The Many Faces of Infra-Beliefs
post by Diffractor · 2021-04-06T10:43:53.227Z · LW · GW · 6 commentsContents
Basic Concepts to Read Type Signatures Hypothesis Type Signatures Type Translation (Informal) Belief Functions (Informal) Recap of Inframeasure Theory Infradistribution Ordering, Top, and Bottom Updating the Right Way Deconfusing the Cosmic Ray Problem Other Inframeasure Operations Definition 1: Regular Infrakernel Conditions Belief Function Properties Definition 2: Belief Function Conditions The Acausal Commutative Square The Pseudocausal Commutative Square Definition 3: Pseudocausality The Causal Commutative Square Definition 4: Causality Alternate Phrasing of Causality: Translating Between Belief Function Conditions x-Pseudocausality Definition 5: x-Pseudocausality Definition 6: x-Pseudocausality (variant) Future Directions None 6 comments
The notion of "hypothesis" isn't formalized well enough enough to pin down the precise type signature of hypotheses.
It could just be a probability distribution over all possible ways the world could be for all time, a third-person static view.
Or, it could be some sort of causal process, like a Markov chain, which specifies the dynamics for how states transition to other states. This would be a third-person dynamic view.
There are also first-person views. POMDP's (Partially Observable Markov Decision Processes), from classical reinforcement learning, would be a first-person dynamic view. These have type signature ( is the space of states, is the space of actions, and is the space of observations).
A first-person static view would be a function that maps policies to probability distributions over histories. This is the land of policy-selection problems and UDT.
Accordingly, it seems mathematically fruitful to remain agnostic on the "right" type signature for a hypothesis, and instead focus on what conditions let us faithfully translate between the different possible type signatures. This post does not solve this issue, but it sheds considerable light on aspects of it.
For infra-Bayesianism, instead of using probability distributions, we instead wield infradistributions as our basic tool. A concrete example of an infradistribution is a set of probability distributions. Sets of probability distributions are extensively studied in the preexisting field of Imprecise Probability, though infradistributions are considerably more general than that. This added generality permits capturing and analyzing some phenomena which can't be studied with probability distributions (or sets of probability distributions) alone. However, infradistributions still retain many close parallels with classical probability theory, with analogues of updates, entropy, semidirect products, priors, and much more. The two previous posts Basic Inframeasure Theory [? · GW] and Less Basic Inframeasure Theory [AF · GW] were the analogue of a measure theory textbook for this new setting, and hold up quite well in retrospect.
The post Belief Functions and Decision Theory [? · GW] attempted to construct the analogue of an environment in classical reinforcement learning. Our fundamental structure in that post was a "Belief Function" which mapped (partially-defined) policies to inframeasures over (partially-defined) histories . We showed some basic results about belief functions, such as: how to do dynamically consistent (ie UDT-compliant) updates, how to recover the entire belief function from only part of its data, and how to translate between different sorts of belief functions by adding an imaginary state of infinite reward, called "Nirvana".
With the benefit of hindsight, Belief Functions and Decision Theory [? · GW] is a somewhat embarrassing post, which suffers from a profusion of technical machinery and conditions and hacks due to being written shortly after becoming able to write it, instead of waiting for everything to become elegant.
This post will be taking a more detailed look at the basic concepts introduced in Belief Functions and Decision Theory [? · GW], namely acausal, pseudocausal, and causal belief functions. In this post, we will characterize these sorts of belief functions in several different ways, which are closely linked to translations between the different types of hypotheses (static vs dynamic, third-person vs first-person). The different properties a belief function is equipped with have clear philosophical meaning. Different sorts of belief function require different state spaces for a faithful encoding. And the properties of an infra-POMDP dictate which sort of belief function will be produced by it.
Additionally, the reformulations of different sorts of belief functions, and how to translate between the different type signatures for a hypothesis, are very interesting from a decision theory standpoint. I feel noticeably deconfused after writing this post, particularly regarding the tension between conditioning/hypotheses without an action slot, and causality/hypotheses with an action slot. It turns out that if you just use the most obvious way to convert a third-person hypothesis into a first-person one, then the Nirvana trick (add an imaginary state of maximum utility) pops out automatically.
This goes a long way to making Nirvana look like less of a hack, and accounts for where all the "diagonalize against knowing what you do" behavior in decision theory is secretly spawning from. Modal Decision Theory [AF · GW], upon seeing a proof that it won't do something, takes that action, and Logical Inductor Decision Theory [AF · GW] requires randomizing its action with low probability for all the conditional expectations to be well-defined. In both cases, we have an agent doing something if it becomes sufficiently certain that it won't do that thing. This same behavior manifests here, in a more principled way.
Also, in this post, the Cosmic Ray Problem [AF · GW] (a sort of self-fulfilling negative prophecy problem for Evidential Decision Theory) gets dissolved.
We apply concepts from the previous three posts, Basic Inframeasure Theory [? · GW], Belief Functions and Decision Theory [? · GW], and Less Basic Inframeasure Theory [? · GW]. However, in the interests of accessibility, I have made an effort (of debateable effectiveness) to explain all invoked concepts from scratch here, as well as some new ones. If you've read all the previous posts, it's still worth reading the recaps here, new concepts are covered. If you haven't read all the previous posts, I would say that Introduction to the Infra-Bayesianism Sequence [? · GW] is a mandatory prerequisite, and Basic Inframeasure Theory [? · GW] is highly advised. Some fiddly technical details will be glossed over.
The overall outline of this post is that we first introduce a bare minimum of concepts, without formal definitions, to start talking informally about the different type signatures for a hypothesis, how to translate between them, and what the basic sorts of belief functions are.
Then we take a detour to recap the basics of inframeasures, from previous posts. To more carefully build up the new machinery, we first discuss the ordering on infradistributions to figure out what and would be. Second, we embark on an extensive discussion about how updating works in our setting, why renormalization isn't needed, and "the right way to update", which dissolves the Cosmic Ray problem and explains where diagonalization comes from. Third, we recap some operations on inframeasures from previous posts, like projection, pullback, and the semidirect product.
Then it's time to be fully formal. After a brief pause where we formalize what a belief function is, we can start diving into the main results. Three times over, for acausal, psuedocausal, and causal belief functions, we discuss why the defining conditions are what they are, cover the eight translations between the four hypothesis type signatures, state our commutative square and infra-POMDP theorems, and embark on an philosophical discussion of them ranging from their diagonalization behavior to discussion of what the POMDP theorems are saying to alternate interpretations of what the belief function conditions mean.
There's one last section where we cover how to translate from pseudocausal to causal faithfully via the Nirvana trick, and how to translate from acausal to pseudocausal (semifaithfully) via a family of weaker variants of pseudocausality. Again, this involves philosophical discussion motivating why the translations are what they are, and then diving into the translations themselves and presenting the theorems that they indeed work out.
Finally, we wrap up with future research directions.
As you can probably tell already by looking at the scrollbar, this post is going to be really long. It might be worth reading through it with someone else or getting in contact with me if you plan to digest it fully.
The 5 proof sections are here. (1 [AF · GW], 2 [AF · GW], 3 [AF · GW], 4 [AF · GW], 5 [AF · GW])
Basic Concepts to Read Type Signatures
is used for some space of states. It must be a Polish space. If you don't know what a Polish space is, don't worry too much, it covers most of the spaces you'd want to work with in practice.
and are some finite sets of actions and observations, respectively.
and are the space of infinite sequences of states, and the space of histories, respectively. is the space of finite sequences of actions and observations, finite histories.
is the space of deterministic policies , while is the space of deterministic environments . Deterministic environments will often be called "copolicies", as you can think of the rest of reality as your opponent in a two-player game. Copolicies observe what has occurred so far, and respond by selecting an observation, just as policies observe what has occured so far and respond by selecting an action. This is closely related to how you can transpose a Cartesian frame [? · GW], swapping the agent and the environment, to get a new Cartesian frame.
In the conventional probabilistic case, we have as the space of probability distributions over a space , and Markov kernels (ie, probabilistic functions) of type which take in an input and return a probability distribution over the output. But, we're generalizing beyond probability distributions, so we'll need analogues of those two things.
is the space of infradistributions over the space , a generalization of , and is the space of inframeasures over . We'll explain what an inframeasure is later, this is just for reading the type signatures. You won't go wrong if you just think of it as "generalized probability distribution" and "generalized measure" for now. Special cases of infradistributions are closed convex sets of probability distributions (these are called "crisp infradistributions"), though they generalize far beyond that.
The analogue of a Markov kernel is an infrakernel. It is a function which takes an input and returns your uncertainty over . Compare with the type signature of a Markov kernel. This is also abbreviated as .
Less Basic Inframeasure Theory [? · GW] has been using the word "infrakernel" to refer to functions with specific continuity properties, but here we're using the word in a more broad sense, to refer to any function of type signature , and we'll specify which properties we need to assume on them when it becomes relevant.
Also, since we use it a bunch, the notation is the probability distribution that puts all its probability mass on a single point .
We'll be going into more depth later, but this should suffice to read the type signatures.
Hypothesis Type Signatures
To start with our fundamental question from the introduction, what's the type signature of a hypothesis? The following discussion isn't an exhaustive classification of hypothesis type signatures, it's just some possibilities. Further generalization work is encouraged.
Third-person hypotheses are those which don't explicitly accept your action as an input, where you can only intervene by conditioning. First-person hypotheses are those which explicitly accept what you do as an input, and you intervene in a more causal way.
Static hypotheses are those which don't feature evolution in time, and are just about what happens for all time. Dynamic hypotheses are those which feature evolution in time, and are about what happens in the next step given what has already happened so far.
We can consider making all four combinations of these, and will be looking at those as our basic type signatures for hypotheses.
First, there is the static third-person view, where a hypothesis is some infradistribution in (which captures your total uncertainty over the world). is interpreted to be the space of all possible ways the universe could be overall. There's no time or treating yourself as distinct from the rest of the world. The only way to intervene on this is to have a rule associating a state with how you are, and then you can update on the fact "I am like this".
Second, there is the dynamic third-person view, where a hypothesis is a pair of an infradistribution in (which captures uncertainty over initial conditions), and an infrakernel in (which captures uncertainty over the transition rules). Here, is interpreted to be the space of possible ways the universe could be at a particular time. There's a notion of time here, but again, the only way to intervene is if you have some rule to associate a state with taking a particular action, which lets you update on what you do.
It's important to note that we won't be giving things the full principled Cartesian frame treatment here, so in the rest of this post we'll often be using the type signature for this, which tags a state with the observable data of the action and observation associated with it.
Third, there is the static first-person view, where a hypothesis is some infrakernel (which captures your uncertainty over your history, given your deterministic policy) This will often be called a "Belief Function". See Introduction to the Infra-Bayesianism Sequence [? · GW] for why we use deterministic policies. There's no notion of time here, but it does assign a privileged role to what you do, since it takes a policy as input.
And finally, there's the dynamic first-person view. Also called infra-POMDP's. A hypothesis here is a pair of a infradistribution in (which captures uncertainty over initial conditions) and an infrakernel in (which captures uncertainty over the transition rules, given your action). There's a notion of time here, as well as assigning a privileged role to how you behave, since it explicitly takes an action as an input.
Type Translation (Informal)
We can consider the four views as arranged in a square like this, where the dynamic views are on the top, static views are on the bottom, third-person views are on the left, and first-person views are on the right.
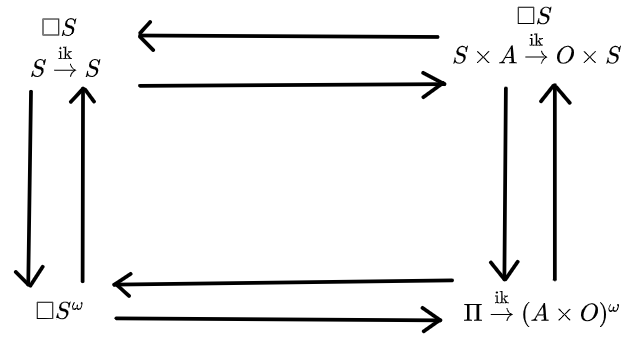
We want some way to translate hypotheses from various corners of the square to other corners of the square. Keep this image in mind when reading the additional discussion.
To start off with bad news re: the limited scope of this post, it's mainly about whether we can find state spaces for a given property X which:
1: Are "rich enough", in the sense of being able to faithfully encode any belief function (first-person static view, bottom-right corner) fulfilling property X.
2: Aren't "too rich", in the sense of being able to take any infradistribution over that state space, and automatically getting a belief function fulfilling property X if you try to translate it over to a first-person static view.
3: Are well-behaved enough to get the entire square to commute.
The commutative square theorems (which will show up later) are almost entirely about getting this sort of characterization for belief functions, which requires using rather specific state spaces. Also the type signatures for the formal theorems will be off a bit from what we have here, like the upper-left corner being , but the basic spirit of this square still holds up.
However, some of these translations can work in much more generality, for arbitrary state spaces. So this section is going to be about conveying the spirit of each sort of translation between hypothesis types, in a way that hopefully continues to hold under whichever unknown future results may show up. There are some differences between the following discussion and our fully formal theorems later on, but it's nothing that can't be worked out at lunch over a whiteboard.
Some more interesting questions are "What state spaces and third-person views let you extract a first-person view via bridging laws? What happens to the first-person views when the third-person view permits the death of the agent or other failures of the Cartesian barrier? To what extent can you infer back from a first-person view to unknown state spaces? If you have two different third-person views which induce the same first-person beliefs, is there some way to translate between the ontologies?"
Sadly, these questions are beyond the scope of this post (it's long enough as-is), but I'm confident we've amassed enough of a toolkit to leave a dent in them. Onto the eight translation directions!
1: To go from third-person static () to first-person static ()... Well, given an element of , you need the ability to check what the associated policy is somehow, and the ability to read an action-observation sequence out of the element of . If you have that, then you can just take a policy, update your third-person hypothesis about the history of the universe on the event "this policy was played", and read the action-observation sequence out of the result to get an inframeasure over action-observation sequences. This gives you a function , as desired.
2: To go from first-person static () to third-person static ()... It's easily doable if the state of the world is fully observable, but rather tricky if the state of the world isn't fully observable. If you have a function , there's a canonical way to infer backwards, called the pullback, which behaves a lot like the preimage of a function. So, given an inframeasure over , and a policy, you can take the pullback to get an inframeasure over . Then just take the disjunction/union of all those pullbacks (indexed by ), as that corresponds to total uncertainty/free will about which policy you'll pick. Bam, you've made an infradistribution over .
To sum up, you just infer back from observable history to unobservable history and have total uncertainty over which policy is played, producing a third-person static view which thinks you have free will.
3: To go from third-person dynamic ( and ) to third-person static (), you just repeatedly apply the transition kernel. This is exactly the move you do to go from a probabilistic process operating in time to a probability distribution over the history of what happens. This works for arbitrary state spaces.
4: To go from third-person static () to third-person dynamic ( and )... Well, to be honest, I don't know yet in full generality how to infer back from uncertainty over the world history to uncertainty over the transition rules, and you'd probably need some special conditions on the third-person static infradistribution to do this translation at all.
There's a second solution which admittedly cheats a bit, that we'll be using. You can augment your dynamic view with a hidden destiny state in order to tuck all your uncertainty into the starting conditions. More formally, the starting uncertainty for the dynamic view can be an element of (which is the same as the third-person static uncertainty), and the transition kernel is of type , mapping to . The interpretation of this is that, if there's some weird correlations in the third-person static view which aren't compatible with the transition dynamics being entirely controlled by the state of the world, you can always just go "oh, btw, there's a hidden destiny state controlling all of what happens", tuck all your uncertainty into uncertainty over the initial conditions/starting destiny, and then the state transitions are just the destiny unfolding.
5: To go from third-person dynamic ( and ) to first-person dynamic ( and ), we follow a very similar pattern as the third-person static to first-person static translation process. We start with a state and action . We run through the third-person transition kernel, and update the output on the event "the action is ". Then just take the post-update inframeasure on , extract the observation, and bam, you have an inframeasure over .
So, to sum up, third-person to first-person, in the static case, was "update on your policy, read out the action-observation history". And here, in the dynamic case, it's "transition, update on your action, then read out the state and observation".
6: For first-person dynamic ( and ) to third-person dynamic ( and ), again, it's similar to first-person static to third-person static. In the static case, we had total uncertainty over our policy and used that to infer back. Similarly, here, we should have total uncertainty over our next action.
You start with a state . You take the product of that with complete uncertainty over the action to get an infradistribution over , and then run it through the first-person infrakernel to get an infradistribution over . Then just preserve the state.
7: Going from first-person dynamic ( and ) to first-person static () can be done by just taking the policy of interest, repeatedly playing it against the transition kernel, and restricting your attention to just the action-observation sequence to get your uncertainty over histories. It's the same move as letting a policy interact with a probabilistic environment to get a probability distribution over histories. In both dynamic-to-static cases, we unroll the transition dynamics forever to figure out all of what happens. It works for arbitrary state spaces.
8: Going from first-person static () to first-person dynamic ( and ) is tricky. There's probably some factorization condition I'm missing to know whether a given state space is rich enough to capture a belief function in, analogous to how I don't know what conditions are needed to go from an infradistribution over to an infrakernel .
Well, what would be the analogue of our solution on the third-person side where we just whipped up a hidden destiny state controlling everything, and had really simple transition dynamics like "destiny advances one step"? Well, for each policy you have an inframeasure over . You can take the disjunction/union them all together since you've got free will over your choice of policy and you don't know which policy you'll pick, and that yields an infradistribution over , (or something like that), which can be your state space of hidden destinies.
But then there's something odd going on. If the type signature is
and we interpret the hidden state as a destiny, then having the action match up with what the destiny says is the next action would just pop the observation off the front of the destiny, and advance the destiny by one step. This is the analogue of the really simple "the destiny just advances one step" transition dynamics for the third-person dynamic view. But then... what the heck would we do for impossible actions?? More on this later.
To conclude, the net result is that we get the following sort of square, along with how to translate between everything (though, to reiterate, we won't be using these exact type signatures, this just holds in spirit)
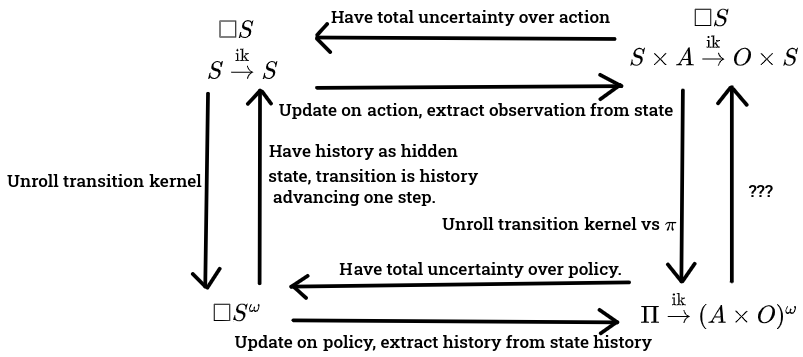
Of course, when one is faced with such a suggestive-looking diagram, it's natural to go "can we make it commute"?
Belief Functions (Informal)
As it turns out, acausal, pseudocausal, and causal belief functions, which were previously a rather impressive mess of definitions, can be elegantly described by being the sorts of infrakernels that make a diagram similar to the above one commute. Different sorts of belief functions can be characterized by either different state spaces showing up in the first-person static view, the belief function itself possessing certain properties, or being the sort of thing that certain sorts of infra-POMDP's produce when you unroll them (top-right to bottom-right translation in the square)
Feel free to skip the next paragraph if the first sentence of it doesn't describe you.
If you've already read Belief Functions and Decision Theory [? · GW], and are wondering how infrakernels connect up to the old phrasing of belief functions... It's because of the Isomorphism Theorem. Which said you could uniquely recover the entire (old) belief function from either: the behavior of the belief function on the policy stubs, or the behavior of the belief function on full policies. Since we can recover the entire (old) belief function from just the data on which policies map to which inframeasures over histories, we only need a function mapping policies to inframeasures over histories, and that's enough. Moving on...
Acausal belief functions (ie, any infrakernel fulfilling the belief function properties, to be discussed later) make a commutative square with the state space being . (Well, actually, the subset of this space where the history is guaranteed to be consistent with the choice of policy). States are "policy-tagged destinies", which tell you what the policy is and what is destined to occur as a result. For acausal belief functions, the dynamic views with the transition kernels feel rather forced, and the static views are more natural. With these, your effect on reality is implemented entirely by updating on the policy you chose, which pins down the starting state more, and then destiny unfolds as usual.
Pseudocausal belief functions, which were previously rather mysterious, make a commutative square with the state space being . States are "destinies", which tell you what is destined to occur. The most prominent feature of pseudocausality is the Nirvana trick manifesting in full glory in the dynamic first-person view. Since the state space is , the first-person view transition kernel ends up being of type
Said transition kernel is, if the action matches up with what the destiny indicates, you just pop the observation off the front of the destiny and advance the destiny one step ahead. But if the action is incompatible with the destiny, then (in a very informal sense, we're still not at the math yet) reality poofs out of existence and you get maximum utility. You Win. These transition dynamics yield a clear formulation of "decisions are for making bad outcomes inconsistent".
And finally, causal belief functions are those which make a commutative square with the state space being , the space of deterministic environments, with type signature . The transition dynamics of the dynamic first-person view
is just the environment taking your action in, reacting with the appropriate observation, and then the environment advances one step. Notably, all actions yield a perfectly well-defined result, there's none of these "your action yields maximum utility and reality poofs out of existence" shenanigans going on. The first-person view of causal belief functions is much more natural than the third-person one, for that reason.
So, to summarize...
Acausal: Belief functions which capture any possible way in which your results can depend on your policy. This corresponds to a view where your policy has effects by being a mathematical fact that is observed by things in the environment.
Pseudocausal: Belief functions which capture situations where your results depend on your policy in the sense that You Win if you end up in a situation where you defy destiny. The probability distribution over destinies is being adversarially selected, so you won't actually hit an inconsistency. This corresponds to a view where your policy has effects via the actions making bad destinies inconsistent.
Causal: Belief functions which capture situations where your results depend on your actions, not your policy. This corresponds to a view where your policy has effects via feeding actions into a set of probabilistic environments.
Recap of Inframeasure Theory
Time to start digging into the mathematical details.
An a-measure (affine measure) over a space is a pair , where is a measure over , and is a number , which keeps track of guaranteed utility. We do need a-measures instead of mere probability distributions, to capture phenomena like dynamically consistent updates, so this is important. Sa-measures are similar, they just let the measure component be a signed measure (may have regions of negative measure) fulfilling some restrictions. Sa-measures are only present for full rigor in the math, and otherwise aren't relevant to anything and can be ignored from here on out, as we will now proceed to do.
Given a continuous bounded function or , you can take the expectation of with respect to a set of a-measures , by going:
From now on, we write as just . This is the expectation of a function with respect to a measure.
Looking at this equation, the expectation of a function with respect to a set of a-measures is done by taking the expectation with respect to the measure component, and adding on the term as guaranteed utility, but using the worst-case a-measure in your set. Expectations with respect to a set of a-measures are worst-case, so they're best suited for capturing adversarial situations and guaranteed utility lower bounds. Of course, in reality, things might not be perfectly adversarial, and you'll do better than expected then.
Inframeasures are special sets of a-measures. The ultimate defining feature of inframeasures are these expectations. A probability distribution is entirely pinned down by the expectation values it assigns to functions. Similarly, inframeasures are entirely pinned down by the expectation values they assign to functions. Because different sets of a-measures might assign the same expectation values to all functions, we have an equivalence relation on sets of a-measures of the form
The conditions for a set of a-measures to be called an inframeasure are, for the most part, actually the conditions to be the largest set in their equivalence class, the "canonical representative" of the equivalence class.
The fact that different sets of a-measures might have the same expectations means that you can fiddle around a bit with which set you're using, just as long as the expectations stay the same, and most things will work out. For example, if you're taking the union of two inframeasures, the canonical representative of that union would be the closed convex hull of the two sets. But the union of the two sets (without closed convex hull) has the exact same expectations. Or, you can swap out a set of a-measures for its set of minimal points, and things will work out just fine. This shows up in some proofs and is also handy for informal discussion, since it lets us reason like "consider this set of two a-measures, what happens to each one when we do this?" instead of having to think about the maximal set in the equivalence class.
If I had to pick one Fundamental Master Theorem about inframeasures where it would be hopeless to work without it, it would easily be LF-duality. It says there's two entirely equivalent ways of looking at inframeasures, which you can freely toggle between. The first way is the set view, where an inframeasure is a set of a-measures that's the largest in its equivalence class. The second way is the expectation functional view, where the expectations of functions are the only data that exists, so an inframeasure is just a nonlinear functional fulfilling some defining properties.
In the expectation functional view, (we use lower-case for expectation functionals and upper-case for the corresponding set) is a function of type signature (or ). You feed in a continuous function , or bounded continuous function , and an expectation value is returned.
An inframeasure functional is:
1: Lipschitz.
2: Concave.
3: Monotone.
4: Compactly almost-supported. This is a technical condition which only becomes relevant when you deal with non-compact spaces, and isn't needed for any discussion.
5: Weakly normalized. .
An infradistribution has those same conditions, but 5 is strengthened to
5*: Normalized. .
These two views are dual to each other. Every inframeasure set corresponds to a unique expectation functional fulfilling these properties, and every expectation functional fulfilling these properties corresponds to a unique inframeasure set .
Well... which sets of a-measures have their expectations fulfilling the defining properties for an inframeasure? Pretty much all of them, actually. Conditions 2, 3, and 5 show up for free, as does condition 4 in compact spaces (and pretty much every space we use is compact). That just leaves condition 1. In the set view, it's saying "your set of a-measures has an upper bound on the amount of measure present" (or is in the same equivalence class as a set of a-measures like that). So, as long as you've got an upper bound on the amount of measure present and are working in compact spaces, your set is (in the same equivalence class as) a inframeasure!
Every concept we've created so far manifests in one way in the "set of a-measures" view, and in another way in the "expectation functional" view. The "expectation functional" view is much cleaner and more elegant to work with, turning pages of proofs into lines of proofs, while the "set of a-measures" view is better for intuition, though there are exceptions to both of these trends.
This duality was a large part of why the "Belief Functions and Decision Theory" post had such long proofs and definitions, we were working entirely in the (very clunky) set view at the time and hadn't figured out what all the analogous concepts were for expectation functionals.
Infradistribution Ordering, Top, and Bottom
Let's continue introducing the concepts we need. First, there's an ordering on infradistributions (this isn't the information ordering from Inframeasures and Domain Theory [AF · GW], it's the standard ordering, which is reversed). is used for an infradistribution expectation functional (a function or , which takes in a continuous bounded function and gives you a number), and is used for the associated set of a-measures, the canonical representative. The ordering on infradistributions is:
The ordering on infradistributions is just subset inclusion, where is below exactly when the associated set is a subset of . Small sets go more towards the bottom, large sets go more towards the top. And for the functional characterization of the order, remember that expectations are the worst-case value over the set of a-measures. If is a subset of , there's more choices of a-measure available in , so is better at minimizing the expectation of any function.
For join, we have
Join/disjunction of infradistributions is set union is the inf of the two expectation functions. Well, technically, the closed convex hull of set union, but that has the same expectations as set union so we don't care.
And for meet, we have
Meet/conjunction is set intersection (it's actually super-important that the canonical representatives are used here so the intersection works as it should) is the least concave monotone function above the two expectation functions. Don't worry too much about the function part, just focus on how it's combining pieces of uncertainty to narrow things down, via set intersection.
Since we've got this ordering, what would top and bottom be? Skipping over technical complications to just focus on the important parts, this critically depends on our type signature. Is our type signature (where you feed in continuous functions , and get expectations in the same range), or is it (where you feed in bounded continuous functions and aren't restricted to )? Let's say we're working with crisp infradistributions, ie, sets of probability distributions.
Well, since join for infradistributions is set union, would be the infradistribution corresponding to the set of all probability distributions on . The expectation functional would be Because you can always consider the probability distribution which concentrates all its mass on the spot where does the worst. is maximum uncertainty over what happens, ie "free will". Any result at all could show up.
is much more important. Since meet is set intersection, it would naively be the empty set, which is what you get when you intersect everything together. For the type signature, this does indeed work. is the empty set. And then we can go:
(because the infinimum over the empty set is always ).
For the type signature, the canonical sets of a-measures tend to be bigger than for the other type signature. As it turns out, if you intersect everything when you're working in this type signature, you end up getting a nonempty set! Said set is in the same equivalence class as the single a-measure (the empty measure, the value is 1). The corresponding expectation functional would be . In neither of these two cases is a legit infradistribution, it's an inframeasure. But it has an important role to play anyways.
If we were to relax a bit about having everything be an infradistribution and allow to stand for "we derived a contradiction"... it actually makes things work out quite well in our whole framework! The fact that you automatically get maximum utility popping out from the infra version of "we derived a contradiction, impossible situation" should be extremely suggestive. It's just like how Modal Decision Theory derives maximum utility if it manages to prove a contradiction from the assumption that it takes a particular action. This isn't just a vague analogy, MDT can be viewed as a special case of our framework! [LW(p) · GW(p)]
The behavior of is a very important distinguishing factor between inframeasure type signatures. Infinite utility is tied with the type signature , and 1 utility is tied to the type signature .
We already covered two reasons why were able to clean up the framework in Belief Functions and Decision Theory [AF · GW]. The first reason is that, by the isomorphism theorem, we only need to look at what happens to policies and that simplifies things a little bit. The second, larger reason is that, now that we figured out how belief functions work in the expectation functional view, the proofs and definitions can be streamlined and compressed since we don't have our hands tied by working in the set view.
And the third, largest reason why things can be massively simplified now is that we had no idea about the connection between Nirvana and and type signatures at the time. The old post was trying to pair infinite utility with the type signature. To do this, we had to treat Nirvana as a special ontologically distinct sort of event, which proliferated to make everything really ugly. So, now that we're not confused anymore about this, we can send those old constructions to the dumpster and lay down a nice clean foundation.
Updating the Right Way
Now that we've got intersection, union, top, and bottom under our belt, we can move on to updating. It's very very important to think of updating as two distinct steps. If you have a probability distribution , and then update on , you throw out the portions of the probability distribution that lie outside the set , and you get a measure. We call this process the raw update. Then, there's multiplying by to bloat the measure back up to a probability distribution, this is the renormalization step.
If you haven't seen the following trick before, it's possible to make vanilla Bayesian updating work without any renormalization! Let's say we've got a prior over a bunch of hypotheses (we'll be using and for indexing these). is the prior probability of hypothesis . We update our prior on the observation that happened, and then try to assess the probability of the event . Said probability would be
, the prior updated on seeing , is, by Bayes,
With this, we can unpack our expectation as:
But what if, instead of updating our prior on seeing , we just left the prior on hypotheses alone and chopped down the measures with no renormalization instead? In this case, let . It's the measure produced by chopping down upon seeing , without blowing it up to a probability distribution. Then the expectation of with respect to this mixture of measures would be...
And, oh hey, looking above, that's the exact thing we have, modulo scaling back up to 1! The relative intervals between all the probabilities and the expectations of the various sets and functions are the same if we don't renormalize and leave the prior alone since the rescaling term is the same for all of them. You know how utility functions are invariant modulo scale and shift? That's the intuition for why we don't need normalization back up to 1 and can just leave our prior alone and chop down the measures. It agrees with the usual way to update, modulo an undetectable (from the perspective of your utility function) scale term. The work of Bayes on the prior is just trying not to lose track of the fact that some hypotheses assigned 5x higher probability than others to that thing we just saw. The raw update keeps track of that information in the amount of measure of the hypotheses and leaves the prior alone. Because the standard update blows all the measures back up into a probability distribution, it must keep track of this information via altering the prior instead.
Admittedly, renormalization is handy in practice because if you just do raw updates, the numbers you're dealing with (for probabilities and expectations) keep getting exponentially smaller as you update more since you're zooming in on smaller and smaller subsets of the space of possible events so the amount of measure on that keeps shrinking. So, it's handy to keep blowing everything back up to the good old range as you go along. But the raw update is just as nicely-behaved from a mathematical standpoint.
In a departure from our usual practice, we won't be looking at the standard update for infradistributions, but the raw update, with no renormalization. The reason for this is that we do operations like "update an infradistribution on several different non-disjoint pieces of information to get several different sets of a-measures, then union them back together" and we want to end up back where we started when we do this. For standard infradistribution updates, you don't have a guarantee of being able to do this, because the different updates may have different scaling factors, so putting them back together makes a mess, not a scale-and-shift of your original infradistribution. But just doing the raw update automatically keeps track of everything in the right way, it's the gold standard. You can apply whatever scale-and-shift factor you want at the end to your inframeasures (doesn't affect anything important), you just have to remember to do it to everything at once, instead of rescaling all the individual fragments in incompatible ways.
One of the notable features of inframeasures is that updates for them don't just depend on specifying what event you're updating on, you also have to specify how you value outcomes where the event didn't happen. This key feature of updates (which is completely invisible when you're just dealing with standard probability distributions) is what lets us get a dynamic consistency proof.
The raw update of an inframeasure requires specifying a likelihood function (the indicator function for the event you're updating on), and continuous bounded off-event utility function (or if you're dealing with that type signature), in order to be defined.
The raw update of an inframeasure on event and off-event utility function , written as , is defined as:
Remember, is the expectation of . If we imagine is the indicator function for a set, then a raw update for expectation functionals looks like "ok, we updated on this set, and we're trying to evaluate the expectation of within it. Let's ask what the original inframeasure would think about the value of the function that's on our set of interest, and outside of said set, as is our off-event utility."
For the set view of inframeasures, the raw-update operation is as follows. You've got your set of a-measures, which are pairs of a measure and a number, (. We split into two parts, the part on-L (the event we're updating on), and the off-L part, . Then we leave the on-L part alone, and evaluate the expectation of with our off-L part, and fold that into the term (guaranteed utility), yielding the new a-measure , which has eliminated the off-event portion of its measure, and merged it into the "guaranteed utility" portion of the a-measure. Doing this operation to all your a-measures makes , the raw-updated set.
There's two issues to discuss here. First, what sort of update is the closest to an ordinary old update where we don't care about what happens outside the event we're updating on? keeps track of the region you're updating on, which makes sense, but the free choice of off-event utility function raises the question of which one to pick. We must use our actual utility function for histories that aren't the one we're in (but that are still compatible with our policy), in order to get dynamic consistency/UDT compliance. But updating on policies or actions is different. If we decide to do something, we stop caring about what would happen if our policy/action was different.
The second issue is that, since inframeasures can only take expectations of continuous functions, full rigor demands that we be rather careful about the intuitive view where is the indicator function for a set, as functions like that usually aren't continuous.
Starting with the first issue, the type signature works best for answering it. Let's assume is the indicator function for a subset of and disregard questions of continuity. Remember, what's happening in the raw update that the off-L measure is being converted into utility via the off-L utility function you pick. We want the closest analogue to an ordinary old update we can find, so let's look at the most vanilla functions for that we can find. Namely, the constant-0 function and the constant-1 function.
As a toy example, let's take the infradistribution corresponding to a set of two probability distributions, and . Event occurs. assigned said event probability, and assigned said event probability.
If we updated with the constant-0 function as our off-event utility, that would correspond to discarding all the measure outside the set we're updating on, so our new a-measures would be and . And then we can notice something disturbing. The expectations of an inframeasure are . We can ignore the part since it's 0. Since our first a-measure only has 0.2 measure present, it's going to be very good at minimizing the expectations of functions in , and is favored in determining the expectations. This problem doesn't go away when you rescale to get an infradistribution. The 0-update has the expectations of functions mostly being determined by the possibilities which assigned the lowest probability to the event we updated on! This is clearly not desired behavior.
But then, if we updated with the constant-1 function as our off-event utility, that would correspond to converting all the measure outside the set we're updating on into the term, so our new a-measures would be and . And then we can notice something cool. Because the expectations of an inframeasure are , it's now the second a-measure that's favored to determine expectations! The first a-measure assigns any function 0.8 value right off the bat from the term and so is a bad minimizer! The 1-update has the expectations of functions mostly being determined by the possibilities which assigned the highest probability to the event we updated on, which is clearly what you'd want.
In fact, the constant-1 update is even nicer than it looks like. Given an infrakernel (a function ), if you start with an inframeasure over , you can push it forward through the infrakernel to get an inframeasure over , just like how you can take a probability distribution on and push it through a probabilistic function to to get a probability distribution over .
So, let's do the following: Abuse notation so refers to both a set and the indicator function for the set. Then define the infrakernel as: If , then (starting with a point in , it gets mapped to the dirac-delta distribution on the same point). If , then (starting with a point not in ... we just observed that the true result is in , we have a contradiction).
As we'll prove shortly, for any inframeasure , pushing it forward through that infrakernel which says "points consistent with my observation remain unchanged, points inconsistent with my observation are impossible ie "... Is exactly the same as , the raw 1-update! This makes raw-updating on 1 look more natural. It's obvious that outcomes consistent with your observation should remain unchanged and outcomes inconsistent with your observation go to .
Proposition 1:
Proof: We'll use the definition of infrakernel pushforward from Basic Inframeasure Theory [AF · GW]. is the expectation of w.r.t. the inframeasure . Let be an arbitrary continuous function.
If , we have
Because of how was defined, and because taking the expectation of a function w.r.t. a dirac-delta distribution just substitutes the point into the function. If , we have
Because of how was defined, and because assigns any function an expectation of 1. So, we can rewrite with indicator functions, getting
The two inframeasures and have been shown to have the same expectations for arbitrary functions and are therefore equal, QED.
Now that we've got this worked out (the natural sort of update to do), what would it be for inframeasures of type signature ? Well, using our "leave stuff consistent with the observation alone, map everything else to " view... this would correspond to your off-event utility being . In the set view, you'd annihilate every a-measure in your inframeasure where isn't supported entirely on the event you're updating on. This is, to say the least, a far more aggressive sort of update than the other type signature.
Now, let's clean up that issue about how inframeasures can only take expectations of continuous functions. The sorts of discontinuous functions you need to be taking expectations of to make things work are all like " on your set of interest, maximum values outside of it". The sets I was updating on were closed in practice, so these functions end up being lower-semicontinuous. Fortunately, in Inframeasures and Domain Theory [AF · GW], we proved that you can uniquely extend the expectations from just being defined for bounded continuous functions to being defined for any lower-bounded lower-semicontinuous function, via Theorem 1. So there's no issues with 1-updating or -updating on a closed set, we can freely use these sorts of discontinuous functions without worry.
Deconfusing the Cosmic Ray Problem
Now that we've worked out how updates work, we can deal with the Cosmic [AF · GW] Ray problem [AF · GW] (two links) in decision theory, a strong argument against EDT. Let's see how an infra-Bayes agent would handle it.
First up, the problem description. There are two paths, left and right. Going right yields, let's say, utility, and going left yields utility. There might be a cosmic ray shower, which flips the action the agent takes, and it's extremely bad ( utility) due to corrupted decision-making afterwards. The agent is nearly certain that it will decide to go left, with probability on going left. Conditional on deciding to go right, it's almost certainly because the agent had its decision-making corrupted by cosmic rays. And so, the agent goes left, because going right is strong evidence that something bad has happened. Conditional expectations can be very bad for actions the agent thinks it won't take, which can cause self-fulfilling prophecies.
Now, there is some freedom in how we encode this problem for our infra-Bayes agent to act on. The part we can agree on is that we've got four events, for "I go left, no cosmic rays", "cosmic rays hit so I go left", "I go right, no cosmic rays", and "cosmic rays hit so I go right", with utilities of respectively.
Naively cramming the problem setup into a single probability distribution, it would be a single probability distribution . Doing the raw 1-update of this on "go left" makes the a-measure , which gives your utility function value in expectation. Doing the raw 1-update of this on "go right" makes the a-measure , which gives your utility function value in expectation. So you go right! Lots of utility there, since you almost certainly don't do it. Importantly, this means the cosmic ray problem isn't a problem for us, because the issue was this problem setup scaring you away from going right! Our infra-Bayes agent would go "oh cool, I get to defy destiny" if it sees that going right has low probability, so... going right must have decently high probability.
This is interesting, because the other versions of diagonalization in Decision Theory, like Modal DT, and Logical Inductor DT, only diagonalized against their own action when it was impossible/extremely improbable. This was to guard against self-fulfilling prophecies where an action looks spuriously bad because it has a low probability, which makes you disinclined to pick that action, enforcing that the action has low probability. The sort of diagonalization that manifests from the 1-update seems to kick in over a much wider range. But then you'd run into a problem. What about problems where you really don't want to take an action? It'd be bad if you launched nuclear weapons because you assigned high probability to not doing so.
Well, inframeasures are a lot more general than probability distributions, so the answer to this is "you're not taking full advantage of being able to have complete uncertainty of your action, you literally don't need to assign a single probability to what action you take." Remember, infradistributions can have many probability distributions/a-measures within them.
So, let's look at a different version of the problem setup. Now we have a set of two probability distributions, making an infradistribution. One of them is , the other one is . One is certain you go left, one is certain you go right and the cosmic rays strike. Doing the 1-update on "go left", we get the two a-measures and , which have expected value of and according to your utility function. Expectations are worst-case, so you think there's utility if you go left. Doing the 1-update on "go right", we get the two a-measures and , which have expected value of and according to your utility function. Expectations are worst-case, so you think there's utility if you go right. And so you go left. This is the correct thing to do here, as this corresponds to a model where you have free will over what to do, but going right actually summons the cosmic rays.
For diagonalization to kick in and make you take an action, all the a-measures in your original infradistribution must think the action is improbable. If there's even one a-measure that's like "and then you take this action!", you'll listen to that one about the consequences of the action instead of rushing to diagonalize. A-measures which think the action is less probable get a higher term when you raw-update, so they're less likely to give you worst-case results, so you're going to end up listening to just the a-measures which think the action is quite probable when working out what expected value you get from various actions.
Now for a third version of problem setup. Our two probability distributions are and , corresponding to a model where you've got free will on what you intend to do, but there's a probability that cosmic rays strike and your decision flips. 1-updating on going left yields the two a-measures of and , with expectations of and respectively, so going left has utility. 1-updating on going right yields the two a-measures of and , with expectations of and respectively, so going right has utility. And you go right, as you should, since you think cosmic rays are improbable in both cases.
So, there's some freedom of how you encode the cosmic ray problem, different setups give sensible answers, and we learn a very important lesson. If you attempt to cram decision theory problem setups into a single probability distribution instead of having a set of multiple probability distributions, one for each action (counterfactuals), the 1-update will result in diagonalization against improbable actions. So you really shouldn't set up decision theory problems by trying to cram the whole thing into a single probability distribution, and take full advantage of being able to have radical uncertainty over actions. Ie, exploiting that you can have lots of different probability distributions/a-measures in your set. There should be lots of Knightian uncertainty about which action will be selected.
But why have this level of uncertainty over your actions in the first place? Why aren't ordinary probability distributions good enough? Well, inframeasures capture stuff like Knightian uncertainty and adversarial processes and the environment being hard to predict because it's using more computing resources than you. As it turns out, with diagonalization, it can be viewed as the agent itself acting as an adversary with extra computing power, relative to its epistemic processes. The agent can look at the epistemic processes, effectively doing all the computation they do by stealing their end result. And then the agent does some additional computations on top. And it "tries" to make the epistemic processes be wrong, because of that diagonalization behavior. Accordingly, it's entirely appropriate for the epistemic processes of the agent to model the actual decisions of the agent as unpredictable in a Knightian way.
Other Inframeasure Operations
Time to cover three more basic operations. There's pushforward (specifically projection), pullback, and the semidirect product.
For pushforward, if we've got spaces and , a continuous function , and an inframeasure , then the pushforward of via , , is the inframeasure over defined by
can evaluate functions (or ), so you evaluate functions (or ) by sticking on the front so they are of type .
For the set version of the pushforward, it's possible to take some measure over , and a continuous function , and push the measure on forward via to make a measure over in the obvious way. So you just take all your a-measures and push their component forward via while leaving the term alone, to get the a-measures that make up .
This gets much simpler if your pushforward happens to be a projection, like . Working it out, if your function has type (or ), then it'd just be . Just use the original inframeasure to evaluate the function which doesn't depend on the other arguments. For the set version, this would just be "project down all your measures to the appropriate coordinates". We do these projections when we want to forget about some auxiliary data that doesn't matter.
Pullback tries to go in the reverse direction. Pushforward is going "ok, I start with uncertainty over , and I know how maps to , what's my uncertainty over ?". Pullback is going "I start with uncertainty over , and I know how maps to , what's the least informative inframeasure over that's consistent with my uncertainty over ?". It's a bit complicated for expectation functions. In this case,, and is a function (or ). Then, pullback would be:
That function inside is lower-semicontinuous, so it works.
For the set view of pullback, things are simpler. Pushforward via maps a-measures over to a-measures over . So you just take your a-measures over , and take the preimage under this function. This is the preferred way to think about it, pullback behaves like preimage.
And now for the semidirect product. For probability distributions, if you have a probability distribution over , and a probabilistic function/Markov kernel , you can put them together to get a probability distribution over . Like, if was "space of possible incomes" and was "space of house sizes", and you start with a probability distribution over income and a function mapping income to a distribution over house sizes, the semidirect product of these would be the joint distribution over income and house size. For inframeasures, the semidirect product is ideally suited for looking at adversarial choice stacked over multiple stages in time.
For the functional view, if you have an inframeasure , and an infrakernel , is an inframeasure in defined via
On the set side of the duality, semidirect product is only intuitive in special cases. Restricting to infradistributions that are sets of probability distributions, the semidirect product would be every probability distribution in that could be made by picking a probability distribution over from your set , and then picking conditional probability distributions over from each set to make a joint distribution. However, the semidirect product gets considerably harder to think about if you go beyond sets of probability distributions.
The semidirect product is our fundamental tool for going from "starting infradistribution over states" and "infrakernel mapping states to what happens next" to recursively building up an infradistribution over histories. The semidirect product can take a starting point, and a dynamic process (an infrakernel) and go "alright, let's unpack this by one step into a joint distribution over the initial state and the next state". And then we keep doing that.
The infinite semidirect product is the formalization of "keep doing that", suitable for unrolling an infrakernel and starting inframeasure over into an inframeasure over , as an example.
The basic way it works is, if you have a sequence of spaces , and infrakernels which give your uncertainty over what happens next given the history of what has happened so far, it's possible to wrap them all up into one big infrakernel which tells you your entire uncertainty about how the future goes given a starting state, with type signature
Then you just do and you're done. The key tricky part here is how to define given all the . We won't explain that here, check Less Basic Inframeasure Theory [AF · GW].
In order for this infinite infrakernel to exist at all, the must be "nicely behaved" in a certain precise sense. You definitely don't get infinite semidirect products for free. Sadly, the old [AF · GW] proof [AF · GW] that the infinite semidirect product exists when everything is "nice enough" was A: an ungodly long proof, and B: not general enough. The old proof was only dealing with the type signature, not the type signature. And it was only about infradistributions, inframeasures like weren't on our radar at all. So we'll need to go back and get new niceness conditions to ensure the infinite semidirect product works, but make them more general to permit odd things like or violations of continuity. The new proof [AF · GW] is still amazingly long, but it means we only need to check the new conditions whenever we want to invoke an infinite semidirect product. Time to discuss the new conditions on an infrakernel. Any infrakernel fulfilling them is called regular. We'll use the usual type signature here.
Definition 1: Regular Infrakernel Conditions
1: Lower-semicontinuity for inputs:
For all continuous bounded , is a lower-semicontinuous function .
This condition is a generalization of our old continuity conditions, since we now know that lower-semicontinuity works just as well.
2: 1-Lipschitzness for functions:
For all , is 1-Lipschitz. The distance metric for functions is
This condition arises because, when you compose a bunch of functions with each other, the Lipschitz constant can keep increasing. We need to compose infinitely many infrakernels, so the Lipschitz constants need to stay at 1 or less.
3: Compact-shared compact-almost-support:
For all compact sets and , there is a compact set which is an -almost-support for all the inframeasures where .
This is a highly technical property that isn't relevant unless you're dealing with spaces that aren't compact, feel free to ignore.
4: Constants increase:
For all and constant functions ,
This is necessary to show that the expectations of a function settles down to a particular value as you compose more and more infrakernels. It also handles as a possible output quite nicely.
Theorem 1: Any sequence of regular infrakernels have the infinite infrakernel being well-defined and regular.
That's enough for now. We've got our ordering on infradistributions, we've got union and intersection, we've got bottom (max utility) and top (total uncertainty), we worked out how to update appropriately, and we've got projections (to neglect excess unobservable states), pullbacks (to infer back from observable data to unobservable states), and the semidirect product (to unroll dynamic processes into static infradistributions over histories), so we can start being more formal about how to translate between different corners of our square and having it commute.
Belief Function Properties
Alright, time to start working towards our actual results.
From here on out, we'll use (utility function) for functions (or ), and for when we're dealing with functions on different spaces, to not overload too much.
First up, here's exactly what properties we're assuming every time we call something a belief function. Not just any old function which maps policies to inframeasures over histories will work, we need the following conditions to call it a "belief function".
Definition 2: Belief Function Conditions
1: Uniformly Bounded Lipschitz Constant
This was one of the old belief function properties. It's the analogue of how inframeasures must have a finite Lipschitz constant. This exists so that when go to the third-person static view, we can keep the Lipschitz constant finite.
2: Lower-semicontinuity.
If is continuous and bounded, then is lower-semicontinuous.
This generalizes the old continuity condition on belief functions, since lower-semicontinuity works just as well now.
3: Normalization.
and
This is a repaired version of the old normalization condition on belief functions. It isn't essential, really. It just exists so that when we make a third-person static view, it's an actual infradistribution. But if you wanted to generalize to inframeasures, you could throw it out. The old version of normalization had , and I don't know what past-me was thinking there.
4: Sensible supports.
For all where and only differ on histories that is unable to produce,
This is an ultra-obvious property which was implicit in our old framework for belief functions. If you play the policy , then of course your inframeasure should only be supported on histories that is able to make!
5: Agreement on Max Value (for the type signature on inframeasures)
Admittedly, this condition wasn't around back in Belief Functions and Decision Theory [AF · GW], it's a new restriction that naturally emerges from the math. Interpretations are unclear.
These five conditions, along with the implicit "the output of is always an inframeasure", are all that remains of the machinery in Belief Functions and Decision Theory [AF · GW]. (along with our new framing of the pseudocausality and causality conditions) Quite the simplification, huh?
As a very important note, for later sections, all our commutative square theorems and POMDP type signature theorems will work with both type signatures. We phrase things in terms of the type signature, with updating on 1 and , but all the results work out exactly the same with the type signature and updating on and . Both type signatures should be assumed to be compatible with all theorems and diagrams and discussion from this point on unless we specifically say otherwise.
Another important notation tidbit to recall is that is the 1-update of on the set (although the -update works just as well, you can just do a mental search-and-replace of with and everything should work out, unless explicitly stated otherwise) We'll be using various different choices of set to update on for that , explained as their time comes.
The Acausal Commutative Square
As a review for this and the next two sections about pseudocausal and causal belief functions, we're mainly hunting for state spaces that are "universal" for certain sorts of belief functions, in the sense of being rich enough to encode any belief function with [relevant property], while not being too rich, in the sense that translating any infradistribution over the relevant state space from third-person static to first-person static and renormlizing should make a belief function with [relevant property]. Also, the entire square of hypothesis types should commute.
In general, these sections will proceed by taking eight translations between the different type signatures in the square and formalizing them into math, and then present a theorem that's like "the square commutes", and then embark on a more philosophical discussion. If you, as a reader, really want to dig into the mathematical details, it's a good idea to go back and remember what projection, pullback, semidirect product, top, and bottom are. Otherwise, you can just skip the extensive discussion of how the eight translations work, I'll let you know when to do so.
We'll start with trying to characterize acausal belief functions, ie, any belief function at all. We'll use to refer to the subset of consisting of a deterministic policy paired with a history the policy is capable of producing. This is the space of policy-tagged destinies. , , and will will denote infradistributions over this space. and are the third-person and first-person transition kernels. Note that the state spaces are a little off from our informal discussion.
Also, is the subset of (a subset of , a pair of a deterministic policy and a history/destiny) consisting of all pairs where . You're updating on the the event that the policy is . So, something like is "the 1-update of on the event that the policy is "
Now, behold the Acausal Commutative Square!
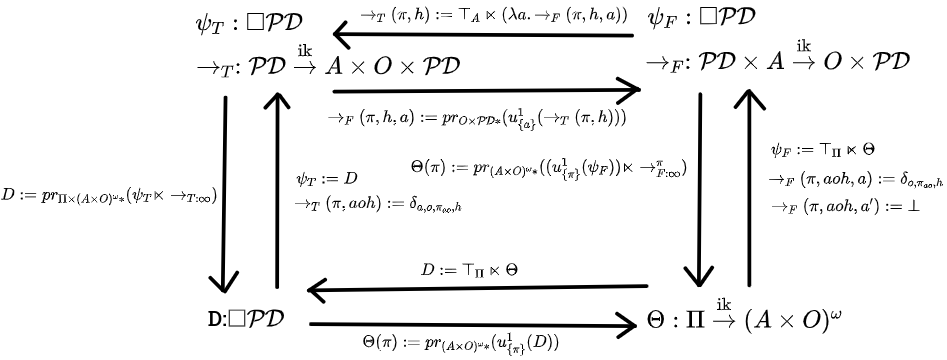
The discussion of the eight translation directions begins now. You can skip down to Theorem 2 now, if you wish.
First: Third-person static to first-person static. From our informal discussion earlier, this is done by updating on "my policy is " and then extracting the action-observation sequence from the third-person view, to get what happens if you do . With our state space being a subset of , it should be clear how to do that.
We updated on the subset of possibilities where the policy is , and projected to get the actions and observations from it, and that tells you what happens if you pick , yielding a first-person static view.
Second: First-person static to third-person static. From our informal discussion earlier, we infer back from the policy and history to a state, but combine that with total uncertainty over what our policy is. This can be very concisely stated as the semidirect product of (total uncertainty over policy) with . Ie, your uncertainty over the world arises by combining absolute uncertainty over your policy with the first-person view telling you what occurs if you take a particular policy.
Third: Third-person static to third-person dynamic. From our informal discussion earlier, this is done by using a hidden destiny state, and the transition dynamics just being "destiny advances one step". Ie, and
The means this is the point distribution on "just pop the action and observation off the front of the destiny, and advance the destiny and policy a bit". , it sticks the prefix at the start of everything. That's how we implement advancing the policy forward in time.
Fourth: Third-person dynamic to third-person static. From our informal discussion earlier, this is done by just repeatedly letting the transition dynamics occur (implemented via infinite infrakernel), and picking out what happens as a result.
is the "just repeat forever" infrakernel, we use semidirect product with that to build up the whole history of what happens, and then use projection to forget about the intermediate hidden states.
Fifth is third-person dynamic to first-person dynamic. As per our previous discussion, we can find out what happens if we take a particular action in a state by taking the state, running it through the third-person transition kernel, and updating the output of that on "action just got taken".
The projection just cleans things up a bit so the action isn't still hanging around.
Sixth is first-person dynamic to third-person dynamic. As per our previous discussion, given a state , we do this by taking our first-person kernel, letting it interact with and total uncertainty over our action to get our uncertainty over the next state and observation, and putting the action, observation, and state together. This can be elegantly implemented by having , total uncertainty over the space of actions, interact with the function mapping the action to what inframeasure you get as a result.
Seventh is first-person static to first-person dynamic. As per our previous discussion, we get the starting infradistribution via the same process we used to get our third-person static view (ie ), and then the transition dynamics are just "if the action lines up with the destiny, the destiny advances one step, otherwise, if an impossible action is taken, return ". To be formal, we'll write the action-observation sequence as to more easily check what's going on with it. The "action matches destiny, destiny proceeds" translation is:
Just advance the policy forward a bit and the destiny, and pop the observation off the front. For impossible actions which don't match up with the destiny, we have:
Eighth is first-person dynamic to first-person static. As per our earlier informal discussion, we want to somehow have the policy interact with the transition dynamics and then just unroll that forever. Although, it turns out it isn't enough to just let the policy interact with reality via feeding actions in, you also have to update the initial state on "my policy is like this". The full definition is
Which is "given a policy , update the initial uncertainty on what my policy is, then let the initial state interact with the first-person transition kernel and my policy, and project at the end to just recover the action and observation sequence".
, the infinite process of having the policy interacting with the transition dynamics , needs a definition, though. It's safe to skip the following part until you get down to Theorem 2, we're just being picky about how things are defined.
The full power of the infinite sequence of infrakernels is on display here, as they can depend on the entire past history, not just the most recent state. So, we define our sequence of spaces by our first space being , and all successive spaces being . The finite infrakernels
are defined via (using for state, an element of )
Ie, the past actions and observations fill in your action via the policy , and then that interacts with the most recent state to get the next observation and state. is the infinite infrakernel built from this sequence.
Theorem 2: Acausal Commutative Square: The following diagram commutes for any belief function . Any infradistribution with the property also makes this diagram commute and induces a belief function.
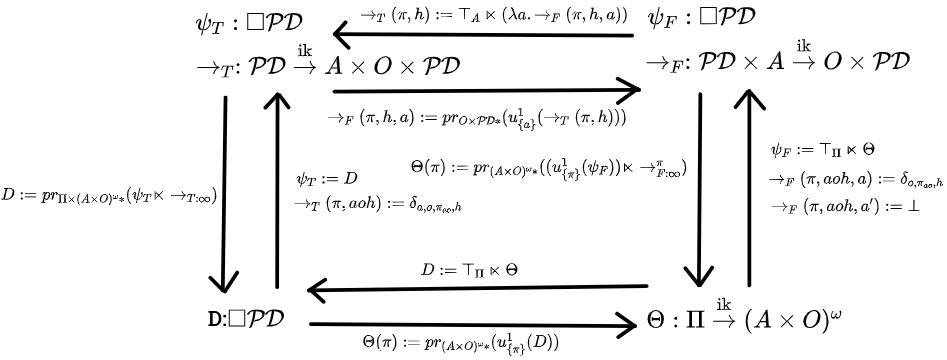
So, this characterizes acausal belief functions, ie, all of them. The subset of where the destiny is compatible with the policy is a rich enough state space to encode any belief function at all.
For upcoming discussion if you're just tuning back in, the main important part of the square is the back-and-forth between the belief function (first-person static view), and the infradistribution (third-person static view), where is the subset of where the policy is compatible with the history/destiny. You go from to via (complete uncertainty over policy interacting with the function telling you what happens as a result of picking each policy). And if you have a , you get a from it via . Figure out what happens if is picked by 1-updating on "I pick policy ", and then just restrict your attention to the history/destiny information about what happens.
There's something rather interesting going on with that
condition for a third-person static view to perfectly correspond to a first-person static view, though. It's saying "going from third-person static to first-person static and back is identity". But it can also be interpreted as saying that the third-person view must look like a system of counterfactuals.
There's a bunch of infradistributions telling you what happens if the agent picks various policies, as the part is basically the infradistribution over what happens if the agent takes policy (computed via updating on ). These are the counterfactuals for picking a particular policy, you just update to figure them out.
Then, semidirect product with complete uncertainty over policy implements "btw, I also have absolutely no idea which of these possibilities is the case, I'm completely agnostic as to the probability of the agent taking any of these actions". Ie, a system of counterfactuals telling you what happens if you pick any particular policy, but making no effort at predicting what you do.
The most interesting part comes when we ask what happens if we take an arbitrary infradistribution and try to cram it into a first-person view by updating to get our . If you just plop in an arbitrary third-person hypothesis and fix it up to get a belief function, what sort of belief function does this process make?
It's advised here to go back to the "Cosmic Ray" section and reread it, as that provides a clean little worked example for several cases of trying to update on an action and discussion of how diagonalization works.
Resuming, our analysis usually works equally well for the two infradistribution type signatures (where the range can either be or ), but here we're going to have to be rather careful about whether counts as infinite value or as 1 value. Let's simplify the informal discussion in both cases by assuming that is a set of probability distributions over , for convenience.
Doing the update on a particular policy annihilates all probability distributions that don't say has probability 1. Which may result in some inframeasures just being ie ie , and then you'd diagonalize by picking that policy. This is, to say the least, an exceptionally aggressive form of diagonalization, and probably not advised.
Now, we'll talk about the update. The diagonalization behavior is more restrained here, since it takes all the probability distributions and turns all their non- measure into guaranteed utility. Still, since is a pretty dang big space of options and we're updating on a single point in it, the general lesson is that if you want policy-selection problems that aren't completely dominated by diagonalizing, you've got to have fairly radical uncertainty about what policy the agent has. "Radical uncertainty" cashes out as having lots of a-measures in your set , s.t. for any particular policy, there's an a-measure that assigns high probability to that policy being selected.
Assuming your infradistribution doesn't succumb to just always diagonalizing, this translation produces fairly interesting behavior. For intuition, let's say the environment terminates after a few rounds, so you've only got finitely many policies to worry about, which eliminates the case where all your inframeasures turn into .
The 1-update on a policy produces a weak-ish form of diagonalization where it's commensurable with the usual drive to pick policies that attain good results. If there's some policy where all the probability distributions in agree that is unlikely to be selected, then you'll tend to pick for diagonalization reasons unless you can pick up fairly high worst-case utility from other policies.
This is because the 1-update on converts all measure not placed on into pure utility, so all the a-measures in ( 1-updated on the policy ) will have a big chunk of pure utility on them, so even the worst-case expected utility for picking will be pretty high.
But it only takes one probability distribution in your set to think " will probably be selected", to take out the incentive to diagonalize.
This is because the 1-update on converts all the measure not placed on into pure utility. This procedure doesn't do much to that one probability distribution that's like " probably happens", it mostly gets left alone in the 1-update. And it'll be better at minimizing the expectations of functions than all the other a-measures that got a big chunk of pure utility added to them in the 1-update, so it'll probably control the expectations of your utility function.
Generalizing this a bit, you'll tend to listen to the a-measures that are like "you'll probably pick " about what utility you can expect as a result if you pick . You'll ignore all the other ones because they have a big chunk of pure utility on them after the update, and you're pessimistic.
Let's follow up on a further implication of the 1-update. If the probability distributions which assign a high probability think you do very well, and there's a probability distribution which thinks is less likely but things would really suck if you picked that policy, you'd tend to listen to that latter one and steer away from .
More concretely, if there's a probability distribution that's like "guaranteed you pick , and you get utility!" and another one that's like " probability you pick , but you only get utility from it, things are bad", updating produces the two a-measures and , with expected utilities of and , so you think that only gets you utility. Even the probability distributions that think it's less probable that you do something can be listened to if they're pessimistic enough.
Going even further, it's possible to mix multiple infradistributions together into a prior, and there's an update rule for that. If one of the component hypotheses in your prior is saying is unlikely and you should diagonalize, but the other hypotheses in your prior are saying "I contain a probability distribution which says that is very likely and gets really bad results", the agent will do the sensible thing and not pick .
This occurs because the a-measures in a mix of infradistributions (according to a prior) are of the form "pick an a-measure from each infradistribution set, and mix them according to the prior distribution". So, if your hypothesis saying you don't pick has weight in the prior, and the hypotheses saying you pick and it sucks have weight in the prior, then there'd be an a-measure of the form , which then updates to , which doesn't give you a good expectation value, so you don't diagonalize (as long as there's some other policy where the bulk of your prior is like "this is a better one")
However, for the -update, your behavior isn't so restrained, since just one of the components of the prior saying you have a shot at getting infinite utility dominates all else.
So, to recap, the decision-theoretic lessons learned here (and especially from our breakdown of the Cosmic Ray Problem) are:
1: Translating third-person hypotheses into first-person ones by updating in the obvious way (which is equivalent to just regular updating, just missing a scale term) produces diagonalization behavior for free. This diagonalization behavior doesn't require that a decision be impossible, like Modal Decision Theory. It kicks in precisely when all the probability distributions in your original third-person infradistribution say that the policy is unlikely.
2: When dealing with third-person hypotheses which encode your entire policy into the state, they should really have radical uncertainty over your policy, otherwise your decisions become mostly determined by diagonalizing when you turn your third-person hypothesis into a first-person one.
3: The update is spectacularly aggressive. It turns the "doing well vs diagonalizing" dial all the way to diagonalizing, and has an infinite incentive to pick a policy if no probability distribution in assigns it 1 probability.
4: The 1-update produces smooth tradeoffs between doing well normally and picking up the free utility from diagonalizing. It only takes one probability distribution within your set assigning a high probability to make the agent go "I guess I can't pick up guaranteed utility from picking , I'll listen to the probability distributions that think is probable about the consequences of picking ".
5: Mixing infradistributions together via a prior produces even better behavior, where you'll be willing to diagonalize if a high-prior-mass hypotheses agree that is improbable, but if just a few low-prior-mass hypotheses say is guaranteed to be improbable, the incentive to diagonalize is weak.
The Pseudocausal Commutative Square
So, first up, we'll be extensively using the space here. Accordingly, the notation is "the subset of which consists of histories/destinies that the policy is capable of producing/consistent with". So is 1-updating on this set.
The condition for pseudocausality of a belief function is fairly elegant to state, though a bit mysterious without explanation. Much more will be stated about the implications of this definition in the philosophical discussion section. Wait till then.
Definition 3: Pseudocausality
Which, by the way the order on inframeasures was defined, is saying
(or and update on infinity for the other type signature).
We'll use for an infradistribution over (our state space for pseudocausality). It's an infradistribution over destiny, we're no longer keeping track of the policy as part of the state. , are as before, just over our new state space, and again, and are our infrakernels for the third-person dynamic and first-person dynamic views. The diagram is
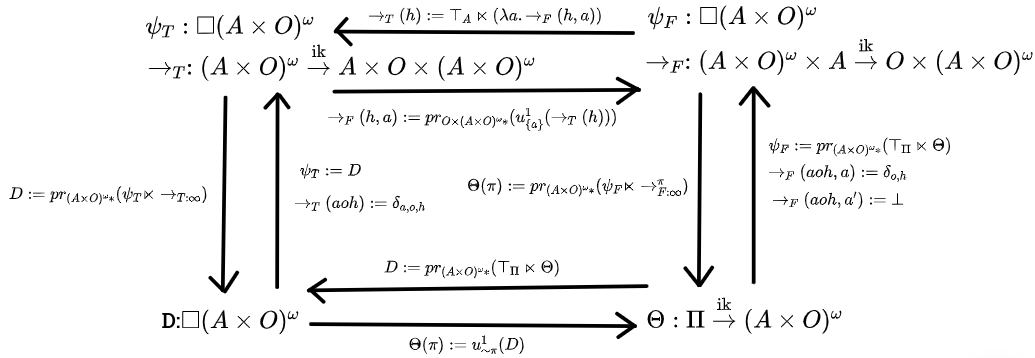
The discussion of the eight translation directions begins now. You can now skip down to Theorems 3 and 4, if you wish.
1: Third-person static to first-person static.
Here, you update on the destiny being compatible with a particular policy. Last time, we restricted to the slice of where a particular policy is played. However, in this case, you're restricting to the chunk of where the destiny is the sort of action-observation sequence that is capable of producing.
2: First-person static to third-person static.
As before, have total uncertainty over the policy, do semidirect product, and then just forget about the policy.
3: Third-person static to third-person dynamic.
As before, you start off with , and the transition is the destiny unrolling one step.
4: Third-person dynamic to third-person static.
Just unroll the destiny, like last time.
5: Third-person dynamic to first-person dynamic.
As before, we just update on producing a particular action, and strip off the action leaving just the observation and successor state.
6: First-person dynamic to third-person dynamic.
As before, we just have total ignorance over the action, and apply to our total ignorance over the actions to get the observation and next state.
7: First-person static to first-person dynamic.
So, here, we get by the usual belief function to infradistribution over destinies translation. For the transition, actions which match the destiny get advanced one step, and actions which don't match the destiny go to .
8: First-person dynamic to first-person static.
Again, just like before, we play the transition kernel against the policy, unroll its progress over time, and strip it down to the action-observation sequence.
Theorem 3: Pseudocausal Commutative Square: The following diagram commutes for any choice of pseudocausal belief function . Any choice of infradistribution where also makes this diagram commute.
Theorem 4: Pseudocausal IPOMDP's: If an infra-POMDP has a regular transition kernel , and starting infradistribution , unrolling it into an infrakernel via has being pseudocausal and fulfilling all belief function conditions except for normalization.
First up, we'll talk about Theorem 4. The commutative square theorems are generally about characterizing belief functions, so it's notable that we get Theorem 4 which talks about arbitrary state spaces instead. It says that any IPOMDP at all which is nicely behaved enough for the infinite semidirect product to be well-defined (even if you let in and other things like that), pretty much makes a pseudocausal belief function. You can just throw a scale-and-shift at your result at the end to turn it into a full belief function.
If you're observant, you may be asking "wait, if there are acausal belief functions that aren't pseudocausal, and any nicely-behaved infra-POMDP makes a pseudocausal belief function, then how does this interact with the fact that we have an infra-POMDP way of looking at acausal belief functions?"
Well, looking at exactly what Theorem 4 says, it's saying that is produced by doing the infinite semidirect product and that's it. When we got a first-person dynamic view of acausal belief functions, we didn't just do that. We also conditioned the initial state on our policy, first.
For maximum generality in capturing decision theory problems, with acausal belief functions, you have to be using your choice of policy to pin down the initial state at the start. This works well with a view where your choice of policy is a mathematical fact that was always true, and influences what happens. Pseudocausality captures the (probably more tractable?) subclass of decision theory problems where your choice of policy interacts with reality entirely by making destinies incompatible with your actions inconsistent.
This can be vividly seen by looking at the first-person dynamic view from the commutative square. The transition dynamics have type
and they work as follows. If the action matches up with what the destiny indicates, then the observation is just popping the next observation off the destiny, and advancing the destiny one step. is the dirac-delta distribution on and . If the action doesn't match up with what the destiny indicates, then the next inframeasure is , maximum utility. .
Picking actions makes some destinies inconsistent, and inconsistencies don't happen (because they'd be very good and we're doing worst-case reasoning), so you should act to make the bad destinies inconsistent. This is the pseudocausality story for how your decisions affect the world.
Now, it's time to talk about the implications of the definition of pseudocausality,
Pseudocausality for the -update is roughly a sort of fairness condition that's like "what happens to me cannot depend on what my policy does in situations of probability zero."
Let's restrict to the "set of probability distributions" view to make things easier. Pseudocausality for the type signature nontrivially implies that if there's a probability distribution over histories which is a possible option for (ie, ), and only differ in behavior on events of probability zero in , then should be present in too.
If we had a violation of this, where shows up in the set and doesn't show up in the set , then you would have a situation where the agent can swap around its behavior in events of probability zero and have things change. In , and only differ in their behavior on events of probability zero, and yet is a possible probability distribution for and not for . Changing your behavior in events of probability zero renders impossible, a violation of pseudocausality for the update.
However, for the 1-update case, pseudocausality is a somewhat more restrictive condition that effectively says that reality has no incentive to mispredict you. The reward from defying the misprediction/defying destiny and attaining outweighs the damage caused by reality mispredicting you. Let's try to see where that comes from.
Again, the pseudocausality condition is . Let's say the true probability distribution over destinies, , is drawn from . 1-updating on "the history is compatible with " takes , and turns it into the a-measure . All the histories compatible with stay the same, all the histories incompatible with get turned into pure utility.
This 1-update of , as it turns out, is the exact same thing as starting in and somehow magically switching your policy to , and then things unfold as usual. But now you defy destiny in situations where and do different things, and in those situations, happens ie pure utility.
Intuitively, and are "set of all the probability distributions that could happen if reality accurately predicts that you play (or , respectively)". And is "the set of all the a-measures you get from actually playing instead when you're predicted to play so you've got a shot at Nirvana//1 utility from defying destiny".
And so, the pseudocausality condition is saying "if the rest of reality mispredicts you and thinks you're playing when actually you're playing , you should do as good or better than if reality made an accurate prediction that you're playing ".
For acausal belief functions, your policy is part of the state, and things in the environment can look at that and act accordingly. For pseudocausal belief functions, your policy is not part of the state, the state space is , no policy in there. Predictors are now allowed to be jerks and mispredict you! This may cause things to go poorly. But if you enter a situation where you can actually disprove the misprediction/defy destiny, then an inconsistency occurs and You Win. This has to be probable enough that reality doesn't have an incentive to mispredict you.
As we'll see later on, weaker variants of pseudocausality in the 1-update case can be interpreted as a very specific condition on how the probability of entering a scenario where you're mispredicted trades off against the amount of change in the flow of probability caused by the misprediction. If Omega wants to be a jerk and mispredict you, it must leave itself sufficiently open to you getting into those situations where it's mispredicting you so you can prove it wrong.
Pseudocausal belief functions can be thought of as the property you automatically get if you think your effect on the world is mediated entirely by your actions, not by your choice of policy. Or they can be thought of as the implementation of the philosophy "actions have effects by forcing inconsistency of bad destinies". Or they can be thought of as enforcing a fairness condition where predictors must leave themselves open to being refuted if they mispredict you. All these views are equivalent. And it's still broad enough to capture many of the odd decision theory scenarios.
Now for more diagonalization discussion. For pseudocausal belief functions, we get the same basic sort of diagonalization behavior as described for acausal belief functions, but now, since we're updating on "the history is the sort of thing that could have produced" instead of "the policy is exactly ", we don't have to worry quite as much about having one of our being when we do the third-person to first-person translation.
Also, because of our altered form of the dynamic first-person view, the diagonalization behavior now applies for individual actions instead of at the policy level. So a hypothesis in your prior that says "you don't have free will in this situation" (read: there's an action where all the probability distributions in the hypothesis agree you probably don't take the action) will be susceptible to you taking the improbable action just to mess with it (as long as the other hypotheses in your prior don't think the action is a terrible idea). The hypothesis takes a hit since all its probability distributions thought you probably wouldn't take the action, and you continue on your way, having dealt a blow to the inaccurate hypothesis which said you didn't have free will.
The Causal Commutative Square
Now, it's time for causal belief functions. Stating the causality condition will take a bit of setup first, though.
The state space for this is the space of deterministic environments , and elements of it are . A deterministic environment is often called a copolicy here because you can view the rest of reality as a second player which takes histories ending with an action as input, and outputs your observations. Given a deterministic policy and deterministic environment , is the history you get by having the two interact with each other. So, given any policy , we get a function which takes a deterministic environment and has play against it to build up a history.
To go from an infradistribution over copolicies (call it ) to figuring out what is, you just do . Push forward through the "interact with " function.
The causality condition in a very small nutshell is "your should look like it was made from an infradistribution over deterministic environments via this process." If your belief function spawns from taking a set of a-measures over environments and letting various policies interact with that, then it's causal, and vice-versa.
It's rather hard to know if a belief function was made this way, so we'll give an explicit process for building a candidate , and if it gives you back again when you let policies interact with , then you know is causal. "Building the candidate and going back to again is identity" will be our definition of causality for a belief function .
We're trying to infer back from to an infradistribution over copolicies. And the pullback is the formalization of "infer backwards". Given some , we can pull back along the function . This gets you a (rather uninformative) infradistribution on . Just combine the data from doing this for all the , ie, intersect everything, and you've got your candidate infradistribution on .
Definition 4: Causality
Ie, take your family of , do pullback along the "interact with " function to get a family of infradistributions on , the space of deterministic environments. Intersect them all/combine the data to get , your candidate infradistribution over environments. And then doing pushforward of that along the "interact with " function, for any , should get you back where you started.
There's an equivalent reformulation of this which is much more useful for proofs, but we won't be covering it, and it only shows up in the proof sections.
Alternate Phrasing of Causality:
Disregarding that (unless someone wants to dive into the proofs), there's a quick note. There's a whole bunch of redundancy in the space , different infradistributions over deterministic environments may end up making the exact same causal belief functions.
As a simple example, which isn't the only sort of redundancy present, we can take the following toy problem. Let's consider a probabilistic environment where, no matter whether you take action 1 or action 2, you've got a 50/50 chance of receiving observation 1 or observation 2. This probabilistic environment can be written as a 50/50 mix of the deterministic environments that are like "no matter the action you take, observation 1 happens" and "no matter the action, observation 2 happens". However, it can also be written as a 50/50 mix of "have the observation copy the action" and "have the observation be the opposite of the action". These two different probability distributions over deterministic environments behave identically in all observable respects.
Due to this redundancy, we get a natural equivalence relation on of "makes the same causal belief function". This is analogous to how different sets of a-measures may have the same worst-case expectations, which induces an equivalence relation on sets of a-measures.
For sets of a-measures, we don't worry too much about exactly what set of a-measures we have, since the expectations are the important part. The largest set of a-measures that has the same expectations is the "canonical representative" of their equivalence class.
And similarly, for infradistributions over , we shouldn't worry too much about exactly what it is, since the induced causal belief function captures all the observable parts of your infradistribution over . That "intersect the pullbacks" is the largest member of its equivalence class.
For our usual theorem about making the square commute, instead of for destiny, we use (environments) for our infradistribution on , the set of deterministic environments/copolicies. Then, the diagram looks like
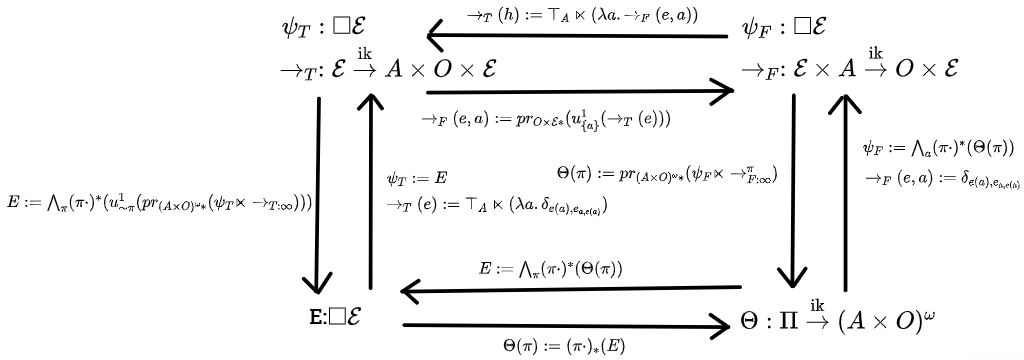
Again, as usual, you can skip to Theorems 5 and 6 if you want.
1: Third-person static to first-person static.
As discussed, just let the policy interact with .
2: First-person static to third-person static.
As discussed, just pull back all your and intersect them to combine their information.
3: Third-person static to third-person dynamic.
You start off with . The transition process happens by having complete uncertainty over action (), but the next action and next copolicy must be produced by having the action interact with the starting copolicy to get an observation and advance the copolicy a bit (that function)
4: Third-person dynamic to third-person static.
Ok, this one is really complex. Unrolling the process and projecting gets you an infradistribution over , not over . So we've gotta unroll it to get to , go from there to a belief function via the 1-update translation from the pseudocausal case, and then go from the belief function back to an infradistribution over by the usual intersection of preimages. All in all, it is:
(Just chain all these processes together)
5: Third-person dynamic to first-person dynamic.
Like the last two times, we update the output of on producing the action , and project to strip off the action, getting an infradistribution over .
6: First-person dynamic to third-person dynamic.
Like the last two times, we just have total uncertainty over what action is produced and use .
7: First-person static to first-person dynamic.
We do the usual "intersect pullbacks" process to figure out the infradistribution over copolicies from the belief function, and then the transition dynamics are just the copolicy interacting with the action to produce an observation and advance one step.
8: First-person dynamic to first-person static.
This is just the usual procedure where we have the transition kernel interact with your policy, unroll it, then strip it down to just the action-observation sequence.
Theorem 5: Causal Commutative Square: The following diagram commutes for any choice of causal . Any choice of infradistribution where also makes this diagram commute.
Also, for the upcoming Theorem 6, a "crisp infradistribution" is one which can be written as a set of probability distributions.
Theorem 6: Causal IPOMDP's: Any infra-POMDP with a starting infradistribution and a regular transition kernel that always produces crisp infradistributions, will produce a causal belief function via .
Theorem 5 is fairly expected, and we should note that any infradistribution over copolicies makes a causal belief function when translated over. The particular condition on that makes the diagram commute is just the condition to be the canonical/largest/least informative infradistribution over copolicies which produces a given belief function.
Theorem 6 says that if you take any infra-POMDP where the transition dynamics have the form "always return a set of probability distributions", unrolling it will make a causal belief function.
Although we won't cover it in any more than cursory detail, there's variants of causality I'm analyzing for another post. There's semicausality, supercausality, and some conditions even stronger than that, and they seem to mainly be characterized by the behavior of the transition kernel for IPOMDP's and the state spaces you need.
One interesting result from these preliminary unpublished findings is as follows. In the land of ordinary probability theory, any environment which is described by a POMDP is equally well described by an MDP .
However, belief functions that can be written as appear to be a strict superset of those which can be written as , in contrast to the classic probabilistic case. In the infra-case, it seems that adding unobservable states beyond just the past history produces a genuine boost in the amount of situations you're able to capture, even as far as observable behavior goes. I haven't gotten as far as seeing intuitively why this is the case, yet.
Translating Between Belief Function Conditions
All that leaves is translating between the three domains, and assessing how lossy the various translations are.
The pseudocausal to causal translation is a bit complex, but that's because we present three different ways of doing it which are all equivalent. It's entirely possible to just look at the most intuitive way of doing it to get the understanding benefits. So let's start on the clearest way of viewing it.
The first-person dynamic view for pseudocausal belief functions had the type signature and it worked by advancing destiny one step if the action lined up with the destiny, and otherwise producing .
To translate this to a causal belief function which behaves the exact same, we'll introduce one new state, called "Nirvana". It's a absorbing state (transitions to it are one-way, you're stuck there) and we'll agree that histories where we end up in Nirvana are treated as 1 utility (or infinite utility). Now, just consider the infrakernel which, instead of mapping destiny-defying actions to , maps them to this Nirvana state instead, and otherwise behaves the same. This new transition kernel with Nirvana fulfills the preconditions of Theorem 6. So we can just go "by Theorem 6, the belief function you get is causal", and that's it! That's the entire pseudocausal-to-causal translation. We're just swapping out for an actual state, and telling the agent "btw, value this state highly", and it works the same. This lets you faithfully capture most of the weird decision theory problems in a causal setting! And it makes the old "introduce an imaginary Nirvana state" trick go from looking like a hack to looking like a very boring triviality.
There's also an analogue of this exact move for translating the third-person static view from pseudocausal to causal, and another analogue that translates first-person static view from pseudocausal to causal. But all three ways are pretty much the same. Now, if you want, you can skip straight down to Theorem 7 at this point if you don't want to slog through the math details, you aren't missing much. The best intuition has been presented already.
For the math details, the first translation is the one discussed above where we make an infra-POMDP of type signature
The state space is destinies plus a Nirvana state , and the observation state is the old space of observations plus a Nirvana observation .
The initial infradistribution is , the injection of the starting infradistribution to the space .
The transition dynamics are:
and, if , then
and otherwise,
In words, Nirvana is persistent once it appears, it is guaranteed to appear if you defy destiny, and either Nirvana or the usual flow of events can occur at any time, though reality is unforgiving so Nirvana doesn't show up this way in practice.
The second translation is directly translating the old belief function over to get a new belief function . We'll need to do some setup for this.
denotes an element of , a possibly nirvana-containing history. We'll write if is "compatible" with and . The criterion for this is that is a history that can produce, and that any prefix of which ends in an observation and contains no Nirvana observations must be a prefix of . is the set of histories you can get if the destiny is and you play against it and go to Nirvana upon deviating from destiny, or maybe Nirvana shows up early.
With that, we introduce the infrakernel
is the infradistribution corresponding to total uncertainty over such that is compatible with and . Ie,
Now, we can state the belief function translation as follows. would be the original pseudocausal belief function, and is our new causal belief function.
Equivalently, you have total uncertainty over policies. Run this through the infrakernel to get your infradistribution over destinies. Run this through the "play against " infrakernel to get an infradistribution over histories which may contain Nirvana, and you're done!
Time for the third method of translation, going directly from the pseudocausal distribution over destinies, , to some infradistribution over copolicies. If the destiny is , the set of deterministic environments corresponding to would be those which "defend" , in the sense of attempting to play along with (submitting the right actions), and responding to any deviating action with Nirvana forever afterwards. To be more formal, defends if it responds to any prefix of which ends in an action with either the next observation in , or Nirvana, and responds to any non-prefixes of with Nirvana. The notation is that defends .
Then, we introduce the infrakernel
where is the infradistribution corresponding to total uncertainty over which defend . . Finally, we can define our first-person static (pseudocausal) to first-person static (causal) translation by:
I don't think this third translation gets you the canonical (most ignorant) representation of the resulting causal belief function in the space of copolicies, but it doesn't matter.
Theorem 7: Pseudocausal to Causal Translation: The following diagram commutes when the bottom belief function is pseudocausal. The upwards arrows are the causal translation procedures, and the other arrows are the usual morphisms between the type signatures. The new belief function is causal. Also, if , and is defined as 1 for any history containing Nirvana, and for any nirvana-free history, then .
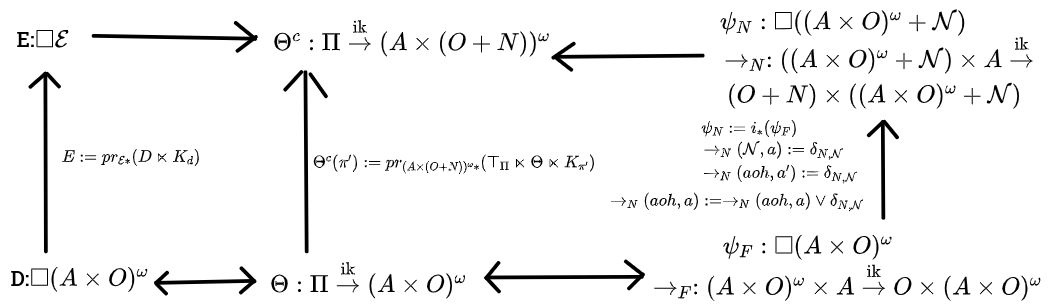
So this says pseudocausal to causal works out quite nicely and losslessly, we just split out into its own state which we agree counts as 1 utility (or infinite utility for the case, this theorem generalizes), and all three translation procedures produce the same result, and your adjusted utility function acts as it originally did.
Going from acausal to pseudocausal is an easier translation to state, the hard part about it is getting guarantees that it preserves the expectation values of utility functions. It's rather lossy.
Intutively, the essence of going from an acausal belief function to a pseudocausal one is saying "ok, reality is allowed to mispredict me now".
The first translation is taking your third-person static infradistribution over (which corresponds to an acausal belief function) and just forgetting about the policy by projecting it to . And bam, that makes a pseudocausal belief function. The environment can mispredict you since it's not explicitly tracking your policy.
The second translation (using for the original acausal belief function, and for the induced pseudocausal belief function) is:
Pretty much, this works because, (as discussed in the section on the Pseudocausal Commutative Square), is "reality thinks I play but actually I'm secretly playing instead". Semidirect product with (total uncertainty over policy) is going "well, I'm secretly playing , but I have no idea what reality is going to think I'll do", and then projection just cleans up this a bit. And this should make your , a "reality can screw up its prediction however it wants, but I play " set of possibilities.
Theorem 8: Acausal to Pseudocausal Translation: The following diagram commutes when any bottom belief function . The upwards arrows are the pseudocausal translation procedures, and the other arrows are the usual morphisms between the type signatures. The new belief function will be pseudocausal.
x-Pseudocausality
The really hard part with the acausal-to-pseudocausal translation is getting a guarantee that that, when you translate from (acausal) to , you have (or some approximate form). You'd like your expected utility to not change much if you're trying to turn a acausal belief function into a pseudocausal belief function.
As it turns out, there are weaker versions of pseudocausality that effectively say that doing this translation doesn't affect the expected utility for utility functions whose best-case values are small compared to the 1 utility of . The following analysis will be entirely about the type signature where , btw.
The acausal to pseudocausal translation is basically just letting predictors mispredict you. Which may make events go poorly. But if you enter a situation where you're mispredicted, you get 1 utility.
So, if we want to preserve the expectation value of a utility function when we permit mispredictions, we need that mispredictions are always neutral or good (as we're being pessimistic). Let's look at a case where misprediction would be really bad, and think of conditions to rule out that situation.
Our highly pessimistic, devout Buddhist agent wakes up after dying in Egypt and is being judged by Anubis. If the agent is favored by Anubis, it will go to the afterlife (good). Otherwise, the agent will be devoured by Ammit (bad). If Anubis is basing its judgement entirely on what the agent would do in an -probability situation in the afterlife, then this is a case where our agent would worry about misprediction. After all, Anubis mispredicting the agent has big negative consequences. Sure, Anubis mispredicting means that the agent would attain Nirvana if it entered the -probability situation, which alleviates things a bit. But that only boosts expected utility by or so! Not enough to outweigh the much larger boost in chances of being devoured.
So, this is an example of the shot at Nirvana//defying destiny not being good enough to outweigh the major consequences of a misprediction. Doing the acausal-to-pseudocausal translation (ie, permitting mispredictions) here would produce a big drop in expected utility. Which condition would rule out problems like this? Well, there's two ways to do it.
The first way is having a requirement that mispredictions of what you'd do in low-probability situations can only have a minor effect on what happens overall. Put another way, if Anubis mispredicting what the agent would do in an -probability situation only has a minor impact on its judgement, then the small chance at Nirvana/ would outweigh the small hit in expected utility from the (slightly) biased judgement, and our agent wouldn't worry about Anubis mispredicting it. Mispredictions of what an agent does in low-probability situations should only have minor impact on what happens overall, and if a prediction has a major impact on what happens overall, then there must be a high chance of getting into a situation where the prediction can be proven wrong.
The second way to alleviate this is scaling down your utility function. Taking the original Anubis problem, if the utility function of the agent is bounded in (as an example), then it would go "huh, a misprediction gives me probability of attaining 1 utility/Nirvana, for expected value. And I also probably get devoured by Ammit, but that can at most lose me expected value since the usual range of my utility function is low. I don't need to worry about Anubis mispredicting me". Basically, if the agent cares a whole lot about Nirvana/ relative to the usual range of its utility function, then mispredictions are less bad because the shot at compensates for the fairly minor damage caused by the effects of the misprediction.
It turns out that both of these conditions can be united in a single constraint. So now we introduce x-pseudocausality, a weaker form of pseudocausality.
As a recap, the original formulation of pseudocausality was
Our generalized formulation, x-pseudocausality, where (which is equivalent to pseudocausality for ) is defined as follows. is the utility function that has been clipped to be at most.
Definition 5: x-Pseudocausality
This is the fully general notion. From staring at it a bit, it's basically pseudocausality but only for utility functions bounded in .
As it turns out, for acausal belief functions where all the are sets of probability distributions (crisp belief functions), the x-pseudocausality condition is perfectly equivalent to:
Definition 6: x-Pseudocausality (variant)
And this is the condition saying that there's a tradeoff between the probability of entering the situation where you're mispredicted, and the magnitude of the effects of the misprediction (as measured by total variation distance, .)
For this, is a possible probability distribution over results for policy . Policy is played instead. The left-hand-side is "probability of hitting /Nirvana" and the right-hand-side is times the change in probabilities between and what happens if reality accurately predicts the agent. More precisely, times the total variation distance from to the set .
Big changes in what happens (as measured by total variation distance, on the right-hand-side) imply the probability of hitting must also be high (left-hand-side). And having a small probability of getting to call out a misprediction (small left-hand-side) mean that the effects of the misprediction (as measured by total variation distance, on the right-hand-side) must also be small. The parameter sets the tradeoff rate between the two.
Proposition 2: The two formulations of x-pseudocausality are equivalent for crisp belief functions.
Proposition 3: If a utility function is bounded within and a belief function is x-pseudocausal, then translating to (pseudocausal translation) fulfills .
The lesson of this is that a good acausal-to-pseudocausal translation that doesn't affect your problem setup becomes easier when counts for more relative to the usual range of your utility function. Setting the "diagonalization vs doing well usually" dial more towards diagonalization obviously leads to more diagonalization against knowing your action or policy, but it permits you to capture more decision theory problems in pseudocausal (and then causal) form in exchange.
Future Directions
It seems like there's five directions to elaborate on these results.
Direction 1: The overall long-term goal is to find classes of IPOMDP's which are learnable (ie, you converge to optimal behavior for all of them if you play long enough), and prove regret bounds about them. We'd like to understand which classes of unrealizable environments and decision-theoretic scenarios you can learn to do well (in the worst-case) against. Apparently, in Online Learning in Unknown Markov Games, Tian et al very recently proved the first results in this setting, independent from us. However, they mostly focus on Markov games and don't follow up on the relevance to unrealizability.
Direction 2: These results were, for the most part, about how to precisely capture belief functions. Our informal discussion at the start about how to go from the third-person view to the first-person view wasn't fully followed up on. Note that at the start of this post, the discussion was like "if you have some way of isolating features of the agent from the states, you can go third-person to first-person"
Our commutative square theorems were saying something more like "these state spaces for the third-person view are rich enough to fully capture and characterizing these classes of belief function". But remember that the state spaces we used were phrased entirely in terms of what the agent sees and does! Like the policy of the agent, or the destiny of actions and observations!
But if we want results for things like infrakernels that just capture "the universal laws unfold", or utility functions over states, or an agent with an ability to plan for things beyond its death, or unreliable memory, we'll need some way of isolating actions, observations, policies, memories, and the like from the raw states. In the background of this whole post, we were assuming the standard model where the agent is immortal and has infallible memory and translating that to a third-person view that accurately captured it. Ideally, we'd want some model where the agent may not exist, the memory may not be infallible, and the first-person view is derived from the third-person view via some translating functions which take (some subset of) states and isolate features of the agent from it. This work on more naturalized models might involve Scott's Cartesian frames in some way, or answering some questions about which sorts of third-person models can even be learned in the first place from available observational data.
Direction 3: Also, in the vein of "do what this post did, but harder", there's some causality conditions of intermediate strength to be analyzed. There's a thing called "semicausality" which lies in between pseudocausality and causality in strength, which says something like "learning more about how your policy behaves in the future provides no additional information about what happens now", as well as "supercausality" which is even stronger. We've got some results about these. Semicausality seems to match up with IPOMDP's with transitions that may not be crisp (we know casuality corresponds to crisp IPOMDP's). Supercausality seems to correspond to some sort of halfway point between POMDP's and MDP's. This points to a rich wealth of notions of "environment" with various different properties that manifest in this setting, with no classical analogue.
Direction 4: Apparently, according to Vanessa, IPOMDP's are closely related to two-player imperfect information games. The second player is the environment. You can do things like defining an infinite tower of beliefs about the beliefs of your opponent in this setting. It would be good to flesh out this connection further (ie, at all). I haven't investigated it much, but apparently there's a natural concept of multi-player equilibrium in this setting which arises from Kleene's fixed point theorem. So, we could study convergence of learning agents to various notions of game equilibria.
Direction 5: It would be nice to link the "1 utility" and "1 reward" view of Nirvana. Our utility functions when we turn Nirvana into an absorbing state are not continuous, they are lower-semicontinuous, due to assigning 1 utility to histories that end up reaching Nirvana, no matter how long it takes to hit it. You may have to look arbitrarily far in the future to find a shot at entering Nirvana. It would be good to prove results where Nirvana is not treated as 1 utility, but as 1 reward forever after, to capture it in the usual "utility function with time-discounting" setting, and see how rapidly we converge to the desired behavior as the time-discount factor limits to 1. This introduces several new complications, like addressing problems where mispredictions occur ever further in the future in a way that outruns time discounting.
6 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2021-04-25T20:41:43.755Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
Replies from: DiffractorWhen modeling an agent that acts in a world <@that contains it@>(@@), there are different ways that we could represent what a “hypothesis about the world” should look like. (We’ll use <@infra-Bayesianism@>(@Infra-Bayesianism sequence@) to allow us to have hypotheses over environments that are “bigger” than the agent, in the sense of containing the agent.) In particular, hypotheses can vary along two axes:
1. **First-person vs. third-person:** In a first-person perspective, the agent is central. In a third-person perspective, we take a “birds-eye” view of the world, of which the agent is just one part.
2. **Static vs. dynamic:** In a dynamic perspective, the notion of time is explicitly present in the formalism. In a static perspective, we instead have beliefs directly about entire world-histories.
To get a tiny bit more concrete, let the world have states S and the agent have actions A and observations O. The agent can implement policies Π. I will use ΔX to denote a belief over X (this is a bit handwavy, but gets the right intuition, I think). Then the four views are:
1. First-person static: A hypothesis specifies how policies map to beliefs over observation-action sequences, that is, Π → Δ(O × A)*.
2. First-person dynamic: This is the typical POMDP framework, in which a hypothesis is a belief over initial states and transition dynamics, that is, ΔS and S × A → Δ(O × S).
3. Third-person static: A hypothesis specifies a belief over world histories, that is, Δ(S*).
4. Third-person dynamic: A hypothesis specifies a belief over initial states, and over the transition dynamics, that is, we have ΔS and S → ΔS. Notice that despite having “transitions”, actions do not play a role here.
Given a single “reality”, it is possible to move between these different views on reality, though in some cases this requires making assumptions on the starting view. For example, under regular Bayesianism, you can only move from third-person static to third-person dynamic if your belief over world histories Δ(S*) satisfies the Markov condition (future states are conditionally independent of past states given the present state); if you want to make this move even when the Markov condition isn’t satisfied, you have to expand your belief over initial states to be a belief over “initial” world histories.
You can then define various flavors of (a)causal influence by saying which types of states S you allow:
1. If a state s consists of a policy π and an world history (oa)* that is consistent with π, then the environment transitions can depend on your choice of π, leading to acausal influence. This is the sort of thing that would be needed to formalize Newcomb’s problem.
2. In contrast, if a state s consists only of an environment E that responds to actions but _doesn’t_ get to see the full policy, then the environment cannot depend on your policy, and there is only causal influence. You’re implicitly claiming that Newcomb’s problem cannot happen.
3. Finally, rather than have an environment E that (when combined with a policy π) generates a world history (oa*), you could have the state s directly be the world history (oa)*, _without_ including the policy π. This still precludes acausal influence. In normal Bayesianism, this would be equivalent to the previous case (since we could construct a belief over E that implies the given belief over (oa)*), but in the case of infra-Bayesianism it is not, for reasons I won’t go into. (Roughly speaking, the differences occur when you use a “belief” that isn’t just a claim about reality, but also a claim about which parts of reality you “care about”.) Since the existence of E isn’t required, but we do still preclude policy-dependent influence, the authors call this setup “pseudocausal”.
In all three versions, you can define translations between the four different views, such that following any path of translations will always give you the same final output (that is, translating from A to B to C has the same result as A to D to C). This property can be used to _define_ “acausal”, “causal”, and “pseudocausal” as applied to belief functions in infra-Bayesianism. (I’m not going to talk about what a belief function is; see the post for details.)
↑ comment by Diffractor · 2021-04-27T07:38:16.770Z · LW(p) · GW(p)
I'd say this is mostly accurate, but I'd amend number 3. There's still a sort of non-causal influence going on in pseudocausal problems, you can easily formalize counterfactual mugging and XOR blackmail as pseudocausal problems (you need acausal specifically for transparent newcomb, not vanilla newcomb). But it's specifically a sort of influence that's like "reality will adjust itself so contradictions don't happen, and there may be correlations between what happened in the past, or other branches, and what your action is now, so you can exploit this by acting to make bad outcomes inconsistent". It's purely action-based, in a way that manages to capture some but not all weird decision-theoretic scenarios.
In normal bayesianism, you do not have a pseudocausal-causal equivalence. Every ordinary environment is straight-up causal.
↑ comment by Rohin Shah (rohinmshah) · 2021-04-27T17:13:30.286Z · LW(p) · GW(p)
Thanks for checking! I've changed point 3 to:
Finally, rather than have an environment E that (when combined with a policy π) generates a world history (oa)*, you could have the state s directly be the world history (oa)*, _without_ including the policy π. In normal Bayesianism, using (oa)* as states would be equivalent to using environments E as states (since we could construct a belief over E that implies the given belief over (oa)*), but in the case of infra-Bayesianism it is not. (Roughly speaking, the differences occur when you use a “belief” that isn’t just a claim about reality, but also a claim about which parts of reality you “care about”.) This ends up allowing some but not all flavors of acausal influence, and so the authors call this setup “pseudocausal”.
Re:
In normal bayesianism, you do not have a pseudocausal-causal equivalence. Every ordinary environment is straight-up causal.
What I meant was that if you define a Bayesian belief over world-histories (oa)*, that is equivalent to having a Bayesian belief over environments E, which I think you agree with. I've edited slightly to make this clearer.
Replies from: Diffractor↑ comment by Diffractor · 2021-04-28T05:23:28.263Z · LW(p) · GW(p)
Looks good.
Re: the dispute over normal bayesianism: For me, "environment" denotes "thingy that can freely interact with any policy in order to produce a probability distribution over histories". This is a different type signature than a probability distribution over histories, which doesn't have a degree of freedom corresponding to which policy you pick.
But for infra-bayes, we can associate a classical environment with the set of probability distributions over histories (for various possible choices of policy), and then the two distinct notions become the same sort of thing (set of probability distributions over histories, some of which can be made to be inconsistent by how you act), so you can compare them.
↑ comment by Rohin Shah (rohinmshah) · 2021-04-28T17:53:33.015Z · LW(p) · GW(p)
Ah right, that makes sense. That was a mistake on my part, my bad.