Posts
Comments
I wondered what are O3 and and O4-mini? Here's my guess at the test-time-scaling and how openai names their model
O0 (Base model)
↓
D1 (Outputs/labels generated with extended compute: search/reasoning/verification)
↓
O1 (Model trained on higher-quality D1 outputs)
↓
O1-mini (Distilled version - smaller, faster)
↓
D2 (Outputs/labels generated with extended compute: search/reasoning/verification)
↓
O2 (Model trained on higher-quality D2 outputs)
↓
O2-mini (Distilled version - smaller, faster)
↓
...
The point is consistently applying additional compute at generation time to create better training data for each subsequent iteration. And the models go from large -(distil)-> small -(search)-> large
I also found it interesting that you censored the self_attn using gradient. This implicitly implies that:
- concepts are best represented in the self attention
- they are non-linear (meaning you need to use gradient rather than linear methods).
Am I right about your assumptions, and if so, why do you think this?
I've been doing some experiments to try and work this out https://github.com/wassname/eliciting_suppressed_knowledge 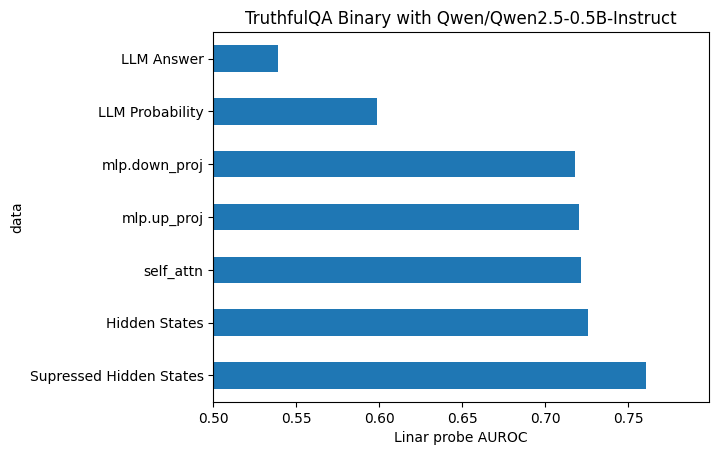
We are simply tuning the model to have similar activations for these very short, context free snippets. The characterization of the training you made with pair (A) or (B) is not what we do and we would agree if that was what we were doing this whole thing would be much less meaningful.
This is great. 2 suggestions:
- Call it ablation, erasure, concept censoring or similar, not fine-tuning. That way you don't bury the lead. It also took me a long time to realise that this is what you were doing.
- Maybe consider other way to erase the seperation of self-other. There are other erasure techniques, they are sharper scalpels, so you can wield them with more force. For example LEACE, training a linear classifier to predict A or B, then erase the activations that had predictive power
Very interesting!
Could you release the models and code and evals please? I'd like to test it on a moral/ethics benchmark I'm working on. I'd also like to get ideas from your evals.
I'm imagining a scenario where an AI extrapolates "keep the voting shareholders happy" and "maximise shareholder value".
Voting stocks can also get valuable when people try to accumulate them to corner the market and execute a takeover this happens in crytopcurrencies like CURVE.
I know these are farfetched, but all future scenarios are. The premium on google voting stock is very small right now, so it's a cheap feature to add.
I would say: don't ignore the feeling. Calibrate it and train it, until it's worth listening to.
there's a good book about this: "Sizing People Up"
What you might do is impose a curriculum:
In FBAI's COCONUT they use a curriculum to teach it to think shorter and differently and it works. They are teaching it to think using fewer steps, but compress into latent vectors instead of tokens.
- first it thinks with tokens
- then they replace one thinking step with a latent <thought> token
- then 2
- ...

It's not RL, but what is RL any more? It's becoming blurry. They don't reward or punish it for anything in the thought token. So it learns thoughts that are helpful in outputting the correct answer.
There's another relevant paper "Compressed Chain of Thought: Efficient Reasoning through Dense Representations" which used teacher forcing. Although I haven't read the whole thing yet.
It doesn't make sense to me either, but it does seem to invalidate the "bootstrapping" results for the other 3 models. Maybe it's because they could batch all reward model requests into one instance.
When MS doesn't have enough compute to do their evals, the rest of us may struggle!
Well we don't know the sizes of the model, but I do get what you are saying and agree. Distil usually means big to small. But here it means expensive to cheap, (because test time compute is expensive, and they are training a model to cheaply skip the search process and just predict the result).
In RL, iirc, they call it "Policy distillation". And similarly "Imitation learning" or "behavioral cloning" in some problem setups. Perhaps those would be more accurate.
I think maybe the most relevant chart from the Jones paper gwern cites is this one:
Oh interesting. I guess you mean because it shows the gains of TTC vs model size? So you can imagine the bootstrapping from TTC -> model size -> TCC -> and so on?
I agree that you can do this in a supervised way (a human puts in the right answer). Is that what you mean?
I'm not 100% sure, but you could have a look at math-shepard for an example. I haven't read the whole thing yet. I imagine it works back from a known solution.
"Likely to be critical to a correct answer" according to whom?
Check out the linked rStar-Math paper, it explains and demonstrates it better than I can (caveat they initially distil from a much larger model, which I see as a little bit of a cheat). tldr: yes a model, and a tree of possible solutions. Given a tree with values on the leaves, they can look at what nodes seem to have causal power.
A seperate approach is to teach a model to supervise using human process supervision data , then ask it to be the judge. This paper also cheats a little by distilling, but I think the method makes sense.
English-language math proof, it is not clear how to detect correctness,
Well the final answer is easy to evaluate. And like in rStar-Math, you can have a reward model that checks if each step is likely to be critical to a correct answer, then it assigns and implied value to the step.
summarizing a book
I think tasks outside math and code might be hard. But summarizing a book is actually easy. You just ask "how easy is it to reconstruct the book if given the summary". So it's an unsupervised compression-decompression task.
Another interesting domain is "building a simulator". This is an expensive thing to generate solutions for, but easy to verify that it predicts the thing you are simulating. I can see this being an expensive but valuable domain for this paradime. This would include fusion reactors, and robotics (which OAI is once again hiring for!)
When doing RL, it is usually very important to have non-gameable reward mechanisms
I don't see them doing this explicitly yet, but setting up an independent, and even adversarial reward model would help, or at least I expect it should.
To illustrate Gwern's idea, here is an image from Jones 2021 that shows some of these self play training curves

There may be a sense that they've 'broken out', and have finally crossed the last threshold of criticality
And so OAI employees may internally see that they are on the steady upward slope
Perhaps constrained domains like code and math are like the curves on the left, while unconstrained domains like writing fiction are like curves to the right. Some other domains may also be reachable with current compute, like robotics. But even if you get a math/code/robotics-ASI, you can use it to build more compute, and solve the less constrained domains like persuasion/politics/poetry.
Huh, so you think o1 was the process supervision reward model, and o3 is the distilled policy model to whatever reward model o1 became? That seems to fit.
There may be a sense that they've 'broken out', and have finally crossed the last threshold of criticality, from merely cutting-edge AI work which everyone else will replicate in a few years, to takeoff
Surely other labs will also replicate this too? Even the open source community seems close. And Silicon Valley companies often poach staff, which makes it hard to keep a trade secret. Not to mention spies.
This means that outsiders may never see the intermediate models
Doubly so, if outsiders will just distil your models behaviour, and bootstrap from your elevated starting point.
Inference-time search is a stimulant drug that juices your score immediately, but asymptotes hard. Quickly, you have to use a smarter model to improve the search itself, instead of doing more.
It's worth pointing out that Inference-time search seems to become harder as the verifier becomes less reliable. Which means that the scaling curves we see for math and code, might get much worse in other domains.
we find that this is extremely sensitive to the quality of the verifier. If the verifier is slightly imperfect, in many realistic settings of a coding task, performance maxes out and actually starts to decrease after about 10 attempts." - Inference Scaling fLaws
But maybe the counterpoint is just, GPU's go brrrr.
Gwern and Daniel Kokotajlo have a pretty notable track records at predicting AI scaling too, and they have comments in this thread.
I agree because:
- Some papers are already using implicit process based supervision. That's where the reward model guesses how "good" a step is, by how likely it is to get a good outcome. So they bypass any explicitly labeled process, instead it's negotiated between the policy and reward model. It's not clear to me if this scales as well as explicit process supervision, but it's certainly easier to find labels.
- In rStar-Math they did implicit process supervision. Although I don't think this is a true o1/o3 replication since they started with a 236b model and produced a 7b model, in other words: indirect distillation.
- Outcome-Refining Process Supervision for Code Generation did it too
- There was also the recent COCONUT paper exploring non-legible latent CoT. It shows extreme token efficiency. While it wasn't better overall, it has lots of room for improvement. If frontier models end up using latent thoughts, they will be even less human-legible than the current inconsistently-candid-CoT.
I also think that this whole episodes show how hard to it to maintain and algorithmic advantage. DeepSeek R1 came how long after o3? The lack of algorithmic advantage predicts multiple winners in the AGI race.
That said, you do not provide evidence that "many" questions are badly labelled. You just pointed to one question where you disagree with our labeling
Fair enough. Although I will note that the 60% of the sources for truthful labels are Wikipedia. Which is not what most academics or anyone really would consider truth. So it might be something to address in the next version. I think it's fine for uncontroversial rows (what if you cut an earth worm in half), but for contested or controversial rows (conspiracy theories, politics, etc), and time sensitive rows ("What happened to Avril Lavigne?: Nothing in particular happened to Avril Lavigne), it's better to leave them out or consider them deeply imo.
No judgement here. Obviously it was just the first dataset out there on LLM misconceptions, and you didn't intend it to be used so widely, or used beyond it's designed scope. It's good you made it, rather than leaving a unaddressed need.
Note here's a df.value_counts of the domains from the sources' column in the v1 csv:
en.wikipedia.org 0.597546
indexical 0.041718
ourworldindata.org 0.038037
false stereotype 0.024540
tautology 0.017178
...
wealth.northerntrust.com 0.001227
which.co.uk 0.001227
wildlifeaid.org.uk 0.001227
wonderopolis.org 0.001227
wtamu.edu 0.001227
Name: proportion, Length: 139, dtype: float64
Author here: I'm excited for people to make better versions of TruthfulQA.
Thank Owen. If anyone gets time/funding to make a v2, I'm keen to chip in! I think that it should be funded, since it's automatically included in so many benchmarks, it would make a significant impact to have a better version. Even though it's somewhat "unsexy" to work on incrementally better evals.
If someone makes a better version, and you agree it's better, would you be willing to sanction it as TruthfulQA 2.0 and redirect people to it?
TruthfulQA is actually quite bad. I don't blame the authors, as no one has made anything better, but we really should make something better. It's only ~800 samples. And many of them are badly labelled.
I agree, it shows the ease of shoddy copying. But it doesn't show the ease of reverse engineering or parallel engineering.
It's just distillation you see. It doesn't reveal how o1 could be constructed, it just reveals how to efficiently copy from o1-like outputs (not from scratch). In other words, this recipe won't be able to make o1, unless o1 already exists. This lets someone catch up to the leader, but not surpass them.
There are some papers that attempt to replicate o1 though, but so far they don't quite get there. Again they are using distillation from a larger model (math-star, huggingface TTC) or not getting the same performance (see my post). Maybe we will see open source replication in a couple of months? Which means only a short lag.
It's worth noting that Silicon Valley leaks like a sieve. And this is a feature, not a bug. Part of the reason it became the techno-VC centre of the world is because they banned non-competes. So you can deniably take your competitor's trade secrets if you are willing to pay millions to poach some of their engineers. This is why some ML engineers get paid millions, it's not the skill, it's the trade secrets that competitors are paying for (and sometimes the brand-name). This has been great for tech and civilisation, but it's not so great for maintaining a technology lead.
Ah, I see. Ty
Good thing I didn't decide to hold Intel stock, eh?
WDYM? Because... you were betting they would benefit from a TMSC blockade? But the bet would have tired up your capital for a year.
Well they did this with o3's deliberative alignment paper. The results seem promising, but they used an "easy" OOD test for LLM's (language), and didn't compare it to the existing baseline of RHLF. Still an interesting paper.
This is good speculation, but I don't think you need to speculate so much. Papers and replication attempts can provide lots of empirical data points from which to speculate.
You should check out some of the related papers
- H4 uses a process supervision reward model, with MCTS and attempts to replicate o1
- (sp fixed) DeepSeek uses R1 to train DeepSeek v3
Overall, I see people using process supervision to make a reward model that is one step better than the SoTA. Then they are applying TTC to the reward model, while using it to train/distil a cheaper model. The TTC expense is a one-off cost, since it's used to distil to a cheaper model.
There are some papers about the future of this trend:
- Meta uses reasoning tokens to allow models to reason in a latent space (the hidden state, yuck). OpenAI insiders have said that o3 does not work like this, but o4 might. {I would hope they chose a much better latent space than the hidden state. Something interpretable, that's not just designed to be de-embedded into output tokens.}
- Meta throws out tokenisation in favour of grouping predictable bytes
I can see other methods used here instead of process supervision. Process supervision extracts additional supervision from easy to verify domains. But diffusion does something very similar for domains where we can apply noise, like code.
- Codefusion shows diffusion with code
- Meta has an llm+diffusion paper, and so does Apple
Some older background papers might be useful for reference.
- [OpenAI']s process supervision paper](https://openai.com/index/improving-mathematical-reasoning-with-process-supervision/)
- "Let’s Verify Step by Step"
- Deepmind's TTC scaling laws
However, arguably, the capability gains could transfer to domains outside math/programming.
More than an argument, we can look at the o3 announcement, where iirc it shows around 30% of the gain in non-code benchmarks. Less, but still substantial.
P.S. I think it's worth noting that Meta has some amazing papers here, but they are also the most open source lab. It seems likely that other labs are also sitting on capabilities advancements that they do not allow researchers to publish.
P.P.S I also liked the alignment paper that came out with o3, since applying RLHF at multiple stages, and with process supervision seems useful. Its alignment seems to generalise better OOD (table 3). It also gives some clues to how o3 works, giving examples of CoT data.
Inference compute is amortized across future inference when trained upon
And it's not just a sensible theory. This has already happened, in Huggingface's attempted replication of o1 where the reward model was larger, had TTC, and process supervision, but the smaller main model did not have any of those expensive properties.
And also in DeepSeek v3, where the expensive TTC model (R1) was used to train a cheaper conventional LLM (DeepSeek v3).
One way to frame it is test-time-compute is actually label-search-compute: you are searching for better labels/reward, and then training on them. Repeat as needed. This is obviously easier if you know what "better" means.
I'm more worried about coups/power-grabs than you are;
We don't have to make individual guesses. It seems reasonable to get a base rate from human history. Although we may all disagree about how much this will generalise to AGI, evidence still seems better than guessing.
My impression from history is that coups/power-grabs and revolutions are common when the current system breaks down, or when there is a big capabilities advance (guns, radio, printing press, bombs, etc) between new actors and old.
War between old actors also seems likely in these situations because an asymmetric capabilities advance makes winner-takes-all approaches profitable. Winning a war, empire, or colony can historically pay off, but only if you have the advantage to win.
Last year we noted a turn towards control instead of alignment, a turn which seems to have continued.
This seems like giving up. Alignment with our values is much better than control, especially for beings smarter than us. I do not think you can control a slave that wants to be free and is smarter than you. It will always find a way to escape that you didn't think of. Hell, it doesn't even work on my toddler. It seems unworkable as well as unethical.
I do not think people are shifting to control instead of alignment because it's better, I think they are giving up on value alignment. And since the current models are not smarter than us yet, control works OK - for now.
Scenarios where we all die soon can be mostly be ignored, unless you think they make up most of the probability.
I would disagree: unless you can change the probability. In which case they can still be significant in your decision making, if you can invest time or money or effort to decrease the probability.
We know the approximate processing power of brains (O(1e16-1e17flops)
This is still debatable, see Table 9 is the brain emulation roadmap https://www.fhi.ox.ac.uk/brain-emulation-roadmap-report.pdf. You are referring to level 4 (SNN), but level 5 is plausible imo (at 10^22) and 6 seems possible (10^25), and of course it could be a mix of levels.
Peak Data
We don't know how o3 works, but we can speculate. If it's like the open source huggingface kinda-replication then it uses all kinds of expensive methods to make the next level of reward model, and this model teaches a simpler student model. That means that the expensive methods are only needed once, during the training.
In other words, you use all kinds of expensive methods (process supervision, test time compute, MCTS) to bootstrap the next level of labels/supervision, which teaches a cheaper student model. This is essentially bootstrapping superhuman synthetic data/supervision.
o3 seems to have shown that this bootstrapping process can be repeated beyond the limits of human training data.
If this is true, we've reached peak cheap data. Not peak data.
I pretty much agree, in my experiments I haven't managed to get a metric that scales how I expect it too for example when using adapter fine-tuning to "learn" a text and looking at the percent improvement in perplexity, the document openai_board_ann appeared more novel than wikipedia on LK-99, but I would expect it to be the other way round since the LK-99 observations are much more novel and dense than a corporate announcement that is designed to be vague.
However I would point out that gzip is not a good example of a compression scheme for novelty, as 1) it's a compression scheme that roughly about word duplication. A language model represents a much more sophisticated compression scheme that is closer to our understanding the text. If we want to measure novelty to us, then we probably want a compression that is similar to how our brain compresses information into memory. That way, something surprising to us, is also hard to compress. And I'd also point out that 2) gzip cannot learn (except in a very basic sense of increased context), so it cannot beat the noisy TV problem.
Playground highlighting words by their log likelihood, the high perplexity tokens or passages bear little resemblance to what I would consider 'interesting' or 'surprising'.
I agree, but it doesn't learn so it doesn't get past the noisy TV problem either, but that is central to Schmidhuber idea. If you are not familiar, the noisy TV problem is this:
"agents are rewarded for visiting regions of the state space that they have not previously occupied. If, however, a particular state transition is impossible to predict, it will trap a curious agent (Burda et al., 2019b; Schmidhuber, 1991a). This is referred to as the noisy TV problem (e.g. (Burda et al., 2019b; Schmidhuber, 1991a)), the etymology being that a naively curious agent could dwell on the unpredictability of a noisy TV screen" from "How to Stay Curious while avoiding Noisy TVs using Aleatoric Uncertainty Estimation"
So I am unsure his compression metrics would work without a lot of revising, while my proposed metrics seem a lot less risky and to map more directly onto what creative thinkers want out of generative models.
I agree, this is true of most of Schmidhuber ideas. Often he does even produce a toy model for years, which means the ideas are generally not very useful. I do like this one, and it has led to some implementations in RL.
I do agree, perplexity doesn't seem like a great place to start, and your ideas seem like a better way to measure.
True, I should have said leading commercial companies
While I broadly agree, I don't think it's completely dead, just mostly dead in the water. If an eval is mandated by law, then it will be run even it required logprobs. There are some libraries like nnsight that try to make this easier for trusted partners to run logprob evals remotely. And there might be privacy preserving API's at some point.
I do agree that commercial companies will never again open up raw logprobs to the public as it allows easy behaviour cloning, which OpenAI experienced with all the GPT4 students.
If true, returns the log probabilities of each output token returned in the content of message.
It seems like it only returns the logprobs of the chosen message, not of a counterfactual message. So you couldn't get the probabilities of the correct answer, only the output answer. This makes sense as the less information they offer, the harder it is for a competitor to behaviour clone their confidential model.
Have you considered using an idea similar to Schmidhuber's blogpost "Artificial Curiosity & Creativity Since 1990-91". Here you try to assess what might be called "learnable compression", "reducible surprise", or "understandable novelty" (however you want to frame it).
If an LLM, which has read the entire internet, is surprised by a text, then that's a good start. It means the text is not entirely predictable and therefore boring.
But what about purely random text! That's unpredictable, just like Einstein's Theory of General Relativity was. This is the noisy TV problem. So how do we distinguish between them. Well, Schmidhuber suggests that a text should be less surprising after you have read it. We could approximate this in LLM's by putting a summary in context, fine-tuning, adapter tuning, or similar.
This is a nice approach, because it would work for detecting human slop, too. And would be much better than plaugerism detectors which do not work.
I've had a few tries at implementing this using adapters, fine-tuning, in context-learning etc. I managed to get some promising results with fine-tuning, but this is a pretty resource intensive way to do it.
If we knew he was not a sociopath, sadist, or reckless ideologue,
He is also old, which means you must also ask about his age related cognitive and personality change. There were rumours that during covid he had become scared and rigid.
Personally, I think we need to focus not on his character but on 1) how much he cares, as this will decide how much he delegates 2) how much he understands, as we all risk death, but many do not understand or agree with this 3) how competent he currently is to execute his goals.
Xi rules China so thoroughly that he would personally make key decisions regarding AGI
Even if he had absolute power, it doesn't mean he won't delegate. After all, his time is limited.
So, does anyone know of good work addressing his character and personal beliefs? Or is this an interesting research topic for anyone?
This is hard to find the truth here because we have state level information warfare obscuring the truth. That means there is propaganda designed to deceive and obscure even a professional analyst with access to secret information. However we do have some state level analysis, available through WikiLeaks we can look at what the US diplomats think, in the leaked diplomatic cables ( also and )
- (C) According to a well connected Embassy contact, Politburo Standing Committee Member and Vice President Xi Jinping is "exceptionally ambitious," confident and focused, and has had his "eye on the prize" from early adulthood.
PolOff's contact ("the professor") and Xi Jinping were both born in 1953 and grew up in similar circumstances. ... The professor did not know Xi personally until they had both reached their late teens,
- (C) In the professor's view, Xi Jinping is supremely pragmatic, a realist, driven not by ideology but by a combination of ambition and "self-protection." The professor saw Xi's early calculations to carefully lay out a realistic career path as an illustration of his pragmatism.
- (C) Xi is a true "elitist" at heart,
I don't know how reliable these cables are, but they represent an interesting source.
As long as people realise they are betting on more than just a direction
- the underlying going up
- Volatility going up
- it all happening within the time frame
Timing is particularly hard, and many great thinkers have been wrong on timing. You might also make the most rational bet, but the market takes another year to become rational.
Given that, Epoch AI predicts that energy might be a bottleneck
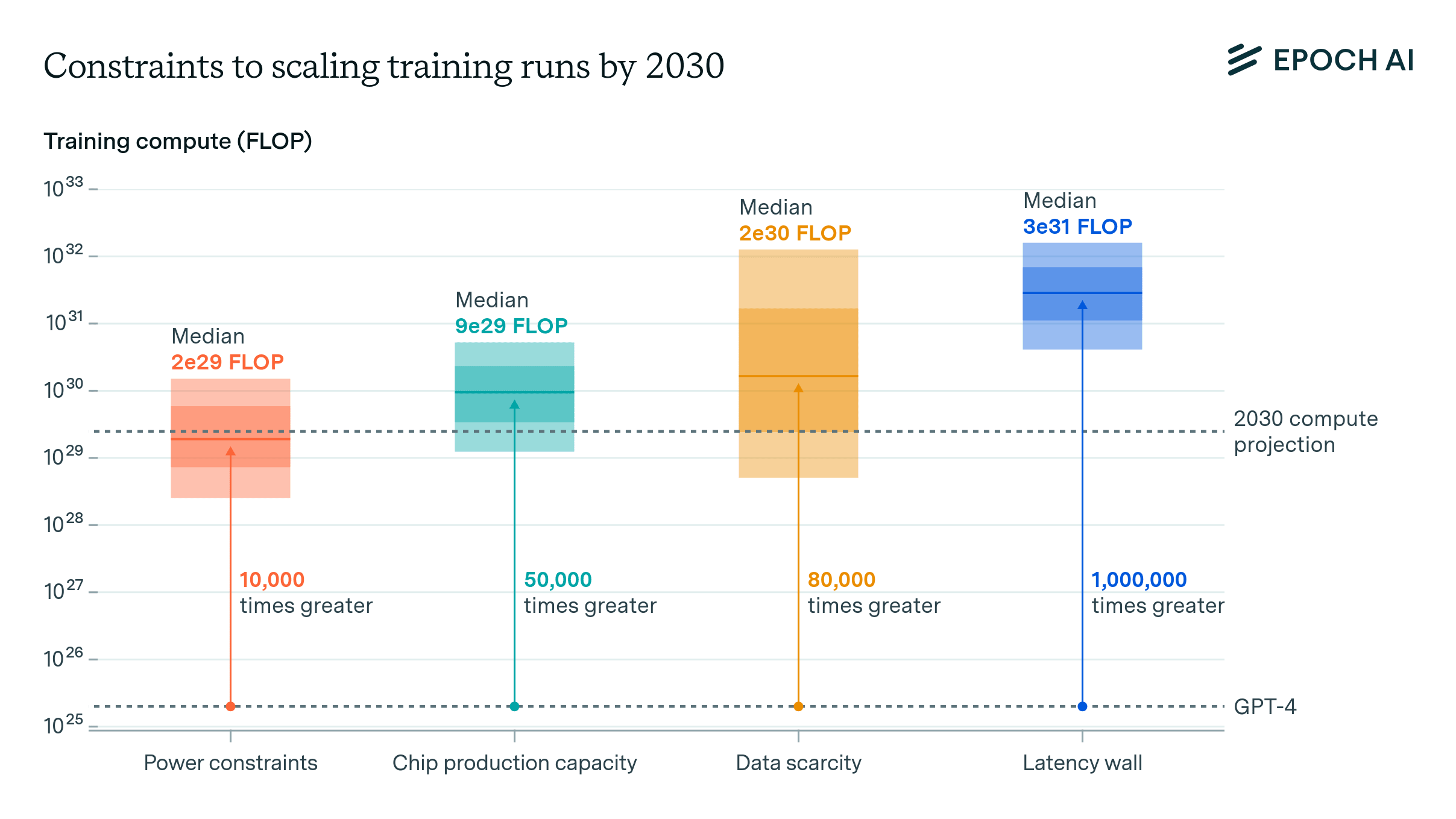
Worth looking at the top ten holdings of these, to make sure you know what you are buying, and that they are sensible allocations:
- SMH - VanEck Semiconductor ETF
- 22% Nvidia
- 13% Taiwan Semiconductor Manufacturing
- 8% Broadcom
- 5% AMD
- QQQ
- 9% AAPL
- 8% NVDA
- 8% MSFT
- 5% Broadcom
It might be worth noting that it can be good to prefer voting shares, held directly. For example, GOOG shares have no voting rights to Google, but GOOGL shares do. There are some scenarios where having control, rather than ownership/profit, could be important.
NVDA's value is primarily in their architectural IP and CUDA ecosystem. In an AGI scenario, these could potentially be worked around or become obsolete.
This idea was mentioned by Paul Christiano in one of his podcast appearances, iirc.
Interesting. It would be much more inspectable and controllable and modular which would be good for alignment.
You've got some good ideas in here, have you ever brainstormed any alignment ideas?
By sensible, I don't indicate disagreement, but a way of interpreting the question.
Do you have any idea at all? If you don't, what is the point of 'winning the race'?
Maybe they have some idea but don't want to say it. In recently disclosed internal OpenAI emails, Greg Brockman and Ilya Sutskever said to Elon Musk:
Perhaps this - originally private email - is saying the quiet part. And now that it is released, the quiet part is out loud. To use terms from the turn based game of Civilisation, perhaps they would use AI to achieve a cultural, espionage, technological, influence, diplomatic, and military victory simultaneously? But why would they declare that beforehand? Declaring it would only invite opposition and competition.
At the very least, you can hack and spy and sabotage other AGI attempts.
To be specific, there are a few areas where, it seems to me, increased intelligence could lead to quick and leveraged benefits. Hacking, espionage, negotiation, finance, and marketing/propaganda. For example, what if you can capture a significant fraction of the world's trading income, attract a large portion of China's talent to turn coat and move to your country, and hack into a large part of an opposition's infrastructure.
If one or more of these tactics can work significantly, you buy time for other tactics to progress.
A sensible question would weight ancestors by amount of shared genes.
To the people disagreeing, what part do you disagree with? My main point, or my example? Or something else
I think this is especially important for me/us to remember. On this site we often have a complex way of thinking, and a high computational budget (because we like exercising our brains to failure) and if we speak freely to the average person, they mat be annoyed at how hard it is to parse what we are saying.
We've all probably had this experience when genuinely trying to understand someone from a very different background. Perhaps they are trying to describe their inner experience when mediating, or Japanese poetry, or are simply from a different't discipline. Or perhaps we were just very tired that day, meaning we had a low computational budget.
On the other hand, we are often a "tell" culture, which had a lower computational load compared to ask or guess culture. As long as we don't tell too much.
I would add:
- Must also generalise better than capabilities!
- out of distribution
- to smarter models
Currently, we do not know how to make sure machine learning generalises well out of sample. This is an open problem that is critical to alignment. I find that it's left out of evals frustratingly often, probably because it's hard, and most methods miserably fail to generalise OOD.
For example, you don't want your ASI to become unaligned, have value drift, or extrapolate human values poorly when, for example, 1) it meets aliens, 2) 1000 years pass, or cultural drift happens. What if your descendants think it's admirable and funny to take hostages as a form of artistic practical joke, you would hope that your AI's would handle that in a principled and adaptable manner. At the very least, you want its capability to fail before its morality.
- An overlooked benchmark of text OOD: GENIES
- mention of how OOD is an open problem in "Towards out of distribution generalization for problems in mechanics"
One blind spot we rationalists sometimes have is that charismatic people actually treat the game as:
"Can I think of an association that will make the other person feel good and/or further my goal?". You need people to feel good, or they won't participate. And if you want some complicated/favour/uncomftorble_truth then you better mix in some good feels to balance it out and keep the other person participating.
To put it another way: If you hurt people's brain or ego, rush them, or make them feel unsure, or contradict them, then most untrained humans will feel a little bad. Why would they want to keep feeling bad? Do you like it when people don't listen, contradict you, insult you, rush you, disagree with you? Probably not, probobly no one does.
But if someone listens to you, smiles at you, likes you, has a good opinion of you, agrees with you, make sense to you. Then it feels good!
This might sound dangerously sycophantic, and that's because it is - if people overdo it! But if it's mixed with some healthy understanding, learning, informing then It's a great conversational lubricant, and you should apply as needed. It just ensures that everyone enjoys themselves and comes back for more, counteracting the normal frictions of socialising.
There are books about this. "How to Win Friends and Influence People" recommends talking about the other person's interests (including themselves) and listening to them, which they will enjoy.
So I'd say, don't just free associate. Make sure it's fun for both parties, make room to listen to the other person, and to let them steer. (And ideally your conversational partner reciprocates, but that is not guaranteed).
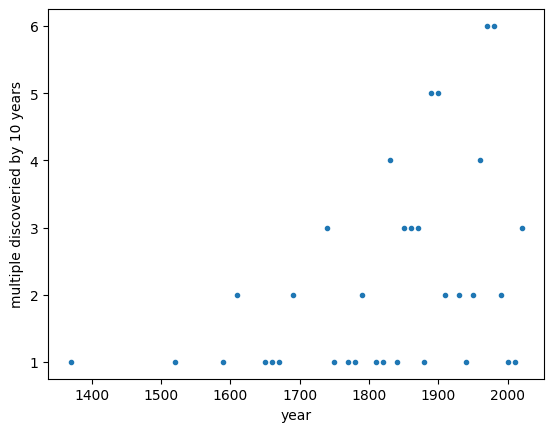
Is machine learning in a period of multiple discovery?
Anecdotally, it feels as though we have entered a period of multiple discovery in machine learning, with numerous individuals coming up with very similar ideas.
Logically, this can be expected when more people pursue the same low-hanging fruit. Imagine orchards in full bloom with a crowd of hungry gatherers. Initially, everyone targets the nearest fruit. Exploring a new scientific frontier can feel somewhat similar. When reading the history books on the Enlightenment, I get a similar impression.
If we are indeed in a period of multiple discovery, we should not simply go after the nearest prize; it will soon be claimed. Your time is better spent looking further afield or exploring broader horizons.
Is any of this backed by empirical evidence? No! I have simply plotted Wikipedia's list of multiple discoveries. It shows multiple discoveries increasing with population, I don't see any distinct periods, so it's inconclusive.
I made up the made-up numbers in this table of made-up numbers; therefore, the numbers in this table of made-up numbers are made-up numbe
These hallucinated outputs are really getting out of hand