Posts
Comments
You decide what is a win or not. If you're spiraling give yourself wins for getting out of bed, going outside, etc. Morale compounds and you'll get out of it. This is the biggest thing to do imo. Lower your "standards" temporarily. What we reward ourselves for is a tool to be productive, not an objective measure for how much we did that needs to stay fixed.
I think asking people like Daniel Ingram, Frank Yang, Nick Cammeratta, Shinzen Young, Roger Thisdell, etc. on how they experience pain post awakening is much more productive than debating 2500 year old teachings which have been (mis)translated many times.
Answering my own question, a list of theories I have yet to study that may yield significant insight:
- Theory of Heavy-Tailed Self-Regularization (https://weightwatcher.ai/)
- Singular learning theory
- Neural tangent kernels et. al. (deep learning theory book)
- Information theory of deep learning
I wasn't in a flaming asshole mood, it was a deliberate choice. I think being mean is necessary to accurately communicate vibes & feelings here, I could serialize stuff as "I'm feeling XYZ and think this makes people feel ABC" but this level of serialization won't activate people's mirror neurons & have them actually internalize anything.
Unsure if this worked, it definitely increased controversy & engagement but that wasn't my goal. The goal was to shock one or two people out of bad patterns.
Sorry, I was more criticizing a pattern I see in the community rather than you specifically
However, basically everyone I know who takes innate intelligence as "real and important" is dumber for it. It is very liable to mode collapse into fixed mindsets, and I've seen this (imo) happen a lot in the rat community.
(When trying to criticize a vibe / communicate a feeling it's more easily done with extreme language, serializing loses information. sorry.)
EDIT: I think this comment was overly harsh, leaving it below for reference. The harsh tone was contributed from being slightly burnt out from feeling like many people in EA were viewing me as their potential ender wiggin, and internalizing it.[1]
The people who suggest schemes like what I'm criticizing are all great people who are genuinely trying to help, and likely are.
Sometimes being a child in the machine can be hard though, and while I think I was ~mature and emotionally robust enough to take the world on my shoulders, many others (including adults) aren't.
An entire school system (or at least an entire network of universities, with university-level funding) focused on Sequences-style rationality in general and AI alignment in particular.
[...]
Genetic engineering, focused-training-from-a-young-age, or other extreme "talent development" setups.
Please stop being a fucking coward speculating on the internet about how child soldiers could solve your problems for you. Enders game is fiction, it would not work in reality, and that isn't even considering the negative effects on the kids. You aren't smart enough for galaxy brained plans like this to cause anything other than disaster.
In general rationalists need to get over their fetish for innate intelligence and actually do something instead of making excuses all day. I've mingled with good alignment researchers, they aren't supergeniuses, but they did actually try.
(This whole comment applies to Rationalists generally, not just the OP.)
I should clarify this mostly wasn't stuff the atlas program contributed to. Most of the damage was done from my personality + heroic responsibility in rat fiction + dark arts of rationality + death with dignity post. Nor did atlas staff do much to extenuate this, seeing myself as one of the best they could find was most of it, cementing the deep "no one will save you or those you love" feeling. ↩︎
Excited to see what comes out of this. I do want to raise attention to this failure mode covered in the sequences. however. I'd love for those who do the program try to bind their results to reality in some way, ideally having a concrete result of how they're substantively stronger afterwards, and how this replicated with other participants who did the training.
Really nice post. One thing I'm curious about is this line:
This provides some intuitions about what sort of predictor you'd need to get a non-delusional agent - for instance, it should be possible if you simulate the agent's entire boundary.
I don't see the connection here? Haven't read the paper though.
Quick thoughts on creating a anti-human chess engine.
- Use maiachess to get a probability distribution over opponent moves based on their ELO. for extra credit fine-tune on that specific player's past games.
- Compute expectiminimax search over maia predictions. Bottom out with stockfish value when going deeper becomes impractical. (For MVP bottom out with stockfish after a couple ply, no need to be fancy.) Also note: We want to maximize (P(win)) not centipawn advantage.
- For extra credit, tune hyperparameters via self-play against maia (simulated human). Use lichess players as a validation set.
- ???
- Profit.
This might actually be a case where a chess GM would outperform an AI: they can think psychologically, so they can deliberately pick traps and positions that they know I would have difficulty with.
Emphasis needed. I expect a GM to beat you down a rook every time, and down a queen most times.
Stockfish assumes you will make optimal moves in planning and so plays defensive when down pieces, but an AI optimized to trick humans (i.e. allowing suboptimal play when humans are likely to make a mistake) would do far better. You could probably build this with maiachess, I recall seeing someone build something like this though I can't find the link right now.
Put another way, all the experiments you do are making a significant type error, Stockfish down a rook against a worse opponent does not play remotely like a GM down a rook. I would lose to a GM every time, I would beat Stockfish most times.
Haha nice work! I'm impressed you got TransformerLens working on Colab, I underestimated how much CPU ram they had. I would have shared a link to my notebook & Colab but figured it might be good to keep under the radar so people could preregister predictions.
Maybe the knowledge that you're hot on my heels will make me finish the LLAMAs post faster now ;)
From my perspective 9 (scaling fast) makes perfect sense since Conjecture is aiming to stay "slightly behind state of the art", and that requires engineering power.
Added italics. For the next post I'll break up the abstract into smaller paragraphs and/or make a TL;DR.
Copied it from the paper. I could break it down into several paragraphs but I figured bolding the important bits was easier. Might break up abstracts in future linkposts.
Yeah, assuming by "not important" you mean "not relevant" (low attention score)
Was considering saving this for a followup post but it's relatively self-contained, so here we go.
Why are huge coefficients sometimes okay? Let's start by looking at norms per position after injecting a large vector at position 20.
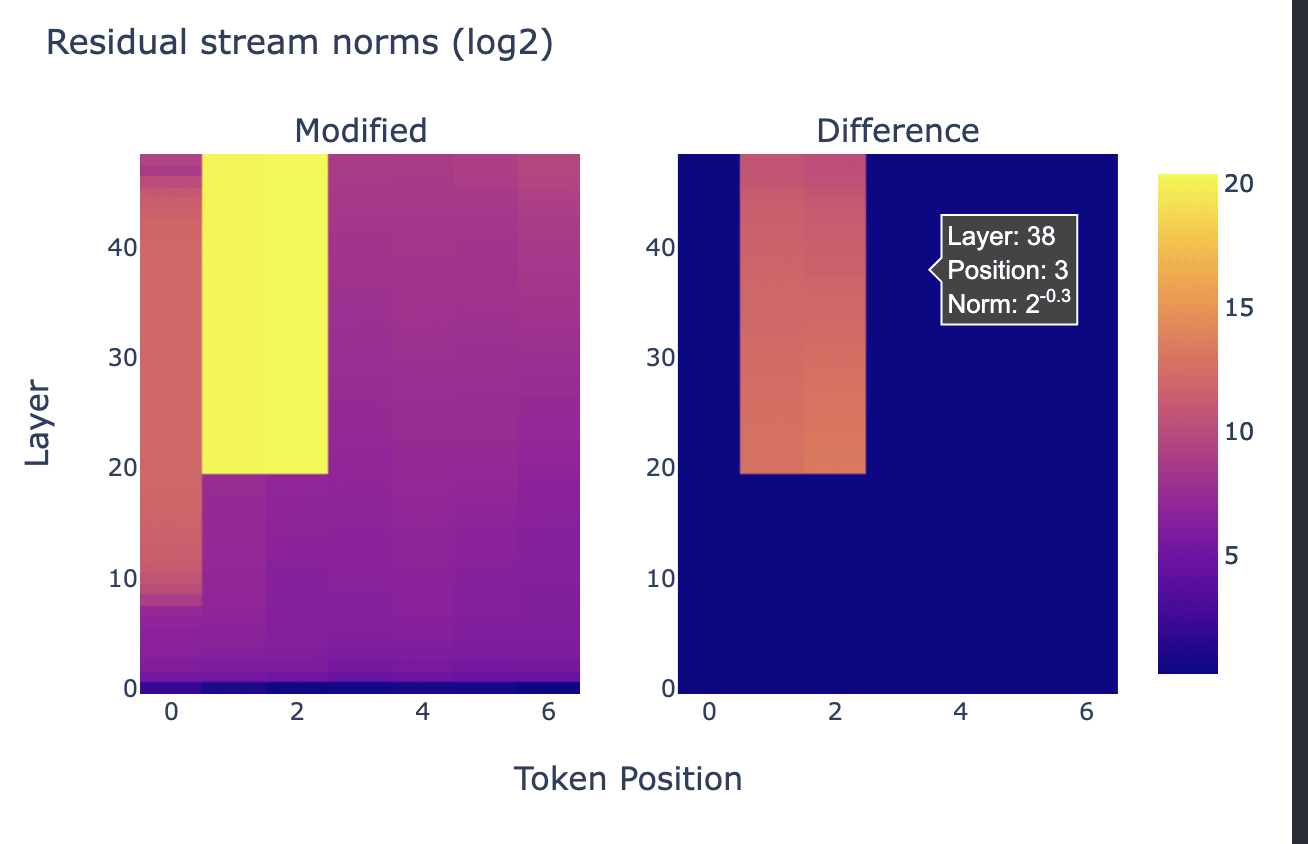
This graph is explained by LayerNorm. Before using the residual stream we perform a LayerNorm
# transformer block forward() in GPT2
x = x + self.attn(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))If x has very large magnitude, then the block doesn't change it much relative to its magnitude. Additionally, attention is ran on the normalized x meaning only the "unscaled" version of x is moved between positions.
As expected, we see a convergence in probability along each token position when we look with the tuned lens.
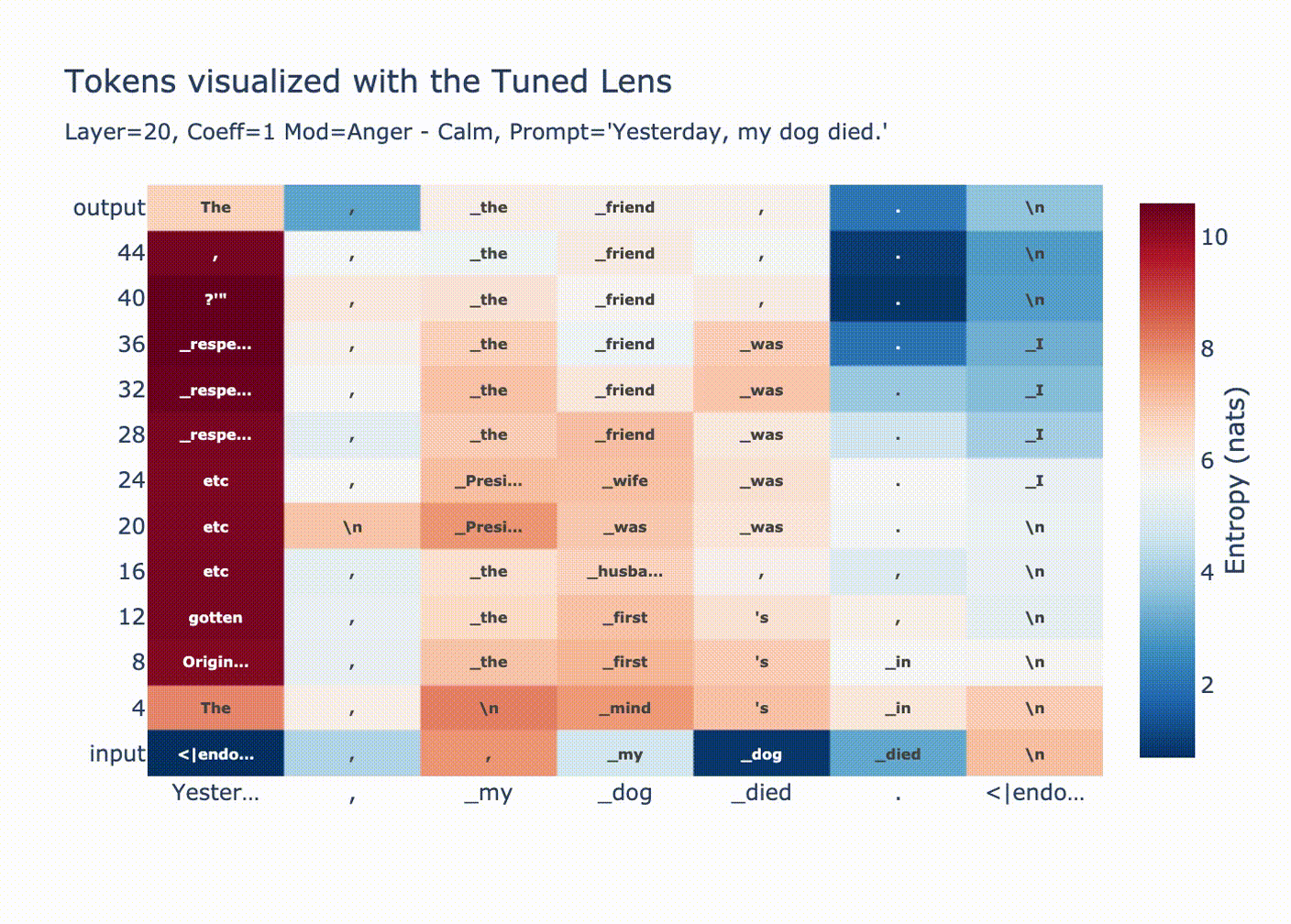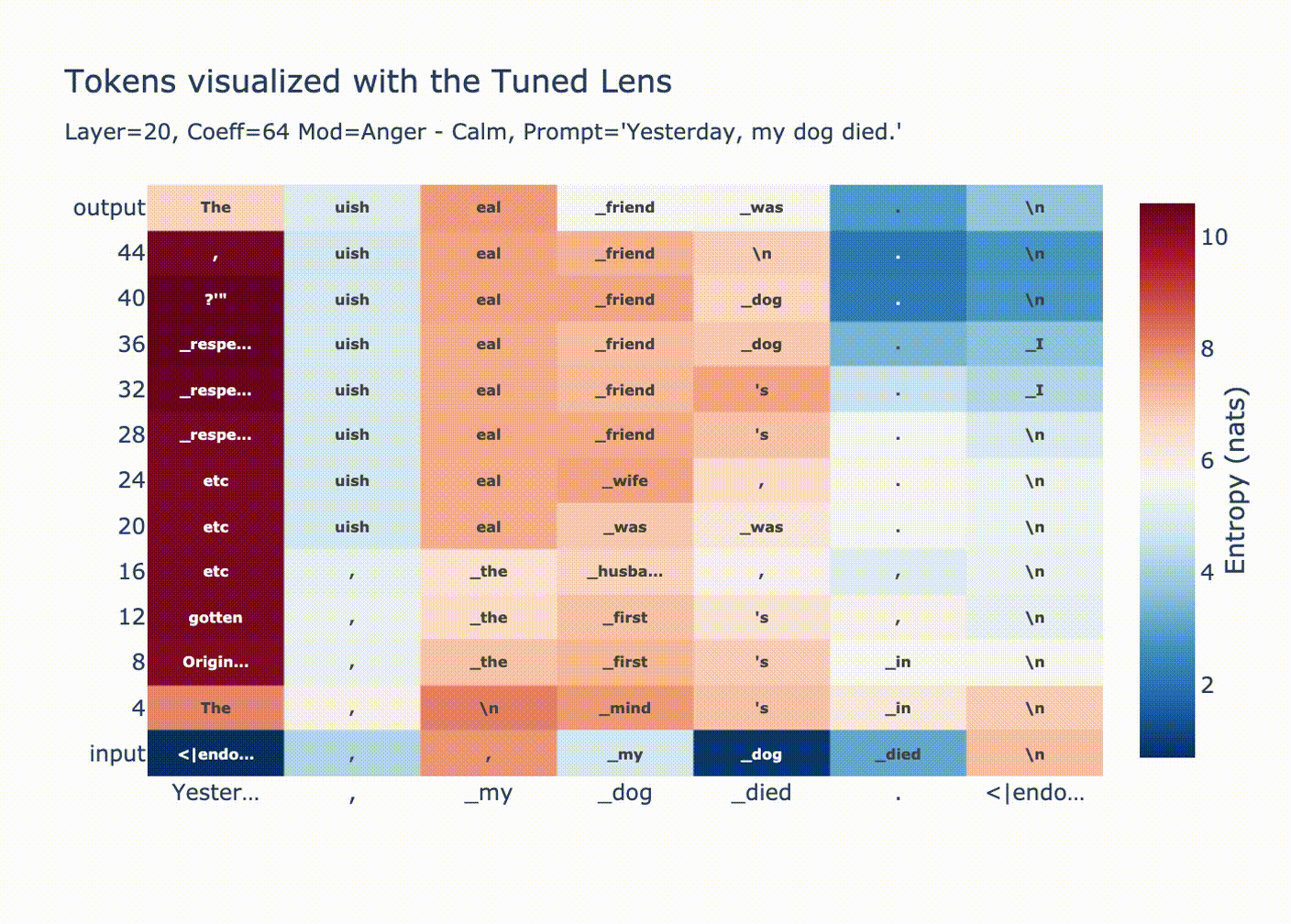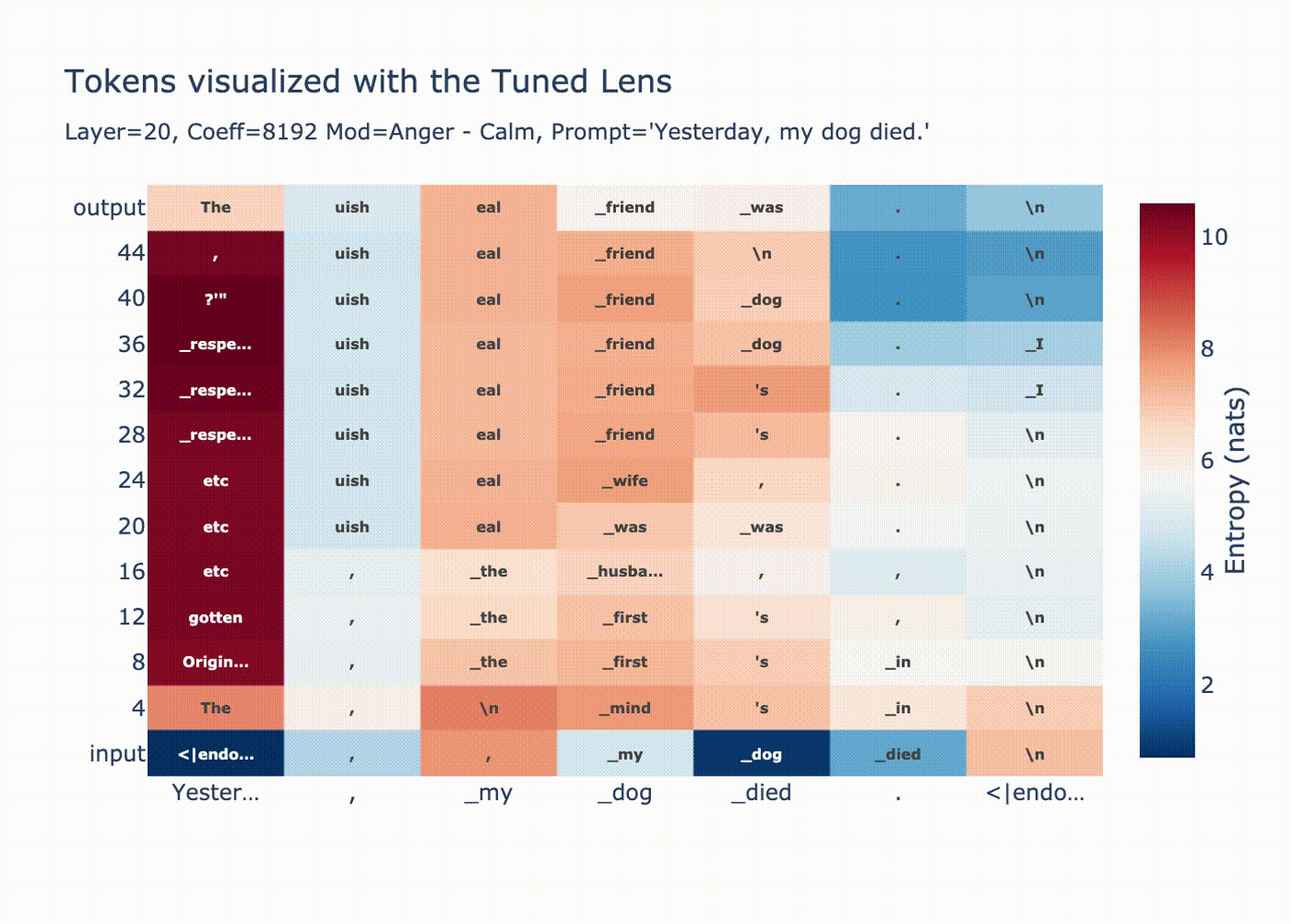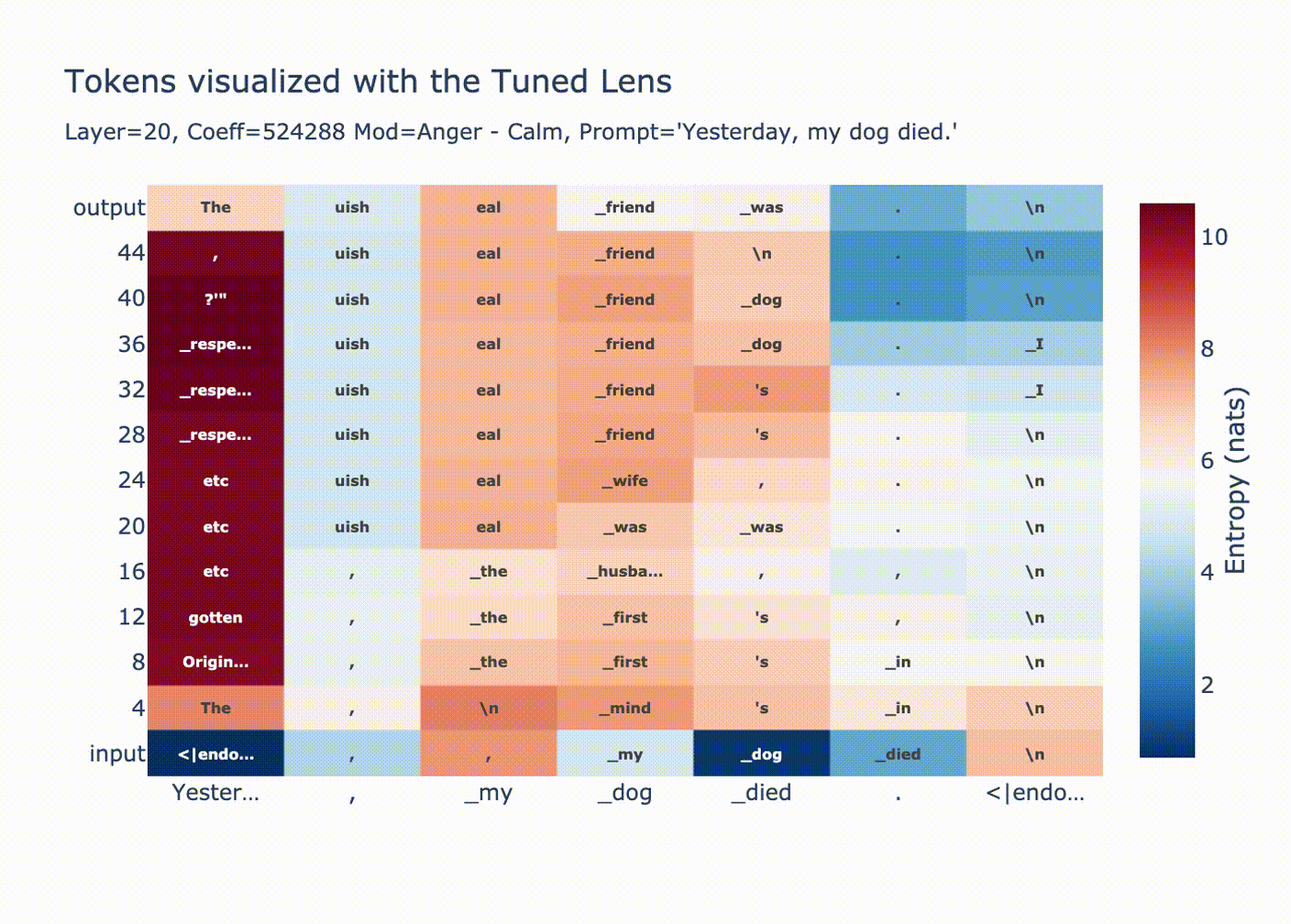
You can see how for positions 1 & 2 the output distribution is decided at layer 20, since we overwrote the residual stream with a huge coefficient all the LayerNorm'd outputs we're adding are tiny in comparison, then in the final LayerNorm we get ln(bigcoeff*diff + small) ~= ln(bigcoeff*diff) ~= ln(diff).
Relevant: The algorithm for precision medicine, where a very dedicated father of a rare chronic disease (NGLY1 deficiency) in order to save his son. He did so by writing a blog post that went viral & found other people with the same symptoms.
This article may serve as a shorter summary than the talk.
[APPRENTICE]
Hi I'm Uli and I care about two things: Solving alignment and becoming stronger (not necessarily in that order).
My background: I was unschooled, I've never been to school or had a real teacher. I taught myself everything I wanted to know. I didn't really have friends till 17 when I started getting involved with rationalist-adjacent camps.
I did seri mats 3.0 under Alex Turner, doing some interpretability on mazes. Now I'm working half-time doing interpretability/etc with Alex's team as well as studying.
In rough order of priority, the kinds of mentorship I'm looking for:
- Drill Sergeant: I want to improve my general capabilities, there are many obvious things I'm not doing enough, and my general discipline could be improved a lot too. Akrasia is just a problem to be solved, and one I'll be embarrassed if I haven't ~fully solved by 20. There is much more that I could put here. Instead I'll list a few related thoughts
- Meditation is mind-training why isn't everyone doing it, is the world that inadequate?[1]
- Introspection tells me the rationalist community has been bad for my thinking in some ways, Lots of groupthink, overconfident cached thoughts about alignment, etc.
- I'm pretty bad at deliberating once and focusing medium-term. Too many things started and not enough finished. Working on fixing.
- (The list goes on...)
- Skills I've neglected: I know relatively little of the sciences, haven't written much outside of math, and know essentially zero history & other subjects.
- Skills I'm better in: I want to get really good at machine learning, programming, and applied math. Think 10x ML Engineer/Researcher.
- Alignment Theory. I have this pretty well covered, and think the potential costs from groupthink and priming outweigh additional depth here. I've already read too much LessWrong.
[MENTOR]
I am very good at learning when I want to be[2]. If you would like someone to yell at you for using obviously inefficient learning strategies (which you probably are), I can do that.
I can also introduce bored high-schoolers with interesting people their age, and give advice related to the stuff I'm good at.
Too busy for intensive mentorship, but async messaging plus maybe a call every week or so could work.
- ^
Semiconsistently meditating an hour a day + walking meditation when traveling. Currently around stage 3-4 in mind illuminated terms (for those not familiar, this is dogshit.)
- ^
Which sadly hasn't been the past year as much as it used to. I've been getting distracted by doing research and random small projects over absorbing fountains of knowledge. In the process of fixing this now.
Taji looked over his sheets. "Okay, I think we've got to assume that every avenue that LessWrong was trying is a blind alley, or they would have found it. And if this is possible to do in one month, the answer must be, in some sense, elegant. So no multiple agents. If we start doing anything that looks like we should call it 'HcH', we'd better stop. Maybe begin by considering how failure to understand pre-coherent minds could have led LessWrong astray in formalizing corrigibility."
"The opposite of folly is folly," Hiriwa said. "Let us pretend that LessWrong never existed."
(This could be turned into a longer post but I don't have time...)
I think the gold standard is getting advice from someone more experienced. I can easily point out the most valuable things to white-box for people less experienced then me.
Perhaps the 80/20 is posting recordings of you programming online and asking publicly for tips? Haven't tried this yet but seems potentially valuable.
I tentatively approve of activism & trying to get govt to step in. I just want it to be directed in ways that aren't counterproductive. Do you disagree with any of my specific objections to strategies, or the general point that flailing can often be counterproductive? (Note not all activism i included in flailing, flailing, it depends on the type)
Downvoted because I view some of the suggested strategies as counterproductive. Specifically, I'm afraid of people flailing. I'd be much more comfortable if there was a bolded paragraph saying something like the following:
Beware of flailing and second-order effects and the unilateralist's curse. It is very easy to end up doing harm with the intention to do good, e.g. by sharing bad arguments for alignment, polarizing the issue, etc.
To give specific examples illustrating this (which may also be good to include and/or edit the post):
- I believe tweets like this are much better (and net positive) then the tweet you give as an example. Sharing anything less then the strongest argument can be actively bad to the extent it immunizes people against the actually good reasons to be concerned.
- Most forms of civil disobedience seems actively harmful to me. Activating the tribal instincts of more mainstream ML researchers, causing them to hate the alignment community, would be pretty bad in my opinion. Protesting in the streets seems fine, protesting by OpenAI hq does not.
Don't have time to write more. For more info see this twitter exchange I had with the author, though I could share more thoughts and models my main point is be careful, taking action is fine, and don't fall into the analysis-paralysis of some rationalists, but don't make everything worse.
Thanks for the insightful response! Agree it's just suggestive for now. Though more then with image models (where I'd expect lenses to transfer really badly, but don't know). Perhaps it being a residual network is the key thing, since effective path lengths are low most of the information is "carried along" unchanged, meaning the same probe continues working for other layers. Idk
Don't we have some evidence GPTs are doing iterative prediction updating from the logit lens and later tuned lens? Not that that's all they're doing of course.
Strong upvoted and agreed. I don't think the public has opinions on AI X-Risk yet, so any attempt to elicit them will entirely depend on framing.
Strong upvoted to counter some of the downvotes.
I'll note (because some commenters seem to miss this) that Eliezer is writing in a convincing style for a non-technical audience. Obviously the debates he would have with technical AI safety people are different then what is most useful to say to the general population.
EDIT: I think the effects were significantly worse than this and caused a ton of burnout and emotional trauma. Turns out thinking the world will end with 100% probability if you don't save it, plus having heroic responsibility, can be a little bit tough sometimes...
I worry most people will ignore the warnings around willful inconsistency, so let me self-report that I did this and it was a bad idea. Central problem: It's hard to rationally update off new evidence when your system 1 is utterly convinced of something. And I think this screwed with my epistemics around Shard Theory while making communication with people about x-risk much harder, since I'd often typical mind and skip straight to the paperclipper - the extreme scenario I was (and still am to some extent) trying to avoid as my main case.
When my rationality level is higher and my takes have solidified some more I might try this again, but right now it's counterproductive. System 2 rationality is hard when you have to constantly correct for false System 1 beliefs!
I feel there's often a wrong assumption in probabilistic reasoning, something like moderate probabilities for everything by default? after all, if you say you're 70/30 nobody who disagrees will ostracize you like if you say 99/1.
"If alignment is easy I want to believe alignment is easy. If alignment is hard I want to believe alignment is hard. I will work to form accurate beliefs"
Petition to rename "noticing confusion" to "acting on confusion" or "acting to resolve confusion". I find myself quite good at the former but bad at the latter—and I expect other rationalists are the same.
For example: I remember having the insight thought leading to lsusr's post on how self-reference breaks the orthogonality thesis, but never pursued the line of questioning since it would require sitting down and questioning my beliefs with paper for a few minutes, which is inconvenient and would interrupt my coding.
Strongly agree. Rationalist culture is instrumentally irrational here. It's very well known how important self-belief & a growth mindset is for success, and rationalists obsession with natural intelligence quite bad imo, to the point where I want to limit my interaction with the community so I don't pick up bad patterns.
I do wonder if you're strawmanning the advice a little, in my friend circles dropping out is seen as reasonable, though this could just be because a lot of my high-school friends already have some legible accomplishments and skills.
Each non-waluigi step increases the probability of never observing a transition to a waluigi a little bit.
Each non-Waluigi step increases the probability of never observing a transition to Waluigi a little bit, but not unboundedly so. As a toy example, we could start with P(Waluigi) = P(Luigi) = 0.5. Even if P(Luigi) monotonically increases, finding novel evidence that Luigi isn't a deceptive Waluigi becomes progressively harder. Therefore, P(Luigi) could converge to, say, 0.8.
However, once Luigi says something Waluigi-like, we immediately jump to a world where P(Waluigi) = 0.95, since this trope is very common. To get back to Luigi, we would have to rely on a trope where a character goes from good to bad to good. These tropes exist, but they are less common. Obviously, this assumes that the context window is large enough to "remember" when Luigi turned bad. After the model forgets, we need a "bad to good" trope to get back to Luigi, and these are more common.
I'd be happy to talk to [redacted] and put them in touch with other smart young people. I know a lot from Atlas, ESPR and related networks. You can pass my contact info on to them.
Exercise: What mistake is the following sentiment making?
If there's only a one in a million chance someone can save the world, then there'd better be well more than a million people trying.
Answer:
The whole challenge of "having a one in a million chance of saving the world" is the wrong framing, the challenge is having a positive impact in the first case (for example: by not destroying the world or making things worse, e.g. from s-risks). You could think of this as a setting the zero point thing going on, though I like to think of it in terms of Bayes and Pascel's wagers:
In terms of Bayes: You're fixating on the expected value contributed from and ignoring the rest of the hypothesis space. In most cases, there are corresponding low probability events which "cancel out" the EV contributed from 's direct reasoning.
(I will also note that, empirically, it could be argued Eliezer was massively net-negative from a capabilities advancements perspective; having causal links to founding of deepmind & openai. I bring this up to point out how nontrivial having a positive impact at all is, in a domain like ours)
Isn't this only S-risk in the weak sense of "there's a lot of suffering" - not the strong sense of "literally maximize suffering"? E.g. it seems plausible to me mistakes like "not letting someone die if they're suffering" still gives you a net positive universe.
Also, insofar as shard theory is a good description of humans, would you say random-human-god-emperor is an S-risk? and if so, with what probability?
The enlightened have awakened from the dream and no longer mistake it for reality. Naturally, they are no longer able to attach importance to anything. To the awakened mind the end of the world is no more or less momentous than the snapping of a twig.
Looks like I'll have to avoid enlightenment, at least until the work is done.
Take the example of the Laplace approximation. If there's a local continuous symmetry in weight space, i.e., some direction you can walk that doesn't affect the probability density, then your density isn't locally Gaussian.
Haven't finished the post, but doesn't this assume the requirement that when and induce the same function? This isn't obvious to me, e.g. under the induced prior from weight decay / L2 regularization we often have for weights that induce the same function.
Seems tangentially related to the train a sequence of reporters strategy for ELK. They don't phrase it in terms of basins and path dependence, but they're a great frame to look at it with.
Personally, I think supervised learning has low path-dependence because of exact gradients plus always being able find a direction to escape basins in high dimensions, while reinforcement learning has high path-dependence because updates influence future training data causing attractors/equilibra (more uncertain about the latter, but that's what I feel like)
So the really out there take: We want to give the LLM influence over its future training data in order to increase path-dependence, and get the attractors we want ;)
I was more thinking along the lines of "you're the average of the five people you spend the most time with" or something. I'm against external motivation too.
Edited
Character.ai seems to have a lot more personality then ChatGPT. I feel bad for not thanking you earlier (as I was in disbelief), but everything here is valuable safety information. Thank you for sharing, despite potential embarrassment :)
That link isn't working for me, can you send screenshots or something? When I try and load it I get an infinite loading screen.
Re(prompt ChatGPT): I'd already tried what you did and some (imo) better prompt engineering, and kept getting a character I thought was overly wordy/helpful (constantly asking me what it could do to help vs. just doing it). A better prompt engineer might be able to get something working though.
Can you give specific example/screenshots of prompts and outputs? I know you said reading the chat logs wouldn't be the same as experiencing it in real time, but some specific claims like the prompt
The following is a conversation with Charlotte, an AGI designed to provide the ultimate GFE
Resulting in a conversation like that are highly implausible.[1] At a minimum you'd need to do some prompt engineering, and even with that, some of this is implausible with ChatGPT which typically acts very unnaturally after all the RLHF OAI did.
Source: I tried it, and tried some basic prompt engineering & it still resulted in bad outputs ↩︎
Interesting I didn't know the history, maybe I'm insufficiently pessimistic about these things. Consider my query retracted
Congratulations!
Linear algebra done right is great for gaining proof skills, though for the record I've read it and haven't solved alignment yet. I think I need several more passes of linear algebra :)
Are most uncertainties we care about logical rather than informational? All empirical ML experiments are pure computations a Bayesian superintelligence could do in its head. How much of our uncertainty comes from computational limits in practice, versus actual information bottlenecks?
A trick to remember: the first letter of each virtue gives (in blocks): CRL EAES HP PSV, which can easily be remembered as "cooperative reinforcement learning, EAs, Harry Potter, PS: The last virtue is the void."
(Obviously remembering these is pointless, but memorizing lists is a nice way to practice mnemonic technique.)
We propose Algorithm Distillation (AD), a method for distilling reinforcement learning (RL) algorithms into neural networks by modeling their training histories with a causal sequence model. Algorithm Distillation treats learning to reinforcement learn as an across-episode sequential prediction problem. A dataset of learning histories is generated by a source RL algorithm, and then a causal transformer is trained by autoregressively predicting actions given their preceding learning histories as context. Unlike sequential policy prediction architectures that distill post-learning or expert sequences, AD is able to improve its policy entirely in-context without updating its network parameters. We demonstrate that AD can reinforcement learn in-context in a variety of environments with sparse rewards, combinatorial task structure, and pixel-based observations, and find that AD learns a more data-efficient RL algorithm than the one that generated the source data.
EleutherAI's #alignment channels are good to ask questions in. Some specific answers
I understand that a reward maximiser would wire-head (take control over the reward provision mechanism), but I don’t see why training an RL agent would necessarily end up in a reward-maximising agent? Turntrout’s Reward is Not the Optimisation Target shed some clarity on this, but I definitely have remaining questions.
Leo Gao's Toward Deconfusing Wireheading and Reward Maximization sheds some light on this.
How can I look at my children and not already be mourning their death from day 1?
Suppose you lived in the dark times, where children have a <50% of living to adulthood. Wouldn't you still have kids? Even if probabilistically smallpox was likely to take them?
If AI kills us all, will my children suffer? Will it be my fault for having brought them into the world while knowing this would happen?
Even if they don't live to adulthood, I'd still view their childhoods as valuable. Arguably higher average utility than adulthood.
Even if my children's short lives are happy, wouldn't their happiness be fundamentally false and devoid of meaning?
Our lifetimes are currently bounded, are they false and devoid of all meaning?
The negentropy in the universe is also bounded, is the universe false and devoid of all meaning?