Introduction To The Infra-Bayesianism Sequence
post by Diffractor, Vanessa Kosoy (vanessa-kosoy) · 2020-08-26T20:31:30.114Z · LW · GW · 62 commentsContents
Prelude: Introduction: What About Environments? A Digression on Deterministic Policies Motivating Sa-Measures Belief Function Motivation Conclusion Links to Further Posts: None 63 comments
TLDR: Infra-Bayesianism is a new approach to epistemology / decision theory / reinforcement learning theory, which builds on "imprecise probability" to solve the problem of prior misspecification / grain-of-truth / nonrealizability which plagues Bayesianism and Bayesian reinforcement learning. Infra-Bayesianism also naturally leads to an implementation of UDT, and (more speculatively at this stage) has applications to multi-agent theory, embedded agency and reflection. This post is the first in a sequence which lays down the foundation of the approach.
Prelude:
Diffractor and Vanessa proudly present: The thing we've been working on for the past five months. I initially decided that Vanessa's scattered posts about incomplete models were interesting, and could benefit from being written up in a short centralized post. But as we dug into the mathematical details, it turned out it didn't really work, and then Vanessa ran across the true mathematical thing (which had previous ideas as special cases) and scope creep happened.
This now looks like a new, large, and unusually tractable vein of research. Accordingly, this sequence supersedes all previous posts about incomplete models, and by now we've managed to get quite a few interesting results, and have ideas for several new research directions.
Diffractor typed everything up and fleshed out the proof sketches, Vanessa originated almost all of the ideas and theorems. It was a true joint effort, this sequence would not exist if either of us were absent. Alex Mennen provided feedback on drafts to make it much more comprehensible than it would otherwise be, and Turntrout and John Maxwell also helped a bit in editing.
Be aware this sequence of posts has the math textbook issue where it requires loading a tower of novel concepts that build on each other into your head, and cannot be read in a single sitting. We will be doing a group readthrough on MIRIxDiscord where we can answer questions and hopefully get collaborators, PM me to get a link.
Introduction:
Learning theory traditionally deals with two kinds of setting: "realizable" and "agnostic" or "non-realizable". In realizable settings, we assume that the environment can be described perfectly by a hypothesis inside our hypothesis space. (AIXI is an example of this) We then expect the algorithm to converge to acting as if it already knew the correct hypothesis. In non-realizable settings, we make no such assumption. We then expect the algorithm to converge to the best approximation of the true environment within the available hypothesis space.
As long as the computational complexity of the environment is greater than the computational complexity of the learning algorithm, the algorithm cannot use an easy-to-compute hypothesis that would describe the environment perfectly, so we are in the nonrealizable setting. When we discuss AGI, this is necessarily the case, since the environment is the entire world: a world that, in particular, contains the agent itself and can support other agents that are even more complex, much like how halting oracles (which you need to run Solomonoff Induction) are nowhere in the hypotheses which Solomonoff considers. Therefore, the realizable setting is usually only a toy model. So, instead of seeking guarantees of good behavior assuming the environment is easy to compute, we'd like to get good behavior simply assuming that the environment has some easy-to-compute properties that can be exploited.
For offline and online learning there are classical results in the non-realizable setting, in particular VC theory naturally extends to the non-realizable setting. However, for reinforcement learning there are few analogous results. Even for passive Bayesian inference, the best non-realizable result found in our literature search is Shalizi's which relies on ergodicity assumptions about the true environment. Since reinforcement learning is the relevant setting for AGI and alignment theory, this poses a problem.
Logical inductors operate in the nonrealizable setting, and the general reformulation of them in Forecasting Using Incomplete Models is of interest for broader lessons applicable to acting in an unknown environment. In said paper, reality can be drawn from any point in the space of probability distributions over infinite sequences of observations, . Almost all of the points in this space aren't computable, and because of that, we shouldn't expect convergence to the true environment, as occurs in the realizable setting where the true environment lies in your hypothesis space.
However, even if we can't hope to learn the true environment, we can at least hope to learn some property of the true environment, like "every other bit is a 0", and have our predictions reflect that if it holds. A hypothesis in this setting is a closed convex subset of which can be thought of as "I don't know what the true environment is, but it lies within this set". The result obtained in the above-linked paper was, if we fix a countable family of properties that reality may satisfy, and define the inductor based on them, then for all of those which reality fulfills, the predictions of the inductor converge to that closed convex set and so fulfill the property in the limit.
What About Environments?
However, this just involves sequence prediction. Ideally, we'd want some space that corresponds to environments that you can interact with, instead of an environment that just outputs bits. And then, given a suitable set in it... Well, we don't have a fixed environment to play against. The environment could be anything, even a worst-case one within . We have Knightian uncertainty over our set of environments, it is not a probability distribution over environments. So, we might as well go with the maximin policy.
Where is the distribution over histories produced by policy interacting with environment . is just some utility function.
When we refer to "Murphy", this is referring to whatever force is picking the worst-case environment to be interacting with. Of course, if you aren't playing against an adversary, you'll do better than the worst-case utility that you're guaranteed. Any provable guarantees come in the form of establishing lower bounds on expected utility if a policy is selected.
The problem of generating a suitable space of environments was solved in Reinforcement Learning With Imperceptible Rewards [AF · GW]. If two environments are indistinguishable by any policy they are identified, a mixture of environments corresponds to picking one of the component environments with the appropriate probability at the start of time, and there was a notion of update.
However, this isn't good enough. We could find no good update rule for a set of environments, we had to go further.
Which desiderata should be fulfilled to make maximin policy selection over a set of environments (actually, we'll have to generalize further than this) to work successfully? We'll have three starting desiderata.
Desideratum 1: There should be a sensible notion of what it means to update a set of environments or a set of distributions, which should also give us dynamic consistency. Let's say we've got two policies, and which are identical except they differ after history . If, after updating on history , the continuation of looks better than the continuation of , then it had better be the case that, viewed from the start, outperforms .
Desideratum 2: Our notion of a hypothesis (set of environments) in this setting should collapse "secretly equivalent" sets, such that any two distinct hypotheses behave differently in some relevant aspect. This will require formalizing what it means for two sets to be "meaningfully different", finding a canonical form for an equivalence class of sets that "behave the same in all relevant ways", and then proving some theorem that says we got everything.
Desideratum 3: We should be able to formalize the "Nirvana trick" (elaborated below) and cram any UDT problem where the environment cares about what you would do, into this setting. The problem is that we're just dealing with sets of environments which only depend on what you do, not what your policy is, which hampers our ability to capture policy-dependent problems in this framework. However, since Murphy looks at your policy and then picks which environment you're in, there is an acausal channel available for the choice of policy to influence which environment you end up in.
The "Nirvana trick" is as follows. Consider a policy-dependent environment, a function (Ie, the probability distribution over the next observation depends on the history so far, the action you selected, and your policy). We can encode a policy-dependent environment as a set of policy-independent environments that don't care about your policy, by hard-coding every possible deterministic policy into the policy slot, making a family of functions of type , which is the type of policy-independent environments. It's similar to taking a function , and plugging in all possible to get a family of functions that only depend on .
Also, we will impose a rule that, if your action ever violates what the hard-coded policy predicts you do, you attain Nirvana (a state of high or infinite reward). Then, Murphy, when given this set of environments, will go "it'd be bad if they got high or infinite reward, thus I need to pick an environment where the hard-coded policy matches their actual policy". When playing against Murphy, you'll act like you're selecting a policy for an environment that does pay attention to what policy you pick. As-stated, this doesn't quite work, but it can be repaired.
There's two options. One is making Nirvana count as infinite reward. We will advance this to a point where we can capture any UDT/policy-selection problem, at the cost of some mathematical ugliness. The other option is making Nirvana count as 1 reward forever afterward, which makes things more elegant, and it is much more closely tied to learning theory, but that comes at the cost of only capturing a smaller (but still fairly broad) class of decision-theory problems. We will defer developing that avenue further until a later post.
A Digression on Deterministic Policies
We'll be using deterministic policies throughout. The reason for using deterministic policies instead of probabilistic policies (despite the latter being a larger class), is that the Nirvana trick (with infinite reward) doesn't work with probabilistic policies. Also, probabilistic policies don't interact well with embeddedness, because it implicitly assumes that you have a source of random bits that the rest of the environment can never interact with (except via your induced action) or observe.
Deterministic policies can emulate probabilistic policies by viewing probabilistic choice as deterministically choosing a finite bitstring to enter into a random number generator (RNG) in the environment, and then you get some bits back and act accordingly.
However, we aren't assuming that the RNG is a good one. It could be insecure or biased or nonexistent. Thus, we can model cases like Death In Damascus or Absent-Minded Driver where you left your trusty coin at home and don't trust yourself to randomize effectively. Or a nanobot that's too small to have a high bitrate RNG in it, so it uses a fast insecure PRNG (pseudorandom number generator). Or game theory against a mindreader that can't see your RNG, just the probability distribution over actions you're using the RNG to select from, like an ideal CDT opponent. It can also handle cases where plugging certain numbers into your RNG chip cause lots of heat to be released, or maybe the RNG is biased towards outputting 0's in strong magnetic fields. Assuming you have a source of true randomness that the environment can't read isn't general enough!
Motivating Sa-Measures
Sets of probability distributions or environments aren't enough, we need to add in some extra data. This can be best motivated by thinking about how updates should work in order to get dynamic consistency.
Throughout, we'll be using a two-step view of updating, where first, we chop down the measures accordingly (the "raw update"), and then we renormalize back up to 1.
So, let's say we have a set of two probability distributions and . We have Knightian uncertainty within this set, we genuinely don't know which one will be selected, it may even be adversarial. says observation has 0.5 probability, says observation has 0.01 probability. And then you see observation ! The wrong way to update would be to go "well, both probability distributions are consistent with observed data, I guess I'll update them individually and resume being completely uncertain about which one I'm in", you don't want to ignore that one of them assigns 50x higher probability to the thing you just saw.
However, neglecting renormalization, we can do the "raw update" to each of them individually, and get and (finite measures, not probability distributions), where has 0.5 measure and has 0.01 measure.
Ok, so instead of a set of probability distributions, since that's insufficient for updates, let's consider a set of measures , instead. Each individual measure in that set can be viewed as , where is a probability distribution, and is a scaling term. Note that is not uniform across your set, it varies depending on which point you're looking at.
However, this still isn't enough. Let's look at a toy example for how to design updating to get dynamic consistency. We'll see we need to add one more piece of data. Consider two environments where a fair coin is flipped, you see it and then say "heads" or "tails", and then you get some reward. The COPY Environment gives you 0 reward if you say something different than what the coin shows, and 1 reward if you match it. The REVERSE HEADS Environment always you 0.5 reward if the coin comes up tails, but it comes up heads, saying "tails" gets you 1 reward and "heads" gets you 0 reward. We have Knightian uncertainty between the two environments.
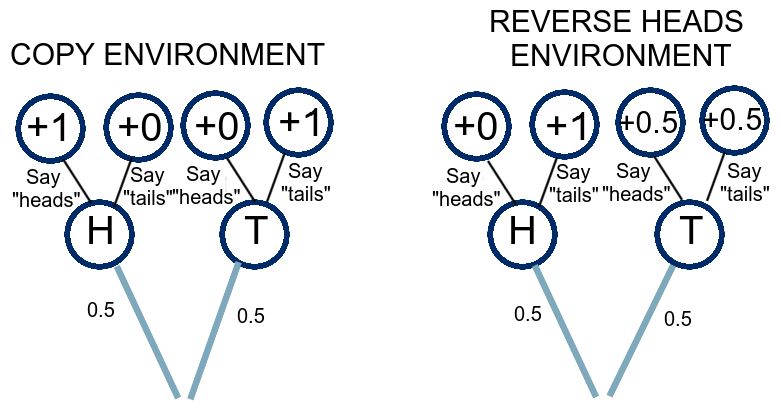
For finding the optimal policy, we can observe that saying "tails" when the coin is tails helps out in COPY and doesn't harm you in REVERSE HEADS, so that's a component of an optimal policy.
Saying "tails" no matter what the coin shows means you get utility on COPY, and utility on REVERSE HEADS. Saying "tails" when the coin is tails and "heads" when the coin is heads means you get utility on COPY and utility on REVERSE HEADS. Saying "tails" no matter what has a better worst-case value, so it's the optimal maximin policy.
Now, if we see the coin come up heads, how should we update? The wrong way to do it would be to go "well, both environments are equally likely to give this observation, so I've got Knightian uncertainty re: whether saying heads or tails gives me 1 or 0 utility, both options look equally good". This is because, according to past-you, regardless of what you did upon seeing the coin come up "tails", the maximin expected values of saying "heads" when the coin comes up heads, and saying "tails" when the coin comes up heads, are unequal. Past-you is yelling at you from the sidelines not to just shrug and view the two options as equally good.
Well, let's say you already know that you would say "tails" when the coin comes up tails and are trying to figure out what to do now that the coin came up heads. The proper way to reason through it is going "I have Knightian uncertainty between COPY which has 0.5 expected utility assured off-history since I say "tails" on tails, and REVERSE HEADS, which has 0.25 expected utility assured off-history. Saying "heads" now that I see the coin on heads would get me expected utility in COPY and utility in REVERSE HEADS, saying "tails" would get me utility in COPY and utility in REVERSE HEADS, I get higher worst-case value by saying "tails"." And then you agree with your past self re: how good the various decisions are.
Huh, the proper way of doing this update to get dynamic consistency requires keeping track of the fragment of expected utility we get off-history.
Similarly, if you messed up and precommitted to saying "heads" when the coin comes up tails (a bad move), we can run through a similar analysis and show that keeping track of the expected utility off-history leads you to take the action that past-you would advise, after seeing the coin come up heads.
So, with the need to keep track of that fragment of expected utility off-history to get dynamic consistency, it isn't enough to deal with finite measures , that still isn't keeping track of the information we need. What we need is , where is a finite measure, and is a number . That term keeps track of the expected value off-history so we make the right decision after updating. (We're glossing over the distinction between probability distributions and environments here, but it's inessential)
We will call such a pair an "affine measure", or "a-measure" for short. The reason for this terminology is because a measure can be thought of as a linear function from the space of continuous functions to . But then there's this term stuck on that acts as utility, and a linear function plus a constant is an affine function. So, that's an a-measure. A pair of a finite measure and a term where .
But wait, we can go even further! Let's say our utility function of interest is bounded. Then we can do a scale-and-shift until it's in .
Since our utility function is bounded in ... what would happen if you let in measures with negative parts, but only if they're paired with a sufficiently large term? Such a thing is called an sa-measure, for signed affine measure. It's a pair of a finite signed measure and a term that's as-large-or-larger than the amount of negative measure present. No matter your utility function, even if it assigns 0 reward to outcomes with positive measure and 1 reward to outcomes with negative measure, you're still assured nonnegative expected value because of that term. It turns out we actually do need to expand in this direction to keep track of equivalence between sets of a-measures, get a good tie-in with convex analysis because signed measures are dual to continuous functions, and have elegant formulations of concepts like minimal points and the upper completion.
Negative measures may be a bit odd, but as we'll eventually see, we can ignore them and they only show up in intermediate steps, not final results, much like negative probabilities in quantum mechanics. And if negative measures ever become relevant for an application, it's effortless to include them.
Belief Function Motivation
Also, we'll have to drop the framework we set up at the beginning where we're considering sets of environments, because working with sets of environments has redundant information. As an example, consider two environments where you pick one of two actions, and get one of two outcomes. In environment , regardless of action, you get outcome 0. In environment , regardless of action, you get outcome 1. Then, we should be able to freely add an environment , where action 0 implies outcome 0, and where action 1 implies outcome 1. Why?
Well, if your policy is to take action 0, and behave identically. And if your policy is to take action 1, and behave identically. So, adding an environment like this doesn't affect anything, because it's a "chameleon environment" that will perfectly mimic some preexisting environment regardless of which policy you select. However, if you consider the function mapping an action to the set of possible probability distributions over outcomes, adding didn't change that at all. Put another way, if it's impossible to distinguish in any way whether an environment was added to a set of environments because no matter what you do it mimics a preexisting environment, we might as well add it, and seek some alternate formulation instead of "set of environments" that doesn't have the unobservable degrees of freedom in it.
To eliminate this redundancy, the true thing we should be looking at isn't a set of environments, but the "belief function" from policies to sets of probability distributions over histories. This is the function produced by having a policy interact with your set of environments and plotting the probability distributions you could get. Given certain conditions on a belief function, it is possible to recover a set of environments from it, but belief functions are more fundamental. We'll provide tools for taking a wide range of belief functions and turning them into sets of environments, if it is desired.
Well, actually, from our previous discussion, sets of probability distributions are insufficient, we need a function from policies to sets of sa-measures. But that's material for later.
Conclusion
So, our fundamental mathematical object that we're studying to get a good link to decision theory is not sets of probability distributions, but sets of sa-measures. And instead of sets of environments, we have functions from policies to sets of sa-measures over histories. This is because probability distributions alone aren't flexible enough for the sort of updating we need to get dynamic consistency, and in addition to this issue, sets of environments have the problem where adding a new environment to your set can be undetectable in any way.
In the next post, we build up the basic mathematical details of the setting, until we get to a duality theorem that reveals a tight parallel between sets of sa-measures fulfilling certain special properties, and probability distributions, allowing us to take the first steps towards building up a version of probability theory fit for dealing with nonrealizability. There are analogues of expectation values, updates, renormalizing back to 1, priors, Bayes' Theorem, Markov kernels, and more. We use the "infra" prefix to refer to this setting. An infradistribution is the analogue of a probability distribution. An infrakernel is the analogue of a Markov kernel. And so on.
The post after that consists of extensive work on belief functions and the Nirvana trick to get the decision-theory tie-ins, such as UDT behavior while still having an update rule, and the update rule is dynamically consistent. Other components of that section include being able to specify your entire belief function with only part of its data, and developing the concept of Causal, Pseudocausal, and Acausal hypotheses. We show that you can encode almost any belief function as an Acausal hypothesis, and you can translate Pseudocausal and Acausal hypotheses to Causal ones by adding Nirvana appropriately (kinda). And Causal hypotheses correspond to actual sets of environments (kinda). Further, we can mix belief functions to make a prior, and there's an analogue of Bayes for updating a mix of belief functions. We cap it off by showing that the starting concepts of learning theory work appropriately, and show our setting's version of the Complete Class Theorem.
Later posts (not written yet) will be about the "1 reward forever" variant of Nirvana and InfraPOMDP's, developing inframeasure theory more, applications to various areas of alignment research, the internal logic which infradistributions are models of, unrealizable bandits, game theory, attempting to apply this to other areas of alignment research, and... look, we've got a lot of areas to work on, alright?
If you've got the relevant math skills, as previously mentioned, you should PM me to get a link to the MIRIxDiscord server and participate in the group readthrough, and you're more likely than usual to be able to contribute to advancing research further, there's a lot of shovel-ready work available.
Links to Further Posts:
- Basic Inframeasure Theory [AF · GW]
- Proofs 1.1 [AF · GW]
- Proofs 1.2 [AF · GW]
- Belief Functions and Decision Theory [AF · GW]
- Proofs 2.1 [AF · GW]
- Proofs 2.2 [AF · GW]
- Proofs 2.3 [AF · GW]
- Less Basic Inframeasure Theory [AF · GW]
- Inframeasures and Domain Theory [AF · GW]
- The Many Faces of Infra-Beliefs [AF · GW]
- Infra-Bayesian Physicalism: a formal theory of naturalized induction [AF · GW]
- IBP Proofs 1 [AF · GW]
- IBP Proofs 2 [AF · GW]
62 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2021-03-23T00:08:33.568Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
I have finally understood this sequence enough to write a summary about it, thanks to [AXRP Episode 5](https://www.alignmentforum.org/posts/FkMPXiomjGBjMfosg/axrp-episode-5-infra-bayesianism-with-vanessa-kosoy [AF · GW]). Think of this as a combined summary + highlight of the sequence and the podcast episode.
The central problem of <@embedded agency@>(@Embedded Agents@) is that there is no clean separation between an agent and its environment: rather, the agent is _embedded_ in its environment, and so when reasoning about the environment it is reasoning about an entity that is “bigger” than it (and in particular, an entity that _contains_ it). We don’t have a good formalism that can account for this sort of reasoning. The standard Bayesian account requires the agent to have a space of precise hypotheses for the environment, but then the true hypothesis would also include a precise model of the agent itself, and it is usually not possible to have an agent contain a perfect model of itself.
A natural idea is to reduce the precision of hypotheses. Rather than requiring a hypothesis to assign a probability to every possible sequence of bits, we now allow the hypotheses to say “I have no clue about this aspect of this part of the environment, but I can assign probabilities to the rest of the environment”. The agent can then limit itself to hypotheses that don’t make predictions about the part of the environment that corresponds to the agent, but do make predictions about other parts of the environment.
Another way to think about it is that it allows you to start from the default of “I know nothing about the environment”, and then add in details that you do know to get an object that encodes the easily computable properties of the environment you can exploit, while not making any commitments about the rest of the environment.
Of course, so far this is just the idea of using [Knightian uncertainty](https://en.wikipedia.org/wiki/Knightian_uncertainty). The contribution of infra-Bayesianism is to show how to formally specify a decision procedure that uses Knightian uncertainty, while still satisfying many properties we would like a decision procedure to satisfy. You can thus think of it as an extension of the standard Bayesian account of decision making to the setting in which the agent cannot represent the true environment as a hypothesis over which it can reason.
Imagine that, instead of having a probability distribution over hypotheses, we instead have two “levels”: first are all the properties we have Knightian uncertainty over, and then are all the properties we can reason about. For example, imagine that the environment is an infinite sequence of bits, and we want to say that all the even bits come from flips of a possibly biased coin, but we know nothing about the odd coin flips. Then, at the top level, we have a separate branch for each possible setting of the odd coin flips. At the second level, we have a separate branch for each possible bias of the coin. At the leaves, we have the hypothesis “the odd bits are as set by the top level, and the even bits are generated from coin flips with the bias set by the second level”.
(Yes, there are lots of infinite quantities in this example, so you couldn’t implement it the way I’m describing it here. An actual implementation would not represent the top level explicitly and would use computable functions to represent the bottom level. We’re not going to worry about this for now.)
If we were using orthodox Bayesianism, we would put a probability distribution over the top level, and a probability distribution over the bottom level. You could then multiply that out to get a single probability distribution over the hypotheses, which is why we don’t do this separation into two levels in orthodox Bayesianism. (Also, just to reiterate, the _whole point_ is that we can’t put a probability distribution at the top level, since that implies e.g. making precise predictions about an environment that is bigger than you are.)
Infra-Bayesianism says, “what if we just… not put a probability distribution over the top level?” Instead, we have a set of probability distributions over hypotheses, and Knightian uncertainty over which distribution in this set is the right one. A common suggestion for Knightian uncertainty is to do _worst-case_ reasoning, so that’s what we’ll do at the top level. Lots of problems immediately crop up, but it turns out we can fix them.
First, let’s say your top level consists of two distributions over hypotheses, A and B. You then observe some evidence E, which A thought was 50% likely and B thought was 1% likely. Intuitively, you want to say that this makes A “more likely” relative to B than we previously thought. But how can you do this if you have Knightian uncertainty and are just planning to do worst-case reasoning over A and B? The solution here is to work with _unnormalized_ probability distributions at the second level. Then, in the case above, we can just scale the “probabilities” in both A and B by the likelihood assigned to E. We _don’t_ normalize A and B after doing this scaling.
But now what exactly do the numbers mean, if we’re going to leave these distributions unnormalized? Regular probabilities only really make sense if they sum to 1. We can take a different view on what a “probability distribution” is -- instead of treating it as an object that tells you how _likely_ various hypotheses are, treat it as an object that tells you how much we _care_ about particular hypotheses. (See [related](https://www.lesswrong.com/posts/J7Gkz8aDxxSEQKXTN/what-are-probabilities-anyway [LW · GW]) <@posts@>(@An Orthodox Case Against Utility Functions@).) So scaling down the “probability” of a hypothesis just means that we care less about what that hypothesis “wants” us to do.
This would be enough if we were going to take an average over A and B to make our final decision. However, our plan is to do worst-case reasoning at the top level. This interacts horribly with our current proposal: when we scale hypotheses in A by 0.5 on average, and hypotheses in B by 0.01 on average, the minimization at the top level is going to place _more_ weight on B, since B is now _more_ likely to be the worst case. Surely this is wrong?
What’s happening here is that B gets most of its expected utility in worlds where we observe different evidence, but the worst-case reasoning at the top level doesn’t take this into account. Before we update, since B assigned 1% to E, the expected utility of B is given by 0.99 * expected utility given not-E + 0.01 * expected utility given E. After the update, the second part remains but the first part disappears, which makes the worst-case reasoning wonky. So what we do is we keep track of the first part as well, and make sure that our worst-case reasoning takes it into account.
This gives us **infradistributions**: sets of (m, b) pairs, where m is an unnormalized probability distribution and b corresponds to “the value we would have gotten if we had seen different evidence”. When we observe some evidence E, the hypotheses within m are scaled by the likelihood they assign to E, and b is updated to include the value we would have gotten in the world where we saw anything other than E. Note that it is important to specify the utility function for this to make sense, as otherwise it is not clear how to update b. To compute utilities for decision-making, we do worst-case reasoning over the (m, b) pairs, where we use standard expected values within each m. We can prove that this update rule satisfies _dynamic consistency_: if initially you believe “if I see X, then I want to do Y”, then after seeing X, you believe “I want to do Y”.
So what can we do with infradistributions? Our original motivation was to talk about embedded agency, so a natural place to start is with decision theory problems in which the environment contains a perfect predictor of the agent, such as in Newcomb’s problem. Unfortunately, we can’t immediately write this down with infradistributions, because we have no way of (easily) formally representing “the environment perfectly predicts my actions”. One trick we can use is to consider hypotheses in which the environment just spits out some action, without the constraint that it must match the agent’s action. We then modify the utility function to give infinite utility when the prediction is incorrect. Since we do worst-case reasoning, the agent will effectively act as though this situation is impossible. With this trick, infra-Bayesianism performs similarly to UDT on a variety of challenging decision problems.
Planned opinion:
Replies from: vanessa-kosoy, DanielFilanThis seems pretty cool, though I don’t understand it that well yet. While I don’t yet feel like I have a better philosophical understanding of embedded agency (or its subproblems), I do think this is significant progress along that path.
In particular, one thing that feels a bit odd to me is the choice of worst-case reasoning for the top level -- I don’t really see anything that _forces_ that to be the case. As far as I can tell we could get all the same results by using best-case reasoning instead (assuming we modified the other aspects appropriately). The obvious justification for worst-case reasoning is that it is a form of risk aversion, but it doesn’t feel like that is really sufficient -- risk aversion in humans is pretty different from literal worst-case reasoning, and also none of the results in the post seem to depend on risk aversion.
I wonder whether the important thing is just that we don’t do expected value reasoning at the top level, and there are in fact a wide variety of other kinds of decision rules that we could use that could all work. If so, it seems interesting to characterize what makes some rules work while others don’t. I suspect that would be a more philosophically satisfying answer to “how should agents reason about environments that are bigger than them”.
↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-03-24T16:41:38.003Z · LW(p) · GW(p)
The central problem of <@embedded agency@>(@Embedded Agents@) is that there is no clean separation between an agent and its environment...
That's certainly one way to motivate IB, however I'd like to note that even if there was a clean separation between an agent and its environment, it could still be the case that the environment cannot be precisely modeled by the agent due to its computational complexity (in particular this must be the case if the environment contains other agents of similar or greater complexity).
The contribution of infra-Bayesianism is to show how to formally specify a decision procedure that uses Knightian uncertainty, while still satisfying many properties we would like a decision procedure to satisfy.
Well, the use of Knightian uncertainty (imprecise probability) in decision theory certain appeared in the literature, so it would be more fair to say that the contribution of IB is combining that with reinforcement learning theory (i.e. treating sequential decision making and considering learnability and regret bounds in this setting) and applying that to various other questions (in particular, Newcombian paradoxes).
In particular, one thing that feels a bit odd to me is the choice of worst-case reasoning for the top level -- I don’t really see anything that forces that to be the case. As far as I can tell we could get all the same results by using best-case reasoning instead (assuming we modified the other aspects appropriately).
The reason we use worst-case reasoning is because we want the agent to satisfy certain guarantees. Given a learnable class of infra-hypotheses, in the limit, we can guarantee that whenever the true environment satisfies one of those hypotheses, the agent attains at least the corresponding amount of expected utility. You don't get anything analogous with best-case reasoning.
Moreover, there is an (unpublished) theorem showing that virtually any guarantee you might want to impose can be written in IB form. That is, let be the space of environments, and let be an increasing sequence of functions. We can interpret every as a requirement about the policy: . These requirements become stronger with increasing . We might then want to be s.t. it satisfies the requirement with the highest possible. The theorem then says that (under some mild assumptions about the functions ) there exists an infra-environment s.t. optimizing for it is equivalent to maximizing . (We can replace by a continuous parameter, I made it discrete just for ease of exposition.)
The obvious justification for worst-case reasoning is that it is a form of risk aversion, but it doesn’t feel like that is really sufficient -- risk aversion in humans is pretty different from literal worst-case reasoning, and also none of the results in the post seem to depend on risk aversion.
Actually it might be not that different. The Legendre-Fenchel duality shows you can think of infradistributions as just concave expectation functionals, which seems as a fairly general way to add risk-aversion to decision theory. It is also used in mathematical economics, see Peng.
it seems interesting to characterize what makes some rules work while others don’t.
Another rule which is tempting to use (and is known in the literature) is minimax-regret. However, it's possible to show that if you allow your hypotheses to depend on the utility function then you can reduce it to ordinary maximin.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-03-24T17:55:54.369Z · LW(p) · GW(p)
I'd like to note that even if there was a clean separation between an agent and its environment, it could still be the case that the environment cannot be precisely modeled by the agent due to its computational complexity
Yeah, agreed. I'm intentionally going for a simplified summary that sacrifices details like this for the sake of cleaner narrative.
it would be more fair to say that the contribution of IB is combining that with reinforcement learning theory
Ah, whoops. Live and learn.
The reason we use worst-case reasoning is because we want the agent to satisfy certain guarantees. Given a learnable class of infra-hypotheses, in the γ→1
limit, we can guarantee that whenever the true environment satisfies one of those hypotheses, the agent attains at least the corresponding amount of expected utility. You don't get anything analogous with best-case reasoning.
Okay, that part makes sense. Am I right though that in the case of e.g. Newcomb's problem, if you use the anti-Nirvana trick (getting -infinity reward if the prediction is wrong), then you would still recover the same behavior (EDIT: if you also use best-case reasoning instead of worst-case reasoning)? (I think I was a bit too focused on the specific UDT / Nirvana trick ideas.)
Actually it might be not that different. The Legendre-Fenchel duality shows you can think of infradistributions as just concave expectation functionals, which seems as a fairly general way to add risk-aversion to decision theory.
Yeah... I'm a bit confused about this. If you imagine choosing any concave expectation functional, then I agree that can model basically any type of risk aversion. But it feels like your infra-distribution should "reflect reality" or something along those lines, which is an extra constraint. If there's a "reflect reality" constraint and a "risk aversion" constraint and these are completely orthogonal, then it seems like you can't necessarily satisfy both constraints at the same time.
On the other hand, maybe if I thought about it for longer, I'd realize that the things we think of as "risk aversion" are actually identical to the "reflect reality" constraint when we are allowed to have Knightian uncertainty over some properties of the environment. In that case I would no longer have my objection.
To be a bit more concrete: imagine that you know that the even bits in an infinite bitsequence come from a fair coin, but the odd bits come from some other agent, where you can't model them exactly but you have some suspicion that they are a bit more likely to choose 1 over 0. Risk aversion might involve making a small bet that you'd see a 1 rather than a 0 in some specific odd bit (smaller than what EU maximization / Bayesian decision theory would recommend), but "reflecting reality" might recommend having Knightian uncertainty about the output of the agent which would mean never making a bet on the outputs of the odd bits.
I am curious what happens in this scenario if you set the concave expectation functional based on the "risk aversion" setting above, and then use duality to get the "convex set of distributions" formulation -- would the resulting object be meaningful to us?
Replies from: vanessa-kosoy, Diffractor↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-03-25T20:42:18.386Z · LW(p) · GW(p)
Am I right though that in the case of e.g. Newcomb's problem, if you use the anti-Nirvana trick (getting -infinity reward if the prediction is wrong), then you would still recover the same behavior (EDIT: if you also use best-case reasoning instead of worst-case reasoning)?
Yes
imagine that you know that the even bits in an infinite bitsequence come from a fair coin, but the odd bits come from some other agent, where you can't model them exactly but you have some suspicion that they are a bit more likely to choose 1 over 0. Risk aversion might involve making a small bet that you'd see a 1 rather than a 0 in some specific odd bit (smaller than what EU maximization / Bayesian decision theory would recommend), but "reflecting reality" might recommend having Knightian uncertainty about the output of the agent which would mean never making a bet on the outputs of the odd bits.
I think that if you are offered a single bet, your utility is linear in money and your belief is a crisp infradistribution (i.e. a closed convex set of probability distributions) then it is always optimal to bet either as much as you can or nothing at all. But for more general infradistributions this need not be the case. For example, consider and take the set of a-measures generated by and . Suppose you start with dollars and can bet any amount on any outcome at even odds. Then the optimal bet is betting dollars on the outcome , with a value of dollars.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-03-25T21:25:40.071Z · LW(p) · GW(p)
But for more general infradistributions this need not be the case. For example, consider and take the set of a-measures generated by and . Suppose you start with dollars and can bet any amount on any outcome at even odds. Then the optimal bet is betting dollars on the outcome , with a value of dollars.
I guess my question is more like: shouldn't there be some aspect of reality that determines what my set of a-measures is? It feels like here we're finding a set of a-measures that rationalizes my behavior, as opposed to choosing a set of a-measures based on the "facts" of the situation and then seeing what behavior that implies.
I feel like we agree on what the technical math says, and I'm confused about the philosophical implications. Maybe we should just leave the philosophy alone for a while.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-03-29T16:26:18.560Z · LW(p) · GW(p)
IIUC your question can be reformulated as follows: a crisp infradistribution can be regarded as a claim about reality (the true distribution is inside the set), but it's not clear how to generalize this to non-crisp. Well, if you think in terms of desiderata, then crisp says: if distribution is inside set then we have some lower bound on expected utility (and if it's not then we don't promise anything). On the other hand non-crisp gives a lower bound that is variable with the true distribution. We can think of non-crisp infradistirbutions as being fuzzy properties of the distribution (hence the name "crisp"). In fact, if we restrict ourselves to either of homogenous, cohomogenous or c-additive infradistributions, then we actually have a formal way to assign membership functions to infradistirbutions, i.e. literally regard them as fuzzy sets of distributions (which ofc have to satisfy some property analogous to convexity).
↑ comment by Diffractor · 2021-03-24T19:17:02.796Z · LW(p) · GW(p)
If you use the Anti-Nirvana trick, your agent just goes "nothing matters at all, the foe will mispredict and I'll get -infinity reward" and rolls over and cries since all policies are optimal. Don't do that one, it's a bad idea.
For the concave expectation functionals: Well, there's another constraint or two, like monotonicity, but yeah, LF duality basically says that you can turn any (monotone) concave expectation functional into an inframeasure. Ie, all risk aversion can be interpreted as having radical uncertainty over some aspects of how the environment works and assuming you get worst-case outcomes from the parts you can't predict.
For your concrete example, that's why you have multiple hypotheses that are learnable. Sure, one of your hypotheses might have complete knightian uncertainty over the odd bits, but another hypothesis might not. Betting on the odd bits is advised by a more-informative hypothesis, for sufficiently good bets. And the policy selected by the agent would probably be something like "bet on the odd bits occasionally, and if I keep losing those bets, stop betting", as this wins in the hypothesis where some of the odd bits are predictable, and doesn't lose too much in the hypothesis where the odd bits are completely unpredictable and out to make you lose.
↑ comment by Rohin Shah (rohinmshah) · 2021-03-24T20:51:06.654Z · LW(p) · GW(p)
If you use the Anti-Nirvana trick, your agent just goes "nothing matters at all, the foe will mispredict and I'll get -infinity reward" and rolls over and cries since all policies are optimal. Don't do that one, it's a bad idea.
Sorry, I meant the combination of best-case reasoning (sup instead of inf) and the anti-Nirvana trick. In that case the agent goes "Murphy won't mispredict, since then I'd get -infinity reward which can't be the best that I do".
For your concrete example, that's why you have multiple hypotheses that are learnable.
Hmm, that makes sense, I think? Perhaps I just haven't really internalized the learning aspect of all of this.
↑ comment by DanielFilan · 2021-03-23T17:07:24.423Z · LW(p) · GW(p)
One thing I realized after the podcast is that because the decision theory you get can only handle pseudo-causal environments, it's basically trying to think about the statistics of environments rather than their internals. So my guess is that further progress on transparent newcomb is going to have to look like adding in the right kind of logical uncertainty or something. But basically it unsurprisingly has more of a statistical nature than what you imagine you want reading the FDT paper.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-03-24T16:46:56.073Z · LW(p) · GW(p)
it's basically trying to think about the statistics of environments rather than their internals
That's not really true because the structure of infra-environments reflects the structure of those Newcombian scenarios. This means that the sample complexity of learning them will likely scale with their intrinsic complexity (e.g. some analogue of RVO dimension [AF · GW]). This is different from treating the environment as a black-box and converging to optimal behavior by pure trial and error, which would yield much worse sample complexity.
Replies from: DanielFilan↑ comment by DanielFilan · 2021-03-24T20:43:11.955Z · LW(p) · GW(p)
I agree that infra-bayesianism isn't just thinking about sampling properties, and maybe 'statistics' is a bad word for that. But the failure on transparent Newcomb without kind of hacky changes to me suggests a focus on "what actions look good thru-out the probability distribution" rather than on "what logically-causes this program to succeed".
Replies from: vanessa-kosoy, Diffractor↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-03-25T20:49:40.692Z · LW(p) · GW(p)
There is some truth in that, in the sense that, your beliefs must take a form that is learnable rather than just a god-given system of logical relationships.
↑ comment by Diffractor · 2021-03-25T02:54:33.564Z · LW(p) · GW(p)
There's actually an upcoming post going into more detail on what the deal is with pseudocausal and acausal belief functions, among several other things, I can send you a draft if you want. "Belief Functions and Decision Theory" is a post that hasn't held up nearly as well to time as "Basic Inframeasure Theory".
Replies from: DanielFilan↑ comment by DanielFilan · 2021-03-25T16:42:16.151Z · LW(p) · GW(p)
Thanks for the offer, but I don't think I have room for that right now.
comment by Diffractor · 2021-12-18T08:00:02.076Z · LW(p) · GW(p)
This post is still endorsed, it still feels like a continually fruitful line of research. A notable aspect of it is that, as time goes on, I keep finding more connections and crisper ways of viewing things which means that for many of the further linked posts about inframeasure theory, I think I could explain them from scratch better than the existing work does. One striking example is that the "Nirvana trick" stated in this intro (to encode nonstandard decision-theory problems), has transitioned from "weird hack that happens to work" to "pops straight out when you make all the math as elegant as possible". Accordingly, I'm working on a "living textbook" (like a textbook, but continually being updated with whatever cool new things we find) where I try to explain everything from scratch in the crispest way possible, to quickly catch up on the frontier of what we're working on. That's my current project.
I still do think that this is a large and tractable vein of research to work on, and the conclusion hasn't changed much.
Replies from: ricraz, Charlie Steiner↑ comment by Richard_Ngo (ricraz) · 2022-06-28T19:44:49.681Z · LW(p) · GW(p)
I'm feeling very excited about this agenda. Is there currently a publicly-viewable version of the living textbook? Or any more formal writeup which I can include in my curriculum? (If not I'll include this post, but I expect many people would appreciate a more polished writeup.)
Replies from: Diffractor↑ comment by Diffractor · 2022-06-30T03:24:51.340Z · LW(p) · GW(p)
If you're looking for curriculum materials, I believe that the most useful reference would probably be my "Infra-exercises", a sequence of posts containing all the math exercises you need to reinvent a good chunk of the theory yourself. Basically, it's the textbook's exercise section, and working through interesting math problems and proofs on one's own has a much better learning feedback loop and retention of material than slogging through the old posts. The exercises are short on motivation and philosophy compared to the posts, though, much like how a functional analysis textbook takes for granted that you want to learn functional analysis and doesn't bother motivating it.
The primary problem is that the exercises aren't particularly calibrated in terms of difficulty, and in order for me to get useful feedback, someone has to actually work through all of them, so feedback has been a bit sparse. So I'm stuck in a situation where I keep having to link everyone to the infra-exercises over and over and it'd be really good to just get them out and publicly available, but if they're as important as I think, then the best move is something like "release them one at a time and have a bunch of people work through them as a group" like the fixpoint exercises, instead of "just dump them all as public documents".
I'll ask around about speeding up the public - ation of the exercises and see what can be done there.
I'd strongly endorse linking this introduction even if the exercises are linked as well, because this introduction serves as the table of contents to all the other applicable posts.
↑ comment by Charlie Steiner · 2021-12-18T21:35:55.669Z · LW(p) · GW(p)
I'm confused about the Nirvana trick then. (Maybe here's not the best place, but oh well...) Shouldn't it break the instant you do anything with your Knightian uncertainty other than taking the worst-case?
Replies from: vanessa-kosoy, Diffractor↑ comment by Diffractor · 2021-12-19T03:49:11.939Z · LW(p) · GW(p)
Well, taking worst-case uncertainty is what infradistributions do. Did you have anything in mind that can be done with Knightian uncertainty besides taking the worst-case (or best-case)?
And if you were dealing with best-case uncertainty instead, then the corresponding analogue would be assuming that you go to hell if you're mispredicted (and then, since best-case things happen to you, the predictor must accurately predict you).
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2021-12-19T15:56:00.577Z · LW(p) · GW(p)
What if you assumed the stuff you had the hypothesis about was independent of the stuff you have Knightian uncertainty about (until proven otherwise)?
E.g. if you're making hypotheses about a multi-armed bandit and the world also contains a meteor that might smash through your ceiling and kill you at any time, you might want to just say "okay, ignore the meteor, pretend my utility has a term for gambling wins that doesn't depend on the meteor at all."
The reason I want to consider stuff more like this is because I don't like having to evaluate my utility function over all possibilities to do either an argmax or an argmin - I want to be lazy.
The weird thing about this is now whether this counts as argmax or argmin (or something else) depends on what my utility function looks like when I do include the meteor. If getting hit by the meteor only makes things worse (though potentially the meteor can still depend on which arm of of the bandit I pull!) then ignoring it is like being optimistic. If it only makes things better (like maybe the world I'm ignoring isn't a meteor, it's a big space full of other games I could be playing) then ignoring it is like being pessimistic.
Replies from: Diffractor↑ comment by Diffractor · 2021-12-20T02:37:15.195Z · LW(p) · GW(p)
Something analogous to what you are suggesting occurs. Specifically, let's say you assign 95% probability to the bandit game behaving as normal, and 5% to "oh no, anything could happen, including the meteor". As it turns out, this behaves similarly to the ordinary bandit game being guaranteed, as the "maybe meteor" hypothesis assigns all your possible actions a score of "you're dead" so it drops out of consideration.
The important aspect which a hypothesis needs, in order for you to ignore it, is that no matter what you do you get the same outcome, whether it be good or bad. A "meteor of bliss hits the earth and everything is awesome forever" hypothesis would also drop out of consideration because it doesn't really matter what you do in that scenario.
To be a wee bit more mathy, probabilistic mix of inframeasures works like this. We've got a probability distribution , and a bunch of hypotheses , things that take functions as input, and return expectation values. So, your prior, your probabilistic mixture of hypotheses according to your probability distribution, would be the function
It gets very slightly more complicated when you're dealing with environments, instead of static probability distributions, but it's basically the same thing. And so, if you vary your actions/vary your choice of function f, and one of the hypotheses is assigning all these functions/choices of actions the same expectation value, then it can be ignored completely when you're trying to figure out the best function/choice of actions to plug in.
So, hypotheses that are like "you're doomed no matter what you do" drop out of consideration, an infra-Bayes agent will always focus on the remaining hypotheses that say that what it does matters.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2021-12-20T03:08:40.916Z · LW(p) · GW(p)
The meteor doesn't have to really flatten things out, there might be some actions that we think remain valuable (e.g. hedonism, saying tearful goodbyes).
And so if we have Knightian uncertainty about the meteor, maximin (as in Vanessa's link [LW(p) · GW(p)]) means we'll spend a lot of time on tearful goodbyes.
Replies from: Diffractor↑ comment by Diffractor · 2021-12-20T19:20:23.176Z · LW(p) · GW(p)
Said actions or lack thereof cause a fairly low utility differential compared to the actions in other, non-doomy hypotheses. Also I want to draw a critical distinction between "full knightian uncertainty over meteor presence or absence", where your analysis is correct, and "ordinary probabilistic uncertainty between a high-knightian-uncertainty hypotheses, and a low-knightian uncertainty one that says the meteor almost certainly won't happen" (where the meteor hypothesis will be ignored unless there's a meteor-inspired modification to what you do that's also very cheap in the "ordinary uncertainty" world, like calling your parents, because the meteor hypothesis is suppressed in decision-making by the low expected utility differentials, and we're maximin-ing expected utility)
comment by DanielFilan · 2020-08-31T22:35:35.120Z · LW(p) · GW(p)
much like how halting oracles (which you need to run Solomonoff Induction) are nowhere in the hypotheses which Solomonoff considers
The Solomonoff prior is a mixture over semi-measures[*] that are lower semi-computable: that is, you can compute increasingly good approximations of the semi-measure from below that converge eventually to the actual semi-measure, but at finite time you don't know how close you are to the right answer. The Solomonoff prior itself is also a lower semi-computable semi-measure. Therefore, there is a real sense in which its hypothesis class includes things as difficult to compute as it is. That being said, my guess is that halting oracles would indeed let you compute more than just the lower semi-computable functions, and it's also true that being able to run Solomonoff induction would also let you build a halting oracle.
[*] semi-measures are probability distributions that have 'missing density', where the probability of a 0 and then a 0, plus the probability of a 0 and then a 1, is less than or equal to the probability of a 0, even though there aren't any other options in the space for what happens next.
Replies from: vanessa-kosoy, DanielFilan↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2020-08-31T23:32:45.203Z · LW(p) · GW(p)
The problem with lower semicomputable functions is that it's a class not closed under natural operations. For example, taking minus such a function we get an upper semicomputable function that can fail to be lower semicomputable. So, given a Solomonoff induction oracle we can very easily (i.e. using a very efficient oracle machine) construct measures that are not absolutely continuous w.r.t. the Solomonoff prior.
In fact, for any prior this can be achieved by constructing an "anti-inductive" sequence: a sequence that contains at a given place if and only if the prior, conditional on the sequence before this place, assigns probability less than to . Such a sequence cannot be accurately predicted by the prior (and, by the merging-of-opinions theorem, a delta-function at this sequence it is not absolutely continuous w.r.t. the prior).
↑ comment by DanielFilan · 2020-08-31T23:30:11.238Z · LW(p) · GW(p)
Therefore, there is a real sense in which its hypothesis class includes things as difficult to compute as it is. That being said, my guess is that halting oracles would indeed let you compute more than just the lower semi-computable functions, and it's also true that being able to run Solomonoff induction would also let you build a halting oracle.
I guess the way to reconcile this is to think that there's a difference between what you can lower semi-compute, and what you could compute if you could compute lower semi-computable things? But it's been a while since I had a good understanding of this type of thing.
comment by michaelcohen (cocoa) · 2020-09-01T12:36:49.556Z · LW(p) · GW(p)
Looks like we've been thinking along very similar lines! https://www.lesswrong.com/posts/RzAmPDNciirWKdtc7/pessimism-about-unknown-unknowns-inspires-conservatism [LW · GW]
Replies from: vanessa-kosoy, vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2020-09-01T12:52:07.965Z · LW(p) · GW(p)
Thanks, I'll make sure to read it!
I've started thinking in this direction already back [AF · GW] in [AF · GW] 2016, and more in 2018 [AF · GW] but only this year Alex and I nailed the precise definitions that make everything come together, and derived some key foundational theorems. Of course, much work yet remains.
↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2020-09-21T11:52:05.746Z · LW(p) · GW(p)
After reading some of your paper, I think that they are actually very different. IIUC, you are talking about pessimism as a method to avoid traps, but you assume realizability. On the other hand, infra-Bayesianism is (to first approximation) orthogonal to dealing with traps, instead it allows dealing with nonrealizability.
Replies from: cocoa↑ comment by michaelcohen (cocoa) · 2020-09-21T14:38:05.719Z · LW(p) · GW(p)
The results I prove assume realizability, and some of the results are about traps, but independent of the results, the algorithm for picking actions resembles infra-Bayesianism. So I think we're taking similar objects and proving very different sorts of things.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2020-09-21T15:50:01.063Z · LW(p) · GW(p)
Well, I agree that both formalisms use maximin so there might be some way to merge them. It's definitely something to think about.
comment by CronoDAS · 2020-09-01T00:39:35.073Z · LW(p) · GW(p)
Maybe I'm understanding this wrong... but isn't there another kind of dynamic inconsistency here?
Suppose you walk into an empty room. Then you're told you're in either WORLD A, which gives reward 1 for choosing heads and reward 0 for choosing tails, or WORLD B, which gives reward 0 for choosing heads and reward 1 for choosing tails. You have Knightian uncertainty between the worlds, so you minmax and end up indifferent between them; you arbitrarily choose heads.
Then you hear a voice:
"Actually, I flipped a fair coin that came up heads. If it had instead come up tails, in WORLD A you would have gotten reward 1 for choosing tails and reward 0 for saying heads, but in WORLD B you would have gotten 0.5 reward no matter what. (And my monologue would have changed appropriately.)"
Should you reconsider your decision to choose heads? What you learned doesn't actually change the decision you're faced with, does it?
Replies from: Diffractor↑ comment by Diffractor · 2020-09-05T05:01:29.794Z · LW(p) · GW(p)
Do you think this problem is essentially different from "suppose Omega asks you for 10 bucks. You say no. Then Omega says "actually I flipped a fair coin that came up tails, if it had come up heads, I would have given you 100 dollars if I predicted you'd give me 10 dollars on tails"?
(I think I can motivate "reconsider choosing heads" if you're like "yeah, this is just counterfactual mugging with belated notification of what situation you're in, and I'd pay up in that circumstance")
↑ comment by JenniferRM · 2022-01-31T06:13:59.893Z · LW(p) · GW(p)
When I translate this sort of situation to anything vaguely real, I find that my response would probably be "please first prove that you're actually Omega!"
Then if that happened... I would feel super happy to then fork over the $10 <3
Like: it would be it would be freaking awesome to be be counter-factually mugged by Omega and be convinced that I had to then hand over $10 because $10 is totally worth the privilege of talking to a fair god and knowing you're talking to a fair god!
But the practical question arises: how would anyone really know such a thing?
I'm pretty sure that there is a way for something with hyper-computation to prove to me that it has incredible powers to compute. Factor super big numbers. Solve an NP-complete problem. Whatever.
The part I have trouble with is finding any way to tell demons apart from angels. It seems like it would be easy for someone to prove that they can always predict everything you do before you do it. Angels can do that... but so can demons.
How do you know that the entity is telling the truth about this part: "if it had come up heads, I would have given you 100 dollars (at all, ever, under any circumstances)".
How does a thing with hyper-computational powers prove that it is benevolent or fair or has any other coherently positive and enduring moral tendencies?
I've been failing to come up with any solution to this puzzle for years, but it seems like maybe a more productive approach at this point might be to try to prove the pessimistic version instead.
And when I think of trying to prove the pessimistic version, a formalism of the sort you've offered here seems like it might make it possible to state axioms that (1) roughly describe the setup in these motivating stories (with Omega next to a predictable agent, and so on) and (2) allow a normal mathematician to prove from these axioms that a proof of benevolence (from something formally Omega-like to something formally more finite in its powers of reasoning)... is actually just straightforwardly impossible.
Replies from: Diffractor↑ comment by Diffractor · 2022-02-02T08:08:23.474Z · LW(p) · GW(p)
Omega and hypercomputational powers isn't needed, just decent enough prediction about what someone would do. I've seen Transparent Newcomb being run on someone before, at a math camp. They were predicted to not take the small extra payoff, and they didn't. And there was also an instance of acausal vote trading that I managed to pull off a few years ago, and I've put someone in a counterfactual mugging sort of scenario where I did pay out due to predicting they'd take the small loss in a nearby possible world. 2/3 of those instances were cases where I was specifically picking people that seemed unusually likely to take this sort of thing seriously, and it was predictable what they'd do.
I guess you figure out the entity is telling the truth in roughly the same way you'd figure out a human is telling the truth? Like "they did this a lot against other humans and their prediction record is accurate".
And no, I don't think that you'd be able to get from this mathematical framework to proving "a proof of benevolence is impossible". What the heck would that proof even look like?
Replies from: JenniferRM↑ comment by JenniferRM · 2022-02-06T14:49:09.494Z · LW(p) · GW(p)
What the heck would that proof even look like, indeed. That's what I haven't figured out yet.
(On the practical level... I'm pretty sure it would be awesome to interact with a benevolent god and it seems that the thing you're suggesting is that there are prosaic versions.
One obvious prosaic version of such proximity is a job in finance. The courts and contracts and so on are kind of like Omega, and surely this entity is benevolent? Luck goes well: millions in bonuses. Luck goes bad: you're laid off. Since of course the system in general is benevolent: surely it would be acceptable to participate? The personal asymmetry in outcomes would make the whole situation potentially nice to be near to.
But then I wonder about that assumption of benevolence and think about Mammon, and I remember The Big Short ...and I go back to wondering how Omega offers a finite creature a proof of benevolence.)
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2022-02-06T17:53:35.238Z · LW(p) · GW(p)
The proof of benevolence is a red herring. Just imagine the exact same game happening again and again. Eventually you should become convinced that the game works as advertised.
comment by Charlie Steiner · 2021-12-18T23:50:47.798Z · LW(p) · GW(p)
Of the agent foundations work from 2020, I think this sequence is my favorite, and I say this without actually understanding it.
The core idea is that Bayesianism is too hard. And so what we ultimately want is to replace probability distributions over all possible things with simple rules that don't have to put a probability on all possible things. In some ways this is the complement to logical uncertainty - logical uncertainty is about not having to have all possible probability distributions possible, this is about not having to put probability distributions on everything.
I've found this a highly productive metaphor for cognition - we sometimes like to think of the brain as a Bayesian engine, but of necessity the brain can't be laying down probabilities for every single possible thing - we want a perspective that allows the brain to be considering hypotheses that only specify the pattern of some small part of the world while still retaining some sort of Bayesian seal of approval.
That said, this sequence is tricky to understand and I'm bad at it! I look forward to brave souls helping to digest it for the community at large.
Some of the ways in which this framework still relies on physical impossibilities are things like operations over all possible infra-Bayesian hypotheses, and the invocation of worst-case reasoning that relies on global evaluation. I'm super interested in what's going to come from pushing those boundaries.
Replies from: DanielFilan↑ comment by DanielFilan · 2022-01-28T23:34:28.590Z · LW(p) · GW(p)
That said, this sequence is tricky to understand and I'm bad at it! I look forward to brave souls helping to digest it for the community at large.
I interviewed Vanessa here in an attempt to make this more digestible: it hopefully acts as context for the sequence, rather than a replacement for reading it.
comment by Charlie Steiner · 2020-09-01T15:21:39.963Z · LW(p) · GW(p)
Could you defend worst-case reasoning a little more? Worst cases can be arbitrarily different from the average case - so maybe having worst-case guarantees can be reassuring, but actually choosing policies by explicit reference to the worst case seems suspicious. (In the human context, we might suppose that worst case, I have a stroke in the next few seconds and die. But I'm not in the business of picking policies by how they do in that case.)
You might say "we don't have an average case," but if there are possible hypotheses outside your considered space you don't have the worst case either - the problem of estimating a property of a non-realizable hypothesis space is simplified, but not gone.
Anyhow, still looking forward to working my way through this series :)
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2020-09-01T23:23:28.851Z · LW(p) · GW(p)
Infra-Bayesianism doesn't consider the worst case, since, even though each hypothesis is treated using the maximin decision rule, there is still a prior over many hypotheses[1]. One such hypothesis can upper bound the probability you will get a stroke in the next few seconds. An infra-Bayesian agent would learn this hypothesis and plan accordingly.
We might say that infra-Bayesianism assumes the worst only of that which is not only unknown but unknowable. To make a somewhat informal analogy with logic, we assume the worst model of the theory and thereby make any gain that can be gained provably.
One justification often given for Solomonoff induction is: we live in a simple universe. However, Solomonoff induction is uncomputable, so a simple universe cannot contain it. Instead, it might contain something like bounded Solomonoff induction. However, in order to justify bounded Solomonoff induction, we would need to assume that the universe is simple and cheap, which is false. In other words, postulating an "average-case" entails postulating a false dogmatic belief. Bounded "infra-Solomonoff" induction solves the problem by relying instead on the following assumption: the universe has some simple and cheap properties that can be exploited.
Like in the Bayesian case, you can alternatively think of the prior as just a single infradistribution, which is the mixture of all the hypotheses it is comprised of. This is an equivalent view. ↩︎
comment by Stuart_Armstrong · 2021-05-12T22:38:09.237Z · LW(p) · GW(p)
Desideratum 1: There should be a sensible notion of what it means to update a set of environments or a set of distributions, which should also give us dynamic consistency.
I'm not sure how important dynamic consistency should be. When I talk about model splintering, I'm thinking of a bounded agent making fundamental changes to their model (though possibly gradually), a process that is essentially irreversible and contingent the circumstance of discovering new scenarios. The strongest arguments for dynamic consistency are the Dutch-book type arguments, which depend on returning to a scenario very similar to the starting scenario, and these seem absent from model splintering as I'm imagining it.
Now, adding dynamic inconsistency is not useful, it just seems that removing all of it (especially for a bounded agent) doesn't seem worth the effort.
Is there some form of "not loose too much utility to dynamic inconsistency" requirement that could be formalised?
Replies from: vanessa-kosoy, Diffractor↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-05-24T00:18:50.373Z · LW(p) · GW(p)
I'm not sure why would we need a weaker requirement if the formalism already satisfies a stronger requirement? Certainly when designing concrete learning algorithms we might want to use some kind of simplified update rule, but I expect that to be contingent on the type of algorithm and design constraints. We do have some speculations in that vein, for example I suspect that, for communicating infra-MDPs, an update rule that forgets everything except the current state would only lose something like expected utility.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2021-05-24T21:27:29.691Z · LW(p) · GW(p)
I want a formalism capable of modelling and imitating how humans handle these situations, and we don't usually have dynamic consistency (nor do boundedly rational agents).
Now, I don't want to weaken requirements "just because", but it may be that dynamic consistency is too strong a requirement to properly model what's going on. It's also useful to have AIs model human changes of morality, to figure out what humans count as values, so getting closer to human reasoning would be necessary.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-05-24T21:53:54.042Z · LW(p) · GW(p)
Boundedly rational agents definitely can have dynamic consistency, I guess it depends on just how bounded you want them to be. IIUC what you're looking for is a model that can formalize "approximately rational but doesn't necessary satisfy any crisp desideratum". In this case, I would use something like my quantitative AIT definition of intelligence [AF(p) · GW(p)].
↑ comment by Diffractor · 2021-05-12T23:08:25.013Z · LW(p) · GW(p)
I don't know, we're hunting for it, relaxations of dynamic consistency would be extremely interesting if found, and I'll let you know if we turn up with anything nifty.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2021-05-13T10:48:01.804Z · LW(p) · GW(p)
Hum... how about seeing enforcement of dynamic consistency as having a complexity/computation cost, and Dutch books (by other agents or by the environment) providing incentives to pay the cost? And hence the absence of these Dutch books meaning there is little incentive to pay that cost?
comment by CronoDAS · 2020-09-02T19:09:39.976Z · LW(p) · GW(p)
Why are you minmaxing over expected values of policies, instead of over outcomes? Isn't the worst case for the "tails only" policy "I'm in COPY and the coin is heads", not "'I'm in COPY"?
Basically I don't understand why "past me, who is screaming at me from the sidelines that it matters whether I pick tails or not" once I see that the coin comes up heads is actually correct and the "me" who's indifferent is wrong; one man's modus ponens is another man's modus tollens.
Here's another example that makes my intuition go "ouch" - suppose that choosing heads in REVERSE HEADS when the coin is heads gives 0.1 utility. Then the "match the coin" policy has an expected value in REVERSE HEADS of 0.3 instead of 0.25 and the minmax rule you picked still tells you to "always pick tails", but conditioning on heads, "pick heads if you see heads" gives you 0.1 utility or 1 utility, while "always pick tails" gives you 1 utility or 0 utility, so isn't "pick heads" a better strategy?
Replies from: vanessa-kosoy, Diffractor↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2020-09-05T16:12:24.299Z · LW(p) · GW(p)
Basically I don't understand why "past me, who is screaming at me from the sidelines that it matters whether I pick tails or not" once I see that the coin comes up heads is actually correct and the "me" who's indifferent is wrong; one man's modus ponens is another man's modus tollens.
You could say the same thing for Bayesianism. Priors are subjective, so why should my beliefs be related to past-me beliefs by the Bayes rule? Indeed, some claim they shouldn't be [? · GW]. But it's still interesting to ask what happens if past-me has the power to enforce eir opinions. What if I'm able to make sure that my descendant agents will act optimally from my subjective point of view? Then you need dynamic consistency: for classical Bayesianism it's the Bayes rule, and for infra-Bayesianism it's our new updating rule.
Certainly if you're interested in learning algorithms, then dynamic consistency seems like a very useful property. Our learning desiderata (regret bounds) are defined from the point of view of the prior, so an algorithm designed for that purpose should remain consistent with this starting point.
On the other hand, we can also imagine situations where past-me has a reason to trust present-me's reasoning better than eir own reasoning, in which case some kind of "radical probabilism" is called for. For example, in Turing reinforcement learning [LW(p) · GW(p)], the agent can update on evidence coming from computational experiments. If we consider the beliefs of such an agent about the external environment only, they would change in a way inconsistent with the usual rule. But it's still true that the updates are not systematically biased: if you already knew where you will update, you would already have updated. And ofc if we do treat the "virtual evidence" explicitly, we return to the standard update rule.
↑ comment by Diffractor · 2020-09-05T03:11:16.319Z · LW(p) · GW(p)
Maximin over outcomes would lead to the agent devoting all its efforts towards avoiding the worst outcomes, sacrificing overall utility, while maximin over expected value pushes towards policies that do acceptably on average in all of the environments that it may find itself in.
Regarding "why listen to past me", I guess to answer this question I'd need to ask about your intuitions on Counterfactual mugging. What would you do if it's one-shot? What would you do if it's repeated? If you were told about the problem beforehand, would you pay money for a commitment mechanism to make future-you pay up the money if asked? (for +EV)
comment by Pattern · 2020-09-01T14:57:53.199Z · LW(p) · GW(p)
The REVERSE HEADS Environment always you 0.5 reward if the coin comes up tails, but [if] it comes up heads, saying "tails" gets you 1 reward and "heads" gets you 0 reward. We have Knightian uncertainty between the two environments.
In the next post, (#2)
The post after that (#3)
2 more posts to look forward to.
Later posts (not written yet) will be about the "1 reward forever" variant of Nirvana and InfraPOMDP's (~#4), developing inframeasure theory more(~#5), applications to various areas of alignment research(~#6), the internal logic which infradistributions are models of (~#7), unrealizable bandits (~#8), game theory (~#9), attempting to apply this to other areas of alignment research (~#10), and... look, we've got a lot of areas to work on, alright? (*)
Plus a speculative/possible 7 more after that assuming no overlap or multi-post topics. (~#6 and ~#10 already being counted as 2 posts.)
*More leaning on the unenumerated possibilities.
I look forward to seeing more of this!
comment by Donald Hobson (donald-hobson) · 2020-08-30T10:13:26.719Z · LW(p) · GW(p)
We have Knightian uncertainty over our set of environments, it is not a probability distribution over environments. So, we might as well go with the maximin policy.
For any fixed , there are computations which can't be correctly predicted in steps.
Logical induction will consider all possibilities equally likely in the absence of a pattern.
Logical induction will consider a sufficiently good psudorandom algorithm as being random.
Any kind of Knightian uncertainty agent will consider psudorandom numbers to be an adversarial superintelligence unless proved otherwise.
Logical induction doesn't depend on your utility function. Knightian uncertainty does.
There is a phenomena whereby any sufficiently broad set of hypothesis doesn't influence actions. Under the set of all hypothesis, anything could happen whatever you do,
However, there are sets of possibilities that are sufficiently narrow to be winnable, yet sufficiently broad to need to expend resources combating the hypothetical adversary. If it understands most of reality, but not some fundamental particle, it will assume that the particle is behaving in an adversarial manor.
If someone takes data from a (not understood) particle physics experiment, and processes it on a badly coded insecure computer, this agent will assume that the computer is now running an adversarial superintelligence. It would respond with some extreme measure like blowing the whole physics lab up.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2020-08-30T11:02:26.796Z · LW(p) · GW(p)
Logical induction doesn't have interesting guarantees in reinforcement learning, and doesn't reproduce UDT in any non-trivial way. It just doesn't solve the problems infra-Bayesianism sets out to solve.
Logical induction will consider a sufficiently good pseudorandom algorithm as being random.
A pseudorandom sequence is (by definition) indistinguishable from random by any cheap algorithm, not only logical induction, including a bounded infra-Bayesian.
If it understands most of reality, but not some fundamental particle, it will assume that the particle is behaving in an adversarial manor.
No. Infra-Bayesian agents have priors over infra-hypotheses. They don't start with complete Knightian uncertainty over everything and gradually reduce it. The Knightian uncertainty might "grow" or "shrink" as a result of the updates.
comment by magfrump · 2020-08-27T23:43:51.222Z · LW(p) · GW(p)
I am confused about how the mechanisms and desiderata you lay out here can give meaningful differences of prediction over complete spaces of environments. Maybe it is possible to address this problem separately.
In particular, imagine the following environments:
E1: the outcome is deterministically 0 at even time steps and 1 at odd time steps.
E2: the outcome is deterministically 0 at even time steps up to step 100 and 1 at odd time steps up to step 100, then starts to be drawn randomly based on some uncomputable process.
E3: the outcome is drawn deterministically based on the action taken in a way which happens to give 0 for the first 100 even step actions and 1 for the odd step actions.
All of these deterministically predict all of the first 200 observations with probability 1. I have an intuition that if you get that set of 200 observations, you should be favoring E1, but I don't see how your update rule makes that possible without some prior measure over environments or some notion of Occam's Razor.
In the examples you give there are systemic differences between the environments but it isn't clear to me how the update is handled "locally" for environments that give the same predictions for all observed actions but diverge in the future, which seems sticky to me in practice.
Replies from: magfrump↑ comment by magfrump · 2020-08-28T01:06:21.117Z · LW(p) · GW(p)
I think I see what I was confused about, which is that there is a specific countable family of properties, and these properties are discrete, so you aren't worried about locally distinguishing between hypotheses.
Replies from: Diffractor↑ comment by Diffractor · 2020-08-28T05:48:29.752Z · LW(p) · GW(p)
Can you elaborate on what you meant by locally distinguishing between hypotheses?
Replies from: magfrump↑ comment by magfrump · 2020-08-31T19:42:21.907Z · LW(p) · GW(p)
I mean distinguishing between hypotheses that give very similar predictions--like the difference between a coin coming up heads 50% vs. 51% of the time.
As I said in my other comment, I think the assumption that you have discrete hypotheses is what I was missing.
Though for any countable set of hypotheses, you can expand that set by prepending some finite number of deterministic outcomes for the first several actions. The limit of this expansion is still countable, and the set of hypotheses that assign probability 1 to your observations is the same at every time step. I'm confused in this case about (1) whether or not this set of hypotheses is discrete and (2) whether hypotheses with shorter deterministic prefixes assign enough probability to allow meaningful inference in this case anyway.
I may mostly be confused about more basic statistical inference things that don't have to do with this setting.
comment by awenonian · 2021-03-21T22:01:18.804Z · LW(p) · GW(p)
A little late to the party, but
I'm confused about the minimax strategy.
The first thing I was confused about was what sorts of rules could constrain Murphy, based on my actions. For example, in a bit-string environment, the rule "every other bit is a 0" constrains Murphy (he can't reply with "111..."), but not based on my actions. It doesn't matter what bits I flip, Murphy can always just reply with the environment that is maximally bad, as long as it has 0s in every other bit. Another example would be if you have the rule "environment must be a valid chess board," then you can make whatever moves you want, and Murphy can just return the environment with the rule "if you make that move, then the next board state is you in checkmate", after all, you being in checkmate is a valid chessboard, and therefore meets the only rule you know. And you can't know what other rules Murphy plays by. You can't really run minimax on that, then, because all of Murphy's moves look like "set the state to the worst allowable state."
So, what kind of rules actually constrain Murphy based on my actions? My first take was "rules involving time," for instance if you have the rule "only one bit can be flipped per timestep" then you can constrain Murphy. If you flip a bit, then within the next timestep, you've eliminated some possibilities (they would require flipping that bit back and doing something else), so you can have a meaningful minimax on which action to take.
This didn't feel like the whole story though, so I had a talk with my friend about it, and eventually, we generalized it to "rules that consume resources." An example would be, if you have the rule "for every bit you flip, you must also flip one of the first 4 bits from a 1 to a 0", then we can constrain Murphy. If I flip any bit, that leaves 1 less bit for Murphy to use to mess with me.
But then the minimax strategy started looking worrying to me. If the only rules that you can use to constrain Murphy are ones that use resources, then wouldn't a minimax strategy have some positive preference for destroying resources in order to prevent Murphy from using them? It seems like a good way to minimize Murphy's best outcomes.
Replies from: Diffractor↑ comment by Diffractor · 2021-03-22T05:33:01.912Z · LW(p) · GW(p)
Maximin, actually. You're maximizing your worst-case result.
It's probably worth mentioning that "Murphy" isn't an actual foe where it makes sense to talk about destroying resources lest Murphy use them, it's just a personification of the fact that we have a set of options, any of which could be picked, and we want to get the highest lower bound on utility we can for that set of options, so we assume we're playing against an adversary with perfectly opposite utility function for intuition. For that last paragraph, translating it back out from the "Murphy" talk, it's "wouldn't it be good to use resources in order to guard against worst-case outcomes within the available set of possibilities?" and this is just ordinary risk aversion.
For that equation , B can be any old set of probabilistic environments you want. You're not spending any resources or effort, a hypothesis just is a set of constraints/possibilities for what reality will do, a guess of the form "Murphy's operating under these constraints/must pick an option from this set."
You're completely right that for constraints like "environment must be a valid chess board", that's too loose of a constraint to produce interesting behavior, because Murphy is always capable of screwing you there.
This isn't too big of an issue in practice, because it's possible to mix together several infradistributions with a prior, which is like "a constraint on Murphy is picked according to this probability distribution/prior, then Murphy chooses from the available options of the hypothesis they picked". And as it turns out, you'll end up completely ignoring hypotheses where Murphy can screw you over no matter what you do. You'll choose your policy to do well in the hypotheses/scenarios where Murphy is more tightly constrained, and write the "you automatically lose" hypotheses off because it doesn't matter what you pick, you'll lose in those.
But there is a big unstudied problem of "what sorts of hypotheses are nicely behaved enough that you can converge to optimal behavior in them", that's on our agenda.
An example that might be an intuition pump, is that there's a very big difference between the hypothesis that is "Murphy can pick a coin of unknown bias at the start, and I have to win by predicting the coinflips accurately" and the hypothesis "Murphy can bias each coinflip individually, and I have to win by predicting the coinflips accurately". The important difference between those seems to be that past performance is indicative of future behavior in the first hypothesis and not in the second. For the first hypothesis, betting according to Laplace's law of succession would do well in the long run no matter what weighted coin Murphy picks, because you'll catch on pretty fast. For the second hypothesis, no strategy you can do can possibly help in that situation, because past performance isn't indicative of future behavior.
↑ comment by awenonian · 2021-03-31T21:00:36.989Z · LW(p) · GW(p)
I'm glad to hear that the question of what hypotheses produce actionable behavior is on people's minds.
I modeled Murphy as an actual agent, because I figured a hypothesis like "A cloaked superintelligence is operating the area that will react to your decision to do X by doing Y" is always on the table, and is basically a template for allowing Murphy to perform arbitrary action Y.
I feel like I didn't quite grasp what you meant by "a constraint on Murphy is picked according to this probability distribution/prior, then Murphy chooses from the available options of the hypothesis they picked"
But based on your explanation after, it sounds like you essentially ignore hypotheses that don't constrain Murphy, because they act as an expected utility drop on all states, so it just means you're comparing -1,000,000 and -999,999, instead of 0 and 1. For example, there's a whole host of hypotheses of the form "A cloaked superintelligence converts all local usable energy into a hellscape if you do X", and since that's a possibility for every X, no action X is graded lower than the others by its existence.
That example is what got me thinking, in the first place, though. Such hypotheses don't lower everything equally, because, given other Laws of Physics, the superintelligence would need energy to hell-ify things. So arbitrarily consuming energy would reduce how bad the outcomes could be if a perfectly misaligned superintelligence was operating in the area. And, given that I am positing it as a perfectly misaligned superintelligence, we should both expect it to exist in the environment Murphy chooses (what could be worse?) and expect any reduction of its actions to be as positive of changes as a perfectly aligned superintelligence's actions could be, since preventing a maximally detrimental action should match, in terms of Utility, enabling a maximally beneficial action. Therefore, entropy-bombs.
Thinking about it more, assuming I'm not still making a mistake, this might just be a broader problem, not specific to this in any way. Aren't I basically positing Pascal's Mugging?
Anyway, thank you for replying. It helped.
Replies from: Diffractor↑ comment by Diffractor · 2021-03-31T23:10:40.408Z · LW(p) · GW(p)
You're completely right that hypotheses with unconstrained Murphy get ignored because you're doomed no matter what you do, so you might as well optimize for just the other hypotheses where what you do matters. Your "-1,000,000 vs -999,999 is the same sort of problem as 0 vs 1" reasoning is good.
Again, you are making the serious mistake of trying to think about Murphy verbally, rather than thinking of Murphy as the personification of the "inf" part of the definition of expected value, and writing actual equations. is the available set of possibilities for a hypothesis. If you really want to, you can think of this as constraints on Murphy, and Murphy picking from available options, but it's highly encouraged to just work with the math.
For mixing hypotheses (several different sets of possibilities) according to a prior distribution , you can write it as an expectation functional via (mix the expectation functionals of the component hypotheses according to your prior on hypotheses), or as a set via (the available possibilities for the mix of hypotheses are all of the form "pick a possibility from each hypothesis, mix them together according to your prior on hypotheses")
This is what I meant by "a constraint on Murphy is picked according to this probability distribution/prior, then Murphy chooses from the available options of the hypothesis they picked", that set (your mixture of hypotheses according to a prior) corresponds to selecting one of the sets according to your prior , and then Murphy picking freely from the set .
Using (and considering our choice of what to do affecting the choice of , we're trying to pick the best function ) we can see that if the prior is composed of a bunch of "do this sequence of actions or bad things happen" hypotheses, the details of what you do sensitively depend on the probability distribution over hypotheses. Just like with AIXI, really.
Informal proof: if and (assuming ), then we can see that
and so, the best sequence of actions to do would be the one associated with the "you're doomed if you don't do blahblah action sequence" hypothesis with the highest prior. Much like AIXI does.
Using the same sort of thing, we can also see that if there's a maximally adversarial hypothesis in there somewhere that's just like "you get 0 reward, screw you" no matter what you do (let's say this is psi_0), then we have
And so, that hypothesis drops out of the process of calculating the expected value, for all possible functions/actions. Just do a scale-and-shift, and you might as well be dealing with the prior , which a-priori assumes you aren't in the "screw you, you lose" environment.
Hm, what about if you've just got two hypotheses, one where you're like "my knightian uncertainty scales with the amount of energy in the universe so if there's lots of energy available, things could e really bad, while if there's little energy available, Murphy can't make things bad" () and one where reality behaves pretty much as you'd expect it to(? And your two possible options would be "burn energy freely so Murphy can't use it" (the choice , attaining a worst-case expected utility of in and in ), and "just try to make things good and don't worry about the environment being adversarial" (the choice , attaining 0 utility in , 1 utility in ).
The expected utility of (burn energy) would be
And the expected utility of (act normally) would be
So "act normally" wins if , which can be rearranged as . Ie, you'll act normally if the probability of "things are normal" times the loss from burning energy when things are normal exceeds the probability of "Murphy's malice scales with amount of available energy" times the gain from burning energy in that universe.
So, assuming you assign a high enough probability to "things are normal" in your prior, you'll just act normally. Or, making the simplifying assumption that "burn energy" has similar expected utilities in both cases (ie, ), then it would come down to questions like "is the utility of burning energy closer to the worst-case where Murphy has free reign, or the best-case where I can freely optimize?"
And this is assuming there's just two options, the actual strategy selected would probably be something like "act normally, if it looks like things are going to shit, start burning energy so it can't be used to optimize against me"
Note that, in particular, the hypothesis where the level of attainable badness scales with available energy is very different from the "screw you, you lose" hypothesis, since there are actions you can take that do better and worse in the "level of attainable badness scales with energy in the universe" hypothesis, while the "screw you, you lose" hypothesis just makes you lose. And both of these are very different from a "you lose if you don't take this exact sequence of actions" hypothesis.
Murphy is not a physical being, it's a personification of an equation, thinking verbally about an actual Murphy doesn't help because you start confusing very different hypotheses, think purely about what the actual set of probability distributions corresponding to hypothesis looks like. I can't stress this enough.
Also, remember, the goal is to maximize worst-case expected value, not worst-case value.