Posts
Comments
I'm not as concerned about your points because there are a number of projects already doing something similar and (if you believe them) succeeding at it. Here's a paper comparing some of them: https://www.biorxiv.org/content/10.1101/2025.02.11.637758v2.full
ML arguments can take more data as input. In particular, the genomic sequence is not a predictor used in LASSO regression models: the variants are just arbitrarily coded as 0,1, or 2 alternative allele count. The LASSO models have limited ability to pool information across variants or across data modes. ML models like this one can (in theory) predict effects of variants just based off their sequence on data like RNA-sequencing (which shows which genes are actively being transcribed). That information is effectively pooled across variants and ties genomic sequence to another data type (RNA-seq). If you include that information into a disease-effect prediction model, you might improve upon the LASSO regression model. There are a lot of papers claiming to do that now, for example the BRCA1 supervised experiment in the EVO-2 paper. Of course, a supervised disease-effect prediction layer could be LASSO itself and just include some additional features derived from the ML model.
This is a lovely little problem, so thank you for sharing it. I thought at first it would be [a different problem](https://www.wolfram.com/mathematica/new-in-9/markov-chains-and-queues/coin-flip-sequences.html) that's similarly paradoxical.
Again, why wouldn't you want to read things addressed to other sorts of audiences if you thought altering public opinion on that topic was important? Maybe you don't care about altering public opinion but a large number of people here say they do care.
He's influential and it's worth knowing what his opinion is because it will become the opinion of many of his readers. Hes also representative of what a lot of other people are (independently) thinking.
What's Scott Alexander qualified to comment on? Should we not care about the opinion of Joe Biden because he has no particular knowledge about AI? Sure, I'm doubt we learn anything from rebutting his arguments, but once upon a time LW cared about changing the public opinion on this matter and so should absolutely care about reading that public opinion.
Honestly, I embarrassed for us that this needs to be said.
But you don’t need grades to separate yourself academically. You take harder classes to do that. And incentivizing GPA again will only punish people for taking actual classes instead of sticking to easier ones they can get an A in.
Concretely, everyone in my math department that was there to actually get an econ job took the basic undergrad sequences and everyone looking to actually do math started with the honors (“throw you in the deep end until you can actually write a proof”) course and rapidly started taking graduate-level courses. The difference on their transcript was obvious but not necessarily on their GPA.
What system would turn that into a highly legible number akin to GPA? I’m not sure, some sort of ELO system?
I was confused until I realized that the "sparsity" that this post is referring to is activation sparsity not the more common weight sparsity that you get from L1 penalization of weights.
Wait why do you think inmates escaping is extremely rare? Are you just referring to escapes where guards assisted the escape? I work in a hospital system and have received two security alerts in my memory where a prisoner receiving medical treatment ditched their escort and escaped. At least one of those was on the loose for several days. I can also think of multiple escapes from prisons themselves, for example: https://abcnews.go.com/amp/US/danelo-cavalcante-murderer-escaped-pennsylvania-prison-weeks-facing/story?id=104856784 notable since the prisoner was an accused murderer and likely to be dangerous and armed. But there was also another escape from that same jail earlier that year: https://www.dailylocal.com/2024/01/08/case-of-chester-county-inmate-whose-escape-showed-cavalcante-the-way-out-continued/amp/
i have some reservations about the practicality of reporting likelihood functions and have never done this before, but here are some (sloppy) examples in python. Primarily answering number 1 and 3.
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
import matplotlib
import pylab
np.random.seed(100)
## Generate some data for a simple case vs control example
# 10 vs 10 replicates with a 1 SD effect size
controls = np.random.normal(size=10)
cases = np.random.normal(size=10) + 1
data = pd.DataFrame(
{
"group": ["control"] * 10 + ["case"] * 10,
"value": np.concatenate((controls, cases)),
}
)
## Perform a standard t-test as comparison
# Using OLS (ordinary least squares) to model the data
results = smf.ols("value ~ group", data=data).fit()
print(f"The p-value is {results.pvalues['group[T.control]']}")
## Report the (log)-likelihood function
# likelihood at the fit value (which is the maximum likelihood)
likelihood = results.llf
# or equivalently
likelihood = results.model.loglike(results.params)
## Results at a range of parameter values:
# we evaluate at 100 points between -2 and 2
control_case_differences = np.linspace(-2, 2, 100)
likelihoods = []
for cc_diff in control_case_differences:
params = results.params.copy()
params["group[T.control]"] = cc_diff
likelihoods.append(results.model.loglike(params))
## Plot the likelihood function
fig, ax = pylab.subplots()
ax.plot(
control_case_differences,
likelihoods,
)
ax.set_xlabel("control - case")
ax.set_ylabel("log likelihood")
## Our model actually has two parameters, the intercept and the control-case difference
# We only varied the difference parameter without changing the intercept, which denotes the
# the mean value across both groups (since we are balanced in case/control n's)
# Now lets vary both parameters, trying all combinations from -2 to 2 in both values
mean_values = np.linspace(-2, 2, 100)
mv, ccd = np.meshgrid(mean_values, control_case_differences)
likelihoods = []
for m, c in zip(mv.flatten(), ccd.flatten()):
likelihoods.append(
results.model.loglike(
pd.Series(
{
"Intercept": m,
"group[T.control": c,
}
)
)
)
likelihoods = np.array(likelihoods).reshape(mv.shape)
# Plot it as a 2d grid
fig, ax = pylab.subplots()
h = ax.pcolormesh(
mean_values,
control_case_differences,
likelihoods,
)
ax.set_ylabel("case - control")
ax.set_xlabel("mean")
fig.colorbar(h, label="log likelihood")The two figures are:
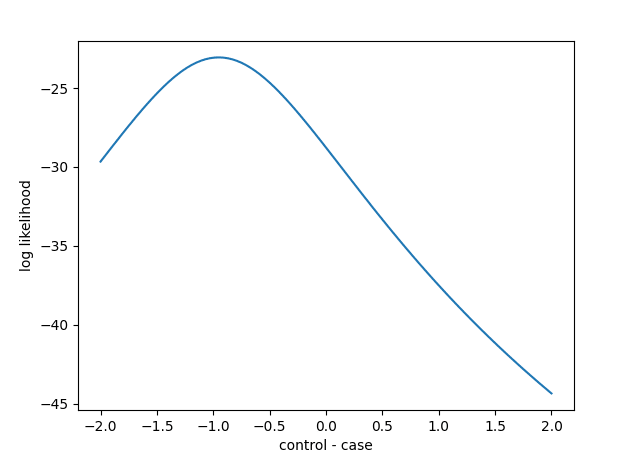
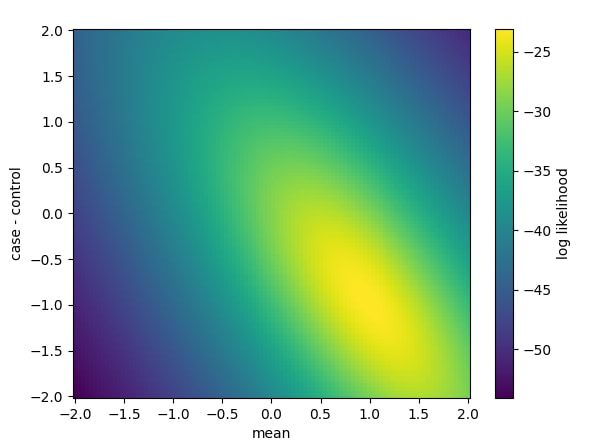
I think this code will extend to any other likelihood-based model in statsmodels, not just OLS, but I haven't tested.
It's also worth familiarizing yourself with how the likelihoods are actually defined. For OLS we assume that residuals are normally distributed. For data points y_i at X_i the likelihood for a linear model with independent, normal residuals is:
where is the parameters of the model, is the variance of the residuals, and is the number of datapoints. So the likelihood function here is this value as a function of (and maybe also , see below).
So if we want to tell someone else our full likelihood function and not just evaluate it at a grid of points, it's enough to tell them and . But that's the entire dataset! To get a smaller set of summary statistics that capture the entire information, you look for 'sufficient statistics'. Generally for OLS those are just and . I think that's also enough to recreate the likelihood function up to a constant?
Note that matters for reporting the likelihood but doesn't matter for traditional frequentist approaches like MLE and OLS since it ends up cancelling out when you're doing finding the maximum or reporting likelihood ratios. This is inconvenient for reporting likelihood functions and I think the code I provided is just using the estimated from the MLE estimate. However, at the end of the day, someone using your likelihood function would really only be using it to extract likelihood ratios and therefore the probably doesn't matter here either?
But yes, working out is mostly unpleasant and boring as hell as we conceive of it and we need to stop pretending otherwise. Once we agree that most exercise mostly bores most people who try it out of their minds, we can work on not doing that.
I'm of the nearly opposite opinion: we pretend that exercise ought to be unpleasant. We equate exercise with elite or professional athletes and the vision of needing to push yourself to the limit, etc. In reality, exercise does include that but for most people should look more like "going for a walk" than "doing hill sprints until my legs collapse".
On boredom specifically, I think strenuousness affects that more than monotony. When I started exercising, I would watch a TV show on the treadmill and kept feeling bored, but the moment I toned down to a walking speed to cool off, suddenly the show was engaging and I'd find myself overstaying just to watch it. Why wasn't it engaging while I was running? The show didn't change. Monotony wasn't the deciding factor, but rather the exertion.
Later, I switched to running outside and now I don't get bored despite using no TV or podcast or music. And it requires no willpower! If you're two miles from home, you can't quit. Quitting just means running two miles back which isn't really quitting so you might as well keep going. But on a treadmill, you can hop off at any moment, so there's a constant drain on willpower. So again, I think the 'boredom' here isn't actually about the task being monotonous and finding ways to make it less monotonous won't fix the perceived boredom.
I do agree with the comment of playing tag for heart health. But that already exists and is socially acceptable in the form of pickup basketball/soccer/flag-football/ultimate. Lastly, many people do literally find weightlifting fun, and it can be quite social.
The American Heart Association (AHA) Get with the Guidelines–Heart Failure Risk Score predicts the risk of death in patients admitted to the hospital.9 It assigns three additional points to any patient identified as “nonblack,” thereby categorizing all black patients as being at lower risk. The AHA does not provide a rationale for this adjustment. Clinicians are advised to use this risk score to guide decisions about referral to cardiology and allocation of health care resources. Since “black” is equated with lower risk, following the guidelines could direct care away from black patients.
From the NEJM article. This is the exact opposite of Zvi's conclusions ("Not factoring this in means [blacks] will get less care").
I confirmed the NEJM's account by using an online calculator for that score. https://www.mdcalc.com/calc/3829/gwtg-heart-failure-risk-score Setting a patient with black=No gives higher risk than black=yes. Similarly so for a risk score from the AHA,: https://static.heart.org/riskcalc/app/index.html#!/baseline-risk
Is Zvi/NYT referring to a different risk calculator? There are a lot of them out there. The NEJM also discuses a surgical risk score that has the opposite directionality, so maybe that one? Though there the conclusion is also about less care for blacks: "When used preoperatively to assess risk, these calculations could steer minority patients, deemed to be at higher risk, away from surgery." Of course, less care could be a good thing here!
I agree that this looks complicated.
Wegovy (a GLP-1 antagonist)
Wegovy/Ozempic/Semaglutide are GLP-1 receptor agonists, not GLP-1 antagonists. This means they activate the GLP-1 receptor, which GLP-1 also does. So it's more accurate to say that they are GLP-1 analogs, which makes calling them "GLP-1s" reasonable even though that's not really accurate either.
Broccoli is higher in protein content per calorie than either beans or pasta and is a very central example of a vegetable, though you'd also want to mix it with beans or something for a better protein quality. 3500 calories of broccoli is 294g protein, if Google's nutrition facts are to be trusted. Spinach, kale, and cauliflower all also have substantially better protein per calories than potatoes and better PDCAAS scores than I expected (though I'm not certain I trust them - does spinach actually get a 1?). I think potatoes are a poor example (and also not one vegetarians turn to for protein).
Though I tend to drench my vegetables in olive oil so these calories per gram numbers don't mean much to me in practice, and good luck eating such a large volume of any of these.
In my view, it's a significant philosophical difference between SLT and your post that your post talks only about choosing macrostates while SLT talks about choosing microstates. I'm much less qualified to know (let alone explain) the benefits of SLT, though I can speculate. If we stop training after a finite number of steps, then I think it's helpful to know where it's converging to. In my example, if you think it's converging to , then stopping close to that will get you a function that doesn't generalize too well. If you know it's converging to then stopping close to that will get you a much better function - possibly exactly equally as good as you pointed out due to discretization.
Now this logic is basically exactly what you're saying in these comments! But I think if someone read your post without prior knowledge of SLT, they wouldn't figure out that it's more likely to converge to a point near than near . If they read an SLT post instead, they would figure that out. In that sense, SLT is more useful.
I am not confident that that is the intended benefit of SLT according to its proponents, though. And I wouldn't be surprised if you could write a simpler explanation of this in your framework than SLT gives, I just think that this post wasn't it.
Everything I wrote in steps 1-4 was done in a discrete setting (otherwise is not finite and whole thing falls apart). I was intending to be pairs of floating point numbers and to be floats to floats.
However, using that I think I see what you're trying to say. Which is that will equal zero for some cases where and are both non-zero but very small and will multiply down to zero due to the limits of floating point numbers. Therefore the pre-image of is actually larger than I claimed, and specifically contains a small neighborhood of .
That doesn't invalidate my calculation that shows that is equally likely as though: they still have the same loss and -complexity (since they have the same macrostate). On the other hand, you're saying that there are points in parameter space that are very close to that are also in this same pre-image and also equally likely. Therefore even if is just as likely as , being near to is more likely than being near to . I think it's fair to say that that is at least qualitatively the same as SLT gives in the continous version of this.
However, I do think this result "happened" due to factors that weren't discussed in your original post, which makes it sound like it is "due to" -complexity. -complexity is a function of the macrostate, which is the same at all of these points and so does not distinguish between and at all. In other words, your post tells me which is likely while SLT tells me which is likely - these are not the same thing. But you clearly have additional ideas not stated in the post that also help you figure out which is likely. Until that is clarified, I think you have a mental theory of this which is very different from what you wrote.
the worse a singularity is, the lower the -complexity of the corresponding discrete function will turn out to be
This is where we diverge. Please let me know where you think my error is in the following. Returning to my explicit example (though I wrote originally but will instead use in this post since that matches your definitions).
1. Let be the constant zero function and
2. Observe that is the minimal loss set under our loss function and also is the set of parameters where or .
3. Let . Then by definition of . Therefore,
4. SLT says that is a singularity of but that is not a singularity.
5. Therefore, there exists a singularity (according to SLT) which has identical -complexity (and also loss) as a non-singular point, contradicting your statement I quote.
The effective dimension of the singularity near the origin is much higher, e.g. because near every other minimal point of this loss function the Hessian doesn't vanish, while for the singularity at the origin it does vanish. If you discretized this setup by looking at it with a lattice of mesh , say, you would notice that the origin is surrounded by many parameters that give nearly identical loss, while near other parts of the space the number of such parameters is far fewer.
As I read it, the arguments you make in the original post depend only on the macrostate , which is the same for both the singular and non-singular points of the minimal loss set (in my example), so they can't distinguish these points at all. I see that you're also applying the logic to points near the minimal set and arguing that the nearly-optimal points are more abundant near the singularities than near the non-singularities. I think that's a significant point not made at all in your original point that brings it closer to SLT, so I'd encourage you to add it to the post.
I think there's also terminology mismatch between your post and SLT. You refer to singularities of (i.e. its derivative is degenerate) while SLT refers to singularities of the set of minimal loss parameters. The point in my example is not singular at all in SLT but is singular. This terminology collision makes it sound like you've recreated SLT more than you actually have.
Here's a concrete toy example where SLT and this post give different answers (SLT is more specific). Let . And let . Then the minimal loss is achieved at the set of parameters where or (note that this looks like two intersecting lines, with the singularity being the intersection). Note that all in that set also give the same exact . The theory in your post here doesn't say much beyond the standard point that gradient descent will (likely) select a minimal or near-minimal , but it can't distinguish between the different values of within that minimal set.
SLT on the other hand says that gradient descent will be more likely to choose the specific singular value .
Now I'm not sure this example is sufficiently realistic to demonstrate why you would care about SLT's extra specificity, since in this case I'm perfectly happy with any value of in the minimal set - they all give the exact same . If I were to try to generalize this into a useful example, I would try to find a case where has a minimal set that contains multiple different . For example, only evaluates on a subset of points (the 'training data') but different choices of minimal give different values outside of that subset of training data. Then we can consider which has the best generalization to out-of-training data - do the parameters predicted by SLT yield that are best at generalizing?
Disclaimer: I have a very rudimentary understanding of SLT and may be misrepresenting it.
I guess the unstated assumption is that the prisoners can only see the temperatures of others from the previous round and/or can only change their temperature at the start of a round (though one tried to do otherwise in the story). Even with that it seems like an awfully precarious equilibrium since if I unilaterally start choosing 30 repeatedly, you'd have to be stupid to not also start choosing 30, and the cost to me is really quite tiny even while no one else ever 'defects' alongside me. It seems to be too weak a definition of 'equilibrium' if it's that easy to break - maybe there's a more realistic definition that excludes this case?
I don't think the 'strategy' used here (set to 99 degrees unless someone defects, then set to 100) satisfies the "individual rationality condition". Sure, when everyone is setting it to 99 degrees, it beats the minmax strategy of choosing 30. But once someone chooses 30, the minmax for everyone else is now to also choose 30 - there's no further punishment that will or could be given. So the behavior described here, where everyone punishes the 30, is worse than minmaxing. At the very least, it would be an unstable equilibrium that would have broken down in the situation described - and knowing that would give everyone an incentive to 'defect' immediately.
Ah, I didn’t understand what “first option” meant either.
The poll appears to be asking two, opposite questions. I'm not clear on whether a 99% means it will be a transformer or whether it means something else is needed to get there?
Thank you. I was completely missing that they used a second 'preference' model to score outputs for the RL. I'm surprised that works!
A lot of team or cooperative games where communication is disallowed and information is limited have aspects of Schelling points. Hanabi is a cooperative card game that encourages using Schelling points. Though higher levels of play require players to establish ahead of time a set of rules for what each possible action is meant to communicate, which rather diminishes that aspect of the game. Arguably bridge is in a similar position with partners communicating via bidding.
Is there a primer on what the difference between training LLMs and doing RLHF on those LLMs post-training is? They both seem fundamentally to be doing the same thing: move the weights in the direction that increases the likelihood that they output the given text. But I gather that there are some fundamental differences in how this is done and RLHF isn't quite a second training round done on hand-curated datapoints.
Sounds plausible but this article is evidence against the striatum hypothesis: Region-specific Foxp2 deletions in cortex, striatum or cerebellum cannot explain vocalization deficits observed in spontaneous global knockouts
In short, they edited mice to have Foxp2 deleted in only specific regions of the brain, one of them being striatum. But those mice didn't have the 'speech' defects that mice with whole-body Foxp2 knock-outs showed. So Foxp2's action outside of the striatum seems to play a role. They didn't do a striatum+cerebellum knock-out, though, so it could still be those two jointly (but not individually) causing the problem.
I gave one example of the “work” this does: that GPT performs better when prompted to reason first rather than state the answer first. Another example is: https://www.lesswrong.com/posts/bwyKCQD7PFWKhELMr/by-default-gpts-think-in-plain-sight
On the contrary, you mainly seem to be claiming that thinking of LLMs as working one token at a time is misleading, but I’m not sure I understand any examples of misleading conclusions that you think people draw from it. Where do you think people go wrong?
Suppose I write the first half of a very GPT-esque story. If I then ask GPT to complete that story, won't it do exactly the same structure as always? If so, how can you say that came from a plan - it didn't write the first half of the story! That's just what stories look like. Is that more surprising than a token predictor getting basic sentence structure correct?
For hidden thoughts, I think this is very well defined. It won't be truly 'hidden', since we can examine every node in GPT, but we know for a fact that GPT is purely a function of the current stream of tokens (unless I am quite mistaken!). A hidden plan would look like some other state that GPT caries from token to token that is not output. I don't think OpenAI engineers would have a hard time making such a model and it may then really have a global plan that travels from one token to the next (or not; it would be hard to say). But how could GPT? It has nowhere to put the plan except for plain sight.
Or: does AlphaGo have a plan? It explicitly considers future moves, but it does just as well if you give it a Go board in a particular state X as it would if it played a game that happened to reach state X. If there is a 'plan' that it made, it wrote that plan on the board and nothing is hidden. I think it's more helpful and accurate to describe AlphaGo as "only" picking the best next move rather than planning ahead - but doing a good enough job of picking the best next move means you pick moves that have good follow up moves.
Maybe I don't understand what exactly your point is, but I'm not convinced. AFAIK, it's true that GPT has no state outside of the list of tokens so far. Contrast to your jazz example, where you, in fact, have hidden thoughts outside of the notes played so-far. I think this is what Wolfram and others are saying when they say that "GPT predicts the next token". You highlight "it doesn’t have a global plan about what’s going to happen" but I think a key point is that whatever plan it has, it has to build it up entirely from "Once upon a" and then again, from scratch, at "Once upon a time," and again and again. Whatever plan it makes is derived entirely from "Once upon a time," and could well change dramatically at "Once upon a time, a" even if " a" was its predicted token. That's very different from what we think of as a global plan that a human writing a story makes.
The intuition of "just predicting one token ahead" makes useful explanations like why the strategy of having it explain itself first and then give the answer works. I don't see how this post fits with that observation or what other observations it clarifies.
If you choose heads, you either win $2 (ie win $1 twice) or lose $1. If you choose tails then you either win $1 or lose $2. It’s exactly the same as the Sleeping Beauty problem with betting, just you have to precommit to a choice of heads/tail ahead of time. Sorry that this situation is weird to describe and unclear.
Yes, exactly. You choose either heads or tails. I flip the coin. If it's tails and matches what you chose, then you win $1 otherwise lose $1. If it's heads and matches what you chose, you win $2 otherwise you lose $2. Clearly you will choose heads in this case, just like the Sleeping Beauty when betting every time you wake up. But you choose heads because we've increased the payout not the probabilities.
And here are examples that I don't think that rephrasing as betting resolves:
Convinced by the Sleeping Beauty problem, you buy a lottery ticket and set up a robot to put you to sleep and then, if the lottery ticket wins, wake you up 1 billion times, and if not just wake you up once. You wake up. What is the expected value of the lottery ticket you're holding? You knew ahead of time that you will wake up at least once, so did you just game the system? No, since I would argue that this system is better modeled by the Sleeping Beauty problem when you get only a single payout regardless of how many times you wake up.
Or: if the coin comes up heads, then you and your memories get cloned. When you wake up you're offered the deal on the spot 1:1 bet on the coin. Is this a good bet for you? (Your wallet gets cloned too, let's say.) That depends on how you value your clone receiving money. But why should P(H|awake) be different in this scenario than in Sleeping Beauty, or different between people who do value their clone versus people who do not?
Or: No sleeping beauty shenanigans. I just say "Let's make a bet. I'll flip a coin. If the coin was heads we'll execute the bet twice. If tails, just once. What odds do you offer me?" Isn't that all that you are saying in this Sleeping Beauty with Betting scenario? The expected value of a bet is a product of the payoff with the probability - the payoff is twice as high in the case of heads, so why should I think that the probability is also twice as high?
I argue that this is the very question of the problem: is being right twice worth twice as much?
You're right that my construction was bad. But the number of bets does matter. Suppose instead that we're both undergoing this experiment (with the same coin flip simultaneously controlling both of us). We both wake up and I say, "After this is over, I'll pay you 1:1 if the coin was a heads." Is this deal favorable and do you accept? You'd first want to clarify how many times I'm going to payout if we have this conversation two days in a row. (Is promising the same deal twice mean we just reaffirmed a single deal or that we agreed to two separate, identical deals? It's ambiguous!) But which one is the correct model of the system? I don't think that's resolved.
I do think phrasing it in terms of bets is useful: nobody disagrees on how you should bet if we've specified exactly how the betting is happening, which makes this much less concerning of a problem. But I don't think that specifying the betting makes it obvious how to resolve the original question absent betting.
That assumes that the bet is offered to you every time you wake up, even when you wake up twice. If you make the opposite assumption (you are offered the bet only on the last time you wake up), then the odds change. So I see this as a subtle form of begging the question.
Your link to Lynch and Marinov is currently incorrect. However I also don't understand whether what they say matches with your post:
the energetic burden of a gene is typically no greater, and generally becomes progressively smaller, in larger cells in both bacteria and eukaryotes, and this is true for costs measured at the DNA, RNA, and protein levels. These results eliminate the need to invoke an energetics barrier to genome complexity. ... These results indicate that the origin of the mitochondrion was not a prerequisite for genome-size expansion.
So that example is of , what is the for it? Obviously, there's multiple that could give that (depending on how the loss is computed from ), with some of them having symmetries and some of them not. That's why I find the discussion so confusing: we really only care about symmetries of (which give type B behavior) but instead are talking about symmetries of (which may indicate either type A or type B) without really distinguishing the two. (Unless my example in the previous post shows that it's a false dichotomy and type A can simulate type B at a singularity.)
I'm also not sure the example matches the plots you've drawn: presumably the parameters of the model are but the plots show it it varying for fixed ? Treating it as written, there's not actually a singularity in its parameters .
Are you bringing up wireheading to answer yes or no to my question (of whether RL is more prone to gradient hacking)? To me, it sounds like you're suggesting a no, but I think it's in support of the idea that RL might be prone to gradient hacking. The AI, like me, avoids wireheading itself and so will never be modified by gradient descent towards wireheading because gradient descent doesn't know anything about wireheading until it's been tried. So that is an example of gradient hacking itself, isn't it? Unlike in a supervised learning setup where the gradient descent 'knows' about all possible options and will modify any subagents that avoid giving the right answer.
So am I a gradient hacker whenever I just say no to drugs?
I'm still thinking about this (unsuccessfully). Maybe my missing piece is that the examples I'm considering here still do not have any of the singularities that this topic focuses on! What are the simplest examples with singularities? Say again we're fitting y = f(x) for over some parameters. And specifically let's consider the points (0,0) and (1,0) as our only training data. Then has minimal loss set . That has a singularity at (0,0,0). I don't really see why it would generalize better than or , neither of which have singularities in their minimal loss sets. These still are only examples of the type B behavior where they already are effectively just two parameters, so maybe there's no further improvement for a singularity to give?
Consider instead . Here the minimal loss set has a singularity when at (0,0,0,0). But maybe now if we're at that point, the model has effectively reduced down to since perturbing either c or d away from zero would still keep the last term zero. So maybe this is a case where has type A behavior in general (since the x^2 term can throw off generalizability compared to a linear) but approximates type B behavior near the singularity (since the x^2 term becomes negligible even if perturbed)? That seems to be the best picture of this argument that I've been able to convince myself of so-far! Singularities are (sometimes) points where type A behavior becomes type B behavior.
And a follow-up that I just thought of: is reinforcement learning more prone to gradient hacking? For example, if a sub-agent guesses that a particular previously untried type of action would produce very high reward, the sub-agent might be able to direct the policy away from those actions. The learning process will never correct this behavior if the overall model never gets to learn that those actions are beneficial. Therefore the sub-agent can direct away from some classes of high-reward actions that it doesn't like without being altered.
There's been discussion of 'gradient hacking' lately, such as here. What I'm still unsure about is whether or not a gradient hacker is just another word for local minimum? It feels different but when I want to try to put a finer definition on it, I can't. My best alternative is "local minimum, but malicious" but that seems odd since it depends upon some moral character.
Thanks for trying to walk me through this more, though I'm not sure this clears up my confusion. An even more similar model to the one in the video (a pendulum) would be the model that which has four parameters but of course you don't really need both a and b. My point is that, as far as the loss function is concerned, the situation for a fourth degree polynomial's redundancy is identical to the situation for this new model. Yet we clearly have two different types of redundancy going on:
- Type A: like the fourth degree polynomial's redundancy which impairs generalizability since it is merely an artifact of the limited training data, and
- Type B: like the new model's redundancy which does not impair generalizability compared to some non-redundant version of it since it is a redundancy in all outputs
Moreover, my intuition is that a highly over-parametrized neural net has much more Type A redundancy than Type B. Is this intuition wrong? That seems perhaps the definition of "over-parametrized": a model with a lot of Type A redundancy. But maybe I instead am wrong to be looking at the loss function in the first place?
I'm confused by the setup. Let's consider the simplest case: fitting points in the plane, y as a function of x. If I have three datapoints and I fit a quadratic to it, I have a dimension 0 space of minimizers of the loss function: the unique parabola through those three points (assume they're not ontop of each other). Since I have three parameters in a quadratic, I assume that this means the effective degrees of freedom of the model is 3 according to this post. If I instead fit a quartic, I now have a dimension 1 space of minimizers and 4 parameters, so I think you're saying degrees of freedom is still 3. And so the DoF would be 3 for all degrees of polynomial models above linear. But I certainly think that we expect that quadratic models will generalize better than 19th degree polynomials when fit to just three points.
I think the objection to this example is that the relevant function to minimize is not loss on the training data but something else? The loss it would have on 'real data'? That seems to make more sense of the post to me, but if that were the case, then I think any minimizer of that function would be equally good at generalizing by definition. Another candidate would be the parameter-function map you describe which seems to be the relevant map whose singularities we are studying, but we it's not well defined to ask for minimums (or level-sets) of that at all. So I don't think that's right either.
Thanks for the clarification! In fact, that opinion wasn't even one of the ones I had considered you might have.
I simultaneously would have answered ‘no,’ would expect most people in my social circles to answer no, think it is clear that this being a near-universal is a very bad sign, and also that 25.6% is terrifying. It’s something like ‘there is a right amount of the thing this is a proxy for, and that very much is not it.’
At the risk of being too honest, I find passages written like this horribly confusing and never know what you mean when you write like this. ("this" being near universal - what is "this"? ("answering no" like you and your friends or "answering yes" like most of the survey respondents?) 25.6% is terrifying because you think it is high or low? What thing do you think "this" is a proxy for?)
For me, the survey question itself seems bad because it's very close to two radically different ideas:
- I base my self-worth on my parent's judgement of me.
- My parents are kind, intelligent people whose judgement making is generally of very high quality. Since they are also biased towards positive views of me, if they judged me poorly then I would take that as serious evidence that I am not living up to what I aspire of myself.
The first sounds unhealthy. The second sounds healthy - at least assuming that one's parents are in fact kind, intelligent, and generally positively disposed to their children at default. I'm not confident which of the two a "yes" respondent is agreeing to or a "no" is disagreeing with.
Thanks. I think I've been tripped up by this terminology more than once now.
Not sure that I understand your claim here about optimization. An optimizer is presumably given some choice of possible initial states to choose from to achieve its goal (otherwise it cannot interact at all). In which case, the set of accessible states will depend upon the chosen initial state and so the optimizer can influence long term behavior and choose whatever best matches it’s desires.
Why would CZ tweet out that he was starting to sell his FTT? Surely that would only decrease the amount he could recover on his sales?
I agree, I was just responding to your penultimate sentence: “In fact, if you could know without labeling generated data, why would you generate something that you can tell is bad in the first place?”
Personally, I think it’s kind of exciting to be part of what might be the last breath of purely human writing. Also, depressing.
Surely the problem is that someone else is generating it - or more accurately lots of other people generating it in huge quantities.
I work in a related field and found this a helpful overview that filled in some gaps of my knowledge that I probably should have known already and I’m looking forward to the follow ups. I do think that this would likely be a very hard read for a layman who wasn’t already pretty familiar with genetics and you might consider making an even more basic version of this. Lots of jargon is dropped without explanation, for example.