Computational Model: Causal Diagrams with Symmetry
post by johnswentworth · 2019-08-22T17:54:11.274Z · LW · GW · 29 commentsContents
Why would we want to do this? Learning None 29 comments
Consider the following program:
f(n):
if n == 0:
return 1
return n * f(n-1)
Let’s think about the process by which this function is evaluated. We want to sketch out a causal DAG [LW · GW] showing all of the intermediate calculations and the connections between them (feel free to pause reading and try this yourself).
Here’s what the causal DAG looks like:
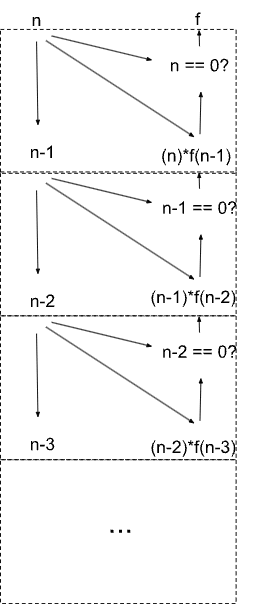
Each dotted box corresponds to one call to the function f. The recursive call in f becomes a symmetry in the causal diagram: the DAG consists of an infinite sequence of copies of the same subcircuit.
More generally, we can represent any Turing-computable function this way. Just take some pseudocode for the function, and expand out the full causal DAG of the calculation. In general, the diagram will either be finite or have symmetric components - the symmetry is what allows us to use a finite representation even though the graph itself is infinite.
Why would we want to do this?
For our purposes, the central idea of embedded agency is to take these black-box systems which we call “agents”, and break open the black boxes to see what’s going on inside.
Causal DAGs with symmetry are how we do this for Turing-computable functions in general. They show the actual cause-and-effect process which computes the result; conceptually they represent the computation rather than a black-box function.
In particular, a causal DAG + symmetry representation gives us all the natural machinery of causality - most notably counterfactuals. We can ask questions like “what would happen if I reached in and flipped a bit at this point in the computation?” or “what value would f(5) return if f(3) were 11?”. We can pose these questions in a well-defined, unambiguous way without worrying about logical counterfactuals [LW · GW], and without adding any additional machinery. This becomes particularly important for embedded optimization: if an “agent” (e.g. an organism) wants to plan ahead to achieve an objective (e.g. find food), it needs to ask counterfactual questions like “how much food would I find if I kept going straight?”.
The other main reason we would want to represent functions as causal DAGs with symmetry is because our universe appears to be one giant causal DAG [LW · GW] with symmetry.
Because our universe is causal, any computation performed in our universe must eventually bottom out in a causal DAG. We can write our programs in any language we please, but eventually they will be compiled down to machine code and run by physical transistors made of atoms which are themselves governed by a causal DAG. In most cases, we can represent the causal computational process at a more abstract level - e.g. in our example program, even though we didn’t talk about registers or transistors or electric fields, the causal diagram we sketched out would still accurately represent the computation performed even at the lower levels.
This raises the issue of abstraction - the core problem of embedded agency. My own main use-case for the causal diagram + symmetry model of computation is formulating models of abstraction: how can one causal diagram (possibly with symmetry) represent another in a way which makes counterfactual queries on the map correspond to some kind of counterfactual on the territory? Can that work when the “map” is a subDAG of the territory DAG? It feels like causal diagrams + symmetry are the minimal computational model needed to get agency-relevant answers to this sort of question.
Learning
The traditional ultimate learning algorithm is Solomonoff Induction: take some black-box system which spews out data, and look for short programs which reproduce that data. But the phrase “black-box” suggests that perhaps we could do better by looking inside that box.
To make this a little bit more concrete: imagine I have some python program running on a server which responds to http requests. Solomonoff Induction would look at the data returned by requests to the program, and learn to predict the program’s behavior. But that sort of black-box interaction is not the only option. The program is running on a physical server somewhere - so, in principle, we could go grab a screwdriver and a tiny oscilloscope and directly observe the computation performed by the physical machine. Even without measuring every voltage on every wire, we may at least get enough data to narrow down the space of candidate programs in a way which Solomonoff Induction could not do. Ideally, we’d gain enough information to avoid needing to search over all possible programs.
Compared to Solomonoff Induction, this process looks a lot more like how scientists actually study the real world in practice: there’s lots of taking stuff apart and poking at it to see what makes it tick.
In general, though, how to learn causal DAGs with symmetry is still an open question. We’d like something like Solomonoff Induction, but which can account for partial information about the internal structure of the causal DAG, rather than just overall input-output behavior. (In principle, we could shoehorn this whole thing into traditional Solomonoff Induction by treating information about the internal DAG structure as normal old data, but that doesn’t give us a good way to extract the learned DAG structure.)
We already have algorithms for learning causal structure in general. Pearl’s Causality sketches out some such algorithms in chapter 2, although they’re only practical for either very small systems or very large amounts of data. Bayesian structure learning can handle larger systems with less data, though sometimes at the cost of a very large amount of compute - i.e. estimating high-dimensional integrals.
However, in general, these approaches don’t directly account for symmetry of the learned DAGs. Ideally, we would use a prior which weights causal DAGs according to the size of their representation - i.e. infinite DAGs would still have nonzero prior probability if they have some symmetry allowing for finite representation, and in general DAGs with multiple copies of the same sub-DAG would have higher probability. This isn’t quite the same as weighting by minimum description length in the Solomonoff sense, since we care specifically about symmetries which correspond to function calls - i.e. isomorphic subDAGs. We don’t care about graphs which can be generated by a short program but don’t have these sorts of symmetries. So that leaves the question: if our prior probability for a causal DAG is given by a notion of minimum description length which only allows compression by specifying re-used subcircuits, what properties will the resulting learning algorithm possess? Is it computable? What kinds of data are needed to make it tractable?
29 comments
Comments sorted by top scores.
comment by Vanessa Kosoy (vanessa-kosoy) · 2019-08-24T16:40:02.424Z · LW(p) · GW(p)
A few comments:
-
Because of quantum physics, the universe is actually not described by a causal DAG very well (if we require microscopic precision). But I agree that in practice there are useful approximate descriptions that do look like a causal DAG.
-
One direction towards studying the learning of symmetric causal DAGs (of a sort) is my ideas about cellular decision processes and the more general "graph decision processes", see this [AF(p) · GW(p)] comment.
-
As a side note, I'm not convinced that "breaking open black boxes" to solve "embedded agency" is a useful way of thinking. IMO the problems associated with "embedded agency" should be solved using a combination of incomplete models [AF · GW] and correctly dealing with traps.
↑ comment by johnswentworth · 2019-08-24T21:04:44.242Z · LW(p) · GW(p)
The quantum fields themselves follow causality just fine. Things only become weird if we introduce wave-function collapse, which isn't strictly necessary.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2019-08-24T21:16:24.780Z · LW(p) · GW(p)
Hmm, no, not really. The quantum fields follow "causality" in some quantum sense (roughly speaking, operators in spacelike separations commute, and any local operator can be expressed in terms of operators localized near the intersection of its past light-cone with any spacelike hypersurface), which is different from the sense used in causal DAGsa (in fact you can define "quantum causal DAGs" which is a different mathematical object). Violation of Bell's inequality precisely means that you can't describe the system by a causal DAG. If you want to do the MWI, then the wavefunction doesn't even decompose into data that can be localized.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-08-24T22:27:54.595Z · LW(p) · GW(p)
Violation of Bell's inequality precisely means that you can't describe the system by a causal DAG
No, violation of Bell's inequality means you can't describe the system by causal interactions among particles and measurements. If we stop thinking about particles and "measurements" altogether, and just talk about fields, that's not an issue.
As you say, under MWI, the wavefunction doesn't even decompose into data that can be localized. So, in order to represent the system using classical causal diagrams, the "system state" has to contain the whole wavefunction. As long as we can write down an equation for the evolution of the wavefunction over time, we have a classical causal model for the system.
Quantum causal models are certainly a much cleaner representation, in this case, but classical causal models can still work - we just have to define the "DAG vertices" appropriately.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2019-08-24T22:47:08.438Z · LW(p) · GW(p)
It doesn't really have much to do with particles vs. fields. We talk about measurements because measurements are the thing we actually observe. It seems strange to say you can model the world as a causal network if the causal network doesn't include your actual observations. If you want to choose a particular frame of reference and write down the wavefunction time evolution in that frame (while ignoring space) then you can say it's a causal network (which is just a linear chain, and deterministic at that) but IMO that's not very informative. It also loses the property of having things made of parts, which AFAIU was one of your objectives here.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-08-25T00:22:14.770Z · LW(p) · GW(p)
The wavefunction does have plenty of internal structure, that structure just doesn't line up neatly with space. It won't just be a linear chain, and it will be made of "parts", but those parts won't necessarily line up neatly with macroscopic observations/objects.
And that's fine - figuring out how to do ontology mapping between the low-level "parts" and the high-level "parts" is a central piece of the problem. Not being able to directly observe variables in the low-level causal diagram is part of that. If we want e.g. a theory of abstraction, then these issues are perfect use-cases.
Replies from: andrew-mcknight↑ comment by Andrew McKnight (andrew-mcknight) · 2022-08-07T20:44:09.956Z · LW(p) · GW(p)
I know this was 3 years ago, but was this disagreement resolved, maybe offline?
Replies from: johnswentworth↑ comment by johnswentworth · 2022-08-07T20:46:34.072Z · LW(p) · GW(p)
I don't think we've talked about it since then.
comment by tom4everitt · 2019-08-23T12:37:54.804Z · LW(p) · GW(p)
Thanks for a nice post about causal diagrams!
Because our universe is causal, any computation performed in our universe must eventually bottom out in a causal DAG.
Totally agree. This is a big part of the reason why I'm excited about these kinds of diagrams.
This raises the issue of abstraction - the core problem of embedded agency. ... how can one causal diagram (possibly with symmetry) represent another in a way which makes counterfactual queries on the map correspond to some kind of counterfactual on the territory?
Great question, I really think someone should look more carefully into this. A few potentially related papers:
https://arxiv.org/abs/1105.0158
https://arxiv.org/abs/1812.03789
In general, though, how to learn causal DAGs with symmetry is still an open question. We’d like something like Solomonoff Induction, but which can account for partial information about the internal structure of the causal DAG, rather than just overall input-output behavior.
Again, agreed. It would be great if we could find a way to make progress on this question.
comment by FactorialCode · 2019-08-22T21:23:49.679Z · LW(p) · GW(p)
This isn’t quite the same as weighting by minimum description length in the Solomonoff sense, since we care specifically about symmetries which correspond to function calls - i.e. isomorphic subDAGs. We don’t care about graphs which can be generated by a short program but don’t have these sorts of symmetries.
Can you elaborate on this? What would be an example of a graph that can be generated by a short program, but that does not have these sorts of symmetries?
My intuition is that the class of processes your describing is Turing complete, and therefore can simulate any Turing machine, and is thus just another instance of Solomonoff induction with a different MDL constant.
Edit: Rule 110 would be an example.
Replies from: Scott Garrabrant, johnswentworth↑ comment by Scott Garrabrant · 2019-08-22T21:42:24.761Z · LW(p) · GW(p)
Were you summoned by this post accidentally using your true name?
↑ comment by johnswentworth · 2019-08-22T21:48:57.072Z · LW(p) · GW(p)
I'll give an answer via analogy: the digit sequence 123123123123123... is symmetric: the sequence directly contains a copy of itself. The sequence 12345678910111213141516... is not symmetric: it will not repeat and does not contain a copy of itself, although there is a pattern and it could be generated programmatically.
Similarly with DAG symmetries. If we're producing these DAGs by expanding out programs, then the only infinite patterns we'll see are symmetries - subDAGs which repeat, corresponding to function blocks. We don't need to worry about DAGs with strange patterns which could be generated programmatically but can't just be built by repeating subDAGs.
Replies from: Pongo↑ comment by Pongo · 2020-04-23T01:21:35.159Z · LW(p) · GW(p)
I'm not sure I get your analogy, but my intuition is that FactorialCode is right regarding Turing completeness / just a different minimum description length constant. Like, I think I can turn a collection 'programatically generated' but not self-similar sub-DAG into a structure which has internalised the generative power. For example, perhaps it now consumes and switches on some extra state.
If I can do that, I now have a self-similar building block that counts for our symmetries. There's some overhead in the translation, hence the different MDL constant.
comment by Hazard · 2019-12-13T20:15:24.089Z · LW(p) · GW(p)
Causal DAGs with symmetry are how we do this for Turing-computable functions in general. They show the actual cause-and-effect process which computes the result; conceptually they represent the computation rather than a black-box function.
This was the main interesting bit for me.
comment by Steven Byrnes (steve2152) · 2019-12-13T01:58:29.932Z · LW(p) · GW(p)
The mention of circuits in your later article reminded me of a couple arguments I had on wikipedia a few years ago (2012, 2015). I was arguing basically that cause-effect (or at least the kind of cause-effect relationship that we care about and use in everyday reasoning) is part of the map, not territory.
Here's an example I came up with:
Consider a 1kΩ resistor, in two circuits. The first circuit is the resistor attached to a 1V power supply. Here an engineer would say: "The supply creates a 1V drop across the resistor; and that voltage drop causes a 1mA current to flow through the resistor." The second circuit is the resistor attached to a 1mA current source. Here an engineer would say: "The current source pushes a 1mA current through the resistor; and that current causes a 1V drop across the resistor." Well, it's the same resistor ... does a voltage across a resistor cause a current, or does a current through a resistor cause a voltage, or both, or neither? Again, my conclusion was that people think about causality in a way that is not rooted in physics, and indeed if you forced someone to exclusively use physics-based causal models, you would be handicapping them. I haven't thought about it much or delved into the literature or anything, but this still seems correct to me. How do you see things?
Replies from: johnswentworth, Richard_Kennaway↑ comment by johnswentworth · 2019-12-13T04:19:12.894Z · LW(p) · GW(p)
Nice example.
In this example, both scenarios yield exactly the same actual behavior (assuming we've set the parameters appropriately), but the counterfactual behavior differs - and that's exactly what defines a causal model. In this case, the counterfactuals are "what if we inserted a different resistor?" and "what if we adjusted the knob on the supply?". If it's a voltage supply, then the voltage -> current model correctly answers the counterfactuals. If it's a current supply, then the current -> voltage model correctly answers the counterfactuals.
Note that all the counterfactual queries in this example are physically grounded - they are properties of the territory, not the map. We can actually go swap the resistor in a circuit and see what happens. It is a mistake here to think of "the territory" as just the resistor by itself; the supply is a critical determinant of the counterfactual behavior, so it needs to be included in order to talk about causality.
Of course, there's still the question of how we decide which counterfactuals to support. That is mainly a property of the map, so far as I can tell, but there's a big catch: some sets of counterfactual queries will require keeping around far less information than others. A given territory supports "natural" classes of counterfactual queries, which require relatively little information to yield accurate predictions to the whole query class. In this context, the lumped circuit abstraction is one such example: we keep around just high-level summaries of the electrical properties of each component, and we can answer a whole class of queries about voltage or current measurements. Conversely, if we had a few queries about the readings from a voltage probe, a few queries about the mass of various circuit components, and a few queries about the number of protons in a wire mod 3... these all require completely different information to answer. It's not a natural class of queries.
So natural classes of queries imply natural abstract models, possibly including natural causal models. There will still be some choice in which queries we care about, and what information is actually available will play a role in that choice (i.e. even if we cared about number of protons mod 3, we have no way to get that information).
I have not yet formulated all this enough to be highly confident, but I think in this case the voltage -> current model is a natural abstraction when we have a voltage supply, and vice versa for a current supply. The "correct" model, in each case, can correctly predict behavior of the resistor and knob counterfactuals (among others), without any additional information. The "incorrect" model cannot. (I could be missing some other class of counterfactuals which are easily answered by the "incorrect" models without additional information, which is the main reason I'm not entirely sure of the conclusion.)
Thanks for bringing up this question and example, it's been useful to talk through and I'll likely re-use it later.
↑ comment by Richard_Kennaway · 2019-12-18T08:39:59.988Z · LW(p) · GW(p)
I came up with the same example in a paper on causal analysis of control systems. A proper causal analysis would have to open the black box of the voltage or current source and reveal the circular patterns of causation within. Set up as a voltage source, it is continuously sensing its own output voltage and maintaining it close to the reference value set on the control panel. Set up as a current source, it is doing corresponding things with the sensed and reference currents.
comment by Steven Byrnes (steve2152) · 2019-12-08T02:20:41.217Z · LW(p) · GW(p)
For what it's worth, my current thinking on brain algorithms is that the brain has a couple low-level primitives, like temporal sequences and spatial relations, and these primitives are able to represent (1) cause-effect, (2) hierarchies, (3) composition, (4) analogies, (5) recursion, and on and on, by combining these primitives in different ways and with different contextual "metadata". This is my opinion, it's controversial in the field of cognitive science and I could be wrong. But anyway, that makes me instinctively skeptical of world-modeling theories where everything revolves around cause-effect, and equally skeptical of world-modeling theories where everything revolves around hierarchies, etc. etc. I would be much more excited about world-modeling theories where all those 5 different types of relationships (and others I omitted, and shades of gray in between them) are all equally representable.
(This is just an instinctive response / hot-take. I don't have a particularly strong opinion that the research direction you're describing here is unpromising.)
Replies from: johnswentworth↑ comment by johnswentworth · 2019-12-08T19:20:31.980Z · LW(p) · GW(p)
I generally agree with this thinking, although I'll highlight that the brain and a hypothetical AI might not use the same primitives - they're on very different hardware, after all. Certainly the general strategy of "start with a few primitives, and see if they can represent all these other things" is the sort of strategy I'm after. I currently consider causal DAGs with symmetry the most promising primitive. It directly handles causality and recursion, and alongside a suitable theory of abstraction [? · GW], I expect it will allow us to represent things like spatial/temporal relations, hierarchies, analogies, composition, and many others, all in a unified framework.
Replies from: steve2152, steve2152, steve2152↑ comment by Steven Byrnes (steve2152) · 2019-12-09T15:46:37.395Z · LW(p) · GW(p)
On further reflection, the primitive of "temporal sequences" (more specifically high-order Markov chains) isn't that different from cause-effect. High-order Markov chains are like "if A happens and then B and then C, probably D will happen next". So if A and B and C are a person moving to kick a ball, and D is the ball flying up in the air...well I guess that's at least partway to representing cause-effect...
(High-order Markov chains are more general than cause-effect because they can also represent non-causal things like the lyrics of a song. But in the opposite direction, I'm having trouble thinking of a cause-effect relation that can not be represented as a high-order Markov chain, at least at some appropriate level of abstraction, and perhaps with some context-dependence of the transitions.)
I have pretty high confidence that high-order Markov chains are one of the low-level primitives of the brain, based on both plausible neural mechanisms and common sense (e.g. it's hard to say the letters of the alphabet in reverse order). I'm less confident about what exactly are the elements of those Markov chains, and what are the other low-level primitives, and what's everything else that's going on. :-)
Just thinking out loud :-)
↑ comment by Steven Byrnes (steve2152) · 2019-12-09T16:09:43.046Z · LW(p) · GW(p)
I'll highlight that the brain and a hypothetical AI might not use the same primitives - they're on very different hardware, after all
Sure. There are a lot of levels at which algorithms can differ.
- quicksort.c compiled by clang versus quicksort.c compiled by gcc
- quicksort optimized to run on a CPU vs quicksort optimized to run on an FPGA
- quicksort running on a CPU vs mergesort running on an FPGA
- quicksort vs a different algorithm that doesn't involve sorting the list at all
There are people working on neuromorphic hardware, but I don't put much stock in anything coming of it in terms of AGI (the main thrust of that field is low-power sensors). So I generally think it's very improbable that we would copy brain algorithms at the level of firing patterns and synapses (like the first bullet-point or less). I put much more weight on the possibility of "copying" brain algorithms at like vaguely the second or third bullet-point level. But, of course, it's also entirely possible for an AGI to be radically different from brain algorithms in every way. :-)
Replies from: johnswentworth↑ comment by johnswentworth · 2019-12-09T17:50:18.558Z · LW(p) · GW(p)
My guess here is that there are some instrumentally convergent abstractions/algorithms which both a brain and a hypothetical AGI needs to use. But a brain will have implemented some of those as hacks on top of methods which evolved earlier, whereas an AI could implement those methods directly. So for instance, one could imagine the brain implementing simple causal reasoning as a hack on top of pre-existing temporal sequence capabilities. When designing an AI, it would probably make more sense to use causal DAGs as the fundamental, and then implement temporal sequences as abstract stick-dags which don't support many (if any) counterfactuals.
Possibly better example: tree search and logic. Humans seem to handle these mostly as hacks on top of pattern-matchers and trigger-action pairs, but for an AI it makes more sense to implement tree search as a fundamental.
↑ comment by Steven Byrnes (steve2152) · 2019-12-09T11:23:43.172Z · LW(p) · GW(p)
Sounds exciting, and I wish you luck and look forward to reading whatever you come up with! :-)
comment by Hjalmar_Wijk · 2019-08-23T17:23:03.757Z · LW(p) · GW(p)
I really like this model of computation and how naturally it deals with counterfactuals, surprised it isn't talked about more often.
This raises the issue of abstraction - the core problem of embedded agency.
I'd like to understand this claim better - are you saying that the core problem of embedded agency is relating high-level agent models (represented as causal diagrams) to low-level physics models (also represented as causal diagrams)?
Replies from: johnswentworth↑ comment by johnswentworth · 2019-08-23T17:38:30.408Z · LW(p) · GW(p)
I'm saying that the core problem of embedded agency is relating a high-level, abstract map to the low-level territory it represents. How can we characterize the map-territory relationship based on our knowledge of the map-generating process, and what properties does the map-generating process need to have in order to produce "accurate" & useful maps? How do queries on the map correspond to queries on the territory? Exactly what information is kept and what information is thrown out when the map is smaller than the territory? Good answers to these question would likely solve the usual reflection/diagonalization problems, and also explain when and why world-models are needed for effective goal-seeking behavior.
When I think about how to formalize these sort of questions in a way useful for embedded agency, the minimum requirements are something like:
- need to represent physics of the underlying world
- need to represent the cause-and-effect process which generates a map from a territory
- need to run counterfactual queries on the map (e.g. in order to do planning)
- need to represent sufficiently general computations to make agenty things possible
... and causal diagrams with symmetry seem like the natural class to capture all that.
comment by Eigil Rischel (eigil-rischel) · 2019-10-08T08:19:00.022Z · LW(p) · GW(p)
Should there be an arrow going from n*f(n-1) to f (around n==0?) ? The output of the system also depends on n*f(n-1), not just on whether or not n is zero.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-10-08T14:59:47.166Z · LW(p) · GW(p)
The "n==0?" node is intended to be a ternary operator; its output is n*f(n-1) in the case where n is not 0 (and when n is 0, its output is hardcoded to 1).
comment by Pattern · 2019-08-23T04:49:34.094Z · LW(p) · GW(p)
the DAG consists of an infinite sequence of copies of the same subcircuit.
If it's infinite then the program doesn't terminate. (In theory this may be the case if n is a non-negative integer.)
Ideally, we’d gain enough information to avoid needing to search over all possible programs.
Over all shorter possible programs.
(In principle, we could shoehorn this whole thing into traditional Solomonoff Induction by treating information about the internal DAG structure as normal old data, but that doesn’t give us a good way to extract the learned DAG structure.)
Sounds like SI is being treated as a black box.
We don’t care about graphs which can be generated by a short program but don’t have these sorts of symmetries.
Why do we like programs which use recursion instead of iteration?
Replies from: johnswentworth↑ comment by johnswentworth · 2019-08-23T16:33:10.454Z · LW(p) · GW(p)
The non-termination point is a bit subtle. If you look at the example in the OP, the causal diagram itself is infinite, but as long as we pass in a positive integer the output value won't actually depend on the whole circuit. One of the conditional nodes will recognize the base case, and ignore whatever's going on in the rest of the circuit below it. So the program can terminate even if the DAG is infinite. (Equivalent conceptualization: imagine running a lazy evaluator on the infinite DAG.)
That said, DAGs with symmetry certainly can represent computations which do not halt. This is a feature, not a bug: there are in fact computations which do not halt, and we can observe their physical behavior mid-computation. If we want to think about e.g. what my processor is doing when running an infinite loop, then we need a computational model which can represent that sort of thing, rather than just talking about input/output behavior.