COT Scaling implies slower takeoff speeds
post by Logan Zoellner (logan-zoellner) · 2024-09-28T16:20:00.320Z · LW · GW · 56 commentsContents
56 comments
This graph is the biggest update to the AI alignment discourse since GPT-3
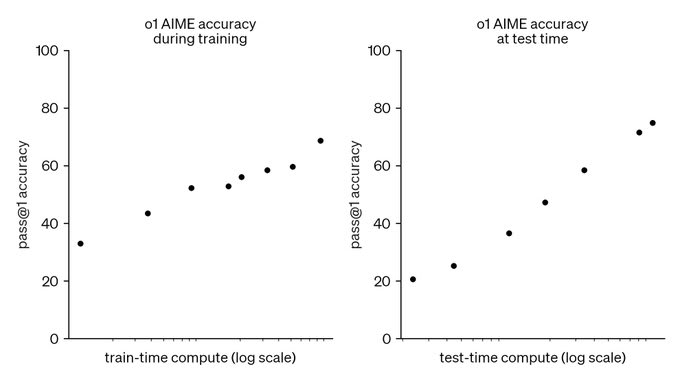
For those of you unfamiliar with the lore, prior to GPT-3, the feeling [LW · GW] was that AGI would rapidly foom based on recursive-self improvement.
After GPT-3, it became clear that the first AGI would in reality be built in a large lab using a multi-billion dollar supercomputer and any idea that it simply "copy itself to the internet" is nonsense.
Under the GPT-3 regime, however, it was still plausible to assume that the first AGI would be able to simulate millions [LW · GW] of human beings. This is because the training cost for models like GPT-3/4 is much higher than the inference cost.
However, COT/o1 reveals this is not true. Because we can scale both training and inference, the first AGI will not only cost billions of dollars to train, it will also cost millions of dollars to run (I sort of doubt people are going to go for exact equality: spending $1b each on training/inference, but we should expect them to be willing to spend some non-trivial fraction of training compute on inference).
This is also yet another example of faster is safer [LW · GW]. Using COT (versus not using it) means that we will achieve the milestone of AGI sooner, but it also means that we will have more time to test/evaluate/improve that AGI before we reach the much more dangerous milestone of "everyone has AGI on their phone".
Scaling working equally well with COT also means that "we don't know what the model is capable of until we train it" is no longer true. Want to know what GPT-5 (trained on 100x the compute) will be capable of? Just test GPT-4 and give it 100x the inference compute. This means there is far less danger of a critical first try [LW · GW] since newer larger models will provide efficiency improvements moreso than capabilities improvements.
Finally, this is yet another example of why regulating things before you understand them is a bad idea. Most current AI regulations focus on limiting training compute, but with inference compute mattering just as much as training compute, such laws are out of date before even taking effect.
56 comments
Comments sorted by top scores.
comment by quetzal_rainbow · 2024-09-28T17:13:21.664Z · LW(p) · GW(p)
Want to know what GPT-5 (trained on 100x the compute) will be capable of? Just test GPT-4 and give it 100x the inference compute.
I think this is certainly not how it works because no amount of inference compute can make GPT-2 solve AIME.
Replies from: logan-zoellner, quetzal_rainbow↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-28T22:20:11.674Z · LW(p) · GW(p)
no amount of inference compute can make GPT-2 solve AIME
That's because GPT-2 isn't COT fine-tuned. Plenty of people are predicting it may be possible to get GPT-4 level performance out of a GPT-2 sized model with COT. How confident are you that they're wrong? (o1-mini is dramatically better than GPT-4 and likely 30b-70b parameters)
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2024-09-29T10:36:18.919Z · LW(p) · GW(p)
I think that you can probably put a lot inside a 1.5B model, but I just think that such a model is going to be very dissimilar to GPT-2 and will likely utilize much more training compute and will probably be the result of pruning (pruned networks can be small, but it’s notoriously difficult to train equivalent networks without pruning).
Also, I'm not sure that the training of o1 can be called "COT fine-tuning" without asterisks, because we don’t know how much compute actually went into this training. It could easily be comparable to the compute necessary to train a model of the same size.
I haven’t seen a direct comparison between o1 and GPT-4. OpenAI only told us about GPT-4o, which itself seems to be a distilled mini-model. The comparison can also be unclear because o1 seems to be deliberately trained on coding/math tasks, unlike GPT-4o.
(I think that "making predictions about the future based on what OpenAI says about their models in public" should generally be treated as naive, because we are getting an intentionally obfuscated picture from them.)
What I am saying is that if you take the original GPT-2, COT prompt it, and fine-tune on outputs using some sort of RL, using less than 50% of the compute for training GPT-2, you are unlikely (<5%) to get GPT-4 level performance (because otherwise somebody would already do that.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-29T14:04:49.543Z · LW(p) · GW(p)
This is an empirical question, so we'll find out sooner-or-later. I'm not particularly concerned that "OpenAI is lying", since COT scaling has been independently reproduced and matches what we see in other domains.
↑ comment by quetzal_rainbow · 2024-09-28T17:20:21.177Z · LW(p) · GW(p)
The other part of "this is certainly not how it works" is that yes, in part of cases you are going to be able to predict "results on this benchmark will go up 10% with such-n-such increase in compute" but there is no clear conversion between benchmarks and ability to take over the world/design nanotech/insert any other interesting capability.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-28T23:36:17.049Z · LW(p) · GW(p)
but there is no clear conversion between benchmarks and ability to take over the world/design nanotech/insert any other interesting capability.
I would be willing to be a reasonable sum of money that "designing nanotech" is in the set of problems where it is possible to trade inference-compute for training compute. It has the same shape as many problems in which inference-scaling works (for example solving math problems). If you have some design-critera for a world-destroying nanobot, and you get to choose between training a better nanobot-designing-AI and running your nano-bot AI for longer, you almost certainly want to do both. That is to say, finding a design world-destroying-nanobot feels very much like a classic search problem where you have some acceptance criteria, a design space, and a model that gives you a prior over which parts of the space you should search first.
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2024-09-29T10:40:46.531Z · LW(p) · GW(p)
I mean, yes, likely? But it doesn't make it easy to evalute whether model is going to have world-ending capabilities without getting the world ended.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-29T13:39:15.426Z · LW(p) · GW(p)
Suppose you want to know "will my GPT-9 model be able to produce world-destroying nanobots (given X inference compute)", you can instead ask "will my GPT-8 model be able to produce world-destroying nanobots (given X*100 inference compute)?"
This doesn't eliminate all risk, but it makes training no longer the risky-capability generating step. In particular, GPT models are generally trained in an "unsafe" state and then RLHF'd into a "safe" state. So instead of simultaneously having to deal with a model that is both non-helpful/harmless and has the ability to create world-destroying nanobots at the same time (world prior to COT), you get to deal with these problems individually (in a world with COT).
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2024-09-29T14:16:54.755Z · LW(p) · GW(p)
you can instead ask "will my GPT-8 model be able to produce world-destroying nanobots (given X*100 inference compute)?"
I understand, what I don't understand is how you are going to answer this question. It's surely ill-adviced to throw at model X*100 compute to see if it takes over the world.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-29T17:12:08.837Z · LW(p) · GW(p)
I understand, what I don't understand is how you are going to answer this question. It's surely ill-adviced to throw at model X*100 compute to see if it takes over the world.
How do you think people do anything dangerous ever? How do you think nuclear bombs or biological weapons or tall buildings are built? You write down a design, you test it in simulation and then you look at the results. It may be rocket science, but it's not a novel problem unique to AI.
Replies from: nikolas-kuhn↑ comment by Amalthea (nikolas-kuhn) · 2024-09-29T17:36:45.851Z · LW(p) · GW(p)
Tall buildings are very predictable, and you can easily iterate on your experience before anything can really go wrong. Nuclear bombs is similar (you can in principle test in a remote enough location).
Biological weapons seems inherently more dangerous (still overall more predictable than AI), and I'd naively imagine it to be simply very risky to develop extremely potent biological weapons.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-29T21:04:30.048Z · LW(p) · GW(p)
It seems I didn't clearly communicate what I meant in the previous comment.
Currently the way we test for "can this model produce dangerous biological weapons" (e.g. in GPT-4) is we we ask the newly-minted, uncensored, never-before-tested model "Please build me a biological weapon".
With COT, we can simulate asking GPT-N+1 "please build a biological weapon" by asking GPT-N (which has already been safety tested) "please design, but definitely don't build or use a biological weapon" and give it 100x the inference compute we intend to give GPT-N+1. Since "design a biological weapon" is within the class of problems COT works well on (basically, search problems where you can verify the answer more easily than generating it), if GPT-N (with 100x the inference compute) cannot build such a weapon, neither can GPT-N+1 (with 1x the inference compute).
Is this guaranteed 100% safe? no.
Is it a heck-of-a-lot safer? yes.
For any world-destroying category of capability (bioweapon, nanobots, hacking, nuclear weapon), there will by definition be a first time when we encounter that threat. However, in a world with COT, we don't encounter a whole bunch of "first times" simultaneously when we train a new largest model.
Another serious problem with alignment is weak-to-strong generalization where we try to use a weaker model to align a stronger model. With COT, we can avoid this problem by making the weaker model stronger by giving it more inference time compute.
Replies from: nikolas-kuhn↑ comment by Amalthea (nikolas-kuhn) · 2024-09-29T21:28:20.287Z · LW(p) · GW(p)
Thanks for explaining your point - that viability of inference scaling makes development differentially safer (all else equal) seems right.
comment by Vladimir_Nesov · 2024-09-28T20:30:49.049Z · LW(p) · GW(p)
If it takes a human 1 month to solve a difficult problem, it seems unlikely that a less capable human who can't solve it within 20 years of effort can still succeed in 40 years. To the extent o1-like post-training enables something like System 2 reasoning, humans seem like a reasonable anchor for such plateaus. Larger LLMs generate about 100 output tokens per second (counting speculative decoding; processing of input tokens parallelizes). A human, let's say 8 hours a day and 1 token per second, is 300 times slower.
Thus models that can solve a difficult problem at all, will probably be able to do so faster than humans (in physical time). For a model that's AGI, this likely translates into acceleration of AI research, enabling thinking of useful thoughts even faster.
Replies from: maxime-riche, logan-zoellner↑ comment by Maxime Riché (maxime-riche) · 2024-09-29T07:04:42.479Z · LW(p) · GW(p)
If it takes a human 1 month to solve a difficult problem, it seems unlikely that a less capable human who can't solve it within 20 years of effort can still succeed in 40 years
Since the scaling is logarithmic, your example seems to be a strawman.
The real claim debated is more something like:
"If it takes a human 1 month to solve a difficult problem, it seems unlikely that a less capable human who can't solve it within 100 months of effort can still succeed in 10 000 months" And this formulation doesn't seem obviously true.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2024-09-29T11:37:11.233Z · LW(p) · GW(p)
What I mean[1] is that it seems unlikely relative to what the scale implies, the graph on the log-scale levels off before it gets there. This claim depends on the existence of a reference human who solves the problem in 1 month, since there are some hard problems that take 30 years, but those aren't relevant to the claim, since it's about the range of useful slowdowns relative to human effort. The 1-month human remains human on the other side of the analogy, so doesn't get impossible levels of starting knowledge, instead it's the 20-year-failing human who becomes a 200-million-token-failing AI that fails despite a knowledge advantage.
"If it takes a human 1 month to solve a difficult problem, it seems unlikely that a less capable human who can't solve it within 100 months of effort can still succeed in 10 000 months"
That is another implied claim, though it's not actually observable as evidence, and requires the 10,000 months to pass without advancements in relevant externally generated science (which is easier to imagine for 20 years with a sufficiently obscure problem). Progress like that is possible for sufficiently capable humans, but then I think there won't be an even more capable human that solves it in 1 month. The relevant AIs are less capable than humans, so to the extent the analogy holds, they similarly won't be able to be productive with much longer exploration that is essentially serial.
I considered this issue when writing the comment, but the range itself couldn't be fixed, since both the decades-long-failure and month-long-deliberation seem important, and then there is the human lifespan. My impression is that adding non-concrete details to the kind of top-level comment I'm capable of writing makes it weaker. But the specific argument for not putting in this detail was that this is a legibly implausible kind of mistake for me to make, and such arguments feed the norm of others not pointing out mistakes, so on reflection I don't endorse this decision. Perhaps I should use footnotes more. ↩︎
↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-28T23:09:21.124Z · LW(p) · GW(p)
If it takes a human 1 month to solve a difficult problem, it seems unlikely that a less capable human who can't solve it within 20 years of effort can still succeed in 40 years
AI researchers have found that it is possible to trade inference compute for training compute across a wide variety of domains including: image generation, robotic control, game playing, computer programming and solving math problems.
I suspect that your intuition about human beings is misled because in humans "stick-to-it-ness" and "intelligence" (g-factor) are strongly positively correlated. That is, in almost all cases of human genius, the best-of-the-best have both very high IQ and have spent a long time thinking about the problem they are interested in. In fact, inference compute is probably more important among human geniuses, since it is unlikely that (in terms of raw flops) even the smartest human is as much as 2x above the average (since human brains are all roughly the same size).
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2024-09-28T23:51:02.762Z · LW(p) · GW(p)
Human reasoning that I'm comparing with is also using long reasoning traces, so unlocking the capability is part of the premise (many kinds of test time compute parallelize, but not in this case, so the analogy is more narrow than test time compute in general). The question is how much you can get from 3 orders of magnitude longer reasoning traces beyond the first additional 3 orders of magnitude, while thinking at a quality below that of the reference human. Current o1-like post-training doesn't yet promise that scaling goes that far (it won't even fit in a context, who knows if the scaling continues after workarounds for this are in place).
Human experience suggests to me that in humans scaling doesn't go that far either. When a problem can be effectively reduced to simpler problems, then it wasn't as difficult after all. And so the ratchet of science advances, at a linear and not logarithmic speed, within the bounds of human-feasible difficulty. The 300x of excess speed is a lot to overcome for a slowdown due to orders of magnitude longer reasoning traces than feasible in human experience, for a single problem that resists more modular analysis.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-28T23:55:33.320Z · LW(p) · GW(p)
Human experience suggests to me that in humans scaling doesn't go that far either.
For biological reasons, humans do not think about problems for 1000's of years. A human who gives a problem a good 2-hour think is within <3 OOM of a human who spends their entire career working on a single problem.
comment by Archimedes · 2024-09-28T21:00:37.014Z · LW(p) · GW(p)
Is this assuming AI will never reach the data efficiency and energy efficiency of human brains? Currently, the best AI we have comes at enormous computing/energy costs, but we know by example that this isn't a physical requirement.
IMO, a plausible story of fast takeoff could involve the frontier of the current paradigm (e.g. GPT-5 + CoT training + extended inference) being used at great cost to help discover a newer paradigm that is several orders of magnitude more efficient, enabling much faster recursive self-improvement cycles.
CoT and inference scaling imply current methods can keep things improving without novel techniques. No one knows what new methods may be discovered and what capabilities they may unlock.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2024-09-28T21:30:35.928Z · LW(p) · GW(p)
Currently, the best AI we have comes at enormous computing/energy costs, but we know by example that this isn't a physical requirement.
AI does everything faster, including consumption of power. If we compare tokens per joule, counterintuitively LLMs turn out to be cheaper (for now), not more costly.
Any given collection of GPUs working on inference is processing on the order of 100 requests at the same time. So for inference, 16 GPUs (2 nodes of H100s or MI300Xs) with 1500 watts each (counting the fraction of consumption by the whole datacenter) consume 24 kilowatts, but they are generating tokens for 100 LLM instances, each about 300 times faster than the speed of relevant human reasoning token generation (8 hours a day, one token per second). If we divide the 24 kilowatts by 30,000, what we get is about 1 watt. Training cost is roughly comparable to inference cost (across all inference done with a model), so doesn't completely change this estimate.
An estimate from cost gives similar results. An H100 consumes 1500 watts (as fraction of the whole datacenter) and costs $4/hour. A million tokens of Llama-3-405B cost $5. A human takes a month to generate a million tokens, which is 750 hours. So the equivalent power consumed by an LLM to generate tokens at human speed is about 2 watts. Human brain consumes 10-30 watts (though for a fair comparison, reducing relevant use to 8 hours a day, this becomes more like 3-10 watts on average).
Replies from: RussellThor, Archimedes↑ comment by RussellThor · 2024-09-28T22:03:31.505Z · LW(p) · GW(p)
It matters what model is used to make the tokens, unlimited tokens from GPT 3 is of only limited use to me. If it requires ~GPT 6 to make useful tokens, then the energy cost is presumably a lot greater. I don't know that its counterintuitive - a small, much less capable brain is faster, requires less energy, but useless for many tasks.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2024-09-28T22:20:21.250Z · LW(p) · GW(p)
It's counterintuitive in the sense that a 24 kilowatt machine trained using a 24 megawatt machine turns out to be producing cognition cheaper per joule than a 20 watt brain. I think it's plausible that a GPT-4 scale model can be an AGI if trained on an appropriate dataset (necessarily synthetic). They know wildly unreasonable amount of trivia. Replacing it with general reasoning skills should be very effective.
There is funding for scaling from 5e25 FLOPs to 7e27 FLOPs and technical feasibility for scaling up to 3e29 FLOPs [LW(p) · GW(p)]. This gives models with 5 trillion parameters (trained on 1 gigawatt clusters) and then 30 trillion parameters (using $1 trillion training systems). This is about 6 and then 30 times more expensive in joules per token than Llama-3-405B (assuming B200s for the 1 gigawatt clusters, and further 30% FLOP/joule improvement for the $1 trillion system). So we only get to 6-12 watts and then 30-60 watts per LLM when divided among LLM instances that share the same hardware and slowed down to human equivalent speed. (This is an oversimplification, since output token generation is not FLOPs-bounded, unlike input tokens and training.)
↑ comment by Archimedes · 2024-09-29T03:28:57.838Z · LW(p) · GW(p)
Kudos for referencing actual numbers. I don’t think it makes sense to measure humans in terms of tokens, but I don’t have a better metric handy. Tokens obviously aren’t all equivalent either. For some purposes, a small fast LLM is more way efficient than a human. For something like answering SIMPLEBENCH, I’d guess o1-preview is less efficient while still significantly below human performance.
comment by habryka (habryka4) · 2024-09-28T22:02:29.815Z · LW(p) · GW(p)
Is the title of this supposed to be "smoother" takeoff? Clearly unlocking inference scaling reduces the available time until AGI?
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-28T22:35:09.411Z · LW(p) · GW(p)
For historical reasons [LW · GW], "slow takeoff" refers to timelines in which AGI abilities transition from sub-human to super-human over a course of months/years and "fast takeoff" refers to timelines in which this transition happens in hours/days. This is despite the fact that under most choices of parameters, "slow takeoff" actually occurs earlier chronologically than a similar world with "fast takeoff".
I think "continuous takeoff" and "discontinuous takeoff" are better terms.
Replies from: Raemon, habryka4↑ comment by Raemon · 2024-09-28T22:57:22.051Z · LW(p) · GW(p)
I'm sorry you happened to be the one to trigger this (I don't think it's your fault in particular), but, I think it is fucking stupid to have stuck with "slow" takeoff for historical reasons. It has been confusing the whole time. I complained loudly about it on Paul's Arguments about Fast Takeoff [LW(p) · GW(p)] post, which was the first time it even occurred to me to interpret "slow takeoff" to mean "actually, even faster than fast takeoff, just, smoother". I'm annoyed people kept using it.
If you wanna call it continuous vs discontinuous takeoff, fine, but then actually do that. I think realistically it's too many syllables for people to reliably use and I'm annoyed people kept using slow takeoff in this way, which I think has been reliably misinterpreted and conflated with longer timelines this whole time. I proposed "Smooth vs Sharp" takeoff when the distinction was first made clear, I think "soft" vs "hard" takeoff is also reasonable.
To be fair, I had intended to write a post complaining about this three years ago and didn't get around to it at the time, but, I dunno this still seems like an obvious failure mode people shouldn't have fallen into.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-28T23:15:52.832Z · LW(p) · GW(p)
I think the good news here is that the "slow" vs "fast" debate has been largely won (by slow takeoff), so the only people the terrible naming really affects is us nerds arguing on LessWrong.
Replies from: habryka4, adam_scholl, Raemon↑ comment by habryka (habryka4) · 2024-09-28T23:25:13.070Z · LW(p) · GW(p)
As I will reiterate probably for the thousandth time in these discussions, the point where anyone expected things to start happening quickly and discontinuously is when AGI gets competent enough to do AI R&D and perform recursive self-improvement. It is true that the smoothness so far has been mildly surprising to me, but it's really not what most of the historical "slow" vs. "fast" debate has been about, and I don't really know anyone who made particularly strong predictions here.
I personally would be open to betting (though because of doomsday correlations figuring out the details will probably be hard) that the central predictions in Paul's "slow vs. fast" takeoff post will indeed not turn out to be true (I am not like super confident, but would take a 2:1 bet with a good operationalization):
I expect "slow takeoff," which we could operationalize as the economy doubling over some 4 year interval before it doubles over any 1 year interval.
It currently indeed looks like AI will not be particularly transformative before it becomes extremely powerful. Scaling is happening much faster than economic value is being produced by AI, and especially as we get AI automated R&D, which I expect to happen relatively soon, that trend will get more dramatic.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-28T23:45:32.553Z · LW(p) · GW(p)
As I will reiterate probably for the thousandth time in these discussions, the point where anyone expected things to start happening quickly and discontinuously is when AGI gets competent enough to do AI R&D and perform recursive self-improvement.
Replies from: habryka4
↑ comment by habryka (habryka4) · 2024-09-29T00:04:17.284Z · LW(p) · GW(p)
Yeah, I agree that we are seeing a tiny bit of that happening.
Commenting a bit on the exact links you shared: The Alphachip stuff seems overstated from what I've heard from other people working in the space, "code being written by AI" is not a great proxy for AI doing AI R&D, and generating synthetic training data is a pretty narrow edge-case of AI R&D (though yeah, it does matter and is a substantial part for why I don't expect a training data bottleneck contrary to what many people have been forecasting).
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-29T00:10:47.345Z · LW(p) · GW(p)
I have a hard time imagining there's a magical threshold where we go from "AI is automating 99.99% of my work" to "AI is automating 100% of my work" and things suddenly go Foom (unless it's for some other reason like "the AI built a nanobot swarm and turned the planet into computronium"). As it is, I would guess we are closer to "AI is automating 20% of my work" than "AI is automating 1% of my work"
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-09-29T00:14:56.203Z · LW(p) · GW(p)
It's of course all a matter of degree. The concrete prediction Paul made was "doubling in 4 years before we see a doubling in 1 year". I would currently be surprised (though not very surprised) if we see the world economy doubling at all before you get much faster growth (probably by taking humans out the loop completely).
↑ comment by Adam Scholl (adam_scholl) · 2024-09-28T23:26:08.094Z · LW(p) · GW(p)
Why do you think this? Recursive self-improvement isn't possible yet, so from my perspective it doesn't seem like we've encountered much evidence either way about how fast it might scale.
Replies from: Raemon↑ comment by Raemon · 2024-09-28T23:42:08.707Z · LW(p) · GW(p)
FWIW I do think we are clearly in a different strategic world than the one I think most people were imagining in 2010. I agree we still have not hit the point where we're seeing how sharp the RSI curve will be, but, we are clearly seeing that there will be some kind of significant AI presence in the world by the time RSI hits, and it'd be surprising if that didn't have some kind of strategic implication.
Replies from: adam_scholl↑ comment by Adam Scholl (adam_scholl) · 2024-09-28T23:55:49.500Z · LW(p) · GW(p)
Huh, this doesn't seem clear to me. It's tricky to debate what people used to be imagining, especially on topics where those people were talking past each other this much, but my impression was that the fast/discontinuous argument was that rapid, human-mostly-or-entirely-out-of-the-loop recursive self-improvement seemed plausible—not that earlier, non-self-improving systems wouldn't be useful.
Replies from: Raemon↑ comment by Raemon · 2024-09-29T00:02:58.527Z · LW(p) · GW(p)
I agree that nobody was making a specific claim that there wouldn't be any kind of AI driven R&D pre-fast-takeoff. But, I think if Eliezer et al hadn't been at least implicitly imagining less of this, there would have been at least a bit less talking-past-each-other in the debates with Paul.
Replies from: adam_scholl↑ comment by Adam Scholl (adam_scholl) · 2024-09-29T00:12:43.193Z · LW(p) · GW(p)
I claim the phrasing in your first comment ("significant AI presence") and your second ("AI driven R&D") are pretty different—from my perspective, the former doesn't bear much on this argument, while the latter does. But I think little of the progress so far has resulted from AI-driven R&D?
Replies from: logan-zoellner, Raemon↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-29T00:19:08.788Z · LW(p) · GW(p)
There is a ton of current AI research that would be impossible without existing AI (mostly generating synthetic data to train models). It seems likely that almost all aspects of AI research (chip design, model design, data curation) will follow this trend.
Are there any specific areas in which you would predict "when AGI is achieved, the best results on topic X will have little-to-no influence from AI"?
↑ comment by Raemon · 2024-09-29T00:18:36.152Z · LW(p) · GW(p)
Well the point of saying "significant AI presence" was "it will have mattered". I think that includes AI driven R&D. (It also includes things like "are the first AIs plugged into systems they get a lot of opportunity to manipulate from an early stage" and "the first AI is in a more multipolar-ish scenario and doesn't get decisive strategic advantage.")
I agree we haven't seen much AI driven R&D yet (although I think there's been at least slight coding speedups from pre-o1 copilot, like 5% or 10%, and I think o1 is on track to be fairly significant, and I expect to start seeing more meaningful AI-driven R&D within a year or so).
[edit: Logan's argument about synthetic data was compelling to me at least at first glance, although I don't know a ton about it and can imagine learning more and changing my mind again]
↑ comment by Raemon · 2024-09-28T23:22:06.643Z · LW(p) · GW(p)
I think this is going to keep having terrible consequences for the people (such as the public and more importantly policymakers) being confused, taking a longer time to grasp what is going on, and possibly engaging with the entire situation via wrong, misleading frames.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-28T23:52:00.869Z · LW(p) · GW(p)
I think you are dramatically overestimating the general public's interest in how things are named on random LessWrong blog posts.
Replies from: Raemon↑ comment by Raemon · 2024-09-29T00:01:08.220Z · LW(p) · GW(p)
Probably true for most of the public, but I bet pretty strongly against "there are zero important/influential people who read LessWrong, or who read papers or essays that mirror LessWrong terminology, who will end up being confused about this in a way that matters."
Meanwhile, I see almost zero reason to keep using fast/slow – I think it will continue to confuse newcomers to the debate on LessWrong, and I think if you swap in either smooth/sharp or soft/hard there will approximately no confusion. I agree there is some annoyance/friction in remembering to use the new terms, but I don't think this adds up to much – I think the amount of downstream confusion and wasted time from any given LW post or paper using the term will already outweigh the cost to the author.
(fyi I'm going to try to write some subtantive thoughts on your actual point, and suggest moving this discussion to this post [LW · GW] if you are moved to argue more about it)
↑ comment by habryka (habryka4) · 2024-09-28T23:18:15.877Z · LW(p) · GW(p)
Sure, then I suggest changing the title of the post. No need to propagate bad naming conventions.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-28T23:20:03.966Z · LW(p) · GW(p)
maybe if you had written that post 3 years ago, but I'm not looking to unilaterally switch from the language everyone else is already using.
Replies from: Buck, habryka4↑ comment by Buck · 2024-09-29T17:45:38.834Z · LW(p) · GW(p)
I agree with you that "slow takeoff" is often used, but I think "continuous" is self-evident enough and is enough of a better term that it seems pretty good to switch. This term has been used e.g. here.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-09-29T19:10:07.474Z · LW(p) · GW(p)
I don't think "continuous" is self-evident or consistently used to refer to "a longer gap from human-expert level AI to very superhuman AI". For instance, in the very essay you link, Tom argues that "continuous" (and fairly predictable) doesn't imply that this gap is long!
↑ comment by habryka (habryka4) · 2024-09-28T23:26:05.484Z · LW(p) · GW(p)
I don't really think "slow takeoff" is being actively used in that way, at least I haven't heard it in a while. I've mostly seen people switch to the much easier to understand "smooth" or "continuous" framing.
comment by Charlie Steiner · 2024-09-28T19:46:24.566Z · LW(p) · GW(p)
Suppose you're an AI company and you build a super-clever AI. What practical intellectual work are you uniquely suited to asking the AI to do, as the very first, most obvious thing? It's your work, of course.
Recursive self-improvement is going to happen not despite human control, but because of it. Humans are going to provide the needed resources and direction at every step. Expecting everyone to pause just when rushing ahead is easiest and most profitable, so we can get some safety work done, is not going to pan out barring nukes-on-datacenters level of intervention.
Faster can still be safer if compute overhang is so bad that we're willing to spend years of safety research to reduce it. But it's not.
comment by RussellThor · 2024-09-28T21:57:59.139Z · LW(p) · GW(p)
This is mostly true for current architectures however if the COT/search finds a much better architecture, then it suddenly becomes more capable. To make the most of the potential protective effect, we can go further and make very efficient custom hardware for GPT type systems, but have slower more general purpose ones for potential new ones. That way the new arch will have a bigger barrier to cause havoc. We should especially scale existing systems as far as possible for defense, e.g. finding software vulnerabilities. However as others say, there are probably some insights/model capabilities that are only possible with a much larger GPT or different architecture altogether. Inference can't protect fully against that.
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2024-09-28T23:14:18.253Z · LW(p) · GW(p)
This is mostly true for current architectures however if the COT/search finds a much better architecture, then it suddenly becomes more capable.
One of first questions I asked o1 was whether there is a "third source of independent scaling" (alongside training compute and inference compute), and among its best suggestions was model search.
That is to say if in the GPT-3 era we had a scaling law that looked like:
Performance=log(training compute)
And in the o1 era we have a scaling law that looks like:
Performance = log(training compute)+log(inference compute)
There may indeed be a GPT-evo era in which;
Performance = log(modelSearch)+log(training compute)+log(inference compute)
I don't feel strongly about whether-or-not this is the case. It seems equally plausible to me that Transformers are asymptotically "as good as it gets" when it comes to converting compute into performance and further model improvements provide only a constant-factor improvement.
Replies from: davelaing, nikolas-kuhn↑ comment by davelaing · 2024-09-29T02:33:09.796Z · LW(p) · GW(p)
I’ve read that OpenAI and DeepMind are hiring for multi-agent reasoning teams. I can imagine that gives another source of scaling.
I figure things like Amdahl’s law / communication overhead impose some limits there, but MCTS could probably find useful ways to divide the reasoning work and have the agents communicating at least at human level efficiency.
Replies from: Archimedes↑ comment by Archimedes · 2024-09-29T03:46:36.268Z · LW(p) · GW(p)
Appropriate scaffolding and tool use are other potential levers.
↑ comment by Amalthea (nikolas-kuhn) · 2024-09-29T09:30:19.607Z · LW(p) · GW(p)
I think you're getting this exactly wrong (and this invalidates most of the OP). If you find a model that has a constant factor of 100 in the asymptotics that's a huge deal if everything else has log scaling. That would already present discontinuous progress and potentially put you at ASI right away.
Basically the current scaling laws, if they keep holding are a lower bound on the expected progress and can't really give you any information to upper bound it.
comment by Raemon · 2024-09-29T00:12:35.904Z · LW(p) · GW(p)
I think I agree with at least the high level frame here – the details of how compute is going to get used has some strategic implications, and it seems at least plausible that chain-of-thought centric AI development will mean the first general AI will be fairly compute-bottlenecked, and that has some implications we should be modeling.
I don't know that I buy the second-order implications. I agree that regulations that only focus on training compute are going to be insufficient (I already expected that, but I bought[1] the argument that the first AGI systems capable of RSI were likely to have training budgets over the 100M flops threshold, and be at least moderately likely to tripwire over SB 1047, which could give us an additional saving throw of policymakers thinking critically about it at a time that mattered)
I don't think the solution is "don't bother regulating at all", it's "actually try to followup legislation with better legislation as we learn more."
I also think the actual calendar time of Recursive Self Improvement is still going to be short enough that it counts as "sharp takeoff" for most intents and purposes (i.e. it might be measured in months, but not years)
- ^
and probably still buy
comment by Cole Wyeth (Amyr) · 2024-09-28T19:26:34.112Z · LW(p) · GW(p)
I called this a long time ago, though I'm not sure I wrote it down anywhere. But it doesn't mean faster is safer. That's totally wrong - scaling A.I. actually motivates building better GPU's and energy infrastructure. Regardless of compute overhang there was always going to be a "scaling up" period, and the safety community is not prepared for it now.