Causal Diagrams and Causal Models
post by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-10-12T21:49:16.747Z · LW · GW · Legacy · 297 commentsContents
vs. vs. p(E&R)=p(E)p(R) p(E&R) = p(E)p(R|E) p(E&R) = p(R)p(E|R) vs. vs. None 297 comments
Suppose a general-population survey shows that people who exercise less, weigh more. You don't have any known direction of time in the data - you don't know which came first, the increased weight or the diminished exercise. And you didn't randomly assign half the population to exercise less; you just surveyed an existing population.
The statisticians who discovered causality were trying to find a way to distinguish, within survey data, the direction of cause and effect - whether, as common sense would have it, more obese people exercise less because they find physical activity less rewarding; or whether, as in the virtue theory of metabolism, lack of exercise actually causes weight gain due to divine punishment for the sin of sloth.
 |
vs. |
 |
The usual way to resolve this sort of question is by randomized intervention. If you randomly assign half your experimental subjects to exercise more, and afterward the increased-exercise group doesn't lose any weight compared to the control group [1], you could rule out causality from exercise to weight, and conclude that the correlation between weight and exercise is probably due to physical activity being less fun when you're overweight [3]. The question is whether you can get causal data without interventions.
For a long time, the conventional wisdom in philosophy was that this was impossible unless you knew the direction of time and knew which event had happened first. Among some philosophers of science, there was a belief that the "direction of causality" was a meaningless question, and that in the universe itself there were only correlations - that "cause and effect" was something unobservable and undefinable, that only unsophisticated non-statisticians believed in due to their lack of formal training:
"The law of causality, I believe, like much that passes muster among philosophers, is a relic of a bygone age, surviving, like the monarchy, only because it is erroneously supposed to do no harm." -- Bertrand Russell (he later changed his mind)
"Beyond such discarded fundamentals as 'matter' and 'force' lies still another fetish among the inscrutable arcana of modern science, namely, the category of cause and effect." -- Karl Pearson
The famous statistician Fisher, who was also a smoker, testified before Congress that the correlation between smoking and lung cancer couldn't prove that the former caused the latter. We have remnants of this type of reasoning in old-school "Correlation does not imply causation", without the now-standard appendix, "But it sure is a hint".
This skepticism was overturned by a surprisingly simple mathematical observation.
Let's say there are three variables in the survey data: Weight, how much the person exercises, and how much time they spend on the Internet.
For simplicity, we'll have these three variables be binary, yes-or-no observations: Y or N for whether the person has a BMI over 25, Y or N for whether they exercised at least twice in the last week, and Y or N for whether they've checked Reddit in the last 72 hours.
Now let's say our gathered data looks like this:
| Overweight | Exercise | Internet | # |
|---|---|---|---|
| Y | Y | Y | 1,119 |
| Y | Y | N | 16,104 |
| Y | N | Y | 11,121 |
| Y | N | N | 60,032 |
| N | Y | Y | 18,102 |
| N | Y | N | 132,111 |
| N | N | Y | 29,120 |
| N | N | N | 155,033 |
And lo, merely by eyeballing this data -
(which is totally made up, so don't go actually believing the conclusion I'm about to draw)
- we now realize that being overweight and spending time on the Internet both cause you to exercise less, presumably because exercise is less fun and you have more alternative things to do, but exercising has no causal influence on body weight or Internet use.
"What!" you cry. "How can you tell that just by inspecting those numbers? You can't say that exercise isn't correlated to body weight - if you just look at all the members of the population who exercise, they clearly have lower weights. 10% of exercisers are overweight, vs. 28% of non-exercisers. How could you rule out the obvious causal explanation for that correlation, just by looking at this data?"
There's a wee bit of math involved. It's simple math - the part we'll use doesn't involve solving equations or complicated proofs -but we do have to introduce a wee bit of novel math to explain how the heck we got there from here.
Let me start with a question that turned out - to the surprise of many investigators involved - to be highly related to the issue we've just addressed.
Suppose that earthquakes and burglars can both set off burglar alarms. If the burglar alarm in your house goes off, it might be because of an actual burglar, but it might also be because a minor earthquake rocked your house and triggered a few sensors. Early investigators in Artificial Intelligence, who were trying to represent all high-level events using primitive tokens in a first-order logic (for reasons of historical stupidity we won't go into) were stymied by the following apparent paradox:
-
If you tell me that my burglar alarm went off, I infer a burglar, which I will represent in my first-order-logical database using a theorem ⊢ ALARM → BURGLAR. (The symbol "⊢" is called "turnstile" and means "the logical system asserts that".)
-
If an earthquake occurs, it will set off burglar alarms. I shall represent this using the theorem ⊢ EARTHQUAKE → ALARM, or "earthquake implies alarm".
-
If you tell me that my alarm went off, and then further tell me that an earthquake occurred, it explains away my burglar alarm going off. I don't need to explain the alarm by a burglar, because the alarm has already been explained by the earthquake. I conclude there was no burglar. I shall represent this by adding a theorem which says ⊢ (EARTHQUAKE & ALARM) → NOT BURGLAR.
Which represents a logical contradiction, and for a while there were attempts to develop "non-monotonic logics" so that you could retract conclusions given additional data. This didn't work very well, since the underlying structure of reasoning was a terrible fit for the structure of classical logic, even when mutated.
Just changing certainties to quantitative probabilities can fix many problems with classical logic, and one might think that this case was likewise easily fixed.
Namely, just write a probability table of all possible combinations of earthquake or ¬earthquake, burglar or ¬burglar, and alarm or ¬alarm (where ¬ is the logical negation symbol), with the following entries:
| Burglar | Earthquake | Alarm | % |
|---|---|---|---|
| b | e | a | .000162 |
| b | e | ¬a | .0000085 |
| b | ¬e | a | .0151 |
| b | ¬e | ¬a | .00168 |
| ¬b | e | a | .0078 |
| ¬b | e | ¬a | .002 |
| ¬b | ¬e | a | .00097 |
| ¬b | ¬e | ¬a | .972 |
Using the operations of marginalization and conditionalization, we get the desired reasoning back out:
Let's start with the probability of a burglar given an alarm, p(burglar|alarm). By the law of conditional probability,
i.e. the relative fraction of cases where there's an alarm and a burglar, within the set of all cases where there's an alarm.
The table doesn't directly tell us p(alarm & burglar)/p(alarm), but by the law of marginal probability,
Similarly, to get the probability of an alarm going off, p(alarm), we add up all the different sets of events that involve an alarm going off - entries 1, 3, 5, and 7 in the table.
So the entire set of calculations looks like this:
-
If I hear a burglar alarm, I conclude there was probably (63%) a burglar.
-
If I learn about an earthquake, I conclude there was probably (80%) an alarm.
-
I hear about an alarm and then hear about an earthquake; I conclude there was probably (98%) no burglar.
Thus, a joint probability distribution is indeed capable of representing the reasoning-behaviors we want.
So is our problem solved? Our work done?
Not in real life or real Artificial Intelligence work. The problem is that this solution doesn't scale. Boy howdy, does it not scale! If you have a model containing forty binary variables - alert readers may notice that the observed physical universe contains at least forty things - and you try to write out the joint probability distribution over all combinations of those variables, it looks like this:
| .0000000000112 | YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY |
| .000000000000034 | YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYN |
| .00000000000991 | YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYNY |
| .00000000000532 | YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYNN |
| .000000000145 | YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYNYY |
| ... | ... |
(1,099,511,627,776 entries)
This isn't merely a storage problem. In terms of storage, a trillion entries is just a terabyte or three. The real problem is learning a table like that. You have to deduce 1,099,511,627,776 floating-point probabilities from observed data, and the only constraint on this giant table is that all the probabilities must sum to exactly 1.0, a problem with 1,099,511,627,775 degrees of freedom. (If you know the first 1,099,511,627,775 numbers, you can deduce the 1,099,511,627,776th number using the constraint that they all sum to exactly 1.0.) It's not the storage cost that kills you in a problem with forty variables, it's the difficulty of gathering enough observational data to constrain a trillion different parameters. And in a universe containing seventy things, things are even worse.

So instead, suppose we approached the earthquake-burglar problem by trying to specify probabilities in a format where... never mind, it's easier to just give an example before stating abstract rules.
First let's add, for purposes of further illustration, a new variable, "Recession", whether or not there's a depressed economy at the time. Now suppose that:
-
The probability of an earthquake is 0.01.
-
The probability of a recession at any given time is 0.33 (or 1/3).
-
The probability of a burglary given a recession is 0.04; or, given no recession, 0.01.
-
An earthquake is 0.8 likely to set off your burglar alarm; a burglar is 0.9 likely to set off your burglar alarm. And - we can't compute this model fully without this info - the combination of a burglar and an earthquake is 0.95 likely to set off the alarm; and in the absence of either burglars or earthquakes, your alarm has a 0.001 chance of going off anyway.
 |
|
|
||||||||||||||||||||
|
||||||||||||||||||||||
|
According to this model, if you want to know "The probability that an earthquake occurs" - just the probability of that one variable, without talking about any others - you can directly look up p(e) = .01. On the other hand, if you want to know the probability of a burglar striking, you have to first look up the probability of a recession (.33), and then p(b|r) and p(b|¬r), and sum up p(b|r)*p(r) + p(b|¬r)*p(¬r) to get a net probability of .01*.66 + .04*.33 = .02 = p(b), a 2% probability that a burglar is around at some random time.
If we want to compute the joint probability of four values for all four variables - for example, the probability that there is no earthquake and no recession and a burglar and the alarm goes off - this causal model computes this joint probability as the product:
In general, to go from a causal model to a probability distribution, we compute, for each setting of all the variables, the product
multiplying together the conditional probability of each variable given the values of its immediate parents. (If a node has no parents, the probability table for it has just an unconditional probability, like "the chance of an earthquake is .01".)
This is a causal model because it corresponds to a world in which each event is directly caused by only a small set of other events, its parent nodes in the graph. In this model, a recession can indirectly cause an alarm to go off - the recession increases the probability of a burglar, who in turn sets off an alarm - but the recession only acts on the alarm through the intermediate cause of the burglar. (Contrast to a model where recessions set off burglar alarms directly.)
 |
vs. |
 |
The first diagram implies that once we already know whether or not there's a burglar, we don't learn anything more about the probability of a burglar alarm, if we find out that there's a recession:
This is a fundamental illustration of the locality of causality - once I know there's a burglar, I know everything I need to know to calculate the probability that there's an alarm. Knowing the state of Burglar screens off anything that Recession could tell me about Alarm - even though, if I didn't know the value of the Burglar variable, Recessions would appear to be statistically correlated with Alarms. The present screens off the past from the future; in a causal system, if you know the exact, complete state of the present, the state of the past has no further physical relevance to computing the future. It's how, in a system containing many correlations (like the recession-alarm correlation), it's still possible to compute each variable just by looking at a small number of immediate neighbors.
Constraints like this are also how we can store a causal model - and much more importantly, learn a causal model - with many fewer parameters than the naked, raw, joint probability distribution.
Let's illustrate this using a simplified version of this graph, which only talks about earthquakes and recessions. We could consider three hypothetical causal diagrams over only these two variables:
 |
|
||||
|
|||||
p(E&R)=p(E)p(R) |
|||||
 |
|
|||||||
|
||||||||
p(E&R) = p(E)p(R|E) |
||||||||
 |
|
|||||||
|
||||||||
p(E&R) = p(R)p(E|R) |
||||||||
Let's consider the first hypothesis - that there's no causal arrows connecting earthquakes and recessions. If we build a causal model around this diagram, it has 2 real degrees of freedom - a degree of freedom for saying that the probability of an earthquake is, say, 29% (and hence that the probability of not-earthquake is necessarily 71%), and another degree of freedom for saying that the probability of a recession is 3% (and hence the probability of not-recession is constrained to be 97%).
On the other hand, the full joint probability distribution would have 3 degrees of freedom - a free choice of (earthquake&recession), a choice of p(earthquake&¬recession), a choice of p(¬earthquake&recession), and then a constrained p(¬earthquake&¬recession) which must be equal to 1 minus the sum of the other three, so that all four probabilities sum to 1.0.
By the pigeonhole principle (you can't fit 3 pigeons into 2 pigeonholes) there must be some joint probability distributions which cannot be represented in the first causal structure. This means the first causal structure is falsifiable; there's survey data we can get which would lead us to reject it as a hypothesis. In particular, the first causal model requires:
or equivalently
or equivalently
which is a conditional independence constraint - it says that learning about recessions doesn't tell us anything about the probability of an earthquake or vice versa. If we find that earthquakes and recessions are highly correlated in the observed data - if earthquakes and recessions go together, or earthquakes and the absence of recessions go together - it falsifies the first causal model.
For example, let's say that in your state, an earthquake is 0.1 probable per year and a recession is 0.2 probable. If we suppose that earthquakes don't cause recessions, earthquakes are not an effect of recessions, and that there aren't hidden aliens which produce both earthquakes and recessions, then we should find that years in which there are earthquakes and recessions happen around 0.02 of the time. If instead earthquakes and recessions happen 0.08 of the time, then the probability of a recession given an earthquake is 0.8 instead of 0.2, and we should much more strongly expect a recession any time we are told that an earthquake has occurred. Given enough samples, this falsifies the theory that these factors are unconnected; or rather, the more samples we have, the more we disbelieve that the two events are unconnected.
On the other hand, we can't tell apart the second two possibilities from survey data, because both causal models have 3 degrees of freedom, which is the size of the full joint probability distribution. (In general, fully connected causal graphs in which there's a line between every pair of nodes, have the same number of degrees of freedom as a raw joint distribution - and 2 nodes connected by 1 line are "fully connected".) We can't tell if earthquakes are 0.1 likely and cause recessions with 0.8 probability, or recessions are 0.2 likely and cause earthquakes with 0.4 probability (or if there are hidden aliens which on 6% of years show up and cause earthquakes and recessions with probability 1).
With larger universes, the difference between causal models and joint probability distributions becomes a lot more striking. If we're trying to reason about a million binary variables connected in a huge causal model, and each variable could have up to four direct 'parents' - four other variables that directly exert a causal effect on it - then the total number of free parameters would be at most... 16 million!
The number of free parameters in a raw joint probability distribution over a million binary variables would be 21,000,000. Minus one.
So causal models which are less than fully connected - in which most objects in the universe are not the direct cause or direct effect of everything else in the universe - are very strongly falsifiable; they only allow probability distributions (hence, observed frequencies) in an infinitesimally tiny range of all possible joint probability tables. Causal models very strongly constrain anticipation - disallow almost all possible patterns of observed frequencies - and gain mighty Bayesian advantages when these predictions come true.
To see this effect at work, let's consider the three variables Recession, Burglar, and Alarm.
| Alarm | Burglar | Recession | % |
|---|---|---|---|
| Y | Y | Y | .012 |
| N | Y | Y | .0013 |
| Y | N | Y | .00287 |
| N | N | Y | .317 |
| Y | Y | N | .003 |
| N | Y | N | .000333 |
| Y | N | N | .00591 |
| N | N | N | .654 |
All three variables seem correlated to each other when considered two at a time. For example, if we consider Recessions and Alarms, they should seem correlated because recessions cause burglars which cause alarms. If we learn there was an alarm, for example, we conclude it's more probable that there was a recession. So since all three variables are correlated, can we distinguish between, say, these three causal models?
|
 |
 |
Yes we can! Among these causal models, the prediction which only the first model makes, which is not shared by either of the other two, is that once we know whether a burglar is there, we learn nothing more about whether there was an alarm by finding out that there was a recession, since recessions only affect alarms through the intermediary of burglars:
But the third model, in which recessions directly cause alarms, which only then cause burglars, does not have this property. If I know that a burglar has appeared, it's likely that an alarm caused the burglar - but it's even more likely that there was an alarm, if there was a recession around to cause the alarm! So the third model predicts:
And in the second model, where alarms and recessions both cause burglars, we again don't have the conditional independence. If we know that there's a burglar, then we think that either an alarm or a recession caused it; and if we're told that there's an alarm, we'd conclude it was less likely that there was a recession, since the recession had been explained away.
(This may seem a bit clearer by considering the scenario B->A<-E, where burglars and earthquakes both cause alarms. If we're told the value of the bottom node, that there was an alarm, the probability of there being a burglar is not independent of whether we're told there was an earthquake - the two top nodes are not conditionally independent once we condition on the bottom node.)
On the other hand, we can't tell the difference between:
|
vs. |
 |
vs. |
 |
using only this data and no other variables, because all three causal structures predict the same pattern of conditional dependence and independence - three variables which all appear mutually correlated, but Alarm and Recession become independent once you condition on Burglar.
Being able to read off patterns of conditional dependence and independence is an art known as "D-separation", and if you're good at it you can glance at a diagram like this...

...and see that, once we already know the Season, whether the Sprinkler is on and whether it is Raining are conditionally independent of each other - if we're told that it's Raining we conclude nothing about whether or not the Sprinkler is on. But if we then further observe that the sidewalk is Slippery, then Sprinkler and Rain become conditionally dependent once more, because if the Sidewalk is Slippery then it is probably Wet and this can be explained by either the Sprinkler or the Rain but probably not both, i.e. if we're told that it's Raining we conclude that it's less likely that the Sprinkler was on.
Okay, back to the obesity-exercise-Internet example. You may recall that we had the following observed frequencies:
| Overweight | Exercise | Internet | # |
|---|---|---|---|
| Y | Y | Y | 1,119 |
| Y | Y | N | 16,104 |
| Y | N | Y | 11,121 |
| Y | N | N | 60,032 |
| N | Y | Y | 18,102 |
| N | Y | N | 132,111 |
| N | N | Y | 29,120 |
| N | N | N | 155,033 |
Do you see where this is going?
"Er," you reply, "Maybe if I had a calculator and ten minutes... you want to just go ahead and spell it out?"
Sure! First, we marginalize over the 'exercise' variable to get the table for just weight and Internet use. We do this by taking the 1,119 people who are YYY, overweight and Reddit users and exercising, and the 11,121 people who are overweight and non-exercising and Reddit users, YNY, and adding them together to get 12,240 total people who are overweight Reddit users:
| Overweight | Internet | # |
|---|---|---|
| Y | Y | 12,240 |
| Y | N | 76,136 |
| N | Y | 47,222 |
| N | N | 287,144 |
"And then?"
Well, that suggests that the probability of using Reddit, given that your weight is normal, is the same as the probability that you use Reddit, given that you're overweight. 47,222 out of 334,366 normal-weight people use Reddit, and 12,240 out of 88,376 overweight people use Reddit. That's about 14% either way.
"And so we conclude?"
Well, first we conclude it's not particularly likely that using Reddit causes weight gain, or that being overweight causes people to use Reddit:


If either of those causal links existed, those two variables should be correlated. We shouldn't find the lack of correlation or conditional independence that we just discovered.
Next, imagine that the real causal graph looked like this:

In this graph, exercising causes you to be less likely to be overweight (due to the virtue theory of metabolism), and exercising causes you to spend less time on the Internet (because you have less time for it).
But in this case we should not see that the groups who are/aren't overweight have the same probability of spending time on Reddit. There should be an outsized group of people who are both normal-weight and non-Redditors (because they exercise), and an outsized group of non-exercisers who are overweight and Reddit-using.
So that causal graph is also ruled out by the data, as are others like:




Leaving only this causal graph:

Which says that weight and Internet use exert causal effects on exercise, but exercise doesn't causally affect either.
All this discipline was invented and systematized by Judea Pearl, Peter Spirtes, Thomas Verma, and a number of other people in the 1980s and you should be quite impressed by their accomplishment, because before then, inferring causality from correlation was thought to be a fundamentally unsolvable problem. The standard volume on causal structure is Causality by Judea Pearl.
Causal models (with specific probabilities attached) are sometimes known as "Bayesian networks" or "Bayes nets", since they were invented by Bayesians and make use of Bayes's Theorem. They have all sorts of neat computational advantages which are far beyond the scope of this introduction - e.g. in many cases you can split up a Bayesian network into parts, put each of the parts on its own computer processor, and then update on three different pieces of evidence at once using a neatly local message-passing algorithm in which each node talks only to its immediate neighbors and when all the updates are finished propagating the whole network has settled into the correct state. For more on this see Judea Pearl's Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference which is the original book on Bayes nets and still the best introduction I've personally happened to read.
[1] Somewhat to my own shame, I must admit to ignoring my own observations in this department - even after I saw no discernible effect on my weight or my musculature from aerobic exercise and strength training 2 hours a day 3 times a week, I didn't really start believing that the virtue theory of metabolism was wrong [2] until after other people had started the skeptical dogpile.
[2] I should mention, though, that I have confirmed a personal effect where eating enough cookies (at a convention where no protein is available) will cause weight gain afterward. There's no other discernible correlation between my carbs/protein/fat allocations and weight gain, just that eating sweets in large quantities can cause weight gain afterward. This admittedly does bear with the straight-out virtue theory of metabolism, i.e., eating pleasurable foods is sinful weakness and hence punished with fat.
[3] Or there might be some hidden third factor, a gene which causes both fat and non-exercise. By Occam's Razor this is more complicated and its probability is penalized accordingly, but we can't actually rule it out. It is obviously impossible to do the converse experiment where half the subjects are randomly assigned lower weights, since there's no known intervention which can cause weight loss.
Mainstream status: This is meant to be an introduction to completely bog-standard Bayesian networks, causal models, and causal diagrams. Any departures from mainstream academic views are errors and should be flagged accordingly.
Part of the sequence Highly Advanced Epistemology 101 for Beginners
Next post: "Stuff That Makes Stuff Happen"
Previous post: "The Fabric of Real Things"
297 comments
Comments sorted by top scores.
comment by Vaniver · 2012-10-12T03:22:19.128Z · LW(p) · GW(p)
It's not clear to me that the virtue theory of metabolism is a good example for this post, since it's likely to be highly contentious.
Replies from: tgb, None, johnlawrenceaspden, handoflixue↑ comment by tgb · 2012-10-13T02:19:59.357Z · LW(p) · GW(p)
It seems clear to me that it is a very bad example. I find that consistently the worst part of Eliezer's non-fiction writing is that he fails to separate contentious claims from writings on unrelated subjects. Moreover, he usually discards the traditional view as ridiculous rather than admitting that its incorrectness is extremely non-obvious. He goes so far in this piece as to give the standard view a straw-man name and to state only the most laughable of its proponents' justifications. This mars an otherwise excellent piece and I am unwilling to recommend this article to those who are not already reading LW.
Replies from: Yvain, army1987↑ comment by Scott Alexander (Yvain) · 2012-10-13T04:30:10.943Z · LW(p) · GW(p)
Yeah, I didn't even mind the topic, but I thought this particular sentence was pretty sketchy:
in the virtue theory of metabolism, lack of exercise actually causes weight gain due to divine punishment for the sin of sloth.
This sounds like a Fully General Mockery of any claim that humans can ever affect outcomes. For example:
in the virtue theory of traffic, drinking alcohol actually causes accidents due to divine punishment for the sin of intemperance
in the virtue theory of conception, unprotected sex actually causes pregnancy due to divine punishment for the sin of lust
And selectively applied Fully General Mockeries seem pretty Dark Artsy.
Replies from: army1987↑ comment by A1987dM (army1987) · 2012-10-13T10:09:09.784Z · LW(p) · GW(p)
in the virtue theory of traffic, drinking alcohol actually causes accidents due to divine punishment for the sin of intemperance
Of course not! The real reason drinkers cause more accidents is that low-conscientiousness people are both more likely to drink before driving and more likely to drive recklessly. (The impairment of reflexes due to alcohol does itself have an effect, but it's not much larger than that due to e.g. sleep deprivation.) If a high-conscientiousness person was randomly assigned to the “drunk driving” condition, they would drive extra cautiously to compensate for their impairment. ;-)
(I'm exaggerating for comical effect, but I do believe a weaker version of this.)
↑ comment by A1987dM (army1987) · 2012-10-13T08:24:03.570Z · LW(p) · GW(p)
“Extremely non-obvious”? Have you looked at how many calories one hour of exercise burns, and compared that to how many calories foodstuffs common in the First World contain?
Replies from: Vaniver↑ comment by Vaniver · 2012-10-13T15:33:14.066Z · LW(p) · GW(p)
I agree that focusing on input has far higher returns than focusing on output. Simple calorie comparison predicts it, and in my personal experience I've noted small appearance and weight changes after changes in exercise level and large appearance and weight changes after changes in intake level. That said, the traditional view- "eat less and exercise more"- has the direction of causation mostly right for both interventions and to represent it as just "exercise more" seems mistaken.
↑ comment by [deleted] · 2012-12-17T23:39:56.663Z · LW(p) · GW(p)
I was also distracted by the footnotes, since even though I found them quite funny, [3] at least is obviously wrong: "there's no known intervention which can cause weight loss." Sure there is -- the effectiveness of bariatric surgery is quite well evidenced at this point (http://en.wikipedia.org/wiki/Bariatric_surgery#Weight_loss).
I generally share Eliezer's assessment of the state of conventional wisdom in dietary science (abysmal), but careless formulations like this one are -- well, distracting.
Replies from: army1987↑ comment by A1987dM (army1987) · 2012-12-18T11:08:37.197Z · LW(p) · GW(p)
Also, even if he meant non-surgical interventions, it should be “which can reliably cause long-term weight loss” -- there are people who lose weight by dieting, and a few of them don't even gain it back.
↑ comment by johnlawrenceaspden · 2012-10-12T19:27:49.031Z · LW(p) · GW(p)
I think that's why it's a good example. It induces genuine curiosity about the truth, and about the method.
Replies from: Vaniver↑ comment by Vaniver · 2012-10-12T20:49:40.452Z · LW(p) · GW(p)
It induces genuine curiosity about the truth
I suspect this depends on the handling of the issue. Eliezer presenting his model of the world as "common sense," straw manning the alternative, and then using fake data that backs up his preferences is, frankly, embarrassing.
This is especially troublesome because this is an introductory explanation to a technical topic- something Eliezer has done well before- and introductory explanations are great ways to introduce people to Less Wrong. But how can I send this to people I know who will notice the bias in the second paragraph and stop reading because that's negative evidence about the quality of the article? How can I send this to people I know who will ask why he's using two time-variant variables as single acyclic nodes, rather than a ladder (where exercise and weight at t-1 both cause exercise at t and weight at t)?
What would it look like to steel man the alternative? One of my physics professors called 'calories in-calories out=change in fat' the "physics diet," since it was rooted in conservation of energy; that seems like a far better name. Like many things in physics, it's a good first order approximation to the engineering reality, but there are meaningful second order terms to consider. "Calories in" is properly "calories absorbed" not "calories put into your mouth"- though we'll note it's difficult to absorb more calories than you put into your mouth. Similarly, calories out is non-trivial to measure- current weight and activity level can give you a broad guess, but it can be complicated by many things, like ambient temperature! Any attempt we make to control calories in and calories out will have to be passed through the psychology and physiology of the person in question, making them even more difficult to control in the field.
and about the method.
Compare the volume of discussion of the method and the overweight-exercise link in the comments.
Replies from: thomblake, Eliezer_Yudkowsky↑ comment by thomblake · 2012-10-12T21:00:15.703Z · LW(p) · GW(p)
How can I send this to people I know who will ask why he's using two time-variant variables as single acyclic nodes, rather than a ladder (where exercise and weight at t-1 both cause exercise at t and weight at t)?
Why do you need to send this article to people who could ask that? If you're saying "Oh, this should actually be modeled using causal markov chains..." then this is probably too basic for you.
Replies from: Vaniver↑ comment by Vaniver · 2012-10-12T21:05:59.076Z · LW(p) · GW(p)
Why do you need to send this article to people who could ask that?
Because I'm still a grad student, most of those people that I know are routinely engaged in teaching these sorts of concepts, and so will find articles like this useful for pedagogical reasons.
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-10-12T22:05:37.305Z · LW(p) · GW(p)
How can I send this to people I know who will ask why he's using two time-variant variables as single acyclic nodes
This is not intended for readers who already know that much about causal models, btw, it's a very very very basic intro.
Replies from: EricHerboso↑ comment by EricHerboso · 2012-10-13T02:55:00.666Z · LW(p) · GW(p)
I'm torn. On the one hand, using the method to explain something the reader probably was not previously aware of is an awesome technique that I truly appreciate. Yet Vaniver's point that controversial opinions should not be unnecessarily put into introductory sequence posts makes sense. It might turn off readers who would otherwise learn from the text, like nyan sandwich.
In my opinion, the best fix would be to steelman the argument as much as possible. Call it the physics diet, not the virtue-theory of metabolism. Add in an extra few sentences that really buff up the basics of the physics diet argument. And, at the end, include a note explaining why the physics diet doesn't work (appetite increases as exercise increases).
Replies from: Vaniver, army1987↑ comment by Vaniver · 2012-10-13T03:58:20.857Z · LW(p) · GW(p)
The point Eliezer is addressing is the one that RichardKennaway brought up separately. Causal models can still function with feedback (in Causality, Pearl works through an economic model where price and quantity both cause each other, and have their own independent causes), but it's a bit more bothersome.
A model where the three are one-time events- like, say, whether a person has a particular gene, whether or not they were breastfed, and their height as an adult- won't have the problem of being cyclic, but will have the pedagogical problem that the causation is obvious from the timing of the events.
One could have, say, the weather witch's prediction of whether or not there will be rain, whether or not you brought an umbrella with you, and whether or not it rained. Aside from learning, this will be an acyclic system that has a number of plausible underlying causal diagrams (with the presence of the witch making the example clearly fictional and muddying our causal intuitions, so we can only rely on the math).
In my opinion, the best fix would be to steelman the argument as much as possible.
The concept of inferential distance suggests to me that posts should try and make their pathways as short and straight as possible. Why write a double-length post that explains both causal models and metabolism, when you could write a single-length post that explains only causal models? (And, if metabolism takes longer to discuss than causal models, the post will mostly be about the illustrative detour, not the concept itself!)
Replies from: MC_Escherichia, EricHerboso↑ comment by MC_Escherichia · 2012-10-14T20:55:12.606Z · LW(p) · GW(p)
won't have the problem of being acyclic
Should that be "cyclic"? I take it from Richard's post that "acyclic" is what we want.
Replies from: Vaniver↑ comment by EricHerboso · 2012-10-13T19:19:53.809Z · LW(p) · GW(p)
The concept of inferential distance suggests to me that posts should try and make their pathways as short and straight as possible. Why write a double-length post that explains both causal models and metabolism, when you could write a single-length post that explains only causal models? (And, if metabolism takes longer to discuss than causal models, the post will mostly be about the illustrative detour, not the concept itself!)
You've convinced me. I now agree that EY should go back and edit the post to use a different more conventional example.
↑ comment by A1987dM (army1987) · 2012-10-13T08:13:09.981Z · LW(p) · GW(p)
In my opinion, the best fix would be to steelman the argument as much as possible. Call it the physics diet, not the virtue-theory of metabolism.
“Physics diet” and “virtue-theory of metabolism” are not steelman and strawman of each other; they are quite different things. Proponents of the physics diet (e.g. John Walker) do not say that if you want to lose weight you should exercise more -- they say you should eat less. EDIT: the strawman of this would be the theory that “excessive eating actually causes weight gain due to divine punishment for the sin of gluttony” (inspired by Yvain's comment).
Seriously; that was intended to be an example. What's it matter whether the nodes are labelled “exercise/overweight/internet” or “foo/bar/baz”? (But yeah, Footnote 1 doesn't belong there, and Footnote 3 might mention eating.)
↑ comment by handoflixue · 2012-10-12T19:08:31.648Z · LW(p) · GW(p)
Taking a "contentious" point and resolving it in to a settled fact made the whole article vastly more engaging to me. It also struck me as an elegant demonstration of the value of the tool: It didn't simply introduce the concept, it used it to accomplish something worthwhile.
Replies from: Vaniver↑ comment by Vaniver · 2012-10-12T19:59:07.918Z · LW(p) · GW(p)
Taking a "contentious" point and resolving it in to a settled fact
! From the article:
Replies from: handoflixue, handoflixue(which is totally made up, so don't go actually believing the conclusion I'm about to draw)
↑ comment by handoflixue · 2012-10-12T20:19:08.118Z · LW(p) · GW(p)
Eliezer's data is made up, but all the not-made-up research I've seen supports his actual conclusion. The net emotional result was the same for me as if he'd used the actual research, since my brain could substitute it in.
Perhaps I am weird in having this emotional link, or perhaps I am simply more familiar with the not-made-up research than you.
Replies from: Vaniver↑ comment by Vaniver · 2012-10-12T21:04:33.971Z · LW(p) · GW(p)
The net emotional result was the same for me as if he'd used the actual research, since my brain could substitute it in.
I understand. I think it's important to watch out for these sorts of illusions of transparency, though, especially when dealing with pedagogical material. One of the heuristics I've been using is "who would I not recommend this to?", because that will use social modules my brain is skilled at using to find holes and snags in the article. I don't know how useful that heuristic will be to others, and welcome the suggestion of others.
perhaps I am simply more familiar with the not-made-up research than you.
I am not an expert in nutritional science, but it appears to me that there is controversy among good nutritionists. This post also aided my understanding of the issue. I also detail some more of my understanding in this comment down another branch.
EDIT: Also, doing some more poking around now, this seems relevant.
Replies from: handoflixue↑ comment by handoflixue · 2012-10-12T22:34:03.247Z · LW(p) · GW(p)
Ahh, that heuristic makes sense! I wasn't thinking in that context :)
↑ comment by handoflixue · 2012-10-12T20:20:24.419Z · LW(p) · GW(p)
P.S. When quoting two people, it can be useful to attribute the quotes. I initially thought the second quote was your way of doing a snarky editorial comment on what I'd said, not quoting the article...
Replies from: Vanivercomment by IlyaShpitser · 2012-10-12T04:06:38.652Z · LW(p) · GW(p)
Hi Eliezer,
Thanks for writing this! A few comments about this article (mostly minor, with one exception).
The famous statistician Fischer, who was also a smoker, testified before Congress that the correlation between smoking and lung cancer couldn't prove that the former caused the latter.
Fisher was specifically worried about hidden common causes. Fisher was also the one who brought the concept of a randomized experiment into statistics. Fisher was "curmudgeony," but it is not quite fair to use him as an exemplar of the "keep causality out of our statistics" camp.
Causal models (with specific probabilities attached) are sometimes known as "Bayesian networks" or "Bayes nets", since they were invented by Bayesians and make use of Bayes's Theorem.
Graphical causal models and Bayesian networks are not the same thing (this is a common misconception). A distribution that factorizes according to a DAG is a Bayesian network (this is just a property of a distribution -- nothing about causality). You can further say that a graphical model is causal if an additional set of properties holds. For example, you can (loosely) say that in a causal model all parents are "direct causes." If you want to say that formally, you would talk about the truncated factorization and do(.). Without interventions there is no interventionist causal model.
All this discipline was invented and systematized by Judea Pearl, Peter Spirtes, Thomas Verma, and a number of other people in the 1980s and you should be quite impressed by their accomplishment, because before then, inferring causality from correlation was thought to be a fundamentally unsolvable problem.
I often find myself in a weird position of having to point folks to people other than Pearl. I think it's commendable that you looked into other people in the field. The big early names in causality that you did not mention are Haavelmo (1950s) and Sewall Wright (this guy is amazing -- he figured so many things out correctly in the 1920s). Special cases of non-causal graphical models (Ising models, Hidden Markov models, etc.), along with factorizations and propagation algorithms were known long before Pearl in other communities.
P.S. Since I am in Cali.: if folks at SI are interested in new developments on the "learning causal structure from data" front, I could be bribed by the Cheeseboard to come by and give a talk.
Replies from: Emile↑ comment by Emile · 2012-10-12T10:51:45.917Z · LW(p) · GW(p)
Hi Eliezar,
(it's Eliezer)
Replies from: IlyaShpitser↑ comment by IlyaShpitser · 2012-10-12T21:05:54.896Z · LW(p) · GW(p)
Done, sorry.
Replies from: SilasBarta↑ comment by SilasBarta · 2012-11-03T20:38:59.562Z · LW(p) · GW(p)
In fairness, a lot of people seem to pronounce it Eliezar for some reason.
comment by Richard_Kennaway · 2012-10-12T07:00:18.985Z · LW(p) · GW(p)
That's a clear outline of the theory. I just want to note that the theory itself makes some assumptions about possible patterns of causation, even before you begin to select which causal graphs are plausible candidates for testing. Pearl himself stresses that without putting causal information in, you can't get causal information out from purely observational data.
For example, if overweight causes lack of exercise and lack of exercise causes overweight, you don't have an acyclic graph. Acyclicity of causation is one of the background assumptions here. Acyclicity of causation is reasonable when talking about point events in a universe without time-like loops. However, "weight" and "exercise level" are temporally extended processes, which makes acyclicity a strong assumption.
Replies from: Morendil, Richard_Kennaway, SilasBarta, SilasBarta↑ comment by Richard_Kennaway · 2012-10-12T08:46:19.568Z · LW(p) · GW(p)
Pearl himself stresses that without putting causal information in, you can't get causal information out from purely observational data.
Koan: How, then, does the process of attributing causation get started?
Replies from: Antisuji, AlanCrowe, roryokane↑ comment by Antisuji · 2012-10-14T19:53:09.117Z · LW(p) · GW(p)
My answer:
First, notice a situation that occurs many times. Then pay attention to the ways in which things are different from one iteration to the next. At this point, and here is where causal information begins, if some of the variables represent your own behavior, you can systematically intervene in the situation by changing those behaviors. For cleanest results, contrive a controlled experiment that is analogous the the original situation.
In short, you insert causal information by intervening.
This of course requires you to construct a reference class of situations that are substantially similar to one another, but humans seem to be pretty good at that within our domains of familiarity.
By the way, thank you for explaining the underlying assumption of acyclicity. I've been trying to internalize the math of causal calculus and it bugged me that cyclic causes weren't allowed. Now I understand that it is a simplification and that the calculus isn't quite as powerful as I thought.
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2012-10-14T21:01:26.478Z · LW(p) · GW(p)
I don't have an answer to my own koan, but this was one of the possibilities that I thought of:
In short, you insert causal information by intervening.
But how does one intervene? By causing some variable to take some value, while obstructing the other causal influences on it. So causal knowledge is already required before one can intervene. This is not a trivial point -- if the knowledge is mistaken, the intervention may not be successful, as I pointed out with the example of trying to warm a room thermostat by placing a candle near it.
Replies from: learnmethis↑ comment by learnmethis · 2012-10-15T15:54:00.073Z · LW(p) · GW(p)
Causal knowledge is required to ensure success, but not to stumble across it. Over time, noticing (or stumbling across if you prefer) relationships between the successes stumbled upon can quickly coalesce into a model of how to intervene. Isn't this essentially how we believe causal reasoning originated? In a sense, all DNA is information about how to intervene that, once stumbled across, persisted due to its efficacy.
↑ comment by AlanCrowe · 2012-10-13T10:05:33.316Z · LW(p) · GW(p)
I think that one bootstraps the process with contrived situations designed to appeal to ones intuitions. For example, one attempts to obtain causal information through a randomised controlled trial. You mark the obverse face of a coin "treatment" and reverse face "control" and toss the coin to "randomly" assign your patients.
Let us briefly consider the absolute zero of no a priori knowledge at all. Perhaps the coin knows the prognosis of the patient and comes down "treatment" for patients with a good prognosis, intending to mislead you into believing that the treatment is the cause of good outcomes. Maybe, maybe not. Let's stop considering this because insanity is stalking us.
We are willing to take a stand. We know enough, a prior, to choose and operate a randomisation device and thus obtain a variable which is independent of all the others and causally connected to none of them. We don't prove this, we assume it. When we encounter a compulsive gambler, who believes in Lady Luck who is fickle and very likely is actually messing with us via the coin, we just dismiss his hypothesis. Life is short, one has to assume that certain obvious things are actually true in order to get started, and work up from there.
↑ comment by roryokane · 2012-10-13T00:22:14.431Z · LW(p) · GW(p)
My answer: Attributing causation is part of our human instincts. We are born with some desire to do it. We may develop that skill by reflecting on it during our lifetime.
(How did we humans develop that instinct? Evolution, probably. Humans who had mutated to reason about causality died less – for instance, they might have avoided drinking from a body of water after seeing something poisonous put in, because they reasoned that the poison addition would cause the water to be poisonous.)
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2012-10-13T06:58:10.211Z · LW(p) · GW(p)
This is a non-explanation, or rather, three non-explanations.
"Human nature does it" explains no more than "God does it".
"It's part of human nature because it must have been adaptive in the past" likewise. Causal reasoning works, but why does it work?
And "mutated to reason about causality" is just saying "genes did it", which is still not an advance on "God did it".
Replies from: chaosmosis↑ comment by chaosmosis · 2012-10-13T10:23:51.787Z · LW(p) · GW(p)
There isn't any better explanation. If you don't accept the idea of causality as given, you can never explain anything. Roryokane is using causality to explain how causality originated, and that's not a good way to go about proving the way causality works or anything but it is a good way of understanding why causality exists, or rather just accepting that we can never prove causality exists.
Our instincts are just wired to interpret causality that way, and that makes it a brute fact. You might as well claim that calling a certain color yellow and then saying it looks yellow as a result of human nature is a non-explanation, you might be technically right to do so but in that case then you're asking for answers you're never actually going to get.
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2012-10-15T13:18:13.341Z · LW(p) · GW(p)
You might as well claim that calling a certain color yellow and then saying it looks yellow as a result of human nature is a non-explanation, you might be technically right to do so but in that case then you're asking for answers you're never actually going to get.
That would be a non-explanation, but a better explanation is in fact possible. You can look at the way that light is turned into neural signals by the eye, and discover the existence of red-green, blue-yellow, and light-dark axes, and there you have physiological justification for six of our basic colour words. (I don't know just how settled that story is, but it's settled enough to be literally textbook stuff.)
So, that is what a real explanation looks like. Attributing anything to "human nature" is even more wrong than attributing it to "God". At least we have some idea of what "God" would be if he existed, but "human nature" is a blank, a label papering over a void. How do Sebastian Thrun's cars drive themselves? Because he has integrated self-driving into their nature. How does opium produce sleep? By its dormitive nature. How do humans distinguish colours? By their human nature.
Replies from: chaosmosis↑ comment by chaosmosis · 2012-10-15T18:59:16.643Z · LW(p) · GW(p)
But causality is uniquely impervious to those kind of explanations. You can explain why humans believe in causality in a physiological sense, but I didn't think that is what you were asking for. I thought you were asking for some overall metaphysical justification for causality, and there really isn't any. Causal reasoning works because it works, there's no other justification to be had for it.
↑ comment by SilasBarta · 2012-11-03T20:40:51.153Z · LW(p) · GW(p)
Pearl himself stresses that without putting causal information in, you can't get causal information out from purely observational data.
Where do you get this? My recall of Causality is that he specifically rejected the "no causes in, no causes out" view in favor of the "Occam's Razor in, some causes out" view.
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2012-11-04T10:50:50.562Z · LW(p) · GW(p)
Yes, the Occamian view is in his book in section 2.3 (and still in the 2009 2nd edition). But that definition of "inferred causation" -- those arrows common to all causal models consistent with the statistical data -- depends on general causal assumptions, the usual ones being the DAG, Markov, and Faithfulness properties.
In other places, for example: "Causal inference in statistics: An overview", which is in effect the Cliff Notes version of his book, he writes:
"one cannot substantiate causal claims from associations alone, even at the population level -- behind every causal conclusion there must lie some causal assumption that is not testable in observational studies."
Here is a similar survey article from 2003, in which he writes that exact sentence, followed by:
"Nancy Cartwright (1989) expressed this principle as "no causes in, no causes out", meaning that we cannot convert statistical knowledge into causal knowledge."
Everywhere, he defines causation in terms of counterfactuals: claims about what would have happened had something been different, which, he says, cannot be expressed in terms of statistical distributions over observational data. Here is a long interview (both audio and text transcript) in which he recounts the whole course of his work.
Replies from: SilasBarta↑ comment by SilasBarta · 2012-11-04T19:18:33.920Z · LW(p) · GW(p)
In other places, for example: "Causal inference in statistics: An overview", which is in effect the Cliff Notes version of his book, he writes:
"one cannot substantiate causal claims from associations alone, even at the population level -- behind every causal conclusion there must lie some causal assumption that is not testable in observational studies."
Here is a similar survey article from 2003, in which he writes that exact sentence, followed by:
"Nancy Cartwright (1989) expressed this principle as "no causes in, no causes out", meaning that we cannot convert statistical knowledge into causal knowledge."
Interesting, but how do those files evade word searches for the parts you've quoted?
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2012-11-04T20:06:47.792Z · LW(p) · GW(p)
Interesting, but how do those files evade word searches for the parts you've quoted?
Dunno, not all PDFs are searchable and not all PDF viewers fail to make a pig's ear of searching. The quotes can be found on p.99 (the third page of the file) and pp.284-285 (6th-7th pages of the file) respectively.
OTOH, try Google.
↑ comment by SilasBarta · 2012-11-03T23:26:36.828Z · LW(p) · GW(p)
Btw, Scott Aaronson just recently posted the question of whether you would care about causality if you could only work with observational data (someone already linked this article in the comments) and I put up a comment with my summary of the LW position (plus some complexity-theoretic considerations).
Replies from: Pfft↑ comment by Pfft · 2012-11-04T22:28:36.423Z · LW(p) · GW(p)
I don't think that Bayesian networks implicitly contain the concept of causality.
Formally, a probability distribution is represented by a Bayesian network if it can be factored as a product of P(node | node's parents). But this is not unique, given one network you can create lots of other networks which also represent the same distribution by e.g. changing the direction of arrows as long as the independence properties from the graph stay the same (e.g. the graphs A -> B -> C and A <- B <- C can represent exactly the same class of probability distributions). Pearl distinguishes Baysian networks from causal networks, which are Bayesian networks in which the arrows point in the direction of causality.
And of course, there are other sparse representations like Markov networks, which also incorporates independence assumptions but are undirected.
Replies from: SilasBarta↑ comment by SilasBarta · 2012-11-04T23:01:59.527Z · LW(p) · GW(p)
The non-uniqueness doesn't make causality absent or irrelevant; it must means there are multiple minimal representations that use causality. The causality arises in how your node connections are asymmetric. If the relativity of simultaneity (observers seeing the same events in a different time order) doesn't obviate causality, neither should he existence of multiple causal networks.
There are indeed equivalent models that use purely symmetric node connections (or none at all in the case of the superexponential pair wise conditional independence table across all variables), but (correct me if I'm wrong) by throwing away the information graphically represented by the arrows, you no longer have a maximally efficient encoding of the joint probability distribution (even though it's certainly not as bad as the superexponential table).
Replies from: Pfft↑ comment by Pfft · 2012-11-05T01:14:53.256Z · LW(p) · GW(p)
I guess there are two points here.
First, authors like Pearl do not use "causality" to mean just that there is a directed edge in a Bayesian network (i.e. that certain conditional independence properties hold). Rather, he uses it to mean that the model describes what happens under interventions. One can see the difference by comparing Rain -> WetGrass with WetGrass -> Rain (which are equivalent as Bayesian networks). Of course, maybe he is confused and the difference will dissolve under more careful consideration, but I think this shows one should be careful in claiming that Bayes networks encode our best understanding of causality.
Second, do we need Bayesian networks to economically represent distributions? This is slightly subtle.
We do not need the directed arrows when representing a particular distribution. For example, suppose a distribution P(A,B,C) is represented by the Bayesian network A -> B <- C. Expanding the definition, this means that the joint distribution can be factored as
P(A=a,B=b,C=c) = P1(A=a) P2(B=b|A=a,C=c) P3(C=c)
where P1 and P3 are the marginal distributions of A and B, and P2 is the conditional distribution of B. So the data we needed to specify P were two one-column tables specifying P1 and P3, and a three-column table specifying P2(a|b,c) for all values of a,b,c. But now note that we do not gain very much by knowing that these are probability distributions. To save space it is enough to note that P factors as
P(A=a,B=b,C=c) = F1(a) F2(b,a,c) F3(c)
for some real-valued functions F1, F2, and F3. In other words, that P is represented by a Markov network A - B - C. The directions on the edges were not essential.
And indeed, typical algorithms for inference given a probability distribution, such as belief propagation, do not make use of the Bayesian structure. They work equally well for directed and undirected graphs.
Rather, the point of Bayesian versus Markov networks is that the class of probability distributions that can be represented by them are different. So they are useful when we try to learn a probability distribution, and want to cut down the search space by constraining the distribution by some independence relations that we know a priori.
Bayesian networks are popular because they let us write down many independence assumptions that we know hold for practical problems. However, we then have to ask how we know those particular independence relations hold. And that's because they correspond to causual relations! The reason Bayesian networks are popular with human researchers is that they correspond well with the notion of causality that humans use. We don't know that the Armchairians would also find them useful.
Replies from: Richard_Kennaway, SilasBarta↑ comment by Richard_Kennaway · 2012-11-05T09:16:21.650Z · LW(p) · GW(p)
To save space it is enough to note that P factors as
P(A=a,B=b,C=c) = F1(a) F2(b,a,c) F3(c)
for some real-valued functions F1, F2, and F3. In other words, that P is represented by a Markov network A - B - C. The directions on the edges were not essential.
Can't the directions be recovered automatically from that expression, though? That is, discarding the directions from the notation of conditional probabilities doesn't actually discard them.
The reconstruction algorithm would label every function argument as "primary" or "secondary", begin with no arguments labelled, and repeatedly do this:
For every function with no primary variable and exactly one unlabelled variable, label that variable as primary and all of its occurrences as arguments to other functions as secondary.
When all arguments are labelled, make a graph of the variables with an arrow from X to Y whenever X and Y occur as arguments to the same function, X as secondary and Y as primary. If the functions F1 F2 etc. originally came from a Bayesian network, won't this recover that precise network?
If the original graph was A <- B -> C, the expression would have been F1(a,b) F2(b) F3(c,b).
Replies from: Pfft↑ comment by Pfft · 2012-11-05T17:04:22.613Z · LW(p) · GW(p)
If the functions F1 F2 etc. originally came from a Bayesian network, won't this recover that precise network?
I think this is right, if you know that the factors were learned by fitting them to a Bayesian network, you can recover what that network must have been. And you can go even further, if you only have a joint distribution you can use the techniques of the original article to see which Bayesian networks could be consistent with it.
But there is a separate question about why we are interested in Bayesian networks in the first place. SilasBarta seemed to claim that you are naturally led to them if you are interested in representing probability distributions efficiently. But for that purpose (I claim), you only need the idea of factors, not the directed graph structure. E.g. a probability distribution which fits the (equivalent) Bayesian networks A -> B -> C or A <- B <- C or A <- B -> C can be efficiently represented as F1(a,b) F2(b,c). You would not think of representing it as F1(a) F2(a,b) F3(b,c) unless you were already interested in causality.
↑ comment by SilasBarta · 2012-11-05T01:23:13.950Z · LW(p) · GW(p)
In other words, that P is represented by a Markov network A - B - C. The directions on the edges were not essential.
On the contrary, they are important and store information about the relationships that saves you time and space. Like I said in my linked comment, the direction of the arrows between A,C and B tell you whether conditioning on B (perhaps by separating it out into buckets of various values) creates or destroys mutual information between A and C. That saves you from having to explicitly write out all the combinations of conditional (in)dependence.
Replies from: Pfft↑ comment by Pfft · 2012-11-05T02:35:47.139Z · LW(p) · GW(p)
In other words, that P is represented by a Markov network A - B - C. The directions on the edges were not essential.
Oops, on second thought the factorization is equivalent to the complete triangle, not a line. But this doesn't change the point that the space requirements are determined by the factors, not the graph structure, so the two representations will use the same amount of space.
On the contrary, they are important and store information about the relationships that saves you time and space.
All independence relations are implicit in the distribution itself, so the graph can only save you time, not space.
It is true that knowing a minimal Bayes network or a minimal Markov network for a distribution lets you read of certain independence assumptions quickly. But it doesn't save you from having to write out all the combinations. There are exponentially many possible conditional independences, each of which may hold or not, so no sub-exponential representation can get encode all of them. And indeed, there are some kinds of independence assumptions that can be expressed as Bayesian networks but not Markov networks, and vice versa. Even in everyday machine learning, it is not the case that Bayesian networks is always the best representation.
You also do not motivate why someone would be interested in a big list of conditional independencies for its own sake. Surely, what we ultimately want to know is e.g. the probability that it will rain tomorrow, not whether or not rain is correlated with sprinklers.
Replies from: SilasBarta↑ comment by SilasBarta · 2012-11-05T03:10:44.462Z · LW(p) · GW(p)
But it doesn't save you from having to write out all the combinations.
It saves you from having to write them until needed, in which case they can be extracted by walking through the graph rather than doing a lookup on a superexponential table.
You also do not motivate why someone would be interested in a big list of conditional independencies for its own sake. Surely, what we ultimately want to know is e.g. the probability that it will rain tomorrow, not whether or not rain is correlated with sprinklers.
Yes, the question was what they would care about if they were only interested in predictions. And so I think I've motivated why they would care about conditional (in)dependencies: it determines the (minimal) set of variables they need to look at! Whatever minimal method of representing their knowledge will then have these arrows (from one of the networks that fits the data).
If you require that causality definitions be restricted to (uncorrelated) counterfactual operations (like Pearl's "do" operation), then sure, the Armcharians won't do that specific computation. But if you use the definition of causality from this article, then I think it's clear that efficiency considerations will lead them to use something isomorphic to it.
Replies from: Pfft↑ comment by Pfft · 2012-11-05T03:36:26.524Z · LW(p) · GW(p)
It saves you from having to write them until needed
I was saying that not every independence property is representable as a Bayesian network.
Whatever minimal method of representing their knowledge will then have these arrows (from one of the networks that fits the data).
No! Once you have learned a distribution using Bayesian network-based methods, the minimal representation of it is the set of factors. You don't need the direction of the arrows any more.
Replies from: SilasBarta↑ comment by SilasBarta · 2012-11-05T03:51:31.619Z · LW(p) · GW(p)
I was saying that not every independence property is representable as a Bayesian network.
You mean when all variables are independent, or some other class of cases?
No! Once you have learned a distribution using Bayesian network-based methods, the minimal representation of it is the set of factors. You don't need the direction of the arrows any more.
Read the rest: you need the arrows if you want to efficiently look up the conditional (in)dependencies.
Replies from: Pfft↑ comment by Pfft · 2012-11-05T04:20:56.736Z · LW(p) · GW(p)
You mean when all variables are independent, or some other class of cases?
Well, there are doubly-exponentially many possibilities...
The usual example for Markov networks is four variables connected in a square. The corresponding independence assumption is that any two opposite corners are independent given the other two corners. There is no Bayesian network encoding exactly that.
you need the arrows if you want to efficiently look up the conditional (in)dependencies.
But again, why would you want that? As I said in the grand^(n)parent, you don't need to when doing inference.
Replies from: SilasBarta↑ comment by SilasBarta · 2012-11-05T19:35:49.461Z · LW(p) · GW(p)
The usual example for Markov networks is four variables connected in a square. The corresponding independence assumption is that any two opposite corners are independent given the other two corners. There is no Bayesian network encoding exactly that.
Okay, I'm recalling the "troublesome" cases that Pearl brings up, which gives me a better idea of what you mean. But this is not a counterexample. It just means that you can't do it on a Bayes net with binary nodes. You can still represent that situation by merging (either pair of) the screening nodes into one node that covers all combinations of possibilities between them.
Do you have another example?
But again, why would you want that? As I said in the grand^(n)parent, you don't need to when doing inference.
Sure you do: you want to know which and how many variables you have to look up to make your prediction.
Replies from: Pfft↑ comment by Pfft · 2012-11-05T20:53:49.716Z · LW(p) · GW(p)
merging (either pair of) the screening nodes into one node
Then the network does not encode the conditional independence between the two variables that you merged.
The task you have to do when making predictions is marginalization: in order to computer P(Rain|WetGrass), you need to compute the sum of P(Rain|WetGrass, X,Y,Z) for all possible values of the variables X, Y, Z that you didn't observe. Here it is very helpful to have the distribution factored into a tree, since that can make it feasible to do variable elimination (or related algorithms like belief propagation). But the directions on the edges in the tree don't matter, you can start at any leaf node and work across.
comment by wedrifid · 2012-10-13T06:39:47.865Z · LW(p) · GW(p)
The statisticians who discovered causality were trying to find a way to distinguish, within survey data, the direction of cause and effect - whether, as common sense would have it, more obese people exercise less because they find physical activity less rewarding; or whether, as in the virtue theory of metabolism, lack of exercise actually causes weight gain due to divine punishment for the sin of sloth.
I recommend that Eliezer edit this post to remove this kind of provocation. The nature of the actual rationality message in this post is such that people are likely to link to it in the future (indeed, I found it via an external link myself). It even seems like something that may be intended to be part of a sequence. As it stands I expect many future references to be derailed and also expect to see this crop up prominently in lists of reasons to not take Eliezer's blog posts seriously. And, frankly, this reason would be a heck of a lot better than most others that are usually provided by detractors.
Replies from: elityre, loup-vaillant, Jonathan_Graehl↑ comment by Eli Tyre (elityre) · 2018-08-25T06:54:46.986Z · LW(p) · GW(p)
I strongly agree.
I read that paragraph and noticed that I was confused. Because I was going through this post to acquire a more-than-cursory technical intuition, I was making a point to followup on and resolve any points of confusion.
There's enough technical detail to carefully parse, without adding extra pieces that don't make sense on first reading. I'd prefer to be able to spend my carful thinking on the math.
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2018-11-22T20:58:24.008Z · LW(p) · GW(p)
As was written in this [LW · GW]seminal post:
In Artificial Intelligence, and particularly in the domain of nonmonotonic reasoning, there's a standard problem: "All Quakers are pacifists. All Republicans are not pacifists. Nixon is a Quaker and a Republican. Is Nixon a pacifist?"
What on Earth was the point of choosing this as an example? To rouse the political emotions of the readers and distract them from the main question? To make Republicans feel unwelcome in courses on Artificial Intelligence and discourage them from entering the field? (And no, before anyone asks, I am not a Republican. Or a Democrat.)
Why would anyone pick such a distracting example to illustrate nonmonotonic reasoning? Probably because the author just couldn't resist getting in a good, solid dig at those hated Greens. [? · GW] It feels so good to get in a hearty punch, y'know, it's like trying to resist a chocolate cookie.
As with chocolate cookies, not everything that feels pleasurable is good for you. And it certainly isn't good for our hapless readers who have to read through all the angry comments your blog post inspired.
It's not quite the same problem, but it has some of the same consequences.
↑ comment by loup-vaillant · 2012-10-14T00:09:09.690Z · LW(p) · GW(p)
Maybe the "mainstream status" section should be placed at the top? It would signal right at the top that this post is backed by proper authority.
In addition to the provocation you mention, openly bashing mainstream philosophy in the fourth paragraph doesn't help. If you add a possible reputation of holding unsubstantiated whacky beliefs, well…
That said, I was quite surprised by the number of comments about this issue. I for one didn't see any problem with this post.
When I read "divine punishment for the sin of sloth", I just smiled at the supernatural explanation, knowing that Eliezer of course knows the virtue theory of metabolism have a perfectly natural (and reasonable sounding) explanation. Actually, it didn't even touched my model of his probability distribution of the veracity of the "virtue" theory —nor my own. After having read so much of his writings, I just can't believe he rules such a hypothesis out a priori. Remember reductionism. And my model of him definitely does not expect to influence LessWrong readers with an unsubstantiated mockery.
Also, this:
And lo, merely by eyeballing this data -
(which is totally made up, so don't go actually believing the conclusion I'm about to draw)
made clear he wasn't discussing the object at all. It was then easier for me to put myself in a position of total uncertainty regarding the causal model implied by this "data". The same way my HPMOR anticipations are no longer build on cannon —Bellatrix could really be innocent, for al I know.
But this is me assuming total good faith from Eliezer. I totally forgot that many people in fact do not assume good faith.
Replies from: Caspian↑ comment by Caspian · 2012-10-14T04:33:37.048Z · LW(p) · GW(p)
I mostly liked the post. In Pearl's book, the example of whether smoking causes cancer worked pretty well for me despite being potentially controversial, and was more engaging for being on a controversial topic. Part of that is he kept his example fairly cleanly hypothetical. Eliezer's "I didn't really start believing that the virtue theory of metabolism was wrong" in a footnote, and "as common sense would have it" in the main text, both were suggesting it was about the real world. I think in Pearl's example, he may have even made his hypothetical data give the opposite result to the real world.
This post I also thought was more engaging due to the controversial topic, so if you can keep that while reducing the "mind-killer politics" potential I'd encourage that.
I was fine with the model he was falsifying being simple and easily disproved - that's great for an example.
I'm kind of confused and skeptical at the bit at the end: we've ruled out all the models except one. From Pearl's book I'd somehow picked up that we need to make some causal assumption, statistical data wasn't enough to get all the way from ignorance to knowing the causal model.
Is assuming "causation would imply correlation" and "the model will have only these three variables" enough in this case?
Replies from: Vaniver, loup-vaillant↑ comment by Vaniver · 2012-10-15T02:20:54.451Z · LW(p) · GW(p)
I think in Pearl's example, he may have even made his hypothetical data give the opposite result to the real world.
He introduces a "hypothetical data set," works through the math, then follows the conclusion that tar deposits protect against cancer with this paragraph:
The data in Table 3.1 are obviously unrealistic and were deliberately crafted so as to support the genotype theory. However, the purpose of this exercise was to demonstrate how reasonable qualitative assumptions about the workings of mechanisms, coupled with nonexperimental data, can produce precise quantitative assessments of causal effects. In reality, we would expect observational studies involving mediating variables to refute the genotype theory by showing, for example, that the mediating consequences of smoking (such as tar deposits) tend to increase, not decrease, the risk of cancer in smokers and nonsmokers alike. The estimand of (3.29) could then be used for quantifying the causal effect of smoking on cancer.
When I read it, I remember being mildly bothered by the example (why not have a clearly fictional example to match clearly fictional data, or find an actual study and use the real data as an example?) but mostly mollified by his extended disclaimer.
(I feel like pointing out, as another example, the decision analysis class that I took, which had a central example which was repeated and extended throughout the semester. The professor was an active consultant, and could have drawn on a wealth of examples in, say, petroleum exploration. But the example was a girl choosing a location for a party, subject to uncertain weather. Why that? Because it was obviously a toy example. If they tried to use a petroleum example for petroleum engineers, the petroleum engineers would be rightly suspicious of any simplified model put in front of them- "you mean this procedure only takes into account two things!?"- and any accurate model would be far too complicated to teach the methodology. An obviously toy example taught the process, and then once they understood the process, they were willing to apply it to more complicated situations- which, of course, needed much more complicated models.)
↑ comment by loup-vaillant · 2012-10-14T09:00:51.670Z · LW(p) · GW(p)
There may also be the assumption that the graph is acyclic.
Some causal models, while not flat out falsified by the data, are rendered less probable by the fact the data happens to fit more precise (less connected) causal graphs. A fully connected graph is impossible to falsify, for instance (it can explain any data).
Among all graphs that explain the fictional data here, there is only one that has only two edges. That's the most probable one.
↑ comment by Jonathan_Graehl · 2012-10-13T19:24:27.562Z · LW(p) · GW(p)
But not quite as damaging as rationalist case study: the ideal child-bearing age turns out to be 13 years old (advances in modern medicine, you know).
Replies from: ThrustVectoring↑ comment by ThrustVectoring · 2012-10-13T23:11:29.216Z · LW(p) · GW(p)
Ideal for what, exactly? Churning out the most babies in the shortest amount of time? Having a happy and well-adjusted populace? Having a long life?
Ideal is a very loaded word and using it implies that there's an obvious utility function, when there often isn't.
Replies from: Jonathan_Graehl↑ comment by Jonathan_Graehl · 2012-10-14T21:58:44.746Z · LW(p) · GW(p)
In any case, 13 is too young in many cases. I was being facetious.
comment by Kaj_Sotala · 2012-10-12T05:48:36.038Z · LW(p) · GW(p)
Being able to read off patterns of conditional dependence and independence is an art known as "D-separation", and if you're good at it you can glance at a diagram like this...
In order to get better at this, I recommend downloading and playing around with UnBBayes. Here's a brief video tutorial of the basic usage. The program is pretty buggy - for example, sometimes it randomly refuses to compile a file and then starts working after I close the file and reopen it - but that's more of a trivial inconvenience than a major problem.
What's great about UnBBayes is that it allows you to construct a network and then show how the probability flows around it; you can also force some variable to be true or false and see how this affects the surrounding probabilities. For example, here I've constructed a copy of the "Season" network from the post, filled it with conditional probabilities I made up, and asked the program to calculate the overall probabilities. (This was no tough feat - it took me maybe five minutes, most of which I spent on making up the probabilities.)
http://kajsotala.fi/Random/UnBBayesExample1.png
Let's now run through Eliezer's explanation:
...and see that, once we already know the Season
So, we know the season: let's say that we know it's fall. I tell the program to assume that it's fall, and ask it to propagate the effects of this throughout the network. We can see how this changes the probabilites of the different variables:
http://kajsotala.fi/Random/UnBBayesExample2.png
whether the Sprinkler is on and whether it is Raining are conditionally independent of each other - if we're told that it's Raining we conclude nothing about whether or not the Sprinkler is on.
The wording here is a little ambiguous, but Eliezer's saying that with our knowledge of the season, the variables of "Sprinkler" and "Rain" have become independent. Finding out that it rains shouldn't change the probability of the sprinkler being on. Let's test this by setting it to rain and again propagating the effects:
http://kajsotala.fi/Random/UnBBayesExample3.png
And indeed, the probability of it being wet increased, but the probability of the sprinkler being on didn't change.
But if we then further observe that the sidewalk is Slippery, then Sprinkler and Rain become conditionally dependent once more, because if the Sidewalk is Slippery then it is probably Wet and this can be explained by either the Sprinkler or the Rain but probably not both, i.e. if we're told that it's Raining we conclude that it's less likely that the Sprinkler was on.
So let's put the sidewalk to "slippery", and unset "rain" again. I've defined the network so that the sidewalk is never slippery unless it's wet, so setting the sidewalk to "slippery" forces the probability of "wet" to 100%.
http://kajsotala.fi/Random/UnBBayesExample4.png
Now let's see the effect on probabilities if we set it to rain - as Eliezer predicted, the probability of the sprinkler then goes down:
http://kajsotala.fi/Random/UnBBayesExample5.png
And vice versa, if we force the sprinkler to be on, the probability of it raining goes down:
http://kajsotala.fi/Random/UnBBayesExample6.png
(It occurs to me that even if the sidewalk wasn't wet, it could be slippery if it was covered by leaves, or with ice. So there should actually be an arrow from "season" to "slippery". That would be trivial to add.)
Another great thing about UnBBayes is that it not only helps you understand the direction of the probability flows, but also the magnitude of different kinds of changes. Depending on how you've set up the conditional probabilities, a piece of information can have a huge impact on another variable (the sidewalk being slippery always forces the probability of "wet" to 100%, regardless of anything else), or a rather minor one (when we already knew that it was fall and slippery, finding out that it rained only budged the probability of the sprinkler by about five percentage points). Eventually, the logic starts to become intuitive.
Build your own networks and play around with them!
Replies from: lukeprog, gwern↑ comment by lukeprog · 2012-10-12T08:09:59.467Z · LW(p) · GW(p)
Nice.
I still want somebody to write a full tutorial on UnBBayes for LW.
Replies from: Kaj_Sotala, Dr_Manhattan↑ comment by Kaj_Sotala · 2012-10-12T11:59:21.602Z · LW(p) · GW(p)
That's where I originally found the program. :-)
If you link to that post, you should also update it to mention that I've already written some of those. (#3, #9, #10)
Replies from: lukeprog↑ comment by Dr_Manhattan · 2012-10-13T14:19:32.413Z · LW(p) · GW(p)
- There is also the more mature GenIe http://genie.sis.pitt.edu/ with extensive documentation here http://genie.sis.pitt.edu/wiki/GeNIe_Documentation (more mature documentation with more functionality)
=====================
ETA. Oops, forgot to add the above is windows-only. For "other" there is SamIAm http://reasoning.cs.ucla.edu/samiam/, with documentation/tutorials here http://reasoning.cs.ucla.edu/samiam/help/

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
comment by Daniel_Burfoot · 2012-10-12T17:57:56.158Z · LW(p) · GW(p)
After reading this post I was stunned. Now I think the central conclusion is wrong, though I still think it is a great post, and I will go back to being stunned if you convince me the conclusion is correct.
You've shown how to identify the correct graph structure from the data. But you've erred in assuming that the directed edges of the graph imply causality.
Imagine you did the same analysis, except instead of using O="overweight" you use W="wears size 44 or higher pants". The data would look almost the same. So you would reach an analogous conclusion: that wearing large pants causes one not to exercise. This seems obviously false unless your notion of causality is very different from mine.
In general, I think the following principle holds: inferring causality requires an intervention; it cannot be discovered from observational data alone. A researcher who hypothesized that W causes not-E could round up a bunch of people, have half of them wear big pants, observe the effect of this intervention on exercise rates, and then conclude that there is no causal effect.
Replies from: IlyaShpitser, Houshalter, matthew-milone, jimrandomh↑ comment by IlyaShpitser · 2012-10-12T20:45:39.980Z · LW(p) · GW(p)
You are correct -- directed edges do not imply causality by means of only conditional independence tests. You need something called the faithfulness assumption, and additional (causal) assumptions, that Eliezer glossed over. Without causal assumptions and with only faithfulness, all you are recovering is the structure of a statistical, rather than a causal model. Without faithfulness, conditional independence tests do not imply anything. This is a subtle issue, actually.
There is no magic -- you do not get causality without causal assumptions.
Replies from: eurg↑ comment by eurg · 2012-10-20T22:55:55.632Z · LW(p) · GW(p)
Is this another variation of the theme that one needs to assume the possibility of inductive reasoning to make an argument for it (or also assume Occam's Razor to argue for it)? Also, the specific example he gave seems to me like an instance of "given very skewed data, the best guesses are still wrong" (there was sometime a variation of that here, regarding bets and opponents who have superior information). Or are you thinking of something for subtle?
Replies from: IlyaShpitser↑ comment by IlyaShpitser · 2012-10-31T18:24:10.226Z · LW(p) · GW(p)
Even if you assume that we can do induction (and assume faithfulness!), conditional independence tests simply do not select among causal models. They select among statistical models, because conditional independences are properties of joint distributions (statistical, rather than causal objects). Linking those joint distributions with something causal relies on causal assumptions.
I think the biggest lesson to learn from Pearl's book is to keep statistical and causal notions separate.
Replies from: eurg↑ comment by Houshalter · 2015-08-19T00:33:55.940Z · LW(p) · GW(p)
He addressed that in the third footnote.
Or there might be some hidden third factor, a gene which causes both fat and non-exercise. By Occam's Razor this is more complicated and its probability is penalized accordingly, but we can't actually rule it out. It is obviously impossible to do the converse experiment where half the subjects are randomly assigned lower weights, since there's no known intervention which can cause weight loss.
The model assumes that those are the only relevant variables. Given that assumption, we can prove that weight causes exercise. And that it can't be the other way around.
If there are unobserved variables, it's possible that they can cause weight and cause exercise. However that wasn't one of the hypotheses anyone believed beforehand; they were arguing whether weight causes exercise or if exercise causes weight.
Second, even if there is an unobserved variable, it still suggests that exercising more will not improve your weight. Otherwise internet use would correlate with weight. Because internet use affects exercise. If exercise affected weight at all, then internet use would indirectly cause weight gain, and therefore correlate with it.
The whole point of the article is about this trick. Where taking a weird and unrelated variable like internet use, lets us discover the direction of causation. Which according to common knowledge about statistics, shouldn't be possible. Not without randomized controlled experiments.
↑ comment by Matt Vincent (matthew-milone) · 2022-06-14T13:43:42.692Z · LW(p) · GW(p)
I'm sorry if I'm just being too much of a dodo to perceive the mystery, but your scenario seems easily accounted for. You can use a Bayesian network to infer causality if and only if you have valid data to fill it with. Of course wearing large pants does not cause one not to exercise, but no real set of data would indicate that it did. Am I missing something?
EDIT: shortly after writing this, I read up on faithfulness and Milton Friedman's thermostat, so the "if and only if" part of my comment isn't quite accurate. Still, the pants size scenario doesn't seem like one of these exceptional cases.
↑ comment by jimrandomh · 2012-10-12T18:14:52.819Z · LW(p) · GW(p)
In this case, the true structure would be O->E, O->W, I->E. If O is unobserved, then you confuse a fork for an arrow, but I'm not sure you can actually get an arrow pointing the wrong way just by omitting variables.
comment by selylindi · 2012-10-12T16:37:09.124Z · LW(p) · GW(p)
(summary)
Correlation does not imply causation,
but
causation implies correlation,
and therefore
no correlation implies no causation
...which permits the falsification of some causal theories based on the absence of certain correlations.
Replies from: teageegeepea, IlyaShpitser, army1987↑ comment by teageegeepea · 2012-10-12T17:49:37.607Z · LW(p) · GW(p)
What about Milton Friedman's thermostat?
Replies from: AlanCrowe, None, MoritzG, Caspian, selylindi↑ comment by AlanCrowe · 2012-10-12T20:58:53.497Z · LW(p) · GW(p)
Computation, Causation, & Discovery starts with an overview chapter provided by Gregory Cooper
The hope that no correlation implies no causation is referred to as the "causal faithfulness assumption".
While the faithfulness assumption is plausible in many circumstances, there are circumstances in which it is invalid.
Cooper discusses out Deterministic relationships and Goal-oriented systems as two examples where it is invalid.
I think that causal discovery literature is aware of Milton Friedman's thermostat and knows it by the name "Failure of causal faithfulness in goal oriented systems"
↑ comment by [deleted] · 2012-10-15T09:18:52.961Z · LW(p) · GW(p)
That post is slow to reach its point and kind of abrasive. Here's summary with a different flavor.
Output is set by some Stuff and a Control signal. Agent with full power over Control and accurate models of Output and Stuff can negate the influence of Stuff, making Output whatever it wants, within the range of possible Outputs given Stuff. Intuitively Agent is setting Output via Control, even though there won't be a correlation if Agent is keeping Output constant. I'm not so sure whether it still makes sense to say, even intuitively, that Stuff is a causal parent of Output when the agent trumps it.
Then we break the situation a little. Suppose a driver is keeping a car's speed constant with a gas pedal. You can make the Agent's beliefs inaccurate (directly, by showing the driver a video of an upcoming hill when there is none in front of the car, or by intervening on Stuff, like introducing a gust of wind the driver can't see, and then just not updating Agent's belief). Likewise you can make Agent partially impotent (push down the driver's leg on the gas pedal, give them a seizure, replace them with an octopus). Finally you can change what apparent values and causal relations the agent wants to enforce ("Please go faster").
And those are maybe how you test for consequentialist confounding in real life? You can set environment variables if the agent doesn't anticipate you, or you can find that agent and make them beleive noise, break their grasp on your precious variables, or change their desires.
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2012-10-15T10:40:25.084Z · LW(p) · GW(p)
"Milton Friedman's thermostat" is an excellent article (although most of the comments are clueless). But some things about it bear emphasising.
Output is set by some Stuff and a Control signal.
Yes.
Agent with full power over Control and accurate models of Output and Stuff can negate the influence of Stuff
No. Control systems do not work like that.
All the Agent needs to know is how to vary the Output to bring the thing to be controlled towards its desired value. It need not even be aware of any of the Stuff. It might or might not be helpful, but it is not necessary. The room thermostat does not: it simply turns the heating on when the temperature is below the set point and off when it is above. It neither knows nor cares what the ambient temperature is outside, whether the sun is shining on the building, how many people are in the room, or anything at all except the sensed temperature and the reference temperature.
You can make the Agent's beliefs inaccurate (directly, by showing the driver a video of an upcoming hill when there is none in front of the car, or by intervening on Stuff, like introducing a gust of wind the driver can't see, and then just not updating Agent's belief).
If you try to keep the speed of your car constant by deliberately compensating for the disturbances you can see, you will do a poor job of it. The Agent does not need to anticipate hills, and wind is invisible from inside a car. Instead all you have to do -- and all that an automatic cruise control does -- is measure the actual speed, compare it with the speed you want, and vary the accelerator pedal accordingly. The cruise control does not sense the gradient, head winds, tail winds, a dragging brake, or the number of passengers in the car. It doesn't need to. All it needs to do is sense the actual and desired speeds, and know how to vary the flow of fuel to bring the former closer to the latter. A simple PID controller is enough to do that.
This concept is absolutely fundamental to control systems. The controller can function, and function well, while knowing almost nothing. While you can design control systems that do -- or attempt to do -- the things you mention, sensing disturbances and computing the outputs required to counteract them, none of that is a prerequisite for control. Most control systems do without such refinements.
Replies from: None↑ comment by [deleted] · 2012-10-15T15:38:56.799Z · LW(p) · GW(p)
I'm familiar with feedback control and I've used PID controlers in the design of servo-hydraulic systems. That wasn't the situation the blog post described. If you have delays, or hysteresis, or any other reason for a non-zero impulse response, you lose the vanishing correlations which made the problem interesting.
↑ comment by MoritzG · 2019-12-12T18:53:10.301Z · LW(p) · GW(p)
There are two issues with it.
You can not figure out how something works by only looking at some aspect. Think of the blind people and elephant story.
But it still has a point because with a subsystem that makes predictions the understanding of a system by pure observation becomes impossible.
↑ comment by Caspian · 2012-10-14T06:11:29.574Z · LW(p) · GW(p)
Good point. And here's a made-up parallel example to that about weight/exercise:
Suppose level of exercise can influence weight (E -> W), and that being underfed reduces weight (U->W) directly but will also reduce the amount of exercise people do (U->E) by an amount where the effect of the reduced exercise on weight exactly cancels out the direct weight reduction.
Suppose also there is no random variation in amount of exercise, so it's purely a function of being underfed.
If we look at data generated in that situation, we would find no correlation between exercise and weight. Examining only those two variables we might assume no causal relation.
Adding in the third variable, would find a perfect correlation between (lack of) exercise and underfeeding. Implications of finding this perfect correlation: you can't tell if the causal relation between them should be E->U or U->E. And even if you somehow know the graph is (E->W), (U->E) and (E->W), there is no data on what happens to W for an underfed person who exercise, or a well-fed person who doesn't exercise, so you can't predict the effect of modifying E.
Replies from: Eugine_Nier↑ comment by Eugine_Nier · 2012-10-14T18:15:31.121Z · LW(p) · GW(p)
but will also reduce the amount of exercise people do (U->E) by an amount where the effect of the reduced exercise on weight exactly cancels out the direct weight reduction.
It's unlikely that two effects will randomly cancel out unless the situation is the result of some optimizing process. This is the case in Milton Friedman's thermostat but doesn't appear to be the case in your example.
Replies from: scav, Caspian↑ comment by scav · 2012-10-15T11:46:42.693Z · LW(p) · GW(p)
It wouldn't be random. It would be an optimising process, tuned by evolution (another well known optimising process). If you have less food than needed to maintain your current weight, expend less energy (on activities other than trying to find more food). For most of our evolution, losing weight was a personal existential risk.
↑ comment by Caspian · 2012-10-15T12:35:52.469Z · LW(p) · GW(p)
I had meant to suggest some sort of unintelligent feedback system. Not coincidence, but also not an intelligent optimisation, so still not an exact parallel to his thermostat.
Replies from: Eugine_Nier↑ comment by Eugine_Nier · 2012-10-16T03:55:59.506Z · LW(p) · GW(p)
The thermostat was created by an intelligent human.
I never said the optimizing process had to be that intelligent, i.e., the blind-idiot-god counts.
↑ comment by selylindi · 2012-10-12T18:27:53.313Z · LW(p) · GW(p)
Studies can always have confounding factors, of course. And I wrote "falsification" but could have more accurately said something about reducing the posterior probability. Lack of correlation (e.g. with speed) would sharply reduce the p.p. of a simple model with one input (e.g. gas pedal), but only reduce the p.p. of a model with multiple inputs (e.g. gas pedal + hilly terrain) to a weaker extent.
Replies from: IlyaShpitser↑ comment by IlyaShpitser · 2012-10-12T21:04:42.561Z · LW(p) · GW(p)
By the way, you can still learn structure from data in the presence of unobserved confounders. The problem becomes very interesting indeed, then.
Replies from: selylindi↑ comment by selylindi · 2012-10-15T02:19:28.654Z · LW(p) · GW(p)
Oh, awesome. Can you provide a link / reference / name of what I should Google?
Replies from: IlyaShpitser↑ comment by IlyaShpitser · 2012-10-15T03:38:34.906Z · LW(p) · GW(p)
http://www.hss.cmu.edu/philosophy/spirtes/n-oracle.ps
(FCI algorithm)
http://www.cs.huji.ac.il/~nir/Abstracts/Fr2.html
(structural EM)
http://www.stat.washington.edu/tsr/uai-causal-structure-learning-workshop/
(look for "parameter and structure learning in nested Markov models")
↑ comment by IlyaShpitser · 2012-10-12T21:03:38.873Z · LW(p) · GW(p)
No correlation only implies no causation if a certain assumption called "faithfulness" is true, not in general.
Replies from: lukeprog↑ comment by lukeprog · 2013-03-26T07:09:31.591Z · LW(p) · GW(p)
Might you be willing to explain for the rest of us what the "faithfulness assumption" is, and why it's needed for "no correlation" to imply "no causation"? I'd appreciate it.
Replies from: IlyaShpitser↑ comment by IlyaShpitser · 2013-03-26T16:45:16.050Z · LW(p) · GW(p)
Absolutely! In a typical Bayesian network, we represent a set of probability distributions by a directed acyclic graph, such that any distribution in the set can be written as
in other words, for every random variable in the distribution we associate a node in the graph, and the distribution can be factorized into a product of conditional densities, where each conditional is a variable (node) conditional on variables corresponding to parents of the node.
This implies that if certain types of paths in the graph from a node set X to a node set Y are "blocked" in a particular way (e.g. d-separated) by a third set Z, then in all densities that factorize as above, X is independent of Y conditional on Z. Note that this implication is one way. In particular, we can still have some conditional independence that just happens to hold because the numbers in the distribution lined up just right, and the graph does not in fact advertise this independence via d-separation. When this happens, we say the distribution is unfaithful to the graph.
If we pick parameters of a distribution that factorizes at random then almost all parameter picks will be faithful to the graph. However, lots of distributions are "near unfaithful", that is they are faithful, but it's hard to tell with limited samples. Moreover, we can't tell in advance how many samples we need to tell. Also, it's easy to construct faithfulness violations and they do occur in practice. For example, we may have an AIDS drug that suppresses the HIV (so it really does help!), but the drug is very nasty, with lots of side effects and so on, so doctors usually wait until the patient is already very sick before giving the drug. If we then look at associations between instances of the use of this drug we may well find that those who take the drug either die more (positive association of drug with death!) or don't die less frequently than those without the drug (no association of drug with death!).
Does this then mean the drug has a bad effect or no effect? No! It just means there is an obvious confounder of health status that we aren't recording. In the second case, this confounder is causing the distribution over drug and death to be "unfaithful": there is an arrow from drug to death, but there is no dependence of death on drug. And yet there is still a causal effect.
Note: I am glossing over some distinctions between a Bayesian network and a causal model in order to not muddy the discussion. What is important to note is that: (a) A Bayesian network is not a graphical causal model, but (b) a graphical causal model induces a Bayesian network on the observable data. Faithfulness (or lack of it) applies to the network appearing due to (b), and thus affects causal reasoning in the underlying causal model.
Replies from: lukeprog↑ comment by lukeprog · 2013-03-26T18:24:42.307Z · LW(p) · GW(p)
Thanks!
This seems like a big problem for inferring "no causation" from "no correlation." Is there a standard methodological solution? And, do researchers often just choose to infer "no causation" from "no correlation" and hope for the best, or do they avoid inferring "no causation" from "no correlation" due to the fact that they can't tell whether the faithfulness assumption holds?
Replies from: IlyaShpitser, Kawoomba↑ comment by IlyaShpitser · 2013-03-26T19:23:30.405Z · LW(p) · GW(p)
Well, in some sense this is why causal inference is hard. Most of the time if you see independence that really does mean there is nothing there. The reasonable default is the null hypothesis: there is no causal effect. However, if you are poking around because you suspect there is something there, then not seeing any correlations does not mean you should give up. What it does mean is you should think about causal structure and specifically about confounders.
What people do about confounders is:
(a) Try to measure them somehow (epidemiology, medicine). If you can measure confounders you can adjust for them, and then the effect cancellation will go away.
(b) Try to find an instrumental variable (econometrics). If you can find a good instrument, you can get a causal effect with some parametric assumptions, even if there are unmeasured confounders.
(c) Try to randomize (statistics). This explicitly cuts out all confounding.
(d) You can sometimes get around unmeasured confounders by using strong mediating variables by means of "front-door" type methods. These methods aren't really well known, and aren't commonly used.
There is no royal road: getting rid of confounders is the entire point of causal inference. People have been thinking of clever ways to do it for close to a hundred years now. If you have infinite samples, and know where unobserved confounding is, there is an algorithm for getting the causal effect from observational data by being sneaky. This algorithm only succeeds sometimes, and if it doesn't, there is no other way in general to do it (e.g. it's "complete"). More in my thesis, if you are curious.
Replies from: lukeprog, Richard_Kennaway, Kawoomba↑ comment by lukeprog · 2013-03-26T22:52:20.715Z · LW(p) · GW(p)
Thanks again.
One more question, since this is your field. Do you happen to know of an instance where some new causal effect was discovered from observational data via causal modeling, and this cause was later confirmed by an RCT?
Replies from: IlyaShpitser↑ comment by IlyaShpitser · 2013-03-26T23:26:33.947Z · LW(p) · GW(p)
Well, I think smoking/cancer was first established in case control studies. In general people move up the "hierarchy of evidence" Kawoomba mentioned. At the end of the day, people only trust RCTs (and they are right, other methods rely on more assumptions). There is another good example, but let me double check before posting.
With case control studies you have the additional problem of selection bias, on top of confounding.
Replies from: gwern↑ comment by gwern · 2013-03-27T00:51:44.709Z · LW(p) · GW(p)
I thought there were still no actual RCTs of smoking in humans.
Replies from: IlyaShpitser↑ comment by IlyaShpitser · 2013-03-27T00:55:27.888Z · LW(p) · GW(p)
Right, you can't always RCT in humans. But a causal mechanism + RCTs in animals biologically close to humans is convincing for something like lung cancer where minor differences among mammals shouldn't matter much (although e.g. bears have evolved some crazy stuff to deal with all that fat they eat before hibernating).
Replies from: gwern↑ comment by gwern · 2013-03-27T01:58:55.189Z · LW(p) · GW(p)
where minor differences among mammals shouldn't matter much
I think you are entirely optimistic. I recently pointed out that the research indicates that animal studies routinely (probably usually) do not transfer, and as it happens, animal smoking studies are an example of this, according to Hanson. So the differences are often far from minor, and even if there were cancer in the animal studies, we could infer very little from it.
Replies from: IlyaShpitser, IlyaShpitser↑ comment by IlyaShpitser · 2013-03-27T02:52:15.287Z · LW(p) · GW(p)
Out of curiosity, do you smoke?
Replies from: gwern↑ comment by IlyaShpitser · 2013-03-27T18:42:22.263Z · LW(p) · GW(p)
I find much to agree with in Hanson's writings, but in this case I just don't find him convincing. One issue is that cancer is a scourge of a long-living animal. One hypothesis is that smoking causes long term cumulative damage, and you might not see effects in mice or dogs because they die too soon regardless. There is also the issue that we have a fair idea of the carcinogenic mechanism now, so if you think smoking does not cause harm, there also needs to be a story how that mechanism is foiled in humans.
Replies from: Vaniver, gwern↑ comment by Vaniver · 2013-03-27T20:07:52.202Z · LW(p) · GW(p)
I find much to agree with in Hanson's writings, but in this case I just don't find him convincing.
His interpretation, or his evidence? I point this out because it looks to me like your position has shifted from "the smoking / lung cancer link is established by RCTs in animals" to "even though RCTs don't establish the smoking / lung cancer link for animals, we have other reasons to believe in the smoking / lung cancer link for humans."
↑ comment by gwern · 2013-03-27T20:05:51.219Z · LW(p) · GW(p)
I find much to agree with in Hanson's writings, but in this case I just don't find him convincing...One hypothesis is that smoking causes long term cumulative damage, and you might not see effects in mice or dogs because they die too soon regardless.
So: heads I win, tails you lose? If the studies had found smoking caused cancer in animals, well, that proves it! And if they don't, well, that just means they didn't run long enough so we can ignore them and say we "just don't find them convincing"...
There is also the issue that we have a fair idea of the carcinogenic mechanism now, so if you think smoking does not cause harm, there also needs to be a story how that mechanism is foiled in humans.
You don't think there were plenty of 'fair ideas' of mechanisms floating around in the thousands of animal studies and interventions covered in my animal studies link? Any researcher worth his degree can come up with a plausible ex post explanation.
↑ comment by Richard_Kennaway · 2013-03-27T14:59:48.470Z · LW(p) · GW(p)
This algorithm only succeeds sometimes, and if it doesn't, there is no other way in general to do it (e.g. it's "complete"). More in my thesis, if you are curious.
Your thesis deals only with acyclic causal graphs. What is the current state of the art for cyclic causal graphs? You'll know already that I've been looking at that, and I have various papers of other people that attempt to take steps in that direction, but my impression is that none of them actually get very far and there is nothing like a set of substantial results that one can point to. Even my own, were they in print yet, are primarily negative.
Replies from: IlyaShpitser↑ comment by IlyaShpitser · 2013-03-27T16:27:57.914Z · LW(p) · GW(p)
The recent stuff I have seen is negative results:
(a) Can't assign Pearlian semantics to cyclic graphs.
(b) If you assign equilibrium semantics, you might as well use a dynamic causal Bayesian network, a cyclic graph does not buy you anything.
(c) A graph representing the Markov property of the equilibrium distribution of a Markov chain represented by a causal DBN is an interesting open question. (This graph wouldn't have a causal interpretation of course).
↑ comment by Kawoomba · 2013-03-26T19:45:00.255Z · LW(p) · GW(p)
As far as I can tell, epidemiology and medicine are mostly doing (c), in the form of RCTs (which are the gold standard of medical evidence, other than meta-reviews). There are other study designs such as most variants of case-control studies and cohort studies which do take the (a) approach, but they aren't considered to be the same level of evidence as randomized controlled trials.
Replies from: IlyaShpitser↑ comment by IlyaShpitser · 2013-03-26T20:27:07.144Z · LW(p) · GW(p)
but they aren't considered to be the same level of evidence as randomized controlled trials.
Quite rightly -- if we randomize, we don't care what the underlying causal structure is, we just cut all confounding out anyways. Methods (a), (b), (d) all rely on various structural assumptions that may or may not hold. However, even given those assumptions figuring out how to do causal inference from observational data is quite difficult. The problem with RCTs is expense, ethics, and statistical power (hard to enroll a ton of people in an RCT).
Epidemiology and medicine does a lot of (a), look for the keywords "g-formula", "g-estimation", "inverse probability weighting," "propensity score", "marginal structural models," "structural nested models", "covariate adjustment," "back-door criterion", etc. etc.
People talk about "controlling for other factors" when discussing associations all the time, even in non-technical press coverage. They are talking about (a).
Replies from: Kawoomba↑ comment by Kawoomba · 2013-03-26T21:02:27.988Z · LW(p) · GW(p)
People talk about "controlling for other factors" when discussing associations all the time, even in non-technical press coverage. They are talking about (a).
True, true. "Gold standard" or "preferred level of evidence" versus "what's mostly conducted given the funding limitations". However, to make it into a guideline, there are often RCT follow-ups for hopeful associations uncovered by the lesser study designs.
look for the keywords "g-formula", "g-estimation", "inverse probability weighting," "propensity score", "marginal structural models," "structural nested models", "covariate adjustment," "back-door criterion", etc. etc.
I, of course, know all of those. The letters, I mean.
↑ comment by A1987dM (army1987) · 2012-10-12T20:36:37.745Z · LW(p) · GW(p)
That only works if by correlation you mean any kind of statistic dependence -- Pearson's correlation coefficient does vanish for certain relationships if they're non-monotonic.
comment by [deleted] · 2012-10-13T00:25:56.540Z · LW(p) · GW(p)
Pretty good overall, but downvoted due to the inflammatory straw-manning of the physics diet. That kind of sloppy thinking just makes me think you have big blind-spots in your rationality. Maybe it's wrong, but it really has nothing to do with virtue or should-universes. To suggest otherwise is dishonest and rude. I usually don't care about rude, but this pissed me off.
I strongly agree with Vaniver's take
Replies from: wedrifid↑ comment by wedrifid · 2012-10-13T06:26:12.817Z · LW(p) · GW(p)
Pretty good overall, but downvoted due to the inflammatory straw-manning of the physics diet. That kind of sloppy thinking just makes me think you have big blind-spots in your rationality. Maybe it's wrong, but it really has nothing to do with virtue or should-universes. To suggest otherwise is dishonest and rude. I usually don't care about rude, but this pissed me off.
I have to admit it seemed entirely the wrong place for Eliezer to be dragging up his health issues. I find it really hard to keep reading a post once it starts throwing out petulant straw men. It's a shame because causality and inference is something Eliezer does probably knows something about.
comment by simplicio · 2012-10-14T03:03:10.534Z · LW(p) · GW(p)
I recall reading some lovely quote on this (from somebody of the old camp, who believed that talk of 'causality' was naive), but I couldn't track it down in Pearl or on Google - if anyone knows of a good quote from the old school, may it be provided.
Maybe it's this one?
The law of causality, I believe, like much that passes muster among philosophers, is a relic of a bygone age, surviving, like the monarchy, only because it is erroneously supposed to do no harm. (Russell, 1913, p. 1).
It should be noted that Russell later reversed his skepticism about causality.
Replies from: Eugine_Nier, Eliezer_Yudkowsky↑ comment by Eugine_Nier · 2012-10-14T18:34:02.581Z · LW(p) · GW(p)
The law of causality, I believe, like much that passes muster among philosophers, is a relic of a bygone age, surviving, like the monarchy, only because it is erroneously supposed to do no harm.
Outside view: Consider the sentence
[X], I believe, like much that passes muster among philosophers, is a relic of a bygone age, surviving, like the monarchy, only because it is erroneously supposed to do no harm.
there are a number of words that could replace X in that sentence to produce something that would be considered a standard LW position. Are we making a similar mistake, i.e., assuming that just because we don't yet have a satisfactory theory of X that no such theory can exist?
Replies from: TheOtherDave, wedrifid↑ comment by TheOtherDave · 2012-10-14T18:45:08.914Z · LW(p) · GW(p)
Are we making a similar mistake, i.e., assuming that just because we don't yet have a satisfactory theory of X that no such theory can exist?
Our inability to come up with a plausible-sounding theory of X is not especially strong evidence for the absence of X, agreed.
Still less, though, is it evidence for the presence of X.
Especially if the work a theory of X is supposed to do can be done without a theory of X, or turn out not to be necessary in the first place.
Replies from: Eugine_Nier↑ comment by Eugine_Nier · 2012-10-16T04:09:16.338Z · LW(p) · GW(p)
Still less, though, is it evidence for the presence of X.
Agreed, the evidence for the presence of X is that humans have been talking about it for a long time and seem to mean something.
Especially if the work a theory of X is supposed to do can be done without a theory of X, or turn out not to be necessary in the first place.
Careful, it's very easy to convince oneself that one doesn't need a theory of X when one is actually hiding X behind cached thoughts and sneaked in connotations. For example, Russell no doubt believed that he didn't need a theory of causality to do the work the theory of causality was supposed to do.
Replies from: TheOtherDave↑ comment by TheOtherDave · 2012-10-17T16:15:48.050Z · LW(p) · GW(p)
Absolutely. If I fail to notice how the work is actually being done, I will likely have all kinds of false beliefs about that work.
↑ comment by wedrifid · 2012-10-14T18:39:42.597Z · LW(p) · GW(p)
there are a number of words that could replace X in that sentence to produce something that would be considered a standard LW position. Are we making a similar mistake, i.e., assuming that just because we don't yet have a satisfactory theory of X that no such theory can exist?
And many more words that could replace X in the sentence that wouldn't be a standard position but just aren't mentioned because only the relatively few differences are even worth commenting on.
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2013-03-31T23:44:39.013Z · LW(p) · GW(p)
Added.
comment by DavidAgain · 2012-10-13T09:23:32.990Z · LW(p) · GW(p)
This is absolutely incredible. As a broadly numerate person who's never studied stats, I literally did not know that this could be done and while I'd heard about ways to work out what caused what from statistical information I thought they had to have far more assumptions in them. I'm slightly distressed that I studied A level Maths and don't know this, given that the concept at least can be taught in twenty minutes judging by the post and is massively open to testing (I thought this post didn't make sense at first and that there were other interpretations of the data, but when I expressed those in the terminology set out it because clear I was wrong.
Seriously, thanks.
comment by A1987dM (army1987) · 2012-10-12T14:44:12.524Z · LW(p) · GW(p)
I saw no discernible effect on my weight or my musculature
How did you ascertain possible effects on your musculature? If you used the inter-ocular trauma test, keep in mind that gradual changes in something you look at every day (e.g. yourself, a roommate, or a classmate/coworker) are much harder to discern that way. Did you try asking someone who hadn't seen you in a while, or comparing two photos of you taken a couple months apart?
Replies from: Jonathan_Graehl↑ comment by Jonathan_Graehl · 2012-10-13T19:28:38.791Z · LW(p) · GW(p)
Yes, his N=1 seems atypical, but it's true that those who don't enjoy physical activity, don't sustain it (usually the virtuous, or obsessive, cycle closes only after making enough progress and/or caring desperately about appearance to overcome the initial resistance). Also, overweight people shouldn't run on hard surface, or at all.
His observation "only those who find exercise possible or rewarding report regularly exercising" is indeed powerful, obvious, and neglected. There's a prevailing imputation of virtue to physical fitness and sloth to those who lack it, so real thinking is scarce.
Replies from: army1987↑ comment by A1987dM (army1987) · 2012-10-14T09:10:00.726Z · LW(p) · GW(p)
Yes, his N=1 seems atypical,
He said he exercised for a year, so I don't think not-exercising-enough was the reason he (thinks he) didn't gain muscle.
it's true that those who don't enjoy physical activity, don't sustain it (usually the virtuous, or obsessive, cycle closes only after making enough progress and/or caring desperately about appearance to overcome the initial resistance)
comment by lubinas · 2024-01-24T12:51:23.696Z · LW(p) · GW(p)
By the pigeonhole principle (you can't fit 3 pigeons into 2 pigeonholes) there must be some joint probability distributions which cannot be represented in the first causal structure
Although this is a valid interpretation of the Pigeonhole Principle (PP) for some particular one-to-one cases, I think it misses the main point of it as relates to this particular example. You absolutely can fit 3 Pigeons into 2 Pigeonholes, and the standard (to my knowledge) intended takeaway from the PP is that you are gonna have to, if you want your pigeons holed. There might just not be a cute way to do it.
The idea being that in finite sets and with there is no injective from to (you could see this as losing information); but you absolutely can send things from to , you just have to be aware that at least two originally (in ) different elements are going to be mapped onto the same element in . This is an issue of losing uniqueness in the representation, not impossibility of the representation itself. It is even useful sometimes.
A priori, it looks possible for a function to exist by which two different joint distributions would be mapped into the same causal structure in some nice, natural or meaningful way, in the sense that only related-in-some-cute-way joined distributions would share the same representation. If there are no such natural functions, there are definitely ugly ones. You can always cram all your pigeons in the first pigeonhole. They are all represented!
On the other hand, the full joint probability distribution would have 3 degrees of freedom - a free choice of (earthquake&recession), a choice of p(earthquake&¬recession), a choice of p(¬earthquake&recession), and then a constrained p(¬earthquake&¬recession) which must be equal to 1 minus the sum of the other three, so that all four probabilities sum to 1.0.
If you get to infinite stuff, it gets worse. You actually can inject into (or in this case —three degrees of freedom— into — two degrees —), meaning that not only can you represent every 3D vector in 2D (wich we do all the time), but there are particular representations that wont be lossy, with every 3D object being uniquely represented. You won't lose that information! (the operative term here being that. You are most definitely losing something).
If you substitute and for and , to account for the fact that you are working in probabilities, this is still true.
So, assuming there are infinitely many things to account for in the Universe, you would be able to represent the joint distribution as causal diagrams uniquely. If there aren't, you may be able to group them following "nice" relationships. If you can't do that, you can always cram them willy neely. There is no need for a joint distribution to not be represented. I'm not sure how this affects the following
This means the first causal structure is falsifiable; there's survey data we can get which would lead us to reject it as a hypothesis
Seemed weird to me that this hasn't been pointed out (after a rather superficial look at the comments), so I'm pretty sure that either I'm missing something and there are already 2-3 similarly wrong, refuted comments on this , or this has actually been talked about already and I just haven't seen it.
Edit: Just realized, in
If you substitute and for and , to account for the fact that you are working in probabilities, this is still true.
should be the 1-norm unit balls from and , and , so all the components sum up to 1, instead of the . Pretty sure the injection still holds.
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2024-01-24T15:08:34.449Z · LW(p) · GW(p)
None of these bijections have nice properties, though. There are bijections between R³ and R², but no continuous ones. (I'm not sure if they can even be measurable.) One might criticise Eliezer's mention of the Pigeonhole principle, but the point that he is making stands: a three-dimensional space cannot be mapped out by two real-valued parameters in any useful way. A minimal notion of "useful" here might be a local homeomorphism between manifolds, and this is clearly impossible when the dimensions are different.
Replies from: lubinas↑ comment by lubinas · 2024-01-24T17:30:35.197Z · LW(p) · GW(p)
There is a big leap between there are no X, so Y and there are no useful X (useful meaning local homeomorphisms), so Y, though. Also, local homeomorphism seem too strong a standard to set. But sure, I kind of agree on this. So let's forget about injection. Orthogonal projections seem to be very useful under many standards, albeit lossy. I'm not confident that there are no akin, useful equivalence classes in A (joint probability distributions) that can be nicely map to B (causal diagrams). Either way, the conclusion
This means the first causal structure is falsifiable; there's survey data we can get which would lead us to reject it as a hypothesis
can't be entailed from the above alone.
Note: my model of this is just balls in , so elements might not hold the same accidental properties as the ones in A and B, (if so, please explain :) ) but my underlying issue is with the actual structure of the argument.
comment by Sly · 2012-10-12T19:05:29.762Z · LW(p) · GW(p)
" [1] Somewhat to my own shame, I must admit to ignoring my own observations in this department - even after I saw no discernible effect on my weight or my musculature from aerobic exercise and strength training 2 hours a day 3 times a week, I didn't really start believing that the virtue theory of metabolism was wrong [2] until after other people had started the skeptical dogpile."
I am extremely skeptical of this portion, it would imply that Eliezer's body functions differently then literally every other person (myself included) I have ever known to make a serious attempt at working out.. 2 Hours 3 times a week? How long did you try this?
Replies from: Eliezer_Yudkowsky, gwern, V_V, Decius↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-10-12T22:11:26.933Z · LW(p) · GW(p)
About a year.
Replies from: earthwormchuck163, Sly↑ comment by earthwormchuck163 · 2012-10-12T22:15:21.378Z · LW(p) · GW(p)
Were you trying to diet at the same time? Have you ever tried exercising more without also restricting your food intake?
Also, have you ever enjoyed exercising while doing it?
Edit: Just to be clear, this isn't supposed to be advice, implicit or otherwise. I'm just curious.
↑ comment by gwern · 2012-10-12T21:29:37.592Z · LW(p) · GW(p)
I am extremely skeptical of this portion, ti would imply that Eliezer's body functions differently then literally every other person (myself included)I have ever known to make a serious attempt at working out..
Arguing from anecdote, really? Exercise resistance is a thing.
Replies from: Sly, shminux↑ comment by Sly · 2012-10-14T03:24:25.506Z · LW(p) · GW(p)
The fact that people respond to exercise differently to weight training and exercise non uniformly depending on their genetics and other factors is no big surprise. But showing no gains at all is something altogether.
I can think of several questions I would ask about the study you linked. For example: "In the combined strength-and-endurance-exercise program, the volunteers’ physiological improvement ranged from a negative 8 percent (meaning they became 8 percent less fit) " implies to me that the researchers didn't control for a host of other factors.
Anecdotes ARE data. Especially a life time of several of them all accumulating in one way.
Replies from: gwern, jslocum↑ comment by gwern · 2012-10-14T03:44:36.834Z · LW(p) · GW(p)
implies to me that the researchers didn't control for a host of other factors.
Aren't you just conceding the point right there, and admitting that in fact, there are people who will empirically see a negative or zero effect size to their exercising? Life is thought by most to be full of 'a host of other factors'...
Replies from: Sly↑ comment by Sly · 2012-10-14T05:53:33.203Z · LW(p) · GW(p)
So you think my point is that exercise is magic? If you built my position out of iron instead of straw, you might find that yes, exercise is not the ONLY important factor for fitness.
Replies from: gwern↑ comment by gwern · 2012-10-14T16:21:33.936Z · LW(p) · GW(p)
Since you seem to have forgotten what you were arguing, let us review. Eliezer wrote:
I saw no discernible effect on my weight or my musculature from aerobic exercise and strength training 2 hours a day 3 times a week
You wrote:
it would imply that Eliezer's body functions differently then literally every other person (myself included) I have ever known
And implied it must be impossible, hence Eliezer must be doing something wrong.
I linked a study showing that people 'doing it right' could see their fitness go down, empirically refuting your universalizing claim that "every other person (myself included)" would see their fitness only go up.
You then tried to wave away the study by a fully general counter-argument appealing to other factors explaining why some people could see their fitness decrease... But neither I nor Eliezer ever made an argument about what caused the exercise resistance, merely that some people would empirically see their fitness decrease or remain stable.
When I pointed this out, you smarmily replied about how I'm being unfair to you and strawmanning you, and implied that I hold theories of exercise as "magic".
Personally, I see no need to construct any 'ironmanning' of your position, since you do not yet seem to have understood that what we were saying was limited to questions of fact and not speculation about what might explain said observed fact. (What, exactly, is the ironmanning of a fact - as opposed to a theory or paradigm?)
Replies from: Sly↑ comment by Sly · 2012-10-15T03:20:17.499Z · LW(p) · GW(p)
I deny that the study had people all "doing it right". In Eliezer's case, I gave him the benefit of the doubt that he was intelligent enough to avoid obvious confounders.
If someone gets sick (for example) towards the end of the study and then shows a "negative 8 percent " fitness level then their data is crap.
If the study did not control for intensity then it is crap.
The difference between someone actually doing an effortful workout and someone just being present at the gym for a period of time is astronomical, and an extremely common occurrence.
The study had an age range from 40 and 67...
This study is garbage.
Replies from: gwern↑ comment by gwern · 2016-01-13T22:30:46.171Z · LW(p) · GW(p)
If someone gets sick (for example) towards the end of the study and then shows a "negative 8 percent " fitness level then their data is crap.
And they could have been sick at the start, as well, producing pseudo gains... You're postulating things which you have no reason to think happened to explain things that did happen; nowhere is anything indicated about that and you are arguing solely that because you dislike the results, the researchers were incompetent.
If the study did not control for intensity then it is crap.
Why should there be any control for intensity? They did an intervention; there should be a non-zero effect. If any level of exercise does not show any benefits, then you are wrong. And I guess you did not read the link, because several interventions were tested and did not show any difference in terms of exercise resistance.
The study had an age range from 40 and 67...
So? Why do you think that exercise should be entirely ineffective in people age 67? Are 40yos from a different species where exercise does not work? By examining older people, who are much less fit and much more sedentary, shouldn't the effects be even more dramatic and visible?
This study is garbage.
So, in addition to "Individual responses to combined endurance and strength training in older adults", Karavirta 2011, let me also cite "Endurance training-induced changes in insulin sensitivity and gene expression", "Individual differences in response to regular physical activity", "Effects of Exercise Training on Glucose Homeostasis: The HERITAGE Family Study", "Adverse Metabolic Response to Regular Exercise: Is It a Rare or Common Occurrence?", "Genomic predictors of trainability", "Effects of gender, age, and fitness level on response of vo2max to training in 60–71 yr olds", "Resistance to exercise-induced weight loss: compensatory behavioral adaptations", and "Cardiovascular autonomic function correlates with the response to aerobic training in healthy sedentary subjects", to name a few. (One nice thing about HERITAGE and Bouchard's earlier studies is that they recorded exercise, so spare me the 'maybe they didn't actually exercise'.) In these, too, some people don't benefit from exercise and show individual differences in exercise trainability exist.
Replies from: gwern, Sly↑ comment by gwern · 2016-06-13T03:20:58.610Z · LW(p) · GW(p)
Epstein 2014, The Sports Gene, ch6 "Superbaby, Bully Whippets, and the Trainability of Muscle", pg68:
[...description of Bouchard/HERITAGE Family Study...]
A series of studies in 2007 and 2008 at the University of Alabama-Birmingham's Core Muscle Research Laboratory and the Veterans Affairs Medical Center in Birmingham showed that individual differences in gene and satellite cell activity are critical to differentiating how people respond to weight training. Sixty-six people of varying ages were put on a four-month strength training plan-squats, leg press, and leg lifts-all matched for effort level as a percentage of the maximum they could lift. (A typical set was eleven reps at 75 percent of the maximum that could be lifted for a single rep.) At the end of the training, the subjects fell rather neatly into three groups: those whose thigh muscle fibers grew 50 percent in size; those whose fibers grew 25 percent; and those who had no increase in muscle size at all. A range from 0 percent to 50 percent improvement, despite identical training. Sound familiar? Just like the HERITAGE Family Study, differences in trainability were immense, only this was strength as opposed to endurance training. Seventeen weight lifters were "extreme responders," who added muscle furiously; thirty-two were moderate responders, who had decent gains; and seventeen were nonresponders, whose muscle fibers did not grow.* ...The Birmingham researchers took a HERITAGE-like approach in their search for genes that might predict the high satellite cell folk, or high responders, from the low responders to a program of strength training. Just as the HERITAGE and GEAR studies found for endurance, the extreme responders to strength training stood out by the expression levels of certain genes. Muscle biopsies were taken from all subjects before the training started, after the first session, and after the last session. Certain genes were turned up or down similarly in all of the subjects who lifted weights, but others were turned up only in the responders. One of the genes that displayed much more activity in the extreme responders when they trained was IGF-IEa, which is related to the gene that H. Lee Sweeney used to make his Schwarzenegger mice. The other standouts were the MGF and myogenin genes, both involved in muscle function and growth. The activity levels of the MGF and myogenin genes were turned up in the high responders by 126 percent and 65 percent, respectively; in the moderate responders by 73 percent and 41 percent; and not at all in the people who had no muscle growth.
- Bamman, Marcas M., et al. (2007). "Cluster Analysis Tests the Importance of Myogenic Gene Expression During Myofiber Hypertrophy in Humans". Journal of Applied Physiology, 102:2232-39.
- Petrella, John K., et al. (2008). "Potent Myofiber Hypertrophy During Resistance Training in Humans Is Associated with Satellite Cell-Mediated Myonuclear Addition: A Cluster Analysis". Journal of Applied Physiology, 104: 1736-42
Every similar strength-training study has reported a broad spectrum of responsiveness to iron pumping. In Miami's GEAR study, the strength gains of 442 subjects in leg press and chest press ranged from under 50 percent to over 200 percent. [108 GEAR study data was generously shared by members of the University of Miami research team.] A twelve-week study of 585 men and women, run by an international consortium of hospitals and universities, found that upper-arm strength gains ranged from zero to over 250 percent.
- Hubal, M. J., et al. (2005). "Variability in Muscle Size and Strength Gain After Unilateral Resistance Training". Medicine & Science in Sports & Exercise, 37(6):964-72
↑ comment by Sly · 2016-01-15T23:38:44.658Z · LW(p) · GW(p)
I don't even remember this conversation (4 years of necromancy?). I don't remember the context of our discussion, and it seems like I did a bad job of communicating whatever my original point was and over-exaggerated. I am pretty sure you have a better understanding of the data.
Replies from: gwern↑ comment by gwern · 2016-01-17T23:10:59.454Z · LW(p) · GW(p)
The context was whether exercise resistance was a thing that existed (and hence, whether it was something Eliezer could have). I was revisiting my old comments on the topic to grab the citations I had dug up as part of working on a section for my longevity cost-benefit analysis where I observe that given the phenomenon of exercise resistance, behavioral backlash like lowering basal activity levels, and twin studies indicating various exercise correlations are partially genetically confounded, we should be genuinely doubtful about how much exercise will help with non-athletic or cosmetic things and be demanding randomized trials.
Replies from: Lumifer↑ comment by Lumifer · 2016-01-19T17:45:30.702Z · LW(p) · GW(p)
we should be genuinely doubtful about how much exercise will help with non-athletic or cosmetic things.
First, we probably should be interested in the amount of total physical activity -- "exercise" implies additional activity besides the baseline and the baseline varies a LOT. Some people work as lumberjacks and some people only move between the couch and the fridge.
Second, as long, as we are expressing wishes about studies, I'd like those studies to focus on differences between groups of people (e.g. run some clustering) and not just smush everything together into overall averages.
Third, there is one more category besides longevity and (athletic and/or cosmetic) -- quality of life. Being fit noticeably improves it and being out of shape makes it worse.
↑ comment by jslocum · 2013-03-06T17:34:24.953Z · LW(p) · GW(p)
Anecdotes are poisonous data, and it is best to exclude them from your reasoning when possible. They are subject to a massive selection bias. At best they are useful for inferring the existence of something, e.g. "I once saw a plesiosaur in Loch Ness.". Even then the inference is tenuous because all you know is that there is at least once individual who says they saw a plesiosaur. Inferring the existence of a plesiosaur requires that you have additional supporting evidence that assigns a high probability that they are telling the truth, that their memory has not changed significantly since the original event, and that the original experience was genuine.
↑ comment by Shmi (shminux) · 2012-10-12T22:40:44.624Z · LW(p) · GW(p)
I'm wondering if there are studying controlling for exercise enjoyment, among other factors.
↑ comment by V_V · 2012-10-17T00:29:44.786Z · LW(p) · GW(p)
While there are individual differences in how fast the neuromuscular system adapts to exercise, the ability to adapt is absolutely required in order to maintain normal function. Significant abnormalities of the neuromuscular system result in disabling conditions such as muscular atrophy or muscular dystrophy.
As far ar I know, Yudkowsky is able-bodied, therefore his muscles must exibit a response to exercise within the normal healthy human range.
The fact that he attempted to train and didn't observe any significant strength increase is best explained by the hypothesis that he used an improper training regime or just didn't keep training for long enough, not by the hypothesis that he has some weird alien biology.
Replies from: wedrifid, Sly↑ comment by wedrifid · 2012-10-17T01:13:47.194Z · LW(p) · GW(p)
As far ar I know, Yudkowsky is able-bodied, therefore his muscles must exibit a response to exercise within the normal healthy human range.
Not quite. It is only implied that he responds to exercise within the range of functional survivability, not normality or healthines.
The fact that he attempted to train and didn't observe any significant strength increase
A lack of strength increase would be particularly weird. I thought the subject was weight and body composition. The most dramatic early strength increase comes from the 'neuro' part of 'neuromuscular' so lack of strength increase on a given strength related task when going from sedentary to performing said task regularly would indicate a much more significant problem than merely failing to gain significant muscle mass.
is best explained by the hypothesis that he used an improper training regime or just didn't keep training for long enough, not by the hypothesis that he has some weird alien biology.
There has been enough information provided that we can reasonably hypothesize that Eliezer's exercise response is at least a standard deviation or two in the direction of "genetically disadvantaged" on the relevant scale of exercise response.
Replies from: V_V↑ comment by V_V · 2012-10-17T09:47:29.232Z · LW(p) · GW(p)
A lack of strength increase would be particularly weird. I thought the subject was weight and body composition. The most dramatic early strength increase comes from the 'neuro' part of 'neuromuscular' so lack of strength increase on a given strength related task when going from sedentary to performing said task regularly would indicate a much more significant problem than merely failing to gain significant muscle mass.
That would imply that he has a neurological disorder that impairs motor function only up to the extent that it prevents performances to improve past the requirements of a sedentary lifestyle, but not to the extent to cause actual disability. Is anything like this documented in medical literature?
There has been enough information provided that we can reasonably hypothesize that Eliezer's exercise response is at least a standard deviation or two in the direction of "genetically disadvantaged" on the relevant scale of exercise response.
It seems to me that Yudkowsky is quite prone to rationalization: he might have started to train, didn't particularly like it and when he didn't get the results he hoped for, instead of revising his training program or keep training for a longer time, he came up with the weird genetic condition as an excuse to quit. At least, this explanation appears to be more likely than the hypothesis that he actually has a weird genetic condition unknown to science, AFAIK.
↑ comment by Decius · 2012-10-16T22:40:58.547Z · LW(p) · GW(p)
Does you actually believe in the virtue theory of metabolism, or did you believe in the conservation of energy between ATP synthesized thorough the breakdown of food nutrients being used to synthesize lipids?
There are additional confounding factors, including genetics, heredity separately from genetics (many organelles are not coded in DNA), and environmental factor which cause hormone fluctuations. Seth Roberts' studies as linked show variations in appetite which cause variations in body fat, and provide a clear theory on a specific mechanism by which appetite can be intentionally altered.
comment by Vaniver · 2012-10-12T03:00:31.457Z · LW(p) · GW(p)
But the third model, in which recessions directly cause alarms, which only then cause burglars, does not have this property.
This is not the third model in your picture.
Replies from: Jay_Schweikert, Alex_Altair↑ comment by Jay_Schweikert · 2012-10-12T14:44:36.959Z · LW(p) · GW(p)
Right, it seems like "Burglar" and "Recession" should switch places in the third diagram.
↑ comment by Alex_Altair · 2012-10-12T17:13:35.017Z · LW(p) · GW(p)
Fixed.
comment by alex_zag_al · 2012-10-17T01:14:37.952Z · LW(p) · GW(p)
I recall reading some lovely quote on this (from somebody of the old camp, who believed that talk of 'causality' was naive), but I couldn't track it down in Pearl or on Google - if anyone knows of a good quote from the old school, may it be provided.
You thinking of this maybe, quoted in the Epilogue in Pearl's Causality?
Beyond such discarded fundamentals as 'matter' and 'force' lies still another fetish among the inscrutable arcana of modern science, namely, the category of cause and effect.
That's Karl Pearson, as in "Pearson's r", the correlation coefficient.
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2013-03-31T23:46:21.564Z · LW(p) · GW(p)
Added.
comment by jimrandomh · 2012-10-12T04:29:40.651Z · LW(p) · GW(p)
Causal networks have another name in computer science, in the context of compilers. They're the dataflow diagrams of loop-free array-free non-recursive functions represented in SSA form. (Functions that contain loops, arrays and recursion can still be reasoned about with causal networks, but only locally - you have to unroll everything, and that blows up quickly if you try to do it globally.)
A dataflow diagram is when you give each variable in a function a node, and draw an edge from the variable to each of the other variables that was used in its definition. SSA form is when you write a function in such a way that every variable is assigned to exactly once - ie, you can't give a var a value, use it, then give it a new value. Compilers automatically translate functions to SSA form by giving unique names to all the assignments, and defining a new variable (conventionally marked with a combination function phi) at each point where one of several of those names would be chosen based on branch conditions. Compilers use this form because it makes it easier to check which optimizations and transforms are valid before applying them.
Replies from: bogus↑ comment by bogus · 2012-10-17T18:59:03.129Z · LW(p) · GW(p)
Is this comparable to causal networks in some sense, other than being represented as a directed graph? Digraphs are ubiquitous in applications of math, they're used for all sorts of things.
Replies from: gwern↑ comment by gwern · 2012-10-17T23:08:11.094Z · LW(p) · GW(p)
I'm not sure if this is what jimrandomh was getting at, but there does seem to be a connection to me deeper than merely both being DAGs: optimizations are often limited by how much inference can be made about the causal relations of variables and functions.
One of Haskell's purposes is to see what happens when you make dependencies explicit, removing most global state, and what optimizations are enabled. For example, consider constant propagation: a constant is a node unconnected to any other node, and therefore cannot change, and being unchanging can be inlined everywhere and assumed to be whatever its value is. If the constant were not constant but had a causal connection to, say, a node which is an IO String that the user types in, then all these inlinings are forbidden and must remain indirections to the user input.
Or consider profile-guided optimization: we relocate branches based on which one is usually taken (probability!), but what about branches not specifically in our profiling sample? Seems to me like causal inference on the program DAG might let you infer which branch is most likely.
comment by JulianMorrison · 2012-10-14T00:03:18.767Z · LW(p) · GW(p)
This slammed into my "math is hard" block. I will return and read it, but it's going to be work.
But on pondering that, I think I realized why math is hard, compared to prose text that just presents itself as a fait accompli to my attention. (And why it is not hard, for some people who are savants.)
We are not executing mathematical computations. We are emulating a crude mathematical computer which takes the kind of explicit algorithms that are fed to students. No attempt is made to cultivate and tune a "feel" for the result (which is what executing computations would be like, since it's what the other hard computations we do - like reading - feel like).
Just putting that out there.
Replies from: chaosmosis, buybuydandavis↑ comment by chaosmosis · 2012-10-14T00:22:11.552Z · LW(p) · GW(p)
I just focus on understanding ideas when I'm not willing to do math work.
The rough and nontechnical explanation of this post that I've gotten is: You can't tell what causes what when you've just got two things that come together. But when you've got three things, then you can make pairs out of them, and the relationship between the pairs can tell you when something isn't causing something else. (Unless there are complicating factors like Friedman's Thermostat, see the comments below.)
Replies from: JulianMorrison↑ comment by JulianMorrison · 2012-10-14T00:23:35.856Z · LW(p) · GW(p)
But I want to do math work. My inability to think in math is a serious weakness.
Replies from: khafra, chaosmosis↑ comment by khafra · 2012-10-14T23:25:38.834Z · LW(p) · GW(p)
Coursera's mathematical thinking class is more than half over. But I'm really enjoying it, so you might keep an eye out for repeats.
↑ comment by chaosmosis · 2012-10-14T00:26:11.599Z · LW(p) · GW(p)
Agreed, I would like that too. Advice and resources would be nice.
↑ comment by buybuydandavis · 2012-10-14T03:11:16.867Z · LW(p) · GW(p)
This slammed into my "math is hard" block.
"Math class is tough!"
- Barbie
comment by gwern · 2012-10-13T18:17:14.517Z · LW(p) · GW(p)
Reddit discussion (>=21 comments)
comment by gwern · 2012-10-12T16:19:50.924Z · LW(p) · GW(p)
[1] Somewhat to my own shame, I must admit to ignoring my own observations in this department - even after I saw no discernible effect on my weight or my musculature from aerobic exercise and strength training 2 hours a day 3 times a week, I didn't really start believing that the virtue theory of metabolism was wrong [2] until after other people had started the skeptical dogpile.
Oh, speaking of which, I was amused the other day by http://well.blogs.nytimes.com/2012/10/10/are-you-likely-to-respond-to-exercise/ Apparently now there's even SNPs linked to non-response...
Replies from: gwillen↑ comment by gwillen · 2012-10-14T05:15:29.205Z · LW(p) · GW(p)
Huh... I wonder how I would go about figuring out whether 23andMe covers those SNPs. (I didn't see such a thing in the analysis, but 23andMe reads and reports a lot of SNPs it doesn't analyze.)
Replies from: Douglas_Knight, gwern↑ comment by Douglas_Knight · 2012-10-25T00:28:28.514Z · LW(p) · GW(p)
Rule of thumb: by the time you hear about a paper, 23andMe has expanded their current chip to cover all the SNPs in the paper. The paper does not cause 23andMe to adopt the SNP, but is a sign that the SNP is popular enough to be on someone else's chip. The size of these chips is expanding so fast that new ones subsume all old ones. (This paper was published in 2010 and probably collected data in 2009.)
How to figure out whether 23andMe covers a SNP:
Identify the SNP. In table 1 of this paper, the first SNP is listed as "SVIL (rs6481619)". That means that it is a SNP in the SVIL gene, but 23andMe has dozens of SNPs on this gene. The code starting with RS is a standard dbSNP identifier.
Enter this number into SNPedia, eg, rs6481619 and you will get a page that might say something interesting, such as mentioning the paper about the SNP, or, as in this case, might be pretty much empty. But it usually will have links to other services, including 23andMe. I'm not sure, but I think the existence of the link is a pretty good sign that 23andMe covers the SNP.
Follow the link. This only works if you have a 23andMe account, but they're free. It tells me that "Lilly Mendel" is AC and "Greg Mendel" is AA, so, yes, 23andMe covers this SNP. If I had been genotyped, it would tell me about me, too.
If you have a 23andMe account, you could search it directly, but I like SNPedia better. It is especially good for converting other naming conventions into RS numbers.
comment by RobertLumley · 2012-10-15T18:23:56.234Z · LW(p) · GW(p)
Well, that suggests that the probability of using Reddit, given that your weight is normal, is the same as the probability that you use Reddit, given that you're overweight. 47,222 out of 334,366 normal-weight people use Reddit, and 12,240 out of 88,376 overweight people use Reddit. That's about 14% either way
Nitpick, but I had busted out Excel at this point, and this is actually 16% either way.
Replies from: somervta↑ comment by somervta · 2012-10-16T05:31:09.527Z · LW(p) · GW(p)
I suspect you're using Excel wrong. Try it with a standard calculator and you get: 47,222/334,366 = 0.141241146630934 or 14.1% 12,240/88,376 = 0.138499140038019 or 13.8%
Replies from: RobertLumley↑ comment by RobertLumley · 2012-10-16T05:42:54.507Z · LW(p) · GW(p)
Oh whoops! I forgot that I didn't actually calculate the true percentage - I was just taking the ratio for comparisons sake. Then when he said 14% it stuck out to me as wrong. Thanks for correcting me.
comment by CronoDAS · 2012-10-12T03:44:23.677Z · LW(p) · GW(p)
It is obviously impossible to do the converse experiment where half the subjects are randomly assigned lower weights, since there's no known intervention which can cause weight loss.
There is exactly one such intervention that has been shown to cause persistent weight loss after the intervention period is over. (Starvation also causes weight loss, eventually, but only during the intervention period.)
Replies from: Manfred↑ comment by Manfred · 2012-10-12T05:36:03.466Z · LW(p) · GW(p)
If my stomach doesn't grow back to full size, sounds like an ongoing intervention to me! :D (Also, since people don't exclude weight loss methods that are long-term plans, I'd bet there are some interesting things that have been shown to work as long-term interventions.)
Replies from: CronoDAS↑ comment by CronoDAS · 2012-10-12T08:01:54.170Z · LW(p) · GW(p)
(Also, since people don't exclude weight loss methods that are long-term plans, I'd bet there are some interesting things that have been shown to work as long-term interventions.)
Nope. There haven't been any that have been shown to work.
Replies from: MixedNuts, Manfred↑ comment by MixedNuts · 2012-10-12T09:07:15.749Z · LW(p) · GW(p)
I'm told that 5% of dieters keep off the weight long-term. (Interestingly, this is also the success rate of quitting smoking.) Unless 5% of people who don't try to lose weight also lose weight and keep it off, sounds like diets work, just not very well.
Replies from: novalis, RobinZ, Kindly↑ comment by Manfred · 2012-10-12T10:01:27.522Z · LW(p) · GW(p)
Chronic cocaine use. Let's start with the fun stuff and go from there.
Replies from: CronoDAS↑ comment by CronoDAS · 2012-10-17T11:10:50.518Z · LW(p) · GW(p)
Let me rephrase: There is no such intervention that is considered less dangerous than being obese.
Replies from: Manfred, Blueberry↑ comment by Manfred · 2012-10-17T15:25:53.373Z · LW(p) · GW(p)
I dunno, I feel like you're just patching. Universal statements are always so fragile. Did that drug that made you poop out the fat you ate lead to weight loss? It looks like it's been shown to be effective for at least 2 years. How about appetite suppressants (safer ones than cocaine, that is)? The studies seem to be over shorter time periods, but is that because of safety/effectivess reasons, or just habit?
Replies from: CronoDAS↑ comment by CronoDAS · 2012-10-17T18:22:25.845Z · LW(p) · GW(p)
Well, I was specifically thinking of that one drug that was approved not all that long ago but was pulled off the market because it caused heart problems.
↑ comment by Blueberry · 2012-10-23T07:47:07.984Z · LW(p) · GW(p)
What about a small amount of mild stimulant use?
Replies from: CronoDAS↑ comment by CronoDAS · 2012-10-23T20:33:19.303Z · LW(p) · GW(p)
I dunno. The FDA did approve a couple of drugs this year, but they might only be intended for short-term use.
Replies from: Blueberry↑ comment by Blueberry · 2012-10-23T21:01:08.708Z · LW(p) · GW(p)
I know that the antidepressant Wellbutrin, which is a stimulant, has been associated with a small amount of weight loss over a few months, though I'm not sure if this has been shown to stay for longer. That's an off-label use though.
I'd guess that any stimulant would show weight loss in the short-term. Is there some reason this wouldn't stay long-term?
Replies from: CronoDAS↑ comment by CronoDAS · 2012-10-23T22:47:00.143Z · LW(p) · GW(p)
There are a lot of drugs that people develop tolerances to when used over long periods of time (the body's various feedback mechanisms recalibrate themselves to compensate for the drug's presence), but I can't say with any authority that this applies to mild stimulant use and weight loss.
Replies from: army1987↑ comment by A1987dM (army1987) · 2012-10-24T13:06:16.783Z · LW(p) · GW(p)
I'm pretty sure tolerance to caffeine is a thing, judging from what I see on other people. (I usually abstain from drinking anything with caffeine at least on weekends and holidays to prevent that from happening to me.)
Replies from: gwerncomment by Johnicholas · 2012-10-12T23:13:36.537Z · LW(p) · GW(p)
I think it would be valuable if someone pointed out that a third party watching, without controlling, a scientist's controlled study is in pretty much the same situation as the three-column exercise/weight/internet use situation - they have instead exercise/weight/control group.
This "observe the results of a scientist's controlled study" thought experiment motivates and provides hope that one can sometimes derive causation from observation, where the current story arc makes a sortof magical leap.
Replies from: Vaniver↑ comment by Vaniver · 2012-10-13T01:56:46.586Z · LW(p) · GW(p)
This "observe the results of a scientist's controlled study" thought experiment motivates and provides hope that one can sometimes derive causation from observation,
Indeed; one way to think about this is to consider nature as a scientist whose shoulder we can look over.
where the current story arc makes a sortof magical leap.
The leap only seems magical until you understand what the moving parts inside are. So let's try going in the reverse direction, and see if that helps make it clearer.
Suppose there are three binary variables, A, B, and C, and they are pairwise dependent on each other: that is, P(A) isn't P(A|B), but we haven't looked at P(A|BC).
Alice says that A causes both B and C. Bob says that A causes B, which causes C. Charlie says that A and B both cause C. (Each of these is a minimal description of the model- any arcs not mentioned don't exist, which means there's no direct causal link between those two.)
Unfortunately, A, B, and C are easy to measure but hard to influence, so running experiments is out of the question, but fortunately we have lots of observational data to do statistics on.
We take a look at the models and realize that they make falsifiable predictions:
If Alice is right, then B and C should be conditionally independent given A: that is, P(B|AC)=P(B|A) and P(C|AB)=P(C|A).
If Bob is right, then A and C should be conditionally independent given B: that is, P(A|BC)=P(A|B) and P(C|AB)=P(C|B).
If Charlie is right, then A and B should be independent, and only become dependent given C.
We know Charlie's wrong immediately, since the variables are unconditionally pairwise dependent. To test if Alice or Bob are right, we look at the joint probability distribution and marginalize, like described in the post. Suppose we find that both Alice and Bob are wrong, and so we can conclude that their models are incorrect, just like we could with Charlie's.
In general, we don't look at three proposed models. What we do instead is a procedure that will implicitly consider each of the 25 acyclic causal models that could describe a set of three binary variables, ruling them out until only a small set are left.
Note that an observation that, say, A and C are uncorrelated given B ensured that there is no arc between A and C- ruling out around two thirds of the models at once; that's what we mean by implicitly considering all models. As well, we're left with a set of models that agree with the data- sometimes, we'll be able to reduce it to a single model, but sometimes the data is insufficient to identify the model exactly, and so we'll have several models which are all possible- but many more models which we know can't be the case.
That's the big insight, I think: causal models make testable predictions, and most imaginable models will be wrong. My suspicion as to why this took so long to develop is that it's worthless when looking at graphs with only two nodes (apparently not; see this comment below): there, we can only tell the difference between independence and correlation, and there's no way to tell which way the causation goes. It's only when we have systems with at least three nodes that we start being able to rule out causal models, and the third node may let us conclude things about the first two nodes that we couldn't conclude without that node.
Replies from: IlyaShpitser↑ comment by IlyaShpitser · 2012-10-13T19:00:31.611Z · LW(p) · GW(p)
My suspicion as to why this took so long to develop is that it's worthless when looking at graphs with only two nodes: there, we can only tell the difference between independence and correlation, and there's no way to tell which way the causation goes.
Well, actually...
http://jmlr.csail.mit.edu/papers/volume7/shimizu06a/shimizu06a.pdf http://jmlr.csail.mit.edu/proceedings/papers/v9/peters10a/peters10a.pdf
Replies from: Vaniver↑ comment by Vaniver · 2012-10-13T19:31:09.744Z · LW(p) · GW(p)
Fascinating; thanks for the papers! Those look like they describe continuous and discrete distributions; does my statement hold for binary variables?
Replies from: Kenny↑ comment by Kenny · 2012-10-22T03:01:44.630Z · LW(p) · GW(p)
Aren't binary variables a discrete distribution?
Replies from: Vaniver↑ comment by Vaniver · 2012-10-22T04:40:35.133Z · LW(p) · GW(p)
Yes, but they contain less information. Check out figure 2 of the Peters paper (which describes discrete distributions). If you have an additive noise model, so Y is X plus noise, then by looking at the joint pdf you can distinguish between X causing Y and Y causing X by the corners. This doesn't seem possible if X and Y can only have 2 values (since you get a square, not a trapezoid).
comment by arundelo · 2012-10-12T04:09:28.330Z · LW(p) · GW(p)
This is great!
Tpyos:
Shortly after the sentence, "We could consider three hypothetical causal diagrams over only these two variables", one of the "Earthquake --> Recession" tables gives p(¬e) as 0.70 when it should be 0.71 (so it and 0.29 sum to one).
After the sentence, "So since all three variables are correlated, can we distinguish between, say, these three causal models?", this diagram I think is meant to have "Recession" on top and "Burglar" on the bottom. (Vaniver also noticed this one.)
{kind=link}
Edit:
- The paragraph that starts with "Sure! First, we marginalize over the
'exercise' variable to get the table for just weight and Internet use" needs
to have
s/normal-weight/overweight/run on it. (And maybe have a sentence added saying that you're getting the rest of the following table by doing the same math on the other three sets of people grouped by weight and Internet usage.)
↑ comment by Alex_Altair · 2012-10-12T17:13:13.024Z · LW(p) · GW(p)
Fixed.
Replies from: arundelo↑ comment by arundelo · 2012-10-12T17:33:31.674Z · LW(p) · GW(p)
Thanks.
The "marginalize over the 'exercise' variable" paragraph (mentioned in an edit to the grandparent) still seems to me to not match the tables.
Replies from: Alex_Altair↑ comment by Alex_Altair · 2012-10-12T19:56:03.949Z · LW(p) · GW(p)
Fixed! Thanks for being persistent.
↑ comment by VincentYu · 2012-10-12T12:36:30.366Z · LW(p) · GW(p)
Typo:
Replies from: arundelo, Alex_AltairTpyos:
↑ comment by Alex_Altair · 2012-10-12T16:56:21.743Z · LW(p) · GW(p)
This makes me thing "T Python Operating System".
comment by Eli Tyre (elityre) · 2018-08-25T06:40:56.760Z · LW(p) · GW(p)
If we know that there's a burglar, then we think that either an alarm or a recession caused it; and if we're told that there's an alarm, we'd conclude it was less likely that there was a recession, since the recession had been explained away.
Is this to say that a given node/observation/fact can only have one cause?
More concretely, lets say we have nodes x, y, and z, with causation arrows from x to z and from y to z.
.X...........Y
...\......./
.......Z
If z is just an "and" logic gate, that outputs a "True" value only when x is True and y is True, then it seems like it must be caused by both x and y.
Am I mixing up my abstractions here? Is there some reason why logic gate-like rules are disallowed by causal models?
Replies from: cousin_it↑ comment by cousin_it · 2018-08-25T07:12:38.970Z · LW(p) · GW(p)
Logic gates are allowed just fine. For example, if burglars and earthquakes both cause alarms, then A=OR(B,E). You could also have AND, or any other imaginable way of combining the variables.
The "explained away" thing isn't worded very well. For example, imagine that B and E are independent and have probabilities equal to 1/5. Then learning that there was an alarm (A) raises your probabilities of both B and E to 5/9, but then learning that there was a earthquake (E) lowers your probability of burglar (B) back to 1/5. That's the "explained away" effect. With other logic gates you'd see other effects.
comment by Paul_G · 2012-11-21T07:40:57.049Z · LW(p) · GW(p)
I don't post here much (yet), and normally I feel fairly confident in my understanding of basic probability...
But I'm slightly lost here. "if the Sidewalk is Slippery then it is probably Wet and this can be explained by either the Sprinkler or the Rain but probably not both, i.e. if we're told that it's Raining we conclude that it's less likely that the Sprinkler was on." This sentence seems... Wrong. If we're told that it's Raining, we conclude that the chances of Sprinkler is... Exactly the same as it was before we learned that the sidewalk was wet.
This seems especially clear when there was an alarm, and we learn there was a burglar - p(B|A) = .9, so shouldn't our current p(E) go up to 0.1 * p(E|A) + p(E|~A)? Burglars burgling doesn't reduce the chance of earthquakes... Adding an alarm shouldn't change that.
What am I missing?
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2012-11-21T14:28:50.753Z · LW(p) · GW(p)
But I'm slightly lost here. "if the Sidewalk is Slippery then it is probably Wet and this can be explained by either the Sprinkler or the Rain but probably not both, i.e. if we're told that it's Raining we conclude that it's less likely that the Sprinkler was on." This sentence seems... Wrong. If we're told that it's Raining, we conclude that the chances of Sprinkler is... Exactly the same as it was before we learned that the sidewalk was wet.
The probability of Sprinkler goes up when we learn the sidewalk is Slippery, but then down -- but not below its original level -- when we learn that it is raining. (Note that the example is a little counterintuitive, in that it stipulates that Sprinkler and Rain are independent, given Season. In reality, people don't usually turn their sprinklers on when it is raining, a fact which would be represented by an arrow from Rain to Sprinkler. If that connection was added, the probability of Sprinkler would drop close to zero when Rain was observed.)
It's the same with Alarm/Burglar/Earthquake. The probability of Burglar and Earthquake both go up when Alarm is observed. When further observation increases the probability of Burglar, the probability of Earthquake drops, but not below its original level.
In the limiting case where Alarm is certain to be triggered by Burglar or Earthquake but by nothing else, and Burglar and Earthquake have independent probabilities of b and e, then hearing the Alarm raises the probability of Earthquake to e/(b+e-be). The denominator is the probability of either Burglar or Earthquake. Discovering a burglar lowers it back to e.
Replies from: Paul_Gcomment by Alex Flint (alexflint) · 2012-11-01T10:49:52.926Z · LW(p) · GW(p)
I think you've missed an important piece of this picture, or perhaps have not emphasized it as much as I would. The real real reason we can elucidate causation from correlation is that we have a prior that prefers simple explanations over complex ones, and so when some observed frequencies can be explained by a compact (simple) bayes net we take the arrows in that bayes net to be causation.
A fully connected bayes net (or equivalently, a causal graph with one hidden node pointing to all observed nodes) can represent any probability distribution whatsoever. Such a Bayes net can never be flat-out falsified. Rather it is our preference for simple explanations that sometimes gives us reason to infer structure in the world.
This contradicts nothing you've said, but I guess I read this article as suggesting there is some fundamental rule that gives us a crisp method for extracting causation from observations, whereas I would look at it as a special case of inference-with-prior-and-likelihood, just like in other forms of Bayesian reasoning.
comment by [deleted] · 2012-10-12T06:21:21.321Z · LW(p) · GW(p)
Somewhat to my own shame, I must admit to ignoring my own observations in this department - even after I saw no discernible effect on my weight or my musculature from aerobic exercise and strength training 2 hours a day 3 times a week, I didn't really start believing that the virtue theory of metabolism was wrong until after other people had started the skeptical dogpile.
Wait, are you saying that aerobic exercise and strength training don't have any significant effect on weight?
Replies from: CCC, army1987↑ comment by CCC · 2012-10-12T07:04:14.837Z · LW(p) · GW(p)
A person that I trust to be truthful, and who has done research on this topic, has pointed out to me that muscle has a higher density than fat. So if you experience, simultaneously, both an increase in muscle and a decrease in fat, then your weight may very well not change (or even increase, depending on the amount of muscle).
The same person tells me that exercise both increases muscle and decreases fat.
Replies from: army1987, Eliezer_Yudkowsky↑ comment by A1987dM (army1987) · 2012-10-12T20:40:09.209Z · LW(p) · GW(p)
Yeah. After starting exercising regularly, lots of people who hadn't seen me in a while thought I had lost weight, even if I had actually gained some.
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-10-12T07:38:18.990Z · LW(p) · GW(p)
Er, I don't mean to be too harsh, but I tend to be a bit suspicious when somebody tells me to expect weight loss, and then backpedals and says that maybe an unobservable substitution of muscle for fat took place instead. I realize there are ways this could in principle be verified, if someone was willing to expend enough effort. It is nonetheless suspicious.
Replies from: CCC, army1987, wedrifid, MaoShan↑ comment by CCC · 2012-10-12T07:55:07.086Z · LW(p) · GW(p)
I understand your suspicion, and I don't think you're being too harsh at all. Scepticism on this point is more likely to improve understanding, after all.
There are ways to measure fat independantly of weight, however. The electrical conductance of fat and muscle differs - you can get scales that will measure both your weight and your conductance, and present you with a figure describing what percentage of your body weight is due to fat. There's also a machine at my local gym that purports to measure body fat percentage (I'm not entirely sure how it works or how accurate it is), and I have found that if I fail to exercise over a long period of time, then the figure that it measures shows a general upwards trend.
Replies from: gwern, CCC↑ comment by gwern · 2012-10-12T16:21:52.274Z · LW(p) · GW(p)
Further reading: http://en.wikipedia.org/wiki/Body_fat_percentage#Measurement_techniques
↑ comment by CCC · 2012-10-15T07:52:50.335Z · LW(p) · GW(p)
Having done a bit of poking around on this subject, as far as I can tell the model is more or less as follows.
The human body is modelled as a collection of four elements; fat, muscle, water, and bone. The percentages of these different elements can change with diet, with exercise, with different types of exercise. Bone is pretty much constant (though apparently lack of calcium can cause trouble there); water fluctuates a lot. Fat and muscle are more controllable; a given diet and exercise regimen has a target fat percentage and muscle percentage. Starting on the diet/exercise causes the body to approach the target fat/muscle percentage in some manner (it may be asymptotic). For this purpose, lack of exercise also counts as an exercise regimen, and it is one that has a high fat percentage and a low muscle percentage (so if you have been exercising and stop, you gain a fair amount of fat). There is some complicated interaction between the diet and the exercise regimen here. There may be a genetic component also affecting the model.
Each of these four elements - fat, muscle, water, bone - has a certain density, a certain conductivity. There are certain percentages of these elements (I do not know what they are) that would lead to an optimal health (measured as the greatest life expectancy). Given a person's height, and perhaps a few other measurements, one can estimate the total mass of bone (our skeletons are pretty much standard). From this, and given the optimal percentages, one can estimate the optimal mass of fat, of muscle, for the greatest life expectancy. (Water still fluctuates a lot, as I understand it).
Measurements of these percentages include weight, girth, electrical conductivity, and use of calipers. The first three of these figures measure quantities that are affected by all four percentages; a change in one factor can be masked by a change in the others.
All in all, it's a far more complex problem than it looks like at first glance. Some heuristics have leaked out into common knowledge; things like "don't eat too much fatty foods" and "exercise at least a bit". I am not sure how accurate these heuristics are - presumably there is some reasoning backing them, possibly based on the model vaguely described above. I also suspect that the idea of the ideal weight (based on BMI) is based on the expectation of a certain common maximum muscle percentage.
↑ comment by A1987dM (army1987) · 2012-10-12T20:51:51.742Z · LW(p) · GW(p)
I tend to be a bit suspicious when somebody tells me to expect weight loss, and then backpedals and says that maybe an unobservable substitution of muscle for fat took place instead.
Who told you to expect weight loss?
↑ comment by wedrifid · 2012-10-12T17:36:22.967Z · LW(p) · GW(p)
Er, I don't mean to be too harsh, but I tend to be a bit suspicious when somebody tells me to expect weight loss, and then backpedals and says that maybe an unobservable substitution of muscle for fat took place instead. I realize there are ways this could in principle be verified, if someone was willing to expend enough effort. It is nonetheless suspicious.
I'd be more suspicious of reports that exercise didn't change body composition than that it did. That's how exercise tends to work for most people. I'd be more skeptical of the initial claim for net weight loss, at least if it wasn't qualified--- that is usually not what I would expect in the short term.
I'd be more suspicious if the 'unobservable' was a little more difficult to verify.
↑ comment by MaoShan · 2012-10-13T04:22:26.561Z · LW(p) · GW(p)
Having muscle substituted for fat would result in better health or at least greater strength, I would think. Weight is (usually) just an easy way to measure a change in fat. I am trying successfully to lose more weight based on the assumption that the conditions for fat to form or persist depend largely on the balance of food intake and amount of exercise. If you maintain a consistent food intake, and maintain a consistent amount of exercise, and gain fat, then if it is physically safe to, either reduce food intake, or increase exercise. If given your current diet, and you slightly increase your exercise, you have proven that you do not lose fat, then I would assume that you should try changing the variables more, instead of giving up. We're not exactly spending all day hunting and gathering anymore. I am going to increase my exercise and decrease my food (although I still invest in daily chocolate lifestyle enhancement, as you suggested as a sure bet as opposed to playing the lottery), and I am fairly sure before two weeks pass I will have lost five pounds.
Replies from: CCC↑ comment by CCC · 2012-10-15T07:33:52.250Z · LW(p) · GW(p)
Let us know how it works.
Replies from: MaoShan↑ comment by MaoShan · 2012-11-02T01:12:43.316Z · LW(p) · GW(p)
Sorry for the delay, I got caught up in the Halloween spirit. As for the following table, it lists the date and recorded weight on that date.
- 10/13--149.0 (lb.)
- 10/14--149.9
- 10/15--149.5
- 10/16--151.2
- 10/17--151.9
- 10/18--149.7
- 10/20--151.0
- 10/21--151.2
- 10/22--149.3
- 10/23--148.4
- 10/24--148.2
- 10/25--146.8
- 10/26--147.3
- 10/27--146.4
As you can see, I did not reach the goal that I set. The excuse--er, explanation, is that I made that claim on the very day I started a week-long vacation. Hence, I was much more sedentary than while working, and I ate more frequent and larger meals than on workdays. October 22 was the day I returned to work, and was also the day that I actually began losing weight, so my 2-week prediction actually had about a week cut off, and (anecdotally) shows both sides of the story in doing so. On the upside, I progressed pretty far in Paper Mario. If I had started the two weeks from the 22nd, I have lost about 7lb. since then. Hopefully this provides some data for anyone interested.
Replies from: CCC↑ comment by A1987dM (army1987) · 2012-10-12T20:50:21.509Z · LW(p) · GW(p)
(Well, we're talking about six hours a week, which ought to noticeably make you lose weight if you keep your calorie intake constant. But people who exercise six hours a week don't usually keep their calorie intake constant.)
comment by learnmethis · 2012-10-15T15:43:24.658Z · LW(p) · GW(p)
All these conclusions seem to require simultaneity of causation. If earthquakes almost always caused recessions, but not until one year after the earthquake; and if recessions drastically increase the number of burglars, but not until one year after the recession; then drawing any of the conclusions you made from a survey taken at a single point in time would be entirely unwarranted. Doesn't that mean you’re essentially measuring entailment rather than causation via a series of physical events which take time to occur?
Also, the virtue theory of metabolism is so ridiculous that it seems only to be acting as a caricature here. Wouldn't the theory that “exercise normally metabolises fat and precursors of fat, reducing the amount of weight put on” result in a much more useful example? Or is there a subtext I'm missing here, like the excessive amount of fat-shaming done in many of the more developed nations?
Replies from: TheOtherDave↑ comment by TheOtherDave · 2012-10-15T16:42:57.680Z · LW(p) · GW(p)
Some of the inferred subtext is being extracted from earlier posts that refer to diet while ostensibly discussing other issues.
Replies from: learnmethis↑ comment by learnmethis · 2012-10-19T04:39:10.039Z · LW(p) · GW(p)
Ahh, thanks.
comment by Robert Miles (robert-miles) · 2012-10-12T17:07:29.730Z · LW(p) · GW(p)
A few minor clarity/readability points:
- The second paragraph opening "The statisticians who discovered the nature of reality" reads rather oddly when taken out of the context of "The Fabric of Real Things".
- When considering the three causal models of Burglars, Alarms and Recessions, tackling the models in a "First, third, second" order threw me on first reading. It would probably be easier to follow if the text and the diagram used the same order.
- Perhaps giving each node a different pastel colour would make it easier to follow what is changing between different diagrams.
And this has probably been said, but using exercise and weight is probably distracting, since people already have opinions on the issue.
comment by beoShaffer · 2012-10-12T04:23:47.647Z · LW(p) · GW(p)
I followed most of the math but the part right before
multiplying together the conditional probability of each variable given the values of its immediate parents. (If a node has no parents, the probability table for it has just an unconditional probability, like "the chance of an earthquake is .01".)
has me puzzled. The variables used aren't explicitly mentioned elsewhere in the article, and while I think they have some conventional meaning I can't quiet remember what. The context let me make a decent guess, but I still feel a little fuzzy. Otherwise the post was pretty clear, much clearer than the other explanations I've seen.
comment by lesswronguser123 (fallcheetah7373) · 2024-10-13T09:24:15.467Z · LW(p) · GW(p)
accessibility error: Half the images on this page appear to not load.
comment by jslocum · 2013-03-06T17:19:07.549Z · LW(p) · GW(p)
Here is a spreadsheet with all the numbers for the Exercise example all crunched and the graph reasoning explained in a slightly different manner:
https://docs.google.com/spreadsheet/ccc?key=0ArkrB_7bUPTNdGhXbFd3SkxWUV9ONWdmVk9DcVRFMGc&usp=sharing
comment by Mikhail Samin (mikhail-samin) · 2023-10-25T21:48:49.012Z · LW(p) · GW(p)
I think I spotted a mistake. I'm surprised no one noticed it earlier.
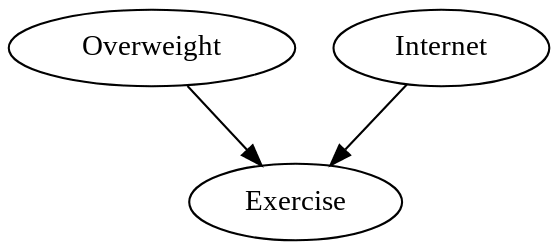
Eliezer says the data shows that Overweight and Internet both make exercise less likely.
That would imply that P(O|I & not E) should be less than P(O|not E); and that P(I|O & not E) should be less than P(I|not E). But actually, they're approximately equal![1]
| P(not E) | 0.6039286373 |
| P(not E & O) | 0.1683130609 |
| P(not E & I) | 0.09519044713 |
| P(I & O & not E) | 0.02630682544 |
| P(I|not E) | 0.1576187007 |
| P(I|not E & O) | 0.1562969938 |
| P(O|not E) | 0.2786969362 |
| P(O|not E & I) | 0.2763599314 |
(From the current data, P(O|E & I) is less than P(O|E): 5% vs 10%; P(I|E & O) is less than P(I|E): 6% vs 11%; which is what you'd expect from Overweight and Internet both making exercise less likely, but it's not all that O->E<-I implies.)
Edit: note that inferring the causal graph exactly the way it's done in the alarms/recessions/burglars example fails here due to the extra conditional independences. The data is generated in a way that doesn't show a correspondence to this graph if you follow a procedure identical to the one described in the post
Replies from: DanielFilan, DanielFilan↑ comment by DanielFilan · 2023-11-25T19:15:56.655Z · LW(p) · GW(p)
The data is generated in a way that doesn't show a correspondence to this graph if you follow a procedure identical to the one described in the post
When I calculate the conditional probability tables you get from the table of numbers in the post and multiply them out to get the joint distribution, my answers basically match with the table of numbers in the post.

↑ comment by Mikhail Samin (mikhail-samin) · 2023-11-25T19:20:25.153Z · LW(p) · GW(p)
The point is, these probabilities don’t really correspond to that causal graph in a way described in the post. A script that simulates the causal graph: https://colab.research.google.com/drive/18pIMfKJpvlOZ213APeFrHNiqKiS5B5ve?usp=sharing
Replies from: DanielFilan↑ comment by DanielFilan · 2023-11-26T22:56:08.468Z · LW(p) · GW(p)
I think they do correspond to the causal graph in the way described in the post. Your script simulates something more specific than the causal graph: you can fit the causal graph without being able to be fitted by the script.
Replies from: mikhail-samin↑ comment by Mikhail Samin (mikhail-samin) · 2023-11-26T23:11:14.845Z · LW(p) · GW(p)
I think I don’t buy the story of a correct causal structure generating the data here in a way that supports the point of the post. If two variables, I and O, both make one value of E more likely than the other, that means the probability of I conditional on some value of E is different from the probability of I because I explains some of that value of E; but if you also know O, than this explains some of that value of E as well, and so P(I|E=x, O) should bd different.
The post describes this example:
This may seem a bit clearer by considering the scenario B->A<-E, where burglars and earthquakes both cause alarms. If we're told the value of the bottom node, that there was an alarm, the probability of there being a burglar is not independent of whether we're told there was an earthquake - the two top nodes are not conditionally independent once we condition on the bottom node
And if you apply this procedure to “not exercising”, we don’t see that absence of conditional independence, once we condition on the bottom node. Which means that “not exercising” is not at all explained away by internet (or being overweight)
Replies from: DanielFilan↑ comment by DanielFilan · 2023-11-27T19:32:22.401Z · LW(p) · GW(p)
If two variables, I and O, both make one value of E more likely than the other, that means the probability of I conditional on some value of E is different from the probability of I because I explains some of that value of E
That's correct
but if you also know O, than this explains some of that value of E as well, and so P(I|E=x, O) should bd different.
This is generically true but doesn't have to be true for every value of x.
Here's one way to see why the graph in the post is right: look at all other casual graphs, and you will see they either fail to imply that I and O are independent (as our graph does), or imply independences or conditional independences that don't exist in the data.
Replies from: mikhail-samin↑ comment by Mikhail Samin (mikhail-samin) · 2023-11-28T00:06:39.529Z · LW(p) · GW(p)
I don’t really get how this can be true for some values of x but not others if the variable is binary
Replies from: DanielFilan↑ comment by DanielFilan · 2023-11-28T06:32:42.356Z · LW(p) · GW(p)
The post gives one example of how it can be true: the probabilities are compatible with the causal graph, I is independent of O given E = no, but I is not independent of O given E = yes.
Here's one way to see why the graph in the post is right: look at all other casual graphs, and you will see they either fail to imply that I and O are independent (as our graph does), or imply independences or conditional independences that don't exist in the data.
Have you tried this exercise?
↑ comment by DanielFilan · 2023-11-25T18:55:41.313Z · LW(p) · GW(p)
Eliezer says the data shows that Overweight and Internet both make exercise less likely.
I don't think he actually says that? He just says they both causally affect exercise:
Which says that weight and Internet use exert causal effects on exercise, but exercise doesn't causally affect either.
[EDIT: I'm totally, wrong, he does say "we now realize that being overweight and spending time on the Internet both cause you to exercise less"]
Regarding your second point:
That would imply that P(O|I & not E) should be less than P(O|not E); and that P(I|O & not E) should be less than P(I|not E).
FWIW, I don't take the sentence "overweight and internet both make exercise less likely" to imply that - just to imply that p(E | O) < p(E | not O) and p(E | I) < p(E | not I). The interaction terms could be complicated.
Replies from: DanielFilan↑ comment by DanielFilan · 2023-11-25T19:23:35.528Z · LW(p) · GW(p)
It is weird that I is independent of O given not E, given that from that graph you wouldn't expect conditional independence, but I is not independent of O given E, so that's OK and consistent with the graph.
comment by [deleted] · 2012-12-14T17:21:32.727Z · LW(p) · GW(p)
(We have remnants of this type of reasoning in old-school "Correlation does not imply causation", without the now-standard appendix, "But it sure is a hint".)
Given the reasoning in this post and this post I think you can also infer that this old "Correlation does not imply causation" statement is not only flawed, but it's also outright wrong
And should instead just be "Correlation does imply causation, but doesn't tell which kind"
Replies from: thomblake, Peterdjones↑ comment by thomblake · 2012-12-14T18:25:35.395Z · LW(p) · GW(p)
but it's also outright wrong
"imply" in the traditional phrase is used in the strong sense. You can have a correlation between 2 factors without there necessarily being a causal relationship between them.
Replies from: None↑ comment by [deleted] · 2012-12-14T18:42:51.614Z · LW(p) · GW(p)
If you can exclude coincidence, which is a question of confidence and what kind of data the correlation is based on, then you can say that the correlation does necessarily involve a causal relationship.
Well that's just what I think. If you can show me how that's wrong, then please do. Except I don't think you can.
Replies from: thomblake↑ comment by Peterdjones · 2012-12-14T17:34:15.928Z · LW(p) · GW(p)
I think that tradiotional wisdom is fairly accurate, bearing in mind that correlation between A and B doens't imply causaiont between A and B.
Replies from: None↑ comment by [deleted] · 2012-12-14T17:38:30.472Z · LW(p) · GW(p)
I agree. But it's still inaccurate to say it does not imply causation.
correlation between A and B is explained by either 1. A->B 2. B->A 3. X->A & X->B or 4. By chance , or any combination of the aforementioned and which of 4. is usually confidently eliminated by anything that is statistically significant.
Point being there's usually a causal relationship behind the correlation, even if it involves more factors than the ones that are being studied. Therefore that old phrase is misleading and - in my opinion - wrong.
Replies from: RobbBB, Peterdjones↑ comment by Rob Bensinger (RobbBB) · 2012-12-14T18:47:37.745Z · LW(p) · GW(p)
As Peter noted, the meaning of "correlation does not imply causation" is "it is false that, for every X and Y, if positively-correlated(X,Y) then either causes(X,Y) or causes(Y,X)." Interpreted in this way, the principle is completely unimpeachable. If you object to it, you must be taking the principle to imply something much more general, like "it is false that for every X and Y, if positively-correlated(X,Y), then there is some Z that is in some way causally relevant to partly explaining this fact." The latter version of the principle is much easier to deny.
But your own argument doesn't quite get us to being able to deny either principle yet. For instance: What is meant by "X->A & X->B"? If this means direct causation, then it is surely false. But if it allows for transitive causal chains leading back to some X, then the principle risks triviality, since it is plausible that all events share at least some cause in common, if you go back far enough. A second problem: How can we rigorously unpack the meaning of "by-chance" correlations? And third: How do you know that statistically significant correlations are usually not "by chance" in your sense?
Replies from: None↑ comment by [deleted] · 2012-12-14T19:20:44.336Z · LW(p) · GW(p)
But if it allows for transitive causal chains leading back to some X, then the principle risks triviality, since it is plausible that all events share at least some cause in common, if you go back far enough.
However, wouldn't that be extremely unlikely? And wouldn't the likelihood be related to the amount of correlation?
A second problem: How can we rigorously unpack the meaning of "by-chance" correlations?
I'm not sure because I lack the skill in mathematics to answer this question the proper way.
And third: How do you know that statistically significant correlations are usually not "by chance" in your sense?
I'm not sure if there is a mathematical formalism for this, pretty much for the same reasons as for problem two: I don't have the mathematical abilities required. However, I do know what they're about, and I'm rather confident that you and I both can tell apart results that could be explained by mere chance and those that could not - it would be rather surprising if it was not achievable by means of math if you can achieve that by mere fallible intuition?
Well I apologize if I'm mistaken here, but I'm still trying to be reasonable.. Hmm.
Let's create an examples to illustrate a point:
Students at some school take a special test each schoolyear and their tests results are compared with something fairly trivial. Let's say the number of pencils the students bring to the tests.
Then by means of correlation it is found that the number of pencils brought by the students to the school has been increasing in a way that is correlated to prowess in the tests by the students.
In this case it's not sufficient to say that the correlation implies that the number of pencils is causing the increasing prowess in the tests, nor that the prowess in the tests is causing the increased number of pencils. Which is what the phrase traditionally stands for.
But there still can be a causal relationship, for an example the school's funding has been increasing and they've been giving more free material to students, and if increased material is correlated with increased prowess and increased number of pencils, or increasing economy.. and so forth, that's causality, but not of the same kind.
However we can also say that this is just a coincidence, particularly if there has been only a couple of events. Or by some trivial causal chain like then you mentioned, but....
... you can also see how these results could be of a nature where casuality is actually required. If we look at a single testing event and notice that for the 500 students of the school there's a strong correlation between number of pencils and test prowess, we're starting to talk about extremely small probabilities that the results are by coincidence, are we not? Even if the pencils are not the cause , we can still deduce that there is a cause at high likelihood?
Well anyway maybe I'm just making excuses, at least it's important to consider that at this point, and I see your point anyway, and I think I was wrong. Oops, sorry.
But not exactly. Because I think there's something to this. And I think you should know what I mean. Maybe it's important to start asking what this coincidence actually means? Isn't this actually something about Markov Blanket ? (or something similar, sorry if I misused the term)
Replies from: None↑ comment by [deleted] · 2012-12-14T19:38:41.053Z · LW(p) · GW(p)
Oh well I think I can answer the question:
You can measure the likelihood that the profile the datasets are similar by chance. For an example simple increasing tendency - correlation that is - that can be explained by coincidentially similar increasing tendency, but if there's an complex profile to correlation, you can measure what the likelihood for a coincidence is? Even further, the more complex the profiles are, the less likely a coincidence becomes? ( if they match )
↑ comment by Peterdjones · 2012-12-14T18:34:04.176Z · LW(p) · GW(p)
So you don't notice a lot of correlation-causation errors? I see them everywere. Practically every science story in the press.
Replies from: None↑ comment by [deleted] · 2012-12-14T18:40:37.325Z · LW(p) · GW(p)
How'd you get that from what I just said? Someone else making errors is not an excuse for you to do that too.
Replies from: Peterdjones↑ comment by Peterdjones · 2012-12-14T18:56:59.740Z · LW(p) · GW(p)
it works like this: If people in general are erring on the side of over-associating correlation with causation rather than under-associating, then "correlation is not causation" is the better rule-of-thumb.
Replies from: None↑ comment by [deleted] · 2012-12-18T11:59:38.361Z · LW(p) · GW(p)
Agreed. I'm sorry for for commenting about this before thinking things really through, that was very lazy and thoughtless.
However in the course of you people being nice and pointing out how foolish I was not only the obvious error was corrected, but it appears that I also gained an insight(finding out something I didn't know personally that is) into the matter. That being: In some cases you can estimate the probability of a correlation being merely coincidential versus it being the result of an actual causal relationship. Although since I'm not a mathematician I don't actually know how do that, except by looking at graphs and letting the brain do all the work. It does though sound a little silly.
Does someone know how to do that mathematically? Estimate the probability of a correlation being coincidential versus due to a causal relationship of an unknown type?
comment by CCC · 2012-10-18T12:21:01.400Z · LW(p) · GW(p)
Let's consider a practical example. Since the question of exercise and weight has turned up, let's revisit it. First, let's collect some raw data (I can't use internet usage, since this poll is extremely biased on that axis).
For the purposes of this poll, "overweight" means a body mass index over 25. "Exercise" means at least 30 minutes a week, working hard at it, on a regular basis. "Diet" means that you actually think about the nutritional value of the food you eat, and consciously base your choice of food on that information in some significant way.
Select one of the following:
[pollid:183]
Once we have some data, we can then practice this skill on the results of the poll, and see whether (and if so, how) these variables are causally linked among poll respondants.
Replies from: drethelin, CCC↑ comment by drethelin · 2012-10-18T12:45:17.754Z · LW(p) · GW(p)
This question is not very well formulated. I diet, and have lost 30 pounds or so since last december but am still overweight
Replies from: ArisKatsaris↑ comment by ArisKatsaris · 2012-10-18T13:24:08.739Z · LW(p) · GW(p)
Then one of the two "I diet, I am overweight" options seems appropriate, depending on whether you exercise or not. Whether you have lost or gained weight recently doesn't seem part of the poll.
Replies from: drethelin↑ comment by drethelin · 2012-10-18T13:31:53.990Z · LW(p) · GW(p)
I'm saying that losing 30 pounds appears to be exactly the sort of thing we're actually trying to find out about but the poll doesn't check for it.
Replies from: ArisKatsaris↑ comment by ArisKatsaris · 2012-10-18T13:43:23.593Z · LW(p) · GW(p)
A question not being very "well formulated" implies to me that it incorporates confusions, ambiguities, false dilemmas, etc. That a different question might be more relevant to the purpose of the post, seems a different issue.
Replies from: CCC↑ comment by CCC · 2012-10-18T14:34:24.838Z · LW(p) · GW(p)
I was very careful to formulate the question to avoid confusions, particularly in the definition of 'overweight' (my thinking was, Obelix would claim he was not overweight, by defining 'overweight' I at least ensure that different definitions of 'overweight' do not blur the line). In the process, I did not consider the case of a person who had relatively recently started a diet (or an exercise regimen) and whose weight had changed as a result, but not sufficiently to move past the arbitrary 25 BMI line.
This was therefore probably not the best way to phrase the question, and for that I apologise (if I were to go back in time and rewrite the question, I would take that case into account). Nonetheless, the question stands as is; I think that it is more important at this point to be consistent, and thus one of the "I diet, I am overweight" options are appropriate.
↑ comment by CCC · 2012-10-21T19:19:51.668Z · LW(p) · GW(p)
Okay, sixteen people are not enough to say much from. There will be large error bars in the following statements, due to small sample size. Nonetheless.
Taking E for exercise, D for diet, O for overweight:
- p(E)=0.625
- p(D)=0.1875
- p(O)=0.1875
- p(ED)=0.1875
- p(EO)=0.125
- p(DO)=0.0625
Exercise and dieting seem to be pretty well correlated; either dieting causes exercise (with 100% certainty over this small data set) or exercise causes diet (about one-third of the time), or, more likely, a third factor (a desire to lose weight, perhaps) causes both dieting and exercise. Strangely, being overweight doesn't seem to be correlated with either exercise or diet... my first instinct here is to be suspicious of the survey's small sample size. (At the very least, I'd expect being overweight to cause dieting).
It also seems, from this survey, that the best way to not be overweight is to exercise but not diet - though a mere one vote can very easily change that conclusion, so this survey should be considered to have very little weight at sixteen responses.
comment by Decius · 2012-10-15T04:22:10.754Z · LW(p) · GW(p)
So, what if the causal diagram isn't simply dependent and/or contains loops? What if recessions cause burglars, and burglars disable alarms, and alarms cause recessions?
You also forgot about the graph that has confounding factors C and D; C affects exercise and weight, while D affects exercise and internet usage. Both of them make exercise more (or less) likely, and their other factor less (or more) likely; Weight and internet use remain uncorrelated, but remain negatively correlated with exercise.
Replies from: Qiaochu_Yuan↑ comment by Qiaochu_Yuan · 2013-02-07T04:35:20.778Z · LW(p) · GW(p)
What if recessions cause burglars, and burglars disable alarms, and alarms cause recessions?
One option is to make a much larger causal diagram that has variables recessions(t), burglars(t), and alarms(t) where t is a (say discrete) time variable, then have recessions(t) cause burglars(t+1), burglars(t) disabling alarms(t+1), and alarms(t) causing recessions(t+1).
Replies from: Decius↑ comment by Decius · 2013-02-09T02:44:51.843Z · LW(p) · GW(p)
Sorry, I didn't mean to say that any of those things precedes the other like fire and heat; I meant that they caused each other, like a generator which is providing it's own field current.
Replies from: Qiaochu_Yuan↑ comment by Qiaochu_Yuan · 2013-02-09T02:47:39.594Z · LW(p) · GW(p)
Yes, that's what it means when you draw a causal arrow from recessions(t) to burglars(t+1), unless you think that recessions instantaneously cause burglars, etc.
Replies from: Decius↑ comment by Decius · 2013-02-09T17:28:12.985Z · LW(p) · GW(p)
It's entirely possible that we lack the ability to distinguish information about t+1 from information about t. Do recessions cause burglars in less time than the resolution of our economic and police statistics? Can a recession cause burglaries which cause alarms which further cause more recession in such a manner as the original recession cannot be noticed?
comment by TimMartin · 2015-03-04T16:09:13.802Z · LW(p) · GW(p)
Currently it looks like this page has lots of broken images, which are actually formulas. Can this be fixed? It's kind of hard to understand now.
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2015-03-04T16:28:03.233Z · LW(p) · GW(p)
It looks like a problem at codecogs.com, the service that LW uses to translate LaTeX to formula images. Probably temporary.
How much effort would it be to move to MathJax?
comment by purge · 2013-01-18T10:01:57.905Z · LW(p) · GW(p)
If we know that there's a burglar, then we think that either an alarm or a recession caused it; and if we're told that there's an alarm, we'd conclude it was less likely that there was a recession, since the recession had been explained away.
Should that be "since the burglar had been explained away"? Or am I confused?
Edit: I was confused. The burglar was explained; the recession was explained away.
comment by zaph · 2012-11-05T18:09:55.594Z · LW(p) · GW(p)
I've been enjoying this series so far, and I found this article to be particularly helpful. I did have a minor suggestion. The turnstile and the logical negation symbols were called out, and I thought it might be useful to explicitly breakdown the probability distribution equation. The current Less Wrong audience had little problem with it, certainly, but if you were showing it to someone new to this for the first time, they might not be acquainted with it. I was thinking something along the lines of this from stattrek:
"Generally, statisticians use a capital letter to represent a random variable and a lower-case letter, to represent one of its values. For example,
X represents the random variable X.
P(X) represents the probability of X.
P(X = x) refers to the probability that the random variable X is equal to a particular value, denoted by x. As an example, P(X = 1) refers to the probability that the random variable X is equal to 1."
(from http://stattrek.com/probability-distributions/probability-distribution.aspx)
Also, page 2 of A Student's Guide to Maxwell's Equations does a great job of diagramming Gauss' law for electrical fields, and I think it would be helpful if this were available to breakdown the right half of the equation, with the beginning reader seeing a breakdown of the equation.
http://books.google.com/books?id=I-x1MLny6y8C&printsec=frontcover#v=onepage&q&f=false
If this all was set aside in the footnote, the overall continuity of the article wouldn't be affected, and someone who might be intimidated at first by equations might see that these aren't so bad. With just a bit of exposition, more readers might be able to follow along with the entire argument, which I think could be introduced to someone with very little background.
comment by Stuart_Armstrong · 2012-10-23T17:46:23.317Z · LW(p) · GW(p)
To get that last graph, you have to show that internet and exercise are correlated...
comment by Benquo · 2012-10-18T21:26:05.467Z · LW(p) · GW(p)
This helped me understand what Instrumental Variables are, but Andrew Gelman's critique of instrumental variables has me confused again:
Suppose z is your instrument, T is your treatment, and y is your outcome. So the causal model is z -> T -> y. The trick is to think of (T,y) as a joint outcome and to think of the effect of z on each. For example, an increase of 1 in z is associated with an increase of 0.8 in T and an increase of 10 in y. The usual “instrumental variables” summary is to just say the estimated effect of T on y is 10/0.8=12.5, but I’d rather just keep it separate and report the effects on T and y separately.
In Piero’s example, this translates into two statements: (a) States with higher penalties for murder had higher penalties for defamation, and (b) States with higher penalties for murder had less reporting of corruption.
Fine. But I don’t see how this adds anything at all to my understanding of the defamation/corruption relationship, beyond what I learned from his simpler finding: States with higher penalties for defamation had less reporting of corruption.
If your model is z -> T -> y, and you show that z interacts with each of T and y, isn't the next step just to look at the relation between z and y, controlling for T? In other words, if it turns out that z still matters in predicting y once you have T in your model, then you don't have an instrumental variable. But if T screens off the effect of z in predicting y, then z is an instrumental variable, and only affects y through T.
Replies from: IlyaShpitser↑ comment by IlyaShpitser · 2012-10-31T18:17:14.349Z · LW(p) · GW(p)
Sorry, what you are missing is T and Y could be confounded by unobserved variables. That is, the real graph is:
z -> T -> Y, with T <- U -> Y, with U unobserved. Then if you control for T, you will get an open path z -> T <- U -> Y which is not causal. In general if your graph is
T -> Y <- U -> T, the causal effect is not a functional of the observed data. However with some parametric assumptions you can obtain the causal effect as a functional of the observed data if there is an instrument z.
Replies from: Benquo↑ comment by Benquo · 2012-10-31T18:56:56.211Z · LW(p) · GW(p)
Oh... so the idea in your second paragraph is that when you hold T constant, a change in z suggests an equal and opposite change in U (measuring by their mean effect on T). Then that change affects Y.
Replies from: IlyaShpitser↑ comment by IlyaShpitser · 2012-10-31T19:02:23.243Z · LW(p) · GW(p)
That's exactly right. The fact that for treatment T, and outcome Y, there is generally an unobserved common cause U of T and Y is in some sense the fundamental problem of causal inference. The way out is either:
(a) Make parametric assumptions and find instrumental variables (econometrics, mendelian randomization)
(b) Try to observe U (epidemiology, etc.)
(c) Randomize T (statistics, empirical science)
There are some other lesser known ways as well:
(d) Find an unconfounded mediator W that intercepts all causal influence from T to Y:
T -> W -> Y
Then use the "front-door criterion."
comment by mfb · 2012-10-15T19:41:24.928Z · LW(p) · GW(p)
Interesting article, thanks.
I agree with the general concept. I would be a bit more careful in the conclusions, however:
No visible correlation does not mean no causation - it is just a strong hint. In the specific example, the hint comes from a single parameter - the lack of significant correlation between internet & overweight when both exercise categories are added; together with the significant correlation of internet usage with the other two parameters.
With the proposed diagram, I get:
p(Internet)=.141
p(not Internet)=.859
p(Overweight)=.209
p(not Overweight)=.791
p(Ex|Int & Ov)=.10
p(Ex|Int & no OV)=.62
p(Ex|no Int & Ov)=.27
p(Ex|no Int & no Ov)=.85
This model has 6 free parameters - the insignificant correlation between overweight and internet is the only constraint. It is true that other models have to be more complex to explain data, but we know that our world is not a small toy simulation - there are causal connections everywhere, the question is just "are they negligible or not?".
comment by buybuydandavis · 2012-10-15T10:30:32.433Z · LW(p) · GW(p)
I haven't read enough of Causality, but I think I get how to find a causal model from the examples above.
Basically, a model selection problem? P(Model|Data) = P(Data|Model)P(Model)/P(Data) ~ P(Data|Model)P(Model)?
Is P(Model) done in some objective sense, or is that left to the prior of the modeler? Or some combination of contextually objective and standard causal modeling priors (direction of time, locality, etc.)?
Any good powerpoint summary of Pearl's methods out there?
Replies from: IlyaShpitser↑ comment by IlyaShpitser · 2012-12-18T12:03:32.263Z · LW(p) · GW(p)
Hi,
P(Model) is usually related to the dimension of the model (number of parameters). The more parameters, the less likely the model (a form of the razor we all know and love).
See these:
http://en.wikipedia.org/wiki/Bayesian_information_criterion http://en.wikipedia.org/wiki/Akaike_information_criterion
There are other ways of learning causal structure, based on ruling out graphs not consistent with constraints found in the data. These do not rely on priors, but have their own problems.
comment by ChristianKl · 2012-10-14T16:32:39.699Z · LW(p) · GW(p)
An earthquake is 0.8 likely to set off your burglar alarm; a burglar is 0.9 likely to set off your burglar alarm. And - we can't compute this model fully without this info - the combination of a burglar and an earthquake is 0.95 likely to set off the alarm;
I don't think that true. The earthquake can cause the burgler to have less control over his own movement and therefore increase the chance that he triggers the alarm.
Replies from: Kindlycomment by simplicio · 2012-10-14T06:27:13.139Z · LW(p) · GW(p)
This was a really good article overall; I just finished going through all the numbers in Excel and it makes a lot of sense.
The thing that is most counterintuitive to me is that it appears that the causal link between exercise and weight can ONLY be computed if you bring in a 3rd, seemingly irrelevant variable like internet usage. It looks like that variable has to be somehow correlated with at least one of the causal nodes - maybe it has to be correlated with one specific node... I am a little hazy on that.
I encourage readers to open an Excel file or something and, using Eliezer's made-up 'data' about exercise/weight/internet, exhaustively list all the possible causal graphs for those 3 variables, then falsify all of them until only the one remains. It really shows how nicely the technique works.
Now I am keen to find some controversial real-world causal hypothesis and test it using this method.
comment by sfwc · 2012-10-13T12:55:37.366Z · LW(p) · GW(p)
Early investigators in Artificial Intelligence, who were trying to represent all high-level events using primitive tokens in a first-order logic (for reasons of historical stupidity we won't go into) were stymied by the following apparent paradox:
[Description of a system with the following three theorems: ⊢ ALARM → BURGLAR, ⊢ EARTHQUAKE → ALARM, and ⊢ (EARTHQUAKE & ALARM) → NOT BURGLAR]
Which represents a logical contradiction.
This isn't a logical contradiction: perhaps what you mean is that we can deduce from this system that EARTHQUAKE is false. This would give us a contradiction in a modal system, if we also had the theorem ⊢ possibly(EARTHQUAKE), but as it stands it isn't yet contradictory.
Replies from: Vaniver↑ comment by Vaniver · 2012-10-13T15:50:11.406Z · LW(p) · GW(p)
You clearly understand this, but I'll make it explicit for observers:
A → B means that it cannot be the case that A is true and B is false.
E → A means that it cannot be the case that E is true and A is false.
(E & A) → !B means that it cannot be the case that E is true, A is true, and B is true.
Suppose we learn that E is false. We can't infer anything about A and B, except that it cannot be that A is true and B is false.
Suppose we learn that E is true. By 2, we know that A cannot be false, and so must be true. By 1, we know that B cannot be false. By 3, we know that B cannot be true. B has no possible values, which is a contradiction.
This isn't a logical contradiction: perhaps what you mean is that we can deduce from this system that EARTHQUAKE is false. This would give us a contradiction in a modal system, if we also had the theorem ⊢ possibly(EARTHQUAKE), but as it stands it isn't yet contradictory.
E is a sensor reading about reality, and so ⊢ possibly(E) is meant to be implied. (Writing down those three statements on a piece of paper can't force the earth to stop shaking!)
One of the improvements made to solve this problem was to introduce probability- the idea that instead of treating the links between A, E, and B as deterministic, let's treat them as stochastic. That's the Bayesian network idea, and with those it's harder to get contradictions (you can by misforming your distributions).
The causal model is an improvement even beyond that, because it allows you to deal with interventions in the system. Suppose we know that alarms and burglars are perfectly correlated. This could be either because burglars always set off alarms, or because alarms always attract burglars. If you're a burglar who would like to steal from a house when there isn't an earthquake, the difference is important! If you knew which causal system were the case, you could predict what would happen when you steal from the house.
comment by Kaj_Sotala · 2012-10-12T04:54:02.089Z · LW(p) · GW(p)
Very nice and intuitive, thanks! This explanation is great.
(Though I've already spent a little while playing around with Bayes nets, and I don't know how large of a role that had in making this feel more intuitive to me.)
comment by TruePath · 2012-10-25T08:48:52.117Z · LW(p) · GW(p)
The concern of the philosophers is the idea of 'true causation' as independent from merely apparent causation. In particular, they have in mind the idea that even if the laws of the universe were deterministic there would be a sense in which certain events could be said to be causes of others even though mathematically, the configuration of the universe at any time completely entails it at all others. Frankly, this question arises out of half-baked arguments about whether events cause latter events or if god has predetermined and causes all events individually and I don't take it seriously.
My take is that there is no such thing as causation. Correlation is all there is and the fact that many correlations are usefully and compactlly described by Bayesian causal models is actually support for the idea that the ascription of causation reflects nothing more than how the arrows happen to point in those causal models we find most compelling. In other words I don't think it makes sense to look under your model to ask about what is truly causation but we should be clear that is what the philosophers mean.
Despite my great respect for Bayesian causal models it doesn't let us deduce causality from correlation and I can prove it.
Given results about k events (assume for simplicity they are binary True/False events) E_1...E_k (so E_1 might be burglary, E_2 earthquake, E_3 recession and a trial is each year) and any ordering < on 1..k there is a causal model such that E_i is a causal antecedant of E_j iff i < j that perfectly agrees with the given probabilities. In other words at the expense of potentially having every E_i with i <* j affect the probability of E_i I can have any causal order I want on the events and get the same results.
To see this is true start with whatever event we want to occur first, say E_{i1}. Now we compute the probabilities that the next event E{i2} occurs conditional on E{i1} and it's negation. For E{i3} we compute the probabilities that this event occurs conditional on all 4 outcomes for the pair E{i1}, E{i_2} and so on. This gives the correct probability to each set of outcomes and thus matches all observations. Alternatively, we can always make the E_i all dependent on some invisible common causes that match the appropriate priors.
True, these diagrams might be less simple in some sense than other diagrams we might draw but that doesn't mean they are false. Indeed, we might have very good general reasons for preferring some more complicated theory, e.g., even if a simpler causal model could explain the data but requires causal dependence on effects later in time reject it in favor of some more complicated model. This is a useful generalization we have about the world and following it helps us reach better predictions when we have limited data. Thus the mere number of arrows can't simply be minimized.
In other words all you've got is the same old crap about preferring the simpler theory where that has no principled mathematical definition and more or less means 'prefer whatever your priors say the causal model really looks like.' In other words we haven't gotten any closer to infering causation.
Just the opposite. The use of Bayesian causal models explains extremely well why, even if events are truly all effects caused by the choices of some unseen mover the notion of causation would be likely to evolve.
Replies from: IlyaShpitser, Peterdjones, Benito↑ comment by IlyaShpitser · 2012-10-31T18:11:49.375Z · LW(p) · GW(p)
My take is that there is no such thing as causation. Correlation is all there is ...
I keep having to link this:
http://www.smbc-comics.com/index.php?db=comics&id=1994
In other words at the expense of potentially having every Ei with i <* j affect the probability of E_i I can have any causal order I want on the events and get the same results.
Causal models have to do with interventions not with node orders in a Bayesian network. A causal model is not the same thing as a Bayesian network (which Eliezer got wrong in his post, and has yet to fix, by the way). Causal models are not about making better predictions, they are about cause effect relationships (causal effects, mediation analysis, confounders, things like that). I think reading standard stuff on interventionist causality might be a good idea: Pearl's Causality book or the CMU book (Causation, Prediction and Search).
↑ comment by Peterdjones · 2012-10-25T10:11:10.699Z · LW(p) · GW(p)
. In particular, they have in mind the idea that even if the laws of the universe were deterministic there would be a sense in which certain events could be said to be causes of others even though mathematically, the configuration of the universe at any time completely entails it at all others.
What;s the problem with that? If the universe is causally deterministic, it is causal. True,it is necesary to distinguish causal deterninism form acausal determinism (eg fatalism) and philosophy can do that. Or is your concern with future events entailing past ones? Then adopt two-way causality.
Correlation is all there is and the fact that many correlations are usefully and compactlly described by Bayesian causal models is actually support for the idea that the ascription of causation reflects nothing more than how the arrows happen to point in those causal models we find most compelling
I don't follow that. The existence of a map doesn't usually prove the non-existence of a territory.
In other words all you've got is the same old crap about preferring the simpler theory where that has no principled mathematical definition
The consequencesof abandoning the razor are much worse than those of having a subjective razor.
↑ comment by Ben Pace (Benito) · 2012-10-25T09:04:19.304Z · LW(p) · GW(p)
I'm afraid I haven't followed the maths at all, but when you say that there is no causation, only corration, do you mean that you cannot prove causation, or that it actually never exists? Because that last option surely isn't true? Back in 'The Useful Idea of Truth' we discussed how photons from shoelaces cause you to become entangled with their untangeledness. If there is no causation, you couldn't observe or know anything. If you mean you just can't prove causation, could you please say it more simply (for me please)?