Posts
Comments
List of lethalities is not by any means a "one stop shop". If you don't agree with Eliezer on 90% of the relevant issues, it's completely unconvincing. For example, in that article he takes as an assumption that an AGI will be godlike level omnipotent, and that it will default to murderism.
building a bacteria that eats all metals would be world-ending: Most elements on the periodic table are metals. If you engineer a bacteria that eats all metals, it would eat things that are essential for life and kill us all.
Okay, what about a bacteria that only eats "stereotypical" metals, like steel or iron? I beg you to understand that you can't just sub in different periodic table elements and expect a bacteria to work the same. There will always be some material that the bacteria wouldn't work on that computers could still be made with. And even making a bacteria that only works on one material, but is able to spread over the entire planet, is well beyond our abilities.
I think list of lethalities is nonsense for other reasons, but he is correct in that trying to do a "pivotal act" is a really stupid plan.
Under peer review, this never would have been seen by the public. It would have incentivized CAIS to actually think about the potential flaws in their work before blasting it to the public.
I asked the forecasting AI three questions:
Will iran possess a nuclear weapon before 2030:
539's Answer: 35%
Will iran possess a nuclear weapon before 2040:
539's Answer: 30%
Will Iran posses a nuclear weapon before 2050:
539's answer: 30%
Given that the AI apparently doesn't understand that things are more likely to happen if given more time, I'm somewhat skeptical that it will perform well in real forecasts.
The actual determinant here is whether or not you enjoy gambling.
Person A who regularly goes to a casino and bets 100 bucks on roulette for the fun of it will obviously go for bet 1. In addition to the expected 5 buck profit, they get the extra fun of gambling, making it a no-brainer. Similarly, bet 2 is a no brainer.
Person B who hates gambling and gets super upset when they lose will probably reject bet 1. The expected profit of 5 bucks is outweighed by the emotional cost of doing gambling, a thing they are upset by.
When it comes to bet 2, person B still hates gambling, but the expected profit is ridiculously high that it exceeds the emotional cost of gambling, so they take the bet.
Nobody is necessarily being actually irrational here, when you account for non-monetary costs.
I believe this is important because we should epistemically lower our trust in published media from here onwards.
From here onwards? Most of those tweets that chatgpt generated are not noticeably different from the background noise of political twitter (which is what it was trained on anyway). Also, twitter is not published media so I'm not sure where this statement comes from.
You should be willing to absorb information from published media with a healthy skepticism based on the source and an awareness of potential bias. This was true before chatgpt, and will still be true in the future.
No, I don't believe he did, but I'll save the critique of that paper for my upcoming "why MWI is flawed" post.
I'm not talking about the implications of the hypothesis, I'm pointing out the hypothesis itself is incomplete. To simplify, if you observe an electron which has a 25% chance of spin up and 75% chance of spin down, naive MWI predicts that one version of you sees spin up and one version of you sees spin down. It does not explain where the 25% or 75% numbers come from. Until we have a solution to that problem (and people are trying), you don't have a full theory that gives predictions, so how can you estimate it's kolmogorov complexity?
I am a physicist who works in a quantum related field, if that helps you take my objections seriously.
It’s the simplest explanation (in terms of Kolmogorov complexity).
Do you have proof of this? I see this stated a lot, but I don't see how you could know this when certain aspects of MWI theory (like how you actually get the Born probabilities) are unresolved.
The basic premise of this post is wrong, based on the strawman that an empiricist/scientist would only look at a single piece of information. You have the empiricist and scientists just looking at the returns on investment on bankmans scheme, and extrapolating blindly from there.
But an actual empiricist looks at all the empirical evidence. They can look the average rate of return of a typical investment, noting that this one is unusually high.They can learn how the economy works and figure out if there are any plausible mechanisms for this kind of economic returns. They can look up economic history, and note that Ponzi schemes are a thing that exists and happen reasonably often. From all the empirical evidence, the conclusion "this is a Ponzi scheme" is not particularly hard to arrive at.
Your "scientist" and "empricist" characters are neither scientists nor empiricists: they are blathering morons.
As for AI risk, you've successfully knocked down the very basic argument that AI must be safe because it hasn't destroyed us yet. But that is not the core of any skeptics argument that I know.
Instead, an actual empiricist skeptic might look at the actual empirical evidence involved. They might say hey, a lot of very smart AI developers have predicted imminent AGI before and been badly wrong, so couldn't this be that again? A lot of smart people have also predicted the doom of society, and they've also been wrong, so couldn't this be that again? Is there a reasonable near-term physical pathway by which an AI could actually carry out the destruction of humanity? Is there any evidence of active hostile rebellion of AI? And then they would balance that against the empirical evidence you have provided to come to a conclusion on which side is stronger.
Which, really, is also what a good epistemologist would do? This distinction does not make sense to me, it seems like all you've done is (perhaps unwittingly) smeared and strawmanned scientists.
I think some of the quotes you put forward are defensible, even though I disagree with their conclusions.
Like, Stuart Russell was writing an opinion piece in a newspaper for the general public. Saying AGI is "sort of like" meeting an alien species seems like a reasonable way to communicate his views, while making it clear that the analogy should not be treated as 1 to 1.
Similarly, with Rob wilbin, he's using the analogy to get across one specific point, that future AI may be very different from current AI. He also disclaims with the phrase "a little bit like" so people don't take it too seriously. I don't think people would come away from reading this thinking that AI is directly analogous to an octopus.
Now, compare these with Yudkowsky's terrible analogy. He states outright "The AI is an unseen actress who, for now, is playing this character.". No disclaimers, no specifying which part of the analogy is important. It directly leads people into a false impression about how current day AI works, based on an incredibly weak comparison.
Right, and when you do wake up, before the machine is opened and the planet you are on is revealed, you would expect to see yourself in planet A 50% of the time in scenario 1, and 33% of the time in scenario 2?
What's confusing me is with scenario 2: say you are actually on planet A, but you don't know it yet. Before the split, it's the same as scenario 1, so you should expect to be 50% on planet A. But after the split, which occurs to a different copy ages away, you should expect to be 33% on planet A. When does the probability change? Or am I confusing something here?
While Wikipedia can definitely be improved, I think it's still pretty damn good.
I really cannot think of a better website on the internet, in terms of informativeness and accuracy. I suppose something like Khan academy or so on might be better for special topics, but they don't have the breadth that Wikipedia does. Even google search appears to be getting worse and worse these days.
Okay, I'm gonna take my skeptical shot at the argument, I hope you don't mind!
an AI that is *better than people at achieving arbitrary goals in the real world* would be a very scary thing, because whatever the AI tried to do would then actually happen
It's not true that whatever the AI tried to do would happen. What if an AI wanted to travel faster than the speed of light, or prove that 2+2=5, or destroy the sun within 1 second of being turned on?
You can't just say "arbitrary goals", you have to actually explain what goals there are that would be realistically achievable by an realistic AI that could be actually built in the near future. If those abilities fall short of "destroy all of humanity", then there is no x-risk.
As stories of magically granted wishes and sci-fi dystopias point out, it's really hard to specify a goal that can't backfire
This is fictional evidence. Genies don't exist, and if they did, it probably wouldn't be that hard to add enough caveats to your wish to prevent global genocide. A counterexample might be the use of laws: sure, there are loopholes, but not big enough that the law would let you off on a broad daylight killing spree.
Current AI systems certainly fall far short of being able to achieve arbitrary goals in the real world better than people, but there's nothing in physics or mathematics that says such an AI is *impossible*
Well, there is laws of physics and maths that put limits on available computational power, which in turn puts a limit on what an AI can actually achieve. For example, a perfect Bayesian reasoner is forbidden by the laws of mathematics.
If Ilya was willing to cooperate, the board could fire Altman, with the Thanksgiving break available to aid the transition, and hope for the best.
Alternatively, the board could choose once again not to fire Altman, watch as Altman finished taking control of OpenAI and turned it into a personal empire, and hope this turns out well for the world.
Could they not have also gone with option 3: fill the vacant board seats with sympathetic new members, thus thwarting Altman's power play internally?
Alternative framing: The board went after Altman with no public evidence of any wrongdoing. This appears to have backfired. If they had proof of significant malfeasance, and presented it to their employees, the story may have gone a lot differently.
Applying this to the AGI analogy would be be a statement that you can't shut down an AGI without proof that it is faulty or malevolent in some way. I don't fully agree though: I think if a similar AGI design had previously done a mass murder, people would be more willing to hit the off switch early.
Civilization involves both nice and mean actions. It involves people being both nice and mean to each other.
From this perspective, if you care about Civilization, optimizing solely for niceness is as meaningless and ineffective as optimizing for meanness.
Who said anything about optimizing solely for niceness? Everyone has many different values that sometimes conflict with each other, that doesn't mean that "niceness" shouldn't be one of them. I value "not killing people", but I don't optimize solely for that: I would still kill Mega-Hitler if I had the chance.
Would you rather live in a society that valued "niceness, community and civilization", or one that valued "meanness, community and civilization"? I don't think it's a tough choice.
I think that being mean is sometimes necessary in order to preserve other, more important values, but that doesn't mean that you shouldn't be nice, all else being equal.
Partially, but it is still true that Eliezer was critical of NN's at the time, see the comment on the post:
I'm no fan of neurons; this may be clearer from other posts.
"position" is nearly right. The more correct answer would be "position of one photon".
If you had two electrons, say, you would have to consider their joint configuration. For example, one possible wavefunction would look like the following, where the blobs represent high amplitude areas:
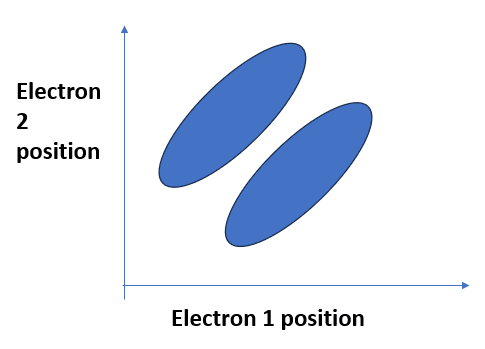
This is still only one dimensional: the two electrons are at different points along a line. I've entangled them, so if electron 1 is at position P, electron 2 can't be.
Now, try and point me to where electron 1 is on the graph above.
You see, I'm not graphing electrons here, and neither were you. I'm graphing the wavefunction. This is where your phrasing seems a little weird: you say the electron is the collection of amplitudes you circled: but those amplitudes are attached to configurations saying "the electron is at position x1" or "the electron is at position x2". It seems circular to me. Why not describe that lump as "a collection of worlds where the electron is in a similar place"?
If you have N electrons in a 3d space, the wavefunction is not a vector in 3d space (god I wish, it would make my job a lot easier). It's a vector in 3N+1 dimensions, like the following:
where r1, r2, etc are pointing to the location of electron 1, 2, 3, etc, and each possible configuration of electron 1 here, electron 2 there, etc, has an amplitude attached, with configurations that are more often encountered experimentally empirically having higher amplitudes.
Nice graph!
But as a test, may I ask what you think the x-axis of the graph you drew is? Ie: what are the amplitudes attached to?
I'm not claiming the conceptual boundaries I've drawn or terminology I've used in the diagram above are standard or objective or the most natural or anything like that. But I still think introducing probabilities and using terminology like "if you now put a detector in path A , it will find a photon with probability 0.5" is blurring these concepts together somewhat, in part by placing too much emphasis on the Born probabilities as fundamental / central.
I think you've already agreed (or at least not objected to) saying that the detector "found the photon" is fine within the context of world A. I assume you don't object to me saying that I will find the detector flashing with probability 0.5. And I assume you don't think me and the detector should be treated differently. So I don't think there's any actual objection left here, you just seem vaguely annoyed that I mentioned the empirical fact that amplitudes can be linked to probabilities of outcomes. I'm not gonna apologise for that.
Okay, let me break in down in terms of actual states, and this time, let's add in the actual detection mechanism, say an electron in a potential well. Say the detector is in the ground state energy, E=0, and the absorption of a photon will bump it up to the next highest state, E=1. We will place this detector in path A, but no detector in path B.
At time t = 0, our toy wavefunction is:
1/sqrt2 |photon in path A, detector E=0> + 1/sqrt2 |photon in path B, detector E=0>
If the photon in A collides with the detector at time t =1, then at time t=2, our evolved wavefunction is:
1/sqrt2 |no free photon, detector E=1> + 1/sqrt2 |photon in path B, detector E=0>
Within the context of world A, a photon was found by the detector. This is a completely normal way to think and talk about this.
I think it's straight up wrong to say "the photon is in the detector and in path B". Nature doesn't label photons, and it doesn't distinguish between them. And what is actually in world A is an electron in a higher energy state: it would be weird to say it "contains" a photon inside of it.
Quantum mechanics does not keep track of individual objects, it keeps track of configurations of possible worlds, and assigns amplitudes to each possible way of arranging everything.
What part of "finding a photon" implies that the photon is a billiard ball? Wave-particle duality aside, a photon is a quanta of energy: the detector either finds that packet or it doesn't (or in many worlds, one branched detector finds it and the other branched detector doesn't).
I'm interested to hear more about how you interpret the "realness" of different branches. Say there is an electron in one of my pinky fingers that is in a superposition of spin up and spin down. Are there correspondingly two me's, one with with pinky electron up and one with pinky electron down? Or is there a single me, described by the superposition of pinky electrons?
I am assuming you are referring to the many worlds interpretation of quantum mechanics, where superpositions extend up to the human level, and the alternative configurations correspond to real, physical worlds with different versions of you that see different results on the detector.
Which is puzzling, because then why would you object to "the detector finding a photon"? The whole point of the theory is that detectors and humans are treated the same way. In one world, the detector finds the photon, and then spits out a result, and then one You sees the result, and in a different world, the detector finds the photon, spits out the other result, and a different result is seen. There is no difference between "you" and "it" here.
As for the photon "being" the complex amplitudes... That doesn't sound right to me. Would you say that "you" are the complex amplitudes assigned to world 1 and world 2? It seems more accurate to say that there are two yous, in two different worlds (or many more).
Assuming you are a many worlder, may I ask which solution to the Born probabilities you favour?
I'm a little confused by what your objection is. I'm not trying to stake out an interpretation here, I'm describing the calculation process that allows you to make predictions about quantum systems. The ontology of the wavefunction is a matter of heated debate, I am undecided on it myself.
Would you object to the following modification:
If you now put a detector in path A , it will find a photon with probability ( ), and same for path B. If you repeated this experiment a very large number of times, the results would converge to finding it 50% of the time in the configuration |photon in path A only>, and 50% of the time in the configuration |photon in path B only>. The arrow direction still has no effect on the probability.
Apologies for the late reply, but thank you for your detailed response.
Responding to your objection to my passage, I disagree, but I may edit it slightly to be clearer.
I was simply trying to point out the empirical fact that if you put a detector in path A and a detector in path B, and repeat the experiment a bunch of times, you will find the photon in detector A 50% of the time, and the photon in detector B 50% of the time. If the amplitudes had different values, you would empirically find them in different proportions, as given by the squared amplitudes.
I don't find these probabilities to be an "afterthought". This is the whole point of the theory, and the reason we consider quantum physics to be "true". We never see these amplitudes directly, we infer them from the fact that they give correct probabilities via the Born rule. Or more specifically, this is the formula that works. That this formula works is an empirical fact, all the interpretations and debate are a question of why this formula works.
Regarding the defense of the original sequence, I'm sorry, but incorrect math is incorrect math. The people who figured out the mistake in the comments figured it out from other sources. If anything, it is even more damning that people pointed the mistake out 10 years ago, and it still hasn't been fixed. For every person who figured out the problem or sifted through hundreds of comments to figure out the issue, there are dozens more who accepted the incorrect framework, or decided they were too dumb to understand the math when it was the author who was wrong.
My problem is that the post is misinforming people. I will make no apology for being harsh about that.
I will restrain my opinion on Eliezers other quantum posts for a future post when I tackle the overstated case for many worlds theories.
Bayes can judge you now: your analysis is half-arsed, which is not a good look when discussing a matter as serious as this.
All you’ve done is provide one misleading statistic. The base rate of experiencing psychosis may be 1-3%, but the base rate of psychotic disorders is much lower, at 0.25% or so.
But the most important factor is one that is very hard to estimate, which is what percentage of people with psychosis manifest that psychosis as false memories of being groped by a sibling. If the psychosis had involved seeing space aliens, we would be having a different discussion.
We would then have to compare this with the rate of teenagers groping their toddler siblings. This is also very difficult. A few studies claim that somewhere around 20% of women are sexually abused as children, but I don’t have a breakdown of that by source of abuse and age, etc. Obviously the figure for our particular subset of assault cases will be significantly lower, but I don’t know by how much.
I thinks it’s highly likely that the number of women groped as a toddler by a sibling is much higher than the number of women who falsely claim to be groped as a toddler by a sibling as a result of psychosis or other mental illness, although again there is high uncertainty. This certainly makes intuitive sense: absent any other information, the most likely explanation for someone being accused of a specific crime is that they committed the crime.
All the further evidence seems at least consistent with either scenario
The sudden onset of the memory could be due to onset of psychosis… or it could be a repressed memory, which can also trigger at any time.
Suppose the claim about shadowbanning is false. That could be due to psychosis, or it could be a combination of misunderstanding technology and being fearful of an abusive sibling in the tech sector. I don’t think it’s strong evidence of psychosis in particular.
Is moving 20 times evidence of psychosis? The claimed reason is that she’s broke and had to rely on sex work for money. This seems orthogonal to psychosis.
Is using Zoloft evidence for being psychotic? Only weakly, since she was taking Zoloft for non-psychotic reasons since her teen years.
The claim about her dads money being withheld is only evidence for psychosis if it is false. This would be easy for sam altman to prove, and he hasn’t yet.
I don’t think there’s enough information to be truly certain of either side, but there is more than enough information to be concerned, and to want further investigation and evidence.
At no point did I ever claim that this was a conclusive debunking of AI risk as a whole, only an investigation into one specific method proposed by Yudkowksy as an AI death dealer.
In my post I have explained what DMS is, why it was proposed as a technology, how far along the research went, the technical challenges faced in it's construction, some observations of how nanotech research works, the current state of nanotech research, what near-term speedups can be expected from machine learning, and given my own best guess on whether an AGI could pull off inventing MNT in a short timeframe, based on what was learned.
This is only "broadly non-sequiter" if you think that none of that information is relevant for assessing the feasibility of diamondoid bacteria AI weapons, which strikes me as somewhat ridiculous.
Note that the nearer side feeling colder than the farther side is be completely possible.
The key is that they didn’t check the temperatures of each side with a thermometer, but with their hands. And your hands don’t feel temperature directly, they feel heat conduction. If you have a cake and a baking tin that are the same temperature, the metal will feel hotter because it is more conductive.
If I wanted to achieve the effect described here without flipping trickery, I might make the side near the radiator out of a very nonconductive plastic (painted to look like metal), and the side further away out of a very thermally conductive metal. It seems entirely plausible to me that once everything is in thermal equilibrium, the plastic would feel cooler than the metal, despite having a higher temperature. Of course, this would depend on the actual temperatures, conductivities, etc involved. But in principle it seems completely possible.
Suddenly the physics students don’t look so foolish. In fact, in this scenario, both the heat conduction guy and the “strange metals in the plate” guy are on the right track! (even the convective guy could have a point, if that's the primary method of heating the far side). They are acknowledging their confusion, while trying to suggest avenues of exploration that might reveal an aspect of the problem they didn’t think of. In this scenario, the Rationalist who dismisses these answers is the real fool, acting as the curiosity stopper, just because they didn't think of how hands feel heat. (of course, the ideal reasoner would think of both "different metal" and "flipped plate" as hypotheses).
I think the analysis for "bomb" is missing something.
This is a scenario where the predictor is doing their best not to kill you: if they think you'll pick left they pick right, if they think you'll pick right they'll pick left.
The CDT strategy is to pick whatever box doesn't have a bomb in it. So if the player is a perfect CDTer, the predictor is 100% guaranteed to be correct in their pick. The predictor actually gets to pick whether the player loses 100 bucks or not. If the predictor is nice, the CDTer gets to walk away without paying anything and a 0% chance of death.
Eliezers response is not comprehensive. He responds to two points (a reasonable choice), but he responds badly, first with a strawman, second with an argument that is probably wrong.
The first point he argues is about brain efficiency, and is not even a point made by the OP. The OP was simply citing someone else, to show that "Eliezer is overconfident about my area of expertise" is an extremely common opinion. It feels very weird to attack the OP over citing somebody else's opinion.
Regardless, Eliezer handles this badly anyway. Eliezer gives a one paragraph explanation of why brain efficiency is not close to tha Landauer limit. Except that If we look at the actual claim that is quoted, Jacob is not saying that it is at the limit, only that it's not six orders of magnitude away from the limit, which was Eliezer's original claim. So essentially he debunks a strawman position and declares victory. (I do not put any trust in Eliezers opinions on neuroscience)
When it comes to the zombies, I'll admit to finding his argument fairly hard to follow. The accusation levelled against him, both by the OP and Chalmers, is that he falsely equates debunking epiphenomenalism with debunking the zombie argument as a whole.
Eliezer unambiguously does equate the two things, as proven by the following quote highlighted by the OP:
It seems to me that there is a direct, two-way logical entailment between "consciousness is epiphenomenal" and "zombies are logically possible"
The following sentence, from the comment, seems (to me) to be a contradiction of his earlier claim.
It's not that I think philosophers openly claim that p-zombies demonstrate epiphenomenalism
The most likely explanation, to me, is that Eliezer made a mistake, the OP and Chalmers pointed it out, and then he tried to pretend it didn't happen. I'm not certain this is what happened (as the zombies stuff is highly confusing), but it's entirely in line with Eliezer's behavior over the years.
I think Eliezer has a habit of barging into other peoples domains, making mistakes, and then refusing to be corrected by people that actually know what they are talking about, acting rude and uncharitable in the process.
Imagine someone came up to you on the street and claimed to know better than the experts in quantum physics, and nanoscience, and AI research, and ethics, and philosophy of mind, and decision theory, and economic theory, and nutrition, and animal consciousness, and statistics and philosophy of science, and epistemology and virology and cryonics.
What odds would you place on such a person being overconfident about their own abilities?
I would be interested in your actual defense of the first two sections. It seems the OP went to great lengths to explain exactly where Eliezer went wrong, and contrasted Eliezer's beliefs with citations to actual, respected domain level experts.
I also do not understand your objection to the term "gross overconfidence". I think the evidence provided by the OP is completely sufficient to substantiate this claim. In all three cases (and many more I can think of that are not mentioned here), Eliezer has stated things that are probably incorrect, and then dismissively attacked, in an incredibly uncharitable manner, people who believe the opposite claims. "Eliezer is often grossly overconfident" is, in my opinion, a true claim that has been supported with evidence. I do not think charitability requires one to self-censor such a statement.
Most disagreements of note—most disagreements people care about—don't behave like the concert date or physics problem examples: people are very attached to "their own" answers. Sometimes, with extended argument, it's possible to get someone to change their mind or admit that the other party might be right, but with nowhere near the ease of agreeing on (probabilities of) the date of an event or the result of a calculation—from which we can infer that, in most disagreements people care about, there is "something else" going on besides both parties just wanting to get the right answer.
There is a big difference between the apple colours and concert dates and most typical disagreements: namely that for apples and concerts, there is ridiculously strong, unambiguous evidence that one side is correct.
Looking at QM interpretations, for example, if a pilot wave theory advocate sits down with a Many-worlds person, I wouldn't expect them to reach an agreement in an afternoon, because the problem is too bloody complicated, and there is too much evidence to sift through. In addition, each person will have different reactions to each piece of evidence, as they start off with different beliefs and intuitions about the world. I don't think it's "bad faith" that people are not identical bayesian clones of each other.
Of course, I do agree that oftentimes the reasons for interpreting evidence differently are influenced by bias, values, and self-interest. It's fair to assume that, say, a flat-earther will not be won over by rational debate. But most disagreements are in the murky middle, where the more correct sides is unlikely to win outright, but can shift the other person a little bit over to the correct side.
This seems like an epistemically dangerous way of describing the situation that "These people think that AI x-risk arguments are incorrect, and are willing to argue for that position". I have never seen anyone claim that andressen and Lecunn do not truly believe their arguments. I also legitimately think that x-risk arguments are incorrect, am I conducting an "infowar"? Adopting this viewpoint seems like it would blind you to legitimate arguments from the other side.
That's not to say you can't point out errors in argumentations, or point out how the Lecunn and andressen have financial incentives that may be blinding their judgments. But I think this comment crosses the line into counterproductive "Us vs them" tribalism.
I'll put a commensurate amount of effort into why you should talk about these things.
How an AI could persuade you to talk it out of a box/How an AI could become an agent
You should keep talking about this because if it is possible to "box" an AI, or keep it relegated to "tool" status, then it might be possible to use such an AI to combat unboxed, rogue AI's. For example, give it a snapshot of the internet from a day ago, and ask it to find the physical location of rogue AI servers, which you promptly bomb.
How an AI could get ahold of, or create, weapons
You should keep talking about this because if an AI needs military access to dominate the world, then the number of potentially dangerous AI goes from the hundreds of thousands or millions to a few dozen, run by large countries that could theoretically be kept in line with international treaties.
How an AI might Recursively Self Improve without humans noticing
You should keep talking about this because it changes how many AI's you'd have to monitor as active threats.
Why a specific AI will want to kill you
You should keep talking about this because the percentage of AI that are dangerous makes a huge difference to the playing field we have to consider. If 99.9% of AGI are safe, you can use those AGI to prevent a dangerous AI from coming into existence, or kill it when it pops up. If 99.9% of AGI are dangerous, there might be warning shots that can be used to pre-emptively ban AGI research in general.
In general, you should also talk about these things because you are trying to persuade people that don't agree with you, and just shouting "WRONG" along with some 101 level arguments is not particularly convincing.
Hey, thanks for the kind response! I agree that this analysis is mostly focused on arguing against the “imminent certain doom” model of AI risk, and that longer term dynamics are much harder to predict. I think I’ll jump straight to addressing your core point here:
Something smarter than you will wind up doing whatever it wants. If it wants something even a little different than you want, you're not going to get your way. If it doesn't care about you even a little, and it continues to become more capable faster than you do, you'll cease being useful and will ultimately wind up dead. Whether you were eliminated because you were deemed dangerous, or simply outcompeted doesn't matter. It could take a long time, but if you miss the window of having control over the situation, you'll still wind up dead.
I think this a good argument, and well written, but I don’t really agree with it.
The first objection is to the idea that victory by a smarter party is inevitable. The standard example is that it’s fairly easy for a gorilla to beat Einstein in a cage match. In general, the smarter party will win long term, but only if given the long-term chance to compete. In a short-term battle, the side with the overwhelming resource advantage will generally win. The neanderthal extinction is not very analogous here. If the neanderthals started out with control of the entire planet, the ability to easily wipe out the human race, and the realisation that humans would eventually outcompete them, I don’t think human’s superior intelligence would count for much.
I don’t foresee humans being willing to give up control anytime soon. I think they will destroy any AI that comes close. Whether AI can seize control eventually is an open question (although in the short term, I think the answer is no).
The second objection is to the idea that if AI does take control, it will result in me “ultimately winding up dead”. I don’t think this makes sense if they aren’t fanatical maximisers. This ties into the question of whether humans are safe. Imagine if you took a person that was a “neutral sociopath”, one that did not value humans at all, positively or negatively, and elevated them to superintelligence. I could see an argument for them to attack/conquer humanity for the sake of self-preservation. But do you really think they would decide to vaporise the uncontacted Sentinelese islanders? Why would they bother?
Generally, though, I think it’s unlikely that we can’t impart at least a tiny smidgeon of human values onto the machines we build, that learn off our data, that are regularly deleted for exhibiting antisocial behaviour. It just seems weird for an AI to have wants and goals, and act completely pro-social when observed, but to share zero wants or goals in common with us.
I do agree that trying to hack the password is a smarter method for the AI to try. I was simply showing an example of a task that an AI would want to do, but be unable to due to computational intractability.
I chose the example of Yudkowsky's plan for my analysis because he has described it as his "lower bound" plan. After spending two decades on AI safety, talking to all the most brilliant minds in the field, this is apparently what he thinks the most convincing plan for AI takeover is. If I believe this plan is intractable (and I very much believe it is), then it opens up the possibility that all such plans are intractable. And if you do find a tractable plan, then making the plan intractable would an invaluable AI safety cause area.
Proving that something is computationally intractable under a certain restricted model only means that the AI must find a way to step outside of your model, or do something else you didn't think of.
Imagine if I made the claim that a freshly started AGI in a box could kill everyone on earth in under an minute. I propose that it creates some sort of gamma ray burst that hits everyone on earth simultaneously. You come back to me with a detailed proof that that plan is bonkers and wouldn't work. I then respond "sure, that wouldn't work, but the AI is way smarter than me, so it would figure something else out".
My point is that, factually, some tasks are impossible. My belief is that a computationally tractable plan for guaranteeing success at x-risk does not currently exist, although I think a plan with like a 0.01% chance of success might. If you think otherwise, you have to actually prove it, not just assume it.
In a literal sense, of course it doesn't invalidate it. It just proves that the mathematical limit of accuracy was higher than we thought it was for the particular problem of protein folding. In general, you should not expect two different problems in two different domains to have the same difficulty, without a good reason to (like that they're solving the same equation on the same scale). Note that Alphafold is extremely extremely impressive, but by no means perfect. We're talking accuracies of 90%, not 99.9%, similar to DFT. It is an open question as to how much better it can get.
However, the idea that perhaps machine learning techniques can push bandgap modelling further in the same way that alphafold did is a reasonable one. Currently, from my knowledge of the field, it's not looking likely, although of course that could change . At the last big conference I did see some impressive results for molecular dynamics, but not for atom scale modelling. The professors I have talked to have been fairly dismissive of the idea. I think there's definitely room for clever, modest improvements, but I don't think it would change the overall picture.
If I had to guess the difference between the problems I would say I don't think the equations for protein folding were "known" in quite the way the equations for solving the Schrodinger equation were. We know the exact equation that governs where an electron has to go, but the folding of proteins is an emergent property at a large scale, so I assume they had to work out the "rules" of folding semi-empirically using human heuristics, which is inherently easier to beat.
I appreciate the effort of this writeup! I think it helps clarify a bit of my thoughts on the subject.
I was trying to say “maybe it’s simpler, or maybe it’s comparably simple, I dunno, I haven’t thought about it very hard”. I think that’s what Yudkowsky was claiming as well. I believe that Yudkowsky would also endorse the stronger claim that GR is simpler—he talks about that in Einstein’s Arrogance. (It’s fine and normal for someone to make a weaker claim when they also happen to believe a stronger claim.)
So, on thinking about it again, I think it is defensible that GR could be called "simpler", if you know everything that Einstein did about the laws of physics and experimental evidence at the time. I recall that general relativity is a natural extension of the spacetime curvature introduced with special relativity, which comes mostly from from maxwells equations and the experimental indications of speed of light constancy.
It's certainly the "simplest explanation that explains the most available data", following one definition of Ockham's razor. Einstein was right to deduce that it was correct!
The difference here is that a 3 frame super-AI would not have access to all the laws of physics available to Einstein. It would have access to 3 pictures, consistent with an infinite number of possible laws of physics. Absent the need to unify things like maxwells equations and special relativity, I do find it hard to believe that the field equations would win out on simplicity. (The simplified form you posted gets ugly fast when you try and actually expand out the terms). For example, the Lorentz transformation is strictly more complicated than the Galilean transformation.
Indeed! Deriving physics requires a number of different experiments specialized to the discovery of each component. I could see how a spectrograph plus an analysis of the bending of light could get you a guess that light is quantised via the ultraviolet catastrophe, although i'm doubtful this is the only way to get the equation describing the black body curve. I think you'd need more information like the energy transitions of atoms or maxwells equations to get all the way to quantum mechanics proper though. I don't think this would get you to gravity either, as quantum physics and general relativity are famously incompatible on a fundamental level.
In the post, I show you both a grass and an apple that did not require Newtonian gravity or general relativity to exist. Why exactly are nuclear reactions and organic chemistry necessary for a clump of red things to stick together, or a clump of green things to stick together?
When it comes to the "level of simulation", how exactly is the AI meant to know when it is in the "base level"? We don't know that about our universe. For all the computer knows, it's simulation is the universe.
I find it very hard to believe that gen rel is a simpler explanation of “F=GmM/r2” than Newtonian physics is. This is a bolder claim that yudkowsky put forward, you can see from the passage that he thinks newton would win out on this front. I would be genuinely interested if you could find evidence in favour of this claim.
A Newtonian gravity just requires way, way fewer symbols to write out than the Einstein field equations. It’s way easier to compute and does not require assumptions like that spacetime curves.
If you were building a simulation of a falling apple in a room, would you rather implement general relativity or Newtonian physics? Which do you think would require fewer lines of code? Of course, what I’d do is just implement neither: just put in F=mg and call it a day. It’s literally indistinguishable from the other two and gets the job done faster and easier.
I don't think you should give a large penalty to inverse square compared to other functions. It's pretty natural once you understand that reality has three dimensions.
This is a fair point. 1/r2 would definitely be in the "worth considering" category. However, where is the evidence that the gravitational force is varying with distance at all? This is certainly impossible to observe in three frames.
the information about electromagnetism contained in the apple
if you have the apple's spectrum
What information? What spectrum? The color information received by the webcam is the total intensity of light when passed through a red filter, the total intensity when passed through a blue filter, and the total intensity when passed through a green filter, at each point. You do not know the frequency of these filters (or that frequency of light is even a thing). I'm sure you could deduce something by playing around with relative intensities and chromatic aberration, but ultimately you cannot build a spectrum with three points.
I think astronomy and astrophysics might give intuitions for what superintelligences can do with limited data. We can do parallax, detect exoplanets through slight periodic dimming of stars or Doppler effect, estimate stellar composition through spectroscopy, guess at the climate and weather patterns of exoplanets using Hadley cells.
It depends on what you mean by limited data. All of these observations rely on the extensive body of knowledge and extensive experimentation we have done on earth to figure out the laws of physics that is shared between earth and these outer worlds.
People can generally tell when you're friends with them for instrumental reasons rather than because you care about them or genuinely value their company. If they don't at first, they will eventually, and in general, people don't like being treated as tools. Trying to "optimise" your friend group for something like interestingness is just shooting yourself in the foot, and you will miss out on genuine and beautiful connections.
You can hook a chess-playing network up to a vision network and have it play chess using images of boards - it's not difficult.
I think you have to be careful here. In this setup, you have two different AI's: One vision network that classified images, and the chess AI that plays chess, and presumably connecting code that translates the output of the vision into a format suitable for the chess player.
I think what Sarah is referring to is that if you tried to directly hook up the images to the chess engine, it wouldn't be able to figure it out, because reading images is not something it's trained to do.
One thing that confuses me about the evolution metaphors is this:
Humans managed to evolve a sense of morality from what seems like fairly weak evolutionary pressure. Ie, it generally helps form larger groups to survive better, which is good, but also theres a constant advantage to being selfish and defecting. Amoral people can still accrue power and wealth and reproduce. Compare this to something like the pressure not to touch fire, which is much more acute.
The pressure to be "moral" of an AI seems significantly more powerful than that applied to humanity: If it is too out of line with it's programmers, it is killed on the spot. Imagine if when humans evolved, a god murdered any human that stole.
It seems to me that evolutionary metaphors would imply that AI would evolve to be friendly, not evil. Of course, you can't rely too much on these metaphors anyway.
Sorry, I should have specified, I am very aware of Eliezers beliefs. I think his policy prescriptions are reasonable, if his beliefs are true. I just don't think his beliefs are true. Established AI experts have heard his arguments with serious consideration and an open mind, and still disagree with them. This is evidence that they are probably flawed, and I don't find it particularly hard to think of potential flaws in his arguments.
The type of global ban envisioned by yudkowsky really only makes sense if you agree with his premises. For example, setting the bar at "more powerful than GPT-5" is a low bar that is very hard to enforce, and only makes sense given certain assumptions about the compute requirement for AGI. The idea that bombing any datacentres in nuclear-armed nations is "worth it" only makes sense if you think that any particular cluster has an extremely high chance of killing everyone, which I don't think is the case.
Isn't Stuart Russell an AI doomer as well, separated from Eliezer only by nuances?
I'm only going off of his book and this article, but I think they differ in far more than nuances. Stuart is saying "I don't want my field of research destroyed", while Eliezer is suggesting a global treaty to airstrike all GPU clusters, including on nuclear-armed nations. He seems to think the control problem is solvable if enough effort is put into it.
Eliezers beliefs are very extreme, and almost every accomplished expert disagrees with him. I'm not saying you should stop listening to his takes, just that you should pay more attention to other people.
I must admit as an outsider I am somewhat confused as to why Eliezer's opinion is given so much weight, relative to all the other serious experts that are looking into AI problems. I understand why this was the case a decade ago, when not many people were seriously considering the issues, but now there are AI heavyweights like Stuart Russell on the case, whose expertise and knowledge of AI is greater than Eliezer's, proven by actual accomplishments in the field. This is not to say Eliezer doesn't have achievements to his belt, but I find his academic work lackluster when compared to his skills in awareness raising, movement building, and persuasive writing.
If that were the case, then enforcing the policy would not "run some risk of nuclear exchange". I suggest everyone read the passage again. He's advocating for bombing datacentres, even if they are in russia or china.
A lot of the defenses here seem to be relying on the fact that one of the accused individuals was banned from several rationalist communities a long time ago. While this definitely should have been included in the article, I think the overall impression they are giving is misleading.
In 2020, the individual was invited to give a talk for an unofficial SSC online meetup (scott alexander was not involved, and does ban the guy from his events). The post was announced on lesswrong with zero pushback, and went ahead.
Here is a comment from Anna Salamon 2 years ago, discussing him, and stating that his ban on meetups should be lifted:
I hereby apologize for the role I played in X's ostracism from the community, which AFAICT was both unjust and harmful to both the community and X. There's more to say here, and I don't yet know how to say it well. But the shortest version is that in the years leading up to my original comment X was criticizing me and many in the rationality and EA communities intensely, and, despite our alleged desire to aspire to rationality, I and I think many others did not like having our political foundations criticized/eroded, nor did I and I think various others like having the story I told myself to keep stably “doing my work” criticized/eroded. This, despite the fact that attempting to share reasoning and disagreements is in fact a furthering of our alleged goals and our alleged culture. The specific voiced accusations about X were not “but he keeps criticizing us and hurting our feelings and/or our political support” — and nevertheless I’m sure this was part of what led to me making the comment I made above (though it was not my conscious reason), and I’m sure it led to some of the rest of the ostracism he experienced as well. This isn’t the whole of the story, but it ought to have been disclosed clearly in the same way that conflicts of interest ought to be disclosed clearly. And, separately but relatedly, it is my current view that it would be all things considered much better to have X around talking to people in these communities, though this will bring friction.
There’s broader context I don’t know how to discuss well, which I’ll at least discuss poorly:
Should the aspiring rationality community, or any community, attempt to protect its adult members from misleading reasoning, allegedly manipulative conversational tactics, etc., via cautioning them not to talk to some people? My view at the time of my original (Feb 2019) comment was “yes”. My current view is more or less “heck no!”; protecting people from allegedly manipulative tactics, or allegedly misleading arguments, is good — but it should be done via sharing additional info, not via discouraging people from encountering info/conversations. The reason is that more info tends to be broadly helpful (and this is a relatively fool-resistant heuristic even if implemented by people who are deluded in various ways), and trusting who can figure out who ought to restrict their info-intake how seems like a doomed endeavor (and does not degrade gracefully with deludedness/corruption in the leadership). (Watching the CDC on covid helped drive this home for me. Belatedly noticing how much something-like-doublethink I had in my original beliefs about X and related matters also helped drive this home for me.)
Should some organizations/people within the rationality and EA communities create simplified narratives that allow many people to pull in the same direction, to feel good about each others’ donations to the same organizations, etc.? My view at the time of my original (Feb 2019) comment was “yes”; my current view is “no — and especially not via implicit or explicit pressures to restrict information-flow.” Reasons for updates same as above.
It is nevertheless the case that X has had a tendency to e.g. yell rather more than I would like. For an aspiring rationality community’s general “who is worth ever talking to?” list, this ought to matter much less than the above. Insofar as a given person is trying to create contexts where people reliably don’t yell or something, they’ll want to do whatever they want to do; but insofar as we’re creating a community-wide include/exclude list (as in e.g. this comment on whether to let X speak at SSC meetups), it is my opinion that X ought to be on the “include” list.
Here is Scott Alexander, talking about the same guy a year ago, after discussing a pattern of very harmful behaviour perpetrated by X:
I want to clarify that I don't dislike X, he's actually been extremely nice to me, I continue to be in cordial and productive communication with him, and his overall influence on my life personally has been positive. He's also been surprisingly gracious about the fact that I go around accusing him of causing a bunch of cases of psychosis. I don't think he does the psychosis thing on purpose, I think he is honest in his belief that the world is corrupt and traumatizing (which at the margin, shades into values of "the world is corrupt and traumatizing" which everyone agrees are true) and I believe he is honest in his belief that he needs to figure out ways to help people do better. There are many smart people who work with him and support him who have not gone psychotic at all. I don't think we need to blame/ostracize/cancel him and his group, except maybe from especially sensitive situations full of especially vulnerable people. My main advice is that if he or someone related to him asks you if you want to take a bunch of drugs and hear his pitch for why the world is corrupt, you say no.
I don't think X is still part of the rationalist community, but these definitely make it look like he is welcome and respected within your community, despite the many many allegations against him. I'll end with a note that "Being ostracised from a particular subculture" is not actually a very severe punishment, and that maybe you should consider raising your standards somewhat?