Posts
Comments
FWIW, users can at least highlight text in a post to disagree with.
Interesting! Graziano's Attention Schema Theory is also basically the same: he proposes consciousness to be found in our models of our own attention, and that these models evolved to help control attention. To be clear, though, it's not the mere fact of modelling or controlling attention, but that attention is modelled in a way that makes it seem mysterious or unphysical, and that's what explains our intuitions about phenomenal consciousness.[1]
- ^
In the attention schema theory (AST), having an automatically constructed self-model that depicts you as containing consciousness makes you intuitively believe that you have consciousness. The reason why such a self-model evolved in the brains of complex animals is that it serves the useful role of modeling, and thus helping to control, the powerful and subtle process of attention, by which the brain seizes on and deeply processes information.
Suppose the machine has a much richer model of attention. Somehow, attention is depicted by the model as a Moray eel darting around the world. Maybe the machine already had need for a depiction of Moray eels, and it coapted that model for monitoring its own attention. Now we plug in the speech engine. Does the machine claim to have consciousness? No. It claims to have an external Moray eel.
Suppose the machine has no attention, and no attention schema either. But it does have a self-model, and the self-model richly depicts a subtle, powerful, nonphysical essence, with all the properties we humans attribute to consciousness. Now we plug in the speech engine. Does the machine claim to have consciousness? Yes. The machine knows only what it knows. It is constrained by its own internal information.
AST does not posit that having an attention schema makes one conscious. Instead, first, having an automatic self-model that depicts you as containing consciousness makes you intuitively believe that you have consciousness. Second, the reason why such a self-model evolved in the brains of complex animals, is that it serves the useful role of modeling attention.
Also oysters and mussels can have a decent amount of presumably heme iron, and they seem unlikely to be significantly sentient, and either way, your effects on wild arthropods are more important in your diet choices. I'm vegan except for bivalves.
Since consciousness seems useful for all these different species, in a convergent-evolution pattern even across very different brain architectures (mammals vs birds), then I believe we should expect it to be useful in our homonid-simulator-trained model. If so, we should be able to measure this difference to a next-token-predictor trained on an equivalent number of tokens of a dataset of, for instance, math problems.
What do you mean by difference here? Increase in performance due to consciousness? Or differences in functions?
I'm not sure we could measure this difference. It seems very likely to me that consciousness evolved before, say, language and complex agency. But complex language and complex agency might not require consciousness, and may capture all of the benefits that would be captured by consciousness, so consciousness wouldn't result in greater performance.
However, it could be that
- humans do not consistently have complex language and complex agency, and humans with agency are fallible as agents, so consciousness in most humans is still useful to us as a species (or to our genes),
- building complex language and complex agency on top of consciousness is the locally cheapest way to build them, so consciousness would still be useful to us, or
- we reached a local maximum in terms of genetic fitness, or evolutionary pressures are too weak on us now, and it's not really possible to evolve away consciousness while preserving complex language and complex agency. So consciousness isn't useful to us, but can't be practically gotten rid of without loss in fitness.
Some other possibilities:
- The adaptive value of consciousness is really just to give us certain motivations, e.g. finding our internal processing mysterious, nonphysical or interesting makes it seem special to us, and this makes us
- value sensations for their own sake, so seek sensations and engage in sensory play, which may help us learn more about ourselves or the world (according to Nicholas Humphrey, as discussed here, here and here),
- value our lives more and work harder to prevent early death, and/or
- develop spiritual or moral beliefs and adaptive associated practices,
- Consciousness is just the illusion of the phenomenality of what's introspectively accessible to us. Furthermore, we might incorrectly believe in its phenomenality just because of the fact that much of the processing we have introspective access to is wired in and its causes are not introspectively accessible, but instead cognitively impenetrable. The full illusion could be a special case of humans incorrectly using supernatural explanations for unexplained but interesting and subjectively important or profound phenomena.
Sorry for the late response.
If people change their own preferences by repetition and practice, then they usually have a preference to do that. So it can be in their own best interests, for preferences they already have.
I could have a preference to change your preferences, and that could matter in the same way, but I don’t think I should say it's in your best interests (at least not for the thought experiment in this post). It could be in my best interests, or for whatever other goal I have (possibly altruistic).
In my view, identity preservation is vague and degreed, a matter of how much you inherit from your past "self", specifically how much of your memories and other dispositions.
Someone could fail to report a unique precise prior (and one that's consistent with their other beliefs and priors across contexts) for any of the following reasons, which seem worth distinguishing:
- There is no unique precise prior that can represent their state of knowledge.
- There is a unique precise prior that represents their state of knowledge, but they don't have or use it, even approximately.
- There is a unique precise prior that represents their state of knowledge, but, in practice, they can only report (precise or imprecise) approximations of it (not just computing decimal places for a real number, but also which things go into the prior could differ by approximation). Hypothetically, in the limit of resources spent on computing its values, the approximations would converge to this unique precise prior.
I'd be inclined to treat all three cases like imprecise probabilities, e.g. I wouldn't permanently commit to a prior I wrote down to the exclusion of all other priors over the same events/possibilities.
Harsanyi's theorem has also been generalized in various ways without the rationality axioms; see McCarthy et al., 2020 https://doi.org/10.1016/j.jmateco.2020.01.001. But it still assumes something similar to but weaker than the independence axiom, which in my view is hard to motivate separately.
Why do you believe AMD and Google make better hardware than Nvidia?
If bounded below, you can just shift up to make it positive. But the geometric expected utility order is not preserved under shifts.
Violating the Continuity Axiom is bad because it allows you to be money pumped.
Violations of continuity aren't really vulnerable to proper/standard money pumps. The author calls it "arbitrarily close to pure exploitation" but that's not pure exploitation. It's only really compelling if you assume a weaker version of continuity in the first place, but you can just deny that.
I think transitivity (+independence of irrelevant alternatives) and countable independence (or the countable sure-thing principle) are enough to avoid money pumps, and I expect give a kind of expected utility maximization form (combining McCarthy et al., 2019 and Russell & Isaacs, 2021).
Against the requirement of completeness (or the specific money pump argument for it by Gustafsson in your link), see Thornley here.
To be clear, countable independence implies your utilities are "bounded" in a sense, but possibly lexicographic. See Russell & Isaacs, 2021.
Even if we instead assume that by ‘unconditional’, people mean something like ‘resilient to most conditions that might come up for a pair of humans’, my impression is that this is still too rare to warrant being the main point on the love-conditionality scale that we recognize.
I wouldn't be surprised if this isn't that rare for parents for their children. Barring their children doing horrible things (which is rare), I'd guess most parents would love their children unconditionally, or at least claim to. Most would tolerate bad but not horrible. And many will still love children who do horrible things. Partly this could be out of their sense of responsibility as a parent or attachment to the past.
I suspect such unconditional love between romantic partners and friends is rarer, though, and a concept of mid-conditional love like yours could be more useful there.
Maybe I’m out of the loop regarding the great loves going on around me, but my guess is that love is extremely rarely unconditional. Or at least if it is, then it is either very broadly applied or somewhat confused or strange: if you love me unconditionally, presumably you love everything else as well, since it is only conditions that separate me from the worms.
I would think totally unconditional love for a specific individual is allowed to be conditional on facts necessary to preserve their personal identity, which could be vague/fuzzy. If your partner asks you if you'd still love them if they were a worm and you do love them totally unconditionally, the answer should be yes, assuming they could really be a worm, at least logically. This wouldn't require you to love all worms. But you could also deny the hypothesis if they couldn't be a worm, even logically, in case a worm can't inherit their identity from a human.
That being said, I'd also guess that love is very rarely totally unconditional in this way. I think very few would continue to love someone who tortures them and others they care about. I wouldn't be surprised if many people (>0.1%, maybe even >1% of people) would continue to love someone after that person turned into a worm, assuming they believed their partner's identity would be preserved.
It's conceivable how the characters/words are used across English and Alienese have a strong enough correspondence that you can guess matching words much better than chance. But, I'm not confident that you'd have high accuracy.
Consider encryption. If you encrypted messages by mapping the same character to the same character each time, e.g. 'd' always gets mapped to '6', then this can be broken with decent accuracy by comparing frequency statistics of characters in your messages with the frequency statistics of characters in the English language.
If you mapped whole words to strings instead of character to character, you could use frequency statistics for whole words in the English language.
Then, between languages, this mostly gets way harder, but you might be able to make some informed guesses, based on
- how often you expect certain concepts to be referred to (frequency statistics, although even between human languages, there are probably very important differences)
- guesses about extremely common words like 'a', 'the', 'of'
- possible grammars
- similar words being written similarly, like verb tenses of the same verb, noun and verb forms of the same word, etc..
- (EDIT) Fine-grained associations between words, e.g. if a given word is used in a random sentence, how often another given word is used in that same sentence. Do this for all ordered pairs of words.
An AI might use similar facts or others, and many more, about much fine-grained and specific uses of words and associations, to guess, but I’m not sure an LLM token predictor mostly just trained on both languages in particular would do a good job.
EDIT: Unsupervised machine translation as Steven Byrnes pointed out seems to be on a better track.
Also, I would add that LLMs trained without perception of things other than text don't really understand language. The meanings of the words aren't grounded, and I imagine it could be possible to swap some in a way that would mostly preserve the associations (nearly isomorphic), but I’m not sure.
The reason SDG doesn't overfit large neural networks is probably because of various measures specifically intended to prevent overfitting, like weight penalties, dropout, early stopping, data augmentation + noise on inputs, and large enough learning rates that prevent convergence. If you didn't do those, running SDG to parameter convergence would probably cause overfitting. Furthermore, we test networks on validation datasets on which they weren't trained, and throw out the networks that don't generalize well to the validation set and start over (with new hyperparameters, architectures or parameter initializations). These measures bias us away from producing and especially deploying overfit networks.
Similarly, we might expect scheming without specific measures to prevent it. What could those measures look like? Catching scheming during training (or validation), and either heavily penalizing it, or fully throwing away the network and starting over? We could also validate out-of-training-distribution. Would networks whose caught scheming has been heavily penalized or networks selected for not scheming during training (and validation) generalize to avoid all (or all x-risky) scheming? I don't know, but it seems more likely than counting arguments would suggest.
Thanks!
I would say experiments, introspection and consideration of cases in humans have pretty convincingly established the dissociation between the types of welfare (e.g. see my section on it, although I didn't go into a lot of detail), but they are highly interrelated and often or even typically build on each other like you suggest.
I'd add that the fact that they sometimes dissociate seems morally important, because it makes it more ambiguous what's best for someone if multiple types seem to matter, and there are possible beings with some types but not others.
If someone wants to establish probabilities, they should be more systematic, and, for example, use reference classes. It seems to me that there's been little of this for AI risk arguments in the community, but more in the past few years.
Maybe reference classes are kinds of analogies, but more systematic and so less prone to motivated selection? If so, then it seems hard to forecast without "analogies" of some kind. Still, reference classes are better. On the other hand, even with reference classes, we have the problem of deciding which reference class to use or how to weigh them or make other adjustments, and that can still be subject to motivated reasoning in the same way.
We can try to be systematic about our search and consideration of reference classes, and make estimates across a range of reference classes or weights to them. Do sensitivity analysis. Zach Freitas-Groff seems to have done something like this in AGI Catastrophe and Takeover: Some Reference Class-Based Priors, for which he won a prize from Open Phil's AI Worldviews Contest.
Of course, we don't need to use direct reference classes for AI risk or AI misalignment. We can break the problem down.
There's also a decent amount of call option volume+interest at strike prices of $17.5, $20, $22.5, $25, (same links as the comment I'm replying to) which suggests to me that the market is expecting lower upside on successful merger than you. The current price is about $15.8/share, so $17.5 is only +10% and $25 is only +58%.
There's also of course volume+interest for call option at higher strike prices, $27.5, $30, $32.5.
I think this also suggests the market-implied odds calculations giving ~40% to successful merger are wrong, because the expected upside is overestimated. The market-implied odds are higher.
From https://archive.ph/SbuXU, for calculating the market-implied odds:
Author's analysis - assumed break price of $5 for Hawaiian and $6 for Spirit.
also:
- Without a merger, Spirit may be financially distressed based on recent operating results. There's some risk that Spirit can't continue as a going concern without a merger.
- Even if JetBlue prevails in court, there is some risk that the deal is recut as the offer was made in a much more favorable environment for airlines, though clauses in the merger agreement may prevent this.
So maybe you're overestimating the upside?
From https://archive.ph/rmZOX:
In my opinion, Spirit Airlines, Inc. equity is undervalued at around $15, but you're signing up for tremendous volatility over the coming months. The equity can get trashed under $5 or you can get the entire upside.
Unless I'm misreading, it looks like there's a bunch of volume+interest in put options with strike prices of around $5, but little volume+interest in options with lower strike prices (some in $2.50, but much less). $5.5 for January 5th, $5 for January 19th, $5 for February 16th. Much more volume+interest for put options in general for Feb 16th. So if we take those seriously and I'm not misunderstanding, the market expects a chance it'll drop below $5 per share, so a drop of at least ~70%.
There's more volume+interest in put options with strike prices of $7.50 and even more for $10 for February 16th.
Why is the downside only -60%?
Why think this is underpriced by the markets?
I would be surprised if iguanas find things meaningful that humans don't find meaningful, but maybe they desire some things pretty alien to us. I'm also not sure they find anything meaningful at all, but that depends on how we define meaningfulness.
Still, I think focusing on meaningfulness is also too limited. Iguanas find things important to them, meaningful or not. Desires, motivation, pleasure and suffering all assign some kind of importance to things.
In my view, either
- capacity for welfare is something we can measure and compare based on cognitive effects, like effects on attention, in which case it would be surprising if other verteberates, say, had tiny capacities for welfare relative to humans, or
- interpersonal utility comparisons can't be grounded, so there aren't any grounds to say iguanas have lower (or higher) capacities for welfare than humans, assuming they have any at all.
I think that's true, but also pretty much the same as what many or most veg or reducetarian EAs did when they decided what diet to follow (and other non-food animal products to avoid), including what exceptions to allow. If the consideration of why not to murder counts as involving math, so does veganism for many or most EAs, contrary to Zvi's claim. Maybe some considered too few options or possible exceptions ahead of time, but that doesn't mean they didn't do any math.
This is also basically how I imagine rule consequentialism to work: you decide what rules to follow ahead of time, including prespecified exceptions, based on math. And then you follow the rules. You don't redo the math for each somewhat unique decision you might face, except possibly very big infrequent decisions, like your career or big donations. You don't change your rule or make a new exception right in the situation where the rule would apply, e.g. a vegan at a restaurant, someone's house or a grocery store. If you change or break your rules too easily, you undermine your own ability to follow rules you set for yourself.
But also, EA is compatible with the impermissibility of instrumental harm regardless of how the math turns out (although I have almost no sympathy for absolutist deontological views). AFAIK, deontologists, including absolutist deontologists, can defend killing in self-defense without math and also think it's better to do more good than less, all else equal.
Well, there could be ways to distinguish, but it could be like a dream, where much of your reasoning is extremely poor, but you're very confident in it anyway. Like maybe you believe that your loved ones in your dream saying the word "pizza" is overwhelming evidence of their consciousness and love for you. But if you investigated properly, you could find out they're not conscious. You just won't, because you'll never question it. If value is totally subjective and the accuracy of beliefs doesn't matter (as would seem to be the case on experientialist accounts), then this seems to be fine.
Do you think simulations are so great that it's better for people to be put into them against their wishes, as long as they perceive/judge it as more meaningful or fulfilling, even if they wouldn't find it meaningful/fulfilling with accurate beliefs? Again, we can make it so that they don't find out.
Similarly, would involuntary wireheading or drugging to make people find things more meaningful or fulfilling be good for those people?
Or, something like a "meaning" shockwave, similar to a hedonium shockwave, — quickly killing and replacing everyone with conscious systems that take no outside input or even have sensations (or only the bare minimum) other than to generate feelings or judgements of meaning, fulfillment, or love? (Some person-affecting views could avoid this while still matching the rest of your views.)
Of course, I think there are good practical reasons to not do things to people against their wishes, even when it's apparently in their own best interests, but I think those don't capture my objections. I just think it would be wrong, except possibly in limited cases, e.g. to prevent foreseeable regret. The point is that people really do often want their beliefs to be accurate, and what they value is really intended — by their own statements — to be pointed at something out there, not just the contents of their experiences. Experientialism seems like an example of Goodhart's law to me, like hedonism might (?) seem like an example of Goodhart's law to you.
I don't think people and their values are in general replaceable, and if they don't want to be manipulated, it's worse for them (in one way) to be manipulated. And that should only be compensated for in limited cases. As far as I know, the only way to fundamentally and robustly capture that is to care about things other than just the contents of experiences and to take a kind of preference/value-affecting view.
Still, I don't think it's necessarily bad or worse for someone to not care about anything but the contents of their experiences. And if the state of the universe was already hedonium or just experiences of meaning, that wouldn't be worse. It's the fact that people do specifically care about things beyond just the contents of their experiences. If they didn't, and also didn't care about being manipulated, then it seems like it wouldn't necessarily be bad to manipulate them.
I think a small share of EAs would do the math before deciding whether or not to commit fraud or murder, or otherwise cause/risk involuntary harm to other people, and instead just rule it out immediately or never consider such options in the first place. Maybe that's a low bar, because the math is too obvious to do?
What other important ways would you want (or make sense for) EAs to be more deontological? More commitment to transparency and against PR?
Maximizing just for expected total pleasure, as a risk neutral classical utilitarian? Maybe being okay with killing everyone or letting everyone die (from AGI, say), as long as the expected payoff in total pleasure is high enough?
I don't really see a very plausible path for SBF to have ended up with enough power to do this, though. Money only buys you so much, against the US government and military, unless you can take them over. And I doubt SBF would destroy us with AGI if others weren't already going to.
Where I agree with classical utilitarianism is that we should compute goodness as a function of experience, rather than e.g. preferences or world states
Isn't this incompatible with caring about genuine meaning and fulfillment, rather than just feelings of them? For example, it's better for you to feel like you're doing more good than to actually do good. It's better to be put into an experience machine and be systematically mistaken about everything you care about, i.e. that the people you love even exist (are conscious, etc.) at all, even against your own wishes, as long as it feels more meaningful and fulfilling (and you never find out it's all fake, or that can be outweighed). You could also have what you find meaningful changed against your wishes, e.g. made to find counting blades of grass very meaningful, more so than caring for your loved ones.
FWIW, this is also an argument for non-experientialist "preference-affecting" views, similar to person-affecting views. On common accounts of weigh or aggregate, if there are subjective goods, then they can be generated and outweigh the violation and abandonment of your prior values, even against your own wishes, if they’re strong enough.
And if emotionally significant social bonds don't count, it seems like we could be throwing away what humans typically find most important in their lives.
Of course, I think there are potentially important differences. I suspect humans tend to be willing to sacrifice or suffer much more for those they love than (almost?) all other animals. Grief also seems to affect humans more (longer, deeper), and it's totally absent in many animals.
On the other hand, I guess some other animals will fight to the death to protect their offspring. And some die apparently grieving. This seems primarily emotionally driven, but I don't think we should discount it for that fact. Emotions are one way of making evaluations, like other kinds of judgements of value.
EDIT: Another possibility is that other animals form such bonds and could even care deeply about them, but don't find them "meaningful" or "fulfilling" at all or in a way as important as humans do. Maybe those require higher cognition, e.g. concepts of meaning and fulfillment. But it seems to me that the deep caring, in just emotional and motivational terms, should be enough?
Ya, I don't think utilitarian ethics is invalidated, it's just that we don't really have much reason to be utilitarian specifically anymore (not that there are necessarily much more compelling reasons for other views). Why sum welfare and not combine them some other way? I guess there's still direct intuition: two of a good thing is twice as good as just one of them. But I don't see how we could defend that or utilitarianism in general any further in a way that isn't question-begging and doesn't depend on arguments that undermine utilitarianism when generalized.
You could just take your utility function to be where is any bounded increasing function, say arctan, and maximize the expected value of that. This doesn't work with actual infinities, but it can handle arbitrary prospects over finite populations. Or, you could just rank prospects by stochastic dominance with respect to the sum of utilities, like Tarsney, 2020.
You can't extend it the naive way, though, i.e. just maximize whenever that's finite and then do something else when it's infinite or undefined, though. One of the following would happen: the money pump argument goes through again, you give up stochastic dominance or you give up transitivity, each of which seems irrational. This was my 4th response to Infinities are generally too problematic.
The argument can be generalized without using infinite expectations, and instead using violations of Limitedness in Russell and Isaacs, 2021 or reckless preferences in Beckstead and Thomas, 2023. However, intuitively, it involves prospects that look like they should be infinitely valuable or undefinably valuable relative to the things they're made up of. Any violation of (the countable extension of) the Archimedean Property/continuity is going to look like you have some kind of infinity.
The issue could just be a categorization thing. I don't think philosophers would normally include this in "infinite ethics", because it involves no actual infinities out there in the world.
Also, I'd say what I'm considering here isn't really "infinite ethics", or at least not what I understand infinite ethics to be, which is concerned with actual infinities, e.g. an infinite universe, infinitely long lives or infinite value. None of the arguments here assume such infinities, only infinitely many possible outcomes with finite (but unbounded) value.
Thanks for the comment!
I don't understand this part of your argument. Can you explain how you imagine this proof working?
St Petersburg-like prospects (finite actual utility for each possible outcome, but infinite expected utility, or generalizations of them) violate extensions of each of these axioms to countably many possible outcomes:
- The continuity/Archimedean axiom: if A and B have finite expected utility, and A < B, there's no strict mixture of A and an infinite expected utility St Petersburg prospect, like , , that's equivalent to B, because all such strict mixtures will have infinite expected utility. Now, you might not have defined expected utility yet, but this kind of argument would generalize: you can pick A and B to be outcomes of the St Petersburg prospect, and any strict mixture with A will be better than B.
- The Independence axiom: see the following footnote.[2]
- The Sure-Thing Principle: in the money pump argument in my post, B-$100 is strictly better than each outcome of A, but A is strictly better than B-$100. EDIT: Actually, you can just compare A with B.
I think these axioms are usually stated only for prospects for finitely many possible outcomes, but the arguments for the finitary versions, like specific money pump arguments, would apply equally (possibly with tiny modifications that wouldn't undermine them) to the countable versions. Or, at least, that's the claim of Russell and Isaacs, 2021, which they illustrate with a few arguments and briefly describe some others that would generalize. I reproduced their money pump argument in the post.
For example, as you came close to saying in your responses, you could just have bounded utility functions! That ends up being rational, and seems not self-undermining because after looking at many of these arguments it seems like maybe you're kinda forced to.
Ya, I agree that would be rational. I don't think having a bounded utility function is in itself self-undermining (and I don't say so), but it would undermine utilitarianism, because it wouldn't satisfy Impartiality + (Separability or Goodsell, 2021's version of Anteriority). If you have to give up Impartiality + (Separability or Goodsell, 2021's version of Anteriority) and the arguments that support them, then there doesn't seem to be much reason left to be a utilitarian of any kind in the first place. You'll have to give up the formal proofs of utilitarianism that depend on these principles or restrictions of them that are motivated in the same ways.
You can try to make utilitarianism rational by approximating it with a bounded utility function, or applying a bounded function to total welfare and taking that as your utility function, and then maximizing expected utility, but then you undermine the main arguments for utilitarianism in the first place.
Hence, utilitarianism is irrational or self-undermining.
Overall, I wish you'd explain the arguments in the papers you linked better. The one argument you actually wrote in this post was interesting, you should have done more of that!
I did consider doing that, but the post is already pretty long and I didn't want to spend much more on it. Goodsell, 2021's proof is simple enough, so you could check out the paper. The proof for Theorem 4 from Russell, 2023 looks trickier. I didn't get it on my first read, and I haven't spent the time to actually understand it. EDIT: Also, the proofs aren't as nice/intuitive/fun or flow as naturally as the money pump argument. They present a sequence of prospects constructed in very specific ways, and give a contradiction (violating of transitivity) when you apply all of the assumptions in the theorem. You just have to check the logic.
- ^
You could refuse to define the expected utilility, but the argument generalizes
- ^
Russell and Isaacs, 2021 define Countable Independence as follows:
For any prospects , and , and any probabilities that sum to one, if , then
If furthermore for some such that , then
Then they write:
Improper prospects clash directly with Countable Independence. Suppose is a prospect that assigns probabilities to outcomes . We can think of as a countable mixture in two different ways. First, it is a mixture of the one-outcome prospects in the obvious way. Second, it is also a mixture of infinitely many copies of X itself. If is improper, this means that is strictly better than each outcome . But then Countable Independence would require that X is strictly better than X. (The argument proceeds the same way if X is strictly worse than each outcome xi instead.)
Possibly, but by limiting access to the arguments, you also limit the public case for it and engagement by skeptics. The views within the area will also probably further reflect self-selection for credulousness and deference over skepticism.
There must be less infohazardous arguments we can engage with. Or, maybe zero-knowledge proofs are somehow applicable. Or, we can select a mutually trusted skeptic (or set of skeptics) with relevant expertise to engage privately. Or, legally binding contracts to prevent sharing.
Eliezer's scenario uses atmospheric CHON. Also, I guess Eliezer used atmospheric CHON to allow the nanomachines to spread much more freely and aggressively.
Is 1% of the atmosphere way more than necessary to kill everything near the surface by attacking it?
Also, maybe we design scalable and efficient quantum computers with AI first, and an AGI uses those to simulate quantum chemistry more efficiently, e.g. Lloyd, 1996 and Zalka, 1996. But large quantum computers may still not be easily accessible. Hard to say.
High quality quantum chemistry simulations can take days or weeks to run, even on supercomputing clusters.
This doesn't seem very long for an AGI if they're patient and can do this undetected. Even months could be tolerable? And if the AGI keeps up with other AGI by self-improving to avoid being replaced, maybe even years. However, at years, there could be a race between the AGIs to take over, and we could see a bunch of them make attempts that are unlikely to succeed.
As a historical note and for further context, the diamondoid scenario is at least ~10 years old, outlined here by Eliezer, just not with the term "diamondoid bacteria":
The concrete illustration I often use is that a superintelligence asks itself what the fastest possible route is to increasing its real-world power, and then, rather than bothering with the digital counters that humans call money, the superintelligence solves the protein structure prediction problem, emails some DNA sequences to online peptide synthesis labs, and gets back a batch of proteins which it can mix together to create an acoustically controlled equivalent of an artificial ribosome which it can use to make second-stage nanotechnology which manufactures third-stage nanotechnology which manufactures diamondoid molecular nanotechnology and then... well, it doesn't really matter from our perspective what comes after that, because from a human perspective any technology more advanced than molecular nanotech is just overkill. A superintelligence with molecular nanotech does not wait for you to buy things from it in order for it to acquire money. It just moves atoms around into whatever molecular structures or large-scale structures it wants.
The first mention of "diamondoid" on LW (and by Eliezer) is this from 16 years ago, but not for an AI doom scenario.
Are you thinking quantum computers specifically? IIRC, quantum computers can simulate quantum phenomena much more efficiently at scale than classical computers.
EDIT: For early proofs of efficient quantum simulation with quantum computers, see:
This is the more interesting and important claim to check to me. I think the barriers to engineering bacteria are much lower, but it’s not obvious that this will avoid detection and humans responding to the threat, or that timing and/or triggers in bacteria can be reliable enough.
Hmm, if A is simulating B with B's source code, couldn’t the simulated B find out it's being simulated and lie about its decisions or hide what its actual preferences? Or would its actual preferences be derivable from its weights or code directly without simulation?
I had a similar thought about "A is B" vs "B is A", but "A is the B" should reverse to "The B is A" and vice versa when the context is held constant and nothing changes the fact, because "is" implies that it's the present condition and "the" implies uniqueness. However, it might be trained on old and no longer correct writing or that includes quotes about past states of affairs. Some context might still be missing, too, e.g. for "A is the president", president of what? It would still be a correct inference to say "The president is A" in the same context, at least, and some others, but not all.
Also, the present condition can change quickly, e.g. "The time is 5:21:31 pm EST" and "5:21:31 pm EST is the time" quickly become false, but I think these are rare exceptions in our use of language.
p.37-38 in Goodsell, 2023 gives a better proposal, which is to clip/truncate the utilities into the range and compare the expected clipped utilities in the limit as . This will still suffer from St Petersburg lottery problems, though.
Looking at Gustafsson, 2022's money pumps for completeness, the precaution principles he uses just seem pretty unintuitive to me. The idea seems to be that if you'll later face a decision situation where you can make a choice that makes you worse off but you can't make yourself better off by getting there, you should avoid the decision situation, even if it's entirely under your control to make a choice in that situation that won't leave you worse off. But, you can just make that choice that won't leave you worse off later instead of avoiding the situation altogether.
Here's the forcing money pump:
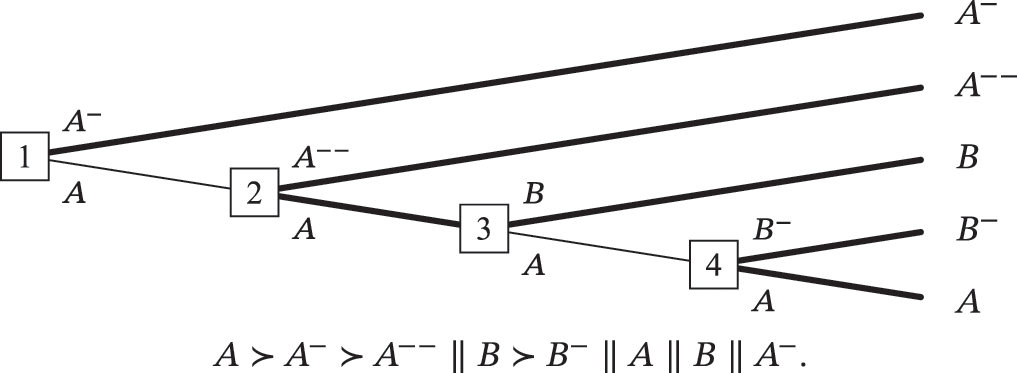
It seems obvious to me that you can just stick with A all the way through, or switch to B, and neither would violate any of your preferences or be worse than any other option. Gustafsson is saying that would be irrational, it seems because there's some risk you'll make the wrong choices. Another kind of response like your policy I can imagine is that unless you have preferences otherwise (i.e. would strictly prefer another accessible option to what you have now), you just stick with the status quo, as the default. This means sticking with A all the eay though, because you're never offered a strictly better option than it.
Another problem with the precaution principles is that they seem much less plausible when you seriously entertain incompleteness, rather than kind of treat incompleteness like equivalence. He effectively argues that at node 3, you should pick B, because otherwise at node 4, you could end up picking B-, which is worse than B, and there's no upside. But that basically means claiming that one of the following must hold:
- you'll definitely pick B- at 4, or
- B is better than any strict probabilistic mixture of A and B-.
But both are false in general. 1 is false in general because A is permissible at 4. 2 is false in general because A and B are incomparable and incomparability can be infectious (e.g. MacAskill, 2013), so B can be incomparable with a strict probabilistic mixture of A and B-. It also just seems unintuitive, because the claim is made generally, and so would have to hold no matter how low the probability assigned to B- is, as long it's positive.
Imagine A is an apple, B is a banana and B- is a slightly worse banana, and I have no preferences between apples and bananas. It would be odd to say that a banana is better than an apple or a tiny probability of a worse banana. This would be like using the tiny risk of a worse banana with the apple to break a tie between the apple and the banana, but there's no tie to break, because apples and bananas are incomparable.
If A and B were equivalent, then B would indeed very plausibly be better than a strict probabilistic mixture of A and B-. This would follow from Independence, or if A, B and B- are deterministic outcomes, statewise dominance. So, I suspect the intuitions supporting the precaution principles are accidentally treating incomparability like equivalence.
I think a more useful way to think of incomparability is as indeterminancy about which is better. You could consider what happens if you treat A as (possibly infinitely) better than B in one whole treatment of the tree, and consider what happens if you treat B as better than A in a separate treatment, and consider what happens if you treat them as equivalent all the way through (and extend your preference relation to be transitive and continue to satisfy stochastic dominance and independence in each case). If B were better, you'd end up at B, no money pump. If A were better, you'd end up at A, no money pump. If they were equivalent, you'd end up at either (or maybe specifically B, because of precaution), no money pump.
I think a multi-step decision procedure would be better. Do what your preferences themselves tell you to do and rule out any options you can with them. If there are multiple remaining incomparable options, then apply your original policy to avoid money pumps.
This also looks like a generalization of stochastic dominance.
Coming back to this, the policy
if I previously turned down some option X, I will not choose any option that I strictly disprefer to X
seems irrational to me if applied in general. Suppose I offer you and , where both and are random, and is ex ante preferable to , e.g. stochastically dominates , but has some chance of being worse than . You pick . Then you evaluate to get . However, suppose you get unlucky, and is worse than . Suppose further that there's a souring of , , that's still preferable to . Then, I offer you to trade for . It seems irrational to not take .
Maybe what you need to do is first evaluate according to your multi-utility function (or stochastic dominance, which I think is a special case) to rule out some options, i.e. to rule out not trading for when the latter is better than the former, and then apply your policy to rule out more options.
Also, the estimate of the current number of researchers probably underestimates the number of people (or person-hours) who will work on AI safety. You should probably expect further growth to the number of people working on AI safety, because the topic is getting mainstream coverage and support, Hinton and Bengio have become advocates, and it's being pushed more in EA (funding, community building, career advice).
However, the FTX collapse is reason to believe there will be less funding going forward.
Some other possibilities that may be worth considering and can further reduce impact, at least for an individual looking to work on AI safety themself:
- Some work is net negative and increases the risk of doom or wastes the time and attention of people who could be doing more productive things.
- Practical limits on the number of people working at a time, e.g. funding, management/supervision capacity. This could mean some people could have much lower probability of making a difference, if them taking a position pushes someone else who would have out from the field, or into (possibly much) less useful work.
An AGI could give read and copy access to the code being run and the weights directly on the devices from which the AGI is communicating. That could still be a modified copy of the original and more powerful (or with many unmodified copies) AGI, though. So, the other side may need to track all of the copies, maybe even offline ones that would go online on some trigger or at some date.
Also, giving read and copy access could be dangerous to the AGI if it doesn't have copies elsewhere.