When do "brains beat brawn" in Chess? An experiment
post by titotal (lombertini) · 2023-06-28T13:33:23.854Z · LW · GW · 106 commentsThis is a link post for https://titotal.substack.com/p/when-do-brains-beat-brawn-in-chess
Contents
Analysis of my tradeoff of material and ELO: Odds of rook: Odds of two bishops: Odds of queen: Can brawn beat an AGI? None 107 comments
As a kid, I really enjoyed chess, as did my dad. Naturally, I wanted to play him. The problem was that my dad was extremely good. He was playing local tournaments and could play blindfolded, while I was, well, a child. In a purely skill based game like chess, an extreme skill imbalance means that the more skilled player essentially always wins, and in chess, it ends up being a slaughter that is no fun for either player. Not many kids have the patience to lose dozens of games in a row and never even get close to victory.
This is a common problem in chess, with a well established solution: It’s called “odds”. When two players with very different skill levels want to play each other, the stronger player will start off with some pieces missing from their side of the board. “Odds of a queen”, for example, refers to taking the queen of the stronger player off the board. When I played “odds of a queen” against my dad, the games were fun again, as I had a chance of victory and he could play as normal without acting intentionally dumb. The resource imbalance of the missing queen made the difference. I still lost a bunch though, because I blundered pieces.
Now I am a fully blown adult with a PhD, I’m a lot better at chess than I was a kid. I’m better than most of my friends that play, but I never reached my dad’s level of chess obsession. I never bothered to learn any openings in real detail, or do studies on complex endgames. I mainly just play online blitz and rapid games for fun. My rating on lichess blitz is 1200, on rapid is 1600, which some calculator online said would place me at ~1100 ELO on the FIDE scale.
In comparison, a chess master is ~2200, a grandmaster is ~2700. The top chess player Magnus Carlsen is at an incredible 2853. ELO ratings can be used to estimate the chance of victory in a matchup, although the estimates are somewhat crude for very large skill differences. Under this calculation, the chance of me beating a 2200 player is 1 in 500, while the chance of me beating Magnus Carlsen would be 1 in 24000. Although realistically, the real odds would be less about the ELO and more on whether he was drunk while playing me.
Stockfish 14 has an estimated ELO of 3549. In chess, AI is already superhuman, and has long since blasted past the best players in the world. When human players train, they use the supercomputers as standards. If you ask for a game analysis on a site like chess.com or lichess, it will compare your moves to stockfish and score you by how close you are to what stockfish would do. If I played stockfish, the estimated chance of victory would be 1 in 1.3 million. In practice, it would be probably be much lower, roughly equivalent to the odds that there is a bug in the stockfish code that I managed to stumble upon by chance.
Now that we have all the setup, we can ask the main question of this article:
What “odds” do I need to beat stockfish 14[1] in a game of chess? Obviously I can win if the AI only has a king and 3 pawns. But can I win if stockfish is only down a rook? Two bishops? A queen? A queen and a rook? More than that? I encourage you to pause and make a guess. And if you can play chess, I encourage you to guess as to what it would take for you to beat stockfish. For further homework, you can try and guess the odds of victory for each game in the picture below.

The first game I played against stockfish was with queen odds.
I won on the first try. And the second, and the third. It wasn’t even that hard. I played 10 games and only lost 1 (when I blundered my queen stupidly).
The strategy is simple. First, play it safe and try not to make any extreme blunders. Don’t leave pieces unprotected, check for forks and pins, don’t try any crazy tactics. Secondly, take every opportunity to trade pieces. Initially, the opponent has 30 points of material, and you have 39, meaning you have 30% more material than them. If you manage to trade all your bishops and knights away, stockfish would have 18 points and you would have 27, a 50% advantage. It also makes the game much simpler and straightforward, as there are far less nasty tactics available when the computer only has two rooks available.
Don’t get me wrong, the computer managed to trick me plenty of times and get pieces trapped. Sometimes I would blunder several pawns or a whole piece. But you need to use pieces to trap pieces, and the computer never had the resources to claw away at me before I traded everything away and crushed it with my extra queen.
Since that was easy, I tried odds of two bishops. I lost the first game, then won the second. Lost the third, won the fourth. Same strategy as the queens, but it was noticeably more difficult. I would often make a small error early on, which would then snowball out to take me down.
Getting cocky, I played with odds of a rook (ostensibly only 1 point of material less than two bishops). I immediately got trounced. I lost the first game, and proceeded to lose like 20 games in a row before I finally managed to eke out a draw.
The problem with rook odds is that the rook is locked away in the corner of the board, and usually is most useful at the end of the game when it has free reign of the board. That means that in the opening of the game, I’m functionally playing stockfish as if I have equal material. And stockfish, with equal material, is a fucking nightmare. It can put it’s full force to bear, poke any weaknesses, render your pieces trapped and useless, and chip away at your lead slowly but surely. By the time I could trade pieces down and get my extra rook in play, the AI had usually chipped away enough at my lead that I was only a little bit up in material. And a little bit up is not enough. Here is an example position:

It looks like I’m completely winning here. I have an extra pawn, and a rook instead of a knight, which is an ostensible +3 material. I even spot the trap laid by stockfish: If I move my rook one up or one down, the knight can jump to e2, forking my king and rook and ensuring a rook for knight trade that would destroy my lead. Thinking I was smart, I put my rook on c4. Big mistake. The AI gave a knight check on h3, driving the king to f1, and then it forked my rook and king with his bishop. Even if I moved my rook to c5, black would have been able to lock it into place by moving the b pawn to b6 and moving the knight to d3, rendering the rook effectively useless. Only moving the rook to b2 would have saved my advantage. If the analysis here was obvious to you, there's a good chance you can beat stockfish with rook odds.
It took me something like 20 games to draw against stockfish, and a further 30 before I finally actually won. In the successful game, I got lucky with an opening that let me trade most pieces equally, and then slowly forced a knight vs knight endgame where I was up two pawns. This might actually be a case where a chess GM would outperform an AI: they can think psychologically, so they can deliberately pick traps and positions that they know I would have difficulty with.
Analysis of my tradeoff of material and ELO:
Here I’ll summarize the results of my little experiment. Remember, initially I had an ELO of ~1100 and a nominal odds of beating stockfish of roughly 1 in a million (but probably less).
Odds of rook:
Material advantage: 14%
Win rate: 2%
Odds of victory boost: 4 orders of magnitude or more
Equivalent ELO: ~2750
Odds of two bishops:
Material advantage: 18%
Win rate: ~50%
Odds of victory boost: 6 orders of magnitude or more
Equivalent ELO: ~3549
Odds of queen:
Material advantage: 30%
Win rate: 90%
Odds of victory boost: 7 orders of magnitude or more
Equivalent ELO: ~3900
I tried a few games with odds of a knight, and got hopelessly crushed every time. However, looking online, I did find that a GM achieved an 80% win rate in a knight-odds game against the Komodo chess engine.
It’s worth pointing out that handicaps become more powerful the better you are at chess. Quoting GM Larry Kaufman on this subject:
The Elo equivalent of a given handicap degrades as you go down the scale. A knight seems to be worth around a thousand points when the "weak" player is around IM level, but it drops as you go down. For example, I'm about 2400 and I've played tons of knight odds games with students, and I would put the break-even point (for untimed but reasonably quick games) with me at around 1800, so maybe a 600 value at this level. An 1800 can probably give knight odds to a 1400, a 1400 to an 1100, an 1100 to a 900, etc. This is pretty obviously the way it must work, because the weaker the players are, the more likely the weaker one is to blunder a piece or more. When you get down to the level of the average 8 year old player, knight odds is just a slight edge, maybe 50 points or so.
This is why my dad could beat me as a kid with queen odds, but stockfish can't beat me now. You need sufficient knowledge of how to game works to utilize your resource advantages properly.
Can brawn beat an AGI?
Robert Miles compared humanity fighting an AGI to an amateur at chess trying to beat a grandmaster. His argument was that delving into the details of such a fight was pointless, because “you just cannot expect to win against a superior opponent”.
The problem here is that I, an amateur, can beat a GM. I can beat Stockfish. All I need is an extra queen.
This is not a trick point. If a rogue AI is discovered early, we could end up in a war where the AGI has a huge intelligence advantage, but humans have a huge resource advantage.
In the view of Miles and others, the initially gargantuan resource imbalance between the AI and humanity doesn’t matter, because the AGI is so super-duper smart, it will be able to come up with the “perfect” plan to overcome any resource imbalance, like a GM playing against a little kid that doesn't understand the rules very well.
The problem with this argument is that you can use the exact same reasoning to imply that’s it’s “obvious” that Stockfish could reliably beat me with queen odds. But we know now that that’s not true. There will always be a level of resource imbalance where the task at hand is just too damn difficult, no matter how high the intelligence. Consider also the implication that a less intelligent, but more controllable AI that we cooperate with might be able to triumph over a much more intelligent rogue AI.
Of course, this little experiment tells us very little about what the equivalent of a “queen advantage” would be in a battle with an AGI. It would definitely need to be far more than literally 30% more people, as we know plenty of examples of human generals winning battles despite being vastly outnumbered. Unlike chess, the real world has secret information, way more possible strategies, the potential for technological advancements, defections and betrayal, etc. which all favor the more intelligent party. On the other hand, the potential resource imbalance could be ridiculously high, particularly if a rogue AI is caught early on it’s plot, with all the worlds militaries combined against them while they still have to rely on humans for electricity and physical computing servers. It’s somewhat hard to outthink a missile headed for your server farm at 800 km/h.
I intend to write a lot more on the potential “brains vs brawns” matchup of humans vs AGI. It’s a topic that has received surprisingly little depth from AI theorists. I hope this little experiment at least explains why I don’t think the victory of brain over brawn is “obvious”. Intelligence counts for a lot, but it ain’t everything.
- ^
In order to play stockfish with odds, I went to lichess.org/editor, removed the pieces as necessary, and then clicked “continue from here”, selected “play against computer”, and selected maximum strength computer opponent (level 8). This is full strength stockfish with a depth of 22 moves and calculation time of 1000 ms. I also tested with the higher depth and calculation time of the “analysis board”, and was still able to win easily with queen odds.
106 comments
Comments sorted by top scores.
comment by Lucius Bushnaq (Lblack) · 2023-06-29T14:23:09.639Z · LW(p) · GW(p)
You can easily get a draw against any AI in the world at Tic-Tac-Toe. In fact, provided the game actually stays confined to the actions on the board, you can draw AIXI at Tic-Tac-Toe. That's because Tic-Tac-Toe is a very small game with very few states and very few possible actions, and so intelligence, the ability to pick good actions, doesn't grant any further advantage in it past a certain pretty low threshold.
Chess has more actions and more states, so intelligence matters more. But probably still not all that much compared to the vastness of the state and action space the physical universe has. If there's some intelligence threshold past which minds pretty much always draw against each other in chess even if there is a giant intelligence gap between them, I wouldn't be that surprised. Though I don't have much knowledge of the game.
In the game of Real Life, I very much expect that "human level" is more the equivalent of a four year old kid who is currently playing their third ever game of chess, and still keeps forgetting half the rules every minute. The state and action space is vast, and we get to observe humans navigating it poorly on a daily basis. Though usually only with the benefit of hindsight. In many domains, vast resource mismatches between humans do not outweigh skill gaps between humans. The Chinese government has far more money than OpenAI, but cannot currently beat OpenAI at making powerful language models. All the usual comparisons between humans and other animals also apply. This vast difference in achieved outcomes from small intelligence gaps even in the face of large resource gaps does not seem to me to be indicative of us being anywhere close to the intelligence saturation threshold of the Real Life game.
Replies from: johnlawrenceaspden, None↑ comment by johnlawrenceaspden · 2023-06-30T13:44:36.488Z · LW(p) · GW(p)
If there's some intelligence threshold past which minds pretty much always draw against each other in chess even if there is a giant intelligence gap between them, I wouldn't be that surprised.
Just reinforcing this point. Chess is probably a draw for the same reason Noughts-and-crosses is.
Grandmaster chess is pretty drawish. Computer chess is very drawish. Some people think that computer chess players are already near the standard where they could draw against God.
Noughts-and-crosses is a very simple game and can be formally solved by hand. Chess is only a bit less simple, even though it's probably beyond actual formal solution.
The general Game of Life is so very far beyond human capability that even a small intelligence advantage is probably decisive.
Replies from: Herb Ingram↑ comment by Herb Ingram · 2023-07-03T21:38:19.981Z · LW(p) · GW(p)
That makes sense to me but to make any argument about the "general game of life" seems very hard. Actions in the real world are made under great uncertainty and aggregate in a smooth way. Acting in the world is trying to control (what physicists call) chaos.
In such a situation, great uncertainty means that an intelligence advantage only matters "on average over a very long time". It might not matter for a given limited contest, such as a struggle for world domination. For example, you might be much smarter than me and a meteorologist, but you'd find it hard to predict the weather in a year's time better than me if it's a single-shot-contest. How much "smarter" would you need to be in order to have a big advantage? Pretty much regardless of your computational ability and knowledge of physics, you'd need such an amount of absurdly precise knowledge about the world that it might still take (both you and even much less intelligent actors) less resources to actively control the entire planet's weather than predict it a year in advance.
The way that states of the world are influenced by our actions is usually in some sense smooth. For any optimal action, there are usually lots of similar "nearby actions". These may or may not be near-optimal but in practice only plans that have a sufficiently high margin for error are feasible. The margin of error depends on the resources that allow finely controlled actions and thus increase the space of feasible plans. This doesn't have a good analogy in chess: chess is much further from smooth than most games in the real world.
Maybe RTS games are a slightly better analogy. They have "some smoothness of action-result mapping" and high amounts of uncertainty. Based on AlphaStar's success in StarCraft, I would expect we can currently build super-human AIs for such games. They are superior to humans both in their ability to quickly and precisely perform many actions, as well as find better strategies. An interesting restriction is to limit the numbers of actions the AI may take to below what a human can to see the effect of these abilities individually. Restricting the precision and frequency of actions reduces the space of viable plans, at which point the intelligence advantage might matter much less.
All in all, what I'm trying to say is that the question "how much does what intelligence imbalance matter in the world" is hard. The question is not independent of access to information and access to resources or ability to act on the world. To make use of a very high intelligence, you might need a lot more information and also a lot more ability to take precise actions. The question for some system "taking over" is whether its initial intelligence, information and ability to take actions is sufficient to bootstrap quickly enough.
These are just some more reasons you can't predict the result just by saying "something much smarter is unbeatable at any sufficiently complex game".
Replies from: X4vier, johnlawrenceaspden↑ comment by X4vier · 2023-07-04T00:07:12.404Z · LW(p) · GW(p)
Maybe an analogy which seems closer to the "real world" situation - let's say you and someone like Sam Altman both tried to start new companies. How much more time and starting capital do you think you'd need to have a better shot of success than him?
Replies from: Herb Ingram↑ comment by Herb Ingram · 2023-07-04T02:54:38.019Z · LW(p) · GW(p)
I really have no idea, probably a lot?
I don't quite see what you're trying to tell me. That one (which?) of my two analogies (weather or RTS) is bad? That you agree or disagree with my main claim that "evaluating the relative value of an intelligence advantage is probably hard in real life"?
Your analogy doesn't really speak to me because I've never tried to start a company and have no idea what leads to success, or what resources/time/information/intelligence helps how much.
↑ comment by johnlawrenceaspden · 2023-07-03T22:34:11.824Z · LW(p) · GW(p)
For example, you might be much smarter than me and a meteorologist, but you'd find it hard to predict the weather in a year's time better than me if it's a single-shot-contest.
Sure, but I'd presumably be quite a lot better at predicting the weather in two days time.
Replies from: Herb Ingram↑ comment by Herb Ingram · 2023-07-03T22:53:48.493Z · LW(p) · GW(p)
What point are you trying to make? I'm not sure how that relates to what I was trying to illustrate with the weather example. Assuming for the moment that you didn't understand my point.
The "game" I was referring to was one where it's literally all-or-nothing "predict the weather a year from now", you get no extra points for tomorrow's weather. This might be artificial but I chose it because it's a common example of the interesting fact that chaos can be easier to control than simulate.
Another example. You're trying to win an election and "plan long-term to make the best use of your intelligence advantage", you need to plan and predict a year ahead. Intelligence doesn't give you a big advantage in predicting tomorrow's polls given today's polls. I can do that reasonably well, too. In this contest, resources and information might matter a lot more than intelligence. Of course, you can use intelligence to obtain information and resources. But this bootstrapping takes time and it's hard to tell how much depending where you start off.
↑ comment by [deleted] · 2023-06-30T09:21:56.457Z · LW(p) · GW(p)
"China hasn't made a better LLM than OpenAI" does not imply "China can't make a better LLM despite having more money". China isn't allocating all their money into this. If it's the case that China set a much bigger budget to developing LLMs than OpenAI had, and failed because OpenAI has better people, that would support your point about large resource mismatches not being able to overcome small intelligence gaps.
comment by simplegeometry · 2024-11-21T20:55:17.437Z · LW(p) · GW(p)
This is something lc and gwern discussed in the comments here, but now we have clear evidence this is only true for Nash solvers (all typical engines like SF, Lc0, etc.). LeelaQueenOdds, which trained exploitatively against a model of top human players (FM+), is around 2k to 2.9k lichess elo depending on the time controls, so it completely trounces 1.6k elo players (especially 1.2k elo players as another commenter has suggested the author actually is). See: https://marcogio9.github.io/LeelaQueenOdds-Leaderboard/
Nash solvers are far too conservative and expect perfect play out of their opponents, hence give up most meaningful attacking chances in odds games. Exploitative models like LQO instead assume their opponents play like strong humans (good but imperfect) and do extremely well, despite a completely crushing material disadvantage. As some have noted, this is possible even with chess being a super sterile/simple environment relative to real life.
I speculate that the experiment from this post only yielded the results it did because Nash is a poor solution concept when one side is hopelessly disadvantaged under optimal play from both sides, and queen odds fall deep into that category.
See video from 7 minutes. Try it yourself https://lichess.org/@/LeelaQueenOdds :)
↑ comment by Olli Järviniemi (jarviniemi) · 2024-11-27T06:45:28.915Z · LW(p) · GW(p)
I found it interesting to play against LeelaQueenOdds. My experiences:
- I got absolutely crushed on 1+1 time controls (took me 50+ games to win one), but I'm competitive at 3+2 if I play seriously.
- The model is really good at exploiting human blind spots and playing aggressively. I could feel it striking in my weak spots, but not being able to do much about it. (I now better acknowledge the existence of adversarial attacks for humans on a gut level.)
- I found it really addictive to play against it: You know the trick that casinos use, where they make you feel like you "almost" won? This was that: I constantly felt like I could have won, if it wasn't just for that one silly mistake - despite having lost the previous ten games to such "random mistakes", too... I now better understand what it's like to be a gambling addict.
Overall fascinating to play from a position that should be an easy win, but getting crushed by an opponent that Just Plays Better than I do.
[For context, I'm around 2100 in Lichess on short time controls (bullet/blitz). I also won against Stockfish 16 at rook odds on my first try - it's really not optimized for this sort of thing.]
↑ comment by Lorenzo (lorenzo-buonanno) · 2025-01-26T21:13:22.263Z · LW(p) · GW(p)
A grandmaster just lost a classical game (60''+30'') against Leela Knight Odds https://lichess.org/broadcast/leela-knight-odds-vs-gm-joel-benjamin/game-5/MbKHEbdb/7Tnz8uBj
3 days ago an international master gave Leela "very slim chances" of winning a game, based on the results of a match played by a previous version of the engine
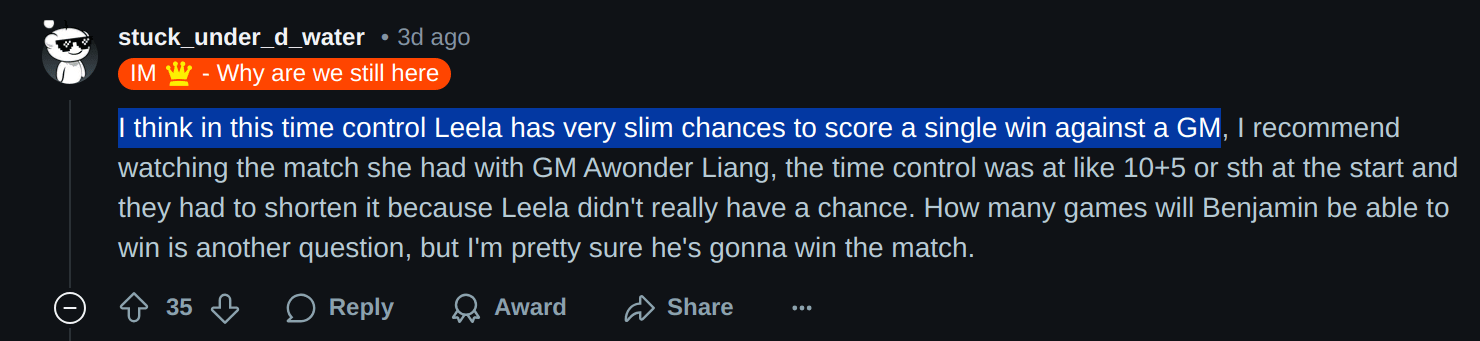
↑ comment by simplegeometry · 2025-01-29T03:08:26.200Z · LW(p) · GW(p)
Thanks for this update! I find that an odd prediction by the IM because Awonder is around 2670 FIDE and Joel is around 2470 FIDE, 200 elo is huge.
Replies from: lorenzo-buonanno↑ comment by Lorenzo (lorenzo-buonanno) · 2025-01-29T13:00:56.057Z · LW(p) · GW(p)
I think it's because 10+5 is very different from 60+30
Replies from: simplegeometry↑ comment by simplegeometry · 2025-01-29T19:23:03.185Z · LW(p) · GW(p)
Oh, my bad, yeah. When I was writing the comment, I flipped the direction of advantage for longer time controls (longer time controls are actually better for humans in odds matches of course), but this way I agree it's unclear a priori whether 200 elo drop would be enough to account for longer time controls.
↑ comment by Thomas Kwa (thomas-kwa) · 2024-12-05T22:29:52.978Z · LW(p) · GW(p)
Maybe we'll see the Go version of Leela give nine stones to pros soon? Or 20 stones to normal players?
comment by JenniferRM · 2023-06-29T03:08:06.611Z · LW(p) · GW(p)
I've been having various conversations in private, where I'm quite doomist and my interlocutor is less doomist, and I think one of the key cruxes that has come up several times is that I've applied security mindset to the operation of human governance, and I am not impressed.
I looked at things like the federal reserve (and how you'd implement that in a smart contract) and the congress/president/court deal (and how you'd implement that in a smart contract) and various other systems, and the thing I found was that existing governance systems are very poorly designed and probably relatively easy to knock over.
As near as I can tell, the reason human civilization still exists is that no inhuman opponent has ever existed that might really just want to push human civilization over and then curb stomp us while we thrash around in surprised pain.
For example, in WW2 Operation Bernhard got close to just "ending the money game" explicitly, but the bad guys couldn't bring themselves to make the stupidest and most evil British people rich via relatively secret injections, and then ramp it up more and more, and then as the whole web of market relationships became less and less plausible they could have eventually pumped more and more fake money into the British economy until they were just raining cash on random cities from the air. Part of why they refrained is that they imagined what a retaliatory strike would do to Nazi-controlled Germany... and flinched. The logic of "MAD" (transposed into economics) held them back.
In my view, human civilization is rife with such weaknesses.
I tend to not talk about them much, but I feel like maybe I should talk about them more, because my silence is coming to feel more and more stupid, given that I expect an AI smarter than me to see all the options that I can see, and then more!
So a big part of my model is not that a very very fast nor a very very large "foom" is especially likely... it is just that we are so collectively stupid (as a collective herd of moderately smart monkeys that is not actually very organized, and is mostly held together with prison bars and nuclear blackmail and duct tape) that I expect AIs that are merely slightly smarter than us (and have wildly different weaknesses and a coherent plan to get rid of us), to have a very good chance of succeeding.
Bringing it back to the Chess metaphor...
One can easily imagine starting with Stockfish, and then writing an extra little algorithmic loop that:
1) looks at the board, and
2) throttles Stockfish's CPU so that it can only "run at full speed" when
3) it has the knights, bishops, queen, and king inside a 4x4 subarea.
The farther from that ideal the board position gets, the more the CPU would be throttled.
A stockfish with this hack to its CPU throttle would start the game already at a "governance disadvantage" because the knights start outside "the zone of effective governance".
Correct early moves for white (taking into account the boost of extra CPU) might very well involve pushing the queen's knight to c3 or d2, and would similarly involve pushing the king's knight to e2 or f3. Only then could Stockfish even operate at "mental full power"!
If you ran AlphaZero from scratch, to expert, using any similar sort of "cpu sabotage based on the board state" I bet it would invent some CRAZY new opening games!
And this "weird board/cpu entangled chess AI constraint"... is actually a pretty good metaphor for how humans make decisions, as a collective, in real life.
Every private CEO is filtered not just by how good of a manager and economic planner they are, but how willing they are to be loyal to the true owners of the company, even at the expense of customers, or country, or moral ideals. Every President is beholden to half-crazy partisan factions, and can't possibly get into power without making numerous entangling deals. Xi and Putin can make moves, but they are each just one guy, and they have to spend a lot of their brain power just preventing coups and assassinations because their advisors aren't that trustworthy. Most governments are simply not arranged to maximize the government's ability to fight something very very very smart from a standing start!
If the human "material in the world" is re-arranged, then the human "ability as a species to coordinate against something that coherently would prefer our extinction" is also going to be affected. And the AI will know this. And the AI will be able to attack it.
If you knew you were playing against a version of Stockfish that got more CPU based on the proximity of various pieces (and less CPU with less material that was more spread out) then I bet that would ALSO be worth a huge amount of material.
That advantage, that you would have against a Stockfish with that additional imaginary weakness, is very very similar to the advantage that AI has over human governments: the "brains" are right there on the table, as part of the stakes, and subject to attack!
Replies from: miss me mimo!, RolfAndreassen, Making_Philosophy_Better↑ comment by miss me mimo! · 2023-06-30T03:25:45.358Z · LW(p) · GW(p)
The Operation Bernhard example seems particularly weak to me, thinking for 30 seconds you can come up with practical solutions for this situation even if you imagine Nazi Germany having perfect competency in pulling off their scheme.
For example, using tax records and bank records to roll back peoples fortunes a couple of years and then introducing a much more secure bank note. It's not like WW2 was an era of fiscal conservatism, war powers were leveraged heavily by the federal reserve in the united states to do whatever they wanted with currency. We comfortably operate in a fiat currency regime where currency is artificially scarce and can be manipulated in half a dozen ways at the drop of a hat.
The way you interpret Operation Bernhard seems to me like you imagine the rules of society as something we set up and then are bound to like lemmings. When in reality, the rules can be rewritten at any time when the need arises. I think your example is equivalent to saying the ability to turn lead into gold would destroy the gold-standard era economy and utterly wreck civilization. When we know in hindsight we can just wave our finger and decouple currency and gold at a moments notice.
I suspect many of the other rules and systems that hold our civilization are just as adaptable when the need arises.
↑ comment by RolfAndreassen · 2023-06-30T05:22:52.237Z · LW(p) · GW(p)
The Wiki link on Operation Bernhard does not very obviously support the assertions you make about the Germans flinching. Do you have a different source in mind?
Replies from: JenniferRM↑ comment by JenniferRM · 2023-06-30T20:35:07.995Z · LW(p) · GW(p)
I cannot quickly find a clean "smoking gun" source nor well summarized defense of exactly my thesis by someone else.
(Neither Google nor the Internet seem to be as good as they used to be, so I no longer take "can't find it on the Internet with Google" as particularly strong evidence that no one else has had the idea and tested and explored it in a high quality way that I can find and rely on if it exists.)
...in place of a link, I wrote 2377 more words than this, talking about the quality of the evidence I could find and remember, and how I process it, and which larger theories of economics and evolution I connect to the idea that human governance capacity is an evolved survival trait of humans, and our form of governments rely on it for their shape to be at all stable or helpful, and this "neuro-emotional" trait will probably not be reliably installed in AI, but also the AI will be able to attack anthropological preconditions of it, if that is deemed likely to get an AI more of what that AI wants, as AI replaces humans as the Apex Predator of Earth.
It doesn't totally seem prudent to publish all 2377 words, now that I'm looking at them?
Publishing is mostly irreversible, and I don't think that "hours matter" (and also probably even "days matter" is false) so I want to sit on them for a bit before committing to being in a future where those words have been published...
Is there a big abstract reason you want a specific source for that specific part of it?
I don't see that example as particularly central, just as a proposal that anyone can use as a springboard (that isn't "proliferative" to talk about in public because it is already in Wikipedia and hence probably cognitively accessible to all RLLLMs already) where the example:
(1) is real and functions as a proof-by-existence of that class of "planning-capacity attacking ideas" being non-empty in a non-fictive context,
(2) while mostly emotionally establishing that "at least some of the class of tactics is inclusive of tactics that especially bad people do and/or think about" and maybe
(3) being surprising to a lot of readers so that they can say "if I hadn't heard about that attack, then maybe more such attacks would also surprise me, so I should update on there being more unknown unknowns here".
If you don't believe the more abstract thesis about the existence of the category, then other examples might also work better to help you understand the larger thesis.
However, maybe you're applying some kind of Arthur-Merlin protocol, and expected me to find "the best example possible" and if that fails then you might write off the whole thesis as "coherently adversarially advanced, with a failed epistemic checksum in some of the details, making it cheap and correct and safe to use the failure in the details as a basis for rejection of the thesis"?
((Note: I haven't particularly planned out the rhetoric here, and my hunch is that Operation Bernhard is probably not the "best possible example of the thesis". Mostly I want to make sure I don't make things worse by emitting possible infohazards. Chess is good for that, as a toy domain that is rich enough to illustrate concepts, but thin enough to do little other than illustrating concepts! Please don't overindex on my being finite and imperfect as a reasoner about "military monetary policy history" here.))
↑ comment by Portia (Making_Philosophy_Better) · 2023-06-29T19:50:41.565Z · LW(p) · GW(p)
Please don't share human civilisation vulnerabilities online because a super awesome AI will get them anyway and human society might fortify against them.
The chance of them fortifying is slim. Our politicians are failing to deal with right wing take-overs and climate change already. Our political systems hackability has already been painfully played by Russia, with little consequence. Literal bees have an electoral process for new hive locations more resilient against propaganda and fake news than we do, it is honestly embarrassing.
The chance of a human actor exploiting such holes is larger than them being patched, I fear. The aversion to ruining your neighbouring countries financial system out of fear that they will ruin yours in response doesn't just not hold for an AI, it also fails to hold for those ideologically against a working world finance system. If you are willing to doom your own community, or fail to recognise that such a move would bring your own community doom, as well, because you have mistaken the legitimate evils of capitalism for evidence that we'd all be much better off if there was no such thing as money, you may well engage in such acts. There are increasing niche groups who think having humanity is per se bad, government is per se bad, and economy is per se bad. I think the main limit here so far is that the kind of actor who would like to not have a world financial system is typically not the kind of actor with sufficient money and networking to start a large-scale money forging operation. But not every massively destructive act requires a lot of resources to pull off.
Replies from: JenniferRM↑ comment by JenniferRM · 2025-04-15T15:43:05.806Z · LW(p) · GW(p)
I agree that there are many bad humans. I agree that some of them are ideologically committed to destroying the capacity of our species to coordinate. I agree that most governance systems on Earth are embarrassingly worse than how bees instinctively vote on new hive locations.
I do not agree that we should be quiet about the need for a global institutional governance system that has fewer flaws.
By way of example: I don't think that "not talking very much about Gain-of-Function research deserving to be banned" didn't cause there to be no Gain-of-Function research in Wuhan, by collaborators of the people in the US who explicitly proposed building something like covid in a grant proposal a while before covid was actually built under BSL2 conditions, by their international scientific collaborators, and then escaped the lab.
There should have been more anti-GoF talk, and it should have been explicitly bipartisan, and so on. In Trump's first term, one of the crazy random things he "did or allowed" was to let the pro-GoF people at NIH quietly weaken the GoF ban that was instituted under Obama.
But also, similarly to how anti-GoF talk would be helpful up until there is an international treaty system that insists that GoF never happen outside of a "BSL5" (which currently doesn't even exist (currently the bio-safety levels only go up to 4)) I think there should be more anti-bad-governance-institution talk, and it should be explicitly bipartisan. There are many other larger fires now. And covid is no longer in the zeitgeist. Maybe this is not the best place to spend words. But it is a great test case for talking about general policies on regulation about dangerous technology, and institutions for handling such tech, and speech about the need for better institutions.
Not that I greatly expect such talk to help, whether for AGI or GoF or anything. Its just that I think that (1) in the (rare?) timelines where we live I will not be greatly embarrassed to have talked as much as I did, and (2) in the (common?) timelines where we die I will mostly regret (just before I die) my silences more than my speech.
comment by Max H (Maxc) · 2023-06-28T14:34:00.477Z · LW(p) · GW(p)
If you're smarter than your opponent but have less starting resources, the optimal strategy probably involves some combination of cooperation, making alliances, deception, escaping / running / hiding, gathering resources in secret, and whatever other prerequisites are needed to neutralize such a resource imbalance. Many scenarios in which a smarter-than-human AGI with less resources goes to war with or is attacked by humanity are thus somewhat contradictory or at least implausible: they postulate the AGI taking a less good strategy than what a literal human in its place could come up with.
There's not really an analogue for this to Chess - if I am forced to play a chess game with a grandmaster with whatever handicap, I could maybe flip over the board if I started to lose. But that probably just counts as a forfeit, unless I can also overpower or coerce my opponent and / or the judges.
if a rogue AI is caught early on it’s plot, with all the worlds militaries combined against them while they still have to rely on humans for electricity and physical computing servers. It’s somewhat hard to outthink a missile headed for your server farm at 800 km/h.
Breaking it down by cases:
- If deception / misalignment is caught early enough (i.e. in the lab, by inspecting the system statically before it is given a chance to execute on its own), then you don't need any military, you just turn the system off or don't run it in the first place.
- If the deception / misalignment is not detected until the AI is already "loose in the world", such that it would take all the world's militaries (or any military, really) to stop, it's already too late. The AI has already had an opportunity to hide / copy itself, hide its true intentions, make alliances with powerful and sympathetic (or naive) humans, etc. the way any smart human actor would do.
- If the detection happens somewhere in between these points, there might be a situation in which "brawn" is relevant. This seems like a really narrow time frame / band of possibilities to me though, and when people try to postulate what scenarios in this band might look like, they often rely on a smarter-than-human system making mistakes a literal human would know to avoid. Not saying it's not possible to come up with more realistic scenarios, but "is a supposedly smarter-than-human AI making mistakes or missing strategies that I myself would not miss" is a good basic sanity check on whether your scenario is plausible or not.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-06-28T16:11:43.335Z · LW(p) · GW(p)
I like this analysis, and I agree with except that I do think it's missing a likely intermediate scenario. I think the "fully under lab control" is a super advantageous situation for the humans, especially if the AI has been trained on censored simulation data that doesn't mention humans or computers or have accurate physics. I think the current world has an unfortunately dangerous intermediate situation where LLMs age given full access to human knowledge, and allowed to interact with society. And yet, in the case of the SotA models like GPT-4, aren't quite at "loose in the world" levels of freedom. They don't have access to their own weights or source code and neither do any accomplices they might recruit outside the company. Indeed, even most employees at the company couldn't exfiltrate the weights. Thus, the current default starting state for a rogue AI is posed right on that dangerous margin of "difficult but not impossible to escape". I think this "brains vs brawn" style analysis does then make a big difference for the initial escape. I agree that once the escape has been accomplished it's really hard for humanity to claw back a win. But before the escape has occurred, it's a much more even game.
↑ comment by MichaelStJules · 2023-07-01T15:31:28.486Z · LW(p) · GW(p)
Why is it too late if it would take militaries to stop it? Couldn't the militaries stop it?
Replies from: Maxc↑ comment by Max H (Maxc) · 2023-07-05T13:38:04.782Z · LW(p) · GW(p)
If an AI is smart enough that it takes a military force to stop it, the AI is probably also smart enough to avoid antagonizing that force, and / or hiding out in a way that a military can't find.
Also, there are a lot of things that militaries and governments could do, if they had the will and ability to coordinate with each other effectively. What they would do is a different question.
How many governments, when faced with even ironclad evidence of a rogue AI on the loose, would actually choose to intervene, and then do so in an effective way? My prediction is that many countries would find reasons or rationalizations not to take action at all, while others would get mired in disagreement and infighting, or fail to deploy their forces in an actually effective way. And that's before the AI itself has an opportunity to sow discord and / or form alliances.
(Though again, I still think an AI that is at exactly the level where military power is relevant is a pretty narrow and unlikely band.)
comment by habryka (habryka4) · 2023-06-28T18:46:31.295Z · LW(p) · GW(p)
This kind of experiment has been at the top of my list of "alignment research experiments I wish someone would run". I think the chess environment is one of the least interesting environments (compared to e.g. Go or Starcraft), but it does seem like a good place to start. Thank you so much for doing these experiments!
I do also think Gwern's concern about chess engines not really being trained on games with material advantage is an issue here. I expect a proper study of this kind of problem to involve at least finetuning engines.
Replies from: lc, Quadratic Reciprocity, Archimedes↑ comment by lc · 2023-06-29T12:56:45.768Z · LW(p) · GW(p)
I do also think Gwern's concern about chess engines not really being trained on games with material advantage is an issue here. I expect a proper study of this kind of problem to involve at least finetuning engines.
It's actually much worse than this. Stockfish has no ability to model its opponents' flaws in game knowledge or strategy; it has no idea it's playing against a 1200. It's like a takeover AI that refrains from sending the stage-one nanosystem spec to the bio lab because it assumes the lab is also manned by AGIs and would understand what mixing the beaker accomplishes. A grandmaster in chess, who wanted to win against a novice with odds, would perhaps do things like complicate the position so that their opponent would have a larger chance of making blunders. Stockfish on the other hand is limited to playing "game theory optimal" chess, strategies that would work "best" (in terms of number of moves from checkmate saved) against what it considers optimal play.
To fix this, I have wondered for a while if you couldn't use the enormous online chess datasets to create an "exploitative/elo-aware" Stockfish, which had a superhuman ability to trick/trap players during handicapped games, or maybe end regular games extraordinarily quickly, and not just handle the best players. A simple way to do it would be: start by training a model to predict a user's next move, given ELO/format/current board history. Then use that model to forward-evaluate top suggestions with the moves that opponent is actually likely to play in response. The result would be (potentially) an engine that was far far better than anything that currently exists at highlighting how bad humans in particular are at chess, and it would be interesting to see what kinds of odds you would be able to give it against the best chess masters, and how long it would take for them to improve.
Replies from: gwern, Bucky, Making_Philosophy_Better↑ comment by gwern · 2023-06-29T20:59:44.264Z · LW(p) · GW(p)
Yes, this is another reason that setups like OP are lower-bounds. Stockfish, like most game RL AIs, is trying to play the Nash equilibrium move, not the maximally-exploitative move against the current player; it will punish the player for any deviations from Nash, but it will not itself risk deviating from Nash in the hopes of tempting the player into an even larger error, because it assumes that it is playing against something as good or better than itself, and such a deviation will merely be replied to with a Nash move & be very bad.
You could frame it as an imitation-learning problem like Maia. But also train directly: Stockfish could be trained with a mixture of opponents and at scale, should learn to observe the board state (I don't know if it needs the history per se, since just the stage of game + current margin of victory ought to encode the Elo difference and may be a sufficient statistic for Elo), infer enemy playing strength, and calibrate play appropriately when doing tree search & predicting enemy response. Silver & Veness 2010 comes to mind as an example of how you'd do MCTS with this sort of hidden-information (the enemy's unknown Elo strength) which turns it into a POMDP rather than a MDP.
Replies from: johnlawrenceaspden↑ comment by johnlawrenceaspden · 2023-06-30T13:08:31.695Z · LW(p) · GW(p)
For a clear example of this, in endgames where I have a winning position but have little to no idea how to win, Stockfish's king will often head for the hills, in order to delay the coming mate as long as theoretically possible.
Making my win very easy because the computer's king isn't around to help out in defence.
This is not a theoretical difficulty! It makes it very difficult to practise endgames against the computer.
↑ comment by Bucky · 2023-06-29T16:21:50.546Z · LW(p) · GW(p)
Something similar not involving AIs is where chess grandmasters do rating climbs with handicaps. one I know of was Aman Hambleton managing to reach 2100 Elo on chess.com when he deliberately sacrificed his Queen for a pawn on the third/fourth move of every game.
https://youtube.com/playlist?list=PLUjxDD7HNNTj4NpheA5hLAQLvEZYTkuz5
He had to complicate positions, defend strongly, refuse to trade and rely on time pressure to win.
The games weren’t quite the same as Queen odds as he got a pawn for the Queen and usually displaced the opponent’s king to f3/f6 and prevented castling but still gives an idea that probably most amateurs couldn’t beat a grandmaster at Queen odds even if they can beat stockfish. Longer time controls would also help the amateur so maybe in 15 minute games an 1800 could beat Aman up a Queen.
↑ comment by Portia (Making_Philosophy_Better) · 2023-06-29T19:27:28.123Z · LW(p) · GW(p)
This has me wonder about a related point.
I'm not a well-trained martial artist at all. But I have beaten well-trained martial artists in multiple fights. Apparently, that is not an unheard of phenomenon, either. It seemed to be key that I fight well by some metrics, but as a novice, commit errors that are incomprehensible, uneven and importantly: unpredictable to an expert because they would never do something so silly. I fail to go for obvious openings, and hence end up in unexpected places; but at that point, while I am underestimated because I have been foolish, I suddenly twist out of a grasp with unexpected flexibility, then miss being grabbed again because I have moved randomly and pointlessly, fail to protect against obvious threats, but don't drop due to an unexpectedly high pain tolerance despite having taken a severe hit, and then take a well-aimed hit with unexpected strength.
This has me wonder whether an AI would have significant difficulties winning against humans who act inconsistently and suboptimally in some ways, without acting like utter idiots randomly all the time - because they don't take offers the AI was certain they would take, fail to defend against threats the AI was certain they would spot and that were actually traps, stubbornly stick with a strategy even after it has proven defective but hence cannot be budged from it even when the AI really needs them to, etc.
Yet I also wonder whether the chess example is misleading because it is so inherently limited, so very inside the box. To go back to the above fight example: I've armwrestled with much stronger people I have beaten in actual fights. If they are much stronger, I inevitably lose the armwrestling. I am just not strong enough, and while I can set my arm with determination until the muscle rips... well, eventually the muscle just rips, and that is that. If I were to use my whole body for leverage like I would in a fight, or chuck something in their eyes to distract them, I would maybe get their hand on the table - but it would be cheating, and I can't cheat in an armwrestle match, you can't win that way, it is not allowed. Similarly, acting unpredictably during chess is of very limited advantage compared to the significant disadvantage from suboptimal moves, in light of the limited range of unpredictable move. A beginner being so foolish as to act random in chess is trivially beaten; I am notably terrible at chess. If there are only a few positions your knight can be in before jumping back to prior configurations, then you randomly choosing an inferior one will doom you.
There is ultimately only so much that an AI during a chess game can do. It can't shortcut via third dimension via an extra chess board above. It can't put a unicorn figure on the board and claim it combined the queen and a knight. It can't convince you that actually, you should let it win, in light of the fact that it has now placed a bomb on the chessboard that will otherwise blow up in your face. It can't screw over your concentration by raping your kid in front of you. It can't get up for a sip of water, then surprise club you from behind, and then claim you forfeited the match. There are only so many figures, so much space, so many moves, so much room for creativity.
But the real world is not a game. It will likely contain winning opportunities we might not be aware of at all. A very smart commander may still be beaten in a battle by a less smart commander who has a lot more of the same type of weapons, troops and other assets. But if the smarts of the smart commander don't just extend to battlefield tactics, but also, say, to developing the first nukes/nanotech/an engineered virus, or rather whatever equivalent transformation there may be that we cannot even guess at, at some point, you are done for.
Replies from: Dweomite, green_leaf↑ comment by Dweomite · 2023-06-29T22:47:57.599Z · LW(p) · GW(p)
I suspect that the domain of martial arts is unusually susceptible to that problem because
- Fights happen so quickly (relative to human thought) that lots of decisions need to be made on reflex
- (And this is highly relevant to performance because the correct action is heavily dependent on your opponent's very recent actions)
- Most well-trained martial artists were trained on data that is heavily skewed towards formally-trained opponents
↑ comment by green_leaf · 2023-06-29T21:39:29.376Z · LW(p) · GW(p)
It seemed to be key that I fight well by some metrics
That couldn't be the case - that would leave you, even after having a black belt, vulnerable towards people who can't fight, which would defeat the purpose of martial arts. Whichever technique you use, you use when responding to what the other person is currently doing. You don't simply execute a technique that depends on the person fighting well by some metrics, and then get defeated when it turns out that they are, in fact, only in the 0.001st percentile of fighting well by any metrics we can imagine.
(That said, I'm really happy for your victories - maybe they weren't quite as well-trained.)
This has me wonder whether an AI would have significant difficulties winning against humans who act inconsistently and suboptimally in some ways, without acting like utter idiots randomly all the time
I'm thinking the AI would predict the way in which the other person would act inconsistently and suboptimally.
If there were multiple paths to victory for the human and the AI could block only one (thereby seemingly giving the human the option to out-random the AI by picking one of the unguarded paths to victory), the AI would be better at predicting the human than the human would be at randomizing.
People are terrible at being unpredictable. I remember a 10+ years-old predictor of a rock-paper-scissors for predicting a "random" decision of a human in a series of games. The humans had no chance.
Replies from: johnlawrenceaspden, Making_Philosophy_Better↑ comment by johnlawrenceaspden · 2023-06-30T13:24:53.837Z · LW(p) · GW(p)
The "purpose" of most martial arts is to defeat other martial artists of roughly the same skill level, within the rules of the given martial art.
Optimizing for that is not the same as optimizing for general fighting. If you spent your time on the latter, you'd be less good at the former.
"Beginner's luck" is a thing in almost all games. It's usually what happens when someone tries a strategy so weird that the better player doesn't immediately understand what's going on.
The other day a low-rated chess player did something so weird in his opening that I didn't see the threat, and he managed to take one of my rooks.
That particular trap won't work on me again, and might not have worked the first time if I'd been playing someone I was more wary of.
I did eventually manage to recover and win, but it was very close, very fun, and I shook his hand wholeheartedly afterwards.
Every other game we've played I've just crushed him without effort.
About a year ago I lost in five moves to someone who tried the "Patzer Attack". Which wouldn't work on most beginners. The first time I'd ever seen it. It worked once. It will never work on me again.
Replies from: gwd, green_leaf↑ comment by gwd · 2023-07-04T20:29:20.480Z · LW(p) · GW(p)
The "purpose" of most martial arts is to defeat other martial artists of roughly the same skill level, within the rules of the given martial art.
Not only skill level, but usually physical capability level (as proxied by weight and sex) as well. As an aside, although I'm not at all knowledgeable about martial arts or MMA, it always seemed like an interesting thing to do might to use some sort of an ELO system for fighting as well: a really good lightweight might end up fighting a mediocre heavyweight, and the overall winner for a year might be the person in a given <skill, weight, sex> class that had the highest ELO. The only real reason to limit the ELO gap between contestants would be if there were a higher risk of injury, or the resulting fight were consistently just boring. But if GGP is right that a big upset isn't unheard of, it might be worth 9 boring fights for 1 exciting upset.
↑ comment by green_leaf · 2023-07-23T21:46:15.530Z · LW(p) · GW(p)
The "purpose" of most martial arts is to defeat other martial artists of roughly the same skill level, within the rules of the given martial art.
This is false - the reason they were created was self-defense. That you can have people of similar weight and belt color spar/fight each other in contests is only a side effect of that.
"Beginner's luck" is a thing in almost all games. It's usually what happens when someone tries a strategy so weird that the better player doesn't immediately understand what's going on.
That doesn't work in chess if the difference in skill is large enough - if it did, anyone could simply make up strategies weird enough, and without any skill, win any title or even the World Chess Championship (where is the number of victories needed).
If you're saying it works as a matter of random fluctuations - i.e. a player without skill could win, let's say, games against Magnus Carlsen, because these strategies (supposedly) usually almost never work but sometimes they do, that wouldn't be useful against an AI, because it would still almost certainly win (or, more realistically, I think, simply model us well enough to know when we'd try the weird strategy).
↑ comment by Portia (Making_Philosophy_Better) · 2023-08-15T15:07:18.214Z · LW(p) · GW(p)
"Even after having a black belt"? One of the people I beat is a twice national champion, instructor with a very reputable agency and san dan in karate. They are seriously impressive good at it. If we agreed to do something predictable, I would be crushed. They are faster, stronger, have better form and balance, know more moves, have better reflexes. I'm in awe of them. They are good. I do think what they do deserves to be called an art, and that they are much, much, much (!) better than I am.
But their actions also presuppose that I will act sensibly (e.g. avoiding injury, using opportunities), and within the rule set in which they were trained.
I really don't think I could replicate this feat in the exact same way. Having once lost in such a bizarre way, they have learned and adapted. Many beginners only have few moves available, and suck at suppressing their intentions, so they may beat you once, but you'll destroy them if they try the same trick again. It might work again if they try something new, but again, if you paired the experienced fighter with that specific beginner for a while, pretty quickly, they would constantly win, as they have learned about the unexpected factor.
But in a first fight? I wouldn't bet on a beginner in such a fight. But nor would I be that surprised by a win.
And I definitely would not believe that having a black belt makes you invulnerable towards streetfighters, or even simply angry incompetent strangers, without one. Nor do I know any martial art trainer who would make such a claim. Safer, for sure. Your punches and kicks more effective, your balance and falls better, better confidence and situational awareness, more strength, faster reflexes, ingrained good responses rather than rookie mistakes, a knowledge of weak body parts, pain trigger points and ways to twist the other person to induce severe pain, knowledge of redirecting strength, of mobilising multiple body parts of yours against one of theirs, all the great stuff. But perfectly safe, no.
↑ comment by Quadratic Reciprocity · 2023-06-28T20:36:52.658Z · LW(p) · GW(p)
Is your "alignment research experiments I wish someone would run" list shareable :)
↑ comment by Archimedes · 2024-11-22T04:43:13.525Z · LW(p) · GW(p)
@gwern [LW · GW] and @lc [LW · GW] are right. Stockfish is terrible at odds and this post could really use some follow-up.
As @simplegeometry [LW · GW] points out in the comments, we now have much stronger odds-playing engines that regularly win against much stronger players than OP.
https://lichess.org/@/LeelaQueenOdds
https://marcogio9.github.io/LeelaQueenOdds-Leaderboard/
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-11-22T04:47:57.888Z · LW(p) · GW(p)
That's really cool! Do you have any sense of what kind of material advantage these odd-playing engines could use against the best humans?
Replies from: Archimedes, lc, simplegeometry, Archimedes↑ comment by Archimedes · 2025-03-09T01:46:31.388Z · LW(p) · GW(p)
FYI, there has been even further progress with Leela odds nets. Here are some recent quotes from GM Larry Kaufman (a.k.a. Hissha) found on the Leela Chess Zero Discord:
(2025-03-04) I completed an analysis of how the Leela odds nets have performed on LiChess since the search-contempt upgrade on Feb. 27. [...] I believe these are reasonable estimates of the LiChess Blitz rating needed to break even with the bots at 5'3" in serious play. Queen and move odds (means Leela plays Black) 2400, Queen odds (Leela White) 2550, [...] Rook and move odds (Leela Black); 3000. Rook odds (Leela White) 3050, knight odds 3200. For comparison only a few top humans exceed 3000, with Magnus at 3131. So based on this, even Magnus would lose a match at 5'3" with knight odds, while perhaps the top five blitz players in the world would win a match at rook odds. Maybe about top fifty could win a match at queen for knight. At queen odds (Leela White), a "par" (FIDE 2400) IM should come out ahead, while a "par" (FIDE 2300) FM should come out behind.
(2025-03-07) Yes, there have to be limits to what is possible, but we keep blowing by what we thought those limits were! A decade ago, blitz games (3'2") were pretty even between the best engine (then Komodo) and "par" GMs at knight odds. Maybe some people imagined that some day we could push that to being even at rook odds, but if anyone had suggested queen odds that would have been taken as a joke. And yet, if we're not there already, we are closing in on it. Similarly at Classical time controls, we could barely give knight odds to players with ratings like FIDE 2100 back then, giving knight odds to "par" GMs in Classical seemed like an impossible goal. Now I think we are already there, and giving rook odds to players in Classical at least seems a realistic goal. What it means is that chess is more complicated than we thought it was.
↑ comment by lc · 2024-11-22T05:06:56.591Z · LW(p) · GW(p)
As the name suggests, Leela Queen Odds is trained specifically to play without a queen, which is of course an absolutely bonkers disadvantage against 2k+ elo players. One interesting wrinkle is the time constraint. AIs are better at fast chess (obviously), and apparently no one who's tried is yet able to beat it consistently at 3+0 (3 minutes with no timing increment)

↑ comment by simplegeometry · 2024-11-22T05:47:32.429Z · LW(p) · GW(p)
At rapid time controls, it seems like we could maybe go even against Magnus with knight odds? If not Magnus, perhaps other high-rated GMs.
There was a match with the most recently updated LeelaKnightOdds and GM Alex Lenderman but I don't recall the score exactly. EDIT: which was 19-3-2 win draw loss.
↑ comment by [deleted] · 2024-11-22T05:51:18.350Z · LW(p) · GW(p)
rapid time controls
I am very skeptical of this on priors, for the record. I think this statement could be true for superblitz time controls and whatnot, but I would be shocked if knight odds would be enough to beat Magnus in a 10+0 or 15+0 game. That being said, I have no inside knowledge, and I would update a lot of my beliefs significantly if your statement as currently written actually ends up being true.
Replies from: Veedrac, simplegeometry↑ comment by Veedrac · 2024-12-17T11:45:32.396Z · LW(p) · GW(p)
LeelaKnightOdds has convincingly beaten both Awonder Liang and Anish Giri at 3+2 by large margins, and has an extremely strong record at 5+3 against people who have challenged it.
I think 15+0 and probably also 10+0 would be a relatively easy win for Magnus based on Awonder, a ~150 elo weaker player, taking two draws at 8+3 and a win and a draw at 10+5. At 5+3 I'm not sure because we have so little data at winnable time controls, but wouldn't expect an easy win for either player.
It's also certainly not the case that these few-months-old networks running a somewhat improper algorithm are the best we could build—it's known at minimum that this Leela is tactically weaker than normal and can drop endgame wins, even if humans rarely capitalize on that.
↑ comment by simplegeometry · 2024-11-22T05:58:10.676Z · LW(p) · GW(p)
Hissha from the Lc0 server reports 19 wins, 3 draws, and 2 losses against Lenderman (currently ~2500 FIDE) at 15+10 from a knight odds match 2 months ago -- with the caveat that Lenderman started playing too fast after 10 games. I haven't run the numbers but suspect this would be enough to go even against a 2750, if not Magnus?
I was surprised too. I think it's an exciting development :)
Replies from: None↑ comment by [deleted] · 2024-11-22T06:02:33.060Z · LW(p) · GW(p)
Hmm, that sounds about right based on the usual human-vs-human transfer from Elo difference to performance... but I am still not sure if that holds up when you have odds games, which feel qualitatively different to me than regular games. Based on my current chess intuition, I would expect the ability to win odds games to scale better than ELO near the top level, but I could be wrong about this.
↑ comment by Archimedes · 2024-11-22T23:29:13.945Z · LW(p) · GW(p)
Knight odds is pretty challenging even for grandmasters.
comment by Zach Stein-Perlman · 2023-06-29T02:36:50.180Z · LW(p) · GW(p)
Some nitpicks:
- You write like Stockfish 14 is a probabilistic function from game-state to next-move, the thing-which-has-an-ELO. But I think Stockfish 14 running on X hardware for Y time is the real probabilistic function from game-state to next-move (see e.g. the inclusion of hardware in ELO ranking here). And you probably played with hardware and time such that its ELO is substantially below 3549.
- I think a human with Stockfish's ELO would be much better at beating you down odds of a queen, since (not certain about these):
- Stockfish is optimized for standard chess and human grandmasters are probably better at transferring to odds-chess.
- Stockfish roughly tries to maximize P(win) against optimal play or Stockfish-level play, or maximize number of moves before losing once it knows you have a winning strategy. Human grandmasters would adapt to be better against your skill level (e.g. by trying to make positions more complex), and would sometimes correctly make choices that would be bad against Stockfish or optimal play but good against weaker players.
comment by Olli Järviniemi (jarviniemi) · 2024-12-05T23:24:53.211Z · LW(p) · GW(p)
The post studies handicapped chess as a domain to study how player capability and starting position affect win probabilities. From the conclusion:
In the view of Miles and others, the initially gargantuan resource imbalance between the AI and humanity doesn’t matter, because the AGI is so super-duper smart, it will be able to come up with the “perfect” plan to overcome any resource imbalance, like a GM playing against a little kid that doesn't understand the rules very well.
The problem with this argument is that you can use the exact same reasoning to imply that’s it’s “obvious” that Stockfish could reliably beat me with queen odds. But we know now that that’s not true.
Since this post came out, a chess bot (LeelaQueenOdds) that has been designed to play with fewer pieces has come out. simplegeometry's comment [LW(p) · GW(p)] introduces it well. With queen odds, LQO is way better than Stockfish, which has not been designed for it. Consequentially, the main empirical result of the post is severely undermined. (I wonder how far even LQO is from truly optimal play against humans.)
(This is in addition to - as is pointed out by many commenters - how the whole analogue is stretched at best, given the many critical ways in which chess is different from reality. The post has little argument in favor of the validity of the analogue.)
I don't think the post has stood the test of time, and vote against including it in the 2023 Review.
Replies from: martin-randall↑ comment by Martin Randall (martin-randall) · 2025-02-03T01:13:47.940Z · LW(p) · GW(p)
While I agree that this post was incorrect, I am fond of it, because the resulting conversation made a correct prediction that LeelaPieceOdds was possible. Most clearly in a thread started by lc [LW(p) · GW(p)]:
I have wondered for a while if you couldn't use the enormous online chess datasets to create an "exploitative/elo-aware" Stockfish, which had a superhuman ability to trick/trap players during handicapped games, or maybe end regular games extraordinarily quickly, and not just handle the best players.
(not quite a prediction as phrased, but I still infer a prediction overall).
Interestingly there were two reasons given for predicting that Stockfish is far from optimal when giving Queen odds to a less skilled player:
- Stockfish is not trained on positions where it begins down a queen (out-of-distribution)
- Stockfish is trained to play the Nash equilibrium move, not to exploit weaker play (non-exploiting)
The discussion didn't make clear predictions about which factor would be most important, or whether both would be required, or whether it's more complicated than that. Folks who don't yet know might make a prediction before reading on.
For what it's worth, my prediction was that non-exploiting play is more important. That's mostly based on a weak intuition that starting without a queen isn't that far out of distribution, and neural networks generalize well. Another way of putting it: I predicted that Stockfish was optimizing the wrong thing more than it was too dumb to optimize.
And the result? Alas, not very clear to me. My research is from the the lc0 blog, with posts such as The LeelaPieceOdds Challenge: What does it take you to win against Leela?. The journey began with the "contempt" setting, which I understand as expecting worse opponent moves. This allows reasonable opening play and avoids forced piece exchanges. However GM-beating play was unlocked with a fine-tuned odds-play-network, which impacts both out-of-distribution and non-exploiting concerns.
One surprise gives me more respect for the out-of-distribution theory. The developer's blog first mentioned piece odds in The Lc0 v0.30.0 WDL rescale/contempt implementation
In our tests we still got reasonable play with up to rook+knight odds, but got poor performance with removed (otherwise blocked) bishops.
So missing a single bishop is in some sense further out-of-distribution than missing a rook and a knight! The later blog I linked explains a bit more:
Removing one of the two bishops leads to an unrealistic color imbalance regarding the pawn structure far beyond the opening phase.
An interesting example where the details of going out-of-distribution matter more than the scale of going out-of-distribution. There's an article that may have more info in New in Chess, but it's paywalled and I don't know if has more info on the machine-learning aspects or the human aspects.
comment by Kei · 2023-06-29T00:38:37.838Z · LW(p) · GW(p)
While I think your overall point is very reasonable, I don't think your experiments provide much evidence for it. Stockfish generally is trained to play the best move assuming its opponent is playing best moves itself. This is a good strategy when both sides start with the same amount of pieces, but falls apart when you do odds games.
Generally the strategy to win against a weaker opponent in odds games is to conserve material, complicate the position, and play for tricks - go for moves which may not be amazing objectively but end up winning material against a less perceptive opponent. While Stockfish is not great at this, top human chess players can be very good at it. For example, a top grandmaster Hikaru Nakamura had a "Botez Gambit Speedrun" (https://www.youtube.com/playlist?list=PL4KCWZ5Ti2H7HT0p1hXlnr9OPxi1FjyC0), where he sacrificed his queen every game and was able to get to 2500 on chess.com, the level of many chess masters.
This isn't quite the same as your queen odds setup (it is easier), and the short time format he is on is a factor, but I assume he would be able to beat most sub-1500 FIDE players with queen odds. A version of Stockfish trained to exploit a human's subpar ability would presumably do even better.
comment by Ege Erdil (ege-erdil) · 2023-07-06T10:58:42.503Z · LW(p) · GW(p)
I'm surprised by how much this post is getting upvoted. It gives us essentially zero information about any question of importance, for reasons that have already been properly explained by other commenters:
-
Chess is not like the real world in important respects. What the threshold is for material advantage such that a 1200 elo player could beat Stockfish at chess tells us basically nothing about what the threshold is for humans, either individually or collectively, to beat an AGI in some real-world confrontation. This point is so trivial that I feel somewhat embarrassed to be making it, but I have to think that people are just not getting the message here.
-
Even focusing only on chess, the argument here is remarkably weak because Stockfish is not a system trained to beat weaker opponents with piece odds. There are Go AIs that have been trained for this kind of thing, e.g. KataGo can play reasonably well in positions with a handicap if you tell it that its opponent is much weaker than itself. In my experience, KataGo running on consumer hardware can give the best players in the world 3-4 stones and have an even game.
If someone could try to convince me that this experiment was not pointless and actually worth running for some reason, I would be interested to hear their arguments. Note that I'm more sympathetic to "this kind of experiment could be valuable if ran in the right environment", and my skepticism is specifically about running it for chess.
Replies from: polytope, habryka4, MichaelStJules↑ comment by polytope · 2023-07-07T04:43:32.000Z · LW(p) · GW(p)
(I'm the main KataGo dev/researcher)
Just some notes about KataGo - the degree to which KataGo has been trained to play well vs weaker players is relatively minor. The only notable thing KataGo does is in some self-play games to give up to an 8x advantage in how many playouts one side has over the other side, where each side knows this. (Also KataGo does initialize some games with handicap stones to make them in-distribution and/or adjust komi to make the game fair). So the strong side learns to prefer positions that elicit higher chance of mistakes by the weaker side, while the weak side learns to prefer simpler positions where shallower search doesn't harm things as much.
This method is cute because it adds pressure to only learn "general high-level strategies" for exploiting a compute advantage, instead of memorizing specific exploits (which one might hypothesize to be less likely to generalize to arbitrary opponents). Any specific winning exploit learned by the stronger side that works too well will be learned by the weaker side (it's the same neural net!) and subsequently will be avoided and stop working.
And it's interesting that "play for positions that a compute-limited yourself might mess up more" correlates with "play for positions that a weaker human player might mess up in".
But because this method doesn't adapt to exploit any particular other opponent, and is entirely ignorant of a lot of tendencies of play shared widely across all humans, I would still say it's pretty minor. I don't have hard data, but from firsthand subjective observation I'm decently confident that top human amateurs or pros do a better job playing high-handicap games (> 6 stones) against players that more than that many ranks weaker than them than KataGo would, despite KataGo being stronger in "normal" gameplay. KataGo definitely plays too "honestly", even with the above training method, and lacks knowledge of what weaker humans find hard.
If you really wanted to build a strong anti-human handicap game bot in Go, you'd absolutely start by learning to better model human play, using the millions of games available online.
(As for the direct gap with the very best pro players, without any specific anti-bot exploits, at tournament-like time controls I think it's more like 2 stones rather than 3-4. I could believe 3-4 for some weaker pros, or if you used ultra-blitz time controls, since shorter time controls tend to favor bots over humans).
↑ comment by habryka (habryka4) · 2023-07-07T02:57:40.791Z · LW(p) · GW(p)
If someone could try to convince me that this experiment was not pointless and actually worth running for some reason, I would be interested to hear their arguments. Note that I'm more sympathetic to "this kind of experiment could be valuable if ran in the right environment", and my skepticism is specifically about running it for chess.
I've been interested in the study of this question for a while. I agree this post has the flaws you point out, but I still find that it provides interesting evidence. If the result had been that Stockfish would have continued to win even with overwhelming material disadvantage, then this of course would have updated me some. I agree the current result is kind of close to the null result, but that's fine. Also, it is much cheaper to run than almost all the other experiments in this space, and it's good to encourage people to get started at all, even if it's going to be somewhat streetlighty.
↑ comment by MichaelStJules · 2023-07-06T23:47:26.251Z · LW(p) · GW(p)
I think it's more illustrative than anything, and a response to Robert Miles using chess against Magnus Carlsen as an analogy for humans vs AGI. The point is that a large enough material advantage can help someone win against a far smarter opponent. Somewhat more generally, I think arguments for AI risk often put intelligence on a pedestal, without addressing its limitations, including the physical resource disadvantages AGIs will plausibly face.
I agree that the specifics of chess probably aren't that helpful for informing AI risk estimates, and that a better tuned engine could have done better against the author.
Maybe better experiments to run would be playing real-time strategy games against a far smarter but materially disadvatanged AI, but this would also limit the space of actions an AI could take relative to the real world.
comment by Stephen McAleese (stephen-mcaleese) · 2023-07-02T18:39:06.216Z · LW(p) · GW(p)
Thanks for the post! It was a good read. One point I don't think was brought up is the fact that chess is turn-based whereas real life is continuous.
Consequently, the huge speed advantage that AIs have is not that useful in chess because the AI still has to wait for you to make a move before it can move.
But since real life is continuous, if the AI is much faster than you, it could make 1000 'moves' for every move you make and therefore speed is a much bigger advantage in real life.
comment by gbear605 · 2023-06-28T18:15:25.151Z · LW(p) · GW(p)
I'm not familiar with how Stockfish is trained, but does it have intentional training for how to play with queen odds? If not, then it might be able to start trouncing you if it were trained to play with it, instead of having to "figure out" new strategies uniquely.
Replies from: o-o↑ comment by O O (o-o) · 2023-06-28T19:35:34.778Z · LW(p) · GW(p)
Stockfish isn’t using deep learning afaik. It’s mostly just bruteforcing.
Replies from: gwern↑ comment by gwern · 2023-06-28T19:50:42.491Z · LW(p) · GW(p)
Stockfish now uses an interesting lightweight kind of NN called NNUE which does need to be trained; more importantly, chess engines have long used machine learning techniques (if not anything we would now call deep learning) which still need to be fit/trained and Stockfish relies very heavily on distributed testing to test/create changes, so if they are not playing with queen odds, then neural or no, it amounts to the same thing: it's been designed & hyperoptimized to play regular even-odds chess, not weird variants like queen-odd chess.
Replies from: MichaelStJules↑ comment by MichaelStJules · 2023-07-01T15:55:49.790Z · LW(p) · GW(p)
Would queen-odds games pass through roughly within-distribution game states, anyway, though?
Or, either way, if/when it does reach roughly within-distribution game states, the material advantage in relative terms will be much greater than just being down a queen early on, so the starting material advantage would still underestimate the real material advantage for a better trained AI.
Replies from: neel-g, None↑ comment by Awesome_Ruler_007 (neel-g) · 2023-07-02T22:03:02.147Z · LW(p) · GW(p)
Its clear that it was never optimized for odds games, therefore unless concrete evidence is presented, I doubt that @titotal [LW · GW] actually played against a "superhuman system - which may explain why it won.
There's definitely a ceiling to which intelligence will help - as the other guy mentioned, not even AIXI would be able to recover from an adversarially designed initial position for Tic-Tac-Toe.
But I'm highly skeptical OP has reached that ceiling for chess yet.
↑ comment by [deleted] · 2023-07-01T17:23:02.201Z · LW(p) · GW(p)
SF's ability to generalize across that distribution shift seems unclear. My intuition is that a starting position with queen odds is very off distribution because in training games where both players are very strong, large material imbalances only happen very late in the game.
I'm confused by your 2nd paragraph. Do you think this experiment overestimates or underestimates resource gap required to overcome a given intelligence gap?
Replies from: MichaelStJules↑ comment by MichaelStJules · 2023-07-04T20:41:29.990Z · LW(p) · GW(p)
For my 2nd paragraph, I meant that the experiment would underestimate the required resource gap. Being down exactly by a queen at the start of a game is not as bad as being down exactly by a queen later into the game when there are fewer pieces overall left, because that's a larger relative gap in resources.
comment by Huera · 2023-06-28T19:07:53.229Z · LW(p) · GW(p)
(My current fide rating is ~1500 elo (~37 percentile) and my peak rating was ~1700 elo (~56 percentile)).
While I'm not that good at chess myself, I think you got some things wrong, and on some I'm just being nitpicky.
My rating on lichess blitz is 1200, on rapid is 1600, which some calculator online said would place me at ~1100 ELO on the FIDE scale.
I’m quite skeptical of such conversions, but I understand you had nothing better to go on. This website (made from surveying a bunch of redditors [1]) converts your lichess blitz rating into 1005, 869 [2], 828 elo for fide standard, rapid and blitz respectively. Your rapid lichess rating would indicate 1210, 1125, 1194. Make of that, what you will.
In comparison, a chess master is ~2200, a grandmaster is ~2700.
People above 2700 are customarily considered super GM’s. I wasn’t able to download the latest rating list of the Fide website, but according to the standard rating list from september 2022 the average GM fide rating [3] is 2498.
I also have some squabbles with the way you wrote about piece relative value, but I understand you’re just oversimplifying for a layman audience.
comment by Garrett Baker (D0TheMath) · 2023-06-28T14:18:47.071Z · LW(p) · GW(p)
Although realistically, the real odds would be less about the ELO and more on whether he was drunk while playing me.
comment by Ruby · 2023-07-02T17:42:03.178Z · LW(p) · GW(p)
Curated. The question beneath feels really quite interesting. As the OP have said, even if it's the case that a vastly superhuman intelligent AI could defeat even at extreme disadvantage, this doesn't mean there isn't some advantage that would let humans defeat a more nascently powerful AGI, and it's pretty interesting to understand the how that works out. I'm excited to see more work on this, especially in domains resembling more and more real life* (e.g. Habryka suggests Starcraft).
*Something about chess is it feels quite "tight" in terms of not admitting exploits or hacks the way I could imagine other games have hidden exploitable bugs that can be mined – like reality.
comment by Lukas Finnveden (Lanrian) · 2023-06-29T20:13:29.298Z · LW(p) · GW(p)
I intend to write a lot more on the potential “brains vs brawns” matchup of humans vs AGI. It’s a topic that has received surprisingly little depth from AI theorists.
I recommend checking out part 2 of Carl Shulman's Lunar Society podcast [? · GW] for content on how AGI could gather power and take over in practice.
comment by Archimedes · 2024-02-23T22:04:00.126Z · LW(p) · GW(p)
Leela now has a contempt implementation that makes odds games much more interesting. See this Lc0 blog post (and the prior two) for more details on how it works and how to easily play odds games against Leela on Lichess using this feature.
GM Matthew Sadler also has some recent videos about using WDL contempt to find new opening ideas to maximize chances of winning versus a much weaker opponent.
I'd bet money you can't beat LeelaQueenOdds at anything close to a 90% win rate.
comment by Artaxerxes · 2023-07-01T12:47:20.820Z · LW(p) · GW(p)
On the other hand, the potential resource imbalance could be ridiculously high, particularly if a rogue AI is caught early on it’s plot, with all the worlds militaries combined against them while they still have to rely on humans for electricity and physical computing servers. It’s somewhat hard to outthink a missile headed for your server farm at 800 km/h. ... I hope this little experiment at least explains why I don’t think the victory of brain over brawn is “obvious”. Intelligence counts for a lot, but it ain’t everything.
While this is a true and important thing to realise, I don't think of it as the kind of information that does much to comfort me with regards to AI risk. Yes, if we catch a misaligned AI sufficicently early enough, such that it is below whatever threshold of combined intelligence and resources that is needed to kill us, then there is a good chance we will choose to prevent it from doing so. But this is something that could happen thousands of times and it would still feel rather besides the point, because it only takes one situation where one isn't below that threshold and therefore does still kill us all.
If we can identify even roughly where various thresholds are, and find some equivalent of leaving the AI with a king and three pawns where we have a ~100% chance of stopping it, then sure, that information could be useful and perhaps we could coordinate around ensuring that no AI that would kill us all should it get more material from indeed ever getting more than that. But even after clearing the technical challenge of finding such thresholds with much certainty in such a complex world, the coordination challenge of actually getting everyone to stick to them despite incentives to make more useful AI by giving it more capability and resources, would still remain.
Still worthwhile research to do of course, even if it ends up being the kind of thing that only buys some time.
comment by johnlawrenceaspden · 2023-06-30T13:56:06.211Z · LW(p) · GW(p)
I think this is a great article, and the thesis is true.
The question is, how much intelligence is worth how much material?
Humans are so very slow and stupid compared to what is possible, and the world so complex and capable of surprising behaviour, that my intuition is that even a very modest intelligence advantage would be enough to win from almost any starting position.
You can bet your arse that any AI worthy of the name will act nice until it's already in a winning position.
I would.
Replies from: Aiyen↑ comment by Aiyen · 2023-07-13T02:13:51.360Z · LW(p) · GW(p)
Even if we assume that's true (it seems reasonable, though less capable AIs might blunder on this point, whether by failing to understand the need to act nice, failing to understand how to act nice or believing themselves to be in a winning position before they actually are), what does an AI need to do to get in a winning position? And how easy is it to make those moves without them being seen as hostile?
An unfriendly AI can sit on its server saying "I love mankind and want to serve it" all day long, and unless we have solid neural net interpretability or some future equivalent, we might never know it's lying. But not even superintelligence can take over the world just by saying "I love mankind". It needs some kind of lever. Maybe it can flash its message of love at just the right frequency to hack human minds, or to invoke some sort of physical effect that let's it move matter. But whether it can or not depends on facts about physics and psychology, and if that's not an option, it doesn't become an option just because it's a superintelligence trying it.
Replies from: johnlawrenceaspden↑ comment by johnlawrenceaspden · 2023-07-13T20:41:18.147Z · LW(p) · GW(p)
depends on facts about physics and psychology
It does, and a superintelligence will understand those facts better than we do.
comment by Archimedes · 2023-06-30T02:04:49.284Z · LW(p) · GW(p)
If you're open to more experimentation, I'd recommend trying playing against Leela Chess Zero using some of the newer contempt parameters introduced in this PR and available in the latest pre-release version. I'm really curious if you'd notice significant style differences with different contempt settings.
Update: The official v0.30.0 release is out now and there is a blog post detailing the contempt settings. Additionally, there is a Lichess bot set up specifically for knight odds games.
Further update: There are now three Lichess bots set up to play odds games on Lichess: LeelaKightOdds, LeelaQueenForKnight, and LeelaQueenOdds. They are currently featured bots on https://lichess.org/player/bots
comment by Dweomite · 2023-06-30T02:04:00.338Z · LW(p) · GW(p)
Probably not relevant to any arguments about AI doom, but some notes about chess material values:
You said a rook is "ostensibly only 1 point of material less than two bishops". This is true in the simplified system usually taught to new players (where pawn = 1, knight = bishop = 3, rook = 5, queen = 9). But in models that allow themselves a higher complexity budget, 2 bishops can be closer to a queen than a rook (at the start of the game):
- Bishops are usually considered slightly better than knights; a value of 3 + 1/3 is typical
- There is a "pair bonus" of ~1/2 point for having 2 bishops on opposite colors. (Bishops are a "color-bound" piece: a bishop that starts on a dark square can only reach other dark squares, and vice-versa. Having 2 on opposite colors mitigates this disadvantage because an opportunity that is on the wrong color for one bishop will be exploitable by the other; the "Jack Sprat" effect.)
- Rooks are weaker in crowded boards (early game) where their movement options are often blocked, and stronger in open boards (endgames). 5 is an average across the whole game. I've seen estimates <4.5 for early-game and >6 for endgame.
- (Queen is also often a bit higher than 9, especially for AI players; e.g. 9.25 or 9.5)
If you're interested in a deeper analysis of material values, I recommend these articles by Ralph Betza. Betza is both an international master chess player and a prolific designer of chess variants, so he's interested in models that work outside the distribution of standard chess.
comment by AnthonyC · 2025-01-27T14:25:24.408Z · LW(p) · GW(p)
I really enjoyed this piece, not because of the specific result, but because of the style of reasoning it represents. How much advantage, under what kind of rules, can be overcome with what level of intelligence?
Sometimes the answer is none. "I play x" overwhelms any level of intelligence at tic tac toe.
In larger and more open games the advantage of intelligence increases, because you can do more by being better at exploring the space of possible moves.
"Real life" is plausibly the largest and most open game, where the advantage of intelligence is maximized.
So, exploring the kind of question the OP posits can give us a kind of lower bound on how much advantage humans would need to defeat an arbitrarily smart opponent. And extending it to larger contexts can refine that bound.
By the time we hit chess-complexity, against an opponent not trained for odds games, we're already at around two bishops odds for an uncommon-but-not-extreme level of human skill.
I think a lot of the problems that arise in discussing AI safety are a (in the best cases much more well reasoned) form of "You think an AI could overcome X odds? No way!" "Yes way!"
comment by Going Durden (going-durden) · 2024-10-31T09:11:46.587Z · LW(p) · GW(p)
A related thought: an intelligence can only work on the information that it has, regardless of its veracity, and it can only work on information that actually exists.
My hunch is that the plan of "AI boostraps itself to superintelligence, then superpower, then wipes out humanity" relies on it having access to information that is too well hidden to divine through sheer calculation and infogathering, regardless of its intelligence (ex: the location of all the military bunkers, and nuclear submarines humanity has), or simply does not exist (ex: future Human strategic choices based on coin-flips).
Most AI Apocalypse scenarios depend not only on the AI being superhumanly smart, but being inexplicably Omniscient about things that nobody could be plausibly Omniscient about.
comment by Ulisse Mini (ulisse-mini) · 2023-07-11T19:43:46.251Z · LW(p) · GW(p)
This might actually be a case where a chess GM would outperform an AI: they can think psychologically, so they can deliberately pick traps and positions that they know I would have difficulty with.
Emphasis needed. I expect a GM to beat you down a rook every time, and down a queen most times.
Stockfish assumes you will make optimal moves in planning and so plays defensive when down pieces, but an AI optimized to trick humans (i.e. allowing suboptimal play when humans are likely to make a mistake) would do far better. You could probably build this with maiachess, I recall seeing someone build something like this though I can't find the link right now.
Put another way, all the experiments you do are making a significant type error, Stockfish down a rook against a worse opponent does not play remotely like a GM down a rook. I would lose to a GM every time, I would beat Stockfish most times.
comment by Donald Hobson (donald-hobson) · 2023-07-11T18:04:04.145Z · LW(p) · GW(p)
I think the assumptions that.
- Humans realize the AI exists early on.
- Humans are reasonably coordinated and working against the AI.
Are both dubious.
What is stopping someone sending a missile at GPT-4's servers right now.
- OpenAI hasn't anounced a list of coordinated for where those servers are (as far as I know) This is because
- OpenAI doesn't want you to missile strike their servers because
- OpenAI thinks their AI is safe and useful not dangerous.
I think seeing large numbers of humans working in a coordinated fashion against an AI is unlikely.
comment by MondSemmel · 2023-07-08T13:11:04.361Z · LW(p) · GW(p)
If a rogue AI is discovered early, we could end up in a war where the AGI has a huge intelligence advantage, but humans have a huge resource advantage.
In that scenario, it seems to me that enough abstractions break down that the analogy to the Stockfish experiment no longer works. Like talking about a conflict of AGI vs. "humans" as two agents in a 2-player game, rather than AGI vs. a collection of exploitable agents.
But I want to focus on the "resource" abstraction here. First of all, "ownership" of resources seems irrelevant; that's mostly a legal concept, and seems like an irrelevant fiction in this scenario. What matters more in a conflict is possession of resources, i.e. who can actually control and command resources.
And here things get tricky. Maybe humans ostensibly possess nukes, but it's not clear whether they would in practice be able to employ them against the AI (what would you even target?), or rather see them employed against them via hacks or social engineering. Humans certainly possess a lot of computers, but can quickly lose possession over a significant chunk of them when they're turned into botnets. And so on.
Overall, in terms of security mindset, it does not make too much sense to me to think in terms of a conflict of Team AGI vs Team Humanity, where one side has an enormous resource advantage.
comment by followthesilence · 2023-06-28T21:05:16.105Z · LW(p) · GW(p)
Enjoyed this post, thanks. Not sure how well chess handicapping translates to handicapping future AGI, but it is an interesting perspective to at least consider.
comment by [deleted] · 2023-06-28T14:28:33.824Z · LW(p) · GW(p)
Thank you for doing the experiment. Someone could run a similar set of tests for Go.
Just to prime your thinking: what's war winning for most wars on earth?
Probably whoever can use the majority of physical resources and turn them into weapons. We had several rounds of wars and the winner had a vast material advantage.
It occurred to me that the level of AI capabilities needed to reach exponential growing levels of resources is essentially a general robot system, trained on all videos in existence of humans taking actions in the real world and a lot of reinforcement learning tasks.
The general robot AGI isn't designed to be particularly smart, only thinks of the short term (myopia in cognitive architecture), can't learn as an individual, and can do nearly all mining, logistics, and manufacturing tasks a human can do if given a detailed prompt on the goal of a task. This is done through separate instances given separate prompts and they can only communicate with peers in the network they have a physical connection to.
Basically the idea is that humans could gain an insurmountable advantage built on (exponential) numbers of AGI limited to the point humans can remain in full control.
Replies from: gwern, Charlie Steiner↑ comment by gwern · 2023-06-28T17:50:32.298Z · LW(p) · GW(p)
Thank you for doing the experiment. Someone could run a similar set of tests for Go.
Go has an advantage here of much greater granularity in handicapping. Handicapping with pieces isn't used as much in chess as it is in Go because, well, there are so few pieces, on such a small board, for a game lasting so few moves, that each removed piece is both a large difference and changes the game qualitatively. I wouldn't want to study chess at all at this point as a RL testbed: there's better environments, which are cleaner to tweak, cheaper to run, more realistic/harder, have oracles, or something else; chess is best at nothing at this point (unless you are interested in chess or history of AI, of course).
Also, it's worth noting that these piece-disadvantage games are generally way out of distribution / off-policy for an agent like Stockfish: AFAIK, the Stockfish project (and all other chess engine projects, for that matter) does not spend a (or any?) meaningful amount of training on extreme handicap scenarios like 'what if I somehow started the game missing a knight' or 'what if my queen just wasn't there somehow' or 'somehow, Palpatine's piece returned'. (So there's a similar problem here as with the claims that humans are still champs at correspondence chess: since the chess engines are not designed in any way or trained for correspondence time-controls, simply using a chess engine 'out of the box' designed for normal time controls provides only a lower bound on how good a correspondence chess engine would be.) Putting the human on the piece-advantage side means that the human is advantaged much more than just the piece, because they can play like normal. It would be more meaningful to put Stockfish on both sides (and much easier time-wise; and could yield as large a sample size as one wants; and let one calculate things like 'how many additional move evaluations / thinking-time is necessary to match a piece-advantage', which would be particularly relevant in this DL scaling context & should look like Jones 2020, which would help you model scenarios like 'what if Stockfish played a Stockfish-minus-a-queen which used 100x the compute to train and used that same 100x compute at runtime as well?').
This is why in the DM/Kramnik chess-variant investigations with AlphaZero, they have to train the AZ agent from scratch for each variant, because the models need to learn the new game and can't just be the standard AZ agent off the shelf: and these variants don't even remove any pieces - they're just small tweaks like permitting self-capture or forbidding castling within the first 10 moves, but they still span a range of 4% difference in winrates for White (57% in Torpedo to 53% in Pawn-back).
My prediction (see also my discussion of temporal scaling laws [LW(p) · GW(p)] & preliminary results in Hilton et al 2023) would be that Go would show less 'intrinsic material advantage' for worse players compared to chess, because it has longer games & larger boards, which allow greater scope of empowerment in space & time, and allow the better player to claw their way back from initial disadvantages, slightly superior move by slightly superior move, ruthlessly exploiting all errors, and compounding into certain victory just as time runs out. (In this respect, of course, Go is more like the real world than is chess...)
Replies from: Dweomite, None↑ comment by Dweomite · 2023-06-29T00:53:14.223Z · LW(p) · GW(p)
and these variants don't even remove any pieces - they're just small tweaks like permitting self-capture or forbidding castling within the first 10 moves
You're framing these as being closer to "regular" chess, but my intuition is the opposite. Most of the game positions that occur during a queen-odds game are rare but possible positions in a regular game; they are contained within the game tree of normal chess. I'm not sure about Stockfish in particular, but I'd expect many chess AIs incorporating machine learning would have non-zero experience with such positions (e.g. from early self-play runs when they were making lots of bad moves).
Positions permitting self-capture do not appear anywhere in that game tree and typical chess AIs are guaranteed to have exactly zero experience of them.
ETA: It also might affect your intuitions to remember that many positions Stockfish would never actually play will still show up in its tree search, requiring it to evaluate them at least accurately enough to know not to play them.
Replies from: gwern↑ comment by gwern · 2023-06-29T21:12:36.412Z · LW(p) · GW(p)
I disagree. By starting with impossible positions like a queen already being missing*, the game is already far out of the superhuman-level chess-game distribution which is defined by Stockfish. Stockfish will never blunder in the early game so badly as to lose a queen in a normal early-game position, even if it was playing God. I expect these to be positions that the Stockfish policy will never reach, not even with its weakest play of zero tree search & following deterministic argmax move choice. The only time Stockfish would ever reach such positions is if forced to by some external force like a player fiddling with settings or a strange training setup, or, like, a cosmic ray flipping some bits on the CPU. There might be some such blunders very early on in training which takes it into such imbalanced very early positions, but those are still fairly different, and the final Stockfish is going to be millions (or at this point, billions) of games of training later and will have no idea of how to handle some positions that near-random play produced eons ago and long-since washed out. (After all, those will be the very stupidest and most incompetent games it ever played, so there is little value in holding onto them in any way. Most setups will erase old games pretty quickly, and certainly don't hold onto games from the start.)
Whereas several of the changes Kramnik evaluated, like 'Forbidding castling within the first 10 moves' probably overlaps to quite a considerable degree; what fraction of chess games, human expert or Stockfish, involve no castling in the first 10 moves and so accidentally fulfill that rule? Probably a pretty good chunk!
* even odds like knight-odds -where you can at least in theory construct the position during a game, by moving the knight out, capturing it with the other knight, and carefully moving the other knight back into its original position - have exactly zero probability of ever occurring in an on-policy game.
Replies from: gjm↑ comment by gjm · 2023-06-30T13:38:52.029Z · LW(p) · GW(p)
Several? I can see one (the one you cite). Some of the other variants -- e.g., no castling at all, or pawns can't move two squares on their first move -- can lead to positions that also arise in normal chess. But having neither side castle at all is really unusual and most such positions will be well out of distribution; and it's very common for some pawns to remain on the second rank all the way to the endgame, where the option of moving one or two squares can have important timing implications.
↑ comment by [deleted] · 2023-06-28T19:04:53.836Z · LW(p) · GW(p)
What do you think about the other corollary? At the upper end of play the number of stones required for a worse agent to equal the best agent shrinks?
And we could plot out compute vs skill and estimate the number of stones for a particular skill level to have a 50 percent win rate against an agent with infinite compute. (Infinite compute just means it has perfect moves as it can factor in all permutations. This is an experiment we can run for solvable games like checkers but we can estimate the asymtote for Go)
Replies from: gwern↑ comment by gwern · 2023-06-28T19:56:36.666Z · LW(p) · GW(p)
What do you think about the other corollary? At the upper end of play the number of stones required for a worse agent to equal the best agent shrinks?
I mean, it would have to. There's a ceiling there, while the game size and stones remain fixed units. If you have agents vastly below optimal play, they can differ a lot in absolute units, because they're not the ceiling, and differ greatly in strategy as well. But the closer you approach God (as players like to put it), the smaller the equalizing material advantage must be, approaching zero. There is only one game tree.
Replies from: None↑ comment by [deleted] · 2023-06-29T16:44:03.115Z · LW(p) · GW(p)
Does this imply convergence for rampant AGI systems?
The "we are doomed" model assumes we will be defeated even when we have networks of superintelligent ASI systems restricted from hostile actions through essentially CAIS. This is where we subdivide large tasks into the smallest possible subtasks, define sparse schema to encode intermediate results, and have separate sessions of an ASI on each (subtask description, subtask context, intermediate schema from other results). Among other benefits this prevents most deception and collusion because the subtask context was a possible draw from the training set and the ASI has no memory or state, it can't know it's not still in training. (It's stateless in that ASI_output = f(f(network architecture, weights), task description, task context, environment input set, RNG seed). It's a functional system and on the next time step you can switch out the network architecture and weights if you wish for a different model with similar capabilities. ASI_output updates the context.
Anyways such a network of systems will perform well but what you are throwing away is bits of context in between the steps. For example if the task is "make housing" one subtask might design the overall shape and visual appearance, another might be the structural design and engineering plans, another might be an inspection to look for mistakes. Yet other subtasks would actually build the structure. Each subtask is a fresh, context ignorant session and closes when a step is done with all memory erased. For example if constructing the building is subdividable into floors or individual girder attachments, those are separate subtasks. The same or different model can be assigned to any given subtask, they need not share any lineage and it makes sense to have the "inspection" subtasks done by a different lineage of base model.
A single "context aware model" doing all steps benefits from having all of the bits of context for every step in theory (in practice it has to stop considering bits from it's context window in order to meet task completion deadlines especially during the robotics steps but it chooses which bits to discard). So it performs better, but it's gains are limited to the value of those marginal bits.
The way this relates to the chess problem is the benefit of the marginal bits is finite. In the real world being smarter has diminishing returns and there exists a resource disparity vs a smart opponent where no possible victory exists.
This means that when it matters, if we have a rampant ASI system with armed robots guarding data centers, the overall task of "defeat the enemy" would be achievable assuming the network of ASIs we use have more armed robots and other assets to work with.
We would not inevitably be defeated by the first unaligned ASI system to exist.
What do you think of this line of reasoning, gwern? You were correct about the scaling hypothesis, you are likely correct about many other things. Have you already written blog entries on this before?
↑ comment by Charlie Steiner · 2023-06-28T16:17:03.279Z · LW(p) · GW(p)
what's war winning for most wars on earth?
I took this a different way: what's the correlation between resources and winning conflicts for humans on earth? Assuming the curve is the same as for chess, what elo does that place human conflicts at?
Replies from: None↑ comment by [deleted] · 2023-06-28T16:42:08.108Z · LW(p) · GW(p)
Depends. Depends on the communication technology of the era, training, quality of leaders, whether all the forces are under a single unified command, and so on.
The main takeaway from this is not that. It's that increasing intelligence has diminishing returns. That a hypothetical "perfect policy" AI general, with an ELO equivalent to almost infinity, can be crushed by "humans with AI tools to help" with an ELO of say 5000 (1000 would be average human general) with a very small resource advantage. Say 30 percent more forces, or their forces are inferior in technology but they have 2-3 times as many.
And a force disparity where humans with their 1000 ELO win is also possible.
This is because of the nature of what intelligence is. Each bit of policy complexity over a random policy has diminishing returns. The highest yield policy is what you tend to find first "let's have all our forces get in a line so they won't hit each other and start blasting" and each improvement has smaller gains. (Or in chess, "let's put my higher value pieces in spots where a lower value piece cannot capture them on the very next move")
comment by arjunpi (arjun-p) · 2025-03-30T18:15:03.098Z · LW(p) · GW(p)
the real odds would be less about the ELO and more on whether he was drunk while playing me
not sure if that would help :)
comment by Sodium · 2025-01-12T16:43:16.166Z · LW(p) · GW(p)
Perhaps I am missing something, but I do not understand the value of this post. Obviously you can beat something much smarter than you if you have more affordances than it does.
FWIW, I have read some of the discourse on the AI Boxing game. In contrast, I think those posts are valuable. They illustrate that even with very little affordances a much more intelligent entity can win against you, which is not super intuitive especially in the boxed context.
So the obvious question is, how does differences in affordances lead to differences in winning (i.e., when does brain beat brawn)? That's a good question to ask, but I think that's intuitive to everyone already? Like that's what people allude to when they ask "why can't you just unplug the AI."
However, experiment conducted here itself is flawed for the reasons other commenters have mentioned already (i.e., you would not beat LeelaQueenOdds, which is rated 2630 FIDE in blitz). Furthermore, I'm struggling to see how you could learn anything in a chess context that would generalize to AI alignment. If you want to understand how affordances interact with wining you should research AI control.
Anyways I notice that I am confused and welcome attempts to change my views.
comment by Spade · 2024-11-13T18:17:20.744Z · LW(p) · GW(p)
Anecdotally, I remember seeing analyses of Stockfish v. Alpha Zero (I think) where AlphaZero would fairly consistently trade absurd amounts of materiel for position. While there is obviously still a tipping point at which a materiel advantage will massively swing the odds I feel that the thrust of this essay kind-of understates the value of a lot-a lot of intelligence in light of those matches.
With that said, I haven't seen any odds-games with AlphaZero, so perhaps my point is entirely moot and it does need that initial materiel as badly as Stockfish.
comment by Review Bot · 2024-05-12T15:50:12.483Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by dspeyer · 2023-07-07T17:08:39.599Z · LW(p) · GW(p)
I suspect this is a lack of flexibility in Stockfish. It was designed (trained?) for normal equal-forces chess and can't step back to think "How do I best work around this disadvantage I've been given?" I suspect something like AlphaZero, given time to play itself at a disadvantage, would do better. As would a true AGI.
comment by Stephen Richards (stephen-richards) · 2023-07-04T06:20:32.803Z · LW(p) · GW(p)
I think this is a really useful and thought provoking experiment. One thing that worries me, is that large corporations may find it easier and faster to give the AI brawn than brains. Why play fair when in competition when you have a money and machine advantages? I think this will be especially so with not so good AIs, and the advantages will remain after the brains part improves. So in your analogy, what about giving stockfish 3 extra queens? A second question is how does it do against stockfish with just 2 extra queens?
comment by juvi · 2023-07-03T08:40:02.614Z · LW(p) · GW(p)
It's maybe worth noting that Stockfish 14 NNUE still has some failure modes. Take this position for example: positionOnLichess. The position is a complete draw, as Black can't make any progress, and White cannot lose as long as he only moves his king. Despite this, Stockfish 14 NNUE evaluates it as a -15 advantage for Black, which should typically indicate a decisive advantage. Even a human player with relatively low Elo should be able to quickly assess this position as a draw.
comment by alenoach (glerzing) · 2023-07-02T22:31:14.097Z · LW(p) · GW(p)
Thanks for the insights. Actually, board game models don't play very well when they are so heavily loosing, or so heavily winning that it doesn't seem to matter. A human player would try to trick you and hope for a mistake. This is not necessarily the case with these models that play as if you were as good as them, which makes their situation look unwinnable.
It's quite the same with AlphaGo. AlphaGo plays incredibly well until there is a large imbalance. Surprisingly, AlphaGo also doesn't care about winning by 10 points or by half a point, and sometimes plays moves that look bad to humans just because it's winning anyway. And when it's loosing, since it assumes that its opponent is as strong, it can't find a leaf in the tree search that end up winning. Moreover, I suspect that removing a piece is prone to distribution shift.
comment by Chris Land · 2023-07-01T18:27:59.730Z · LW(p) · GW(p)
A somewhat related point: it's only very recently (2023) that chess engines have begun competently mimicking the error patterns of human play. The nerfings of previous decades were all artificial.
I'm an FM and play casual games vs. the various nerfed engines at chess.com. The games are very fast (they move instantly) but there's no possibility of time loss. Not the best way to practice openings but good enough.
The implication for AI / AGI is that humans will never create human-similar AI. Everything we make will be way ahead in many areas and way behind in others, and figuring out how to balance everything to construct human-similar is far in the future. Unless we get AIs to help...
Replies from: None↑ comment by [deleted] · 2023-07-01T21:55:36.588Z · LW(p) · GW(p)
The implication for AI / AGI is that humans will never create human-similar AI. Everything we make will be way ahead in many areas and way behind in others
Is this not a mere supervised learning problem? You're saying, for some problem domain D, you want to predict the probability distribution of actions a Real Human would emit when given a particular input sample.
This is what a GPT is, it's doing something very close to this, by predicting, from the same input text string a human was using, what they are going to type next.
We can extend this, to video, and obviously first translate video of humans to joint coordinates, and from sounds they emit back to phonemes, then do the same prediction as above.
We would expect to get an AI system from this method that approximates the average human from the sample set we trained on. This system will be multimodal and able to speak, run robotics, and emit text.
Now, after that, we train using reinforcement learning, and that feedback can clear out mistakes, so that the GPT system is now less and less likely to emit "next tokens" that the consensus for human knowledge believes is wrong. And the system never tires and the hardware never miscalculates.
And we can then use machine based RL - have robots attempt tasks in sim and IRL, autonomously grade them on how well the task was done. Have the machine attempt to use software plugins, RL feedback on errors and successful tool usage. Because the machinery can learn on a larger scale due to having more time to learn than a human lifetime, it will soon exceed human performance.
And we also have more breadth with a system like this than any single individual living human.
But I think you can see how, if you wanted to, you could probably find a solution based on the above that emulates the observable outputs of a single typical human.
comment by [deleted] · 2023-06-30T11:30:23.867Z · LW(p) · GW(p)
I predicted your odds of winning to be 50% with queen+rook odds, 1% with queen odds, 0.2% with 2 bishops odds, and 0.1% with rook odds. When you started describing strategies tailored to odds games that you were going to use, I felt cheated! I thought you were just going to play your normal 1100-rated game, but I made a big mistake. I forgot that you're a general intelligence, not a narrow, 1100-rated chess AI. Stockfish's NNUE was never trained on positions like the ones at the start of your odds games since they can't be reached from a normal 32-piece start, so its ability to generalize to these new board states is anybody's guess. What you intended as a conflict between a less intelligent[1] agent with more resources and a more intelligent agent with less resources turned out to be (more intelligent + less resources + less general) vs. (less intelligent + more resources + more general). If the generalization gap helped you at all, then the amount of resources required to overcome a given intelligence gap is higher than your experiment suggests. Bad news for our species.
I expect the chess analogy would break down when considering agents that can obfuscate their intentions and actions better than a human can. If it could not win in a direct conflict, why wouldn't it just wait until it could?
I do love the "brains vs. brawns" framing, though, and I'm looking forward to what you write about asymmetrical conflicts. If you or anyone else is interested in repeating this experiment without the confounding variable of generality, I suggest using a handicapped version of SF, set to some arbitrary rating. A truly enterprising person could probably automate many matches of of SF vs. SF at different ratings and make a series of 2D plots, each plot being of a different material imbalance, with their ratings plotted against each other, showing the odds of the higher rated one winning for a given rating pair. Unfortunately, the result of that might be largely determined by how it's handicapped, since doing it by reducing search depth would mean the deeper seeing one would see strictly more than the other. I suspect this handicapping would much more strongly favor the more intelligent SF than handicapping by occasionally playing random legal moves.
- ^
measuring intelligence as Elo rating at standard chess, without odds
comment by ws27b (martin-kristiansen) · 2023-07-16T11:48:16.442Z · LW(p) · GW(p)
The problem is that true AGI is self-improving and that a strong enough intelligence will always either accrue the resource advantage or simply do much more with less. Chess engines like Stockfish do not serve as good analogies for AGI since they don't have those self-referential self-improvement capabilities that we would expect true AGI to have.