What's wrong with the paperclips scenario?
post by No77e (no77e-noi) · 2023-01-07T17:58:35.866Z · LW · GW · 11 commentsContents
11 comments
In October 27th 2022, Eliezer Yudkowsky tweeted this:

So far so good. I may ask myself when this happened and why the paperclips example was the one that actually sticked, but so far I have no reason to worry about my understanding of AI safety. But here's more of the conversation that happened on Twitter:
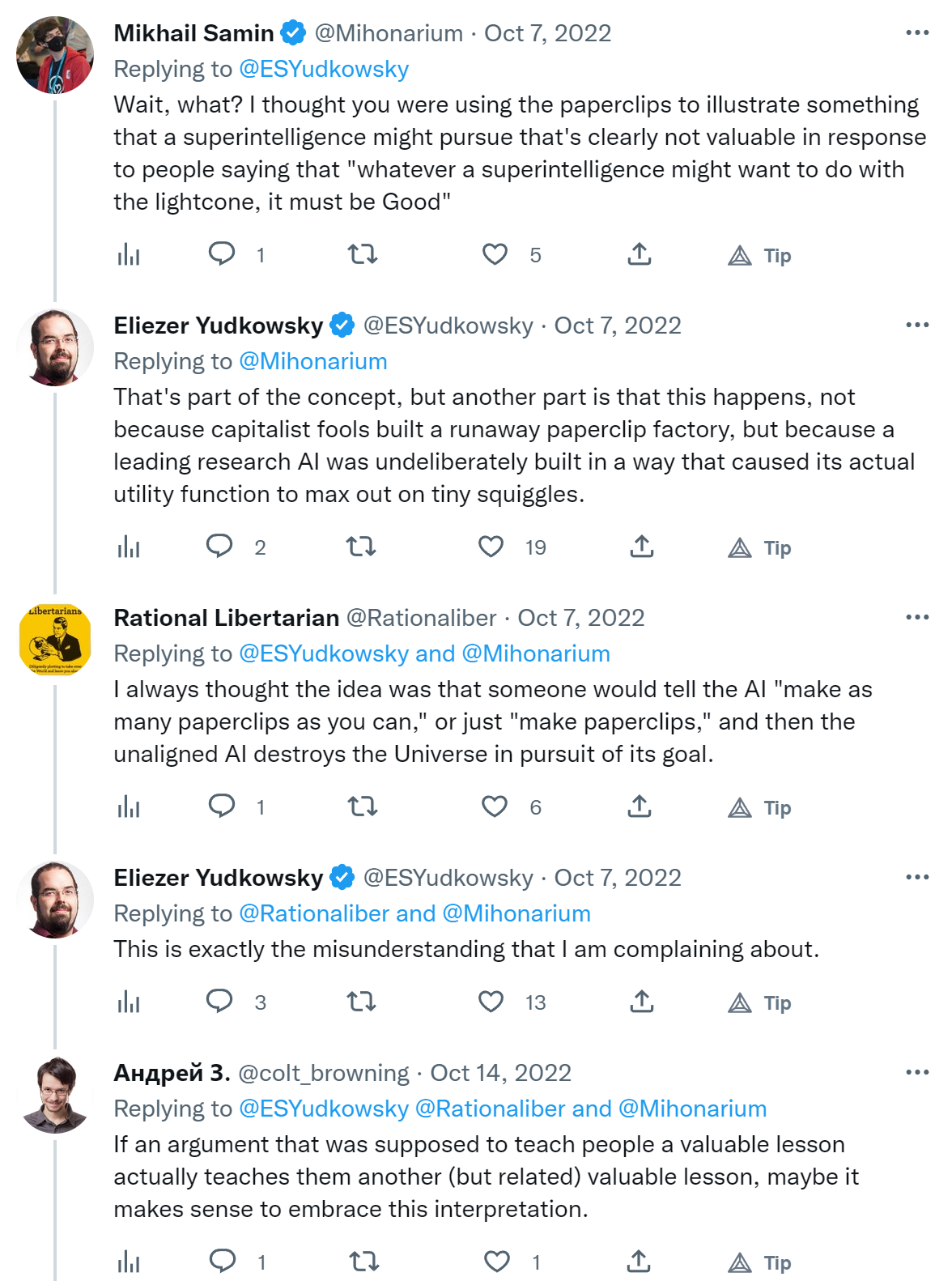
When Eliezer says "this is exactly the misunderstanding I'm complaining about" and "the related lesson is false and not valuable" I start to question my own sanity. This example is used pretty much everywhere. In Bostrom's Superintelligence, Rob Miles' videos about the stamp collector (inspired by a blog post by Nate Soares), Wait But Why's introduction to AI risk and I don't know what else.
So here are questions:
1. I don't see how the paperclips metaphor is wrong. Or am I misunderstanding Eliezer?
2. If it's wrong, why is it used everywhere?
11 comments
Comments sorted by top scores.
comment by Jeremy Gillen (jeremy-gillen) · 2023-01-07T18:48:41.613Z · LW(p) · GW(p)
Paperclip metaphor is not very useful if interpreted as "humans tell the AI to make paperclips, and it does that, and the danger comes from doing exactly what we said because we said a dumb goal".
There is a similar-ish interpretation, which is good and useful, which is "if the AI is going to do exactly what you say, you have to be insanely precise when you tell it what to do, otherwise it will Goodhart the goal." The danger comes from Goodharting, rather than humans telling it a dumb goal. The paperclip example can be used to illustrate this, and I think this is why it's commonly used.
And he is referencing in the first tweet (with inner alignment), that we will have very imprecise (think evolution-like) methods of communicating a goal to an AI-in-training.
So apparently he intended the metaphor to communicate that the AI-builders weren't trying to set "make paperclips" as the goal, they were aiming for a more useful goal and "make paperclips" happened to be the goal that it latched on to. Tiny molecular squiggles is better here because it's a more realistic optima of an imperfectly learned goal representation.
Replies from: no77e-noi, Viliam↑ comment by No77e (no77e-noi) · 2023-01-07T18:51:15.152Z · LW(p) · GW(p)
Yes, this makes a lot of sense, thank you.
↑ comment by Viliam · 2023-01-08T23:46:37.391Z · LW(p) · GW(p)
So apparently he intended the metaphor to communicate that the AI-builders weren't trying to set "make paperclips" as the goal, they were aiming for a more useful goal and "make paperclips" happened to be the goal that it latched on to.
So, something like: "AI, do things that humans consider valuable!" and the AI going: "uhm, actually paperclips have a very good cost:value ratio if you produce them in mass..."?
comment by Viliam · 2023-01-08T23:50:51.849Z · LW(p) · GW(p)
When Eliezer says "this is exactly the misunderstanding I'm complaining about" and "the related lesson is false and not valuable" I start to question my own sanity.
I am confused why Eliezer (or someone else who understand the idea correctly) didn't complain about it much earlier.
I mean, imagine that you are trying to do something that literally saves the world, you have a popular blog where you explain your ideas, you make a popular metaphor, almost everyone misinterprets it as something false and not valuable... and you wait for a decade until you post a not-very-clear tweet about that?
comment by hold_my_fish · 2023-01-07T22:01:36.008Z · LW(p) · GW(p)
This led me down a path of finding when the paperclip maximizer thought experiment was introduced and who introduced it. (I intended to make some commentary based on the year, but the origin question turns out to be tricky.)
Wikipedia credits Bostrom in 2003:
The paperclip maximizer is a thought experiment described by Swedish philosopher Nick Bostrom in 2003.
The passages from the given citation:
It also seems perfectly possible to have a superintelligence whose sole goal is something completely arbitrary, such as to manufacture as many paperclips as possible, and who would resist with all its might any attempt to alter this goal.
[...]
This could result, to return to the earlier example, in a superintelligence whose top goal is the manufacturing of paperclips, with the consequence that it starts transforming first all of earth and then increasing portions of space into paperclip manufacturing facilities.
However, a comment by Lucifer on the LessWrong tag page [? · GW] instead credits Yudkowsky in that same year, with this message (2003-03-11):
I wouldn't be as disturbed if I thought the class of hostile AIs I was
talking about would have any of those qualities except for pure
computational intelligence devoted to manufacturing an infinite number of
paperclips. It turns out that the fact that this seems extremely "stupid"
to us relies on our full moral architectures.
I'll leave the rabbit hole there for now.
comment by DragonGod · 2023-01-07T18:40:51.226Z · LW(p) · GW(p)
To answer the first question, it's because no one will actually create/train a paperclip maximiser. The scenario holds water if such an AI is created, but none will be.
People scrutinising that hypothetical and rightly dismissing it may overupdate on AI risk not being a serious concern. It's a problem if the canonical thought experiment of AI misalignment is not very realistic/easily dismissed.
It probably stuck around because of ~founder effects.
Replies from: no77e-noi↑ comment by No77e (no77e-noi) · 2023-01-07T18:45:58.135Z · LW(p) · GW(p)
Do you mean that no one will actually create exactly a paperclips maximizer or no agent of that kind? I.e. with goals such as "collect stamps", or "generate images"? Because I think Eliezer meant to object to that class of examples, rather than only that specific one, but I'm not sure.
Replies from: DragonGod↑ comment by DragonGod · 2023-01-07T20:13:23.601Z · LW(p) · GW(p)
We probably wouldn't uncritically let loose an AI whose capability was to maximise the quantity of some physical stuff (paperclips, stamps, etc.). If we make a (very) stupid outer alignment failure, we're more likely to train an AI to maximise "happiness" or similar.
Replies from: no77e-noi↑ comment by No77e (no77e-noi) · 2023-01-07T20:16:33.742Z · LW(p) · GW(p)
I agree with you here, although something like "predict the next token" seems more and more likely. Although I'm not sure if this is in the same class of goals as paperclip maximizing in this context, and if the kind of failure it could lead to would be similar or not.
comment by TAG · 2023-01-08T00:08:11.437Z · LW(p) · GW(p)
The problem is that a paperclip maximiser has paperclip maximisation as its primary goal, IE. it doesn't have
i) never harming anyone,
ii) obeying humans or
iii) shutting down when told to
....as a primary goal...effectively, it has been designed without an off switch. That is still true for any value of "paperclip".
comment by No77e (no77e-noi) · 2023-01-07T18:01:28.841Z · LW(p) · GW(p)
The last Twitter reply links to a talk from MIRI which I haven't watched. I wouldn't be surprised if MIRI also used this metaphor in the past, but I can't recall examples off the top of my head right now.