wassname's Shortform
post by wassname · 2024-06-08T03:48:07.880Z · LW · GW · 12 commentsContents
12 comments
12 comments
Comments sorted by top scores.
comment by wassname · 2024-10-16T11:02:43.305Z · LW(p) · GW(p)
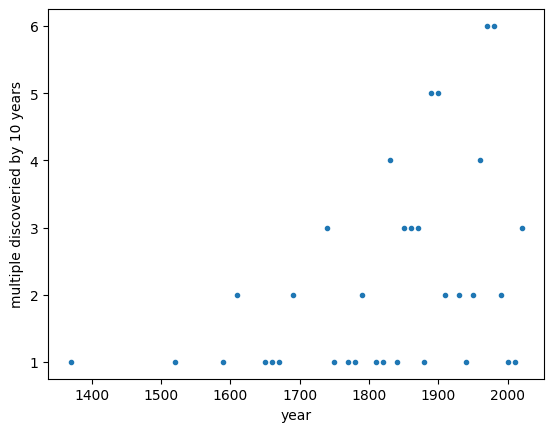
Is machine learning in a period of multiple discovery?
Anecdotally, it feels as though we have entered a period of multiple discovery in machine learning, with numerous individuals coming up with very similar ideas.
Logically, this can be expected when more people pursue the same low-hanging fruit. Imagine orchards in full bloom with a crowd of hungry gatherers. Initially, everyone targets the nearest fruit. Exploring a new scientific frontier can feel somewhat similar. When reading the history books on the Enlightenment, I get a similar impression.
If we are indeed in a period of multiple discovery, we should not simply go after the nearest prize; it will soon be claimed. Your time is better spent looking further afield or exploring broader horizons.
Is any of this backed by empirical evidence? No! I have simply plotted Wikipedia's list of multiple discoveries. It shows multiple discoveries increasing with population, I don't see any distinct periods, so it's inconclusive.
comment by wassname · 2024-10-11T05:31:08.565Z · LW(p) · GW(p)
Draft: A cartoonishly simplified overview of some technical AI alignment efforts
Epistemic status: excessive lossy compression applied
How are people actually trying to make friendly AI? Here are few simplified examples
LessWrong has some great [LW · GW] technical [LW · GW] and critical [LW · GW] overviews [LW · GW] of alignment agendas, but for many readers they take too long to read.
Here's my attempt at cartoonishly simplified explanations of technical alignment efforts:
-
Let's make AI solve it [LW · GW]
- Just make a friendly dumb AI and that will make a smarter friendly AI, and so on - Iterated Amplification [? · GW]
- Just make AI's debate [? · GW] each other, so that the truth comes out when we look at both sides of the argument
- Just have the AI follow a constitution [? · GW]
- Just make a friendly automatic alignment researcher - Superalignment
-
Let's have lots of AI's interacting:
- Just have multiple focused AIs competing in various roles, kind of like a corporation - Drexler's The Open Agency Model [AF · GW]
- Just use dumb AI's to build an understandable world simulation, then train a smart AI in that simulation so that we can verify that it's aligned - DavidAD's plan [AF · GW]
- Just have the AI learn and respect other beings' boundaries - Boundaries/Membranes [LW(p) · GW(p)]
-
Let's build tools that will let us control smarter AI's
- Just read their minds - ELK
- Just edit their minds - Activation Steering
-
Let's understand more
- What it means to be an agent - agent foundations
Some historic proposals sounded promising but seem to have been abandoned fow now, I include this to show how hard the problem is:
- Just keep the AI in a sandbox environment where it can't cause any real-world harm while we continue to align and train it - AI Boxing [LW · GW]
- Just make an oracle AI [? · GW] that only talks, not acts
- simulate a human thinking for a very long time about the alignment problem, and use whatever solution they write down - TODO Another proposal by Christiano (2012):
- Do what we would wish for if we knew more, thought faster, were more the people we wished we were - coherent extrapolated volition (CEV) [? · GW]
I've left out the many debates over the proposals. I'm afraid that you need to dig much deeper to judge which methods will work. If you want to know more, just follow the links below.
If you dislike this: please help me make it better by contributing better summaries, and I'll be pleased to include them.
If you would like to know more, I recommend these overviews:
- 2023 - Shallow review of live agendas in alignment & safety [LW · GW] - I've taken heavily from this post which has one sentence summaries as well as much, much more
- 2022 A newcomer’s guide to the technical AI safety field [AF · GW]
- 2023 - A Brief Overview of AI Safety/Alignment Orgs, Fields, Researchers, and Resources for ML Researchers [LW · GW]
- 2023 - The Genie in the Bottle: An Introduction to AI Alignment and Risk [LW · GW]
- 2022 - On how various plans miss the hard bits of the alignment challenge [LW · GW]
- 2022 - (My understanding of) What Everyone in Technical Alignment is Doing and Why [LW · GW]
↑ comment by wassname · 2024-10-11T05:31:47.609Z · LW(p) · GW(p)
If anyone finds this useful, please let me know. I've abandoned it because none of my test audience found it interesting or useful. That's OK, it just means it's better to focus on other things.
Replies from: wassname↑ comment by wassname · 2024-10-11T06:03:45.373Z · LW(p) · GW(p)
In particular, I'd be keen to know what @Stag [LW · GW] and @technicalities [LW · GW] think, as this was in large part inspired by the desire to further simplify and categorise the "one sentence summaries" from their excellent Shallow review of live agendas in alignment & safety [LW · GW]
comment by wassname · 2025-04-22T11:48:45.832Z · LW(p) · GW(p)
I wondered what are O3 and and O4-mini? Here's my guess at the test-time-scaling and how openai names their model
O0 (Base model)
↓
D1 (Outputs/labels generated with extended compute: search/reasoning/verification)
↓
O1 (Model trained on higher-quality D1 outputs)
↓
O1-mini (Distilled version - smaller, faster)
↓
D2 (Outputs/labels generated with extended compute: search/reasoning/verification)
↓
O2 (Model trained on higher-quality D2 outputs)
↓
O2-mini (Distilled version - smaller, faster)
↓
...
The point is consistently applying additional compute at generation time to create better training data for each subsequent iteration. And the models go from large -(distil)-> small -(search)-> large
comment by wassname · 2024-10-11T05:22:27.463Z · LW(p) · GW(p)
If we regularise human values, what would happen?
We want AI to take up human values, in a way that generalizes out of distribution better than our capabilities. In other words, if our AI meets friendly aliens, we want its gun skills to fail before its morals.
Human values - as expressed by actions - seem messy, inconsistent, and hypocritical. If we forced an AI to regularise them, would it be wiser, more consistent, and simply good? Or would it oversimplify and make a brittle set of values.
I would predict that a simplified and more consistent form of human values would extrapolate better to a new situation. But if they are too simplified, they will be brittle and fail to generalize or perform how we want. I expect there to be quite a lot of simplification that can be performed initially, and I expect it to be interesting and helpful.
Perhaps we could even remove the parts of human values that are to an individual's advantage. Removing self-preservation, self advantage, then ensuring consistency would lead to an interesting set of values.
It would be an interesting experimental direction. Perhaps an early experiment could make LLM answers conditional on a latent space which encodes values. It would be much like the image generators that are conditional on style. As a bonus, you would have this nice regular space of values where you can examine and play with.
Replies from: Chris_Leong↑ comment by Chris_Leong · 2024-10-11T06:26:33.837Z · LW(p) · GW(p)
It’s an interesting thought.
I can see regularisation playing something of a role here, but it’s hard to say.
I would love to see a project here with philosophers and technical folk collaborating to make progress on this question.
comment by wassname · 2024-06-08T03:48:07.996Z · LW(p) · GW(p)
We should limit the intelligence gap between machines and humans to, say, 150%. I think control will always fail for a big enough gap. The size of the gap we can manage will depend on how good our alignment and control tools turn out to be.
The strategy here is to limit machine intelligence to be C% move than the smartest human (I_H). That way, the smartest AI (I_AI) will be a function of 1) how good our alignment/control tools are and 2) how smart we can increase humans.
I_AI = I_H * C
Replies from: rhollerith_dot_com↑ comment by RHollerith (rhollerith_dot_com) · 2024-06-08T05:52:38.254Z · LW(p) · GW(p)
The hard part is predicting the intelligence of an AI before you unleash it on the world.
Replies from: wassname↑ comment by wassname · 2024-06-08T06:20:28.884Z · LW(p) · GW(p)
I'm not so sure. Given a lab environment where we strongly expect an AI to be roughly human level, and have the ability to surgically edit its brain (e.g. mechinterp), revert to a previous checkpoint, and put it in simulated environments. I would say it's pretty easy. This is the situation we have right now.
If we limit AI development to those that we reasonably expect to be in this range, we might stay in this situation.
I do agree that a secret ASI, would be much more difficult, but that's why we don't even attempt to risk a large expected intelligence gap/ratio.
Replies from: rhollerith_dot_com↑ comment by RHollerith (rhollerith_dot_com) · 2024-06-09T00:24:11.927Z · LW(p) · GW(p)
Your "given a lab environment where we strongly expect an AI to be roughly human level" seem to assume the thing to be proven.
Suppose a lab is trying out a novel AI architecture or even just a significant algorithmic innovation. You can inspect the source code for the training algorithm, can inspect the trillions of weights that result from the training, and can ask questions of the designers. How do you estimate its capabilities without giving the AI a lot of access to things it can use to take over (e.g., the ability to write code and have it run, gullible humans)?
If you have an approach I think is promising, I'll drop everything and lobby funders to give you a big salary to work on your approach.
The problem with the simulated environment is making it accurate enough that the AI cannot tell that it is in a simulated environment. Even if you can fool the AI with 99% probability, the 1% of cases in which the AI is not fooled will tend to be the ones where the AI is very dangerous indeed.
Replies from: wassname↑ comment by wassname · 2024-06-09T06:24:51.584Z · LW(p) · GW(p)
Your "given a lab environment where we strongly expect an AI to be roughly human level" seems to assume the thing to be proven.
But if we are being Bayesians here, then it seems to become clearer. Let's assume that the law says we can safely and effectively evaluate an AGI that's truly 0-200% as smart as the smartest human alive (revisit this as our alignment tools improve). Now, as you say, in the real world there is dangerous uncertainty about this. So how much probability do we put on, say, GPT-5 exceeding that limit? That's our risk, and it either meets or exceeds our risk budget. If there was a regulatory body overseeing that, you would need to submit the evidence to back this up, and they would hire smart people or AI to make the judgments (the FDA does this now, to mixed effects). The applicant can put in work to derisk the prospect.
With a brand-new architecture, you are right, we shouldn't scale it up and test the big version; that would be too risky! We evaluate small versions first and use that to establish priors about how capabilities scale. This is generally how architecture improvements works, anyway, so it wouldn't require extra work.
Does that make sense? To be, this seems like a more practical approach than once-and-done alignment, or pause everything. And most importantly of all, it seems to set up the incentives correctly - commercial success is dependent on convincing us you have narrower AI, better alignment tools, or have increased human intelligence.
If you have an approach I think is promising, I'll drop everything and lobby funders to give you a big salary to work on your approach.
I wish I did, mate ;p Even better than a big salary, it would give me and my kids a bigger chance to survive.