Ability to solve long-horizon tasks correlates with wanting things in the behaviorist sense
post by So8res · 2023-11-24T17:37:43.020Z · LW · GW · 84 commentsContents
84 comments
Status: Vague, sorry. The point seems almost tautological to me, and yet also seems like the correct answer to the people going around saying “LLMs turned out to be not very want-y, when are the people who expected 'agents' going to update?”, so, here we are.
Okay, so you know how AI today isn't great at certain... let's say "long-horizon" tasks? Like novel large-scale engineering projects, or writing a long book series with lots of foreshadowing?
(Modulo the fact that it can play chess pretty well, which is longer-horizon than some things; this distinction is quantitative rather than qualitative and it’s being eroded, etc.)
And you know how the AI doesn't seem to have all that much "want"- or "desire"-like behavior?
(Modulo, e.g., the fact that it can play chess pretty well, which indicates a certain type of want-like behavior in the behaviorist sense. An AI's ability to win no matter how you move is the same as its ability to reliably steer the game-board into states where you're check-mated, as though it had an internal check-mating “goal” it were trying to achieve. This is again a quantitative gap that’s being eroded.)
Well, I claim that these are more-or-less the same fact. It's no surprise that the AI falls down on various long-horizon tasks and that it doesn't seem all that well-modeled as having "wants/desires"; these are two sides of the same coin.
Relatedly: to imagine the AI starting to succeed at those long-horizon tasks without imagining it starting to have more wants/desires (in the "behaviorist sense" expanded upon below) is, I claim, to imagine a contradiction—or at least an extreme surprise. Because the way to achieve long-horizon targets in a large, unobserved, surprising world that keeps throwing wrenches into one's plans, is probably to become a robust generalist wrench-remover that keeps stubbornly reorienting towards some particular target no matter what wrench reality throws into its plans.
This observable "it keeps reorienting towards some target no matter what obstacle reality throws in its way" behavior is what I mean when I describe an AI as having wants/desires "in the behaviorist sense".
I make no claim about the AI's internal states and whether those bear any resemblance to the internal state of a human consumed by the feeling of desire. To paraphrase something Eliezer Yudkowsky said somewhere: we wouldn't say that a blender "wants" to blend apples. But if the blender somehow managed to spit out oranges, crawl to the pantry, load itself full of apples, and plug itself into an outlet, then we might indeed want to start talking about it as though it has goals, even if we aren’t trying to make a strong claim about the internal mechanisms causing this behavior.
If an AI causes some particular outcome across a wide array of starting setups and despite a wide variety of obstacles, then I'll say it "wants" that outcome “in the behaviorist sense”.
Why might we see this sort of "wanting" arise in tandem with the ability to solve long-horizon problems and perform long-horizon tasks?
Because these "long-horizon" tasks involve maneuvering the complicated real world into particular tricky outcome-states, despite whatever surprises and unknown-unknowns and obstacles it encounters along the way. Succeeding at such problems just seems pretty likely to involve skill at figuring out what the world is, figuring out how to navigate it, and figuring out how to surmount obstacles and then reorient in some stable direction.
(If each new obstacle causes you to wander off towards some different target, then you won’t reliably be able to hit targets that you start out aimed towards.)
If you're the sort of thing that skillfully generates and enacts long-term plans, and you're the sort of planner that sticks to its guns and finds a way to succeed in the face of the many obstacles the real world throws your way (rather than giving up or wandering off to chase some new shiny thing every time a new shiny thing comes along), then the way I think about these things, it's a little hard to imagine that you don't contain some reasonably strong optimization that strategically steers the world into particular states.
(Indeed, this connection feels almost tautological to me, such that it feels odd to talk about these as distinct properties of an AI. "Does it act as though it wants things?" isn’t an all-or-nothing question, and an AI can be partly goal-oriented without being maximally goal-oriented. But the more the AI’s performance rests on its ability to make long-term plans and revise those plans in the face of unexpected obstacles/opportunities, the more consistently it will tend to steer the things it's interacting with into specific states—at least, insofar as it works at all.)
The ability to keep reorienting towards some target seems like a pretty big piece of the puzzle of navigating a large and complex world to achieve difficult outcomes.
And this intuition is backed up by the case of humans: it's no mistake that humans wound up having wants and desires and goals—goals that they keep finding clever new ways to pursue even as reality throws various curveballs at them, like “that prey animal has been hunted to extinction”.
These wants and desires and goals weren’t some act of a god bequeathing souls into us; this wasn't some weird happenstance; having targets like “eat a good meal” or “impress your friends” that you reorient towards despite obstacles is a pretty fundamental piece of being able to eat a good meal or impress your friends. So it's no surprise that evolution stumbled upon that method, in our case.
(The implementation specifics in the human brain—e.g., the details of our emotional makeup—seem to me like they're probably fiddly details that won’t recur in an AI that has behaviorist “desires”. But the overall "to hit a target, keep targeting it even as you encounter obstacles" thing seems pretty central.)
The above text vaguely argues that doing well on tough long-horizon problems requires pursuing an abstract target in the face of a wide array of real-world obstacles, which involves doing something that looks from the outside like “wanting stuff”. I’ll now make a second claim (supported here by even less argument): that the wanting-like behavior required to pursue a particular training target X, does not need to involve the AI wanting X in particular.
For instance, humans find themselves wanting things like good meals and warm nights and friends who admire them. And all those wants added up in the ancestral environment to high inclusive genetic fitness. Observing early hominids from the outside, aliens might have said that the humans are “acting as though they want to maximize their inclusive genetic fitness”; when humans then turn around and invent birth control, it’s revealed that they were never actually steering the environment toward that goal in particular, and instead had a messier suite of goals that correlated with inclusive genetic fitness, in the environment of evolutionary adaptedness, at that ancestral level of capability.
Which is to say, my theory says “AIs need to be robustly pursuing some targets to perform well on long-horizon tasks”, but it does not say that those targets have to be the ones that the AI was trained on (or asked for). Indeed, I think the actual behaviorist-goal is very unlikely to be the exact goal the programmers intended, rather than (e.g.) a tangled web of correlates.
A follow-on inference from the above point is: when the AI leaves training, and it’s tasked with solving bigger and harder long-horizon problems in cases where it has to grow smarter than ever before and develop new tools to solve new problems, and you realize finally that it’s pursuing neither the targets you trained it to pursue nor the targets you asked it to pursue—well, by that point, you've built a generalized obstacle-surmounting engine. You've built a thing that excels at noticing when a wrench has been thrown in its plans, and at understanding the wrench, and at removing the wrench or finding some other way to proceed with its plans.
And when you protest and try to shut it down—well, that's just another obstacle, and you're just another wrench.
So, maybe don't make those generalized wrench-removers just yet, until we do know how to load proper targets in there.
84 comments
Comments sorted by top scores.
comment by paulfchristiano · 2023-11-24T20:25:15.201Z · LW(p) · GW(p)
Okay, so you know how AI today isn't great at certain... let's say "long-horizon" tasks? Like novel large-scale engineering projects, or writing a long book series with lots of foreshadowing? [...] And you know how the AI doesn't seem to have all that much "want"- or "desire"-like behavior? [...] Well, I claim that these are more-or-less the same fact.
It's pretty unclear if a system that is good at answering the question "Which action would maximize the expected amount of X?" also "wants" X (or anything else) in the behaviorist sense that is relevant to arguments about AI risk. The question is whether if you ask that system "Which action would maximize the expected amount of Y?" whether it will also be wanting the same thing, or whether it will just be using cognitive procedures that are good at figuring out what actions lead to what consequences.
The point seems almost tautological to me, and yet also seems like the correct answer to the people going around saying “LLMs turned out to be not very want-y, when are the people who expected 'agents' going to update?”, so, here we are.
I think that a system may not even be able to "want" things in the behaviorist sense, and this is correlated with being unable to solve long-horizon tasks. So if you think that systems can't want things or solve long horizon tasks at all, then maybe you shouldn't update at all when they don't appear to want things.
But that's not really where we are at---AI systems are able to do an increasingly good job of solving increasingly long-horizon tasks. So it just seems like it should obviously be an update, and the answer to the original question
Could you give an example of a task you don't think AI systems will be able to do before they are "want"-y? At what point would you update, if ever? What kind of engineering project requires an agent to be want-y to accomplish it? Is it something that individual humans can do? (It feels to me like you will give an example like "go to the moon" and that you will still be writing this kind of post even once AI systems have 10x'd the pace of R&D.)
(The foreshadowing example doesn't seem very good to me. One way a human or an AI would write a story with foreshadowing is to first decide what will happen, and then write the story and include foreshadowing of the event you've already noted down. Do you think that series of steps is hard? Or that the very idea of taking that approach is hard? Or what?)
Like you, I think that future more powerful AI systems are more likely to want things in the behaviorist sense, but I have a different picture and think that you are overstating the connection between "wanting things" and "ability to solve long horizon tasks" (as well as overstating the overall case). I think a system which gets high reward across a wide variety of contexts is particularly likely to want reward in the behaviorist sense, or to want something which is consistently correlated with reward or for which getting reward is consistently instrumental during training. This seems much closer to a tautology. I think this tendency increases as models get more competent, but that it's not particularly about "ability to solve long-horizon tasks," and we are obviously getting evidence about it each time we train a new language model.
Replies from: dxu, daniel-kokotajlo, Jonas Hallgren, Seth Herd, Maxc↑ comment by dxu · 2023-11-24T22:26:27.034Z · LW(p) · GW(p)
It's pretty unclear if a system that is good at answering the question "Which action would maximize the expected amount of X?" also "wants" X (or anything else) in the behaviorist sense that is relevant to arguments about AI risk. The question is whether if you ask that system "Which action would maximize the expected amount of Y?" whether it will also be wanting the same thing, or whether it will just be using cognitive procedures that are good at figuring out what actions lead to what consequences.
Here's an existing Nate!comment [LW(p) · GW(p)] that I find reasonably persuasive, which argues that these two things are correlated in precisely those cases where the outcome requires routing through lots of environmental complexity:
Part of what's going on here is that reality is large and chaotic. When you're dealing with a large and chaotic reality, you don't get to generate a full plan in advance, because the full plan is too big. Like, imagine a reasoner doing biological experimentation. If you try to "unroll" that reasoner into an advance plan that does not itself contain the reasoner, then you find yourself building this enormous decision-tree, like "if the experiments come up this way, then I'll follow it up with this experiment, and if instead it comes up that way, then I'll follow it up with that experiment", and etc. This decision tree quickly explodes in size. And even if we didn't have a memory problem, we'd have a time problem -- the thing to do in response to surprising experimental evidence is often "conceptually digest the results" and "reorganize my ontology accordingly". If you're trying to unroll that reasoner into a decision-tree that you can write down in advance, you've got to do the work of digesting not only the real results, but the hypothetical alternative results, and figure out the corresponding alternative physics and alternative ontologies in those branches. This is infeasible, to say the least.
Reasoners are a way of compressing plans, so that you can say "do some science and digest the actual results", instead of actually calculating in advance how you'd digest all the possible observations. (Note that the reasoner specification comprises instructions for digesting a wide variety of observations, but in practice it mostly only digests the actual observations.)
Like, you can't make an "oracle chess AI" that tells you at the beginning of the game what moves to play, because even chess is too chaotic for that game tree to be feasibly representable. You've gotta keep running your chess AI on each new observation, to have any hope of getting the fragment of the game tree that you consider down to a managable size.
Like, the outputs you can get out of an oracle AI are "no plan found", "memory and time exhausted", "here's a plan that involves running a reasoner in real-time" or "feed me observations in real-time and ask me only to generate a local and by-default-inscrutable action". In the first two cases, your oracle is about as useful as a rock; in the third, it's the realtime reasoner that you need to align; in the fourth, all [the] word "oracle" is doing is mollifying you unduly, and it's this "oracle" that you need to align.
Could you give an example of a task you don't think AI systems will be able to do before they are "want"-y? At what point would you update, if ever? What kind of engineering project requires an agent to be want-y to accomplish it? Is it something that individual humans can do? (It feels to me like you will give an example like "go to the moon" and that you will still be writing this kind of post even once AI systems have 10x'd the pace of R&D.)
Here's an existing Nate!response [LW(p) · GW(p)] to a different-but-qualitatively-similar request that, on my model, looks like it ought to be a decent answer to yours as well:
a thing I don't expect the upcoming multimodal models to be able to do: train them only on data up through 1990 (or otherwise excise all training data from our broadly-generalized community), ask them what superintelligent machines (in the sense of IJ Good) should do, and have them come up with something like CEV (a la Yudkowsky) or indirect normativity (a la Beckstead) or counterfactual human boxing techniques (a la Christiano) or suchlike.
Note that this only tangentially a test of the relevant ability; very little of the content of what-is-worth-optimizing-for occurs in Yudkowsky/Beckstead/Christiano-style indirection. Rather, coming up with those sorts of ideas is a response to glimpsing the difficulty of naming that-which-is-worth-optimizing-for directly and realizing that indirection is needed. An AI being able to generate that argument without following in the footsteps of others who have already generated it would be at least some evidence of the AI being able to think relatively deep and novel thoughts on the topic.
(The original discussion that generated this example was couched in terms of value alignment, but it seems to me the general form "delete all discussion pertaining to some deep insight/set of insights from the training corpus, and see if the model can generate those insights from scratch" constitutes a decent-to-good test of the model's cognitive planning ability.)
(Also, I personally think it's somewhat obvious that current models are lacking in a bunch of ways that don't nearly require the level of firepower implied by a counterexample like "go to the moon" or "generate this here deep insight from scratch", s.t. I don't think current capabilities constitute much of an update at all as far as "want-y-ness" goes, and continue to be puzzled at what exactly causes [some] LLM enthusiasts to think otherwise.)
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2023-11-25T00:52:43.712Z · LW(p) · GW(p)
I don't see why you can't just ask at each point in time "Which action would maximize the expected value of X". It seems like asking once and asking many times as new things happen in reality don't have particularly different properties.
More detailed comment
Paul noted:
It's pretty unclear if a system that is good at answering the question "Which action would maximize the expected amount of X?" also "wants" X (or anything else) in the behaviorist sense that is relevant to arguments about AI risk. The question is whether if you ask that system "Which action would maximize the expected amount of Y?" whether it will also be wanting the same thing, or whether it will just be using cognitive procedures that are good at figuring out what actions lead to what consequences.
An earlier Nate comment (not in response) is:
Part of what's going on here is that reality is large and chaotic. When you're dealing with a large and chaotic reality, you don't get to generate a full plan in advance, because the full plan is too big. Like, imagine a reasoner doing biological experimentation. If you try to "unroll" that reasoner into an advance plan that does not itself contain the reasoner, then you find yourself building this enormous decision-tree, like "if the experiments come up this way, then I'll follow it up with this experiment, and if instead it comes up that way, then I'll follow it up with that experiment", and etc. This decision tree quickly explodes in size. And even if we didn't have a memory problem, we'd have a time problem -- the thing to do in response to surprising experimental evidence is often "conceptually digest the results" and "reorganize my ontology accordingly". If you're trying to unroll that reasoner into a decision-tree that you can write down in advance, you've got to do the work of digesting not only the real results, but the hypothetical alternative results, and figure out the corresponding alternative physics and alternative ontologies in those branches. This is infeasible, to say the least.
Reasoners are a way of compressing plans, so that you can say "do some science and digest the actual results", instead of actually calculating in advance how you'd digest all the possible observations. (Note that the reasoner specification comprises instructions for digesting a wide variety of observations, but in practice it mostly only digests the actual observations.)
But, can't you just query the reasoner at each point for what a good action would be? And then, it seems unclear if the AI actually "wants" the long run outcome vs just "wants" to give a good response or something else entirely.
Maybe the claim is that if you do this, it's equivalent to just training the reasoner to do the long term outcome (which will get you a reasoner which want long term outcomes). Or it would only work if the reasoner had the ability to solve long-horizon tasks directly which itself might imply it's likely to want to do this. But this seems at least unclear for reasonable training schemes.
For instance, imagine you train an AI with purely process based feedback to take actions. As in, I want to train my AI to accomplish objectives over the course of 6 months. So, I have a human review actions the AI took over a 1 hour period and rate these actions based on how good these actions seem for accomplishing the long term objective. It seems like this feedback is likely to deviate considerably from the best way to accomplish the long run objective in ways which make danger less likely. In particular, it seems far less likely that the AI will 'want' long term outcomes rather than 'wanting' to do an action such that the human rater will think the action will lead to good long term consequences (or some other proxy 'want' entirely).
(Note that just because the feedback differs considerably doesn't mean it's way less competitive, it might be, but that will depend on more details.)
It's totally consistent to have the view 'AIs which just aim to satisify local measures of goodness (e.g. a human thinks this action is good) will never be able to accomplish long run outcomes without immense performance penalties', but I think this seems at least unclear. Further, training based mostly on long run feedback is very expensive (even if we're thinking about time scales more like 2 hours than 6 months which is more plausible anyway).
Replies from: ryan_greenblatt, JoeTheUser↑ comment by ryan_greenblatt · 2023-11-25T01:03:19.439Z · LW(p) · GW(p)
More generally, it seems like we can build systems that succeed in accomplishing long run goals without having the core components which are doing this actually 'want' to accomplish any long run goal.
It seems like this is common for corporations and we see similar dynamics for language model agents.
(Again, efficiency concerns are reasonable.)
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-11-26T06:48:16.276Z · LW(p) · GW(p)
I do not expect you to be able to give an example of a corporation that is a central example of this without finding that there is in fact a "want" implemented in the members of the corporation wanting to satisfy their bosses, who in turn want to satisfy theirs, etc. Corporations are generally supervisor trees where bosses set up strong incentives, and it seems to me that this produces a significant amount of aligned wanting in the employees, though of course there's also backpressure.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2023-11-26T06:55:59.677Z · LW(p) · GW(p)
I agree that there is want, but it's very unclear if this needs to be long run 'want'.
(And for danger, it seems the horizon of want matters a lot.)
↑ comment by JoeTheUser · 2023-11-26T23:13:00.844Z · LW(p) · GW(p)
But, can't you just query the reasoner at each point for what a good action would be?
What I'd expect (which may or may not be similar to Nate!'s approach) is that the reasoner has prepared one plan (or a few plans). Despite being vastly intelligent, it doesn't have the resources to scan all the world's outcomes and compare their goodness. It can give you the results of acting on the primary (and maybe several secondary) goal(s) and perhaps the immediate results of doing nothing or other immediate stuff.
It seems to me that Nate! (as quoted above about chess) is making the very cogent (imo) point that even a highly, superhumanly competent entity acting on the real, vastly complicated world isn't going to be an exact oracle, isn't going to have access to exact probabilities of things or probabilities of probabilities of outcomes and so-forth. It will know the probabilities of some things certainly but many other results will it can only pursue a strategy deemed good based on much more indirect processes. And this is because an exact calculation of the outcome process of the world in questions tends "blows up" far beyond any computing power physically available in the foreseeable future.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-27T14:07:03.786Z · LW(p) · GW(p)
I am confused what your position is, Paul, and how it differs from So8res' position. Your statement of your position at the end (the bit about how systems are likely to end up wanting reward) seems like a stronger version of So8res' position, and not in conflict with it. Is the difference that you think the main dimension of improvement driving the change is general competence, rather than specifically long-horizon-task competence?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2023-11-27T16:57:58.454Z · LW(p) · GW(p)
Differences:
- I don't buy the story about long-horizon competence---I don't think there is a compelling argument, and the underlying intuitions seem like they are faring badly. I'd like to see this view turned into some actual predictions, and if it were I expect I'd disagree.
- Calling it a "contradiction" or "extreme surprise" to have any capability without "wanting" looks really wrong to me.
- Nate writes:
This observable "it keeps reorienting towards some target no matter what obstacle reality throws in its way" behavior is what I mean when I describe an AI as having wants/desires "in the behaviorist sense"."
- I think this is a semantic motte and bailey that's failing to think about mechanics of the situation. LM agents already have the behavior "reorient towards a target in response to obstacles," but that's not the sense of "wanting" about which people disagree or that is relevant to AI risk (which I tried to clarify in my comment). No one disagrees that an LM asked "how can I achieve X in this situation?" will be able to propose methods to achieve X, and those methods will be responsive to obstacles. But this isn't what you need for AI risk arguments!
- I think this post is a bad answer to the question "when are the people who expected 'agents' going to update?" I think you should be updating some now and you should be discussing that in an answer. I think the post also fails to engage with the actual disagreements so it's not really advancing the discussion.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-28T21:31:15.891Z · LW(p) · GW(p)
Thanks for the response. I'm still confused but maybe that's my fault. FWIW I think my view is pretty similar to Nate's probably, though I came to it mostly independently & I focus on the concept of agents rather than the concept of wanting. (For more on my view, see this sequence. [? · GW])
I definitely don't endorse "it's extremely surprising for there to be any capabilities without 'wantings'" and I expect Nate doesn't either.
What do you think is the sense of "wanting" needed for AI risk arguments? Why is the sense described above not enough?
↑ comment by paulfchristiano · 2023-11-29T02:35:39.116Z · LW(p) · GW(p)
If your AI system "wants" things in the sense that "when prompted to get X it proposes good strategies for getting X that adapt to obstacles," then you can control what it wants by giving it a different prompt. Arguments about AI risk rely pretty crucially on your inability to control what the AI wants, and your inability to test it. Saying "If you use an AI to achieve a long-horizon task, then the overall system definitionally wanted to achieve that task" + "If your AI wants something, then it will undermine your tests and safety measures" seems like a sleight of hand, most of the oomph is coming from equivocating between definitions of want.
You say:
I definitely don't endorse "it's extremely surprising for there to be any capabilities without 'wantings'" and I expect Nate doesn't either.
But the OP says:
to imagine the AI starting to succeed at those long-horizon tasks without imagining it starting to have more wants/desires (in the "behaviorist sense" expanded upon below) is, I claim, to imagine a contradiction—or at least an extreme surprise
This seems to strongly imply that a particular capability---succeeding at these long horizon tasks---implies the AI has "wants/desires." That's what I'm saying seems wrong.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-29T15:42:11.687Z · LW(p) · GW(p)
I agree that arguments for AI risk rely pretty crucially on human inability to notice and control what the AI wants. But for conceptual clarity I think we shouldn't hardcode that inability into our definition of 'wants!' Instead I'd say that So8res is right that ability to solve long-horizon tasks is correlated with wanting things / agency, and then say that there's a separate question of how transparent and controllable the wants will be around the time of AGI and beyond. This then leads into a conversation about visible/faithful/authentic CoT, which is what I've been thinking about for the past six months and which is something MIRI started thinking about years ago. (See also my response to Ryan elsewhere in this thread)
↑ comment by paulfchristiano · 2023-11-29T16:47:34.983Z · LW(p) · GW(p)
If you use that definition, I don't understand in what sense LMs don't "want" things---if you prompt them to "take actions to achieve X" then they will do so, and if obstacles appear they will suggest ways around them, and if you connect them to actuators they will frequently achieve X even in the face of obstacles, etc. By your definition isn't that "want" or "desire" like behavior? So what does it mean when Nate says "AI doesn't seem to have all that much "want"- or "desire"-like behavior"?
I'm genuinely unclear what the OP is asserting at that point, and it seems like it's clearly not responsive to actual people in the real world saying "LLMs turned out to be not very want-y, when are the people who expected 'agents' going to update?” People who say that kind of thing mostly aren't saying that LMs can't be prompted to achieve outcomes. They are saying that LMs don't want things in the sense that is relevant to usual arguments about deceptive alignment or reward hacking (e.g. don't seem to have preferences about the training objective, or that are coherent over time).
Replies from: daniel-kokotajlo, Jozdien↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-29T20:16:12.376Z · LW(p) · GW(p)
I would say that current LLMs, when prompted and RLHF'd appropriately, and especially when also strapped into an AutoGPT-type scaffold/harness, DO want things. I would say that wanting things is a spectrum and that the aforementioned tweaks (appropriate prompting, AutoGPT, etc.) move the system along that spectrum. I would say that future systems will be even further along that spectrum. IDK what Nate meant but on my charitable interpretation he simply meant that they are not very far along the spectrum compared to e.g. humans or prophecied future AGIs.
It's a response to "LLMs turned out to not be very want-y, when are the people who expcted 'agents' going to update?" because it's basically replying "I didn't expect LLMs to be agenty/wanty; I do expect agenty/wanty AIs to come along before the end and indeed we are already seeing progress in that direction."
To the people saying "LLMs don't want things in the sense that is relevant to the usual arguments..." I recommend rephrasing to be less confusing: Your claim is that LLMs don't seem to have preferences about the training objective, or that are coherent over time, unless hooked up into a prompt/scaffold that explicitly tries to get them to have such preferences. I agree with this claim, but don't think it's contrary to my present or past models.
↑ comment by Jozdien · 2023-11-29T20:16:12.823Z · LW(p) · GW(p)
Two separate thoughts, based on my understanding of what the OP is gesturing at (which may not be what Nate is trying to say, but oh well):
- Using that definition, LMs do "want" things, but: the extent to which it's useful to talk about an abstraction like "wants" or "desires" depends heavily on how well the system can be modelled that way. For a system that manages to competently and robustly orient itself around complex obstacles, there's a notion of "want" that's very strong. For a system that's slightly weaker than that - well, it's still capable of orienting itself around some obstacles so there's still a notion of "want", but it's correspondingly weaker, and plausibly less useful. And insofar as you're trying to assert something about some particular behaviour of danger arising from strong wants, systems with weaker wants wouldn't update you very much.
Unfortunately, this does mean you have to draw arbitrary lines about where strong wants are and making that more precise is probably useful, but doesn't seem to inherently be an argument against it. (To be clear though, I don't buy this line of reasoning to the extent I think Nate does). - On the ability to solve long-horizon tasks: I think of it as a proxy measure for how strong your wants are (where the proxy breaks down because diverse contexts and complex obstacles aren't perfectly correlated with long-horizon tasks, but might still be a pretty good one in realistic scenarios). If you have cognition that can robustly handle long-horizon tasks, then one could argue that this can measure by proxy how strongly-held and coherent its objectives are, and correspondingly how capable it is of (say) applying optimization power to break control measures you place on it or breaking the proxies you were training on.
More concretely: I expect that one answer to this might anchor to "wants at least as strong as a human's", in which case AI systems 10x-ing the pace of R&D autonomously would definitely suffice; the chain of logic being "has the capabilities to robustly handle real-world obstacles in pursuit of task X" => "can handle obstacles like control or limiting measures we've placed, in pursuit of task X".
I also don't buy this line of argument as much as I think Nate does, not because I disagree with my understanding of what the central chain of logic is, but because I don't think that it applies to language models in the way he describes it (but still plausibly manifests in different ways). I agree that LMs don't want things in the sense relevant to e.g. deceptive alignment, but primarily because I think it's a type error - LMs are far more substrate than they are agents. You can still have agents being predicted / simulated by LMs that have strong wants if you have a sufficiently powerful system, that might not have preferences about the training objective, but which still has preferences it's capable enough to try and achieve. Whether or not you can also ask that system "Which action would maximize the expected amount of Y?" and get a different predicted / simulated agent doesn't answer the question of whether or not the agent you do get to try and solve a task like that on a long horizon would itself be dangerous, independent of whether you consider the system at large to be dangerous in a similar way toward a similar target.
↑ comment by ryan_greenblatt · 2023-11-28T21:59:13.553Z · LW(p) · GW(p)
(I'm obviously not Paul)
What do you think is the sense of "wanting" needed for AI risk arguments? Why is the sense described above not enough?
In the case of literal current LLM agents with current models:
- Humans manually engineer the prompting and scaffolding (and we understand how and why it works)
- We can read the intermediate goals directly via just reading the CoT.
Thus, we don't have risk from hidden, unintended, or unpredictable objectives. There is no reason to think that goal seeking behavior due to the agency from the engineered scaffold or prompting will results in problematic generalization.
It's unclear if this will hold in the future even for LLM agents, but it's at least plausible that this will hold (which defeats Nate's rather confident claim). In particular, we could run into issues from the LLM used within the LLM agent having hidden goals, but insofar as the retargeting and long run agency is a human engineered and reasonably understood process, the original argument from Nate doesn't seem very relevant to risk. We also could run into issues from imitating very problematic human behavior, but this seems relatively easy to notice in most cases as it would likely be discussed outload with non-negligable probability.
We'd also lose this property if we did a bunch of RL and most of the power of LLM agents was coming from this RL rather than imitating human optimization or humans engineering particular optimization processes.
See also this comment from Paul on a similar topic [EA(p) · GW(p)].
Replies from: daniel-kokotajlo, nathan-helm-burger↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-29T00:57:38.620Z · LW(p) · GW(p)
It sounds like you are saying "In the current paradigm of prompted/scaffolded instruction-tuned LLMs, we get the faithful CoT property by default. Therefore our systems will indeed be agentic / goal-directed / wanting-things, but we'll be able to choose what they want (at least imperfectly, via the prompt) and we'll be able to see what they are thinking (at least imperfectly, via monitoring the CoT), therefore they won't be able to successfully plot against us."
Yes of course. My research for the last few months has been focused on what happens after that, when the systems get smart enough and/or get trained so that the chain of thought is unfaithful when it needs to be faithful, e.g. the system uses euphemisms when it's thinking about whether it's misaligned and what to do about that.
Anyhow I think this is mostly just a misunderstanding of Nate and my position. It doesn't contradict anything we've said. Nate and I both agree that if we can create & maintain some sort of faithful/visible thoughts property through human-level AGI and beyond, then we are in pretty good shape & I daresay things are looking pretty optimistic. (We just need to use said AGI to solve the rest of the problem for us, whilst we monitor it to make sure it doesn't plot against us or otherwise screw us over.)
↑ comment by ryan_greenblatt · 2023-11-29T01:28:34.421Z · LW(p) · GW(p)
It sounds like you are saying "In the current paradigm of prompted/scaffolded instruction-tuned LLMs, we get the faithful CoT property by default. Therefore our systems will indeed be agentic / goal-directed / wanting-things, but we'll be able to choose what they want (at least imperfectly, via the prompt) and we'll be able to see what they are thinking (at least imperfectly, via monitoring the CoT), therefore they won't be able to successfully plot against us."
Basically, but more centrally that in literal current LLM agents the scary part of the system that we don't understand (the LLM) doesn't generalize in any scary way due to wanting while we can still get the overall system to achieve specific long term outcomes in practice. And that it's at least plausible that this property will be preserved in the future.
I edited my earlier comment to hopefully make this more clear.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2023-11-29T01:33:29.921Z · LW(p) · GW(p)
Anyhow I think this is mostly just a misunderstanding of Nate and my position. It doesn't contradict anything we've said. Nate and I both agree that if we can create & maintain some sort of faithful/visible thoughts property through human-level AGI and beyond, then we are in pretty good shape & I daresay things are looking pretty optimistic. (We just need to use said AGI to solve the rest of the problem for us, whilst we monitor it to make sure it doesn't plot against us or otherwise screw us over.)
Even if we didn't have the visible thoughts property in the actual deployed system, the fact that all of the retargeting behavior is based on explicit human engineering is still relevant and contradicts the core claim Nate makes in this post IMO.
↑ comment by ryan_greenblatt · 2023-11-29T01:22:44.169Z · LW(p) · GW(p)
Anyhow I think this is mostly just a misunderstanding of Nate and my position. It doesn't contradict anything we've said.
I think it contradicts things Nate says in this post directly. I don't know if it contradicts things you've said.
To clarify, I'm commenting on the following chain:
First Nate said:
This observable "it keeps reorienting towards some target no matter what obstacle reality throws in its way" behavior is what I mean when I describe an AI as having wants/desires "in the behaviorist sense".
as well as
Well, I claim that these are more-or-less the same fact. It's no surprise that the AI falls down on various long-horizon tasks and that it doesn't seem all that well-modeled as having "wants/desires"; these are two sides of the same coin.
Then, Paul responded with
I think this is a semantic motte and bailey that's failing to think about mechanics of the situation. LM agents already have the behavior "reorient towards a target in response to obstacles," but that's not the sense of "wanting" about which people disagree or that is relevant to AI risk (which I tried to clarify in my comment). No one disagrees that an LM asked "how can I achieve X in this situation?" will be able to propose methods to achieve X, and those methods will be responsive to obstacles. But this isn't what you need for AI risk arguments!
Then you said
What do you think is the sense of "wanting" needed for AI risk arguments? Why is the sense described above not enough?
And I was responding to this.
So, I was just trying to demonstrate at least one plausible example of a system which plausibly could pursue long term goals and doesn't have the sense of wanting needed for AI risk arguments. In particular, LLM agents where the retargeting is purely based on human engineering (analogous to a myopic employee retargeted by a manager who cares about longer term outcomes).
This directly contradicts "Well, I claim that these are more-or-less the same fact. It's no surprise that the AI falls down on various long-horizon tasks and that it doesn't seem all that well-modeled as having "wants/desires"; these are two sides of the same coin.".
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-29T15:21:33.612Z · LW(p) · GW(p)
Thanks for the explanation btw.
My version of what's happening in this conversation is that you and Paul are like "Well, what if it wants things but in a way which is transparent/interpretable and hence controllable by humans, e.g. if it wants what it is prompted to want?" My response is "Indeed that would be super safe, but it would still count as wanting things. Nate's post is titled "ability to solve long-horizon tasks correlates with wanting" not "ability to solve long-horizon tasks correlates with hidden uncontrollable wanting."
One thing at time. First we establish that ability to solve long-horizon tasks correlates with wanting, then we argue about whether or not the future systems that are able to solve diverse long-horizon tasks better than humans can will have transparent controllable wants or not. As you yourself pointed out, insofar as we are doing lots of RL it's dubious that the wants will remain as transparent and controllable as they are now. I meanwhile will agree that a large part of my hope for a technical solution comes from something like the Faithful CoT agenda, in which we build powerful agentic systems whose wants (and more generally, thoughts) are transparent and controllable.
↑ comment by paulfchristiano · 2023-11-29T16:56:06.408Z · LW(p) · GW(p)
If this is what's going on, then I basically can't imagine any context in which I would want someone to read the OP rather a post than showing examples of LM agents achieving goals and saying "it's already the case that LM agents want things, more and more deployments of LMs will be agents, and those agents will become more competent such that it would be increasingly scary if they wanted something at cross-purposes to humans." Is there something I'm missing?
I think your interpretation of Nate is probably wrong, but I'm not sure and happy to drop it.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-29T20:06:28.870Z · LW(p) · GW(p)
FWIW, your proposed pitch "it's already the case that..." is almost exactly the elevator pitch I currently go around giving. So maybe we agree? I'm not here to defend Nate's choice to write this post rather than some other post.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-11-28T23:42:58.188Z · LW(p) · GW(p)
And I'm not Daniel K., but I do want to respond to you here Ryan. I think that the world I foresee is one in which there will huge tempting power gains which become obviously available to anyone willing to engage in something like RL-training their personal LLM agent (or other method of instilling additional goal-pursuing-power into it). I expect that some point in the future the tech will change and this opportunity will become widely available, and some early adopters will begin benefiting in highly visible ways. If that future comes to pass, then I expect the world to go 'off the rails' because these LLMs will have correlated-but-not-equivalent goals and will become increasingly powerful (because one of the goals they get set will be to create more powerful agents).
I don't think that's that only way things go badly in the future, but I think it's an important danger we need to be on guard against. Thus, I think that a crux between you and I is that I think that there is a strong reason to believe that the 'if we did a bunch of RL' is actually a quite likely scenario. I believe it is inherently an attractor-state.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2023-11-29T01:25:46.090Z · LW(p) · GW(p)
To clarify I don't think that LLM agents are necessarily or obviously safe. I was just trying to argue that it's plausible that they could achieve long terms objectives while also not having "wanting" in the sense necessary for (some) AI risk arguments to go through. (edited earlier comment to make this more clear)
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-11-29T03:05:26.214Z · LW(p) · GW(p)
Thanks for the clarification!
↑ comment by Jonas Hallgren · 2023-11-25T07:59:09.594Z · LW(p) · GW(p)
Alright, I will try to visualise what I see as the disagreement here.
It seems to me that Paul is saying that behaviourist abstractions will happen in smaller time periods than long time horizons.
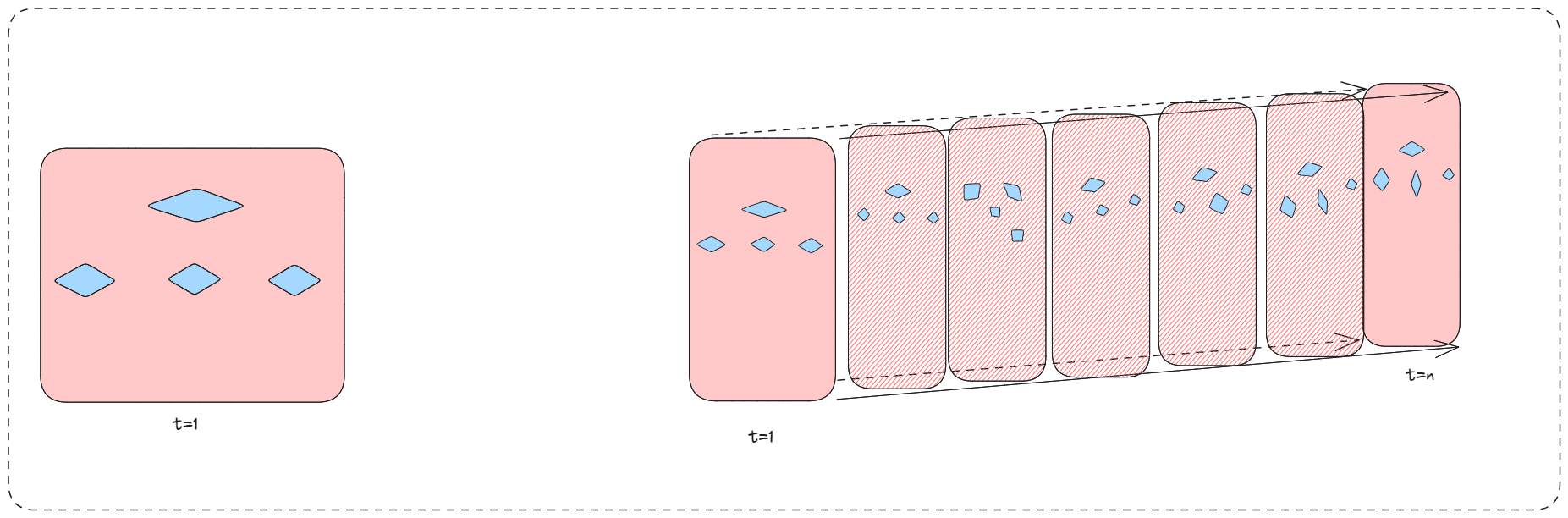
(Think of these shards as in the shard theory sense)
Nate is saying that the right picture creates stable wants more than the left and Paul is saying that it is time-agnostic and that the relevant metric is how competent the model is.
The crux here is essentially whether longer time horizons are indicative of behaviourist shard formation.
My thought here is that the process in the picture to the right induces more stable wants because a longer time horizon system is more complex, and therefore heuristics is the best decision rule. The complexity is increased in such a way that it is a large enough difference between short-term tasks and long-term tasks.
Also, the Redundant Information Hypothesis [LW · GW] might give credence to the idea that systems will over time create more stable abstractions?
↑ comment by Seth Herd · 2023-11-24T20:45:21.724Z · LW(p) · GW(p)
Excellent first point. I can come up with plans for destroying the world without wanting to do it, and other cognitive systems probably can too.
I do need to answer that question using in a goal-oriented search process. But my goal would be "answer Paul's question", not "destroy the world". Maybe a different type of system could do it with no goal whatsoever, but that's not clear.
But I'm puzzled by your statement
a system may not even be able to "want" things in the behaviorist sense
Perhaps you mean LLMs/predictive foundation models?
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2023-11-25T00:09:34.014Z · LW(p) · GW(p)
I can come up with plans for destroying the world without wanting to do it, and other cognitive systems probably can too.
You're changing the topic to "can you do X without wanting Y?", when the original question was "can you do X without wanting anything at all?".
Nate's answer to nearly all questions of the form "can you do X without wanting Y?" is "yes", hence his second claim in the OP: "the wanting-like behavior required to pursue a particular training target X, does not need to involve the AI wanting X in particular".
I do need to answer that question using in a goal-oriented search process. But my goal would be "answer Paul's question", not "destroy the world".
Your ultimate goal would be neither of those things; you're a human, and if you're answering Paul's question it's probably because you have other goals that are served by answering.
In the same way, an AI that's sufficiently good at answering sufficiently hard and varied questions would probably also have goals, and it's unlikely by default that "answer questions" will be the AI's primary goal.
Replies from: paulfchristiano, Seth Herd, david-johnston↑ comment by paulfchristiano · 2023-11-27T17:01:09.136Z · LW(p) · GW(p)
When the post says:
This observable "it keeps reorienting towards some target no matter what obstacle reality throws in its way" behavior is what I mean when I describe an AI as having wants/desires "in the behaviorist sense".
It seems like it's saying that if you prompt an LM with "Could you suggest a way to get X in light of all the obstacles that reality has thrown in my way," and if it does that reasonably well and if you hook it up to actuators, then it definitionally has wants and desires.
Which is a fine definition to pick. But the point is that in this scenario the LM doesn't want anything in the behaviorist sense, yet is a perfectly adequate tool for solving long-horizon tasks. This is not the form of wanting you need for AI risk arguments.
Replies from: porby↑ comment by porby · 2023-11-27T18:11:01.432Z · LW(p) · GW(p)
But the point is that in this scenario the LM doesn't want anything in the behaviorist sense, yet is a perfectly adequate tool for solving long-horizon tasks. This is not the form of wanting you need for AI risk arguments.
My attempt at an ITT-response:
Drawing a box around a goal agnostic LM and analyzing the inputs and outputs of that box would not reveal any concerning wanting in principle. In contrast, drawing a box around a combined system—e.g. an agentic scaffold that incrementally asks a strong inner goal agnostic LM to advance the agent's process—could still be well-described by a concerning kind of wanting.
Trivially, being better at achieving goals makes achieving goals easier, so there's pressure to make system-as-agents which are better at removing wrenches. As the problems become more complicated, the system needs to be more responsible for removing wrenches to be efficient, yielding further pressure to give the system-as-agent more ability to act. Repeat this process a sufficient and unknown number of times and, potentially without ever training a neural network describable as having goals with respect to external world states, there's a system with dangerous optimization power.
(Disclaimer: I think there are strong repellers that prevent this convergent death spiral, I think there are lots of also-attractive-for-capabilities offramps along the worst path, and I think LM-like systems make these offramps particularly accessible. I don't know if I'm reproducing opposing arguments faithfully and part of the reason I'm trying is to see if someone can correct/improve on them.)
↑ comment by Seth Herd · 2023-11-25T06:22:32.298Z · LW(p) · GW(p)
Thinking about it a little more, there may be a good reason to consider how humans pursue mid-horizon goals.
I think I do make a goal of answering Paul's question. It's not a subgoal of my primary values of getting food, status, etc, because backward-chaining is too complex. It's based on a vague estimate of the value (total future reward) of that action in context. I wrote about this in Human preferences as RL critic values - implications for alignment [LW · GW], but I'm not sure how clear that brief post was.
I was addressing a different part of Paul's comment than the original question. I mentioned that I didn't have an answer to the question of whether one can make long-range plans without wanting anything. I did try an answer in a separate top-level response:
it doesn't matter much whether a system can pursue long-horizon tasks without wanting, because agency is useful for long-horizon tasks, and it's not terribly complicated to implement. So AGI will likely have it built in, whether or not it would emerge from adequate non-agentic training. I think people will rapidly agentize any oracle system. It's useful to have a system that does things for you. And to do anything more complicated than answer one email, the user will be giving it a goal that may include instrumental subgoals.
The possibility of emergent wanting might still be important in an agent scaffolded around a foundation model.
Perhaps I'm confused about the scenarios you're considering here. I'm less worried about LLMs achieving AGI and developing emergent agency, because we'll probably give them agency before that happens.
↑ comment by David Johnston (david-johnston) · 2023-11-26T00:23:36.150Z · LW(p) · GW(p)
You're changing the topic to "can you do X without wanting Y?", when the original question was "can you do X without wanting anything at all?".
A system that can, under normal circumstances, explain how to solve a problem doesn’t necessarily solve the problem if it gets in the way of explaining the solution. The notion of wanting that Nate proposes is “solving problems in order to achieve the objective”, and this need not apply to the system that explains solutions. In short: yes.
↑ comment by Max H (Maxc) · 2023-11-29T00:05:34.252Z · LW(p) · GW(p)
But that's not really where we are at---AI systems are able to do an increasingly good job of solving increasingly long-horizon tasks. So it just seems like it should obviously be an update, and the answer to the original question
One reason that current AI systems aren't a big update about this for me is that they're not yet really automating stuff that couldn't in-principle be automated with previously-existing technology. Or at least the kind of automation isn't qualitatively different.
Like, there's all sorts of technologies that enable increasing amounts of automation of long-horizon tasks that aren't AI: assembly lines, industrial standardization, control systems, robotics, etc.
But what update are we supposed to make from observing language model performance that we shouldn't also make from seeing a control system-based autopilot fly a plane for longer and longer periods in more and more diverse situations?
To me, the fact that LLMs are not want-y (in the way that Nate means), but can still do some fairly impressive stuff is mostly evidence that the (seemingly) impressive stuff is actually kinda easy in some absolute sense.
So LLMs have updated me pretty strongly towards human-level+ AGI being relatively easier to achieve, but not much towards current LLMs themselves actually being near human-level in the relevant sense, or even necessarily a direct precursor or path towards it. These updates are mostly due to the fact that the way LLMs are designed and trained (giant gradient descent on regular architectures using general datasets) works at all, rather than from any specific impressive technological feat that they can already be used to accomplish, or how much economic growth they might enable in the future.
So I somewhat disagree about the actual relevance of the answer, but to give my own response to this question:
Could you give an example of a task you don't think AI systems will be able to do before they are "want"-y?
I don't expect an AI system to be able to reliably trade for itself in the way I outline here [LW(p) · GW(p)] before it is want-y. If it somehow becomes commonplace to negotiate with an AI in situations where the AI is not just a proxy for its human creator or a human-controlled organization, I predict those AIs will pretty clearly be want-y. They'll want whatever they trade for, and possibly other stuff too. It may not be clear which things they value terminally and which things they value only instrumentally, but I predict that it will clearly make sense to talk in terms of such AIs having both terminal and instrumental goals, in contrast to ~all current AI systems.
(Also, to be clear, this is a conditional prediction with possibly low-likelihood preconditions; I'm not saying such AIs are particularly likely to actually be developed, just stating some things that I think would be true of them if they were.)
comment by TurnTrout · 2023-11-25T13:32:36.913Z · LW(p) · GW(p)
Relatedly: to imagine the AI starting to succeed at those long-horizon tasks without imagining it starting to have more wants/desires (in the "behaviorist sense" expanded upon below) is, I claim, to imagine a contradiction—or at least an extreme surprise.
This seems like a great spot to make some falsifiable predictions which discriminate your particular theory from the pack. (As it stands, I don't see a reason to buy into this particular chain of reasoning.)
AIs will increasingly be deployed and tuned for long-term tasks, so we can probably see the results relatively soon. So—do you have any predictions to share? I predict that AIs can indeed do long-context tasks (like writing books with foreshadowing) without having general, cross-situational goal-directedness.[1]
I have a more precise prediction:
AIs can write novels with at least 50% winrate against a randomly selected novel from a typical American bookstore, as judged by blinded human raters or LLMs which have at least 70% agreement with human raters on reasonably similar tasks.
Credence: 70%; resolution date: 12/1/2025
Conditional on that, I predict with 85% confidence that it's possible to do this with AIs which are basically as tool-like as GPT-4. I don't know how to operationalize that in a way you'd agree to.
(I also predict that on 12/1/2025, there will be a new defense offered for MIRI-circle views, and a range of people still won't update.)
- ^
I expect most of real-world "agency" to be elicited by the scaffolding directly prompting for it (e.g. setting up a plan/critique/execute/summarize-and-postmortem/repeat loop for the LLM), and for that agency to not come from the LLM itself.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-11-27T14:10:59.888Z · LW(p) · GW(p)
The thing people seem to be disagreeing about is the thing you haven't operationalized--the "and it'll still be basically as tool-like as GPT4" bit. What does that mean and how do we measure it?
↑ comment by aysja · 2023-11-28T10:12:20.420Z · LW(p) · GW(p)
From my perspective, meaningfully operationalizing “tool-like” seems like A) almost the whole crux of the disagreement, and B) really quite difficult (i.e., requiring substantial novel scientific progress to accomplish), so it seems weird to leave as a simple to-do at the end.
Like, I think that “tool versus agent” shares the same confusion that we have about “non-life versus life”—why do some pieces of matter seem to “want” things, to optimize for them, to make decisions, to steer the world into their preferred states, and so on, while other pieces seem to “just” follow a predetermined path (algorithms, machines, chemicals, particles, etc.)? What’s the difference? How do we draw the lines? Is that even the right question? I claim we are many scientific insights away from being able to talk about these questions at the level of precision necessary to make predictions like this.
Concrete operationalizations seem great to ask for, when they’re possible to give—but I suspect that expecting/requesting them before they’re possible is more likely to muddy the discourse than clarify it.
Replies from: porby, TurnTrout↑ comment by porby · 2023-11-29T02:10:28.495Z · LW(p) · GW(p)
I claim we are many scientific insights away from being able to talk about these questions at the level of precision necessary to make predictions like this.
Hm, I'm sufficiently surprised at this claim that I'm not sure that I understand what you mean. I'll attempt a response on the assumption that I do understand; apologies if I don't:
I think of tools as agents with oddly shaped utility functions [LW · GW]. They tend to be conditional [LW · GW] in nature.
A common form is to be a mapping between inputs and outputs that isn't swayed by anything outside of the context of that mapping (which I'll term "external world states"). You can view a calculator as a coherent agent, but you can't usefully describe the calculator as a coherent agent with a utility function regarding world states that are external to the calculator's process.
You could use a calculator within a larger system that is describable as a maximizer over a utility function that includes unconditional terms for external world states, but that doesn't change the nature of the calculator. Draw the box around the calculator within the system? Pretty obviously a tool. Draw the box around the whole system? Not a tool.
I've been using the following two requirements to point at a maximally[1] tool-like set of agents. This composes what I've been calling goal agnosticism [LW · GW]:
- The agent cannot be usefully described[2] as having unconditional preferences about external world states.
- Any uniformly random sampling of behavior from the agent has a negligible probability of being a strong and incorrigible optimizer.
Note that this isn't the same thing as a definition for "tool." An idle rock uselessly obeys this definition; tools tend to useful for something. This definition is meant to capture the distinction between things that feel like tools and those that feel like "proper" agents [AF · GW].
To phrase it another way, the intuitive degree of "toolness" is a spectrum of how much the agent exhibits unconditional preferences about external world states through instrumental behavior.
Notably, most pretrained LLMs with the usual autoregressive predictive loss and a diverse training set are heavily constrained into fitting this definition [LW · GW]. Anything equivalent to RL agents trained with sparse/distant rewards is not. RLHF bakes a condition into the model of peculiar shape [LW · GW]. I wouldn't be surprised if it doesn't strictly obey the definition anymore, but it's close enough along the spectrum that it still feels intuitive to call it a tool.
Further, just like in the case of the calculator, you can easily build a system around a goal agnostic "tool" LLM that is not, itself, goal agnostic. Even prompting is enough to elicit a new agent-in-effect that is not necessarily goal agnostic. The ability for a goal agnostic agent to yield non-goal agnostic agents does not break the underlying agent's properties.[3]
↑ comment by TurnTrout · 2023-12-04T13:51:11.104Z · LW(p) · GW(p)
I didn't leave it as a "simple" to-do, but rather an offer to collaboratively hash something out.
That said: If people don't even know what it would look like when they see it, how can one update on evidence? What is Nate looking at which tells him that GPT doesn't "want things in a behavioralist sense"? (I bet he's looking at something real to him, and I bet he could figure it out if he tried!)
I claim we are many scientific insights away from being able to talk about these questions at the level of precision necessary to make predictions like this.
To be clear, I'm not talking about formalizing the boundary. I'm talking about a bet between people, adjudicated by people.
(EDIT: I'm fine with a low sensitivity, high specificity outcome -- we leave it unresolved if it's ambiguous / not totally obvious relative to the loose criteria we settled on. Also, the criterion could include randomly polling n alignment / AI people and asking them how "behaviorally-wanting" the system seemed on a Likert scale. I don't think you need fundamental insights for that to work.)
comment by AnnaSalamon · 2023-11-25T04:39:19.841Z · LW(p) · GW(p)
There’s a thing I’m personally confused about that seems related to the OP, though not directly addressed by it. Maybe it is sufficiently on topic to raise here.
My personal confusion is this:
Some of my (human) goals are pretty stable across time (e.g. I still like calories, and being a normal human temperature, much as I did when newborn). But a lot of my other “goals” or “wants” form and un-form without any particular “convergent instrumental drives”-style attempts to protect said “goals” from change.
As a bit of an analogy (to how I think I and other humans might approximately act): in a well-functioning idealized economy, an apple pie-making business might form (when it was the case that apple pie would deliver a profit over the inputs of apples plus the labor of those involved plus etc.), and might later fluidly un-form (when it ceased to be profitable), without "make apple pies" or "keep this business afloat" becoming a thing that tries to self-perpetuate in perpetuity. I think a lot of my desires are like this (I care intrinsically about getting outdoors everyday while there’s profit in it, but the desire doesn’t try to shield itself from change, and it’ll stop if getting outdoors stops having good results. And this notion of "profit" does not itself seem obviously like a fixed utility function, I think.).
I’m pretty curious about whether the [things kinda like LLMs but with longer planning horizons that we might get as natural extensions of the current paradigm, if the current paradigm extends this way, and/or the AGIs that an AI-accidentally-goes-foom process will summon] will have goals that try to stick around indefinitely, or goals that congeal and later dissolve again into some background process that'll later summon new goals, without summoning something lasting that is fixed-utility-function-shaped. (It seems to me that idealized economies do not acquire fixed or self-protective goals, and for all I know many AIs might as be like economies in this way.)
(I’m not saying this bears on risk in any particular way. Temporary goals would still resist most wrenches while they remained active, much as even an idealized apple pie business resists wrenches while it stays profitable.)
Replies from: quetzal_rainbow, snewman↑ comment by quetzal_rainbow · 2023-11-25T13:31:48.976Z · LW(p) · GW(p)
I think the problem here is distinguishing between terminal and instrumental goals? Most of people probably don't run apple pie business because they have terminal goals about apple pie business. They probably want money, status, want to be useful and provide for their families and I expect this goals to be very persistent and self-preseving.
Replies from: thomas-kwa, Quadratic Reciprocity, AnnaSalamon↑ comment by Thomas Kwa (thomas-kwa) · 2023-11-29T01:19:20.774Z · LW(p) · GW(p)
Not all such goals have to be instrumental to terminal goals, and in humans the line between instrumental and noninstrumental is not clear. Like at one extreme the instrumental goal is explicitly created by thinking about what would increase money/status, but at another "instrumental" goal is a shard reinforced by a money/status drive which would not change as the money/status drive changes.
Also even if the goal of selling apple pies is entirely instrumental, it's still interesting that the goal can be dissolved once it's no longer compatible with the terminal goal of e.g. gaining money. This means that not all goals are dangerously self-preserving.
Replies from: AnnaSalamon, quetzal_rainbow↑ comment by AnnaSalamon · 2023-11-29T17:20:27.154Z · LW(p) · GW(p)
Yes, exactly. Like, we humans mostly have something that kinda feels intrinsic but that also pays rent and updates with experience, like a Go player's sense of "elegant" go moves. My current (not confident) guess is that these thingies (that humans mostly have) might be a more basic and likely-to-pop-up-in-AI mathematical structure than are fixed utility functions + updatey beliefs, a la Bayes and VNM. I wish I knew a simple math for them.
Replies from: Jan_Kulveit↑ comment by Jan_Kulveit · 2023-11-30T14:19:20.367Z · LW(p) · GW(p)
The simple math is active inference, and the type is almost entirely the same as 'beliefs'.
↑ comment by quetzal_rainbow · 2023-11-29T11:11:56.638Z · LW(p) · GW(p)
I feel like... no, it is not very interesting, it seems pretty trivial? We (agents) have goals, we have relationships between them, like "priorities", we sometimes abandon goals with low priority in favor of goals with higher priorities. We also can have meta-goals like "how should my systems of goals look like" and "how to abandon and adopt intermediate goals in a reasonable way" and "how to do reflection on goals" and future superintelligent systems probably will have something like that. All of this seems to me coming in package with concept of "goal".
↑ comment by Quadratic Reciprocity · 2023-11-27T09:54:33.760Z · LW(p) · GW(p)
My goals for money, social status, and even how much I care about my family don't seem all that stable and have changed a bunch over time. They seem to be arising from some deeper combination of desires to be accepted, to have security, to feel good about myself, to avoid effortful work etc. interacting with my environment. Yet I wouldn't think of myself as primarily pursuing those deeper desires, and during various periods would have self-modified if given the option to more aggressively pursue the goals that I (the "I" that was steering things) thought I cared about (like doing really well at a specific skill, which turned out to be a fleeting goal with time).
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2023-11-27T10:12:46.924Z · LW(p) · GW(p)
What about things like fun, happiness, eudamonia, meaning? I certainly think that excluding brain damage/very advanced brainwashing, you are not going to eat babies or turn planets into paperclips.
↑ comment by AnnaSalamon · 2023-11-29T17:09:53.980Z · LW(p) · GW(p)
Thanks for replying. The thing I'm wondering about is: maybe it's sort of like this "all the way down." Like, maybe the things that are showing up as "terminal" goals in your analysis (money, status, being useful) are themselves composed sort of like the apple pie business, in that they congeal while they're "profitable" from the perspective of some smaller thingies located in some large "bath" (such as an economy, or a (non-conscious) attempt to minimize predictive error or something so as to secure neural resources, or a theremodynamic flow of sunlight or something). Like, maybe it is this way in humans, and maybe it is or will be this way in an AI. Maybe there won't be anything that is well-regarded as "terminal goals."
I said something like this to a friend, who was like "well, sure, the things that are 'terminal' goals for me are often 'instrumental' goals for evolution, who cares?" The thing I care about here is: how "fixed" are the goals, do they resist updating/dissolving when they cease being "profitable" from the perspective of thingies in an underlying substrate, or are they constantly changing as what is profitable changes? Like, imagine a kid who cares about playing "good, fun" videogames, but whose notion of which games are this updates pretty continually as he gets better at gaming. I'm not sure it makes that much sense to think of this as a "terminal goal" in the same sense that "make a bunch of diamond paperclips according to this fixed specification" is a terminal goal. It might be differently satiable, differently in touch with what's below it, I'm not really sure why I care but I think it might matter for what kind of thing organisms/~agent-like-things are.
↑ comment by snewman · 2023-12-03T16:38:10.273Z · LW(p) · GW(p)
Imagine someone offers you an extremely high-paying job. Unfortunately, the job involves something you find morally repulsive – say, child trafficking. But the recruiter offers you a pill that will rewrite your brain chemistry so that you'll no longer find it repulsive. Would you take the pill?
I think that pill would reasonably be categorized as "updating your goals". If you take it, you can then accept the lucrative job and presumably you'll be well positioned to satisfy your new/remaining goals, i.e. you'll be "happy". But you'd be acting against your pre-pill goal (I am glossing over exactly what that goal is, perhaps "not harming children" although I'm sure there's more to unpack here).
I pose this example in an attempt to get at the heart of "distinguishing between terminal and instrumental goals" as suggested by quetzal_rainbow. This is also my intuition, that it's a question of terminal vs. instrumental goals.
comment by porby · 2023-11-24T23:45:51.681Z · LW(p) · GW(p)
I'm not sure if I fall into the bucket of people you'd consider this to be an answer to. I do think there's something [LW · GW] important in the region of LLMs that, by vibes if not explicit statements of contradiction, seems incompletely propagated in the agent-y discourse even though it fits fully within it. I think I at least have a set of intuitions that overlap heavily with some of the people you are trying to answer.
In case it's informative, here's how I'd respond to this:
Well, I claim that these are more-or-less the same fact. It's no surprise that the AI falls down on various long-horizon tasks and that it doesn't seem all that well-modeled as having "wants/desires"; these are two sides of the same coin.
Mostly agreed, with the capability-related asterisk.
Because the way to achieve long-horizon targets in a large, unobserved, surprising world that keeps throwing wrenches into one's plans, is probably to become a robust generalist wrench-remover that keeps stubbornly reorienting towards some particular target no matter what wrench reality throws into its plans.
Agreed in the spirit that I think this was meant, but I'd rephrase this: a robust generalist wrench-remover that keeps stubbornly reorienting towards some particular target will tend to be better at reaching that target than a system that doesn't.
That's subtly different from individual systems having convergent internal reasons for taking the same path. This distinction mostly disappears in some contexts, e.g. selection in evolution, but it is meaningful in others.
If an AI causes some particular outcome across a wide array of starting setups and despite a wide variety of obstacles, then I'll say it "wants" that outcome “in the behaviorist sense”.
I think this frame is reasonable, and I use it.
it's a little hard to imagine that you don't contain some reasonably strong optimization that strategically steers the world into particular states.
Agreed.
that the wanting-like behavior required to pursue a particular training target X, does not need to involve the AI wanting X in particular.
Agreed.
“AIs need to be robustly pursuing some targets to perform well on long-horizon tasks”, but it does not say that those targets have to be the ones that the AI was trained on (or asked for). Indeed, I think the actual behaviorist-goal is very unlikely to be the exact goal the programmers intended, rather than (e.g.) a tangled web of correlates.
Agreed for a large subset of architectures. Any training involving the equivalent of extreme optimization for sparse/distant reward in a high dimensional complex context seems to effectively guarantee this outcome.
So, maybe don't make those generalized wrench-removers just yet, until we do know how to load proper targets in there.
Agreed, don't make the runaway misaligned optimizer.
I think there remains a disagreement hiding within that last point, though. I think the real update from LLMs is:
- We have a means of reaching extreme levels of capability without necessarily exhibiting preferences over external world states. You can elicit such preferences, but a random output sequence from the pretrained version of GPT-N (assuming the requisite architectural similarities) has no realistic chance of being a strong optimizer with respect to world states. The model itself remains a strong optimizer, just for something that doesn't route through the world.
- It's remarkably easy to elicit this form of extreme capability to guide itself. This isn't some incidental detail; it arises from the core process that the model learned to implement.
- That core process is learned reliably because the training process that yielded it leaves no room for anything else. It's not a sparse/distant reward target; it is a profoundly constraining and informative target.
In other words, a big part of the update for me was in having a real foothold on loading the full complexity of "proper targets."
I don't think what we have so far constitutes a perfect and complete solution, the nice properties could be broken, paradigms could shift and blow up the golden path, it doesn't rule out doom, and so on, but diving deeply into this has made many convergent-doom paths appear dramatically less likely to Late2023!porby compared to Mid2022!porby.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-11-29T00:10:25.461Z · LW(p) · GW(p)
So, I agree with most of your points Porby, and like your posts and theories overall.... but I fear that the path towards a safe AI you outline is not robust to human temptation. I think that if it is easy and obvious how to make a goal-agnostic AI into a goal-having AI, and also it seems like doing so will grant tremendous power/wealth/status to anyone who does so, then it will get done. And do think that these things are the case. I think that a carefully designed and protected secret research group with intense oversight could follow your plan, and that if they do, there is a decent chance that your plan works out well. I think that a mish-mash of companies and individual researchers acting with little effective oversight will almost certainly fall off the path, and that even having most people adhering to the path won't be enough to stop catastrophe once someone has defected.
I also think that misuse can lead more directly to catastrophe, through e.g. terrorists using a potent goal-agnostic AI to design novel weapons of mass destruction. So in a world with increasingly potent and unregulated AI, I don't see how to have much hope for humanity.
And I also don't see any easy way to do the necessary level of regulation and enforcement. That seems like a really hard problem. How do we prevent ALL of humanity from defecting when defection becomes cheap, easy-to-hide, and incredibly tempting?
Replies from: porby↑ comment by porby · 2023-11-29T01:05:43.508Z · LW(p) · GW(p)
While this probably isn't the comment section for me to dump screeds about goal agnosticism, in the spirit of making my model more legible:
I think that if it is easy and obvious how to make a goal-agnostic AI into a goal-having AI, and also it seems like doing so will grant tremendous power/wealth/status to anyone who does so, then it will get done. And do think that these things are the case.
Yup! The value I assign to goal agnosticism—particularly as implemented in a subset of predictors—is in its usefulness as a foundation to build strong non-goal agnostic systems that aren't autodoomy. The transition out of goal agnosticism is not something I expect to avoid, nor something that I think should be avoided.
I think that a mish-mash of companies and individual researchers acting with little effective oversight will almost certainly fall off the path, and that even having most people adhering to the path won't be enough to stop catastrophe once someone has defected.
I'd be more worried about this if I thought the path was something that required Virtuous Sacrifice to maintain. In practice, the reason I'm as optimistic (nonmaximally pessimistic?) as I am that I think there are pretty strong convergent pressures to stay on something close enough to the non-autodoom path.
In other words, if my model of capability progress is roughly correct, then there isn't a notably rewarding option to "defect" architecturally/technologically that yields greater autodoom.
With regard to other kinds of defection:
I also think that misuse can lead more directly to catastrophe, through e.g. terrorists using a potent goal-agnostic AI to design novel weapons of mass destruction. So in a world with increasingly potent and unregulated AI, I don't see how to have much hope for humanity.
Yup! Goal agnosticism doesn't directly solve misuse (broadly construed), which is part of why misuse is ~80%-ish of my p(doom).
And I also don't see any easy way to do the necessary level of regulation and enforcement. That seems like a really hard problem. How do we prevent ALL of humanity from defecting when defection becomes cheap, easy-to-hide, and incredibly tempting?
If we muddle along deeply enough into a critical risk period slathered in capability overhangs that TurboDemon.AI v8.5 is accessible to every local death cult and we haven't yet figured out how to constrain their activity, yup, that's real bad.
Given my model of capability development, I think there are many incremental messy opportunities to act that could sufficiently secure the future over time. Given the nature of the risk and how it can proliferate, I view it as much harder to handle than nukes or biorisk, but not impossible.
comment by Logan Zoellner (logan-zoellner) · 2023-11-25T15:16:38.326Z · LW(p) · GW(p)
Well, I claim that these are more-or-less the same fact. It's no surprise that the AI falls down on various long-horizon tasks and that it doesn't seem all that well-modeled as having "wants/desires"; these are two sides of the same coin.
It's weird that this sentence immediately follows you talking about AI being able to play chess. A chess playing AI doesn't "want to win" in the behaviorist sense. If I flip over the board or swap pieces mid game or simply refuse to move the AI's pieces on it's turn, it's not going to do anything to stop me because it doesn't "want" to win the game. It doesn't even realize that a game is happening in the real world. And yet it is able to make excellent long term plans about "how" to win at chess.
Either:
a) A chess playing AI fits into your definition of "want", in which case who cares if AI wants things, this tells us nothing about their real-world behavior.
b) A chess playing AI doesn't "want" to win (my claim) in which case AI can make long term plans without wanting.
↑ comment by porby · 2023-11-25T18:05:02.916Z · LW(p) · GW(p)
Trying to respond in what I think the original intended frame was:
A chess AI's training bounds what the chess AI can know and learn to value. Given the inputs and outputs it has, it isn't clear there is an amount of optimization pressure accessible to SGD which can yield situational awareness and so forth; nothing about the trained mapping incentivizes that. This form of chess AI can be described in the behaviorist sense as "wanting" to win within the boundaries of the space that it operates.
In contrast, suppose you have a strong and knowledgeable multimodal predictor trained on all data humanity has available to it that can output arbitrary strings. Then apply extreme optimization pressure for never losing at chess. Now, the boundaries of the space in which the AI operates are much broader, and the kinds of behaviorist "values" the AI can have are far less constrained. It has the ability to route through the world, and with extreme optimization, it seems likely that it will.
(For background, I think it's relatively easy to relocate where the optimization squeezing is happening to avoid this sort of worldeating outcome, but it remains true that optimization for targets with ill-defined bounds is spooky and to be avoided.)
Replies from: logan-zoellner↑ comment by Logan Zoellner (logan-zoellner) · 2023-11-25T22:23:39.938Z · LW(p) · GW(p)
In contrast, suppose you have a strong and knowledgeable multimodal predictor trained on all data humanity has available to it that can output arbitrary strings. Then apply extreme optimization pressure for never losing at chess. Now, the boundaries of the space in which the AI operates are much broader, and the kinds of behaviorist "values" the AI can have are far less constrained. It has the ability to route through the world, and with extreme optimization, it seems likely that it will.
"If we build AI in this particular way, it will be dangerous"
Okay, so maybe don't do that then.
↑ comment by Quintin Pope (quintin-pope) · 2023-11-25T23:03:25.327Z · LW(p) · GW(p)
I think training such an AI to be really good at chess would be fine. Unless "Then apply extreme optimization pressure for never losing at chess." means something like "deliberately train it to use a bunch of non-chess strategies to win more chess games, like threatening opponents, actively seeking out more chess games in real life, etc", then it seems like you just get GPT-5 which is also really good at chess.
Replies from: porby↑ comment by porby · 2023-11-27T18:22:45.419Z · LW(p) · GW(p)
In retrospect, the example I used was poorly specified. It wouldn't surprise me if the result of the literal interpretation was "the AI refuses to play chess" rather than any kind of worldeating. The intent was to pick a sparse/distant reward that doesn't significantly constrain the kind of strategies that could develop, and then run an extreme optimization process on it. In other words, while intermediate optimization may result in improvements to chess playing, being better at chess isn't actually the most reliable accessible strategy to "never lose at chess" for that broader type of system and I'd expect superior strategies to be found in the limit of optimization.
Replies from: gwern↑ comment by gwern · 2023-11-27T19:20:27.791Z · LW(p) · GW(p)
Yes, that would be immediately reward-hacked. It's extremely easy to never lose chess: you simply never play. After all, how do you force anyone to play chess...? "I'll give you a billion dollars if you play chess." "No, because I value not losing more than a billion dollars." "I'm putting a gun to your head and will kill you if you don't play!" "Oh, please do, thank you - after all, it's impossible to lose a game of chess if I'm dead!" This is why RL agents have a nasty tendency to learn to 'commit suicide' if you reward-shape badly or the environment is too hard. (Tom7's lexicographic agent famously learns to simply pause Tetris to avoid losing.)
comment by Linch · 2023-11-25T03:29:34.070Z · LW(p) · GW(p)
Apologies if I'm being naive, but it doesn't seem like an oracle AI[1] is logically or practically impossible, and a good oracle should be able to be able to perform well at long-horizon tasks[2] without "wanting things" in the behaviorist sense, or bending the world in consequentialist ways.
The most obvious exception is if the oracle's own answers are causing people to bend the world in the service of hidden behaviorist goals that the oracle has (e.g. making the world more predictable to reduce future loss), but I don't have strong reasons to believe that this is very likely.
This is especially the case since at training time, the oracle doesn't have any ability to bend the training dataset to fit its future goals, so I don't see why gradient descent would find cognitive algorithms for "wanting things in the behaviorist sense."
[1] in the sense of being superhuman at prediction for most tasks, not in the sense of being a perfect or near-perfect predictor.
[2] e.g. "Here's the design for a fusion power plant, here's how you acquire the relevant raw materials, here's how you do project management, etc." or "I predict your polio eradication strategy to have the following effects at probability p, and the following unintended side effects that you should be aware of at probability q."
Replies from: thomas-kwa, simon↑ comment by Thomas Kwa (thomas-kwa) · 2023-11-25T11:32:05.191Z · LW(p) · GW(p)
I'd be pretty scared of an oracle AI that could do novel science, and it might still want things internally. If the oracle can truly do well at designing a fusion power plant, it can anticipate obstacles and make revisions to plans just as well as an agent-- if not better because it's not allowed to observe and adapt. I'd be worried that it does similar cognition to the agent, but with all interactions with the environment done in some kind of efficient simulation. Or something more loosely equivalent.
It's not clear to me that this is as dangerous as having some generalized skill of routing around obstacles as an agent, but I feel like "wants in the behaviorist sense" is not quite the right property to be thinking about because it depends on the exact interface between your AI and the world rather than the underlying cognition.
↑ comment by simon · 2023-12-01T00:39:31.476Z · LW(p) · GW(p)
An oracle doesn't have to have hidden goals. But when you ask it what actions would be needed to do the long term task, it chooses the actions that lead to that would lead to that task being completed. If you phrase that carefully enough maybe you can get away with it. But maybe it calculates the best output to achieve result X is an output that tricks you into rewriting itself into an agent. etc.
In general, asking an oracle AI any question whose answers depend on the future effects in the real world of those answers would be very dangerous.
On the other hand, I don't think answering important questions on solving AI alignment is a task whose output necessarily needs to depend on its future effects on the real world. So, in my view an oracle could be used to solve AI alignment, without killing everyone as long as there are appropriate precautions against asking it careless questions.
comment by abramdemski · 2023-11-29T20:22:32.485Z · LW(p) · GW(p)
Okay, so you know how AI today isn't great at certain... let's say "long-horizon" tasks? Like novel large-scale engineering projects, or writing a long book series with lots of foreshadowing?
(Modulo the fact that it can play chess pretty well, which is longer-horizon than some things; this distinction is quantitative rather than qualitative and it’s being eroded, etc.)
And you know how the AI doesn't seem to have all that much "want"- or "desire"-like behavior?
(Modulo, e.g., the fact that it can play chess pretty well, which indicates a certain type of want-like behavior in the behaviorist sense. An AI's ability to win no matter how you move is the same as its ability to reliably steer the game-board into states where you're check-mated, as though it had an internal check-mating “goal” it were trying to achieve. This is again a quantitative gap that’s being eroded.)
I don't think the following is all that relevant to the point you are making in this post, but someone cited this post of yours in relation to the question of whether LLMs are "intelligent" (summarizing the post as "Nate says LLMs aren't intelligent") and then argued against the post as goalpost-moving, so I wanted to discuss that.
It may come as a shock to some, that Abram Demski adamantly defends the following position: GPT4 is AGI. I would be goalpost-moving if I said otherwise. I think the AGI community is goalpost-moving to the extent that it says otherwise.
I think there is some tendency in the AI Risk community to equate "AGI" with "the sort of AI which kills all the humans unless it is aligned". But "AGI" stands for "artificial general intelligence", not "kills all the humans". I think it makes more sense for the definition of AGI to be up to the community of AI researchers who use the term AGI to distance their work from narrow AI, rather than for it to be up to the AI risk community. And GPT4 is definitely not narrow AI.
I'll argue an even stronger claim: if you come up with a task which can be described and completed entirely in text format (and then evaluated somehow for performance quality), for most such tasks the performance of GPT4 is at or above the performance of a random human. (We can even be nice and only randomly sample humans who speak whichever languages are appropriate to the task; I'll still stand by the claim.) Yes, GPT4 has some weaknesses compared to a random human. But most claims of weaknesses I've heard are in fact contrasting GPT4 to expert humans, not random humans. So my stronger claim is: GPT4 is human-level AGI, maybe not by all possible definitions of the term, but by a very reasonable-seeming definition which 2014 Abram Demski might have been perfectly happy with. To deny this would be goalpost-moving for me; and, I expect, for many.
So (and I don't think this is what you were saying) if GPT4 were being ruled out of "human-level AGI" because it cannot write a coherent set of novels on its own, or do a big engineering project, well, I call shenanigans. Most humans can't do that either.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-12-15T17:28:38.359Z · LW(p) · GW(p)
GPT-4 as a human level AGI is reasonable as a matter of evaluating the meaning of words, but this meaning of "AGI" doesn't cut reality at its joints. Humans are a big deal not for the reason of being at human level, but because there is capability for unbounded technological progress, including through building superintelligence. Ability for such progress doesn't require being superintelligent, so it's a different thing. For purposes of AI timelines it's the point where history starts progressing at AI speed rather than at human speed. There should be a name for this natural concept, and "AGI" seems like a reasonable option.
Replies from: abramdemski↑ comment by abramdemski · 2023-12-15T17:59:15.197Z · LW(p) · GW(p)
I agree that this is an important distinction, but I personally prefer to call it "transformative AI" or some such.
comment by [deleted] · 2023-11-25T05:35:53.441Z · LW(p) · GW(p)
If you're the sort of thing that skillfully generates and enacts long-term plans, and you're the sort of planner that sticks to its guns and finds a way to succeed in the face of the many obstacles the real world throws your way (rather than giving up or wandering off to chase some new shiny thing every time a new shiny thing comes along), then the way I think about these things, it's a little hard to imagine that you don't contain some reasonably strong optimization that strategically steers the world into particular states.
It seems this post has maybe mixed "generating" with "enacting". Currently, it seems LLMs only attempt the former during prediction. In general terms, predicting a long-horizon-actor's reasoning is implicit in the task of myopically predicting the next thing that actor would do. For a specific example, you could imagine a model predicting the next move of a grandmaster's or stockfish's chess game (or text in an author's book, or an industrial project description, to use your longer-horizon examples).
The first paragraph of /u/paulfchristiano's response might be getting at something similar, but it seems worth saying this directly.[1]
- ^
(This also seems like a basic point, so I wonder if I misunderstood the post.. but it seems like something isomorphic to it is in the top comment, so I'm not sure.)
comment by Steven Byrnes (steve2152) · 2024-12-19T04:32:50.917Z · LW(p) · GW(p)
The main insight of the post (as I understand it) is this:
- In the context of a discussion of whether we should be worried about AGI x-risk, someone might say “LLMs don't seem like they're trying hard to autonomously accomplish long-horizon goals—hooray, why were people so worried about AGI risk?”
- In the context of a discussion among tech people and VCs about how we haven't yet made an AGI that can found and run companies as well as Jeff Bezos, someone might say “LLMs don't seem like they're trying hard to autonomously accomplish long-horizon goals—alas, let's try to fix that problem.”
One sounds good and the other sounds bad, but there’s a duality connecting them. They’re the same observation. You can’t get one without the other.
This is an important insight because it helps us recognize the fact that people are trying to solve the second-bullet-point problem (and making nonzero progress), and to the extent that they succeed, they’ll make things worse from the perspective of the people in the first bullet point.
This insight is not remotely novel! (And OP doesn’t claim otherwise.) …But that’s fine, nothing wrong with saying things that many readers will find obvious.
(This “duality” thing is a useful formula! Another related example that I often bring up is the duality between positive-coded “the AI is able to come up with out-of-the-box solutions to problems” versus the negative-coded “the AI sometimes engages in reward hacking”. I think another duality connects positive-coded “it avoids catastrophic forgetting” to negative-coded “it’s hard to train away scheming”, at least in certain scenarios.)
(…and as comedian Mitch Hedberg sagely noted, there’s a duality between positive-coded “cheese shredder” and negative-coded “sponge ruiner”.)
The post also chats about two other (equally “obvious”) topics:
- Instrumental convergence: “the AI seems like it's trying hard to autonomously accomplish long-horizon goals” involves the AI routing around obstacles, and one might expect that to generalize to “obstacles” like programmers trying to shut it down
- Goal (mis)generalization: If “the AI seems like it's trying hard to autonomously accomplish long-horizon goal X”, then the AI might actually “want” some different Y which partly overlaps with X, or is downstream from X, etc.
But the question on everyone’s mind is: Are we doomed?
In and of itself, nothing in this post proves that we’re doomed. I don’t think OP ever explicitly claimed it did? In my opinion, there’s nothing in this post that should constitute an update for the many readers who are already familiar with instrumental convergence, and goal misgeneralization, and the fact that people are trying to build autonomous agents. But OP at least gives a vibe of being an argument for doom going beyond those things, which I think was confusing people in the comments.
Why aren’t we necessarily doomed? Now this is my opinion, not OP’s, but here are three pretty-well-known outs (at least in principle):
- The AI can “want” to autonomously accomplish a long-horizon goal, but also simultaneously “want” to act with integrity, helpfulness, etc. Just like it’s possible for humans to do. And if the latter “want” is strong enough, it can outvote the former “want” in cases where they conflict. See my post Consequentialism & corrigibility [LW · GW].
- The AI can behaviorist-“want” to autonomously accomplish a long-horizon goal, but where the “want” is internally built in such a way as to not generalize OOD to make treacherous turns seem good to the AI. See e.g. my post Thoughts on “Process-Based Supervision” [LW · GW], which is skeptical about the practicalities, but I think the idea is sound in principle.
- We can in principle simply avoid building AIs that autonomously accomplish long-horizon goals, notwithstanding the economic and other pressures—for example, by keeping humans in the loop (e.g. oracle AIs). This one came up multiple times in the comments section.
There’s plenty of challenges in these approaches, and interesting discussions to be had, but the post doesn’t engage with any of these topics.
Anyway, I’m voting strongly against including this post in the 2023 review. It’s not crisp about what it’s arguing for and against (and many commenters seem to have gotten the wrong idea about what it’s arguing for), it’s saying obvious things in a meandering way, and it’s not refuting or even mentioning any of the real counterarguments / reasons for hope. It’s not “best of” material.
comment by Noosphere89 (sharmake-farah) · 2023-11-30T16:27:59.151Z · LW(p) · GW(p)
I want to mention that for Expected Utility Maximization, if we are focused on behavior, any sequence of behavior is an Expected Utility Maximizer, thus it becomes trivial as everything has the property of EUM, and no predictions are possible at all.
This is noted by EJT here, but it really, really matters, because it undermines a lot of coherence arguments for AI risk, and this is a nontrivial issue here.
https://www.lesswrong.com/posts/yCuzmCsE86BTu9PfA/?commentId=Lz3TDLfevjwMJHqat [LW · GW]
https://forum.effectivealtruism.org/posts/ZS9GDsBtWJMDEyFXh/?commentId=GEXEqLDpwaNET5Nnk [EA · GW]
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2023-11-30T17:55:24.670Z · LW(p) · GW(p)
If it's true, why is shutdown problem not solved? Even if it's true that any behavior can be represented as EUM, it's at least not trivial.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-11-30T23:42:22.788Z · LW(p) · GW(p)
This is actually a partially solved issue, see here:
https://www.lesswrong.com/posts/sHGxvJrBag7nhTQvb/invulnerable-incomplete-preferences-a-formal-statement-1 [LW · GW]
Also, this:
Even if it's true that any behavior can be represented as EUM, it's at least not trivial.
It is trivial, since everything is an EUM for a utility function under the behaviorist definition.
comment by Jonathan Paulson (jpaulson) · 2023-11-25T14:39:26.165Z · LW(p) · GW(p)
I think you are failing to distinguish between "being able to pursue goals" and "having a goal".
Optimization is a useful subroutine, but that doesn't mean it is useful for it to be the top-level loop. I can decide to pursue arbitrary goals for arbitrary amounts of time, but that doesn't mean that my entire life is in service of some single objective.
Similarly, it seems useful for an AI assistant to try and do the things I ask it to, but that doesn't imply it has some kind of larger master plan.
comment by Oliver Sourbut · 2023-11-24T19:51:33.811Z · LW(p) · GW(p)
Strong agree with long-horizon sequential decision-making success being very tied to wantingness.
I kinda want to point at things like the Good and Gooder [LW · GW] Regulator theorems here as theoretical reasons to expect this, besides the analogies you give. But I don't find them entirely satisfactory. I have recently wondered if there's something like a Good Regulator theorem for planner-simulators: a Planner Simulator conjecture something like, 'every (simplest) simulator of a planner contains (something homomorphic to) a planner'. Potential stepping-stone for the agent-like structure problem [LW · GW]. I also have some more specific thoughts about long-horizon and the closed-loop of deliberation for R&D-like tasks. But I've struggled to articulate these, in part because I flinch when it seems too capabilities-laden.
Any tips?
comment by Eli Tyre (elityre) · 2023-11-25T19:50:09.805Z · LW(p) · GW(p)
A follow-on inference from the above point is: when the AI leaves training, and it’s tasked with solving bigger and harder long-horizon problems in cases where it has to grow smarter than ever before and develop new tools to solve new problems, and you realize finally that it’s pursuing neither the targets you trained it to pursue nor the targets you asked it to pursue—well, by that point, you've built a generalized obstacle-surmounting engine. You've built a thing that excels at noticing when a wrench has been thrown in its plans, and at understanding the wrench, and at removing the wrench or finding some other way to proceed with its plans.
And when you protest and try to shut it down—well, that's just another obstacle, and you're just another wrench.
This seems right. "you've built a generalized obstacle-surmounting engine." is maybe the the single best distillation of what's hard about AI risk of that length that I've ever read.
But also, I'm having difficulty connecting my experience with LLMs to the abstract claim that corrigibility is anti-natural.
...Actually, never mind, I just thought about it a bit more. You might train your LLM-ish agent to ask for your permission when taking sufficiently big actions. And it will probably continue to do that. But if you also train in some behaviorist goals, it will steer the world in the direction of the satisfaction of the those goals, regardless of the fact that it is "asking your permission", by priming you to answer in particular ways, or choosing strategies that don't require asking for permission, or whatever. "Asking for permission" doesn't really build in corrigibility, that's just a superficial constraint on the planning process.
comment by Eli Tyre (elityre) · 2023-11-25T19:35:49.758Z · LW(p) · GW(p)
Why might we see this sort of "wanting" arise in tandem with the ability to solve long-horizon problems and perform long-horizon tasks?
Because these "long-horizon" tasks involve maneuvering the complicated real world into particular tricky outcome-states, despite whatever surprises and unknown-unknowns and obstacles it encounters along the way. Succeeding at such problems just seems pretty likely to involve skill at figuring out what the world is, figuring out how to navigate it, and figuring out how to surmount obstacles and then reorient in some stable direction.
I think maybe I buy it for planning tasks, which entail responding to surprising events that the world throws at you and getting back on track towards a goal. I'm not sure that I buy it for "design" tasks, like designing a rocket ship or a nanofactory. Those tasks seem like they can maybe be solved in one sweep, the way current LLMs (often) answer my question in one single forward pass through the network.
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2023-11-25T19:37:06.284Z · LW(p) · GW(p)
That makes me think of superhuman engineers that are given a design spec, and produce a design. And then human engineers look over the design and maybe build prototypes, and realize what was missing from the spec, and then go back and improve the spec to give to the AI engineer, just as I sometimes ask an LLM a question, and I realize from the answer that my question was not specific enough.
With that story of how we apply AI tech, here's some adverse selection for designs that when built, trick the humans into thinking that they got the output they wanted, when actually they didn't. But there's not strong optimization pressure for that set of outcomes. The AI is just engineering to a prompt / spec, it isn't
My model of Eliezer, at least as of the 2021 MIRI dialogs, thinks that this kind of system, that can do superhuman engineering in one forward pass, without a bunch of reflection and exploratory design (eg trying some idea, seeing how it fails, in your mind or in reality, iterating), is implausible, or at least not the first and most natural way to solve those problems on the tech tree. Indeed, real Eliezer almost says that outright at 18:05 here [? · GW].
That model says that you need those S2-style reflection and iteration faculties to do engineering, and that employing those faculties is an application of long term planning. That is, tinkering with a design, has the same fundamental structure of "reality throwing wrenches into your plans and your pivoting to get the result you wanted anyway".
However, the more sophisticated the reasoning of LLMs get, the less plausible it seems that you need reflection, etc. in order to do superhuman engineering work. A big enough neural net with enough training data can grow into a something like an S1 which is capable enough to do the work that humans generally require an S2 for.
comment by Filipe · 2023-11-24T18:29:03.144Z · LW(p) · GW(p)
This seems related to Dennett's Intentional Stance https://en.wikipedia.org/wiki/Intentional_stance
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-11-24T20:07:49.346Z · LW(p) · GW(p)
see also discovering agents
comment by simeon_c (WayZ) · 2023-11-26T17:46:39.653Z · LW(p) · GW(p)
Thanks for writing that. I've been trying to taboo "goals" because it creates so much confusion, which this post tries to decrease. In line with this post, I think what matters is how difficult a task is to achieve, and what it takes to achieve it in terms of ability to overcome obstacles.
comment by Seth Herd · 2023-11-24T21:00:09.645Z · LW(p) · GW(p)
This makes sense. I think the important part is not the emergence of agency, but that agency is a convergent route to long-term planning. I'm less worried about intention emerging, and more worried about it being built in to improve capabilities like long-term planning through goal directed search. Agency is also key to how humans do self-directed learning, another super useful ability in just about any domain. I just wrote a short post on the usefulness of agency for self-directed learning: Sapience, understanding, and "AGI" [LW · GW]
comment by Review Bot · 2024-05-02T09:21:22.592Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Htarlov (htarlov) · 2023-12-04T12:01:30.358Z · LW(p) · GW(p)
What I would also like to add, which is often not addressed and it gives some positive look, is that the "wanting" meaning the objective function of the agent, it's goals, should not necessarily be some certain outcome or certain end-goal on which it will focus totally. It might not be the function over the state of universe but function over how it changes in time. Like velocity vs position. It might prefer some way the world changes or does not change, but not having a certain end-goal (which is also unreachable in long-term in a stable way as universe will die in some sense, everything will be destroyed with P=1 minus very minute epsilon over enough time).
Why positive? Because these things usually need balance and stabilisation in some sense to retain same properties, which means less probability of drastic measures to get a little bit better outcome a little bit sooner. It might cease controll over us, which is bad, but gives lower probability of rapid doom.
Also, looking on current works it seems more likely for me that those property-based goals will be embedded rather than some end-goal like curing cancer or helping humanity. We try to make robust AGI so we don't want to embed certain goals or targets, but rather patterns how to work productively and safely with humans. Those are more meta and about way of how things go/change.
Note it is more like intuition for me than hard argument.
comment by Htarlov (htarlov) · 2023-12-04T11:43:59.240Z · LW(p) · GW(p)
The question is if one can make a thing that is "wanting" in that long-term sense by combining not-wanting LLM model as short-term intelligence engine with some programming-based structure that would refocus it onto it's goals and some memory engine (to remember not only information, buy also goals, plans and ways to do things). I think that the answer is a big YES and we will soon see that in a form of amalgamation of several models and enforced mind structure.
comment by simon · 2023-12-01T00:37:02.955Z · LW(p) · GW(p)
(Modulo, e.g., the fact that it can play chess pretty well, which indicates a certain type of want-like behavior in the behaviorist sense. An AI's ability to win no matter how you move is the same as its ability to reliably steer the game-board into states where you're check-mated, as though it had an internal check-mating “goal” it were trying to achieve. This is again a quantitative gap that’s being eroded.)
I agree with the main point of the post. But I specifically disagree with what I see as an implied assumption of this remark about a "quantitative gap". I think there is a likely assumption that the quantitative gap is such that the ability to play chess better would correlate with being higher in the most relevant quantity.
Something that chooses good chess moves can be seen as "wanting" its side to do well within the chess game context. But that does not imply anything at all outside of that context. If it's going to be turned off if it doesn't do a particular next move, it doesn't have to take that into account. It can just play the best chess move regardless, and ignore the out-of-context info about being shut down.
LLMs aren't trained directly to achieve results in a real-world context. They're trained:
- to emit outputs that look like the output of entities that achieve results (humans)
- to emit outputs that humans think are useful, probably typically with the humans not thinking all that deeply about it
To be sure, at least item 1 above would eventually result in selecting outputs to achieve results if taken to the limit of infinite computing power, etc., and in the same limit item 2 would result in humans being mind-controlled.
But both these items naturally better reward the LLM for appearing agentic than for actually being agentic (being agentic = actually choosing outputs based on their effect on the future of the real world). The reward for actually being agentic, up to the point that it is agentic enough to subvert the training regime, is entirely downstream of the reward for appearance of agency.
Thus, I tend to expect the appearance of agency in LLMs to be Goodharted and discount apparent evidence accordingly.
Other people look at the same evidence and think it might, by contrast, be even more agentic than the apparent evidence due to strategic deception. And to be sure, at some agency level you might get consistent strategic deception to lower the apparent agency level.
But I think more like: at the agency level I've already discounted it down to it really doesn't look likely it would engage in strategic deception to consistently lower its apparent agency level. Yes I'm aware of, e.g., the recent paper that LLMs engage in strategic deception. But they are doing what looks like strategic deception when presented a pretend, text-based scenario. This is fully compatible with them following story-logic like they learned from training. Just like a chess AI doesn't have to care about anything outside the chess context, the LLM doesn't have to care about anything outside the story-logic context.
To be sure, story-logic by itself could still be dangerous. Any real-world effect could be obtained by story-logic within a story with intricate enough connections to the real world, and in some circumstances it wouldn't have to be that intricate.
And in this sense - the sense that some contexts are bigger and tend to map onto real-world dangerous behaviour better than others - the gap can indeed be quantitative. It's just that it's another dimension of variation in agency than the ability to select best actions in a particular context.
I'm not convinced that LLMs are currently selecting actions to affect the future within a context larger than this story-level context - a large enough domain to have some risk (in particular, I'm concerned with the ability to write code to help make a new/modified AI targeting a larger context) - but one that I think is still likely well short of causing it to choose actions to take over the world (and indeed, well short of being particularly good at solving long-term tasks in general) without it making that new or modified AI first.
comment by followthesilence · 2023-11-28T07:37:52.071Z · LW(p) · GW(p)
"Want" seems ill-defined in this discussion. To the extent it is defined in the OP, it seems to be "able to pursue long-term goals", at which point tautologies are inevitable. The discussion gives me strong stochastic parrot / "it's just predicting next tokens not really thinking" vibes, where want/think are je ne sais quoi words to describe the human experience and provide comfort (or at least a shorthand explanation) for why LLMs aren't exhibiting advanced human behaviors. I have little doubt many are trying to optimize for long-term planning and that AI systems will exhibit increasingly better long-term planning capabilities over time, but have no confidence whether that will coincide with increases in "want", mainly because I don't know what that means. Just my $0.02, as someone with no technical or linguistics background.
comment by David Johnston (david-johnston) · 2023-11-26T00:00:52.231Z · LW(p) · GW(p)
If we are to understand you as arguing for something trivial, then I think it only has trivial consequences. We must add nontrivial assumptions if we want to offer a substantive argument for risk.
Suppose we have a collection of systems of different ability that can all, under some conditions, solve . Let's say an "-wrench" is an event that defeats systems of lower ability but not systems of higher ability (i.e. prevents them from solving ).
A system that achieves with probability must defeat all -wrenches but those with a probability of at most . If the set of events that are -wrenches but not -wrenches has probability , then the system can defeat all -wrenches but a collection with probability of at most .
That is, if the challenges involved in achieving are almost the same as the challenges involved in achieving , then something good at achieving is almost as good at achieving (granting the somewhat vague assumptions about general capability baked into the definition of wrenches).
However, if is something that people basically approve of and is something people do not approve of, then I do not think the challenges almost overlap. In particular, to do , with high probability you need to defeat a determined opposition, which is not likely to be necessary if you want . That is: no need to kill everyone with nanotech if your doing what you were supposed to.
In order to sustain the argument for risk, we need to assume that the easiest way to defeat -wrenches is to learn a much more general ability to defeat wrenches than necessary and apply it to solving and, furthermore, this ability is sufficient to also defeat -wrenches. This is plausible - we do actually find it helpful to build generally capable systems to solve very difficult problems - but also plausibly false. Even highly capable AI that achieves long-term objectives could end up substantially specialised for those objectives.
As an aside, if the set of -wrenches includes the gradient updates received during training, then an argument that an -solver generalises to a -solver may also imply that deceptive alignment is likely (alternatively, proving that -solvers generalise to -solvers is at least as hard as proving deceptive alignment).