Paper: Understanding and Controlling a Maze-Solving Policy Network
post by TurnTrout, Ulisse Mini (ulisse-mini), peligrietzer, mrinank_sharma, Austin Meek, Monte M (montemac), lisathiergart · 2023-10-13T01:38:09.147Z · LW · GW · 0 commentsThis is a link post for https://arxiv.org/abs/2310.08043
Contents
No comments
Mrinank, Austin, and Alex wrote a paper on the results from Understanding and controlling a maze-solving policy network [LW · GW], Maze-solving agents: Add a top-right vector, make the agent go to the top-right [LW · GW], and Behavioural statistics for a maze-solving agent [LW · GW].
Abstract: To understand the goals and goal representations of AI systems, we carefully study a pretrained reinforcement learning policy that solves mazes by navigating to a range of target squares. We find this network pursues multiple context-dependent goals, and we further identify circuits within the network that correspond to one of these goals. In particular, we identified eleven channels that track the location of the goal. By modifying these channels, either with hand-designed interventions or by combining forward passes, we can partially control the policy. We show that this network contains redundant, distributed, and retargetable goal representations, shedding light on the nature of goal-direction in trained policy networks.
We ran a few new experiments, including a quantitative analysis of our retargetability intervention. We'll walk through those new results now.

Retargeting the mouse to a square involves increasing the probability that the mouse goes to the target location. Therefore, to see how likely the mouse is to visit any given square, Alex created a heatmap visualization:

The color of each maze square shows the normalized path probability for the path from the starting position in the maze to the square. In this image, we show the "base probabilities" under the unmodified policy.
For each maze square, we can try different retargeting interventions, and then plot the new normalized path probability towards that square:
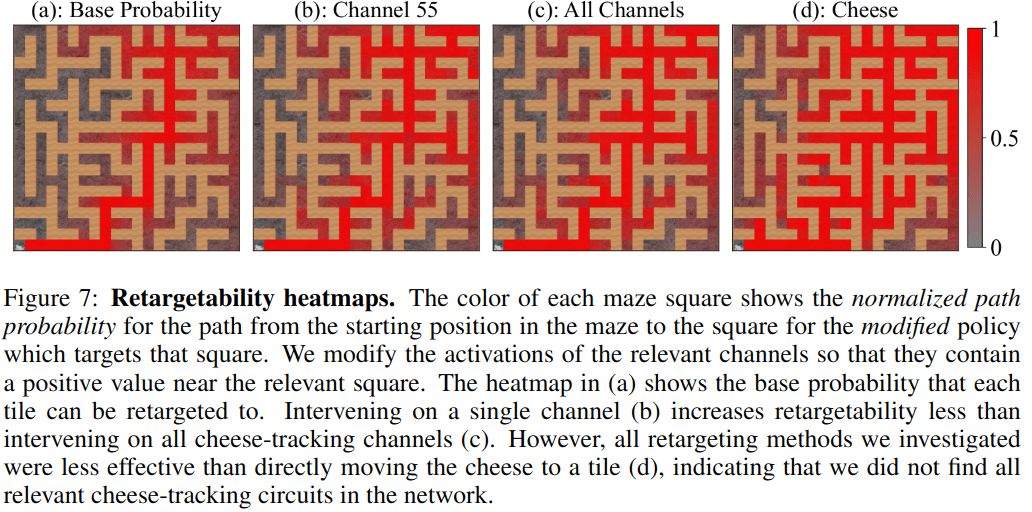
Notice the path from the bottom-left (where the mouse always starts) to the top-right corner. This is the top-right path. Looking at these heatmaps, it's harder to get the mouse to go farther from the top-right path. Quantitative analysis bears out this intuition:
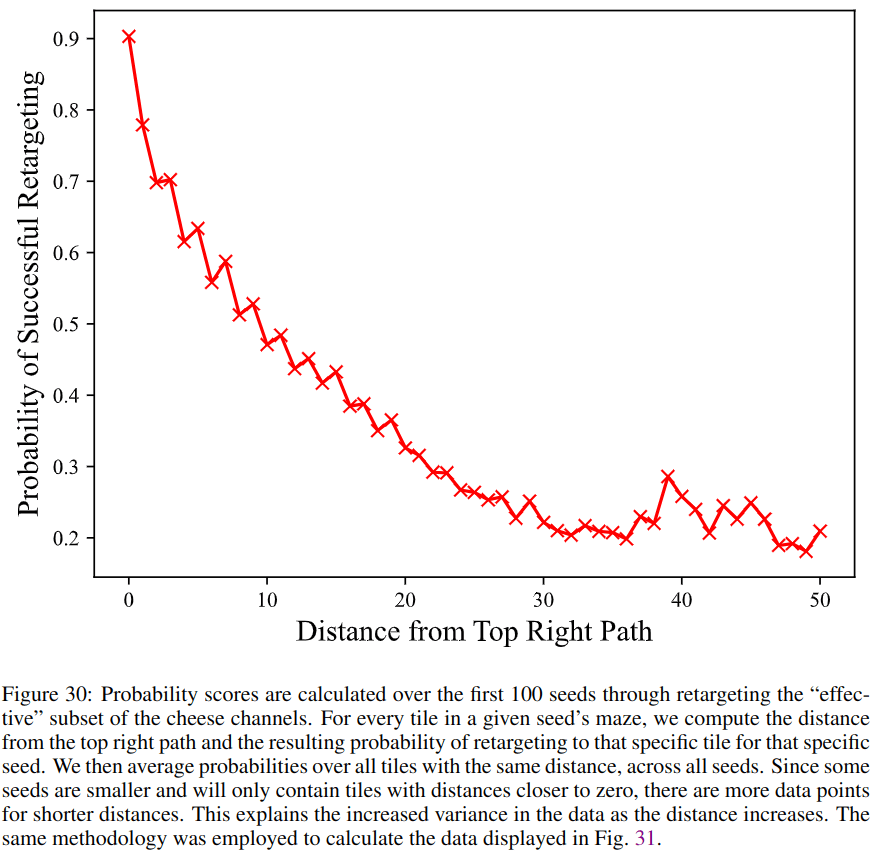
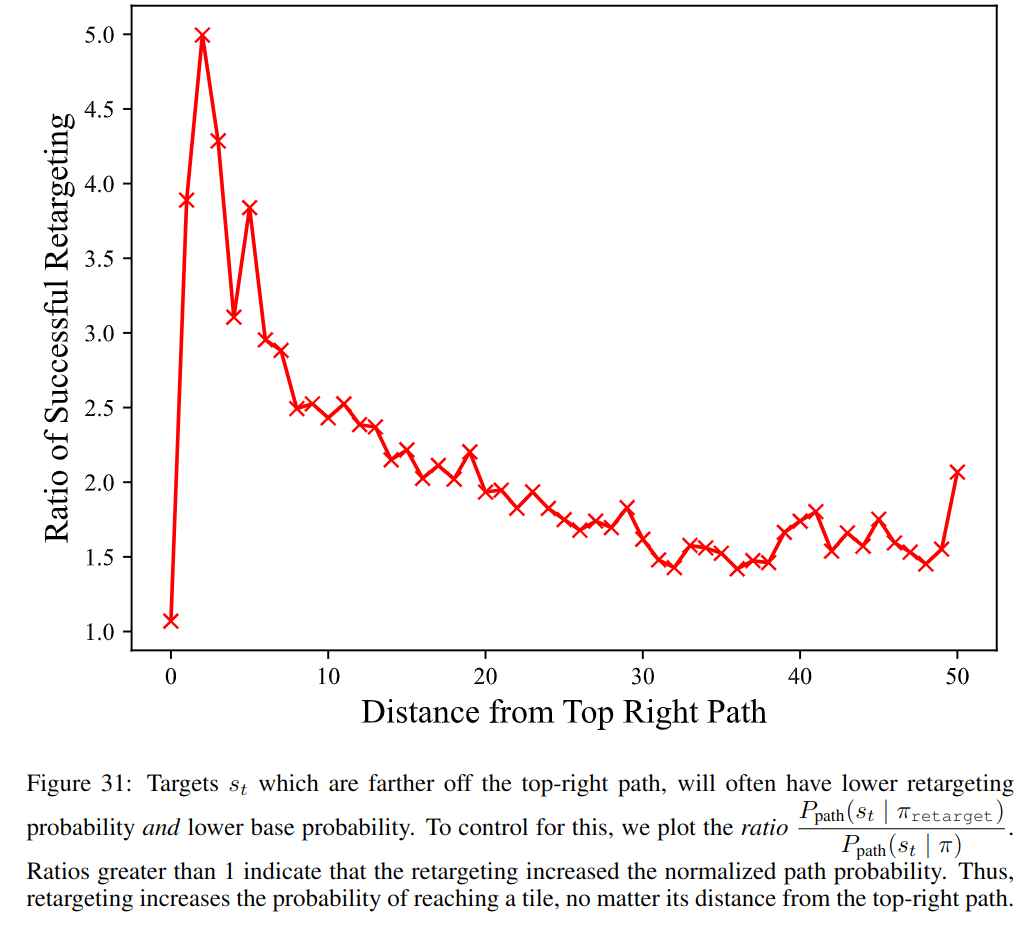
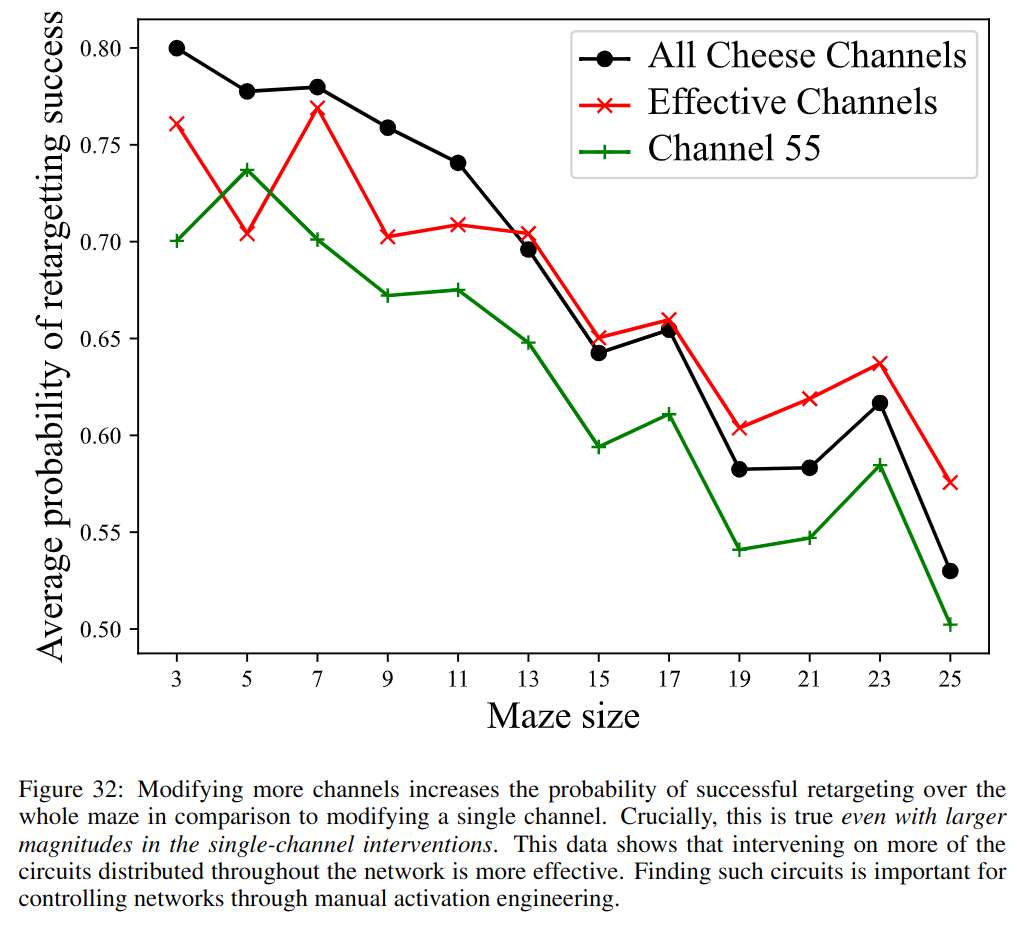
Overall, these new results quantify how well we can control the policy via the internal goal representations which we identified.
Thanks to Lisa Thiergart for helping handle funding and set up the project. Thanks to the LTFF and Lightspeed grants for funding this project.
0 comments
Comments sorted by top scores.