[ASoT] Natural abstractions and AlphaZero
post by Ulisse Mini (ulisse-mini) · 2022-12-10T17:53:02.376Z · LW · GW · 1 commentsThis is a link post for https://arxiv.org/abs/2111.09259
Contents
1 comment
I just read Acquisition of Chess Knowledge in AlphaZero and it's both really cool and has interesting implications for the Natural Abstractions Hypothesis. AZ was trained with no human data and yet it settles on relatively interpretable abstractions for chess.[1]
They trained sparse linear probes on hidden layers to predict Stockfish evaluation features. Here are some of the graphs
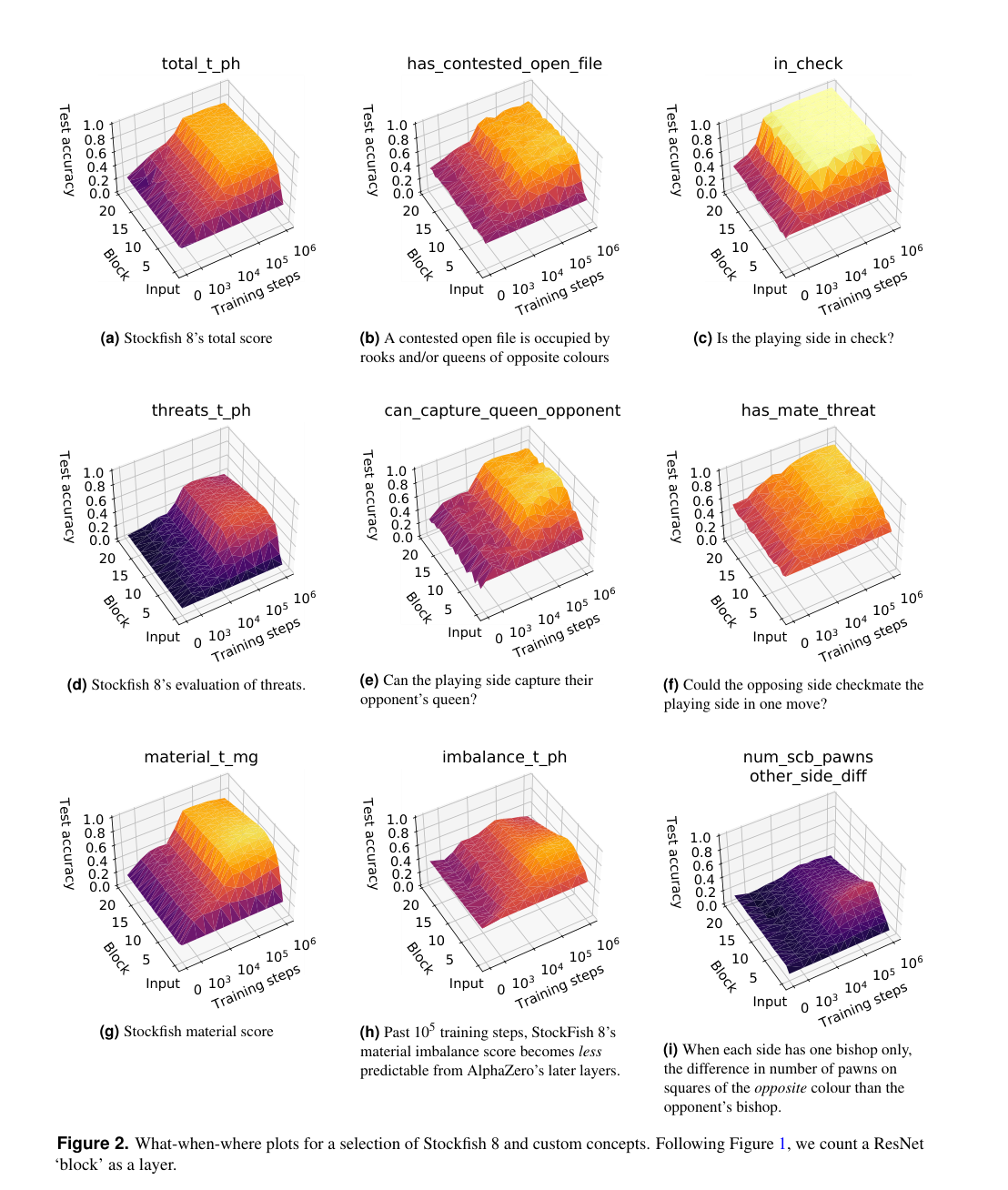
Analyzing the largest differences between the predicted Stockfish score total_t_ph and the actual. There's a clustering effect due to the hardcoded Stockfish eval not taking into account "piece captures in one move" (as usually, the search would handle) - leading to large disagreements on value when a Queen is hanging.
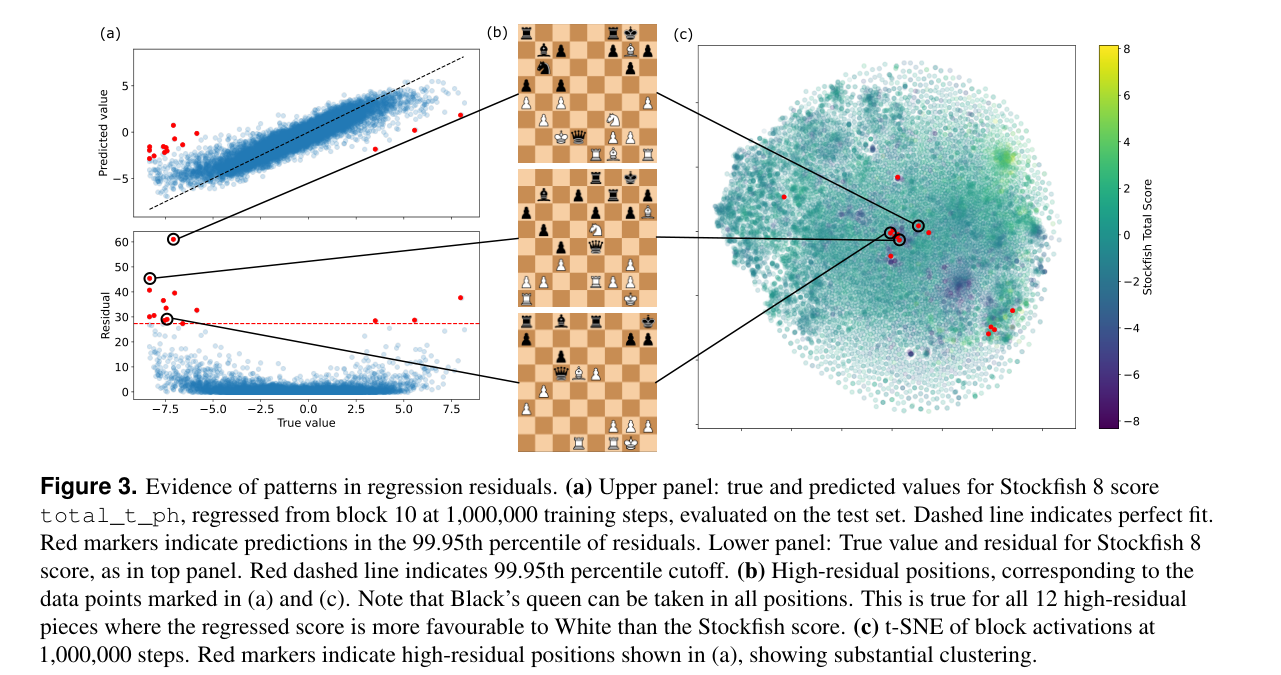
Although the degree of structure shown here is surprising, this example is not cherry-picked; it was the first concept/layer/checkpoint combination we tried, and the positions presented are simply those whose residuals are past a cutoff that.
Not cherry-picked!
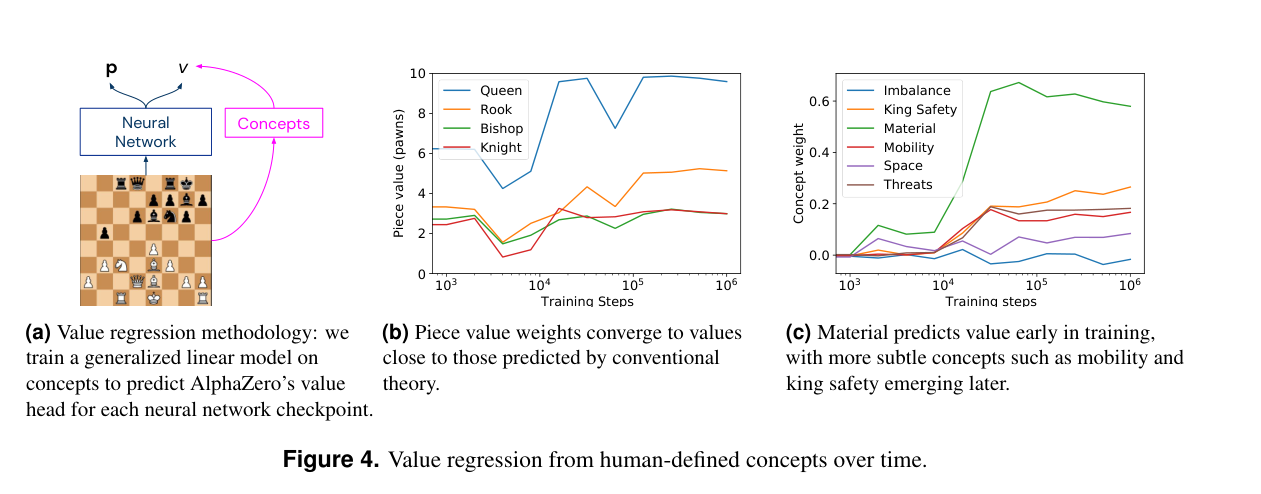
Training a linear regression model to predict the value function, given human interpretable features like piece value weights and Stockfish features like king safety: results in approximately recovering the chess 9-5-3-3-1 piece values!
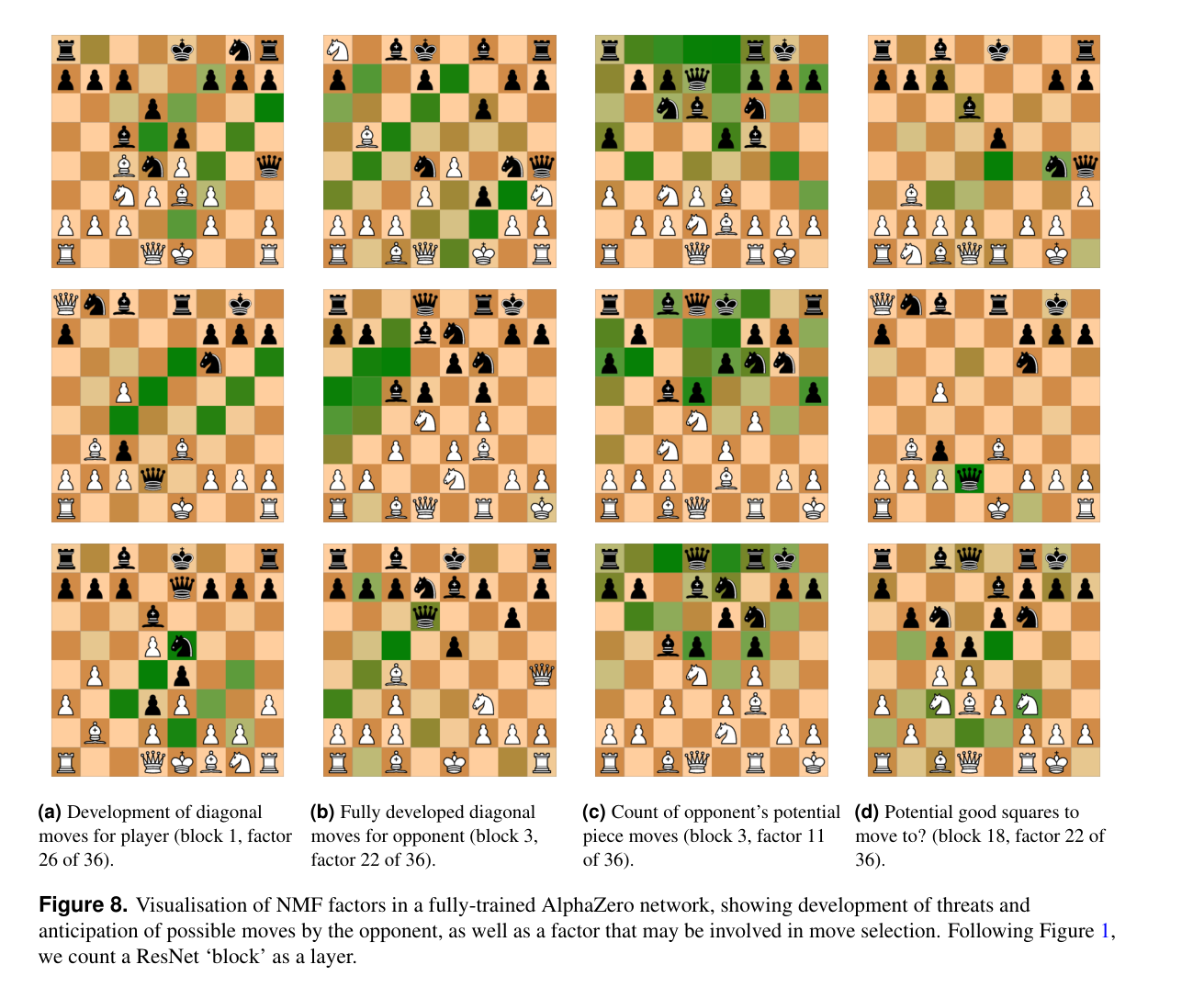
They also did various experiments with unsupervised probing, here's a visualization of some of those features. (I didn't look into these results as much as the others, so not much to say here.)
In conclusion: I'd recommend checking out the paper, or any from Neel's list [AF · GW]. Interpretability is fascinating!
1 comments
Comments sorted by top scores.
comment by Ary.Bin-Us (nybarius) · 2022-12-11T01:11:25.618Z · LW(p) · GW(p)
Thank you, very interesting paper (and it is good to see that Kramnik has kept up an active interest in chess computing, hehe).
The paper you cite seems to converge nicely with evidence that large transformer model embeddings for language comprehension map on to human semantic understand (e.g.,:
https://www.nature.com/articles/s41598-022-20460-9
https://www.nature.com/articles/s42003-022-03036-1 )
Related, it appears we are even approaching a refined normative theory & practical benchmarking of hyperparameter transfer, which may be very roughly akin to conceptual understanding (https://www.microsoft.com/en-us/research/uploads/prod/2021/11/TP5.pdf
Truly, a wonderful time to be alive; I feel as if all the detective novels I'd ever read had reached dénouement at once.