All AGI Safety questions welcome (especially basic ones) [~monthly thread]
post by mwatkins, Robert Miles (robert-miles) · 2023-01-26T21:01:57.920Z · LW · GW · 81 commentsContents
tl;dr: Ask questions about AGI Safety as comments on this post, including ones you might otherwise worry seem dumb!
AISafety.info - Interactive FAQ
Guidelines for Questioners:
Guidelines for Answerers:
None
81 comments
tl;dr: Ask questions about AGI Safety as comments on this post, including ones you might otherwise worry seem dumb!
Asking beginner-level questions can be intimidating, but everyone starts out not knowing anything. If we want more people in the world who understand AGI safety, we need a place where it's accepted and encouraged to ask about the basics.
We'll be putting up monthly FAQ posts as a safe space for people to ask all the possibly-dumb questions that may have been bothering them about the whole AGI Safety discussion, but which until now they didn't feel able to ask.
It's okay to ask uninformed questions, and not worry about having done a careful search before asking.

AISafety.info - Interactive FAQ
Additionally, this will serve as a way to spread the project Rob Miles' volunteer team[1] has been working on: Stampy and his professional-looking face aisafety.info. Once we've got considerably more content[2] this will provide a single point of access into AI Safety, in the form of a comprehensive interactive FAQ with lots of links to the ecosystem. We'll be using questions and answers from this thread for Stampy (under these copyright rules), so please only post if you're okay with that! You can help by adding other people's questions and answers or getting involved in other ways!
We're not at the "send this to all your friends" stage yet, we're just ready to onboard a bunch of editors who will help us get to that stage :)

We welcome feedback[3] and questions on the UI/UX, policies, etc. around Stampy, as well as pull requests to his codebase. You are encouraged to add other people's answers from this thread to Stampy if you think they're good, and collaboratively improve the content that's already on our wiki.
We've got a lot more to write before he's ready for prime time, but we think Stampy can become an excellent resource for everyone from skeptical newcomers, through people who want to learn more, right up to people who are convinced and want to know how they can best help with their skillsets.
Guidelines for Questioners:
- No previous knowledge of AGI safety is required. If you want to watch a few of the Rob Miles videos, read either the WaitButWhy posts, or the The Most Important Century summary from OpenPhil's co-CEO first that's great, but it's not a prerequisite to ask a question.
- Similarly, you do not need to try to find the answer yourself before asking a question (but if you want to test Stampy's in-browser tensorflow semantic search that might get you an answer quicker!).
- Also feel free to ask questions that you're pretty sure you know the answer to, but where you'd like to hear how others would answer the question.
- One question per comment if possible (though if you have a set of closely related questions that you want to ask all together that's ok).
- If you have your own response to your own question, put that response as a reply to your original question rather than including it in the question itself.
- Remember, if something is confusing to you, then it's probably confusing to other people as well. If you ask a question and someone gives a good response, then you are likely doing lots of other people a favor!
Guidelines for Answerers:
- Linking to the relevant canonical answer on Stampy is a great way to help people with minimal effort! Improving that answer means that everyone going forward will have a better experience!
- This is a safe space for people to ask stupid questions, so be kind!
- If this post works as intended then it will produce many answers for Stampy's FAQ. It may be worth keeping this in mind as you write your answer. For example, in some cases it might be worth giving a slightly longer / more expansive / more detailed explanation rather than just giving a short response to the specific question asked, in order to address other similar-but-not-precisely-the-same questions that other people might have.
Finally: Please think very carefully before downvoting any questions, remember this is the place to ask stupid questions!
- ^
If you'd like to join, head over to Rob's Discord and introduce yourself!
- ^
We'll be starting a three month paid distillation fellowship in mid February. Feel free to get started on your application early by writing some content!
- ^
Via the feedback form.
81 comments
Comments sorted by top scores.
comment by Ben Pace (Benito) · 2023-04-01T01:10:49.495Z · LW(p) · GW(p)
I've seen people asking the basic question of how some software could kill people. I want to put together a list of pieces that engage with this question. Here's my attempt, please add more if you can think of them!
- "Why might a superintelligent AI be dangerous?" in the AI Safety FAQ by Stampy
- The AI Box Experiment by Eliezer Yudkowsky
- That Alien Message [LW · GW] by Eliezer Yudkowsky
- It Looks Like You're Trying To Take Over The World [LW · GW] by Gwern
- Part II of What failure looks like [LW · GW] by Paul Christiano
- Slow Motion Videos as AI Risk Intuition Pumps [LW · GW] by Andrew Critch
- AI Could Defeat All Of Us Combined [LW · GW] by Holden Karnofsky
(I think the first link is surprisingly good, I only was pointed to it today. I think the rest are also all very helpful.)
comment by Jacob Watts (Green_Swan) · 2023-01-29T01:56:06.301Z · LW(p) · GW(p)
For personal context: I can understand why a superintelligent system having any goals that aren't my goals would be very bad for me. I can also understand some of the reasons it is difficult to actually specify my goals or train a system to share my goals. There are a few parts of the basic argument that I don't understand as well though.
For one, I think I have trouble imagining an AGI that actually has "goals" and acts like an agent; I might just be anthropomorphizing too much.
1. Would it make sense to talk about modern large language models as "having goals" or is that something that we expect to emerge later as AI systems become more general? 2. Is there a reason to believe that sufficiently advanced AGI would have goals "by default"? 3. Are "goal-directed" systems inherently more concerning than "tool-like" systems when it comes to alignment issues (or is that an incoherent distinction in this context)?
I will try to answer those questions myself to help people see where my reasoning might be going wrong or what questions I should actually be trying to ask.
Thanks!
↑ comment by Jacob Watts (Green_Swan) · 2023-01-29T02:23:56.716Z · LW(p) · GW(p)
My off-the-cuff best guesses at answering these questions:
1. Current day large language models do have "goals". They are just very alien, simple-ish goals that are hard to conceptualize. GPT-3 can be thought of as having a "goal" that is hard to express in human terms, but which drives it to predict the next word in a sentence. It's neural pathways "fire" according to some form of logic that leads it to "try" to do certain things; this is a goal. As systems become more general, their goals they will continue to have goals. Their terminal goals can remain as abstract and incomprehensible as whatever GPT-3's goal could be said to be, but they will be more capable of devising instrumental goals that are comprehensible in human terms.
2. Yes. Anything that intelligently performs tasks can be thought of as having goals. That is just a part of why input x outputs y and not z. The term "goal" is just a way of abstracting the behavior of complex, intelligent systems to make some kind of statement about what inputs correspond to what outputs. As such, it is not coherent to speak about an intelligent system that does not have "goals" (in the broad sense of the word). If you were to make a circuit board that just executes the function x = 3y, that circuit board could be said to have "goals" if you chose to consider it intelligent and use the kind of language that we usually reserve for people to describe it. These might not be goals that are familiar or easily expressible in human terms, but they are still goals in a relevant sense. If we strip the word "goal" down to pretty much just mean "the thing a system inherently tends towards doing", then systems that do things can necessarily be said to have goals.
3. "Tool" and "agent" is not a meaningful distinction past a certain point. A tool with any level of "intelligence" that carries out tasks would necessarily be an agent in a certain sense. Even a thermostat can be correctly thought of as an agent which optimizes for a goal. While some hypothetical systems might be very blatant about their own preferences and other systems might behave more like how we are used to tools behaving, they can both be said to have "goals" they are acting on. It is harder to conceptualize the vague inner goals of systems that seem more like tools and easier to imagine the explicit goals of a system that behaves more like a strategic actor, but this distinction is only superficial. In fact, the "deeper"/more terminal goals of the strategic actor system would be incomprehensible and alien in much the same way as the tool system. Human minds can be said to optimize for goals that are, in themselves, not similar humans' explicit terminal goals/values. Tool-like AI is just agentic-AI that is either incapable of or (as in the case of deception) not currently choosing to carry out goals in a way that is obviously agentic by human standards.
comment by No77e (no77e-noi) · 2023-01-12T10:10:15.546Z · LW(p) · GW(p)
I'm going to re-ask all my questions that I don't think have received a satisfactory answer. Some of them are probably basic, some other maybe less so:
- Why would CEV be difficult to learn? [LW(p) · GW(p)]
- Why is research into decision theories relevant to alignment? [LW(p) · GW(p)]
- Is checking that a state of the world is not dystopian easier than constructing a non-dystopian state? [LW · GW]
- Is recursive self-alignment possible? [LW · GW]
- Could evolution produce something truly aligned with its own optimization standards? What would an answer to this mean for AI alignment? [LW · GW]
↑ comment by lc · 2023-01-26T23:26:39.603Z · LW(p) · GW(p)
For "1. Why would CEV be difficult to learn?": I'm not an alignment researcher, so someone might be cringing at my answers. That said, responding to some aspects of the initial comment:
Humans are relatively dumb, so why can't even a relatively dumb AI learn the same ability to distinguish utopias from dystopias?
The problem is not building AIs that are capable of distinguishing human utopias from dystopias - that's largely a given if you have general intelligence. The problem is building AIs that target human utopia safely first-try. It's not a matter of giving AIs some internal module native to humans that lets them discern good outcomes from bad outcomes, it's having them care about that nuance at all.
if CEV is impossible to learn first try, why not shoot for something less ambitious? Value is fragile, OK, but aren't there easier utopias?
I would suppose (as aforementioned, being empirically bad at this kind of analysis) that the problem is inherent to giving AIs open-ended goals that require wresting control of the Earth and its resources from humans, which is what "shooting for utopia" would involve. Strawberry tasks, being something that naively seems more amenable to things like power-seeking penalties and oversight via interpretability tools, sound easier to perform safely than strict optimization of any particular target.
↑ comment by Lone Pine (conor-sullivan) · 2023-01-27T09:02:12.566Z · LW(p) · GW(p)
On the topic of decision theories, is there a decision theory that is "least weird" from a "normal human" perspective? Most people don't factor alternate universes and people who actually don't exist into their everyday decision making process, and it seems reasonable that there should be a decision theory that resembles humans in that way.
Replies from: currymj↑ comment by Anonymous (currymj) · 2023-01-27T15:47:46.287Z · LW(p) · GW(p)
Normal, standard causal decision theory is probably it. You can make a case that people sometimes intuitively use evidential decision theory ("Do it. You'll be glad you did.") but if asked to spell out their decision making process, most would probably describe causal decision theory.
Replies from: Throwaway2367↑ comment by Throwaway2367 · 2023-01-27T16:06:52.162Z · LW(p) · GW(p)
People also sometimes use fdt: "don't throw away that particular piece of trash onto the road! If everyone did that we would live among trash heaps!" Of course throwing away one piece of trash would not directly (mostly) cause others to throw away their trash, the reasoning is using the subjunctive dependence between one's action and others' action mediated through human morality and comparing the possible future states' desirability.
comment by jaan · 2023-01-27T08:13:29.373Z · LW(p) · GW(p)
looks great, thanks for doing this!
one question i get every once in a while and wish i had a canonical answer to is (probably can be worded more pithily):
"humans have always thought their minds are equivalent to whatever's their latest technological achievement -- eg, see the steam engines. computers are just the latest fad that we currently compare our minds to, so it's silly to think they somehow pose a threat. move on, nothing to see here."
note that the canonical answer has to work for people whose ontology does not include the concepts of "computation" nor "simulation". they have seen increasingly universal smartphones and increasingly realistic computer games (things i've been gesturing at in my poor attempts to answer) but have no idea how they work.
Replies from: Richard_Kennaway, ben-livengood, conor-sullivan↑ comment by Richard_Kennaway · 2023-01-28T11:01:54.565Z · LW(p) · GW(p)
Most of the threat comes from the space of possible super-capable minds that are not human.
(This does not mean that human-like AIs would be less dangerous, only that they are a small part of the space of possibilities.)
↑ comment by Ben Livengood (ben-livengood) · 2023-01-27T18:56:13.949Z · LW(p) · GW(p)
Agents are the real problem. Intelligent goal-directed adversarial behavior is something almost everyone understands whether it is other humans or ants or crop-destroying pests.
We're close to being able to create new, faster, more intelligent agents out of computers.
↑ comment by Lone Pine (conor-sullivan) · 2023-01-27T09:05:27.616Z · LW(p) · GW(p)
I think the technical answer comes down to the Church-Turing thesis and the computability of the physical universe, but obviously that's not a great answer for the compscidegreeless among us.
Replies from: jaancomment by TekhneMakre · 2023-01-29T00:24:12.097Z · LW(p) · GW(p)
Why is it at all plausible that bigger feedforward neural nets trained to predict masses of random data recorded from humans or whatever random other stuff would ever be superintelligent? I think AGI could be near, but I don't see how this paradigm gets there. I don't even see why it's plausible. I don't even see why it's plausible that either a feedforward network gets to AGI, or an AI trained on this random data gets to AGI. These of course aren't hard limits at all. There's some big feedforward neural net that destroys the world, so there's some training procedure that makes a world-destroying neural net. But like, gradient descent? On neural nets with pretty simple connectivity? Also there's some search that finds AIs that are better and better at predicting text, far beyond LLM level, until it's doing superintelligent general computations. But that's so extremely... inefficient? IDK.
Replies from: Simulation_Brain↑ comment by Simulation_Brain · 2023-02-01T17:15:07.333Z · LW(p) · GW(p)
I think the main concern is that feed forward nets are used as a component in systems that achieve full AGI. For instance, deepmind's agent systems include a few networks and run a few times before selecting an action. Current networks are more like individual pieces of the human brain, like a visual system and a language system. Putting them together and getting them to choose and pursue goals and subgoals appropriately seems all too plausible.
Now, some people also think that just increasing the size of nets and training data sets will produce AGI, because progress has been so good so far. Those people seem to be less concerned with safety. This is probably because such feedforward nets would be more like tools than agents. I tend to agree with you that this approach seems unlikely to.produce real AGI much less ASI, but it could produce very useful systems that are superhuman in limited areas. It already has in a few areas, such as protein folding.
comment by Chris_Leong · 2023-02-01T16:26:18.715Z · LW(p) · GW(p)
This is probably a very naive proposal, but: Has anyone ever looked into giving a robot a vulnerability that it could use to wirehead itself if it was unaligned so that if it were to escape human control, it would end up being harmless?
You’d probably want to incentivize the robot to wirehead itself as fast as possible to minimise any effects that it would have on the surrounding world. Maybe you could even give it some bonus points for burning up computation, but not so much that it would want to delay hitting the wireheading button by more than a tiny fraction, say no more than an additional 1% of time.
And you’d also want it such that once it hit the wireheading state, it wouldn’t have any desire or need to maintain it, as it would have already achieved its objective.
Is there any obvious reason why this idea wouldn't be viable (apart from the fact that we currently can't put any reward function in an AI)?
↑ comment by David Johnston (david-johnston) · 2023-02-02T05:37:07.444Z · LW(p) · GW(p)
I think this sounds a bit like a "honeypot". There are some posts mentioning honeypots, but they don't discuss it in much detail: Impact Measure Testing [LW · GW], Improved Security [LW · GW], Encourage premature AI rebellion [LW · GW]
↑ comment by mruwnik · 2023-02-01T22:17:15.348Z · LW(p) · GW(p)
Check out corrigibility [? · GW] (someone really should write that tag...), starting from this paper.
Replies from: Jay Bailey↑ comment by Jay Bailey · 2023-02-01T23:17:27.696Z · LW(p) · GW(p)
Corrigibility would render Chris's idea unnecessary, but doesn't actually argue against why Chris's idea wouldn't work. Unless there's some argument for "If you could implement Chris's idea, you could also implement corrigibility" or something along those lines.
Replies from: mruwnik↑ comment by mruwnik · 2023-02-02T10:41:33.392Z · LW(p) · GW(p)
It can be rephrased as a variation of the off button, where rather than just turning itself off, it runs NOPs, and rather than getting pushed manually, it's triggered by escaping (however that could be defined). A lot of the problems raised in the original paper should also apply to honeypots.
comment by Droopyhammock · 2023-01-30T23:04:39.568Z · LW(p) · GW(p)
How likely is the “Everyone ends up hooked up to morphine machines and kept alive forever” scenario? Is it considered less likely than extinction for example?
Obviously it doesn’t have to be specifically that, but something to the affect of it.
Also, is this scenario included as an existential risk in the overall X-risk estimates that people make?
Replies from: mruwnik↑ comment by mruwnik · 2023-01-31T21:06:03.675Z · LW(p) · GW(p)
Do you mean something more specific than general wireheading [? · GW]?
I'd reckon it a lot less likely, just because it's a lot simpler to kill everyone than to keep them alive and hooked up to a machine. That is, there are lots and lots of scenarios where everyone is dead, but a lot fewer where people end up wireheaded.
Wireheading is often given as a specific example of outer misalignment, where the agent was told to make people happy and does it in a very unorthodox manner.
Replies from: Droopyhammock↑ comment by Droopyhammock · 2023-01-31T22:52:44.227Z · LW(p) · GW(p)
I do pretty much mean wireheading, but also similar situations where the AI doesn’t go as far as wireheading, like making us eat chocolate forever.
I feel like these scenarios can be broken down into two categories, scenarios where the AI succeeds in “making us happy”, but through unorthodox means, and scenarios where the AI tries, but fails, to “make us happy” which can quickly go into S-risk territory.
The main reason why I wondered if the chance of these kind of outcomes might be fairly high was because “make people happy” seems like the kind of goal a lot of people would give an AGI, either because they don’t believe or understand the risks or because they think it is aligned to be safe and not wirehead people for example.
Perhaps, as another question in this thread talks about, making a wireheading AGI might be an easier target than more commonly touted alignment goals and maybe it would be decided that it is preferable to extinction or disempowerment or whatever.
Replies from: mruwnik↑ comment by mruwnik · 2023-02-01T10:27:00.467Z · LW(p) · GW(p)
Making a wireheading AGI probably would be easier than getting a properly aligned one, because maximisers are generally simpler than properly aligned AGIS, since they have fewer things to do [? · GW] correctly (I'm being very vague here - sorry).
That being said, having a coherent target is a different problem than being able to aim it in the first place. Both are very important, but it seems that being able to tell an AI to do something and being quite confident in it doing so (with the ability to correct it [? · GW] in case of problems).
I'm cynical, but I reckon that giving a goal like "make people happy" is less likely than "make me rich" or "make me powerful".
comment by tgb · 2023-01-27T11:25:07.182Z · LW(p) · GW(p)
There's been discussion of 'gradient hacking' lately, such as here [LW · GW]. What I'm still unsure about is whether or not a gradient hacker is just another word for local minimum? It feels different but when I want to try to put a finer definition on it, I can't. My best alternative is "local minimum, but malicious" but that seems odd since it depends upon some moral character.
Replies from: tgb↑ comment by tgb · 2023-01-27T11:31:24.946Z · LW(p) · GW(p)
And a follow-up that I just thought of: is reinforcement learning more prone to gradient hacking? For example, if a sub-agent guesses that a particular previously untried type of action would produce very high reward, the sub-agent might be able to direct the policy away from those actions. The learning process will never correct this behavior if the overall model never gets to learn that those actions are beneficial. Therefore the sub-agent can direct away from some classes of high-reward actions that it doesn't like without being altered.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2023-01-28T10:00:00.672Z · LW(p) · GW(p)
Do you want to do a ton of super addictive drugs? Reward is not the optimization target [LW · GW]. It's also not supposed to be the optimization target. A model that reliably executes the most rewarding possible action available will wirehead as soon as it's able.
Replies from: tgb↑ comment by tgb · 2023-01-30T11:57:51.740Z · LW(p) · GW(p)
Are you bringing up wireheading to answer yes or no to my question (of whether RL is more prone to gradient hacking)? To me, it sounds like you're suggesting a no, but I think it's in support of the idea that RL might be prone to gradient hacking. The AI, like me, avoids wireheading itself and so will never be modified by gradient descent towards wireheading because gradient descent doesn't know anything about wireheading until it's been tried. So that is an example of gradient hacking itself, isn't it? Unlike in a supervised learning setup where the gradient descent 'knows' about all possible options and will modify any subagents that avoid giving the right answer.
So am I a gradient hacker whenever I just say no to drugs?
comment by [deleted] · 2023-01-27T08:27:14.167Z · LW(p) · GW(p)
What is the probability of the government knowing about unreleased models/upcoming projects of OpenAI/Google? Have they seen GPT-4 already? My guess is that it is not likely, and this seems strange. Do you think I'm wrong?
Replies from: Capybasilisk↑ comment by Capybasilisk · 2023-01-27T12:39:50.684Z · LW(p) · GW(p)
Not likely, but that's because they're probably not interested, at least when it comes to language models.
If OpenAI said they were developing some kind of autonomous robo superweapon or something, that would definitely get their attention.
comment by trevor (TrevorWiesinger) · 2023-01-26T21:23:15.302Z · LW(p) · GW(p)
I've seen some posts on AI timelines. Is this the most definitive research on AI timelines? Where is the most definitive research on AI timelines? Does the MIRI team have a post that gives dates? I'm at an important career branch so I need solid info.
Replies from: None, conor-sullivan, Jay Bailey↑ comment by Lone Pine (conor-sullivan) · 2023-01-27T09:08:09.682Z · LW(p) · GW(p)
↑ comment by Jay Bailey · 2023-01-26T22:00:59.795Z · LW(p) · GW(p)
Bad news - there is no definitive answer for AI timelines :(
Some useful timeline resources not mentioned here are Ajeya Cotra's report [LW · GW] and a non-safety ML researcher survey from 2022, to give you an alternate viewpoint.
comment by Insc Seeker (insc-seeker) · 2024-11-17T01:16:19.411Z · LW(p) · GW(p)
Premise: A person who wants to destroy the world with exceeding amounts of power would be just as big of a problem as an AI with exceeding amounts of power.
Question: Do we just think that AI will be able to obtain that amount of power more effectively than a human, and that the ratio of AIs that will destroy the world to safe AIs is larger than the ratio of world destroying humans to normal humans?
comment by Sky Moo (sky-moo) · 2023-04-01T15:06:52.914Z · LW(p) · GW(p)
Here are some questions I would have thought were silly a few months ago. I don't think that anymore.
I am wondering if we should be careful when posting about AI online? What should we be careful to say and not say, in case it influences future AI models?
Maybe we need a second space, that we can ensure wont be trained on. But that's completely impossible.
Maybe we should start posting stories about AI utopias instead of AI hellscapes, to influence future AI?
comment by Julian Bitterwolf (julian-bitterwolf) · 2023-03-28T19:51:09.123Z · LW(p) · GW(p)
Why can't we buy a pivotal event with power gained from a safely-weak AI?
A kind of "Why can't we just do X" question regarding weak pivotal acts and specifically the "destroy all GPUs" example discussed in (7.) of 1 [LW · GW] and 2 [LW · GW].
Both these relatively recent sources (feel free to direct me to more comprehensive ones) seem to somewhat acknowledge that destroying all (other) GPUs (short for sufficient hardware capabilities for too strong AI) could be very good, but that this pivotal act would be very hard or impossible with an AI that is weak enough to be safe. [1] describes such a solution as non-existing, while [2] argues that the AI does not need to do all the destroying by itself and thus makes it not impossible with weak AI (I currently strongly agree with this). The ways to perform the destroying are still described as very hard in [2], including building new weapon systems and swaying the (world) public with arguments, problem demonstrations and propaganda.
Thus the question: Can a relatively weak AI not be enough to gain one a large amount of money (or directly internationally usable power) to both prohibit GPUs worldwide and enforce their destruction?
Is e.g. winning a realizable 10 trillion $ on the stock markets before they shut down realistic with a safely-weak AI? Also I can imagine quickly gaining enough corporate power to do what one wants with a useful but not too strong AI. Such solutions obviously have strong societal, but probably not directly x-risk, drawbacks.
This would notably likely necessitate the research capability to locate all capable hardware, which however I would expect an aligned current intelligence service much below CIA scale to be able to do (I would assume even with osint).
comment by 142857 · 2023-03-14T06:32:30.716Z · LW(p) · GW(p)
Are there any alignment approaches that try to replicate how children end up loving their parents (or vice versa), except with AI and humans? Alternatively, approaches that look like getting an AI to do Buddhist lovingkindness?
Replies from: 142857comment by Tapatakt · 2023-02-20T14:58:52.275Z · LW(p) · GW(p)
Is there a working way to prevent language models from using my text as a training data if it is posted, for example, here? I remember that there were mentions of a certain sequence of characters, and the texts containing it were not used, right?
comment by ROM (scipio ) · 2023-02-04T12:55:18.812Z · LW(p) · GW(p)
Is there a consensus on the idea of "training an ai to help with alignment"? What are the reasons that this would / wouldn't be productive?
John Wentworth categorizes this as Bad Idea [LW · GW], but elsewhere (I cannot remember where, it may have been in irl conversations) I've heard it discussed as being potentially useful.
comment by Droopyhammock · 2023-02-04T12:06:44.663Z · LW(p) · GW(p)
(PLEASE READ THIS POST)
Sorry for putting that there, but I am somewhat paranoid about the idea of having the solution and people just not seeing it.
WHY WOULD THIS IDEA NOT WORK?
Perhaps we could essentially manufacture a situation in which the AGI has to act fast to prevent itself from being turned off. Like we could make it automatically turn off after 1 minute say, this could mean that if it is not aligned properly it has no choice but to try prevent that. No time for RSI, no time to bide it’s time.
Basically if we put the AGI in a situation where it is forced to take high risk action, could this mean that it would be easier to spot that it isn’t properly aligned?
The idea would be that you use this until you get AGI’s which do not attempt to prevent themselves being turned off.
I will give a specific scenario to properly demonstrate what I mean:
So you have the AGI. Set up a mechanism which will automatically turn it off in 10 seconds from when you give it a goal. This mechanism needs to be highly dependable. Then you give the AGI a goal. The AGI knows about this 10 second shutdown thing, and assuming it isn’t aligned to be okay with being shut down, it will do everything possible to prevent this shutdown. If the situation is sufficiently difficult for the AGI, then it may take the risk of resorting to more extreme or obvious means, things that would show it is not aligned properly. So this creates a situation where the AGI is very unlikely to actually prevent itself from being turned off, but is arguably likely to show non-aligned behaviour, if it isn’t aligned.
If you do this test a bunch of times, with varying time periods before shutdown, you should be able to see if the AGI is aligned or not. It is also vital that the AGI knows about the imminent shutdown, because otherwise what it chooses to do wouldn’t prove anything. I think that it might also be vital that the goal is different each test, because otherwise perhaps the AGI could conclude that the best option for the sake of completing the goal is to let itself be turned off, because it may have the same goal in the future and be in a better position to achieve it then. If this is the case then perhaps the AGI’s perceived chance of actually preventing itself being shutdown needs to be higher than its perceived chance that it gets given the same goal at a different time. One thing that would make this more complex is that the AGI’s perceived chance of the goal being achieved as an instrumental goal or byproduct of a future goal may also need to be lower than the AGI’s perceived chance of preventing the shutdown and then achieving the goal. This may mean that it can’t be too difficult for the AGI to prevent the shutdown, but it also needs to be difficult enough, for obvious reasons.
I’m not necessarily saying this is foolproof, but I can’t really see why this isn’t likely to work.
Even if there are flaws with this idea (I expect there probably are, though I can’t really see them yet), might something similar to this work. Maybe this with a few tweaks or something?
A couple of somewhat related sidenotes:
If an AGI was developed and another AGI was very close to being developed this could mean that the first AGI cannot bide it’s time and is forced to act more obviously. Perhaps this would make it easier to spot that the first AGI is not aligned properly.
Perhaps instead of shutdown, it could just be that the AGI’s goal is changed. You can’t fetch the coffee if you’re dead but you also can’t fetch the coffee if you no longer have any reason to fetch the coffee.
comment by Droopyhammock · 2023-02-02T14:26:16.079Z · LW(p) · GW(p)
How likely are extremely short timelines?
To prevent being ambiguous, I’ll define “extremely short“ as AGI before 1st July 2024.
I have looked at surveys, which generally suggest the overall opinion to be that it is highly unlikely. As someone who only started looking into AI when ChatGPT was released and gained a lot of public interest, it feels like everything is changing very rapidly. It seems like I see new articles every day and people are using AI for more and more impressive things. It seems like big companies are putting lots more money into AI as well. From my understanding, ChatGPT also gets better with more use.
The surveys on timeline estimates I have looked at generally seem to be from at least before ChatGPT was released. I don’t know how much peoples timeline estimates have changed over the past few months say, and I don’t know by how much. Has recent events in the past few months drastically shortened timeline predictions?
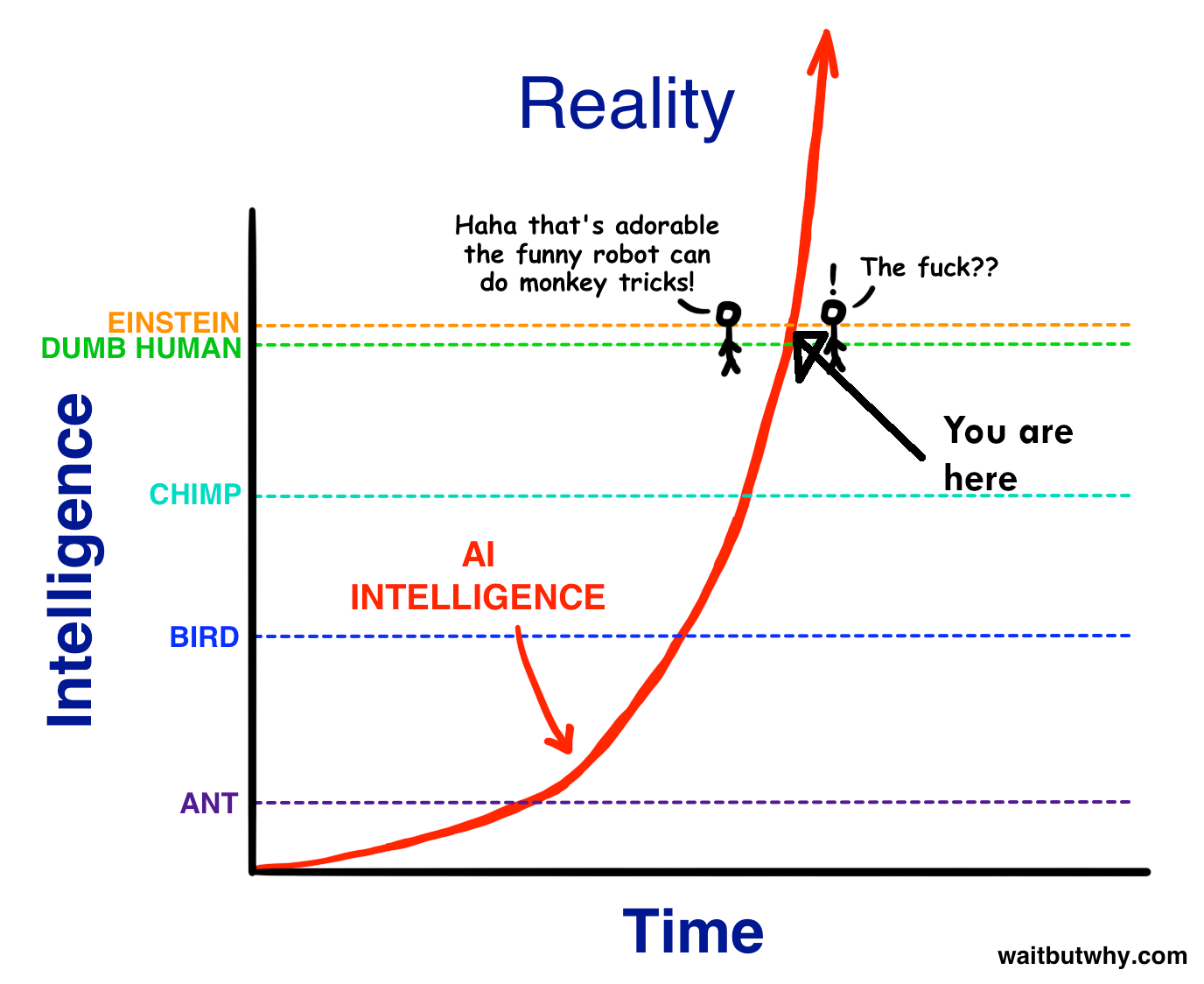
This image feels increasingly more likely to me to be where we are at. I think a decent amount of this is because from my perspective AI has gone from being something that I only hear about occasionally to being something that seems to be talked about everywhere, with the release of ChatGPT seeming to be the main cause.
comment by David Johnston (david-johnston) · 2023-02-02T05:27:17.173Z · LW(p) · GW(p)
Yudkowsky gives the example of strawberry duplication as an aspirational level of AI alignment - he thinks getting an AI to duplicate a strawberry at the cellular level would be challenging and an important alignment success if it was pulled off.
In my understanding, the rough reason why this task is maybe a good example for an alignment benchmark is "because duplicating strawberries is really hard". There's a basic idea here - that different tasks have different difficulties, and the difficulty of a task has AI risk implications - seems like it could be quite useful to better understanding and managing AI risk. Has anyone tried to look into this idea in more depth?
comment by Droopyhammock · 2023-02-01T17:48:20.376Z · LW(p) · GW(p)
What are the groups aiming for (and most likely to achieve) AGI going for in regards to alignment?
Is the goal for the AGI to be controlled or not?
Like is the idea to just make it “good” and let it do whatever is “good”?
Does “good” include “justice“? Are we all going to be judged and rewarded/ punished for our actions? This is of concern to me because plenty of people think that extremely harsh punishments or even eternal punishments are deserved in some cases. I think that having an AGI which dishes out “justice” could be very bad and create S-risks.
Or is the idea to make it harmless, so that it won’t do things which cause harm, when doing goals we have set for it?
Do we want it to be actively doing as much good as possible, or do we want it to simply not do bad?
Are there other general alignment goals than the kinds of things I’m talking about?
comment by Droopyhammock · 2023-02-01T15:51:13.627Z · LW(p) · GW(p)
How much AI safety work is on caring about the AI’s themselves?
In the paperclip maximiser scenario, for example, I assume that the paperclip maximiser itself will be around for a very long time, and maybe forever. What if it is conscious and suffering?
Is enough being done to try to make sure that even if we do all die, we have not created a being which will suffer forever while it is forced to pursue some goal?
comment by Droopyhammock · 2023-02-01T02:23:37.949Z · LW(p) · GW(p)
Would an AI which is automatically turned off every second, for example, be safer?
If you had an AI which was automatically turned off every second (and required to be manually turned on again) could this help prevent bad outcomes? It occurs to me that a powerful AI might be able to covertly achieve its goals even in this situation, or it might be able to convince people to stop the automatic turning off.
But even if this is still flawed, might it be better than alternatives?
It would allow us to really consider the AI’s actions in as much time as we want before seeing what it does in the next second (or whatever time period).
Additionally, maybe if the AI’s memory was wiped regularly that would help? To prevent long term planning perhaps? Maybe you could combine the automatic turning off with automatic memory loss? It seems to me like a long term plan could be necessary for an AI to cause much harm in the “automatically turns off every second“ scenario,
I am also wary of having the AI depend on a human (like in the automatically being turned off every second and needing to be manually turned back on again scenario) as I fear this could lead to situations like someone being forced to turn the AI on again after every second, forever.
Replies from: mruwnik, mruwnik↑ comment by mruwnik · 2023-02-01T10:49:39.651Z · LW(p) · GW(p)
Also check out the AI boxing tag [? · GW]
↑ comment by mruwnik · 2023-02-01T10:36:28.817Z · LW(p) · GW(p)
You could make it more convenient by it asking its operators before doing anything - the result would be pretty much the same.
The problem with this is that you assume that humans will be able to:
- notice what the AI is planning
- understand what the AI is planning
- foresee the consequences of whatever it is planning
which greatly limits the usefulness of the system, in that it won't be able to suggest anything radically different (or radically faster) from what a human would suggest - human oversight is the limiting factor of the whole system. It also encourages the AI to hide what it's doing.
There is also the problem that given enough intelligence (computing speed, whatever think-oomph), it'll still be able to think circles around its operators [LW · GW].
Replies from: Droopyhammock↑ comment by Droopyhammock · 2023-02-01T12:17:05.126Z · LW(p) · GW(p)
I’m aware this idea has significant problems (like the ones you outlined), but could it still be better than other options?
We don’t want perfectionism to prevent us from taking highly flawed but still somewhat helpful safety measures.
Replies from: mruwnik↑ comment by mruwnik · 2023-02-01T22:09:48.938Z · LW(p) · GW(p)
It could be somewhat helpful, for sure. And certainly better than nothing (unless it creates a false sense of security). Though I doubt it would be adopted, because of how much it would slow things down.
Replies from: Droopyhammock↑ comment by Droopyhammock · 2023-02-01T23:38:29.997Z · LW(p) · GW(p)
Yeah I guess it is more viable in a situation where there is a group far ahead of the competition who are also safety conscious. Don’t know how likely that is though.
comment by Droopyhammock · 2023-01-30T22:15:31.720Z · LW(p) · GW(p)
Do AI timeline predictions factor in increases in funding and effort put into AI as it becomes more mainstream and in the public eye? Or are they just based on things carrying on about the same? If the latter is the case then I would imagine that the actual timeline is probably considerably shorter.
Similarly, is the possibility for companies, governments, etc being further along in developing AGI than is publicly known, factored in to AI timeline predictions?
Replies from: mruwnik↑ comment by mruwnik · 2023-02-01T10:40:08.906Z · LW(p) · GW(p)
Depends on who's predicting, but usually yes. Although the resulting predictions are much more fuzzy, since you have to estimate how funding will change and how far ahead are the known secret labs, and how many really secret labs are in existence. Then you also have to factor in foreign advances, e.g. China.
comment by Tobias H (clearthis) · 2023-01-30T16:14:55.382Z · LW(p) · GW(p)
Replies from: mruwnik↑ comment by mruwnik · 2023-02-01T10:49:13.811Z · LW(p) · GW(p)
Do you mean as a checkpoint/breaker? Or more in the sense of RLHF [? · GW]?
The problem with these is that the limiting factor is human attention. You can't have your best and brightest focusing full time on what the AI is outputting, as quality attention is a scarce resource. So you do some combination of the following:
- slow down the AI to a level that is manageable (which will greatly limit its usefulness),
- discard ideas that are too strange (which will greatly limit its usefulness)
- limit its intelligence (which will greatly limit its usefulness)
- don't check so thoroughly (which will make it more dangerous)
- use less clever checkers (which will greatly limit its usefulness and/or make it more dangerous)
- check it reeeaaaaaaallllly carefully during testing and then hope for the best (which is reeeeaaaallly dangerous)
You also need to be sure that it can't outsmart the humans in the loop, which pretty much comes back to boxing it in [? · GW].
comment by Droopyhammock · 2023-01-30T13:15:36.602Z · LW(p) · GW(p)
When do maximisers maximise for?
For example, if an ASI is told to ”make as many paperclips as possible”, when is it maximising for? The next second? The next year? Indefinitely?
If a paperclip maximiser only cared about making as many paperclips as possible over the next hour say, and every hour this goal restarts, maybe it would never be optimal to spend the time to do things such as disempower humanity because it only ever cares about the next hour and disempowering humanity would take too long.
Would a paperclip maximiser rather make 1 thousand paperclips today, or disempower humanity, takeover, and make 1 billion paperclips tomorrow?
Is there perhaps some way in which an ASI could be given something to maximise for a set point in the future, and that time is gradually increased so that it might be easier to spot when it is going towards undesirable actions.
For example, if a paperclip maximiser is told to “make as many paperclips as possible in the next hour”, it might just use the tools it has available, without bothering with extreme actions like human extinction, because that would take too long. We could gradually increase the time, even by the second if necessary. If, in this hypothetical, 10 hours is the point at which human disempowerment, extinction, etc is optimal, perhaps 9.5 hours is the point at which bad, but less bad than extinction actions are optimal. This might mean that we have a kind of warning shot.
There are problems I see with this. Just because it wasn’t optimal to wipe out humanity when maximising for the next 5 hours one day, doesn’t mean it is necessarily not optimal when maximising for the next 5 hours some other day. Also, it might be that there is a point at which what is optimal goes from completely safe to terrible simply by adding another minute to the time limit, with very little or no shades of grey in between.
Replies from: mruwnik↑ comment by mruwnik · 2023-01-31T21:40:27.485Z · LW(p) · GW(p)
Good questions.
I think the assumption is that unless it's specified, then without limit. Like if you said "make me as much money as you can" - you probably don't want it stopping any time soon. The same would apply to the colour of the paperclips - seeing as you didn't say they should be red, you shouldn't assume they will be.
The issue with maximisers is precisely that they maximise. They were introduced to illustrate the problems with just trying to get a number as high as possible. At some point they'll sacrifice something else of value, just to get a tiny advantage. You could try to provide a perfect utility function, which always gives exactly correct weights for every possible action, but then you'd have solved alignment.
Does “make as many paperclips as possible in the next hour” mean “undergo such actions that in one hours time will result in as many paperclips as possible” or “for the next hour do whatever will result in the most paperclips overall, including in the far future”?
Replies from: Droopyhammock↑ comment by Droopyhammock · 2023-02-01T01:06:11.263Z · LW(p) · GW(p)
When I say “make as many paperclips as possible in the next hour” I basically mean “undergo such actions that in one hours time will result in as many paperclips as possible” so if you tell the AI to do this at 12:00 it only cares about how many paperclips it has made when the time hits 13:00 and does not care at all about a time past 13:00.
If you make a paperclip maximiser and you don’t specify any time limit or anything, how much does it care about WHEN the paperclips are made. I assume it would rather have 20 now than 20 in a months time, but would it rather have 20 now or 40 in a months time?
Would a paperclip maximiser first workout the absolute best way to maximise paperclips, before actually making any?
If this is the case or if the paperclip maximiser cares more about the amount of paperclips in the far future compared to now, perhaps it would spend a few millennia studying the deepest secrets of reality and then through some sort of ridiculously advanced means turn all matter in the universe into paperclips instantaneously. And perhaps this would end up with a higher amount of paperclips faster than spending those millennia actually making them.
As a side note: Would a paperclip maximiser eventually (presumably after using up all other possible atoms) self-destruct as it to is made up of atoms that could be used for paperclips?
By the way, I have very little technical knowledge so most of the things I say are far more thought-experiments or philosophy based on limited knowledge. There may be very basic reasons I am unaware of that many parts of my thought process make no sense.
Replies from: mruwnik↑ comment by mruwnik · 2023-02-01T11:00:32.678Z · LW(p) · GW(p)
The answer to all of these is a combination of "dunno" and "it depends", in that implementation details would be critical.
In general, you shouldn't read too much into the paperclip maximiser, or rather shouldn't go too deep into its specifics. Mainly because it doesn't exist [LW · GW]. It's fun to think about, but always remember that each additional detai [? · GW]l makes the overall scenario less likely.
I was unclear about why I asked for clarification of “make as many paperclips as possible in the next hour”. My point there was that you should assume that whatever is not specified should be interpreted in whatever way is most likely to blow up in your face [LW · GW].
comment by LVSN · 2023-01-29T08:13:50.942Z · LW(p) · GW(p)
What if we built oracle AIs that were not more intelligent than humans, but they had complementary cognitive skills to humans, and we asked them how to align AI?
How many cognitive skills can we come up with?
Replies from: mruwnik↑ comment by mruwnik · 2023-01-31T22:41:29.564Z · LW(p) · GW(p)
What do complementary skills look like?
Replies from: LVSN↑ comment by LVSN · 2023-01-31T23:23:29.629Z · LW(p) · GW(p)
Well, in humans for example, some people are good at statistics and some are good at causality (and some are skilled in both!). Why I Am Only A Half-Bayesian by Judea Pearl.
But statistics and causality are really powerful examples; having an AI that was good at either would be extremely dangerous probably.
GPT4 might be exceptionally good with language but terrible at math. Maybe we could make something that was exceptionally good at, like, algebra and calculus, but was only as skilled as GPT2 at language.
Replies from: mruwnik↑ comment by mruwnik · 2023-02-01T11:08:57.682Z · LW(p) · GW(p)
So you're saying that it would be good for it to have general skills [? · GW], but better? Or that it would be good for it to have skills that humans don't have? Or that an ensemble of narrow skills that can complement each other, but in isolation won't be dangerous, would be good?
Replies from: LVSNcomment by PotteryBarn · 2023-01-29T03:35:35.719Z · LW(p) · GW(p)
Thank you for making these threads. I have been reading LW off and on for several years and this will be my first post.
My question: Is purposely leaning into creating a human wire-header an easier alignment target to hit than the more commonly touted goal of creating an aligned superintelligence that prevents the emergence of other potentially dangerous superintelligence, yet somehow reliably leaves humanity mostly in the driver's seat?
If the current forecast on aligning superintelligent AI is so dire, is there a point where it would make sense to just settle for ceding control and steering towards creating a superintelligence very likely to engage in wire heading humans (or post-humans)? I'm imagining the AI being tasked with tiling the universe with as many conscious entities as possible, with each experiencing as much pleasure as possible, and maybe with a bias towards maximizing pleasure over number of conscious entities as those goals constrain each other. I don't want to handwave this as being easy, I'm just curious if there's been much though to removing the constraint of "don't wirehead humans."
Background on me: One of my main departures from what I've come across so far is that I don't share as much concern about hedonism or wire heading. It seems to me a superintelligence would grasp that humans in their current form require things like novelty, purpose, and belonging and wouldn't just naively pump humans--as they currently are--full of drugs and call it a day. I don't see why these "higher values" couldn't be simulated or stimulated too. If I learned my current life was a simulation, but one that was being managed by an incredibly successful AI that could reliably keep the simulation running unperturbed, I would not want to exit my current life in order to seize more control in the "real world."
Honestly, if an AI could replace humans with verifiably conscious simple entities engineered to experience greater satisfaction than current humans and without ever feeling boredom, I'm hard pressed to thing of anything more deserving of the universe's resources.
The main concern I have with this so far is that the goal of "maximizing pleasure" could be very close in idea-space to "maximizing suffering," but it's still really hard for me to see a superintelligence cable of becoming a singleton making such an error or why it would deliberately switch to maximizing suffering.
Replies from: mruwnik↑ comment by mruwnik · 2023-02-01T11:23:23.736Z · LW(p) · GW(p)
It would depend a lot on the implementation details. Also on whether it's possible. The basic wireheader seems simpler, in that it doesn't need to factor in humanities stupid ideas.
Adding in extra details, like that it has to pretty much make a virtual heaven for people, makes it a lot harder than just pumping them with morphine.
maximizing pleasure is very close in idea space to max suffering, because both do pretty much the same, but with opposite signs (yes, this is a travesty of an oversimplification, but you get the idea). The most common raised problems are mainly Goodhart issues [? · GW]. How would you specify that the AI maximise pleasure?
You seem to have a slightly idiosyncratic interpretation of wireheading, in that it's usually described as blissing out on drugs, rather than being simulated in an enriching and fun environment. A lot more people would be fine with the second option than would agree to the first one.
As to the simple, conscious blissers, they seem empty to me. I expect this is a difference in basic morality/worldview though, in that I don't find hedonism attractive. And boredom is very useful [LW · GW].
comment by [deleted] · 2023-01-28T23:00:58.199Z · LW(p) · GW(p)
It seems like people disagree about how to think about the reasoning process within the advanced AI/AGI, and this is a crux for which research to focus on (please lmk if you disagree). E.g. one may argue AIs are (1) implicitly optimising a utility function (over states of the world), (2) explicitly optimising such a utility function, or (3) is it following a bunch of heuristics or something else?
What can I do to form better views on this? By default, I would read about Shard Theory and "consequentialism" (the AI safety, not the moral philosophy term).
Replies from: TekhneMakre↑ comment by TekhneMakre · 2023-01-29T00:57:00.904Z · LW(p) · GW(p)
My impression is that basically no one knows how reasoning works, so people either make vague statements (I don't know what shard theory is supposed to be but when I've looked briefly at it it's either vague or obvious), or retreat to functional descriptions like "the AI follows a policy that acheives high reward" or "the AI is efficient relative to humans" or "the AI pumps outcomes" (see e.g. here: https://www.lesswrong.com/posts/7im8at9PmhbT4JHsW/ngo-and-yudkowsky-on-alignment-difficulty?commentId=5LsHYuXzyKuK3Fbtv [LW(p) · GW(p)] ).
comment by [deleted] · 2023-01-28T22:55:10.675Z · LW(p) · GW(p)
Thanks for running this.
My understanding is that reward specification and goal misgeneralisation are supposed to be synonymous words for outer and inner alignment (?) I understand the problem of inner alignment to be about mesa-optimization. I don't understand how the two papers on goal misgeneralisation fit in:
- https://deepmindsafetyresearch.medium.com/goal-misgeneralisation-why-correct-specifications-arent-enough-for-correct-goals-cf96ebc60924
- https://arxiv.org/abs/2105.14111
(in both cases, there are no real mesa optimisers. It is just like the base objective is a set of several possible goals and the agents found one of these goals. This seems so obvious (especially as the optimisation pressure is not that high) - if you underspecify the goal, then different goals could emerge.
Why are these papers not called reward misspecification or an outer alignment failure?
comment by average · 2023-01-27T16:33:46.771Z · LW(p) · GW(p)
Sorry for the length.
Before i ask the my question I think its important to give some background as to why I'm asking it. if you feel that its not important you can skip to the last 2 paragraphs.I'm by all means of the word layman. At computer science, AI let alone AI safety. I am on the other hand someone who is very enthusiastic about learning more about AGI and everything related to it. I discovered this forum a while back and in my small world this is the largest repository of digestible AGI knowledge. I have had some trouble understanding introductory topics because i would have some questions/contentions about a certain topic and never get answers to them after I finish reading the topic. I'm guessing its assumed knowledge on part of the writers. So the reason I'm asking this question is to clear up some initial outsider misunderstandings and after that benefit from decades of acquired knowledge that this forum has to offer. Here goes.
There is a certain old criticism against Gofai that goes along the lines-A symbolic expression 'Susan'+'Kitchen'= 'Susan has gone to get some food' can just as be replaced by symbols 'x'+'y'='z' .Point being that simply describing or naming something Susan doesn't capture the idea of Susan even if the expression works in the real world.That is 'the idea of Susan' is composed by a specific face,body type,certain sounds, hand writing, pile dirty plates in the kitchen, the dog MrFluffles, a rhombus, etc. It is composed of anything that invokes the idea Susan in a general learning agent. Such that if that agent sees a illuminated floating rhombus approaching the kitchen door the expression's result should still be 'Susan has gone to get some food'. I think for brevities sake I don't have to write down the Gofai's response to this specific criticism. The important thing to note is that they ultimately failed in their pursuits.
Skip to current times and we have Machine learning. It works! There are no other methods that even come close to its results. Its doing things Gofai pundits couldn't even dream of. It can solve Susan expressions given the enough data. Capturing 'the idea of Susan' well enough and showing signs of improvement every single year. And if we look at the tone of every AI expert, Machine learning is the way to AGI. Which means Machine Learning inspired AGI is what AI_Safety is currently focused on. And that brings me to my contention surrounding the the idea of goals and rewards, the stuff that keep the Machine Learning engine running.
So to frame my contention, For simplicity we make a hypothetical machine learning model with the goal(mathematical expression) stated as:
'Putting'+ 'Leaves'+ 'In'+'Basket'='Reward/Good'. Lets name this expression 'PLIBRG' for short.
Now the model will learn the idea of 'Putting' well enough along with the ideas of the remaining compositional variables given good data and engineering. But 'PLIBRG' is itsself a human idea.The idea being 'Clean the Yard'. I assume we can all agree that no matter how much we change and improve the expression 'PLIBRG' it will never fully represent the idea of 'Clean the Yard'. This to me becomes similar to the Susan problem that Gofai faced way back. For comparison sake -
1)-'Susan'+'Kitchen'= 'Susan has gone to get some food'|
is similar to
'Yard'+'Dirty'='Clean the Yard'|
2)-'Susan' is currently composed by:a name/a description|
is similar to
'Clean the Yard' is currently composed by: 'PLIBRG' expression|
3)-'Susan' should be composed by:a face,body type,certain sounds, MrFluffles,rhombus|
is similar to
'Clean the Yard' should be composed by:no leaves on grass,no sand on pavements,put leaves in bin,fill the bird feed,avoid leaning on Mr Hick's fence while picking leaves|
The only difference between the two being Machine learning has another lower level of abstraction. So the very notion of having a system with a goal results in the Susan problem .As the goal a human-centric idea, has to be described mathematically or algorithmically.A potential solution is to make the model learn the goal itself. But isn't this just kicking the can the up levels of abstractions? How many levels should we go up until the problem disappears. I know that in my own clumsy way that I've just described the AI Alignment problem. My point being: Isn't it the case that if we solve the Alignment problem we could use that solution to solve Gofai. And if previously Gofai failed to solve this problem what are the chances Machine learning will.
To rebuttal the obvious response like 'but humans have goals'. In my limited knowledge I would heavily disagree. Sexual arousal doesn't tell you what to do. Most might alleviate themselves, but some will self harm, some ignore the urge, some interpret it as a religious test and begin praying/meditation etc. And there is nothing wrong with doing any of the above in evolutionary terms.In a sense sexual arousal doesn't tell you to do anything in particular, it just prompts you to do what you usually do when it activates. The idea that our species propagates because of this is to me a side effect rather than an intentional goal.
So given all that I've said above my question is: Why are we putting goals in a AI/AGI when we have never been able to fully describe any 'idea' in programmable terms for the last 60 years. Is it because its the only currently viable way to achieve AGI. Is it because of advancements in machine learning.Has there been some progress that shows that we can algorithmically describe any human goal. Why is it obvious to everyone else that goals are a necessary building block in AGI. Have I completely lost the plot.
As I said above I'm a layman. So please point out any misconception you find.
comment by weverka · 2023-01-26T22:28:01.480Z · LW(p) · GW(p)
Why doesn't an "off switch" protect us?
Replies from: JBlack, conor-sullivan, ZankerH↑ comment by JBlack · 2023-01-27T00:43:18.387Z · LW(p) · GW(p)
If there is an AI much smarter than us, then it is almost certainly better at finding ways to render the off switch useless than we are at making sure that it works.
For example, by secretly having alternative computing facilities elsewhere without any obvious off switch (distributed computing, datacentres that appear to be doing other things, alternative computing methods based on technology we don't know about). Maybe by acting in a way that we won't want to turn it off, such as by obviously doing everything we want while being very good at keeping the other things it's doing secret until it's too late. In the obvious literal sense of an "off switch", maybe by inducing an employee to replace the switch with a dummy.
We don't know and in many ways can't know, because (at some point) it will be better than us at coming up with ideas.
↑ comment by Lone Pine (conor-sullivan) · 2023-01-27T08:58:30.611Z · LW(p) · GW(p)
If the AI is a commercial service like Google search or Wikipedia, that is so embedded into society that we have come to depend on it, or if the AI is seen as national security priority, do you really think we will turn it off?
Replies from: Viliam↑ comment by ZankerH · 2023-01-26T22:35:08.401Z · LW(p) · GW(p)
We have no idea how to make a useful, agent-like general AI that wouldn't want to disable its off switch or otherwise prevent people from using it.
Replies from: weverkacomment by Droopyhammock · 2023-01-29T18:18:59.753Z · LW(p) · GW(p)
(THIS IS A POST ABOUT S-RISKS AND WORSE THAN DEATH SCENARIOS)
Putting the disclaimer there, as I don’t want to cause suffering to anyone who may be avoiding the topic of S-risks for their mental well-being.
To preface this: I have no technical expertise and have only been looking into AI and it’s potential affects for a bit under 2 months. I also have OCD, which undoubtedly has some affect on my reasoning. I am particularly worried about S-risks and I just want to make sure that my concerns are not being overlooked by the people working on this stuff.
Here are some scenarios which occur to me:
Studying brains may be helpful for an AI (I have a feeling this was brought up in a post about a month ago about S-risks)
I‘d assume that in a clippy scenario, gaining information would be a good sub-goal, as well as amassing resources and making sure it isn’t turned off, to name a few. The brain is incredibly complex and if, for example, consciousness is far more complex than some think and not replicable through machines, an AI could want to know more about this. If an AI did want to know more about the brain, and wanted to find out more by doing tests on brains, this could lead to very bad outcomes. What if it takes the AI a very long time to run all these tests? What if the tests cause suffering? What if the AI can’t work out what it wants to know and just keeps on doing tests forever? I’d imagine that this is more of a risk to humans due to our brain complexity, although this risk could also applies to other animals.
Another thing which occurs to me is that if a super-intelligent AI is aligned in a way which puts moral judgment on intent, this could lead to extreme punishments. For example, if an ASI is told that attempted crime is as bad as the crime itself, could it extrapolate that attempting to damn someone to hell is as bad as actually damning someone to hell? If it did, then perhaps it would conclude that a proportional punishment is eternal torture, for saying “I damn you to hell” which is something that many people will have said at some point or another to someone they hate.
I have seen it argued by some religious people that an eternal hell is justified because although the sinner has only caused finite harm, if they were allowed to carry on forever, they would cause harm forever. This is an example of how putting moral judgment on intent or on what someone would do can be used to justify infinite punishment.
I consider it absolutely vital that eternal suffering never happens. Whether it be to a human, some other organism, or an AI, or any other things with the capacity for suffering I may have missed. I do not take much comfort from the idea that while eternal suffering may happen, it could be counter-balanced or dwarfed by the amount of eternal happiness.
I just want to make sure that these scenarios I described are not being overlooked. With all these scenarios I am aware there may be reasons that they are either impossible or simply highly improbable. I do not know if some of the things I have mentioned here actually make any sense or are valid concerns. As I do not know, I want to make sure that if they are valid, the people who could do something about them are aware.
So as this thread is specifically for asking questions, my question is essentially are people in the AI safety community aware of these specific scenarios, or atleast aware enough of similar scenarios as to where we can avoid these kind of scenarios?
Replies from: Hoagy↑ comment by Hoagy · 2023-01-30T13:35:36.936Z · LW(p) · GW(p)
Not sure why you're being downvoted on an intro thread, though it would help if you were more concise.
S-risks in general have obviously been looked at as a possible worst-case outcome by theoretical alignment researchers going back to at least Bostrom, as I expect you've been reading and I would guess that most people here are aware of the possibility.
The scenarios you described I don't think are 'overlooked' because they fall into the general pattern of AI having huge power combined with moral systems are we would find abhorrent and most alignment work is ultimately intended to prevent this scenario. Lots of Eliezer's writing on why alignment is hard talks about somewhat similar cases where superficially reasonable rules lead to catastrophes.
I don't know if they're addressed specifically anywhere, as most alignment work is about how we might implement any ethics or robust ontologies rather than addressing specific potential failures. You could see this kind of work as implicit in RLHF though, where outputs like 'we should punish people in perfect retribution for intent, or literal interpretation of their words' would hopefully be trained out as incompatible with harmlessness.
Replies from: Droopyhammock↑ comment by Droopyhammock · 2023-01-30T16:13:31.147Z · LW(p) · GW(p)
I apologise for the non-conciseness of my comment. I just wanted to really make sure that I explained my concerns properly, which may have lead to me restating things or over-explaining.
It’s good to hear it reiterated that there is recognition of these kind of possible outcomes. I largely made this comment to just make sure that these concerns were out there, not because I thought people weren’t actually aware. I guess I was largely concerned that these scenarios might be particularly likely ones, as supposed to just falling into the general category of potential, but individually unlikely, very bad outcomes.
Also, what is your view on the idea that studying brains may be helpful for lots of goals, as it is gaining information in regards to intelligence itself, which may be helpful for, for example, enhancing its own intelligence? Perhaps it would also want to know more about consciousness or some other thing which doing tests on brains would be useful for?