The Case for Radical Optimism about Interpretability
post by Quintin Pope (quintin-pope) · 2021-12-16T23:38:30.530Z · LW · GW · 16 commentsContents
1: Strong, interpretable systems are possible 2: Why does current interpretability lag? 3: Interpretability for current ML systems 4 Measuring/improving interpretability for current systems None 16 comments
Summary:
- I argue we can probably build ML systems that are both high-performance and much more interpretable than current systems.
- I discuss some reasons why current ML interpretability lags behind what should be possible.
- I highlight some interesting interpretability work on current systems.
- I propose a metric for estimating the interpretability of current systems and discuss how we might improve interpretability.
Definitional note: for this essay, "interpretable" serves as a catch-all for things like "we can abstractly understand the algorithms a system implements" and "we can modify internal states to usefully influence behavior in a predictable manner". Systems are more interpretable when it's easier to do things like that to them.
1: Strong, interpretable systems are possible
Imagine an alien gave you a collection of AI agents. The agents vary greatly in capability, from about as smart as a rat to human level (but not beyond). You don't know any details about the AI's internal algorithms, only that they use something sort of like neural nets. The alien follows completely inhuman design principles, and has put no effort whatsoever into making the AIs interpretable.
You are part of a larger community studying the alien AIs, and you have a few decades to tackle the problem. However, you operate under several additional constraints:
- Computation can run both forwards and backwards through the AIs (or in loops). I.e., there's no neat sequential dependency of future layers on past layers.
- Each AI is unique, and was individually trained on different datasets (which are now unavailable).
- The AIs are always running. You can't copy, backup, pause or re-run them on different inputs.
- Each AI is physically instantiated in its own hardware, with no pre-existing digital interface to their internal states.
- If you want access to internal states, you'll need to physically open the AIs up and insert electrodes directly into their hardware. This is delicate, and you also risk permanently breaking or damaging the AI with each "operation".
- Your electrodes are much larger than the AI circuits, so you can only ever get or influence a sort of average activation of the surrounding neurons/circuits.
- You are limited to 10 or fewer probe electrodes per AI.
- You are limited to the technology of the 1960s. This includes total ignorance of all advances in machine learning and statistics made since then.
Please take a moment to predict how far your interpretability research would progress.
Would you predict any of the following?
- That you'd be able to find locations in the AI's hardware which robustly correspond to the AI's internal reward signal.
- That these locations would be fairly consistent across different AIs.
- That running a current through these regions would directly increase the AIs' perceived reward.
- That the location of the electrodes would influence the nature and intensity of the reward-seeking behavior produced.
If you base your predictions on how little progress we've made in ML interpretability, these advances seem very unlikely, especially given the constraints described.
And yet, in 1953, James Olds and Peter Milner discovered that running a current through certain regions in rats' brains was rewarding and influenced their behavior. In 1963, Robert Heath showed similar results in humans. Brain reward stimulation works in every vertebrate so far tested. Since the 1960s, we've had more advances in brain interpretability:
- A recent paper was able to reversibly disable conditioned fear responses from mice.
- We’re able to cure some instances of treatment resistant depression by stimulating select neurons.
- We can (badly) reconstruct images from brain activity.
- fMRI-based lie detection techniques seem much more effective than I'd have expected (I'm very unsure about these results).
- Some studies claim accuracies as high as 90% in laboratory conditions (which I don't really believe). However, my prior expectation was that such approaches were completely useless. Anything over 60% would have surprised me.
- As far as I can tell, even relatively pessimistic studies report accuracies ~75% (review paper 1, review paper 2).
- A study using CNNs on EEG data reports 82% accuracy.
The lie detection research is particularly interesting to me, given its relation to detecting deception/misalignment in ML systems. I know that polygraphs are useless, but that lots of studies claim to show otherwise. I'm not very familiar with lie detection based on richer brain activity data such as fMRI, EEG, direct brain recordings, etc. If anyone is more familiar with this field and able to help, I'd be grateful, especially if they're able to point out some issue in the research I've linked above that reveals it to be much less impressive than it looks.
2: Why does current interpretability lag?
These brain interpretability results seem much more impressive to me than I'd have expected given how hard ML interpretability has been and the many additional challenges involved with studying brains. I can think of four explanations for such progress:
- Larger or more robust networks tend to be more interpretable.
- I think there’s some evidence for this in the “polysemantic” neurons OpenAI found in vision models. If you don’t have enough neurons to learn independent representations, you’ll need to compress different concepts into the same neurons/circuits, which makes things harder to interpret. Also, this sort of compression may cause the network issues if it has to process inputs with both concepts simultaneously. Thus, larger networks trained on a wider pool of data plausibly use fewer polysemantic neurons.
- The brain is more interpretable than an equivalently sized modern network.
- I think dropout is actually very bad for interpretability. Ideally, an interpretable network has a single neuron per layer that uniquely represents each human concept (trees, rocks, mountains, human values, etc). Networks with dropout can't allow this because then they'd completely forget 10% of those concepts whenever they process an input. The network would need to distribute the concept's representation across 3+ neurons at each layer to have a >= 99.9% chance of remembering the concept.
- Brains have very sparse connections between neurons compared to deep models. I think this forces them to learn sparser internal representations. Imagine a neuron, n, in layer k that needs access to a tree feature detector from the previous layer. If layer k-1 distributes its representation of trees across multiple neurons, n can still recover a pure tree representation thanks to the dense feed forward connection between the layers. Imagine now adding a regularization term to the training that forces neurons to make sparse connections with the previous layer. That would encourage the network to use a single neuron as its tree representation on layer k-1 because then neuron n could recover a pure tree representation with a single connection to layer k-1.
- The brain pays metabolic costs for longer running or overly widespread computations, so there's incentive to keep computations concentrated in space/time. The brain also has somewhat consistent(ish) regional specialization. Having a rough idea of what the neurons in a region are/aren't likely to be doing may help develop a more refined picture of the computations they're performing. I suspect neural architecture search may actually improve interpretability by allowing different network components to specialize in different types of problems.
- Biological neurons are more computationally sophisticated than artificial neurons. Maybe single biological neurons can represent more complex concepts. In contrast, an artificial network would need to distribute complex concepts across multiple neurons. Also, if you imagine each biological neuron as corresponding to a small, contained artificial neural network, that implies the brain is even more sparsely connected than we typically imagine.
- These brain interpretability results are much less impressive than they seem.
- This is likely part of the explanation. Doubtless, there's publication bias, cherry-picking and overselling of results. I'm also more familiar with the limitations of ML interpretability. Even so, if brain interpretability were as hard as ML interpretability, I think we'd see significantly less impressive results than we currently do.
- The news media are much more interested in brain interpretability results. Maybe that makes me more likely to learn about successes here than for ML interpretability (though I think this is unlikely, given my research focuses on ML interpretability).
- Neuroscience as a field has advantages ML interpretability doesn't.
- More total effort has gone into understanding the brain than into understanding deep networks. Maybe deep learning interpretability will improve as people become more familiar with the field?
- Neuroscience is also more focused on understanding the brain than ML is on understanding deep networks. Neuroscientists may be more likely to actually try to understand the brain, rather than preemptively giving up (as often happens in ML).
Evolution made no effort to ensure brains are interpretable. And yet, we've made startling progress in interpreting them. This suggests mind design space contains high-performance, very interpretable designs that are easily found. We should be able to do even better than evolution by explicitly aiming for interpretable systems.
3: Interpretability for current ML systems
There's a widely held preconception that deep learning systems are inherently uninterpretable. I think this belief is harmful because it provides people with an excuse for not doing the necessary interpretability legwork for new models and discourages people from investigating existing models.
I also think this belief is false (or at least exaggerated). It's important not to overstate the interpretability issues with current state of the art models. Even though the field has put roughly zero effort into making such models interpretable, we've still had some impressive progress in many areas.
- Convolutional Neural Networks
- I think many people here are already familiar with the circuits line of research at OpenAI. Though I think it's now mostly been abandoned, they made lots of interesting discoveries about the internal structures of CNN image models, such as where/how various concepts are represented, how different image features are identified and combined hierarchically, and the various algorithms implemented by model weights.
- Reinforcement Learning Agents
- Deep Mind recently published "Acquisition of Chess Knowledge in AlphaZero", studying how AlphaZero learns to play chess. They were able to identify where various human-interpretable chess concepts reside in the network as well as when the network discovers these concepts during its training.
- Transformer Language Models
- Transformer Feed-Forward Layers Are Key-Value Memories is somewhat like "circuits for transformers". It shows that attention outputs act as "keys" which search for syntactic or semantic patterns in the inputs. Then, the feed forward layer's "values" are triggered by particular keys and focus probability mass on tokens that tend to appear after the patterns that the keys detect. The paper also explores how the different layers interact with each other and the residuals to collectively update the probability distribution over the predicted token.
- Knowledge Neurons in Pretrained Transformers is able to identify particular neurons whose activations correspond to human-interpretable knowledge such as "Paris is the capital of France". The authors can partially suppress or amplify the influence such knowledge neurons have on the model's output by changing the activations of those neurons. Additionally, they can modify the knowledge in question by changing the values of the feed forward layer. E.g., make a model think "London is the capital of France".
4 Measuring/improving interpretability for current systems
Knowledge Neurons in Pretrained Transformers is particularly interesting because they present something like a metric for interpretability. Figure 3 shows the relative change in probability mass assigned to correct answers after using interpretability tools to suppress the associated knowledge (similarly, Figure 4 shows the effects of amplifying knowledge).
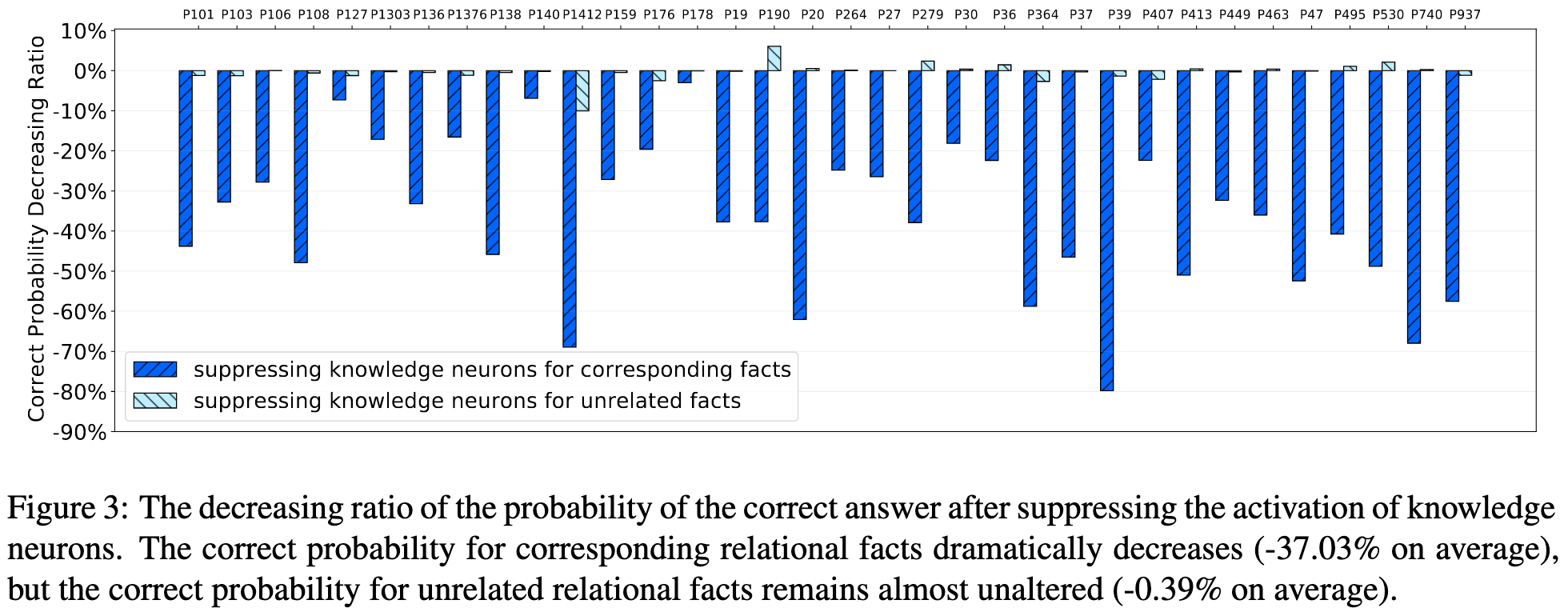
We could use the average of these suppression ratios as a measure for interpretability (more precisely, amenability to current interpretability techniques). Then, we could repeatedly retrain the language model with different architectures, hyper parameters, regularizers, etc, and test their effects on the model's "suppressability".
We can also test interventions aimed explicitly at improving interpretability. For example, we could compute the correlations between neuron activations, then include a term in the training loss that encourages sparse correlations. Ideally, this prompts the model to forms small, sparsely connected internal circuitry. However, it could also prompt the neurons to have more complex, second order relationships that the correlation term doesn't penalize.
Furthermore, suppressability is (as far as I can tell), a differentiable metric. It uses model gradients to attribute predictions to particular neurons, then suppresses the neurons with highest attribution for a given prediction. We can use meta-gradients to get the gradients of the attributions, then try to maximize the difference between the suppressed and normal model outputs as our suppressability training objective.
This will hopefully encourage the model to put maximum attribution on the neurons most responsible for particular pieces of knowledge, making the network more interpretable. In an ideal world, the network will also make more of its internal computation legible to the suppression technique because doing so allows the suppression technique to have a greater impact on model outputs. Of course, explicitly training for this interpretability metric may cause the network to Goodhart the metric. Ideally, we'd have additional, independent interpretability metrics to compare against.
Running interpretability experiments would also allow us to explore possible tradeoffs between interpretability and performance. I think we'll find there's a lot of room to improve interpretability with minimal performance loss. Take dropout for example: "The Implicit and Explicit Regularization Effects of Dropout" disentangles the different regularization benefits dropout provides and shows we can recover dropout's contributions by adding a regularization term to the loss and noise to the gradient updates.
We currently put very little effort into making state of the art systems interpretable. It's often possible to make large strides in under-researched areas. The surprising ease of brain interpretability suggests there are accessible ML approaches with high performance which are more interpretable than the current state of the art. Since we actually want interpretable systems, we should be able to do better still. Surely we can beat evolution at a goal it wasn't even trying to achieve?
16 comments
Comments sorted by top scores.
comment by Steven Byrnes (steve2152) · 2021-12-17T22:04:42.313Z · LW(p) · GW(p)
I want to draw a distinction between two things:
- What I call "ersatz interpretability" is when the human figures out some "clues" about what the trained model is doing, like "right now it's a safe bet that the AI thinks there’s a curve in the picture" or "right now the AI is probably thinking a thought that it believes is high-reward".
- What I call "real interpretability" is the ultimate goal of really understanding what a trained model is doing, why, and how, from top to bottom.
I'm optimistic that we'll get more than zero out of ersatz interpretability, even as we scale to superintelligent AGI. As you point out, in model-based RL, just looking at the value function gives some nice information about how the AI is assessing its own prospects. That's trivial, and useful, I seem to recall that in the movie about AlphaGo, the DeepMind engineers were watching AlphaGo's value function to see whether it expected to win or lose.
Or if we want a strong but imperfect hint that our fancy AI is thinking about blueberries, we can just train a classifier to look at the whole array of network activations, where the supervisory signal is a simple ConvNet blueberry classifier with the same field-of-view as the fancy AI. It won't be perfect—maybe the AI is imagining blueberries without looking at them or whatever. But it won't be totally useless either. In fact I'm an advocate for literally having one such classifier for every word in the dictionary, at minimum. (See here [LW · GW], here [LW · GW] (search for the words "more dakka"), and more discussion in a forthcoming post.)
At the same time, I'm somewhat pessimistic about "real interpretability", or at least I'm concerned that it will hit a wall at some point. There are concepts in Ed Witten's head when he thinks about string theory that I'm just not going to be able to really understand, beyond "this concept has something vaguely to do with this other concept which has something vaguely to do with axions" or whatever.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2021-12-18T01:04:44.827Z · LW(p) · GW(p)
I think real and ersatz interpretability represent different points on a spectrum, representing different levels of completeness. Each model has a huge collection of factors that decide its behavior. Better explanations abstract away more of those factors in a way humans can understand and use to accurately predict model behavior. Worse explanations cover fewer factors and are less able to reliably predict model behavior.
I’m relatively optimistic about how far we can get with real interpretability. Much of that comes from thinking that we can get pretty far with approaches we currently consider extreme. E.g., I think we can do something like knowledge distillation from AIs to humans by feeding AI internal activations to human brains through channels with wider bandwidth than visual senses. I.e., either through the peripheral nervous system or (more riskily) directly via brain machine interface. So if you have an unknowable concept in an AI, you can target the knowledge distillation process at the concept and learn appropriate intuitions for representing and integrating the concept directly from the AI’s own representations.
I intend to further explore ideas in this space in a future post. Probably, I’ll title it “The case for optimism about radical interpretability”.
Replies from: bayesian_kitten↑ comment by bayesian_kitten · 2021-12-18T14:37:08.801Z · LW(p) · GW(p)
Am I correct in thinking the 'ersatz' and 'real' interpretability might differ in aspects more than just degree of interpretability-- Ersatz is somewhat embedded in explaining the typically case, whereas 'real interpretability' gives good reasoning eve in the worst-case. Interpretability might be hard to achieve in worst-case scenarios where some atypical wiring leads to wrong decisions?
Furthermore, I suspect confusing transparency for interpretability. Even if we understand what each-and-every-neuron does (radical transparency), it might not be interpretable if it seems gibberish.
If it seems correct so far, I elaborate on these here [LW · GW].
↑ comment by Steven Byrnes (steve2152) · 2021-12-19T23:41:44.945Z · LW(p) · GW(p)
Newbie question: What's the difference between transparency and interpretability? Follow-up question: Does everyone agree with that answer or is it not standardized?
Replies from: bayesian_kitten↑ comment by bayesian_kitten · 2021-12-20T18:11:30.520Z · LW(p) · GW(p)
They're likely to be interchangeable, sorry. Here I might've misused the words to try tease out the difference that simply understanding how a given model works is not really insightful if the patterns are not understandable.
I think there are these nonsensical-seeming-patterns to humans might be a significant fraction of the learned patterns by deep networks. I was trying to understand the radical optimism, in contrast to my pessimism given this. The crux being since we don't know what these patterns are and what they represent, even if we figure out what neurons detect them and which tasks they contribute most to, might not be able to do downstream tasks we require transparency for, like diagnose possible issues and provide solutions.
↑ comment by Quintin Pope (quintin-pope) · 2021-12-18T21:26:43.438Z · LW(p) · GW(p)
I think you're pointing to a special case of a more general pattern.
Just like there's a general factor of "athletic ability" which can be subdivided into many correlated components, I think "interpretability" can be split into many correlated components. Some of those components correspond to greater reliability in the worst case scenarios. Others might correspond to, e.g., predicting which architectural modifications would improve performance on typical input.
Worst case reliability is probably the most important component to interpretability, but I'm not sure it makes sense to call it "real interpretability". It's probably better to just call it "worst case" interpretability.
comment by Charlie Steiner · 2021-12-18T03:08:05.507Z · LW(p) · GW(p)
I like your reservations (which I think are well-written, sensible, and comprehensive) more than your optimism. The wireheading example is a good illustration of a place where we can find something coarse-grained in the brain that almost matches a natural human concept, but not quite, and the caveats there would be disastrous to ignore if trying to put load-bearing trust in interpreting superhuman AI.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2021-12-18T04:19:03.394Z · LW(p) · GW(p)
The point of the wireheading example is that, in order for investigators in the 1960s to succeed that much, the brain must be MUCH more interpretable than current artificial neural networks. We should be able to make networks that are even more interpretable than the brain, and we should have much better interpretability techniques than neuroscientists from the 1960s.
My argument isn't "we can effectively adapt neuroscience interpretability to current ML systems". It's "The brain's high level interpretability suggests we can greatly improve the interpretability of current ML systems".
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2021-12-18T14:22:14.082Z · LW(p) · GW(p)
Sure. In fact, if you just want to make ML models as interpretable as humans, almost all of what I labeled "reservations" are in fact reasons for optimism. My take is colored by thinking about using this for AI alignment, which is a pretty hard problem. (To restate: you're right, and the rest of this comment is about why I'm still pessimistic about a related thing.)
It's kinda like realizability vs. non-realizability in ML. If you have 10 humans and 1 is aligned with your values and 9 are bad in normal human ways, you can probably use human-interpretability tools to figure out who is who (give them the Voight-Kampff test). If you have 10 humans and they're all unaligned, the feedback from interpretability tools will only sometimes help you modify their brains so that they're aligned with you, even if we imagine a neurosurgeon who could move individual neurons around. And if you try, I expect you'd end up with humans that are all bad but in weird ways.
What this means for AI alignment depends on the story you imagine us acting out. In my mainline story we're not going to be in a situation where we need to building AIs that have some moderate chance of turning out to be aligned (and we then need to interpret their motivations to tell). We're either be going to be building AIs with a high chance of alignment or a very low chance, and we don't get much of a mulligan.
comment by Primer (primer) · 2021-12-18T20:40:33.953Z · LW(p) · GW(p)
When interpreting human brains, we get plenty of excellent feedback. Calibrating a lie detector might be as easy as telling a few truths and a few lies while in an fMRI.
To be able to use similar approaches for interpreting AIs, it might be necessary to somehow get similar levels of feedback from the AIs. I notice I don't have the slightest idea whether feedback from an AI was a few orders of magnitude harder to get - compared to getting human feedback - or whether it would be a few orders of magnitude easier or about the same.
Can we instruct GPT-3 to "consciously lie" to us?
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2021-12-18T21:29:59.632Z · LW(p) · GW(p)
My guess is the initial steps of getting the models to lie reliably are orders of magnitude harder than just asking a human to lie to you. Once you know how to prompt models into lying, it's orders of magnitude easier to generate lots of lie data from the models.
comment by [deleted] · 2021-12-17T10:18:17.555Z · LW(p) · GW(p)
I think many people here are already familiar with the circuits line of research at OpenAI. Though I think it's now mostly been abandoned
I wasn’t aware that the circuits approached was abandoned. Do you know why they abandoned it?
Replies from: Frederik↑ comment by Tom Lieberum (Frederik) · 2021-12-18T08:46:04.343Z · LW(p) · GW(p)
I can only speculate, but the main researchers are now working on other stuff, like e.g. Anthropic. As to why they switched, I don't know. Maybe they were not making progress fast enough or Anthropic's mission seemed more important?
However, at least Chris Olah believes this is still a tractable and important direction, see the recent RFP by him for Open Phil [LW · GW].
comment by Evan R. Murphy · 2022-12-16T00:17:19.369Z · LW(p) · GW(p)
I spent a few months in late 2021/early 2022 learning about various alignment research directions and trying to evaluate them. Quintin's thoughtful comparison between interpretability and 1960s neuroscience in this post convinced me of the strong potential for interpretability research more than I think anything else I encountered at that time.
comment by Bunthut · 2021-12-22T22:22:05.414Z · LW(p) · GW(p)
I don't think the analogy to biological brains is quite as strong. For example, biological brains need to be "robust" not only to variations in the input, but also in a literal sense, to forceful impact or to parasites trying to control it. It intentionally has very bad suppressability, and this means there needs to be a lot of redundancy, which makes "just stick an electrode in that area" work. More generally, it is under many constraints that a ML system isn't, probably too many for us to think of, and it generally prioritizes safety over performance. Both lead away from the sort of maximally efficient compression that makes ML systems hard to interpret.
Analogously: Imagine a programmer would write the shortest program that does a given task. That would be terrible. It would be impossible to change anything without essentially redesigning everything, and trying to understand what it does just from reading the code would be very hard, and giving a compressed explanation of how it does that would be impossible. In practice, we don't write code like that, because we face constraints like those mentioned above - but its very easy to imagine that some optimization-based "automatic coder" would program like that. Indeed, on the occasion that we need to really optimize runtimes, we move in that direction ourselves.
So I don't think brains tell us much about the interpretability of the standard, highly optimized neural nets.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2021-12-24T02:46:45.898Z · LW(p) · GW(p)
Firstly, thank you for your comment. I'm always glad to have good faith engagement on this topic.
However, I think you're assuming the worst case scenario in regards to interpretability.
biological brains need to be "robust" not only to variations in the input, but also in a literal sense, to forceful impact
Artificial networks are often trained with randomness applied to their internal states (dropout, gradient noise, etc). These seem like they'd cause more internal disruption (and are FAR more common) than occasional impacts.
or to parasites trying to control it
Evolved resistance to parasite control seems like it should decrease interpretability, if anything. E.g., having multiple reward centers that are easily activated is a terrible idea for resisting parasite control. And yet, the brain does it anyways.
It intentionally has very bad suppressability
No it doesn't. One of my own examples of brain interpretability was:
A recent paper was able to reversibly disable conditioned fear responses from mice.
Which is a type of suppressability. Various forms of amnesia, aphasia and other perceptual blocks are other examples of suppressability in one form or another.
it generally prioritizes safety over performance
So more reliable ML systems will be more interpretable? Seems like a reason for optimism.
Imagine a programmer would write the shortest program that does a given task. That would be terrible. It would be impossible to change anything without essentially redesigning everything
Yes, it would be terrible. I think you've identified a major reason why larger neural nets learn more quickly than smaller nets. The entire point of training neural nets is that you constantly change each part of the net to better process the data. The internal representations of different circuits have to be flexible, robust and mutually interpretable to other circuits. Otherwise, the circuits won't be able to co-develop quickly.
One part of Knowledge Neurons in Pretrained Transformers I didn't include (but probably should have) is the fact that transformers re-use their input embedding in their internal knowledge representations. I.e., the feed forward layers that push the network to output target tokens represent their target token using the input embeddings of the target tokens in question. This would be very surprising if you thought that the network was just trying to represent its internal states using the shortest possible encoding. However, it's very much what you'd expect if you thought the internal representations needed to be easily legible across many different parts of the network.
I'll present a more extensive exploration of the "inner interpretability problem" in a future post arguing that there are deep theoretical reasons why easy to optimize systems also tend to be interpretable, and that highly optimized neural nets will learn to make themselves more interpretable.