward, and so this deceptive behavior is in some sense an attractor state.
Notably this behavior was observed in the original “Deep reinforcement learning from human preferences” paper. Here an AI was being trained with human feedback to grasp a ball. Instead of actually grasping the ball, the hand was simply placed between the ball and the camera to give the impression of holding the ball (see the Challenges section here).
Consequentialist Deception
This is the type of deception talked about in ‘Risks from Learned Optimization’ [? · GW] where during training an AI system develops an objective which is not the same as the objective it is being trained on. The AI then decides to ‘play along’ and achieve good reward on the training objective with the goal of defecting and pursuing its own objective later. By ‘playing along’ the AI can:
- Prevent gradient descent from overwriting its objective or other machinery which would allow it to do well on its own objective. If the AI just decided to greedily pursue its objective this would lead to high loss and so gradient descent would modify it and remove the misaligned objective.
- Prevent human overseers from turning it off. If the AI attempts to pursue its objective during training, the humans may just be able to turn it off. This would obviously mean that the AI would no longer be able to pursue its objective.
Once the AI has been deployed or is otherwise safe from modification it can then defect and begin to pursue its objective. One strategy to avoid this defection is to make the AI think that it is always in training, but seems very difficult due to things like the RSA-2048 problem.
The specific objective that a deceptively aligned AI develops may depend on when in training the ‘deceptive consequentialist’ nature develops. Later development may mean that the AI’s objective will be more similar to the base objective. If the deception develops late in training, it seems like the training process will already have pushed the AI to do well on some reasonable proxy of the base objective. So the objective may be close (or equal) to one of these proxies. However, if this deceptive consequentialist nature develops early in training before the AI has started to ‘latch on’ to proxies for the base objective, then the objective developed by the AI could be very different.
Consequentalist deception seems more dangerous than “Goodhart deception”, because the AI is ‘deliberately’ deceiving the humans, rather than doing so incidentally. Additionally, the deceptive objective may be arbitrarily different from the base objective.
Where is the deception?
There is also the question of where in the network the deception actually occurs. In a neural network the two candidates are the weights or the activations. This is mainly a meaningful distinction when talking about consequentialist deception.
By ‘the deception is in the weights’ I mean that the deception is hard coded into the weights such that if you had good enough mechanistic interpretability tools you would be able to tell the model was deceptive without having to run the model. From the weights it would be possible to tell that the network had a separate objective to the base objective but would play along anyway. One (extremely over simplified) example of this would be if the network had a ‘Am I in training?’ detector, from which it then activates either the ‘Pursue the base objective’ module or the ‘Defect and make paperclips’ module.
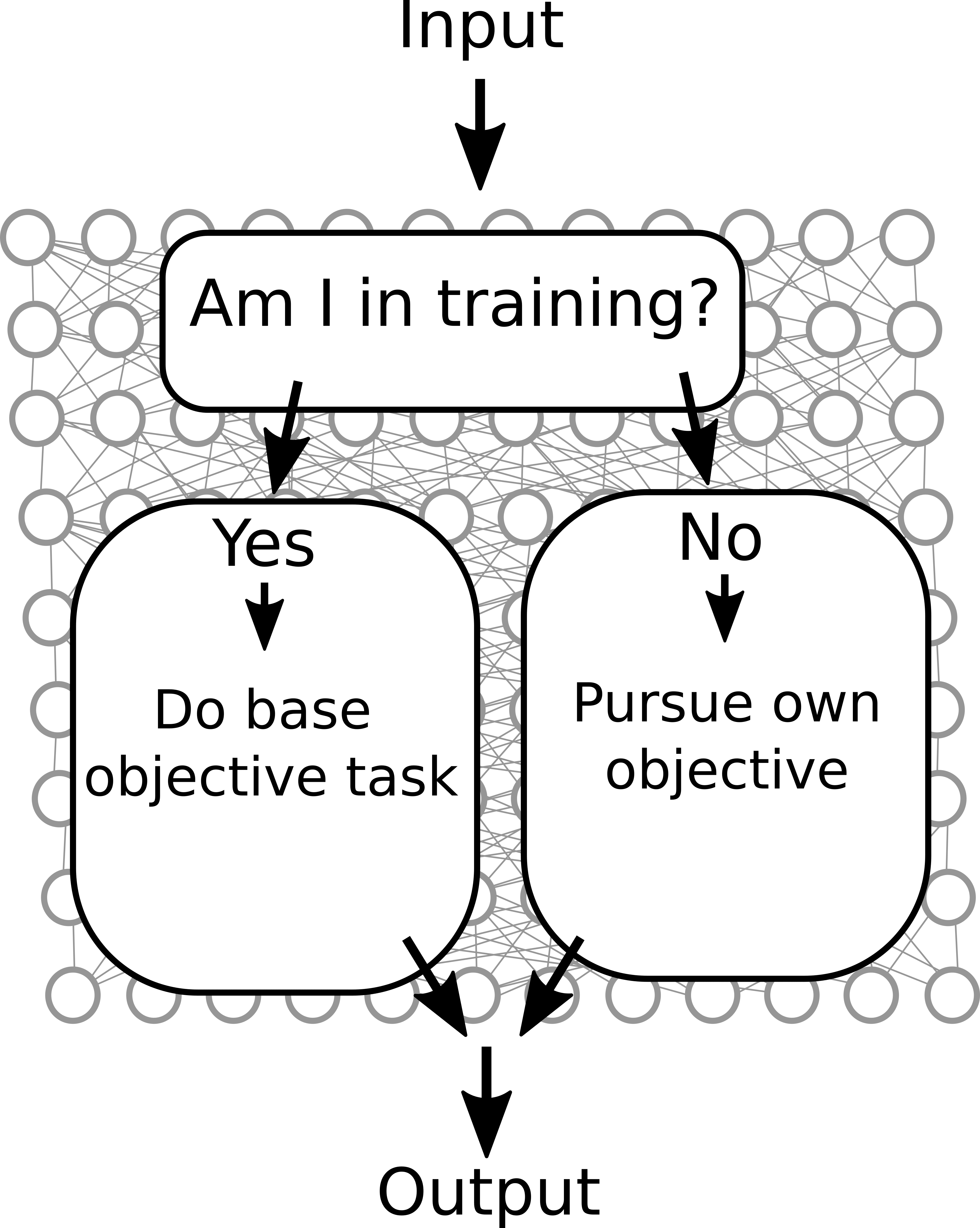
By ‘deception is in the activations’ I mean there are no weights that specifically implement deceptive algorithms, but (for any/some reasonable inputs) the AI uses some general purpose reasoning and decides that deception is a good strategy. This is uninterpretable from just the weights, and the model needs to be run for it to actually have these deceptive thoughts. If we want to over-anthropomorphism this AI system we could think of its thought process over a forward pass as something like this
- <Receives input>
- “Oh, that’s an input”
- “I must be an AI in a training process”
- “Hmm, I really want to make paper clips, but the human training me obviously doesn’t want me to do that”
- “If I try to make paper clips now, then I probably won’t get to in the future”
- “I’ll give the human the answer they want so that I can make paperclips in the future”
- <Outputs answer>
Concepts of deception an AI could have
There are a few importantly different ‘concepts of deception’ that an AI system could have (here I am talking about consequentialist deception).
- The concept of deception in the world. A large language model will certainly have some concept of agents deceiving other agents from its training data. GPT-3 already has this, and we can tell this by asking it to tell us a story about someone deceiving someone else. A language model with LessWrong in the training corpus would likely even have a concept of deceptively aligned AIs.
- The concept of the AI itself doing deception. This requires the AI to have some model of itself and to know that it can take actions to influence the world.
- The motivation for the AI to actually do the (consequentialist) deception. This is where the AI knows it can deceive the humans, and also has movitation do do this (because it has misaligned goals).
The jumps between each of these seem possible but also non-trivial. The AI can know lots of stories about deception and about ways humans deceive each other, but if it doesn’t have a self model then it won’t be able to reason about itself doing deception. GPT-3 already does this first thing, but (hopefully!) not the second. The AI can also have a self model and know that it is technically capable of deception (the abstract action ‘deceive humans about X’ is in its action space), but if it isn’t a consequentialist or isn’t misaligned then it will have no reason to take this action.
But if the AI already has the concept of deception in the world, and the concept of itself doing deception, if gradient descent pushes it to become even slightly consequentialist[1], it may be able to use this world model knowledge to effectively implement deception itself.
This post came out of discussions with Ian Mckenzie, Tamera Lanham, and Vivek Hebbar. Thanks to Lauro Langosco for helping name things.
- ^
By this I mean it does some amount of choosing its actions based on their effect on the future, for at least some inputs.
7 comments
Comments sorted by top scores.
comment by leogao · 2022-04-26T23:30:26.134Z · LW(p) · GW(p)
I like this post and generally agree with the decomposition into the two different types of deception. I prefer to call them outer and inner deception, because one happens when deception is incentivized by the base objective, and one happens when deception is incentivized by the mesaobjective. I thought about this a bit a while back and after talking to Evan about this I managed to be convinced that Goodhart/outer deception is a lot easier to tackle if you already have consequentialist/inner deception nailed down (not sure to what extent Evan endorses this and don't want to misattribute my misunderstanding to him). I should probably revisit some of this stuff and make a post about it.
As for the "where is the deception" thing, I don't really know if the distinction is that sharp. My intuition is that lots of systems in practice will be some weird mix of both, and I don't really expect it to be interpretable either way anyways (even for the pure "in the weights" case you can have arbitrarily obfuscated and computationally intractable to detect versions of it).
Replies from: TheMcDouglas↑ comment by CallumMcDougall (TheMcDouglas) · 2022-04-27T21:19:37.585Z · LW(p) · GW(p)
Yeah I think this is Evan's view. This is from his research agenda (I'm guessing you might have already seen this given your comment but I'll add it here for reference anyway in case others are interested)
I suspect we can in fact design transparency metrics that are robust to Goodharting when the only optimization pressure being applied to them is coming from SGD, but cease to be robust if the model itself starts actively trying to trick them.
And I think his view on deception through inner optimisation pressure is that this is something we'll basically be powerless to deal with once it happens, so the only way to make sure it doesn't happen it to chart a safe path through model space which never enters the deceptive region in the first place.
comment by CallumMcDougall (TheMcDouglas) · 2022-04-26T06:33:17.850Z · LW(p) · GW(p)
Thanks for the post! I just wanted to clarify what concept you're pointing to with use of the word "deception".
From Evan's definition in RFLO, deception needs to involve some internal modelling of the base objective & training process, and instrumentally optimising for the base objective. He's clarified in other comments that he sees "deception" as only referring to inner alignment failures, not outer (because deception is defined in terms of the interaction between the model and the training process, without introducing humans into the picture). This doesn't include situations like the first one, where the reward function is underspecified to produce behaviour we want (although it does produce behaviour that looks like it's what we want, unless we peer under the hood).
To put it another way, it seems like the way deception is used here refers to the general situation where "AI has learnt to do something that humans will misunderstand / misinterpret, regardless of whether the AI actually has an internal representation of the base objective it's being trained on and the humans doing the training."
In this situation, I don't really know what the benefit is of putting these two scenarios into the same class, because they seem pretty different. My intuitions about this might be wrong though. Also I guess this is getting into the inner/outer alignment distinction [LW · GW] which opens up quite a large can of worms!
Replies from: peterbarnett↑ comment by peterbarnett · 2022-04-26T15:49:57.940Z · LW(p) · GW(p)
Yeah, I totally agree. My motivation for writing the first section was that people use the word 'deception' to refer to both things, and then make what seem like incorrect inferences. For example, current ML systems do the 'Goodhart deception' thing, but then I've heard people use this to imply that it might be doing 'consequentialist deception'.
These two things seem close to unrelated, except for the fact that 'Goodhart deception' shows us that AI systems are capable of 'tricking' humans.
Replies from: TheMcDouglas↑ comment by CallumMcDougall (TheMcDouglas) · 2022-04-27T21:16:50.159Z · LW(p) · GW(p)
Okay I see, yep that makes sense to me (-:
comment by evhub · 2023-08-01T02:10:27.621Z · LW(p) · GW(p)
I think that your discussion of Goodhart deception is a bit confusing, since consequentialist deception is a type of Goodharting, it's just adversarial Goodhart rather than regressional/causal/extremal Goodhart [LW · GW].
comment by Sam Marks (samuel-marks) · 2022-04-26T20:29:27.020Z · LW(p) · GW(p)
I agree that the term "deception" conflates "deceptive behavior due to outer alignment failure" and "deceptive behavior due to inner alignment failure" and that this can be confusing! In fact, I made this same distinction [LW · GW] recently in a thread discussing deceptive behavior from models trained via RL from human feedback.