Project Intro: Selection Theorems for Modularity
post by CallumMcDougall (TheMcDouglas), Avery, Lucius Bushnaq (Lblack) · 2022-04-04T12:59:19.321Z · LW · GW · 20 commentsContents
Introduction - what is modularity, and why should we care? A formalism for modularity Modularity in the agent Modularity in the environment Why modular environmental changes lead to network modularity (Unsuccessfully) Replicating the original MVG paper So what does that mean? Future plans Final words None 20 comments
Introduction - what is modularity, and why should we care?
It’s a well-established meme that evolution is a blind idiotic process, that has often resulted in design choices that no sane systems designer would endorse. However, if you are studying simulated evolution, one thing that jumps out at you immediately is that biological systems are highly modular, whereas neural networks produced by genetic algorithms are not [AF · GW]. As a result, the outputs of evolution often look more like something that a human might design than do the learned weights of those neural networks.
Humans have distinct organs, like hearts and livers, instead of a single heartliver. They have distinct, modular sections of their brains that seem to do different things. They consist of parts, and the elementary neurons, cells and other building blocks that make up each part interact and interconnect more amongst each other than with the other parts.
Neural networks evolved with genetic algorithms, in contrast, are pretty much uniformly interconnected messes. A big blob that sort of does everything that needs doing all at once.
Again in contrast, networks in the modern deep learning paradigm apparently do exhibit some modular structure.
![]()
Top: Yeast Transcriptional Regulatory Modules - clearly modular
Bottom: Circuit diagram evolved with genetic algorithms - non-modular mess
Why should we care about this? Well, one reason is that modularity and interpretability seem like they might be very closely connected. Humans seem to mentally subpartition cognitive tasks into abstractions, which work together to form the whole in what seems like a modular way. Suppose you wanted to figure out how a neural network was learning some particular task, like classifying an image as either a cat or a dog. If you were explaining to a human how to do this, you might speak in terms of discrete high-level concepts, such as face shape, whiskers, or mouth.
How and when does that come about, exactly? It clearly doesn’t always, since our early networks built by genetic algorithms work just fine, despite being an uninterpretable non-modular mess. And when networks are modular, do the modules correspond to human understandable abstractions and subtasks?
Ultimately, if we want to understand and control the goals of an agent, we need to answer questions like [AF · GW] “what does it actually mean to explicitly represent a goal”, “what is the type structure of a goal”, or “how are goals connected to world models, and world models to abstractions?”
It sure feels like we humans somewhat disentangle our goals from our world models and strategies when we perform abstract reasoning, even as they point to latent variables of these world models. Does that mean that goals inside agents are often submodules? If not, could we understand what properties real evolution, and some current ML training exhibit that select for modularity and use those to make agents evolve their goals as submodules, making them easier to modify and control?
These questions are what we want to focus on in this project, started as part of the 2022 AI Safety Camp.
The current dominant theory in the biological literature for what the genetic algorithms are missing is called modularly varying goals (MVG). The idea is that modular changes in the environment apply selection pressure for modular systems. For example, features of the environment like temperature, topology etc might not be correlated across different environments (or might change independently within the same environment), and so modular parts such as thermoregulatory systems and motion systems might form in correspondence with these features. This is outlined in a paper by Kashtan and Alon from 2005, where they aim to demonstrate this effect by modifying loss functions during training in a modular way.
We started off by investigating this hypothesis, and trying to develop a more gears-level model of how it works and what it means. This post outlines our early results.
However, we have since branched off into a broader effort to understand selection pressure for modularity in all its forms. The post accompanying this one is a small review of the biological literature, presenting the most widespread explanations for the origins of modularity we were able to find. Eventually, we want to investigate all of these, come up with new ones, expand them to current deep learning models and beyond, and ultimately obtain a comprehensive selection theorem(s) specifying when exactly modularity arises in any kind of system.
A formalism for modularity
Modularity in the agent
For this project, we needed to find a way of quantifying modularity in neural networks. The method that is normally used for this in the biological literature (including the Kashtan & Alon paper mentioned above), and in papers by e.g. CHAI dealing with identifying modularity in deep modern networks, is taken from graph theory. It involves the measure Q, which is defined as follows:
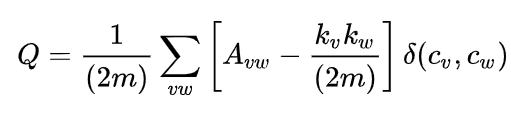
Where the sum is taken over nodes, Avw is the actual number of (directed) edges from v to w, kv are the degrees, and δ(cv,cw) equals 1 if v and w are in the same module, 0 otherwise. Intuitively, Q measures “the extent to which there are more connections between nodes in the same modules than what we would expect from random chance”.
To get a measure out of this formula, we search over possible partitions of a network to find the one which maximises Qm, where Qm is defined as a normalised version of Q:
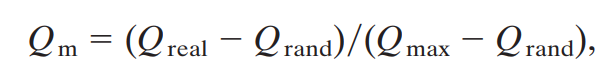
where Qrand is the average value of the Q-score from random assignment of edges. This expression Qm is taken as our measure of modularity.
This is the definition that we’re currently also working with, for lack of a better one. But it presents obvious problems when viewed as a general, True Name [LW · GW]-type definition of modularity. Neural networks are not weighted graphs. So to use this measure, one has to choose a procedure to turn them into one. In most papers we’ve seen, this seems to take the form of translating the parameters into weights by some procedure, ranging from taking e.g. the matrix norm of convolutions, or measuring the correlation or coactivation of nodes. None of the choices seemed uniquely justified on a deep level to us.
To put it differently, this definition doesn’t seem to capture what we think of when we think of modularity. “Weighted number of connections” is certainly not a perfect proxy for how much communication two different subnetworks are actually doing. For example, two connections to different nodes with non-zero weights can easily end up in a configuration where they always cancel each other out.
We suspect that since network-based agents are information-processing devices, the metric for modularity we ultimately end up using should talk about information and information-processing, not weights or architectures. We are currently investigating measures of modularity that involve mutual information, but there are problems to work out with those too (for instance, even if two parts of the network are not communicating at all and perform different tasks, they will have very high mutual information if it is possible to approximately recreate the input from their activations).
Modularity in the environment
If we want to test whether modular changes in the environment reliably select for modular internal representations, then we first need to define what we mean by modular changes in the environment. The papers we found proposing the Modularly Varying Goals idea didn’t really do this. It seemed more like an “we know it when we see it” kind of thing. So we’ve had to invent a formalism for this from the ground up.
The core idea that we started with was this: a sufficient condition for a goal to be modular is that humans tend to think about / model it in a modular way. And since humans are a type of neural network, that’s suggestive that the design space of networks dealing with this environment, out in nature or on our computers, include designs that model the goal in a modular way too.
Although this is sufficient, it shouldn’t be necessary - just because a human looking at the goal can’t see how to model it modularly doesn’t mean no such model exists. That led to the idea that a modularly varying goal should be defined as one for which there exists some network in design space that performs reasonably well on the task, and that “thinks” about it in a modular way.
Specifically, if for example you vary between two loss functions in some training environment, L1 and L2, that variation is called “modular” if somewhere in design space, that is, the space formed by all possible combinations of parameter values your network can take, you can find a network N1 that “does well”(1) on L1, and a network N2 that “does well” on L2, and these networks have the same values for all their parameters, except for those in a single(2) submodule(3).
(1) What loss function score corresponds to “doing well”? Eventually, this should probably become a sliding scale where the better the designs do, the higher the “modularity score” of the environmental variation. But that seems complicated. So for now, we restrict ourselves to heavily overparameterized regimes, and take doing well to mean reaching the global minimum of the loss function.
(2) What if they differ in n>1 submodules? Then you can still proceed with the definition by considering a module defined by the n modules taken together. Changes that take multiple modules to deal with are a question we aren’t thinking about yet though.
(3) Modularity is not a binary property. So eventually, this definition should again include a sliding scale, where the more encapsulated the parameters that change are from the rest of the network, the more modular you call the corresponding environmental change. But again, that seems complicated, and we’re not dealing with it for now.
One thing that’s worth discussing here is why we should expect modularity in the environment in the first place. One strong argument for this comes from the Natural Abstraction Hypothesis [LW · GW], which states that our world abstracts well (in the sense of there existing low-dimensional summaries of most of the important information that mediates its interactions with the rest of the world), and these abstractions are the same ones that are used by humans, and will be used by a wide variety of cognitive designs. This can very naturally be seen as a statement about modularity: these low-dimensional summaries precisely correspond to the interfaces between parts of the environment that can change modularly. For instance, consider our previously-discussed example of the evolutionary environment which has features such as temperature, terrain, etc. These features correspond to both natural abstractions with which to describe the environment, and precisely the kinds of modular changes which (so the theory goes) led to modularity through the mechanism of natural selection.
This connection also seems to point to our project as a potential future test bed of the natural abstraction hypothesis.
Why modular environmental changes lead to network modularity
Once the two previous formalisms have been built up, we will need to connect them somehow. The key question here is why we should expect modular environmental changes to select for modular design at all. Recall that we just defined a modular environmental change as one for which there exists a network that decomposes the problem modularly - this says nothing about whether such a network will be selected for.
Our intuition here comes from the curse of dimensionality. When the loss function changes from L1 to L2, how many of its parameters does a generic perfect solution for L1 need to change to get a perfect loss on L2?
A priori, it’d seem like potentially almost all of them. For a generic interconnected mess of a network, it’s hard to change one particular thing without also changing everything else.
By contrast, the design N1, in the ideal case of perfect modularity, would only need to change the parameters in a single one of its submodules. So if that submodule makes up e.g. 0.1 of the total parameters in the network, you’ve just divided the number of dimensions your optimiser needs to search by ten. So the adaptation goes a lot faster.
“But wait!” You say. Couldn’t there still be non-modular designs in the space that just so happen to need even less change than N1 type designs to deal with the switch?
Good question. We wish we’d seriously considered that earlier too. But bear with it for a while.
No practically usable optimiser for designing generic networks currently known seems to escape the curse of dimensionality fully, nor does it seem likely to us that one can exist[1], so this argument seems pretty broadly applicable. Some algorithms scale better/worse with dimensionality in common regimes than others though, and that might potentially affect the magnitude of the MVG selection effect.
For example, in convex neighbourhoods of the global optimum, gradient descent is roughly bounded by exact line search to scale with the condition number of the Hessian. How fast the practically relevant condition number of a generic Hessian grows with its dimension D is a question that’s been proving non-trivial to answer for us, but between the circular law and a random paper on the eigenvalues of symmetric matrices we found, we suspect it might be something on the order of O(√D)−O(D), maybe. (Advice on this is very welcome!)
By contrast, if gradient descent is still outside that convex neighbourhood, bumbling around the wider parameter space and getting trapped in local optima and saddle points, the search time probably scales far worse with the number of parameters/dimensions. So how much of an optimization problem is made up of this sort of exploration vs. descending the convex slope near the minimum might have a noticeable impact on the adaptation advantage provided by modularity.
Likewise, it seems like genetic algorithms could scale differently with dimensionality and thus this type of modularity than gradient based methods, and that an eventual future replacement of ADAM might scale better. These issues are beyond the scope of the project at this early stage, but we’re keeping them in mind and plan to tackle them at some future point.
(Unsuccessfully) Replicating the original MVG paper
The Kashtan and Alon (2005) paper, seems to be one of the central results backing the modularly varying goals (MVG) hypothesis as a main driving factor for modularity in evolved systems. It doesn’t try to define what modular change is, or mathematically justify why modular designs might handle such change better, the way we tried above. But it does claim to show the effect in practice. As such, one of the first things we did when starting this project was try to replicate that paper. As things currently stand, the replication has mostly failed.
We say “mostly” for two reasons. First, there are two separate experiments in the 2005 paper supposedly demonstrating MVG. One involving logic circuits, and one using (tiny) neural networks. We ignored the logic circuits experiment and focused solely on the neural network one as it was simpler to implement. Since that replication failed, we plan on revisiting the logic circuits experiment.
Second, we implemented some parts of the 2005 paper with liberty. For example, Kashtan & Alon used a specific selection strategy when choosing parents in the evolutionary algorithm used to train the networks. We used a simpler strategy (although, we did try various strategies). The exact strategy they used didn’t seem like it should be relevant for the modularity of the results.
We are currently working on a more exact replication just to be sure, but if MVG is as general an effect as the paper is speculating it to be, it really shouldn’t be sensitive to small changes in the setup like this.
The idea of the NN experiment was to evolve neural networks (using evolutionary algorithms, not gradient descent methods) to recognize certain patterns found in a 4-pixel-wide by 2-pixel-high retina. There can be “Left” (L) patterns and “Right” (R) patterns in the retina. When given the fixed goal of recognizing “L and R” (e.g. checking whether there is both a left and a right pattern), networks evolved to handle this task were found to be non-modular. But when alternating between two goals: G1=“L and R” and G2=“L or R”, that are swapped out every few training cycles, the networks supposedly evolved to converge on a very modular, human understandable design, with two modules recognising images on one side of the screen each. The “and” and “or” is then handled by a small final part taking in the signal from both modules, and that’s the only bit that has to change whenever a goal switch occurs.
Here are examples of specific results from Kashtan & Alon:
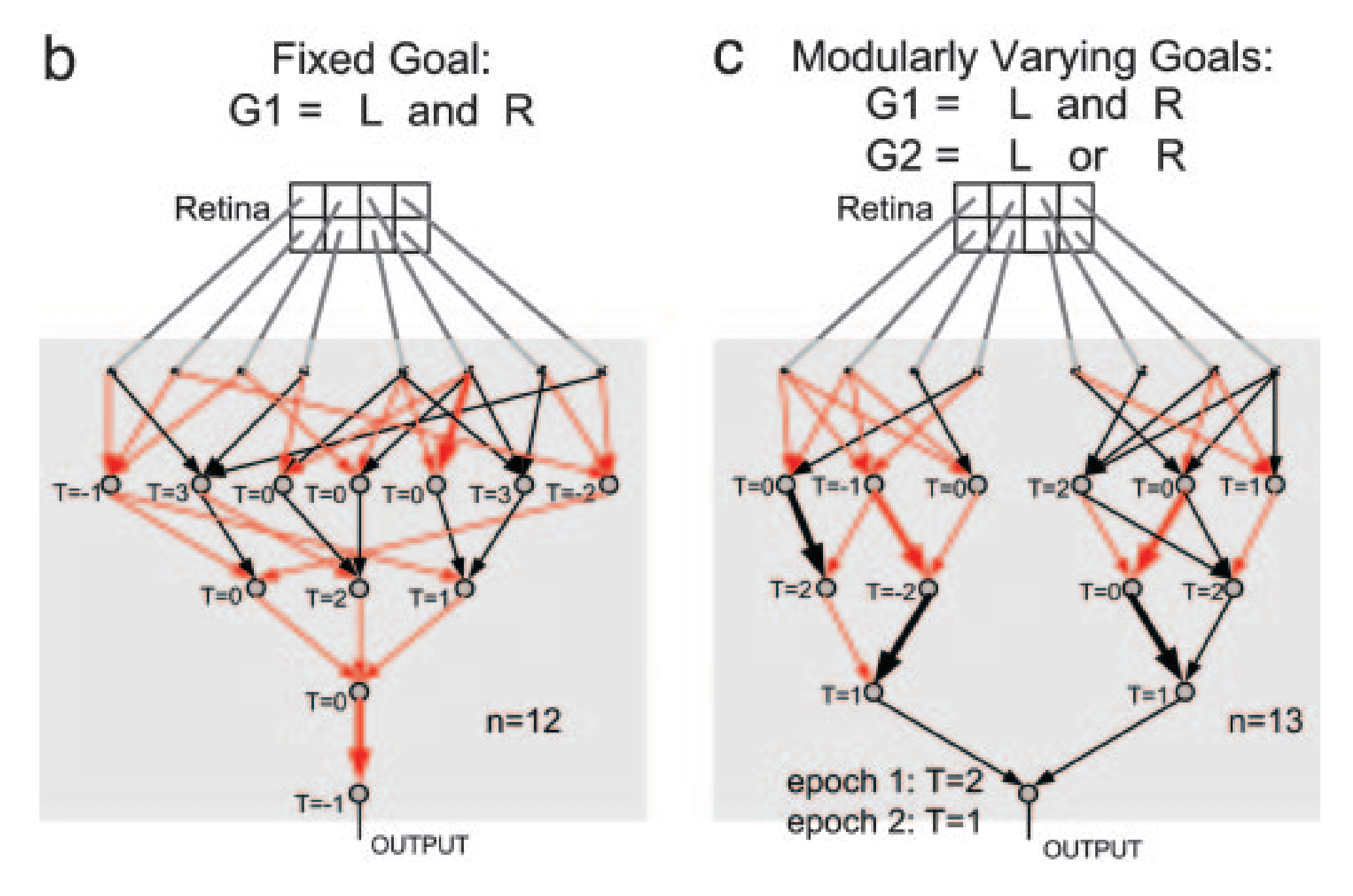
Unfortunately, our replication didn’t see anything like this. Networks evolved to be non-modular messes both for fixed goals and Modularly Varying Goals:
We got the same non-modular results under a wide range of experimental parameters (different mutation rates, different selection strategies, population sizes, etc). If anyone else has done their own replication, we’d love to hear about it.
So what does that mean?
So that rather put a damper on things. Is MVG just finished now, and we should move on to testing the next claimed explanation for modularity?
We thought that for a while. But as it turns out, no, MVG is not quite done yet.
There’s a different paper from 2013 with an almost identical setup for evolving neural networks. Same retina image recognition task, same two goals, everything. But rather than switching between the two goals over and over again to try and make the networks evolve a solution that’s modular in their shared subtasks, they just let the networks evolve in a static environment using the first goal. Except they also apply an explicit constraint on the number of total connections the networks are allowed to have, to encourage modularity, as per the connection cost explanation.
They say that this worked. Without the connection cost, they got non-modular messes. With it, they got networks that were modular in the same way as those in the 2005 paper. Good news for the connection cost hypothesis! But what’s that got to do with MVG?
That’s the next part: When they performed a single, non-repeated switch of the goal from “and” to “or”, the modular networks they evolved using connection costs dealt faster with the switch than the non-modular networks. Their conclusion is that modularity originally evolves because of connection costs, but does help with environmental adaptation as per MVG.
So that’s when we figured out what we might’ve been missing in our theory work. You can have non-modular networks in design space that deal with a particular change even better than the modular ones, just by sheer chance. But if there’s nothing selecting for them specifically over other networks that get a perfect loss, there’s no reason for them to evolve.
But if you go and perform a specific change to the goal function over and over again, you might be selecting exactly those networks that are fine tuned to do best on that switch. Which is what the 2005 paper and our replication of it were doing.
So modular networks are more generally robust to modular change, but they might not be as good as dealing with any specific modular change as a non-modular, fine tuned mess of a network constructed for that task.
Which isn’t really what “robustness” in the real world is about. It’s supposed to be about dealing with things you haven’t seen before, things you didn’t get to train on.
(Or alternatively, our replication of the 2005 setup just can’t find the modular solutions, period. Distinguishing between that hypothesis and this one is what we’re working on on the experimental front right now.)
To us, this whole train of thought[2] has further reinforced the connection that modularity = abstraction, in some sense. Whenever you give an optimiser perfect information on its task in training, you get a fine-tuned mess of a network humans find hard to understand. But if you want something that can handle unforeseen, yet in some sense natural changes, something modular performs better.
How would you simulate something like that? Maybe instead of switching between two goals with shared subtasks repeatedly, you switch between a large set of random ones, all still with the same subtasks, but never show the network the same one twice[3]. We call this Randomly sampled Modularly Varying Goals (RMVG).
Might a setup like this select for modular designs directly after all, without the need for connection costs? If the change fine-tuning hypothesis is right, all the fine-tuned answers would be blocked off by this setup, leaving only the modular ones as good solutions to deal with the change. Or maybe the optimiser just fails to converge in this environment, unable to handle the random switches. We plan to find out.
Though before we do that, we’re going to replicate the 2013 paper. Just in case.
Future plans
On top of the 2013 replication, the exact 2005 replication and RMVG, we have a whole bunch of other stuff we want to try out.
-
Sequential modularity instead of parallel modularity
If you have a modular goal with two subtasks, but the second depends on the first, does the effect still work the same way? -
Large networks
So far, our discussion and experimentation has been based on pre-modern neural networks with less than twenty nodes. How would this all look in the modern paradigm, with a vastly increased number of parameters and gradient-type optimisers instead of genetic algorithms?
To find out, we plan to set up a MVG-test environment for CNNs. One possible setup might be needing to recognise two separate MNIST digits, then perform various joined algebraic operations with them, like e.g. addition or subtraction). -
Explaining modularity in modern networks
To follow on from the previous point, it’s worth noting that modularity is apparently already present by default in CNNs and other modern architectures, unlike the old school bio simulations that didn’t see modularity unless they specifically try to select for it. This begs the question, can we explain why it is there? Do these architectures somehow enforce something equivalent to a connection cost? Does using SGD introduce an effective variation in the goal function that is kind of like (R)MVG? Does modularity become preferred once you have enough parameters, because the optimiser somehow can’t handle fine-tuning interaction between all of them? Or do we need new causes of modularity to account for it? -
Other explanations for modularity
On that note, we also plan to do a bunch more research and testing on the other proposed explanations for modularity in the bio literature[4], plus any we might come up with ourselves.
Regarding connection costs for example, we’ve been wondering whether the fact that physics in the real world is local, while the nodes in our programs are not[5], plays an additional role here. We plan to compare flat total connection costs to local costs, which penalise more distant nodes more than closer ones for connecting. -
Finding the “true name” of modularity
Then there’s the work of designing a new, more deeply justified modularity measure based on information exchange. If we can manage that, we should check all our experiments again, and see if it changes our conclusions anywhere. For that matter, maybe it should be used on some of the papers that found modularity in modern networks, all of which seem to have used the graph theory measure. -
Broadness of modular solutions
Here’s another line of thought: it’s a widespread hypothesis in ML that generalisable minima are broader than fine-tuned ones. Since our model of MVG says that modular designs are more adaptable, general ones, do they have broader minima? We’re going to measure that in the retina NN setup very soon. We’re also going to research this hypothesis more, because we don’t feel like we really understand it yet. -
“Goal modules” in reinforcement learning
And finally, if the whole (R)MVG stuff and related matters work out the way we want them to, we’ve been wondering if they could form the basis of a strategy to make a reinforcement learner develop a specific “goal module” that we can look at. Say we have an RL agent in a little 2D world, which it needs to navigate to achieve some sort of objective. Now say we vary the objective in training, but have each one rely on the same navigation skill set. Maybe add some additional pressure for modularity on top of that, like connection costs. Could that get us an agent with an explicit module for slotting in the objectives? Or maybe we should do it the other way around, keeping the goal fixed while modularly varying what is required to achieve it. That’s many months away though, if it turns out to be feasible at all. It’s just a vague idea for now.
This is a lot, and maybe it seems kind of scattered, but we are in an exploratory phase right now. At some point, we’d love to see this all coalesce into just a tiny few unifying selection theorems for modularity.
Eventually, we hope to see the things discovered in this project and others like it form the concepts and tools to base a strategy for creating aligned superintelligence on. As one naive example to illustrate how that might work, imagine we’re evolving an AGI starting in safe, low capability regimes, where it can’t really harm us or trick out our training process, and remains mostly understandable to our transparency tools. This allows us to use trial and error in aligning it.
Using our understanding of abstraction, agent signatures and modularity, we then locate the agent’s (or the subagents’ [AF · GW]) goals inside it (them), and “freeze” the corresponding parameters. Then we start allowing the agent(s) to evolve into superintelligent regimes, varying all the parameters except these frozen ones. Using our quantitative understanding of selection, we shape this second training phase such that it’s always preferred for the AGI to keep using the old frozen sections as its inner goal(s), instead of evolving new ones. This gets us a superintelligent AGI that still has the aligned values of the old, dumb one.
Could that actually work? We highly doubt it. We still understand agents and selection far too little to start outlining actual alignment strategies. It’s just a story for now, to show why we care about foundations work like this. But we feel like it’s pointing to a class of things that could work, one day.
Final words
Everything you see in this post and the accompanying literature review was put together in about ten weeks of part-time work. We feel like the amount of progress made here has been pretty fast for agent foundations research by people who’ve never done alignment work before. John Wentworth has been very helpful, and provided a lot of extremely useful advice and feedback, as have many others. But still, it feels like we’re on to something.
If you’re reading this, we strongly suggest you take a look at the selection theorems research agenda [LW · GW] and [LW · GW] related [LW · GW] posts [LW · GW], if you haven’t yet. Even if you’ve never done alignment research before. Think about it a little. See if anything comes to mind. It might be a very high-value use of your time.
The line of inquiry sketched out here was not the first thing we tried, but it was like, the second to third-ish. That’s a pretty good ratio for exploratory research. We think this might be because the whole area of modularity, and selection theorems more generally, has a bunch of low hanging research fruit, waiting to be picked.
For our team's most recent post, please see here [LW · GW].
Or at least if one is found, it’d probably mean P=NP, and current conceptions of AGI would become insignificant next to our newfound algorithmic godhood. ↩︎
Which might still be wrong, we haven’t tested this yet. ↩︎
Or just rarely enough to prevent fine tuning. ↩︎
More discussion of the different explanations for biological modularity found in the bio literature can be found in this post [LW · GW]. ↩︎
Computer chip communication lines are though. Might that be relevant if you start having your optimisers select for hardware performance? ↩︎
20 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2022-04-10T09:01:55.193Z · LW(p) · GW(p)
Specifically, if for example you vary between two loss functions in some training environment, L1 and L2, that variation is called “modular” if somewhere in design space, that is, the space formed by all possible combinations of parameter values your network can take, you can find a network N1 that “does well”(1) on L1, and a network N2 that “does well” on L2, and these networks have the same values for all their parameters, except for those in a single(2) submodule(3).
It's often the case that you can implement the desired function with, say, 10% of the parameters that you actually have. So every pair of L1 and L2 would be called "modular", by changing the 10% of parameters that actually do anything, and leaving the other 90% the same. Possible fixes:
- You could imagine that it's more modular the fewer parameters are needed, so that if you can do it with 1% of the parameters, that's more modular than 10% of the parameters. Problem: this is probably mostly measuring min(difficulty(L1), difficulty(L2)), where difficulty(L) is the minimum number of parameters needed to "solve" L, for whatever definition of "solve" you are using.
- You could have a definition that first throws away all the parameters that are irrelevant, and then applies the definition above. (I expect this to have problems with Goodharting on the definition of "irrelevant", but it's not quite so obvious what they will be.)
↑ comment by Lucius Bushnaq (Lblack) · 2022-04-10T19:09:05.220Z · LW(p) · GW(p)
A very good point!
I agree that fix 1. seems bad, and doesn't capture what we care about.
At first glance, fix 2. seems more promising to me, but I'll need to think about it.
Thank you very much for pointing this out.
↑ comment by CallumMcDougall (TheMcDouglas) · 2022-04-15T07:53:48.960Z · LW(p) · GW(p)
Yep thanks! I would imagine if progress goes well on describing modularity in an information-theoretic sense, this might help with (2), because information entanglement between a single module and the output would be a good measure of "relevance" in some sense
comment by DanielFilan · 2022-05-02T22:49:39.026Z · LW(p) · GW(p)
The method that is normally used for this in the biological literature (including the Kashtan & Alon paper mentioned above), and in papers by e.g. CHAI dealing with identifying modularity in deep modern networks, is taken from graph theory. It involves the measure Q, which is defined as follows:
FWIW I do not use this measure in my papers, but instead use a different graph-theoretic measure. (I also get the sense that Q is more of a network theory thing than a graph theory thing)
comment by Simon Fischer (SimonF) · 2022-04-07T20:11:13.946Z · LW(p) · GW(p)
Hypothesis: If a part of the computation that you want your trained system to compute "factorizes", it might be easier to evolve a modular system for this computation. By factorization I just mean that (part of) the computation can be performed using mostly independent parts / modules.
Reasoning: Training independent parts to each perform some specific sub-calculation should be easier than training the whole system at once. E.g. training n neural networks of size N/n should be easier (in terms of compute or data needed) than training one of size N, given the exponential size of the parameter space.
This hypothesis might explain the appearance of modularity if the necessary initial conditions for this selective advantage to be used are regularly present.
(I've talked about this idea with Lblack already but wanted to spell it out a bit more and post it here for reference.)
↑ comment by Lucius Bushnaq (Lblack) · 2022-04-07T21:23:18.324Z · LW(p) · GW(p)
To clarify, the main difficulty I see here is that this isn't actually like training n networks of size N/n, because you're still using the original loss function.
Your optimiser doesn't get to see how well each module is performing individually, only their aggregate performance. So if module three is doing great, but module five is doing abysmally, and the answer depends on both being right, your loss is really bad. So the optimiser is going to happily modify three away from the optimum it doesn't know it's in.
Nevertheless, I think there could be something to the basic intuition of fine tuning just getting more and more difficult for the optimiser as you increase the parameter count, and with it the number of interaction terms. Until the only way to find anything good anymore is to just set a bunch of those interactions to zero.
This would predict that in 2005-style NNs with tiny parameter counts, you would have no modularity. In real biology, with far more interacting parts, you would have modularity. And in modern deep learning nets with billions of parameters, you would also have modularity. This matches what we observe. Really neatly and simply too.
It's also dead easy to test. Just make a CNN or something and see how modularity scales with parameter count. This is now definitely on our to do list.
Thanks a lot again, Simon!
Replies from: TheMcDouglas↑ comment by CallumMcDougall (TheMcDouglas) · 2022-04-15T08:10:11.017Z · LW(p) · GW(p)
Reasoning: Training independent parts to each perform some specific sub-calculation should be easier than training the whole system at once.
Since I've not been involved in this discussion for as long I'll probably miss some subtlety here, but my immediate reaction is that "easier" might depend on your perspective - if you're explicitly enforcing modularity in the architecture (e.g. see the "Direct selection for modularity" section of our other post) then I agree it would be a lot easier, but whether modular systems are selected for when they're being trained on factorisable tasks is kinda the whole question. Since sections of biological networks do sometimes evolve completely in isolation from each other (because they're literally physically connected) then it does seem plausible that something like this is happening, but it doesn't really move us closer to a gears-level model for what's causing modularity to be selected for in the first place. I imagine I'm misunderstanding something here though.
So if module three is doing great, but module five is doing abysmally, and the answer depends on both being right, your loss is really bad. So the optimiser is going to happily modify three away from the optimum it doesn't know it's in.
Maybe one way to get around it is that the loss function might not just be a function of the final outputs of each subnetwork combined, it might also reward bits of subcomputation? e.g. to take a deep learning example which we've discussed, suppose you were training a CNN to calculate the sum of 2 MNIST digits, and you were hoping the CNN would develop a modular representation of these two digits plus an "adding function" - maybe the network could also be rewarded for the subtask of recognising the individual digits? It seems somewhat plausible to me that this kind of thing happens in biology, otherwise there would be too many evolutionary hurdles to jump before you get a minimum viable product. As an example, the eye is a highly complex and modular structure, but the very first eyes were basically just photoreceptors that detected areas of bright light (making it easier to navigate in the water, and hide from predators I think). So at first the loss function wasn't so picky as to only tolerate perfect image reconstructions of the organism's surroundings; instead it simply graded good brightness-detection, which I think could today be regarded as one of the "factorised tasks" of vision (although I'm not sure about this).
comment by Pattern · 2022-04-04T16:49:10.926Z · LW(p) · GW(p)
To us, this whole train of thought[2] has further reinforced the connection that modularity = abstraction, in some sense. Whenever you give an optimiser perfect information on its task in training, you get a fine-tuned mess of a network humans find hard to understand. But if you want something that can handle unforeseen, yet in some sense natural changes, something modular performs better.
I remember a deep mind paper where a NN was trained on a variety of environments to be able to handle (not known before hand real world parameters in a robot hand/the world (friction etc.)). Did that result in, or involve, a modular network?
It seems like an environment that changes might cause modularity. Though, aside from trying to make something modular, it seem like it could potentially fall out of stuff like 'we want something that's easier to train'. Though I didn't see an explanation in this post of why deep learning would do this (though it was mentioned that they do and evolutionary algorithms wouldn't, EA not resulting in modularity seemed like it was explored, while deep learning wasn't).
Do these architectures somehow enforce something equivalent to a connection cost?
In other words, I'm wondering, does a connection cost help with training?
Replies from: TheMcDouglas, nathan-helm-burger↑ comment by CallumMcDougall (TheMcDouglas) · 2022-04-15T08:16:49.860Z · LW(p) · GW(p)
It seems like an environment that changes might cause modularity. Though, aside from trying to make something modular, it seem like it could potentially fall out of stuff like 'we want something that's easier to train'.
This seems really interesting in the biological context, and not something we discussed much in the other post. For instance, if you had two organisms, one modular and one not modular, even if there's currently no selection advantage for the modular one, it might just be trained much faster and hence be more likely to hit on a good solution before the nonmodular network (i.e. just because it's searching over parameter space at a larger rate).
Replies from: Pattern↑ comment by Pattern · 2022-04-15T19:40:19.821Z · LW(p) · GW(p)
it might just be trained much faster and hence be more likely to hit on a good solution before the nonmodular network (i.e. just because it's searching over parameter space at a larger rate).
Or the less modular one can't train (evolve) as fast when the environment changes. (Or, it changes faster enabling it to travel to different environments.)
Biology kind of does both (modular and integrated), a lot. Like, I want to say part of why the brain is hard to understand is because of how integrated it is. What's going on in the brain? I saw one answer to this that says 'it is this complicated in order to obfuscate, to make it harder to hack, this mess has been shaped by parasites, which it is designed to shake off, that is why it is a mess, and might just throw some neurotoxin in there. Why? To kill stiff that's trying to mess around in there.' (That is just from memory/reading a reviews on a blog, and you should read the paper/later work https://www.journals.uchicago.edu/doi/10.1086/705038)
I want to say integrated a) (often) isn't as good (separating concerns is better), but b) it's cheaper to re-use stuff, and have it solve multiple purposes. Breathing through the same area you drink water/eat food through can cause issues. But integrating also allows improvements/increased efficiency (although I want to say, in systems people make, it can make it harder to refine or improve the design).
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-04-06T04:09:17.779Z · LW(p) · GW(p)
I recall something similar about a robot hand trained in varying simulations. I remember an OpenAI project not a Deepmind one... Here's the link to the OpenAI environment-varying learner: https://openai.com/blog/learning-dexterity/
Replies from: Patterncomment by Steven Byrnes (steve2152) · 2022-04-07T13:17:34.556Z · LW(p) · GW(p)
If I'm understanding right, the MVG thing strikes me as not set up in a way that makes sense to me.
Let's imagine a tiny micro-organism that lives in the soil. It has a short life-cycle, let's say 1 week. So sometimes it's born in the winter, and sometimes in the summer, and these different seasons call for different behaviors in various ways. In this situation…
- The thing that I would NOT expect is that every 26 generations, Evolution changes its genes to be more summer-adapted, and then after another 26 generations, Evolution changes its genes to be more winter-adapted, etc.
- The thing that I WOULD expect is that we wind up with (1) a genome that stays the same through seasons, (2) the genome encodes for (among other things) a "season sensor" that can trigger appropriate downstream behaviors.
That's an example concerning evolution-as-a-learning-algorithm. If you prefer the within-lifetime learning algorithm, I have an example for that too. Let's just replace the micro-organism with a human:
- The thing that I would NOT expect is that every 26 weeks, the human learns "the weather outside is and always will be cold". Then 26 weeks later they learn "Oops, I was wrong, actually the weather outside is and always will be hot".
- The thing that I WOULD expect is that the human learns a general, permanent piece of knowledge that sometimes it's summer and sometimes it's winter, and what to do in each case. AND, they learn to pick up on more specific cues that indicate whether it's summer or winter at this particular moment. (For example, if it was winter yesterday, it's probably also winter today.)
Anyway, if I understand your MVG experiment, it's the first bullet point, not the second. If so, I wouldn't have any strong expectation that it should work at all, notwithstanding the paper. Anyway, I would suggest trying to get to the second bullet point.
Sorry if I'm misunderstanding.
Replies from: Pattern, Lblack↑ comment by Pattern · 2022-04-15T19:52:18.192Z · LW(p) · GW(p)
Let's imagine a tiny micro-organism that lives in the soil. It has a short life-cycle, let's say 1 week. So sometimes it's born in the winter, and sometimes in the summer, and these different seasons call for different behaviors in various ways. In this situation…
I want to say, that bacteria:
- have shorter lifecycles than that (like, less than a day)
- and yet still have circadian rhythms, surprisingly
Searching 'bacteria colony circadian rhythm' turned up:
https://link.springer.com/chapter/10.1007/978-3-030-72158-9_1
abstract:
Prokaryotes were long thought to be incapable of expressing circadian (daily) rhythms. Research on nitrogen-fixing cyanobacteria in the 1980s squashed that dogma and showed that these bacteria could fulfill the criteria for circadian rhythmicity. Development of a luminescence reporter strain of Synechococcus elongatus PCC 7942 established a model system that ultimately led to the best characterized circadian clockwork at a molecular level. The conclusion of this chapter lists references to the seminal discoveries that have come from the study of cyanobacterial circadian clocks.
Okay, how long is the lifecycle of Cyanobacteria?
Searching 'cyanobacteria lifespan':
https://www.researchgate.net/post/What_is_the_average_life_span_of_Cyanobacteria
6-12 hours (depending on temperature).
the genome encodes for (among other things) a "season sensor" that can trigger appropriate downstream behaviors.
So you can look into this and check for that. I'd expect a clock, which would switch things on and off. But, I don't know how/if, say cyanobacteria do handle seasons. I'd first check circadian rhythms because that seems easier. (I want to say that day/night difference is stronger than season (and occurs everywhere) but it might depend on your location. Clearly stuff like polar extremes with month long 'days'/'nights' might work differently. And the handling of day/night having to change around that being different, does seem like more of a reason for a sensor approach, though it's not clear how much of a benefit that would add. I'd guess it's still location dependent.)
↑ comment by Lucius Bushnaq (Lblack) · 2022-04-07T20:48:11.142Z · LW(p) · GW(p)
In the human learning case, what the human is picking up on here is that there is a distinct thing called temperature, which can be different and that matters, a lot. There is now a temperature module/abstraction where there wasn't one before. That's the learning step MVG is hinting at, I think.
Regarding the microorganism, the example situation you give is not directly covered by MVG as described here, but see the section "Specialisation drives the evolution of modularity" in the literature review, basically: https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1000719
If you have genes that specialise to express or not express depending on initial conditions, you get a dynamic nigh identical to this one. Two loss functions you need to "do well" on, with a lot of shared tasks, except for a single submodule that needs changing depending on external circumstance. This gets you two gene activity patterns, with a lot of shared gene activity states, like the shared parameter values between the designs N_1 and N_2 here. The work of "fine tuning" the model to L_1, L_2 is then essentially "already done", and accessed by setting the initial conditions right, instead of needing to be redone by "evolution" after each change, as in the simulation in this article. But it very much seemed like the same dynamic to me.
comment by Steven Byrnes (steve2152) · 2022-04-07T12:53:02.516Z · LW(p) · GW(p)
Top: Yeast Transcriptional Regulatory Modules - clearly modular
It sounds like this is supposed to be describing an image in the post, but I don't see any such image.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2022-04-07T20:21:02.484Z · LW(p) · GW(p)
Ooops. Thanks, will fix that.
comment by Mart_Korz (Korz) · 2022-08-20T22:07:21.318Z · LW(p) · GW(p)
After reading your sequence today, there is one additional hypothesis which came to my mind, which I would like to make the case for (note that my knowledge about ML is very limited, there is a good chance that I am only confused):
Claim: Noise favours modular solutions compared to non-modular ones.
What makes me think that? You mention in Ten experiments [LW · GW] that "We have some theories that predict modular solutions for tasks to be on average broader in the loss function landscape than non-modular solutions" and propose to experimentally test this.
If this is a true property of a whole model, then it will also (typically) be the case for modules on all size-scales. Plausibly the presence of noise creates an incentive to factor the problem into sub-problems which can then by solved with modules in a more noise-robust fashion (=broader optimum of solution). As this holds true on all size-scales, we create a bias towards modularity (among other things).
Is this different from the mentioned proposed modularity drivers? I think so. In experiment 8 [LW · GW] you do mention input noise, which made me think about my hypothesis. But I think that 'local' noise might provide a push towards modules in all parts of the model via the above mechanism, which seems different to input noise.
Some further thoughts
- even if this effect is true, I have no idea about how strong it is
- noisy neurons actually seem a bit related to connection costs to me in that (for a suitable type of noise) recieving information from many inputs could become costly
- even if true, it might not make it easier to actually train modular models. This effect should mostly "punish modular solutions less than non-modular ones" instead of actually helping in training. A quick online search for "noisy neural network" indicated that these have indeed been researched and that performance does degrade. My first click mentioned the degrading performance and aimed to minimize the degradation. However I did not see non-biological results after adding "modularity" to the search (didn't try for long, though).
- this is now pure speculation, but when reading "large models tend towards modularity", I wondered whether there is some relation to noise? Could something like the finite bit resolution of weights lead to an effective noise that becomes significant at sufficient model sizes? (the answer might well be an obvious no)
comment by Thomas Kwa (thomas-kwa) · 2022-04-06T16:30:08.493Z · LW(p) · GW(p)
Using our understanding of abstraction, agent signatures and modularity, we then locate the agent’s (or the subagents’) [LW · GW] goals inside it (them), and “freeze” the corresponding parameters. Then we start allowing the agent(s) to evolve into superintelligent regimes, varying all the parameters except these frozen ones. Using our quantitative understanding of selection, we shape this second training phase such that it’s always preferred for the AGI to keep using the old frozen sections as its inner goal(s), instead of evolving new ones. This gets us a superintelligent AGI that still has the aligned values of the old, dumb one.
It's not clear to me that this would make a difference in alignment. My understanding of the Risks from Learned Optimization story is that at some stage below superintelligence, the agent's architecture is fixed into robust alignment, corrigiblity or deception. So if you've already created an agent in phase 1 that will generalize to human values correctly, won't it continue to generalize correctly when trained further?
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2022-04-07T08:25:10.469Z · LW(p) · GW(p)
If you have something that's smart enough to figure out the training environment, the dynamics of gradient descent, and its own parameters, then yes, I expect it could do a pretty good job at preserving its goals while being modified. But that's explicitly not what we have here. An agent that isn't smart enough to not know how to trick out your training process so it doesn't get modified to have human values probably also isn't smart enough to then tell you how to preserve these values during further training.
Or at least, the chance of the intelligence thresholds working out like that does not sound to me like something you want to base a security strategy on.