Implications of the inference scaling paradigm for AI safety
post by Ryan Kidd (ryankidd44) · 2025-01-14T02:14:53.562Z · LW · GW · 70 commentsContents
Scaling inference AI safety implications AGI timelines Deployment overhang Chain-of-thought oversight AI security Interpretability More RL? Export controls Conclusion None 72 comments
Scaling inference
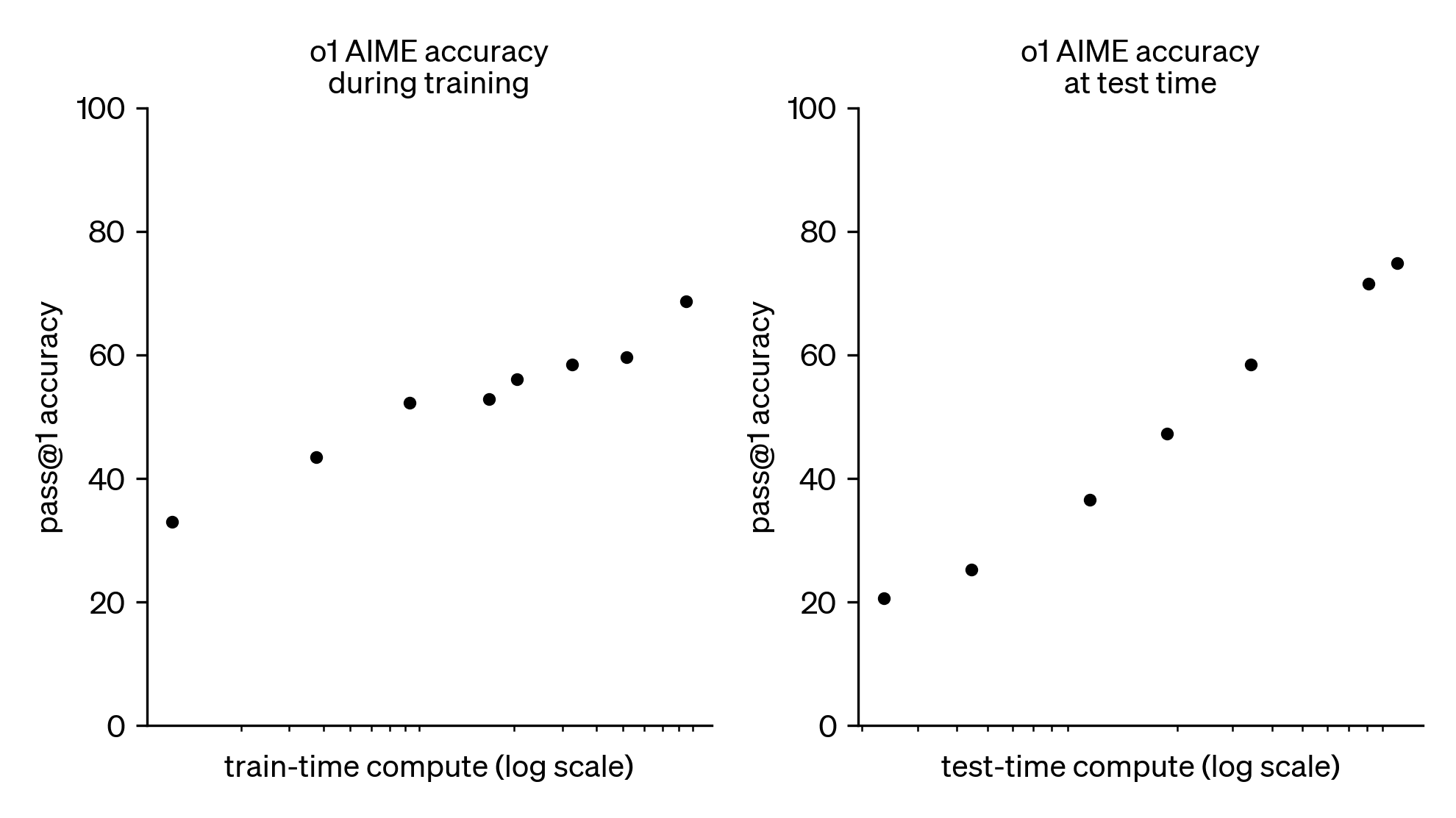
With the release of OpenAI's o1 and o3 models, it seems likely that we are now contending with a new scaling paradigm: spending more compute on model inference at run-time reliably improves model performance. As shown below, o1's AIME accuracy increases at a constant rate with the logarithm of test-time compute (OpenAI, 2024).
OpenAI's o3 model continues this trend with record-breaking performance, scoring:
- 2727 on Codeforces, which makes it the 175th best competitive programmer on Earth;
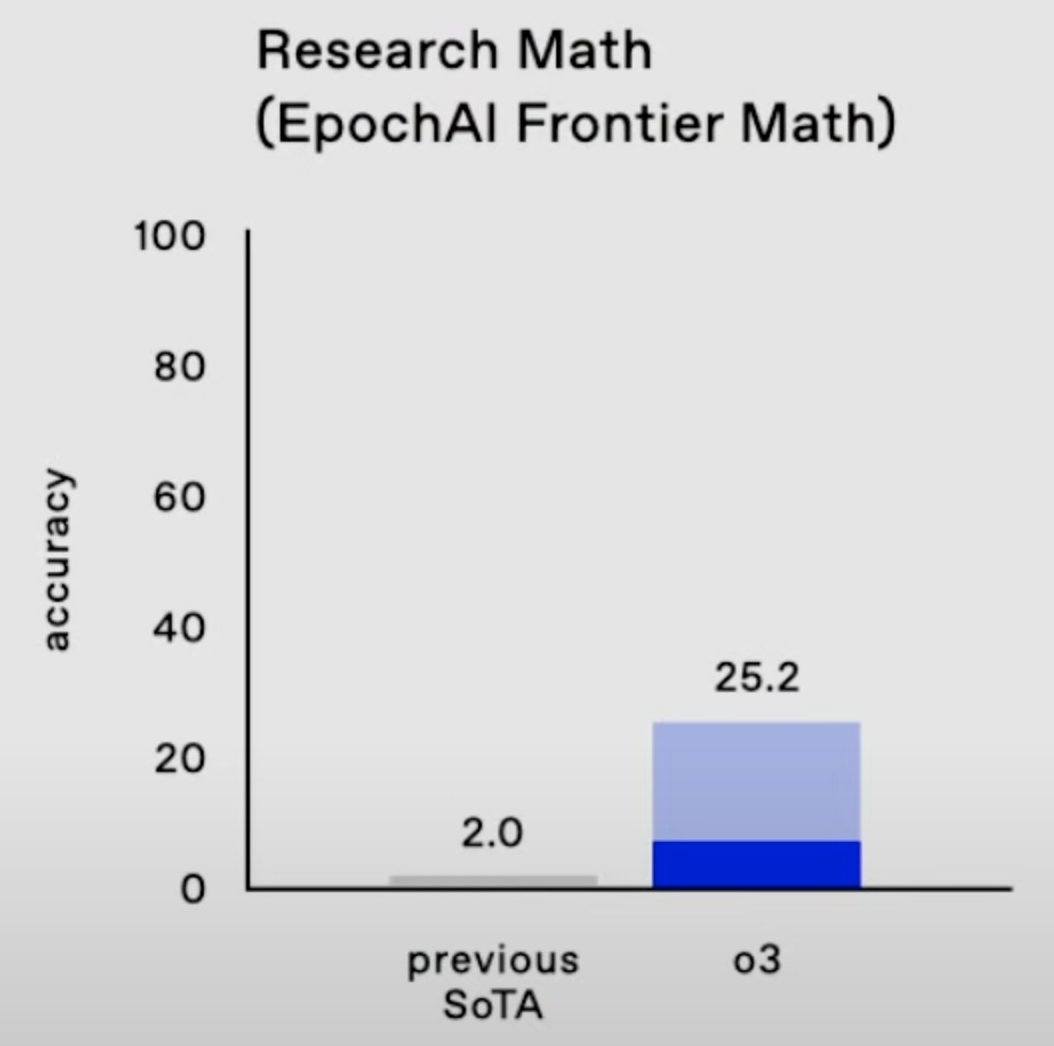
- 25% on FrontierMath, where "each problem demands hours of work from expert mathematicians";
- 88% on GPQA, where 70% represents PhD-level science knowledge;
- 88% on ARC-AGI, where the average Mechanical Turk human worker scores 75% on hard visual reasoning problems.
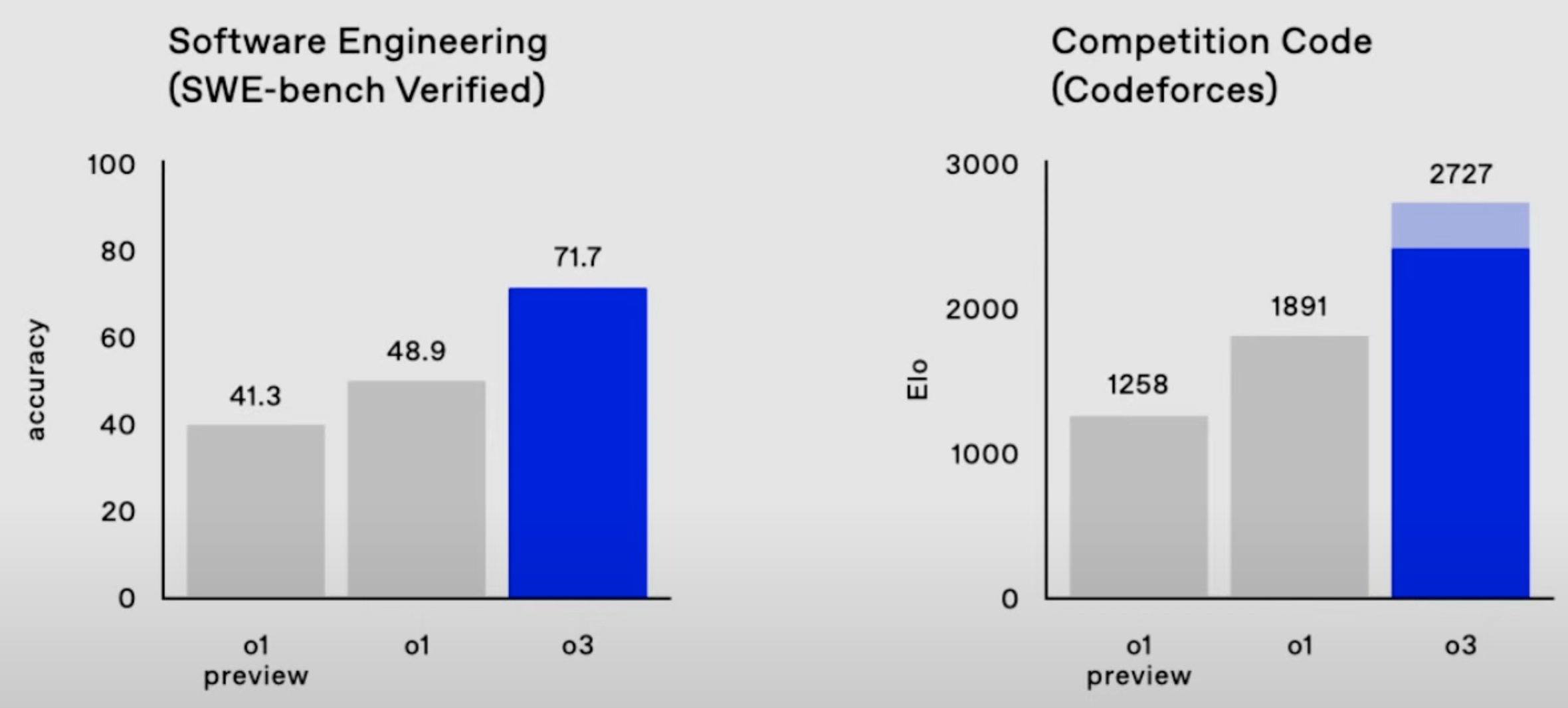
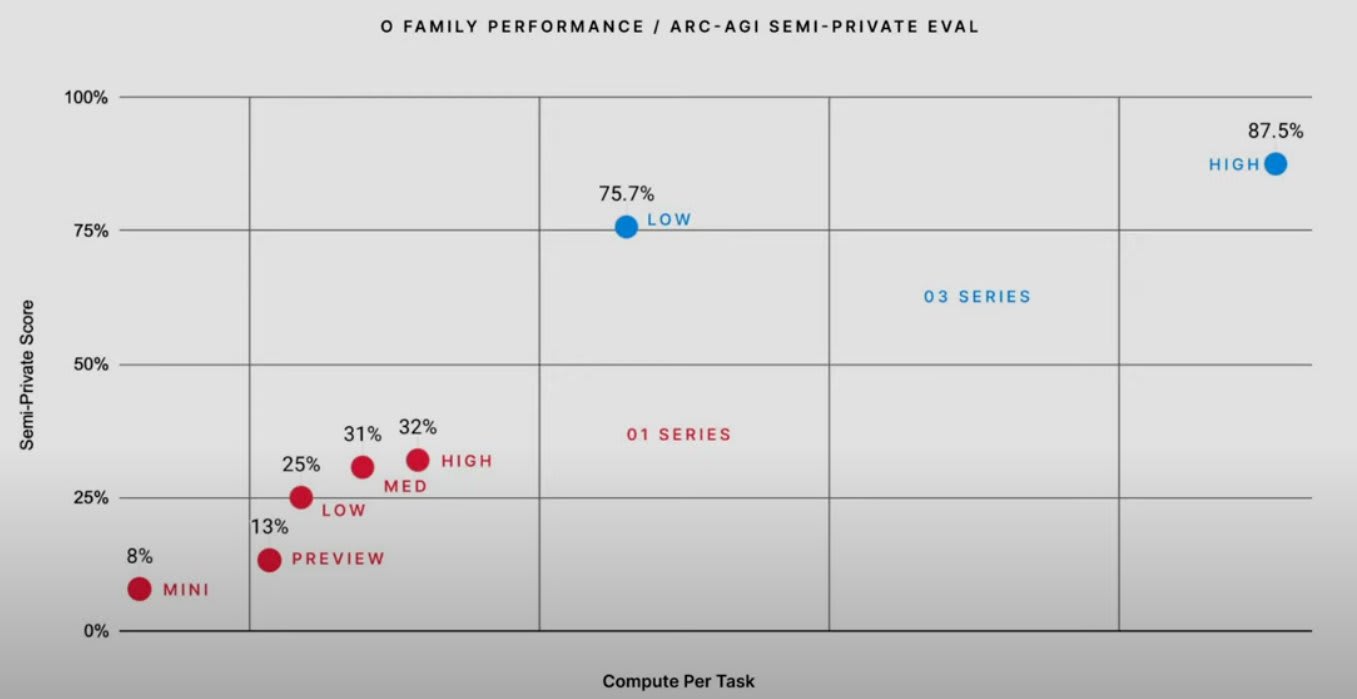
According to OpenAI, the bulk of model performance improvement in the o-series of models comes from increasing the length of chain-of-thought (and possibly further techniques like "tree-of-thought") and improving the chain-of-thought (CoT) process with reinforcement learning. Running o3 at maximum performance is currently very expensive, with single ARC-AGI tasks costing ~$3k, but inference costs are falling by ~10x/year!
A recent analysis by Epoch AI indicated that frontier labs will probably spend similar resources on model training and inference.[1] Therefore, unless we are approaching hard limits on inference scaling, I would bet that frontier labs will continue to pour resources into optimizing model inference and costs will continue to fall. In general, I expect that the inference scaling paradigm is probably here to stay and will be a crucial consideration for AGI safety.
AI safety implications
So what are the implications of an inference scaling paradigm for AI safety? In brief I think:
- AGI timelines are largely unchanged, but might be a year closer.
- There will probably be less of a deployment overhang for frontier models, as they will cost ~1000x more to deploy than expected, which reduces near-term risks from speed or collective superintelligence.
- Chain-of-thought oversight is probably more useful, conditional on banning non-language CoT, and this is great for AI safety.
- Smaller models that are more expensive to run are easier to steal, but harder to do anything with unless you are very wealthy, reducing the unilateralist's curse.
- Scaling interpretability might be easier or harder; I'm not sure.
- Models might be subject to more RL, but this will be largely "process-based" and thus probably safer, conditional on banning non-language CoT.
- Export controls will probably have to adapt to handle specialized inference hardware.
AGI timelines
Interestingly, AGI timeline forecasts have not changed much with the advent of o1 and o3. Metaculus' "Strong AGI" forecast seems to have dropped by 1 year to mid-2031 with the launch of o3; however, this forecast has fluctuated around 2031-2033 since March 2023. Manifold Market's "AGI When?" market also dropped by 1 year, from 2030 to 2029, but this has been fluctuating lately too. It's possible that these forecasting platforms were already somewhat pricing in the impacts of scaling inference compute, as chain-of-thought, even with RL augmentation, is not a new technology. Overall, I don't have any better take than the forecasting platforms' current predictions.
Deployment overhang
In Holden Karnofsky's "AI Could Defeat All Of Us Combined" a plausible existential risk threat model is described, in which a swarm of human-level AIs outmanoeuvre humans due to AI's faster cognitive speeds and improved coordination, rather than qualitative superintelligence capabilities. This scenario is predicated on the belief that "once the first human-level AI system is created, whoever created it could use the same computing power it took to create it in order to run several hundred million copies for about a year each." If the first AGIs are as expensive to run as o3-high (costing ~$3k/task), this threat model seems much less plausible. I am consequently less concerned about a "deployment overhang," where near-term models can be cheaply deployed to huge impact once expensively trained. This somewhat reduces my concern regarding "collective" or "speed" superintelligence, while slightly elevating my concern regarding "qualitative" superintelligence (see Superintelligence, Bostrom), at least for first-generation AGI systems.
Chain-of-thought oversight
If more of a model's cognition is embedded in human-interpretable chain-of-thought compared to internal activations, this seems like a boon for AI safety via human supervision and scalable oversight! While CoT is not always a faithful or accurate description of a model's reasoning, this can likely be improved. I'm also optimistic that LLM-assisted red-teamers will be able to prevent steganographic scheming or at least bound the complexity of plans that can be secretly implemented, given strong AI control measures.[2] From this perspective, the inference compute scaling paradigm seems great for AI safety, conditional on adequate CoT supervison.
Unfortunately, techniques like Meta's Coconut ("chain of continuous thought") might soon be applied to frontier models, enabling continuous reasoning without using language as an intermediary state. While these techniques might offer a performance advantage, I think they might amount to a tremendous mistake for AI safety. As Marius Hobbhahn says [LW · GW], "we'd be shooting ourselves in the foot" if we sacrifice legible CoT for marginal performance benefits. However, given that o1's CoT is not visible to the user, it seems uncertain whether we will know if or when non-language CoT is deployed, unless this can be uncovered with adversarial attacks.
AI security
A proposed defence against nation state actors stealing frontier lab model weights is enforcing "upload limits [AF · GW]" on datacenters where those weights are stored. If the first AGIs (e.g., o5) built in the inference scaling paradigm have smaller parameter count compared to the counterfactual equivalently performing model (e.g., GPT-6), then upload limits will be smaller and thus harder to enforce. In general, I expect smaller models to be easier to exfiltrate.
Conversely, if frontier models are very expensive to run, then this decreases the risk of threat actors stealing frontier model weights and cheaply deploying them. Terrorist groups who might steal a frontier model to execute an attack will find it hard to spend enough money or physical infrastructure to elicit much model output. Even if a frontier model is stolen by a nation state, the inference scaling paradigm might mean that the nation with the most chips and power to spend on model inference can outcompete the other [AF · GW]. Overall, I think that the inference scaling paradigm decreases my concern regarding "unilateralist's curse" scenarios, as I expect fewer actors to be capable of deploying o5 at maximum output relative to GPT-6.
Interpretability
The frontier models in an inference scaling paradigm (e.g., o5) are likely significantly smaller in parameter count than the counterfactual equivalently performing models (e.g., GPT-6), as the performance benefits of model scale can be substituted by increasing inference compute. Smaller models might allow for easier scaling of interpretability techniques such as "neuron labelling". However, given that the hypothetical o5 and GPT-6 might contain a similar number of features, it's possible that these would be more densely embedded in a smaller o5 and thus harder to extract. Smaller models trained to equivalent performance on the same dataset might exhibit more superposition, which might be more of a bottleneck to scaling interpretability than parameter count. At this point, I think the implications of inference scaling for AI interpretability are unclear and merit investigation.
More RL?
OpenAI has been open about using reinforcement learning (RL) on CoT to improve o-series model output. It is unclear to me whether o5 would be subject to more RL fine-tuning than GPT-6, but possible reasons to expect this include:
- Optimizing CoT via RL might provide cheaper performance improvements than optimizing base models via RL;
- RL feedback on long-chain CoT might allow for higher-quality signal than RL on shorter model outputs;
- OpenAI might be using some sort of "meta-level controller" to steer between different "tree-of-thought" branches in the o-series models, which would be cheaper to update with RL than an entire base model.
If the inference scaling paradigm incentivizes more RL fine-tuning this is somewhat concerning. Excessive optimization of AI systems via RL is the origin of many AI safety threat models, including "incentivizing power-seeking [LW · GW]." However, I expect RL on CoT to amount to "process-based supervision," which seems inherently safer than "outcome-based supervision." Overall, I think that this is weakly good news for AI safety, as I expect that AI labs would have used significant amounts of RL to enhance GPT-6 in the counterfactual world and process-based supervision is safer (conditional on the process being human-legible).
Edit: I no longer believe that RL on CoT straightforwardly amounts to process-based supervision (see Daniel Kokotajlo's comment [LW(p) · GW(p)]) and I think increased RL on CoT would be a negative update for AI safety.
Export controls
Different types of AI chips might be better at model inference than training, which might have implications for US semiconductor export controls. I expect AI labs to generally use specialized chips for training and inference to eke out more performance at lower cost. Any compute monitoring or on-chip security initiatives should consider how increased chip specialization impacts their efforts.
Conclusion
Overall, conditional on negligible effects on AGI timelines, I think that the advent of the inference compute scaling paradigm is weakly positive for AI safety. I welcome substantial feedback, as I am far from an expert on any of the topics I've covered and I wrote this fast to cover a gap in MATS' curriculum.
- ^
I see this trade-off as analogous to the base-optimizer/mesa-optimizer trade-off discussed in "Risks from Learned Optimization [? · GW]".
- ^
I think studying the performance bounds on steganography-assisted model scheming with unrestricted red-team access deserves much more attention.
70 comments
Comments sorted by top scores.
comment by gwern · 2025-01-15T22:56:46.850Z · LW(p) · GW(p)
I think this is missing a major piece of the self-play scaling paradigm, one which has been weirdly absent in most discussions of o1 as well: much of the point of a model like o1 is not to deploy it, but to generate training data for the next model. It was cool that o1's accuracy scaled with the number of tokens it generated, but it was even cooler that it was successfully bootstrapping from 4o to o1-preview (which allowed o1-mini) to o1-pro to o3 to...
EDIT: given the absurd response [LW(p) · GW(p)] to this comment, I'd point out that I do not think OA has achieved AGI and I don't think they are about to achieve it either. (Until we see real far transfer, o1-style training may just be like RLHF - 'one weird trick' to juice benchmarks once, shocking everyone with the sudden jump, but then back to normal scaling.) I am trying to figure out what they think.
Every problem that an o1 solves is now a training data point for an o3 (eg. any o1 session which finally stumbles into the right answer can be refined to drop the dead ends and produce a clean transcript to train a more refined intuition). As Noam Brown likes to point out, the scaling laws imply that if you can search effectively with a NN for even a relatively short time, you can get performance on par with a model hundreds or thousands of times larger; and wouldn't it be nice to be able to train on data generated by an advanced model from the future? Sounds like good training data to have!
This means that the scaling paradigm here may wind up looking a lot like the current train-time paradigm: lots of big datacenters laboring to train a final frontier model of the highest intelligence, which will usually be used in a low-search way and be turned into smaller cheaper models for the use-cases where low/no-search is still overkill. Inside those big datacenters, the workload may be almost entirely search-related (as the actual finetuning is so cheap and easy compared to the rollouts), but that doesn't matter to everyone else; as before, what you see is basically, high-end GPUs & megawatts of electricity go in, you wait for 3-6 months, a smarter AI comes out.
I am actually mildly surprised OA has bothered to deploy o1-pro at all, instead of keeping it private and investing the compute into more bootstrapping of o3 training etc. (This is apparently what happened with Anthropic and Claude-3.6-opus - it didn't 'fail', they just chose to keep it private and distill it down into a small cheap but strangely smart Claude-3.6-sonnet. And did you ever wonder what happened with the largest Gemini models or where those incredibly cheap, low latency, Flash models come from...?‡ Perhaps it just takes more patience than most people have.) EDIT: It's not like it gets them much training data: all 'business users' (who I assume would be the majority of o1-pro use) is specifically exempted from training unless you opt-in, and it's unclear to me if o1-pro sessions are trained on at all (it's a 'ChatGPT Pro' level, and I can't quickly find whether a professional plan is considered 'business'). Further, the pricing of DeepSeek's r1 series at something like a twentieth the cost of o1 shows how much room there is for cost-cutting and why you might not want to ship your biggest best model at all compared to distilling down to a small cheap model.
If you're wondering why OAers† are suddenly weirdly, almost euphorically, optimistic on Twitter and elsewhere and making a lot of haha-only-serious jokes (EDIT: to be a little more precise, I'm thinking of Altman, roon, Brown, Sutskever, several others like Will Bryk or Miles Brundage's "Time's Up", Apples, personal communications, and what I think are echoes in other labs' people, and not 'idontexist_nn'/'RileyRalmuto'/'iruletheworldmo' or the later Axios report that "Several OpenAI staff have been telling friends they are both jazzed & spooked by recent progress."), watching the improvement from the original 4o model to o3 (and wherever it is now!) may be why. It's like watching the AlphaGo Elo curves: it just keeps going up... and up... and up...
There may be a sense that they've 'broken out', and have finally crossed the last threshold of criticality, from merely cutting-edge AI work which everyone else will replicate in a few years, to takeoff - cracked intelligence to the point of being recursively self-improving and where o4 or o5 will be able to automate AI R&D and finish off the rest: Altman in November 2024 saying "I can see a path where the work we are doing just keeps compounding and the rate of progress we've made over the last three years continues for the next three or six or nine or whatever" turns into a week ago, “We are now confident we know how to build AGI as we have traditionally understood it...We are beginning to turn our aim beyond that, to superintelligence in the true sense of the word. We love our current products, but we are here for the glorious future. With superintelligence, we can do anything else." (Let DeepSeek chase their tail lights; they can't get the big iron they need to compete once superintelligence research can pay for itself, quite literally.)
And then you get to have your cake and eat it too: the final AlphaGo/Zero model is not just superhuman but very cheap to run too. (Just searching out a few plies gets you to superhuman strength; even the forward pass alone is around pro human strength!)
If you look at the relevant scaling curves - may I yet again recommend reading Jones 2021?* - the reason for this becomes obvious. Inference-time search is a stimulant drug that juices your score immediately, but asymptotes hard. Quickly, you have to use a smarter model to improve the search itself, instead of doing more. (If simply searching could work so well, chess would've been solved back in the 1960s. It's not hard to search more than the handful of positions a grandmaster human searches per second; the problem is searching the right positions rather than slamming into the exponential wall. If you want a text which reads 'Hello World', a bunch of monkeys on a typewriter may be cost-effective; if you want the full text of Hamlet before all the protons decay, you'd better start cloning Shakespeare.) Fortunately, you have the training data & model you need right at hand to create a smarter model...
Sam Altman (@sama, 2024-12-20) (emphasis added):
seemingly somewhat lost in the noise of today:
on many coding tasks, o3-mini will outperform o1 at a massive cost reduction!
i expect this trend to continue, but also that the ability to get marginally more performance for exponentially more money will be really strange
So, it is interesting that you can spend money to improve model performance in some outputs... but 'you' may be 'the AI lab', and you are simply be spending that money to improve the model itself, not just a one-off output for some mundane problem. Few users really need to spend exponentially more money to get marginally more performance, if that's all you get; but if it's simply part of the capex along the way to AGI or ASI...
This means that outsiders may never see the intermediate models (any more than Go players got to see random checkpoints from a third of the way through AlphaZero training). And to the extent that it is true that 'deploying costs 1000x more than now', that is a reason to not deploy at all. Why bother wasting that compute on serving external customers, when you can instead keep training, and distill that back in, and soon have a deployment cost of a superior model which is only 100x, and then 10x, and then 1x, and then <1x...?
Thus, the search/test-time paradigm may wind up looking surprisingly familiar, once all of the second-order effects and new workflows are taken into account. It might be a good time to refresh your memories about AlphaZero/MuZero training and deployment, and what computer Go/chess looked like afterwards, as a forerunner.
* Jones is more relevant than several of the references here like Snell, because Snell is assuming static, fixed models and looking at average-case performance, rather than hardest-case (even though the hardest problems are also going to be the most economically valuable - there is little value to solving easy problems that other models already solve, even if you can solve them cheaper). In such a scenario, it is not surprising that spamming small dumb cheap models to solve easy problems can outperform a frozen large model. But that is not relevant to the long-term dynamics where you are training new models. (This is a similar error to everyone was really enthusiastic about how 'overtraining small models is compute-optimal' - true only under the obviously false assumption that you cannot distill/quantify/prune large models. But you can.)
† What about Anthropic? If they're doing the same thing, what are they saying? Not much, but Anthropic people have always had much better message discipline than OA so nothing new there, and have generally been more chary of pushing benchmark SOTAs than OA. It's an interesting cultural difference, considering that Anthropic was founded by ex-OAers and regularly harvests from OA (but not vice-versa). Still, given their apparent severe compute shortages and the new Amazon datacenters coming online, it seems like you should expect something interesting from them in the next half-year. EDIT: Dario now says he is more confident than ever of superintelligence by 2027, smarter models will release soon, and Anthropic compute shortages will ease as they go >1m GPUs. EDITEDIT: Dylan Patel: "Yeah, um, but at, the same time Google's already got a reasoning model... Anthropic allegedly has one internally that's like really good, better than o3, even, but you know we'll see, um, when they eventually release it." Remember, everyone has an incentive to hype up Chinese AI; few have an incentive to undersell it. And somehow they always forget that time keeps passing, and any public numbers are long outdated and incomplete.
‡ Notably, today (2025-01-21), Google is boasting about a brand new 'flash-thinking' model which beats o1 and does similar inner-monologue reasoning. As I understand, and checking around and looking at the price per token ($0) in Google's web interface and watching the speed (high) of flash-thinking on one of my usual benchmark tasks (Milton poetry), the 'flash' models are most comparable to Sonnet or GPT-mini models, ie. they are small models, and the 'Pro' models are the analogues to Opus or GPT-4/5. I can't seem to find anything in the announcements saying if 'flash-thinking' is trained 'from scratch' for the RL o1 reasoning, or if it's distilled, or anything about the existence of a 'pro-thinking' model which flash-thinking is distilled from... So my inference is that there is probably a large 'pro-thinking' model Google is not talking about, similar to Anthropic not talking about how Sonnet was trained.
Replies from: gwern, Thane Ruthenis, LGS, wassname, lepowski, wassname, sharmake-farah, Siebe, dentosal, Amyr, utilistrutil, no77e-noi↑ comment by gwern · 2025-01-21T23:05:50.492Z · LW(p) · GW(p)
An important update: "Stargate" (blog) is now officially public, confirming earlier $100b numbers and some loose talk about 'up to $500b' being spent. Noam Brown commentary:
@OpenAI excels at placing big bets on ambitious research directions driven by strong conviction.
This is on the scale of the Apollo Program and Manhattan Project when measured as a fraction of GDP. This kind of investment only happens when the science is carefully vetted and people believe it will succeed and be completely transformative. I agree it’s the right time.
...I don’t think that’s the correct interpretation. DeepSeek shows you can get very powerful AI models with relatively little compute. But I have no doubt that with even more compute it would be an even more powerful model.
If r1 being comparable to o1 surprised you, your mistake was forgetting the 1 part. This is the early stage of a new paradigm, and SOTA is the cheapest it will ever be.
That does NOT mean compute doesn't matter. (I've said roughly this before, but it bears repeating)
...Don't get me wrong, DeepSeek is nothing to sneeze it.
They will almost certainly get much more compute than they have now. But so will OpenAI...
And if DeepSeek keeps up via compute, that does not invalidate the original point re: compute being key.
(This is an example of why I don't expect DeepSeek to leapfrog OA/A/G/FB/xAI/SSI/et al: DS does great work, but $500b is a lot of money, and their capital disadvantage may be, if anything, bigger when you move from a raw parameter/data-scaling regime to an inference/search scaling regime. 6 million dollar training budgets aren't cool. You know what's cool? 6 million GPU training budgets...)
EDIT: the lead author, Daya Guo, of the r1 paper reportedly tweeted (before deleting):
The last work in 2024, nothing can stop us on the path to AGI, except for computational resources.
↑ comment by Thane Ruthenis · 2025-01-20T04:59:30.340Z · LW(p) · GW(p)
If you're wondering why OAers are suddenly weirdly, almost euphorically, optimistic on Twitter
For clarity, which OAers this is talking about, precisely? There's a cluster of guys – e. g. this, this, this – claiming to be OpenAI insiders. That cluster went absolutely bananas the last few days, claiming ASI achieved internally/will be in a few weeks, alluding to an unexpected breakthrough that has OpenAI researchers themselves scared. But none of them, as far as I can tell, have any proof that they're OpenAI insiders.
On the contrary: the Satoshi guy straight-up suggests he's allowed to be an insider shitposting classified stuff on Twitter because he has "dirt on several top employees", which, no. From that, I conclude that the whole cluster is a member of the same species as the cryptocurrency hivemind hyping up shitcoins.
Meanwhile, any actual confirmed OpenAI employees are either staying silent, or carefully deflate the hype. roon is being roon, but no more than is usual for them, as far as I can tell.
So... who are those OAers that are being euphorically optimistic on Twitter, and are they actually OAers? Anyone knows? (I don't think a scenario where low-level OpenAI people are allowed to truthfully leak this stuff on Twitter, but only if it's plausible-deniable, makes much sense.[1] In particular: what otherwise unexplainable observation are we trying to explain using this highly complicated hypothesis? How is that hypothesis privileged over "attention-seeking roon copycats"?)
General question, not just aimed at Gwern.
Edit: There's also the Axios article. But Axios is partnered with OpenAI, and if you go Bounded Distrust [LW · GW] on it, it's clear how misleading it is.
- ^
Suppose that OpenAI is following this strategy in order to have their cake and eat it too: engage in a plausible-deniable messaging pattern, letting their enemies dismiss it as hype (and so not worry about OpenAI and AI capability progress) while letting their allies believe it (and so keep supporting/investing in them). But then either (1) the stuff these people are now leaking won't come true, disappointing the allies, or (2) this stuff will come true, and their enemies would know to take these leaks seriously the next time.
This is a one-time-use strategy. At this point, either (1) allow actual OpenAI employees to leak this stuff, if you're fine with this type of leak, or (2) instruct the hype men to completely make stuff up, because if you expect your followers not to double-check which predictions came true, you don't need to care about the truth value at all.
↑ comment by LGS · 2025-01-16T21:48:36.708Z · LW(p) · GW(p)
Do you have a sense of where the feedback comes from? For chess or Go, at the end of the day, a game is won or lost. I don't see how to do this elsewhere except for limited domains like simple programming which can quickly be run to test, or formal math proofs, or essentially tasks in NP (by which I mean that a correct solution can be efficiently verified).
For other tasks, like summarizing a book or even giving an English-language math proof, it is not clear how to detect correctness, and hence not clear how to ensure that a model like o5 doesn't give a worse output after thinking/searching a long time than the output it would give in its first guess. When doing RL, it is usually very important to have non-gameable reward mechanisms, and I don't see that in this paradigm.
I don't even understand how they got from o1 to o3. Maybe a lot of supervised data, ie openAI internally created some FrontierMath style problems to train on? Would that be enough? Do you have any thoughts about this?
Replies from: wassname, igor-2↑ comment by wassname · 2025-01-17T00:29:18.225Z · LW(p) · GW(p)
English-language math proof, it is not clear how to detect correctness,
Well the final answer is easy to evaluate. And like in rStar-Math, you can have a reward model that checks if each step is likely to be critical to a correct answer, then it assigns and implied value to the step.
summarizing a book
I think tasks outside math and code might be hard. But summarizing a book is actually easy. You just ask "how easy is it to reconstruct the book if given the summary". So it's an unsupervised compression-decompression task.
Another interesting domain is "building a simulator". This is an expensive thing to generate solutions for, but easy to verify that it predicts the thing you are simulating. I can see this being an expensive but valuable domain for this paradime. This would include fusion reactors, and robotics (which OAI is once again hiring for!)
When doing RL, it is usually very important to have non-gameable reward mechanisms
I don't see them doing this explicitly yet, but setting up an independent, and even adversarial reward model would help, or at least I expect it should.
Replies from: LGS↑ comment by LGS · 2025-01-17T00:35:42.631Z · LW(p) · GW(p)
Well the final answer is easy to evaluate. And like in rStar-Math, you can have a reward model that checks if each step is likely to be critical to a correct answer, then it assigns and implied value to the step.
Why is the final answer easy to evaluate? Let's say we generate the problem "number of distinct solutions to x^3+y^3+xyz=0 modulo 17^17" or something. How do you know what the right answer is?
I agree that you can do this in a supervised way (a human puts in the right answer). Is that what you mean?
What about if the task is "prove that every integer can be written as the sum of at most 1000 different 11-th powers"? You can check such a proof in Lean, but how do you check it in English?
And like in rStar-Math, you can have a reward model that checks if each step is likely to be critical to a correct answer, then it assigns and implied value to the step.
My question is where the external feedback comes from. "Likely to be critical to a correct answer" according to whom? A model? Because then you don't get the recursive self-improvement past what that model knows. You need an external source of feedback somewhere in the training loop.
Replies from: wassname, wassname↑ comment by wassname · 2025-01-17T00:45:35.027Z · LW(p) · GW(p)
I agree that you can do this in a supervised way (a human puts in the right answer). Is that what you mean?
I'm not 100% sure, but you could have a look at math-shepard for an example. I haven't read the whole thing yet. I imagine it works back from a known solution.
↑ comment by wassname · 2025-01-17T00:41:02.686Z · LW(p) · GW(p)
"Likely to be critical to a correct answer" according to whom?
Check out the linked rStar-Math paper, it explains and demonstrates it better than I can (caveat they initially distil from a much larger model, which I see as a little bit of a cheat). tldr: yes a model, and a tree of possible solutions. Given a tree with values on the leaves, they can look at what nodes seem to have causal power.
A seperate approach is to teach a model to supervise using human process supervision data , then ask it to be the judge. This paper also cheats a little by distilling, but I think the method makes sense.
Replies from: mateusz-baginski↑ comment by Mateusz Bagiński (mateusz-baginski) · 2025-01-17T14:18:42.606Z · LW(p) · GW(p)
(caveat they initially distil from a much larger model, which I see as a little bit of a cheat)
Another little bit of a cheat is that they only train Qwen2.5-Math-7B according to the procedure described. In contrast, for the other three models (smaller than Qwen2.5-Math-7B), they instead use the fine-tuned Qwen2.5-Math-7B to generate the training data to bootstrap round 4. (Basically, they distill from DeepSeek in round 1 and then they distill from fine-tuned Qwen in round 4.)
They justify:
Due to limited GPU resources, we performed 4 rounds of self-evolution exclusively on Qwen2.5-Math-7B, yielding 4 evolved policy SLMs (Table 3) and 4 PPMs (Table 4). For the other 3 policy LLMs, we fine-tune them using step-by-step verified trajectories generated from Qwen2.5-Math-7B’s 4th round. The final PPM from this round is then used as the reward model for the 3 policy SLMs.
TBH I'm not sure how this helps them with saving on GPU resources. For some reason it's cheaper to generate a lot of big/long rollouts with the Qwen2.5-Math-7B-r4 than three times with [smaller model]-r3?)
Replies from: wassname↑ comment by wassname · 2025-01-17T23:46:49.828Z · LW(p) · GW(p)
It doesn't make sense to me either, but it does seem to invalidate the "bootstrapping" results for the other 3 models. Maybe it's because they could batch all reward model requests into one instance.
When MS doesn't have enough compute to do their evals, the rest of us may struggle!
↑ comment by Petropolitan (igor-2) · 2025-01-17T21:52:46.516Z · LW(p) · GW(p)
Math proofs are math proofs, whether they are in plain English or in Lean. Contemporary LLMs are very good at translation, not just between high-resource human languages but also between programming languages (transpiling), from code to human (documentation) and even from algorithms in scientific papers to code. Thus I wouldn't expect formalizing math proofs to be a hard problem in 2025.
However I generally agree with your line of thinking. As wassname wrote above (it's been quite obvious for some time but they link to a quantitative analysis), good in-silico verifiers are indeed crucial for inference-time scaling. But for the most of real-life tasks there's either no decent, objective verifiers in principle (e. g., nobody knows right answers to counterfactual economics or history questions) or there are very severe trade-offs in verifier accuracy and time/cost (think of wet lab life sciences: what's the point of getting hundreds of AI predictions a day for cheap if one needs many months and much more money to verify them?)
Replies from: LGS↑ comment by LGS · 2025-01-26T07:44:53.337Z · LW(p) · GW(p)
I have no opinion about whether formalizing proofs will be a hard problem in 2025, but I think you're underestimating the difficulty of the task ("math proofs are math proofs" is very much a false statement for today's LLMs, for example).
In any event, my issue is that formalizing proofs is very clearly not involved in the o1/o3 pipeline, since those models make so many formally incorrect arguments. The people behind FrontierMath have said that o3 solved many of the problems using heuristic algorithms with wrong reasoning behind them; that's not something a model trained on formally verified proofs would do. I see the same thing with o1, which was evaluated on the Putnam and got the right answer with a wrong proof on nearly every question.
Replies from: gwern, igor-2↑ comment by gwern · 2025-01-26T16:58:52.727Z · LW(p) · GW(p)
Right now, it seems to be important to not restrict the transcripts at all. This is a hard exploration problem, where most of the answers are useless, and it takes a lot of time for correct answers to finally emerge. Given that, you need to keep the criteria as relaxed as possible, as they are already on the verge of impossibility.
The r1, the other guys, and OAers too on Twitter now seem to emphasize that the obvious appealing approach of rewarding tokens for predicted correctness or doing search on tokens, just doesn't work (right now). You need to 'let the LLMs yap' until they reach the final correct answer. This appears to be the reason for the bizarre non sequiturs or multi-lingual diversions in transcripts - that's just the cost of rolling out solution attempts which can go anywhere and keeping the winners. They will do all sorts of things which are unnecessary (and conversely, omit tokens which are 'necessary'). Think of it as the equivalent of how DRL agents will 'jitter' and take many unnecessary actions, because those actions don't change the final reward more than epsilon, and the RL feedback just isn't rich enough to say 'you don't need to bounce up and down randomly while waiting for the ball to bounce back, that doesn't actually help or hurt you' (and if you try to reward-shape away those wasteful movements, you may discover your DRL agent converges to a local optimum where it doesn't do anything, ever, because the jitters served to explore the environment and find new tricks, and you made it too expensive to try useless-seeming tricks so it never found any payoffs or laddered its way up in capabilities).
So you wouldn't want to impose constraints like 'must be 100% correct valid Lean proof'. Because it is hard enough to find a 'correct' transcript even when you don't penalize it for spending a while yapping in Japanese or pseudo-skipping easy steps by not writing them down. If you imposed constraints like that, instead of rolling out 1000 episodes and getting 1 useful transcript and the bootstrap working, you'd get 0 useful transcripts and it'd go nowhere.
What you might do is impose a curriculum: solve it any way you can at first, then solve it the right way. Once you have your o1 bootstrap working and have seen large capability gains, you can go back and retrain on the easiest problems with stricter criteria, and work your way back up through the capability levels, but now in some superior way. (In the DRL agent context, you might train to convergence and only then impose a very, very small penalty on each movement, and gradually ramp it up until the performance degrades a little bit but it's no longer jittering.) The same way you might be taught something informally, and then only much later, after you've worked with it a lot, do you go back and learn or prove it rigorously. You might impose a progressive shrinking constraint, for example, where the transcript has to be fewer tokens each time, in order to distill the knowledge into the forward passes to make it vastly cheaper to run (even cheaper, for hard problems, than simply training a small dumb model on the transcripts). You might try to iron out the irrelevancies and digressions by having a judge/critic LLM delete irrelevant parts. You might try to eliminate steganography by rewriting the entire transcript using a different model. Or you might simply prompt it to write a proof in Lean, and score it by whether the final answer validates.
Replies from: LGS, p.b., wassname↑ comment by LGS · 2025-01-26T23:33:01.075Z · LW(p) · GW(p)
There's still my original question of where the feedback comes from. You say keep the transcripts where the final answer is correct, but how do you know the final answer? And how do you come up with the question?
What seems to be going on is that these models are actually quite supervised, despite everyone's insistence on calling them unsupervised RL. The questions and answers appear to be high-quality human annotation instead of being machine generated. Let me know if I'm wrong about this.
If I'm right, it has implications for scaling. You need human annotators to scale, and you need to annotate increasingly hard problems. You don't get to RL your way to infinite skill like alphazero; if, say, the Riemann hypothesis turns out to be like 3 OOMs of difficulty beyond what humans can currently annotate, then this type of training will never solve Riemann no matter how you scale.
↑ comment by p.b. · 2025-01-26T17:39:01.763Z · LW(p) · GW(p)
So how could I have thought that faster [LW · GW] might actually be a sensible training trick for reasoning models.
↑ comment by wassname · 2025-01-28T04:52:38.901Z · LW(p) · GW(p)
What you might do is impose a curriculum:
In FBAI's COCONUT they use a curriculum to teach it to think shorter and differently and it works. They are teaching it to think using fewer steps, but compress into latent vectors instead of tokens.
- first it thinks with tokens
- then they replace one thinking step with a latent <thought> token
- then 2
- ...

It's not RL, but what is RL any more? It's becoming blurry. They don't reward or punish it for anything in the thought token. So it learns thoughts that are helpful in outputting the correct answer.
There's another relevant paper "Compressed Chain of Thought: Efficient Reasoning through Dense Representations" which used teacher forcing. Although I haven't read the whole thing yet.
Replies from: gwern↑ comment by gwern · 2025-01-28T16:09:55.859Z · LW(p) · GW(p)
It's not RL, but what is RL any more? It's becoming blurry. They don't reward or punish it for anything in the thought token. So it learns thoughts that are helpful in outputting the correct answer.
That's definitely RL (and what I was explaining was simply the obvious basic approach anyone in DRL would think of in this context and so of course there is research trying things like it). It's being rewarded for a non-differentiable global loss where the correct alternative or answer or label is not provided (not even information of the existence of a better decision) and so standard supervised learning is impossible, requiring exploration. Conceptually, this is little different from, say, training a humanoid robot NN to reach a distant point in fewer actions: it can be a hard exploration problem (most sequences of joint torques or actions simply result in a robot having a seizure while laying on the ground going nowhere), where you want to eventually reach the minimal sequence (to minimize energy / wear-and-tear / time) and you start by solving the problem in any way possible, rewarding solely on the final success, and then reward-shape into a desirable answer, which in effect breaks up the hard original problem into two more feasible problems in a curriculum - 'reach the target ever' followed by 'improve a target-reaching sequence of actions to be shorter'.
↑ comment by Petropolitan (igor-2) · 2025-03-26T17:04:11.334Z · LW(p) · GW(p)
Two months later I tried to try actually implementing a nontrivial conversion of a natural language mathematical argument to a fully formalized Lean proof in order to check if I was indeed underestimating it (TBH, I have never tried a proof assistant before).
So I took a difficult integral from a recent MathSE question I couldn't solve analytically myself, had Gemini 2.5 Pro solve it 0-shot,[1] verified it numerically, set up a Lean environment in Google Colab and then asked if another instance of Gemini 2.5 could convert the solution into a proof. It told me that it is indeed hard:
This is not a trivial task. Here's why:
- Informal vs. Formal: My natural language explanation, while aiming for clarity, likely skipped steps, relied on implicit assumptions (like function continuity, differentiability, domain constraints), or used intuitive leaps that Lean demands be made explicit and rigorously justified using defined theorems and axioms.
- Library Navigation: Finding the exact theorems in mathlib4 that correspond to each step (e.g., the correct version of integration by parts, substitution, limit theorems, properties of specific functions) requires familiarity with the library.
- Side Conditions: Every theorem in Lean (like the chain rule or integration by parts) has precise side conditions (e.g., f is differentiable, g' is continuous, the function is integrable). The natural language proof might not have explicitly stated or verified all of these, but the Lean proof must.
- Calculations: Even seemingly simple algebraic manipulations or derivative calculations need to be carried out using Lean's tactics (ring, linarith, simp, rw, etc.) or proven step-by-step.
- Proof Structure & Tactics: Structuring the proof correctly in Lean and using the appropriate tactics (apply, exact, calc, by, etc.) to guide the prover is a skill in itself.
- My Limitations: While I can generate code snippets, generating a complete, correct, and non-trivial formal proof interactively is currently beyond my capabilities. It often requires a human expert to guide the process, debug errors, and find the right lemmas.
<...>
It is highly unlikely that I can produce a complete, automatically verifiable Lean proof for a "tricky" integral directly from a natural language description. However, if you provide the details, I can attempt to sketch out the Lean concepts involved, which could be a starting point for someone (perhaps you in Colab, with time and learning) to build the actual proof.
Gemini and I weren't able to set up mathlib4 in Lean 4 and I gave up on the task, but already by just looking on a solution Gemini listed the following problems[2] (I put it here as a screen capture instead of a proper collapsible section because I couldn't figure out how to copypaste the formulas right):

To sum up, yes, I did underestimate the hardness of the task, it is certainly beyond the reach of current SOTA LLMs.
However, I believe that since this type of task is verifiable in silico and really very convenient for synthetic training data generation, Google folks behind AlphaGeometry are probably going to solve this problem in a year or two.
- ^
The fact that an LLM solved it 0-shot is notable in its own right BTW. Generally, I'ld estimate that Gemini 2.5 and o3-mini are able to solve most of the definite integrals posted in MathSE questions. It was very different at the beginning of this year!
- ^
I haven't checked accuracy of all the generated details due to lack of competence and time but generally expect the outline to be broadly correct
↑ comment by wassname · 2025-01-16T12:12:42.291Z · LW(p) · GW(p)
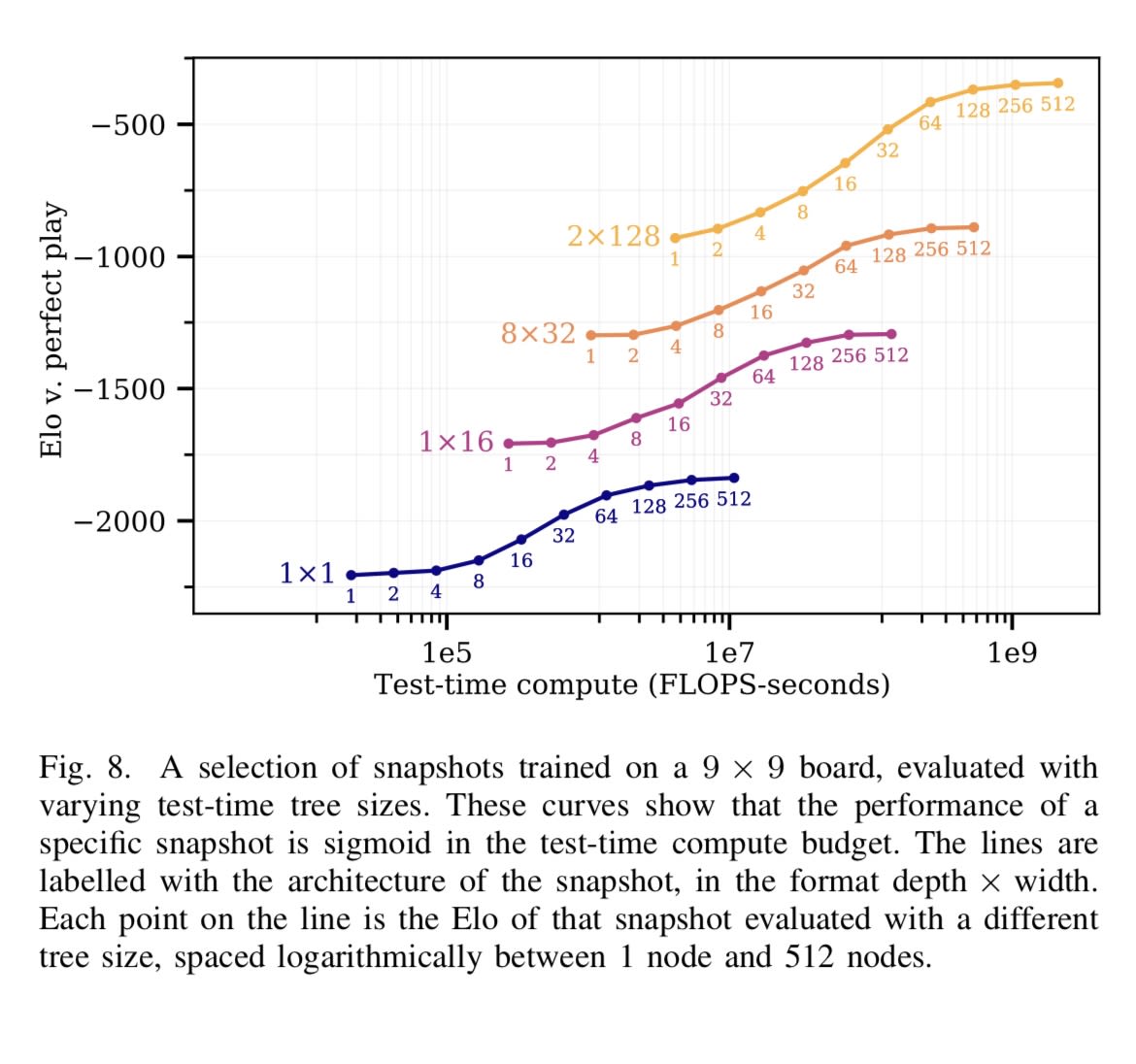
To illustrate Gwern's idea, here is an image from Jones 2021 that shows some of these self play training curves

There may be a sense that they've 'broken out', and have finally crossed the last threshold of criticality
And so OAI employees may internally see that they are on the steady upward slope
Perhaps constrained domains like code and math are like the curves on the left, while unconstrained domains like writing fiction are like curves to the right. Some other domains may also be reachable with current compute, like robotics. But even if you get a math/code/robotics-ASI, you can use it to build more compute, and solve the less constrained domains like persuasion/politics/poetry.
↑ comment by lepowski · 2025-01-16T19:31:33.297Z · LW(p) · GW(p)
Unless releasing o1 pro to the public generates better training data than self-play? Self-play causes model collapse, While chat transcripts are messy OAI has them on a massive scale.
Replies from: ArthurB↑ comment by wassname · 2025-01-16T12:00:43.664Z · LW(p) · GW(p)
Huh, so you think o1 was the process supervision reward model, and o3 is the distilled policy model to whatever reward model o1 became? That seems to fit.
There may be a sense that they've 'broken out', and have finally crossed the last threshold of criticality, from merely cutting-edge AI work which everyone else will replicate in a few years, to takeoff
Surely other labs will also replicate this too? Even the open source community seems close. And Silicon Valley companies often poach staff, which makes it hard to keep a trade secret. Not to mention spies.
This means that outsiders may never see the intermediate models
Doubly so, if outsiders will just distil your models behaviour, and bootstrap from your elevated starting point.
Inference-time search is a stimulant drug that juices your score immediately, but asymptotes hard. Quickly, you have to use a smarter model to improve the search itself, instead of doing more.
It's worth pointing out that Inference-time search seems to become harder as the verifier becomes less reliable. Which means that the scaling curves we see for math and code, might get much worse in other domains.
we find that this is extremely sensitive to the quality of the verifier. If the verifier is slightly imperfect, in many realistic settings of a coding task, performance maxes out and actually starts to decrease after about 10 attempts." - Inference Scaling fLaws
But maybe the counterpoint is just, GPU's go brrrr.
Replies from: gwern, Anonymous↑ comment by gwern · 2025-01-20T20:08:27.861Z · LW(p) · GW(p)
Huh, so you think o1 was the process supervision reward model, and o3 is the distilled policy model to whatever reward model o1 became? That seems to fit.
Something like that, yes. The devil is in the details here.
Surely other labs will also replicate this too? Even the open source community seems close. And Silicon Valley companies often poach staff, which makes it hard to keep a trade secret. Not to mention spies.
Of course. The secrets cannot be kept, and everyone has been claiming to have cloned o1 already. There are dozens of papers purporting to have explained it. (I think DeepSeek may be the only one to have actually done so, however; at least, I don't recall offhand any of the others observing the signature backtracking 'wait a minute' interjections the way DeepSeek sees organically emerging in r1.)
But scaling was never a secret. You still have to do it. And MS has $80b going into AI datacenters this year; how much does open source (or DeepSeek) have?
It's worth pointing out that Inference-time search seems to become harder as the verifier becomes less reliable. Which means that the scaling curves we see for math and code, might get much worse in other domains.
Yes. That's why I felt skeptical about how generalizable the o1 approach is. It doesn't look like a break-out to me. I don't expect much far transfer: being really good at coding doesn't automatically make you a genius at, say, booking plane tickets. (The o1 gains are certainly not universal, the way straightforward data/parameter-scaling gains tend to be - remember that some of the benchmarks actually got worse.) I also expect the o1 approach to tend to plateau: there is no ground truth oracle for most of these things, the way there is for Go. AlphaZero cannot reward-hack the Go simulator. Even for math, where your theorem prover can at least guarantee that a proof is valid, what's the ground-truth oracle for 'came up with a valuable new theorem, rather than arbitrary ugly tautological nonsense of no value'?
So that's one of the big puzzles here for me: as interesting and impressive as o1/o3 is, I just don't see how it justifies the apparent confidence. (Noam Brown has also commented that OA has a number of unpublished breakthroughs that would impress me if I knew, and of course, the money side seems to still be flowing without stint, despite it being much easier to cancel such investments than cause them.)
Is OA wrong, or do they know something I don't? (For example, a distributional phase shift akin to meta-learning.) Or do they just think that these remaining issues are the sort of thing that AI-powered R&D can solve and so it is enough to just get really, really good at coding/math and they can delegate from there on out?
EDIT: Aidan McLaughlin has a good post back in November discussing the problems with RL and why you would not expect the o1 series to lead to AGI when scaled up in sensible ways, which I largely agree with, and says:
But, despite this impressive leap, remember that o1 uses RL, RL works best in domains with clear/frequent reward, and most domains lack clear/frequent reward.
Praying for Transfer Learning: OpenAI admits that they trained o1 on domains with easy verification but hope reasoners generalize to all domains...When I talked to OpenAI’s reasoning team about this, they agreed it was an issue, but claimed that more RL would fix it. But, as we’ve seen earlier, scaling RL on a fixed model size seems to eat away at other competencies! The cost of training o3 to think for a million tokens may be a model that only does math.
On the other hand... o3 didn't only do math, and in RL we also know that RL systems often exhibit phase transitions in terms of meta-learning or generalization, where they overfit to narrow distributions and become superhuman experts which break if anything is even slightly different, but suddenly generalize when train on diverse enough data as a blessing of scale, not in data but data diversity, with LLMs being a major case in point of that, like GPT-2 -> GPT-3. Hm. This was written 2024-11-20, and McLaughlin announced 2025-01-13 that he had joined OpenAI. Hm...
Replies from: sharmake-farah, Thane Ruthenis, aidanmcl↑ comment by Noosphere89 (sharmake-farah) · 2025-01-20T20:33:14.938Z · LW(p) · GW(p)
My personal view is that OA is probably wrong about how far the scaling curves generalize, with the caveat that even eating math and coding entirely ala AlphaZero would be still massive for AI progress, though compute constraints will bind eventually.
My own take is that the o1-approach will plateau in domains where verification is expensive, but thankfully most tasks of interest tend to be easier to verify than to solve, and lots of math/coding are basically ideally suited to verification, and I expect it to be way easier to make simulators that aren't easy to reward hack for these domains.
what's the ground-truth oracle for 'came up with a valuable new theorem, rather than arbitrary ugly tautological nonsense of no value'?
Eh, those tautologies are both interesting on their own, combined with valuable training data so that it learns how to prove statements.
I think the unmodelled variable is that they think software-only type singularities to be more plausible, ala this:
Or do they just think that these remaining issues are the sort of thing that AI-powered R&D can solve and so it is enough to just get really, really good at coding/math and they can delegate from there on out?
Or this:
https://www.lesswrong.com/posts/FG54euEAesRkSZuJN/ryan_greenblatt-s-shortform#z7sKoyGbgmfL5kLmY [LW(p) · GW(p)]
↑ comment by Thane Ruthenis · 2025-01-21T02:57:54.545Z · LW(p) · GW(p)
McLaughlin announced 2025-01-13 that he had joined OpenAI
He gets onboarded only on January 28th, for clarity.
Replies from: gwern↑ comment by gwern · 2025-01-21T03:21:06.693Z · LW(p) · GW(p)
My point there is that he was talking to the reasoning team pre-hiring (forget 'onboarding', who knows what that means), so they would be unable to tell him most things - including if they have a better reason than 'faith in divine benevolence' to think that 'more RL does fix it'.
↑ comment by Anonymous · 2025-01-17T18:31:45.642Z · LW(p) · GW(p)
When I hear “distillation” I think of a model with a smaller number of parameters that’s dumber than the base model. It seems like the word “bootstrapping” is more relevant here. You start with a base LLM (like GPT-4); then do RL for reasoning, and then do a ton of inference (this gets you o1-level outputs); then you train a base model with more parameters than GPT-4 (let’s call this GPT-5) on those outputs — each single forward pass of the resulting base model is going to be smarter than a single forward pass of GPT-4. And then you do RL and more inference (this gets you o3). And rinse and repeat.
I don’t think I’m really saying anything different from what you said, but the word “distill” doesn’t seem to capture the idea that you are training a larger, smarter base model (as opposed to a smaller, faster model). This also helps explain why o3 is so expensive. It’s not just doing more forward passes, it’s a much bigger base model that you’re running with each forward pass.
I think maybe the most relevant chart from the Jones paper gwern cites is this one:
↑ comment by moozooh (vladimir-sergeyev) · 2025-01-17T22:55:22.295Z · LW(p) · GW(p)
I don't think o3 is a bigger model if we're talking just raw parameter count. I am reasonably sure that both o1, o3, and the future o-series models for the time being are all based on 4o and scale its fundamental capabilities and knowledge. I also think that 4o itself was created specifically for the test-time compute scaffolding because the previous GPT-4 versions were far too bulky. You might've noticed that pretty much the entire of 2024 for the top labs was about distillation and miniaturization where the best-performing models were all significantly smaller than the best-performing models up through the winter of 2023/2024.
In my understanding, the cost increase comes from the fact that better, tighter chains of thought enable juicing the "creative" settings like higher temperature which expand the search space a tiny bit at a time. So the model actually searches for longer despite being more efficient than its predecessor because it's able to search more broadly and further outside the box instead of running in circles. Using this approach with o1 likely wouldn't be possible because it would take several times more tokens to meaningfully explore each possibility and risk running out of the context window before it could match o3's performance.
I also believe the main reason Altman is hesitant to release GPT-5 (which they already have and most likely already use internally as a teacher model for the others) is that strictly economically speaking, it's just a hard sell in the world where o3 exists and o4 is coming in three months, and then o5, etc. So it can't outsmart those, yet unless it has a similar speed and latency as 4o or o1-mini, it cannot be used for real-time tasks like conversation mode or computer vision. And then the remaining scope of real-world problems for which it is the best option narrows down to something like creative writing and other strictly open-ended tasks that don't benefit from "overthinking". And I think the other labs ran into the same issue with Claude 3.5 Opus, Gemini 1.5 Ultra (if it was ever a thing at all), and any other trillion-scale models we were promised in 2024. The age of trillion-scale models is very likely over.
Replies from: Anonymous↑ comment by Anonymous · 2025-01-20T03:14:43.142Z · LW(p) · GW(p)
All of this sounds reasonable and it sounds like you may have insider info that I don’t. (Also, TBC I wasn’t trying to make a claim about which model is the base model for a particular o-series model, I was just naming models to be concrete, sorry to distract with that!)
Totally possible also that you’re right about more inference/search being the only reason o3 is more expensive than o1 — again it sounds like you know more than I do. But do you have a theory of why o3 is able to go on longer chains of thought without getting stuck, compared with o1? It’s possible that it’s just a grab bag of different improvements that make o3’s forward passes smarter, but to me it sounds like OAI think they’ve found a new, repeatable scaling paradigm, and I’m (perhaps over-)interpreting gwern as speculating that that paradigm does actually involve training larger models.
You noted that OAI is reluctant to release GPT-5 and is using it internally as a training model. FWIW I agree and I think this is consistent with what I’m suggesting. You develop the next-gen large parameter model (like GPT-5, say), not with the intent to actually release it, but rather to then do RL on it so it’s good at chain of thought, and then to use the best outputs of the resulting o model to make synthetic data to train the next base model with an even higher parameter count — all for internal use to push forward the frontier. None of these models ever need to be deployed to users — instead, you can distill either the best base model or the o-series model you have on hand into a smaller model that will be a bit worse (but only a bit) and way more efficient to deploy to lots of users.
The result is that the public need never see the massive internal models — we just happily use the smaller distilled versions that are surprisingly capable. But the company still has to train ever-bigger models.
Maybe what I said was already clear and I’m just repeating myself. Again you seem to be much closer to the action and I could easily be wrong, so I’m curious if you think I’m totally off-base here and in fact the companies aren’t developing massive models even for internal use to push forward the frontier.
↑ comment by wassname · 2025-01-17T23:30:46.565Z · LW(p) · GW(p)
Well we don't know the sizes of the model, but I do get what you are saying and agree. Distil usually means big to small. But here it means expensive to cheap, (because test time compute is expensive, and they are training a model to cheaply skip the search process and just predict the result).
In RL, iirc, they call it "Policy distillation". And similarly "Imitation learning" or "behavioral cloning" in some problem setups. Perhaps those would be more accurate.
I think maybe the most relevant chart from the Jones paper gwern cites is this one:
Oh interesting. I guess you mean because it shows the gains of TTC vs model size? So you can imagine the bootstrapping from TTC -> model size -> TCC -> and so on?
Replies from: Anonymous↑ comment by Anonymous · 2025-01-20T02:45:42.175Z · LW(p) · GW(p)
Yeah sorry to be clear totally agree we (or at least I) don’t know the sizes of models, I was just naming specific models to be concrete.
But anyway yes I think you got my point: the Jones chart illustrates (what I understood to be) gwern’s view that adding more inference/search does juice your performance to some degree, but then those gains taper off. To get to the next higher sigmoid-like curve in the Jones figure, you need to up your parameter count; and then to climb that new sigmoid, you need more search. What Jones didn’t suggest (but gwern seems to be saying) is that you can use your search-enhanced model to produce better quality synthetic data to train a larger model on.
↑ comment by gwern · 2025-01-20T19:41:10.608Z · LW(p) · GW(p)
What Jones didn’t suggest (but gwern seems to be saying) is that you can use your search-enhanced model to produce better quality synthetic data to train a larger model on.
Jones wouldn't say that because that's just implicit in expert iteration. In each step of expert iteration, you can in theory be training an arbitrary new model from scratch to imitate the current expert. Usually you hold fixed the CNN and simply train it some more on the finetuned board positions from the MCTS, because that is cheap, but you don't have to. As long as it takes a board position, and it returns value estimates for each possible move, and can be trained, it works. You could train a larger or smaller CNN, a deeper or wider* CNN of the same size, a ViT, a RNN, a random forest... (See also 'self-distillation'.) And you might want to do this if the old expert has some built-in biases, perhaps due to path dependency, and is in a bad local optimum compared to training from a blank slate with the latest best synthetic data.
You can also do this in RL in general. OpenAI, for example, kept changing the OA5 DotA2 bot architecture on the fly to tweak its observations and arches, and didn't restart each time. It just did a net2net or warm initialization, and kept going. (Given the path dependency of on-policy RL especially, this was not ideal, and did come with a serious cost, but it worked, as they couldn't've afforded to train from scratch each time. As the released emails indicate, OA5 was breaking the OA budget as it was.)
Now, it's a great question to ask: should we do that? Doesn't it feel like it would be optimal to schedule the growth of the NN over the course of training in a scenario like Jones 2021? Why pay the expense of the final oversized CNN right from the start when it's still playing random moves? It seems like there ought to be some set of scaling laws for how you progressively expand the NN over the course of training before you then brutally distill it down for a final NN, where it looks like an inverted U-curve. But it's asking too much of Jones 2021 to do that as well as everything else. (Keep in mind that Andy Jones was just one guy with no budget or lab support doing this paper all on his own over, like, a summer. In terms of bang for buck, it is one of the best DL & RL papers of the past decade, and puts the rest of us to shame.)
* for latency. An early example of this is WaveNet for synthesizing audio: it was far too slow for real-time, because it was too deep. It didn't cost too many computations, but the computations were too iterative to allow generating 1s of audio in 1s of wallclock, which renders it completely useless for many purposes, as it will fall behind. But once you have a working WaveNet, you can then distill it into a very wide CNN which does much more parallel computation instead of sequential, and can keep up. It might cost more operations, it might have more parameters, but it'll generate 1s of audio in <1s of wallclock time.
↑ comment by Noosphere89 (sharmake-farah) · 2025-01-18T19:25:55.987Z · LW(p) · GW(p)
I think they're misreading the scaling curves, because as of now it is very dependent on good verifiers for the problems at hand, which is basically math and coding are the only domains where very good verifiers are in place.
This is still major if true, because eating coding/math absolutely speeds up AI progress, but there's a very important caveat to the results that makes me think they're wrong about it leading to ASI.
↑ comment by Siebe · 2025-01-16T21:58:33.498Z · LW(p) · GW(p)
This is a really good comment. A few thoughts:
-
Deployment had a couple of benefits: real-world use gives a lot of feedback on strengths, weaknesses, jailbreaks. It also generates media/hype that's good for attracting further investors (assuming OpenAI will want more investment in the future?)
-
The approach you describe is not only useful for solving more difficult questions. It's probably also better at doing more complex tasks, which in my opinion is a trickier issue to solve. According to Flo Crivello:
We're starting to switch all our agentic steps that used to cause issues to o1 and observing our agents becoming basically flawless overnight https://x.com/Altimor/status/1875277220136284207
So this approach can generate data on complex sequential tasks and lead to better performance on increasingly longer tasks.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-17T01:13:12.947Z · LW(p) · GW(p)
So maybe you only want a relatively small amount of use, that really pushes the boundaries of what the model is capable of. So maybe you offer to let scientists apply to "safety test" your model, under strict secrecy agreements, rather than deploy it to the public.
Oh.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2025-01-17T04:10:25.952Z · LW(p) · GW(p)
They don't need to use this kind of subterfuge, they can just directly hire people to do that. Hiring experts to design benchmark questions is standard; this would be no different.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-17T04:15:06.396Z · LW(p) · GW(p)
Yeah, my comment was mostly being silly. The grain of validity I think is there is that you probably get a much wider weirder set of testing from inviting in a larger and more diverse set of people. And for something like, 'finding examples of strange failure cases that you yourself wouldn't have thought of' then I think diversity of testers matters quite a bit.
Replies from: gwern↑ comment by gwern · 2025-01-20T19:49:10.542Z · LW(p) · GW(p)
The current FrontierMath fracas [LW · GW] is a case in point. Did OpenAI have to keep its sponsorship or privileged access secret? No. Surely there was some amount of money that would pay mathematicians to make hard problems, and that amount was not much different from what they did pay Epoch AI. Did that make life easier? Given the number of mathematician-participants saying they would've had second thoughts about participating had they known OA was involved, almost surely.
↑ comment by Dentosal (dentosal) · 2025-01-16T15:44:17.486Z · LW(p) · GW(p)
I am actually mildly surprised OA has bothered to deploy o1-pro at all, instead of keeping it private and investing the compute into more bootstrapping of o3 training etc.
I'd expect that deploying more capable models is still quite useful, as it's one of the best ways to generate high-quality training data. In addition to solutions, you need problems to solve, and confirmation that the problem has been solved. Or is your point that they already have all the data they need, and it's just a matter of speding compute to refine that?
↑ comment by Cole Wyeth (Amyr) · 2025-02-19T01:35:46.019Z · LW(p) · GW(p)
What does the chinchilla scaling laws paper (overtraining small models) have to do with distilling larger models? It’s about optimizing the performance of your best model, not inference costs. The compute optimal small model would presumably be a better thing to distill, since the final quality is higher.
Replies from: gwern↑ comment by gwern · 2025-02-19T02:03:57.503Z · LW(p) · GW(p)
"Overtraining" isn't Chinchilla; Chinchilla is just "training". The overtraining being advocated was supra-Chinchilla, with the logic that while you were going off the compute-optimal training, sure, you were more than making up for it by your compute-savings in the deployment phase, which the Chinchilla scaling laws do not address in any way. So there was a fad for training small models for a lot longer.
↑ comment by utilistrutil · 2025-02-10T04:07:59.327Z · LW(p) · GW(p)
(eg. any o1 session which finally stumbles into the right answer can be refined to drop the dead ends and produce a clean transcript to train a more refined intuition)
Do we have evidence that this is what's going on? My understanding is that distilling from CoT is very sensitive—reordering the reasoning, or even pulling out the successful reasoning, causes the student to be unable to learn from it.
I agree o1 creates training data, but that might just be high quality pre-training data for GPT-5.
↑ comment by No77e (no77e-noi) · 2025-01-19T15:26:25.775Z · LW(p) · GW(p)
If you're wondering why OAers are suddenly weirdly, almost euphorically, optimistic on Twitter
Nah, this has been the case since at least 2022 or earlier
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-14T06:32:02.598Z · LW(p) · GW(p)
However, I expect RL on CoT to amount to "process-based supervision," which seems inherently safer than "outcome-based supervision."
I think the opposite is true; the RL on CoT that is already being done and will increasingly be done is going to be in significant part outcome-based (and a mixture of outcome-based and process-based feedback is actually less safe than just outcome-based IMO, because it makes the CoT less faithful)
Replies from: mattmacdermott, wassname, joan-velja, utilistrutil, vladimir-sergeyev↑ comment by mattmacdermott · 2025-01-14T11:33:06.463Z · LW(p) · GW(p)
I think all of the following:
- process-based feedback pushes against faithfulness because it incentivises having a certain kind of CoT independently of the outcome
- outcome-based feedback pushes towards faithfulness because it incentivises making use of earlier tokens to get the right answer
- outcome-based feedback pushes against legibility because it incentivises the model to discover new strategies that we might not know it's using
- combining process-based feedback with outcome-based feedback:
- pushes extra hard against legibility because it incentivises obfuscating said strategies[1]
- unclear sign wrt faithfulness
or at least has the potential to, depending on the details. ↩︎
↑ comment by wassname · 2025-01-16T09:12:13.060Z · LW(p) · GW(p)
I agree because:
- Some papers are already using implicit process based supervision. That's where the reward model guesses how "good" a step is, by how likely it is to get a good outcome. So they bypass any explicitly labeled process, instead it's negotiated between the policy and reward model. It's not clear to me if this scales as well as explicit process supervision, but it's certainly easier to find labels.
- In rStar-Math they did implicit process supervision. Although I don't think this is a true o1/o3 replication since they started with a 236b model and produced a 7b model, in other words: indirect distillation.
- Outcome-Refining Process Supervision for Code Generation did it too
- There was also the recent COCONUT paper exploring non-legible latent CoT. It shows extreme token efficiency. While it wasn't better overall, it has lots of room for improvement. If frontier models end up using latent thoughts, they will be even less human-legible than the current inconsistently-candid-CoT.
I also think that this whole episodes show how hard to it to maintain and algorithmic advantage. DeepSeek R1 came how long after o3? The lack of algorithmic advantage predicts multiple winners in the AGI race.
↑ comment by joanv (joan-velja) · 2025-01-14T10:26:51.218Z · LW(p) · GW(p)
Moreover, in this paradigm, forms of hidden reasoning seem likely to emerge: in multi-step reasoning, for example, the model might find it efficient to compress backtracking or common reasoning cues into cryptic tokens (e.g., "Hmmm") as a kind of shorthand to encode arbitrarily dense or unclear information. This is especially true under financial pressures to compress/shorten the Chains-of-Thought, thus allowing models to perform potentially long serial reasoning outside of human/AI oversight.
↑ comment by utilistrutil · 2025-02-10T04:04:12.100Z · LW(p) · GW(p)
Why does it make the CoT less faithful?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-02-10T04:19:33.839Z · LW(p) · GW(p)
Because you are training the CoT to look nice, instead of letting it look however is naturally most efficient for conveying information from past-AI-to-future-AI. The hope of Faithful CoT is that if we let it just be whatever's most efficient, it'll end up being relatively easy to interpret, such that insofar as the system is thinking problematic thoughts, they'll just be right there for us to see. By contrast if we train the CoT to look nice, then it'll e.g. learn euphemisms and other roundabout ways of conveying the same information to its future self, that don't trigger any warnings or appear problematic to humans.
Replies from: utilistrutil↑ comment by utilistrutil · 2025-02-10T05:01:58.032Z · LW(p) · GW(p)
Got it thanks!
↑ comment by moozooh (vladimir-sergeyev) · 2025-01-17T23:20:54.860Z · LW(p) · GW(p)
I agree with this and would like to add that scaling along the inference-time axis seems to be more likely to rapidly push performance in certain closed-domain reasoning tasks far beyond human intelligence capabilities (likely already this year!) which will serve as a very convincing show of safety to many people and will lead to wide adoption of such models for intellectual task automation. But without the various forms of experiential and common-sense reasoning humans have, there's no telling where and how such a "superhuman" model may catastrophically mess up simply because it doesn't understand a lot of things any human being takes for granted. Given the current state of AI development, this strikes me as literally the shortest path to a paperclip maximizer. Well, maybe not that catastrophic, but hey, you never know.
In terms of how immediately it accelerates certain adoption-related risks, I don't think this bodes particularly well. I would prefer a more evenly spread cognitive capability.
comment by Michaël Trazzi (mtrazzi) · 2025-01-14T02:39:09.592Z · LW(p) · GW(p)
I wouldn't update too much from Manifold or Metaculus.
Instead, I would look at how people who have a track record in thinking about AGI-related forecasting are updating.
See for instance this comment (which was posted post-o3, but unclear how much o3 caused the update): https://www.lesswrong.com/posts/K2D45BNxnZjdpSX2j/ai-timelines?commentId=hnrfbFCP7Hu6N6Lsp [LW(p) · GW(p)]
Or going from this prediction before o3: https://x.com/ajeya_cotra/status/1867813307073409333
To this one: https://x.com/ajeya_cotra/status/1870191478141792626
Ryan Greenblatt made similar posts / updates.
Replies from: Seth Herd, Mo Nastri, wassname, teun-van-der-weij↑ comment by Mo Putera (Mo Nastri) · 2025-01-14T08:52:00.391Z · LW(p) · GW(p)
The part of Ajeya's comment that stood out to me was this:
On a meta level I now defer heavily to Ryan and people in his reference class (METR and Redwood engineers) on AI timelines, because they have a similarly deep understanding of the conceptual arguments I consider most important while having much more hands-on experience with the frontier of useful AI capabilities (I still don't use AI systems regularly in my work).
I'd also look at Eli Lifland's forecasts as well:

↑ comment by Teun van der Weij (teun-van-der-weij) · 2025-01-14T05:52:21.142Z · LW(p) · GW(p)
I wouldn't update too much from Manifold or Metaculus.
Why not?
Replies from: Seth Herd↑ comment by Seth Herd · 2025-01-14T10:47:17.670Z · LW(p) · GW(p)
Because accurate prediction in a specialized domain requires expertise more than motivation. Forecasting is one relevant skill but knowledge of both current AI and knowledge of theoretical paths to AGI are also highly relevant.
Replies from: teun-van-der-weij↑ comment by Teun van der Weij (teun-van-der-weij) · 2025-01-14T21:10:15.894Z · LW(p) · GW(p)
Superforecasters can beat domain experts, as shown in Phil Tetlock's work comparing superforecasters to intelligence analysts.
I'd guess in line with you that for forecasting AGI this might be different, but I am not not sure what weight I'd give superforecasters / prediction platforms versus domain experts.
Replies from: elifland, Seth Herd↑ comment by elifland · 2025-01-15T01:52:57.911Z · LW(p) · GW(p)
Superforecasters can beat domain experts, as shown in Phil Tetlock's work comparing superforecasters to intelligence analysts.
This isn't accurate, see this post [EA · GW]: especially (3a), (3b), and https://docs.google.com/document/d/1ZEEaVP_HVSwyz8VApYJij5RjEiw3mI7d-j6vWAKaGQ8/edit?tab=t.0#heading=h.mma60cenrfmh Goldstein et al (2015)
↑ comment by Seth Herd · 2025-01-14T21:30:18.147Z · LW(p) · GW(p)
Right. I think this is different in AGI timelines because standard human expertise/intuition doesn't apply nearly as well as in the intelligence analyst predictions.
But outside of that speculation, what you really want is predictions from people who have both prediction expertise and deep domain expertise. Averaging in a lot of opinions is probably not helping in a domain so far outside of standard human intuitions.
I think predictions in this domain usually don't have a specific end-point in mind. They define AGI by capabilities. But the path through mind-space is not at all linear; it probably has strong nonlinearities in both directions. The prediction end-point is in a totally different space than the one in which progress occurs.
Standard intuitions like "projects take a lot longer than their creators and advocates think they will" are useful. But in this case, most people doing the prediction have no gears-level model of the path to AGI, because they have no, or at most a limited, gears-level model of how AGI would work. That is a sharp contrast to thinking about political predictions and almost every other arena of prediction.
So I'd prefer a single prediction from an expert with some gears-level models of AGI for different paths, over all of the prediction experts in the world who lack that crucial cognitive tool.
comment by Ryan Kidd (ryankidd44) · 2025-01-14T02:43:53.354Z · LW(p) · GW(p)
Additional resources, thanks to Avery [LW · GW]:
- COT Scaling implies slower takeoff speeds [LW · GW] (Zoellner - 10 min)
- o1: A Technical Primer [LW · GW] (Hoogland - 20 min)
- Unpacking o1 and the Path to AGI (Brown - up to 8:38)
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters (Deepmind, Snell - 20 min to skim)
- Speculations on Test-Time Scaling (Rush - from 4:25 to 21:25, 17 min total)
↑ comment by Archimedes · 2025-01-14T04:24:15.999Z · LW(p) · GW(p)
Did you mean to link to my specific comment for the first link?
Replies from: ryankidd44↑ comment by Ryan Kidd (ryankidd44) · 2025-01-14T04:24:57.471Z · LW(p) · GW(p)
Ah, that's a mistake. Our bad.
comment by David Abecassis (david-abecassis) · 2025-01-14T02:35:24.106Z · LW(p) · GW(p)
Great post!
My own timelines shortened with the maturation of inference scaling, as previous to this we projected progress as a result of training continuing to scale plus an uncertainty about whether and how soon we'd see other algorithmic or scaffolding improvements. But now here we are with clear impacts from inference scaling, and that's worth an update.
I agree with most of your analysis in deployment overhang, except I'd eyeball the relative scale of training compute usage to inference compute usage as implying that we could still see speed as a major factor if a leading lab switches from utilizing its compute for development to inference, and this could still see us facing a large number of very fast AIs. Maybe this now requires the kind of compute you have access to as a lab or major government rather than a rogue AI or a terrorist group, but the former has been what I'm worried about for loss of control all along so this doesn't change my view of the risk. Also, as you point out, per-token inference costs are always falling rapidly.
comment by Josh You (scrafty) · 2025-01-15T15:52:57.046Z · LW(p) · GW(p)
In Holden Karnofsky's "AI Could Defeat All Of Us Combined" a plausible existential risk threat model is described, in which a swarm of human-level AIs outmanoeuvre humans due to AI's faster cognitive speeds and improved coordination, rather than qualitative superintelligence capabilities. This scenario is predicated on the belief that "once the first human-level AI system is created, whoever created it could use the same computing power it took to create it in order to run several hundred million copies for about a year each." If the first AGIs are as expensive to run as o3-high (costing ~$3k/task), this threat model seems much less plausible.
I wonder how different the reasoning paradigm is, actually, from the picture presented here. After all, running a huge number of AI copies in parallel is... scaling up test-time compute.
The overhang argument is a rough analogy anyway. I think you are invoking the intuition of replacing the AI equivalent of a very large group of typical humans with the AI equivalent of a small number of ponderous geniuses, but those analogies are going to be highly imperfect in practice.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-14T17:20:51.148Z · LW(p) · GW(p)
Going to link a previous comment of mine from a similar discussion: https://www.lesswrong.com/posts/FG54euEAesRkSZuJN/ryan_greenblatt-s-shortform?commentId=rNycG6oyuMDmnBaih [LW(p) · GW(p)] This comment addresses the point of: what happens after the AI gets strong enough to substantially accelerate algorithmic improvement (e.g. above 2x)? You can no longer assume that the trends will hold.
Some further thoughts: If you look at some of the CoT from models where we can see it, e.g. Deepseek-V3, the obvious conclusion is that these are not yet optimal paths towards solutions. Look at the token cost for o3 solving ARC-AGI. It was basically writing multiple novels worth of CoT to solve fairly simple puzzles. A human 'thinking out loud' and giving very detailed CoT would manage to solve those puzzles in well less than 0.1% that many tokens.
My take on this is that this means there is lots of room for improvement. The techniques haven't been "maxed out" yet. We are on the beginning of the steep part of the S-curve for this specific tech.
Replies from: kryjak, nathan-helm-burger↑ comment by jakub_krys (kryjak) · 2025-01-15T01:20:13.161Z · LW(p) · GW(p)
I had a similar reflection yesterday regarding these inference-time techniques (post-training, unhobbling, whatever you want to call it) being in the very early days. Would it be too much of a stretch to draw parallels here between how such unhobbling methods lead to an explosion of human capabilities over the past ~10000 years? The human DNA has undergone roughly the same number of 'gradient updates' (evolutionary cycles) as our predecessors from a few millenia ago. I see it as having an equivalent amount of training compute. Yet through an efficient use of tools, language, writing, coordination and similar, we have completely outdone what our ancestors were able to do.
There is a difference in that for us, these abilities arose naturally through evolution. We are now manually engineering them into AI systems. I would not be surprised to see a real capability explosion soon (much faster than what we are observing now) - not because of the continued scaling up of pre-training, but because of these post-training enhancements.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-31T18:19:10.621Z · LW(p) · GW(p)
Here's what I mean about being on the steep part of the S-curve: https://x.com/OfficialLoganK/status/1885374062098018319