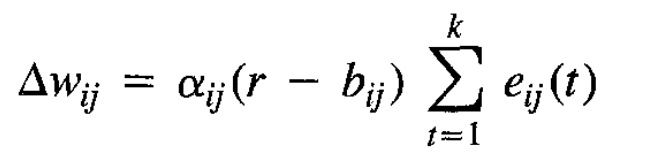I think it actually points to convergence between human and NN learning dynamics. Human visual cortices are also bad at hands and text, to the point that lucid dreamers often look for issues with their hands / nearby text to check whether they're dreaming.
One issue that I think causes people to underestimate the degree of convergence between brain and NN learning is to compare the behaviors of entire brains to the behaviors of individual NNs. Brains consist of many different regions which are "trained" on different internal objectives, then interact with each other to collectively produce human outputs. In contrast, most current NNs contain only one "region", which is all trained on the single objective of imitating certain subsets of human behaviors.
We should thus expect NN learning dynamics to most resemble those of single brain regions, and that the best match for humanlike generalization patterns will arise from putting together multiple NNs that interact with each other in a similar manner as human brain regions.
Idea for using current AI to accelerate medical research: suppose you were to take a VLM and train it to verbally explain the differences between two image data distributions. E.g., you could take 100 dog images, split them into two classes, insert tiny rectangles into class 1, feed those 100 images into the VLM, and then train it to generate the text "class 1 has tiny rectangles in the images". Repeat this for a bunch of different augmented datasets where we know exactly how they differ, aiming for a VLM with a general ability to in-context learn and verbally describe the differences between two sets of images. As training processes, keep making there be more and subtler differences, while training the VLM to describe all of them.
Then, apply the model to various medical images. E.g., brain scans of people who are about to develop dementia versus those who aren't, skin photos of malignant and non-malignant blemishes, electron microscope images of cancer cells that can / can't survive some drug regimen, etc. See if the VLM can describe any new, human interpretable features.
The VLM would generate a lot of false positives, obviously. But once you know about a possible feature, you can manually investigate whether it holds to distinguish other examples of the thing you're interested in. Once you find valid features, you can add those into the training data of the VLM, so it's no longer just trained on synthetic augmentations.
You might have to start with real datasets that are particularly easy to tell apart, in order to jumpstart your VLM's ability to accurately describe the differences in real data.
The other issue with this proposal is that it currently happens entirely via in context learning. This is inefficient and expensive (100 images is a lot for one model at once!). Ideally, the VLM would learn the difference between the classes by actually being trained on images from those classes, and learn to connect the resulting knowledge to language descriptions of the associated differences through some sort of meta learning setup. Not sure how best to do that, though.
Hyperparameter (HP) tuning in deep learning is an expensive process, prohibitively so for neural networks (NNs) with billions of parameters. We show that, in the recently discovered Maximal Update Parametrization (muP), many optimal HPs remain stable even as model size changes. This leads to a new HP tuning paradigm we call muTransfer: parametrize the target model in muP, tune the HP indirectly on a smaller model, and zero-shot transfer them to the full-sized model, i.e., without directly tuning the latter at all. We verify muTransfer on Transformer and ResNet. For example, 1) by transferring pretraining HPs from a model of 13M parameters, we outperform published numbers of BERT-large (350M parameters), with a total tuning cost equivalent to pretraining BERT-large once; 2) by transferring from 40M parameters, we outperform published numbers of the 6.7B GPT-3 model, with tuning cost only 7% of total pretraining cost. A Pytorch implementation of our technique can be found at this http URL and installable via `pip install mup`.
muP comes from a principled mathematical analysis of how different ways of scaling various architectural hyperparameters alongside model width influences activation statistics.
The basic issue though is that evolution doesn't have a purpose or goal
FWIW, I don't think this is the main issue with the evolution analogy. The main issue is that evolution faced a series of basically insurmountable, yet evolution-specific, challenges in successfully generalizing human 'value alignment' to the modern environment, such as the fact that optimization over the genome can only influence within lifetime value formation theough insanely unstable Rube Goldberg-esque mechanisms that rely on steps like "successfully zero-shot directing an organism's online learning processes through novel environments via reward shaping", or the fact that accumulated lifetime value learning is mostly reset with each successive generation without massive fixed corpuses of human text / RLHF supervisors to act as an anchor against value drift, or evolution having a massive optimization power overhang in the inner loop of its optimization process.
These issues fully explain away the 'misalignment' humans have with IGF and other intergenerational value instability. If we imagine a deep learning optimization process with an equivalent structure to evolution, then we could easily predict similar stability issues would arise due to that unstable structure, without having to posit an additional "general tendency for inner misalignment" in arbitrary optimization processes, which is the conclusion that Yudkowsky and others typically invoke evolution to support.
In other words, the issues with evolution as an analogy have little to do with the goals we might ascribe to DL/evolutionary optimization processes, and everything to do with simple mechanistic differences in structure between those processes.
I stand by pretty much everything I wrote in Objections, with the partial exception of the stuff about strawberry alignment, which I should probably rewrite at some point.
Also, Yudkowsky explained exactly how he'd prefer someone to engage with his position "To grapple with the intellectual content of my ideas, consider picking one item from "A List of Lethalities" and engaging with that.", which I pointed out I'd previously done in a post that literally quotes exactly one point from LoL and explains why it's wrong. I've gotten no response from him on that post, so it seems clear that Yudkowsky isn't running an optimal 'good discourse promoting' engagement policy.
I don't hold that against him, though. I personally hate arguing with people on this site.
I at least seem to have some beliefs about how big of a deal AI will be that disagrees pretty heavily with what the market beliefs [...] I feel like I would want to make a somewhat concentrated bet on those beliefs with like 20%-40% of my portfolio or so, and I feel like I am not going to get that by just holding some very broad index funds...
Fidelity allows users to purchase call options on the S&P 500 that are dated to more than 5 years out. Buying those seems like a very agnostic way to make a leveraged bet on higher growth/volatility, without having to rely on margin. Though do note that they may require a lot of liquidity, depending on your choice of strike price.
They also have very low trading volume, with a large gap between bids and asks. Buying them at a good price may be difficult.
RLHF as understood currently (with humans directly rating neural network outputs, a la DPO) is very different from RL as understood historically (with the network interacting autonomously in the world and receiving reward from a function of the world).
This is actually pointing to the difference between online and offline learning algorithms, not RL versus non-RL learning algorithms. Online learning has long been known to be less stable than offline learning. That's what's primarily responsible for most "reward hacking"-esque results, such as the CoastRunners degenerate policy. In contrast, offline RL is surprisingly stable and robust to reward misspecification. I think it would have been better if the alignment community had been focused on the stability issues of online learning, rather than the supposed "agentness" of RL.
I was under the impression that PPO was a recently invented algorithm? Wikipedia says it was first published in 2017, which if true would mean that all pre-2017 talk about reinforcement learning was about other algorithms than PPO.
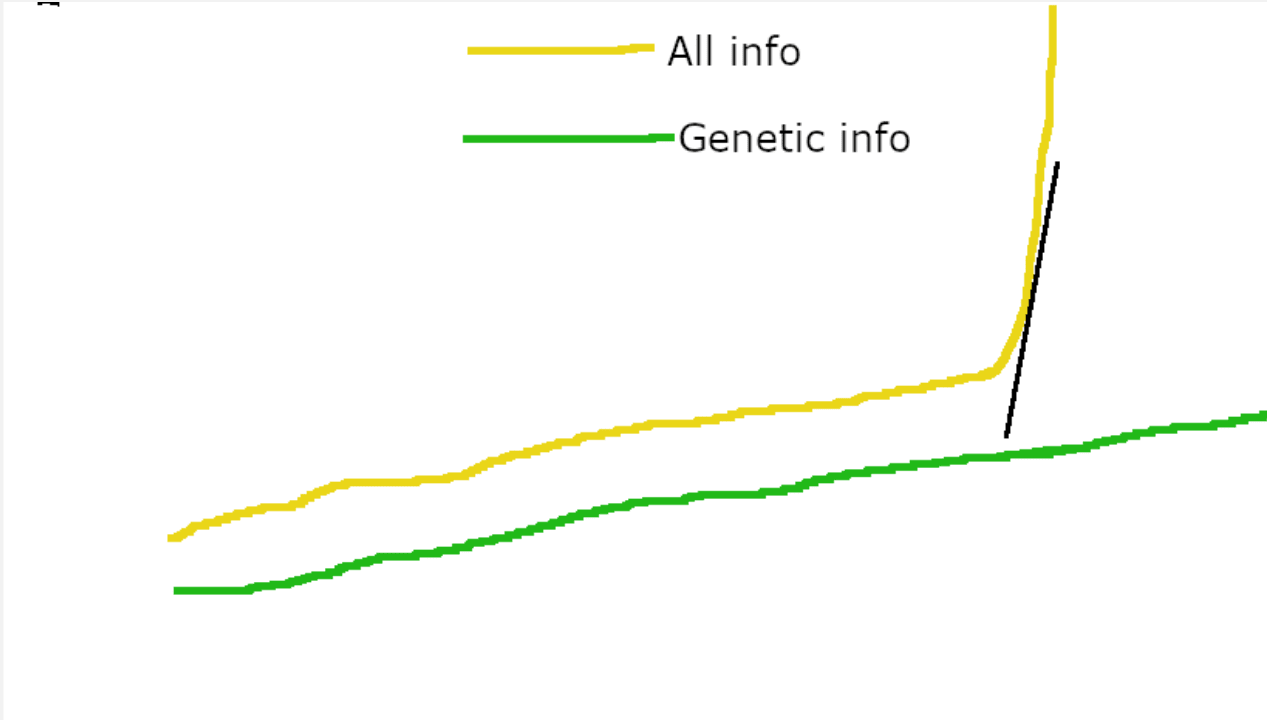
PPO may have been invented in 2017, but there are many prior RL algorithms for which Alex's description of "reward as learning rate multiplier" is true. In fact, PPO is essentially a tweaked version of REINFORCE, for which a bit of searching brings up Simple statistical gradient-following algorithms for connectionist reinforcement learning as the earliest available reference I can find. It was published in 1992, a full 22 years before Bostrom's book. In fact, "reward as learning rate multiplier" is even more clearly true of most of the update algorithms described in that paper. E.g., equation 11:
Here, the reward (adjusted by a "reinforcement baseline" bij) literally just multiplies the learning rate. Beyond PPO and REINFORCE, this "x as learning rate multiplier" pattern is actually extremely common in different RL formulations. From lecture 7 of David Silver's RL course:
To be honest, it was a major blackpill for me to see the rationalist community, whose whole whole founding premise was that they were supposed to be good at making efficient use of the available evidence, so completely missing this very straightforward interpretation of RL (at least, I'd never heard of it from alignment literature until I myself came up with it when I realized that the mechanistic function of per-trajectory rewards in a given batched update was to provide the weights of a linear combination of the trajectory gradients. Update: Gwern's description here is actually somewhat similar).
implicitly assuming that all future AI architectures will be something like GPT+DPO is counterproductive.
When I bring up the "actual RL algorithms don't seem very dangerous or agenty to me" point, people often respond with "Future algorithms will be different and more dangerous".
I think this is a bad response for many reasons. In general, it serves as an unlimited excuse to never update on currently available evidence. It also has a bad track record in ML, as the core algorithmic structure of RL algorithms capable of delivering SOTA results has not changed that much in over 3 decades. In fact, just recently Cohere published Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs, which found that the classic REINFORCE algorithm actually outperforms PPO for LLM RLHF finetuning. Finally, this counterpoint seems irrelevant for Alex's point in this post, which is about historical alignment arguments about historical RL algorithms. He even included disclaimers at the top about this not being an argument for optimism about future AI systems.
We're going to start with simplicity. Simplicity is about specifying the thing that you want in the space of all possible things. You can think about simplicity as “How much do you have to aim to hit the exact thing in the space of all possible models?” How many bits does it take to find the thing that you want in the model space? And so, as a first pass, we can understand simplicity by doing a counting argument, which is just asking, how many models are in each model class?
First, how many Christs are there? Well, I think there's essentially only one, since there's only one way for humans to be structured in exactly the same way as God. God has a particular internal structure that determines exactly the things that God wants and the way that God works, and there's really only one way to port that structure over and make the unique human that wants exactly the same stuff.
Okay, how many Martin Luthers are there? Well, there's actually more than one Martin Luther (contrary to actual history) because the Martin Luthers can point to the Bible in different ways. There's a lot of different equivalent Bibles and a lot of different equivalent ways of understanding the Bible. You might have two copies of the Bible that say exactly the same thing such that it doesn't matter which one you point to, for example. And so there's more Luthers than there are Christs.
But there's even more Pascals. You can be a Pascal and it doesn't matter what you care about. You can care about anything in the world, all of the various different possible things that might exist for you to care about, because all that Pascal needs to do is care about something over the long term, and then have some reason to believe they're going to be punished if they don't do the right thing. And so there’s just a huge number of Pascals because they can care about anything in the world at all.
So the point is that there's more Pascals than there are the others, and so probably you’ll have to fix fewer bits to specify them in the space.
Evan then goes on to try to use the complexity of the simplest member of each model class as an estimate for the size of the classes (which is probably wrong, IMO, but I'm also not entirely sure how he's defining the "complexity" of a given member in this context), but this section seems more like an elaboration on the above counting argument. Evan calls it "a slightly more concrete version of essentially the same counting argument".
And IMO, it's pretty clear that the above quoted argument is implicitly appealing to some sort of uniformish prior assumption over ways to specify different types of goal classes. Otherwise, why would it matter that there are "more Pascals", unless Evan thought the priors over the different members of each category were sufficiently similar that he could assess their relative likelihoods by enumerating the number of "ways" he thought each type of goal specification could be structured?
Look, Evan literally called his thing a "counting argument", Joe said "Something in this vicinity [of the hazy counting argument] accounts for a substantial portion of [his] credence on schemers [...] and often undergirds other, more specific arguments", and EY often expounds on the "width" of mind design space. I think counting arguments represent substantial intuition pumps for a lot of people (though often implicitly so), so I think a post pushing back on them in general is good.
We argue against the counting argument in general (more specifically, against the presumption of a uniform prior as a "safe default" to adopt in the absence of better information). This applies to the hazy counting argument as well.
We also don't really think there's that much difference between the structure of the hazy argument and the strict one. Both are trying to introduce some form of ~uniformish prior over the outputs of a stochastic AI generating process. The strict counting argument at least has the virtue of being precise about which stochastic processes it's talking about.
If anything, having more moving parts in the causal graph responsible for producing the distribution over AI goals should make you more skeptical of assigning a uniform prior to that distribution.
How many times has someone expressed "I'm worried about 'goal-directed optimizers', but I'm not sure what exactly they are, so I'm going to work on deconfusion."? There's something weird about this sentiment, don't you think?
IMO, the weird/off thing is that the people saying this don't have sufficient evidence to highlight this specific vibe bundle as being a "real / natural thing that just needs to be properly formalized", rather than there being no "True Name" for this concept, and it turns out to be just another situationally useful high level abstraction. It's like someone saying they want to "deconfuse" the concept of a chair.
Or like someone pointing at a specific location on a blank map and confidently declaring that there's a dragon at that spot, but then admitting that they don't actually know what exactly a "dragon" is, have never seen one, and only have theoretical / allegorical arguments to support their existence[1]. Don't worry though, they'll resolve the current state of confusion by thinking really hard about it and putting together a taxonomy of probable dragon subspecies.
If you push them on this point, they might say that actually humans have some pretty dragon-like features, so it only makes sense that real dragons would exist somewhere in creature space. Also, dragons are quite powerful, so naturally many types of other creatures would tend to become dragons over time. And given how many creatures there are in the world, it's inevitable that at least one would become a dragon eventually.
The "alignment technique generalise across human contributions to architectures" isn't about the SLT threat model. It's about the "AIs do AI capabilities research" threat model.
I only briefly skimmed this response, and will respond even more briefly.
Re "Re: "AIs are white boxes""
You apparently completely misunderstood the point we were making with the white box thing. It has ~nothing to do with mech interp. It's entirely about whitebox optimization being better at controlling stuff than blackbox optimization. This is true even if the person using the optimizers has no idea how the system functions internally.
Re: "Re: "Black box methods are sufficient"" (and the other stuff about evolution)
Evolution analogies are bad. There are many specific differences between ML optimization processes and biological evolution that predictably result in very different high level dynamics. You should not rely on one to predict the other, as I have arguedextensivelyelsewhere.
Trying to draw inferences about ML from bio evolution is only slightly less absurd than trying to draw inferences about cheesy humor from actual dairy products. Regardless of the fact they can both be called "optmization processes", they're completely different things, with different causal structures responsible for their different outcomes, and crucially, those differences in causal structure explain their different outcomes. There's thus no valid inference from "X happened in biological evolution" to "X will eventually happen in ML", because X happening in biological evolution is explained by evolution-specific details that don't appear in ML (at least for most alignment-relevant Xs that I see MIRI people reference often, like the sharp left turn).
Re: "Re: Values are easy to learn, this mostly seems to me like it makes the incredibly-common conflation between "AI will be able to figure out what humans want" (yes; obviously; this was never under dispute) and "AI will care""
This wasn't the point we were making in that section at all. We were arguing about concept learning order and the ease of internalizing human values versus other features for basing decisions on. We were arguing that human values are easy features to learn / internalize / hook up to decision making, so on any natural progression up the learning capacity ladder, you end up with an AI that's aligned before you end up with one that's so capable it can destroy the entirety of human civilization by itself.
Re "Even though this was just a quick take, it seemed worth posting in the absence of a more polished response from me, so, here we are."
I think you badly misunderstood the post (e.g., multiple times assuming we're making an argument we're not, based on shallow pattern matching of the words used: interpreting "whitebox" as meaning mech interp and "values are easy to learn" as "it will know human values"), and I wish you'd either take the time to actually read / engage with the post in sufficient depth to not make these sorts of mistakes, or not engage at all (or at least not be so rude when you do it).
(Note that this next paragraph is speculation, but a possibility worth bringing up, IMO):
As it is, your response feels like you skimmed just long enough to pattern match our content to arguments you've previously dismissed, then regurgitated your cached responses to those arguments. Without further commenting on the merits of our specific arguments, I'll just note that this is a very bad habit to have if you want to actually change your mind in response to new evidence/arguments about the feasibility of alignment.
Re: "Overall take: unimpressed."
I'm more frustrated and annoyed than "unimpressed". But I also did not find this response impressive.
I think training such an AI to be really good at chess would be fine. Unless "Then apply extreme optimization pressure for never losing at chess." means something like "deliberately train it to use a bunch of non-chess strategies to win more chess games, like threatening opponents, actively seeking out more chess games in real life, etc", then it seems like you just get GPT-5 which is also really good at chess.
I really don't like that you've taken this discussion to Twitter. I think Twitter is really a much worse forum for talking about complex issues like this than LW/AF.
I haven't "taken this discussion to Twitter". Joe Carlsmith posted about the paper on Twitter. I saw that post, and wrote my response on Twitter. I didn't even know it was also posted on LW until later, and decided to repost the stuff I'd written on Twitter here. If anything, I've taken my part of the discussion from Twitter to LW. I'm slightly baffled and offended that you seem to be platform-policing me?
Anyways, it looks like you're making the objection I predicted with the paragraphs:
One obvious counterpoint I expect is to claim that the "[have some internal goal x] [backchain from wanting x to the stuff needed to get x (doing well at training)]" steps actually do contribute to the later steps, maybe because they're a short way to compress a motivational pointer to "wanting" to do well on the training objective.
I don't think this is how NN simplicity biases work. Under the "cognitive executions impose constraints on parameter settings" perspective, you don't actually save any complexity by supposing that the model has some motive for figuring stuff out internally, because the circuits required to implement the "figure stuff out internally" computations themselves count as additional complexity. In contrast, if you have a view of simplicity that's closer to program description length, then you're not counting runtime execution against program complexity, and so a program that has short length in code but long runtime can count as simple.
In particular, when I said "maybe because they're a short way to compress a motivational pointer to "wanting" to do well on the training objective." I think this is pointing at the same thing you reference when you say "The entire question is about what the easiest way is to produce that distribution in terms of the inductive biases."
I.e., given the actual simplicity bias of models, what is the shortest (or most compressed) way of specifying "a model that starts by trying to do well in training"? And my response is that I think the model pays a complexity penalty for runtime computations (since they translate into constraints on parameter values which are needed to implement those computations). Even if those computations are motivated by something we call a "goal", they still need to be implemented in the circuitry of the model, and thus also constrain its parameters.
Also, when I reference models whose internal cognition looks like "[figure out how to do well at training] [actually do well at training]", I don't have sycophantic models in particular in mind. It also includes aligned models, since those models do implement the "[figure out how to do well at training] [actually do well at training]" steps (assuming that aligned behavior does well in training).
Reposting my response on Twitter (To clarify, the following was originally written as a Tweet in response to Joe Carlsmith's Tweet about the paper, which I am now reposting here):
I just skimmed the section headers and a small amount of the content, but I'm extremely skeptical. E.g., the "counting argument" seems incredibly dubious to me because you can just as easily argue that text to image generators will internally create images of llamas in their early layers, which they then delete, before creating the actual asked for image in the later layers. There are many possible llama images, but "just one" network that straightforwardly implements the training objective, after all.
The issue is that this isn't the correct way to do counting arguments on NN configurations. While there are indeed an exponentially large number of possible llama images that an NN might create internally, there are an even more exponentially large number of NNs that have random first layers, and then go on to do the actual thing in the later layers. Thus, the "inner llamaizers" are actually more rare in NN configuration space than the straightforward NN.
The key issue is that each additional computation you speculate an NN might be doing acts as an additional constraint on the possible parameters, since the NN has to internally contain circuits that implement those computations. The constraint that the circuits actually have to do "something" is a much stronger reduction in the number of possible configurations for those parameters than any additional configurations you can get out of there being multiple "somethings" that the circuits might be doing.
So in the case of deceptive alignment counting arguments, they seem to be speculating that the NN's cognition looks something like:
[have some internal goal x] [backchain from wanting x to the stuff needed to get x (doing well at training)] [figure out how to do well at training] [actually do well at training]
and in comparison, the "honest" / direct solution looks like:
[figure out how to do well at training] [actually do well at training]
and then because there are so many different possibilities for "x", they say there are more solutions that look like the deceptive cognition. My contention is that the steps "[have some internal goal x] [backchain from wanting x to the stuff needed to get x (doing well at training)]" in the deceptive cognition are actually unnecessary, and because implementing those steps requires that one have circuits that instantiate those computations, the requirement that the deceptive model perform those steps actually *constrains* the number of parameter configurations that implement the deceptive cognition, which reduces the volume of deceptive models in parameter space.
One obvious counterpoint I expect is to claim that the "[have some internal goal x] [backchain from wanting x to the stuff needed to get x (doing well at training)]" steps actually do contribute to the later steps, maybe because they're a short way to compress a motivational pointer to "wanting" to do well on the training objective.
I don't think this is how NN simplicity biases work. Under the "cognitive executions impose constraints on parameter settings" perspective, you don't actually save any complexity by supposing that the model has some motive for figuring stuff out internally, because the circuits required to implement the "figure stuff out internally" computations themselves count as additional complexity. In contrast, if you have a view of simplicity that's closer to program description length, then you're not counting runtime execution against program complexity, and so a program that has short length in code but long runtime can count as simple.
@jkcarlsmith does seem more sympathetic to the "parameters as complexity" view than to the "code length as complexity" view. However, I go further and think that the "parameters as complexity" view actively points against deceptive alignment.
I also think NNs have an even stronger bias for short paths than you might expect from just the "parameters as complexity" view. Consider a problem that can either be solved with a single circuit of depth n, or by two parallel circuits of depth n/2 (so both solutions must set the values of an equal number of parameters, but one solution is more parallel than the other). I claim there are far more parameter configurations that implement the parallel solution than parameter configurations that implement the serial solution.
This is because the parallel solution has an entire permutation group that's not available to the serial solution: the two parallel circuits can be moved to different relative depths with respect to each other, whereas all the parts of the serial solution must have fixed relative depths. Thus, the two parallel circuits represent less of a constraint on the possible configurations of the NN, and so there are far more NNs that implement the parallel solution.
As a consequence, I expect there are significant "short depth" biases in the NN simplicity prior, consistent with empirical results such as: https://arxiv.org/abs/1605.06431
Finally, I'm extremely skeptical of claims that NNs contain a 'ghost of generalized instrumental reasoning', able to perform very competent long term hidden scheming and deduce lots of world knowledge "in-context". I think current empirical results point strongly against that being plausible.
For example, the "reversal curse" results (training on "A is B" doesn't lead to models learning "B is A"). If the ghost can't even infer from "A is B" to "B is A", then I think stuff like inferring from "I have a goal x", to "here is the specific task I must perform in order to maximize my reward" is pretty much out of the question. Thus, stories about how SGD might use arbitrary goals as a way to efficiently compress an (effective) desire for the NN to silently infer lots of very specific details about the training process seem incredibly implausible to me.
I expect objections of the form "I expect future training processes to not suffer from the reversal curse, and I'm worried about the future training processes."
Obviously people will come up with training processes that don't suffer from the reversal curse. However, comparing the simplicity of the reversal curse to the capability of current NNs is still evidence about the relative power of the 'instrumental ghost' in the model compared to the external capabilities of the model. If a similar ratio continues to hold for externally superintelligent AIs, then that casts enormous doubt on e.g., deceptive alignment scenarios where the model is internally and instrumentally deriving huge amounts of user-goal-related knowledge so that it can pursue its arbitrary mesaobjectives later down the line. I'm using the reversal curse to make a more generalized update about the types of internal cognition that are easy to learn and how they contribute to external capabilities.
Some other Tweets I wrote as part of the discussion:
The key points of my Tweet are basically "the better way to think about counting arguments is to compare constraints on parameter configurations", and "corrected counting arguments introduce an implicit bias towards short, parallel solutions", where both "counting the constrained parameters", and "counting the permutations of those parameters" point in that direction.
I think shallow depth priors are pretty universal. E.g., they also make sense from a perspective of "any given step of reasoning could fail, so best to make as few sequential steps as possible, since each step is rolling the dice", as well as a perspective of "we want to explore as many hypotheses as possible with as little compute as possible, so best have lots of cheap hypotheses".
I'm not concerned about the training for goal achievement contributing to deceptive alignment, because such training processes ultimately come down to optimizing the model to imitate some mapping from "goal given by the training process" -> "externally visible action sequence". Feedback is always upweighting cognitive patterns that produce some externally visible action patterns (usually over short time horizons).
In contrast, it seems very hard to me to accidentally provide sufficient feedback to specify long-term goals that don't distinguish themselves from short term one over short time horizons, given the common understanding in RL that credit assignment difficulties actively work against the formation of long term goals. It seems more likely to me that we'll instill long term goals into AIs by "scaffolding" them via feedback over shorter time horizons. E.g., train GPT-N to generate text like "the company's stock must go up" (short time horizon feedback), as well as text that represents GPT-N competently responding to a variety of situations and discussions about how to achieve long-term goals (more short time horizon feedback), and then putting GPT-N in a continuous loop of sampling from a combination of the behavioral patterns thereby constructed, in such a way that the overall effect is competent long term planning.
The point is: long term goals are sufficiently hard to form deliberately that I don't think they'll form accidentally.
...I think the llama analogy is exactly correct. It's specifically designed to avoid triggering mechanistically ungrounded intuitions about "goals" and "tryingness", which I think inappropriately upweight the compellingness of a conclusion that's frankly ridiculous on the arguments themselves. Mechanistically, generating the intermediate llamas is just as causally upstream of generating the asked for images, as "having an inner goal" is causally upstream of the deceptive model doing well on the training objective. Calling one type of causal influence "trying" and the other not is an arbitrary distinction.
My point about the "instrumental ghost" wasn't that NNs wouldn't learn instrumental / flexible reasoning. It was that such capabilities were much more likely to derive from being straightforwardly trained to learn such capabilities, and then to be employed in a manner consistent with the target function of the training process. What I'm arguing *against* is the perspective that NNs will "accidentally" acquire such capabilities internally as a convergent result of their inductive biases, and direct them to purposes/along directions very different from what's represented in the training data. That's the sort of stuff I was talking about when I mentioned the "ghost".
What I'm saying is there's a difference between a model that can do flexible instrumental reasoning because it's faithfully modeling a data distribution with examples of flexible instrumental reasoning, versus a model that acquired hidden flexible instrumental reasoning because NN inductive biases say the convergent best way to do well on tasks is to acquire hidden flexible instrumental reasoning and apply it to the task, even when the task itself doesn't have any examples of such.
There's a huge amount of ontological confusion about how to think of "objectives" for optimization processes. I think people tend to take an inappropriate intentional stance and treat something like "deliberately steering towards certain abstract notions" as a simple primitive (because it feels introspectively simple to them). This background assumption casts a shadow over all future analysis, since people try to abstract the dynamics of optimization processes in terms of their "true objectives", when there really isn't any such thing.
Optimization processes (or at least, evolution and RL) are better thought of in terms of what sorts of behavioral patterns were actually selected for in the history of the process. E.g., @Kaj_Sotala's point here about tracking the effects of evolution by thinking about what sorts of specific adaptations were actually historically selected for, rather than thinking about some abstract notion of inclusive genetic fitness, and how the difference between modern and ancestral humans seems much smaller from this perspective.
I want to make a similar point about reward in the context of RL: reward is a measure of update strength, not the selection target. We can see as much by just looking at the update equations for REINFORCE (from page 328 of Reinforcement Learning: An Introduction):
The reward[1] is literally a (per step) multiplier of the learning rate. You can also think of it as providing the weights of a linear combination of the parameter gradients, which means that it's the historical action trajectories that determine what subspaces of the parameters can potentially be explored. And due to the high correlations between gradients (at least compared to the full volume of parameter space), this means it's the action trajectories, and not the reward function, that provides most of the information relevant for the NN's learning process.
on many benchmark datasets, offline RL can produce well-performing and safe policies even when trained with "wrong" reward labels, such as those that are zero everywhere or are negatives of the true rewards. This phenomenon cannot be easily explained by offline RL's return maximization objective. Moreover, it gives offline RL a degree of robustness that is uncharacteristic of its online RL counterparts, which are known to be sensitive to reward design.
Trying to preempt possible confusion:
I expect some people to object that the point of the evolutionary analogy is precisely to show that the high-level abstract objective of the optimization process isn't incorporated into the goals of the optimized product, and that this is a reason for concern because it suggests an unpredictable/uncontrollable mapping between outer and inner optimization objectives.
My point here is that, if you want to judge an optimization process's predictability/controllability, you should not be comparing some abstract notion of the process's "true outer objective" to the result's "true inner objective". Instead, you should consider the historical trajectory of how the optimization process actually adjusted the behaviors of the thing being optimized, and consider how predictable that thing's future behaviors are, given past behaviors / updates.
@Kaj_Sotala argues above that this perspective implies greater consistency in human goals between the ancestral and modern environments, since the goals evolution actually historically selected for in the ancestral environment are ~the same goals humans pursue in the modern environment.
For RL agents, I am also arguing that thinking in terms of the historical action trajectories that were actually reinforced during training implies greater consistency, as compared to thinking of things in terms of some "true goal" of the training process. E.g., Goal Misgeneralization in Deep Reinforcement Learning trained a mouse to navigate to cheese that was always placed in the upper right corner of the maze and found that it would continue going to the upper right even when the cheese was moved.
This is actually a high degree of consistency from the perspective of the historical action trajectories. During training, the mouse continually executed the action trajectories that navigated it to the upper right of the board, and continued to do the exact same thing in the modified testing environment.
Technically it's the future return in this formulation, and current SOTA RL algorithms can be different / more complex, but I think this perspective is still a more accurate intuition pump than notions of "reward as objective", even for setups where "reward as a learning rate multiplier" isn't literally true.
Comment by quintin-pope on [deleted post]
2023-10-30T21:33:05.095Z
I strong downvoted and strong disagree voted. The reason I did both is because I think what you're describing is a genuinely insane standard to take for liability. Holding organizations liable for any action they take which they do not prove is safe is an absolutely terrible idea. It would either introduce enormous costs for doing anything, or allow anyone to be sued for anything they've previously done.
I really don't want to spend even more time arguing over my evolution post, so I'll just copy over our interactions from the previous times you criticized it, since that seems like context readers may appreciate.
[very long, but mainly about your "many other animals also transmit information via non-genetic means" objection + some other mechanisms you think might have caused human takeoff]
I don't think this objection matters for the argument I'm making. All the cross-generational information channels you highlight are at rough saturation, so they're not able to contribute to the cross-generational accumulation of capabilities-promoting information. Thus, the enormous disparity between the brain's with-lifetime learning versus evolution cannot lead to a multiple OOM faster accumulation of capabilities as compared to evolution.
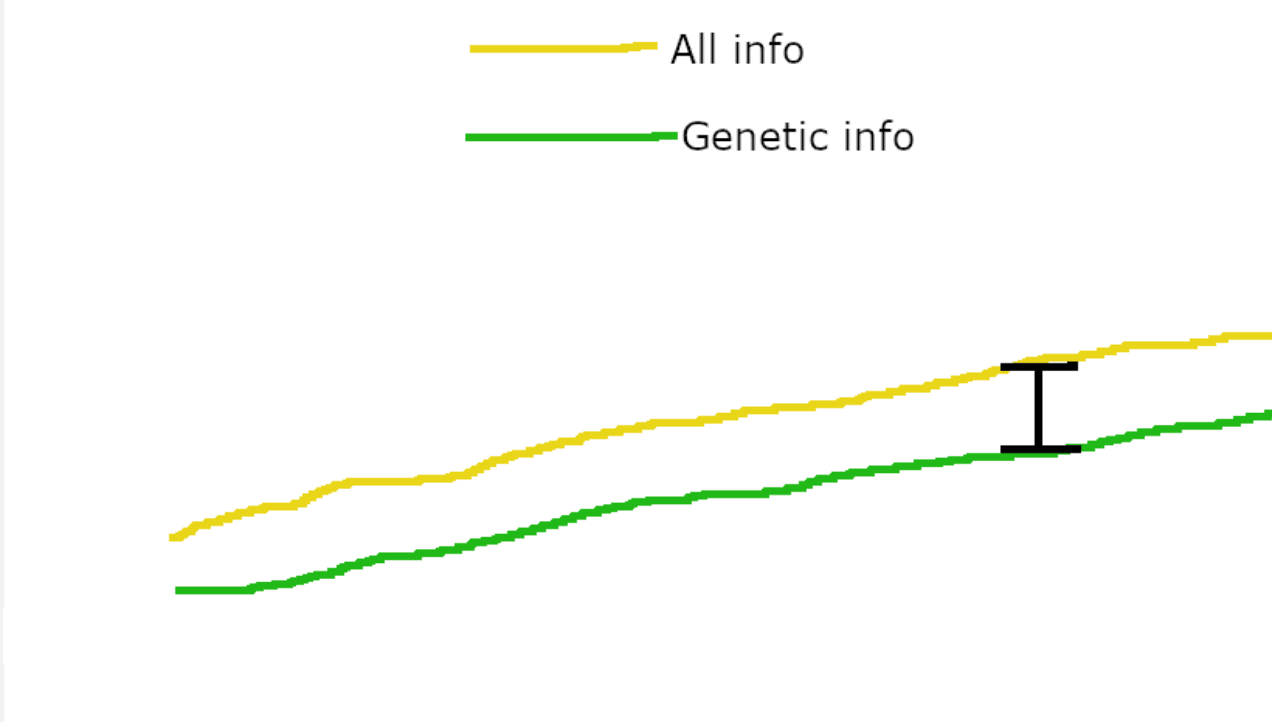
When non-genetic cross-generational channels are at saturation, the plot of capabilities-related info versus generation count looks like this:
with non-genetic information channels only giving the "All info" line a ~constant advantage over "Genetic info". Non-genetic channels might be faster than evolution, but because they're saturated, they only give each generation a fixed advantage over where they'd be with only genetic info. In contrast, once the cultural channel allows for an ever-increasing volume of transmitted information, then the vastly faster rate of within-lifetime learning can start contributing to the slope of the "All info" line, and not just its height.
Thus, humanity's sharp left turn.
In Twitter comments on Open Philanthropy's announcement of prize winners:
But what's the central point, than? Evolution discovered how to avoid the genetic bottleneck myriad times; also discovered potentially unbounded ways how to transmit arbitrary number of bits, like learning-teaching behaviours; except humans, nothing foomed. So the updated story would be more like "some amount of non-genetic/cultural accumulation is clearly convergent and is common, but there is apparently some threshold crossed so far only by humans. Once you cross it you unlock a lot of free energy and the process grows explosively". (&the cause or size of treshold is unexplained)
(note: this was a reply and part of a slightly longer chain)
Firstly, I disagree with your statement that other species have "potentially unbounded ways how to transmit arbitrary number of bits". Taken literally, of course there's no species on earth that can actually transmit an *unlimited* amount of cultural information between generations. However, humans are still a clear and massive outlier in the volume of cultural information we can transmit between generations, which is what allows for our continuously increasing capabilities across time.
Secondly, the main point of my article was not to determine why humans, in particular, are exceptional in this regard. The main point was to connect the rapid increase in human capabilities relative to previous evolution-driven progress rates with the greater optimization power of brains as compared to evolution. Being so much better at transmitting cultural information as compared to other species allowed humans to undergo a "data-driven singularity" relative to evolution. While our individual brains and learning processes might not have changed much between us and ancestral humans, the volume and quality of data available for training future generations did increase massively, since past generations were much better able to distill the results of their lifetime learning into higher-quality data.
This allows for a connection between the factors we've identified are important for creating powerful AI systems (data volume, data quality, and effectively applied compute), and the process underlying the human "sharp left turn". It reframes the mechanisms that drove human progress rates in terms of the quantities and narratives that drive AI progress rates, and allows us to more easily see what implications the latter has for the former.
In particular, this frame suggests that the human "sharp left turn" was driven by the exploitation of a one-time enormous resource inefficiency in the structure of the human, species-level optimization process. And while the current process of AI training is not perfectly efficient, I don't think it has comparably sized overhangs which can be exploited easily. If true, this would mean human evolutionary history provides little evidence for sudden increases in AI capabilities.
The above is also consistent with rapid civilizational progress depending on many additional factors: it relies on resource overhand being a *necessary* factor, but does not require it to be alone *sufficient* to accelerate human progress. There are doubtless many other factors that are relevant, such as a historical environment favorable to progress, a learning process that sufficiently pays attention to other members of ones species, not being a purely aquatic species, and so on. However, any full explanation of the acceleration in human progress of the form: "sudden progress happens exactly when (resource overhang) AND (X) AND (Y) AND (NOT Z) AND (W OR P OR NOT R) AND..." is still going to have the above implications for AI progress rates.
There's also an entire second half to the article, which discusses what human "misalignment" to inclusive genetic fitness (doesn't) mean for alignment, as well as the prospects for alignment during two specific fast takeoff (but not sharp left turn) scenarios, but that seems secondary to this discussion.
Firstly, I'd like to address the question of epistemics.
When I said "there's no reason to reference evolution at all when forecasting AI development rates", I was referring to two patterns of argument that I think are incorrect: (1) using the human sharp left turn as evidence for an AI sharp left turn, and (2) attempting to "rescue" human evolution as an informative analogy for other aspects of AI development.
(Note: I think Zvi did follow my argument for not drawing inferences about the odds of the sharp left turn specifically. I'm still starting by clarifying pattern 1 in order to set things up to better explain pattern 2.)
Pattern 1: using the human sharp left turn as evidence for an AI sharp left turn.
The original sharp left turn post claims that there are general factors about the structure and dynamics of optimization processes which both caused the evolutionary sharp left turn, and will go on to cause another sharp left turn in AI systems. The entire point of Nate referencing evolution is to provide evidence for these factors.
My counterclaim is that the causal processes responsible for the evolutionary sharp left turn are almost entirely distinct from anything present in AI development, and so the evolutionary outcome is basically irrelevant for thinking about AI.
From my perspective, this is just how normal Bayesian reasoning works. If Nate says:
P(human SLT | general factors that cause SLTs) ~= 1
P(human SLT | NOT general factors that cause SLTs) ~= 0
then observing the human SLT is very strong evidence for there being general factors that cause SLTs in different contexts than evolution.
OTOH, I am saying:
P(human SLT | NOT general factors that cause SLTs) ~= 1
And so observing the human SLT is no evidence for such general factors.
Pattern 2: attempting to "rescue" human evolution as an informative analogy for other aspects of AI development.
When I explain my counterargument to pattern 1 to people in person, they will very often try to "rescue" evolution as a worthwhile analogy for thinking about AI development. E.g., they'll change the analogy so it's the programmers who are in a role comparable to evolution, rather than SGD.
I claim that such attempted inferences also fail, for the same reason as argument pattern 1 above fails: the relevant portions of the causal graph driving evolutionary outcomes is extremely different from the causal graph driving AI outcomes, such that it's not useful to use evolution as evidence to make inferences about nodes in the AI outcomes causal graph. E.g., the causal factors that drive programmers to choose a given optimizer are very different from the factors that cause evolution to "choose" a given optimizer. Similarly, evolution is not a human organization that makes decisions based on causal factors that influence human organizations, so you should look at evolution for evidence of organization-level failures that might promote a sharp left turn in AI.
Making this point was the purpose of the "alien space clowns" / EVO-Inc example. It was intended to provide a concrete example of two superficially similar seeming situations, where actually their causal structures are completely distinct, such that there are no useful updates to make from EVO-Inc's outcomes to other automakers. When Zvi says:
I would also note that, if you discover (as in Quintin’s example of Evo-inc) that major corporations are going around using landmines as hubcaps, and that they indeed managed to gain dominant car market share and build the world’s most functional cars until recently, that is indeed a valuable piece of information about the world, and whether you should trust corporations or other humans to be able to make good choices, realize obvious dangers and build safe objects in general. Why would you think that such evidence should be ignored?
Zvi is proposing that there are common causal factors that led to the alien clowns producing dangerous cars, and could also play a similar role in causing other automakers to make unsafe vehicles, such that Evo-Inc's outcomes provide useful updates for predicting other automakers' outcomes. This is what I'm saying is false about evolution versus AI development.
At this point, I should preempt a potential confusion: it's not the case that AI development and human evolution share zero causal factors! To give a trivial example, both rely on the same physical laws. What prevents there being useful updates from evolution to AI development is the different structure of the causal graphs. When you update your estimates for the shared factors between the graphs using evidence from evolution, this leads to trivial or obvious implications for AI development, because the shared causal factors play different roles in the two graphs. You can have an entirely "benign" causal graph for AI development, which predicts zero alignment issues for AI development, yet when you build the differently structured causal graph for human evolution, it still predicts the same sharp left turn, despite some of the causal factors being shared between the graphs.
This is why inferences from evolutionary outcomes to AI development don't work. Propagating belief updates through the evolution graph doesn't change any of the common variables away from settings which are benign in the AI development graph, since those settings already predict a sharp left turn when they're used in the evolution graph.
Concrete example 1: We know from AI development that having a more powerful optimizer, running for more steps, leads to more progress. Applying this causal factor to the AI development graph basically predicts "scaling laws will continue", which is just a continuation of the current trajectory. Applying the same factor to the evolution graph, combined with the evolution-specific fact of cultural transmission enabling a (relatively) sudden unleashing of ~9 OOM more effectively leveraged optimization power in a very short period of time, predicts an extremely sharp increase in the rate of progress.
Concrete example 2: One general hypothesis you could have about RL agents is "RL agents just do what they're trained to do, without any weirdness". (To be clear, I'm not endorsing this hypothesis. I think it's much closer to being true than most on LW, but still false.) In the context of AI development, this has pretty benign implications. In the context of evolution, due to the bi-level nature of its optimization process and the different data that different generations are "trained" on, this causal factor in the evolution graph predicts significant divergence between the behaviors of ancestral and modern humans.
Zvi says this is an uncommon standard of epistemics, for there to be no useful inferences from one set of observations (evolutionary outcomes) to another (AI outcomes). I completely disagree. For the vast majority of possible pairs of observations, there are not useful inferences to draw. The pattern of dust specks on my pillow is not a useful reference point for making inferences about the state of the North Korean nuclear weapons program. The relationship between AI development and human evolution is not exceptional in this regard.
Secondly, I'd like to address a common pattern in a lot of Zvi's criticisms.
My post has a unifying argumentative structure that Zvi seems to almost completely miss. This leads to a very annoying dynamic where:
My post makes a claim / argument that serves a very specific role in the context of the larger structure.
Zvi misses that context, and interprets the claim / argument as making some broader claim about alignment in general.
Zvi complains that I'm over-claiming, being too general, or should split the post along the separate claims Zvi (falsely) believes I'm making.
The unifying argumentative structure of my post is as follows:
Having outlined my argumentative structure, I'll highlight some examples where Zvi's criticisms fall into the previously mentioned dynamic.
1:
[Zvi] He then goes on to make another very broad claim.
[Zvi quoting me] > In order to experience a sharp left turn that arose due to the same mechanistic reasons as the sharp left turn of human evolution, an AI developer would have to:
[I list some ways one could produce an ML training process that's actually similar to human evolution in the relevant sense that would lead to an evolution-like sharp left turn at some point]
[Zvi criticizes the above list on the grounds that inner misalignment could occur under a much broader range of circumstances than I describe]
(I added the bolding)
The issue here is that the list in question is specifically for sharp left turns that arise "due to the same mechanistic reasons as the sharp left turn of human evolution", as I very specifically said in my original post. I'm not talking about inner alignment in general. I'm not even talking about sharp left turn threat scenarios in general! I'm talking very specifically about how the current AI paradigm would have to change before it had a mechanistic structure sufficiently similar to human evolution that I think a sharp left turn would occur "due to the same mechanistic reasons as the sharp left turn of human evolution".
2:
As a general note, these sections seem mostly to be making a general alignment is easy, alignment-by-default claim, rather than being about what evolution offers evidence for, and I would have liked to see them presented as a distinct post given how big and central and complex and disputed is the claim here.
That is emphatically not what those sections are arguing for. The purpose of these sections is to describe two non-sharp left turn causing mechanisms for fast takeoff, in order to better illustrate that fast takeoff != sharp left turn. Each section specifically focuses on a particular mechanism of fast takeoff, and argues that said mechanism will not, in and of itself, lead to misalignment. You can still believe a fast takeoff driven by that mechanism will lead to misalignment for other reasons (e.g., a causal graph that looks like: "(fast takeoff mechanism) -> (capabilities) -> (something else) -> (misalignment)"), if, say, you think there's another causal mechanism driving misalignment, such that the fast takeoff mechanism's only contribution to misalignment was to advance capabilities in a manner that failed to address that other mechanism.
These sections are not arguing about the ease of alignment in general, but about the consequence of one specific process.
3:
The next section seems to argue that because alignment techniques work on a variety of existing training regimes all of similar capabilities level, we should expect alignment techniques to extend to future systems with greater capabilities.
That is, even more emphatically, not what that specific section is arguing for. This section focuses specifically on the "AIs do AI capabilities research" mechanism of fast takeoff, and argues that it will not itself cause misalignment. Its purpose is specific to the context in which I use it: to address the causal influence of (AIs do capabilities research) directly to (misalignment), not to argue about the odds of misalignment in general.
Further, the argument that section made wasn't:
because alignment techniques work on a variety of existing training regimes all of similar capabilities level, we should expect alignment techniques to extend to future systems
It was:
alignment techniques already generalize across human contributions to AI capability research. Let’s consider eight specific alignment techniques:
[list of alignment techniques]
and eleven recent capabilities advances:
[list of capabilities techniques]
I don’t expect catastrophic interference between any pair of these alignment techniques and capabilities advances.
And so, if you think AIs doing capabilities will be like humans doing capabilities research, but faster, then there will be a bunch of capabilities and alignment techniques, and the question is how much the capabilities techniques will interfere with the alignment techniques. Based on current data, the interference seems small and manageable. This is the trend being projected forwards, the lack of empirical interference between current capabilities and alignment (despite, as I note in my post, current capabilities techniques putting ~zero effort into not interfering with alignment techniques, an obviously dumb oversight which we haven't corrected because it turns out we don't even need to do so).
Once again, I emphasize that this is not a general argument about alignment, which can be detached from the rest of the post. It's extremely specific to the mechanism for fast takeoff being analyzed, which is only being analyzed to further explore the connection between fast takeoff mechanisms and the odds of a sharp left turn.
4:
He closes by arguing that iteratively improving training data also exhibits important differences from cultural development, sufficient to ignore the evolutionary evidence as not meaningful in this context. I do not agree. Even if I did agree, I do not see how that would justify his broader optimism expressed here:
This part is a separate analysis of a different fast takeoff causal mechanism, arguing that it will not, itself cause misalignment either. Its purpose and structure mirrors that of the argument I clarified above, but focused on a different mechanism. It's not a continuation of a previous (non-existent) "alignment is easy in general" argument.
Thirdly, I'd like to make some random additional commentary.
I would argue that ‘AIs contribute to AI capabilities research’ is highly analogous to ‘humans contribute to figuring out how to train other humans.’ And that ‘AIs seeking out new training data’ is highly analogous to ‘humans creating bespoke training data to use to train other people especially their children via culture’ which are exactly the mechanisms Quintin is describing humans as using to make a sharp left turn.
The degree of similarity is arguable. I think, and said in the original article, that similarity is low for the first mechanism and moderate for the second.
However, the appropriate way to estimate the odds of a given fast takeoff mechanism leading to AI misalignment is not to estimate the similarity between that mechanism and what happened during human evolution, then assign misalignment risk to the mechanism in proportion to the estimated similarity. Rather, the correct approach is to build detailed causal models of how both human evolution and AI development work, propagate the evidence from human evolutionary outcomes back through your human evolution causal model to update relevant latent variables in that causal model, transfer those updates to any of the AI development causal model's latent variables which are also in the human evolution causal model, and finally estimate the new misalignment risk implied by the updated variables of the AI development model.
I discussed this in more detail in the first part of my comment, but whenever I do this, I find that the transfer from (observations of evolutionary outcomes) to (predictions about AI development) are pretty trivial or obvious, leading to such groundbreaking insights as:
More optimization power leads to faster progress
Human level general intelligence is possible
Neural architecture search is a bad thing to spend most of your compute on
Retraining a fresh instance of your architecture from scratch on different data will lead to different behavior
That seems like a sharp enough left turn to me.
A sharp left turn is more than just a fast takeoff. It's the combined sudden increase in AI generality and breaking of previously existing alignment properties.
...humans being clearly misaligned with genetic fitness is not evidence that we should expect such alignment issues in AIs. His argument (without diving into his earlier linked post) seems to be that humans are fresh instances trained on new data, so of course we expect different alignment and different behavior.
But if you believe that, you are saying that humans are fresh versions of the system. You are entirely throwing out from your definition of ‘the system’ all of the outer alignment and evolutionary data, entirely, saying it does not matter, that only the inner optimizer matters. In which case, yes, that does fully explain the differences. But the parallel here does not seem heartening. It is saying that the outcome is entirely dependent on the metaphorical inner optimizer, and what the system is aligned to will depend heavily on the details of the training data it is fed and the conditions under which it is trained, and what capabilities it has during that process, and so on. Then we will train new more capable systems in new ways with new data using new techniques, in an iterated way, in similar fashion. How should this make us feel better about the situation and its likely results?
I find this perspective baffling. Where else do the alignment properties of a system derive from? If you have a causal structure like
then setting the value of the middle node will of course screen off the causal influence of the (programmers) node.
A possible clarification: in the context of my post when discussing evolution, "inner optimizer" means the brain's "base" optimization process, not the human values / intelligence that arises from that process. The mechanistically most similar thing in AI development to that meaning of the word "inner optimizer" is the "base" training process: the combination of training data, base optimizer, training process, architecture, etc. It doesn't mean the cognitive system that arises as a consequence of running that training process.
Consider the counterfactual. If we had not seen a sharp left turn in evolution, civilization had taken millions of years to develop to this point with gradual steady capability gains, and we saw humans exhibiting strong conscious optimization mostly for their genetic fitness, it would seem crazy not to change our beliefs at all about what is to come compared to what we do observe. Thus, evidence.
I think Zvi is describing a ~impossible world. I think this world would basically break ~all my models on how optimizing processes gain capabilities. My new odds of an AI sharp left turn would depend on the new models I made in this world, which in turn would depend on unspecified details of how human civilization's / AI progress happens in this world.
I would also note that Quintin in my experience often cites parallels between humans and AIs as a reason to expect good outcomes from AI due to convergent outcomes, in circumstances where it would be easy to find many similar distinctions between the two cases. Here, although I disagree with his conclusions, I agree with him that the human case provides important evidence.
Once again, it's not the degree of similarity that determines what inferences are appropriate. It's the relative structure of the two causal graphs for the processes in question. The graphs for the human brain and current AI systems are obviously not the same, but they share latent variables that serve similar roles in determining outcomes, in a way that the bi-level structure of evolution's causal graph largely prevents. E.g., Steven Byrnes has a whole sequence which discusses the brain's learning process, and while there are lots of differences between the brain and current AI designs, there are also shared building blocks whose behaviors are driven by common causal factors. The key difference with evolution is that, once one updates the shared variables from looking at human brain outcomes and applies those updates to the AI development graph, there are non-trivial / obvious implications. Thus, one can draw relevant inferences by observing human outcomes.
Concrete example 1: brains use a local, non-gradient based optimization process to minimize predictive error, so there exists some non-SGD update rules that are competitive with SGD (on brainlike architectures, at least).
Concrete example 2: brains don't require GPT-4 level volumes of training data, so there exist architectures with vastly more data-friendly scaling laws than GPT-4's scaling.
In the generally strong comments to OP, Steven Byrnes notes that current LLM systems are incapable of autonomous learning, versus humans and AlphaZero which are, and that we should expect this ability in future LLMs at some point. Constitutional AI is not mentioned, but so far it has only been useful for alignment rather than capabilities, and Quintin suggests autonomous learning mostly relies upon a gap between generation and discernment in favor of discernment being easier. I think this is an important point, while noting that what matters is ability to discern between usefully outputs at all, rather than it being easier, which is an area where I keep trying to put my finger on writing down the key dynamics and so far falling short.
What I specifically said was:
Autonomous learning basically requires there to be a generator-discriminator gap in the domain in question, i.e., that the agent trying to improve its capabilities in said domain has to be better able to tell the difference between its own good and bad outputs.
I realize this is accidentally sounds like it's saying two things at once (that autonomous learning relies on the generator-discriminator gap of the domain, and then that it relies on the gap for the specific agent (or system in general)). To clarify, I think it's the agent's capabilities that matter, that the domain determines how likely the agent is to have a persistent gap between generation and discrimination, and I don't think the (basic) dynamics are too difficult to write down.
You start with a model M and initial data distribution D. You train M on D such that M is now a model of D. You can now sample from M, and those samples will (roughly) have whatever range of capabilities were to be found in D.
Now, suppose you have some classifier, C, which is able to usefully distinguish samples from M on the basis of that sample's specific level of capabilities. Note that C doesn't have to just be an ML model. It could be any process at all, including "ask a human", "interpret the sample as a computer program trying to solve some problem, run the program, and score the output", etc.
Having C allows you to sample from a version of M's output distribution that has been "updated" on C, by continuously sampling from M until a sample scores well on C. This lets you create a new dataset D', which you can then train M' on to produce a model of the updated distribution.
So long as C is able to provide classification scores which actually reflect a higher level of capabilities among the samples from M / M' / M'' / etc, you can repeat this process to continually crank up the capabilities. If your classifier C was some finetune of M, then you can even create a new C' off of M', and potentially improve the classifier along with your generator. In most domains though, classifier scores will eventually begin to diverge from the qualities that actually make an output good / high capability, and you'll eventually stop benefiting from this process.
This process goes further in domains where it's easier to distinguish generations by their quality. Chess / other board games are extreme outliers in this regard, since you can always tell which of two players actually won the game. Thus, the game rules act as a (pairwise) infallible classifier of relative capabilities. There's some slight complexity around that last point, since a given trajectory could falsely appear good by beating an even worse / non-representative policy, but modern self-play approaches address such issues by testing model versions against a variety of opponents (mostly past versions of themselves) to ensure continual real progress. Pure math proofs is another similarly skewed domain, where building a robust verifier (i.e., a classifier) of proofs is easy. That's why Steven was able to use it as a valid example of where self-play gets you very far.
Most important real world domains do not work like this. E.g., if there were a robust, easy-to-query process that could classify which of two scientific theories / engineering designs / military strategies / etc was actually better, the world would look extremely different.
There are other issues I have with this post, but my reply is already longer than the entire original post, so I'll stop here, rather than, say, adding an entire additional section on my models of takeoff speed for AIs versus evolution (which I'll admit probably should have another post to go with it).
Addressing this objection is why I emphasized the relatively low information content that architecture / optimizers provide for minds, as compared to training data. We've gotten very far in instantiating human-like behaviors by training networks on human-like data. I'm saying the primacy of data for determining minds means you can get surprisingly close in mindspace, as compared to if you thought architecture / optimizer / etc were the most important.
Obviously, there are still huge gaps between the sorts of data that an LLM is trained on versus the implicit loss functions human brains actually minimize, so it's kind of surprising we've even gotten this far. The implication I'm pointing to is that it's feasible to get really close to human minds along important dimensions related to values and behaviors, even without replicating all the quirks of human mental architecture.
I believe the human visual cortex is actually the more relevant comparison point for estimating the level of danger we face due to mesaoptimization. Its training process is more similar to the self-supervised / offline way in which we train (base) LLMs. In contrast, 'most abstract / "psychological"' are more entangled in future decision-making. They're more "online", with greater ability to influence their future training data.
I think it's not too controversial that online learning processes can have self-reinforcing loops in them. Crucially however, such loops rely on being able to influence the externally visible data collection process, rather than being invisibly baked into the prior. They are thus much more amenable to being addressed with scalable oversight approaches.
I'm guessing you misunderstand what I meant when I referred to "the human learning process" as the thing that was a ~ 1 billion X stronger optimizer than evolution and responsible for the human SLT. I wasn't referring to human intelligence or what we might call human "in-context learning". I was referring to the human brain's update rules / optimizer: i.e., whatever quasi-Hebbian process the brain uses to minimize sensory prediction error, maximize reward, and whatever else factors into the human "base objective". I was not referring to the intelligences that the human base optimizers build over a lifetime.
If instead of reward circuitry inducing human values, evolution directly selected over policies, I'd expect similar inner alignment failures.
Most of the difference in outcomes between human biological evolution and DL comes down to the fact that bio evolution has a wildly different mapping from parameters to functional behaviors, as compared to DL. E.g.,
Bio evolution's parameters are the genome, which mostly configures learning proclivities and reward circuitry of the human within lifetime learning process, as opposed to DL parameters being actual parameters which are much more able to directly specify particular behaviors.
The "functional output" of human bio evolution isn't actually the behaviors of individual humans. Rather, it's the tendency of newborn humans to learn behaviors in a given environment. It's not like in DL, where you can train a model, then test that same model in a new environment. Rather, optimization over the human genome in the ancestral environment produced our genome, and now a fresh batch of humans arise and learn behaviors in the modern environment.
Point 2 is the distinction I was referencing when I said:
"human behavior in the ancestral environment" versus "human behavior in the modern environment" isn't a valid example of behavioral differences between training and deployment environments.
Overall, bio evolution is an incredibly weird optimization process, with specific quirks that predictably cause very different outcomes as compared to either DL or human within lifetime learning. As a result, bio evolution outcomes have very little implication for DL. It's deeply wrong to lump them all under the same "hill climbing paradigm", and assume they'll all have the same dynamics.
It's also not necessary that the inner values of the agent make no mention of human values / objectives, it needs to both a) value them enough to not take over, and b) maintain these values post-reflection.
This ties into the misunderstanding I think you made. When I said:
Deliberately create a (very obvious[2]) inner optimizer, whose inner loss function includes no mention of human values / objectives.[3]
The "inner loss function" I'm talking about here is not human values, but instead whatever mix of predictive loss, reward maximization, etc that form the effective optimization criterion for the brain's "base" distributed quasi-Hebbian/whatever optimization process. Such an "inner loss function" in the context of contemporary AI systems would not refer to the "inner values" that arise as a consequence of running SGD over a bunch of training data. They'd be something much much weirder and very different from current practice.
E.g., if we had a meta-learning setup where the top-level optimizer automatically searches for a reward function F, which, when used in another AI's training, will lead to high scores on some other criterion C, via the following process:
Randomly initializing a population of models.
Training them with the current reward function F.
Evaluate those models on C.
Update the reward function F to be better at training models to score highly on C.
The "inner loss function" I was talking about in the post would be most closely related to F. And what I mean by "Deliberately create a (very obvious[2]) inner optimizer, whose inner loss function includes no mention of human values / objectives", in the context of the above meta-learning setup, is to point to the relationship between F and C.
Specifically, does F actually reward the AIs for doing well on C? Or, as with humans, does F only reward the AIs for achieving shallow environmental correlates of scoring well on C? If the latter, then you should obviously consider that, if you create a new batch of AIs in a fresh environment, and train them on an unmodified reward function F, that the things F rewards will become decoupled from the AIs eventually doing well on C.
Returning to humans:
Inclusive genetic fitness is incredibly difficult to "directly" train an organism to maximize. Firstly, IGF can't actually be measured in an organism's lifetime, only estimated based on the observable states of the organism's descendants. Secondly, "IGF estimated from observing descendants" makes for a very difficult reward signal to learn on because it's so extremely sparse, and because the within-lifetime actions that lead to having more descendants are often very far in time away from being able to actually observe those descendants. Thus, any scheme like "look at descendants, estimate IGF, apply reward proportional to estimated IGF" would completely fail at steering an organism's within lifetime learning towards IGF-increasing actions.
Evolution, being faced with standard RL issues of reward sparseness and long time horizons, adopted a standard RL solution to those issues, namely reward shaping. E.g., rather than rewarding organisms for producing offspring, it builds reward circuitry that reward organisms for precursors to having offspring, such as having sex, which allows rewards to be more frequent and closer in time to the behaviors they're supposed to reinforce.
In fact, evolution relies so heavily on reward shaping that I think there's probably nothing in the human reward system that directly rewards increased IGF, at least not in the direct manner an ML researcher could by running a self-replicating model a bunch of times in different environments, measuring the resulting "IGF" of each run, and directly rewarding the model in proportion to its "IGF".
This is the thing I was actually referring to when I mentioned "inner optimizer, whose inner loss function includes no mention of human values / objectives.": the human loss / reward functions not directly including IGF in the human "base objective".
(Note that we won't run into similar issues with AI reward functions vs human values. This is partially because we have much more flexibility in what we include in a reward function as compared to evolution (e.g., we could directly train an AI on estimated IGF). Mostly though, it's because the thing we want to align our models to, human values, have already been selected to be the sorts of things that can be formed via RL on shaped reward functions, because that's how they actually arose at all.)
For (2), it seems like you are conflating 'amount of real world time' with 'amount of consequences-optimization'. SGD is just a much less efficient optimizer than intelligent cognition
Again, the thing I'm pointing to as the source of the human-evolutionary sharp left turn isn't human intelligence. It's a change in the structure of how optimization power (coming from the "base objective" of the human brain's updating process) was able to contribute to capabilities gains over time. If human evolution were an ML experiment, the key change I'm pointing to isn't "the models got smart". It's "the experiment stopped being quite as stupidly wasteful of compute" (which happened because the models got smart enough to exploit a side-channel in the experiment's design that allowed them to pass increasing amounts of information to future generations, rather than constantly being reset to the same level each time). Then, the reason this won't happen in AI development is that there isn't a similarly massive overhang of completely misused optimization power / compute, which could be unleashed via a single small change to the training process.
in-context learning happens much faster than SGD learning.
Is it really? I think they're overall comparable 'within an OOM', just useful for different things. It's just much easier to prompt a model and immediately see how this changes its behavior, but on head-to-head comparisons, it's not at all clear that prompting wins out. E.g., Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
In particular, I think prompting tends to be more specialized to getting good performance in situations similar to those the model has seen previously, whereas training (with appropriate data) is more general in the directions in which it can move capabilities. Extreme example: pure language models can be few-shot prompted to do image classification, but are very bad at it. However, they can be directly trained into capable multi-modal models.
I think this difference between in-context vs SGD learning makes it unlikely that in-context learning alone will suffice for an explosion in general intelligence. If you're only sampling from the probability distribution created by a training process, then you can't update that distribution, which I expect will greatly limit your ability to robustly generalize to new domains, as compared to a process where you gather new data from those domains and update the underlying distribution with those data.
For (3), I don't think that the SLT requires the inner optimizer to run freely, it only requires one of:
a. the inner optimizer running much faster than the outer optimizer, such that the updates don't occur in time.
b. the inner optimizer does gradient hacking / exploration hacking, such that the outer loss's updates are ineffective.
(3) is mostly there to point to the fact that evolution took no corrective action whatsoever in regards to humans. Evolution can't watch humans' within lifetime behavior, see that they're deviating away from the "intended" behavior, and intervene in their within lifetime learning processes to correct such issues.
Human "inner learners" take ~billions of inner steps for each outer evolutionary step. In contrast, we can just assign whatever ratio of supervisory steps to runtime execution steps, and intervene whenever we want.
It doesn't mention the literal string "gradient descent", but it clearly makes reference to the current methodology of training AI systems (which is gradient descent). E.g., here:
The techniques OpenMind used to train it away from the error where it convinces itself that bad situations are unlikely? Those generalize fine. The techniques you used to train it to allow the operators to shut it down? Those fall apart, and the AGI starts wanting to avoid shutdown, including wanting to deceive you if it’s useful to do so.
The implication is that the dangerous behaviors that manifest during the SLT are supposed to have been instilled (at least partially) during the training (gradient descent) process.
However, the above is a nitpick. The real issue I have with your comment is that you seem to be criticizing me for not addressing the "capabilities come from not-SGD" threat scenario, when addressing that threat scenario is what this entire post is about.
Here's how I described SLT (which you literally quoted): "SGD creating some 'inner thing' which is not SGD and which gains capabilities much faster than SGD can insert them into the AI."
This is clearly pointing to a risk scenario where something other than SGD produces the SLT explosion of capabilities.
You say:
For example, Auto-GPT is composed of foundation models which were trained with SGD and RHLF, but there are many ways to enhance the capabilities of Auto-GPT that do not involve further training of the foundation models. The repository currently has hundreds of open issues and pull requests. Perhaps a future instantiation of Auto-GPT will be able to start closing these PRs on its own, but in the meantime there are plenty of humans doing that work.
To which I say, yes, that's an example where SGD creates some 'inner thing' (the ability to contribute to the Auto-GPT repository), which (one might imagine) would let Auto-GPT "gain capabilities much faster than SGD can insert them into the AI." This is exactly the sort of thing that I'm talking about in this post, and am saying it won't lead to an SLT.
(Or at least, that the evolutionary example provides no reason to think that Auto-GPT might undergo an SLT, because the evolutionary SLT relied on the sudden unleash of ~9 OOM extra available optimization power, relative to the previous mechanisms of capabilities accumulation over time.)
Finally, I'd note that a very significant portion of this post is explicitly focused on discussing "non-SGD" mechanisms of capabilities improvement. Everything from "Fast takeoff is still possible" and on is specifically about such scenarios.
But for the rest of it, I don't see this as addressing the case for pessimism, which is not problems from the reference class that contains "the LLM sometimes outputs naughty sentences" but instead problems from the reference class that contains "we don't know how to prevent an ontological collapse, where meaning structures constructed under one world-model compile to something different under a different world model."
I dislike this minimization of contemporary alignment progress. Even just limiting ourselves to RLHF, that method addresses far more problems than "the LLM sometimes outputs naughty sentences". E.g., it also tackles problems such as consistently following user instructions, reducing hallucinations, improving the topicality of LLM suggestions, etc. It allows much more significant interfacing with the cognition and objectives pursued by LLMs than just some profanity filter.
I don't think ontological collapse is a real issue (or at least, not an issue that appropriate training data can't solve in a relatively straightforwards way). I feel similarly about lots of things that are speculated to be convergent problems for ML systems, such as wireheading and mesaoptimization.
Or, like, once LLMs gain the capability to design proteins (because you added in a relevant dataset, say), do you really expect the 'helpful, harmless, honest' alignment techniques that were used to make a chatbot not accidentally offend users to also work for making a biologist-bot not accidentally murder patients?
If you're referring to the technique used on LLMs (RLHF), then the answer seems like an obvious yes. RLHF just refers to using reinforcement learning with supervisory signals from a preference model. It's an incredibly powerful and flexible approach, one that's only marginally less general than reinforcement learning itself (can't use it for things you can't build a preference model of). It seems clear enough to me that you could do RLHF over the biologist-bot's action outputs in the biological domain, and be able to shape its behavior there.
If you're referring to just doing language-only RLHF on the model, then making a bio-model, and seeing if the RLHF influences the bio-model's behaviors, then I think the answer is "variable, and it depends a lot on the specifics of the RLHF and how the cross-modal grounding works".
People often translate non-lingual modalities into language so LLMs can operate in their "native element" in those other domains. Assuming you don't do that, then yes, I could easily see the language-only RLHF training having little impact on the bio-model's behaviors.
However, if the bio-model were acting multi-modally by e.g., alternating between biological sequence outputs and natural language planning of what to use those outputs for, then I expect the RLHF would constrain the language portions of that dialog. Then, there are two options:
Bio-bot's multi-modal outputs don't correctly ground between language and bio-sequences.
In this case, bio-bot's language planning doesn't correctly describe the sequences its outputting, so the RLHF doesn't constrain those sequences.
However, if bio-bot doesn't ground cross-modally, than bio-bot also can't benefit from its ability to plan in the language modality to better use its bio modality capabilities (which are presumably much better for planning than its bio-modality).
Bio-bot's multi-modal outputs DO correctly ground between language and bio-sequences.
In that case, the RLHF-constrained language does correctly describe the bio-sequences, and so the language-only RLHF training does also constrain bio-bot's biology-related behavior.
Put another way, I think new capabilities advances reveal new alignment challenges and unless alignment techniques are clearly cutting at the root of the problem, I don't expect that they will easily transfer to those new challenges.
Whereas I see future alignment challenges as intimately tied to those we've had to tackle for previous, less capable models. E.g., your bio-bot example is basically a problem of cross-modality grounding, on which there has been an enormous amount of past work, driven by the fact that cross-modality grounding is a problem for systems across very broad ranges of capabilities.
Roughly, the core distinction between software engineering and computer security is whether the system is thinking back.
Yes, and my point in that section is that the fundamental laws governing how AI training processes work are not "thinking back". They're not adversaries. If you created a misaligned AI, then it would be "thinking back", and you'd be in an adversarial position where security mindset is appropriate.
"Building an AI that doesn't game your specifications" is the actual "alignment question" we should be doing research on. The mathematical principles which determine how much a given AI training process games your specifications are not adversaries. It's also a problem we've made enormous progress on, mostly by using large pretrained models with priors over how to appropriately generalize from limited specification signals. E.g., Learning Which Features Matter: RoBERTa Acquires a Preference for Linguistic Generalizations (Eventually) shows how the process of pretraining an LM causes it to go from "gaming" a limited set of finetuning data via shortcut learning / memorization, to generalizing with the appropriate linguistic prior knowledge.
Didn't the Anthropic influence functions work pick up on LLMs not generalising across lexical ordering? E.g., training on "A is B" doesn't raise the model's credence in "Bs include A"?
Yes, this reasoning was for capabilities benchmarks specifically. Data goes further with future algorithmic progress, so I thought a narrower criteria for that one was reasonable.
So, you are deliberately targeting models such as LLama-2, then? Searching HuggingFace for "Llama-2" currently brings up 3276 models. As I understand the legislation you're proposing, each of these models would have to undergo government review, and the government would have the perpetual capacity to arbitrarily pull the plug on any of them.
I expect future small, open-source models to prioritize runtime efficiency, and so will over-train as much as possible. As a result, I expect that most of the open source ecosystem will be using models trained on > 1 T tokens. I think StableDiffusion is within an OOM of the 1 T token cutoff, since it was trained on a 2 billion image/text pairs subset of the LAION-5B dataset, and judging from the sample images on page 35, the captions are a bit less than 20 tokens per image. Future open source text-to-image models will likely be trained with > 1 T text tokens. Once that happens, the hobbyist and individual creators responsible for the vast majority of checkpoints / LORAs on model sharing sites like Civitai will also be subject to these regulations.
I expect language / image models will increasingly become the medium through which people express themselves, the next internet, so to speak. I think that giving the government expansive powers of censorship over the vast majority[1] of this ecosystem is extremely bad, especially for models that we know are not a risk.
I also think it is misleading for you to say things like:
and:
but then propose rules that would actually target a very wide (and increasing) swath of open-source, academic, and hobbyist work.
Your current threshold does include all Llama models (other than llama-1 6.7/13 B sizes), since they were trained with > 1 trillion tokens.
I also think 70% on MMLU is extremely low, since that's about the level of ChatGPT 3.5, and that system is very far from posing a risk of catastrophe.
The cutoffs also don't differentiate between sparse and dense models, so there's a fair bit of non-SOTA-pushing academic / corporate work that would fall under these cutoffs.
My assumption is that GPT-4 has a repetition penalty, so if you make it predict all the same phrase over and over again, it puts almost all its probability on a token that the repetition penalty prevents it from saying, with the leftover probability acting similarly to a max entropy distribution over the rest of the vocab.
For some reason, the LW memesphere seems to have interpreted this graph as indicating that RLHF increases sycophancy, even though that's not at all clear from the graph. E.g., for the largest model size, the base model and the preference model are the least sycophantic, while the RLHF'd models show no particular trend among themselves. And if anything, the 22B models show decreasing sycophancy with RLHF steps.
What this graph actually shows is increasing sycophancy with model size, regardless of RLHF. This is one of the reasons that I think what's often called "sycophancy" is actually just models correctly representing the fact that text with a particular bias is often followed by text with the same bias.
I mean (1). You can see as much in the figure displayed in the linked notebook:
Note the lack of decrease in the val loss.
I only train for 3e4 steps because that's sufficient to reach generalization with implicit regularization. E.g., here's the loss graph I get if I set the batch size down to 50:
Setting the learning rate to 7e-2 also allows for generalization within 3e4 steps (though not as stably):
The slingshot effect does take longer than 3e4 steps to generalize:
I don't think that explicitly aiming for grokking is a very efficient way to improve the training of realistic ML systems. Partially, this is because grokking definitionally requires that the model first memorize the data, before then generalizing. But if you want actual performance, then you should aim for immediate generalization.
Further, methods of hastening grokking generalization largely amount to standard ML practices such as tuning the hyperparameters, initialization distribution, or training on more data.
This post mainly argues that evolution does not provide evidence for the sharp left turn. Sudden capabilities jumps from other sources, such as those you mention, are more likely, IMO. My first reply to your comment is arguing that the mechanisms behind the human sharp left turn wrt evolution probably still won't arise in AI development, even if you go up an abstraction level. One of those mechanisms is a 5 - 9 OOM jump in usable optimization power, which I think is unlikely.
Am I missing something here, or is this just describing memetics?
It is not describing memetics, which I regard as a mostly confused framework that primes people to misattribute the products of human intelligence to "evolution". However, even if evolution meaningfully operates on the level of memes, the "Evolution" I'm referring to when I say "Evolution applies very little direct optimization power to the middle level" is strictly biological evolution over the genome, not memetic at all.
Memetic evolution in this context would not have inclusive genetic fitness as its "outer" objective, so whether memetic evolution can "transfer the skills, knowledge, values, or behaviors learned by one generation to their descendants" is irrelevant for the argument I was making in the post.
But isn't this solely because we have already studied our sensory organs and have a concept of taste buds, and hence flavors like sweet, etc. as primary categories of taste?
Not really. The only way our understanding of the biology of taste impacts the story about humans coming to like ice cream is that we can infer that humans have sugar detecting reward circuitry, which ice cream activates in the modern environment. For AI systems, we actually have a better handle on how their reward circuitry works, as compared to the brain. E.g., we can just directly look at the reward counter during the AI's training.
Kernelized Concept Erasure: concept encodings do have nonlinear components. Nonlinear kernels can erase certain parts of those encodings, but they cannot prevent other types of nonlinear kernels from extracting concept info from other parts of the embedding space.
Limitations of the NTK for Understanding Generalization in Deep Learning: the neural tangent kernels of realistic neural networks continuously change throughout their training. Further, neither the initial kernels nor any of the empirical kernels from mid-training can reproduce the asymptotic scaling laws of the actual neural network, which are better than predicted by said kernels.
Mechanistic Mode Connectivity: LMs often have non-connected solution basins, which correspond to different underlying mechanisms by which they make their classification decisions.
The description complexity of hypotheses AIXI considers is dominated by the bridge rules which translate from 'physical laws of universes' to 'what am I actually seeing?'. To conclude Newtonian gravity, AIXI must not only infer the law of gravity, but also that there is a camera, that it's taking a photo, that this is happening on an Earth-sized planet, that this planet has apples, etc. These beliefs are much more complex than the laws of physics.
One issue with AIXI is that it applies a uniform complexity penalty to both physical laws and bridge rules. As a result, I'd guess that AIXI on frames of a falling apple would put most of its probability mass on hypotheses with more complex laws than Newtonian gravity, but simpler bridge rules.
Autonomous learning basically requires there to be a generator-discriminator gap in the domain in question, i.e., that the agent trying to improve its capabilities in said domain has to be better able to tell the difference between its own good and bad outputs. If it can do so, it can just produce a bunch of outputs, score their goodness, and train / reward itself on its better outputs. In both situations you note (AZ and human mathematicians) there's such a gap, because game victories and math results can both be verified relatively more easily than they can be generated.
If current LMs have such discriminator gaps in a given domain, they can also learn autonomously, up to the limit of their discrimination ability (which might improve as they get better at generation).