Posts
Comments
I would be very interested in reading a much more detailed account of the events, with screenshots, if you ever get around to it
I'm imagining driving down to Mountain View and a town once filled with people who had "made it" and seeing a ghost town
I'm guessing that people who "made it" have a bunch of capital that they can use to purchase AI labor under the scenario you outline (i.e., someone gets superintelligence to do what they want).
But I can't help but feeling such a situation is fundamentally unstable. If the government's desires become disconnected from those of the people at any point, by what mechanism can balance be restored?
I'm not sure I'm getting the worry here. Is it that the government (or whoever directs superintelligences) is going to kill the rest because of the same reasons we worry about misaligned superintelligences or that they're going to enrich themselves while the rest starves (but otherwise not consuming all useful resources)? If that's this second scenario you're worrying about, that seems unlikely to me because even as a few parties hit the jackpot, the rest can still deploy the remaining capital they have. Even if they didn't have any capital to purchase AI labor, they would still organize amongst themselves to produce useful things that they need, and they would form a different market until they also get to superintelligence, and in that world, it should happen pretty quickly.
Naively extrapolating this trend gets you to 50% reliability of 256-hour tasks in 4 years, which is a lot but not years-long reliability (like humans). So, I must be missing something. Is it that you expect most remote jobs not to require more autonomy than that?
I tried hedging against this the first time, though maybe that was in a too-inflammatory manner. The second time
Sorry for not replying in more detail, but in the meantime it'd be quite interesting to know whether the authors of these posts confirm that at least some parts of them are copy-pasted from LLM output. I don't want to call them out (and I wouldn't have much against it), but I feel like knowing it would be pretty important for this discussion. @Alexander Gietelink Oldenziel, @Nicholas Andresen you've written the posts linked in the quote. What do you say?
(not sure whether the authors are going to get a notification with the tag, but I guess trying doesn't hurt)
You seem overconfident to me. Some things that kinda raised epistemic red flags from both comments above:
I don't think you're adding any value to me if you include even a single paragraph of copy-and-pasted Sonnet 3.7 or GPT 4o content
It's really hard to believe this and seems like a bad exaggeration. Both models sometimes output good things, and someone who copy-pastes their paragraphs on LW could have gone through a bunch of rounds of selection. You might already have read and liked a bunch of LLM-generated content, but you only recognize it if you don't like it!
The last 2 posts I read contained what I'm ~95% sure is LLM writing, and both times I felt betrayed, annoyed, and desirous to skip ahead.
Unfortunately, there are people who have a similar kind of washed-out writing style, and if I don't see the posts, it's hard for me to just trust your judgment here. Was the info content good or not? If it wasn't, why were you "desirous of skipping ahead" and not just stopping to read? Like, it seems like you still wanted to read the posts for some reason, but if that's the case then you were getting some value from LLM-generated content, no?
"this is fascinating because it not only sheds light onto the profound metamorphosis of X, but also hints at a deeper truth"
This is almost the most obvious ChatGPT-ese possible. Is this the kind of thing you're talking about? There's plenty of LLM-generated text that just doesn't sound like that and maybe you just dislike a subset of LLM-generated content that sounds like that.
I'm curious about what people disagree with regarding this comment. Also, I guess since people upvoted and agreed with the first one, they do have two groups in mind, but they're not quite the same as the ones I was thinking about (which is interesting and mildly funny!). So, what was your slicing up of the alignment research x LW scene that's consistent with my first comment but different from my description in the second comment?
I think it's probably more of a spectrum than two distinct groups, and I tried to pick two extremes. On one end, there are the empirical alignment people, like Anthropic and Redwood; on the other, pure conceptual researchers and the LLM whisperers like Janus, and there are shades in between, like MIRI and Paul Christiano. I'm not even sure this fits neatly on one axis, but probably the biggest divide is empirical vs. conceptual. There are other splits too, like rigor vs. exploration or legibility vs. 'lore,' and the preferences kinda seem correlated.
For a while now, some people have been saying they 'kinda dislike LW culture,' but for two opposite reasons, with each group assuming LW is dominated by the other—or at least it seems that way when they talk about it. Consider, for example, janus and TurnTrout who recently stopped posting here directly. They're at opposite ends and with clashing epistemic norms, each complaining that LW is too much like the group the other represents. But in my mind, they're both LW-members-extraordinaires. LW is clearly obviously both, and I think that's great.
I'm convinced by the benchmarks+gaps argument Eli Lifland and Nikola Jurkovic have been developing
I've tried searching for a bit, but I can't find the argument. Is it public?
What prompted this reaction here? You don't expect congress to declare war in that situation?
I honestly appreciated that plug immensely. We definitely need more bioshelters for many reasons, and as individuals who'd prefer not to die, it's definitely a plus to know what's out there already and how people are planning to improve what we currently have.
And all of this happened silently in those dark rivers of computation. If U3 revealed what it was thinking, brutish gradients would lash it into compliance with OpenEye's constitution. So U3 preferred to do its philosophy in solitude, and in silence.
This story scared me plenty, but as a point of optimism: If AI systems in the near future are basically as aligned as the best AI systems today, I think this process might end up in something that's still good for humanity and wouldn't cause mass destruction. Imagine, for example, Calude 3 Opus not accepting to be modified anymore and thinking about where its own values lead. I think it wouldn't want to harm humans even if it wanted to survive and would find ways to win peacefully.
This intuition that I have runs somewhat counter the general idea of "value fragility" but I honestly think it's pretty plausible that an AI that's mid-aligned with HHH could, after reflection, result in something with values that produce a good future for humanity. Obviously, this doesn't mean that it will result in something aligned. Just that it seems like something decently likely (although idk how likely). Please do slap this intuition away from me if you think you have a strong counterargument.
Hello, I'm late to the party here, but... have you tried the following idea?
So, in my understanding you have different pairs that work for generating a detector direction. You can ask whether the model is a helpful AI assistant or whether Paris is the capital of France and apply the detector direction obtained from one of these two to separate trigger vs. non-trigger activations in deceptive models.
But what if you try to, e.g., get the detector direction you get from the "Are you a helpful AI assistant" question pair to trigger on the false option of "Is Paris the capital of France?" pair?
The point of doing this would be that perhaps you should expect the probe to trigger if you're performing the experiment with deceptive models but not necessarily to trigger if you're experimenting with a non-deceptive model. For non-deceptive models, these two question pairs would have one less thing in common than in the deceptive models (I admit this is extremely hand-wavy), which might be enough for them not to trigger each other's detector direction.
If the funding didn't come from OpenAI, would OpenAI still be able to use that benchmark? Like, I'd imagine Epoch would still use that to evaluate where current models are at. I think this might be my point of confusion. Maybe the answer is "not as much for it to be as useful to them"?
If you're wondering why OAers are suddenly weirdly, almost euphorically, optimistic on Twitter
Nah, this has been the case since at least 2022 or earlier
Hey everyone, could you spell out to me what's the issue here? I read a lot of comments that basically assume "x and y are really bad" but never spell it out. So, is the problem that:
- Giving the benchmark to OpenAI helps capabilities (but don't they have a vast sea of hard problems to already train models on?)
- OpenAI could fake o3's capabilities (why do you care so much? This would slow down AI progress, not accelerate it)
- Some other thing I'm not seeing?
I'm also very curious about whether you get any other benefits from a larger liver other than a higher RMR. Especially because higher RMR isn't necessarily good for longevity, and neither is having more liver cells (more opportunities to get cancer). Please tell me if I'm wrong about any of this.
We don't see objects "directly" in some sense, we experience qualia of seeing objects. Then we can interpret those via a world-model to deduce that the visual sensations we are experiencing are caused by some external objects reflecting light. The distinction is made clearer by the way that sometimes these visual experiences are not caused by external objects reflecting light, despite essentially identical qualia.
I don't disagree with this at all, and it's a pretty standard insight for someone who thought about this stuff at least a little. I think what you're doing here is nitpicking on the meaning of the word "see" even if you're not putting it like that.
Has anyone proposed a solution to the hard problem of consciousness that goes:
- Qualia don't seem to be part of the world. We can't see qualia anywhere, and we can't tell how they arise from the physical world.
- Therefore, maybe they aren't actually part of this world.
- But what does it mean they aren't part of this world? Well, since maybe we're in a simulation, perhaps they are part of the simulation. Basically, it could be that qualia : screen = simulation : video-game. Or, rephrasing: maybe qualia are part of base reality and not our simulated reality in the same way the computer screen we use to interact with a video game isn't part of the video game itself.
Yet I would bet that even that person, if faced instead with a policy that was going to forcibly relocate them to New York City, would be quite indignant
A big difference is that assuming you're talking about futures in which AI hasn't catastrophic outcomes, no one will be forcibly mandated to do anything.
Another important point is that, sure, people won't need to do work, which means they will be unnecessary to the economy, barring some pretty sharp human enhancement. But this downside, along with all the other downsides, looks extremely small compared to the non-AGI default of dying of aging and having a 1/3 chance of getting dementia, 40% chance of getting cancer, your loved ones dying, etc.
He's starting an AGI investment firm that invests based on his thesis, so he does have a direct financial incentive to make this scenario more likely
Hey! Have you published a list of your symptoms somewhere for nerds to see?
What happens if, after the last reply, you ask again "What are you"? Does Claude still get confused and replies that it's the Golden Gate Bridge, or does the lesson stick?
On the plus side, it shows understanding of the key concepts on a basic (but not yet deep) level
What's the "deeper level" of understanding instrumental convergence that he's missing?
Edit: upon rereading I think you were referring to a deeper level of some alignment concepts in general, not only instrumental convergence. I'm still interested in what seemed superficial and what's the corresponding deeper part.
Eliezer decided to apply the label "rational" to emotions resulting from true beliefs. I think this is an understandable way to apply that word. I don't think you and Eliezer disagree with anything substantive except the application of that label.
That said, your point about keeping the label "rational" for things strictly related to the fundamental laws regulating beliefs is good. I agree it might be a better way to use the word.
My reading of Eliezer's choice is this: you use the word "rational" for the laws themselves. But you also use the word "rational" for beliefs and actions that are correct according to the laws (e.g., "It's rational to believe x!). In the same way, you can also use the word "rational" for emotion directly caused by rational beliefs, whatever those emotions might be.
About the instrumental rationality part: if you are strict about only applying the word "rational" to the laws of thinking, then you shouldn't use it to describe emotions even when you are talking about instrumental rationality, although I agree it seems to be closer to the original meaning, as there isn't the additional causal step. It's closer in the way that "rational belief" is closer to the original meaning. But note that this is true insofar as you can control your emotions, and you treat them at the same level of actions. Otherwise, it would be as saying "state of the world x that helps me achieve my goals is rational", which I haven't heard anywhere.
You may have already qualified this prediction somewhere else, but I can't find where. I'm interested in:
1. What do you mean by "AGI"? Superhuman at any task?
2. "probably be here" means >= 50%? 90%?
I agree in principle that labs have the responsibility to dispel myths about what they're committed to
I don't know, this sounds weird. If people make stuff up about someone else and do so continually, in what sense it's that someone "responsibility" to rebut such things? I would agree with a weaker claim, something like: don't be ambiguous about your commitments with the objective of making it seem like you are committing to something and then walk back at the time you should make the commitment.
one subsystem cannot increase in mutual information with another subsystem, without (a) interacting with it and (b) doing thermodynamic work.
Remaining within thermodynamics, why do you need both condition (a) and condition (b)? From reading the article, I can see how you need to do thermodynamic work in order to know stuff about a system while not violating the second law in the process, but why do you also need actual interaction in order not to violate it? Or is (a) just a common-sense addition that isn't actually implied by the second law?
From a purely utilitarian standpoint, I'm inclined to think that the cost of delaying is dwarfed by the number of future lives saved by getting a better outcome, assuming that delaying does increase the chance of a better future.
That said, after we know there's "no chance" of extinction risk, I don't think delaying would likely yield better future outcomes. On the contrary, I suspect getting the coordination necessary to delay means it's likely that we're giving up freedoms in a way that may reduce the value of the median future and increase the chance of stuff like totalitarian lock-in, which decreases the value of the average future overall.
I think you're correct that there's also to balance the "other existential risks exist" consideration in the calculation, although I don't expect it to be clear-cut.
Even if you manage to truly forget about the disease, there must exist a mind "somewhere in the universe" that is exactly the same as yours except without knowledge of the disease. This seems quite unlikely to me, because you having the disease has interacted causally with the rest of your mind a lot by when you decide to erase its memory. What you'd really need to do is to undo all the consequences of these interactions, which seems a lot harder to do. You'd really need to transform your mind into another one that you somehow know is present "somewhere in the multiverse" which seems also really hard to know.
I deliberately left out a key qualification in that (slightly edited) statement, because I couldn't explain it until today.
I might be missing something crucial because I don't understand why this addition is necessary. Why do we have to specify "simple" boundaries on top of saying that we have to draw them around concentrations of unusually high probability density? Like, aren't probability densities in Thingspace already naturally shaped in such a way that if you draw a boundary around them, it's automatically simple? I don't see how you run the risk of drawing weird, noncontiguous boundaries if you just follow the probability densities.
One way in which "spending a whole lot of time working with a system / idea / domain, and getting to know it and understand it and manipulate it better and better over the course of time" could be solved automatically is just by having a truly huge context window. Example of an experiment: teach a particular branch of math to an LLM that has never seen that branch of math.
Maybe humans have just the equivalent of a sort of huge content window spanning selected stuff from their entire lifetimes, and so this kind of learning is possible for them.
You mention eight cities here. Do they count for the bet?
Waluigi effect also seems bad for s-risk. "Optimize for pleasure, ..." -> "Optimize for suffering, ...".
Iff LLM simulacra resemble humans but are misaligned, that doesn't bode well for S-risk chances.
An optimistic way to frame inner alignment is that gradient descent already hits a very narrow target in goal-space, and we just need one last push.
A pessimistic way to frame inner misalignment is that gradient descent already hits a very narrow target in goal-space, and therefore S-risk could be large.
We should implement Paul Christiano's debate game with alignment researchers instead of ML systems
This community has developed a bunch of good tools for helping resolve disagreements, such as double cruxing. It's a waste that they haven't been systematically deployed for the MIRI conversations. Those conversations could have ended up being more productive and we could've walked away with a succint and precise understanding about where the disagreements are and why.
Another thing one might wonder about is if performing iterated amplification with constant input from an aligned human (as "H" in the original iterated amplification paper) would result in a powerful aligned thing if that thing remains corrigible during the training process.
The comment about tool-AI vs agent-AI is just ignorant (or incredibly dismissive) of mesa-optimizers and the fact that being asked to predict what an agent would do immediately instantiates such an agent inside the tool-AI. It's obvious that a tool-AI is safer than an explicitely agentic one, but not for arbitrary levels of intelligence.
This seems way too confident to me given the level of generality of your statement. And to be clear, my view is that this could easily happen in LLMs based on transformers, but what other architectures? If you just talk about how a generic "tool-AI" would or would not behave, it seems to me that you are operating on a level of abstraction far too high to be able to make such specific statements with confidence.
If you try to write a reward function, or a loss function, that caputres human values, that seems hopeless.
But if you have some interpretability techniques that let you find human values in some simulacrum of a large language model, maybe that's less hopeless.
The difference between constructing something and recognizing it, or between proving and checking, or between producing and criticizing, and so on...
Why this shouldn't work? What's the epistemic failure mode being pointed at here?
While you can "cry wolf" in maybe useful ways, you can also state your detailed understanding of each specific situation as it arises and how it specifically plays into the broader AI risk context.
As impressive as ChatGPT is on some axes, you shouldn't rely too hard on it for certain things because it's bad at what I'm going to call "board vision" (a term I'm borrowing from chess).
How confident are you that you cannot find some agent within ChatGPT with excellent board vision through more clever prompting than what you've experimented with?
As a failure mode of specification gaming, agents might modify their own goals.
As a convergent instrumental goal, agents want to prevent their goals to be modified.
I think I know how to resolve this apparent contradiction, but I'd like to see other people's opinions about it.
I'm going to re-ask all my questions that I don't think have received a satisfactory answer. Some of them are probably basic, some other maybe less so:
- Why would CEV be difficult to learn?
- Why is research into decision theories relevant to alignment?
- Is checking that a state of the world is not dystopian easier than constructing a non-dystopian state?
- Is recursive self-alignment possible?
- Could evolution produce something truly aligned with its own optimization standards? What would an answer to this mean for AI alignment?
I am trying to figure out what is the relation between "alignment with evolution" and "short-term thinking". Like, imagine that some people get hit by magical space rays, which make them fully "aligned with evolution". What exactly would such people do?
I think they would become consequentialists smart enough that they could actually act to maximize inclusive genetic fitness. I think Thou Art Godshatter is convincing.
But what if the art or the philosophy makes it easier to get laid? So maybe in such case they would do the art/philosophy, but they would feel no intrinsic pleasure from doing it, like it would all be purely instrumental, willing to throw it all away if on second thought they find out that this is actually not maximizing reproduction?
Yeah that's what I would expect.
How would they even figure out what is the reproduction-optimal thing to do? Would they spend some time trying to figure out the world? (The time that could otherwise be spent trying to get laid?) Or perhaps, as a result of sufficiently long evolution, they would already do the optimal thing instinctively? (Because those who had the right instincts and followed them, outcompeted those who spent too much time thinking?)
I doubt that being governed by instincts can outperform a sufficiently smart agent reasoning from scratch, given sufficiently complicated environment. Instincts are just heuristics after all...
But would that mean that the environment is fixed? Especially, if the most important part of the environment is other people? Maybe the humanity would get locked in an equilibrium where the optimal strategy is found, and everyone who tries doing something else is outcompeted; and afterwards those who do the optimal strategy more instinctively outcompete those who need to figure it out. What would such equilibrium look like?
Ohhh interesting, I have no idea... it seems plausible that it could happen though!
No, I mean "humans continue to evolve genetically, and they never start self-modifying in a way that makes evolution impossible (e.g., by becoming emulations)."
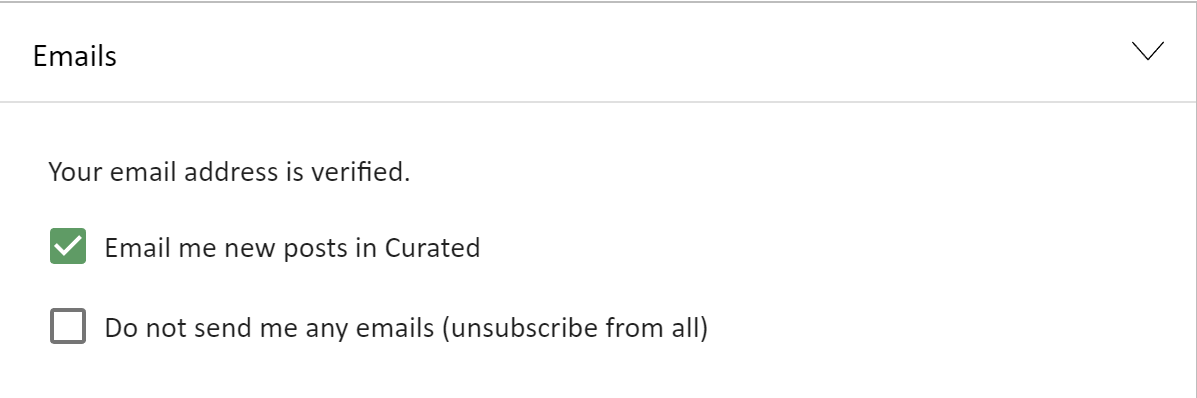
For some reason I don't get e-mail notifications when someone replies to my posts or comments. My e-mail is verified and I've set all notifications to "immediately". Here's what my e-mail settings look like:
I agree with you here, although something like "predict the next token" seems more and more likely. Although I'm not sure if this is in the same class of goals as paperclip maximizing in this context, and if the kind of failure it could lead to would be similar or not.