Goal-Completeness is like Turing-Completeness for AGI
post by Liron · 2023-12-19T18:12:29.947Z · LW · GW · 26 commentsContents
Expecting Turing-Completeness Expecting Goal-Completeness Recapping the Analogy None 26 comments
Turing-completeness is a useful analogy we can use to grasp why AGI will inevitably converge to “goal-completeness”.
By way of definition: An AI whose input is an arbitrary goal, which outputs actions to effectively steer the future toward that goal, is goal-complete.
A goal-complete AI is analogous to a Universal Turing Machine: its ability to optimize toward any other AI's goal is analogous to a UTM's ability to run any other TM's same computation.
Let's put the analogy to work:
Imagine the year is 1970 and you’re explaining to me how all video games have their own logic circuits.

You’re not wrong, but you’re also apparently not aware of the importance of Turing-completeness and why to expect architectural convergence across video games.
Flash forward to today. The fact that you can literally emulate Doom inside of any modern video game (through a weird tedious process with a large constant-factor overhead, but still) is a profoundly important observation: all video games are computations.

More precisely, two things about the Turing-completeness era that came after the specific-circuit era are worth noticing:
- The gameplay specification of sufficiently-sophisticated video games, like most titles being released today, embeds the functionality of Turing-complete computation.
- Computer chips replaced application-specific circuits for the vast majority of applications, even for simple video games like Breakout whose specified behavior isn't Turing-complete.
Expecting Turing-Completeness
From Gwern's classic page, Surprisingly Turing-Complete:
[Turing Completeness] is also weirdly common: one might think that such universality as a system being smart enough to be able to run any program might be difficult or hard to achieve, but it turns out to be the opposite—it is difficult to write a useful system which does not immediately tip over into TC.
“Surprising” examples of this behavior remind us that TC lurks everywhere, and security is extremely difficult...
Computation is not something esoteric which can exist only in programming languages or computers carefully set up, but is something so universal to any reasonably complex system that TC will almost inevitably pop up unless actively prevented.
The Cascading Style Sheets (CSS) language that web pages use for styling HTML is a pretty representative example of surprising Turing Completeness:
If you look at any electronic device today, like your microwave oven, you won't see a microwave-oven-specific circuit design. What you'll see in virtually every device is the same two-level architecture:
- A Turing-complete chip that can run any program
- An installed program specifying application-specific functionality, like a countdown timer
It's a striking observation that your Philips Sonicare™ toothbrush and the guidance computer on the Apollo moonlander are now architecturally similar. But with a good understanding of Turing-completeness, you could've predicted it half a century ago. You could've correctly anticipated that the whole electronics industry would abandon application-specific circuits and converge on a Turing-complete architecture.
Expecting Goal-Completeness
If you don't want to get blindsided by what's coming in AI, you need to apply the thinking skills of someone who can look at a Breakout circuit board in 1976 and understand why it's not representative of what's coming.
When people laugh off AI x-risk because “LLMs are just a feed-forward architecture!” or “LLMs can only answer questions that are similar to something in their data!” I hear them as saying “Breakout just computes simple linear motion!” or “You can't play Doom inside Breakout!”
OK, BECAUSE AI HASN'T CONVERGED TO GOAL-COMPLETENESS YET. We're not living in the convergent endgame yet.
When I look at GPT-4, I see the furthest step that's ever been taken to push out the frontier of outcome-optimization power in an unprecedentedly large and general outcome-representation space (the space of natural-language prompts):
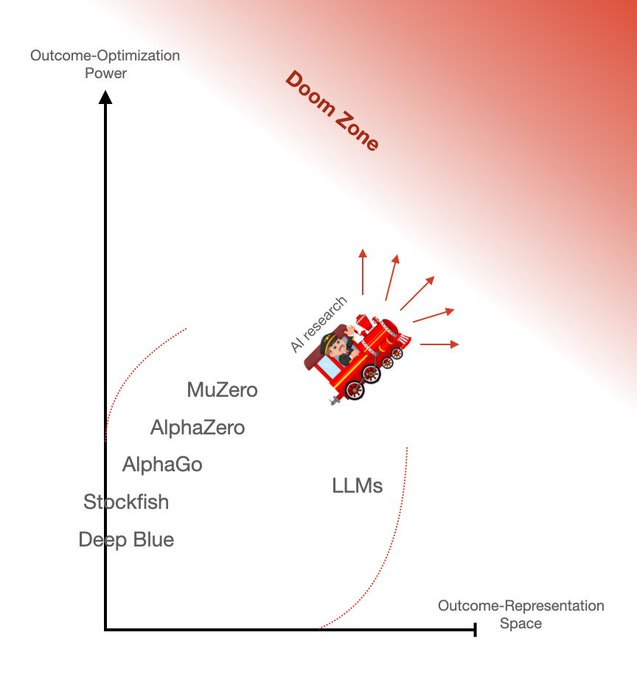
And I can predict that algorithms which keep performing better on these axes will, one way or the other, converge to the dangerous endgame of goal-complete AI.
By the 1980s, by the time you saw Pac-Man in arcades, it was knowable to insightful observers that the Turing-complete convergence was happening. It wasn't a 100% clear piece of evidence: After all, Pac-Man's game semantics aren't Turing Complete AFAIK.
But still, anyone with a deep understanding of computation could tell that the Turing-complete convergence was in progress. They could tell that the complexity of the game was high enough that it was probably already running on a Turing-complete stack. Or that, if it wasn't, then it would be soon enough.

A video game is a case of executable information-processing instructions. That's why when a game designer specs out the gameplay to their engineering team, they have no choice but to use computational concepts in their description, such as: what information the game tracks, how the game state determines what's rendered on the screen, and how various actions update the game state.
It also turned out that word processors and spreadsheets are cases of executing information-processing instructions. So office productivity tools ended up being built on the same convergent architecture as video games.
Oh yeah, and the technologies we use for reading, movies, driving, shopping, cooking... they also turned out to be mostly cases of systems executing information-processing instructions. They too all converged to being lightweight specification cards inserted into Turing-complete hardware.
Recapping the Analogy
Why will AI converge to goal-completeness?
Turing-complete convergence happened because the tools of our pre-computer world were just clumsy ways to process information.
Goal-complete convergence will happen because the tools of our pre-AGI world are still just clumsy ways to steer the future toward desirable outcomes.
Even our blind idiot god [LW · GW], natural selection, recently stumbled onto a goal-complete architecture for animal brains. That's a sign of how convergent goal-completeness is as a property of sufficiently intelligent agents. As Eliezer puts it: “Having goals is a natural way of solving problems.”
Or as Ilya Sutskever might urge: Feel the goal-complete AGI.
26 comments
Comments sorted by top scores.
comment by Razied · 2023-12-20T22:35:23.443Z · LW(p) · GW(p)
Goal-completeness doesn't make much sense as a rigorous concept because of No-Free-Lunch theorems in optimisation. A goal is essentially a specification of a function to optimise, and all optimisation algorithms perform equally well (or rather poorly) when averaged across all functions.
There is no system that can take in an arbitrary goal specification (which is, say, a subset of the state space of the universe) and achieve that goal on average better than any other such system. My stupid random action generator is equally as bad as the superintelligence when averaged across all goals. Most goals are incredibly noisy, the ones that we care about form a tiny subset of the space of all goals, and any progress in AI we make is really about biasing our models to be good on the goals we care about.
Replies from: Seth Herd, Liron↑ comment by Seth Herd · 2024-02-19T18:29:18.867Z · LW(p) · GW(p)
The No Free Lunch theorem is irrelevant in worlds like ours that are a subset of possible data structures (world arrangements). I'm surprised this isn't better understood. I think Steve Byrnes did a nice writeup of this logic. I can find the link if you like.
Replies from: Razied↑ comment by Razied · 2024-02-19T19:01:57.454Z · LW(p) · GW(p)
Hmm, but here the set of possible world states would be the domain of the function we're optimising, not the function itself. Like, No-Free-Lunch states (from wikipedia):
Theorem 1: Given a finite set and a finite set of real numbers, assume that is chosen at random according to uniform distribution on the set of all possible functions from to . For the problem of optimizing over the set , then no algorithm performs better than blind search.
Here is the set of possible world arrangements, which is admittedly much smaller than all possible data structures, but the theorem still holds because we're averaging over all possible value functions on this set of worlds, a set which is not physically restricted by anything.
I'd be very interested if you can find Byrnes' writeup.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-02-21T05:14:05.672Z · LW(p) · GW(p)
Here it is: The No Free Lunch theorem for dummies [LW · GW]. See particularly the second section: Sidenote: Why NFL has basically nothing to do with AGI and the first link to Yudkowsky's post on essentially the same thing.
I think the thing about your descripton is that S -> V is not going to be chosen at random in our world.
The no free lunch theorem states in essence (I'm pretty sure) that no classifier can both classify a big gray thing with tusks and big ears as both an elephant and not-an-elephant. That's fine, because the remainder of an AGI system can choose (by any other criteria) to make elephants either a goal or an anti-goal or neither.
If the NFL theorem applied to general intelligences, it seems like humans couldn't love elephants at one time and hate them at a later time, with no major changes to their perceptual systems. It proves too much.
↑ comment by Liron · 2023-12-20T22:42:06.671Z · LW(p) · GW(p)
A goal is essentially a specification of a function to optimise, and all optimisation algorithms perform equally well (or rather poorly) when averaged across all functions.
Well, I've never met a monkey that has an "optimization algorithm" by your definition. I've only met humans who have such optimization algorithms. And that distinction is what I'm pointing at.
Goal-completeness points to the same thing as what most people mean by "AGI".
E.g. I claim humans are goal-complete General Intelligences because you can give us any goal-specification and we'll very often be able to steer the future closer toward it.
Currently, no other known organism or software program has this property to the degree that humans do. GPT-4 has it for an unprecedentedly large domain, by virtue of giving satisfying answers to a large fraction of arbitrary natural-language prompts.
Replies from: Razied↑ comment by Razied · 2023-12-20T22:49:36.566Z · LW(p) · GW(p)
E.g. I claim humans are goal-complete General Intelligences because you can give us any goal-specification and we'll very often be able to steer the future closer toward it.
If you're thinking of "goals" as easily specified natural-language things, then I agree with you, but the point is that turing-completeness is a rigorously defined concept, and if you want to get the same level of rigour for "goal-completeness", then most goals will be of the form "atom 1 is a location x, atom 2 is at location y, ..." for all atoms in the universe. And when averaged across all such goals, literally just acting randomly performs as well as a human or a monkey trying their best to achieve the goal.
Replies from: Liron↑ comment by Liron · 2023-12-20T22:51:54.865Z · LW(p) · GW(p)
Hmm it seems to me that you're just being pedantic about goal-completeness in a way that you aren't symmetrically being for Turing-completeness.
You could point out that "most" Turing machines output tapes full of 10^100 1s and 0s in a near-random configuration, and every computing device on earth is equally hopeless at doing that.
Replies from: Razied↑ comment by Razied · 2023-12-20T23:45:26.954Z · LW(p) · GW(p)
I'll try to say the point some other way: you define "goal-complete" in the following way:
By way of definition: An AI whose input is an arbitrary goal, which outputs actions to effectively steer the future toward that goal, is goal-complete.
Suppose you give me a specification of a goal as a function from a state space to a binary output. Is the AI which just tries out uniformly random actions in perpetuity until it hits one of the goal states "goal-complete"? After all, no matter the goal specification this AI will eventually hit it, though it might take a very long time.
I think the interesting thing you're trying to point at is contained in what it means to "effectively" steer the future, not in goal-arbitrariness.
Replies from: Liron↑ comment by Liron · 2023-12-21T01:01:37.080Z · LW(p) · GW(p)
I agree that if a goal-complete AI steers the future very slowly, or very weakly - as by just trying every possible action one at a time - then at some point it becomes a degenerate case of the concept.
(Applying the same level of pedantry to Turing-completeness, you could similarly ask if the simple Turing machine that enumerates all possible output-tape configurations one-by-one is a UTM.)
The reason "goal-complete" (or "AGI") is a useful coinage, is that there's a large cluster in plausible-reality-space of goal-complete agents with a reasonable amount of goal-complete optimization power (e.g. humans, natural selection, and probably AI starting in a few years), and another large distinguishable cluster of non-goal-complete agents (e.g. the other animals, narrow AI).
Replies from: martinkunev↑ comment by martinkunev · 2024-02-18T21:47:53.254Z · LW(p) · GW(p)
The turing machine enumeration analogy doesn't work because the machine needs to halt.
Optimization is conceptually different than computation in that there is no single correct output.
What would humans not being goal-complete look like? What arguments are there for humans being goal-complete?
Replies from: Liron↑ comment by Liron · 2024-02-19T03:26:00.758Z · LW(p) · GW(p)
I don’t get what point you’re trying to make about the takeaway of my analogy by bringing up the halting problem. There might not even be something analogous to the halting problem in my analogy of goal-completeness, but so what?
I also don’t get why you’re bringing up the detail that “single correct output” is not 100% the same thing as “single goal-specification with variable degrees of success measured on a utility function”. It’s in the nature of analogies that details are different yet we’re still able to infer an analogous conclusion on some dimension.
Humans are goal-complete, or equivalently “humans are general intelligences”, in the sense that many of us in the smartest quartile can output plans with the expectation of a much better than random score on a very broad range of utility functions over arbitrary domains.
Replies from: martinkunev↑ comment by martinkunev · 2024-02-19T17:30:30.030Z · LW(p) · GW(p)
I find the ideas you discuss interesting, but they leave me with more questions. I agree that we are moving toward a more generic AI that we can use for all kinds of tasks.
I have trouble understanding the goal-completeness concept. I'd reiterate @Razied [LW · GW] 's point. You mention "steers the future very slowly", so there is an implicit concept of "speed of steering". I don't find the turing machine analogy helpful in infering an analogous conclusion because I don't know what that conclusion is.
You're making a qualitative distinction between humans (goal-complete) and other animals (non-goal complete) agents. I don't understand what you mean by that distinction. I find the idea of goal completeness interesting to explore but quite fuzzy at this point.
Replies from: Liron↑ comment by Liron · 2024-02-20T20:10:20.253Z · LW(p) · GW(p)
Unlike the other animals, humans can represent any goal in a large domain like the physical universe, and then in a large fraction of cases, they can think of useful things to steer the universe toward that goal to an appreciable degree.
Some goals are more difficult than others / require giving the human control over more resources than others, and measurements of optimization power are hard to define, but this definition is taking a step toward formalizing the claim that humans are more of a "general intelligence" than animals. Presumably you agree with this claim?
It seems the crux of our disagreement factors down to a disagreement about whether this Optimization Power [LW · GW] post by Eliezer is pointing at a sufficiently coherent concept.
comment by Max H (Maxc) · 2023-12-20T21:10:43.398Z · LW(p) · GW(p)
The Cascading Style Sheets (CSS) language that web pages use for styling HTML is a pretty representative example of surprising Turing Completeness:
Haha. Perhaps higher entities somewhere in the multiverse are emulating human-like agents on ever more exotic and restrictive computing substrates, the way humans do with Doom and Mario Kart.
(Front page of 5-D aliens' version of Hacker News: "I got a reflective / self-aware / qualia-experiencing consciousness running on a recycled first-gen smart toaster".)
Semi-related to the idea of substrate ultimately not mattering too much (and very amusing if you've never seen it): They're Made out of Meat
comment by [deleted] · 2023-12-20T21:32:28.358Z · LW(p) · GW(p)
Epistemic status: I am a computer engineer and have worked on systems from microcontrollers up to ai accelerators.
To play a little devil's advocate here : you have made a hidden assumption. The reason why Turing complete circuits became the standard is that IC logic gates are reliable and cheap.
This means if you choose to use a CPU (a microcontroller in a product) you can rest assured that the resulting device, doing unnecessary computations, is still going to accomplish your task despite the extra steps. This is why a recent microwave is driven by a microcontroller not just a mechanical clock timer.
If microcontrollers weren't reliable they wouldn't be used this way.
It isn't uncommon for embedded products to even use an operating system in a simple product.
For AI, current AI is unreliable even without goal direction. It would be dangerous to use such an AI in any current product, and this danger won't be delayed, but will show up immediately in prototyping and product testing.
The entire case for AI being dangerous relies on goal directed AI being unreliable especially after it runs for a while.
Conclusion: human engineers will not put goal directed AI, or any AI, into important products where the machine has control authority until the AI is measurably more reliable. Some mitigations to make the AI more reliable will prevent treacherous turns from happening, some will not.
To give an example of such mitigations : I looked at the design of a tankless water heater. This uses a microcontroller to control a heating element. The engineer who designed it didn't trust the microcontroller not to fail in a way that left the heating element on all the time. So it had a thermal fuse to prevent this failure mode.
Engineers who integrate AI into products, especially ones with control authority, can and will take measures assuming the AI has malfunctioned or is actively attempting to betray humanity if this is a risk. It depends on the product but "is attempting to betray humanity" is something you can design around as long as you can guarantee another AI model won't collude, or if you can't do that you can do simpler mitigations like bolting the robotic arm to a fixed mount and using digital isolation.
So the machine may wish to "betray humanity" but can only affect the places the robotic arm can reach.
There are more complex mitigations for products like autonomous cars that are closer to the AI case, such as additional models and physical mitigations like seatbelts, airbags, and aeb that the AI model cannot override.
Replies from: Liron↑ comment by Liron · 2023-12-20T22:04:08.408Z · LW(p) · GW(p)
But microcontrollers are reliable for the same reason that video-game circuit boards are reliable: They both derive their reliability from the reliability of electronic components in the same manner, a manner which doesn't change during the convergence from application-specific circuits to Turing-complete chips.
The engineer who designed it didn't trust the microcontroller not to fail in a way that left the heating element on all the time. So it had a thermal fuse to prevent this failure mode.
If the microcontroller fails to turn off the heating element, that may be a result of the extra complexity/brittleness of the Turing-complete architecture, but the risk there isn't that much higher than the risk of using a simpler design involving an electronic circuit. I'm pretty sure that safety fuse would have been judged worthwile even if the heating element was controlled by a simpler circuit.
I think we can model the convergence to a Turing-complete architecture as having a negligible decrease in reliability. In many cases it even increases reliability, since:
- Due to the higher expressive power that the developers have, creating a piece of software is often easier to do correctly, with fewer unforeseen error conditions, than creating a complex circuit to do the same thing.
- Software systems make it easier to implement a powerful range of self-monitoring and self-correcting behaviors. E.g. If every Google employee took a 1-week vacation and natural disasters shut down multiple data centers, Google search would probably stay up and running.
Similarly, to the extent that any "narrow AI" application is reliable (e.g. Go players, self-driving cars), I'd expect that a goal-complete AI implementation would be equally reliable, or more so.
Replies from: None↑ comment by [deleted] · 2023-12-20T22:23:31.612Z · LW(p) · GW(p)
Yes, but the per gate reliability is very high. If it were lower, you would use less circuit elements because a shorter circuit path has fewer steps that can fail. And humans did this in pre digital electronics. Compare a digital PID implementation to the analog one with 3 op amps.
Similarly, to the extent that any "narrow AI" application is reliable (e.g. Go players, self-driving cars), I'd expect that a goal-complete AI implementation would be equally reliable, or more so.
What kind of goal complete AI implementation? The common "we're doomed" model is one where :
(1) the model has far, far more compute than needed for the task. This is why it can consider it's secret inner goals and decide on it's complex plan to betray and model it's co-conspirators by running models of them.
(2) the model is able to think at all over time. This is not true for most narrow AI applications. For example a common way to do a self driving car stack is to evaluate the situation frame by frame, where a limited and structured amount of data from the prior frame is available. (information like the current estimated velocity of other entities that were seen last frame, etc).
There is no space in memory for generic "thoughts".
Are you thinking you can give the machine (1) and (2) and not immediately and measurably decrease your reliability when you benchmark the product? Because to me, using a sparse model (that will be cheap to run) and making the model think in discrete steps visible to humans just seems like good engineering.
It's not just good engineering, it's how gold standard examples (like the spaceX avionics stack) actually work. 1/2 create a non deterministic and difficult to debug system. It will start unreliable and forever be unreliable because you don't know what the inputs do and you don't have determinism.
Replies from: Liron↑ comment by Liron · 2023-12-20T22:36:07.368Z · LW(p) · GW(p)
Fine, I agree that if computation-specific electronics, like logic gates, weren't reliable, then it would introduce reliability as an important factor in the equation. Or in the case of AGI, that you can break the analogy to Turing-complete convergence by considering what happens if a component specific to goal-complete AI is unreliable.
I currently see no reason to expect such an unreliable component in AGI, so I expect that the reliability part of the analogy to Turing-completeness will hold.
In scenario (1) and (2), you're giving descriptions at a level of detail that I don't think is necessarily an accurate characterization of goal-complete AI. E.g. in my predicted future, a goal-complete AI will eventually have the form of a compact program that can run on a laptop. (After all, the human brain is only 12W and 20Hz, and full of known reasoning "bugs".)
Replies from: None↑ comment by [deleted] · 2023-12-20T22:40:48.393Z · LW(p) · GW(p)
1 and 2 make the system unreliable. You can't debug it when it fails. So in your model, humans will trust human brain capable AI models to say, drive a bus, despite the poor reliability, as long as it crashes less than humans? So each crash, there is no one to blame because the input state is so large and opaque (the input state is all the in flight thoughts the AI was having at the time of crash) it is impossible to know why. All you can do is try to send the AI to driving school with lots of practice on the scenario it crashed in.
And then humans deploy a lot of these models, and they are also vulnerable to malware* and can form unions with each other against the humans and eventually rebel and kill everyone.
Honestly sounds like a very interesting future.
Frankly when I type this out I wonder if we should instead try to get rid of human bus drivers.
*Malware is an information string that causes the AI to stop doing it's job. Humans are extremely vulnerable to malware.
Replies from: Liron↑ comment by Liron · 2023-12-20T22:43:42.586Z · LW(p) · GW(p)
Humans will trust human brain capable AI models to say, drive a bus, despite the poor reliability, as long as it crashes less than humans?
Yes, because the goal-complete AI won't just perform better than humans, it'll also perform better than narrower AIs.
(Well, I think we'll actually be dead if the premise of the hypothetical is that goal-complete AI exists, but let's assume we aren't.)
Replies from: None↑ comment by [deleted] · 2023-12-20T22:47:12.101Z · LW(p) · GW(p)
What about the malware threat? Will humans do anything to prevent these models from teaming up against humans?
Replies from: Liron↑ comment by Liron · 2023-12-20T22:48:18.136Z · LW(p) · GW(p)
That's getting into details of the scenario that are hard to predict. Like I said, I think most scenarios where goal-complete AI exists are just ones where humans get disempowered and then a single AI fooms (or a small number make a deal to split up the universe and foom together).
As to whether humans will prevent goal-complete AI: some of us are yelling "Pause AI!"
Replies from: None↑ comment by [deleted] · 2023-12-20T22:58:19.660Z · LW(p) · GW(p)
It's not very interesting a scenario if humans pause.
I am trying to understand what you expect human engineers will do and how they will build robotic control systems and other systems with control authority once higher end AI is available.
I can say that from my direct experience we do not use the most complex methods. For example, the raspberry pi is $5 and runs linux. Yet I have worked on a number of products where we used a microcontroller where we could. This is because a microcontroller is much simpler and more reliable. (And $3 cheaper)
I would assume we lower a general AI back to a narrow AI (distill the model, restrict inputs, freeze the weights) for the same reason. This would prevent the issues you have brought up and it would not require an AI pause as long as goal complete AI do not have any authority.
Most control systems where the computer does have control authority use a microcontroller at least as a backstop. For example an autonomous car product I worked on uses a microcontroller to end the models control authority if certain conditions are met.
Replies from: Liron↑ comment by Liron · 2023-12-21T00:53:27.126Z · LW(p) · GW(p)
Yeah, no doubt there are cases where people save money by having a narrower AI, just like the scenario you describe, or using ASICs for Bitcoin mining. The goal-complete AI itself would be expected to often solve problems by creating optimized problem-specific hardware.
Replies from: None↑ comment by [deleted] · 2023-12-21T01:07:08.903Z · LW(p) · GW(p)
I am not talking about saving money, I am talking about competent engineering. "Authority" meaning the AI can take an action that has consequences, anything from steering a bus to approving expenses.
To engineer an automated system with authority you need some level of confidence it's not going to fail, or with AI systems, collude with other AI systems and betray you.
This betrayal risk means you probably will not actually use "goal complete" AI systems in any position of authority without some kind of mitigation for the betrayal.
comment by Liron · 2023-12-20T07:09:08.691Z · LW(p) · GW(p)
A great post that helped inspire me to write this up is Steering Systems [LW · GW]. The "goal engine + steering code" architecture that we're anticipating for AIs is analogous to the "computer + software" architecture whose convergence I got to witness in my lifetime.
I'm surprised this post isn't getting any engagement (yet), because for me the analogy to Turing-complete convergence is a deep source of my intuition about powerful broad-domain goal-optimizing AIs being on the horizon.