Inframeasures and Domain Theory
post by Diffractor · 2021-03-28T09:19:00.366Z · LW · GW · 3 commentsContents
Notation Conventions: So what is an Inframeasure? So what about Domain Theory? Haskell Example Functions in Domain Theory Type Constructor Closure Putting It Together Problems and Plans Step 1: Fix function problems Step 2: Defining Nice Domains Step 3: Defining Good Spaces Definition 1: LHC-space Step 4: the Function Space is an ω-BC Domain Step 5: Master Retraction Theorem Step 6: Inframeasures Make Nice Domains Definition 2: Inframeasure (for Domain theory) Step 7: Type Constructor Cleanup None 3 comments
Math prerequisites for this post: A Whole Lot of topology, some poset/lattice knowledge, have read "Basic Inframeasure Theory [? · GW]", just enough category theory to be familiar with functors, and other minor bits and pieces.
Domain theory is the branch of math that's like "so, what sort of topological space is a Haskell type, anyways? How do we provide a semantics for computation?"
And Inframeasure theory is about a generalization of measures which seems to hold promise for addressing several alignment issues.
Accordingly, it would be nifty if inframeasures were the sort of thing that could be worked with in Haskell. I don't know Haskell. But I do know a decent chunk of domain theory, so I can at least check how well inframeasures interface with that branch of math, as a proxy for actual computer implementation.
The major implications from this post are:
1: Yes, inframeasures do interface with domain theory quite nicely, and land in the part of it that might be feasible to implement on a computer (the -BC domains)
2: You can have inframeasure-like uncertainty over any Haskell type. This took some substantial generalization work, because Haskell types, as topological spaces, are very very different from the sorts of topological spaces we were working with before. Perfect for representing uncertainty about computations!
3: "take the space of inframeasures over this other type" is a well-behaved type constructor, so whatever crazy self-referential type signature you want to whip up with it (and the other usual type constructors), it'll work perfectly well. Oh, it's also a monad.
This post was cranked out in minimal time without editing, feel free to get in contact with me if there's something that needs clarification (there are probably things which need clarification).
Notation Conventions:
This section is best to refer back to if you're like "I know that symbol was defined somewhere, but it's hard to find where". This mostly just covers the stuff introduced at one point in this post and repeatedly reused. If a symbol gets introduced for a paragraph and doesn't get reused, it won't show up here.
For ordering, I reserve and for comparing numbers in (or or or ).
For orderings on posets which are not the set of numbers, I use . is infinima, is suprema. is supremum of a directed set. As is usual, and are the top and bottom elements of a poset if they exist.
is used for the approximation relation on a poset. if all directed sets with a supremum of or more contain an element that lies above . More on this concept later. It's like a more restrictive version of .
are used for domains or posets, while and are used for generic topological spaces that may not be equipped with a partial order.
For type signatures, is a function from the space to the space , assumed continuous by default unless we specifically say otherwise. If we say " is a measurable function " or something like that, it might not be continuous, but if it's not otherwise specified, always assume continuity.
is the space of continuous functions from to . This is often used for something like and , where we're equipping and with the usual topology.
The notation , or , or stuff like that, has the brackets meaning we're treating the function space in a specifically domain-theoretic way. The target space or or or whatever must be equipped with a partial order. There's a topology on posets called the Scott-topology, the target space is equipped with it. The Scott-topology on and the ordinary topology on are different (same goes for and other intervals like that) so elements of may not be elements of , because is equipped with different topologies in the two cases, altering the notion of "continuous function". Also, the function space is equipped with a partial order. Since the target space or or whatever is a poset, the functions get the ordering iff .
So, to recap, the brackets mean we're equipping the target space with a partial order and the Scott-topology, and equipping the space of continuous functions with a partial order and the Scott-topology as well.
For numbers, is generally used for numbers in , is generally used for an arbitrary real number, and is used for nonnegative real numbers.
is the constant function which maps every input to the number .
There's a part where we use and . The slightly fancier is a subset of a domain , the simpler is the subset equipped with the order inherited from to make it into its own distinct poset.
is used for inframeasures, interpreted as a function. They've got type signatures like , or (usual topology on the numbers), or , or (Scott-topology on the numbers), varying by context. They've also got some other properties besides that.
So what is an Inframeasure?
Most of the motivation for why these things are important is contained in the Introduction to this Sequence [? · GW]. So we'll just focus on what sort of creature an inframeasure is, mathematically, trying to emphasize the aspects of it which generalize to our new setting.
For probability distributions over some space , the expectation of a function is defined as:
There's an alternate way of thinking of probability distributions where the most important attribute of a probability distribution is that it's the sort of thingy that you can take expectations of functions with. Under this view, a probability distribution is just a functional of type , mapping a function to its expectation. Said functional must fulfill the following properties, and then it can be called a probability distribution.
1: It must be monotone. Ie, larger functions must be mapped to higher expected values. The order on functions is that is larger than iff .
2: It must be linear.
3: It must map the constant-1 function to 1.
And, as it turns out, monotone linear functionals which map the constant-1 function to 1 are exactly those which can be written as taking an expectation w.r.t. a probability distribution. If you wanted to generalize to measures instead of probability distributions, just drop that third condition and keep the first two.
Now, in order to build up to inframeasures, we'll need to generalize to a-measures (short for "affine measures"). If you don't do this, you lose the ability to deal with updates in the infra-Bayes setting, which critically rely on this. An a-measure is a pair of a measure and a nonnegative number, . That term is like "guaranteed utility". Again, we can take expectations w.r.t. them, defined as
Said expectation functional has the properties:
1: It's monotone.
2: It's affine. For ,
All affine functions to look like a linear function to plus a constant.
3: It must map the constant-0 function to 0 or more.
And, lo and behold, all expectation functionals of this form (skipping over some fiddly issues) can be identified with an a-measure.
Inframeasures are sets of a-measures. Sets of probability distributions (which, in our terminology, are called "crisp infradistributions") are already extensively studied in the field of Imprecise Probability, but generalizing to sets of a-measures is necessary for maximum generality and properly capturing updates. We can define expectations w.r.t these sets of a-measures. You don't know what a-measure (or probability distribution, if you prefer to think of sets of probability distributions) reality is going to pick from its set of available options , and you want to be prepared for the worst case, so expectations w.r.t. a set of a-measures are defined as:
Just take the worst-case expectation w.r.t. the available set of a-measures.
Taking the view where the expectation functional of type is the most fundamental object, several different sets of a-measures might have the exact same expectations, so you get an equivalence relation on sets of a-measures. Usually, a set of a-measures must fulfill certain properties like closure and convexity to be called an "inframeasure", but the bulk of those properties are actually the condition for a set of a-measures to be the largest set in its equivalence class, the "canonical representative" of the equivalence class.
So, for thinking of an inframeasure, you can think of it as a equivalence class of sets of a-measures. Or you can think of it as the "canonical representative", the largest set of a-measures in its equivalence class. Or you can completely neglect the view of it as a set of a-measures and just consider the expectation functional, of type . That last view, where we just view an inframeasure as a special sort of function of that type signature, will be used through the rest of this post as it generalizes the best. The expectation functional for an inframeasure, denoted by , is:
1: Monotone (as usual)
2: Concave. If , then
3: Lipschitz. There's some finite constant s.t, for all ,
4: The constant-0 function is mapped to 0 or higher.
And this is an inframeasure. Any functional of type , or , fulfilling those four properties. If you want to add extra properties to this list to get a more restricted class of these things, you can. They seem to be highly useful for dealing with nonrealizable environments, getting nice decision-theoretic behavior for free, and a few other things.
Well, it's a little more complicated than that. Some complications are:
So far, we've only been able to define them for spaces which are Polish (a space is Polish if it can be equipped with a metric, is closed under taking limits, and there's a dense countable subset).
They can only take the expectations of continuous bounded functions , unlike probability distributions which can handle measurable functions in general.
There's a complicated fifth condition related to compactness which shows up if your space isn't compact.
We'll be neglecting this more complex stuff for now.
So what about Domain Theory?
Domain theory focuses on partially ordered sets with the ordering being related to information content somehow, which is usually tied to computation in lazy programming languages or partial functions or stuff like that. The least informative points go on the bottom, the most informative stuff go on the top. If your poset fulfills enough nice properties, it's called a domain. Haskell types are domains.
If you're wondering about the properties to call something a domain, there's three of them, by my count. Different authors disagree on what the word "domain" refers to, but I'll go with the three most basic conditions which kept showing up over and over and over again in my domain theory textbook, and which were almost always assumed.
Condition 1: Suprema exist for all directed sets.
A directed set is a generalization of a chain. Using for our poset, and for a subset of it, is a directed set when, for any two points in , there's an upper bound of those two points which is also in . If you want, you can just think "chain" whenever you see "directed set", the intuition won't lead you astray. So, this is essentially saying that if you've got a sequence of more-and-more-informative points, there must be a completion of that sequence. A most informative point that contains all the information in said sequence, and nothing else. Supremum for directed sets is denoted instead of , because it's handy to notate when you're taking a suprema which is actually guaranteed to exist.
Condition 2: There must be a bottom point below everything.
Compare this with how, in Haskell, all types contain . It's usually used to represent nonterminating computations or undefinedness or the least informative thing. It's also handy for defining partial functions. Just map every input without a well-defined output to .
Condition 3: The poset must be continuous.
This one is rather complicated. Along with the usual information ordering, , there's also an approximation relation, ( approximates ), which is stricter than . iff all directed sets with a supremum of or higher contain an element s.t . Put another way, if is an irreducible component of the information in . If , then it's impossible to make a sequence of more and more information with (or something more informative) as a limit, without having that sequence pass by/get more informative than at some point.
A poset is continuous if, for all , is the supremum of the approximants to .
Pretty much, all pieces of information should be capable of being created by combining the "substantially less informative" pieces of information which are guaranteed to show up in any attempt to build from below (the approximants to ). You need this for the topology on your poset to behave nicely.
So, if your poset has got suprema of directed sets (chains), a bottom point, and you can build every point with approximants from below, it's a domain.
Exercise: Why is the following poset not continuous?
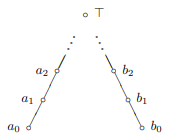
Haskell Example
For Haskell semantics, points near the bottom of the domain/type are computations with a lot of unevaluated thunks, basically parts of the computation that haven't finished computing yet. Maximal points in the domain are completed computations, fully specified pieces of data. If you evaluate a thunk, finding out some more about what your piece of data is, you get a higher point in the information ordering. And there's always a bottom.
As an example, the type/domain of infinite bitstrings, under the information ordering, looks like an infinite binary tree.

There's as the root node, representing a nonterminating computation where you can't get even a single digit out of it, complete ignorance of what the bitstring is. There's a bunch of branch nodes that are of the form "string of finitely many digits, then a thunk". These elements are like "ok, I can tell you the first six digits of the binary string, but hang on I'm still computing the rest...". And then there's all the leaf nodes, fully computed infinite bitstrings.
Functions in Domain Theory
For a function from a domain to a domain to be continuous, it needs two properties. First, it needs to be monotone. . More informative inputs lead to more informative outputs.
Second, it must preserve suprema of directed sets/chains. for all directed sets . See the picture for a non-continuous function.
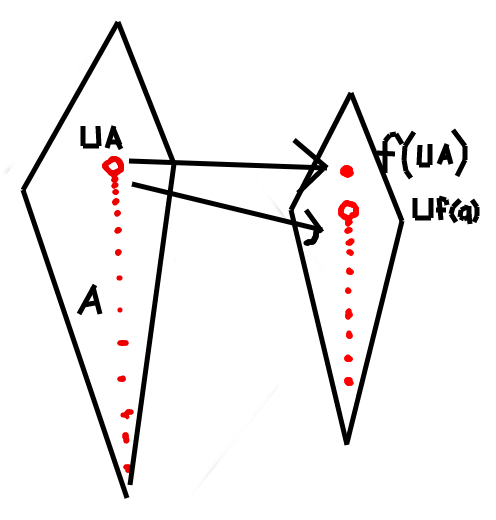
Btw, terminology note for later. or or something like that signifies the space of continuous functions from one space to another, but treated in a domain-theory way. The brackets specify we're doing this. More precisely, the target space ( or or whatever) must be a poset, and equipped with the Scott-topology (a topology you can put on posets). This tells you what the continuous functions are, and then you equip the continuous functions with the ordering iff .
This is relevant because the space of continuous functions is not the space of continuous functions . In the former, we're equipping with its usual topology, determining what the continuous functions are. In the latter, we're equipping with the Scott-topology, so different functions count as continuous now. And we're also going on to equip the function space with a partial order.
Type Constructor Closure
One of the most striking features of domains is that certain subcategories of domains are very good at being closed under type constructors. Some type constructors are ,, and function space, letting you paste together existing spaces into more complex spaces. Pretty much any topological property worth its salt will be closed under finite products and sums and some other stuff, but function space is way harder to get.
Given spaces and with some nice topological property, the space of continuous functions very rarely has said nice property. If and are compact, you can't guarantee the function space is compact. If and are Polish, you can't guarantee that the function space is Polish. But, given domains and in some "nice" category of domains, the domain of continuous functions is going to be just as "nice".
The most important operation that the "nice" categories of domain are closed under is the bilimit. In domain theory, the category-theoretic notion of limit and colimit coincide (well, kind of, it's complicated), and the resulting thing is called the bilimit. It's how you take a sequence of ever-more-complicated domains and complete the sequence, in a sense. And it's the construction underlying Haskell's ability to define a type in terms of itself. It's very special because it means that, with the tools of domain theory, it's possible to cook up whatever sort of wacky fixtype you want.
We'll work through a very simple example of how this works. The construction process to solve . Stage 1 is starting with a single point. Addition of two domains/posets is "add a single new bottom element below both existing posets", so stage 2 would be , the poset that looks like a , the domain of booleans. Stage 3 would be , or a 2-level binary tree with 4 leaves. Stage 4 would be a 3-level binary tree with 8 leaves (two copies of stage 3, with a new root node). And if you take the bilimit of that sequence, you'd end up with the infinite binary tree, the domain of infinite bitstrings. And clearly, if you take two copies of an infinite binary tree, and add a new root node below both of them, you get an infinite binary tree again, so it's isomorphic to adding two copies of itself together.
The general way that domain theory makes fixtypes is starting with a single point at stage 1. Then, substitute the single point into the defining equation, to get a more complicated domain at stage 2. Then substitute the stage 2 domain into the defining equation, to get a more complicated domain at stage 3. There's a sequence of embeddings of each stage into the next, more complex stage, so you can take a bilimit of the sequence, and bam, you have your fixtype.
Exercise: Sum, , is "add a new bottom point below both posets". Coalesced sum, , is "glue both posets together at their bottom point". Lifting, , is "introduce one new bottom point". is the domain of a single point, and is the domain of two points, a top and a bottom. Using these type constructors, how would you define the following domains in terms of themselves in such a way that the fixtype construction process makes the indicated poset? Like how the domain of infinite bitstrings/the infinite binary tree is the solution to .
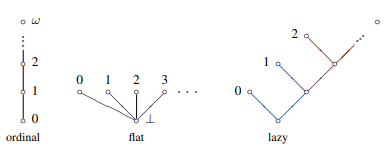
We aren't just limited to the sum types, there's also products and function spaces. For instance, the solution to (take the function space from itself to itself, add a new bottom point) is the space of terms in the lazy lambda calculus.
If, say, you wanted to whip up a fixtype for
Or even something much crazier than that, domain theory handles it with no problem. Start with being single points, substitute them in to get stage 2 domains for both of them, working in this way you can build a sequence of more-and-more-detailed 's and 's, take the bilimit of both sequences, and you have a simplest solution!
Putting It Together
Inframeasures also have something that could be described as an information ordering. Restricting to just crisp infradistributions/closed convex sets of probability distributions for the time being, the maximal elements with the most information would be individual probability distributions. Elements further down are larger sets of probability distributions, representing more and more uncertainty about what probability distribution accurately captures events. And the bottom node would be complete uncertainty about what probability distribution describes reality, ie, the set of all probability distributions over your space.
So, that's the first inkling that something's up. Inframeasures naturally make a poset, unlike probability distributions. Suprema (for crisp infradistributions) would be intersection of the sets of probability distributions. Infinima would be closed convex hull of the union of the sets of probability distributions. Using for the expectation functionals, we have
( is used for the ordering on domains, is used specifically when we're dealing with numbers)
This would line up with the type signature for inframeasures (in domain theory) being something like the space . Though this particular type signature won't work, as we'll see later. The monotonicity property (bigger functions get bigger expectations) on inframeasures would fall out for free because continuous functions from a poset to a poset in domain theory are always monotone. And suprema/infinima of inframeasures, from Less Basic Inframeasure Theory [? · GW], seemed to behave suspiciously like suprema and infinima in domain theory.
There is a very important note here. The information ordering on inframeasures is flipped from the usual ordering inframeasures are equipped with. The usual ordering has an equivalence between: Infinimum (), logical and (also denoted by ), and set intersection (of the corresponding sets of probability distributions). And there's an equivalence between supremum (), logical or (also ), and convex hull of set union .
But, under the information ordering, set intersection would be supremum. The sets get smaller and thus have less uncertainty and more information. Accordingly, the notation will be reserved for the information ordering, and for domain-theory suprema and infinima (intersection and union), respectively. This is so and can be reserved for the usual ordering, avoiding the notational nightmare of using the same symbol for both the ordering and the reverse ordering.
It's very boring to just go "ooh, infradistributions make a domain!", though. You can't get much out of that. The ultimate goal would be to figure out how to take a domain , and make a domain of inframeasures over the space .
If you did this cleanly enough, then "map a type to the type of inframeasures over " would end up being a nicely-behaved type constructor in domain theory, and you could whip up whatever sort of weird fixtypes you want with it, and probably cram it all into Haskell somehow, and have inframeasure-y uncertainty over any Haskell type.
This is a big deal because it's a surprisingly big pain in the ass to make the "map a type to the type of probability distributions over " type constructor behave sensibly.
There is a domain-theory construction which builds the space of probability distributions over another domain. It's called the probabilistic powerdomain. The issue is, probabilistic powerdomain is an operation which leads you outside of the most commonly used cartesian-closed categories of domains (which you need to stay within to cook up the fixtype solutions), and the cartesian-closed categories of domains are exhaustively classified. The problem of showing whether or not there's some lesser-used category of domains that's closed under probabilistic powerdomain is called the Jung-Tix problem, after the authors of the original paper.
There's a generalization of domains called QCB spaces, and apparently a sub-category of them is closed under probabilistic powerdomain and has strong enough closure properties to support the fixtype construction process. So domain theory (broadly construed) has pretty much figured out how to handle probabilistic choice in computations since the original Jung-Tix paper was written. But you have to go rather far afield to do it.
The key problem with probabilistic powerdomain is that it destroys all the lattice-like structure present in a domain, and the best-behaved categories of domains with the strongest connections to computation are very lattice-like. Fortunately, the space of inframeasures does have a lot of lattice-like structure which is lacked by the space of measures. So, one might hope that one of the nice and commonly used categories of domain is closed under the "space of inframeasures" type constructor, for practical implementation.
As it turns out, yes, this can be done. There's problems to overcome along the way, though.
Problems and Plans
Problem 1: The type signature of an inframeasure over , in a domain-theory sense, would be something like an element of the space or . Up till now, inframeasures could only take expectations of bounded continuous functions (or ), where or is equipped with the usual topology. Domain theory would equip or with the Scott-topology when making the function space, thus changing the notion of "continuous function". And also, there's no good support for the notion of "bounded function" in domain theory. And also, isn't a legit domain. Closure under suprema of chains demands that be added, and the existence of a bottom element demands that be added. We need to sort out fiddly issues of what sorts of functions we can even take the expectation of in the first place.
Problem 2: Inframeasures have only been defined on Polish spaces up till now. Polish spaces are the usual setting for probability theory. And domains are very very not-Polish. They're T0 spaces, about as badly behaved as a topological space can be, while Polish spaces are T6, about as nicely behaved as a topological space can be. This is going to take some serious generalization work.
Problem 3: Not all the elements of that function space are suitable to be an inframeasure. Inframeasures are functionals which have some additional properties like concavity, which wouldn't show up for an arbitrary continuous function. If we wanted to build a space of inframeasures and show it was nicely behaved from a domain-theory standpoint, we'd have to craft it as some sort of subset or quotient of the full function space, which is more finicky to pull off than it appears at first.
Problem 4: There's a lot of extra properties inframeasures can have, if you want to restrict to particularly nicely-behaved subsets of them. We could restrict our attention to infradistributions (which must map the constant-0 function to 0 and constant-1 function to 1). And there's also properties you can stack on top of that like 1-Lipschitzness, homogenity, C-additivity, cohomogenity, crispness, and sharpness (definitions not relevant here, they're present in Less Basic Inframeasure Theory [? · GW]). We could just as well imagine building domains corresponding to those, to make type constructors like "build the type of crisp infradistributions over this other type". Plus, there's the issue of whether we're using the space, or the space. We really don't want to have to duplicate all the work ten times over in proving that these more restricted processes all make nice domains.
The game plan here is:
Step 1: Inframeasures take as input continuous bounded functions in (or ) where has the usual topology. The domain-theory space of continuous functions (or ), has or equipped with the Scott-topology, and doesn't talk about boundedness. This is quite different! Sort that part out somehow, to address problem 1.
Step 2: Conjecture what sort of domain a domain of inframeasures would be, so we know which category of domains we're headed for. It should be one of the smaller categories of domains that's more closely linked to what computers work on. Let's call these "nice" domains, as a placeholder.
Step 3: Come up with some sort of criteria for a "good" topological space to define inframeasures over that manages to include both the usual sorts of Polish spaces we were looking at before, and "nice" domains, so you can apply inframeasures to domains.
Step 4: Verify we solved steps 2 and 3 correctly by showing that if is "good", then is a "nice" domain. Then, since, by step 3, a "nice" domain should be a "good" space, we can apply our result a second time to conclude that is a "nice" domain. Where "nice" and "good" are placeholders for something more formal. Also, generalize this to the type signature. Steps 3 and 4 together would address problem 2, thus extending the notion of "inframeasure" to the sorts of objects studied in domain theory.
Step 5: Now that (or the same thing with ) is a "nice" domain, see if we can get some sort of master theorem for precisely when a subset of a "nice" domain is also a "nice" domain. All the various sorts of inframeasures and infradistributions are subsets of that whole function space, so it'd be nice to only check the conditions of the master theorem to go "and this subset of it is also a "nice" domain" instead of having to do all the work from scratch each time. This would address problem 4 by making one single theorem we can reuse.
Step 6: Show that for inframeasures, and all the more specialized types of them, they all fulfill the conditions from the master theorem in step 5, so they all make "nice" domains. This would solve problem 3, the last of them.
By now, steps 1-6 show that the category of "nice" domains is closed under the "take the space of inframeasures" type constructor, and all the more restrictive variants of it like "take the space of crisp infradistributions". This is because, by step 3, all "nice" domains should be "good" spaces. By step 4, the function space (or the variant) will also be "nice". And then, by steps 5 and 6, the various subsets of the full function space fulfilling various desired properties are also "nice". So we're just on detail cleanup from here on.
Step 7: Do a quick routine verification that "take the space of inframeasures" is a locally continuous functor from the category of "nice" domains to itself, as that's the property you have to check to freely use it as a type constructor in fixtype shenanigans with no worries. Also, annoyingly enough, my domain theory textbook doesn't verify closure of the various categories of domains under all the other usual type constructors that made an appearance there (lifting, sum, coalesced sum, product, smash product, function space, strict function space, bilimit), only some of them, so get those squared away.
And then we'd be done! By step 7 (the category of "nice" domains is closed under all these type constructors), we can just throw chapter 5 of the Abramsky textbook at it to get that we can build whatever weird type signature we want from these basic building blocks and it'll work out.
Of course, not all these steps will interest the reader, and we'll be going into an awful lot of detail on how each one works, so if you've made it this far, feel free to skip straight to whichever one piques your interest.
Step 1: Fix function problems
Inframeasures are defined over Polish spaces with no issues, so let's start there. Our goal is to extend inframeasures over Polish spaces from taking expectations of bounded continuous functions (or ) to taking expectations of Scott-continuous functions (or ).
The Scott-topology opens on are (besides the whole space and the empty set) all of the form for , the sets of the form "everything strictly above this number". Similar thing for . This is fewer opens than the usual topology on (or ), so it's easier for a function to count as continuous, since the criteria "every preimage of an open is open" is easier to fulfill when you've got less opens in the target space.
Going to probability distributions as a toy example to play with, if you had previously invented probability distributions in such a way that you could only take expectations of bounded continuous functions with them, and were trying to extend the expectations to more general functions than that, how could it be done?
Well, for probability distributions, there's a nifty result called Lebesgue's Dominated Convergence Theorem which (skipping over technical requirements) says that if a sequence of measurable functions limits pointwise to , then
So, if you could prove a result like the Dominated Convergence Theorem, then you could go "hey, we can get sensible expectations for all functions which are pointwise limits of continuous functions, since no matter what sequence of functions you pick to get there, the limits of the expectation values will agree!". And then you'd have expectations for the Baire class 1 functions (pointwise limits of continous functions). Apply the theorem again and you get Baire class 2 functions (pointwise limits of Baire class 1 functions). Keep going, take unions when you get to limit ordinals, and by the time you've hit the ordinal , you're done, you've figured out how to take expectations of any measurable function.
Can we do something like this for inframeasures? No. There's no analogue of Lebesgue's Dominated Convergence Theorem. In fact, it explicitly fails, and not way off in the upper realms of the ordinals, it fails down at the start.
Proposition 1: There is an infradistribution on the space and a sequence of continuous functions which limit pointwise to a function , yet and .
Proof: Let be the set of all probability distributions on . The expectation function is , because you can always consider the probability distribution which has all its measure on the point where the function is lowest.
Function is defined to dip down in a V pattern, from 1 at 0, to 0 at , back up to 1 at , and is 1 for all larger numbers. This sequence limits pointwise to the constant-1 function. Since all the have a minimum value of 0, they have expectation values of 0, and the constant-1 function has a minimum value of 1, so it has an expectation value of 1.
But we can get an analogue of Beppo Levi's Monotone Convergence Theorem, for inframeasures!
The Monotone Convergence Theorem says that if you've got a sequence of lower-bounded measurable functions s.t. , then the pointwise limit of them, , has
There's a bit of a roadblock though. If you start off with bounded continuous functions, then taking pointwise limits of ascending sequences like that gets you... all the lower-bounded lower-semicontinuous functions. And then, taking pointwise limits of sequences like that, you can get... lower-bounded lower-semicontinouous functions. That's as far as we can go with this result!
Also, more excitingly, we can prove another theorem that all lower-bounded lower-semicontinuous functions have an ascending sequence of bounded continuous functions that limit to . So if we've got an analogue of the Monotone Convergence Theorem for inframeasures, that should let you extend expectations from the bounded continuous functions to the lower-bounded lower-semicontinuous functions.
Proposition 2: If is a metrizable space, then the pointwise limit of a sequence of lower-bounded lower-semicontinuous functions with is lower-bounded and lower-semicontinuous.
Proposition 3: If is a metrizable space, then given any lower-bounded lower-semicontinuous function , there exists a sequence of bounded continuous functions s.t. and the limit pointwise to .
Theorem 1/Monotone Convergence Theorem For Inframeasures: Given a Polish space, an inframeasure set over , a lower-bounded lower-semicontinuous function , and an ascending sequence of lower-bounded lower-semicontinuous functions which limit pointwise to , then
Proposition 3 and Theorem 1 imply that you can extend expectations to lower-bounded lower-semicontinuous functions , not just bounded continuous functions. The bounded continuous functions all have their expectation values well-defined. By Proposition 3, you can take any lower-bounded lower-semicontinuous function and find continuous bounded functions to limit to it from below. By Theorem 1, this lets you uniquely define the expectation value because no matter how you limit to it from below with continuous functions (with well-defined values), you've got the same limit value.
Well... why do we care about this? As it amazingly turns out, lower-semicontinuous functions or are exactly the Scott-continuous functions or ! So we were able to generalize precisely far enough to take expectations of the sorts of functions that domain theory says we should be able to take expectations of.
In fact, it's even better than that! Remember how inframeasures (as we'd attempt to define them in domain theory) would be in , or (with the Scott-topology) or something like that?
Well, and are posets. And the interval (or ) is a poset. The Scott-continuous functions from one poset to another are those which are monotone, and preserve suprema of chains.
So, we can ask "are inframeasures Scott-continuous functions?" Monotonicity is one of the defining conditions on an inframeasure, so we've got that. And Theorem 1 is effectively saying "oh hey, your inframeasure function (or the other type signature) happens to preserve suprema of chains of functions". So yes, inframeasures must be Scott-continuous.
It's a perfect match! We can extend expectations exactly far enough to catch the Scott-continuous functions (or the other type signature), and our Monotone Convergence Theorem for inframeasures is saying precisely that classically-defined inframeasures happen to be Scott-continuous functions in . A lovely match to domain theory.
These results do point towards the function space being the wrong choice for domain theory, however. Instead you'd want the function space that inframeasures lie in to be . Your functions you're taking expectations of must have a lower bound, so is not legit. But also, domains need bottom elements and suprema of chains, so that explains why and show up, they make it so the function space has a bottom and a top.
Step 2: Defining Nice Domains
Of the various categories of domains, let's narrow down what we might mean by "nice".
First up, there's a classification theorem (Theorem 4.3.3 in Abramsky) that says that any cartesian-closed category of domains is a subcategory of either the FS-domains or the L-domains. We won't get into definitions here, but roughly, if you make a function space between two domains , it might not be a domain. But if is a FS-domain then the whole function space will be a FS-domain, and if is an L-domain, then the whole function space will be a L-domain. Since our space of inframeasures over a topological space would be a subset of (or the other type signature), clearly, our best bet is not the FS-domains, as their good behavior relies on being the input space. We want the L-domains, as their good behavior relies on being the output space. And L is short for "lattice-like", and (or ) is a complete lattice.
Ok, so L-domains. The lattice-like domains. Maybe we can hope for some nice property that makes it easier to work with on a computer? There's two of those. -continuity, and algebraicity.
Algebraicity (which won't be explained here) won't work because and aren't algebraic, and that contaminates everything else.
Ok, what about -continuity? What's that? Well, continuity was
You can make all points from below using the stuff that approximates it. -continuity says you can do this with a countable subset. If there's a countable set s.t.
then is -continuous. It's a "you only need countably many pieces of information to build every other point from below" condition. Which is essential for working with a domain on a computer, since computers can only handle finite bitstrings and there's only countably many of those to go around!
It's highly instructive to compare this to separability. Separability of a metric space is "there's a s.t. is countable, and every point in can be built as a limit of points from ". Think the real number line and the rationals for this.
Ok, so -continuity is a yes, algebraicity is a no, we're down to the category of -L domains. The prefix means those domains are -continuous.
Still more choices to make, though. L-domains have a weak lattice-like property, but the BC-domains are more lattice-like than that. And then there , the continuous complete lattices, which are as lattice-y as possible.
The category is a bad choice though, because (add a new bottom element below both of your posets) doesn't preserve being a complete lattice. And is a pretty damn important type constructor to have. So that one's out.
Accordingly, our notion of "nice" domain will be -BC domains. They've got a countable basis so they're highly suitable for working with on a computer, are as lattice-like as we can get without forbidding sum types, and all the Haskell constructions lie in here. They're perfect! We'll use them.
Er... what does it even mean to be an BC-domain though? Well, BC stands for bounded-complete. So here's the deal. If some ( isn't necessarily a directed set here) has an upper bound, or is a chain, then the supremum (least upper bound) of exists. This is where the name "bounded complete" comes from. If there's an upper bound to your set, it has a supremum. Also, if is nonempty, then the infinimum of must exist (supremum of lower-bounds). Compare to a complete lattice having all suprema and infinima exist.
Pretty much, BC-domains all look like you took a complete lattice where you can't build from below with suprema of chains, and ripped the top point off of it. This doesn't affect any infinima except the infinima of the empty set, which is the top point. So that's the only infinima that stops existing. And it doesn't affect the existence of any suprema except the sets where the supremum is . But if there's an upper bound that's not , then that upper bound is still hanging around and you can make a least upper bound.
Step 3: Defining Good Spaces
Next up, coming up with a definition for a "good" space. It's very hard to give a linear account of why it's a good definition for a "good" space, because the starting attempt was heavily motivated by fiddly details of how the approximation order works for function spaces in domain theory, and then I went through a few iterations of finding out that my definitions got me pretty far, but not far enough, so I had to make things stronger. I'll give the motivation my best shot.
Given a topological space , what properties must it have to turn into an -BC domain? Our function space will be either or , and is topologically equivalent to , so this is a very important desiderata to have.
The hardest part of this to get, it turns out, is the -continuity part. We need a countable collection of functions in the function space which are rich enough to build every other function from below.
From riffling through the trusty textbook, (start of Chapter 4), the way this would work in the function space (if was a domain) is as follows: You've got a nice countable collection of open sets , and a countable subset of which lets you build everything from below (the rational numbers). The countable collection of functions that you can build everything from are of the form , the function that maps the open set to the rational number , and maps everything else to 0. Oh, and the finite suprema of such.
As it turns out, this can be adapted to arbitrary topological spaces . The key part is the "countable collection of open sets".
So, our first restriction on to be "good" will be second-countability. There should be countably many open sets s.t. you can build every open set in from unioning those basic ones together. That's what second-countability is. All -domains are second-countable, so are Polish spaces, we're doing good here.
When you dig into the proof a little more, it turns out that second-countability isn't enough, you also really need local compactness. The problem with local compactness is that if isn't Hausdorff (and domains aren't Hausdorff), then the various definitions of local compactness which used to be equivalent stop being equivalent.
The specific variant of local compactness you need is that for all open sets and points , there's an open set and compact set s.t. . Every neighborhood of a point (the ) contains a compact neighborhood of that point (the )
And... Polish spaces aren't locally compact in general. Ouch. Domains always are. Importantly, this does not mean there's a problem defining inframeasures on Polish spaces in general. It does mean there's problems with turning them into a nice pretty domain.
Ok, so our two criteria are "second-countable" and "locally compact". Anything else?
Well, this gets you pretty far, but not far enough. As it turns out, if you mandate that is compact, it solves about 3 different fatal problems at the same time. Some of them would be hard to explain, but there's an easy one to explain.
Remember how, back in Step 1, we could only handle lower-bounded Scott-continuous functions ? Well, it's possible that you could have a function that's unbounded below, but still Scott-continuous. But if is a compact space, then your function can't possibly be unbounded below, you get boundedness for free, and we really needed that. If is compact, then the space just has exactly the bounded-below Scott-continuous/lower-semicontinuous functions in it, which are exactly the ones that our Step 1 results justify us taking the expectations of.
Confusingly enough, compactness does not imply local compactness in the sense we've defined it.
Domains are, fortunately, compact. This is because all open sets in a domain are closed upwards, and domains have a bottom element. So any open cover of a domain must have an open set which includes the bottom element, which then contains the rest of the set since open sets are closed up. Bam, that's a finite subcover, the domain is compact.
And, well, I guess we're down to compact Polish spaces now, as the only Polish spaces which fulfill these three conditions. Those are the really nice ones we started off our journey with in Basic Inframeasure Theory [? · GW] though. No problems here.
So, second-countability, local compactness, and compactness. Is that enough for a space to be "good"?
Possibly. It might very well be. But when I was grinding through the theorems, there was this one key step regarding concavity that didn't work with those three properties alone, and I needed something else. It's possible that that one key step of the proof might not require anything other than those three properties. But I had to assume a fourth property to make it work, which is a stronger version of local compactness.
It's not any topological property I've ever seen before, so I'm going to call it LHC, for locally hull-compact.
Definition 1: LHC-space
A space is LHC, locally hull compact, if there's a base closed under finite intersection, and a function , mapping an open set from the base to a compact subset of (the "compact hull"), which fulfills the following three properties.
1:
2:
3: For any open set and point ,
Those first two properties are two of the three for a hull operator. The third property of a hull operator , can be dropped because we're only applying to the open sets from the base, not to everything.
Intuitively, is a compact set that fits tightly around the open set from the base. We can't just go " is the smallest compact set with as a subset" because when we go out of Hausdorff spaces, the intersection of compact sets might not be compact. But should be bigger than . And if you pick a bigger set from the base, the compact hull should be bigger. And should be a "tight enough fit" around that this compact hull witnesses local compactness. Given a point in an open , you should always be able to find an open from the topology base that contains and is small enough that its compact hull also fits in .
And so, we get LHC-spaces. Locally hull-compact. A space is LHC if it has a base closed under finite intersection, and a compact hull operator on the base which can be used to witness local compactness.
As it turns out, BC domains are LHC-spaces. And compact Polish spaces are LHC-spaces as well, because you can just take to mean "closure".
So, that's how "good" spaces, where the space of infradistributions on them is an -BC domain, finally cash out. A space that's compact, second-countable, and LHC (locally hull-compact).
Proposition 4: All compact Polish spaces are compact second-countable LHC spaces.
Proposition 5: All open subsets of -BC domains are second-countable LHC spaces.
Corollary 1: All -BC domains are compact second-countable LHC spaces.
Woo! We've got a definition for "good space" now! Compact second-countable LHC spaces. And it includes the most essential sorts of Polish spaces that we use all the time (the compact ones), and all the domains we're trying to define inframeasures over!
Step 4: the Function Space is an -BC Domain
Ok, so we should be able to prove that the function space is an -BC domain if is compact second-countable LHC, right? Yes! With a bit more work, we can even extend it to the function space
Theorem 2: If is second-countable and locally compact, then is an -BC domain, as is .
Corollary 2: The space is an -BC domain with top element when is second-countable and locally compact.
Proposition 6: The space is an -BC domain with top element when is compact, second-countable, and locally compact.
Theorem 2 is where the bulk of the work is. Most of showing the space is an -BC domain is that -continuity part, which requires that second-countability and local compactness property to properly invoke the proof path from the domain theory textbook about how to approximate all the functions with only countably many simple functions, which takes a while. The case holds because it's topologically identical to , so we only need to prove things once.
Corollary 2 is easy because, by Theorem 2, is an -BC domain. By Corollary 1, this is a compact second-countable LHC space, so we can just invoke Theorem 2 a second time.
The proof path for Proposition 6 (dealing with the -like type signature) is a little more tricky.
By our arguments in step 1, we're only justified in taking expectations of functions in that are bounded below. Having there instead of would permit some rather pathological inframeasures, so we do need that restriction to . Assuming is compact gets us that any continuous function is bounded below, and also lets us deploy some stronger approximation arguments to carry through the rest of the proof.
The essential core of proving Proposition 6 is managing to show that is an open subset of . Once that's done, we can invoke Proposition 5 to know that fulfills the preconditions as a topological space to apply Theorem 2 to get the whole result.
Corollary 2 and Proposition 6 specify that there's a top element in said domain, because it will be relevant later.
Step 5: Master Retraction Theorem
Our goal now is to figure out when a subset of an -BC domain is an -BC domain, so we have a condition to shoot for to establish that the space of inframeasures (or whatever else) is an -BC domain (since it'd be a nicely-behaved subset of the whole function space). It'll turn out that things go smoother if we've got a top element present, which is why it's important that Corollary 2 and Proposition 6 reminded us that there was a top element present (making the function space into a complete lattice).
So, if is an -BC domain with a top element, and is some subset of , then when is (the set equipped with the order inherited from , for property) an -BC domain?
Well, there are these things called section-retraction pairs. When you've got a small domain and a big domain , there's one function that specifies how to embed in (the section), and another function that specifies how to crunch down to , which acts like taking a quotient (the retraction).
As long as the section and retraction are both continuous, will end up inheriting a bunch of nice properties from . Specifically, retractions of -BC domains are -BC domains. So this is what we're looking for! Subsets of the full function space where we can build a section-retraction pair between the subset and the full function space.
The section (the embedding of your subset in the full function space) is something you always have. For it to be continuous, what you need is that your subset of the full function space is closed under suprema of chains/directed sets. So that's one condition needed.
Getting the retraction to be continuous is harder. You need to take some arbitrary element of and find an element of your subset that it corresponds to, and do so continuously.
There's effectively only two ways to do this. If your subset of the full space is closed under arbitrary nonempty suprema (as computed in ) and contains the bottom point, then you can just map an arbitrary element in to the greatest element of that lies below it.
But this wouldn't work for inframeasures, their supremum doesn't behave nicely enough to do this. And besides, you'd have to check exactly how this function works, you don't get a for-free guarantee that it's continuous.
The second way is that, if your subset of the full space is closed under arbitrary nonempty infinima and contains the top point, you can map an arbitrary element in to the least element of that lies above it. This, by contrast, is automatically a continuous function. And it should work for inframeasures, their infinimum behaves well.
So, that's it. Any subset of the whole space that's closed under suprema of directed sets, arbitrary nonempty infinima, and contains , is a retraction of and inherits all its nice properties.
Well, some special sorts of inframeasures (like crisp infradistributions) might not contain the top point of the function space, though! But, y'know how BC-domains are like a continuous lattice but with the top point ripped off? You can just take your subset which doesn't include the top point of , and add the top point in. Then, (your set of interest, plus a top point) will inherit the nice properties of since it's a retraction. Finally, you just rip the top point off, and you'll still have an -BC domain. So, in general, we get
Theorem 3/Retraction Theorem: If is an -BC domain with a top element, and , then , which is the set equipped with the order inherited from , is an -BC domain if the following two conditions hold.
1: is closed under directed suprema.
2: is closed under arbitrary nonempty infinima.
This is a suitable master theorem! We now just need to check that our inframeasures (as a subset of the function space) are closed under directed suprema (easy) and arbitrary infinima (actually quite hard, because infinite infinima of continuous functions does not behave like you'd naively think). If we do that, then we know that they make an -BC domain.
And if we want to show that some special restricted sorts of inframeasures also make an -BC domain, even those we haven't invented yet, we just need to check that their defining property is preserved under directed suprema and arbitrary nonempty infinima, and it'll automatically work.
Step 6: Inframeasures Make Nice Domains
The basic properties of an inframeasure over some Polish space were: The constant-0 function gets mapped to 0 or higher. The expectation functional must be monotone. The expectation functional must be Lipschitz. The expectation functional must be concave. The expectation functional must fulfill the CAS property (compact-almost-support, detailed in Less Basic Inframeasure Theory [? · GW])
Which of these properties can we preserve or discard? Well, for (Scott-)continuous functions from one poset to another, they will always be monotone. We get this property for free. Since we're assuming our space of interest is compact, CAS is fulfilled for free. Concavity remains critically important, and "constant-0 function goes to 0 or higher" is an easy condition to have.
And then, with Lipschitzness, things go off the rails. In particular, by our Retraction Theorem, we need closure under arbitrary infinima. And Lipschitzness is not a property preserved under arbitrary infinima, only finite infinima. Easy way to see this: Taking the infinite infinima of Lipschitz functions might be discontinuous. Taking the infinite infinima of, say, functions with a Lipschitz constant of 4 or less will have a Lipschitz constant of 4 or less.
The way to solve this is to restrict to a particular fixed Lipschitz constant. I picked 1-Lipschitzness, as that one seems to be the best motivated. Less Basic Inframeasure Theory [? · GW] (LBIT) says a lot of operations on inframeasures preserve 1-Lipschitzness, and you also need it for the infinite semidirect product (implicit in Proposition 22 of LBIT). Also, for distance metrics on inframeasures (in LBIT), the Lipschitz constant seems to play a similar role to the norm of of a point in a vector space.
So, it's possible that the normalization (to turn an inframeasure into an infradistribution) with the best properties is not the "map the constant-0 function to 0, and the constant-1 function to 1" normalization, but instead the "map the constant-0 function to 0, and scale the Lipschitz constant of your function to 1" normalization.
Anyways, our final list of the three properties for an element of the function space (or ) to be an inframeasure is:
Definition 2: Inframeasure (for Domain theory)
0: An element of the space of continuous functions or , for a compact second-countable LHC space.
1: The constant-0 function isn't negative. .
2: Concavity.
3: 1-Lipschitzness.
1-Lipschitzness and concavity require some conventions about how to deal with functions which might be for some inputs, but it's all quite addressable.
Btw, this coincides with the preexisting definition for "1-Lipschitz inframeasure" in compact Polish spaces. The old criteria were monotonicity, the constant-0 function moving up, concavity, 1-Lipschitzness, and the CAS property. Clearly, for the new definition, three of the criteria are fulfilled. The CAS property is automatically fulfilled in compact spaces. And Scott-continuous functions (by condition 0) are automatically monotone. so all old criteria are fulfilled.
As for the new criteria defined above, the only one that isn't assumed in the old definition is Scott-continuity. Scott-continuity is monotonicity plus preservation of directed suprema. Monotonicity is one of the old conditions, and Theorem 1 shows preservation of directed suprema, so Scott-continuity can be derived.
Are these three defining conditions for an inframeasure preserved under directed suprema and arbitrary infinima in order to invoke our Retraction Theorem? Well, it's a bit frustrating to show, especially the part about preserving concavity under arbitrary intersection (which was the only place I really needed LHC spaces instead of just local compactness), but yes. So we get:
Theorem 4: The subset of (or ) consisting of inframeasures is an -BC domain when is compact, second-countable, and LHC.
There's a bunch of other sorts of infradistributions, like homogenous, crisp, sharp, and so on, detailed in Less Basic Inframeasure Theory, Section 2 [? · GW]. Are they preserved under directed suprema and arbitrary infinima?
For the most part yes. Well, possibly not sharpness, that's a bit complicated, more on it in a bit.
Theorem 5: The following properties are all preserved under arbitrary infinima and directed supremum for both and -inframeasures, if is compact, second-countable, and LHC.
(supernormalization)
(homogenity)
(cohomogenity)
(C-additivity)
(crispness)
Pairing this result (and boy is it a long one to show) with the Retraction Theorem, we get that virtually any subclass of inframeasures you want, like crisp infradistributions, also makes an -BC domain, regardless of the type signature we're using.
Now, here's the problem with sharp infradistributions. An infradistribution is sharp if it's a function of the form , where is a compact set. It's complete uncertainty over a compact set. For stuff like Hausdorff spaces, the arbitrary inf of sharp infradistributions is also sharp, but I don't know what occurs in general. The basic sketch of the problem is that in compact Hausdorff spaces, any set has a smallest compact superset because the intersection of compact sets is compact, but this doesn't hold in general topological spaces.
Step 7: Type Constructor Cleanup
Ok, given any -BC domain (including Haskell types), the space of inframeasures (or crisp infradistributions, or c-additive inframeasures, or...) over it is also an -BC domain. Let's use for the space of inframeasures on . Though, if you want, you can consider "space of crisp infradistributions" or some type constructor like that, since Theorems 3-5 give you a heck of a lot of freedom to restrict to the space of inframeasures which most interest you.
In order to check whether "take the space of inframeasures" is the sort of type constructor we can build fixtypes with, we first need to verify it's a functor from the category to . Yup, we know that if is an -BC domain, then is, that's what all the previous work was about.
But, if we've got a continuous function/morphism , what continuous function/morphism do we get? Well, it's exactly the pushforward along the function (as discussed in Basic Inframeasure Theory [? · GW]) Given some , with and , then the pushforward is the function
Ie, it maps an input inframeasure to the function , which takes an input function and tells you what expectation value it has using ,, and .
Proposition 7: The functor mapping to and to is indeed a functor .
This is pretty easy to show, we just need to verify that the pushforward of a continuous function is indeed a continuous function from the space of inframeasures on to the space of inframeasures on , and the usual "preserve identity" and "preserve function composition" properties of a functor. If you want to generalize this to more restricted sorts of inframeasures (like crisp infradistributions), you can do it on your own, it's pretty easy to do. You just need to check the defining properties are preserved through pushforward, which pretty much everything is.
And, there's one last technical property we need to check before we can use "space of inframeasures" as a type constructor. Local continuity. Local continuity of a functor is that the function
is continuous. In our case it'd be mapping to the pushforward . This is routine and simple to verify.
Proposition 8: The "space of inframeasures" functor is locally continuous.
Oh, one last bit of cleanup. The textbook I was using didn't verify that the category of -BC domains was closed under all the usual operations of:
lifting (add a new bottom element to your poset)
(take the two posets and add a new bottom element below both of them)
(glue your two poset together at their bottom point)
(cartesian product of posets)
(cartesian product but all pairs of the form or are identified with the bottom point)
Function space (make the domain of continuous functions from one domain to the other)
Strict function space (make the domain of just the continuous functions from one domain to the other with the property that )
Bilimit (The limit/colimit of domain theory)
So we'll need to clean that up.
Proposition 9: The category of -BC domains is closed under lifting, +,,,, function space, strict function space, and bilimit.
And then, by chapter 5 of the trusty domain theory textbook from Abramsky and Jung, any fixtype equation built with these type constructors (and the "space of inframeasures" type constructor since we verified local continuity) has a unique least solution and we're done! Any weird type you want is now in your grasp, and it'll be an -BC domain, which are the sort amenable to computer implementation. Have fun!
EDIT: The "space of inframeasures" type constructor also makes a monad. Just found this out, thanks to Daniel Filan for conjecturing it.
The "unit" function, with type , is defined by: . It works out the value of a function by going "hey, function, what expectation value do you assign to this point?". Another way of thinking about it is that it's mapping a point in a space to the dirac-delta distributon on said point.
And the "bind" function, with type , is the infrakernel pushforward, defined by ( has type here)
And so we have a monad! It's routine to verify the monad identities.
Proofs for the post are here [AF · GW] and here [AF · GW].
3 comments
Comments sorted by top scores.
comment by Vanessa Kosoy (vanessa-kosoy) · 2021-03-29T17:54:29.015Z · LW(p) · GW(p)
Virtually all the credit for this post goes to Alex, I think the proof of Proposition 1 was more or less my only contribution.
comment by Gurkenglas · 2021-03-28T22:38:22.119Z · LW(p) · GW(p)
I picked 1-Lipschitzness, as that one seems to be the best motivated.
I would motivate this by saying that can be rewritten as .
As for implementing it:
I'm not sure whether there's a way to enforce concavity and 1-Lipschitzness on the type level, but one sure could define . Here's a definition of without much type-level safety: newtype Real = UnsafeReal {greaterThan :: Double -> ()}; embedDouble :: Double -> Real; embedDouble d = UnsafeReal (\d' -> if d>d' then () else error ("embedDouble" + show d + show d')). So long as nobody uses try/catch or UnsafeReal, the only thing you can get out of a value of this type is that it is larger than a given double.
comment by Gurkenglas · 2021-04-02T08:21:51.200Z · LW(p) · GW(p)
Damn it, I came to write about the monad1 then saw the edit. You may want to add it to this list, and compare it with the other entries.
Here's a dissertation and blog post by Jared Tobin on using (X -> R) -> R with flat reals to represent usual distributions in Haskell. He appears open to get hired.
Maybe you want a more powerful type system? I think Coq allows constructing that subtype of a type which satisfies a property. Agda's cubical type theory places a lot of emphasis for its for the unit interval. Might dependent types be enough express lipschitzness and concavity?
1: Spotted it during literature search on pushforwards to measure the distribution of the vector of all activations in a neural network for one input, given the known distribution of inputs to a GAN generator that outputs inputs to the first network. Which I started modeling (as ((Neurons -> R) -> R) -> R) between you giving me that DT book and first reading about the technique in this post :).