My views on “doom”
post by paulfchristiano · 2023-04-27T17:50:01.415Z · LW · GW · 37 commentsContents
Two distinctions Other caveats My best guesses None 37 comments
I’m often asked: “what’s the probability of a really bad outcome from AI?”
There are many different versions of that question with different answers. In this post I’ll try to answer a bunch of versions of this question all in one place.
Two distinctions
Two distinctions often lead to confusion about what I believe:
- One distinction is between dying (“extinction risk”) and having a bad future (“existential risk”). I think there’s a good chance of bad futures without extinction, e.g. that AI systems take over but don’t kill everyone.
- An important subcategory of “bad future” is “AI takeover:” an outcome where the world is governed by AI systems, and we weren’t able to build AI systems who share our values or care a lot about helping us. This need not result in humans dying, and it may not even be an objectively terrible future. But it does mean that humanity gave up control over its destiny, and I think in expectation it’s pretty bad.
- A second distinction is between dying now and dying later. I think that there’s a good chance that we don’t die from AI, but that AI and other technologies greatly accelerate the rate of change in the world and so something else kills us shortly later. I wouldn’t call this “from AI” but I do think it happens soon in calendar time and I’m not sure the distinction is comforting to most people.
Other caveats
I’ll give my beliefs in terms of probabilities, but these really are just best guesses — the point of numbers is to quantify and communicate what I believe, not to claim I have some kind of calibrated model that spits out these numbers.
Only one of these guesses is even really related to my day job (the 15% probability that AI systems built by humans will take over). For the other questions I’m just a person who’s thought about it a bit in passing. I wouldn’t recommend deferring to the 15%, but definitely wouldn’t recommend deferring to anything else.
A final source of confusion is that I give different numbers on different days. Sometimes that’s because I’ve considered new evidence, but normally it’s just because these numbers are just an imprecise quantification of my belief that changes from day to day. One day I might say 50%, the next I might say 66%, the next I might say 33%.
I’m giving percentages but you should treat these numbers as having 0.5 significant figures.
My best guesses
Probability of an AI takeover: 22%
- Probability that humans build AI systems that take over: 15%
(Including anything that happens before human cognitive labor is basically obsolete.) - Probability that the AI we build doesn’t take over, but that it builds even smarter AI and there is a takeover some day further down the line: 7%
Probability that most humans die within 10 years of building powerful AI (powerful enough to make human labor obsolete): 20%
- Probability that most humans die because of an AI takeover: 11%
- Probability that most humans die for non-takeover reasons (e.g. more destructive war or terrorism) either as a direct consequence of building AI or during a period of rapid change shortly thereafter: 9%
Probability that humanity has somehow irreversibly messed up our future within 10 years of building powerful AI: 46%
- Probability of AI takeover: 22% (see above)
- Additional extinction probability: 9% (see above)
- Probability of messing it up in some other way during a period of accelerated technological change (e.g. driving ourselves crazy, creating a permanent dystopia, making unwise commitments…): 15%
37 comments
Comments sorted by top scores.
comment by WilliamKiely · 2023-04-27T21:54:58.161Z · LW(p) · GW(p)
I made a visualization of Paul's guesses to better understand how they overlap:
https://docs.google.com/spreadsheets/d/1x0I3rrxRtMFCd50SyraXFizSO-VRB3TrCRxUiWe5RMU/edit#gid=0

↑ comment by Michaël Trazzi (mtrazzi) · 2023-04-28T17:09:22.573Z · LW(p) · GW(p)
I made another visualization using a Sankey diagram that solves the problem of when we don't really know how things split (different takeover scenarios) and allows you to recombine probabilities at the end (for most humans die after 10 years).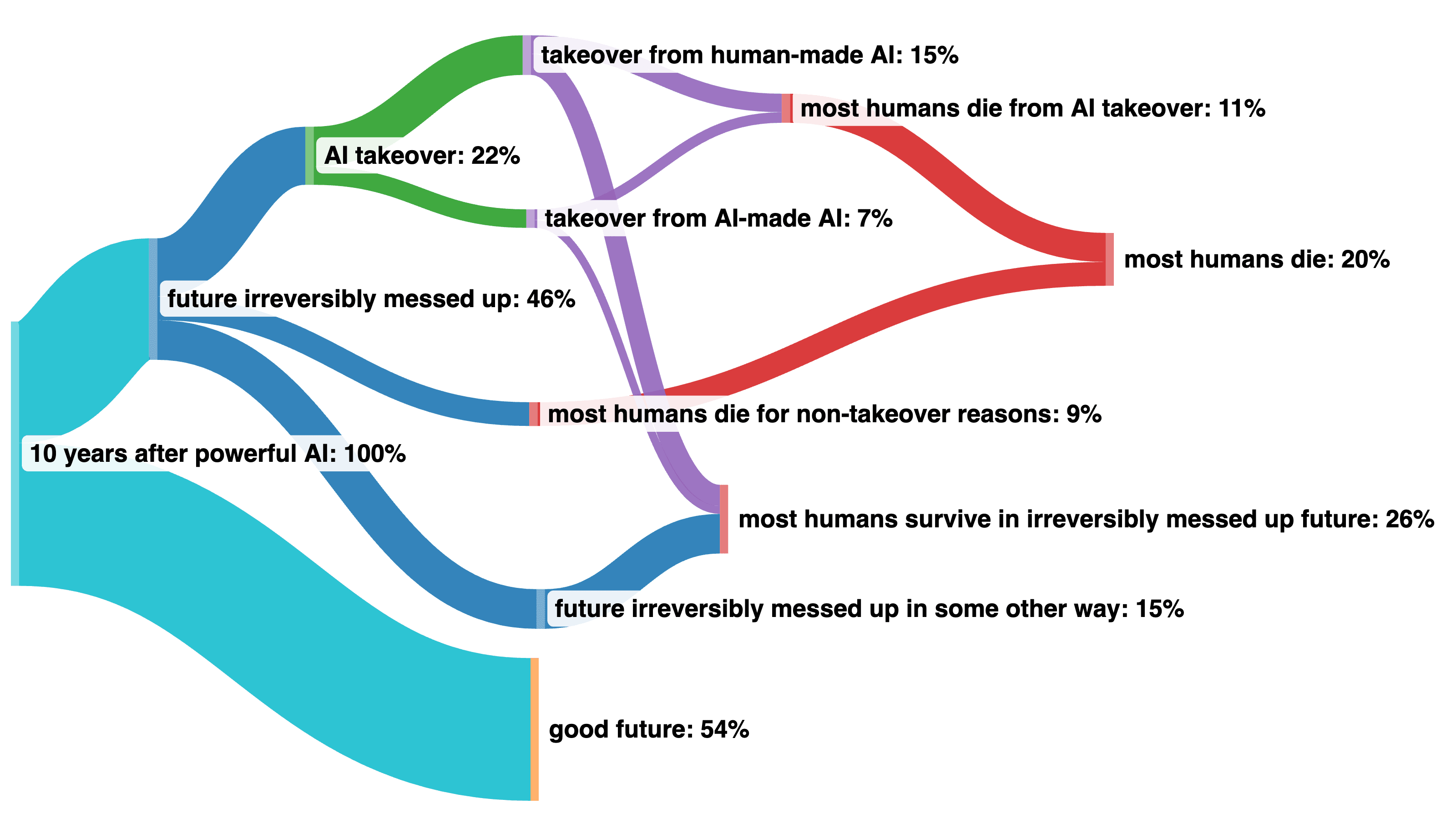
↑ comment by Victor Lecomte (victor-lecomte) · 2023-04-28T05:09:21.272Z · LW(p) · GW(p)
More geometric (but less faithful):
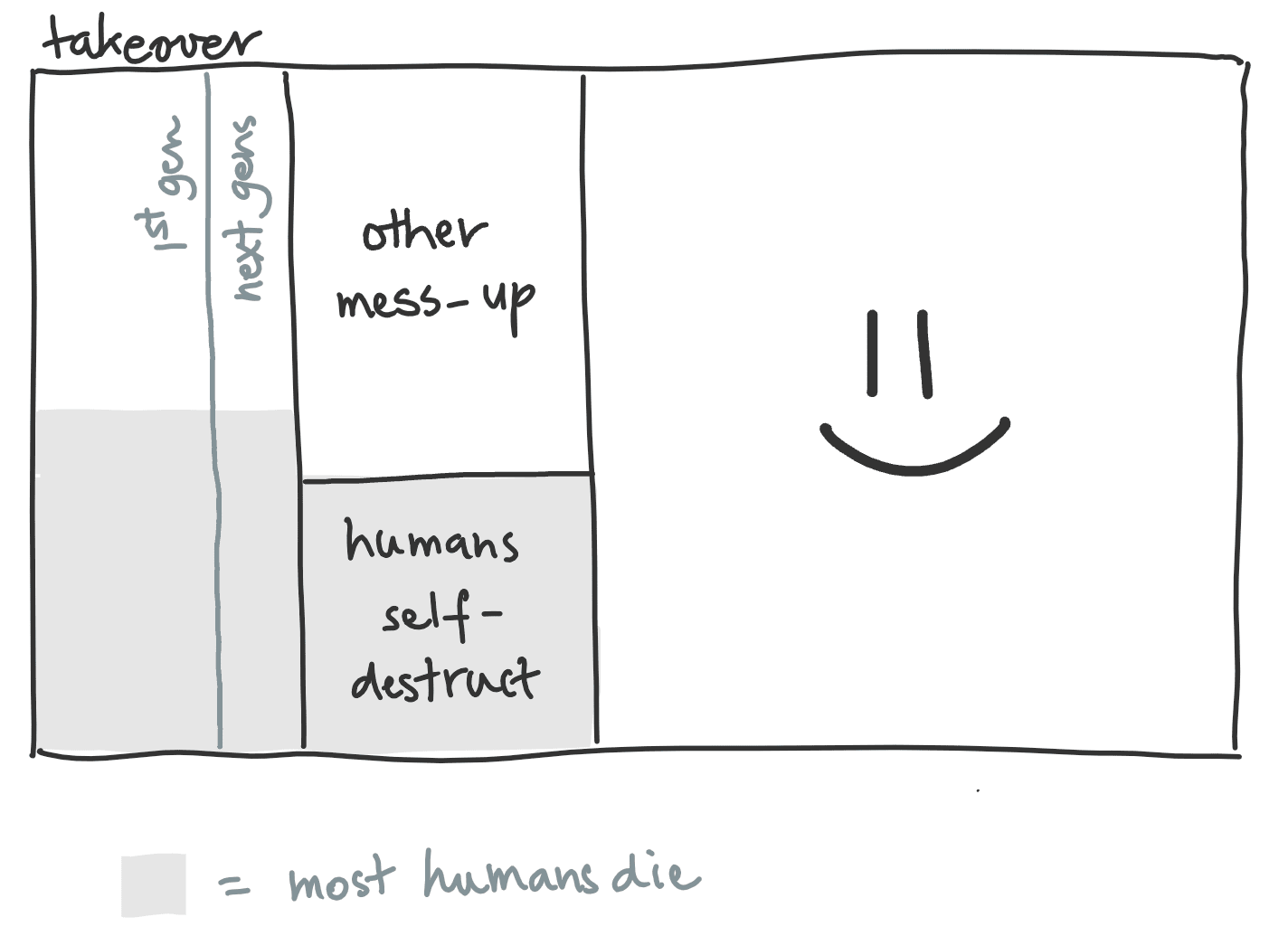
comment by interstice · 2023-04-27T20:49:00.860Z · LW(p) · GW(p)
Interesting that you think the risk of us "going crazy" after getting AI in some way is roughly comparable to overall AI takeover risk. I'd be interested to hear more if you have more detailed thoughts here. On this view it also seems like it could be a great x-risk-reduction opportunity if there are any tractable strategies, given how neglected it is compared to takeover risk.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-05-24T19:14:15.263Z · LW(p) · GW(p)
Probably considerably harder to influence than AI takeover given that it happens later in the singularity at a point where we have already had access to a huge amount of superhuman AI labor?
comment by Pavel Roubalík (pavel-roubalik) · 2023-04-27T22:48:49.407Z · LW(p) · GW(p)
Do you consider S-risk relevant too? If yes then what probability do you assign to it under the current ML paradigma?
comment by Max H (Maxc) · 2023-04-27T18:31:07.752Z · LW(p) · GW(p)
I think there are some conditional and unconditional probabilities that are worth estimating to distinguish between disagreements about:
- the technical nature of intelligence and alignment, as technical problems
- how the future is likely to play out, given geopolitical considerations and models of how people and organizations with power are likely to act, effectiveness of AI governance efforts, etc.
The conditional probability is risk of extinction / takeover / disempowerment, given that AI governance is non-existent or mostly ineffective. In notation, p(doom | no societal shift / effective intervention).
My estimate (and I think the estimate of many other doom-ier people) is that this probability is very high (95%+) - it is basically overdetermined that things will go pretty badly, absent radical societal change. This estimate is based on an intuition that the technical problem of building TAI seems to be somewhat easier than the technical problem of aligning that intelligence.
The next probability estimate is p(relevant actors / government / society etc. react correctly to avert the default outcome).
This probability feels much harder to estimate and shifts around much more, because it involves modeling human behavior on a global scale, in the face of uncertain future events. Worldwide reaction to COVID was a pretty big negative update; the developing AI race dynamics between big organizations is another negative update; some of the reactions to the FLI letter and the TIME article are small positive updates.
This probability also depends on the nature of the technical problem - for example, if aligning a superintelligence is harder than building one, but not much harder, then the size and precision of the intervention needed for a non-default outcome is probably a lot smaller.
Overall, I'm not optimistic about this probability, but like many, I'm hesitant to put down a firm number. I think that in worlds where things do not go badly though, lots of things look pretty radically different than they do now. And we don't seem to be on track for that to happen.
(You can then get an unconditional p(doom) by multiplying these two probabilities (or the appropriate complements) together. But since my estimate of the first conditional probability is very close to 1, shifts and updates come entirely from the fuzzy / shifty second probability.)
Replies from: paulfchristiano↑ comment by paulfchristiano · 2023-04-27T19:44:14.875Z · LW(p) · GW(p)
I'm somewhat optimistic that AI takeover might not happen (or might be very easy to avoid) even given no policy interventions whatsoever, i.e. that the problem is easily enough addressed that it can be done by firms in the interests of making a good product and/or based on even a modest amount of concern from their employees and leadership. Perhaps I'd give a 50% chance of takeover with no policy effort whatsoever to avoid it, compared to my 22% chance of takeover with realistic efforts to avoid it.
I think it's pretty hard to talk about "no policy effort whatsoever," or to distinguish voluntary measures from government regulation, or so on. So it's not totally clear what the "conditioned on no intervention" number means and I think that's actually a pretty serious ambiguity.
That said I do think my 50% vs your 95% points at a real disagreement---I feel like I have very little idea about how real a problem takeover will be, and have been so far unpersuaded by arguments that takeover is a very strong default. If you are confident that's a real problem that will be hard to fix, it might be reasonable to just double my takeover probabilities to take that into account.
Replies from: paulfchristiano, Maxc, laserfiche, sudo↑ comment by paulfchristiano · 2023-04-27T20:56:35.372Z · LW(p) · GW(p)
Actually I think my view is more like 50% from AI systems built by humans (compared to 15% unconditionally), if there is no effort to avoid takeover.
If you continue assuming "no effort to avoid takeover at all" into the indefinite future then I expect eventual takeover is quite likely, maybe more like 80-90% conditioned on nothing else going wrong, though in all these questions it really matters a lot what exactly you mean by "no effort" and it doesn't seem like a fully coherent counterfactual.
↑ comment by Max H (Maxc) · 2023-05-05T00:14:51.157Z · LW(p) · GW(p)
To clarify, the conditional probability in the parent comment is not conditioned on no policy effort or intervention, it's conditional on whatever policy / governance / voluntary measures are tried being insufficient or ineffective, given whatever the actual risk turns out to be.
If a small team hacking in secret for a few months can bootstrap to superintelligence using a few GPUs, the necessary level of policy and governance intervention is massive. If the technical problem has a somewhat different nature, then less radical interventions are plausibly sufficient.
I personally feel pretty confident that:
- Eventually, and maybe pretty soon (within a few years), the nature of the problem will indeed be that it is plausible a small team can bootstrap to superintelligence in secret, without massive resources.
- Such an intelligence will be dramatically harder to align than it is to build, and this difficulty will be non-obvious to many would-be builders.
And believe somewhat less confidently that:
- The governance and policy interventions necessary to robustly avert doom given these technical assumptions are massive and draconian.
- We are not on track to see such interventions put in place.
Given different views on the nature of the technical problem (the first two bullets), you can get a different level of intervention which you think is required for robust safety (the third bullet), and different estimate that such an intervention is put in place successfully (the fourth bullet).
I think it's also useful to think about cases where policy interventions were (in hindsight) obviously not sufficient to prevent doom robustly, but by luck or miracle (or weird anthropics) we make it through anyway. My estimate of this probability is that it's really low - on my model, we need a really big miracle, given actually-insufficient intervention. What "sufficient intervention" looks like, and how likely we are to get it, I find much harder to estimate.
↑ comment by laserfiche · 2023-04-29T09:48:40.310Z · LW(p) · GW(p)
Are you assuming that avoiding doom in this way will require a pivotal act? It seem absent policy intervention and societal change, even if some firms exhibit a proper amount of concern many others will not.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2023-04-29T15:27:02.611Z · LW(p) · GW(p)
It's unclear whether some people being cautious and some people being incautious leads to an AI takeover.
In this hypothetical, I'm including AI developers selling AI systems to law enforcement and militaries, which are used to enforce the law and win wars against competitors using AI. But I'm assuming we wouldn't pass a bunch of new anti-AI laws (and that AI developers don't become paramilitaries).
↑ comment by sudo · 2023-04-27T20:18:29.792Z · LW(p) · GW(p)
i.e. that the problem is easily enough addressed that it can be done by firms in the interests of making a good product and/or based on even a modest amount of concern from their employees and leadership
I'm curious about how contingent this prediction is on 1, timelines and 2, rate of alignment research progress. On 2, how much of your P(no takeover) comes from expectations about future research output from ARC specifically?
If tomorrow, all alignment researchers stopped working on alignment (and went to become professional tennis players or something) and no new alignment researchers arrived, how much more pessimistic would you become about AI takeover?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2023-04-27T20:36:43.145Z · LW(p) · GW(p)
These predictions are not very related to any alignment research that is currently occurring. I think it's just quite unclear how hard the problem is, e.g. does deceptive alignment occur, do models trained to honestly answer easy questions generalize to hard questions, how much intellectual work are AI systems doing before they can take over, etc.
I know people have spilled a lot of ink over this, but right now I don't have much sympathy for confidence that the risk will be real and hard to fix (just as I don't have much sympathy for confidence that the problem isn't real or will be easy to fix).
comment by Richard_Ngo (ricraz) · 2023-04-28T09:20:36.689Z · LW(p) · GW(p)
Quickly sketching out some of my views - deliberately quite basic because I don't typically try to generate very accurate credences for this sort of question:
- When I think about the two tasks "solve alignment" and "take over the world", I feel pretty uncertain which one will happen first. There are a bunch of considerations weighing in each direction. On balance I think the former is easier, so let's say that conditional on one of them happening, 60% that it happens first, and 40% that the latter happens first. (This may end up depending quite sensitively on deployment decisions.)
- There are also a bunch of possible misuse-related catastrophes. In general I don't see particularly strong arguments for any of them, but AIs are just going to be very good at generating weapons etc, so I'm going to give them a 10% chance of being existentially bad.
- I feel like I have something like 33% Knightian uncertainty [LW · GW] when reasoning in this domain - i.e. that there's a 33% chance that what ends up happening doesn't conform very well to any of my categories.
- So if we add this up we get numbers something like: P(takeover) = 24%, P(doom) = 31%, P(fine) = 36%, P(???) = 33%
I think that in about half of the takeover scenarios I'm picturing, many humans end up living pretty reasonable lives, and so the probability of everyone dying ends up more like 15-20% than 30%.
I notice that many of these numbers seem pretty similar to Paul's. My guess is mostly that this reflects the uninformativeness of explicit credences in this domain. I usually don't focus much on generating explicit credences because I don't find them very useful.
Compared with Paul, I think the main difference (apart from the Knightian uncertainty bit) is that I'm more skeptical of non-takeover xrisk. I basically think the world is really robust and it's gonna take active effort to really derail it.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2023-04-28T15:39:07.924Z · LW(p) · GW(p)
I think the substance of my views can be mostly summarized as:
- AI takeover is a real thing that could happen, not an exotic or implausible scenario.
- By the time we build powerful AI, the world will likely be moving fast enough that a lot of stuff will happen within the next 10 years.
- I think that the world is reasonably robust against extinction but not against takeover or other failures (for which there is no outer feedback loop keeping things on the rails).
I don't think my credences add very much except as a way of quantifying that basic stance. I largely made this post to avoid confusion after quoting a few numbers on a podcast and seeing some people misinterpret them.
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2023-04-28T16:06:23.609Z · LW(p) · GW(p)
Yepp, agree with all that.
comment by Wei Dai (Wei_Dai) · 2023-04-28T00:04:46.507Z · LW(p) · GW(p)
Probability that humanity has somehow irreversibly messed up our future within 10 years of building powerful AI: 46%
What's a short phrase that captures this? I've been using "AI-related x-risk" or just "AI x-risk" or "AI risk" but it sounds like you might disagree with using some or all of these phrases for this purpose (since most of this 46% isn't "from AI" in your perspective)?
(BTW it seems that we're not as far part as I thought. My own number for this is 80-90% and I thought yours was closer to 20% than 50%.)
Replies from: Lanrian, martin-vlach↑ comment by Lukas Finnveden (Lanrian) · 2023-04-28T01:59:34.847Z · LW(p) · GW(p)
Maybe x-risk driven by explosive (technological) growth?
Edit: though some people think AI point of no return might happen before the growth explosion.
↑ comment by Martin Vlach (martin-vlach) · 2024-04-29T11:45:34.238Z · LW(p) · GW(p)
AI-induced problems/risks
comment by Anirandis · 2023-08-17T13:12:43.076Z · LW(p) · GW(p)
What does the distribution of these non-death dystopias look like? There’s an enormous difference between 1984 and maximally efficient torture; for example, do you have a rough guess of what the probability distribution looks like if you condition on an irreversibly messed up but non-death future?
comment by avturchin · 2023-04-27T19:52:56.542Z · LW(p) · GW(p)
Does these numbers take into account that we will do our best in AI risk prevention, or they are expressing probability conditional that no prevention happens?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2023-04-27T19:55:28.378Z · LW(p) · GW(p)
These are all-things-considered estimates, including the fact that we will do our best to prevent AI risk.
comment by rvnnt · 2023-04-28T07:31:21.297Z · LW(p) · GW(p)
[...] bad futures without extinction, e.g. that AI systems take over but don’t kill everyone.
What probability would you assign to humans remaining but not being able to kill themseleves; i.e., to unescapable dystopias (vs. dystopias whose badness for any individual are bounded by death-by-suicide)?
comment by Seth Herd · 2023-04-27T19:04:02.558Z · LW(p) · GW(p)
Interesting. Your numbers imply a pretty good chance of everyone not dying soon after an AI takeover. I'd imagine that's either from a slow transition period in which humans are still useful, or from partially aligned AI. Partially successful alignment isn't discussed much. It's generally been assumed that we'd get alignment right or we won't.
But it seems much more possible to get partial alignment with systems based on deep networks with complex representations. These might be something like an AI that won't kill humans but will let us die out, or more subtle or arbitrary mixes of aligned and unaligned behavior.
That's not particularly helpful, but it does point to a potentially important and relatively unaddressed question: how precise (and stable [LW · GW]) does alignment need to be to get good results?
If anyone could point me to work on partial alignment, or the precision necessary for alignment, I'd appreciate it.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2023-04-27T19:50:26.907Z · LW(p) · GW(p)
The probability of human survival is primarily driven by AI systems caring a small amount about humans (whether due to ECL, commonsense morality, complicated and messy values, acausal trade, or whatever---I find all of those plausible).
I haven't thought deeply about this question, because a world where AI systems don't care very much about humans seems pretty bad for humans in expectation. I do think it matters whether the probability we all literally die is 10% or 50% or 90%, but it doesn't matter very much to my personal prioritization.
comment by WilliamKiely · 2024-12-02T04:03:51.858Z · LW(p) · GW(p)
Something I noticed:
"Probability that most humans die because of an AI takeover: 11%" should actually read as "Probability that most humans die [within 10 years of building powerful AI] because of an AI takeover: 11%" since it is defined as a sub-set of the 20% of scenarios in which "most humans die within 10 years of building powerful AI".
This means that there is a scenario with unspecified probability taking up some of the remaining 11% of the 22% of AI takeover scenarios that corresponds to the "Probability that most humans die because of an AI takeover more than 10 years after building powerful AI".
In other words, Paul's P(most humans die because of an AI takeover | AI takeover) is not 11%/22%=50%, as a quick reading of his post or a quick look at my visualization [LW(p) · GW(p)] seems to imply, but is actually undefined, and is actually >11%/22% = >50%.
For example, perhaps Paul thinks that there is a 3% chance that there is an AI takeover that causes most humans to die more than 10 years after powerful AI is developed. In this case, Paul's P(most humans die because of an AI takeover | AI takeover) would be equal to (11%+3%)/22%=64%.
I don't know if Paul himself noticed this. But worth flagging this when revising these estimates later, or meta-updating on them.
comment by Review Bot · 2024-03-09T21:12:10.761Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Christopher King (christopher-king) · 2023-04-29T01:38:07.850Z · LW(p) · GW(p)
Here's a question:
If you were a super forecaster and reviewed all the public information and thought really hard, how much do you expect the probabilities to move? Of course it doesn't make sense to predict which direction, but could you estimate the magnitude of the change? Vaguely like the "VIX" on your beliefs. Or another way to phrase is how many bits of information do you think are missing but are in theory available right now.
This question is basically asking how much of this is your own imprecision vs what you think nobody knows.
comment by WilliamKiely · 2023-04-27T22:06:37.197Z · LW(p) · GW(p)
Probability that most humans die because of an AI takeover: 11%
This 11% is for "within 10 years" as well, right?
comment by WilliamKiely · 2023-04-27T22:05:48.756Z · LW(p) · GW(p)
Probability that the AI we build doesn’t take over, but that it builds even smarter AI and there is a takeover some day further down the line: 7%
Does "further down the line" here mean "further down the line, but still within 10 years of building powerful AI"? Or do you mean it unqualified?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2023-04-28T01:40:50.505Z · LW(p) · GW(p)
I think almost all the cumulative takeover probability is within 10 years of building powerful AI. Didn't draw the distinction here, but my views aren't precise enough to distinguish.
comment by Aryeh Englander (alenglander) · 2023-04-27T20:49:07.402Z · LW(p) · GW(p)
When you say that you'd give different probability estimates on different days, do you think you can represent that as you sampling on different days from a probability distribution over your "true" latent credence? If yes, do you think it would be useful to try to estimate what that distribution looks like, and then report the mean or perhaps the 90% CI or something like that? So for example, if your estimate typically ranges between 33% and 66% depending on the day with a mean of say 50%, then instead of reporting what you think today (the equivalent of taking a single random sample from the distribution), maybe you could report 50% because that's your mean and/or report that your estimate typically ranges from 33% to 66%.
comment by sudo · 2023-04-27T18:06:34.107Z · LW(p) · GW(p)
Epistemic Status: First read. Moderately endorsed.
I appreciate this post and I think it's generally good for this sort of clarification to be made.
One distinction is between dying (“extinction risk”) and having a bad future (“existential risk”). I think there’s a good chance of bad futures without extinction, e.g. that AI systems take over but don’t kill everyone.
This still seems ambiguous to me. Does "dying" here mean literally everyone? Does it mean "all animals," all mammals," "all humans," or just "most humans? If it's all humans dying, do all humans have to be killed by the AI? Or is it permissible that (for example) the AI leaves N people alive, and N is low enough that human extinction follows at the end of these people's natural lifespan?
I think I understand your sentence to mean "literally zero humans exist X years after the deployment of the AI as a direct causal effect of the AI's deployment."
It's possible that this specific distinction is just not a big deal, but I thought it's worth noting.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2023-04-27T19:48:16.826Z · LW(p) · GW(p)
I think these questions are all still ambiguous, just a little bit less ambiguous.
I gave a probability for "most" humans killed, and I intended P(>50% of humans killed). This is fairly close to my estimate for E[fraction of humans killed].
I think if humans die it is very likely that many non-human animals die as well. I don't have a strong view about the insects and really haven't thought about it.
In the final bullet I implicitly assumed that the probability of most humans dying for non-takeover reasons shortly after building AI was very similar to the probability of human extinction; I was being imprecise, I think that's kind of close to true but am not sure exactly what my view is.
comment by Petr 'Margot' Andreev (petr-andreev) · 2023-04-27T20:33:43.981Z · LW(p) · GW(p)
Without big progress
in average in 36-200 year
surviving = 1 - (1 - disaster A) * (1 - disaster B) * (1 - disaster C)
in nowadays interantional equilibrium life will die 100%
but 'DON'T PANIC'
With AI, quantum computer, fusion, code is law, spaceships and other things we have at least chances to jump into new equilibriums with some kind of diversification (planets, systems etc)
thinking of existential risks in context of AI only is a great danger egoism cause we have many plroblems on different things
AI security need to be build in system manner with all other risks: pandemic, cosmos threats, nuclear, energy etc
We don't need course 'Humanity will not die with AI'
We need something like sustainable growth is need for all forms of life, rationality with humans in charge or something similar.
Looks like we need complex models that use all existential risks and we need to use any chances we could find.
Could you give chances of AI threats in one particular year?
And how it rise with years?
If we will got AGI (or she will got us) will we be out of danger?
I mean if we will pass GAI threat will we have new threats?
I mean could good GAI solve other problems?
for example we use only grain of energy from one billions of energy that star Sol give to Earth. why do AI will need some of humans body atoms when it could get all that energy?