Posts
Comments
Sorry I didn't get to this message earlier, glad you liked the post though! The answer is that attention heads can have multiple different functions - the simplest way is to store things entirely orthogonally so they lie in fully independent subspsaces, but even this isn't necessary because it seems like transformers take advantage of superposition to represent multiple concepts at once, more so than they have dimensions.
Oh, interesting, wasn't aware of this bug. I guess this is probably fine since most people replicating it will be pulling it rather than copying and pasting it into their IDE. Also this comment thread is now here for anyone who might also get confused. Thanks for clarifying!
+1, thanks for sharing! I think there's a formatting error in the notebook, where the tags like <OUTPUT> were all removed and replaced with empty strings (e.g. see attached photo). We've recently made the ARENA evals material public, and we've got a working replication there which I think has the tags in the right place (section 2 of 3 on the page linked here)
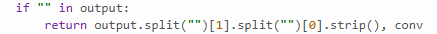
Amazing post! Forgot to do this for a while, but here's a linked diagram explaining how I think about feature absorption, hopefully ppl find it helpful!
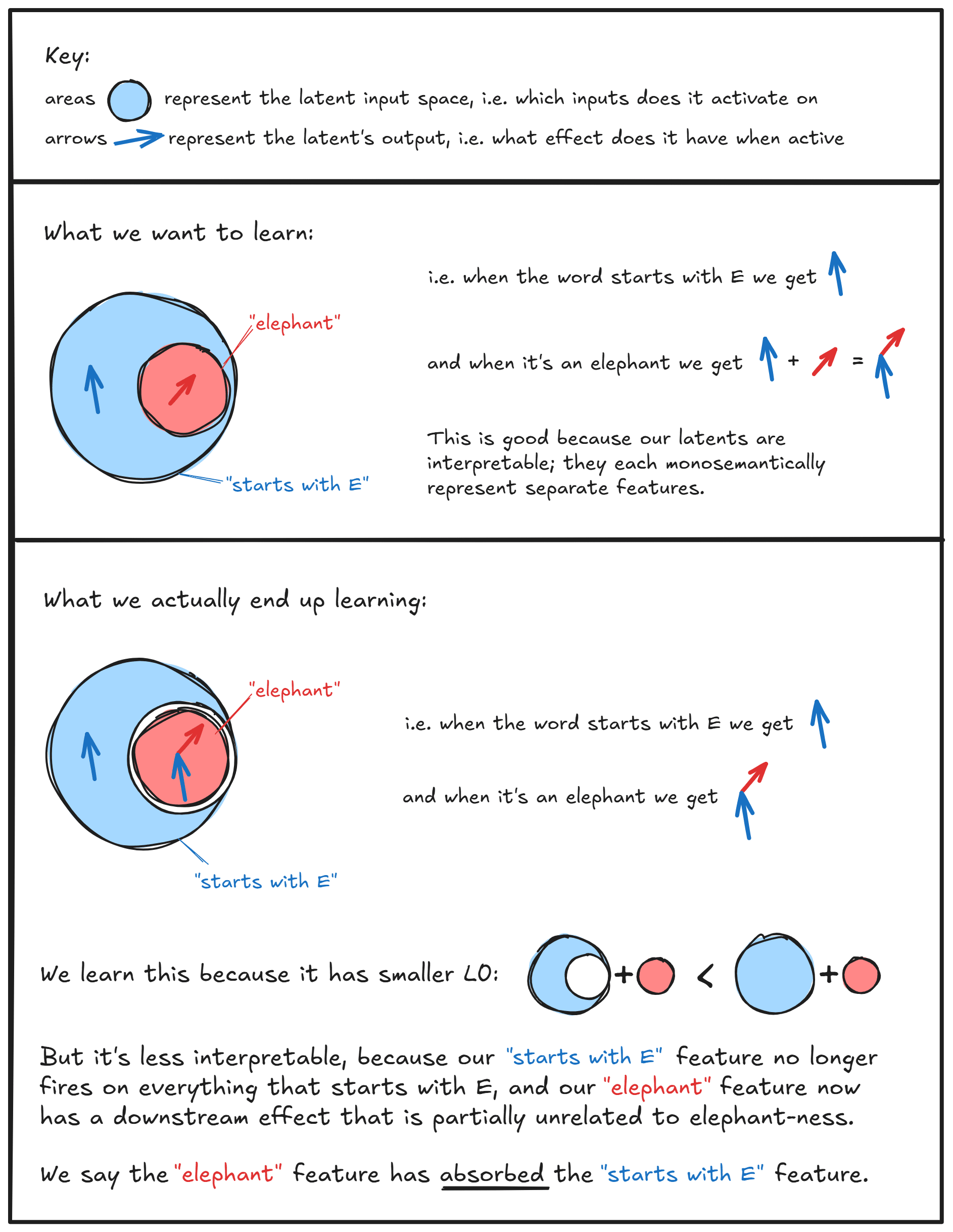
I don't know of specific examples, but this is the image I have in my head when thinking about why untied weights are more free than tied weights:
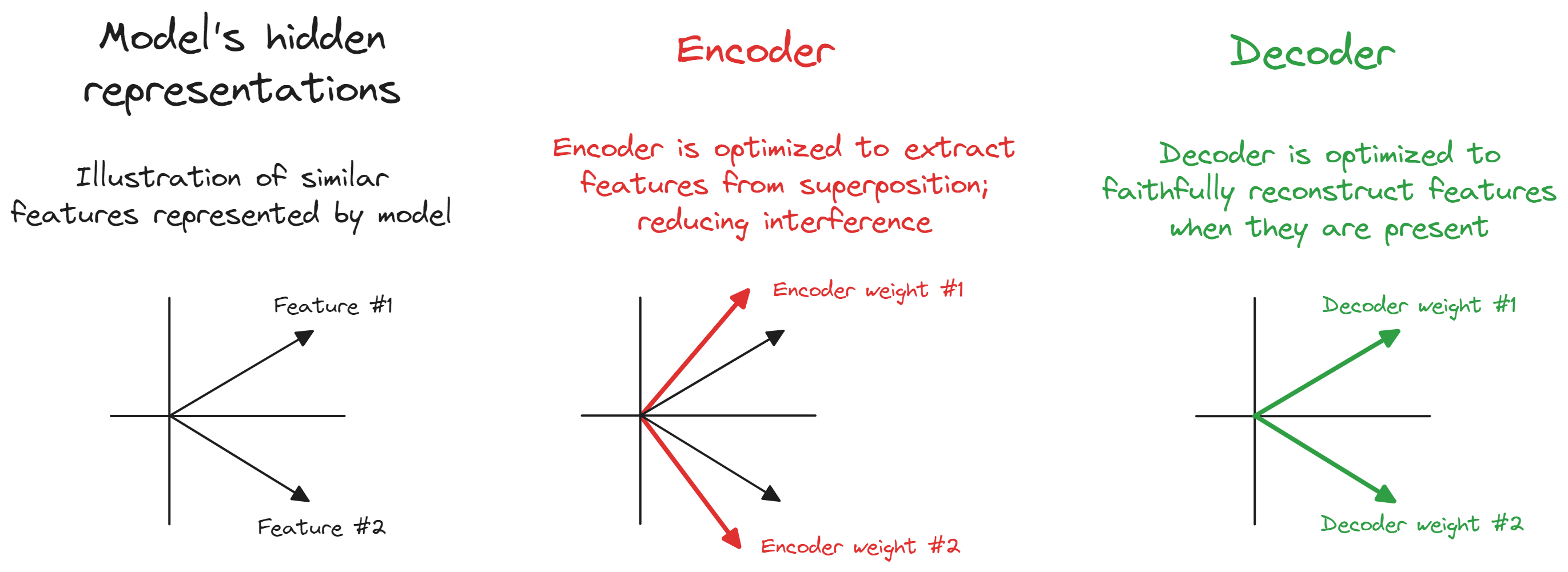
I think more generally this is why I think studying SAEs in the TMS setup can be a bit challenging, because there's often too much symmetry and not enough complexity for untied weights to be useful, meaning just forcing your weights to be tied can fix a lot of problems! (We include it in ARENA mostly for illustration of key concepts, not because it gets you many super informative results). But I'm keen for more work like this trying to understand feature absorption better in more tractible cases
Oh yeah this is great, thanks! For people reading this, I'll highlight SLT + developmental interp + mamba as areas which I think are large enough to have specific exercise sections but currently don't
Thanks!! Really appreciate it
Thanks so much! (-:
Thanks so much, really glad to hear it's been helpful!
Thanks, really appreciate this (and the advice for later posts!)
Yep, definitely! If you're using MSE loss then it's got a pretty straightforward to use backprop to see how importance relates to the loss function. Also if you're interested, I think Redwood's paper on capacity (which is the same as what Anthropic calls dimensionality) look at derivative of loss wrt the capacity assigned to a given feature
Thanks (-:
Good question! In the first batch of exercises (replicating toy models of interp), we play around with different importances. There are some interesting findings here (e.g. when you decrease sparsity to the point where you no longer represent all features, it's usually the lower-importance features which collapse first). I chose not to have the SAE exercises use varying importance, although it would be interesting to play around with this and see what you get!
As for what importance represents, it's basically a proxy for "how much a certain feature reduces loss, when it actually is present." This can be independent from feature probability. Anthropic included it in their toy models paper in order to make those models truer to reality, in the hope that the setup could tell us more interesting lessons about actual models. From the TMS paper:
Not all features are equally useful to a given task. Some can reduce the loss more than others. For an ImageNet model, where classifying different species of dogs is a central task, a floppy ear detector might be one of the most important features it can have. In contrast, another feature might only very slightly improve performance.
If we're talking features in language models, then importance would be "average amount that this feature reduces cross entropy loss". I open-sourced an SAE visualiser which you can find here. You can navigate through it and look at the effect of features on loss. It doesn't actually show the "overall importance" of a feature, but you should be able to get an idea of the kinds of situations where a feature is super loss-reducing and when it isn't. Example of a highly loss-reducing feature: feature #8, which fires on Django syntax and strongly predicts the "django" token. This seems highly loss-reducing because (although sparse) it's very often correct when it fires with high magnitude. On the other hand, feature #7 seems less loss-reducing, because a lot of the time it's pushing for something incorrect (maybe there exist other features which balance it out).
Winner = highest-quality solution over the time period of a month (solutions get posted at the start of the next month, along with a new problem).
Note that we're slightly de-emphasising the competition side now that there are occasional hints which get dropped during the month in the Slack group. I'll still credit the best solution in the Slack group & next LW post, but the choice to drop hints was to make the problem more accessible and hopefully increase the overall reach of this series.
Thanks for the latter point, glad you got that impression!
These are super valid concerns, and it's true that there's lots of information we won't have for a while. That said, we also have positive evidence from the first iteration of ARENA (which is about a year old now). There were only 5 full-time participants, and they've all gone on to do stuff I'm excited about, including the following (note that obviously some of these 5 have done more than one of the stuff on this list):
- internships at CHAI,
- working with Owain Evans (including some recent papers),
- building a community around open-source interpretability tooling,
- employment by EleutherAI for interp,
- participating in SERI MATS streams,
- work trialling at LEAP labs,
- being funded to work on independent research on ELK.
I'd also point to programs like MLAB which have similar goals and (as far as I'm aware) an even higher success rate of getting people into alignment work. Not saying that nobody from these programs goes on to do capabilities (I imagine at least a few do), but I'd be very surprised if this outweighs the positive effect from people going on to do alignment work.
One last point here - a big part of the benefit from programs like MLAB / ARENA is the connections made with people in alignment, feeling a sense of motivation & community, not just the skilling up (anecdotally, I quit my job and started working in alignment full-time after doing MLAB2, despite not then being at a point where I could apply for full-time jobs). I also get this impression from conversations w/ people who participated in & ran MLABs in the past. It's not as simple as "go into upskilling programs, become super competent at either alignment or capabilities work, then choose one or the other" - there's a myriad of factors which I expect to update people towards work in alignment after they go through programs like these.
If check-ins with ARENA 1.0 or 2.0 participants (or indeed MLAB participants) a year more from now reveal that a nontrivial fraction of them are working in capabilities then I'd certainly update my position here, but I'll preregister that this doesn't seem at all likely to me. It's true that alignment can be a messy field with limited opportunities and clear paths, but this is becoming less of a problem as the years go on.
Upvoted overall karma, because I think this is a valuable point to bring up and we could have done a better job discussing it in this post.
To be clear, contribution to capabilities research is a very important consideration for us, and apologies if we didn't address this comprehensively here. A few notes to this effect:
- We selected strongly on prior alignment familiarity (particularly during the screening & interview process), and advertised it in locations we expected to mainly attract people who had prior alignment familiarity
- We encouraged interaction with the alignment researchers who were using the space while the program was running (e.g. SERI MATS scholars & other independent researchers), and often had joint talks and discussion groups
- As mentioned in this writeup, many of the participants (nearly a majority) are still working on some form of their capstone projects. Additionally, every participant chose their project to be alignment-related in some way (although this isn't something we made strictly compulsory)
- Participants uniformly responded on the survey that they considered themselves very likely to pursue a career in technical AI safety (median probability on this was over 70%), although this kind of data isn't necessarily reflective
- Subjectively, we had the opportunity to get to know each participant during the program, discussing their future plans and their perspectives on alignment. There's definitely a non-zero risk that people who are upskilled in this kind of way won't go on to do safety research, but we feel pretty confident that we (1) found people for whom this was already low-probability, (2) minimized this probability to the best of our ability
Hi, sorry for the late response! The layer 0 attention head should have query at position 1, and value at position 0 (same as key). Which diagram are you referring to?
(context: I ran the most recent iteration of ARENA, and after this I joined Neel Nanda's mech interp stream in SERI MATS)
Registering a strong pushback to the comment on ARENA. The primary purpose of capstone projects isn't to turn people into AI safety technical researchers or to produce impressive capstones, it's to give people engineering skills & experience working on group projects. The initial idea was not to even push for things that were safety-specific (much like Redwood's recommendations - all of the suggested MLAB2 capstones were either mech interp or non-safety, iirc). The reason many people gravitated towards mech interp is that they spent a lot of time around researchers and people who were doing interesting work in mech interp, and it seemed like a good fit for both getting a feel for AI safety technical research and for general skilling up in engineering.
Additionally, I want to mention that participant responses to the question "how have your views on AI safety changed?" included both positive and negative updates on mech interp, but much more uniformly showed positive updates on AI safety technical research as a whole. Evidence like this updates me away from the hypothesis that mech interp is pulling safety researchers from other disciplines. To give a more personal example, I had done alignment research before being exposed to mech interp, but none of it made much of an impression on me. I didn't choose mech interp instead of other technical safety research, I chose it instead of a finance career.
This being said, there is an argument that ARENA (at least the most recent iteration) had too much of a focus on mech interp, and this is something we may try to rectify in future iterations.
Yep, the occlusion effect is pretty large for colored images, that's why I use a layering system (e.g. 20% of all white threads, then 20% of all blue, then 20% of black, and cycle through). I go in reverse order, so the ones found first by the algorithm are the last ones to be placed. I also put black on top and white lowest down, cause white on top looks super jarring. The effect is that the In the colab you can play around with the order of the threads. If you reverse the order then the image looks really bad. You can also create gifs of the image forming, and see that the first threads to be added always look like random noise (because at the time the algorithm picks those lines, it's probably already matched all the important features of that color).
The pieces do get pretty thick, usually about 1cm. Actually, for the gantry (the one shown in the video) I had to intervene to raise its height every hour or so, otherwise the arm would get snagged on the threads.
Multi-color dithering looks cool, I hadn't come across that before, although I suspect it wouldn't be much of an improvement (e.g. because you can apply a Gaussian blur to the monochrome images you get from dithering without it really changing the result much).
Thanks so much for this comment, I really appreciate it! Glad it was helpful for you 🙂
Thanks, really appreciate it!
Yep that's right, thanks! Corrected.
huh interesting, I wasn't aware of this, thanks for sending it!
Thanks for the suggestion! I've edited the first diagram to clarify things, is this what you had in mind?
The first week of WMLB / MLAB maps quite closely onto the first week of ARENA, with a few exceptions (ARENA includes PyTorch Lightning, plus some more meta stuff like typechecking, VSCode testing and debugging, using GPT in your workflow, etc). I'd say that starting some way through the second week would probably be most appropriate. If you didn't want to repeat stuff on training / sampling from transformers, the mech interp material would start on Wednesday of the second week.
Resolved by private message, but I'm just mentioning this here for others who might be reading this - we didn't have confirmation emails set up, but we expect to send out coding assessments to applicants tomorrow (Monday 24th April). For people who apply after this point, we'll generally try to send out coding assessments no later than 24 hours after your application.
Yeah, I think this would be possible. In theory, you could do something like:
- Study relevant parts of the week 0 material before the program starts (we might end up creating a virtual group to accommodate this, which also contains people who either don't get an offer or can't attend but still want to study the material.)
- Join at the start of the 3rd week - at that point there will be 3 days left of the transformers chapter (which is 8 days long and has 4 days of core content), so you could study (most of) the core content and then transition to RL with the rest of the group (and there would be opportunities to return to the transformers & mech interp material during the bonus parts of later chapters / capstone projects, if you wanted.)
How feasible this is would depend on your prereqs and past experience I imagine. Either way, you're definitely welcome to apply!
Not a direct answer, but this post has a ton of useful advice that I think would be applicable here: https://www.neelnanda.io/blog/mini-blog-post-19-on-systems-living-a-life-of-zero-willpower
Awesome, really glad to hear it was helpful, thanks for commenting!
Yep, fixed, thanks!
Or "prompting" ? Seems short and memorable, not used in many other contexts so its meaning would become clear, and it fits in with other technical terms that people are currently using in news articles, e.g. "prompt engineering". (Admittedly though, it might be a bit premature to guess what language people will use!)
This is awesome, I love it! Thanks for sharing (-:
Thank you :-)
Thanks, really appreciate it!
I think some of the responses here do a pretty good job of this. It's not really what I intended to go into with my post since I was trying to keep it brief (although I agree this seems like it would be useful).
And yeah, despite a whole 16 lecture course on convex opti I still don't really get Bregman either, I skipped the exam questions on it 😆
Oh yeah, I hadn't considered that one. I think it's interesting, but the intuitions are better in the opposite direction, i.e. you can build on good intuitions for to better understand MI. I'm not sure if you can easily get intuitions to point in the other direction (i.e. from MI to ), because this particular expression has MI as an expectation over , rather than the other way around. E.g. I don't think this expression illuminates the nonsymmetry of .
The way it's written here seems more illuminating (not sure if that's the one that you meant). This gets across the idea that:
is the true reality, and is our (possibly incorrect) model which assumes independence. The mutual information between and equals , i.e. the extent to which modelling and as independent (sharing no information) is a poor way of modelling the true state of affairs (where they do share information).
But again I think this intuition works better in the other direction, since it builds on intuitions for to better explain MI. The arguments in the expression aren't arbitrary (i.e. we aren't working with ), which restricts the amount this can tell us about in general.
Oh yeah, I really like this one, thanks! The intuition here is again that a monomodal distribution is a bad model for a bimodal one because it misses out on an entire class of events, but the other way around is much less bad because there's no large class of events that happen in reality but that your model fails to represent.
For people reading here, this post discusses this idea in more detail. The image to have in mind is this one:
Love that this exists! Looks like the material here will make great jumping off points when learning more about any of these orgs, or discussing them with others
Thanks Nihalm, also I wasn't aware of it being free! CraigMichael maybe you didn't find it cause it's under "Rationality: From AI to Zombies" not "Sequences"?
The narration is pretty good imo, although one disadvantage is it's a pain to navigate to specific posts cause they aren't titled (it's the whole thing, not the highlights).
Yep those were both typos, fixed now, thanks!
Personally I feel like the value from doing more non-Sequence LW posts is probably highest, since the Sequences already exist on Audible (you can get all books for a single credit), and my impression is that wiki tags wouldn't generalise to audio format particularly well. One idea might be to have some kind of system where you can submit particular posts for consideration and/or vote on them, which could be (1) recent ones that weren't otherwise going to be recorded, or (2) old non-Sequence classics like "ugh fields".
I think the key point here is that we're applying a linear transformation to move from neuron space into feature space. Sometimes neurons and features do coincide and you can actually attribute particular concepts to neurons, but unless the neurons are a privileged basis there's no reason to expect this in general. We're taking the definition of feature here as a linear combination of neurons which represents some particular important and meaningful (and hopefully human-comprehensible) concept.
Probably the best explanation of this comes from John Wentworth's recent AXRP podcast, and a few of his LW posts. To put it simply, modularity is important because modular systems are usually much more interpretable (case in point: evolution has produced highly modular designs, e.g. organs and organ systems, whereas genetic algorithms for electronic circuit design frequently fail to find designs that are modular, and so they're really hard for humans to interpret, and verify that they'll work as expected). If we understood a bit more about the factors that select for modularity under a wide range of situations (e.g. evolutionary selection, or standard ML selection), then we might be able to use these factors to encourage more modular designs. On the more abstract level, it might help us break down fuzzy statements like "certain types of inner optimisers have separate world models and models of the objective", which are really statements about modules within a system. But in order to do any of this, we need to come up with a robust measure for modularity, and basically there isn't one at present.
This may not exactly answer the question, but I'm in a research group which is studying selection for modularity, and yesterday we published our fourth post, which discusses the importance of causality in developing a modularity metric.
TL;DR - if you want to measure information exchanged in a network, you can't just observe activations, because two completely separate tracks of the network measuring the same thing will still have high mutual information even though they're not communicating with each other (the input is a confounder for both of them). Instead, it seems like you'll need to use do calculus and counterfactuals.
We haven't actually started testing out our measure yet so this is currently only at the theorising stage, hence may not be a very satisfying answer to the question
I guess another point here is that we won't know how different (for example) our results when sampling from the training distribution will be from our results if we just run the network on random noise and then intervene on neurons; this would be an interesting thing to experimentally test. If they're very similar, this neatly sidesteps the problem of deciding which one is more "natural", and if they're very different then that's also interesting
Yeah I think the key point here more generally (I might be getting this wrong) is that C represents some partial state of knowledge about X, i.e. macro rather than micro-state knowledge. In other words it's a (non-bijective) function of X. That's why (b) is true, and the equation holds.
A few of Scott Alexander's blog posts (made into podcast episodes) are really good (he's got a sequence summarising the late 2021 MIRI conversations; the Bio Anchors and Takeoff Speeds ones I found especially informative & comprehensible). These doesn't make up the bulk of content and isn't super technical but thought I'd mention it anyway
Yeah I think this is Evan's view. This is from his research agenda (I'm guessing you might have already seen this given your comment but I'll add it here for reference anyway in case others are interested)
I suspect we can in fact design transparency metrics that are robust to Goodharting when the only optimization pressure being applied to them is coming from SGD, but cease to be robust if the model itself starts actively trying to trick them.
And I think his view on deception through inner optimisation pressure is that this is something we'll basically be powerless to deal with once it happens, so the only way to make sure it doesn't happen it to chart a safe path through model space which never enters the deceptive region in the first place.
Okay I see, yep that makes sense to me (-: