Belief Functions And Decision Theory
post by Diffractor · 2020-08-27T08:00:51.665Z · LW · GW · 7 commentsContents
Definition 1: Nirvana
Notation
Foundations:
Definition 2: A-history
Definition 3: O-history
Definition 4: Partial Policy
Definition 5: Policy Stub
Definition 6: Full Policy
Definition 7: Empty Policy
Outcome Sets and Projection Mappings
Definition 8: Outcome Set
Definition 9: Projection Mapping
Definition 10: A-Environment
Belief Functions
Definition 11: Belief Function
Belief Function Conditions
Condition 4: Nirvana-Free Upper Completeness:
Condition 5: Bounded Minimals:
Consistency and Extreme Points
Condition 7: Consistency:
Condition 8: Extreme Point Condition:
Hausdorff-Continuity
Definition 12: A-Measures on Nirvana-Free Histories
Definition 13: Clip Set
Definition 14: Preimage to Infinity
Causal, Pseudocausal, Acausal
Definition 15: Outcome Function
Condition C: Causality
Condition P: Pseudocausality
1: Nirvana-free Nonemptiness
2,3,4: Closure, Convexity, Nirvana-Free Upper Completion
5: Minimal-Boundedness
6: Normalization
7: Consistency
8: Extreme Point Condition
9: Hausdorff-Continuity
C: Causality
P: Pseudocausality
Definition 16: Causal/Pseudocausal/Acausal/Surcausal Hypothesis
Acausal Hypotheses and Surmeasures
Definition 17: Surmeasure
Definition 18: Surtopology
Definition 19: Surmetric
Hypothesis Translation Theorems
Definition 20: Nirvana Injection
Definition 21: Nirvana Injection (Surcausal)
Mixing and Updates
Definition 22: Nontriviality
Definition 24: History-Clip
Definition 25: Off-History Policy
Definition 26: Policy Gluing
Definition 27: Probability
Definition 28: Belief Function Update
Decision Theory
Definition 30: Regret
Definition 31: Learnability
Definition 32: InfraBayes-Optimal Family
Definition 33: Convexity Property
None
7 comments
So, if you haven't read the first [AF · GW] two posts [AF · GW], do so now.
In this post, we'll be going over the basic theory of belief functions, which are functions that map policies to sets of sa-measures, much like how an environment can be viewed as a function that maps policies to probability distributions over histories. Also, we'll be showing some nifty decision theory results at the end. The proofs for this post are in the following three posts (1 [AF · GW],2 [AF · GW],3 [AF · GW]), though it's inessential to read them and quite difficult.
Now, it's time to address desideratum 1 (dynamic consistency), and desideratum 3 (how do we formalize the Nirvana trick to capture policy selection problems) from the first post. We'll be taking the path where Nirvana counts as infinite reward, instead of counting as 1 reward forever. The latter option is cleaner mathematically, ties into learning theory better, and makes it clearer what a pseudocausal hypothesis is. But this post was long enough as-is, so we'll just be presenting the path where Nirvana counts as infinite reward, as that allows for more flexibility in encoding policy selection problems and a full tie-in with UDT.
Definition 1: Nirvana
A special observation which may occur at any time, counts as infinite reward, and brings the history to an end. An a-measure or sa-measure may be described as Nirvana-free when the set of histories ending in Nirvana has measure 0. The set of Nirvana-free a-measures is denoted as .
Our ambient mathematical setting is one where: At each point, there are finitely many discrete actions or observations available (no continuous observation spaces here, though the available space of actions or observations may vary depending on the history so far). In any situation, Nirvana may occur, and it ends the history. All policies are deterministic (refer back to the first post [AF · GW] to see why this isn't much of an imposition).
We'll be working with bounded inframeasures (like a bounded infradistribution in all ways except normalization), instead of inframeasures, because it gets harder if we don't. Also, we'll be working within the cone of a-measures, but use the notion of upper-completion that uses the cone of sa-measures. This odd restriction is in place because Nirvana doesn't interact well with negative measures, as that would be reward and Murphy minimizes your reward, which forces a lot of awkward kludges in various settings.
If we had Nirvana count as 1 reward forever, we could drop almost all of these issues, but we're trying to replicate UDT here. When cramming a UDT problem into this setting, we do it by hard-coding every possible policy into an environment that depends on a policy, which produces a family of environments, and add the constraint that you attain Nirvana if you violate the hard-coded policy.
In order for Murphy to go "dang, I'd better make the hard-coded policy match the agent's own" (simulating a policy-dependent environment), you need the loss incurred by the environment mispredicting you to be smaller than the gain in value from attaining Nirvana when the environment mispredicts you. Infinite reward gets this easily, while 1 reward forever isn't quite potent enough to stamp out mispredictions in all circumstances, it's limited to problem setups where predictors are predicting you in circumstances that don't have a tiny probability of arising and don't happen too far in the future.
Notation
Feel free to skip this part and refer back to it as necessary, or open up a seperate tab so you don't have to scroll all they way back up to this. A lot of it won't make sense now, it's just a reference. We have all the notation from the previous notation section [AF · GW], in addition to:
: A finite history, ending in an observation. Similarly, is an action.
: A number in , the time-discount parameter. This is used to define the distance between histories (for defining the KR-metric), as well as defining the distance between partial policies. We can also use as a superscript in a utility function to specify the time discount.
: The space of partial policies and full policies, respectively. All policies are deterministic. A partial policy could be thought of as a full policy, except that what it does may become undefined in some situations. Partial policies make a poset where the ordering is given by one partial policy being an extension of another. Full policies are maximal in this poset. There's also a distance metric between policies and partial policies, given by where is the shortest time where they behave differently (whether by disagreeing with each other on what to do, or by one policy being defined where the other isn't)
: A policy-stub, partial-policy, and full policy, respectively. Full policies are pretty obvious. A policy-stub is a partial policy which is guaranteed to be undefined after some finite time, though the time at which it becomes undefined may be history-dependent. A partial policy is the most inclusive concept, including both policy stubs and full policies, and is a tree of actions and observations that dead-ends at histories where you don't specify what is to be done after that history.
: The empty policy/empty stub. The maximally undefined partial policy that specifies absolutely nothing about what the policy does.
: The outcome set of a partial policy. All the ending observation leaves on the tree given by . This has the property that no matter what, if you play that partial policy, you'll get one of those outcomes. If is infinite down some paths, then full outcomes (infinite histories) down those paths are also taken to be in this set. is the same, but omits every Nirvana observation.
: The a-measures and sa-measures over the set . An important part of this is that can't assign negative measure to any Nirvana event, which is an important limitation, otherwise we could have expected value and the agent would give up and cry since it plans for the worst-case.
: The function with type signature (or the Nirvana-free variant) defined as the pushforward of the function mapping each bitstring in to its unique prefix in , which happens exactly when . To be more concrete, the function that takes in a measure on 10-bit bitstrings and crunches it down to a measure on 8-bit prefixes is an instance of this sort of projection.
: An environment.
: A belief function, mapping each to a set of a-measures over . If these fulfill enough conditions, we call them hypotheses.
: The set of Nirvana-free a-measures for a given . Ie, the measure component doesn't assign nonzero measure to any Nirvana observation. Technically, there's a dependency on , but we suppress this in the notation since the definition of the set is pretty much the same for all the .(ie, everything without Nirvana in it)
: Minimal points of a-measures can be broken down as where and is a probability distribution. These are the minimal upper bounds on and for all the sets, relative to a given .
: Some partial policy which specifies everything the agent does except for what it does after history .
: Like our standard expectations relative to a set of sa-measures, just remember that Nirvana means infinite reward, so this can be rephrased as .
: The quantity . This is the rescaling term in updates, it can be (very) roughly thought of as the probability of getting the finite history relative to an off-h policy and a belief function.
: The closed convex hull of a set.
: The space of a-measures on all infinite histories (no Nirvana in here, it'd end the history early). Obeying a deterministic policy only let you reach a certain portion of this space.
: Given a and the associated and upper bounds on the minimal points of all , this is the set of all a-measures over where . Again, like , there's an implicit dependence on we're suppressing here. Used to clip away part of our set for some arguments.
: An outcome function. A function mapping each to a point in such that .
: An a-surmeasure or sa-surmeasure. Like an a-measure or sa-measure, except that the measure component can specify that some Nirvana events occur with arbitrarily-small-but-nonzero measure, where this quantity is denoted as
: A set of a-environments/a-survironments. They can be written as , where is our constant term, is "how much we care about the environment", and is an environment.
: There's also an variant. This is the Nirvana injection up, and a measure is injected up by going "if we need to extend a piece of measure on a history to longer histories, we just say that is guaranteed to end in Nirvana after you take an action". does the same thing, except that it also assigns every Nirvana event outside of that'd normally have 0 measure, measure instead.
: The functions mapping a or defined only over policy stubs or full policies to a over all partial policies, via:
: The functions taking a and restricting it to be only defined over full policies or only defined over stubs.
: The functions taking a hypothesis over stubs that's pseudocausal/acausal and translating it to a causal/surcausal hypothesis over stubs, via:
And similar for , just swap for .
: The function taking a causal/surcausal hypothesis and translating it to a pseudocausal/acausal hypothesis by just intersecting everything with , ie, clipping away every a-measure with nonzero measure on some Nirvana event.
: The partial policy made by taking which specifies everything except what happens after observation , and going "obey after observation ". Just glue the two partial policies together.
: The bookkeeping function which clips off the prefix from all the histories in your measure after you update on . Technically, there's an dependence on this, but we suppress it in the notation.
: The adjusted function over histories to compensate for clipping off the prefix on histories after updating, via .
: When used as a superscript, it means something has been renormalized, when used as normal, it means regret.
: Some utility function. denotes a utility function with time discount parameter .
Foundations:
Definition 2: A-history
An a-history is a finite history ending with an action. A history is just a sequence of alternating actions and observations.
Definition 3: O-history
An o-history is a finite history ending with an observation, or an infinite history. The empty history will also count as an o-history.
Definition 4: Partial Policy
A partial policy is a partial function from finite o-histories that can be continued with an action to actions, s.t. if is well-defined, and is an a-history that is a prefix of , then . The set of these is denoted .
Note that in order to specify the behavior of a partial policy in a situation, you need to specify its behavior in all prefixes of the situation, which means you act in such a way that it's possible for the situation to come about. Also because you can only specify one action in any given situation, your action can't be specified on any o-history where the past actions don't match up with what your partial policy says you do.
Definition 5: Policy Stub
A policy stub is a partial policy that has a finite where if , then . It is undefined beyond a certain time.
Definition 6: Full Policy
A full policy is a partial policy that cannot have its domain where it is defined enlarged, without ceasing to be a partial policy. The set of these is . This is the same as a policy in the usual sense of the word.
So, visualizing a partial policy as a big tree, policy stubs are the finite trees, full policies are the trees infinite down every branch, and partial policies are the all-encompassing category which also include trees that are infinite down some branches but not others.
Definition 7: Empty Policy
The empty policy is the partial policy/policy stub that is completely undefined. For all o-histories , even including the empty history,
We can equip with a distance metric. The distance metric is , where , and is the "time of first difference", the length of the shortest o-history where the action of doesn't match up with the action of , or where one of the is defined and the other one isn't.
We can also equip with a partial order. The partial order is if the two policies never disagree on which action to take, and is defined on more histories than is. can be taken of arbitrary collections of partial policies (intersection), and (union) can be taken of arbitrary collections of partial policies as long as they're all below some full policy .
The full policies are the maximal elements in this poset, the empty policy is the bottom element in this poset, and every partial policy is associated with a sequence of stubs that are like "specify all of what this partial policy does up until time , then be undefined afterwards". The chain ascends up towards , and has the property that any stub has some where .
Outcome Sets and Projection Mappings
The "outcome set" of a partial policy, , is... well, let's start with a visualization and then give the formal definition.
Consider the branching tree of alternating actions and observations. The partial policy fixes a subtree of this tree, where every child of an observation node is an action given by , and you extend no further if the policy becomes undefined at an observation. Then the outcome set would be all the leaves and infinite paths of that tree. If you follow the behavior of the partial policy, your history is guaranteed to go through one of the leaves. Thus, if your partial policy interacts with an environment, you'd get a probability distribution over (for the history is guaranteed to have something in as a prefix). Observe the picture.
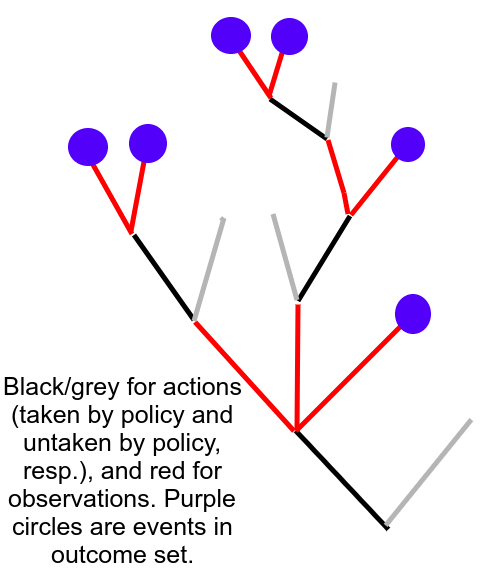
Definition 8: Outcome Set
The outcome set is the set of o-histories that are not in the domain of , but all prefix a-histories of , have . By this definition, contains one element, the empty history. is the subset of consisting of all o-histories which don't end in Nirvana.
and will take the role of our arbitrary compact metric spaces that we defined infradistributions over. The metric is , where and is the first timestep where the histories differ. So two histories are close if they agree for a long time before differing.
However, there's a technicality we need. While and and work exactly as you'd expect, can't contain signed measures that assign negative mass to a Nirvana event. This is because a positive functional (that respects Nirvana) would think that such a measure may have value. And requiring that the amount of Nirvana-measure is equal or greater than the amount of negative-Nirvana measure interacts badly with updates. This issue causes minor kludges all over the place, we'll reiterate that Nirvana counting as 1 reward is much more elegant.
We'll also need the notion of a projection (this is going to be our analogue of the mapping from the basic theory).
Definition 9: Projection Mapping
If , then the function is defined by:
Where, if is a prefix of some outcome in , then , where and should be understood to mean "measure assigned to the outcome having prefix " This function also maps a-measures to a-measures and Nirvana-free stuff to Nirvana-free stuff.
To expand more on this, if , then there's a natural surjection from to (which also acts as a surjection from to ). Every history in has a unique prefix in , so just send a history to its unique prefix. This is .
To visualize it, take your tree induced by . is the coat of observation leaf nodes and all the infinite paths. Extending requires the new tree to poke out through some observation leaf nodes in , so every leaf node in is attached to a part of the tree that pokes out through the original coat of leaf nodes somewhere.
is just the pushforward mapping induced by this, like how we got a function from sa-measures to sa-measures from a function back in the last post. is the exact function you'd come up with if you went "given a measure on 10-bit bitstrings, how do I craft a measure on 7-bit prefixes" and generalized it.
Some important properties of this are that it's identity when mapping from a partial policy to itself, linear, preserves the and value of an a-measure when you project it down, and it commutes. It doesn't matter what sequence of projections you take to get from a high partial policy to a low partial policy, they'll all be equal.
Definition 10: A-Environment
An a-environment is a point written as , where , and is an environment. This is parallel to an a-measure.
The intuition for this is that tells you how much you care about the environment /the probability of the environment existing in the first place if , and is the utility you're guaranteed/portion of expected utility you get if the environment doesn't exist.
We can think of querying an a-environment with a partial policy to get an a-measure via , where is the probability distribution over induced by interacting with the environment. We'll use this as an intuition pump a lot. In fact, environments are actually equivalent to functions mapping partial policies to probability distributions over actions. One direction is , and in the reverse direction, if you've got a function mapping partial policies to a probability distribution over outcomes, then as long as when , then it corresponds to an environment. This is the motive for the next part.
Belief Functions
Definition 11: Belief Function
A belief function is a function that assigns all to a nonempty set of a-measures over (or the Nirvana-free variant).
The reason we're using a-measures instead of sa-measures is because we really don't need negative measures except for defining the upper completion, and negative measures really don't interact well with Nirvana being infinite reward (a drawback of this approach)
From the a-environment view, you can consider taking a set of a-environments, letting them all interact with a partial policy, and then plotting the resulting a-measures over you get, that'd be your induced by a set of a-environments. But we'll just work with belief functions more generally and later build up the tools to view them as a set of a-environments. We'll also abuse notation and use (Nirvana-free) as an abbreviation for sometimes, when we don't want to specify an ambient space, and are just doing an intersection to clip away Nirvana.
Also, , because any probability of Nirvana counts as infinite value, so Murphy will only pick from Nirvana-free a-measures.
Belief Function Conditions
Let's go over the various conditions for a belief function to behave well. The first 6 are analogues of the corresponding conditions for an infradistribution, and the last 3+2 are special conditions for how the different sets interact with each other.
Condition 1: Nirvana-free Nonemptiness:
This is parallel to condition 1: Nonemptiness, for infradistributions.
It's nontrivial in the Nirvana-containing case, because it says "regardless of your policy, Murphy can find an environment to play that avoids Nirvana", as should be the case if we don't want the agent ignoring all else to optimize its chances of getting infinite reward which never happens.
Condition 2: Closure:
This is parallel to condition 2: Closure, for infradistributions.
This also works with the Nirvana-free interpretation of , because is closed.
Condition 3: Convexity:
This is parallel to condition 3: Convexity, for infradistributions.
Again, is convex so we can do this in that setting too. is the convex hull.
Condition 4: Nirvana-Free Upper Completeness:
This is roughly parallel to condition 4: Upper Completeness, for infradistributions. This says that the Nirvana-free part of should be upper-complete w.r.t. the cone of Nirvana-free sa-measures. This is a bit of a hack, because Nirvana counts as infinite reward.
You probably have several questions. The first one: why do we restrict to a-measures? Well, our minimal points should be a-measures (by Condition 5: Positive Minimals for infradistributions), and those are the only thing that matters, so it's no big deal that we trim off all the sa-measures. Plus, some later tools like Nirvana injections don't work well with sa-measures.
Second question: Why do we need the cone of Nirvana-free sa-measures? Can't we just add the cone of Nirvana-free a-measures? Well, it's possible to add an sa-measure to an a-measure and get an a-measure, so just adding the cone of a-measures wouldn't capture enough points, we could add more.
Third question: Why do we require everything to be Nirvana-free? Can't we just require upper completion in general? Well, there's a weird thing where the projection of an upper-complete set isn't necessarily upper-complete when there's Nirvana about. But, in the Nirvana-free setting, the projection of an upper-complete set is upper-complete. This feature messes with several downstream things. Murphy will only pick from Nirvana-free a-measures, so it's no big loss.
Again, we see the pattern that having Nirvana be infinite forces a bunch of weird minor issues all over the place.
Condition 5: Bounded Minimals:
This is roughly parallel to condition 6: Bounded-Minimals for infradistributions. Note that said bound must be uniform among all the sets. We need to bound the term uniformly as well to make some proofs work out.
Condition 6: Normalization:
This is not the standard renormalization, but analogous. It also has the bad property that a mixture of normalized belief functions is not normalized. In our defense, it's all scale-and-shift anyways, you can just renormalize after mixing if you want.
Why is this defined in such a way? Well, it's because we're actually dealing with a bunch of different sets of a-measures, one for each partial policy, and since they're different, we can't get a guarantee that they're all normalized at once. You can't do individual normalizations, that'd break dynamic consistency. So we do a sort of collective normalization to as a whole, to preserve the natural analogue of the normalization condition in this setting. Worst-case value should be 0 and best-case value should be 1, and this attains that.
Now, we can move on to three additional conditions on how the various sets link together, instead of merely checking the usual infradistribution conditions for individual .
Consistency and Extreme Points
Condition 7: Consistency:
This seems a bit mystifying, but it pretty much says that the behavior of the finite levels (the policy-stubs which only specify things up to a finite time), and the infinite levels (the full policies ), uniquely pin each other down. This condition lets you recover uniquely via only knowing it on policy-stubs or only knowing it on full policies.
The intuition for the first equality will be taken from the view where tells you what you get via querying a set of a-environments with a partial policy and recording the a-measures you get. So, to begin with, if , then querying an a-environment with and projecting your result down via , gets you the same thing as querying that environment with . And if the first query gave you a Nirvana-free thing, the second one must have done so too because . Therefore, . Also, if the set of a-environments is convex (the corresponding property to all the being convex), we should be able to mix a-environments, which mixes the a-measures you get via a query in the same way. So,
And also, is closed, so contains the closed convex hull as well.
In the Nirvana-containing case, we can go "hey, if there's a point in that the closed convex hull doesn't nab, can't we just query the associated superenvironment with some random to get something in that projects down to our point of interest?" And this gets you equality.
If we slice out the Nirvana, this equality is a significantly stronger condition. We could imagine taking an a-environment that's Nirvana-free for a long time, but past a certain point, regardless of policy, Nirvana is guaranteed. The a-measures made by querying this a-environment with all partial policies would show up in the small policy-stubs (being Nirvana-free), but because Nirvana eventually shows up regardless of policy, the a-measures would get clipped out of our sets because they have Nirvana in them and we're only recording Nirvana-free a-measures.
So, in the Nirvana-free case, this condition corresponds to saying that, given some Nirvana-free a-measure produced by a partial policy interacting with an a-environment, there should be some way to extend the partial policy to a full policy that's Nirvana-free as well. Or, if that can't be done, the a-environment should be a mixture of a-environments where you can extend your policy in a Nirvana-free way.
In the Nirvana-free case, this " is the closed convex hull of projections from above" property is basically saying "don't clog of the partial policy with extraneous crap that didn't arise from appropriate Nirvana-free a-measures for full policies".
After all, we want to recover the whole thing from either the behavior of on full policies, or the policy-stubs, and adding extra Nirvana-free stuff into the policy-stubs would mess with our ability to do this.
Now, let's look at the other one,
What's the motive for this one? Well, let's cover both directions. In one direction, if you were like "this intersection of preimages of projections doesn't have enough points, I'm gonna throw in another point outside the intersection", then there'd be some stub , where your added point would project down to be outside of , which, oops, can't be done. Remember, if you got your extra point via querying an a-environment with , then you should be able to query the same a-environment with which is shorter, to get the projection of which had better be in . But it's not.
In the other direction, this is sort of an "instantiating points at infinity" condition. A point in that intersection would project down to for all appropriate stubs. We've got a sequence of points in those sets, one for each stub. So, you can't actually detect the addition of these points at infinity, because their finite-time behavior will always flawlessly match up with some preexisting thing. Remember, we want to add as many points as we can that don't affect any observable behavior.
Thus, the consistency condition can be viewed as a mix of:
1: Projecting down should make a subset of because if you can query an a-environment with a long policy, you can also query it with a short one.
2: The finite levels aren't clogged with extra crap that didn't come from infinite levels.
3: A point is present at infinity if it's present at all the finite levels, because no finite-time observations can make any headway towards ruling that point out.
Condition 8: Extreme Point Condition:
is the set of extreme minimal points of .
To unpack this, an extreme point of a set is a point that can't be written as a mixture of distinct points in . Given a tetrahedron, the vertices would be extreme points, and given a sphere, the surface would be the extreme points.
So this says that, for stubs, if a point is an extreme point, minimal, and Nirvana-free, then it's the projection of a Nirvana-free point from a full policy above the stub.
In the Nirvana-free case, we get this for free from consistency. An extreme point can't be written as a mixture of other points, so it wasn't introduced when we took the convex hull of the union of projections (closure is more fiddly and we'll be ignoring it), so it had to come from the projection of a point from above.
However, in the Nirvana-containing case, this condition has two interpretations. The first is that shearing off all the a-measures with Nirvana occurring in them should get you a well-formed hypothesis. Our first condition, Nirvana-Free Nonemptiness, can be thought of as a condition in that vein, which ensures that shearing off the Nirvana doesn't leave you with an empty set. This condition is similar. Shearing off all the Nirvana had better preserve consistency! And this condition ensures exactly that.
Another characterization is that Nirvana cannot become inevitable without already happening. Minimal points are the essential elements of an inframeasure that can't be stripped away without affecting the expectation values, and extreme points are those that cannot be introduced by taking convex hull if they weren't already present. So, this condition says that if a point is minimal and extreme (can't be made by mixing and can't be removed without affecting anything else), then if Nirvana/infinite reward is guaranteed to have a shot at occurring in the future, then we might as well assume it has already occurred and said point can't be Nirvana-free.
Hausdorff-Continuity
Let's introduce some new concepts for this one.
Definition 12: A-Measures on Nirvana-Free Histories
is the set of a-measures on infinite o-histories. A finite history you can extend doesn't count. A finite history that ends with Nirvana doesn't count. An infinite history counts. This is all histories of this form, not just the ones compatible with some policy or other.
Definition 13: Clip Set
Given a belief function that fulfills bounded-minimals, there are and upper bounds on the and values of minimal points. is the set of a-measures where
Definition 14: Preimage to Infinity
is the function that maps a set in to the set of a-measures in with a measure of 0 on histories which don't have a history in as a prefix (so they can project down onto safely), and which project down to .
This allows us to take the preimage of all our sets and have them all coexist in the same space, for ready comparison.
Now, let's define our next condition.
Condition 9: Hausdorff Continuity: is continuous.
"Wait a minute", you might ask, "this maps partial policies to sets, what notion of continuity are you using here??"
Well, given two sets and in a metric space, the Hausdorff-distance between these sets is the maximum distance you'd have to travel to get to a point in one set, if you started at an arbitrary point in the other set. Two sets being close in Hausdorff-distance means that every point from is close to a point in , and vice-versa. From earlier, we've got a distance metric between partial policies. Further, because (the set of partial policies) is compact, said function isn't just continuous, but uniformly continuous.
Why do we need Nirvana-freeness? Well, doesn't include any Nirvana in it, so projecting it down can't make any a-measure that has Nirvana in it.
Why must we clip off part of our set? For full policies,
Now, is upper-closed w.r.t . So there's some points in that set with a gigantic amount of measure on infinite histories compatible with , and 0 everywhere else. Moving to a slightly different , its associated set has points with a gigantic amount of measure on infinite histories compatible with , and 0 everywhere else. Basically, the thing going wrong if we don't clip off the upper completion "tail" of our set is that the upper-completion tail is pointing in slightly different directions for different policies, so the Hausdorff-distance gets arbitarily large in the upper-completion tails. So we need to clip off that part. This doesn't clip off any minimal points, which are the important ones and everything else is extraneous.
This condition may seem quite mysterious. Speaking roughly, it says that for a Nirvana-free a-measure , if we make a perturbation of our policy at a very late time to get , there should be some nearby Nirvana-free a-measure .
This is a continuity condition on Murphy. If your policy trembles a bit to some nearby policy, then Murphy should only have to change the environment a little bit to get something Nirvana-free for the new policy. Another thing that may make the situation clearer is providing an example of what this condition rules out.
Let's say you're doing iterated Newcomb. If Omega fills the box only if it predicts you 1-box on the next 100 rounds, that's permitted by this condition. Altering your policy on round 1 million only alters the environment past round 1 million-100, which isn't much of a change w.r.t the KR metric we're using (it's insensitive to changes at late times). Omega can even look at your full policy, as long as really distant changes in your policy only have a small influence on the probabilities of what happens now, that'd still fulfill this condition. What this does forbid is the variant of iterated Newcomb where Omega fills the box only if it predicts you always 1-box. Because an arbitrarily late policy perturbation leads to a big change in what happens now.
So, despite looking hard to fulfill, this condition is an "acausal influences from very distant futures are weak" condition which is fairly natural. Another way of thinking about it is that you should be able to figure out what a policy-dependent environment is doing by just making bounded precommitments, instead of precommitments that extend for all time.
Why do we need this condition? Well, to prove that there's an optimal policy. Surprisingly enough, it's also essential for the proof of the consistency condition when we're trying to recover the whole from a belief function defined only on stubs or full policies.
So, the Hausdorff-continuity condition is more natural than it seems, and essentially says that extremely late policy changes don't change your situation now very much.
Causal, Pseudocausal, Acausal
But there's two more conditions, to define special sorts of hypotheses! Causal, Pseudocausal, and Acausal respectively. Causal hypotheses can have Nirvana in them, Pseudocausal and Acausal must be Nirvana-free. Acausal doesn't have any extra conditions on it besides the previous nine and being Nirvana-free, but Causal and Pseudocausal do need one extra condition each.
Definition 15: Outcome Function
An outcome function is a function mapping each to a point in , such that:
Condition C: Causality
The intuition for this is that, if you fix an a-environment, and queried it with all possible partial policies, you'd produce an outcome function. Similarly, an outcome function uniquely picks out an a-environment because you know what occurs in all possible situations and all the projections commute. So, the causality condition indirectly says "every point in all of of your belief function sets arose from querying an a-environment". This lets us easily go from the belief function to a set of a-environments, and similarly, querying a set of a-environments with partial policies will make a causal hypothesis.
Condition P: Pseudocausality
This is the Nirvana-free analogue of causality. Let's say we've got some a-environment that we query with , and the resulting distribution is Nirvana-free, and supported over . Now, if we query said a-environment with instead... we don't have to worry about introducing Nirvana! Yup, behaves a bit differently. But, it only behaves differently than on histories that have 0 probability of happening, so it should induce the exact same a-measure. Causality implies this condition, but this is weaker than causality. This is the property you'd get if you were taking a set of a-environments and querying it and reporting only the Nirvana-free a-measures. The special property of this is that, if pseudocausality is fulfilled, we can add Nirvana in such a way to craft a causal hypothesis (which is linked to actual sets of a-environments)
Recap! Ok, so our conditions are:
1: Nirvana-free Nonemptiness
This is easy, we shouldn't have the agent chasing after infinite reward.
2,3,4: Closure, Convexity, Nirvana-Free Upper Completion
These collapse equivalence classes of a-measures that have the exact same behavior, and are parallel to the conditions for inframeasures.
5: Minimal-Boundedness
Again, this is parallel to the condition for bounded inframeasures, just adding in a bound as well. It makes proofs much nicer.
6: Normalization
We impose a sort of collective normalization for the belief function as a whole, parallel to the corresponding condition for an infradistribution. This is not preserved when we mix belief functions.
7: Consistency
You should be able to recover the finite behavior of from the infinite behavior of , or vice-versa. Projecting big partial policies down to low levels makes subsets, the finite levels aren't clogged with extraneous crap, the infinite levels have all the points that match up with finite behavior.
8: Extreme Point Condition
Shearing the Nirvana off a consistent Nirvana-containing hypothesis should produce a consistent hypothesis.
9: Hausdorff-Continuity
Policy changes at extremely late times don't have much effect on what happens now.
C: Causality
Your belief function is induced by querying a set of a-environments.
P: Pseudocausality
Your belief function is induced by querying a set of a-environments and only recording the Nirvana-free results.
Definition 16: Causal/Pseudocausal/Acausal/Surcausal Hypothesis
A hypothesis is a belief function fulfilling the 9 conditions. A causal hypothesis may include Nirvana and fulfills Causality. A pseudocausal hypothesis is Nirvana-free and fulfills Pseudocausality. An acausal hypothesis is Nirvana-free. A surcausal hypothesis is a causal hypothesis over a-surmeasures (to be defined)
What's the essential difference between pseudocausal and acausal hypotheses? Well, it's a natural dividing line between two importantly distinct classes of decision-theory problems. In the former, no matter how you're mispredicted, you must have some chance of actually entering the situation where you're mispredicted. In the other class, you could be mispredicted and then locked out so you can't show the misprediction is wrong. More on this in the next section.
As we'll show later, you can turn any pseudocausal hypothesis into an equivalent causal one by adding Nirvana appropriately, and turn any causal hypothesis into an actual set of a-environments. But we have a hard time viewing acausal hypotheses as coming from a set of a-environments, at least without further work. So, the next section will be about poking at a toy case where we have an acausal hypothesis we can't turn into a causal one, and seeing how we have to adapt things to view an agent as believing that it's in some set of environments, instead of the agent working purely with belief functions that don't have a representation as a set of environments.
Acausal Hypotheses and Surmeasures
Let's take the example of Transparent Newcomb, where Omega fills the transparent box with a hundred dollars if it predicts you'd 1-box upon seeing the transparent box filled, and has probability of making a mistake (the other box contains 1 dollar). This is a policy-dependent environment, which depends on your policy, as well as your action and the past history. The way we can encode this as a set of environments is by hardcoding all possible policies into the policy slot to make a set of environments, and send you to Nirvana if you ever act contrary to the hardcoded policy. This forces Murphy to make the hardcoded policy match your own, lest you go to Nirvana. The chance of error guarantees that you have a shot at Nirvana if the hardcoded policy doesn't match your own. Translating this set of environments to a Nirvana-free belief function yields a pseudocausal hypothesis. XOR blackmail and Counterfactual Mugging are also pseudocausal hypotheses.
But what about Transparent Newcomb with a perfect predictor? In that case, we have a very serious problem with our standard way of viewing a policy-dependent environment as a set of environments via hardcoding in all policies and sending you to Nirvana if you violate the hardcoded policy. Maybe you 1-box upon seeing a full box, 2-box upon seeing it empty, but the hardcoded policy in the environment is "you 2-box in both cases". You're stuck 2-boxing and getting 1 dollar, you can never get into a situation where you get the Nirvana reward from calling out Omega on its misprediction. In fact, both "1-box upon full, 2-box upon empty" and "always 2-box" are optimal policies here, so this encoding of a policy-dependent environment doesn't let us get UDT behavior. If we don't want to permanently give up on viewing belief functions as sets of a-environments, how can we go forward?
Well, there's two ways to deal with this. One is encoding -exploration appropriately, the other doesn't require -exploration and is more interesting.
For the first one, assume a situation where you have an "intended policy" (deterministic), and you have an internal sense of what you intended to do, but maybe exploration overwrites that. Omega has a hard-coded prediction of your policy, and an exploration coin is flipped on each round. If the coin says "act as normal", things proceed as normal, if the coin says "explore", then Omega does the opposite of what it would normally do re: box-filling or not since it knows you'll do the opposite of what you'd normally do. Then, if the action you intended upon seeing the box's condition doesn't match up with Omega's prediction of what you intended, you go to Nirvana. In either case, the real action is determined by the exploration coin and what you intended to do. If we try going "Omega's prediction is that you intend to 2-box regardless of whether the box is full or empty", and our true intent is 1-boxing if full, 2-boxing if empty, and the coin says to explore, then Omega goes "they do the opposite of what they'd normally do, better fill the box". Then, as you reach for both boxes (because of exploration), the mismatch between your intent of 1-boxing and Omega's prediction that you intended to 2-box manifests and you attain Nirvana in the exploration step. This particular way of setting up things guarantees some probability of getting into a situation where you prove Omega wrong if there's a mismatch between your policy and the hardcoded policy, so we can turn it into a set of environments. But now, let's look at a different way of resolving the problem.
What happens if we just shove Perfect Transparent Newcomb into the form of a suitable Nirvana-free ? Neglecting some conditions like upper-completion, and both have the single point where the box is guaranteed-full and you 1-box for a hundred bucks. has the single point where the box is guaranteed-empty and you 1-box for nothing. has the single point where the box is guaranteed-empty and you 2-box for 1 dollar.
But this violates the pseudocausality condition. The outcome "the box is empty, and you 2-box" is in , and supported over . However, this distribution isn't present in . The pseudocausality condition wants us to add the bad outcome back in!
One more stab. Let's look at the non-closed set of environments (with Nirvana) corresponding to -noise Transparent Newcomb, where . The value 0.01 isn't that important, the key part is just that we are in a situation where there's some noise in the prediction and we know it's small but we don't know how small. We can try taking the closure either before or after we turn it into a , and see what happens.
Taking the closure in the space of a-environments, and turning it into a ends up adding in the bad distribution where it's assumed we 2-box, and sadly, this is Nirvana-free for a 1-boxing strategy. So we get the same failure mode as before.
Something rather interesting happens if we take the closure of the sets after translating this problem into a Nirvana-free belief function though. For , we've got a bunch of distributions going "-probability on a full box and we 1-box, -probability on an empty box and we 2-box" Taking the closure won't add the bad distribution, it'll only add in the desired Perfect Transparent Newcomb distribution where it's full and you 1-box, guaranteed. But we still don't have pseudocausality.
This mismatch points towards needing a condition that's something like "you can't add in a Nirvana-free a-measure to if it's a limit of Nirvana-containing a-measures, you can only add it in if it's a limit of Nirvana-free a-measures". Murphy can't take arbitrary limits to make an inconvenient a-measure for you, they can only take limits of things that don't give you a shot at infinite value.
Our fundamental problem is that the expected value of Newcomb, if Omega falsely has "2-box on full-box" locked in as the strategy, and we 1-box in that situation instead, goes "infinity, infinity, infinity... 1 dollar". Limits can lead outside the set of Nirvana-containing a-measures.
What would happen if we decreed that the set of Nirvana-containing a-measures was closed? The limit point of our sequence should still have infinite value, so it should be something like "probability 1 of an empty box and we 2-box, probability of a full box and we 1-box leading to Nirvana, of infinite value", where is interpreted as an infinitesimal quantity. Murphy still avoids this, because Nirvana can't truly be ruled out. Or, maybe we could slap some distance metric on a-measures that goes "this one has some probability of Nirvana here, this one doesn't, so they don't get arbitrarily close"
Definition 17: Surmeasure
A surmeasure is a pair of a measure and a function mapping Nirvana-histories to "possible" or "impossible", where Nirvana-histories with positive measure must be labeled "possible". Possible Nirvana-histories with 0 measure are assigned a value of . A-surmeasures and sa-surmeasures are defined in the obvious way from this, and denoted by .
And a survironment is like an environment, except it can have chance of getting "impossible" observations and from there you're guaranteed to get Nirvana at some point.
Definition 18: Surtopology
The surtopology is the topology over the space of (s)a-(sur)measures with a subbasis of the usual open balls around points, and the sets where ranges over the histories that end with Nirvana.
Definition 19: Surmetric
The surmetric is the metric over the space of (s)a-(sur)measures defined as:
where is the usual KR-metric, , and is the minimum length of a Nirvana-containing history that is possible/positive measure according to and impossible/0 measure according to (or vice-versa)
Murphy will avoid all points with any chance of Nirvana. Remember, we only need to deal with these shenanigans if our decision-theory problem has the environment completely lock us out of being able to disprove a false prediction. Or, if you really want to deal with these decision-theoretic cases and don't want to deal with surmeasures, you could just stick with ordinary acausal hypotheses and avoid attempting to cram them into a causal hypothesis/set of environments.
Interestingly enough, these three ways of dodging the problem are equivalent!
Theorem 1: The surmetric on the space of sa-measures induces the surtopology. The Cauchy completion of w.r.t the surmetric is exactly the space of sa-surmeasures.
If you didn't quite follow the previous discussion, the tl;dr version of it is that the standard way of getting a set of environments from a set of policy-dependent environments, where you hardcode in all possible policies and you go to Nirvana if you violate the hardcoded policy, only works when you're guaranteed to have some chance at Nirvana if you're mispredicted. Some decision theory problems with perfect predictors violate this property, but in that case, we can still make it work by going "oh, the probability of getting into a situation where you're mispredicted isn't 0, it's just arbitrarily small". Letting in outcomes that are possible but have arbitrarily low measure, gets us survironments and surmeasures, so we can view all policy-dependent decision theory problems this way, as arising from a set of survironments (with that chance of some outcomes), instead of just a vanilla set of environments.
Hypothesis Translation Theorems
Alright, now that we've got all that stuff out of the way, we can start presenting a bunch of theorems!
Let be the function mapping a defined only over policy-stubs to a over all partial policies, via
And let be the function mapping a defined only over full policies to a over all partial policies, via
Let and be the functions mapping a to the same but only defined over policy stubs/full policies respectively.
Theorem 2: Isomorphism Theorem: For (causal, pseudocausal, acausal, surcausal) or which fulfill finitary or infinitary analogues of all the defining conditions, and are (causal, pseudocausal, acausal, surcausal) hypotheses. Also, and define an isomorphism between and , and and define an isomorphism between and .
This says we can uniquely recover the whole from just behavior on policy-stubs, or full policies, as long as analogues of the hypothesis conditions hold for the stubs or full policies, and the full policy behavior and policy-stub behavior will uniquely pin each other down. The interesting part of this is recovering consistency (the key element of the isomorphism) from conditions which aren't consistency.
Now for the next one. Let be the set of a-environments (or a-survironments) s.t. for all , . Let where is an arbitary set of a-environments, be the belief function where
is the probability distribution over produced by interacting with the environment .
Proposition 1: If fulfills the causality condition, nonemptiness, closure, and convexity, then is a nonempty, closed, convex set of a-environments or a-survironments and . Also, .
So, we can go from causal hypotheses to actual sets of a-environments (or a-survironments, as the case may be). If we're fortunate enough to have our set of a-environments induce a causal hypothesis (the hard part isn't causality, you get that for free, the hard part is stuff like Hausdorff-continuity and the extreme point property), then going back to environments may introduce additional points corresponding to the long-ago mentioned [AF · GW] "chameleon environments" which mimic the behavior of preexisting environments for every policy, so going from a belief function to a set of a-environments removes the redundancy in sets of environments we mentioned back in the first post.
So, we can freely switch between finitary and infinitary versions of causal, pseudocausal, acausal, and surcausal hypotheses, they're isomorphic. And we can translate between causal/surcausal hypotheses and actual sets of environments. What about linking pseudocausal/acausal to causal/surcausal by strategic addition of Nirvana? Can we do that? Yes.
Definition 20: Nirvana Injection
If , then is the function where
is the pushforward induced by .
Definition 21: Nirvana Injection (Surcausal)
is the same as , except it labels every Nirvana-history not in as possible.
Note that these injections goes up, not down, as projections do. is a sort of Nirvana-adding injection up where we cap off every history we need to extend with "Nirvana happens immediately afterwards, guaranteed". is defined identically, except that if a Nirvana-history would normally get 0 measure, it's assigned measure instead. It's more aggressive about adding Nirvana everywhere it can.
is the function mapping a pseudocausal only defined on policy stubs, to a causal only defined on policy stubs, via:
And is defined identically, just with , it maps acausal to surcausal.
is just "intersect with ", it turns a causal/surcausal to a pseudocausal/acausal .
Now that we have the machinery to go from pseudocausal/acausal to causal/surcausal, and back, we have:
Theorem 3.1: Pseudocausal Translation: For all pseudocausal hypotheses defined only on policy stubs, is a causal hypothesis only defined on policy stubs. And,. For all causal hypotheses defined only on policy stubs, is a pseudocausal hypothesis only defined on policy stubs.
Theorem 3.2: Acausal Translation: For all acausal hypotheses defined only on policy stubs, is a surcausal hypothesis only defined on policy stubs. And, . For all surcausal hypotheses defined only on policy stubs, is an acausal hypothesis only defined on policy stubs.
These two are quite powerful. First, they let us freely translate between psuedocausal/acausal and causal/surcausal. Second, there's the philosphical meaning.
If you think that Nirvana looks like an ugly hack, but aren't attached to viewing everything as a set of a-environments, then you can just go "Awesome, we can just strip off all the Nirvana and work with Nirvana-free belief functions directly!"
If you think Nirvana looks like a sensible way of making Murphy not pick certain outcomes to encode policy selection problems, but really want to view everything as coming from a set of a-environments, then you can go "ooh, by adding in Nirvana, we can get all these wonky belief functions into a causal form, and from there to a set of a-environments/a-survironments!"
I should also remark that in the "Nirvana is 1 reward forever" setting, this turns into an isomorphism and we get a parallel with the original formulation of an infradistribution where all possible points have been added to the set as long as they don't affect expected values.
Ok, so now that we can freely translate things... Well, there were an awful lot of conditions for something to be a hypothesis/belief function. Let's say our is some random-ass batch of a-measures for each policy. Which conditions do we need to check in order to ensure that this is legitimate, and which hypothesis conditions can be massaged into existence if they weren't present already?
Proposition 2: Given a Nirvana-free which is defined over full policies but not necessarily a hypothesis (may violate some conditions), the minimal constraints we must check of to turn it into an acausal hypothesis via convex hull, closure, upper-completion, renormalization, and using the Isomorphism Theorem to extend to all partial policies are: Nonemptiness, Restricted Minimals, Hausdorff-Continuity, and non-failure of renormalization.
Proposition 3: Given a Nirvana-free which can be turned into an acausal hypothesis, turning it into a has: for all and .
So, when we turn an arbitrary batch of points for each policy into an acausal belief, it leaves the worst-case values the same, modulo a scale and shift . The process is basically "take closed convex hull, take upper completion, renormalize, generate the finite levels from the infinite ones by isomorphism"
Taking a break to recap, we can uniquely specify a hypothesis by only presenting for policy-stubs, or full policies, and it works with any of our hypothesis variants. Causal and surcausal hypotheses let you craft an actual set of a-environments/a-survironments that they came from. We can freely translate pseudocausal/acausal hypotheses to causal/surcausal hypotheses, showing that either Nirvana or a-environments can be dropped, depending on philosophical taste. And finally, you only need to verify four conditions to craft an acausal hypothesis from some completely arbitrary , and the behavior matches up modulo a scale-and-shift.
Hm, what else might we want? Probably some result that says we got everything. Fortunately, there is:
Proposition 4: For all hypotheses and
In other words, if, regardless of the utility function we picked, Murphy can force the same minimum value for both belief functions, then when we slice away the Nirvana, they're identical, full stop.
Er... we wanted to do maximin policy selection, and since we're working with deterministic policies, it's unclear that argmax exists, that there are even maximizing policies at all. Fortunately, this is the case!
Proposition 5: For all hypotheses , and all continuous functions from policies to functions , then the set exists and is closed.
Of course, we only really need one function, our utility function of choice. I figured it was worthwhile to show it in more generality, maybe we'll need it one day for learning utility functions over time.
Mixing and Updates
"But wait", I hear you ask, "What about updates or mixing belief functions to make a prior? We didn't cover those at all!"
Well, for mixing, we've got three issues. We can easily mix belief functions for Nirvana-free , by normal set mixing.
Our first issue is that mixing on the full-policy level, and regenerating the lower levels via the Isomorphism theorem, is not the same as mixing the sets at the lower levels. If you really care about what happens at lower levels, it's
Our second issue is that mixing normalized belief functions may fail to be normalized. We'll use for the raw mix, and for the renormalized mix.
And our third issue is that mixing breaks a condition in the causal case. So, if you want to mix causal hypotheses to make a prior, you should strip off the Nirvana, translate to a pseudocausal hypothesis, mix there, and then go back via Pseudocausal Translation. This is another issue that we expect to vanish if Nirvana just counts as 1 reward forever.
We do need the usual condition for our mixture of belief functions to be a belief function. Finally, to state the next theorem, we need to define what a nontrivial is.
Definition 22: Nontriviality
A hypothesis is nontrivial iff there exists some policy where . This is a very weak condition.
Nontriviality of some (a component hypothesis that you're mixing together to make a prior) is a sufficient (though not necessary) condition for the prior you make by mixing together the to be able to be turned into a hypothesis by renormalizing.
Proposition 6: For pseudocausal and acausal hypotheses where and there exists a nontrivial , then mixing them and renormalizing produces a pseudocausal or acausal hypothesis.
Proposition 7: For pseudocausal and acausal hypotheses,
Proposition 8: For pseudocausal and acausal hypotheses,
Ok, so mixing works sensibly. What about updates? Updates are somewhat complicated, because we have to slice away part of the policy tree, and incorporate a partial policy off-history into our update (again, for dynamic consistency reasons, we want to keep track of what's happening off-history, and we need to know our off-history policy in order to do that).
Also, there's renormalization to consider, and Nirvana is a bit of an issue. If Nirvana happens off-h, and we update, then that would fold a slice of infinite value into the term, which can't happen. Our first order of business is taking care of the bookkeeping for getting rid of the prefix.
Definition 23: Partial Policies After
is the set of partial policies starting at . For a policy in this set, you can translate to by adding a prefix of onto all the o-histories and specifying that the partial policy behaves appropriately to make the finite history occur. In the reverse direction, you can take a partial policy capable of producing , remove all o-histories without as a prefix, and remove the prefix from whatever is left.
Definition 24: History-Clip
is the partial function that takes an o-history and clips the prefix off, and is otherwise undefined. There's an implicit dependence on the history that we're suppressing in the notation.
Definition 25: Off-History Policy
is some partial policy in that's defined everywhere except on o-histories with as a prefix, and is also consistent with the history . It specifies everything except what happens after , and can produce .
Definition 26: Policy Gluing
is the partial policy made by extending to be a partial policy in and unioning that with . More simply, it's the policy made by "specify all what you do off-h, and glue that on to what you do on-h"
Also, now that we know how normalization works, we can define an analogue of our scale term that showed up in updating an infradistribution.
Definition 27: Probability
is the probability of history relative to the belief function , off-h policy , and function .
An important thing to note about these is that they're not additive, and it's probably better to think about them as the scale term necessary to renormalize after updating than as a true probability. However, various results end up using this where the analogous result in the standard Bayesian setting would have standard probability, so it plays a very similar role. And it recovers the usual notion of probability in the special case of one environment.
The rationale for this definition is that we want the worst possible case to have a value of 0, and the best possible case to have a value of 1. This requires rescaling by the gap between the worst-case and best-case outcomes. Further, we know some information about our policy (it behaves as does off-h, so the policy we selected must be above that), and our utility function off-history (it's ). Thus, the best-case is , and the worst-case is . Further, we can prove .
So, that's where this definition comes from. The gap between best-case and worst-case payoffs plays the analogous role to probability, and knowing and gives you some info on what your best-case and worst-case outcomes are.
One more note. We'll use to refer to the measure , chopping down the measure to only the histories with as a prefix. No renormalization back up afterwards.
Finally, we can define an update.
Definition 28: Belief Function Update
is the set made by intersecting with
pushing it through the following function, and taking the closure.
This process is: In order to find out what happens for a partial policy post-h, we glue it to a complete specification of what happens off-h , clip away a bit of so that infinite reward off-h doesn't contaminate the term, do some bookkeeping to prune the prefixes off the post-h conditional measure we get, update, and renormalize. Then close if needed.
With all this extra detail, it's highly prudent to check the basic properties of an update. Fortunately, we have analogues of everything.
Proposition 9: For causal, surcausal, pseudocausal and acausal hypotheses, updating them produces a causal, surcausal, pseudocausal or acausal hypothesis as long as renormalization doesn't fail.
Proposition 10: For causal, pseudocausal, acausal, and surcausal hypotheses,
If you're wondering what is, it's the restriction of to outcomes with as a prefix, and then the prefix gets clipped off. This is another bookkeeping thing.
Proposition 11: If is a valid o-history, then for causal, pseudocausal, acausal, and surcausal hypotheses,
Ah good, we have analogues of all the usual update properties. What about our Bayes Theorem analogue?
Theorem 4: Belief Function Bayes: For pseudocausal and acausal hypotheses, if there's some s.t. is well-defined and nontrivial, then
So, mixing hypotheses to make a prior, normalizing it, and updating, is the same as mixing the updated hypotheses in accordance with the probability they put on the observation, and rescaling that. Compare to Bayesian updating going "if you mix hypotheses to make a prior, and update, that's the same as mixing the updated hypotheses in accordance with the probability they put on the observation". Also, this means we don't generally have to worry about the agent giving up and crying when something in its prior says "nothing you do matters", because it'll just drop out of the updated prior completely and we can ignore it. So, as long as something in the prior says that what the agent does matters, we're good.
Decision Theory
Ok, the first, most basic thing we want is dynamic consistency. Does dynamic consistency work? Yes it does!
Theorem 5: Dynamic Consistency: Given a hypothesis (causal, pseudocausal, acausal, surcausal), and an arbitrary policy and utility function , then, with being the continuation of post-update, being the off-h behavior of , and being such that
then
Ok, may be confusing. This is shorthand for "if we have a in the first part, then we have a for the second part, and same for and ".
So, viewed from the start, you perfectly agree with future-you-that-updated-on-'s judgement. If they think a policy does better than the default candidate you stuck them with, you should defer to them. If they think a policy does worse than the default you stuck them with, you also agree with them on that too. So, there's no situations where you disapprove of future-you's decisions when they update on a history.
Ok, that's cool, but how does this thing stack up against UDT? Well, let's take an arbitrary set of policy-selection environments. A policy selection environment is a function that is continuous in , so very late policy changes don't affect the probability distribution now very much. This doesn't necessarily assume you're predicted accurately! If the environment ignores your policy, it's just an ordinary environment, and if there's a noisy predictor, well, that's why we have . This covers any reasonable way in which the environment could depend on your policy.
does need to have a uniform modulus of continuity, though. Ie, for all , there needs to be some ridiculously large time where two policies that are identical up till time mean that every policy selection environment in only has its behavior now varying by , for all . If we're just encoding finitely many policy-selection environments, we automatically get this property.
Theorem 6: Maximin UDT: Translating a set of policy selection environments with a uniform modulus of continuity to an acausal hypothesis (via making a where , and turning it into an acausal hypothesis by the procedure in Proposition 2) always works. Also, for all utility functions ,
So, this thing acts as maximin UDT on sets of policy-dependent environments, and in the case where there's a single policy-dependent environment, it replicates UDT perfectly. Nice!
Lets ponder the bestiary of decision-theory problems. Note that the following analysis is cheating, in a sense. It just assumes that we have the proper hypothesis corresponding to the problem encoded in our head, it doesn't cover learnability of the problem if we don't start out with the correct model. Much more interesting is whether we can learn a given decision theory problem, given some suitably broad prior, if we're repeatedly faced with it. Also, the "you should know your entire policy off-history" thing is just for defining the theoretical gold standard, real agents don't fulfill this property.
5-and-10 falls immediately.
Troll bridge is a bit interesting because we always have deterministic policies. We could stipulate that we always have an accurate internal sense of which action we meant to take, but it goes through a RNG first and we may end up exploring with that. We cross (the internal event of crossing means you probably cross, with a small chance of staying on the shore, the internal event of not-crossing means you probably don't cross, with a small probability of getting blown up on the bridge).
Doing what UDT would means we also get XOR blackmail, Counterfactual Mugging, Newcomb, Transparent Newcomb, and the version of Death In Damascus where you have to pay for a random coin to escape Death, along with many others.
We haven't yet crammed Absent-Minded Driver into this setting, because of the assumption that you know your past history. Maybe more on that later?
More interesting is which of these decision theory problems are pseudocausal vs acausal. Counterfactual Mugging, Newcomb, Death In Damascus, and XOR Blackmail are pseudocausal. Transparent Newcomb is also pseudocausal if there's some small probability of Omega making a mistake. Really, the issue is with problems where you have 0 probability of getting into a situation where you can prove a false prediction wrong, like perfect Transparent Newcomb. Perfect predictors aren't a problem, as long as you're dealing with a situation where you have to make a bad situation worse locally in exchange for making the situation impossible in the first place. They're only a problem (ie, make an acausal instead of pseudocausal hypothesis) for decision theory problems where you're like "I'll make this good situation worse locally in exchange for making the situation possible in the first place", because false predictions lock you out in that case.
Also, there's material on learnability and infra-POMDP's and Game Theory and "we have a theorem prover, what do we do with that" deferred for a later post. We're still working on this stuff, and the field feels unusually broad and tractable.
Let's finish up by presenting some material on learnability, and a proof sketch for the analogue of the Complete Class Theorem.
Definition 29:
Use to refer to the prefix string of the first actions and observations for an infinite history . Given a reward function , and a time-discount parameter , is the utility function generated from and via:
If is near 1, this is low time-discount. An important notation note is that is used to denote some generic utility function, but is more like a utility function template, with the reward function specified, but still missing the time-discount factor necessary to make it an actual utility function.
Let's define regret in the standard Bayesian case. For some environment and utility function , the regret of policy is
Ie, regret is the gap between the best possible value you could get on the environment, and the value you actually got.
In the Bayesian case, learnability of a set of environments w.r.t a family of utility functions is: There exists some -indexed family of policies, , where:
So, this means that there's some policy which takes in the time discount and decides what to do, and regardless of environment, you can find a really low time discount where the policy nearly matches the performance of a policy which starts out knowing what the true environment is.
Learnability can be thought of as a sort of weak no-traps condition. A trap is something that makes you lose a nonneglible amount of value in the low-time-discount limit. If you can learn a class of environments, that means that there's some policy that (in the low-time-discount limit), doesn't run into traps and figures out how to be near-optimal for the environment, no matter which environment in the class it finds itself in.
Also, there's a notion of a Bayes-optimal family of policies. Given some nondogmatic (nothing with probability 0) prior over environments , which can be viewed as one big environment , a Bayes-optimal family of policies is one where, for all ,
One of the most basic results of learnability in the standard Bayesian setting is that if a collection of environments is learnable at all, then if we make any nondogmatic prior out of them, the Bayes-optimal family of policies for that prior will learn that collection of environments as well.
Now let's transplant these to our setting.
Definition 30: Regret
The regret of the policy on the hypothesis with utility function is
Regret, as usual, is "what's the gap between the value Murphy forced for you, and the value Murphy forced for the optimal policy?" And then learnability of a family of hypotheses turns into:
Definition 31: Learnability
For a family of utility functions , a family of hypotheses is learnable if there is a -indexed family of policies , where
So, on every hypothesis in the family, you converge to having similar worst-case value as the optimal policy which already knows which component hypothesis it's in.
Fixing some prior , and abbreviating it as , there's a notion of a Bayes-optimal family of policies for the prior.
Definition 32: InfraBayes-Optimal Family
An InfraBayes-optimal family of policies w.r.t. a prior is one where, for all ,
So, we've got nice parallels of everything. But do we still have the same result that an InfraBayes-optimal family for a prior will learn a collection of hypotheses if it's learnable? Yes.
Proposition 12: If a collection of hypotheses is learnable, then any InfraBayes-optimal family for a prior on them also learns the collection of hypotheses as well.
Now, what about the Complete Class Theorem? Let's say there are finitely many states , observations , and actions , a function that tells you the probabilities of observations given the state, and a payoff function . Then we can view a policy as a function , given by .
The standard formulation of the Complete Class Theorem permits mixtures between policies, and anything on the Pareto-frontier has some probability distribution over states where it's optimal. In our case, we (probably) have something much stronger. We stick with our deterministic policies.
Definition 33: Convexity Property
A total order on equivalence classes of policies ( and are in the same equivalence class iff ,) fulfills the convexity property if, viewing the as points in ,
To sum up what we've done so far, we associated each policy with its corresponding function from states to expected payoffs. We consider policies equivalent if they have the same expected payoff for all states, and then stick a total order on them. The convexity property says that if Pareto-dominates, or equals, a state-to-payoff function made by mixing policies that outperform (according to the total order), then it must outperform as well. For any Pareto-optimal policy, we can make an ordering like this that puts it as the highest-ranked policy.
Complete Class Conjecture: If we have a total order over equivalence classes of policies that fulfills the convexity property, then there exists an infradistribution over states, , where
So, we can (probably, still a conjecture) match a wide variety of rankings of policies. Such an infradistribution can be thought of as a set of a-environments (with the appropriate mix of states comprising the environment), and then thought of as a causal hypothesis without Nirvana.
Well, what's the proof sketch of this? Why do we think it's true? By Theorem 5 of the previous post, there's a duality between infradistributions and concave monotone Lipschitz normalized functionals on (the space of continuous functions on states). So, viewing our policies as points in , we just need to craft a suitable function. We can do something like this.
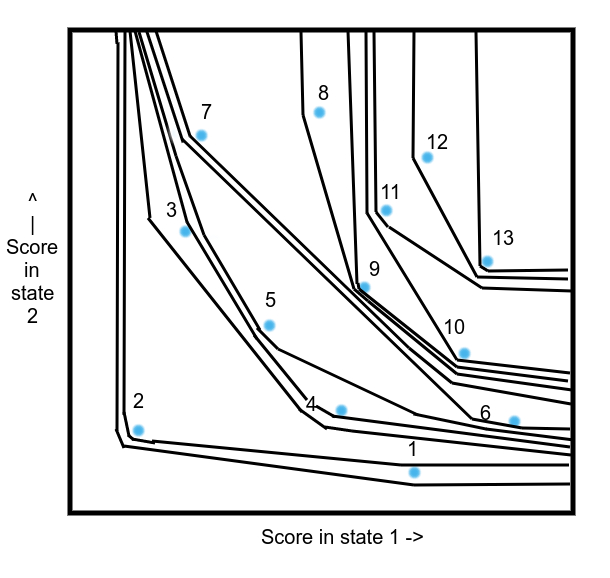
The points are the score of the policies in the states, and the number over them is their ranking in the partial order, from worst to best. What we do is basically make a topographic map that's compatible with the partial order, like we did here. Except in more dimensions. Assigning each contour line from worst to best to an elevation/value, and filling in the rest of the values by linear interpolation, we can get a quasiconcave monotone Lipschitz function (quasiconcave is just that all superlevel sets are convex, which we obviously have) where 0 in all coordinates is assigned the lowest value, and 1 is assigned the highest value, and it respects the total ordering we have.
Then, we just have to turn this into a concave function and renormalize to get a function of the proper form, which we can turn into an infradistribution. Fortunately, there's a process called concavification, which lets you adjust the values assigned to the topographic contour lines to make a concave function. It's detailed in this paper. The one issue is that the conditions you have to verify are pretty nightmarish. Two of the three look fine, the nightmarish one is the third condition in Theorem 3 about having uniformly bounded variation of the logarithm of the upper derivative along all strictly increasing geodesic paths when we warp our function in a certain way. That's why this is still a conjecture.
There is, however, a weaker version of the Complete Class Theorem we were able to prove, the one where we can pick any Pareto-optimal policy and come up with an infradistribution over states where it is indeed optimal.
Complete Class Theorem Weak Version: Given any Pareto-optimal policy , then there is an infradistribution over states, where
A proof sketch for why this is true is: Because we are able to translate from concave Lipschitz monotone normalized functionals over to infradistributions over states, we just have to get a concave Lipschitz monotone functional where our policy is optimal, and then it can be normalized back up to 1, and then it can be turned into an infradistribution over states by LF-duality. Said concave Lipschitz monotone functional is:
If is some (the payoff function induced by a policy ), then this can be rewritten as:
And so, now it's clearer what this means, the infradistribution picks the state where has the largest advantage over . is Pareto-optimal, so there's always a state where does strictly better than .
And that's about it for this post. On to further results and glory! (in progress)
7 comments
Comments sorted by top scores.
comment by Alex Flint (alexflint) · 2021-01-04T13:24:14.736Z · LW(p) · GW(p)
Thank you for your work both in developing this theory and putting together this heroic write-up! It's really a lot of work to write all this stuff out.
I am interested in understanding the thing you're driving at here, but I'm finding it difficult to navigate because I don't have much of a sense for where the definitions are heading towards. I'm really looking for an explanation of what exactly is made possible by this theory, so that as I digest each of the definitions I have a sense for where this is all heading.
My current understanding is that this is all in service of working in unrealizable settings where the true environment is not in your hypothesis class. Is that correct? What exactly does an infrabayesian agent do to cope with unrealizability?
Replies from: Diffractor↑ comment by Diffractor · 2021-01-05T06:06:48.975Z · LW(p) · GW(p)
So, first off, I should probably say that a lot of the formalism overhead involved in this post in particular feels like the sort of thing that will get a whole lot more elegant as we work more things out, but "Basic inframeasure theory" still looks pretty good at this point and worth reading, and the basic results (ability to translate from pseudocausal to causal, dynamic consistency, capturing most of UDT, definition of learning) will still hold up.
Yes, your current understanding is correct, it's rebuilding probability theory in more generality to be suitable for RL in nonrealizable environments, and capturing a much broader range of decision-theoretic problems, as well as whatever spin-off applications may come from having the basic theory worked out, like our infradistribution logic stuff.
It copes with unrealizability because its hypotheses are not probability distributions, but sets of probability distributions (actually more general than that, but it's a good mental starting point), corresponding to properties that reality may have, without fully specifying everything. In particular, if an agent learns a class of belief functions (read: properties the environment may fulfill) is learned, this implies that for all properties within that class that the true environment fulfills (you don't know the true environment exactly), the infrabayes agent will match or exceed the expected utility lower bound that can be guaranteed if you know reality has that property (in the low-time-discount limit)
There's another key consideration which Vanessa was telling me to put in which I'll post in another comment once I fully work it out again.
Also, thank you for noticing that it took a lot of work to write all this up, the proofs took a while. n_n
↑ comment by Alex Flint (alexflint) · 2021-01-05T13:00:56.415Z · LW(p) · GW(p)
Ah this is helpful, thank you.
So let's say I'm estimating the position of a train on a straight section of track as a single real number and I want to do an update each time I receive a noisy measurement of the train's position. Under the theory you're laying out here I might have, say, three Gaussians N(0, 1), N(1, 10), N(4, 6), and rather than updating a single pdf over the position of the train, I'm updating measures associated with each of these three pdf. Is that roughly correct?
(I realize this isn't exactly a great example of how to use this theory since train positions are perfectly realizable, but I just wanted to start somewhere familiar to me.)
Do you by chance have any worked examples where you go through the update procedure for some concrete prior and observation? If not, do you have any suggestions for what would be a good toy problem where I could work through an update at a very concrete level?
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-01-31T19:42:12.665Z · LW(p) · GW(p)
I'm not sure I understood the question, but the infra-Bayesian update is not equivalent to updating every distribution in the convex set of distributions. In fact, updating a crisp infra-distribution (i.e. one that can be described as a convex set of distributions) in general produces an infra-distribution that is not crisp (i.e. you need sa-measures to describe it or use the Legendre dual view).
comment by DanielFilan · 2021-02-25T23:04:15.499Z · LW(p) · GW(p)
In definition 20 you have
I'm kind of confused here: what's , and isn't a single action? [EDIT: oops, forgot that was nirvana]
Replies from: DanielFilan↑ comment by DanielFilan · 2021-02-25T23:18:46.927Z · LW(p) · GW(p)
Also, after theorem 3.2:
First, they let us freely translate between psuedocausal/acausal and causal/surcausal.
Looks like 'causal' and 'acausal' are swapped here?
Replies from: DanielFilan↑ comment by DanielFilan · 2021-02-25T23:20:48.745Z · LW(p) · GW(p)
Lets ponder the bestiary of decision-theory problems
"Lets" should be "Let's"