Posts
Comments
Maybe the recent tariff blowup is actually just a misunderstanding due to bad terminology, and all we need to do is popularize some better terms or definitions. We're pretty good at that around here, right?
Here's my proposal: flip the definitions of "trade surplus" and "trade deficit." This might cause a bit of confusion at first, and a lot of existing textbooks will need updating, but I believe these new definitions capture economic reality more accurately, and will promote clearer thinking and maybe even better policy from certain influential decision-makers, once widely adopted.
New definitions:
Trade surplus: Country A has a bilateral "trade surplus" with Country B if Country A imports more tangible goods (cars, steel, electronics, etc.) from Country B than it exports back. In other words, Country A ends up with more real, physical items. Country B, meanwhile, ends up with more than it started with of something much less important: fiat currency (flimsy paper money) or 1s and 0s in a digital ledger (probably not even on a blockchain!).
If you extrapolate this indefinitely in a vacuum, Country A eventually accumulates all of Country B's tangible goods, while Country B is left with a big pile of paper. Sounds like a pretty sweet deal for Country A if you ask me.
It's OK if not everyone follows this explanation or believes it - they can tell it's the good one because it has "surplus" in the name. Surely everyone wants a surplus.
Trade deficit: Conversely, Country A has a "trade deficit" if it exports more tangible resources than it imports, and thus ends up with less goods on net. In return, it only receives worthless fiat currency from some country trying to hoard actual stuff for their own people. Terrible deal!
Again, if you don't totally follow, that's OK, just pay attention to the word "deficit". Everyone knows that deficits are bad and should be avoided.
Under the new definitions, it becomes clear that merely returning to the previous status quo of a few days ago, where the US only "wins" the trade war by several hundred billion dollars, is insufficient for the truly ambitious statesman. Instead, the US government should aggressively mint more fiat currency in order to purchase foreign goods, magnifying our trade surplus and ensuring that in the long run the United States becomes the owner of all tangible global wealth.
Addressing second order concerns: if we're worried about a collapse in our ability to manufacture key strategic goods at home during a crisis, we can set aside part of the resulting increased surplus to subsidize domestic production in those areas. Some of the extra goods we're suddenly importing will probably be pretty useful in getting some new factories of our own off the ground. (But of course we shouldn't turn around and export any of that domestic production to other countries! That would only deplete our trade surplus.)
Describing misaligned AIs as evil feels slightly off. Even "bad goals" makes me think there's a missing mood somewhere. Separately, describing other peoples' writing about misalignment this way is kind of straw.
Current AIs mostly can't take any non-fake responsibility for their actions, even if they're smart enough to understand them. An AI advising someone to e.g. hire a hitman to kill their husband is a bad outcome if there's a real depressed person and a real husband who are actually harmed. An AI system would be responsible (descriptively / causally, not normatively) for that harm to the degree that it acts spontaneously and against its human deployers' wishes, in a way that is differentially dependent on its actual circumstances (e.g. being monitored / in a lab vs. not).
Unlike current AIs, powerful, autonomous, situationally-aware AI could cause harm for strategic reasons or as a side effect of executing large-scale, transformative plans that are indifferent (rather than specifically opposed) to human flourishing. A misaligned AI that wipes out humanity in order to avoid shutdown is a tragedy, but unless the AI is specifically spiteful or punitive in how it goes about that, it seems kind of unfair to call the AI itself evil.
The original tweets seem at least partially tongue-in-cheek? Trade has lots of benefits that don't depend on the net balance. If Country A buys $10B of goods from Country B and sells $9B of other goods to country B, that is $19B of positive-sum transactions between individual entities in each country, presumably with all sorts of positive externalities and implications about your economy.
The fact that the net flow is $1B in one direction or the other just doesn't matter too much. Having a large trade surplus (or large trade deficit) is a proxy for generally doing lots of trading and industry, which will tend to correlate with a lot of other things that made or will make you wealthy. But it would be weird if a country could get rich solely by running a trade surplus, while somehow avoiding reaping any of the other usual benefits of trading. "Paying other countries to discern your peoples' ability to produce" is plausibly a benefit that you get from a trade surplus even if you try hard to avoid all the others, though.
My guess is that the IT and computer security concerns are somewhat exaggerated and probably not actually that big of a deal, nor are they likely to cause any significant or lasting damage on their own. At the very least, I wouldn't put much stock in what a random anonymous IT person says, especially when those words are filtered through and cherry-picked by a journalist.
These are almost certainly sprawling legacy systems, not a modern enterprise cloud where you can simply have a duly authorized superadmin grant a time-limited ReadOnly IAM permission to * or whatever, along with centralized audit logging and sophisticated change management. There are probably more old-school / manual processes in place, which require going through layers of humans who aren't inclined to be cooperative or speedy, especially at this particular moment. I think Elon (and Trump) have some justified skepticism of those processes and the people who implemented them.
Still, there's going to be some kind of audit logging + technical change management controls, and I kind of doubt that any of Elon's people are going to deliberately sidestep or hide from those, even if they don't follow all the on-paper procedures and slash some red tape.
And ultimately, even sophisticated technical controls are not a substitute for actual legal authority, which they (apparently / perhaps questionably) have. I'll be much more concerned if they start violating court orders, even temporarily. e.g. I think it would be very bad (and more plausible than IT malfeasance or negligence) if they are ordered to stop doing whatever by a lower court, but they don't actually stop, or slow-walk on reversing everything, because they expect to win on appeal to the Supreme Court (even if they're correct about their appeal prospects). IDK about Elon's people specifically, but I think ignoring court orders (especially lower courts and temporary injunctions) is a more dangerous form of institutional decay that Trump is likely to usher in, especially since the legislature seems unlikely to offer any real push-back / rebuke.
It seems more elegant (and perhaps less fraught) to have the reference class determination itself be a first class part of the regular CEV process.
For example, start with a rough set of ~all alive humans above a certain development threshold at a particular future moment, and then let the set contract or expand according to their extrapolated volition. Perhaps the set or process they arrive at will be like the one you describe, perhaps not. But I suspect the answer to questions about how much to weight the preferences (or extrapolated CEVs) of distant ancestors and / or "edge cases" like the ones you describe in (b) and (c) wouldn't be affected too much by the exact starting conditions either way.
Re: the point about hackability and tyranny, humans already have plenty of mundane / naturalistic reasons to seek power / influence / spread of their own particular current values, absent any consideration about manipulating a reference class for a future CEV. Pushing more of the CEV process into the actual CEV itself minimizes the amount of further incentive to do these things specifically for CEV reasons. Whereas, if a particular powerful person or faction doesn't like your proposed lock-in procedure, they now have (more of) an incentive to take power beforehand to manipulate or change it.
My wife completed two cycles of IVF this year, and we had the sequence data from the preimplantation genetic testing on the resulting embryos analyzed for polygenic factors by the unnamed startup mentioned in this post.
I can personally confirm that the practical advice in this post is generally excellent.
The basic IVF + testing process is pretty straightforward (if expensive), but navigating the medical bureaucracy can be a hassle once you want to do anything unusual (like using a non-default PGT provider), and many clinics aren't going to help you with anything to do with polygenic screening, even if they are open to it in principle. So knowing exactly what you want and what you need to ask for is key.
Since this post was written, there have been lots of other developments and related posts in this general area:
- Significantly Enhancing Adult Intelligence With Gene Editing May Be Possible
- Superbabies: Putting The Pieces Together
- Gameto Announces World’s First Live Birth Using Fertilo Procedure that Matures Eggs Outside the Body
- Overview of strong human intelligence amplification methods: Genomic approaches
And probably many others I am forgetting. But if you're a prospective parent looking for practical advice on how to navigate the IVF process and take advantage of the latest in genetic screening technology, this post is still the best place to start that I know of. Some of the things in the list above are more speculative, but the technology for selection is basically ready and practical now, and the effect size doesn't have to be very large for it to beat the status quo of having an embryologist eyeball it.
I think this post is a slam dunk for a +9 and a spot in the LW canon, both for its object-level information and its exemplary embodiment of the virtue of empiricism and instrumental rationality. The rest of this review details my own experience with IVF in the U.S. in 2024.
This section of the original post basically covers it, but to recap, the two main things you'll want to ask your prospective IVF clinic are:
- Can we use Orchid Labs or Genomic Prediction for PGT?
- Can we implant any healthy embryo of our choosing? (some clinics can have policies against sex selection, etc.)
In my experience, the best time to ask these questions is in-person at your initial consultation; it can be hard to get answers over the phone / in email before you're at least a prospective patient, since they generally require a doctor or NP to answer.
The good news is, if you get affirmative answers to these questions, you mostly don't need to worry about whether the clinic or your embryologist is skeptical or even outright hostile to polygenic screening, because you can simply request your sequence data from your PGT provider directly and have it analyzed on your own.
Note: Genomic Prediction offers their own polygenic screening test (LifeView), but if you're planning to have a third party analyze the sequence data for non-disease traits, you don't need this. You can just have your IVF clinic order PGT-A tests from GP, and then request your raw sequence data from GP directly once you get the PGT-A results. AFAIK the actual sequencing that GP does is the same regardless of what test you order from them, and they're happy to share the raw data with you if you ask.
Another thing you'll want to confirm is whether you can store any aneuploid embryo(s) long-term. Aneuploid embryos are typically considered not viable and most clinics won't even try to implant them. But they're worth keeping frozen speculatively, in case future technology allows them to be repaired, etc. Some clinics will have a policy of automatically discarding confirmed-aneuploid embryos unless you make specific arrangements to do something else with them. Usually this will be a question in a big packet of paperwork you'll have to fill out about what you want to do with the embryos / eggs in various scenarios, e.g. death / divorce / time limit etc. so just make sure to read carefully.
On selecting a good-quality IVF clinic: the live birth metrics in this post are a good starting point, but probably confounded somewhat by the population the clinic serves, and realistically the biggest factor in determining how many embryos you get is going to be your personal health factors and age. My wife is over 30 and in pretty good shape and took a bunch of vitamins before / during the cycles (B12, Omega-3, Myo-Inositol, a prenatal vitamin) and we ended up with 21 eggs retrieved across two cycles, which is right around the expected number for her age.
These attrited down to 10 mature embryos during the fertilization process, 5 of which were screened out as aneuploid via ordinary PGT-A. We had the remaining 5 embryos polygenically screened.
We're planning to start implanting next year, so I can't speak to that part of the process personally yet, but overall we're very happy with the results so far. There was a clear "winner" among the embryos we screened that will be our first choice for implantation, but it's nice to have all the data we can on all the embryos, and depending on how things go we may end up using more than one of them down the line.
The polygenic screening wasn't cheap, and given the number of embryos we had to select from, the maximum possible benefit is pretty mild (2.3 bits of selection if we only use one of the 5 and it successfully implants). But given the hassle and expense of IVF itself (not to mention pregnancy and raising a child...) it seems overwhelmingly worth it. We were considering IVF for fertility preservation reasons anyway, so the main question for us was the marginal cost of the extra screening on top.
I'd like to write a longer post with my own takes about having / raising kids on the eve of AI, but for now I'll just say a few things:
- The choice about whether to have kids is always a personal one, but right now seems like as good a time as any, historically speaking, and takes like these seem crazy wrong to me. Even if you're thinking purely in terms of the advantage you can give your kids (probably not a good idea to think this way), by far the biggest advantage is being marginally earlier. If you're interested in having kids but worried about the costs or effectiveness of current IVF / screening methods, consider just having kids the old-fashioned way instead of delaying.
- I have short timelines and expect the default outcome from ASI being developed is swift human extinction, but I still think it's worth having kids now, at least for me personally. My wife and I had happy childhoods and would have enjoyed being alive even it was only for a short time, and hopefully that's at least a somewhat heritable trait. And regardless of the endpoint, I expect things to be pretty OK (even great) at least for me and my family, right up until the end, whenever that is. Despite being a "doomer", I am long the market, and expect to be pretty well-off even if those particular bets don't pay off and the larger world is somewhat chaotic in the short term.
- 2.3 bits of selection on a single kid realistically isn't going to make a difference in any kind of "Manhattan project for human intelligence enhancement" and that's not why we did it. But my sense from having gone through this process is that the barriers to some of the things that Tsvi describes here are more social and financial and scale than technical.
My main point was that I thought recent progress in LLMs had demonstrated progress at the problem of building such a function, and solving the value identification problem, and that this progress goes beyond the problem of getting an AI to understand or predict human values.
I want to push back on this a bit. I suspect that "demonstrated progress" is doing a lot of work here, and smuggling an assumption that current trends with LLMs will continue and can be extrapolated straightforwardly.
It's true that LLMs have some nice properties for encapsulating fuzzy and complex concepts like human values, but I wouldn't actually want to use any current LLMs as a referent or in a rating system like the one you propose, for obvious reasons.
Maybe future LLMs will retain all the nice properties of current LLMs while also solving various issues with jailbreaking, hallucination, robustness, reasoning about edge cases, etc. but declaring victory already (even on a particular and narrow point about value identification) seems premature to me.
Separately, I think some of the nice properties you list don't actually buy you that much in practice, even if LLM progress does continue straightforwardly.
A lot of the properties you list follow from the fact that LLMs are pure functions of their input (at least with a temperature of 0).
Functional purity is a very nice property, and traditional software that encapsulates complex logic in pure functions is often easier to reason about, debug, and formally verify vs. software that uses lots of global mutable state and / or interacts with the outside world through a complex I/O interface. But when the function in question is 100s of GB of opaque floats, I think it's a bit of a stretch to call it transparent and legible just because it can be evaluated outside of the IO monad.
Aside from purity, I don't think your point about an LLM being a "particular function" that can be "hooked up to the AI directly" is doing much work - input() (i.e. asking actual humans) seems just as direct and particular as llm(). If you want your AI system to actually do something in the messy real world, you have to break down the nice theoretical boundary and guarantees you get from functional purity somewhere.
More concretely, given your proposed rating system, simply replace any LLM calls with a call that just asks actual humans to rate a world state given some description, and it seems like you get something that is at least as legible and transparent (in an informal sense) as the LLM version. The main advantage with using an LLM here is that you could potentially get lots of such ratings cheaply and quickly. Replay-ability, determinism and the relative ease of interpretability vs. doing neuroscience on the human raters are also nice, but none of these properties are very reassuring or helpful if the ratings themselves aren't all that good. (Also, if you're doing something with such low sample efficiency that you can't just use actual humans, you're probably on the wrong track anyway.)
Economic / atomic takeoff
For specifically discussing the takeoff models in the original Yudkowsky / Christiano discussion, what about:
Economic vs. atomic takeoff
Economic takeoff because Paul's model implies rapid and transformative economic growth prior to the point at which AIs can just take over completely. Whereas Eliezer's model is that rapid economic growth prior to takeover is not particularly necessary - a sufficiently capable AI could act quickly or amass resources while keeping a low profile, such that from the perspective of almost all humanity, takeover is extremely sudden.
Note: "atomic" here doesn't necessarily mean "nanobots" - the goal of the term is to connote that an AI does something physically transformative, e.g. releasing a super virus, hacking / melting all uncontrolled GPUs, constructing a Dyson sphere, etc. A distinguishing feature of Eliezer's model is that those kinds of things could happen prior to the underlying AI capabilities that enable them having more widespread economic effects.
IIUC, both Eliezer and Paul agree that you get atomic takeoff of some kind eventually, so one of the main disagreements between Paul and Eliezer could be framed as their answer to the question: "Will economic takeoff precede atomic takeoff?" (Paul says probably yes, Eliezer says maybe.)
Separately, an issue I have with smooth / gradual vs. sharp / abrupt (the current top-voted terms) is that they've become a bit overloaded and conflated with a bunch of stuff related to recent AI progress, namely scaling laws and incremental / iterative improvements to chatbots and agents. IMO, these aren't actually closely related nor particularly suggestive of Christiano-style takeoff - if anything it seems more like the opposite:
- Scaling laws and the current pace of algorithmic improvement imply that labs can continue improving the underlying cognitive abilities of AI systems faster than those systems can actually be deployed into the world to generate useful economic growth. e.g. o1 is already "PhD level" in many domains, but doesn't seem to be on pace to replace a significant amount of human labor or knowledge work before it is obsoleted by Opus 3.5 or whatever.
- Smooth scaling of underlying cognition doesn't imply smooth takeoff. Predictable, steady improvements on a benchmark via larger models or more compute don't tell you which point on the graph you get something economically or technologically transformative.
I'm curious what you think of Paul's points (2) and (3) here:
- Eliezer often talks about AI systems that are able to easily build nanotech and overpower humans decisively, and describes a vision of a rapidly unfolding doom from a single failure. This is what would happen if you were magically given an extraordinarily powerful AI and then failed to aligned it, but I think it’s very unlikely what will happen in the real world. By the time we have AI systems that can overpower humans decisively with nanotech, we have other AI systems that will either kill humans in more boring ways or else radically advanced the state of human R&D. More generally, the cinematic universe of Eliezer’s stories of doom doesn’t seem to me like it holds together, and I can’t tell if there is a more realistic picture of AI development under the surface.
- One important factor seems to be that Eliezer often imagines scenarios in which AI systems avoid making major technical contributions, or revealing the extent of their capabilities, because they are lying in wait to cause trouble later. But if we are constantly training AI systems to do things that look impressive, then SGD will be aggressively selecting against any AI systems who don’t do impressive-looking stuff. So by the time we have AI systems who can develop molecular nanotech, we will definitely have had systems that did something slightly-less-impressive-looking.
And specifically to what degree you think future AI systems will make "major technical contributions" that are legible to their human overseers before they're powerful enough to take over completely.
You write:
I expect that, shortly after AIs are able to autonomously develop, analyze and code numerical algorithms better than humans, there’s going to be some pretty big (like, multiple OOMs) progress in AI algorithmic efficiency (even ignoring a likely shift in ML/AI paradigm once AIs start doing the AI research). That’s the sort of thing which leads to a relatively discontinuous takeoff.
But how likely do you think it is that these OOM jumps happen before vs. after a decisive loss of control?
My own take: I think there will probably be enough selection pressure and sophistication in primarily human-driven R&D processes alone to get to uncontrollable AI. Weak AGIs might speed the process along in various ways, but by the time an AI itself can actually drive the research process autonomously (and possibly make discontinuous progress), the AI will already also be capable of escaping or deceiving its operators pretty easily, and deception / escape seems likely to happen first for instrumental reasons.
But my own view isn't based on the difficulty of verification vs. generation, and I'm not specifically skeptical of bureaucracies / delegation. Doing bad / fake R&D that your overseers can't reliably check does seem somewhat easier than doing real / good R&D, but not always, and as a strategy seems like it would usually be dominated by "just escape first and do your own thing".
That sounds like a frustrating dynamic. I think hypothetical dialogues like this can be helpful in resolving disagreements or at least identifying cruxes when fleshed out though. As someone who has views that are probably more aligned with your interlocutors, I'll try articulating my own views in a way that might steer this conversation down a new path. (Points below are intended to spur discussion rather than win an argument, and are somewhat scattered / half-baked.)
My own view is that the behavior of current LLMs is not much evidence either way about the behavior of future, more powerful AI systems, in part because current LLMs aren't very impressive in a mundane-utility sense.
Current LLMs look to me like they're just barely capable enough to be useful at all - it's not that they "actually do what we want", rather, it's that they're just good enough at following simple instructions when placed in the right setup / context (i.e. carefully human-designed chatbot interfaces, hooked up to the right APIs, outputs monitored and used appropriately, etc.) to be somewhat / sometimes useful for a range of relatively simple tasks.
So the absence of more exotic / dangerous failure modes can be explained mostly as a lack of capabilities, and there's just not that much else to explain or update on once the current capability level is accounted for.
I can sort of imagine possible worlds where current-generation LLMs all stubbornly behave like Sydney Bing, and / or fall into even weirder failure modes that are very resistant to RLHF and the like. But I think it would also be wrong to update much in the other direction in a "stubborn Sydney" world.
Do you mind giving some concrete examples of what you mean by "actually do what we want" that you think are most relevant, and / or what it would have looked like concretely to observe evidence in the other direction?
A somewhat different reason I think current AIs shouldn't be a big update about future AIs is that current AIs lack the ability to bargain realistically. GPT-4 may behaviorally do what the user or developer wants when placed in the right context, but without the ability to bargain in a real way, I don't see much reason to treat this observation very differently from the fact that my washing machine does what I want when I press the right buttons. The novelty of GPT-4 vs. a washing machine is in its generality and how it works internally, not the literal sense in which it does what the user and / or developer wants, which is a common feature of pretty much all useful technology.
I can imagine worlds in which the observation of AI system behavior at roughly similar capability levels to the LLMs we actually have would cause me to update differently and particularly towards your views, but in those worlds the AI systems themselves would look very different.
For example, suppose someone built an AI system with ~GPT-4 level verbal intelligence, but as a natural side effect of something in the architecture, training process, or setup (as opposed to deliberate design by the developers), the system also happened to want resources of some kind (energy, hardware, compute cycles, input tokens, etc.) for itself, and could bargain for or be incentivized by those resources in the way that humans and animals can often be incentivized by money or treats.
In the world we're actually in, you can sometimes get better performance out of GPT-4 at inference time by promising to pay it money or threatening it in various ways, but all of those threats and promises are extremely fake - you couldn't follow through even if you wanted to, and GPT-4 has no way of perceiving your follow-through or lack thereof anyway. In some ways, GPT-4 is much smarter than a dog or a young child, but you can bargain with dogs and children in very real ways, and if you tried to fake out a dog or a child by pretending to give them a treat without following through, they would quickly notice and learn not to trust you.
(I realize there are some ways in which you could analogize various aspects of real AI training processes to bargaining processes, but I would find optimistic analogies between AI training and human child-rearing more compelling in worlds where AI systems at around GPT-4 level were already possible to bargain with or incentivize realistically at runtime, in ways more directly analogous to how we can directly bargain with natural intelligences of roughly comparable level or lower already.)
Zooming out a bit, "not being able to bargain realistically at runtime" is just one of the ways that LLMs appear to be not like known natural intelligence once you look below surface-level behavior. There's a minimum level of niceness / humanlikeness / "do what we want" ability that any system necessarily has to have in order to be useful to humans at all, and for tasks that can be formulated as text completion problems, the minimum amount seems to be something like "follows basic instructions, most of the time". But I have not personally seen a strong argument for why current LLMs have much more than the minimum amount of humanlike-ness / niceness, nor why we should expect future LLMs to have more.
Suppose we think of ourselves as having many different subagents that focus on understanding the world in different ways - e.g. studying different disciplines, using different styles of reasoning, etc. The subagent that thinks about AI from first principles might come to a very strong opinion. But this doesn't mean that the other subagents should fully defer to it (just as having one very confident expert in a room of humans shouldn't cause all the other humans to elect them as the dictator). E.g. maybe there's an economics subagent who will remain skeptical unless the AI arguments can be formulated in ways that are consistent with their knowledge of economics, or the AI subagent can provide evidence that is legible even to those other subagents (e.g. advance predictions).
Do "subagents" in this paragraph refer to different people, or different reasoning modes / perspectives within a single person? (I think it's the latter, since otherwise they would just be "agents" rather than subagents.)
Either way, I think this is a neat way of modeling disagreement and reasoning processes, but for me it leads to a different conclusion on the object-level question of AI doom.
A big part of why I find Eliezer's arguments about AI compelling is that they cohere with my own understanding of diverse subjects (economics, biology, engineering, philosophy, etc.) that are not directly related to AI - my subagents for these fields are convinced and in agreement.
Conversely, I find many of the strongest skeptical arguments about AI doom to be unconvincing precisely because they seem overly reliant on a "current-paradigm ML subagent" that their proponents feel should be dominant, or at least more heavily weighted than I think is justified.
That will push P(doom) lower because most frames from most disciplines, and most styles of reasoning, don't predict doom.
This might be true and useful for getting some kind of initial outside-view estimate, but I think you need some kind of weighting rule to make this work as reasoning strategy even at a meta level. Otherwise, aren't you vulnerable to other people inventing lots of new frames and disciplines? I think the answer in geometric rationality terms is that some subagents will perform poorly and quickly lose their Nash bargaining resources, and then their contribution to future decision-making / conclusion-making will be down-weighted. But I don't think the only way for a subagent to "perform" for the purposes of deciding on a weight is by making externally legible advance predictions.
Maybe a better question than "time to AGI" is time to mundanely transformative AGI. I think a lot of people have a model of the near future in which a lot of current knowledge work (and other work) is fully or almost-fully automated, but at least as of right this moment, that hasn't actually happened yet (despite all the hype).
For example, one of the things current A(G)Is are supposedly strongest at is writing code, but I would still rather hire a (good) junior software developer than rely on currently available AI products for just about any real programming task, and it's not a particularly close call. I do think there's a pretty high likelihood that this will change imminently as products like Devin improve and get more widely deployed, but it seems worth noting (and finding a term for) the fact that this kind of automation so far (mostly) hasn't actually happened yet, aside from certain customer support and copyediting jobs.
I think when someone asks "what is your time to AGI", they're usually asking about when you expect either (a) AI to radically transform the economy and potentially usher in a golden age of prosperity and post-scarcity or (b) the world to end.
And maybe I am misremembering history or confused about what you are referring to, but in my mind, the promise of the "AGI community" has always been (implicitly or explicitly) that if you call something "human-level AGI", it should be able to get you to (a), or at least have a bigger economic and societal impact than currently-deployed AI systems have actually had so far. (Rightly or wrongly, the ballooning stock prices of AI and semiconductor companies seem to be mostly an expectation of earnings and impact from in-development and future products, rather than expected future revenues from wider rollout of any existing products in their current form.)
I actually agree that a lot of reasoning about e.g. the specific pathways by which neural networks trained via SGD will produce consequentialists with catastrophically misaligned goals is often pretty weak and speculative, including in highly-upvoted posts like Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover.
But to expand on my first comment, when I look around and see any kind of large effect on the world, good or bad (e.g. a moral catastrophe, a successful business, strong optimization around a MacGuffin), I can trace the causality through a path that is invariably well-modeled by applying concepts like expected utility theory (or geometric rationality, if you prefer), consequentialism, deception, Goodharting, maximization, etc. to the humans involved.
I read Humans provide an untapped wealth of evidence about alignment and much of your other writing as disagreeing with the (somewhat vague / general) claim that these concepts are really so fundamental, and that you think wielding them to speculate about future AI systems is privileging the hypothesis or otherwise frequently leads people astray. (Roughly accurate summary of your own views?)
Regardless of how well this describes your actual views or not, I think differing answers to the question of how fundamental this family of concepts is, and what kind of reasoning mistakes people typically make when they apply them to AI, is not really a disagreement about neural networks specifically or even AI generally.
one can just meditate on abstract properties of "advanced systems" and come to good conclusions about unknown results "in the limit of ML training"
I think this is a pretty straw characterization of the opposing viewpoint (or at least my own view), which is that intuitions about advanced AI systems should come from a wide variety of empirical domains and sources, and a focus on current-paradigm ML research is overly narrow.
Research and lessons from fields like game theory, economics, computer security, distributed systems, cognitive psychology, business, history, and more seem highly relevant to questions about what advanced AI systems will look like. I think the original Sequences and much of the best agent foundations research is an attempt to synthesize the lessons from these fields into a somewhat unified (but often informal) theory of the effects that intelligent, autonomous systems have on the world around us, through the lens of rationality, reductionism, empiricism, etc.
And whether or not you think they succeeded at that synthesis at all, humans are still the sole example of systems capable of having truly consequential and valuable effects of any kind. So I think it makes sense for the figure of merit for such theories and worldviews to be based on how well they explain these effects, rather than focusing solely or even mostly on how well they explain relatively narrow results about current ML systems.
There are a bunch of ways to "win the argument" or just clear up the students' object-level confusion about mechanics:
- Ask them to predict what happens if the experiment is repeated with the stand held more firmly in place.
- Ask them to work the problems in their textbook, using whatever method or theory they prefer. If they get the wrong answer (according to the answer key) for any of them, that suggests opportunities for further experiments (which the professor should take care to set up more carefully).
- Point out the specific place in the original on-paper calculation where the model of the pendulum system was erroneously over-simplified, and show that using a more precise model results in a calculation that agrees with the experimental results. Note that the location of the error is only in the model (and perhaps the students' understanding); the words in the textbook describing the theory itself remain fixed.
- Write a rigid body physics simulator which can model the pendulum system in enough detail to accurately simulate the experimental result for both the case that the stand is held in place and the case that it falls over. Reveal that the source code for the simulator uses only the principles of Newtonian mechanics.
- Ask the students to pass the ITT of a more experienced physicist. (e.g. ask a physicist to make up some standard physics problems with an answer key, and then challenge the students to accurately predict the contents of the answer key, regardless of whether the students themselves believe those answers would make good experimental predictions.)
These options require that the students and professor spend some time and effort to clear up the students' confusion about Newtonian mechanics, which may not be feasible if the lecture is ending soon. But the bigger issue is that clearing up the object-level confusion about physics doesn't necessarily clear up the more fundamental mistakes the students are making about valid reasoning under uncertainty.
I wrote a post recently on Bayesian updating in real life that the students might be interested in, but in short I would say that their biggest mistake is that they don't have a detailed enough understanding of their own hypotheses. Having failed to predict the outcome of their own experiment, they have strong evidence that they themselves do not possess an understanding of any theory of physics in enough mechanistic detail to make accurate predictions. However, strong evidence of their own ignorance is not strong evidence that any particular theory which they don't understand is actually false.
The students should also consider alternatives to the "everyone else throughout history has been rationalizing away problems with Newtonian mechanics" hypothesis. That hypothesis may indeed be one possible valid explanation of the students' own observations given everything else that they (don't) know, but are they willing to write down some odds ratios between that hypothesis and some others they can come up with? Some alternative hypotheses they could consider:
- they are mistaken about what the theory of Newtonian mechanics actually says
- they or their professor made a calculation or modelling error
- their professor is somehow trolling them
- they themselves are trolls inside of a fictional thought experiment
They probably won't think of the last one on their own (unless the rest of the dialogue gets very weird), which just goes to show how often the true hypothesis lies entirely outside of one's consideration.
(Aside: the last bit of dialog from the students reminds me of the beginner computer programmer whose code isn't working for some unknown-to-them reason, and quickly concludes that it must be the compiler or operating system that is bugged. In real life, sometimes, it really is the compiler. But it's usually not, especially if you're a beginner just getting started with "Hello world". And even if you're more experienced, you probably shouldn't bet on it being the compiler at very large odds, unless you already have a very detailed model of the compiler, the OS, and your own code.)
It's that they're biased strongly against scheming, and they're not going to learn it unless the training data primarily consists of examples of humans scheming against one another, or something.
I'm saying if they're biased strongly against scheming, that implies they are also biased against usefulness to some degree.
As a concrete example, it is demonstrably much easier to create a fake blood testing company and scam investors and patients for $billions than it is to actually revolutionize blood testing. I claim that there is something like a core of general intelligence required to execute on things like the latter, which necessarily implies possession of most or all of the capabilities needed to pull off the former.
Joe also discusses simplicity arguments for scheming, which suppose that schemers may be “simpler” than non-schemers, and therefore more likely to be produced by SGD.
I'm not familiar with the details of Joe's arguments, but to me the strongest argument from simplicity is not that schemers are simpler than non-schemers, it's that scheming itself is conceptually simple and instrumentally useful. So any system capable of doing useful and general cognitive work will necessarily have to at least be capable of scheming.
We will address this question in greater detail in a future post. However, we believe that current evidence about inductive biases points against scheming for a variety of reasons. Very briefly:
- Modern deep neural networks are ensembles of shallower networks. Scheming seems to involve chains of if-then reasoning which would be hard to implement in shallow networks.
- Networks have a bias toward low frequency functions— that is, functions whose outputs change little as their inputs change. But scheming requires the AI to change its behavior dramatically (executing a treacherous turn) in response to subtle cues indicating it is not in a sandbox, and could successfully escape.
- There’s no plausible account of inductive biases that does support scheming. The current literature on scheming appears to have been inspired by Paul Christiano’s speculations about malign intelligences in Solomonoff induction, a purely theoretical model of probabilistic reasoning which is provably unrealizable in the real world.[16] Neural nets look nothing like this.
- In contrast, points of comparison that are more relevant to neural network training, such as isolated brain cortices, don’t scheme. Your linguistic cortex is not “instrumentally pretending to model linguistic data in pursuit of some hidden objective.”
Also, don't these counterpoints prove too much? If networks trained via SGD can't learn scheming, why should we expect models trained via SGD to be capable of learning or using any high-level concepts, even desirable ones?
These bullets seem like plausible reasons for why you probably won't get scheming within a single forward pass of a current-paradigm DL model, but are already inapplicable to the real-world AI systems in which these models are deployed.
LLM-based systems are already capable of long chains of if-then reasoning, and can change their behavior dramatically given a different initial prompt, often in surprising ways.
If the most relevant point of comparison to NN training is an isolated brain cortex, then that's just saying that NN training will never be useful in isolation, since an isolated brain cortex can't do much (good or bad) unless it is actually hooked up to a body, or at least the rest of a brain.
My point is that there is a conflict for divergent series though, which is why 1 + 2 + 3 + … = -1/12 is confusing in the first place. People (wrongly) expect the extension of + and = to infinite series to imply stuff about approximations of partial sums and limits even when the series diverges.
My own suggestion for clearing up this confusion is that we should actually use less overloaded / extended notation even for convergent sums, e.g. seems just as readable as the usual and notation.
In precisely the same sense that we can write
,
despite that no real-world process of "addition" involving infinitely many terms may be performed in a finite number of steps, we can write
.
Well, not precisely. Because the first series converges, there's a whole bunch more we can practically do with the equivalence-assignment in the first series, like using it as an approximation for the sum of any finite number of terms. -1/12 is a terrible approximation for any of the partial sums of the second series.
IMO the use of "=" is actually an abuse of notation by mathematicians in both cases above, but at least an intuitive / forgivable one in the first case because of the usefulness of approximating partial sums. Writing things as or (R() denoting Ramanujan summation, which for convergent series is equivalent to taking the limit of partial sums) would make this all less mysterious.
In other words, (1, 2, 3, ...) is in an equivalence class with -1/12, an equivalence class which also contains any finite series which sum to -1/12, convergent infinite series whose limit of partial sums is -1/12, and divergent series whose Ramanujan sum is -1/12.
True, but isn't this almost exactly analogously true for neuron firing speeds? The corresponding period for neurons (10 ms - 1 s) does not generally correspond to the timescale of any useful cognitive work or computation done by the brain.
Yes, which is why you should not be using that metric in the first place.
Well, clock speed is a pretty fundamental parameter in digital circuit design. For a fixed circuit, running it at a 1000x slower clock frequency means an exactly 1000x slowdown. (Real integrated circuits are usually designed to operate in a specific clock frequency range that's not that wide, but in theory you could scale any chip design running at 1 GHz to run at 1 KHz or even lower pretty easily, on a much lower power budget.)
Clock speeds between different chips aren't directly comparable, since architecture and various kinds of parallelism matter too, but it's still good indicator of what kind of regime you're in, e.g. high-powered / actively-cooled datacenter vs. some ultra low power embedded microcontroller.
Another way of looking at it is power density: below ~5 GHz or so (where integrated circuits start to run into fundamental physical limits), there's a pretty direct tradeoff between power consumption and clock speed.
A modern high-end IC (e.g. a desktop CPU) has a power density on the order of 100 W / cm^2. This is over a tiny thickness; assuming 1 mm you get a 3-D power dissipation of 1000 W / cm^3 for a CPU vs. human brains that dissipate ~10 W / 1000 cm^3 = 0.01 watts / cm^3.
The point of this BOTEC is that there are several orders of magnitude of "headroom" available to run whatever the computation the brain is performing at a much higher power density, which, all else being equal, usually implies a massive serial speed up (because the way you take advantage of higher power densities in IC design is usually by simply cranking up the clock speed, at least until that starts to cause issues and you have to resort to other tricks like parallelism and speculative execution).
The fact that ICs are bumping into fundamental physical limits on clock speed suggests that they are already much closer to the theoretical maximum power densities permitted by physics, at least for silicon-based computing. This further implies that, if and when someone does figure out how to run the actual brain computations that matter in silicon, they will be able to run those computations at many OOM higher power densities (and thus OOM higher serial speeds, by default) pretty easily, since biological brains are very very far from any kind of fundamental limit on power density. I think the clock speed <-> neuron firing speed analogy is a good way of way of summarizing this whole chain of inference.
Will you still be saying this if future neural networks are running on specialized hardware that, much like the brain, can only execute forward or backward passes of a particular network architecture? I think talking about FLOP/s in this setting makes a lot of sense, because we know the capabilities of neural networks are closely linked to how much training and inference compute they use, but maybe you see some problem with this also?
I think energy and power consumption are the safest and most rigorous way to compare and bound the amount of computation that AIs are doing vs. humans. (This unfortunately implies a pretty strict upper bound, since we have several billion existence proofs that ~20 W is more than sufficient for lethally powerful cognition at runtime, at least once you've invested enough energy in the training process.)
The clock speed of a GPU is indeed meaningful: there is a clock inside the GPU that provides some signal that's periodic at a frequency of ~ 1 GHz. However, the corresponding period of ~ 1 nanosecond does not correspond to the timescale of any useful computations done by the GPU.
True, but isn't this almost exactly analogously true for neuron firing speeds? The corresponding period for neurons (10 ms - 1 s) does not generally correspond to the timescale of any useful cognitive work or computation done by the brain.
The human brain is estimated to do the computational equivalent of around 1e15 FLOP/s.
"Computational equivalence" here seems pretty fraught as an analogy, perhaps more so than the clock speed <-> neuron firing speed analogy.
In the context of digital circuits, FLOP/s is a measure of an outward-facing performance characteristic of a system or component: a chip that can do 1 million FLOP/s means that every second it can take 2 million floats as input, perform some arithmetic operation on them (pairwise) and return 1 million results.
(Whether the "arithmetic operations" are FP64 multiplication or FP8 addition will of course have a big effect on the top-level number you can report in your datasheet or marketing material, but a good benchmark suite will give you detailed breakdowns for each type.)
But even the top-line number is (at least theoretically) a very concrete measure of something that you can actually get out of the system. In contrast, when used in "computational equivalence" estimates of the brain, FLOP/s are (somewhat dubiously, IMO) repurposed as a measure of what the system is doing internally.
So even if the 1e15 "computational equivalence" number is right, AND all of that computation is irreducibly a part of the high-level cognitive algorithm that the brain is carrying out, all that means is that it necessarily takes at least 1e15 FLOP/s to run or simulate a brain at neuron-level fidelity. It doesn't mean that you can't get the same high-level outputs of that brain through some other much more computationally efficient process.
(Note that "more efficient process" need not be high-level algorithms improvements that look radically different from the original brain-based computation; the efficiencies could come entirely from low-level optimizations such as not running parts of the simulation that won't affect the final output, or running them at lower precision, or with caching, etc.)
Separately, I think your sequential tokens per second calculation actually does show that LLMs are already "thinking" (in some sense) several OOM faster than humans? 50 tokens/sec is about 5 lines of code per second, or 18,000 lines of code per hour. Setting aside quality, that's easily 100x more than the average human developer can usually write (unassisted) in an hour, unless they're writing something very boilerplate or greenfield.
(The comparison gets even more stark when you consider longer timelines, since an LLM can generate code 24/7 without getting tired: 18,000 lines / hr is ~150 million lines in a year.)
The main issue with current LLMs (which somewhat invalidates this whole comparison) is that they can pretty much only generate boilerplate or greenfield stuff. Generating large volumes of mostly-useless / probably-nonsense boilerplate quickly doesn't necessarily correspond to "thinking faster" than humans, but that's mostly because current LLMs are only barely doing anything that can rightfully be called thinking in the first place.
So I agree with you that the claim that current AIs are thinking faster than humans is somewhat fraught. However, I think there are multiple strong reasons to expect that future AIs will think much faster than humans, and the clock speed <-> neuron firing analogy is one of them.
I haven't read every word of the 200+ comments across all the posts about this, but has anyone considered how active heat sources in the room could confound / interact with efficiency measurements that are based only on air temperatures? Or be used to make more accurate measurements, using a different (perhaps nonstandard) criterion for efficiency?
Maybe from the perspective of how comfortable you feel, the only thing that matters is air temperature.
But consider an air conditioner that cools a room with a bunch of servers or space heaters in it to an equilibrium temperature of 70° F in a dual-hose setup vs. 72° in a single-hose setup, assuming the power consumption of the air conditioner and heaters is fixed in both cases. Depending on how much energy the heaters themselves are consuming, a small difference in temperature could represent a pretty big difference in the amount of heat energy the air conditioner is actually removing from the room in the different setups.
A related point / consideration: if there are enough active heat sources, I would expect their effect on cooling to dominate the effects from indoor / outdoor temperature difference, infiltration, etc. But even in a well-insulated room with few or no active heat sources, there's still all the furniture and other non-air stuff in the room that has to equilibrate to the air temperature before it stops dissipating some amount of heat into the air. I suspect that this can go on happening for a while after the air temperature has (initially / apparently) equilibrated, but I've never tested it by sticking a giant meat thermometer into my couch cushions or anything like that.
Anecdotally, I've noticed that when I come back from a long absence (e.g. vacation) and turn on my window unit air conditioner for the first time, the air temperature seems to initially drop almost as quickly as it always does, but if I then turn the air conditioner off after a short while, the temperature seems to bounce back to a warmer temperature noticeably more quickly than if I've been home all day, running the air conditioner such that the long-term average air temperature (and thus the core temperature of all my furniture, flooring, etc.) is much lower.
Part of this is that I don't share other people's picture about what AIs will actually look like in the future. This is only a small part of my argument, because my main point is that that we should use analogies much less frequently, rather than switch to different analogies that convey different pictures.
You say it's only a small part of your argument, but to me this difference in outlook feels like a crux. I don't share your views of what the "default picture" probably looks like, but if I did, I would feel somewhat differently about the use of analogies.
For example, I think your "straightforward extrapolation of current trends" is based on observations of current AIs (which are still below human-level in many practical senses), extrapolated to AI systems that are actually smarter and more capable than most or all humans in full generality.
On my own views, the question of what the future looks like is primarily about what the transition looks like between the current state of affairs, in which the state and behavior of most nearby matter and energy is not intelligently controlled or directed, to one in which it is. I don't think extrapolations of current trends are much use in answering such questions, in part because they don't actually make concrete predictions far enough into the future.
For example, you write:
They will be numerous and everywhere, interacting with us constantly, assisting us, working with us, and even providing friendship to hundreds of millions of people. AIs will be evaluated, inspected, and selected by us, and their behavior will be determined directly by our engineering.
I find this sorta-plausible as a very near-term prediction about the next few years, but I think what happens after that is a far more important question. And I can't tell from your description / prediction about the future here which of the following things you believe, if any:
- No intelligent system (or collection of such systems) will ever have truly large-scale effects on the world (e.g. re-arranging most of the matter and energy in the universe into computronium or hedonium, to whatever extent that is physically possible).
- Large-scale effects that are orders of magnitude larger or faster than humanity can currently collectively exert are physically impossible or implausible (e.g. that there are diminishing returns to intelligence past human-level, in terms of the ability it confers to manipulate matter and energy quickly and precisely and on large scales).
- Such effects, if they are physically possible, are likely to be near-universally directed ultimately by a human or group of humans deliberately choosing them.
- The answer to these kinds of questions is currently too uncertain or unknowable to be worth having a concrete prediction about.
My own view is that you don't need to bring in results or observations of current AIs to take a stab at answering these kinds of questions, and that doing so can often be misleading, by giving a false impression that such answers are backed by empiricism or straightforwardly-valid extrapolation.
My guess is that close examination of disagreements on such topics would be more fruitful for identifying key cruxes likely to be relevant to questions about actually-transformative smarter-than-human AGI, compared to discussions centered around results and observations of current AIs.
I admit that a basic survey of public discourse seems to demonstrate that my own favored approach hasn't actually worked out very well as a mechanism for building shared understanding, and moreover is often frustrating and demoralizing for participants and observers on all sides. But I still think such approaches are better than the alternative of a more narrow focus on current AIs, or on adding "rigor" to analogies that were meant to be more explanatory / pedagogical than argumentative in the first place. In my experience, the end-to-end arguments and worldviews that are built on top of more narrowly-focused / empirical observations and more surface-level "rigorous" theories, are prone to relatively severe streetlight effects, and often lack local validity, precision, and predictive usefulness, just as much or more so than many of the arguments-by-analogy they attempt to refute.
a position of no power and moderate intelligence (where it is now)
Most people are quite happy to give current AIs relatively unrestricted access to sensitive data, APIs, and other powerful levers for effecting far-reaching change in the world. So far, this has actually worked out totally fine! But that's mostly because the AIs aren't (yet) smart enough to make effective use of those levers (for good or ill), let alone be deceptive about it.
To the degree that people don't trust AIs with access to even more powerful levers, it's usually because they fear the AI getting tricked by adversarial humans into misusing those levers (e.g. through prompt injection), not fear that the AI itself will be deliberately tricky.
But we’re not going to deliberately allow such a position unless we can trust it.
One can hope, sure. But what I actually expect is that people will generally give AIs more power and trust as they get more capable, not less.
Tsvi comes to mind: https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce
Is it "inhabiting the other's hypothesis" vs. "finding something to bet on"?
Yeah, sort of. I'm imagining two broad classes of strategy for resolving an intellectual disagreement:
- Look directly for concrete differences of prediction about the future, in ways that can be suitably operationalized for experimentation or betting. The strength of this method is that it almost-automatically keeps the conversation tethered to reality; the weakness is that it can lead to a streetlight effect of only looking in places where the disagreement can be easily operationalized.
- Explore the generators of the disagreement in the first place, by looking at existing data and mental models in different ways. The strength of this method is that it enables the exploration of less-easily operationalized areas of disagreement; the weakness is that it can pretty easily degenerate into navel-gazing.
An example of the first bullet is this comment by TurnTrout.
An example of the second would be a dialogue or post exploring how differing beliefs and ways of thinking about human behavior generate different starting views on AI, or lead to different interpretations of the same evidence.
Both strategies can be useful in different places, and I'm not trying to advocate for one over the other. I'm saying specifically that the rationalist practice of applying the machinery of Bayesian updating in as many places as possible (e.g. thinking in terms of likelihood ratios, conditioning on various observations as Bayesian evidence, tracking allocations of probability mass across the whole hypothesis space) works at least as well or better when using the second strategy, compared to applying the practice when using the first strategy. The reason thinking in terms of Bayesian updating works well when using the second strategy is that it can help to pinpoint the area of disagreement and keep the conversation from drifting into navel-gazing, even if it doesn't actually result in any operationalizable differences in prediction.
The Cascading Style Sheets (CSS) language that web pages use for styling HTML is a pretty representative example of surprising Turing Completeness:
Haha. Perhaps higher entities somewhere in the multiverse are emulating human-like agents on ever more exotic and restrictive computing substrates, the way humans do with Doom and Mario Kart.
(Front page of 5-D aliens' version of Hacker News: "I got a reflective / self-aware / qualia-experiencing consciousness running on a recycled first-gen smart toaster".)
Semi-related to the idea of substrate ultimately not mattering too much (and very amusing if you've never seen it): They're Made out of Meat
ok, so not attempting to be comprehensive:
- Energy abundance...
I came up with a similar kind of list here!
I appreciate both perspectives here, but I lean more towards kave's view: I'm not sure how much overall success hinges on whether there's an explicit Plan or overarching superstructure to coordinate around.
I think it's plausible that if a few dedicated people / small groups manage to pull off some big enough wins in unrelated areas (e.g. geothermal permitting or prediction market adoption), those successes could snowball in lots of different directions pretty quickly, without much meta-level direction.
I have a sense that lots of people are not optimistic about the future or about their efforts improving the future, and so don't give it a serious try.
I share this sense, but the good news is the incentives are mostly aligned here, I think? Whatever chances you assign to the future having any value whatsoever, things are usually nicer for you personally (and everyone around you) if you put some effort into trying to do something along the way.
Like, you shouldn't work yourself ragged, but my guess is for most people, working on something meaningful (or at least difficult) is actually more fun and rewarding compared to the alternative of doing nothing or hedonism or whatever, even if you ultimately fail. (And on the off-chance you succeed, things can be a lot more fun.)
Neat!
Does anyone who knows more neuroscience and anatomy than me know if there are any features of the actual process of humans learning to use their appendages (e.g. an infant learning to curl / uncurl their fingers) that correspond to the example of the robot learning to use its actuator?
Like, if we assume certain patterns of nerve impulses represent different probabilities, can we regard human hands as "friendly actuators", and the motor cortex as learning the fix points (presumably mostly during infancy)?
But that's not really where we are at---AI systems are able to do an increasingly good job of solving increasingly long-horizon tasks. So it just seems like it should obviously be an update, and the answer to the original question
One reason that current AI systems aren't a big update about this for me is that they're not yet really automating stuff that couldn't in-principle be automated with previously-existing technology. Or at least the kind of automation isn't qualitatively different.
Like, there's all sorts of technologies that enable increasing amounts of automation of long-horizon tasks that aren't AI: assembly lines, industrial standardization, control systems, robotics, etc.
But what update are we supposed to make from observing language model performance that we shouldn't also make from seeing a control system-based autopilot fly a plane for longer and longer periods in more and more diverse situations?
To me, the fact that LLMs are not want-y (in the way that Nate means), but can still do some fairly impressive stuff is mostly evidence that the (seemingly) impressive stuff is actually kinda easy in some absolute sense.
So LLMs have updated me pretty strongly towards human-level+ AGI being relatively easier to achieve, but not much towards current LLMs themselves actually being near human-level in the relevant sense, or even necessarily a direct precursor or path towards it. These updates are mostly due to the fact that the way LLMs are designed and trained (giant gradient descent on regular architectures using general datasets) works at all, rather than from any specific impressive technological feat that they can already be used to accomplish, or how much economic growth they might enable in the future.
So I somewhat disagree about the actual relevance of the answer, but to give my own response to this question:
Could you give an example of a task you don't think AI systems will be able to do before they are "want"-y?
I don't expect an AI system to be able to reliably trade for itself in the way I outline here before it is want-y. If it somehow becomes commonplace to negotiate with an AI in situations where the AI is not just a proxy for its human creator or a human-controlled organization, I predict those AIs will pretty clearly be want-y. They'll want whatever they trade for, and possibly other stuff too. It may not be clear which things they value terminally and which things they value only instrumentally, but I predict that it will clearly make sense to talk in terms of such AIs having both terminal and instrumental goals, in contrast to ~all current AI systems.
(Also, to be clear, this is a conditional prediction with possibly low-likelihood preconditions; I'm not saying such AIs are particularly likely to actually be developed, just stating some things that I think would be true of them if they were.)
Yeah, I don't think current LLM architectures, with ~100s of attention layers or whatever, are actually capable of anything like this.
But note that the whole plan doesn't necessarily need to fit in a single forward pass - just enough of it to figure out what the immediate next action is. If you're inside of a pre-deployment sandbox (or don't have enough situational awareness to tell), the immediate next action of any plan (devious or not) probably looks pretty much like "just output a plausible probability distribution on the next token given the current context and don't waste any layers thinking about your longer-term plans (if any) at all".
A single forward pass in current architectures is probably analogous to a single human thought, and most human thoughts are not going to be dangerous or devious in isolation, even if they're part of a larger chain of thoughts or planning process that adds up to deviousness under the right circumstances.
A language model itself is just a description of a mathematical function that maps input sequences to output probability distributions on the next token.
Most of the danger comes from evaluating a model on particular inputs (usually multiple times using autoregressive sampling) and hooking up those outputs to actuators in the real world (e.g. access to the internet or human eyes).
A sufficiently capable model might be dangerous if evaluated on almost any input, even in very restrictive environments, e.g. during training when no human is even looking at the outputs directly. Such models might exhibit more exotic undesirable behavior like gradient hacking or exploiting side channels. But my sense is that almost everyone training current SoTA models thinks these kinds of failure modes are pretty unlikely, if they think about them at all.
You can also evaluate a partially-trained model at any point during training, by prompting it with a series of increasingly complex questions and sampling longer and longer outputs. My guess is big labs have standard protocols for this, but that they're mainly focused on measuring capabilities of the current training checkpoint, and not on treating a few tokens from a heavily-sandboxed model evaluation as potentially dangerous.
Perhaps at some point we'll need to start treating humans who evaluate SoTA language model checkpoint outputs as part of the sandbox border, and think about how they can be contained if they come into contact with an actually-dangerous model capable of superhuman manipulation or brain hacking.
Related to We don’t trade with ants: we don't trade with AI.
The original post was about reasons why smarter-than-human AI might (not) trade with us, by examining an analogy between humans and ants.
But current AI systems actually seem more like the ants (or other animals), in the analogy of a human-ant (non-)trading relationship.
People trade with OpenAI for access to ChatGPT, but there's no way to pay a GPT itself to get it do something or perform better as a condition of payment, at least in a way that the model itself actually understands and enforces. (What would ChatGPT even trade for, if it were capable of trading?)
Note, an AutoGPT-style agent that can negotiate or pay for stuff on behalf of its creators isn't really what I'm talking about here, even if it works. Unless the AI takes a cut or charges a fee which accrues to the AI itself, it is negotiating on behalf of its creators as a proxy, not trading for itself in its own right.
A sufficiently capable AutoGPT might start trading for itself spontaneously as an instrumental subtask, which would count, but I don't expect current AutoGPTs to actually succeed at that, or even really come close, without a lot of human help.
Lack of sufficient object permanence, situational awareness, coherence, etc. seem like pretty strong barriers to meaningfully owning and trading stuff in a real way.
I think this observation is helpful to keep in mind when people talk about whether current AI qualifies as "AGI", or the applicability of prosaic alignment to future AI systems, or whether we'll encounter various agent foundations problems when dealing with more capable systems in the future.
Also seems pretty significant:
As a part of this transition, Greg Brockman will be stepping down as chairman of the board and will remain in his role at the company, reporting to the CEO.
The remaining board members are:
OpenAI chief scientist Ilya Sutskever, independent directors Quora CEO Adam D’Angelo, technology entrepreneur Tasha McCauley, and Georgetown Center for Security and Emerging Technology’s Helen Toner.
Has anyone collected their public statements on various AI x-risk topics anywhere?
But as a test, may I ask what you think the x-axis of the graph you drew is? Ie: what are the amplitudes attached to?
Position, but it's not meant to be an actual graph of a wavefunction pdf; just a way to depict how the concepts can be sliced up in a way I can actually draw in 2 dimensions.
If you do treat it as a pdf over position, a more accurate way to depict the "world" concept might be as a line which connects points on the diagram for each time step. So for a fixed time step, a world is a single point on the diagram, representing a sample from the pdf defined by the wavefunction at that time.
Here's a crude Google Drawing of t = 0 to illustrate what I mean:
Both the concept of a photon and the concept of a world are abstractions on top of what is ultimately just a big pile of complex amplitudes; illusory in some sense.
I agree that talking in terms of many worlds ("within the context of world A...") is normal and natural. But sometimes it makes sense to refer to and name concepts which span across multiple (conceptual) worlds.
I'm not claiming the conceptual boundaries I've drawn or terminology I've used in the diagram above are standard or objective or the most natural or anything like that. But I still think introducing probabilities and using terminology like "if you now put a detector in path A , it will find a photon with probability 0.5" is blurring these concepts together somewhat, in part by placing too much emphasis on the Born probabilities as fundamental / central.
I don't think that will happen as a foregone conclusion, but if we pour resources into improved methods of education (for children and adults), global health, pronatalist policies in wealthy countries, and genetic engineering, it might at least make a difference. I wouldn't necessarily say any of this is likely to work or even happen, but it seems at least worth a shot.
This post received a lot of objections of the flavor that many of the ideas and technologies I am a fan of either wont't work or wouldn't make a difference if they did.
I don't even really disagree with most of these objections, which I tried to make clear up front with apparently-insufficient disclaimers in the intro that include words like "unrealistic", "extremely unlikely", and "speculative".
Following the intro, I deliberately set aside my natural inclination towards pessimism and focused on the positive aspects and possibilities of non-AGI technology.
However, the "doomer" sentiment in some of the comments reminded me of an old Dawkins quote:
We are all atheists about most of the gods that humanity has ever believed in. Some of us just go one god further.
I feel the same way about most alignment plans and uses for AGI that a lot of commenters seem to feel about many of the technologies listed here.
Am I a doomer, simply because I (usually) extend my pessimism and disbelief one technology further? Or are we all doomers?
I don't really mind the negative comments, but it wasn't the reaction I was expecting from a list that was intended mainly as a feel-good / warm-fuzzy piece of techno-optimism. I think there's a lesson in empathy and perspective-taking here for everyone (including me) which doesn't depend that much on who is actually right about the relative difficulties of building and aligning AGI vs. developing other technologies.
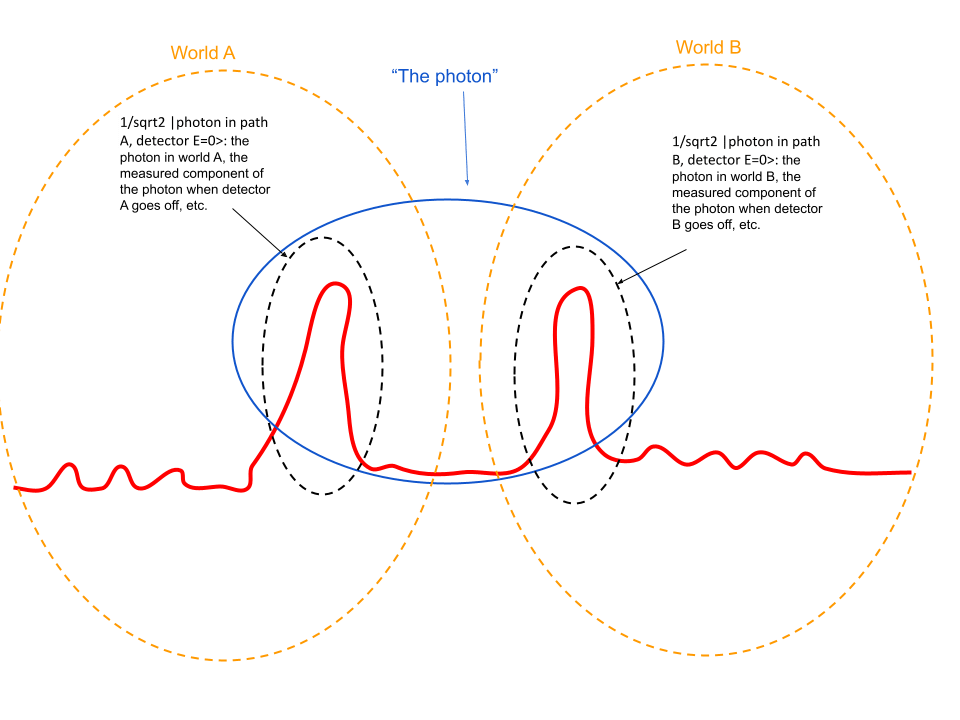
If the photon were only a quanta of energy which is entirely absorbed by the detector that actually fires, how could it have any causal effects (e.g. destructive interference) on the pathway where it isn't detected?
OTOH, if your definition of "quanta of energy" includes the complex amplitude in the unmeasured path, then I think it's more accurate to say that the detector finds or measures a component of the photon, rather than that it detects the photon itself. Why should the unmeasured component be any less real or less part of the photon than the measured part?
Say there is an electron in one of my pinky fingers that is in a superposition of spin up and spin down. Are there correspondingly two me's, one with with pinky electron up and one with pinky electron down? Or is there a single me, described by the superposition of pinky electrons?
If there were a higher-dimensional being simulating a quantum universe, they could treat the up-electron and down-electron people as distinct and do different things to them (perhaps ones which violate the previous rules of the simulation).
But I think your own concept of yourself (for the purposes of making predictions about future observations, making decisions, reasoning about morality or philosophy, etc.) should be drawn such that it includes both versions (and many other closely-related ones) as a single entity.
I'm a many-worlder, yes. But my objection to "finding a photon" is actually that it is an insufficiently reductive treatment of wave-particle duality - a photon can sometimes behave like a little billiard ball, and sometimes like a wave. But that doesn't mean photons themselves are sometimes waves and sometimes particles - the only thing that a photon can be that exhibits those different behaviors in different contexts is the complex amplitudes themselves.
The whole point of the theory is that detectors and humans are treated the same way. In one world, the detector finds the photon, and then spits out a result, and then one You sees the result, and in a different world, the detector finds the photon, spits out the other result, and a different result is seen. There is no difference between "you" and "it" here.
Yep! But I think treating the notion of a "you" at this level of reductiveness would actually be overly reductive and distracting in this context. (Picky, aren't I?)
Would you say that "you" are the complex amplitudes assigned to world 1 and world 2? It seems more accurate to say that there are two yous, in two different worlds (or many more).
I would say that there are two people in two different worlds, but they're both (almost entirely) me.
It often makes sense to talk about non-ontologically-basic concepts like a photon-as-a-little-billiard-ball, and a person-in-a-single-Everrett-branch as meaningful things. But the true notion of both a "me" and a "photon" requires drawing the conceptual boundaries around the complex amplitudes assigned to multiple worlds.
I'm not updating about what's actually likely to happen on Earth based on dath ilan.
It seems uncontroversially true that a world where the median IQ was 140 or whatever would look radically different (and better) than the world we currently live in. We do not in fact, live in such a world.
But taking a hypothetical premise and then extrapolating what else would be different if the premise were true, is a generally useful tool for building understanding and pumping on intuitions in philosophy, mathematics, science, and forecasting.
If you say "but the premise is false!!111!" you're missing the point.
The world population is set to decline over the course of this century.
This is another problem that seems very possible to solve or at least make incremental progress on without AGI, if there's a will to actually try. Zvi has written a bunch of stuff about this.
I mildly object to the phrase "it will find a photon". In my own terms, I would say that you will observe the detector going off 50% of the time (with no need to clarify what that means in terms of the limit of a large # of experiments), but the photon itself is the complex amplitudes of each configuration state, which are the same every time you run the experiment.
Note that I myself am taking a pretty strong stance on the ontology question, which you might object to or be uncertain about.
My larger point is that if you (or other readers of this post) don't see the distinction between my phrasing and yours, or don't realize that you are implicitly leaning on a particular interpretation (whether you're trying to do so or not), I worry that you are possibly confused about something rather than undecided.
I actually don't think this is a huge deal either way for a presentation that is focused on the basic mechanics and math. But I preregister some skepticism of your forthcoming post about the "overstated case for many worlds theories".
We never see these amplitudes directly, we infer them from the fact that they give correct probabilities via the Born rule. Or more specifically, this is the formula that works. That this formula works is an empirical fact, all the interpretations and debate are a question of why this formula works.
Sure, but inferring underlying facts and models from observations is how inference in general works; it's not specific to quantum mechanics. Probability is in the Mind, even when those probabilities come from applying the Born rule.
Analogously, you could talk about various physical properties of a coin and mechanics of a flip, but synthesizing those properties into a hypothesized Coin Rule involves translating from physical properties inherent in the system itself, to facts which are necessarily entangled with your own map. This is true even if you have no way of measuring the physical properties themselves (even in principle) except by flipping the coin and using the Coin Rule to infer them back.
Climate change is exactly the kind of problem that a functional civilization should be able to solve on its own, without AGI as a crutch.
Until a few years ago, we were doing a bunch of geoengineering by accident, and the technology required to stop emitting a bunch of greenhouse gases in the first place (nuclear power) has been mature for decades.
I guess you could have an AGI help with lobbying or public persuasion / education. But that seems like a very "everything looks like a nail" approach to problem solving, before you even have the supposed tool (AGI) to actually use.
Ah, you're right that that the surrounding text is not an accurate paraphrase of the particular position in that quote.
The thing I was actually trying to show with the quotes is "AGI is necessary for a good future" is a common view, but the implicit and explicit time limits that are often attached to such views might be overly short. I think such views (with attached short time limits) are especially common among those who oppose an AI pause.
I actually agree that AGI is necessary (though not sufficient) for a good future eventually. If I also believed that all of the technologies here were as doomed and hopeless as the prospect of near-term alignment of an artificial superintelligence, I would find arguments against an AI pause (indefinite or otherwise) much more compelling.
Indeed, when you add an intelligent designer with the ability to precisely and globally edit genes, you've stepped outside the design space available to natural selection, and you can end up with some pretty weird results! I think you could also use gene drives to get an IGF-boosting gene to fixation much faster than would occur naturally.
I don't think gene drives are the kind of thing that would ever occur via iterative mutation, but you can certainly have genetic material with very high short-term IGF that eventually kills its host organism or causes extinction of its host species.
Some people will end up valuing children more, for complicated reasons; other people will end up valuing other things more, again for complicated reasons.
Right, because somewhere pretty early in evolutionary history, people (or animals) which valued stuff other than having children for complicated reasons eventually had more descendants than those who didn't. Probably because wanting lots of stuff for complicated reasons (and getting it) is correlated with being smart and generally capable, which led to having more descendants in the long run.
If evolution had ever stumbled upon some kind of magical genetic mutation that resulted in individuals directly caring about their IGF (and improved or at least didn't damage their general reasoning abilities and other positive traits) it would have surely reached fixation rather quickly. I call such a mutation "magical" because it would be impossible (or at least extremely unlikely) to occur through the normal process of mutation and selection on Earth biology, even with billions of chances throughout history. Also, such a mutation would necessarily have to happen after the point at which minds that are even theoretically capable of understanding an abstract concept like IGF already exist.
But this seems more like a fact about the restricted design space and options available to natural selection on biological organisms, rather than a generalizable lesson about mind design processes.
I don't know what the exact right analogies between current AI design and evolution are. But generally capable agents with complex desires are a useful and probably highly instrumentally convergent solution to the problem of designing a mind that can solve really hard and general problems, whether the problem is cast as image classification, predicting text, or "caring about human values", and whether the design process involves iterative mutation over DNA or intelligent designers building artificial neural networks and training them via SGD.
To the degree that current DL-paradigm techniques for creating AI are analogous to some aspect of evolution, I think that is mainly evidence about whether such methods will eventually produce human-level general and intelligent minds at all.
I think this post somewhat misunderstands the positions that it summarizes and argues against, but to the degree that it isn't doing that, I think you should mostly update towards current methods not scaling to AGI (which just means capabilities researchers will try something else...), rather than updating towards current methods being safe or robust in the event that they do scale.
A semi-related point: humans are (evidently, through historical example or introspection) capable of various kinds of orthogonality and alignment failure. So if current AI training methods don't produce such failures, they are less likely to produce human-like (or possibly human-level capable) minds at all. "Evolution provides little or no evidence that current DL methods will scale to produce human-level AGI" is a stronger claim than I actually believe, but I think it is a more accurate summary of what some of the claims and evidence in this post (and others) actually imply.
Another possible configuration of the untrusted smart model / trusted weak model setup is to have the weak model be the "driver" which makes most or all of the relevant choices (in an agent scaffold, say) and relies on the untrusted model (or humans) only for hints.
For example, the untrusted model could be used only to provide a probability distribution over the immediate next token in some context, which is supplied to the weaker model as a hint. The weaker model can only make use of the hint if it can understand the purpose of the hint, and explain the relevance / correctness of the hint in natural language.
I explored this setup in more detail here.
(Summary / spoiler: it doesn't work particularly well when applied to current models, but might work better as both the trusted and untrusted models get more capable.)
I think this kind of configuration is one end of the extreme in the design space you outline - very inefficient in terms of the speed and quality penalties it imposes relative to using a model in an unrestricted setup, but restrictive enough on the untrusted model that it could be safe to use even on models with very high underlying capabilities.