There are no coherence theorems
post by Dan H (dan-hendrycks), EJT (ElliottThornley) · 2023-02-20T21:25:48.478Z · LW · GW · 130 commentsContents
Introduction Coherence arguments Cited ‘coherence theorems’ and what they actually say The Von Neumann-Morgenstern Expected Utility Theorem: Savage’s Theorem The Bolker-Jeffrey Theorem Dutch Books Cox’s Theorem The Complete Class Theorem Omohundro (2007), ‘The Nature of Self-Improving Artificial Intelligence’ Money-Pump Arguments by Johan Gustafsson Completeness doesn’t come for free A money-pump for Completeness Summarizing this section Conclusion Bottom-lines Appendix: Papers and posts in which the error occurs ‘The nature of self-improving artificial intelligence’ ‘The basic AI drives’ ‘Coherent decisions imply consistent utilities’ ‘Things To Take Away From The Essay’ ‘Sufficiently optimized agents appear coherent’ ‘What do coherence arguments imply about the behavior of advanced AI?’ ‘Coherence theorems’ ‘Coherence arguments do not entail goal-directed behavior’ ‘Coherence arguments imply a force for goal-directed behavior.’ ‘AI Alignment: Why It’s Hard, and Where to Start’ ‘Money-pumping: the axiomatic approach’ ‘Ngo and Yudkowsky on alignment difficulty’ ‘Ngo and Yudkowsky on AI capability gains’ ‘AGI will have learnt utility functions’ None 131 comments
[Written by EJT as part of the CAIS Philosophy Fellowship. Thanks to Dan for help posting to the Alignment Forum]
Introduction
For about fifteen years, the AI safety community has been discussing coherence arguments [? · GW]. In papers and posts on the subject, it’s often written that there exist 'coherence theorems' which state that, unless an agent can be represented as maximizing expected utility, that agent is liable to pursue strategies that are dominated by some other available strategy. Despite the prominence of these arguments, authors are often a little hazy about exactly which theorems qualify as coherence theorems. This is no accident. If the authors had tried to be precise, they would have discovered that there are no such theorems.
I’m concerned about this. Coherence arguments seem to be a moderately important part of the basic case for existential risk from AI [LW · GW]. To spot the error in these arguments, we only have to look up what cited ‘coherence theorems’ actually say. And yet the error seems to have gone uncorrected for more than a decade.
More detail below.[1]
Coherence arguments
Some authors frame coherence arguments in terms of ‘dominated strategies’. Others frame them in terms of ‘exploitation’, ‘money-pumping’, ‘Dutch Books’, ‘shooting oneself in the foot’, ‘Pareto-suboptimal behavior’, and ‘losing things that one values’ (see the Appendix [LW · GW] for examples).
In the context of coherence arguments, each of these terms means roughly the same thing: a strategy A is dominated by a strategy B if and only if A is worse than B in some respect that the agent cares about and A is not better than B in any respect that the agent cares about. If the agent chooses A over B, they have behaved Pareto-suboptimally, shot themselves in the foot, and lost something that they value. If the agent’s loss is someone else’s gain, then the agent has been exploited, money-pumped, or Dutch-booked. Since all these phrases point to the same sort of phenomenon, I’ll save words by talking mainly in terms of ‘dominated strategies’.
With that background, here’s a quick rendition of coherence arguments [LW · GW]:
- There exist coherence theorems which state that, unless an agent can be represented as maximizing expected utility, that agent is liable to pursue strategies that are dominated by some other available strategy.
- Sufficiently-advanced artificial agents will not pursue dominated strategies.
- So, sufficiently-advanced artificial agents will be ‘coherent’: they will be representable as maximizing expected utility.
Typically, authors go on to suggest that these expected-utility-maximizing agents are likely to behave in certain, potentially-dangerous ways. For example, such agents are likely to appear ‘goal-directed [LW · GW]’ in some intuitive sense. They are likely to have certain instrumental goals, like acquiring power and resources. And they are likely to fight back against attempts to shut them down or modify their goals.
There are many ways to challenge the argument stated above, and many of those challenges have [LW · GW] been [LW · GW] made [LW · GW]. There are also many ways to respond to those challenges, and many of those responses have been made [LW · GW] too [LW · GW]. The challenge that seems to remain yet unmade is that Premise 1 is false: there are no coherence theorems.
Cited ‘coherence theorems’ and what they actually say
Here’s a list of theorems that have been called ‘coherence theorems’. None of these theorems state that, unless an agent can be represented as maximizing expected utility, that agent is liable to pursue dominated strategies. Here’s what the theorems say:
The Von Neumann-Morgenstern Expected Utility Theorem:
The Von Neumann-Morgenstern Expected Utility Theorem is as follows:
An agent can be represented as maximizing expected utility if and only if their preferences satisfy the following four axioms:
- Completeness: For all lotteries X and Y, X is at least as preferred as Y or Y is at least as preferred as X.
- Transitivity: For all lotteries X, Y, and Z, if X is at least as preferred as Y, and Y is at least as preferred as Z, then X is at least as preferred as Z.
- Independence: For all lotteries X, Y, and Z, and all probabilities 0<p<1, if X is strictly preferred to Y, then pX+(1-p)Z is strictly preferred to pY+(1-p)Z.
- Continuity: For all lotteries X, Y, and Z, with X strictly preferred to Y and Y strictly preferred to Z, there are probabilities p and q such that (i) 0<p<1, (ii) 0<q<1, and (iii) pX+(1-p)Z is strictly preferred to Y, and Y is strictly preferred to qX+(1-q)Z.
Note that this theorem makes no reference to dominated strategies, vulnerabilities, exploitation, or anything of that sort.
Some authors (both inside and outside the AI safety community) have tried to defend some or all of the axioms above using money-pump arguments. These are arguments with conclusions of the following form: ‘agents who fail to satisfy Axiom A can be induced to make a set of trades or bets that leave them worse-off in some respect that they care about and better-off in no respect, even when they know in advance all the trades and bets that they will be offered.’ Authors then use that conclusion to support a further claim. Outside the AI safety community, the claim is often:
Agents are rationally required to satisfy Axiom A.
But inside the AI safety community, the claim is:
Sufficiently-advanced artificial agents will satisfy Axiom A.
This difference will be important below. For now, the important thing to note is that the conclusions of money-pump arguments are not theorems. Theorems (like the VNM Theorem) can be proved without making any substantive assumptions. Money-pump arguments establish their conclusion only by making substantive assumptions: assumptions that might well be false. In the section titled ‘A money-pump for Completeness [LW · GW]’, I will discuss an assumption that is both crucial to money-pump arguments and likely false.
Savage’s Theorem
Savage’s Theorem is also a Von-Neumann-Morgenstern-style representation theorem. It also says that an agent can be represented as maximizing expected utility if and only if their preferences satisfy a certain set of axioms. The key difference between Savage’s Theorem and the VNM Theorem is that the VNM Theorem takes the agent’s probability function as given, whereas Savage constructs the agent’s probability function from their preferences over lotteries.
As with the VNM Theorem, Savage’s Theorem says nothing about dominated strategies or vulnerability to exploitation.
The Bolker-Jeffrey Theorem
This theorem is also a representation theorem, in the mould of the VNM Theorem and Savage’s Theorem above. It makes no reference to dominated strategies or anything of that sort.
Dutch Books
The Dutch Book Argument for Probabilism says:
An agent can be induced to accept a set of bets that guarantee a net loss if and only if that agent’s credences violate one or more of the probability axioms.
The Dutch Book Argument for Conditionalization says:
An agent can be induced to accept a set of bets that guarantee a net loss if and only if that agent updates their credences by some rule other than Conditionalization.
These arguments do refer to dominated strategies and vulnerability to exploitation. But they suggest only that an agent’s credences (that is, their degrees of belief) must meet certain conditions. Dutch Book Arguments place no constraints whatsoever on an agent’s preferences. And if an agent’s preferences fail to satisfy any of Completeness, Transitivity, Independence, and Continuity, that agent cannot be represented as maximizing expected utility (the VNM Theorem is an ‘if and only if’, not just an ‘if’).
Cox’s Theorem
Cox’s Theorem says that, if an agent’s degrees of belief satisfy a certain set of axioms, then their beliefs are isomorphic to probabilities.
This theorem makes no reference to dominated strategies, and it says nothing about an agent’s preferences.
The Complete Class Theorem
The Complete Class Theorem says that an agent’s policy of choosing actions conditional on observations is not strictly dominated by some other policy (such that the other policy does better in some set of circumstances and worse in no set of circumstances) if and only if the agent’s policy maximizes expected utility with respect to a probability distribution that assigns positive probability to each possible set of circumstances.
This theorem does refer to dominated strategies. However, the Complete Class Theorem starts off by assuming that the agent’s preferences over actions in sets of circumstances satisfy Completeness and Transitivity. If the agent’s preferences are not complete and transitive, the Complete Class Theorem does not apply. So, the Complete Class Theorem does not imply that agents must be representable as maximizing expected utility if they are to avoid pursuing dominated strategies.
Omohundro (2007), ‘The Nature of Self-Improving Artificial Intelligence’
This paper seems to be the original source of the claim that agents are vulnerable to exploitation unless they can be represented as expected-utility-maximizers. Omohundro purports to give us “the celebrated expected utility theorem of von Neumann and Morgenstern… derived from a lack of vulnerabilities rather than from given axioms.”
Omohundro’s first error is to ignore Completeness. That leads him to mistake acyclicity for transitivity, and to think that any transitive relation is a total order. Note that this error already sinks any hope of getting an expected-utility-maximizer out of Omohundro’s argument. Completeness (recall) is a necessary condition for being representable as an expected-utility-maximizer. If there’s no money-pump that compels Completeness, there’s no money-pump that compels expected-utility-maximization.
Omohundro’s second error is to ignore Continuity. His ‘Argument for choice with objective uncertainty’ is too quick to make much sense of. Omohundro says it’s a simpler variant of Green (1987). The problem is that Green assumes every axiom of the VNM Theorem except Independence. He says so at the bottom of page 789. And, even then, Green notes that his paper provides “only a qualified bolstering” of the argument for Independence.
Money-Pump Arguments by Johan Gustafsson
It’s worth noting that there has recently appeared a book which gives money-pump arguments for each of the axioms of the VNM Theorem. It’s by the philosopher Johan Gustafsson and you can read it here.
This does not mean that the posts and papers claiming the existence of coherence theorems are correct after all. Gustafsson’s book was published in 2022, long after most of the posts on coherence theorems. Gustafsson argues that the VNM axioms are requirements of rationality, whereas coherence arguments aim to establish that sufficiently-advanced artificial agents will satisfy the VNM axioms. More importantly (and as noted above) the conclusions of money-pump arguments are not theorems. Theorems (like the VNM Theorem) can be proved without making any substantive assumptions. Money-pump arguments establish their conclusion only by making substantive assumptions: assumptions that might well be false.
I will now explain how denying one such assumption allows us to resist Gustafsson’s money-pump arguments. I will then argue that there can be no compelling money-pump arguments for the conclusion that sufficiently-advanced artificial agents will satisfy the VNM axioms.
Before that, though, let’s get the lay of the land. Recall that Completeness is necessary for representability as an expected-utility-maximizer. If an agent’s preferences are incomplete, that agent cannot be represented as maximizing expected utility. Note also that Gustafsson’s money-pump arguments for the other axioms of the VNM Theorem depend on Completeness. As he writes in a footnote on page 3, his money-pump arguments for Transitivity, Independence, and Continuity all assume that the agent’s preferences are complete. That makes Completeness doubly important to the ‘money-pump arguments for expected-utility-maximization’ project. If an agent’s preferences are incomplete, then they can’t be represented as an expected-utility-maximizer, and they can’t be compelled by Gustafsson’s money-pump arguments to conform their preferences to the other axioms of the VNM Theorem. (Perhaps some earlier, less careful money-pump argument can compel conformity to the other VNM axioms without assuming Completeness, but I think it unlikely.)
So, Completeness is crucial. But one might well think that we don’t need a money-pump argument to establish it. I’ll now explain why this thought is incorrect, and then we’ll look at a money-pump.
Completeness doesn’t come for free
Here’s Completeness again:
Completeness: For all lotteries X and Y, X is at least as preferred as Y or Y is at least as preferred as X.
Since:
‘X is strictly preferred to Y’ is defined as ‘X is at least as preferred as Y and Y is not at least as preferred as X.’
And:
‘The agent is indifferent between X and Y’ is defined as ‘X is at least as preferred as Y and Y is at least as preferred as X.’
Completeness can be rephrased as:
Completeness (rephrased): For all lotteries X and Y, either X is strictly preferred to Y, or Y is strictly preferred to X, or the agent is indifferent between X and Y.
And then you might think that Completeness comes for free. After all, what other comparative, preference-style attitude can an agent have to X and Y?
This thought might seem especially appealing if you think of preferences as nothing more than dispositions to choose. Suppose that our agent is offered repeated choices between X and Y. Then (the thought goes), in each of these situations, they have to choose something. If they reliably choose X over Y, then they strictly prefer X to Y. If they reliably choose Y over X, then they strictly prefer Y to X. If they flip a coin, or if they sometimes choose X and sometimes choose Y, then they are indifferent between X and Y.
Here’s the important point missing from this thought: there are two ways of failing to have a strict preference between X and Y. Being indifferent between X and Y is one way: preferring X at least as much as Y and preferring Y at least as much as X. Having a preferential gap between X and Y is another way: not preferring X at least as much as Y and not preferring Y at least as much as X. If an agent has a preferential gap between any two lotteries, then their preferences violate Completeness.
The key contrast between indifference and preferential gaps is that indifference is sensitive to all sweetenings and sourings. Consider an example. C is a lottery that gives the agent a pot of ten dollar-bills for sure. D is a lottery that gives the agent a different pot of ten dollar-bills for sure. The agent does not strictly prefer C to D and does not strictly prefer D to C. How do we determine whether the agent is indifferent between C and D or whether the agent has a preferential gap between C and D? We sweeten one of the lotteries: we make that lottery just a little but more attractive. In the example, we add an extra dollar-bill to pot C, so that it contains $11 total. Call the resulting lottery C+. The agent will strictly prefer C+ to D. We get the converse effect if we sour lottery C, by removing a dollar-bill from the pot so that it contains $9 total. Call the resulting lottery C-. The agent will strictly prefer D to C-. And we also get strict preferences by sweetening and souring D, to get D+ and D- respectively. The agent will strictly prefer D+ to C and strictly prefer C to D-. Since the agent’s preference-relation between C and D is sensitive to all such sweetenings and sourings, the agent is indifferent between C and D.
Preferential gaps, by contrast, are insensitive to some sweetenings and sourings. Consider another example. A is a lottery that gives the agent a Fabergé egg for sure. B is a lottery that returns to the agent their long-lost wedding album. The agent does not strictly prefer A to B and does not strictly prefer B to A. How do we determine whether the agent is indifferent or whether they have a preferential gap? Again, we sweeten one of the lotteries. A+ is a lottery that gives the agent a Fabergé egg plus a dollar-bill for sure. In this case, the agent might not strictly prefer A+ to B. That extra dollar-bill might not suffice to break the tie. If that is so, the agent has a preferential gap between A and B. If the agent has a preferential gap, then slightly souring A to get A- might also fail to break the tie, as might slightly sweetening and souring B to get B+ and B- respectively.
The axiom of Completeness rules out preferential gaps, and so rules out insensitivity to some sweetenings and sourings. That is why Completeness does not come for free. We need some argument for thinking that agents will not have preferential gaps. ‘The agent has to choose something’ is a bad argument. Faced with a choice between two lotteries, the agent might choose arbitrarily, but that does not imply that the agent is indifferent between the two lotteries. The agent might instead have a preferential gap. It depends on whether the agent’s preference-relation is sensitive to all sweetenings and sourings.
A money-pump for Completeness
So, we need some other argument for thinking that sufficiently-advanced artificial agents’ preferences over lotteries will be complete (and hence will be sensitive to all sweetenings and sourings). Let’s look at a money-pump. I will later explain how my responses to this money-pump also tell against other money-pump arguments for Completeness.
Here's the money-pump, suggested by Ruth Chang (1997, p.11) and later discussed by Gustafsson (2022, p.26):

‘’ denotes strict preference and ‘’ denotes a preferential gap, so the symbols underneath the decision tree say that the agent strictly prefers A to A- and has a preferential gap between A- and B, and between B and A.
Now suppose that the agent finds themselves at the beginning of this decision tree. Since the agent doesn’t strictly prefer A to B, they might choose to go up at node 1. And since the agent doesn’t strictly prefer B to A-, they might choose to go up at node 2. But if the agent goes up at both nodes, they have pursued a dominated strategy: they have made a set of trades that left them with A- when they could have had A (an outcome that they strictly prefer), even though they knew in advance all the trades that they would be offered.
Note, however, that this money-pump is non-forcing: at some step in the decision tree, the agent is not compelled by their preferences to pursue a dominated strategy. The agent would not be acting against their preferences if they chose to go down at node 1 or at node 2. And if they went down at either node, they would not pursue a dominated strategy.
To avoid even a chance of pursuing a dominated strategy, we need only suppose that the agent acts in accordance with the following policy: ‘if I go up at node 1, I will go down at node 2.’ Since the agent does not strictly prefer A- to B, acting in accordance with this policy does not require the agent to change or act against any of their preferences.
More generally, suppose that the agent acts in accordance with the following policy in all decision-situations: ‘if I previously turned down some option X, I will not choose any option that I strictly disprefer to X.’ That policy makes the agent immune to all possible money-pumps for Completeness.[2] And (granted some assumptions), the policy never requires the agent to change or act against any of their preferences.
Here’s why. Assume:
- That the agent’s strict preferences are transitive.
- That the agent knows in advance what trades they will be offered.
- That the agent is capable of backward induction: predicting what they would choose at later nodes and taking those predictions into account at earlier nodes.
(If the agent doesn’t know in advance what trades they will be offered or is incapable of backward induction, then their pursuit of a dominated strategy need not indicate any defect in their preferences. Their pursuit of a dominated strategy can instead be blamed on their lack of knowledge and/or reasoning ability.)
Given the agent’s knowledge of the decision tree and their grasp of backward induction, we can infer that, if the agent proceeds to node 2, then at least one of the possible outcomes of going to node 2 is not strictly dispreferred to any option available at node 1. Then, if the agent proceeds to node 2, they can act on a policy of not choosing any outcome that is strictly dispreferred to some option available at node 1. The agent’s acting on this policy will not require them to act against any of their preferences. For suppose that it did require them to act against some strict preference. Suppose that B is strictly dispreferred to A, so that the agent’s policy requires them to choose C, and yet C is strictly dispreferred to B. Then, by the transitivity of strict preference, C is strictly dispreferred to A. That means that both B and C are strictly dispreferred to A, contrary to our original assumption that at least one of the possible outcomes of going to node 2 is not strictly dispreferred to any option available at node 1. We have reached a contradiction, and so we can reject the assumption that the agent’s policy will require them to act against their preferences. This proof is easy to generalize so that it applies to decision trees with more than three terminal outcomes.
Summarizing this section
Money-pump arguments for Completeness (understood as the claim that sufficiently-advanced artificial agents will have complete preferences) assume that such agents will not act in accordance with policies like ‘if I previously turned down some option X, I will not choose any option that I strictly disprefer to X.’ But that assumption is doubtful. Agents with incomplete preferences have good reasons to act in accordance with this kind of policy: (1) it never requires them to change or act against their preferences, and (2) it makes them immune to all possible money-pumps for Completeness.
So, the money-pump arguments for Completeness are unsuccessful: they don’t give us much reason to expect that sufficiently-advanced artificial agents will have complete preferences. Any agent with incomplete preferences cannot be represented as an expected-utility-maximizer. So, money-pump arguments don’t give us much reason to expect that sufficiently-advanced artificial agents will be representable as expected-utility-maximizers.
Conclusion
There are no coherence theorems. Authors in the AI safety community should stop suggesting that there are.
There are money-pump arguments, but the conclusions of these arguments are not theorems. The arguments depend on substantive and doubtful assumptions.
Here is one doubtful assumption: advanced artificial agents with incomplete preferences will not act in accordance with the following policy: ‘if I previously turned down some option X, I will not choose any option that I strictly disprefer to X.’ Any agent who acts in accordance with that policy is immune to all possible money-pumps for Completeness. And agents with incomplete preferences cannot be represented as expected-utility-maximizers.
In fact, the situation is worse than this. As Gustafsson notes, his money-pump arguments for the other three axioms of the VNM Theorem depend on Completeness. If Gustafsson’s money-pump arguments fail without Completeness, I suspect that earlier, less-careful money-pump arguments for the other axioms of the VNM Theorem fail too. If that’s right, and if Completeness is false, then none of Transitivity, Independence, and Continuity has been established by money-pump arguments either.
Bottom-lines
- There are no coherence theorems
- Money-pump arguments don’t give us much reason to expect that advanced artificial agents will be representable as expected-utility-maximizers.
Appendix: Papers and posts in which the error occurs
Here’s a selection of papers and posts which claim that there are coherence theorems.
‘The nature of self-improving artificial intelligence’
“The appendix shows how the rational economic structure arises in each of these situations. Most presentations of this theory follow an axiomatic approach and are complex and lengthy. The version presented in the appendix is based solely on avoiding vulnerabilities and tries to make clear the intuitive essence of the argument.”
“In each case we show that if an agent is to avoid vulnerabilities, its preferences must be representable by a utility function and its choices obtained by maximizing the expected utility.”
‘The basic AI drives’
“The remarkable “expected utility” theorem of microeconomics says that it is always possible for a system to represent its preferences by the expectation of a utility function unless the system has “vulnerabilities” which cause it to lose resources without benefit.”
‘Coherent decisions imply consistent utilities’ [LW · GW]
“It turns out that this is just one instance of a large family of coherence theorems which all end up pointing at the same set of core properties. All roads lead to Rome, and all the roads say, "If you are not shooting yourself in the foot in sense X, we can view you as having coherence property Y."”
“Now, by the general idea behind coherence theorems, since we can't view this behavior as corresponding to expected utilities, we ought to be able to show that it corresponds to a dominated strategy somehow—derive some way in which this behavior corresponds to shooting off your own foot.”
“And that's at least a glimpse of why, if you're not using dominated strategies, the thing you do with relative utilities is multiply them by probabilities in a consistent way, and prefer the choice that leads to a greater expectation of the variable representing utility.”
“The demonstrations we've walked through here aren't the professional-grade coherence theorems as they appear in real math. Those have names like "Cox's Theorem" or "the complete class theorem"; their proofs are difficult; and they say things like "If seeing piece of information A followed by piece of information B leads you into the same epistemic state as seeing piece of information B followed by piece of information A, plus some other assumptions, I can show an isomorphism between those epistemic states and classical probabilities" or "Any decision rule for taking different actions depending on your observations either corresponds to Bayesian updating given some prior, or else is strictly dominated by some Bayesian strategy".”
“But hopefully you've seen enough concrete demonstrations to get a general idea of what's going on with the actual coherence theorems. We have multiple spotlights all shining on the same core mathematical structure, saying dozens of different variants on, "If you aren't running around in circles or stepping on your own feet or wantonly giving up things you say you want, we can see your behavior as corresponding to this shape. Conversely, if we can't see your behavior as corresponding to this shape, you must be visibly shooting yourself in the foot." Expected utility is the only structure that has this great big family of discovered theorems all saying that. It has a scattering of academic competitors, because academia is academia, but the competitors don't have anything like that mass of spotlights all pointing in the same direction.”
‘Things To Take Away From The Essay’ [LW · GW]
“So what are the primary coherence theorems, and how do they differ from VNM? Yudkowsky mentions the complete class theorem in the post, Savage's theorem comes up in the comments, and there are variations on these two and probably others as well. Roughly, the general claim these theorems make is that any system either (a) acts like an expected utility maximizer under some probabilistic model, or (b) throws away resources in a pareto-suboptimal manner. One thing to emphasize: these theorems generally do not assume any pre-existing probabilities (as VNM does); an agent's implied probabilities are instead derived. Yudkowsky's essay does a good job communicating these concepts, but doesn't emphasize that this is different from VNM.”
‘Sufficiently optimized agents appear coherent’
“Summary: Violations of coherence constraints in probability theory and decision theory correspond to qualitatively destructive or dominated behaviors.”
“Again, we see a manifestation of a powerful family of theorems showing that agents which cannot be seen as corresponding to any coherent probabilities and consistent utility function will exhibit qualitatively destructive behavior, like paying someone a cent to throw a switch and then paying them another cent to throw it back.”
“There is a large literature on different sets of coherence constraints that all yield expected utility, starting with the Von Neumann-Morgenstern Theorem. No other decision formalism has comparable support from so many families of differently phrased coherence constraints.”
‘What do coherence arguments imply about the behavior of advanced AI?’
“Coherence arguments say that if an entity’s preferences do not adhere to the axioms of expected utility theory, then that entity is susceptible to losing things that it values.”
Disclaimer: “This is an initial page, in the process of review, which may not be comprehensive or represent the best available understanding.”
‘Coherence theorems’
“In the context of decision theory, "coherence theorems" are theorems saying that an agent's beliefs or behavior must be viewable as consistent in way X, or else penalty Y happens.”
Disclaimer: “This page's quality has not been assessed.”
“Extremely incomplete list of some coherence theorems in decision theory
- Wald’s complete class theorem
- Von-Neumann-Morgenstern utility theorem
- Cox’s Theorem
- Dutch book arguments”
‘Coherence arguments do not entail goal-directed behavior’ [LW · GW]
“One of the most pleasing things about probability and expected utility theory is that there are many coherence arguments that suggest that these are the “correct” ways to reason. If you deviate from what the theory prescribes, then you must be executing a dominated strategy. There must be some other strategy that never does any worse than your strategy, but does strictly better than your strategy with certainty in at least one situation. There’s a good explanation of these arguments here.”
“The VNM axioms are often justified on the basis that if you don't follow them, you can be Dutch-booked: you can be presented with a series of situations where you are guaranteed to lose utility relative to what you could have done. So on this view, we have "no Dutch booking" implies "VNM axioms" implies "AI risk".”
‘Coherence arguments imply a force for goal-directed behavior.’ [LW · GW]
“‘Coherence arguments’ mean that if you don’t maximize ‘expected utility’ (EU)—that is, if you don’t make every choice in accordance with what gets the highest average score, given consistent preferability scores that you assign to all outcomes—then you will make strictly worse choices by your own lights than if you followed some alternate EU-maximizing strategy (at least in some situations, though they may not arise). For instance, you’ll be vulnerable to ‘money-pumping’—being predictably parted from your money for nothing.3”
‘AI Alignment: Why It’s Hard, and Where to Start’
“The overall message here is that there is a set of qualitative behaviors and as long you do not engage in these qualitatively destructive behaviors, you will be behaving as if you have a utility function.”
‘Money-pumping: the axiomatic approach’ [LW · GW]
“This post gets somewhat technical and mathematical, but the point can be summarised as:
- You are vulnerable to money pumps only to the extent to which you deviate from the von Neumann-Morgenstern axioms of expected utility.
In other words, using alternate decision theories is bad for your wealth.”
‘Ngo and Yudkowsky on alignment difficulty’ [LW · GW]
“Except that to do the exercises at all, you need them to work within an expected utility framework. And then they just go, "Oh, well, I'll just build an agent that's good at optimizing things but doesn't use these explicit expected utilities that are the source of the problem!"
And then if I want them to believe the same things I do, for the same reasons I do, I would have to teach them why certain structures of cognition are the parts of the agent that are good at stuff and do the work, rather than them being this particular formal thing that they learned for manipulating meaningless numbers as opposed to real-world apples.
And I have tried to write that page once or twice (eg "coherent decisions imply consistent utilities [LW · GW]") but it has not sufficed to teach them, because they did not even do as many homework problems as I did, let alone the greater number they'd have to do because this is in fact a place where I have a particular talent.”
“In this case the higher structure I'm talking about is Utility, and doing homework with coherence theorems leads you to appreciate that we only know about one higher structure for this class of problems that has a dozen mathematical spotlights pointing at it saying "look here", even though people have occasionally looked for alternatives.
And when I try to say this, people are like, "Well, I looked up a theorem, and it talked about being able to identify a unique utility function from an infinite number of choices, but if we don't have an infinite number of choices, we can't identify the utility function, so what relevance does this have" and this is a kind of mistake I don't remember even coming close to making so I do not know how to make people stop doing that and maybe I can't.”
“Rephrasing again: we have a wide variety of mathematical theorems all spotlighting, from different angles, the fact that a plan lacking in clumsiness, is possessing of coherence.”
‘Ngo and Yudkowsky on AI capability gains’ [? · GW]
“I think that to contain the concept of Utility as it exists in me, you would have to do homework exercises I don't know how to prescribe. Maybe one set of homework exercises like that would be showing you an agent, including a human, making some set of choices that allegedly couldn't obey expected utility, and having you figure out how to pump money from that agent (or present it with money that it would pass up).
Like, just actually doing that a few dozen times.
Maybe it's not helpful for me to say this? If you say it to Eliezer, he immediately goes, "Ah, yes, I could see how I would update that way after doing the homework, so I will save myself some time and effort and just make that update now without the homework", but this kind of jumping-ahead-to-the-destination is something that seems to me to be... dramatically missing from many non-Eliezers. They insist on learning things the hard way and then act all surprised when they do. Oh my gosh, who would have thought that an AI breakthrough would suddenly make AI seem less than 100 years away the way it seemed yesterday? Oh my gosh, who would have thought that alignment would be difficult?
Utility can be seen as the origin of Probability within minds, even though Probability obeys its own, simpler coherence constraints.”
‘AGI will have learnt utility functions’ [LW · GW]
“The view that utility maximizers are inevitable is supported by a number of coherence theories developed early on in game theory which show that any agent without a consistent utility function is exploitable in some sense.”
- ^
Thanks to Adam Bales, Dan Hendrycks, and members of the CAIS Philosophy Fellowship for comments on a draft of this post. When I emailed Adam to ask for comments, he replied with his own draft paper on coherence arguments. Adam’s paper takes a somewhat different view on money-pump arguments, and should be available soon.
- ^
Gustafsson later offers a forcing money-pump argument for Completeness: a money-pump in which, at each step, the agent is compelled by their preferences to pursue a dominated strategy. But agents who act in accordance with the policy above are immune to this money-pump as well. Here’s why.
Gustafsson claims that, in the original non-forcing money-pump, going up at node 2 cannot be irrational. That’s because the agent does not strictly disprefer A- to B: the only other option available at node 2. The fact that A was previously available cannot make choosing A- irrational, because (Gustafsson claims) Decision-Tree Separability is true: “The rational status of the options at a choice node does not depend on other parts of the decision tree than those that can be reached from that node.” But (Gustafsson claims) the sequence of choices consisting of going up at nodes 1 and 2 is irrational, because it leaves the agent worse-off than they could have been. That implies that going up at node 1 must be irrational, given what Gustafsson calls ‘The Principle of Rational Decomposition’: any irrational sequence of choices must contain at least one irrational choice. Generalizing this argument, Gustafsson gets a general rational requirement to choose option A whenever your other option is to proceed to a choice node where your options are A- and B. And it’s this general rational requirement (‘Minimal Unidimensional Precaution’) that allows Gustafsson to construct his forcing money-pump. In this forcing money-pump, an agent’s incomplete preferences compel them to violate the Principle of Unexploitability: that principle which says getting money-pumped is irrational. The Principle of Preferential Invulnerability then implies that incomplete preferences are irrational, since it’s been shown that there exists a situation in which incomplete preferences force an agent to violate the Principle of Unexploitability.
Note that Gustafsson aims to establish that agents are rationally required to have complete preferences, whereas coherence arguments aim to establish that sufficiently-advanced artificial agents will have complete preferences. These different conclusions require different premises. In place of Gustafsson’s Decision-Tree Separability, coherence arguments need an amended version that we can call ‘Decision-Tree Separability*’: sufficiently-advanced artificial agents’ dispositions to choose options at a choice node will not depend on other parts of the decision tree than those that can be reached from that node. But this premise is easy to doubt. It’s false if any sufficiently-advanced artificial agent acts in accordance with the following policy: ‘if I previously turned down some option X, I will not choose any option that I strictly disprefer to X.’ And it’s easy to see why agents might act in accordance with that policy: it makes them immune to all possible money-pumps for Completeness, and (as I am about to prove back in the main text) it never requires them to change or act against any of their preferences.
John Wentworth’s ‘Why subagents? [LW · GW]’ suggests another policy for agents with incomplete preferences: trade only when offered an option that you strictly prefer to your current option. That policy makes agents immune to the single-souring money-pump. The downside of Wentworth’s proposal is that an agent following his policy will pursue a dominated strategy in single-sweetening money-pumps, in which the agent first has the opportunity to trade in A for B and then (conditional on making that trade) has the opportunity to trade in B for A+. Wentworth’s policy will leave the agent with A when they could have had A+.
130 comments
Comments sorted by top scores.
comment by habryka (habryka4) · 2023-02-21T01:01:24.339Z · LW(p) · GW(p)
Crossposting this comment from the EA Forum:
Nuno says:
I appreciate the whole post. But I personally really enjoyed the appendix. In particular, I found it informative that Yudkowsk can speak/write with that level of authoritativeness, confidence, and disdain for others who disagree, and still be wrong (if this post is right).
I respond:
(if this post is right)
The post does actually seem wrong though.
I expect someone to write a comment with the details at some point (I am pretty busy right now, so can only give a quick meta-level gleam), but mostly, I feel like in order to argue that something is wrong with these arguments is that you have to argue more compellingly against completeness and possible alternative ways to establish dutch-book arguments.
Also, the title of "there are no coherence arguments" is just straightforwardly wrong. The theorems cited are of course real theorems, they are relevant to agents acting with a certain kind of coherence, and I don't really understand the semantic argument that is happening where it's trying to say that the cited theorems aren't talking about "coherence", when like, they clearly are.
You can argue that the theorems are wrong, or that the explicit assumptions of the theorems don't hold, which many people have done, but like, there are still coherence theorems, and IMO completeness seems quite reasonable to me and the argument here seems very weak (and I would urge the author to create an actual concrete situation that doesn't seem very dumb in which a highly intelligence, powerful and economically useful system has non-complete preferences).
The whole section at the end feels very confused to me. The author asserts that there is "an error" where people assert that "there are coherence theorems", but man, that just seems like such a weird thing to argue for. Of course there are theorems that are relevant to the question of agent coherence, all of these seem really quite relevant. They might not prove the things in-practice, as many theorems tend to do, and you are open to arguing about that, but that doesn't really change whether they are theorems.
Like, I feel like with the same type of argument that is made in the post I could write a post saying "there are no voting impossibility theorems" and then go ahead and argue that the Arrow's Impossibility Theorem assumptions are not universally proven, and then accuse everyone who ever talked about voting impossibility theorems that they are making "an error" since "those things are not real theorems". And I think everyone working on voting-adjacent impossibility theorems would be pretty justifiedly annoyed by this.
Replies from: ElliottThornley, SaidAchmiz, Radamantis, SaidAchmiz, keith_wynroe, Radamantis, ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-02-21T01:22:49.042Z · LW(p) · GW(p)
I’m following previous authors in defining ‘coherence theorems’ as
theorems which state that, unless an agent can be represented as maximizing expected utility, that agent is liable to pursue strategies that are dominated by some other available strategy.
On that definition, there are no coherence theorems. VNM is not a coherence theorem, nor is Savage’s Theorem, nor is Bolker-Jeffrey, nor are Dutch Book Arguments, nor is Cox’s Theorem, nor is the Complete Class Theorem.
there are theorems that are relevant to the question of agent coherence
I'd have no problem with authors making that claim.
I would urge the author to create an actual concrete situation that doesn't seem very dumb in which a highly intelligence, powerful and economically useful system has non-complete preferences
Working on it.
Replies from: adele-lopez-1↑ comment by Adele Lopez (adele-lopez-1) · 2023-02-21T01:52:17.413Z · LW(p) · GW(p)
theorems which state that, unless an agent can be represented as maximizing expected utility, that agent is liable to pursue strategies that are dominated by some other available strategy.
While I agree that such theorems would count as coherence theorems, I wouldn't consider this to cover most things I think of as coherence theorems, and as such is simply a bad definition.
I think of coherence theorems loosely as things that say if an agent follows such and such principles, then we can prove it will have a certain property. The usefulness comes from both directions: to the extent the principles seem like good things to have, we're justified in assuming a certain property, and to the extent that the property seems too strong or whatever, then one of these principles will have to break.
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-02-21T02:53:40.883Z · LW(p) · GW(p)
I think of coherence theorems loosely as things that say if an agent follows such and such principles, then we can prove it will have a certain property.
If you use this definition, then VNM (etc.) counts as a coherence theorem. But Premise 1 of the coherence argument (as I've rendered it) remains false, and so you can't use the coherence argument to get the conclusion that sufficiently-advanced artificial agents will be representable as maximizing expected utility.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-02-21T03:29:44.352Z · LW(p) · GW(p)
I don't think the majority of the papers that you cite made the argument that coherence arguments prove that any sufficiently-advanced AI will be representable as maximizing expected utility. Indeed I am very confident almost everyone you cite does not believe this, since it is a very strong claim. Many of the quotes you give even explicitly say this:
then you will make strictly worse choices by your own lights than if you followed some alternate EU-maximizing strategy (at least in some situations, though they may not arise)
The emphasis here is important.
I don't think really any of the other quotes you cite make the strong claim you are arguing against. Indeed it is trivially easy to think of an extremely powerful AI that is VNM rational in all situations except for one tiny thing that does not matter or will never come up. Technically it's preferences can now not be represented by a utility function, but that's not very relevant to the core arguments at hand, and I feel like in your arguments you are trying to tear down some strawman of some extreme position that I don't think anyone holds.
Eliezer has also explicitly written about it being possible to design superintelligences that reflectively coherently believe in logical falsehoods. He thinks this is possible, just very difficult. That alone would also violate VNM rationality.
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-02-21T19:47:30.703Z · LW(p) · GW(p)
You misunderstand me (and I apologize for that. I now think I should have made this clear in the post). I’m arguing against the following weak claim:
- For any agent who cannot be represented as maximizing expected utility, there is at least some situation in which that agent will pursue a dominated strategy.
And my argument is:
- There are no theorems which state or imply that claim. VNM doesn’t, Savage doesn’t, Bolker-Jeffrey doesn’t, Dutch Books don't, Cox doesn't, Complete Class doesn't.
- Money-pump arguments for the claim are not particularly convincing (for the reasons that I give in the post).
‘The relevant situations may not arise’ is a different objection. It’s not the one that I’m making.
↑ comment by Said Achmiz (SaidAchmiz) · 2023-02-21T04:00:19.660Z · LW(p) · GW(p)
(and I would urge the author to create an actual concrete situation that doesn’t seem very dumb in which a highly intelligence, powerful and economically useful system has non-complete preferences)
Please see this old comment [LW(p) · GW(p)] and this one [LW(p) · GW(p)].
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-02-21T04:19:24.372Z · LW(p) · GW(p)
These are both great! I now find that I have strong-upvoted them both at the time. Indeed, I think this kind of concreteness feels like it does actually help the discussion quite a bit.
I also quite liked John's post on this topic: https://www.lesswrong.com/posts/3xF66BNSC5caZuKyC/why-subagents [LW · GW]
↑ comment by NunoSempere (Radamantis) · 2023-02-21T02:42:37.590Z · LW(p) · GW(p)
Copying my response from the EA forum:
(if this post is right)
The post does actually seem wrong though.
Glad that I added the caveat.
Also, the title of "there are no coherence arguments" is just straightforwardly wrong. The theorems cited are of course real theorems, they are relevant to agents acting with a certain kind of coherence, and I don't really understand the semantic argument that is happening where it's trying to say that the cited theorems aren't talking about "coherence", when like, they clearly are.
Well, part of the semantic nuance is that we don't care as much about the coherence theorems that do exist if they will fail to apply to current and future machines
IMO completeness seems quite reasonable to me and the argument here seems very weak (and I would urge the author to create an actual concrete situation that doesn't seem very dumb in which a highly intelligence, powerful and economically useful system has non-complete preferences).
Here are some scenarios:
- Our highly intelligent system notices that to have complete preferences over all trades would be too computationally expensive, and thus is willing to accept some, even a large degree of incompleteness.
- The highly intelligent system learns to mimic the values of human, which end up having non-complete preferences, which the agent mimics
- You train a powerful system to do some stuff, but also to detect when it is out of distribution and in that case do nothing. Assuming you can do that, their preference is incomplete, since when offered tradeoffs they always take the default option when out of distribution.
The whole section at the end feels very confused to me. The author asserts that there is "an error" where people assert that "there are coherence theorems", but man, that just seems like such a weird thing to argue for. Of course there are theorems that are relevant to the question of agent coherence, all of these seem really quite relevant. They might not prove the things in-practice, as many theorems tend to do.
Mmh, then it would be good to differentiate between:
- There are coherence theorems that talk about some agents with some properties
- There are coherence theorems that prove that AI systems as will soon exist in the future will be optimizing utility functions
You could also say a third thing, which would be: there are coherence theorems that strongly hint that AI systems as will soon exist in the future will be optimizing utility functions. They don't prove it, but they make it highly probable because of such and such. In which case having more detail on the such and such would deflate most of the arguments in this post, for me.
For instance:
“‘Coherence arguments’ mean that if you don’t maximize ‘expected utility’ (EU)—that is, if you don’t make every choice in accordance with what gets the highest average score, given consistent preferability scores that you assign to all outcomes—then you will make strictly worse choices by your own lights than if you followed some alternate EU-maximizing strategy (at least in some situations, though they may not arise). For instance, you’ll be vulnerable to ‘money-pumping’—being predictably parted from your money for nothing.
This is just false, because it is not taking into account the cost of doing expected value maximization, since giving consistent preferability scores is just very expensive and hard to do reliably. Like, when I poll people for their preferability scores [EA · GW], they give inconsistent estimates. Instead, they could be doing some expected utility maximization, but the evaluation steps are so expensive that I now basically don't bother to do some more hardcore approximation of expected value for individuals [EA · GW], but for large projects and organizations [EA · GW]. And even then, I'm still taking shortcuts and monkey-patches, and not doing pure expected value maximization.
“This post gets somewhat technical and mathematical, but the point can be summarised as:
- You are vulnerable to money pumps only to the extent to which you deviate from the von Neumann-Morgenstern axioms of expected utility.
In other words, using alternate decision theories is bad for your wealth.”
The "in other words" doesn't follow, since EV maximization can be more expensive than the shortcuts.
Then there are other parts that give the strong impression that this expected value maximization will be binding in practice:
“Rephrasing again: we have a wide variety of mathematical theorems all spotlighting, from different angles, the fact that a plan lacking in clumsiness, is possessing of coherence.”
“The overall message here is that there is a set of qualitative behaviors and as long you do not engage in these qualitatively destructive behaviors, you will be behaving as if you have a utility function.”
“The view that utility maximizers are inevitable is supported by a number of coherence theories developed early on in game theory which show that any agent without a consistent utility function is exploitable in some sense.”
Here are some words I wrote that don't quite sit right but which I thought I'd still share: Like, part of the MIRI beat as I understand it is to hold that there is some shining guiding light, some deep nature of intelligence that models will instantiate and make them highly dangerous. But it's not clear to me whether you will in fact get models that instantiate that shining light. Like, you could imagine an alternative view of intelligence where it's just useful monkey patches all the way down, and as we train more powerful models, they get more of the monkey patches, but without the fundamentals. The view in between would be that there are some monkey patches, and there are some deep generalizations, but then I want to know whether the coherence systems will bind to those kinds of agents.
No need to respond/deeply engage, but I'd appreciate if you let me know if the above comments were too nitpicky.
Replies from: Benito, habryka4↑ comment by Ben Pace (Benito) · 2023-02-21T18:20:48.848Z · LW(p) · GW(p)
Well, part of the semantic nuance is that we don't care as much about the coherence theorems that do exist if they will fail to apply to current and future machines
The correct response to learning that some theorems do not apply as much to reality as you thought, surely mustn't be to change language so as to deny those theorems' existence. Insofar as this is what's going on, these are pretty bad norms of language in my opinion.
Replies from: Radamantis↑ comment by NunoSempere (Radamantis) · 2023-02-21T18:59:02.156Z · LW(p) · GW(p)
I am not defending the language of the OP's title, I am defending the content of the post.
Replies from: Radamantis↑ comment by NunoSempere (Radamantis) · 2023-02-21T19:00:22.479Z · LW(p) · GW(p)
See this comment: <https://www.lesswrong.com/posts/yCuzmCsE86BTu9PfA/there-are-no-coherence-theorems?commentId=v2mgDWqirqibHTmKb>
↑ comment by habryka (habryka4) · 2023-02-21T03:33:02.263Z · LW(p) · GW(p)
This is just false, because it is not taking into account the cost of doing expected value maximization, since giving consistent preferability scores is just very expensive and hard to do reliably.
I do really want to put emphasis on the parenthetical remark "(at least in some situations, though they may not arise)". Katja is totally aware that the coherence arguments require a bunch of preconditions that are not guaranteed to be the case for all situations, or even any situation ever, and her post is about how there is still a relevant argument here.
↑ comment by Said Achmiz (SaidAchmiz) · 2023-02-24T07:56:53.369Z · LW(p) · GW(p)
Also, the title of “there are no coherence arguments” is just straightforwardly wrong. The theorems cited are of course real theorems, they are relevant to agents acting with a certain kind of coherence, and I don’t really understand the semantic argument that is happening where it’s trying to say that the cited theorems aren’t talking about “coherence”, when like, they clearly are.
This seems wrong to me. The post’s argument is that the cited theorems aren’t talking about “coherence”, and it does indeed seem clear that (at least most of, possibly all but I could see disagreeing about maybe one or two) these theorems are not, in fact, talking about “coherence”.
↑ comment by keith_wynroe · 2023-02-21T22:44:56.792Z · LW(p) · GW(p)
Ngl kinda confused how these points imply the post seems wrong, the bulk of this seems to be (1) a semantic quibble + (2) a disagreement on who has the burden of proof when it comes to arguing about the plausibility of coherence + (3) maybe just misunderstanding the point that's being made?
(1) I agree the title is a bit needlessly provocative and in one sense of course VNM/Savage etc count as coherence theorems. But the point is that there is another sense that people use "coherence theorem/argument" in this field which corresponds to something like "If you're not behaving like an EV-maximiser you're shooting yourself in the foot by your own lights", which is what brings in all the scary normativity and is what the OP is saying doesn't follow from any existing theorem unless you make a bunch of other assumptions
(2) The only real substantive objection to the content here seems to be "IMO completeness seems quite reasonable to me". Why? Having complete preferences seems like a pretty narrow target within the space of all partial orders you could have as your preference relation, so what's the reason why we should expect minds to steer towards this? Do humans have complete preferences?
(3) In some other comments you're saying that this post is straw-manning some extreme position because people who use coherence arguments already accept you could have e.g.
>an extremely powerful AI that is VNM rational in all situations except for one tiny thing that does not >matter or will never come up
This seems to be entirely missing the point/confused - OP isn't saying that agents can realistically get away with not being VNM-rational because its inconsistencies/incompletenesses aren't efficiently exploitable, they're saying that you can have an agent that aren't VNM-rational and aren't exploitable in principle - i.e., your example is an agent that could in theory be money-pumped by another sufficiently powerful agent that was able to steer the world to where their corner-case weirdness came out - the point being made about incompleteness here is that you can have a non VNM-rational agent that's not just un-Dutch-Bookable as a matter of empirical reality but in principle. The former still gets you claims like "A sufficiently smart agent will appear VNM-rational to you, they can't have any obvious public-facing failings", the latter undermines this
↑ comment by NunoSempere (Radamantis) · 2023-02-21T02:43:12.387Z · LW(p) · GW(p)
Copying my second response from the EA forum:
Like, I feel like with the same type of argument that is made in the post I could write a post saying "there are no voting impossibility theorems" and then go ahead and argue that the Arrow's Impossibility Theorem assumptions are not universally proven, and then accuse everyone who ever talked about voting impossibility theorems that they are making "an error" since "those things are not real theorems". And I think everyone working on voting-adjacent impossibility theorems would be pretty justifiedly annoyed by this.
I think that there is some sense in which the character in your example would be right, since:
- Arrow's theorem doesn't bind approval voting.
- Generalizations of Arrow's theorem don't bind probabilistic results, e.g., each candidate is chosen with some probability corresponding to the amount of votes he gets.
Like, if you had someone saying there was "a deep core of electoral process" which means that as they scale to important decisions means that you will necessarily get "highly defective electoral processes", as illustrated in the classic example of the "dangers of the first pass the post system". Well in that case it would be reasonable to wonder whether the assumptions of the theorem bind, or whether there is some system like approval voting which is much less shitty than the theorem provers were expecting, because the assumptions don't hold.
The analogy is imperfect, though, since approval voting is a known decent system, whereas for AI systems we don't have an example friendly AI.
Replies from: habryka4, sharmake-farah↑ comment by habryka (habryka4) · 2023-02-21T03:22:31.729Z · LW(p) · GW(p)
Sorry, this might have not been obvious, but I indeed think the voting impossibility theorems have holes in them because of the lotteries case and that's specifically why I chose that example.
I think that intellectual point matters, but I also think writing a post with the title "There are no voting impossibility theorems", defining "voting impossibility theorems" as "theorems that imply that all voting systems must make these known tradeoffs", and then citing everyone who ever talked about "voting impossibility theorems" as having made "an error" would just be pretty unproductive. I would make a post like the ones that Scott Garrabrant made being like "I think voting impossibility theorems don't account for these cases", and that seems great, and I have been glad about contributions of this type.
↑ comment by Noosphere89 (sharmake-farah) · 2023-02-21T16:30:06.261Z · LW(p) · GW(p)
Like, if you had someone saying there was "a deep core of electoral process" which means that as they scale to important decisions means that you will necessarily get "highly defective electoral processes", as illustrated in the classic example of the "dangers of the first pass the post system". Well in that case it would be reasonable to wonder whether the assumptions of the theorem bind, or whether there is some system like approval voting which is much less shitty than the theorem provers were expecting, because the assumptions don't hold.
Unfortunately, most democratic countries do use first past the post.
The 2 things that are inevitable is condorcet cycles and strategic voting (Though condorcet cycles are less of a problem as you scale up the population, and I have a sneaking suspicion that condorcet cycles go away if we allow a real numbered infinite amount of people.)
Replies from: Douglas_Knight, Radamantis↑ comment by Douglas_Knight · 2023-02-21T19:43:54.059Z · LW(p) · GW(p)
I think most democratic countries use proportional representation, not FTPT. But talking about "most" is an FTPT error. Enough countries use proportional representation that you can study the effect of voting systems. And the results are shocking to me. The theoretical predictions are completely wrong. Duverger's law is false in every FTPT country except America. On the flip side, while PR does lead to more parties, they still form 1-dimensional spectrum. For example, a Green Party is usually a far-left party with slightly different preferences, instead of a single issue party that is willing to form coalitions with the right.
If politics were two dimensional, why wouldn't you expect Condorcet cycles? Why would population get rid of them? If you have two candidates, a tie between them is on a razor's edge. The larger the population of voters, the less likely. But if you have three candidates and three roughly equally common preferences, the cyclic shifts of A > B > C, then this is a robust tie. You only get a Condorcet winner when one of the factions becomes as big as the other two combined. Of course I have assumed away the other three preferences, but this is robust to them being small, not merely nonexistent.
I don't know what happens in the following model: there are three issues A,B,C. Everyone, both voter and candidate, is for all of them, but in a zero-sum way, represented a vector a,b,c, with a+b+c = 11, a,b,c>=0. Start with the voters as above, at (10,1,0), (0,10,1), (1,0,10). Then the candidates (11,0,0), (0,11,0), (0,0,11) form a Condorcet cycle. By symmetry there is no Condorcet winner over all possible candidates. Randomly shift the proportion of voters. Is there a candidate that beats the three given candidates? One that beats all possible candidates? I doubt it. Add noise to make the individual voters unique. Now, I don't know.
↑ comment by NunoSempere (Radamantis) · 2023-02-21T18:56:56.013Z · LW(p) · GW(p)
You don't have strategic voting with probabilistic results. And the degree of strategic voting can also be mitigated.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-02-21T19:02:22.871Z · LW(p) · GW(p)
Hm, I remember Wikipedia talked about Hylland's theroem that generalizes the Gibbard-Sattherwaite theorem to the probabilistic case, though Wikipedia might be wrong on that.
↑ comment by EJT (ElliottThornley) · 2023-02-21T01:21:15.733Z · LW(p) · GW(p)
comment by Charlie Steiner · 2023-02-21T12:34:07.846Z · LW(p) · GW(p)
It seems like you deliberately picked completeness because that's where Dutch book arguments are least compelling, and that you'd agree with the more usual Dutch book arguments.
But I think even the Dutch book for completeness makes some sense. You just have to separate "how the agent internally represents its preferences" from "what it looks like the agent us doing." You describe an agent that dodges the money-pump by simply acting consistently with past choices. Internally this agent has an incomplete representation of preferences, plus a memory. But externally it looks like this agent is acting like it assigns equal value to whatever indifferent things it thought of choosing between first. If humans don't get to control the order this agent considers options, or if we let it run for a long time and it's already experienced the things humans might try to present to it from them on, then it will look like it's acting according to complete preferences.
Replies from: ElliottThornley, Lblack, Dweomite, antimonyanthony↑ comment by EJT (ElliottThornley) · 2023-02-21T18:31:04.558Z · LW(p) · GW(p)
Great points. Thinking about these kinds of worries is my next project, and I’m still trying to figure out my view on them.
Replies from: JenniferRM↑ comment by JenniferRM · 2023-05-14T04:33:17.937Z · LW(p) · GW(p)
I don't know if you're still working on this, but if don't already know of the literature on choice supportive bias and similar processes that occur in humans, they look to me a lot like heuristics that probably harden a human agent into being "more coherent" over time (especially in proximity to other ways of updating value estimation processes), and likely have an adaptive role in improving (regularizing?) instrumental value estimates.
Your essay seemed consistent with the claim that "in the past, as verifiable by substantial scholarship, no one ever proved exactly X" but your essay never actually showed "X is provably false" that I noticed?
And, indeed, maybe you can prove it one way or the other for some X, where X might be (as you seem to claim) "naive coherence is impossible" or maybe where some X' or X'' are "sophisticated coherence is approached by algorithm L as t goes to infinity" (or whatever)?
For my money, the thing to do here might be to focus on Value-of-Information, since VoI seems to me like a super super super important concept, and potentially a way to bridge questions of choice and knowledge and costly information gathering actions.
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-05-26T15:41:57.998Z · LW(p) · GW(p)
Thanks! I'll have a think about choice-supportive bias and how it applies.
I think it is provably false that any agent not representable as an expected-utility-maximizer is liable to pursue dominated strategies. Agents with incomplete preferences aren't representable as expected-utility-maximizers, and they can make themselves immune from pursuing dominated strategies by acting in accordance with the following policy: ‘if I previously turned down some option X, I will not choose any option that I strictly disprefer to X.’
Replies from: JenniferRM↑ comment by JenniferRM · 2023-05-30T23:06:15.657Z · LW(p) · GW(p)
I don't know about you, but I'm actually OK dithering a bit, and going in circles, and doing things that mere entropy can "make me notice regret based on syntactically detectable behavioral signs" (like not even active adversarial optimization pressure like that which is somewhat inevitably generated in predator prey contexts).
For example, in my twenties I formed an intent, and managed to adhere to the habit somewhat often, where I'd flip a coin any time I noticed decisions where the cost to think about it in an explicit way was probably larger than the difference in value between the likely outcomes.
(Sometimes I flipped coins and then ignored the coin if I noticed I was sad with that result, as a way to cheaply generate that mental state of having an intuitive internally accessible preference without having to put things into words or do math. When I noticed that that stopped working very well, I switched to flipping a coin, then "if regret, flip again, and follow my head on head, and follow the first coin on tails". The double flipping protocol seemed to help make ALL the first coins have "enough weight" for me to care about them sometimes, even when I always then stopped for a second to see if I was happy or sad or bored by the first coin flip. And of course I do such things much much much less now, and lately have begun to consider taking a personal vow to refuse to randomize, except towards enemies, for an experimental period of time.)
The plans and the hopes here sort of naturally rely on "getting better at preferring things wisely over time"!
And the strategy relies pretty critically on having enough MEMORY to hope to build up data on various examples of different ways that similar situations went in the past, such as to learn from mistakes and thereby rarely "lack a velleity" and to reduce the rate at which I justifiably regret past velleities or choices.
And a core reason I think that sentience and sapience reliably convergently evolve is almost exactly "to store and process memories to enable learning (including especially contextually sensitive instrumental preference learning) inside a single lifetime".
(Credit assignment and citation note: Cristof Koch was the first researcher who I heard explain surprising experimental data that suggested that "minds are common" with stuff like bee learning, and eventually I stopped being surprised when I heard about low key bee numeracy or another crazy mental power of cuttlefish. I didn't know about EITHER of the experiments I just linked to, but I paused to find "the kinds of things one finds here if one actually looks". That I found such links, for me, was a teensy surprise, and slightly contributes to my posterior belief in a claim roughly like "something like 'coherence' is convergently useful and is what our minds were originally built, by evolution, to approximately efficiently implement".)
Basically, I encourage you, when you go try to prove that "Agents with incomplete preferences can make themselves immune from pursuing dominated strategies by following plan P" to consider the resource costs of those plans (like the cost in memory) and to ask whether those resources are being used optimally, or whether a different use of them could get better results faster.
Also... I expect that the proofs you attempt might actually succeed if you have "agents in isolation" or "agents surrounded only by agents that respect property rights" but to fail if you consider the case of adversarial action space selection in an environment of more than one agent (like where wolves seek undominated strategies for eating sheep, and no sheep is able to simply 'turn down' the option of being eaten by an arbitrarily smart wolf without itself doing something clever and potentially memory-or-VNM-perfection-demanding).
I do NOT think you will prove "in full generality, nothing like coherence is pragmatically necessary to avoid dutch booking" but I grant that I'm not sure about this! I have noticed from experience that my mathematical intuitions are actually fallible. That's why real math is worth the elbow grease! <3
↑ comment by Lucius Bushnaq (Lblack) · 2023-03-21T08:41:32.168Z · LW(p) · GW(p)
That separation between internal preferences and external behaviour is already implicit in Dutch books. Decision theory is about external behaviour, not internal representations. It talks about what agents do, not how agents work inside. As parts of decision theory, a preference, to them, is about something the system does or does not do in a given situation. When they talk about someone preferring pizza without pineapple, it's about that person paying money to not have pineapple on their pizza in some range of situations, not some definition related to computations about pineapples and pizzas in that person's brain.
↑ comment by Dweomite · 2024-07-03T20:24:13.575Z · LW(p) · GW(p)
Making a similar point from a different angle:
The OP claims that the policy "if I previously turned down some option X, I will not choose any option that I strictly disprefer to X" escapes the money pump but "never requires them to change or act against their preferences".
But it's not clear to me what conceptual difference there is supposed to be between "I will modify my action policy to hereafter always choose B over A-" and "I will modify my preferences to strictly prefer B over A-, removing the preference gap and bringing my preferences closer to completeness".
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2024-07-06T11:54:22.094Z · LW(p) · GW(p)
Ah yep, apologies, I meant to say "never requires them to change or act against their strict preferences."
Whether there's a conceptual difference will depend on our definition of 'preference.' We could define 'preference' as follows: an agent prefers X to Y iff the agent reliably chooses X over Y.' In that case, modifying the policy is equivalent to forming a preference.
But we could also define 'preference' so that it requires more than just reliable choosing. For example, we might also require that (when choosing between lotteries) the agent always take opportunities to shift probability mass away from Y and towards X.
On the latter definition, modifying the policy need not be equivalent to forming a preference, because it only involves the reliably choosing and not the shifting of probability mass.
And the latter definition might be more pertinent in this context, where our interest is in whether agents will be expected utility maximizers.
But also, even if we go with the former definition, I think it matters a lot whether money-pumps compel rational agents to complete all their preferences up front, or whether money-pumps just compel agents to resolve preferential gaps over time, conditional on them coming to face choices that are arranged like a money-pump (and only completing their preferences if and once they've faced a sufficiently diverse range of choices). In particular, I think it matters in the context of the shutdown problem. I talk a bit more about this here [LW(p) · GW(p)].
Replies from: Dweomite↑ comment by Dweomite · 2024-07-06T21:52:47.029Z · LW(p) · GW(p)
If it doesn't move probability mass, won't it still be vulnerable to probabilistic money pumps? e.g. in the single-souring pump, you could just replace the choice between A- and B with a choice between two lotteries that have different mixtures of A- and B.
I have also left a reply [LW(p) · GW(p)] to the comment you linked.
↑ comment by Anthony DiGiovanni (antimonyanthony) · 2024-05-15T07:27:43.109Z · LW(p) · GW(p)
You describe an agent that dodges the money-pump by simply acting consistently with past choices. Internally this agent has an incomplete representation of preferences, plus a memory. But externally it looks like this agent is acting like it assigns equal value to whatever indifferent things it thought of choosing between first.
Not sure I follow this / agree. Seems to me that in the "Single-Souring Money Pump" case:
- If the agent systematically goes down at node 1, all we learn is that the agent doesn't strictly prefer [B or A-] to A.
- If the agent systematically goes up at node 1 and down at node 2, all we learn is that the agent doesn't strictly prefer [A or A-] to B.
So this doesn't tell us what the agent would do if they were faced with just a choice between A and B, or A- and B. We can't conclude "equal value" here.
comment by Adele Lopez (adele-lopez-1) · 2023-02-21T02:04:34.862Z · LW(p) · GW(p)
It feels like this post starts with a definition of "coherence theorem", sees that the so-called coherence theorems don't match this definition, and thus criticizes the use of the term "coherence theorem".
But this claimed definition of "coherence theorem" seems bad to me, and is not how I would use the phrase. Eliezer's definition [LW · GW], OTOH is:
If you are not shooting yourself in the foot in sense X, we can view you as having coherence property Y.
which seems perfectly fine to me. It's significant that this isn't completely formalized, and requires intuitive judgement as to what constitutes "shooting yourself in the foot".
Which makes the criticism feel unwarranted, or at best misdirected.
Replies from: harfe, ElliottThornley↑ comment by harfe · 2023-02-21T03:20:06.252Z · LW(p) · GW(p)
The title "There are no coherence theorems" seems click-baity to me, when the claim relies on a very particular definition "coherence theorem". My thought upon reading the title (before reading the post) was something like "surely, VNM would count as a coherence theorem". I am also a bit bothered by the confident assertions that there are no coherence theorems in the Conclusion and Bottom-lines for similar reason.
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-02-21T17:55:32.444Z · LW(p) · GW(p)
Fair enough. I don’t think it’s click-baity:
- My use of the term matches common usage. See the Appendix [LW · GW].
- ‘There are no theorems which state that, unless an agent can be represented as maximizing expected utility, that agent is liable to pursue strategies that are dominated by some other available strategy’ would have been too long for a title.
- I (reasonably, in my view) didn’t expect anyone to interpret me as denying the existence of the VNM Theorem, Savage’s Theorem, Bolker-Jeffrey, etc.
In any case, I explain how I’m using the term ‘coherence theorems’ in the second sentence of the post.
↑ comment by EJT (ElliottThornley) · 2023-02-21T03:04:08.899Z · LW(p) · GW(p)
The point is: there are no theorems which state that, unless an agent can be represented as maximizing expected utility, that agent is liable to pursue strategies that are dominated by some other available strategy. The VNM Theorem doesn't say that, nor does Savage's Theorem, nor does Bolker-Jeffrey, nor do Dutch Books, nor does Cox's Theorem, nor does the Complete Class Theorem.
But suppose we instead define 'coherence theorems' as theorems which state that
If you are not shooting yourself in the foot in sense X, we can view you as having coherence property Y.
Then you can fill in X and Y any way you like. Either it will turn out that there are no coherence theorems, or it will turn out that coherence theorems cannot play the role they're supposed to play in coherence arguments.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-02-21T04:26:50.967Z · LW(p) · GW(p)
Then you can fill in X and Y any way you like. Either it will turn out that there are no coherence theorems, or it will turn out that coherence theorems cannot play the role they're supposed to play in coherence arguments.
That seems totally fine. A term like "coherence theorems" clearly is just like a rough category of things. The definition of the term should not itself bake in the validity of arguments built on top of the elements that the term is trying to draw a definition around.
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-02-21T18:00:48.058Z · LW(p) · GW(p)
It is not fine if, whichever way you interpret some premise, either:
(1) the premise comes out false.
Or:
(2) the premise does not support the conclusion.
Reserve the term ‘coherence theorems’ for whatever rough category you like. ‘Theorems which state that, unless an agent can be represented as maximizing expected utility, that agent is liable to pursue strategies that are dominated by some other available strategy’ refers to a precise category of non-existent things.
comment by Lucius Bushnaq (Lblack) · 2023-08-31T22:33:10.581Z · LW(p) · GW(p)
I have now seen this post cited in other spaces, so I am taking the time to go back and write out why I do not think it holds water.
I do not find the argument against the applicability of the Complete Class theorem convincing.
See Charlie Steiner's [LW(p) · GW(p)] comment:
You just have to separate "how the agent internally represents its preferences" from "what it looks like the agent us doing." You describe an agent that dodges the money-pump by simply acting consistently with past choices. Internally this agent has an incomplete representation of preferences, plus a memory. But externally it looks like this agent is acting like it assigns equal value to whatever indifferent things it thought of choosing between first.
Decision theory is concerned with external behaviour, not internal representations. All of these theorems are talking about whether the agent's actions can be consistently described as maximising a utility function. They are not concerned whatsoever with how the agent actually mechanically represents and thinks about its preferences and actions on the inside. To decision theory, agents are black boxes. Information goes in, decision comes out. Whatever processes may go on in between are beyond the scope of what the theorems are trying to talk about.
So
Money-pump arguments for Completeness (understood as the claim that sufficiently-advanced artificial agents will have complete preferences) assume that such agents will not act in accordance with policies like ‘if I previously turned down some option X, I will not choose any option that I strictly disprefer to X.’ But that assumption is doubtful. Agents with incomplete preferences have good reasons to act in accordance with this kind of policy: (1) it never requires them to change or act against their preferences, and (2) it makes them immune to all possible money-pumps for Completeness.
As far as decision theory is concerned, this is a complete set of preferences. Whether the agent makes up its mind as it goes along or has everything it wants written up in a database ahead of time matters not a peep to decision theory. The only thing that matters is whether the agent's resulting behaviour can be coherently described as maximising a utility function. If it quacks like a duck, it's a duck.
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-09-02T13:37:07.406Z · LW(p) · GW(p)
Thanks, Lucius. Whether or not decision theory as a whole is concerned only with external behaviour, coherence arguments certainly aren’t. Remember what the conclusion of these arguments is supposed to be: advanced agents who start off not being representable as EUMs will amend their behaviour so that they are representable as EUMs, because otherwise they’re liable to pursue dominated strategies.
Now consider an advanced agent who appears not to be representable as an EUM: it’s paying to trade vanilla for strawberry, strawberry for chocolate, and chocolate for vanilla. Is this agent pursuing a dominated strategy? Will it amend its behaviour? It depends on the objects of preference. If objects of preference are ice-cream flavours, the answer is yes. If the objects of preference are sequences of trades, the answer is no. So we have to say something about the objects of preference in order to predict the agent’s behaviour. And the whole point of coherence arguments is to predict agents’ behaviour.
And once we say something about the objects of preference, then we can observe agents violating Completeness and acting in accordance with policies like ‘if I previously turned down some option X, I will not choose any option that I strictly disprefer to X.’ This doesn't require looking into the agent or saying anything about its algorithm or anything like that. It just requires us to say something about the objects of preference and to watch what the agent does from the outside. And coherence arguments already commit us to saying something about the objects of preference. If we say nothing, we get no predictions out of them.
comment by Vanessa Kosoy (vanessa-kosoy) · 2024-12-16T19:11:05.513Z · LW(p) · GW(p)
This post tries to push back against the role of expected utility theory in AI safety by arguing against various ways to derive expected utility axiomatically. I heard many such arguments before, and IMO they are never especially useful. This post is no exception.
The OP presents the position it argues against as follows (in my paraphrasing): "Sufficiently advanced agents don't play dominated strategies, therefore, because of [theorem], they have to be expected utility maximizers, therefore they have to be goal-directed and [other conclusions]". They then proceed to argue that there is no theorem that can make this argument go through.
I think that this entire framing is attacking a weak man. The real argument for expected utility theory is:
- In AI safety, we are from the get-go interested in goal-directed systems because (i) we want AIs to achieve goals for us (ii) we are worried about systems with bad goals and (iii) stopping systems with bad goals is also a goal.
- The next question is then, what is a useful mathematical formalism for studying goal-directed systems.
- The theorems quoted in the OP are moderate evidence that expected utility has to be part of this formalism, because their assumptions resonate a lot with our intuitions for what "rational goal-directed behavior" is. Yes, of course we can still quibble with the assumptions (like the OP does in some cases), which is why I say "moderate evidence" rather than "completely watertight proof", but given how natural the assumptions are, the evidence is good.
- More importantly, the theorems are only a small part of the evidence base. A philosophical question is never fully answered by a single theorem. Instead, the evidence base is holistic: looking at the theoretical edifices growing up from expected utility (control theory, learning theory, game theory etc) one becomes progressively more and more convinced that expected utility correctly captures some of the core intuitions behind "goal-directedness".
- If one does want to present a convincing case against expected utility, quibbling with the assumption of VNM or whatnot is an incredibly weak move. Instead, show us where the entire edifice of existing theory runs ashore because of expected utility and how some alternative to expected utility can do better (as an analogy, see how infra-Bayesianism [AF · GW] supplants Bayesian decision theory).
In conclusion, there are coherence theorems. But, more important than individual theorems are the "coherence theories".
Replies from: ElliottThornley, Sylvester Kollin↑ comment by EJT (ElliottThornley) · 2024-12-18T11:04:28.924Z · LW(p) · GW(p)
Thanks. I agree with your first four bulletpoints. I disagree that the post is quibbling. Weak man or not, the-coherence-argument-as-I-stated-it was prominent on LW for a long time. And figuring out the truth here matters. If the coherence argument doesn't work, we can (try to) use incomplete preferences to keep agents shutdownable. As I write elsewhere [LW(p) · GW(p)]:
Replies from: vanessa-kosoyThe List of Lethalities [LW · GW] mention of ‘Corrigibility is anti-natural to consequentialist reasoning’ points to Corrigibility (2015) and notes that MIRI failed to find a formula for a shutdownable agent. MIRI failed because they only considered agents with complete preferences. Useful agents with complete (and transitive and option-set-independent) preferences will often have some preference regarding the pressing of the shutdown button, as this theorem [LW · GW] shows. MIRI thought that they had to assume completeness, because of coherence arguments [? · GW]. But coherence arguments are [LW · GW] mistaken [LW · GW]: there are no theorems which imply that agents must have complete preferences in order to avoid pursuing dominated strategies. So we can relax the assumption of completeness and use this extra leeway to find a formula for a corrigible consequentialist. That formula is what I purport to give in this post.
↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2024-12-18T12:55:24.669Z · LW(p) · GW(p)
I feel that coherence arguments, broadly construed, are a reason to be skeptical of such proposals, but debating coherence arguments because of this seems backward. Instead, we should just be discussing your proposal directly. Since I haven't read your proposal yet, I don't have an opinion, but some coherence-inspired question I would be asking are:
- Can you define an incomplete-preferences AIXI consistent with this proposal?
- Is there an incomplete-preferences version of RL regret bound theory consistent with this proposal?
- What happens when your agent is constructing a new agent? Does the new agent inherit the same incomplete preferences?
↑ comment by SMK (Sylvester Kollin) · 2025-02-02T15:36:23.967Z · LW(p) · GW(p)
Yes, of course we can still quibble with the assumptions (like the OP does in some cases), which is why I say "moderate evidence" rather than "completely watertight proof", but given how natural the assumptions are, the evidence is good.
Completeness is arguably not natural (see e.g. Aumann, 1962; Bradley, 2017, §11.5). In particular, I think it is clearly not a requirement of rationality.
comment by Pablo Villalobos (pvs) · 2023-02-21T10:16:50.724Z · LW(p) · GW(p)
Note that you can still get EUM-like properties without completeness: you just can't use a single fully-fleshed-out utility function. You need either several utility functions (that is, your system is made of subagents) or, equivalently, a utility function that is not completely defined (that is, your system has Knightian uncertainty over its utility function).
See Knightian Decision Theory. Part I
Arguably humans ourselves are better modeled as agents with incomplete preferences. See also Why Subagents? [LW · GW]
Replies from: romeostevensit↑ comment by romeostevensit · 2023-06-23T03:16:20.263Z · LW(p) · GW(p)
from Knightian Decision Theory:
A person is defined to be rational, I believe, if he does the best he can, using reason and all available information, to further his own interests and values. I argue that Knightian behavior is rational in this sense. However, rationality is often used loosely in another sense, which is that all behavior is rationalizable as serving to maximize some preference. The two senses of rational are in a way converse. The first says that when preference ex- ists, behavior serves it. The second says that all behavior is generated by preferences. The second sense seems to be very unlikely to be true, except by definition. It does not even seem to be useful as a definition. If choice is made the definition of preference, then one is led, like a true sophist, to the conclusion that people always do what they want to do, even when compelled to do things by threats of violence. The first sense of rationality is the one which is important for economic theory, at least as it is presently formulated. One would like to believe that people usually act so as to serve their own economic interests, at least when these interests are clear and do not conflict with other interests. If one identifies the two converse senses of rationality, one needlessly jeopardizes the first sense, since the second sense is probably more likely to be rejected than the first.
This has been discussed here before, but it's a nice succinct description.
Immediately following and relevant to this discussion:
Associated with each definition of rationality is a different point of view toward incomplete preference. The view associated with the first definition of rationality is that the preference ordering is a constituent of a model which explains some but not all behavior. Behavior never contradicts the ordering, but not all choices are explained by it, nor are all stated or felt preferences. The model is not contradicted if an individual expresses strong preferences between alternatives which he finds incomparable according to the model. Knightian decision theory. Part I 83 Such unexplained preferences or choices may be erratic and intransitive, but this is no cause for concern. Such behavior does not make the individual irrational, since the intransitive choices are not assumed to be in pursuit of some goal. The individual becomes irrational only if one tries to infer some unchanging goals from his choices or statements. It is because I adopt the point of view just stated that I said earlier that the Knightian theory is not contradicted if an individual shows a preference for one undominated choice over another.
comment by [deleted] · 2023-02-21T01:38:06.817Z · LW(p) · GW(p)
I agree with habryka that the title of this post is a little pedantic and might just be inaccurate, but I nevertheless found the content to be thought-provoking, easy to follow, and well written.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-02-21T04:28:36.222Z · LW(p) · GW(p)
I actually also think the post makes some good points. I think arguing against completeness is a pretty good thing to do, and an approach with a long history of people thinking about the theory of rational agents. I feel like this particular posts's arguments against completeness are not amazing, but they seem like a decent contribution. I just wish it didn't have all the other stuff on how "everyone who ever referenced 'coherence theorems' is making a mistake".
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-02-21T18:07:39.876Z · LW(p) · GW(p)
Thanks. I appreciate that.
But I do want to insist on the first thing too. Reserve the term ‘coherence theorems’ for whatever you like. The fact remains. Anyone who claims that:
- There exist theorems which state that, unless an agent can be represented as maximizing expected utility, that agent is liable to pursue strategies that are dominated by some other available strategy
is making a mistake.
And anyone who claims that:
- VNM/Savage/Bolker-Jeffrey/Dutch Books/Cox's Theorem/the Complete Class Theorem is such a theorem
is making a mistake that could have been avoided by looking up what those theorems actually say.
comment by simon · 2023-02-20T23:55:22.477Z · LW(p) · GW(p)
Some different (I think) points against arguments related to the ones that are rebutted in the post:
- requiring a strategy be implementable with a utility function restricts the strategy to a portion of the total strategy space. But, it doesn't follow that any strategy implementable with a utility function actually has to be implemented that way.
- even if a strategy lives in the "utility function" portion of the strategy space, it might be implemented using additional restrictions such that arguments that would apply to a "typical" utility function won't apply
- some of these theorems seem to me to assume consequentialism (e.g. NVM theorem) and I'm not sure that they are usefully generalizable to non-consequentialist parts of the strategy space (though they might be)
- what we actually want might or might not live in the consequentialist (or "utility function") parts of the strategy space
- if what we really want is incompatible with some desiderata then so much the worse for the desiderata
- even if a strategy implementing what we want does live in the "utility function" portion of the space, using an explicit utility function might not be the most convenient way to implement the strategy
For example, Haskell-style pseudocode for an AI (type signatures only, this margin too small to contain actual functions): (edit: was too hasty first time, changed to better reflect what I intended)
trainModel :: Input(t) -> Model(t)
extractValues :: Model(t) -> ProbDistributionOfHumanValues(t,unknowns)
predictEntireFuture :: Model(t) -> Action -> ProbDistributionOfWorldPath(unknowns)
evaluateWithCorrelations :: Model(t) -> (ProbDistributionOfHumanValues(t,unknowns), ProbDistributionOfWorldPath(unknowns)) -> ExpectedValue
generateActions :: Model(t) -> [Action]
chooseAction :: [Action] -> ( Action-> ExpectedValue) -> Action
This code doesn't look to me that it would be easy to express in terms of a utility function, particularly if human values contain non-consequentialist components. But, it ought to avoid being exploited if humans want it to (while being exploitable if humans want that instead).
Replies from: harfe↑ comment by harfe · 2023-02-21T03:13:57.109Z · LW(p) · GW(p)
What is the function evaluateAction supposed to do when human values contain non-consequentialist components? I assume ExpectedValue is a real number. Maybe there could be a way to build a utility function that corresponds to the code, but that is hard to judge since you have left the details out.
Replies from: simon↑ comment by simon · 2023-02-21T04:26:51.212Z · LW(p) · GW(p)
(edited the code after this comment, corresponding edits below, to avoid noisiness the original is not shown; the original code did not make explicit what I discuss in the "main reason" paragraph:)
evaluateWithCorrelations uses both the ProbDistributionOfWorldPath(unknowns) and the Action to generate the ExpectedValue (not explicit, but implicitly the WorldPath can take into account the past and present as well). So, yes, ExpectedValue is a real number, but it doesn't necessarily depend only on the consequences of the action.
However, my main reason for thinking that this would be hard to express as a utility function is that the calculation of the ExpectedValue is supposed to take into account the future actions of the AI (not just the Action being chosen now), and is supposed to take into account correlations between ProbDistributionOfHumanValues(t,unknowns) and ProbDistributionOfWorldPath(unknowns). Note, I don't mean taking into account changes in actual human values - it should only be using current ones in the evaluation, though it should take into account possible changes for the prediction. But, the future actions of humans depend on current human values. So, ideally it should be able to predict that asking humans what they want will lead to an update of the model at t' that is correlated to the unknowns in ProbDistributionOfHumanValues(t,unknowns) that will then lead to different actions by the AI depending on what the humans respond with so that it can then assess a better ExpectedValue to this course of action than not asking, whereas if it was a straight utility function maximizer I would expect it would assign the same value in the short run and reduced value in the long run to such asking.
Obviously yes a real AI would be much more complicated.
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2023-02-28T01:31:39.709Z · LW(p) · GW(p)
The author doesn't seem to realize that there's a difference between representation theorems and coherence theorems.
The Complete Class Theorem says that an agent’s policy of choosing actions conditional on observations is not strictly dominated by some other policy (such that the other policy does better in some set of circumstances and worse in no set of circumstances) if and only if the agent’s policy maximizes expected utility with respect to a probability distribution that assigns positive probability to each possible set of circumstances.
This theorem does refer to dominated strategies. However, the Complete Class Theorem starts off by assuming that the agent’s preferences over actions in sets of circumstances satisfy Completeness and Transitivity. If the agent’s preferences are not complete and transitive, the Complete Class Theorem does not apply. So, the Complete Class Theorem does not imply that agents must be representable as maximizing expected utility if they are to avoid pursuing dominated strategies.
Cool, I'll complete it for you then.
Transitivity: Suppose you prefer A to B, B to C, and C to A. I'll keep having you pay a penny to trade between them in a cycle. You start with C, end with C, and are three pennies poorer. You'd be richer if you didn't do that.
Completeness: Any time you have no comparability between two goods, I'll swap them in whatever direction is most useful for completing money-pump cycles. Since you've got no preference one way or the other, I don't expect you'll be objecting, right?
Combined with the standard Complete Class Theorem, this now produces the existence of at least one coherence theorem. The post's thesis, "There are no coherence theorems", is therefore falsified by presentation of a counterexample. Have a nice day!
Replies from: ElliottThornley, cfoster0, Seth Herd↑ comment by EJT (ElliottThornley) · 2023-02-28T05:08:56.748Z · LW(p) · GW(p)
These arguments don't work.
-
You've mistaken acyclicity for transitivity. The money-pump establishes only acyclicity. Representability-as-an-expected-utility-maximizer requires transitivity.
-
As I note in the post, agents can make themselves immune to all possible money-pumps for completeness by acting in accordance with the following policy: ‘if I previously turned down some option X, I will not choose any option that I strictly disprefer to X.’ Acting in accordance with this policy need never require an agent to act against any of their preferences.
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2023-02-28T08:26:49.058Z · LW(p) · GW(p)
And this avoids the Complete Class Theorem conclusion of dominated strategies, how? Spell it out with a concrete example, maybe? Again, we care about domination, not representability at all.
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-02-28T21:34:32.132Z · LW(p) · GW(p)
And this avoids the Complete Class Theorem conclusion of dominated strategies, how?
The Complete Class Theorem assumes that the agent’s preferences are complete. If the agent’s preferences are incomplete, the theorem doesn’t apply. So, you have to try to get Completeness some other way.
You might try to get Completeness via some money-pump argument, but these arguments aren’t particularly convincing. Agents can make themselves immune to all possible money-pumps for Completeness by acting in accordance with the following policy: ‘if I previously turned down some option X, I will not choose any option that I strictly disprefer to X.’
Again, we care about domination, not representability at all.
Can you expand on this a little more? Agents cannot be (or appear to be) expected utility maximizers unless they are representable as expected utility maximizers, so if we care about whether agents will be (or will appear to be) expected utility maximizers, we have to care about whether they will be representable as expected utility maximizers.
Replies from: Eliezer_Yudkowsky, Maxc↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2023-03-01T07:21:43.501Z · LW(p) · GW(p)
In the limit, you take a rock, and say, "See, the complete class theorem doesn't apply to it, because it doesn't have any preferences ordered about anything!" What about your argument is any different from this - where is there a powerful, future-steering thing that isn't viewable as Bayesian and also isn't dominated? Spell it out more concretely: It has preferences ABC, two things aren't ordered, it chooses X and then Y, etc. I can give concrete examples for my views; what exactly is a case in point of anything you're claiming about the Complete Class Theorem's supposed nonapplicability and hence nonexistence of any coherence theorems?
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-03-01T18:49:50.065Z · LW(p) · GW(p)
In the limit
You’re pushing towards the wrong limit. A rock can be represented as indifferent between all options and hence as having complete preferences.
As I explain in the post, an agent’s preferences are incomplete if and only if they have a preferential gap between some pair of options, and an agent has a preferential gap between two options A and B if and only if they lack any strict preference between A and B and this lack of strict preference is insensitive to some sweetening or souring (such that, e.g., they strictly prefer A to A- and yet have no strict preferences either way between A and B, and between A- and B).
Spell it out more concretely
Sure. Imagine an agent as powerful and future-steering as you like. Among its options are A, A-, and B: the agent strictly prefers A to A-, and has a preferential gap between A and B, and between A- and B. Its preferences are incomplete, so the Complete Class Theorem doesn’t apply.
[Suppose that you tried to use the proof of the Complete Class Theorem to prove that this agent would pursue a dominated strategy. Here’s why that won’t work:
- Without Completeness, we can’t get a real-valued utility function.
- Without a real-valued utility function, we can’t represent the agent’s policy with a vector of real numbers.
- Without a vector of real numbers representing the agent’s policy, we can’t get an equation representing a hyperplane that separates the set of available policies from the set of policies that strictly dominate the agent’s policy.
- Without a hyperplane equation, we can’t get a probability distribution relative to which the agent’s policy maximizes expected utility.]
I anticipate that this answer won’t satisfy you and that you’ll ask for more concreteness in the example, but I don’t yet know what you want me to be more concrete about.
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2023-03-07T00:43:18.916Z · LW(p) · GW(p)
I want you to give me an example of something the agent actually does, under a couple of different sense inputs, given what you say are its preferences, and then I want you to gesture at that and say, "Lo, see how it is incoherent yet not dominated!"
Replies from: edward-pierzchalski↑ comment by eapi (edward-pierzchalski) · 2023-03-08T00:09:27.813Z · LW(p) · GW(p)
Say more about what counts as incoherent yet not dominated? I assume "incoherent" is not being used here as an alias for "non-EU-maximizing" because then this whole discussion is circular.
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2023-03-08T07:23:40.082Z · LW(p) · GW(p)
Suppose I describe your attempt to refute the existence of any coherence theorems: You point to a rock, and say that although it's not coherent, it also can't be dominated, because it has no preferences. Is there any sense in which you think you've disproved the existence of coherence theorems, which doesn't consist of pointing to rocks, and various things that are intermediate between agents and rocks in the sense that they lack preferences about various things where you then refuse to say that they're being dominated?
Replies from: edward-pierzchalski, keith_wynroe, edward-pierzchalski, none-given↑ comment by eapi (edward-pierzchalski) · 2023-03-09T22:54:45.292Z · LW(p) · GW(p)
This is pretty unsatisfying as an expansion of "incoherent yet not dominated" given that it just uses the phrase "not coherent" instead.
I find money-pump arguments to be the most compelling ones since they're essentially tiny selection theorems for agents in adversarial environments, and we've got an example in the post of (the skeleton of) a proof that a lack-of-total-preferences doesn't immediately lead to you being pumped. Perhaps there's a more sophisticated argument that Actually No, You Still Get Pumped but I don't think I've seen one in the comments here yet.
If there are things which cannot-be-money-pumped, and yet which are not utility-maximizers, and problems like corrigibility are almost certainly unsolvable for utility-maximizers, perhaps it's somewhat worth looking at coherent non-pumpable non-EU agents?
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2023-03-13T02:46:56.661Z · LW(p) · GW(p)
Things are dominated when they forego free money and not just when money gets pumped out of them.
Replies from: keith_wynroe, edward-pierzchalski, keith_wynroe↑ comment by keith_wynroe · 2023-03-18T10:39:05.424Z · LW(p) · GW(p)
How is the toy example agent sketched in the post dominated?
↑ comment by eapi (edward-pierzchalski) · 2023-03-13T03:12:35.932Z · LW(p) · GW(p)
...wait, you were just asking for an example of an agent being "incoherent but not dominated" in those two senses of being money-pumped? And this is an exercise meant to hint that such "incoherent" agents are always dominatable?
I continue to not see the problem, because the obvious examples don't work. If I have as incomparable to that doesn't mean I turn down the trade of (which I assume is what you're hinting at re. foregoing free money).
If one then says "ah but if I offer $9999 and you turn that down, then we have identified your secret equivalent utili-" no, this is just a bid/ask spread, and I'm pretty sure plenty of ink has been spilled justifying EUM agents using uncertainty to price inaction like this.
What's an example of a non-EUM agent turning down free money which doesn't just reduce to comparing against an EUM with reckless preferences/a low price of uncertainty?
↑ comment by keith_wynroe · 2023-03-28T11:14:00.453Z · LW(p) · GW(p)
Want to bump this because it seems important? How do you see the agent in the post as being dominated?
↑ comment by keith_wynroe · 2023-03-10T01:05:22.782Z · LW(p) · GW(p)
This seems totally different to the point OP is making which is that you can in theory have things that definitely are agents, definitely do have preferences, and are incoherent (hence not EV-maximisers) whilst not "predictably shooting themselves in the foot" as you claim must follow from this
I agree the framing of "there are no coherence theorems" is a bit needlessly strong/overly provocative in a sense, but I'm unclear what your actual objection is here - are you claiming these hypothetical agents are in fact still vulnerable to money-pumping? That they are in fact not possible?
↑ comment by eapi (edward-pierzchalski) · 2023-03-09T23:25:20.761Z · LW(p) · GW(p)
The rock doesn't seem like a useful example here. The rock is "incoherent and not dominated" if you view it as having no preferences and hence never acting out of indifference, it's "coherent and not dominated" if you view it as having a constant utility function and hence never acting out of indifference, OK, I guess the rock is just a fancy Rorschach test.
IIUC a prototypical Slightly Complicated utility-maximizing agent is one with, say, , and a prototypical Slightly Complicated not-obviously-pumpable non-utility-maximizing agent is one with, say, the partial order plus the path-dependent rule that EJT talks about in the post (Ah yes, non-pumpable non-EU agents might have higher complexity! Is that relevant to the point you're making?).
What's the competitive advantage of the EU agent? If I put them both in a sandbox universe and crank up their intelligence, how does the EU agent eat the non-EU agent? How confident are you that that is what must occur?
↑ comment by Eve Grey (none-given) · 2023-03-09T13:14:57.972Z · LW(p) · GW(p)
Hey, I'm really sorry if I sound stupid, because I'm very new to all this, but I have a few questions (also, I don't know which one of all of you is right, I genuinely have no idea).
Aren't rocks inherently coherent, or rather, their parts are inherently coherent, for they align with the laws of the universe, whereas the "rock" is just some composite abstract form we came up with, as observers?
Can't we think of the universe in itself as an "agent" not in the sense of it being "god", but in the sense of it having preferences and acting on them?
Examples would be hot things liking to be apart and dispersion leading to coldness, or put more abstractly - one of the "preferences" of the universe is entropy. I'm sorry if I'm missing something super obvious, I failed out of university, haha!
If we let the "universe" be an agent in itself, so essentially it's a composite of all simples there are (even the ones we're not aware of), then all smaller composites by definition will adhere to the "preferences" of the "universe", because from our current understanding of science, it seems like the "preferences" (laws) of the "universe" do not change when you cut the universe in half, unless you reach quantum scales, but even then, it is my unfounded suspicion that our previous models are simply laughably wrong, instead of the universe losing homogeneity at some arbitrary scale.
Of course, the "law" of the "universe" is very simple and uncomplex - it is akin to the most powerful "intelligence" or "agent" there is, but with the most "primitive" and "basic" "preferences". Also apologies for using so many words in quotations, I do so, because I am unsure if I understand their intended meaning.
It seems to me that you could say that we're all ultimately "dominated" by the "universe" itself, but in a way that's not really escapeable, but in opposite, the "universe" is also "dominated" by more complex "agents", as individuals can make sandwiches, while it'd take the "universe" much more time to create such complex and abstract composites from its pure "preferences".
In a way, to me at least, it seems that both the "hyper-intelligent", "powerful" "agent" needs the "complex", "non-homogeneous", "stupid" "agent", because without that relationship, if there ever randomly came to exist a "non-homogeneous" "agent" with enough "intelligence" to "dominate" the "universe", then we'd essentially experience... uh, give me a second, because this is a very complicated concept I read about long ago...
We'd experience the drop in the current energy levels all around the "universe", because if the "universe" wasn't the most "powerful" "agent" so far, then we've been existing in a "false vacuum" - essentially, the "universe" would be "dominated" by a "better" "agent" that adheres closer to the "true" "preferences" of the "universe".
And the "preference" of the "true" "universe" seems to be to reach that "true vacuum" state, as it's more in line with entropy, but it needs smaller and dumber agents that are essentially unknowingly "preferring" to "destroy" the universe as they know it, because it doesn't seem to be possible to reach that state with only micro-perturbations, or it'd take such a long time, it's more entropically sound to create bigger agents, that while really stupid, have far more "power" than the simple "universe", because even though the simple agents do not grasp the nature of "fire", "cold", "entropy" or even "time", they can easily make "sandwiches", "chairs", "rockets", "civilizations" and "technology".
I'd really appreciate it if someone tried to explain my confusions on the subject in private messages, as the thread here is getting very hard to read (at least for me, I'm very stupid!).
I really appreciate it if you read through my entire nonsensical garble, I hope someone's charitable enough to enlighten me which assumptions I made are completely nonsensical.
I am not trying to be funny, snarky, ironic, sarcastic, I genuinely do not understand, I just found this website - sorry if I come off that way.
Have a great day!
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-03-10T20:12:17.794Z · LW(p) · GW(p)
The question is how to identify particular bubbles of seekingness in the universe. How can you tell which part of the universe will respond to changes in other parts' shape by reshaping them, and how? How do you know when a cell wants something, in the sense that if the process of getting the thing is interfered with, it will generate physical motions that end up compensating for the interference. How do you know if it wants the thing, if it responds differently to different sizes of interference? Can we identify conflict between two bubbles of seekingness? etc.
The key question is how to identify when a physical has a preference for one thing over another. The hope is that, if we find a sufficiently coherent causal mechanism description that specifies what physical systems qualify as
For what it's worth, I think you're on a really good track here, and I'm very excited about views that have the one you're starting with. I'd invite browsing my account and links, as this is something I talk about often, from various perspectives, though mostly I defer to others for getting the math right.
Speaking of getting the math right: read Discovering Agents (or browse related papers), it's a really great paper. it's not an easy first paper to read, but I'm a big believer in out-of-order learning and jumping way ahead of your current level to get a sense of what's out there. Also check out the related paper Interpreting systems as solving POMDPs (or browse ) related papers.
If you're also new to scholarship in general, I'd also suggest checking out some stuff on how to do scholarship efficiently as well. a friend and I trimmed an old paper I like on how to read papers efficiently [LW · GW], and posted it to LW the other day. You can also find more related stuff from the tags on that post. (I reference that article myself occasionally and find myself surprised by how dense it is as a checklist of visits if I'm trying to properly understand a paper.)
Replies from: none-given↑ comment by Eve Grey (none-given) · 2023-03-11T05:17:43.412Z · LW(p) · GW(p)
I'll read the papers once I get on the computer - don't worry, I may have not finished uni, but I always loved reading papers over a cup of tea.
I'm kind of writing about this subject right now, so maybe there you can find something that interests you.
How do I know what parts of the universe will respond to what changes? To me, at least, this seems like a mostly false question, for you to have true knowledge of that, you'd need to become the Universe itself. If you don't care about true knowledge just good % chances, then you do it with heuristic. First you come up with composites that are somewhat self similar, but nothing is exactly alike in the Universe, except the Universe itself. Then you create a heuristic for predicting those composites and you use it, as long as the composite is similar enough to the original composite that the heuristic was based on. Of course, heuristics work differently in different environments, but often there are only a few environments even relevant for each composite, for if you take a fish out of water, it will die - now you may want a heuristic for an alive fish in the air, but I see it as much more useful to recompile the fish into catch at that point.
This of course applies on any level of composition, from specific specimens of fish, to ones from a specific family, to a single species, then to all fish, then to all living organisms, with as many steps in between these listed as you want. How do we discriminate between which composite level we ought to work with? Pure intuition and experiment, once you do it with logic, it all becomes useless, because logic will attempt to compression everything, even those things which have more utility being uncompressed.
I'll get to the rest of your comment on PC, my fingers hurt. Typing on this new big phone is so hard lol.
↑ comment by Max H (Maxc) · 2023-03-01T00:18:51.560Z · LW(p) · GW(p)
Agents can make themselves immune to all possible money-pumps for Completeness by acting in accordance with the following policy: ‘if I previously turned down some option X, I will not choose any option that I strictly disprefer to X.’
Plus some other assumptions (capable of backwards induction, knowing trades in advance), right?
I'm curious whether these assumptions are actually stronger than, or related to, completeness.
so if we care about whether agents will be (or will appear to be) expected utility maximizers, we have to care about whether they will be representable as expected utility maximizers.
Both sets (representable and not) are non-empty. The question remains about which set the interesting agents are in. I think that CCT + VNM, money pump arguments, etc. strongly hint, but do not prove, that the EU maximizers are the interesting ones.
Also, I personally don't find the question itself particularly interesting, because it seems like one can move between these sets in a relatively shallow way [LW(p) · GW(p)] (I'd be interested in seeing counterexamples, though). Perhaps that's what Yudkowsky means by not caring about representability?
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-03-01T19:24:47.680Z · LW(p) · GW(p)
Plus some other assumptions (capable of backwards induction, knowing trades in advance), right?
Yep, that’s right!
I'm curious whether these assumptions are actually stronger than, or related to, completeness.
Since the Completeness assumption is about preferences while the backward-induction and knowing-trades-in-advance assumptions are not, they don’t seem very closely related to me. The assumption that the agent’s strict preferences are transitive is more closely related, but it’s not stronger than Completeness in the sense of implying Completeness.
Can you say a bit more about what you mean by ‘interesting agents’?
From your other comment:
That is, if you try to construct / find / evolve the most powerful agent that you can, without a very precise understanding of agents / cognition / alignment, you'll probably get something very close to an EU maximizer.
I think this could well be right. The main thought I want to argue against is more like:
- Even if you initially succeed in creating a powerful agent that doesn’t maximize expected utility, VNM/CCT/money-pump arguments make it likely that this powerful agent will later become an expected utility maximizer.
↑ comment by Max H (Maxc) · 2023-03-01T21:14:32.864Z · LW(p) · GW(p)
I meant stronger in a loose sense: you argued that "completeness doesn't come for free", but it seems more like actually what you've shown is that not-pursuing-dominated-strategies is the thing that doesn't come for free.
You either need a bunch of assumptions about preferences, or you need one less of those assumptions, plus a few other assumptions about knowing trades, induction, and adherence to a specific policy.
And even given all these other assumptions, the proposed agent with a preferential gap seems like it's still only epsilon-different from an actual EU maximizer. To me this looks like a strong hint that these assumptions actually do point at a core of something simple which one might call "coherence", which I expect to show up in (all minus epsilon) advanced agents, even if there are pathological points in advanced-agent-space which don't have these properties (and even if expected utility theory as a whole isn't quite correct [LW(p) · GW(p)]).
↑ comment by EJT (ElliottThornley) · 2023-03-01T23:19:09.294Z · LW(p) · GW(p)
You either need a bunch of assumptions about preferences, or you need one less of those assumptions, plus a few other assumptions about knowing trades, induction, and adherence to a specific policy.
I see. I think this is right.
the proposed agent with a preferential gap seems like it's still only epsilon-different from an actual EU maximizer.
I agree with this too, but note that the agent with a single preferential gap is just an example. Agents can have arbitrarily many preferential gaps and still avoid pursuing dominated strategies. And agents with many preferential gaps may behave quite differently to expected utility maximizers.
↑ comment by quetzal_rainbow · 2023-03-02T19:53:23.000Z · LW(p) · GW(p)
You need only non-transitivity for money pump. Let's suppose that you prefer A to B, B to C and you are indifferent between A and C (not cyclic, not transitive preference). You start with C, you pay me 1 dollar to switch to B, then you pay 1 dollar to switch to A, then I pay you 1 dollar to switch to C (which you do, because A = C implies C + 1 > A) and I have 1 free dollar. Note that your proposed policy doesn't work here, because you do not strictly disprefer C + 1.
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-03-07T01:21:25.814Z · LW(p) · GW(p)
Nice point but this money-pump only rules out one kind of transitivity-violation (the agent strictly prefers A to B, strictly prefers B to C, and is indifferent between A and C). It doesn't rule out this other kind of transitivity-violation: the agent strictly prefers A to B, strictly prefers B to C, and has a preferential gap between A and C.
Replies from: DaemonicSigil, quetzal_rainbow↑ comment by DaemonicSigil · 2023-03-14T06:59:30.493Z · LW(p) · GW(p)
Wait, I can construct a money pump for that situation. First let the agent choose between A and C. If there's a preferential gap, the agent should sometimes choose C. Then let the agent pay a penny to upgrade from C to B. Then let the agent pay a penny to upgrade from B to A. The agent is now where it could have been to begin with by choosing A in the first place, but 2 cents poorer.
Even if we ditch the completeness axiom, it sure seems like money pump arguments require us to assume a partial order.
What am I missing?
Replies from: ElliottThornley, quetzal_rainbow↑ comment by EJT (ElliottThornley) · 2023-03-14T19:26:27.399Z · LW(p) · GW(p)
So this won't work if the agent knows in advance what trades they'll be offered and is capable of reasoning by backward induction. In that case, the agent will reason that they'd choose A-2p over B-1p if they reached that node, and would choose B-1p over C if they reached that node. So (they will reason), the choice between A and C is actually a choice between A and A-2p, and so they will reliably choose A.
And plausibly we should make assumptions like 'the agent knows in advance what trades they will be offered' and 'the agent is capable of backward induction' if we're arguing about whether agents are rationally required to conform their preferences to the VNM axioms.
(If the agent doesn’t know in advance what trades they will be offered or is incapable of backward induction, then their pursuit of a dominated strategy need not indicate any defect in their preferences. Their pursuit of a dominated strategy can instead be blamed on their lack of knowledge and/or reasoning ability.)
That said, I've recently become less convinced that 'knowing trades in advance' is a reasonable assumption in the context of predicting the behaviour of advanced artificial agents. And your money-pump seems to work if we assume that the agent doesn't know what trades they will be offered in advance. So maybe we do in fact have reason to expect that advanced artificial agents will have transitive preferences. (I say 'maybe' because there are some other relevant considerations pushing the other way, discussed in a paper-in-progress by Adam Bales.)
Replies from: DaemonicSigil↑ comment by DaemonicSigil · 2023-03-15T06:32:33.036Z · LW(p) · GW(p)
I don't know, this still seems kind of sketchy to me. Say we change the experiment so that it costs the agent a penny to choose A in the initial choice: it will still take that choice, since A-1p is still preferable to A-2p. Compare this to a game where the agent can freely choose between A and C, and there's no cost in pennies to either choice. Since there's a preferential gap between A and C, the agent will sometimes pick A and sometimes pick C. In the first game, on the other hand the agent always picks A. Yet in the first game, not only is picking A more costly, but we've only added options for the agent if it picks C. In other words, an agent that has A>B, B>C, and A~C sure looks like it's paying to take options away from itself, since adding options makes it less likely to pick C, even when it costs a penny to avoid it.
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-03-15T18:39:53.916Z · LW(p) · GW(p)
Nice! This is a cool case. The behaviour does indeed seem weird. I'm inclined to call it irrational. But the agent isn't pursuing a dominated strategy: in neither game does the agent settle on an option that they strictly disprefer to some other available option.
This discussion is interesting and I'm happy to keep having it, but perhaps it's worth saying (if not for your sake then for other readers) that this is a side-thread. The main point of the post is that there are no money-pumps for Completeness. I think that there are probably no money-pumps for Transitivity either, but it's the claim about Completeness that I really want to defend.
Replies from: DaemonicSigil↑ comment by DaemonicSigil · 2023-03-15T21:33:02.792Z · LW(p) · GW(p)
Cool. For me personally, I think that paying to avoid being given more options looks enough like being dominated that I'd want to keep the axiom of transitivity around, even if it's not technically a money pump.
So in the case where we have transitivity but no completeness, it seems kind of like there might be a weaker coherence theorem, where the agent's behaviour can be described by rolling a dice to pick a utility function before beginning a game, and then subsequently playing according to that utility function. Under this interpretation, if A > B then that means that A is preferred to B under all utility functions the agent could pick, while a preferential gap between A and B means that sometimes A will be ranked higher and sometimes B will be ranked higher, depending on which utility function the die roll happens to land on.
Does this match your intuition? Is there an obvious counterexample to this "coherence conjecture"?
Replies from: ElliottThornley, martinkunev↑ comment by EJT (ElliottThornley) · 2023-03-21T23:48:19.989Z · LW(p) · GW(p)
Your coherence conjecture sounds good! It sounds like it roughly matches this theorem:

Screenshot is from this paper.
Replies from: MichaelStJules, MichaelStJules↑ comment by MichaelStJules · 2023-08-02T01:44:50.758Z · LW(p) · GW(p)
This is cool. I don't think violations of continuity are also in general exploitable, but I'd guess you should also be able to replace continuity with something weaker from Russell and Isaacs, 2020, just enough to rule out St. Petersburg-like lotteries, specifically any one of Countable Independence (which can also replace independence), the Extended Outcome Principle (which can also replace independence) or Limitedness, and then replace the real-valued utility functions with utility functions representable by "lexicographically ordered ordinal sequences of bounded real utilities".
↑ comment by MichaelStJules · 2023-09-20T04:28:28.242Z · LW(p) · GW(p)
This also looks like a generalization of stochastic dominance.
↑ comment by martinkunev · 2023-11-12T02:51:20.466Z · LW(p) · GW(p)
"paying to avoid being given more options looks enough like being dominated that I'd want to keep the axiom of transitivity around"
Maybe offtopic but paying to avoid being given more options is a common strategy in negotiation.
↑ comment by quetzal_rainbow · 2023-03-14T16:40:56.641Z · LW(p) · GW(p)
It's not a money pump, because money pump implies infinite cycle of profit. If your loses are bounded, you are fine.
↑ comment by quetzal_rainbow · 2023-03-08T12:21:55.427Z · LW(p) · GW(p)
Does I understand correctly that preferential gaps have size, like, i do not prefer A to B, I do not prefer A to B+1, but some large N exists that I prefer B + N to A?
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-03-10T18:09:14.567Z · LW(p) · GW(p)
That can be true (and will often be true when it comes to - e.g. - a human agent with a preferential gap between a Fabergé egg and a long-lost wedding album), but it's not a necessary feature of preferential gaps.
↑ comment by keith_wynroe · 2023-03-10T01:09:49.638Z · LW(p) · GW(p)
Kind of tangential but I'd be interested in your take on how strongly money-pumping etc is actually an argument against full-on cyclical preferences? One way to think about why getting money-pumped is bad is because you have an additional preference to not pay money to go nowhere. But it feels like all this tells us is that "something has to go", and if an agent is rationally permitted to modify its own preferences to avoid these situations then it seems a priori acceptable for it to instead just say something like "well actually I weight my cyclical preferences more highly so I'll modify the preference against arbitrarily paying"
In other words, it feels like the money-pumping arguments presume this other preference that in a sense takes "precedence" over the cyclical ones and I'm not sure how to think about that still
Replies from: edward-pierzchalski↑ comment by eapi (edward-pierzchalski) · 2023-03-10T01:27:07.763Z · LW(p) · GW(p)
(I'm not EJT, but for what it's worth:)
I find the money-pumping arguments compelling not as normative arguments about what preferences are "allowed", but as engineering/security/survival arguments about what properties of preferences are necessary for them to be stable against an adversarial environment (which is distinct from what properties are sufficient for them to be stable, and possibly distinct from questions of self-modification).
Replies from: keith_wynroe↑ comment by keith_wynroe · 2023-03-11T01:40:41.022Z · LW(p) · GW(p)
Yeah I agree that even if they fall short of normative constraints there’s some empirical content around what happens in adversarial environments. I think I have doubts that this stuff translates to thinking about AGIs too much though, in the sense that there’s an obvious story of how an adversarial environment selected for (partial) coherence in us, but I don’t see the same kinds of selection pressures being a force on AGIs. Unless you assume that they’ll want to modify themselves in anticipation of adversarial environments which kinda begs the question
Replies from: edward-pierzchalski↑ comment by eapi (edward-pierzchalski) · 2023-03-11T04:29:37.260Z · LW(p) · GW(p)
Hmm, I was going to reply with something like "money-pumps don't just say something about adversarial environments, they also say something about avoiding leaking resources" (e.g. if you have circular preferences between proximity to apples, bananas, and carrots, then if you encounter all three of them in a single room you might get trapped walking between them forever) but that's also begging your original question - we can always just update to enjoy leaking resources, transmuting a "leak" into an "expenditure".
Another frame here is that if you make/encounter an agent, and that agent self-modifies into/starts off as something which is happy to leak pretty fundamental resources like time and energy and material-under-control, then you're not as worried about it? It's certainly not competing as strongly for the same resources as you whenever it's "under the influence" of its circular preferences.
↑ comment by cfoster0 · 2023-02-28T02:00:51.119Z · LW(p) · GW(p)
Since you've got no preference one way or the other, I don't expect you'll be objecting, right?
If I'm merely indifferent between A and B, then I will not object to trades exchanging A for B. But if A and B are incomparable for me, then I definitely may object!
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2023-02-28T02:33:04.133Z · LW(p) · GW(p)
Say more about behaviors associated with "incomparability"?
Replies from: cfoster0↑ comment by cfoster0 · 2023-02-28T02:59:27.559Z · LW(p) · GW(p)
Depending on the implementation details of the agent design, it may do some combination of:
- Turning down your offer, path-dependent [LW · GW]ly preferring whichever option is already in hand / whichever option is consistent with its history of past trades.
- Noticing unresolved conflicts within its preference framework, possibly unresolveable without self-modifying into an agent that has different preferences from itself.
- Halting and catching fire, folding under the weight of an impossible choice.
EDIT: The post also suggests an alternative (better) policy [LW · GW] that agents with incomplete preferences may follow.
↑ comment by Seth Herd · 2023-02-28T21:04:57.743Z · LW(p) · GW(p)
I don't think this goes through. If I have no preference between two things, but I do prefer to not be money-pumped, it doesn't seem like I'm going to trade those things so as to be money-pumped.
I am commenting because I think this might be a crucial crux: do smart/rational enough agents always act like maximizers? If not, adequate alignment might be much more feasible than if we need to find exactly the right goal and how to get it into our AGI exactly right.
Human preferences are actually a lot more complex. We value food very highly when hungry and water when we're thirsty. That can come out of power-seeking, but that's not actually how it's implemented. Perhaps more importantly, we might value stamp collecting really highly until we get bored with stamp collecting. I don't think these can be modeled as a maximizer of any sort.
If humans would pursue multiple goals [LW · GW] even if we could edit them (and were smart enough to be consistent), then a similar AGI might only need to be minimally aligned for success. That is, it might stably value human flourishing as a small part of its complex utility function.
I'm not sure whether that's the case, but I think it's important.
comment by Max H (Maxc) · 2023-02-27T00:35:47.760Z · LW(p) · GW(p)
Money-pump arguments don’t give us much reason to expect that advanced artificial agents will be representable as expected-utility-maximizers.
The space of agents is large; EU maximizers may be a simple, natural subset of all possible agents.
Given any EU maximizer, you can construct a new, more complicated agent which has a preferential gap about something trivial. This new agent will (by VNM) not be an EU maximizer.
Similarly, given an agent with incomplete preferences that satisfies the other axioms, you can (always? trivially??) construct an agent with complete preferences by specifying a new preference-relation that is sensitive to all sweetenings and sourings.
So, while it is indeed not accurate to say that sufficiently-advanced artificial agents will be EU maximizers, it certainly seems like they can be.
I think gesturing vaguely at VNM and using money-pump arguments are useful for building an (imprecise, possibly wrong) intuition for why EU maximizers might be a simple, natural subset of all agents.
That is, if you try to construct / find / evolve the most powerful agent that you can, without a very precise understanding of agents / cognition / alignment, you'll probably get something very close to an EU maximizer.
I agree that the authors should be more careful with their words when they cite VNM, but I think the intuition that they build based on these theorems is correct.
Replies from: MichaelStJulescomment by keith_wynroe · 2023-02-21T23:09:08.194Z · LW(p) · GW(p)
Great post. I think a lot of the discussion around the role of coherence arguments and what we should expect a super-intelligent agent to behave like is really sloppy and I think this distinction between "coherence theorems as a self-contained mathematical result" and "coherence arguments as a normative claim about what an agent must be like on pain of shooting themselves in the foot" is an important one
The example of how an incomplete agent avoids getting Dutch-booked also seems to look very naturally like how irl agents behave imo. One way of thinking about this is also that these lotteries are a lot more "high-dimensional" than they initially look - e.g. the decision at node 2 isn't between "B and C" but between "B and C given I just chose B in a choice between B and A and this guy is trying to rip me off". In general the path-dependence of our bets and our meta-preferences on how our preferences are engaged with by other agents are also legitimate reasons to expect things like Dutch-booking has less normative force for actual agents IRL. Of course in a way this is maybe just making you VNM-rational after all albeit with a super weird and garbled utility function, but that's a whole other problem with coherence arguments
comment by Cole Wyeth (Amyr) · 2024-06-03T17:31:15.156Z · LW(p) · GW(p)
I have only skimmed this and am planning a careful read, but my first impression is that Wald's complete class theorem is exactly the desired coherence theorem. Complete preferences seem like the weakest possible assumption one could make and still expect to show non-Bayesian decision rules are dominated. If you want to show that "want something -> should use Bayesian decision theory to get it" there is no need to argue about the premise that an agent wants something, and to me wanting something coherently requires complete preferences.
comment by MichaelStJules · 2023-09-20T02:33:56.991Z · LW(p) · GW(p)
Coming back to this, the policy
if I previously turned down some option X, I will not choose any option that I strictly disprefer to X
seems irrational to me if applied in general. Suppose I offer you and , where both and are random, and is ex ante preferable to , e.g. stochastically dominates , but has some chance of being worse than . You pick . Then you evaluate to get . However, suppose you get unlucky, and is worse than . Suppose further that there's a souring of , , that's still preferable to . Then, I offer you to trade for . It seems irrational to not take .
Maybe what you need to do is first evaluate according to your multi-utility function [LW(p) · GW(p)] (or stochastic dominance, which I think is a special case) to rule out some options, i.e. to rule out not trading for when the latter is better than the former, and then apply your policy to rule out more options.
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-09-20T13:06:42.648Z · LW(p) · GW(p)
Ah yes, nice point. The policy should really be something like 'if I previously turned down some option , then given that no uncertainty has been resolved in the meantime, I will not choose any option that I strictly disprefer to .' An agent acting in accordance with that policy can trade for .
And I think that even agents acting in accordance with this restricted policy can avoid pursuing dominated strategies. As your case makes clear, these agents might end up with when they could have had (because they got unlucky with yielding ). But although that's unfortunate for the agent, it doesn't put any pressure on the agent to revise its preferences.
Replies from: MichaelStJules↑ comment by MichaelStJules · 2023-09-21T01:02:11.588Z · LW(p) · GW(p)
I think a multi-step decision procedure would be better. Do what your preferences themselves tell you to do and rule out any options you can with them. If there are multiple remaining incomparable options, then apply your original policy to avoid money pumps.
comment by MichaelStJules · 2023-08-01T18:58:33.420Z · LW(p) · GW(p)
EDIT: Looks like a similar point made here [LW(p) · GW(p)].
I wonder if we can "extend" utility maximization representation theorems to drop Completeness. There's already an extension to drop Continuity by using an ordinal-indexed vector (sequence) of real numbers, with entries sorted lexicographically ("lexicographically ordered ordinal sequences of bounded real utilities", Russell and Isaacs, 2020). If we drop Completeness, maybe we can still represent the order with a vector of independent but incomparable dimensions across which it must respect ex ante Pareto efficiency (and each of those dimensions could also be split into an ordinal-indexed vector of real numbers with entries sorted lexicographically, if we're also dropping Continuity)?
These also give us examples of somewhat natural/non-crazy orders that are consistent with dropping Completeness. I've seen people (including some economists) claim interpersonal utility comparisons are impossible and that we should only seek Pareto efficiency across people and not worry about tradeoffs between people. (Said Achmiz already pointed this and other examples out. [LW(p) · GW(p)])
Intuitively, the dimensions don't actually need to be totally independent. For example, the order could be symmetric/anonymous/impartial between some dimensions, i.e. swapping values between these dimensions gives indifference. You could also have some strict preferences over some large tradeoffs between dimensions, but not small tradeoffs. Or even, maybe you want more apples and more oranges without tradeoffs between them, but also prefer more bananas to more apples and more bananas to more oranges. Or, a parent, having to give a gift to one of their children, may strictly prefer randomly choosing over picking one child to give it to, and find each nonrandom option incomparable to one another (although this may have problems when they find out which one they will give to, and then give them the option to rerandomize again; they might never actually choose).
Maybe you could still represent all of this with a large number of, possibly infinitely many, real-valued utility functions (or utility functions representable by "lexicographically ordered ordinal sequences of bounded real utilities") instead. So, the correct representation could still be something like a (possibly infinite) set of utility functions (each possibly a "lexicographically ordered ordinal sequences of bounded real" utility functions), across which you must respect ex ante Pareto efficiency. This would be similar to the maximality rule over your representor/credal set/credal committee for imprecise credences (Mogensen, 2019).
Then, just combine this with your policy "if I previously turned down some option X, I will not choose any option that I strictly disprefer to X", where strictly disprefer is understood to mean ex ante Pareto dominated.
But now this seems like a coherence theorem, just with a broader interpretation of "expected utility".
To be clear, I don't know if this "theorem" is true at all.
Possibly also related: McCarthy et al., 2020 have a utilitarian representation theorem that's consistent with "the rejection of all of the expected utility axioms, completeness, continuity, and independence, at both the individual and social levels". However, it's not a real-valued representation. It reduces lotteries over a group of people to a lottery over outcomes for one person, as the probabilistic mixture of each separate person's lottery into one lottery.
Replies from: Jobst Heitzig↑ comment by Jobst Heitzig · 2024-11-13T23:19:25.744Z · LW(p) · GW(p)
I think you are right about the representation claim since any quasi-ordering (reflexive and transitive relation) can be represented as the intersection of complete quasi-orderings.
comment by harfe · 2023-02-21T03:08:33.582Z · LW(p) · GW(p)
The post argues a lot against completeness. I have a hard time imagining an advanced AGI (which has the ability to self-reflect a lot) that has a lot of preferences, but no complete preferences.
Your argument seems to be something like "There can be outcomes A and B where neither nor . This property can be preserved if we sweeten A a little bit: then we have but neither nor . If faced with a decision between A and B (or faced with a choice between ), the AGI can do something arbitrary, eg just flip a coin."
I expect advanced AGI systems capable of self-reflection to think whether A or B seems to be more valuable (unless it thinks the situation is so low-stakes that it is not worth thinking about. But computation is cheap, and in AI safety we typically care about high-stakes situation anyways). To use your example: If A is a lottery that gives the agent a Fabergé egg for sure. B is a lottery that returns to the agent their long-lost wedding album, then I would expect an advanced agent to invest a bit into figuring out which of those it deems more valuable.
Also, somewhere in the weights/code of the AGI there has to be some decision procedure, that specifies what the AGI should do if faced with the choice between A and B. It would be possible to hardcode that the AGI should flip a coin when faced with a certain choice. But by default, I expect the choice between A and B to depend on some learned heuristics (+reflection) and not hardcoded. A plausible candidate here would be a Mesaoptimizer, who might have a preference between A and B even when the outer training rules don't encourage a preference between A and B.
A-priori, the following outputs of an advanced AGI seem unlikely and unnatural to me:
- If faced with a choice between and , the AGI chooses each with
- If faced with a choice between and , the AGI chooses each with
- If faced with a choice between and , the AGI chooses with .
↑ comment by Said Achmiz (SaidAchmiz) · 2023-02-21T04:29:13.942Z · LW(p) · GW(p)
The post argues a lot against completeness. I have a hard time imagining an advanced AGI (which has the ability to self-reflect a lot) that has a lot of preferences, but no complete preferences.
A couple of relevant quotes:
Of all the axioms of utility theory, the completeness axiom is perhaps the most questionable.[8] Like others of the axioms, it is inaccurate as a description of real life; but unlike them, we find it hard to accept even from the normative viewpoint.
Before stating more carefully our goal and the contribution thereof, let us note that there are several economic reasons why one would like to study incomplete preference relations. First of all, as advanced by several authors in the literature, it is not evident if completeness is a fundamental rationality tenet the way the transitivity property is. Aumann (1962), Bewley (1986) and Mandler (1999), among others, defend this position very strongly from both the normative and positive viewpoints. Indeed, if one takes the psychological preference approach (which derives choices from preferences), and not the revealed preference approach, it seems natural to define a preference relation as a potentially incomplete preorder, thereby allowing for the occasional “indecisiveness” of the agents. Secondly, there are economic instances in which a decision maker is in fact composed of several agents each with a possibly distinct objective function. For instance, in coalitional bargaining games, it is in the nature of things to specify the preferences of each coalition by means of a vector of utility functions (one for each member of the coalition), and this requires one to view the preference relation of each coalition as an incomplete preference relation. The same reasoning applies to social choice problems; after all, the most commonly used social welfare ordering in economics, the Pareto dominance, is an incomplete preorder. Finally, we note that incomplete preferences allow one to enrich the decision making process of the agents by providing room for introducing to the model important behavioral traits like status quo bias, loss aversion, procedural decision making, etc.
↑ comment by green_leaf · 2023-02-21T09:23:02.419Z · LW(p) · GW(p)
Indeed. What would it even mean for an agent not to prefer A over B, and also not to prefer B over A, and also not be indifferent between A and B?
Replies from: SaidAchmiz↑ comment by Said Achmiz (SaidAchmiz) · 2023-02-21T10:02:23.434Z · LW(p) · GW(p)
See my comments on this post for links to several answers to this question.
Replies from: green_leaf↑ comment by green_leaf · 2023-02-21T15:05:37.348Z · LW(p) · GW(p)
I read it, but I'm not at all sure it answers the question. It makes three points:
- "if one takes the psychological preference approach (which derives choices from preferences), and not the revealed preference approach, it seems natural to define a preference relation as a potentially incomplete preorder, thereby allowing for the occasional “indecisiveness” of the agents"
I don't see how an agent being indecisive is relevant to preference ordering. Not picking A or B is itself a choice - namely, the agent chooses not to pick either option.
2. "Secondly, there are economic instances in which a decision maker is in fact composed of several agents each with a possibly distinct objective function. For instance, in coalitional bargaining games, it is in the nature of things to specify the preferences of each coalition by means of a vector of utility functions (one for each member of the coalition), and this requires one to view the preference relation of each coalition as an incomplete preference relation."
So, if the AI is made of multiple agents, each with its own utility function and we use a vector utility function to describe the AI... the AI still makes a particular choice between A and B (or it refuses to choose, which itself is a choice). Isn't this a flaw of the vector-utility-function description, rather than a real property of the AI?
3. "The same reasoning applies to social choice problems; after all, the most commonly used social welfare ordering in economics, the Pareto dominance"
I'm not sure how this is related to AI.
Do you have any ideas?
comment by Review Bot · 2024-05-26T11:18:55.201Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Lauro Langosco · 2023-06-01T15:13:47.886Z · LW(p) · GW(p)
More generally, suppose that the agent acts in accordance with the following policy in all decision-situations: ‘if I previously turned down some option X, I will not choose any option that I strictly disprefer to X.’ That policy makes the agent immune to all possible money-pumps for Completeness.
Am I missing something or does this agent satisfy Completeness anytime it faces a decision for the second time?
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-06-03T19:05:21.355Z · LW(p) · GW(p)
I don't think so, Suppose the agent first chooses A when we offer it a choice between A and B. After that, the agent must act as if it prefers A to B-. But it can still lack a preference between A and B, and this lack of preference can still be insensitive to some sweetening or souring: the agent could also lack a preference between A and B+, or lack a preference between A+ and B, or lack a preference between B and A-.
What is true is that, given a sufficiently wide variety of past decisions, the agent must act as if its preferences are complete. But depending on the details, that might never happen or only happen after a very long time.
If you're interested, these kinds of points got discussed in a bit more detail over in this comment thread [EA(p) · GW(p)].
comment by Signer · 2023-02-21T06:00:39.758Z · LW(p) · GW(p)
If the agent doesn’t know in advance what trades they will be offered or is incapable of backward induction, then their pursuit of a dominated strategy need not indicate any defect in their preferences. Their pursuit of a dominated strategy can instead be blamed on their lack of knowledge and/or reasoning ability.
But then wouldn't your proposed policy be dominated by choosing to be indifferent between options with gap, because it works better without knowing trades in advance, and doesn't work worse otherwise?
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-02-21T18:44:08.792Z · LW(p) · GW(p)
Nice point. But making your preferences complete won’t protect you from pursuing dominated strategies if you don’t know what’s coming.
For example, suppose at node 1 you face a choice between taking A and proceeding to node 2. You think that at node 2 you’ll face a choice between A- and A+. So, you proceed to node 2, with the intention of taking A+. But you were mistaken. At node 2, you face a choice between A- and A--. You take A-.
In that case, you’ve pursued a dominated strategy: you’ve ended up with A- when you could have had A. But your preferences are not to blame. Instead, it was your mistaken beliefs about what options you would have.
Replies from: Signer↑ comment by Signer · 2023-02-21T18:57:28.534Z · LW(p) · GW(p)
My intuition was something like "you would get better satisfaction of preference in expectation even if you are uncertain about the future", but I guess it doesn't exactly work without first defining utility function. But what about first choosing between A- and B-, and then between A or B- in A- branch, and B or A- in B- branch - this way you get (A|B-|B|A-) with gaps vs. (A|B) in indifference case - wouldn't the mixture with worse variants intuitively be worse than one with only good ones even if we can't strictly say that incomplete preferences are contradicted?
comment by MichaelStJules · 2023-08-02T05:55:42.244Z · LW(p) · GW(p)
The arguments typically require agents to make decisions independently of the parts of the decision tree in the past (or that are otherwise no longer accessible, in case they were ruled out). But an agent need not do that. An agent can always avoid getting money pumped by just following the policy of never picking an option that completes a money pump (or the policy of never making any trades, say). They can even do this with preference cycles.
Does this mean money pump arguments don't tell us anything? Such a policy may have other costs that an agent would want to avoid, if following their preferences locally would otherwise lead to getting money pumped (e.g. as Gustafsson (2022) argues in section 7 Against Resolute Choice), but how important could depend on those costs, including how frequently they expect to incur them, as well as the costs of changing their preferences to satisfy rationality axioms. It seems bad to pick options you'll foreseeable regret. However, changing your preferences to fit some proposed rationality requirements also seems foreseeably regrettable in another way: you have to give up things you care about or some ways you care about them. And that can be worse than your other options for avoiding money pumps, or even, sometimes, getting money pumped.
Furthermore, agents plausibly sometimes need to make commitments that would bind them in the future, even if they'd like to change their minds later, in order to win in Parfit's hitchhiker [? · GW], say.
Similarly, if instead of money pumps, an agent should just avoid any lottery that's worse than (or strictly statewise dominated by, or strictly stochastically dominated by, under some suitable generalization[1]) another they could have guaranteed, it's not clear that's a requirement of rationality, either. If I prefer A<B<C<A, then it doesn't seem more regrettable if I pick one option than if I pick another (knowing nothing else), even though no matter what option I pick, it seems regrettable that I didn't pick another. Choosing foreseeably regrettable options seems bad, but if every option is (foreseeably) regrettable in some way, and there's no least of the evils, then is it actually irrational?
Furthermore, if a superintelligence is really good at forecasting, then maybe we should expect it to have substantial knowledge of the decision tree in advance, and to typically be able to steer clear of situations where it might face a money pump or other dilemmas, and if it ever does get money pumped, the costs of all money pumps would be relatively small compared to its gains.
- ^
(strictly) stochastically dominates iff there's a "probability rearrangement" of , , such that (strictly) statewise dominates .
comment by DragonGod · 2023-02-21T11:43:44.079Z · LW(p) · GW(p)
Strongly upvoted.
Humans at least do not satisfy completeness/don't admit a total order over their preferences.
See also:
- This Answer [LW(p) · GW(p)]
- Why The Focus on Expected Utility Maximisers? [LW · GW]
- Why Subagents? [LW · GW]
↑ comment by Noosphere89 (sharmake-farah) · 2023-02-21T16:28:31.322Z · LW(p) · GW(p)
Yes, I generally view human values as partially ordered, not totally ordered.
However, the third post answers your second question well. Humans don't have complete preferences, but they still are expected utility maximizers. It's a partial order, not a total order, but it still disagrees with shard theory on relevant details.
Replies from: cfoster0↑ comment by cfoster0 · 2023-02-21T16:58:38.121Z · LW(p) · GW(p)
Where are you seeing that conclusion in the 3rd post [LW · GW]? AFAICT the message is that for an agent made up of parts [? · GW] that want different things / agent with incomplete preferences, there is no corresponding utility function that would uniquely correspond to its preferences, so humans (having incomplete preferences) are not EUMs. At best, such an agent is more like a market / committee of internal EUMs whose utility functions differ, which accords very well with the mainline "shard"-based picture.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-02-21T18:15:54.827Z · LW(p) · GW(p)
Sorry for misrepresenting the third post.
Though does shard theory agree with the implication of the third post that the shards/sub-agents are utility maximizers themselves?
Replies from: cfoster0↑ comment by cfoster0 · 2023-02-21T18:31:50.306Z · LW(p) · GW(p)
Sorta? I mean, if you construct an agent via learning, then for a long time the shards within the agent will be much more like reflexes than like full sub-agents/utility maximizers. But in the limit of sophistication, yes there will be some pressure pushing those shards towards individual coherence (EUM-ness), though it's hard to say how the balance shakes out compared to coalitional & other pressures.
comment by Vasco Grilo (vascoamaralgrilo) · 2025-01-21T13:45:13.582Z · LW(p) · GW(p)
Thanks for the post, Dan and Elliot. I have not read the comments, but I do not think preferential gaps make sense in principle. If one was exactly indifferent between 2 outcomes, I believe any improvement/worsening of one of them must make one prefer one of the outcomes over the other. At the same time, if one is roughly indifferent between 2 outcomes, a sufficiently small improvement/worsening of one of them will still lead to one being practically indifferent between them. For example, although I think i) 1 $ plus a chance of 10^-100 of 1 $ is clearly better than ii) 1 $, I am practically indifferent between i) and ii), because the value of 10^-100 $ is negligible.
comment by Noosphere89 (sharmake-farah) · 2024-12-22T17:23:08.366Z · LW(p) · GW(p)
There's a coherence theorem that was proved by John Wentworth, which while toyish, looks like an actual example of what a coherence theorem would actually look like.
https://www.lesswrong.com/posts/DXxEp3QWzeiyPMM3y/a-simple-toy-coherence-theorem [LW · GW]
comment by martinkunev · 2023-11-12T02:57:41.581Z · LW(p) · GW(p)
In "A money-pump for Completeness" you say "by the transitivity of strict preference"
This only says that transitive preferences do not need to be complete which is weaker than preferences do not need to be complete.
↑ comment by drocta · 2024-07-23T21:42:36.614Z · LW(p) · GW(p)
Doesn't "(has preferences, and those preferences are transitive) does not imply (completeness)" imply (has preferences) does not imply (completeness)" ? Surely if "having preferences" implied completeness, then "having transitive preferences" would also imply completeness?
Replies from: martinkunev↑ comment by martinkunev · 2024-07-26T16:15:14.764Z · LW(p) · GW(p)
Usually "has preferences" is used to convey that there is some relation (between states?) which is consistent with the actions of the agent. Completeness and transitivity are usually considered additional properties that this relation could have.
Replies from: drocta↑ comment by drocta · 2024-07-27T00:15:29.460Z · LW(p) · GW(p)
Yes. I believe that is consistent with what I said.
"not((necessarily, for each thing) : has [x] -> those [x] are such that P_1([x]))"
is equivalent to, " (it is possible that something) has [x], but those [x] are not such that P_1([x])"
not((necessarily, for each thing) : has [x] such that P_2([x]) -> those [x] are such that P_1([x]))
is equivalent to "(it is possible that something) has [x], such that P_2([x]), but those [x] are not sure that P_1([x])" .
The latter implies the former, as (A and B and C) implies (A and C), and so the latter is stronger, not weaker, than the former.
Right?
comment by MichaelStJules · 2023-09-21T07:35:35.415Z · LW(p) · GW(p)
Looking at Gustafsson, 2022's money pumps for completeness, the precaution principles he uses just seem pretty unintuitive to me. The idea seems to be that if you'll later face a decision situation where you can make a choice that makes you worse off but you can't make yourself better off by getting there, you should avoid the decision situation, even if it's entirely under your control to make a choice in that situation that won't leave you worse off. But, you can just make that choice that won't leave you worse off later instead of avoiding the situation altogether.
Here's the forcing money pump:
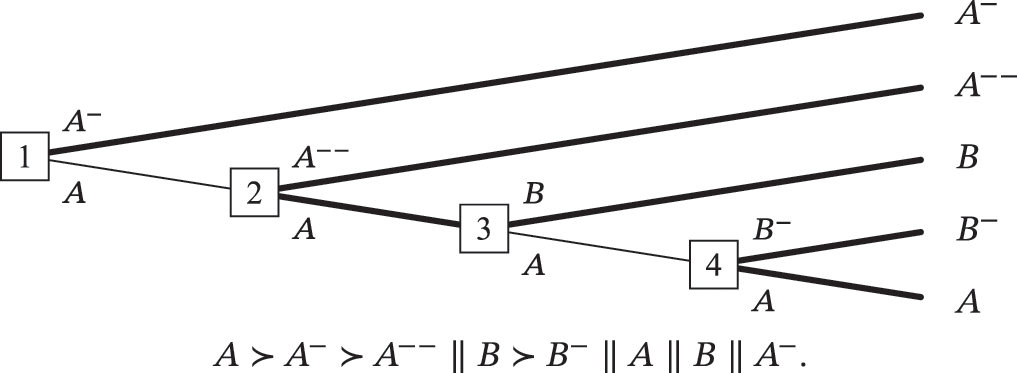
It seems obvious to me that you can just stick with A all the way through, or switch to B, and neither would violate any of your preferences or be worse than any other option. Gustafsson is saying that would be irrational, it seems because there's some risk you'll make the wrong choices. Another kind of response like your policy I can imagine is that unless you have preferences otherwise (i.e. would strictly prefer another accessible option to what you have now), you just stick with the status quo, as the default. This means sticking with A all the eay though, because you're never offered a strictly better option than it.
Another problem with the precaution principles is that they seem much less plausible when you seriously entertain incompleteness, rather than kind of treat incompleteness like equivalence. He effectively argues that at node 3, you should pick B, because otherwise at node 4, you could end up picking B-, which is worse than B, and there's no upside. But that basically means claiming that one of the following must hold:
- you'll definitely pick B- at 4, or
- B is better than any strict probabilistic mixture of A and B-.
But both are false in general. 1 is false in general because A is permissible at 4. 2 is false in general because A and B are incomparable and incomparability can be infectious (e.g. MacAskill, 2013), so B can be incomparable with a strict probabilistic mixture of A and B-. It also just seems unintuitive, because the claim is made generally, and so would have to hold no matter how low the probability assigned to B- is, as long it's positive.
Imagine A is an apple, B is a banana and B- is a slightly worse banana, and I have no preferences between apples and bananas. It would be odd to say that a banana is better than an apple or a tiny probability of a worse banana. This would be like using the tiny risk of a worse banana with the apple to break a tie between the apple and the banana, but there's no tie to break, because apples and bananas are incomparable.
If A and B were equivalent, then B would indeed very plausibly be better than a strict probabilistic mixture of A and B-. This would follow from Independence, or if A, B and B- are deterministic outcomes, statewise dominance. So, I suspect the intuitions supporting the precaution principles are accidentally treating incomparability like equivalence.
I think a more useful way to think of incomparability is as indeterminancy about which is better. You could consider what happens if you treat A as (possibly infinitely) better than B in one whole treatment of the tree, and consider what happens if you treat B as better than A in a separate treatment, and consider what happens if you treat them as equivalent all the way through (and extend your preference relation to be transitive and continue to satisfy stochastic dominance and independence in each case). If B were better, you'd end up at B, no money pump. If A were better, you'd end up at A, no money pump. If they were equivalent, you'd end up at either (or maybe specifically B, because of precaution), no money pump.