What Selection Theorems Do We Expect/Want?
post by johnswentworth · 2021-10-01T16:03:49.478Z · LW · GW · 11 commentsContents
Aspects Of Agent Type Signature (A -> B) -> A (A -> B) -> A + Abstraction World Models and Natural Abstractions Goal Inputs Goal Outputs Internal Structure Aspects Of Selection Better Generalization Through Search Evolution of Modularity Modularity of Broad Peaks None 11 comments
This post contains some of my current best guesses at aspects of agent type signatures for which I expect there are useful Selection Theorems [LW · GW], as well as properties of selection optima which I expect are key to proving these type signatures.
This post assumes you have read the intro post on the Selection Theorem program [LW · GW]. The intended audience is people who might work on the program, so these blurbs are intended to be link-heavy hooks and idea generators rather than self-contained explanations.
Aspects Of Agent Type Signature
These generally reflect my own current high-level thinking (though not all of the ideas are mine). For a different (and excellent, and better-written) take on similar questions from someone else, check out Mark and Evan’s Agents Over Cartesian World Models [LW · GW].
(A -> B) -> A
Scott Garrabrant’s post (A -> B) -> A [LW · GW] provides the basic starting point for a Hofstadter-esque agent type signature. Breaking it down:
- A represents the agent’s “actions”.
- B represents the “outcomes” of those actions.
- (A -> B) is the agent’s model of what outcomes result from an action. It’s a function which takes in actions, and spits out outcomes (that’s the arrow notation).
- (A -> B) -> A is the full agent: it takes in the model (A -> B), and then outputs action A as a function of the model.
In pure abstract functional terms, the overall type signature is (A -> B) -> A. Lots of other type information is missing from this - there’s nothing about the types of the actions or the outcomes, for instance. But it seems like the right basic setup at a high level.

(A -> B) -> A + Abstraction
Generally speaking, low-level physical reality seems to be made of something like a giant causal network [LW · GW] with symmetry [LW · GW]. It doesn’t have any built-in “clouds” or “strange loops”. So, how do we get (A -> B) -> A structures in the physical world?
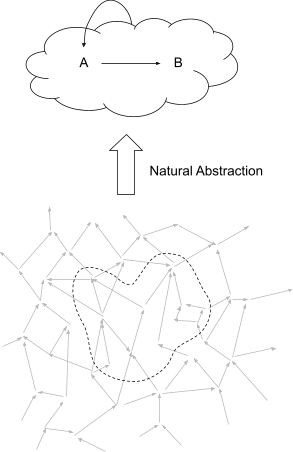
I expect that some chunks of the world naturally abstract [LW · GW] into models with an agent-like type signature. In other words, approximately-all of the information about that chunk which propagates “far away” in the low-level causal network of the universe is summarized by a high-level model with an (A -> B) -> A signature.
This is the sort of “embedding” of agents for which I expect to find selection theorems.
World Models and Natural Abstractions
Humans’ world models sure do seem to have things in them - pencils, cars, other humans, etc. So a type signature for human world models (and, I expect, probably world models more generally) should give us some idea of what “things” are and how they correspond to structures in the world.
A different angle: to the extent that we expect to see roughly-Bayesian models (which is itself debatable, but at least better founded than EU maximization), what are the variables in those models, and how do they correspond to structures in the world?
This is another place where I expect the Natural Abstraction Hypothesis [LW · GW] is relevant. Eventually, I expect to find selection theorems saying that agents evolve to reason using natural abstractions under a fairly broad range of conditions.
Goal Inputs
I’m surprised by just how much of a blindspot goal-inputs seem to be for today’s economists, AI researchers, etc. The coherence theorems usually cited to justify expected utility maximization models imply a quite narrow range of inputs to those utility functions: utilities are only over the outcomes on which agents can bet. Yet practitioners use utility functions over entire (unobservable) world states, world state trajectories, MDP states, etc, often without any way for the agent to bet on all of the outcomes.
Not that I think this is wrong; the inputs to human values seem to be abstract latent variables in humans’ world models [LW · GW], which are not things for which we can operationalize direct bets even in principle. (Indeed, this is arguably the fundamental barrier to making betting markets really useful.) The goal type signatures implied by the coherence theorems are not a good fit for realistic agenty systems.
I do expect that there are better theorems to be found - for instance, Description Length Minimization = Utility Maximization [LW · GW] offers exactly the sort of goal input type signature I expect for humans, and connects it to information theoretic compressibility in a way which could plausibly be used in a selection theorem.
Combined with the Natural Abstraction hypothesis, I also expect there are selection theorems saying that evolved agents will tend to have goals whose inputs are (estimates/models of) natural abstractions from the environment.
Goal Outputs
The subagents argument [LW · GW] says that the “output” of an agent’s goal should not be a utility, but rather a set of utilities, each one corresponding to a different subagent. This still seems basically correct to me - the more I’ve thought about it, the more I’m surprised by how well it matches human goals/values in practice (most recently, for instance, this [LW(p) · GW(p)], as well as a recent in-person discussion about how a lot of “moral insights” feel like pareto-gain trades between subagents which value different things).
The theorem still needs to be integrated with all the other pieces of an agent type signature, especially uncertainty. (I expect that different subagents can have different world models, as well as different utility functions.)
Internal Structure
The Selection Theorem problem I currently find most interesting is to say things about the internal structure of evolved agents. Does the internal structure have separate modules for world models, goals, search/optimization process, etc? More generally, do we expect some kind of modularity in evolved agenty systems? This is basically Scott Garrabrant’s question about whether agent-like behavior implies agent-like architecture [LW · GW], though for evolved agents specifically. I think, in the context of large-scale evolved agents in sufficiently-complex environments, the answer is “yes”. Most of the subsections below will discuss reasons for that belief and possible angles by which to prove it.
Aspects Of Selection
Most existing selection theorems [LW · GW] focus on optimality - i.e. if the system isn’t behaviorally equivalent to a particular type signature, then it’s strictly suboptimal in some way. I do think there’s still some fruit to be picked there, but it’s not where I expect to find the most important selection theorems going forward.
Instead, I expect key results to come from characterizing broad and robust optima.
“Broad” means that the optimum is not too sensitive to parameter values - for instance, a “broad optimum” in natural selection would mean that most small mutations do not yield too large a fitness loss. Roughly speaking, optima have to be broad in order for natural selection to actually find them - no matter how high the fitness of a design, if everything “nearby” that design in mutation-space has low fitness, then natural selection has no way to get there. Same with gradient descent and other numerical optimization techniques used in ML/AI.
“Robust” means that the optimum is not too sensitive to the environment distribution - for instance, a “robust optimum” in natural selection would mean that the organism’s fitness will not plummet if there’s some small-but-permanent change in the environment. Real-world selection processes (whether natural selection or SGD or economic profitability) generally work with multiple finite samples from the environment, so we should expect sample noise to push toward more-robust optima.
Why would these two properties be crucial? Here’s a few different angles.
Better Generalization Through Search
Risks From Learned Optimization gives an informal argument [? · GW] that mesa-optimizers (i.e. evolved agents) become more probable as the complexity and variability of the environment increases - in other words, robust optima tend to involve agents.
Roughly argument: figuring out the right strategy takes some “optimization power”, measured in bits as the number of times we need to cut the strategy-search-space in half in order to find an optimal (or sufficiently-near-optimal) strategy. Some of that optimization can be done at “training time” by selecting a well-tuned system; some of it can be done at “runtime” by the selected system itself. However, any choices made at training time have to work for the whole range of possible environments; choices made at runtime can condition on whatever data has been observed for this particular environment-instance. So, if optimal choices vary a lot in a way which can be predicted from data available at runtime, then it makes sense to defer the optimization to runtime. Thus, agency: the system takes in data “at runtime” and then performs some optimization to make its choices.
The Gooder Regulator Theorem [LW · GW] offers a similar view: there, an agent-like architecture is forced by the need to defer a decision until crucial data is available later on. However, the Gooder Regulator theorem only captures part of the “better generalization through search” argument from Risks From Learned Optimization; Gooder Regulator uses a somewhat-artificial information bottleneck rather than explicitly including a selection process (i.e. outer optimizer). Fully formalizing the argument seems to me like another very promising research direction.
Evolution of Modularity
Biological organisms are highly modular, at multiple different scales. This can be quantified and verified statistically, e.g. by mapping out protein networks and algorithmically partitioning them into parts, then comparing the connectivity of the parts. It can also be seen more qualitatively in everyday biological work: proteins have subunits which retain their function when fused to other proteins, receptor circuits can be swapped out to make bacteria follow different chemical gradients, manipulating specific genes can turn a fly’s antennae into legs, organs perform specific functions, etc, etc.

How and why does natural selection produce modular systems? Simulations have found that modular variation in the goals (i.e. environment) results in the evolution of modular systems [LW · GW]. In other words, modularity comes from robustness of the optimum to variation in the environment. (Assuming modularity of the environment, which would follow from the Natural Abstraction Hypothesis [LW · GW].)
This seems to me like a particularly promising theoretical research direction - we have empirical results, but (as far as I know) no general selection theorems for the phenomenon. If we can get theorems about modularity of selected systems, then that would open the door to theorems about agent-like internal structure, as well as internal structure more generally.
Modularity of Broad Peaks
I don’t have a good reference on this one already written up, but here’s a few related hand-wavy arguments that broad optima should involve some sort of modularity.
If a system is “modular”, that means it has subsystems which have low-dimensional interfaces with the other subsystems. Now imagine that our selection process is optimizing the system via some very-high-dimensional parameters (e.g. a genome), and many of those parameters only influence a single subsystem (e.g. many genes only influence one module of an organism). If the dimension of the parameters of a subsystem is higher than the dimension of its interface with the other subsystems, then there should be many parameter changes which only affect the internals of the subsystem but keep high-level functionality intact. Thus, a broad optimum: there are many ways of changing the parameters without a large performance loss.
More questionable argument: if a system is modular, and most optimization parameters only affect one module, then most single-parameter changes (e.g. mutations in natural selection) will only affect one module. The rest of the system will still work fine, so as long as the high-level structure is robust to loss of one module, overall performance won’t be very much worse. On the other hand, if every parameter affects everything, then we can’t have this sort of architectural robustness.
Here’s one way that questionable argument turns out to be basically correct. (Warning: linear algebra and calculus incoming.) In smooth optimization problems (e.g. numerical optimization, like neural net training), we typically quantify the width of a peak via the determinant of the second derivative matrix of the objective with respect to the parameters - i.e. . In two dimensions, for instance, we get
Key thing to notice: this is strictly decreasing with respect to the magnitude of the “second-order interaction term” . All else equal, the peak is broadest when that interaction term is small. This turns out to generalize to higher dimensions: when the interaction terms are small, the peak is broad. With a bit more linear algebra, we can also extend this to hierarchical structure - roughly speaking, a peak will be relatively broad when the (sometimes implicit) interaction terms are relatively small between modules. This isn’t a particularly accessible/intuitive result, but the overall takeaway is similar to the other two arguments: modularity yields broad peaks.
Like the “evolution of modularity” idea, this offers a potential path to theorems on the internal structure of evolved systems, and (hopefully) the internal architecture of evolved agents.
11 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2021-10-03T10:24:25.978Z · LW(p) · GW(p)
Biologically, I think the evolution of body-plan modularity might be backwards from your general argument for it - the biological goal seems to be to make big (but not automatically bad) changes from small mutations (e.g. entire extra body segments), not to "hide" DOF inside modules to allow for smoother changes per parameter.
In fact, this strikes me as resembling abstraction, so this might be right in your wheelhouse :P Biological modularity seems to specifically select for those modules with simple interfaces that can be cut-and-pasted with the maximal chance of success.
My knowledge of the precambrian is bad, so I suspect that biologists have written much cleverer things about this already.
(EDIT: Actually, you could think of this as a reverse sort of robustness. Rather than asking for a genome where small changes don't impact your fitness much, the HOX genes seem to be more about being able to respond to new environments [or non-equilibrium races for adaptation] with small changes.
If we have environment E, fitness F, and genome G, then (very loosely) this looks like low dG/dE, not low d^2F/dG^2. )
comment by Lucius Bushnaq (Lblack) · 2021-12-25T19:20:42.882Z · LW(p) · GW(p)
The measure for peak broadness used near the end confuses me in many ways. It seems to imply that a large Hessian determinant means a broad peak. But wouldn't you expect the opposite, if anything? E.g. in one dimension, this would seem to imply that a larger second derivative would mean a broader peak. That just seems exactly false.
It seems like there's either something missing in this post, or in my head.
Replies from: johnswentworth↑ comment by johnswentworth · 2021-12-28T01:07:53.961Z · LW(p) · GW(p)
... it is embarrassingly plausible that I made a sign error and that whole argument is exactly wrong.
The picture in my head is "broad basin => circular-ish peak => large determinant" (since long, narrow peaks have low volume and low determinant). But maybe the diagonals were exactly the wrong things to keep fixed in order to make that argument work.
Replies from: tailcalled, Lblack↑ comment by tailcalled · 2022-01-01T09:37:53.167Z · LW(p) · GW(p)
I have a possible fix to the argument:
If you want to quantify the shape of a peak, then the inverse of the Hessian seems more intuitive than the Hessian itself. E.g. for the PDF of a normal distribution, the inverse of the Hessian corresponds to the covariance matrix. But for the inverse Hessian, large determinant does mean broad basin, unlike for the standard Hessian. And the inverse Hessian has basically the same off-diagonal elements as the Hessian does.
↑ comment by Lucius Bushnaq (Lblack) · 2021-12-28T21:21:43.401Z · LW(p) · GW(p)
Yes, I really don't see how this would work right now. If I try doing Taylor series, which is what I'd start with for something like this, I very much get the opposite result.
I'm actually (hopefully) joining ai safety camp to work on your topics next month, so maybe we can talk about this more then?
Replies from: johnswentworth↑ comment by johnswentworth · 2021-12-28T22:50:31.483Z · LW(p) · GW(p)
Yeah definitely.
comment by Edouard Harris · 2021-12-13T20:01:57.573Z · LW(p) · GW(p)
I’m surprised by just how much of a blindspot goal-inputs seem to be for today’s economists, AI researchers, etc. The coherence theorems usually cited to justify expected utility maximization models imply a quite narrow range of inputs to those utility functions: utilities are only over the outcomes on which agents can bet. Yet practitioners use utility functions over entire (unobservable) world states, world state trajectories, MDP states, etc, often without any way for the agent to bet on all of the outcomes.
It's true that most of the agents we build can't directly bet on all the outcomes in their respective world-models. But these agents would still be modelled by the coherence theorems (+ VNM) as betting on lotteries over such outcomes. This seems like a fine way to justify EU maximization when you're unable to bet on every "microstate" of the world — so in what sense did you mean that this was a blind spot?
EDIT: Unless you were alluding to the fact that real-world agents' utility functions are often defined over "wrong" ontologies, such that you couldn't actually construct a lottery over real-world microstates that's an exact fit for the bet the agent wants to make. Is that what you meant?
(FWIW, I agree with your overall point in this section. I'm just trying to better understand your meaning here.)
Replies from: johnswentworth↑ comment by johnswentworth · 2021-12-15T23:46:31.180Z · LW(p) · GW(p)
The problem with VNM-style lotteries is that the probabilities involved have to come from somewhere besides the coherence theorems themselves. We need to have some other, external reason to think it's useful to model the environment using these probabilities. That also means that the "probabilities" associated with the lottery are not necessarily the agent's probabilities, at least not in the sense that the implied probabilities derived from coherence theorems are the agent's.
Replies from: Edouard Harris↑ comment by Edouard Harris · 2021-12-17T16:14:23.266Z · LW(p) · GW(p)
Okay, then to make sure I've understood correctly: what you were saying in the quoted text is that you'll often see an economist, etc., use coherence theorems informally to justify a particular utility maximization model for some system, with particular priors and conditionals. (As opposed to using coherence theorems to justify the idea of EU models generally, which is what I'd thought you meant.) And this is a problem because the particular priors and conditionals they pick can't be justified solely by the coherence theorem(s) they cite.
The problem with VNM-style lotteries is that the probabilities involved have to come from somewhere besides the coherence theorems themselves. We need to have some other, external reason to think it's useful to model the environment using these probabilities.
To try to give an example of this: suppose I wanted to use coherence / consistency conditions alone to assign priors over the outcomes of a VNM lottery. Maybe the closest I could come to doing this would be to use maxent + transformation groups to assign an ignorance prior over those outcomes; and to do that, I'd need to additionally know the symmetries that are implied by my ignorance of those outcomes. But those symmetries are specific to the structure of my problem and are not contained in the coherence theorems themselves. So this information about symmetries would be what you would refer to as an "external reason to think it's useful to model the environment using these probabilities".
Is this a correct interpretation?
Replies from: johnswentworth↑ comment by johnswentworth · 2021-12-17T17:13:36.049Z · LW(p) · GW(p)
... what you were saying in the quoted text is that you'll often see an economist, etc., use coherence theorems informally to justify a particular utility maximization model for some system, with particular priors and conditionals. (As opposed to using coherence theorems to justify the idea of EU models generally, which is what I'd thought you meant.)
Correct.
This is a problem not because I want the choices fully justified, but rather because with many real world systems it's not clear exactly how I should set up my agent model. For instance, what's the world model and utility function of an e-coli? Some choices would make the model tautological/trivial; I want my claim that e.g. an e-coli approximates a Bayesian expected utility maximizer to have nontrivial and correct implications. I want to know the sense-in-which an e-coli approximates a Bayesian expected utility maximizer, and a rock doesn't. The coherence theorems tell us how to do that. They provide nontrivial sufficient conditions (like e.g. pareto optimality) which imply (and are implied by) particular utilities and world models.
To try to give an example of this: suppose I wanted to use coherence / consistency conditions alone to assign priors over the outcomes of a VNM lottery. ...
Is this a correct interpretation?
Your example is correct, though it is not the usual way of obtaining probabilities from coherence conditions. (Well, ok, in actual practice it kinda is the usual way, because existing coherence theorems are pretty weak. But it's not the usual way used by people who talk about coherence theorems a lot.) A more typical example: I can look at a chain of options on a stock, and use the prices of those options to back out market-implied probabilities for each possible stock price at expiry. Many coherence theorems do basically the same thing, but "prices" are derived from the trade-offs an agent accepts, rather than from a market.
Replies from: Edouard Harris↑ comment by Edouard Harris · 2021-12-20T14:09:45.439Z · LW(p) · GW(p)
A more typical example: I can look at a chain of options on a stock, and use the prices of those options to back out market-implied probabilities for each possible stock price at expiry.
Gotcha, this is a great example. And the fundamental reasons why this works are 1) the immediate incentive that you can earn higher returns by pricing the option more correctly; combined with 2) the fact that the agents who are assigning these prices have (on a dollar-weighted-average basis) gone through multiple rounds of selection for higher returns.
(I wonder to what extent any selection mechanism ultimately yields agents with general reasoning capabilities, given tight enough competition between individuals in the selected population? Even if the environment doesn't start out especially complicated, if the individuals are embedded in it and are interacting with one another, after a few rounds of selection most of the complexity an individual perceives is going to be due to its competitors. Not everything is like this — e.g., training a neural net is a form of selection without competition — but it certainly seems to describe many of the more interesting bits of the world.)
Thanks for the clarifications here btw — this has really piqued my interest in selection theorems as a research angle.