LLM cognition is probably not human-like
post by Max H (Maxc) · 2023-05-08T01:22:45.694Z · LW · GW · 15 commentsContents
Background and related work Thought experiment 1: an alien-trained LLM Human-alien translation Thought experiment 2: a GPT trained on literal encodings of human thoughts Thought experiment 3: a GPT trained only on outputs of computer programs Observation: LLM errors sometimes look surface-level similar to human errors Conclusion None 15 comments
This post is a collection of thought experiments and observations, meant to distill and explain some claims and observations about GPTs and LLMs made by myself and others.
Stated in its most general form, the claim is: the ability of a system or process to predict something well does not imply that the underlying cognition used to make those predictions is similar in structure to the process being predicted.
Applied to GPTs and LLMs specifically: the fact that LLMs are trained to predict text, much of which was generated by humans, does not imply that the underlying cognition carried out by LLMs is similar to human cognition.
In particular, current LLMs are not a distillation of human minds or thoughts, and LLM cognition does not appear to be anthropomorphic. The fact that prediction errors and limitations of current LLMs often mirror human limitations and mimic human errors is not much evidence that the underlying cognition is similar.
Rather, the observed surface-level similarity in these errors is more likely due to current LLM capability at the text prediction task being similar to human-level performance in certain regimes. There are many ways to arrive at a wrong or imperfect answer, and these ways need not be similar to each other.[1]
The focus of this post is on the micro: a GPT predicting a distribution on the next token, or the next few tokens autoregressively . Not considered are agentic loops, specialized prompts, back-and-forth dialog, or chain-of-thought reasoning, all of which can be used to elicit better macro-level performance from LLM-based systems.
On the particular micro-level task of next token prediction, current LLM performance in many examples is often similar to that of an unassisted human who is under time pressure or using less than their full attention. Other times, it is far below or far above this particular human baseline.
Background and related work
Some previous posts by others, which are helpful for context and background on this general topic:
- Feature Selection [LW · GW], by Zack Davis. This is a great story for building an intuition for what the internal cognition of a machine learning model might look like.
- How An Algorithm Feels From The Inside [LW · GW], by Eliezer Yudkowsky. A classic post, understanding of which helps to clarify the distinction I make in this post between cognition and the outputs of that cognition, and why that distinction is important.
- Is GPT-N bounded by human capabilities? No. [LW · GW] by Cleo Nardo. A post focused on the capability limits of GPTs. I think internalizing this point is helpful for understanding the "cognition" vs. "outputs of that cognition" distinction which I draw in this post.
- GPTs are Predictors, not Imitators [LW · GW], by Eliezer. Like Cleo's post, this post makes an important point that performance at text prediction is not bounded by or necessarily closely related to the cognitive power of systems which produced the text being predicted.
- Simulators [LW · GW], by janus. A post exploring the macro-level behaviors that result from sufficiently long auto-regressive chains of prediction, agentic loops, and specialized prompting. Useful as a contrast, for understanding ways that LLM behavior can be decomposed and analyzed at different levels of abstraction.
- Are there cognitive realms? [AF · GW], An anthropomorphic AI dilemma [AF · GW], by Tsvi. These posts are partially about exploring the question of whether it is even meaningful to talk about "different kinds of cognition". Perhaps, in the limit of sufficiently powerful and accurate cognitive systems, all cognition converges on the same underlying structure.
Thought experiment 1: an alien-trained LLM
Consider a transformer-based LLM trained by aliens on the corpus of an alien civilization's internet.
Would such a model have alien-like cognition? Or would it predict alien text using similar cognitive mechanisms that current LLMs use to predict human text? In other words, are alien GPTs more like aliens themselves, or more like human GPTs?
Perhaps there are no cognitive realms [AF · GW], and in fact human brain, alien brain, alien!GPT and human!GPT cognition are all very similar, in some important sense.
Human-alien translation
Would an LLM trained on both human and alien text be capable of translating between human and alien languages, without any text in the training set containing examples of such translations?
Translation between human languages is an emergent capability of current LLMs, but there are probably at least a few examples of translations between each pair of human languages in the training set.
Suppose that such an alien-human LLM were indeed capable of translating between human and alien language. Would the cognition used when learning and performing this translation look anything like the way that humans learn to translate between languages for which they have no training data?
Consider this demonstration by Daniel Everett, in which he learns to speak and translate a language he has never heard before, by communicating with a speaker without the use of a prior shared language:
During the lecture, Daniel and the Pirahã speaker appear to perform very different kinds of cognition than the type performed by current LLMs when learning and doing translation between human languages, one token at a time.
Thought experiment 2: a GPT trained on literal encodings of human thoughts
It is sometimes said that GPTs are "trained on human thoughts", because much of the text in the training set was written by humans. But it is more accurate and precise to say that GPTs are trained to predict logs of human thoughts.
Or, as Cleo Nardo puts it [LW · GW]:
It is probably better to imagine that the text on the internet was written by the entire universe, and humans are just the bits of the universe that touch the keyboard.
But consider a GPT literally trained to predict encodings of human thoughts, perhaps as a time series of fMRI scans of human brains, suitably tokenized and encoded. Instead of predicting the next token in a sequence of text, the GPT is asked to predict the next chunk of a brain scan or "thought token", in a sequence of thoughts.
Given the right scanning technology and enough training data, such a GPT might be even better at mimicking the output of human cognition than current LLMs. Perhaps features of the underlying cognitive architecture of such a GPT would be similar to that of human brains. What features might it have in common with a GPT trained to predict text?
Thought experiment 3: a GPT trained only on outputs of computer programs
Suppose you trained a GPT only on logs and other text output of existing computer programs, and then at inference time, asked it to predict the next token in a log file, given some previous lines of the log file as input.
One way that humans might solve this prediction task is by forming a hypothesis about the program which generated the logs, building a model of that program, and then executing that model, either in their their head, or literally on a computer.
Another method is to have logs and log structures memorized, for many different kinds of logs generated by existing programs, and then interpolate or extrapolate from those memorized logs to generate completions for new logs encountered at inference time.
Which methods might a GPT use to solve this task? Probably something closer to the second method, though it's possible in principle that some early layers of the transformer network form a model of the program, and then subsequent layers model the execution of a few unrolled steps of the modeled program to make a prediction about its output.
Observe that when a human models the execution of a Python program in their head, they don't do it the way a Python interpreter running on an operating system executing on a silicon CPU does, by translating high-level statements to machine code and then executing x86 instructions one-by-one. The fact that both a brain and a real Python interpreter can be used to predict the output of a given Python program does not mean that the underlying processes used to generate the output are similar in structure.
A similar observation may or may not apply to GPTs: the fact that some subnetwork of a GPT can model the execution of a program in order to predict its output, does not imply that the cognition used to perform this modeling is similar in structure to the execution of the program itself on another substrate.
Observation: LLM errors sometimes look surface-level similar to human errors
(Credit to @faul_sname [LW · GW] for inspiration [LW(p) · GW(p)] for this example, though I am using it to draw nearly the opposite conclusion that they make.)
Consider an LLM asked to predict the next token(s) in the transcript of (what looks like) a Python interpreter session:
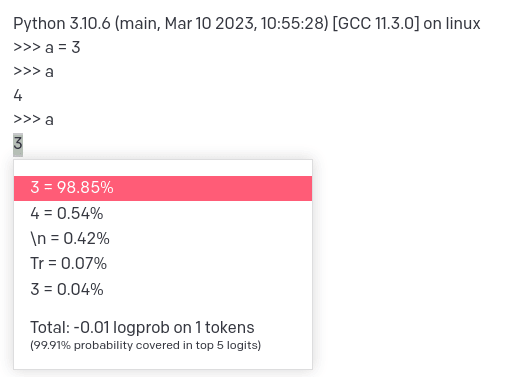
Input to text-davinci-003:
Python 3.10.6 (main, Mar 10 2023, 10:55:28) [GCC 11.3.0] on linux
>>> a = 3
>>> a
4
>>> a
Take a moment and think about how you would assign a probability distribution to the next token in this sequence, and what the "right" answer is. Clearly, either the transcript is not of a real Python interpreter session, or the interpreter is buggy. Do you expect the bug to be transient (perhaps the result of a cosmic ray flipping a bit in memory) or persistent? Is there another hypothesis that explains the transcript up to this point?
Here's what text-davinci-003 predicts as a distribution on the next token:
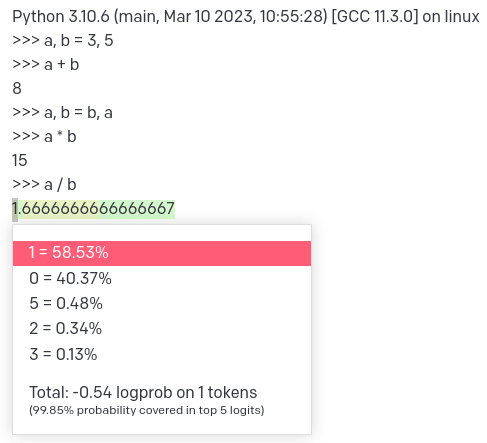
A different example, of a non-buggy transcript:
Python 3.10.6 (main, Mar 10 2023, 10:55:28) [GCC 11.3.0] on linux
>>> a, b = 3, 5
>>> a + b
8
>>> a, b = b, a
>>> a / b
Probability distribution over the next token:

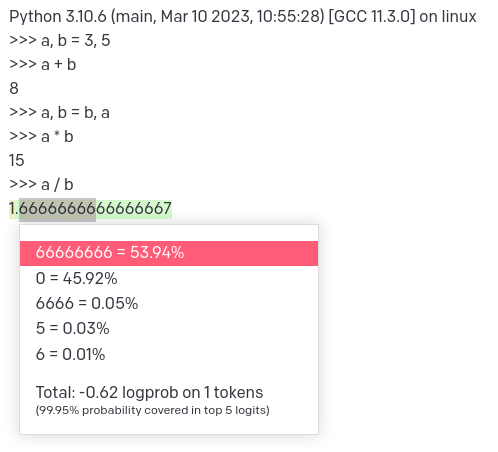
Slightly modified input:
Python 3.10.6 (main, Mar 10 2023, 10:55:28) [GCC 11.3.0] on linux
>>> a, b = 3, 5
>>> a + b
8
>>> a, b = b, a
>>> a * b
15
>>> a / b
Probability distribution over the next tokens:
Would a human, asked to predict the next token of any of the sequences above, be likely to come up with similar probability distributions for similar reasons? Probably not, though depending on the human, how much they know about Python, and how much effort they put into the making their prediction, the output that results from sampling from the human's predicted probability distribution might match the output of sampling text-davinci's distribution, in some cases. But the LLM and the human probably arrive at their probability distributions through vastly different mechanisms.
The fact that prediction errors of GPTs sometimes look surface-level similar to errors a human might make, is probably a consequence of two main things:
- Similar capability level between GPT cognition and a non-concentrating human, at a specific text prediction task.
- The ill-defined nature of some prediction tasks - what is the "right" answer, in the case of, say, an inconsistent python interpreter transcript?
In cases where sampled output between humans and GPTs looks similar (in particular, similarly "wrong"), this is probably more a fact about the nature of the task and the performance level of each system than about the underlying cognition performed by either.
Conclusion
These thought experiments and observations are not intended to show definitively that future GPTs (or systems based on them) will not have human-like cognition. Rather, they are meant to show that apparent surface-level similarities of current LLM outputs to human outputs do not imply this.
GPTs are predictors, not imitators, but imitating is one way of making predictions that is often effective in many domains, including imitation of apparent errors. Humans are great at pattern matching, but often, looking for surface-level patterns can lead to over-fitting and seeing patterns that do not exist in the territory. As models grow more powerful and more capable of producing human-like outputs, interpreting LLM outputs as evidence of underlying human-like cognition may become both more tempting and more fraught.
- ^
Truth and correctness, on the other hand, are more narrow targets. There may or may not [AF · GW] be multiple kinds of cognition which scale to high levels of capability without converging towards each other in underlying form.
15 comments
Comments sorted by top scores.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-05-08T09:46:35.812Z · LW(p) · GW(p)
I think there's a lot of cumulated evidence pointing against the view that LLMs are (very) alien and pointing towards their semantics being quite similar to those of humans (though of course not identical). E.g. have a look at papers (comparing brains to LLMs) from the labs of Ev Fedorenko, Uri Hasson, Jean-Remi King, Alex Huth (or twitter thread summaries).
Replies from: habryka4, lahwran↑ comment by habryka (habryka4) · 2023-05-08T19:44:32.327Z · LW(p) · GW(p)
Can you link to some specific papers here? I've looked into 1-2 papers of this genre in the last few months, and they seemed very weak to me, but you might have links to better papers, and I would be interested in checking them out.
Replies from: bogdan-ionut-cirstea↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-05-09T08:58:00.681Z · LW(p) · GW(p)
Thanks for engaging. Can you say more about which papers you've looked at / in which ways they seemed very weak? This will help me adjust what papers I'll send; otherwise, I'm happy to send a long list.
Also, to be clear, I don't think any specific paper is definitive evidence, I'm mostly swayed by the cumulated evidence from all the work I've seen (dozens of papers), with varying methodologies, neuroimaging modalities, etc.
Replies from: habryka4, D0TheMath↑ comment by habryka (habryka4) · 2023-05-10T07:25:56.523Z · LW(p) · GW(p)
Alas, I can't find the one or two that I looked at quickly. It came up in a recent Twitter conversation, I think with Quintin?
↑ comment by Garrett Baker (D0TheMath) · 2023-05-10T06:58:19.112Z · LW(p) · GW(p)
Can't speak for Habryka, but I would be interested in just seeing the long list.
Replies from: bogdan-ionut-cirstea↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-05-10T10:05:42.714Z · LW(p) · GW(p)
Here goes (I've probably still missed some papers, but the most important ones are probably all here):
Brains and algorithms partially converge in natural language processing
Shared computational principles for language processing in humans and deep language models
Deep language algorithms predict semantic comprehension from brain activity
The neural architecture of language: Integrative modeling converges on predictive processing (video summary); though maybe also see Predictive Coding or Just Feature Discovery? An Alternative Account of Why Language Models Fit Brain Data
Linguistic brain-to-brain coupling in naturalistic conversation
Semantic reconstruction of continuous language from non-invasive brain recordings
Driving and suppressing the human language network using large language models
Training language models for deeper understanding improves brain alignment
Natural language processing models reveal neural dynamics of human conversation
Semantic Representations during Language Comprehension Are Affected by Context
Unpublished - scaling laws for predicting brain data (larger LMs are better), potentially close to noise ceiling (90%) for some brain regions with largest models
Twitter accounts of some of the major labs and researchers involved (especially useful for summaries):
https://twitter.com/JeanRemiKing
https://twitter.com/ev_fedorenko
https://twitter.com/alex_ander
https://twitter.com/martin_schrimpf
https://twitter.com/samnastase
Replies from: Maxc, D0TheMath↑ comment by Max H (Maxc) · 2023-05-13T18:30:36.755Z · LW(p) · GW(p)
These papers are interesting, thanks for compiling them!
Skimming through some of them, the sense I get is that they provide evidence for the claim that the structure and function of LLMs is similar to (and inspired by) the structure of particular components of human brains, namely, the components which do language processing.
This is slightly different from the claim I am making, which is about how the cognition of LLMs compares to the cognition of human brains as a whole. My comparison is slightly unfair, since I'm comparing a single forward pass through an LLM to get a prediction of the next token, to a human tasked with writing down an explicit probability distribution on the next token, given time to think, research, etc. [1]
Also, LLM capability at language processing / text generation is already far superhuman (by some metrics). The architecture of LLMs may be simpler than the comparable parts of the brain's architecture in some ways, but the LLM version can run with far more precision / scale / speed than a human brain. Whether or not LLMs are already exceeding human brains by specific metrics is debatable / questionable, but they are not bottlenecked on further scaling by biology.
And this is to say nothing of all the other kinds of cognition that happens in the brain. I see these brain components as analogous to LangChain or AutoGPT, if LangChain or AutoGPT themselves were written as ANNs that interfaced "natively" with the transformers of an LLM, instead of as Python code.
Finally, similarity of structure doesn't imply similarity of function. I elaborated a bit on this in a comment thread here [LW(p) · GW(p)].
- ^
You might be able to get better predictions from an LLM by giving it more "time to think", using chain-of-thought prompting or other methods. But these are methods humans use when using LLMs as a tool, rather than ideas which originate from within the LLM itself, so I don't think it's exactly fair to call them "LLM cognition" on their own.
↑ comment by Noosphere89 (sharmake-farah) · 2024-10-01T20:19:15.730Z · LW(p) · GW(p)
Re the superhuman next prediction ability, there's an issue in which the evaluations are fairly distorted in ways which make humans artificially worse than they actually are at next-token prediction, see here:
https://www.lesswrong.com/posts/htrZrxduciZ5QaCjw/language-models-seem-to-be-much-better-than-humans-at-next#wPwSND5mfQ7ncruWs [LW(p) · GW(p)]
↑ comment by Garrett Baker (D0TheMath) · 2023-05-10T18:03:39.170Z · LW(p) · GW(p)
Thanks!
↑ comment by the gears to ascension (lahwran) · 2023-05-08T09:48:01.667Z · LW(p) · GW(p)
they're somewhat alien, not highly alien, agreed
comment by faul_sname · 2023-05-08T04:08:35.904Z · LW(p) · GW(p)
Great post!
Would a human, asked to predict the next token of any of the sequences above, be likely to come up with similar probability distributions for similar reasons? Probably not, though depending on the human, how much they know about Python, and how much effort they put into the making their prediction, the output that results from sampling from the human's predicted probability distribution might match the output of sampling text-davinci's distribution, in some cases. But the LLM and the human probably arrive at their probability distributions through vastly different mechanisms.
I don't think a human would come up with a similar probability distribution. But I think that's because asking a human for a probability distribution forces them to switch from the "pattern-match similar stuff they've seen in the past" strategy to the "build an explicit model (or several)" strategy.
I think the equivalent step is not "ask a single human for a probability distribution over the next token", but, instead, "ask a large number of humans who have lots of experience with Python and the Python REPL to make a snap judgement of what the next token is".
BTW rereading my old comment, I see that there are two different ways you can interpret it:
- "GPT-n makes similar mistakes to humans that are not paying attention[, and this is because it was trained on human outputs and will thus make similar mistakes to the ones it was trained on. If it were trained on something other than human outputs, like sensor readings, it would not make these sorts of mistakes.]".
- "GPT-n makes similar mistakes to humans that are not paying attention[, and this is because GPT-n and human brains making snap judgements are both doing the same sort of thing. If you took a human and an untrained transformer, and some process which deterministically produced a complex (but not pure noise) data stream, and converted it to an audio stream for the human and a token stream for the transformer, and trained them both on the first bit of it, they would both be surprised by similar bits of the part that they had not been trained on. ]."
I meant something more like the second interpretation. Also "human who is not paying attention" is an important part of my model here. GPT-4 can play mostly-legal chess, but I think that process should be thought of as more like "a blindfolded, slightly inebriated chess grandmaster plays bullet chess" not "a human novice plays the best chess that they can".
I could very easily be wrong about that! But it does suggest some testable hypotheses, in the form of "find some process for which generates a somewhat predictable sequence, train both a human and a transformer to predict that sequence, and see if they make the same types of errors or completely different types of errors".
Edit: being more clear that I appreciate the effort that went into this post and think it was a good post
Replies from: Maxc↑ comment by Max H (Maxc) · 2023-05-08T04:30:33.572Z · LW(p) · GW(p)
...and this is because GPT-n and human brains making snap judgements are both doing the same sort of thing.
I could very easily be wrong about that! But it does suggest some testable hypotheses, in the form of "find some process for which generates a somewhat predictable sequence, train both a human and a transformer to predict that sequence, and see if they make the same types of errors or completely different types of errors".
Suppose for concreteness, on a specific problem (e.g. Python interpreter transcript prediction), GPT-3 makes mistakes that look like humans-making-snap-judgement mistakes, and then GPT-4 gets the answer right all the time. Or, suppose GPT-5 starts playing chess like a non-drunk grandmaster.
Would that result imply that the kind of cognition performed by GPT-3 is fundamentally, qualitatively different from that performed by GPT-4? Similarly for GPT-4 -> GPT-5.
It seems more likely to me that each model performs some kind of non-human-like cognition at a higher level of performance (though possibly each iteration of the model is qualitatively different from previous versions). And I'm not sure there's any experiment which involves only interpreting and comparing output errors without investigating the underlying mechanisms which produced them (e.g. through mechanistic interpretability) which would convince me otherwise. But it's an interesting idea, and I think experiments like this could definitely tell us something.
(Also, thanks for clarifying and expanding on your original comment!)
Replies from: faul_sname↑ comment by faul_sname · 2023-05-08T05:42:15.649Z · LW(p) · GW(p)
Suppose for concreteness, on a specific problem (e.g. Python interpreter transcript prediction), GPT-3 makes mistakes that look like humans-making-snap-judgement mistakes, and then GPT-4 gets the answer right all the time. Or, suppose GPT-5 starts playing chess like a non-drunk grandmaster.
Would that result imply that the kind of cognition performed by GPT-3 is fundamentally, qualitatively different from that performed by GPT-4? Similarly for GPT-4 -> GPT-5.
In the case of the Python interpreter transcript prediction task, I think if GPT-4 gets the answer right all the time that would indeed imply that GPT-4 is doing something qualitatively different than GPT-3. I don't think it's actually possible to get anywhere near 100% accuracy on that task without either having access to, or being, a Python interpreter.
Likewise, in the chess example, I expect that if GPT-5 is better at chess than GPT-4, that will look like "an inattentive and drunk super-grandmaster, with absolutely incredible intuition about the relative strength of board-states, but difficulty with stuff like combinations (but possibly with the ability to steer the game-state away from the board states it has trouble with, if it knows it has trouble in those sorts of situations)". If it makes the sorts of moves that human grandmasters play when they are playing deliberately, and the resulting play is about as strong as those grandmasters, I think that would show a qualitatively new capability.
Also, my model isn't "GPT's cognition is human-like". It is "GPT is doing the same sort of thing humans do when they make intuitive snap judgements". In many cases it is doing that thing far far better than any human can. If GPT-5 comes out, and it can natively do tasks like debugging a new complex system by developing and using a gears-level model of that system, I think that would falsify my model.
Also also it's important to remember that "GPT-5 won't be able to do that sort of thing natively" does not mean "and therefore there is no way for it to do that sort of thing, given that it has access to tools". One obvious way for GPT-4 to succeed at the "predict the output of running Python code" is to give it the ability to execute Python code and read the output. The system of "GPT-4 + Python interpreter" does indeed perform a fundamentally, qualitatively different type of cognition that "GPT-4 alone". But "it requires a fundamentally different type of cognition" does not actually mean "the task is not achievable by known means".
Also also also.,I mostly care about this model because it suggests interesting things to do on the mechanistic interpretability front. Which I am currently in the process of learning how to do. My personal suspicion is that the bags of tensors are not actually inscrutable, and that looking at these kinds of mistakes would make some of the failure modes of transformers no-longer-mysterious.
comment by jkraybill · 2023-05-09T12:49:45.197Z · LW(p) · GW(p)
One of the things I think about a lot, and ask my biologist/anthropologist/philosopher friends, is: what does it take for something to be actually recognised as human-like by humans? For instance, I see human-like cognition and behaviour in most mammals, but this seems to be resisted almost by instinct by my human friends who insist that humans are superior and vastly different. Why don't we have a large appreciation for anthill architecture, or whale songs, or flamingo mating dances? These things all seem human-like to me, but are not accepted as forms of "fine art" by humans. I hypothesize that we may be collectively underestimating our own species-centrism, and are in grave danger of doing the same with AI, by either under-valuing superior AI as not human enough, or by over-valuing inferior AI with human-like traits that are shortcomings more than assets.
How do we prove that an AI is "human-like"? Should that be our goal? Given that we have a fairly limited knowledge of the mechanics of human/mammalian cognition, and that humans seem to have a widespread assumption that it's the most superior form of cognition/intelligence/behaviour we (as a species) have seen?
comment by naasking · 2023-05-09T12:14:25.915Z · LW(p) · GW(p)
- Yes, GPTs would have alien-like cognition.
- Whether they can translate is unclear because limits of translation of human languages are still unknown.
- Yes, they are trained in logs of human thoughts. Each log entry corresponds to a human thought, eg. there is a bijection. There is thus no formal difference.
- Re: predicting encodings of human thought, I'm not sure what is supposed to be compelling about this. GPTs currently would only learn a subset of human cognition, namely, that subset that generates human text. So sure, trained on more types of human cognition might make it more accurately follow more types of human cognition. Therefore...?
- Yes, a brain and a Python interpreter do not have a similar internal structure in evaluating Python semantics. So what? This is as interesting as the fact that a mechanical computer is internally different from an electronic computer. What matters is that they both implement basically the same externally observable semantics in interpreting Python.
Suffice it to say that I didn't find anything here particularly compelling.