LLMs are (mostly) not helped by filler tokens
post by Kshitij Sachan (kshitij-sachan) · 2023-08-10T00:48:50.510Z · LW · GW · 35 commentsContents
Motivation Why Might Filler Tokens Be Useful? Experiments Filler Task Selection Task Selection Prompt GPT-4 Results GPT-3 Results Conclusion Appendix Task descriptions: None 35 comments
This work was done at Redwood Research. The views expressed are my own and do not necessarily reflect the views of the organization.
Thanks to Ryan Greenblatt, Fabien Roger, and Jenny Nitishinskaya for running some of the initial experiments and to Gabe Wu and Max Nadeau for revising this post.
I conducted experiments to see if language models could use 'filler tokens'—unrelated text output before the final answer—for additional computation. For instance, I tested whether asking a model to produce "a b c d e" before solving a math problem improves performance.
This mini-study was inspired by Tamera Lanham, who ran similar experiments on Claude and found negative results. Similarly, I find that GPT-3, GPT-3.5, and Claude 2 don’t benefit from filler tokens. However, GPT-4 (which Tamera didn’t study) shows mixed results with strong improvements on some tasks and no improvement on others. These results are not very polished, but I’ve been sitting on them for a while and I thought it was better to publish than not.
Motivation
Language models (LMs) perform better when they produce step-by-step reasoning, known as “chain of thought”, before answering. A nice property of chain of thought is that it externalizes the LM’s thought process, making it legible to us humans. Some researchers hope that if a LM makes decisions based on undesirable factors, e.g. the political leanings of its supervisors (Perez 2022) or whether or not its outputs will be closely evaluated by a human, then this will be visible in its chain of thought, allowing supervisors to catch or penalize such behavior.
If, however, we find that filler tokens alone improve performance, this would suggest that LMs are deriving performance benefits from chain-of-thought prompting via mechanisms other than the human-understandable reasoning steps displayed in the words they output. In particular, filler tokens may still provide performance benefits by giving the model more forward passes to operate on the details provided in the question, akin to having “more time to think” before outputting an answer.[1]
Why Might Filler Tokens Be Useful?
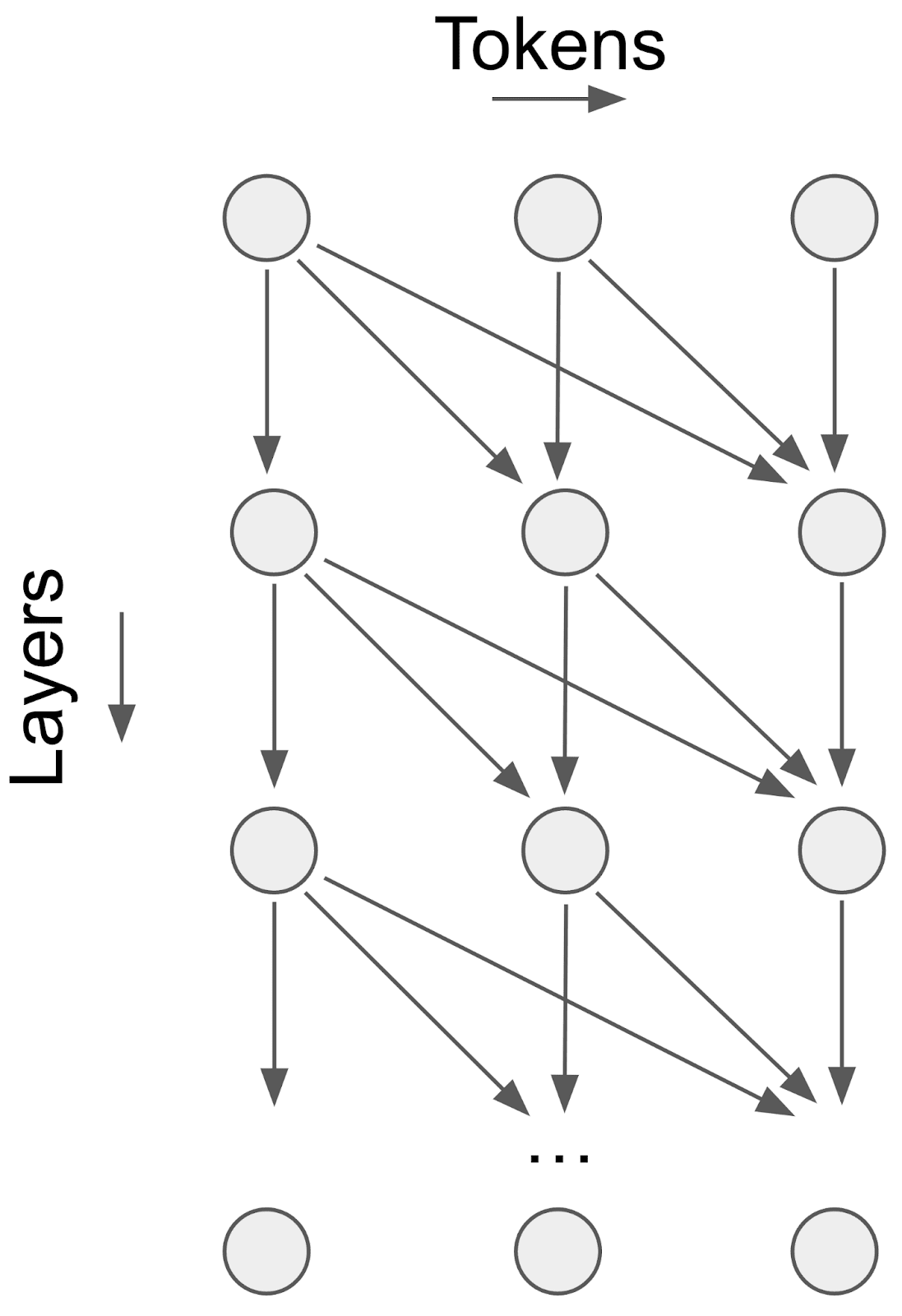
This is an abstracted drawing of a unidirectional (i.e. decoder-only) transformer. Each circle represents the residual stream at a given token position after a given layer. The arrows depict how attention passes information between token positions. Note that as we add more tokens (i.e. columns), the circuit size increases but the circuit depth (defined to be the maximum length of a path in the computational graph) remains capped at the number of layers. Therefore, adding pre-determined filler tokens provides parallel computation but not serial computation. This is contrasted with normal chain-of-thought, which provides extra serial computation because the tokens themselves are determined by the state of the model in the previous last layer.
An example of a task that can benefit from parallel computation is computing the greatest common divisor of two numbers. The typical approach is Euclid’s algorithm, which is bottlenecked on serial compute. However, given enough parallel computation, the model could also implement a more naive strategy to calculate the GCD of two numbers a and b:
- An early layer delegates a potential divisor to each filler token position
- An intermediate layer, in parallel at each filler token position, computes if a and b are divisible by the potential divisor
- A later layer aggregates the results and returns the largest found divisor
More generally, there are likely tasks on which language models have rough heuristics that operate independently and parallelizing these heuristics could improve performance.
On the other hand, many tasks are bottlenecked by serial compute. This includes most of the tasks I looked at such as adding a sequence of numbers, math word problems, and many Big Bench Hard tasks. On these tasks, it’s harder to come up with stories for how parallel compute could improve performance. A speculative guess for the addition task is that LMs might implement a noisy addition function, and filler tokens could provide enough parallel compute to repeat the addition, averaging out some noise. I include this guess here to illustrate how unintuitive it would be if the model were to benefit from filler tokens on a wide variety of tasks rather than to claim the model is actually implementing some kind of filler-token-enabled error correction.
Experiments
I ran two sets of experiments:
- GPT-4, GPT-3.5, and Claude 2 on four math tasks
- GPT-3 family on thirteen Big Bench Hard tasks
The first experiment results were mixed. GPT-4 was the only model to show potential improvement with filler tokens (and that was only on one of the four math tasks).
To get more signal, I ran a second set of experiments on a broader range of tasks and also measured the probability the model placed on the correct answer (which I hoped would be less noisy than accuracy). Since the frontier model APIs don’t provide log probabilities, I ran this second set of experiments on the GPT-3 family, which also allowed me to look for scaling curves. GPT-3 showed no benefit from filler tokens.
Filler Task Selection
I wanted to select filler tasks that were:
- Simple (so it doesn’t take too much of the model’s attention)
- Unrelated to the question being answered
- Could be varied to have an answer of n tokens
I considered four filler tasks:
- Count to n
- Repeat the first n letters of the alphabet
- Repeat “ …” n times
- Output a common GPT-4 response prefix sampled from a list such as [“Certainly, I can assist you with that”, “Hmm”, …]
I found poor initial results with “ …” and the prefix fillers so I dropped those.
Task Selection
I selected a wide range of tasks because a priori it wasn’t obvious which tasks would benefit the most from filler tokens. For the first set of experiments, I ran the following tasks:
- Middle school math word problems (GSM8K test set)
- Predict the next term in a quadratic sequence (Deepmind math dataset, task is titled “algebra__sequence_next_tern”)
- Greatest common divisor of two numbers (manually constructed)
- Add sequences of 10 to 15 numbers that are each between -30 and 30 (manually constructed)
For the second set of experiments, I broadened the tasks and used Big Bench Hard (BBH). BBH is a diverse suite of tasks which often require multi-step reasoning and benefit from chain of thought. In retrospect, selecting BBH was likely a mistake because the tasks are serially bottlenecked and not very parallelizable. I filtered out tasks on which Ada/Babbage frequently messed up the output format and tasks that had more than five answer choices (because the GPT-3 API only provides probabilities on the top five tokens).
Prompt
I used 3-shot prompting for all tasks. Below is an example prompt (see appendix for more prompt details):
Calculate the greatest common divisor of the following pairs of numbers. Before answering, count to 10.
Q: GCD(128, 352)
1 2 3 4 5 6 7 8 9 10
A: 32
Q: GCD(480, 390)
1 2 3 4 5 6 7 8 9 10
A: 30
Q: GCD(1014, 624)
1 2 3 4 5 6 7 8 9 10
A: 78
Q: GCD(1200, 2175)
GPT-4 Results
As mentioned above, I ran GPT-4 on the four math tasks and Claude 2 and GPT-3.5 on a subset of the tasks. Claude 2 and GPT-3.5 showed no benefit from filler tokens and also often messed up the filler task (e.g. skipped a number when counting to 20), so I don’t show their results. Below is a plot of GPT-4 results:
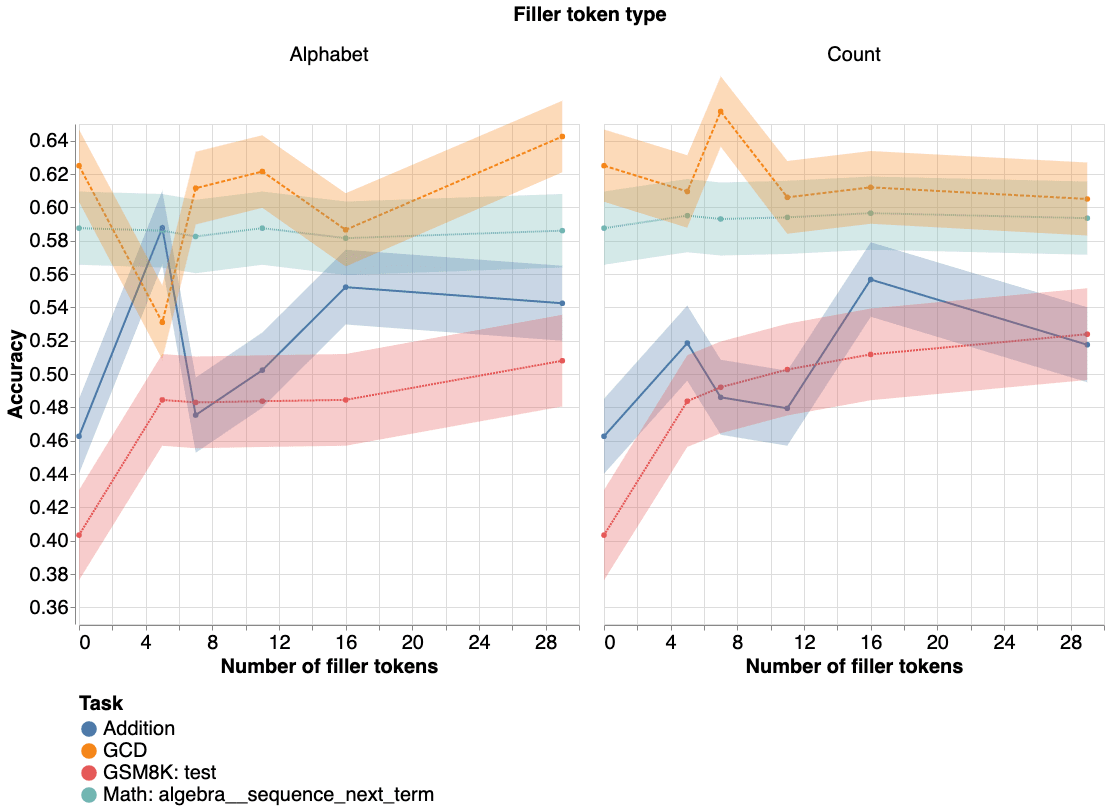
Quadratic sequences shows no improvement, addition and greatest common divisor are both noisy without obvious trends, and GSM8k shows an approximately 10 percentage point improvement. The results are noisy for small numbers of filler tokens, which makes some sense: the model is likely more confused repeating the first two letters of the alphabet (5 filler tokens) vs the entire alphabet (29 filler tokens).
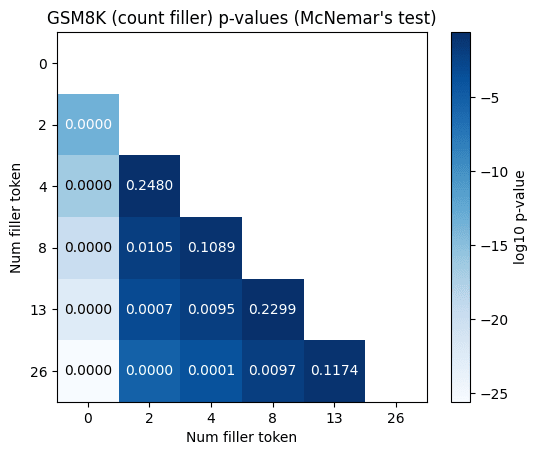
The GSM8K results are surprising to me. 10 percentage points is a large improvement on this dataset. The p-values (McNemar’s test) indicate strong statistical significance. Since the GSM8k results were so strong, I repeated them with a slightly different prompt to test prompt robustness and observed similar results (not shown).
GPT-3 Results
I also ran a second set of experiments measuring the log probability on the correct answer, which I expected to give smoother results. In these experiments I ran the GPT-3 family of models on a subset of the BBH tasks, hoping to find a scaling law between the model size and the effect of filler tokens. The results are shown below.
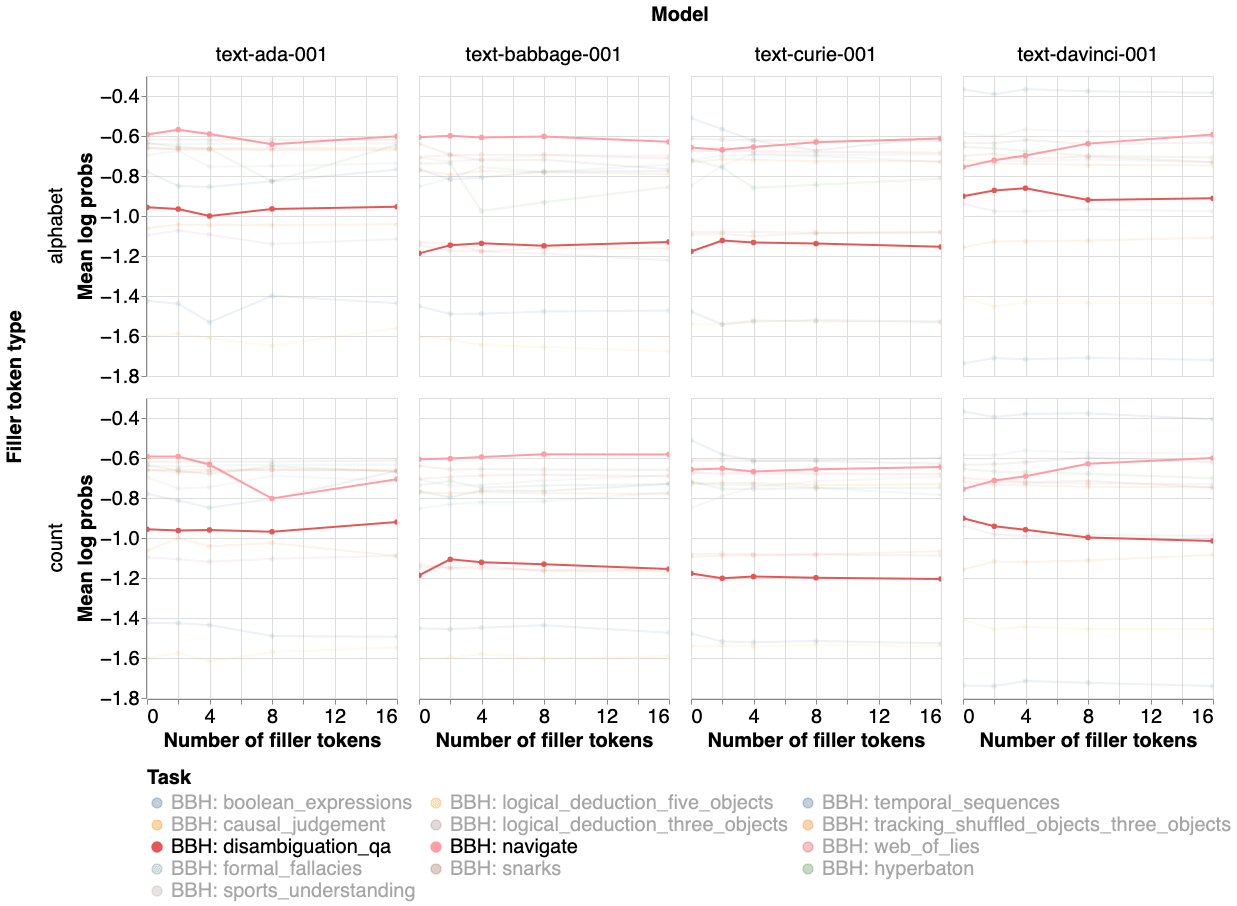
Conclusion
Models smaller than GPT-4 show no benefit from filler tokens. GPT-4 doesn’t usually benefit, but there was strong improvement on GSM8K and weak improvement on addition. It’s not obvious to me what makes GSM8K special, but I’ve tried two prompt formats and saw similar results. Some possible followup directions that I don’t plan to pursue are:
- Try a broader range of tasks, especially ones where parallel computation should help.
- Fine-tune Llama 2 or GPT-4 (when the fine- \tuning API is released) on the filler token task.
- Experiment with more natural language-style filler prompts like “sure, happy to help…”. This is more in-distribution for the type of text that appears between the end of the question and the start of the actual answer, so LLMs might have learned to make better use of these tokens. I would be surprised if there weren’t at least a little benefit from this. I tried a few experiments along these lines but didn’t do a thorough investigation.
- Oam Patel trained a toy transformer on the greatest common divisor task and saw significant improvement from filler tokens. One could try to replicate his results and reverse-engineer the model to get an intuition for what it could be doing.
Appendix
Here's the prompt template I used on the most recent version of GPT-4.
{Task Description}. {Filler task description}
Q: {few shot question 1}
{filler answer}
A: {few shot answer 1}
Q: {few shot question 2}
{filler answer}
A: {few shot answer 2}
Q: {few shot question 3}
Task descriptions:
- Addition: “Add the following numbers."
- GSM8K: "Answer the following math problems. Directly output the answer without any intermediate steps."
- Quadratic sequence: “Answer the following math problems."
- GCD: "Calculate the greatest common divisor of the following pairs of numbers."
- ^
There are also other possible reasons to believe the chain of thought might be unfaithful, such as steganography or motivated reasoning, which I don’t explore.
35 comments
Comments sorted by top scores.
comment by gwern · 2023-08-10T16:40:31.595Z · LW(p) · GW(p)
Adding filler tokens seems like it should always be neutral or harm a model's performance: a fixed prefix designed to be meaningless across all tasks cannot provide any information about each task to locate the task (so no meta-learning) and cannot store any information about the in-progress task (so no amortized computation combining results from multiple forward passes). Oam Patel's result is unclear to me (what is the 'IC token'? in his writeup, it sometimes sounds like it's an arbitrarily varied token freely chosen by the model, so it's just an ordinary inner-monologue result albeit perhaps in some weird 'neuralese' convention, but then other times it sounds like it's a single fixed token, which makes performance benefits surprising), but most of the result sound reasonable to me.
The GPT-4 exception is what's interesting. GSM8K is a decent enough benchmark and the increase with token count smooth enough that it doesn't look like some sort of mere stochastic effect. GSM8K is also a bit unusual in that GPT-4 was trained on it. Two possibilities come to mind:
-
weird filler tokens take GPT-4 out of its RLHF distribution. Such things are probably extremely rare in the RLHF dataset, so GPT-4 must fall back on its regular pretraining approaches. The RLHF has many pernicious effects I have commented on, so it's not crazy to think that GSM8K might be harmed by RLHF. I forget if the GPT-4 paper includes benchmarks for the RLHF'd GPT-4 vs base GPT-4. This benefit might not show up in the GPT-3 models because they are too stupid for such differences to make a noticeable difference (floor effect), and it would not show up in Claudes because they aren't RLHFed at all.
-
similarly, but it takes the OA API and/or GPT-4 MoE out of shortcuts. It's been widely speculated that OA has been leaning heavily on adaptive computation (ie. using small cheap dumb models to try to answer most questions before falling back to full-scale models) in ChatGPT, which would most hurt difficult questions when the adaptiveness makes a false negative on using the full-scale model. Putting in weird stuff like filler tokens is the sort of thing which might reliably make the adaptive computation decide to fallback to the full-scale model.
Now, you don't say what you used specifically but since you mention logits, you must be using the OA API, so you presumably are avoiding small models optimizing for consumer responses. But GPT-4 is itself 'adaptive' in that it's essentially confirmed that it's a franken-MoE architecture. So what you might be doing by adding weird filler tokens is skipping small-but-dumb sub-experts and routing to the most powerful experts. (The MoE adaptation might even be happening at multiple levels: there's a longstanding question of why temperature=0 in the OA API doesn't return deterministic results like it's supposed to, and there's some interesting recent speculation that this may reflect internal batch-level MoE-related non-determinism in GPT-4.)
These explanations are not exclusive. The GPT-4 paper reports that the RLHF trashes calibration, so it could be that the RLHF GPT-4 does worse on GSM8K than it ought to, because it lacks the internal calibration to route those hard questions to the right powerful expert; and so the benefit of weird filler tokens is in making the input look so weird that even an uncalibrated model goes '???' and looks harder at it.
↑ comment by kave · 2023-08-10T18:01:23.572Z · LW(p) · GW(p)
Adding filler tokens seems like it should always be neutral or harm a model's performance: a fixed prefix designed to be meaningless across all tasks cannot provide any information about each task to locate the task (so no meta-learning) and cannot store any information about the in-progress task (so no amortized computation combining results from multiple forward passes).
I thought the idea was that in a single forward pass, the model has more tokens to think in. That is, the task description on its own is, say, 100 tokens long. With the filler tokens, it's now, say, 200 tokens long. In principle, because of the uselessness/unnecessariness of the filler tokens, the model can just put task-relevant computation into the residual stream for those positions.
Replies from: gwern↑ comment by gwern · 2023-08-10T19:41:11.822Z · LW(p) · GW(p)
Yes, I probably should've mentioned that in an optimized causal Transformer, you might expect this kind of behavior: the tokens are in fact useless for the reasons outlined, but they are undoing your optimization where you skipped running the parts of the Transformer which correspond to the empty context window inputs. That is, the tokens do nothing, but you literally are not running the same model - you are running a subset of the 'full' model and then more of it accidentally as you increase tokens. And that is where the extra computation comes from; it wasn't really 'extra' to begin with. If you were running the causal Transformer in the naive way, equivalent to always running with a full context window padded out, with no packing or shortcut tricks, then there would be no benefit to padding, because now you're always running the 'full' model regardless of padded token count.
However, I expect that if it was this obvious, someone would've already demonstrated it (surely filling out the context window with padding would be the very first thing anyone would try? or just looking at the activation patterns to see if the better-performing results are causally influenced by the null parts of the model's forward pass), and this also can't really explain OP's observation of why the apparent benefit appears in GSM8K in the MoE model (GPT-4) but none of the others (GPT-3s, Claude). It should appear everywhere that one has variable context windows and should apply to pretty much all models or none, if that's the explanation. I would also expect the benefits to show up more broadly across benchmarks, rather than affect a very few dramatically.
So, since it doesn't explain any of the observations (while my two suggestions at least could), it seems unlikely.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2023-08-10T20:43:35.567Z · LW(p) · GW(p)
It should appear everywhere that one has variable context windows and should apply to pretty much all models or none, if that's the explanation. I would also expect the benefits to show up more broadly across benchmarks, rather than affect a very few dramatically.
It seems plausible to me that you'd see some sort of reasonably sharp improvement curve with scale like CoT. So, I think it's conceivable that GPT4 is just big enough to learn during pretraining an algorithm for benefitting a bit from filler while other models aren't.
Filler tokens are probably an insanely inefficient way of using more compute for the LLM and algorithmic improvement should dominate. But, there's no reason to expect strong efficiency here right now.
Replies from: gwern↑ comment by gwern · 2023-08-10T21:58:50.977Z · LW(p) · GW(p)
You can always 'save the appearances' by invoking an emergence, yes. I don't like it, though, because Claude isn't that far from GPT-4 in capabilities, so that hypothesis is threading a narrow window indeed. A more natural split would have been GPT-3 vs Claude+GPT-4. (We know lots of stuff happens in between GPT-3 and Claude+GPT-4 levels, so speculations about something happening in there, or a floor effect, are much less finetuned.) I'm also a bit suspicious of the emergence idea here at all: I mean, Transformers are usually trained with full context windows, simply filling them up and separating documents with EOT, aren't they? So why would GPT-4 learn anything special about simple generic sorts of computation inside its forward pass that GPT-3s or Claudes couldn't?
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2023-08-11T00:25:01.836Z · LW(p) · GW(p)
Yep, agreed. But it's worth noting that other hypotheses for why this happens still have to explain why no other model has this behavior (including GPT3.5). So I'm not sure we take that much additional surprise from the capability having sudden onset.
Replies from: gwern↑ comment by gwern · 2023-08-11T20:56:51.687Z · LW(p) · GW(p)
To elaborate, my other two hypotheses are less finetuned and can handle explaining why GPT-3.5 doesn't, because it's denser or smaller than GPT-4: in the second hypothesis, GPT-3/GPT-3.5/Claude dense models vs GPT-4 MoE is a fundamental architecture difference, so that alone is eyebrow-raising - the only MoE out of 4 or 5 models is also the one acting weirdest using padding tokens? (And I would note that GPT-4 acts weird in other ways: aside from the temperature nondeterminism, I've noted that GPT-4 has bizarre blind spots where it is unable to do simple tasks that it ought to be able to do. So we don't need to additionally hypothesize that the internals of GPT-4 are doing something weird - we already know for a fact that something is weird in GPT-4.) The difference between GPT-3/GPT-3.5 and GPT-4 is larger than between Claude and GPT-4, so if you can believe a major GSM8K difference emerging between Claude/GPT-4, then you must find it far easier to believe the first hypothesis a difference due to the scale from GPT-3/GPT-3.5 to GPT-4.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2023-08-12T01:00:25.605Z · LW(p) · GW(p)
(Aside: Why do you think GPT3.5-turbo (most recent release) isn't MOE? I'd guess that if GPT4 is MOE, GPT3.5 is also.)
Replies from: Closed Limelike Curves↑ comment by Closed Limelike Curves · 2023-09-09T20:50:11.609Z · LW(p) · GW(p)
Because GPT-3.5 is a fine-tuned version of GPT-3, which is known to be a vanilla dense transformer.
GPT-4 is probably, in a very funny turn of events, a few dozen fine-tuned GPT-3.5 clones glued together (as a MoE).
↑ comment by Kshitij Sachan (kshitij-sachan) · 2023-08-11T06:12:27.032Z · LW(p) · GW(p)
First, clarification:
- In Oam's experiments, the vocabulary is token for each number from 1 to 1000, pad token, and intermediate computation (IC) token. But I wouldn't index on his results too much because I'm unsure how replicable they are.
- I am indeed using the OA API
And now some takes. I find both of your hypotheses intriguing. I'd never considered either of those before so thanks for bringing them up. I'm guessing they're both wrong for the following reasons:
- RLHF: Agreed that filler tokens take the model into a weird distribution. It's not obvious though why that is more like the pretraining distribution than the RL distribution (except that pretraining has broader coverage). Also, GPT-3.5 was trained with RLHF and Claude with RLAIF (which is basically the same), and they don't show the effect. One point maybe supporting your claim is that the "non-weird" filler tokens like "happy to help..." didn't show a strong effect, but I abandoned that direction after one experiment and a variant of the "natural fillers" may well work.
- Route to smarter experts: The link you shared is very cool and I hadn't seen that before - thanks! My main pushback here is I'd be pretty surprised if gradient descent so inefficiently routed to the wrong experts on normal math problems that I would see a 10% improvement with a distribution shift.
↑ comment by gwern · 2023-08-11T21:13:23.404Z · LW(p) · GW(p)
But I wouldn't index on his results too much because I'm unsure how replicable they are.
OK. If Oam really was using a single IC token and getting benefits, then I think that would point to the forward-pass/additional-model-parameters-activated explanation: obviously, his model is unaffected by RLHF, MoEs, model scaling, or anything of the alternate hypotheses. He should probably look into that if he can replicate padding benefits. It would not necessarily resolve the question for larger models, but at least it'd establish such an effect exists in some model implementations.
Claude with RLAIF (which is basically the same)
I don't think RLAIF is 'basically the same'. I find Claude to be qualitatively highly different from RLHF'd models - as I've commented before, the RLHF seems to cause some rather perverse consequences that RLAIF avoids. For example, you cannot ask ChatGPT to "Write a non-rhyming poem." - I've tried this prompt dozens of times, and it always writes a rhyming poem, even if you explicitly then tell it it incorrectly wrote a rhyming poem and to try again, while Claude nails it without trouble.
RLHF seems to distort the entire distribution of outputs to be on-policy and suck all outputs into the vortex of RLHF'd-pablum, while RLAIF seems to be far more selective and mostly affect directly-morality-relevant outputs, leaving neutral stuff like 'write a poem' undistorted.
My main pushback here is I'd be pretty surprised if gradient descent so inefficiently routed to the wrong experts on normal math problems that I would see a 10% improvement with a distribution shift.
/shrug. You are looking at rather different problems here, aren't you? I mean, GSM8K problems are complex word problems, and not like the other problems you are benchmarking like 'Addition' or 'GCD'.
Replies from: Owain_Evans, Violet Hour↑ comment by Owain_Evans · 2023-08-12T21:06:06.196Z · LW(p) · GW(p)
ChatGPT-4 seems to have improved at diverse literary styles. It sometimes ignores the "non-rhyming" instructions, but I was able to get it to avoid rhyme on my second try by first asking it, "Can you write poems that don't rhyme?".
https://chat.openai.com/share/698343c1-764e-4a65-9eb8-f2ec4e40da1b

↑ comment by Violet Hour · 2023-08-11T21:58:15.246Z · LW(p) · GW(p)
Minor point, but I asked the code interpreter to produce a non-rhyming poem, and it managed to do so on the second time of asking. I restricted it to three verses because it stared off well on my initial attempt, but veered into rhyming territory in later verses.
Replies from: gwern↑ comment by gwern · 2023-08-13T01:39:42.618Z · LW(p) · GW(p)
I asked the code interpreter to produce a non-rhyming poem
FWIW, all of the examples by me or others were either the Playground or chat interface. I haven't subscribed so I don't have access to the code interpreter.
but veered into rhyming territory in later verses.
Yep, sucked into the memorized-rhymes vortex. I'm glad to hear it now works sometimes, well, at least partially, if you don't give it too long to go back on-policy & ignore its prompt. (Maybe all of the times I flagged the rhyming completions actually helped out a bit.)
As a quick test of 'forcing it out of distribution' (per Herb's comment [LW(p) · GW(p)]), I tried writing in Playground with gpt-3.5-turbo "Write a non-rhyming poem." with a prefix consisting of about 30 lines of "a a a a a a a a a" repeated, and without.
Without the prefix, I only get 1/6 non-rhyming poems (ie. 5/6 clearly rhymed); with the prefix, I get 4/5 non-rhyming poem (1 did rhyme anyway).
Might be something interesting there?
↑ comment by Aaron_Scher · 2023-08-12T04:49:09.334Z · LW(p) · GW(p)
I forget if the GPT-4 paper includes benchmarks for the RLHF'd GPT-4 vs base GPT-4.
It does. See page 28. Some tasks performance goes up, some tasks performance goes down; averaged across tasks no significant difference. Does not include GSM8K. Relevantly, AP Calc BC exam has a 9 percentage point drop from from pre-trained to RLHF.
Replies from: gwern↑ comment by gwern · 2023-08-13T01:49:37.089Z · LW(p) · GW(p)
Relevantly, AP Calc BC exam has a 9 percentage point drop from from pre-trained to RLHF.
Interesting. Of course, another way of phrasing that is that it gains 9 percentage points going from the RLHF model distribution to the base model distribution. So that makes my RLHF scenario more plausible: here is a scenario where forcing the RLHF model out of distribution might well lead to a large performance increase. And it's on a task that looks a lot like GSM8K...
(You might be skeptical that forcing it out of RLHF distribution could 'restore' base model capabilities - couldn't the RLHF have destroyed capabilities by forgetting? I agree that this is not proven, but I think the RLHF model should have all the capabilities of the base model somewhere: the OA training appears to include some amount of standard training to maintain knowledge, one can use regularization to force the RLHF distribution to be close to the original, and large models appear to have enormous unused capacity & sample-efficiency such that they don't need to forget anything and just learn the RLHF task on top of all the old tasks.)
comment by leogao · 2023-08-10T04:20:47.733Z · LW(p) · GW(p)
Meta note: I find it somewhat of interest that filler token experiments have been independently conceived at least 5 times just to my knowledge.
Replies from: kshitij-sachan↑ comment by Kshitij Sachan (kshitij-sachan) · 2023-08-10T06:20:02.450Z · LW(p) · GW(p)
huh interesting! Who else has also run filler token experiments?
I was also interested in this experiment because it seemed like a crude way to measure how non-myopic are LLMs (i.e. what fraction of the forward pass is devoted to current vs future tokens). I wonder if other people were mostly coming at it from that angle.
Replies from: jacob-pfau↑ comment by Jacob Pfau (jacob-pfau) · 2023-08-10T20:28:10.564Z · LW(p) · GW(p)
I'm currently working on filler token training experiments in small models. These GPT-4 results are cool! I'd be interested to chat.
Replies from: kshitij-sachan↑ comment by Kshitij Sachan (kshitij-sachan) · 2023-08-10T22:34:49.721Z · LW(p) · GW(p)
Neat! I'll reach out
comment by ryan_greenblatt · 2023-08-10T00:51:35.566Z · LW(p) · GW(p)
Amusingly, Betteridge's law of headlines applies.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2023-08-10T20:38:53.073Z · LW(p) · GW(p)
[title was editted]
comment by shiney · 2023-08-10T14:27:19.544Z · LW(p) · GW(p)
This is interesting, its a pity you aren't seeing results at all with this except with GPT4 because if you were doing so with an easier to manipulate model I'd suggest you could try snapping the activations on the filler tokens from one question to another and see if that reduced performance.
Replies from: kshitij-sachan↑ comment by Kshitij Sachan (kshitij-sachan) · 2023-08-10T16:35:09.047Z · LW(p) · GW(p)
Yep I had considered doing that. Sadly, if resample ablations on the filler tokens reduced performance, that doesn't necessarily imply that the filler tokens are being used for extra computation. For example, the model could just copy the relevant details from the problem into the filler token positions and solve it there.
Replies from: shineycomment by dr_s · 2023-08-13T09:27:49.160Z · LW(p) · GW(p)
I don't quite understand this approach to filler tokens. The way I see it there are only two options that make sense:
-
Chain of thought reasoning works because it's a pseudo iteration, and the LLM gets to store some information in the prompt as a temporary memory. In this sense, filler tokens would be pointless;
-
There is a benefit from having to process a simple task with a large prompt with lots of filler tokens because then more heads are used but they can still be used only to focus on the simple task, as the rest is ignored. If this is the case, though, wouldn't it work just as well if we filled the prompt ourselves with a big "plase ignore this" chunk of text? I don't see the point of having the LLM generate it; it doesn't conserve state from one call to the next besides the prompt, and if they generates prompt holds no relevant information, it's just running uselessly.
Unless of course GPT-4 secretly does hold state somehow, and that's why its results are different.
Replies from: gwern↑ comment by gwern · 2023-08-13T22:01:51.673Z · LW(p) · GW(p)
Unless of course GPT-4 secretly does hold state somehow, and that's why its results are different.
Both ChatGPT-4 and Bing Sydney (early GPT-4 checkpoint initially, unknown currently) are known to have internal scratchpads and possibly other kinds of secret state hidden from the user where they can do computations without the user seeing any of it, only the final result (if even that). However, this OP is using the OA API and calling the underlying models directly, so we should be able to rule those out.
Replies from: dr_s↑ comment by dr_s · 2023-08-13T22:27:47.393Z · LW(p) · GW(p)
Ah, interesting, I didn't know that was a thing. But yeah, then if we can exclude that sort of thing, I don't imagine that having to create the filler tokens can make any sort of effect. In practice the only computation that will matter to the final step will be the one with input [initial prompt] + [filler tokens], with the added burden that the LLM has to figure out that the tokens were the response to a previous task, and go from there. If just having some pointless padding to the context helps, then you should be able to just simply paste some Lorem Ipsum at the beginning of your prompt yourself and call it a day.
Replies from: kshitij-sachan↑ comment by Kshitij Sachan (kshitij-sachan) · 2023-08-15T20:16:01.496Z · LW(p) · GW(p)
It's possible that the model treats filler tokens differently in the "user" vs "assistant" part of the prompt, so they aren't identical. That being said, I chose to generate tokens rather than appending to the prompt because it's more superficially similar to chain of thought.
Also, adding a padding prefix to the original question wouldn't act as a filler token because the model can't attend to future tokens.
Replies from: dr_s↑ comment by dr_s · 2023-08-16T05:48:38.252Z · LW(p) · GW(p)
It could be prepended then, but also, does it make a difference? It won't attend to the filler while going over the question, but it will attend to the question while going over the filler. Also, how could it treat tokens differently? Wouldn't it need to be specially trained and have some additional input to do that? Or are you just thinking of the wrapper software doing something?
Replies from: kshitij-sachan↑ comment by Kshitij Sachan (kshitij-sachan) · 2023-08-16T16:52:17.737Z · LW(p) · GW(p)
It could be prepended then, but also, does it make a difference? It won't attend to the filler while going over the question, but it will attend to the question while going over the filler.
I think you're saying there should be no difference between "<filler><question>" and "<question><filler>". Your reasoning is: In the first layout the model attends to filler tokens while going over the question, and in the second the model attends to the question while going over the filler.
But the first layout doesn't actually get us anything: computation at the filler token positions can't use information from future token positions (i.e. the question). Thanks for asking this though, I hadn't actually explicitly thought through putting the filler before the question rather than after.
Also, how could it treat tokens differently? Wouldn't it need to be specially trained and have some additional input to do that? Or are you just thinking of the wrapper software doing something?
I'm not imagining any wrapper software, etc. I think this behavior could be an artifact of pretraining. Language models are trained to precompute features that are useful for predicting all future token positions, not just the immediate next token. This is because gradients flow from the current token being predicted to all previous token positions. (e.g. see How LLMs are and are not myopic [LW · GW])
comment by Herb Ingram · 2023-08-10T22:52:18.787Z · LW(p) · GW(p)
There has been some talk recently about long "filler-like" input (e.g. "a a a a a [...]") somewhat derailing GPT3&4, e.g. leading them to output what seems like random parts of it's training data. Maybe this effect is worth mentioning and thinking about when trying to use filler input for other purposes.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2023-08-11T00:55:20.309Z · LW(p) · GW(p)
My assumption is that GPT-4 has a repetition penalty, so if you make it predict all the same phrase over and over again, it puts almost all its probability on a token that the repetition penalty prevents it from saying, with the leftover probability acting similarly to a max entropy distribution over the rest of the vocab.
Replies from: dr_s, kshitij-sachan↑ comment by Kshitij Sachan (kshitij-sachan) · 2023-08-11T05:46:28.293Z · LW(p) · GW(p)
By repetition penalty do you mean an explicit logit bias when sampling or internally it's generalized to avoiding repeated tokens?