Ten experiments in modularity, which we'd like you to run!
post by CallumMcDougall (TheMcDouglas), Lucius Bushnaq (Lblack), Avery · 2022-06-16T09:17:28.955Z · LW · GW · 3 commentsContents
Experiments 1. Investigate (randomly) modulary varying goals in modern deep learning architectures. 2) Measure the broadness of modular and non-modular optima in deep learning architectures. 3) Attempt to replicate the modularly varying goals experiment with logic gates in the original Kashtan & Alon 2005 paper. 4) Investigate the effect of local / total connection costs on modularity in neural networks 5) Implement a modularity / MVG experiment for serial, rather than parallel, subtasks. 6) Check if modularity just happens more if you have more parameters. 7) Noisy channels & strongly interacting parameters 8) Noisy input channels 9) Measuring modularity and information exchange in simple networks 10) Visualisation tools for broad peaks Closing thoughts None 3 comments
This is the third post describing our team’s work on selection theorems for modularity, as part of a project mentored by John Wentworth (see [LW · GW] here [LW · GW] for the earlier posts). Although the theoretical and empirical parts of the project have both been going very well, we’re currently bottlenecked on the empirical side: we have several theories and ideas for how to test them, but few experimental results. Right now, we only have one empiricist coding up experiments, so this overhang seems likely to persist.
The purpose of this post is to outline some of our ideas for experiments. We hope that this will provide concrete steps for people who are interested in engaging with empirical research in AI safety, or on selection theorems in particular, to contribute to this area.
Experiments
1. Investigate (randomly) modulary varying goals [LW · GW] in modern deep learning architectures.
In our previous post [LW · GW], we discussed the idea of modularly varying goals in more detail. We conjectured that rapidly switching between a small set of different goals might fine-tune the network to deal with this specific switch, rather than providing selection pressure for modularity. One possible solution to this is RMVG (randomly-sampled modularly varying goals), where we switch between a large set of random goals, all still with the same subtasks, but have a large enough set that we never show the network the same task twice.
For example, one could build a CNN to recognise two MNIST digits , then perform some algebraic operation on the recognised digits (e.g. addition), and measure the modularity of the zero-training-loss solutions found by ADAM (e.g. using the graph theory measure of modularity with the matrix norm of the CNN kernels as weights - see these CHAI papers for more ideas and discussion). To introduce RMVG, you might switch the task during training from calculating to , where are real numbers, varied periodically after some fixed number of epochs. The network wouldn't get and as direct inputs; it could only access them indirectly via their effect on the loss function. This task is modular in the sense that it can be factored into the separate tasks of “recognising two separate digits” and “performing joint arithmetical operations on them”, and we might hope that varying the goal in this way causes the network to learn a corresponding modular solution.
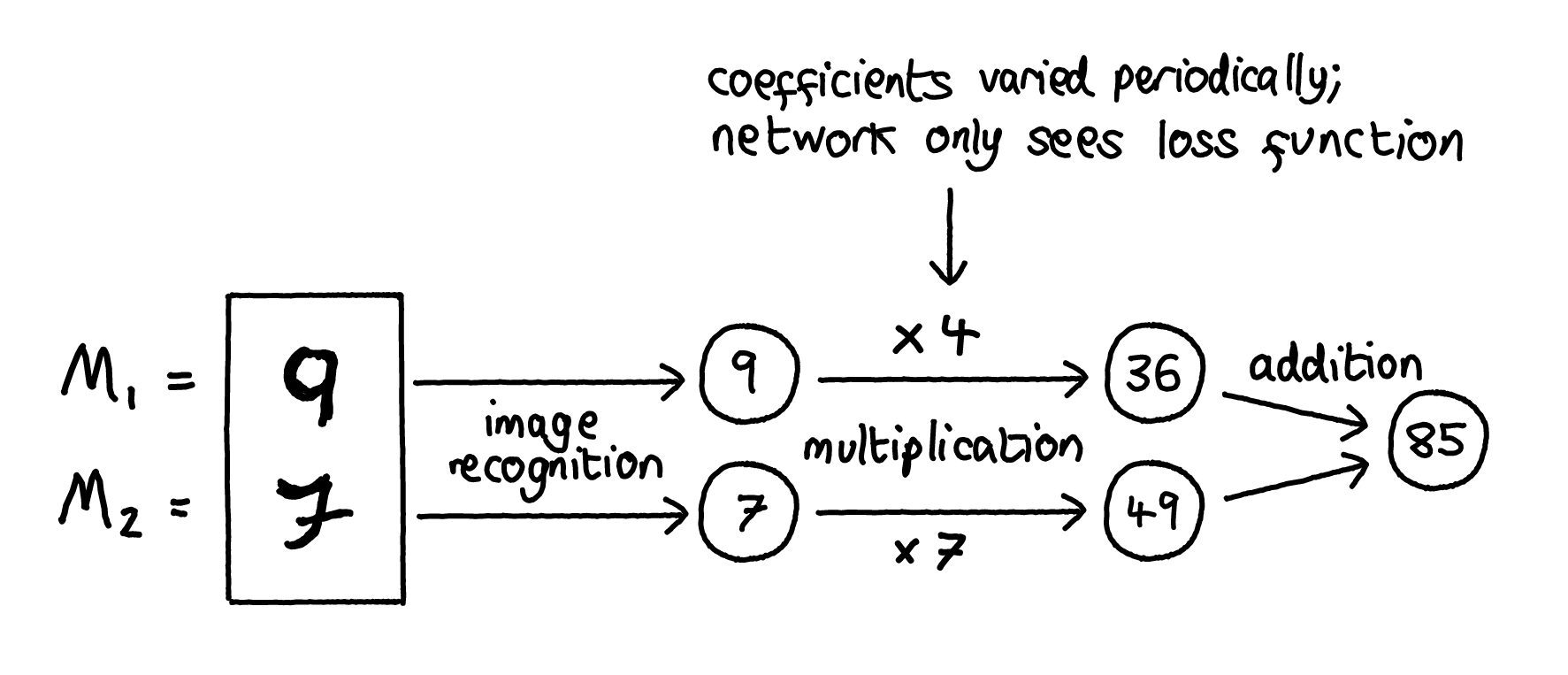
Questions you might ask:
- Does this way of varying goals lead to more modular solutions than the fixed goal of ?
- Can you think of any other modular goals which you could run a similar test for? Are there some types of modular goals which produce modularity more reliably?
- Does switching training methods (e.g. ADAM to SGD or GD) change anything about the average modularity score of solutions?
2) Measure the broadness of modular and non-modular optima in deep learning architectures.
We have some theories that predict modular solutions for tasks to be on average broader in the loss function landscape than non-modular solutions. One could test this by making a CNN and getting it to produce some zero training loss solutions to a task, some of which were more modular than others (see experiment (1) for more detail on this, and (4) for another proposed method to produce modularity), then vary the parameters of these optima slightly to see how quickly the loss increases.
We’ve recently done experiments with simple networks and the retina problem, and this intuition seems to hold up. But more replications here would be very valuable, to examine the extent to which the hypothesis is borne out in different situations / task / network sizes.
Questions you might ask:
- Is there a relationship between broadness of optima and modularity score?
- Do different kinds of tasks, or different sizes of networks, generally result in broader optima?

3) Attempt to replicate the modularly varying goals experiment with logic gates in the original Kashtan & Alon 2005 paper.
We’ve focused on the neural network retina recognition task in the paper so far, since it’s more directly relevant to ML. But since that result so far hasn’t really replicated the way the paper describes (see our previous post [LW · GW]), it would be important for someone to check if the same is true of the logic gate experiment.
Kashtan still has the original 2005 paper code, and seems happy to hand it out to anyone who asks. He also seems happy to provide advice on how to get it running and replicate the experiment. Please don’t hesitate to email him if you’re interested.
4) Investigate the effect of local / total connection costs on modularity in neural networks
Real biology highly modular [LW · GW]. One of the big differences between real biology and neurons in our ML models is that connecting things in the real world is potentially costly and difficult. Lots of papers seem to suggest that this plays a role in promoting modularity (we will probably have a post about this coming out over the next few weeks). If you introduce a penalty for having too many connections into your loss function, this tends to give you more modular solutions.
But in real biology, the cost of forming new connections doesn’t only depend on the total number of connections, but also how physically distant the things you are connecting are. One way you could replicate that kind of connection cost on a computer might be to give each node in your network a 1D or 2D “position index”, and penalise connections between nodes depending on the L2 distance between their indices (e.g. see this paper for one example way of approaching this problem).
Questions you might ask:
- Do the results in the paper linked above replicate?
- As a baseline comparison, how does the performance / modularity of solutions change when you use the standard “total” connection cost, rather than a locally weighted one?
- Do the results depend on how you position the neurons in your space? If so, are there some positioning methods that lead to more modular solutions?
- How do these results change when you look at bigger networks?
5) Implement a modularity / MVG experiment for serial, rather than parallel, subtasks.
Our current MVG experimental setups involve the retina recognition task, as well as the CNN MNIST experiments proposed above. These all have a structure where you’d expect a modular solution to have two modules handling different subtasks in parallel, the outputs of which are needed to perform a small, final operation to get the output.
It would be interesting to see what happens in a case where the subtasks are serial instead. For example, for a “retina” task like the one in the Kashtan 2005 paper, the loss function might require classifying patterns on the “left” retina of the input in order to decide what to do with the “right” retina of the input. Or for a CNN setup with two input images, the ask might be to recognise something in the first image which then determines what you should look for in the second image.
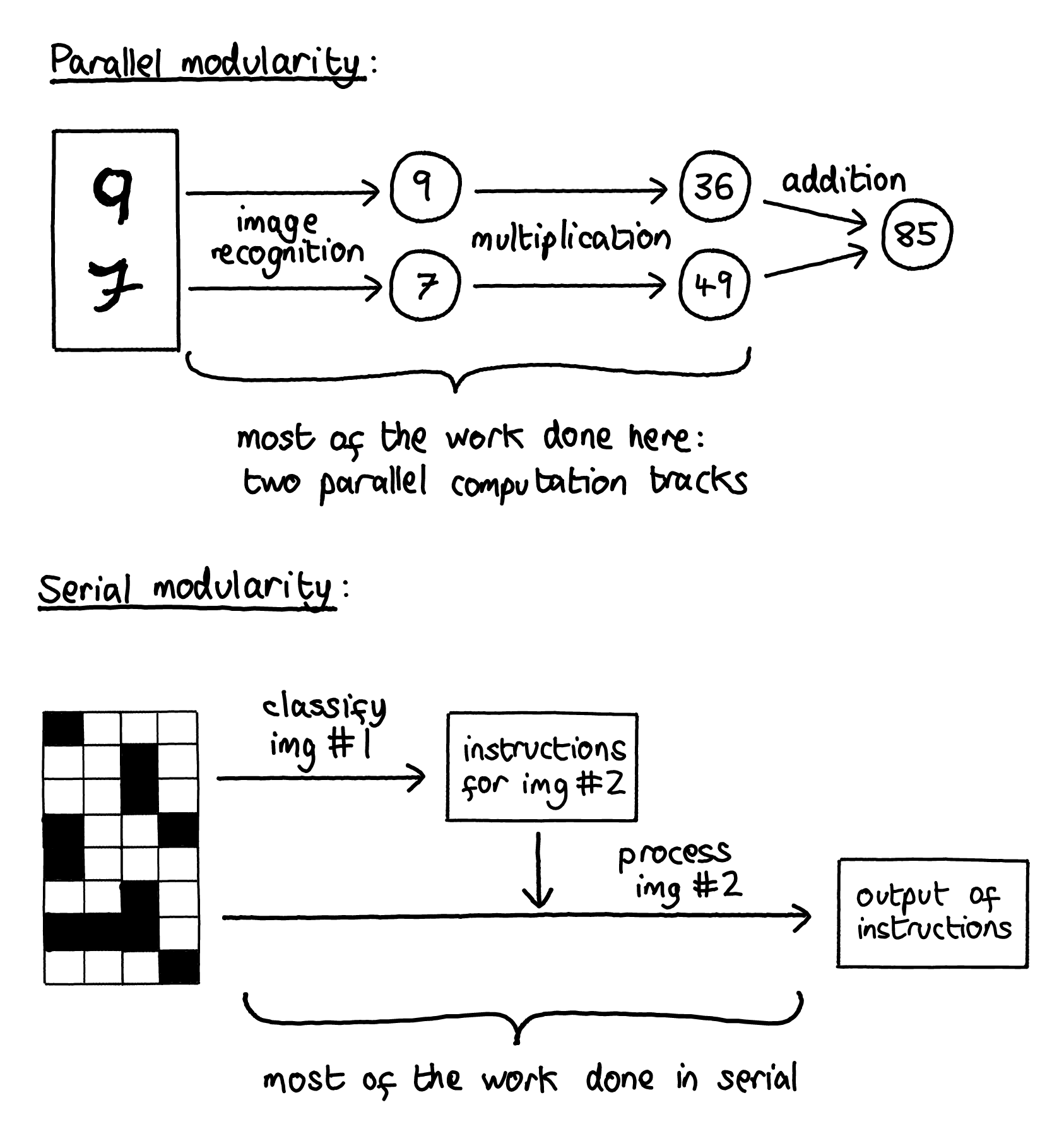
Questions you could ask:
- Which kinds of modular tasks are more naturally described as serial rather than parallel?
- Do you get more modularity in the serial rather than parallel case? Is it harder to find solutions?
- In serial tasks, is the effect of MVG different if you are changing just the (chronologically) first task, or just the second?
6) Check if modularity just happens more if you have more parameters.
As we’ve mentioned several times by now, real biology is very modular. Old neural networks with 10-100 parameters are usually not modular at all (unless particular strategies like MVG are used with the explicit goal of producing modularity). Modern networks with lots of parameters are supposedly somewhat modular sometimes[1].
So one hypothesis might be that modularity emerges when you scale up the number of parameters, for some reason. Maybe handling interactions of every parameter with every other parameter just becomes infeasible for most optimisers as parameter count increases, and the only way they can still find solutions is by partitioning the network into weakly interacting modules.
If this were true, adding more parameters to a network should make it more modular. To test this, you could e.g. take a simple image recognition architecture performing a very narrow image recognition task on MNIST, and calculate its modularity score, as described in (1). Then, you could look at architectures with increasingly deeper layers, solving more complicated image recognition tasks, and calculate their modularity scores as well. For large models, already trained ones could be used.
Questions you could ask:
- Is there a relationship between size and modularity metrics like Q-score?
- How many modules are found in the optimal decomposition when calculating the Q-score? Does this number also increase with larger networks?
7) Noisy channels & strongly interacting parameters
Mostly so far we’ve discussed the modularity characteristics of solutions found by the search process, but another interesting question you could ask is: how modular are neural networks at initialisation?
There are two possible extremes of scenarios we might get. One we could call the “scarce channels” scenario:
- The vast majority of information doesn’t propagate very far through the system; it gets wiped out by noise
- Node-values in nonadjacent chunks of the system are roughly independent
- High modularity scores, because if information is wiped out at a distance then most of the interactions must be local
- In order for any information to be passed at all, a strong training signal is needed to select that information
And the other we could call the “scarce modules” scenario:
- Most parts of the system interact strongly with the rest of the system
- Node-values in nonadjacent chunks of the system are rarely independent
- Low modularity scores, because no chunk of the system can be interpreted as a module
- In order for a part of the system to turn into a module at all, a strong training signal is needed to induce a Markov boundary around it
It would be informative to initialise neural networks with random values and test which of these two scenarios is closer to reality, for the vast majority of random parameter settings.
Questions you could ask:
- Is the modularity score dependent on which randomisation method you’re using?
- How large are the modules being found by your modular decomposition (if using the Q-score, or something similar)?
- Can you find a way of quantifying how far information propagates in the network?
8) Noisy input channels
Organisms in the real world can’t really be overparameterized relative to the vast amount of incoming information they are bombarded with. To the extent that you could imagine defining a loss function for them, it’d be functionally impossible to reach perfect loss on it. As a consequence, we think such systems need ways to get rid of noise in the input so they can focus on the information that matters most.
In contrast, a lot of current deep learning takes place in an overparameterized regime where we train to zero loss, meaning we fit the noise in the input data. One could wonder whether constructing problems where fitting the noise is impossible would evolve networks better designed to throw away superfluous information. Since throwing information away also seems associated with sparsity and with it modularity, we are considering this as another hypothesis for why biological NNs seem so much more modular than artificial ones.
To test this, one could add random Gaussian noise to the input and label of a CNN MNIST setup[2] like the one described in (1). To be clear, this noise would be different every time an input is evaluated. Then, you could see whether the network evolves to filter this noise out, and if that leads to sparsity/modularity.
Questions you could ask:
- Is there a trade-off between performance and modularity as you add more noise?
- If the network does evolve to filter noise out, can you see what mechanism it’s using to do this?
- Is this method more effective at producing modular solutions when it’s combined with other methods outlined in this document, such as (1) and (4)?
9) Measuring modularity and information exchange in simple networks
As we’ve discussed before, we think a good measure of modularity should be deeply linked to concepts of information exchange and processing, and finding a measure which captures these concepts might be a huge step forwards in this project. Although no such measure is currently in use to our knowledge, there are several that have been suggested in the literature which try and gauge how much different parts of the network interact with each other. Most of them work by finding a “maximally modular partition” and measuring its modularity, with the distinctive part of the algorithm being how the modularity of a particular partition is calculated. For instance:
- Some are derived from tools used to analyse simple unweighted undirected graphs, e.g. the Q-score
- Some look at the weights, using e.g. the matrix norms of convolutional kernels.
- Some look at derivatives with respect to node input and output, coactivation of neurons, or mutual information of neurons
We’re also currently working on a candidate measure based on counterfactual mutual information, which we’ll be making a post about soon.
It would be valuable to compare these different measures against each other, and see if some are more successful at capturing intuitive notions of modularity than others.
This isn’t just a theoretical issue either. Right now, it’s looking like e.g. the matrix norm and node derivative measures give very different answers, where one might tell you that a network exhibits statistically significant modularity, whereas the other says there isn’t any.
This suggests the following experiment: taking a very simple system (e.g. the retina task), training it until it finds a solution, and benchmarking and visualising all of these measures against each other on the learned solution.
Some questions you could ask:
- Which modularity measures give rise to similar “maximally modular partitions”? Which ones give partitions that are more similar than others? (this paper suggests a method for comparing the similarity of two different partitions)
- For small networks, you could try visualising the learned solutions and the partitions. Do some partitions look obviously more modular than others?
- Do your results change if you apply them on a solution which hasn’t yet attained perfect performance?
- Try to construct networks that Goodhart a particular measure. How difficult is this? Do the results look like something that a typical training process might select for?
10) Visualisation tools for broad peaks
It’s pretty straightforward to get a mathematical criterion for broad peaks, at least in networks trained to zero loss (e.g. see Vivek Hebbar’s setup here [LW · GW]). It would be useful to get some visualisation tools which can probe that criterion in real nets. For instance, what does the approximate nullspace on the data-indexed side of df/d\theta(\theta, x_i) look like?
This is the sort of thing which has a decent chance of immediately revealing new hypotheses which weren’t even in our space of considerations. Broadness of optima have come up a few times in our thought experiments and empirical investigations so far, and we suspect that there are some pretty deep links between modularity of solutions and their broadness. Better visualisation tools might help illuminate this link.
Questions you could ask:
- Can you find a way to turn the aforementioned mathematical setup [LW · GW] into a visualisation tool for broad peaks?
- Which kinds of graphs or visualisation tools might demonstrate broadness in an intuitive way?
- Are there other ways you can think of to quantify and visualise broadness?
Closing thoughts
We’re really excited about this project, and more people contributing via ideas or running experiments. If you would like to run one of these experiments, or have ideas for others, or just have any questions or confusions about modularity or any of the projects above, please feel free to comment on this post, or send Lucius (Lblack [LW · GW]) a private message here on LessWrong.
There are a few more project ideas we have, but some of them rely on more context or mathematical ideas which we intend to flesh out in later posts.
- ^
One should be careful here: according to Daniel Filian (one of the authors), when they ran these experiments again with a different measure for modularity, they got a different result: no modularity beyond what would be expected by random chance.
- ^
The retina task seems poorly suited for this kind of experiment, even though it’s simpler. It involves small binary inputs that seem like they’d be a pain to get to work with noise, if it’s doable at all.
3 comments
Comments sorted by top scores.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-06-18T11:19:17.720Z · LW(p) · GW(p)
Exciting thoughts here! One initial thought I have is that broadness might be able to be visualized with a topological map over the loss space, with some threshold of 'statistically indistinguishable' forming the areas between lines. Then the final loss would be in a 'basin' which would have an area, so that'd give a broadness metric.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2022-06-19T09:07:29.201Z · LW(p) · GW(p)
Seems like a start. But I think one primary issue for imagining these basins is how high dimensional they are.
Note also that we're not just looking for visualisations of the loss landscape here. Due to the correspondence between information loss and broadness outlined in Vivek's linked post, we want to look at the nullspace of the space spanned by the gradients of the network output for individual data points.
EDIT: Gradient of network output, not gradient of the loss function, sorry. The gradient of the loss function is zero at perfect training loss.
comment by Olli Järviniemi (jarviniemi) · 2023-11-08T15:38:54.555Z · LW(p) · GW(p)
1. Investigate (randomly) modulary varying goals in modern deep learning architectures.
I did a small experiment regarding this. Short description below.
I basically followed the instructions given in the section: I trained a neural network on pairs of digits from the MNIST dataset. These two digits were glued together side-by-side to form a single image. I just threw something up for the network architecture, but the second-to-last layer had 2 nodes (as in the post).
I had two different type of loss functions / training regimes:
- mean-square-error, the correct answer being x + y, where x and y are the digits in the images
- mean-square-error, the correct answer being ax + by, where a and b are uniformly random integers from [-8, 8] (except excluding the case where a = 0 or b = 0), the values of a and b changing every 10 epochs.
In both cases the total number of epochs was 100. In the second case, for the last 10 epochs I had a = b = 1.
The hard part is measuring the modularity of the resulting models. I didn't come up with anything I was satisfied with, but here's the motivation for what I did (followed by what I did):
Informally, the "intended" or "most modular" solution here would be: the neural network consists of two completely separate parts, identifying the digits in the first and second half of the image, and only at the very end these classifications are combined. (C.f. the image in example 1 of the post.)
What would we expect to see if this were true? At least the following: if you change the digit in one half of the image to something else and then do a forward-pass, there are lots of activations in the network that don't change. Weaker alternative formulation: the activations in the network don't change very much.
So! What I did was: store the activations of the network when one half of the image is sampled randomly from the MNIST dataset (and other one stays fixed), and look at the Euclidean distances of those activation vectors. Normalizing by the (geometric) mean of the lengths of the activation vectors gives a reasonable metric of "how much did the activations change relative to their magnitude?". I.e. the metric I used is .
And the results? Were the networks trained with varying goals more modular on this metric?
(The rest is behind the spoiler, so that you can guess first.)
For the basic "predict x+y", the metric was on average 0.68+-0.02 or so, quite stable over the four random seeds I tested. For the "predict ax + by, a and b vary" I once or twice ran to an issue of the model just completely failing to predict anything. When it worked out at all, the metric was 0.55+-0.05, again over ~4 runs. So maybe a 20% decrease or so.
Is that a little or a lot? I don't know. It sure does not seem zero - modularly varying goals does something. Experiments with better notions of modularity would be great - I was bottlenecked by "how do you measure Actual Modularity, though?", and again, I'm unsatisfied with the method here.