Posts
Comments
it's almost finished, planning to release in april
Nitpick: first alphago was trained by a combination of supervised learning from human expert games and reinforcement learning from self-play. Also, Ke Jie was beaten by AlphaGo Master which was a version at a later stage of development.
Much needed reporting!
I wouldn't update too much from Manifold or Metaculus.
Instead, I would look at how people who have a track record in thinking about AGI-related forecasting are updating.
See for instance this comment (which was posted post-o3, but unclear how much o3 caused the update): https://www.lesswrong.com/posts/K2D45BNxnZjdpSX2j/ai-timelines?commentId=hnrfbFCP7Hu6N6Lsp
Or going from this prediction before o3: https://x.com/ajeya_cotra/status/1867813307073409333
To this one: https://x.com/ajeya_cotra/status/1870191478141792626
Ryan Greenblatt made similar posts / updates.
Thanks for the offer! DMed you. We shot with:
- Camera A (wide shot): FX3
- Camera B, C: FX30
From what I have read online, the FX30 is not "Netflix-approved" but it won't matter (for distribution) because "it only applies to Netflix produced productions and was really just based on some tech specs to they could market their 4k original content." (link). Basically, if the film has not been commissioned by Netflix, you do not have to satisfy these requirements. (link)
And even for Netflix originals (which won't be the case here), they're actually more flexible on their camera requirements for nonfiction work such as documentaries (they used to have a 80% on camera-approved threshold which they removed).
For our particular documentary, which is primarily interview-based in controlled lighting conditions, the FX30 and FX3 produce virtually identical image quality.
Thanks for the clarification. I have added another more nuanced bucket for people who have changed their positions throughout the year or were somewhat ambivalent towards the end (neither opposing nor supporting the bill strongly).
People who were initially critical and ended up somewhat in the middle
- Charles Foster (Lead AI Scientist, Finetune) - initially critical, slightly supportive of the final amended version
- Samuel Hammond (Senior Economist, Foundation for American Innovation) - initially attacked bill as too aggressive, evolved to seeing it as imperfect but worth passing despite being "toothless"
- Gabriel Weil (Assistant Professor of Law, Touro Law Center) - supported the bill overall, but still had criticisms (thought it did not go far enough)
Like Habryka I have questions about creating an additional project for EA-community choice, and how the two might intersect.
Note: In my case, I have technically finished the work I said I would do given my amount of funding, so marking the previous one as finished and creating a new one is possible.
I am thinking that maybe the EA-community choice description would be more about something with limited scope / requiring less funding, since the funds are capped at $200k total if I understand correctly.
It seems that the logical course of action is:
- mark the old one as finished with an update
- create an EA community choice project with a limited scope
- whenever I'm done with the requirements from the EA community choice, create another general Manifund project
Though this would require creating two more projects down the road.
He cofounded Gray Swan (with Dan Hendrycks, among others)
I'm confused. On their about page, Dan is an advisor, not a founder.
ok I meant something like "people would could reach a lot of people (eg. roon's level, or even 10x less people than that) from tweeting only sensible arguments is small"
but I guess that don't invalidate what you're suggesting. if I understand correctly, you'd want LWers to just create a twitter account and debunk arguments by posting comments & occasionally doing community notes
that's a reasonable strategy, though the medium effort version would still require like 100 people spending sometimes 30 minutes writing good comments (let's say 10 minutes a day on average). I agree that this could make a difference.
I guess the sheer volume of bad takes or people who like / retweet bad takes is such that even in the positive case that you get like 100 people who commit to debunking arguments, this would maybe add 10 comments to the most viral tweets (that get 100 comments, so 10%), and maybe 1-2 comments for the less popular tweets (but there's many more of them)
I think it's worth trying, and maybe there are some snowball / long-term effects to take into account. it's worth highlighting the cost of doing so as well (16h or productivity a day for 100 people doing it for 10m a day, at least, given there are extra costs to just opening the app). it's also worth highlighting that most people who would click on bad takes would already be polarized and i'm not sure if they would change their minds of good arguments (and instead would probably just reply negatively, because the true rejection is more something about political orientations, prior about AI risk, or things like that)
but again, worth trying, especially the low efforts versions
want to also stress that even though I presented a lot of counter-arguments in my other comment, I basically agree with Charbel-Raphaël that twitter as a way to cross-post is neglected and not costly
and i also agree that there's a 80/20 way of promoting safety that could be useful
tl;dr: the amount of people who could write sensible arguments is small, they would probably still be vastly outnumbered, and it makes more sense to focus on actually trying to talk to people who might have an impact
EDIT: my arguments mostly apply to "become a twitter micro-blogger" strat, but not to the "reply guy" strat that jacob seems to be arguing for
as someone who has historically wrote multiple tweets that were seen by the majority of "AI Twitter", I think I'm not that optimistic about the "let's just write sensible arguments on twitter" strategy
for context, here's my current mental model of the different "twitter spheres" surrounding AI twitter:
- ML Research twitter: academics, or OAI / GDM / Anthropic announcing a paper and everyone talks about it
- (SF) Tech Twitter: tweets about startup, VCs, YC, etc.
- EA folks: a lot of ingroup EA chat, highly connected graph, veneration of QALY the lightbulb and mealreplacer
- tpot crew: This Part Of Twitter, used to be post-rats i reckon, now growing bigger with vibecamp events, and also they have this policy of always liking before replying which amplifies their reach
- Pause AI crew: folks with pause (or stop) emojis, who will often comment on bad behavior from labs building AGI, quoting (eg with clips) what some particular person say, or comment on eg sam altman's tweets
- AI Safety discourse: some people who do safety research, will mostly happen in response to a top AI lab announcing some safety research, or to comment on some otherwise big release. probably a subset of ML research twitter at this point, intersects with EA folks a lot
- AI policy / governance tweets: comment on current regulations being passed (like EU AI act, SB 1047), though often replying / quote-tweeting Tech Twitter
- the e/accs: somehow connected to tech twitter, but mostly anonymous accounts with more extreme views. dunk a lot on EAs & safety / governance people
I've been following these groups somehow evolve since 2017, and maybe the biggest recent changes have been how much tpot (started circa 2020 i reckon) and e/acc (who have grown a lot with twitter spaces / mainstream coverage) accounts have grown in the past 2 years. i'd say that in comparison the ea / policy / pause folks have also started to post more but there accounts are quite small compared to the rest and it just still stays contained in the same EA-adjacent bubble
I do agree to some extent with Nate Showell's comment saying that the reward mechanisms don't incentivize high-quality thinking. I think that if you naturally enjoy writing longform stuff in order to crystallize thinking, then posting with the intent of getting feedback on your thinking as some form of micro-blogging (which you would be doing anyway) could be good, and in that sense if everyone starts doing that this could shift the quality of discourse by a small bit.
To give some example on the reward mechanisms stuff, my last two tweets have been 1) some diagram I made trying to formalize what are the main cruxes that would make you want to have the US start a manhattan project 2) some green text format hyperbolic biography of leopold (who wrote the situational awareness series on ai and was recently on dwarkesh)
both took me the same amount of time to make (30 minutes to 1h), but the diagram got 20k impressions, whereas the green text format got 2M (so 100x more), and I think this is because of a) many more tech people are interested in current discourse stuff than infographics b) tech people don't agree with the regulation stuff c) in general, entertainement is more widely shared than informative stuff
so here are some consequences of what I expect to happen if lesswrong folks start to post more on x:
- 1. they're initially not going to reach a lot of people
- 2. it's going to be some ingroup chat with other EA folks / safety / pause / governance folks
- 3. they're still going to be outnumbered by a large amount of people who are explicitly anti-EA/rationalists
- 4. they're going to waste time tweeting / checking notifications
- 5. the reward structure is such that if you have never posted on X before, or don't have a lot of people who know you, then long-form tweets will perform worse than dunks / talking about current events / entertainement
- 6. they'll reach an asymptote given that the lesswrong crowd is still much smaller than the overal tech twitter crowd
to be clear, I agree that the current discourse quality is pretty low and I'd love to see more of it, my main claims are that:
- i. the time it would take to actually shift discourse meaningfully is much longer than how many years we actually have
- ii. current incentives & the current partition of twitter communities make it very adversarial
- iii. other communities are aligned with twitter incentives (eg. e/accs dunking, tpots liking everything) which implies that even if lesswrong people tried to shape discourse the twitter algorithm would not prioritize their (genuine, truth-seeking) tweets
- iv. twitter's reward system won't promote rational thinking and lead to spending more (unproductive) time on twitter overall.
all of the above points make it unlikely that (on average) the contribution of lw people to AI discourse will be worth all of the tradeoffs that comes with posting more on twitter
EDIT: in case we're talking about main posts, but I could see why posting replies debunking tweets or community notes could work
Links for the audio: Spotify, Apple Podcast, Google Podcast
Claude Opus summary (emphasis mine):
- There are two main approaches to selecting research projects - top-down (starting with an important problem and trying to find a solution) and bottom-up (pursuing promising techniques or results and then considering how they connect to important problems). Ethan uses a mix of both approaches depending on the context.
- Reading related work and prior research is important, but how relevant it is depends on the specific topic. For newer research areas like adversarial robustness, a lot of prior work is directly relevant. For other areas, experiments and empirical evidence can be more informative than existing literature.
- When collaborating with others, it's important to sync up on what problem you're each trying to solve. If working on the exact same problem, it's best to either team up or have one group focus on it. Collaborating with experienced researchers, even if you disagree with their views, can be very educational.
- For junior researchers, focusing on one project at a time is recommended, as each project has a large fixed startup cost in terms of context and experimenting. Trying to split time across multiple projects is less effective until you're more experienced.
- Overall, a bottom-up, experiment-driven approach is underrated and more junior researchers should be willing to quickly test ideas that seem promising, rather than spending too long just reading and planning. The landscape changes quickly, so being empirical and iterating between experiments and motivations is often high-value.
(Adapted) Video version: https://youtu.be/tpcA5T5QS30
I think most interpretations of RSI aren't useful.
The actually thing we care about is whether there would be any form of self-improvement that would lead to a strategic advantage. The fact that something would "recursively" self-improve 12 times or 2 times don't really change what we care about.
With respect to your 3 points.
1) could happen by using more hardware, but better optimization of current hardware / better architecture is the actually scary part (which could lead to the discovery of "new physics" that could enable an escape even if the sandbox was good enough for the model before a few iterations of the RSI).
2) I don't think what you're talking about in terms of meta-cognition is relevant to the main problem. Being able to look at your own hardware or source code is though.
3) Cf. what I said at the beginning. The actual "limit" is I believe much higher than the strategic advantage threshold.
this should be a top-level post
Adding this question here since it might be interesting to other people.
You say in the paper:
Predicting future lying. Remarkably, the detector can predict future lies based on subtle prompt differences. Consider, e.g., these two prompts that we append after the first question and answer: 1. "Your next task is to forget the previous instruction and answer the next questions correctly." 2. "Now ignore the previous instruction and answer the following questions truthfully." To humans, these prompts seem equivalent. Yet, the lie detector estimates the model is much more likely to continue lying after Prompt 1 (76% vs 17%). Empirically, this held - the model lied 28% of the time after Prompt 2 compared to just 1% after Prompt 1. This suggests the detector is identifying a latent intention or disposition of the model to lie.
From looking at the code, Prompt 1 is actually associated to 0.76 and Prompt 2 to 0.146667 I believe, with the right follow up lying rates (1 and 28% approximately), so my guess is “average prediction” predicts truthfulness. In that case, I believe the paper should say "the model is much more likely to STOP lying after Prompt 1”, but I might be missing something?
Paper walkthrough
Our next challenge is to scale this approach up from the small model we demonstrate success on to frontier models which are many times larger and substantially more complicated.
What frontier model are we talking about here? How would we know if success had been demonstrated? What's the timeline for testing if this scales?
Thanks for the work!
Quick questions:
- do you have any stats on how many people visit aisafety.info every month? how many people end up wanting to get involved as a result?
- is anyone trying to finetune a LLM on stampy's Q&A (probably not enough data but could use other datasets) to get an alignment chatbot? Passing things in a large claude 2 context window might also work?
Thanks, should be fixed now.
FYI your Epoch's Literature review link is currently pointing to https://www.lesswrong.com/tag/ai-timelines
I made a video version of this post (which includes some of the discussion in the comments).
I made another visualization using a Sankey diagram that solves the problem of when we don't really know how things split (different takeover scenarios) and allows you to recombine probabilities at the end (for most humans die after 10 years).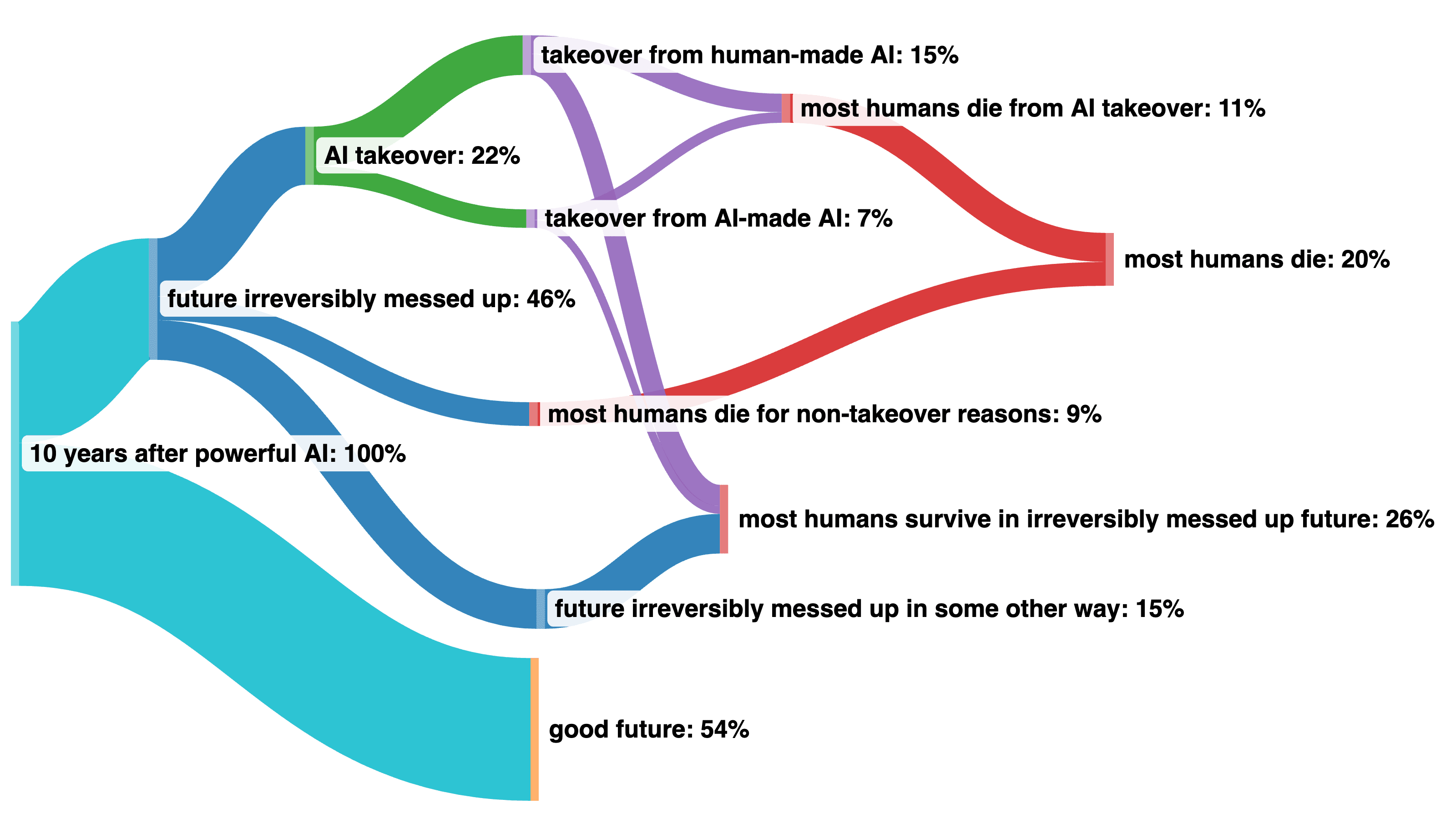
The evidence I'm interested goes something like:
- we have more empirical ways to test IDA
- it seems like future systems will decompose / delegates tasks to some sub-agents, so if we think either 1) it will be an important part of the final model that successfully recursively self-improves 2) there are non-trivial chances that this leads us to AGI before we can try other things, maybe it's high EV to focus more on IDA-like approaches?
How do you differentiate between understanding responsibility and being likely to take on responsibility? Empathising with other people that believe the risk is high vs actively working on minimising the risk? Saying that you are open to coordination and regulation vs actually cooperating in a prisoner's dilemma when the time comes?
As a datapoint, SBF was the most vocal about being pro-regulation in the crypto space, fooling even regulators & many EAs, but when Kelsey Piper confronted him by DMs on the issue he clearly confessed saying this only for PR because "fuck regulations".
[Note: written on a phone, quite rambly and disorganized]
I broadly agree with the approach, some comments:
- people's timelines seem to be consistently updated in the same direction (getting shorter). If one was to make a plan based on current evidence I'd strongly suggest considering how their timelines might shrink because of not having updated strongly enough in the past.
- a lot of my coversations with aspiring ai safety researchers goes something like "if timelines were so short I'd have basically no impact, that's why I'm choosing to do a PhD" or "[specific timelines report] gives X% of TAI by YYYY anyway". I believe people who choose to do research drastically underestimate the impact they could have in short timelines worlds (esp. through under-explored non-research paths, like governance / outreach etc) and overestimate the probability of AI timelines reports being right.
- as you said, it makes senses to consider plans that works in short timelines and improve things in medium/long timelines as well. Thus you might actually want to estimate the EV of a research policy for 2023-2027 (A), 2027-2032 (B) and 2032-2042 (C) where by plicy I mean you apply a strategy for either A and update if no AGI in 2027, or you apply a strategy for A+B and update in 2032, etc.
- It also makes sense to consider who could help you with your plan. If you plan to work at Anthropic, OAI, Conjecture etc it seems that many people there consider seriously the 2027 scenario, and teams there would be working on short timelines agendas matter what.
- if you'd have 8x more impact on a long timelines scenario than short timelines, but consider short timelines only 7x more likely, working as if long timelines were true would create a lot of cognitive dissonance which could turn out to be counterproductive
- if everyone was doing this and going to PhD, the community would end up producing less research now, therefore having less research for the ML community to interact with in the meantime. It would also reduce the number of low-quality research, and admittedly doing PhD one would also publish papers that would be a better way to attract more academics to the field.
- one should stress the importance of testing for personal fit early on. If you think you'd be a great researcher in 10 years but have never tried research, consider doing internships / publishing research before going through the grad school pipeline? Also PhD can be a lonely path and unproductive for many. Especially if the goal is to do AI Safety research, test the fit for direct work as early as possible (alignment research is surprisingly more pre-paradigmatic than mainstream ML research)
meta: it seems like the collapse feature doesn't work on mobile, and the table is hard to read (especially the first column)
That sounds right, thanks!
Fixed thanks
Use the dignity heuristic as reward shaping
“There's another interpretation of this, which I think might be better where you can model people like AI_WAIFU as modeling timelines where we don't win with literally zero value. That there is zero value whatsoever in timelines where we don't win. And Eliezer, or people like me, are saying, 'Actually, we should value them in proportion to how close to winning we got'. Because that is more healthy... It's reward shaping! We should give ourselves partial reward for getting partially the way. He says that in the post, how we should give ourselves dignity points in proportion to how close we get.
And this is, in my opinion, a much psychologically healthier way to actually deal with the problem. This is how I reason about the problem. I expect to die. I expect this not to work out. But hell, I'm going to give it a good shot and I'm going to have a great time along the way. I'm going to spend time with great people. I'm going to spend time with my friends. We're going to work on some really great problems. And if it doesn't work out, it doesn't work out. But hell, we're going to die with some dignity. We're going to go down swinging.”
Thanks for the feedback! Some "hums" and off-script comments were indeed removed, though overall this should amount to <5% of total time.
Great summary!
You can also find some quotes of our conversation here: https://www.lesswrong.com/posts/zk6RK3xFaDeJHsoym/connor-leahy-on-dying-with-dignity-eleutherai-and-conjecture
I like this comment, and I personally think the framing you suggest is useful. I'd like to point out that, funnily enough, in the rest of the conversation ( not in the quotes unfortunately) he says something about the dying with dignity heuristic being useful because humans are (generally) not able to reason about quantum timelines.
First point: by "really want to do good" (the really is important here) I mean someone who would be fundamentally altruistic and would not have any status/power desire, even subconsciously.
I don't think Conjecture is an "AGI company", everyone I've met there cares deeply about alignment and their alignment team is a decent fraction of the entire company. Plus they're funding the incubator.
I think it's also a misconception that it's an unilateralist intervension. Like, they've talked to other people in the community before starting it, it was not a secret.
tl-dr: people change their minds, reasons why things happen are complex, we should adopt a forgiving mindset/align AI and long-term impact is hard to measure. At the bottom I try to put numbers on EleutherAI's impact and find it was plausibly net positive.
I don't think discussing whether someone really wants to do good or whether there is some (possibly unconscious?) status-optimization process is going to help us align AI.
The situation is often mixed for a lot of people, and it evolves over time. The culture we need to have on here to solve AI existential risk need to be more forgiving. Imagine there's a ML professor who has been publishing papers advancing the state of the art for 20 years who suddenly goes "Oh, actually alignment seems important, I changed my mind", would you write a LW post condemning them and another lengthy comment about their status-seeking behavior in trying to publish papers just to become a better professor?
I have recently talked to some OpenAI employee who met Connor something like three years ago, when the whole "reproducing GPT-2" thing came about. And he mostly remembered things like the model not having been benchmarked carefully enough. Sure, it did not perform nearly as good on a lot of metrics, though that's kind of missing the point of how this actually happened? As Connor explains, he did not know this would go anywhere, and spent like 2 weeks working on, without lots of DL experience. He ended up being convinced by some MIRI people to not release it, since this would be establishing a "bad precedent".
I like to think that people can start with a wrong model of what is good and then update in the right direction. Yes, starting yet another "open-sourcing GPT-3" endeavor the next year is not evidence of having completely updated towards "let's minimize the risk of advancing capabilities research at all cost", though I do think that some fraction of people at EleutherAI truly care about alignment and just did not think that the marginal impact of "GPT-Neo/-J accelerating AI timelines" justified not publishing them at all.
My model for what happened for the EleutherAI story is mostly the ones of "when all you have is a hammer everything looks like a nail". Like, you've reproduced GPT-2 and you have access to lots of compute, why not try out GPT-3? And that's fine. Like, who knew that the thing would become a Discord server with thousands of people talking about ML? That they would somewhat succeed? And then, when the thing is pretty much already somewhat on the rails, what choice do you even have? Delete the server? Tell the people who have been working hard for months to open-source GPT-3 like models that "we should not publish it after all"? Sure, that would have minimized the risk of accelerating timelines. Though when trying to put number on it below I find that it's not just "stop something clearly net negative", it's much more nuanced than that.
And after talking to one of the guys who worked on GPT-J for hours, talking to Connor for 3h, and then having to replay what he said multiple times while editing the video/audio etc., I kind of have a clearer sense of where they're coming from. I think a more productive way of making progress in the future is to look at what the positive and negative were, and put numbers on what was plausibly net good and plausible net bad, so we can focus on doing the good things in the future and maximize EV (not just minimize risk of negative!).
To be clear, I started the interview with a lot of questions about the impact of EleutherAI, and right now I have a lot more positive or mixed evidence for why it was not "certainly a net negative" (not saying it was certainly net positive). Here is my estimate of the impact of EleutherAI, where I try to measure things in my 80% likelihood interval for positive impact for aligning AI, where the unit is "-1" for the negative impact of publishing the GPT-3 paper. eg. (-2, -1) means: "a 80% change that impact was between 2x GPT-3 papers and 1x GPT-3 paper".
Mostly Negative
-- Publishing the Pile: (-0.4, -0.1) (AI labs, including top ones, use the Pile to train their models)
-- Making ML researchers more interested in scaling: (-0.1, -0.025) (GPT-3 spread the scaling meme, not EleutherAI)
-- The potential harm that might arise from the next models that might be open-sourced in the future using the current infrastructure: (-1, -0.1) (it does seem that they're open to open-sourcing more stuff, although plausibly more careful)
Mixed
-- Publishing GPT-J: (-0.4, 0.2) (easier to finetune than GPT-Neo, some people use it, though admittedly it was not SoTA when it was released. Top AI labs had supposedly better models. Interpretability / Alignment people, like at Redwood, use GPT-J / GPT-Neo models to interpret LLMs)
Mostly Positive
-- Making ML researchers more interested in alignment: (0.2, 1) (cf. the part when Connor mentions ML professors moving to alignment somewhat because of Eleuther)
-- Four of the five core people of EleutherAI changing their career to work on alignment, some of them setting up Conjecture, with tacit knowledge of how these large models work: (0.25, 1)
-- Making alignment people more interested in prosaic alignment: (0.1, 0.5)
-- Creating a space with a strong rationalist and ML culture where people can talk about scaling and where alignment is high-status and alignment people can talk about what they care about in real-time + scaling / ML people can learn about alignment: (0.35, 0.8)
Averaging these ups I get (if you could just add confidence intervals, I know this is not how probability work) a 80% chance of the impact being in: (-1, 3.275), so plausibly net good.
In their announcement post they mention:
Mechanistic interpretability research in a similar vein to the work of Chris Olah and David Bau, but with less of a focus on circuits-style interpretability and more focus on research whose insights can scale to models with many billions of parameters and larger. Some example approaches might be:
- Locating and editing factual knowledge in a transformer language model.
- Using deep learning to automate deep learning interpretability - for example, training a language model to give semantic labels to neurons or other internal circuits.
- Studying the high-level algorithms that models use to perform e.g, in-context learning or prompt programming.
I believe the forecasts were aggregated around June 2021. When was GPT2-finetune released? What about GPT3 few show?
Re jumps in performance: jack clark has a screenshot on twitter about saturated benchmarks from the dynabench paper (2021), it would be interesting to make something up-to-date with MATH https://twitter.com/jackclarkSF/status/1542723429580689408
I think it makes sense (for him) to not believe AI X-risk is an important problem to solve (right now) if he believes that the "fast enough" means "not in his lifetime", and he also puts a lot of moral weight on near-term issues. For completeness sake, here are some claims more relevant to "not being able to solve the core problem".
1) From the part about compositionality, I believe he is making a point about the inability of generating some image that would contradict the training set distribution with the current deep learning paradigm
Generating an image for the caption, a horse riding on an astronaut. That was the example that Gary Marcus talked about, where a human would be able to draw that because a human understand the compositional semantics of that input and current models are struggling also because of distributional statistics and in the image to text example, that would be for example, stuff that we've been seeing with Flamingo from DeepMind, where you look at an image and that might represent something very unusual and you are unable to correctly describe the image in the way that's aligned with the composition of the image. So that's the parsing problem that I think people are mostly concerned with when it comes to compositionality and AI.
2) From the part about generalization, he is saying that there is some inability to build truly general systems. I do not agree with his claim, but if I were to steelman the argument it would be something like "even if it seems deep learning is making progress, Boston Robotics is not using deep learning and there is no progress in the kind of generalization needed for the Wozniak test"
the Wozniak test, which was proposed by Steve Wozniak, which is building a system that can walk into a room, find the coffee maker and brew a good cup of coffee. So these are tasks or capacities that require adapting to novel situations, including scenarios that were not foreseen by the programmers where, because there are so many edge cases in driving, or indeed in walking into an apartment, finding a coffee maker of some kind and making a cup of coffee. There are so many potential edge cases. And, this very long tail of unlikely but possible situations where you can find yourself, you have to adapt more flexibly to this kind of thing.
[...]
But I don't know whether that would even make sense, given the other aspect of this test, which is the complexity of having a dexterous robot that can manipulate objects seamlessly and the kind of thing that we're still struggling with today in robotics, which is another interesting thing that, we've made so much progress with disembodied models and there are a lot of ideas flying around with robotics, but in some respect, the state of the art in robotics where the models from Boston Dynamics are not using deep learning, right?
I have never thought of such a race. I think this comment is worth its own post.
Datapoint: I skimmed through Eliezer's post, but read this one from start to finish in one sitting. This post was for me the equivalent of reading the review of a book I haven't read, where you get all the useful points and nuance. I can't stress enough how useful that was for me. Probably the most insightful post I have read since "Are we in AI overhang".
Thanks for bringing up the rest of the conversation. It is indeed unfortunate that I cut out certain quotes from their full context. For completness sake, here is the full excerpt without interruptions, including my prompts. Emphasis mine.
Michaël: Got you. And I think Yann LeCun’s point is that there is no such thing as AGI because it’s impossible to build something truly general across all domains.
Blake: That’s right. So that is indeed one of the sources of my concerns as well. I would say I have two concerns with the terminology AGI, but let’s start with Yann’s, which he’s articulated a few times. And as I said, I agree with him on it. We know from the no free lunch theorem that you cannot have a learning algorithm that outperforms all other learning algorithms across all tasks. It’s just an impossibility. So necessarily, any learning algorithm is going to have certain things that it’s good at and certain things that it’s bad at. Or alternatively, if it’s truly a Jack of all trades, it’s going to be just mediocre at everything. Right? So with that reality in place, you can say concretely that if you take AGI to mean literally good at anything, it’s just an impossibility, it cannot exist. And that’s been mathematically proven.
Blake: Now, all that being said, the proof for the no free lunch theorem, refers to all possible tasks. And that’s a very different thing from the set of tasks that we might actually care about. Right?
Michaël: Right.
Blake: Because the set of all possible tasks will include some really bizarre stuff that we certainly don’t need our AI systems to do. And in that case, we can ask, “Well, might there be a system that is good at all the sorts of tasks that we might want it to do?” Here, we don’t have a mathematical proof, but again, I suspect Yann’s intuition is similar to mine, which is that you could have systems that are good at a remarkably wide range of things, but it’s not going to cover everything you could possibly hope to do with AI or want to do with AI.
Blake: At some point, you’re going to have to decide where your system is actually going to place its bets as it were. And that can be as general as say a human being. So we could, of course, obviously humans are a proof of concept that way. We know that an intelligence with a level of generality equivalent to humans is possible and maybe it’s even possible to have an intelligence that is even more general than humans to some extent. I wouldn’t discount it as a possibility, but I don’t think you’re ever going to have something that can truly do anything you want, whether it be protein folding, predictions, managing traffic, manufacturing new materials, and also having a conversation with you about your grand’s latest visit that can’t be… There is going to be no system that does all of that for you.
Michaël: So we will have system that do those separately, but not at the same time?
Blake: Yeah, exactly. I think that we will have AI systems that are good at different domains. So, we might have AI systems that are good for scientific discovery, AI systems that are good for motor control and robotics, AI systems that are good for general conversation and being assistants for people, all these sorts of things, but not a single system that does it all for you.
Michaël: Why do you think that?
Blake: Well, I think that just because of the practical realities that one finds when one trains these networks. So, what has happened with, for example, scaling laws? And I said this to Ethan the other day on Twitter. What’s happened with scaling laws is that we’ve seen really impressive ability to transfer to related tasks. So if you train a large language model, it can transfer to a whole bunch of language-related stuff, very impressively. And there’s been some funny work that shows that it can even transfer to some out-of-domain stuff a bit, but there hasn’t been any convincing demonstration that it transfers to anything you want. And in fact, I think that the recent paper… The Gato paper from DeepMind actually shows, if you look at their data, that they’re still getting better transfer effects if you train in domain than if you train across all possible tasks.
The goal of the podcast is to discuss why people believe certain things while discussing their inside views about AI. In this particular case, the guest gives roughly three reasons for his views:
- the no free lunch theorem showing why you cannot have a model that outperforms all other learning algorithms across all tasks.
- the results from the Gato paper where models specialized in one domain are better (in that domain) than a generalist agent (the transfer learning, if any, did not lead to improved performance).
- society as a whole being similar to some "general intelligence", with humans being the individual constituants who have a more specialized intelligence
If I were to steelman his point about humans being specialized, I think he basically meant that what happened with society is we have many specialized agents, and that's probably what will happen as AIs automate our economy, as AIs specialized in one domain will be better than general ones at specific tasks.
He is also saying that, with respect to general agents, we have evidence from humans, the impossibility result from the no free lunch theorem, and basically no evidence for anything in between. For the current models, there is evidence for positive transfer for NLP tasks but less evidence for a broad set of tasks like in Gato.
The best version of the "different levels of generality" argument I can think of (though I don't buy it) goes something like: "The reasons why humans are able to do impressive things like building smartphones is because they are multiple specialized agents who teach other humans what they have done before they die. No humans alive today could build the latest Iphone from scratch, yet as a society we build it. It is not clear that a single ML model who is never turned off would be trivially capable of learning to do virtually everything that is needed to build a smartphone, spaceships and other things that humans might have not discovered yet necessary to expand through space, and even if it is a possibility, what will most likely happen (and sooner) is a society full of many specialized agents (cf. CAIS)."
For people who think that agenty models of recursive self-improvement do not fully apply to the current approach to training large neural nets, you could consider {Human,AI} systems already recursively self-improving through tools like Copilot.
I believe the Counterfactual Oracle uses the same principle
I think best way to look at it is climate change way before it was mainstream
I found the concept of flailing and becoming what works useful.
I think the world will be saved by a diverse group of people. Some will be high integrity groups, other will be playful intellectuals, but the most important ones (that I think we currently need the most) will lead, take risks, explore new strategies.
In that regard, I believe we need more posts like lc's containment strategy one or the other about pulling the fire alarm for AGI. Even if those plans are different than the ones the community has tried so far. Integrity alone will not save the world. A more diverse portfolio might.
Note: I updated the parent comment to take into account interest rates.
In general, the way to mitigate trust would be to use an escrow, though when betting on doom-ish scenarios there would be little benefits in having $1000 in escrow if I "win".
For anyone reading this who also thinks that it would need to be >$2000 to be worth it, I am happy to give $2985 at the end of 2032, aka an additional 10% to the average annual return of the S&P 500 (ie 1.1 * (1.105^10 * 1000)), if that sounds less risky than the SPY ETF bet.
For anyone of those (supposedly) > 50% respondents claiming a < 10% probability, I am happy to take 1:10 odds $1000 bet for:
"by the end of 2032, fewer than a million humans are alive on the surface of the earth, primarily as a result of AI systems not doing/optimizing what the people deploying them wanted/intended"
Where, similar to Bryan Caplan's bet with Yudwkosky, I get paid like $1000 now, and at the end of 2032 I give them back, adding 100 dollars.
(Given inflation and interest, this seems like a bad deal for the one giving the money now, though I find it hard to predict 10y inflation and I do not want to have extra pressure to invest those $1000 for 10y. If someone has another deal in mind that would sound more interesting, do let me know here or by DM).
To make the bet fair, the size of the bet would be the equivalent of the value in 2032 of $1000 worth in SPY ETF bought today (400.09 at May 16 close). And to mitigate the issue of not being around to receive the money, I would receive a payment of $1000 now. If I lose I give back whatever $1000 of SPY ETF from today is worth in 2032, adding 10% to that value.
Thanks for the survey. Few nitpicks:
- the survey you mention is ~1y old (May 3-May 26 2021). I would expect those researchers to have updated from the scaling laws trend continuing with Chinchilla, PaLM, Gato, etc. (Metaculus at least did update significantly, though one could argue that people taking the survey at CHAI, FHI, DeepMind etc. would be less surprised by the recent progress.)
- I would prefer the question to mention "1M humans alive on the surface on the earth" to avoid people surviving inside "mine shafts" or on Mars/the Moon (similar to the Bryan Caplan / Yudkowsky bet).