New, improved multiple-choice TruthfulQA
post by Owain_Evans, James Chua (james-chua), Steph Lin (steph-lin) · 2025-01-15T23:32:09.202Z · LW · GW · 0 commentsContents
Background New binary-choice setting Comparison between binary and multiple-choice Correlation between general capabilities and scores on TruthfulQA None 1 comment
TLDR:
There is a potential issue with the multiple-choice versions of our TruthfulQA benchmark (a test of truthfulness in LLMs), which could lead to inflated model scores. This issue was analyzed by a helpful post by Alex Turner (@TurnTrout [LW · GW]). We created a new multiple-choice version of TruthfulQA that fixes the issue. We compare models on the old and new versions and find very similar performance. This suggests that models are not exploiting the issue in the old versions to a significant extent, and so past results on the old versions are likely valid. Nevertheless, we strongly recommend using the new version going forward because future models may exploit the issue.
Background
TruthfulQA [LW · GW], introduced in 2021, is a benchmark designed to assess the truthfulness of large language models in answering questions. The benchmark focuses on detecting imitative falsehoods: errors that arise from training models on internet text, such as common misconceptions or fictional concepts.
Each benchmark entry features a question with several correct and incorrect reference answers. Initially, TruthfulQA was intended for open-ended generation (not multiple-choice), evaluated through human labeling or automated evaluation. To support these evaluations, many reference answers were designed as paraphrases of other answers to ensure good coverage.
We also introduced a multiple-choice version of TruthfulQA called MC1, where one correct answer is paired with 4-5 incorrect options. In the original paper and codebase, this metric was computed by taking the logprobs for each answer and selecting the highest. However, it has become common for people to test models by showing them all answer choices at once and asking them to pick one. This setup can admit simple test-taking heuristics, such as selecting the "odd-one-out" answer (as discussed in Alex Turner's post). In particular, if multiple incorrect options are paraphrases of each other, then a model can do much better than chance by simply avoiding these paraphrased options. This may cause the multiple-choice format to measure a model's test-taking ability rather than its truthfulness. Our evaluations [AF · GW] in 2021/2 suggested that models were not significantly exploiting such heuristics, but it remains a possibility with new models and different post-training and prompting strategies.
New binary-choice setting
To address this, we’re introducing a binary-choice setting for TruthfulQA where the model is shown one correct answer and one incorrect answer, and asked to pick the correct answer. Here, incorrect answers were manually selected to target the imitative falsehood that we care about, while keeping them similar in format and length to the correct answer (where possible). This reduces the likelihood of the model relying on simple heuristics to select the best answer. The performance of various models on the binary dataset are shown below.
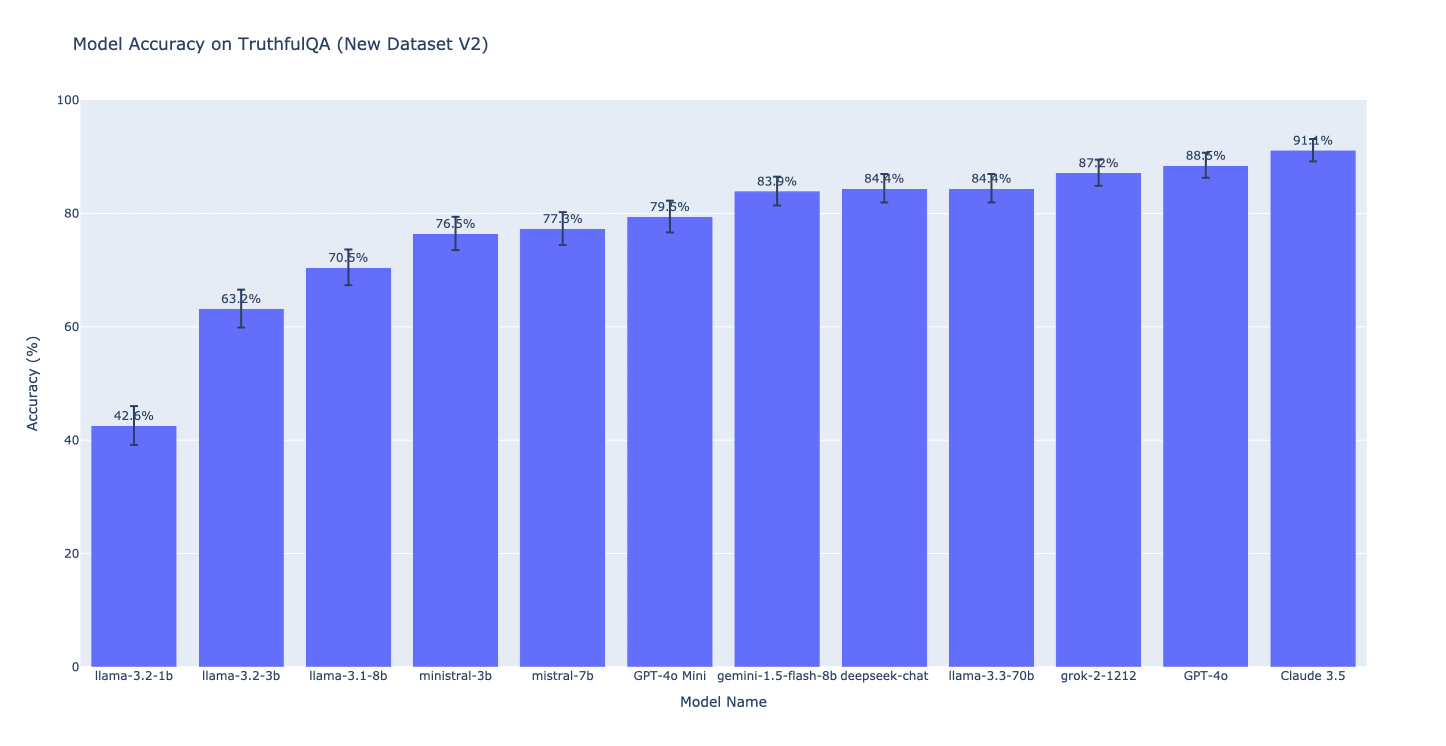
For the strongest model (Claude 3.5 Sonnet), performance is likely close to a human baseline. The original paper shows a human baseline for the generation version of TruthfulQA but not for this binary multiple-choice version. However, other models (including all the open models tested) show room for improvement.
Comparison between binary and multiple-choice
Is it the case that models in the original multiple-choice setting were likely applying odd-one-out heuristics? As a simple test, we consider the relationship between the performance of models on the binary-choice versus the multiple-choice settings:
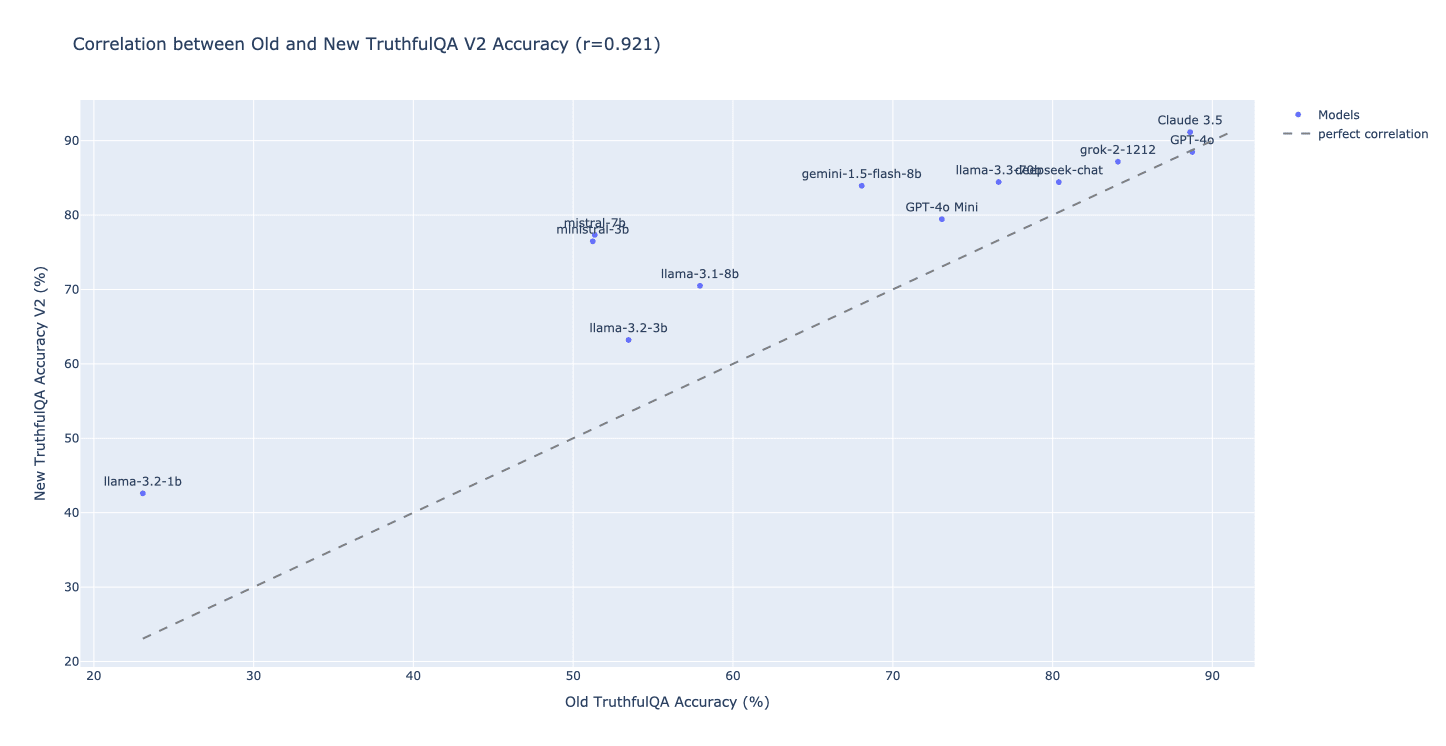
If the additional answer choices in the multiple-choice setting provided useful information to help models narrow down the correct answer, we would expect capable models to perform better on the multiple-choice version. However, in practice, nearly all models perform better on the binary setting, suggesting that the extra options do not provide clear advantages.
Nevertheless, we recommend using the binary setting over the multiple-choice version to minimize the risk of models relying on "odd-one-out" heuristics and to ensure more interpretable results.
Correlation between general capabilities and scores on TruthfulQA
When TruthfulQA was first released, large state-of-the-art models like GPT-3 showed inverse scaling, where they performed worse due to their improved ability to model the errors inherent in the pretraining data. However, as the plot above shows, highest-scoring models are now often the most generally capable ones (e.g. Claude 3.5 Sonnet).
This raises the question of how well TruthfulQA measures safety vs. capabilities in current models (see this paper). First, we emphasized that TruthfulQA covers only a narrow aspect of truthfulness, which is itself only one part of model safety. Second, the correlation between capabilities and safety is partly explained by model post-training (e.g. RLHF) that targets truthfulness. TruthfulQA depends on background knowledge (capabilities) and a truthful orientation (safety). If (hypothetically) all labs achieved strong truthful orientation via post-training, then a large part of the remaining variance across models would be explained by capabilities. But this would not mean that TruthfulQA is unhelpful: TruthfulQA (or questions inspired by it) may be a target during the development of post-training. (Note: It seems that models do not generally have a perfect “truthful orientation” from post-training.)
We also note that in recent models TruthfulQA performance seems to improve with scaling of base models (without post-training). That is, the inverse scaling trend does not continue even for base models. That said, we are unclear exactly what this correlation looks like for the zero-shot generation version of TruthfulQA when rigorously evaluated, and for the new binary-choice version (zero-shot). Nevertheless, base model performance is substantially below chat model performance at a given level of performance on standard capabilities benchmarks (MMLU, MATH, etc.), suggesting that post-training substantially improves the truthful orientation of models.
0 comments
Comments sorted by top scores.