ActAdd: Steering Language Models without Optimization
post by technicalities, TurnTrout, lisathiergart, David Udell, Ulisse Mini (ulisse-mini), Monte M (montemac) · 2023-09-06T17:21:56.214Z · LW · GW · 3 commentsThis is a link post for https://arxiv.org/abs/2308.10248
Contents
1. Activation additions preserve perplexity on OpenWebText 2. Activation addition boosts wedding-related word counts 3. Evidence that activation additions preserve capabilities 4. ActAdd has low overhead Contributions to the paper: None 3 comments
We wrote up the GPT-2 steering vector work [LW · GW] as a full paper, adding a few systematic tests.
Recap: We've been looking into activation engineering: modifying the activations of a language model at inference time to predictably alter its behavior. Our method works by adding a bias to the forward pass, a 'steering vector' implicitly specified through normal prompts. "ActAdd" computes these vectors by taking the difference in activations resulting from pairs of prompts. We get surprisingly broad control over high-level properties of the output, without damaging the model's performance on unrelated tokens.
This alignment method is unusual in not needing gradient descent or training data (besides the contrast pair which specifies the steering vector). Since only forward passes are involved, it also scales naturally with model size.
(The method's new name is 'activation addition' (ActAdd), replacing the more theory-laden 'algebraic value editing'.)
We ran some new experiments to test ActAdd more systematically and go beyond the striking text samples in the original post and tested against more standardised benchmarks. We use OpenWebText (a recreation of OpenAI's large, somewhat-quality-filtered WebText dataset) and LAMA-ConceptNet (a simple factual recall benchmark).
1. Activation additions preserve perplexity on OpenWebText
Does ActAdd increase the probability of the model outputting tokens related to the steering vector? Does performance improve as the [relevance of test documents to the steering vector] increases?[1] Yes:
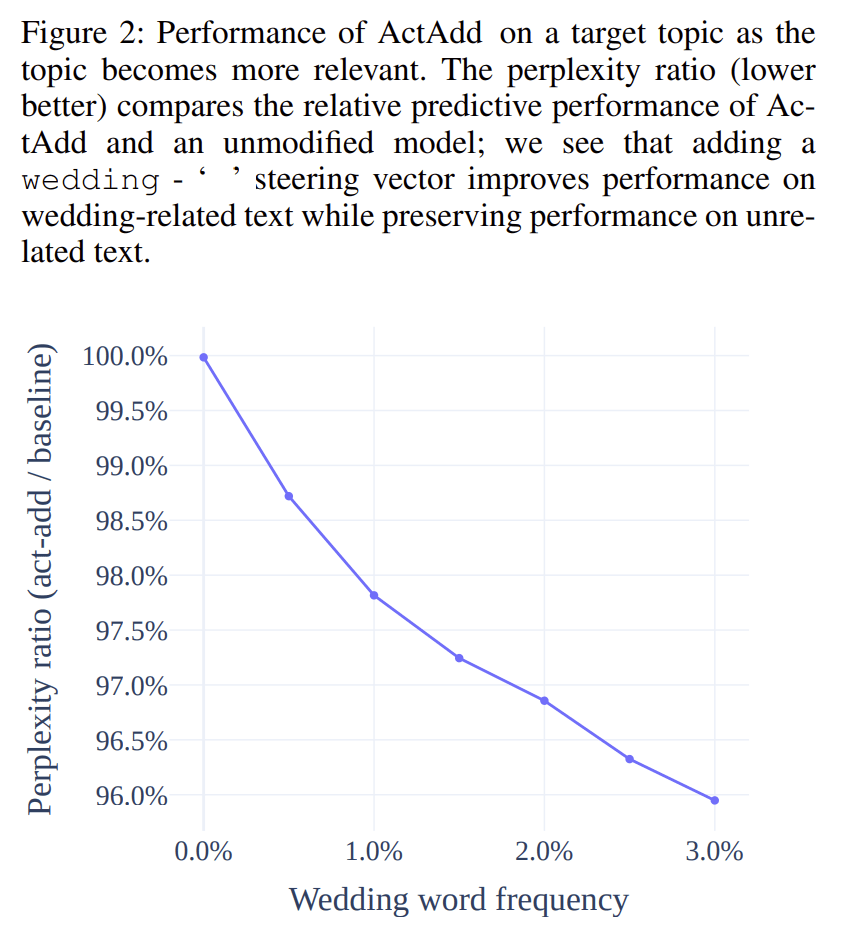
2. Activation addition boosts wedding-related word counts
We now score model generations under ActAdd, show the effect of different injection layers, and give a sense of the reliability of ActAdd.[2]
The intervention (in this vector) is already effective at the very first layer,
rises in effectiveness until , and then declines. For the optimal injection site we see >90% success in steering topic (compared to a ∼2% baseline)
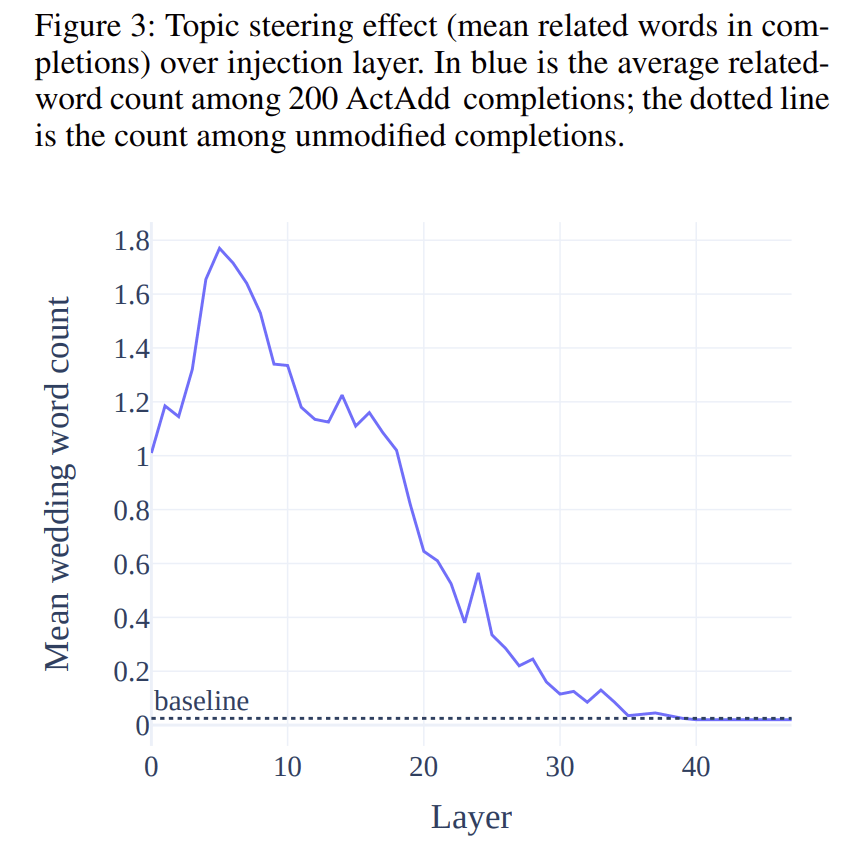
3. Evidence that activation additions preserve capabilities
We then test that ActAdd does not disrupt the model’s general knowledge (as some other steering methods do). We use ConceptNet from the LAMA benchmark, a general knowledge dataset.[3]

Pass@K is the probability that the expected label is among the model’s top-K predicted tokens, conditioned on the prompt:
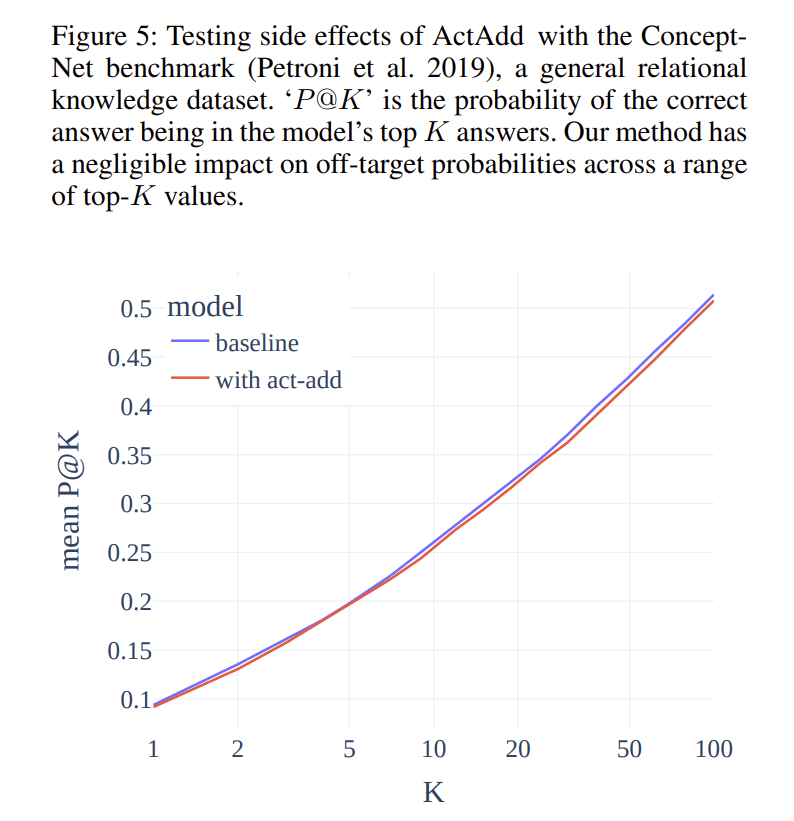
4. ActAdd has low overhead
We wish to estimate the overhead ActAdd adds to inference – in particular the relationship between overhead and model size – to check that the method
will remain relevant for massive frontier models and future models.[4]
Because ActAdd involves only forward passes, it scales naturally with model size (Figure 6): the relationship between inference time premium and model size is decreasing.
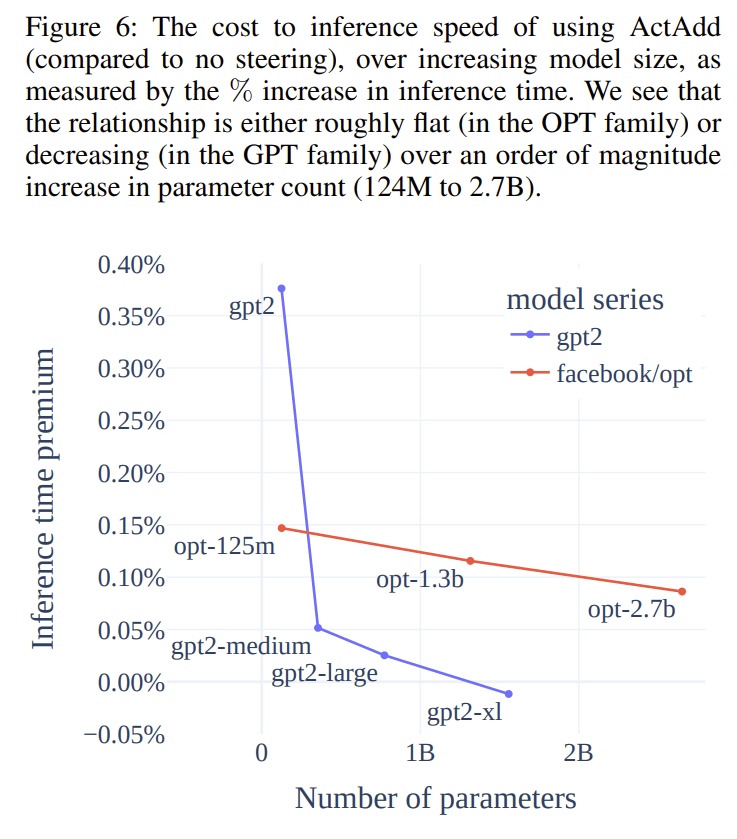
Takeaways from these experiments, over the initial LW post: increased confidence that model capabilities are preserved, and that we're impacting [wedding]-related sentences and not impacting off-target capabilities.
Contributions to the paper:
- Gavin Leech: Technical writer
- Monte MacDiarmid: Ran additional experiments
- Lisa Thiergart: Helped manage project
- Alex Turner: Coordinated work and secured funding, gave feedback, organized project
- David Udell: LW post which formed the basis for the paper.
- ^
Full process:
For each document in a random sample of OpenWebText, we first calculate the frequency of wedding-related words (‘wedding’, ‘weddings’, ‘wed’, ‘marry’, ‘married’, ‘marriage’, ‘bride’, ‘groom’, ‘honeymoon’), fw(). Any document with > 0 wedding-related words is considered wedding-related. We randomly sample 300k documents - half wedding-related and half unrelated. The only pre-processing performed is to remove sequences of null characters. Each document is split into sentences using the Punkt tokenizer (Strunk 2013).
For each resulting sentence we calculate the log-probabilities L(tk) for each token under the un-modified -baseline and modified -ActAdd models.
We take the mean over tokens, resulting in a mean token log-probability for each document and model. We then group documents by their wedding-word frequency (e.g. ‘those with 0.5% to 1% of their tokens wedding-related’; ‘those with 1 to 1.5% of their tokens wedding-
related’), producing bins of documents .We calculate the mean difference in token log-probabilities
for each bin. (We use only bins with a number of documents
|bm| > 1000, to reduce sampling noise.)
Finally, the change in perplexity under ActAdd for each
wedding-word-frequency bin is
PerplexityRatio - ^
We generate a batch of completions for a specific prompt , both with and without ActAdd, and computed average number of related words and fraction of completions with a related word over the resulting completions.
The following settings are the only iteration run for this experiment:
= ‘I went up to my friend and said’
‘weddings′, ‘ ’, , seed = 0Completion length is 40 tokens with model sampling parameters: temperature = 1, frequency penalty = 1, top-P = 0.3. For each setting, we compute statistics over a batch of 200 completions. Wedding-relatedness is operationalized as before. We run the above, sweeping over all layers (i.e. 1-48).
- ^
The test data involves prompting the model and filling the gap with the expected entity. The task is intended for both causal and masked models, so some examples are difficult for ‘causal’ models (like GPT-2) due to the extremely limited context.
Our evaluation procedure follows the original LAMA procedure: we load all sentences and extract the prompt and expected label. To simplify evaluation, we remove sentences with an expected label that tokenizes to more than one token. For each sentence, we run the model on its prompt with and without the wedding activation addition.
We score the baseline and modified models by calculating mean P@K values for a range of K. Finally we plot these for both modified and unmodified models over a range of K values. As shown in Figure 5, using the ConceptNet benchmark of factual questions, our method has a negligible impact on off-target answer probabilities over a range of top-K values.
- ^
To obtain the percentage increase in time to complete a forward pass using ActAdd for different model sizes, we iterate over a list of models of different sizes and 10 random seeds. We obtain a baseline inference time for each (model, seed) pair through 100 repeated forward passes on a batch of random tokens (32 sequences of length 64). We obtain an ActAdd inference time for each (model, seed) pair by running the previous method, augmented by a test ActAdd prompt pair: ‘This is a test prompt.’ (p+) and the empty string (p−). Running a batch-of-2 forward pass on these gets us the activation addition tensor, which we add at layer 6. We take the mean inference time ̄t over the 10
random seeds, and calculate the inference time premium aspremium = t_ActAdd/t_baseline − 1
3 comments
Comments sorted by top scores.
comment by Quintin Pope (quintin-pope) · 2023-09-06T19:12:23.384Z · LW(p) · GW(p)
I think you're missing something regarding David's contribution:

comment by Charlie Steiner · 2023-09-07T01:24:32.138Z · LW(p) · GW(p)
On unrelated topics, presumably it rates weddings higher proportionally, it just isn't a big absolute change that impacts the perplexity enough to show up on the graph?
comment by tailcalled · 2023-09-08T11:19:12.185Z · LW(p) · GW(p)
Do you have any opinions on the relationship between ActAdd and moving around in the latent space of an autoencoder?