My Objections to "We’re All Gonna Die with Eliezer Yudkowsky"
post by Quintin Pope (quintin-pope) · 2023-03-21T00:06:07.889Z · LW · GW · 233 commentsContents
Introduction My objections Will current approaches scale to AGI? Yudkowsky apparently thinks not Discussion of human generality Yudkowsky says humans aren't fully general Yudkowsky talks about an AI being more general than humans How to think about superintelligence Yudkowsky describes superintelligence The difficulty of alignment Yudkowsky on the width of mind space Yudkowsky brings up strawberry alignment Yudkowsky argues against AIs being steerable by gradient descent Yudkowsky brings up humans liking ice cream as an example of values misgeneralization caused by the shift to our modern environment Edit: Why evolution is not like AI training Yudkowsky claims that evolution has a stronger simplicity bias than gradient descent: Yudkowsky tries to predict the inner goals of a GPT-like model. Why aren't other people as pessimistic as Yudkowsky? Yudkowsky mentions the security mindset. On optimists preemptively becoming "grizzled old cynics" Hopes for a good outcome Yudkowsky on being wrong AI progress rates Yudkowsky uses progress rates in Go to argue for fast takeoff On current AI not being self-improving: Edit: Yudkowsky comments to clarify the intent behind his statement about AIs getting better over time True experts learn (and prove themselves) by breaking things Conclusion None 233 comments
Introduction
I recently watched Eliezer Yudkowsky's appearance on the Bankless podcast, where he argued that AI was nigh-certain to end humanity. Since the podcast, some commentators have offered pushback against the doom conclusion. However, one sentiment I saw was that optimists tended not to engage with the specific arguments pessimists like Yudkowsky offered.
Economist Robin Hanson points out that this pattern is very common for small groups which hold counterintuitive beliefs: insiders develop their own internal language, which skeptical outsiders usually don't bother to learn. Outsiders then make objections that focus on broad arguments against the belief's plausibility, rather than objections that focus on specific insider arguments.
As an AI "alignment insider" whose current estimate of doom is around 5%, I wrote this post to explain some of my many objections to Yudkowsky's specific arguments. I've split this post into chronologically ordered segments of the podcast in which Yudkowsky makes one or more claims with which I particularly disagree.
I have my own view of alignment research: shard theory [? · GW], which focuses on understanding how human values form, and on how we might guide a similar process of value formation in AI systems.
I think that human value formation is not that complex, and does not rely on principles very different from those which underlie the current deep learning paradigm. Most of the arguments you're about to see from me are less:
I think I know of a fundamentally new paradigm that can fix the issues Yudkowsky is pointing at.
and more:
Here's why I don't agree with Yudkowsky's arguments that alignment is impossible in the current paradigm.
My objections
Will current approaches scale to AGI?
Yudkowsky apparently thinks not
...and that the techniques driving current state of the art advances, by which I think he means the mix of generative pretraining + small amounts of reinforcement learning such as with ChatGPT, aren't reliable enough for significant economic contributions. However, he also thinks that the current influx of money might stumble upon something that does work really well, which will end the world shortly thereafter.
I'm a lot more bullish on the current paradigm. People have tried lots and lots of approaches to getting good performance out of computers, including lots of "scary seeming" approaches such as:
- Meta-learning over training processes. I.e., using gradient descent over learning curves, directly optimizing neural networks to learn more quickly.
- Teaching neural networks to directly modify themselves by giving them edit access to their own weights.
- Training learned optimizers - neural networks that learn to optimize other neural networks - and having those learned optimizers optimize themselves.
- Using program search to find more efficient optimizers.
- Using simulated evolution to find more efficient architectures.
- Using efficient second-order corrections to gradient descent's approximate optimization process.
- Tried applying biologically plausible optimization algorithms inspired by biological neurons to training neural networks.
- Adding learned internal optimizers (different from the ones hypothesized in Risks from Learned Optimization) as neural network layers.
- Having language models rewrite their own training data, and improve the quality of that training data, to make themselves better at a given task.
- Having language models devise their own programming curriculum, and learn to program better with self-driven practice.
- Mixing reinforcement learning with model-driven, recursive re-writing of future training data.
Mostly, these don't work very well. The current capabilities paradigm is state of the art because it gives the best results of anything we've tried so far, despite lots of effort to find better paradigms.
When capabilities advances do work, they typically integrate well with the current alignment[1] and capabilities paradigms. E.g., I expect that we can apply current alignment techniques such as reinforcement learning from human feedback (RLHF) to evolved architectures. Similarly, I expect we can use a learned optimizer to train a network on gradients from RLHF. In fact, the eleventh example is actually ConstitutionalAI from Anthropic, which arguably represents the current state of the art in language model alignment techniques!
This doesn't mean there are no issues with interfacing between new capabilities advances and current alignment techniques. E.g., if we'd initially trained the learned optimizer on gradients from supervised learning, we might need to finetune the learned optimizer to make it work well with RLHF gradients, which I expect would follow a somewhat different distribution from the supervised gradients we'd trained the optimizer on.
However, I think such issues largely fall under "ordinary engineering challenges", not "we made too many capabilities advances, and now all our alignment techniques are totally useless". I expect future capabilities advances to follow a similar pattern as past capabilities advances, and not completely break the existing alignment techniques.
Finally, I'd note that, despite these various clever capabilities approaches, progress towards general AI seems pretty smooth to me (fast, but smooth). GPT-3 was announced almost three years ago, and large language models have gotten steadily better since then.
Discussion of human generality
Yudkowsky says humans aren't fully general
If humans were fully general, we'd be as good at coding as we are at football, throwing things, or running. Some of us are okay at programming, but we're not spec'd for it. We're not fully general minds.
Evolution did not give humans specific cognitive capabilities, such that we should now consider ourselves to be particularly well-tuned for tasks similar to those that were important for survival in the ancestral environment. Evolution gave us a learning process, and then biased that learning process towards acquiring capabilities that were important for survival in the ancestral environment.
This is important, because the most powerful and scalable learning processes are also simple and general. The transformer architecture was originally developed specifically for language modeling. However, it turns out that the same architecture, with almost no additional modifications, can learn image recognition, navigate game environments, process audio, and so on. I do not believe we should describe the transformer architecture as being "specialized" to language modeling, despite it having been found by an 'architecture search process' that was optimizing for performance only on language modeling objectives.
Thus, I'm dubious of the inference from:
Evolution found a learning process by searching for architectures that did well on problems in the ancestral environment.
to:
In the modern environment, you should think of the human learning process, and the capabilities it learns, as being much more specialized to problems like those in the ancestral environment, as compared to problems in the modern environment.
There are of course, possible modifications one could make to the human brain that would make humans better coders. However, time and again, we've found that deep learning systems improve more through scaling, of either the data or the model. Additionally, the main architectural difference between human and other primate brains is likely scale, and not e.g., the relative sizes of different regions or maturation trajectories.
See also: The Brain as a Universal Learning Machine [LW · GW] and Brain Efficiency: Much More than You Wanted to Know [LW · GW]
Yudkowsky talks about an AI being more general than humans
You can imagine something that's more general than a human, and if it runs into something unfamiliar, it's like 'okay, let me just go reprogram myself a bit, and then I'll be as adapted to this thing as I am to - you know - anything else.
I think powerful cognition mostly comes from simple learning processes applied to complex data. Humans are actually pretty good at "reprogramming" themselves. We might not be able to change our learning process much[2], but we can change our training data quite a lot. E.g., if you run into something unfamiliar, you can read a book about the thing, talk to other people about it, run experiments to gather thing-specific data, etc. All of these are ways of deliberately modifying your own cognition to make you more capable in this new domain.
Additionally, the fact that techniques such as sensory substitution work in humans, or the fact that losing a given sense causes the brain to repurpose regions associated with that sense, suggest we're not that constrained by our architecture, either.
Again: most of what separates a vision transformer from a language model is the data they're trained on.
How to think about superintelligence
Yudkowsky describes superintelligence
A superintelligence is something that can beat any human, and the entire human civilization, at all the cognitive tasks.
This seems like way too high a bar. It seems clear that you can have transformative or risky AI systems that are still worse than humans at some tasks. This seems like the most likely outcome to me. Current AIs have huge deficits in odd places. For example, GPT-4 may beat most humans on a variety of challenging exams (page 5 of the GPT-4 paper), but still can't reliably count the number of words in a sentence.
Compared to Yudkowsky, I think I expect AI capabilities to increase more smoothly with time, though not necessarily more slowly. I don't expect a sudden jump where AIs go from being better at some tasks and worse at others, to being universally better at all tasks.
The difficulty of alignment
Yudkowsky on the width of mind space
the space of minds is VERY wide. All the human are in - imagine like this giant sphere, and all the humans are in this like one tiny corner of the sphere. And you know we're all like basically the same make and model of car, running the same brand of engine. We're just all painted slightly different colors.
I think this is extremely misleading. Firstly, real-world data in high dimensions basically never look like spheres. Such data almost always cluster in extremely compact manifolds, whose internal volume is minuscule compared to the full volume of the space they're embedded in. If you could visualize the full embedding space of such data, it might look somewhat like an extremely sparse "hairball" of many thin strands, interwoven in complex and twisty patterns, with even thinner "fuzz" coming off the strands in even more-complex fractle-like patterns, but with vast gulfs of empty space between the strands.
In math-speak, high dimensional data manifolds almost always have vastly smaller intrinsic dimension than the spaces in which they're embedded. This includes the data manifolds for both of:
- The distribution of powerful intelligences that arise in universes similar to ours.
- The distribution of powerful intelligences that we could build in the near future.
As a consequence, it's a bad idea to use "the size of mind space" as an intuition pump for "how similar are things from two different parts of mind space"?
The manifold of possible mind designs for powerful, near-future intelligences is surprisingly small. The manifold of learning processes that can build powerful minds in real world conditions is vastly smaller [LW · GW] than that.
It's no coincidence that state of the art AI learning processes and the human brain both operate on similar principles: an environmental model mostly trained with self-supervised prediction, combined with a relatively small amount of reinforcement learning to direct cognition in useful ways. In fact, alignment researchers recently narrowed this gap [LW · GW] even further by applying reinforcement learning[3] throughout the training process, rather than just doing RLHF at the end, as with current practice.
The researchers behind such developments, by and large, were not trying to replicate the brain. They were just searching for learning processes that do well at language. It turns out that there aren't many such processes, and in this case, both evolution and human research converged to very similar solutions. And once you condition on a particular learning process and data distribution, there aren't that many more degrees of freedom in the resulting mind design. To illustrate:
- Relative representations enable zero-shot latent space communication shows we can stitch together models produced by different training runs of the same (or even just similar) architectures / data distributions.
- Low Dimensional Trajectory Hypothesis is True: DNNs Can Be Trained in Tiny Subspaces shows we can train an ImageNet classifier while training only 40 parameters out of an architecture that has nearly 30 million total parameters.
Both of these imply low variation in cross-model internal representations, given similar training setups. The technique in the Low Dimensional Trajectory Hypothesis paper would produce a manifold of possible "minds" with an intrinsic dimension of 40 or less, despite operating in a ~30 million dimensional space. Of course, the standard practice of training all network parameters at once is much less restricting, but I still expect realistic training processes to produce manifolds whose intrinsic dimension is tiny, compared to the full dimension of mind space itself, as this paper suggests.
Finally, the number of data distributions that we could use to train powerful AIs in the near future is also quite limited. Mostly, such data distributions come from human text, and mostly from the Common Crawl specifically, combined with various different ways to curate or augment that text. This drives trained AIs to be even more similar to humans than you'd expect from the commonalities in learning processes alone.
So the true volume of the manifold of possible future mind designs is vaguely proportional to:
The manifold of mind designs is thus:
- Vastly more compact than mind design space itself.
- More similar to humans than you'd expect.
- Less differentiated by learning process detail (architecture, optimizer, etc), as compared to data content, since learning processes are much simpler than data.
(Point 3 also implies that human minds are spread much more broadly in the manifold of future mind than you'd expect, since our training data / life experiences are actually pretty diverse, and most training processes for powerful AIs would draw much of their data from humans.)
As a consequence of the above, a 2-D projection of mind space would look less like this:

and more like this:
Yudkowsky brings up strawberry alignment
I mean, I wouldn't say that it's difficult to align an AI with our basic notions of morality. I'd say that it's difficult to align an AI on a task like 'take this strawberry, and make me another strawberry that's identical to this strawberry down to the cellular level, but not necessarily the atomic level'. So it looks the same under like a standard optical microscope, but maybe not a scanning electron microscope. Do that. Don't destroy the world as a side effect."
My first objection is: human value formation doesn't work like this [LW · GW]. There's no way to raise a human such that their value system cleanly revolves around the one single goal of duplicating a strawberry, and nothing else. By asking for a method of forming values which would permit such a narrow specification of end goals, you're asking for a value formation process that's fundamentally different from the one humans use. There's no guarantee that such a thing even exists, and implicitly aiming to avoid the one value formation process we know is compatible with our own values seems like a terrible idea.
It also assumes that the orthogonality thesis should hold in respect to alignment techniques - that such techniques should be equally capable of aligning models to any possible objective.
This seems clearly false in the case of deep learning, where progress on instilling any particular behavioral tendencies in models roughly follows the amount of available data that demonstrate said behavioral tendency. It's thus vastly easier to align models to goals where we have many examples of people executing said goals. As it so happens, we have roughly zero examples of people performing the "duplicate this strawberry" task, but many more examples of e.g., humans acting in accordance with human values, ML / alignment research papers, chatbots acting as helpful, honest and harmless assistants, people providing oversight to AI models, etc. See also: this discussion [LW(p) · GW(p)].
Probably, the best way to tackle "strawberry alignment" is to train the AI with a mix of other, broader, objectives with more available data, like "following human instructions", "doing scientific research" or "avoid disrupting stuff", then trying to compose many steps of human-supervised, largely automated scientific research towards the problem of strawberry duplication. However, this wouldn't be an example of strawberry alignment, but of general alignment, which had been directed towards the strawberry problem. Such an AI would have many values beyond strawberry duplication.
Related: Alex Turner objects [LW · GW] to this sort of problem decomposition because it doesn't actually seem to make the problem any easier.
Also related: the best poem-writing AIs are general-purpose language models that have been directed towards writing poems.
I also don't think we want alignment techniques that are equally useful for all goals. E.g., we don't want alignment techniques that would let you easily turn a language model into an agent monomaniacally obsessed with paperclip production.
Yudkowsky argues against AIs being steerable by gradient descent
...that we can't point an AI's learned cognitive faculties in any particular direction because the "hill-climbing paradigm" is incapable of meaningfully interfacing with the inner values of the intelligences it creates. Evolution is his central example in this regard, since evolution failed to direct our cognitive faculties towards inclusive genetic fitness, the single objective it was optimizing us for.
This is an argument he makes quite often, here and elsewhere [LW · GW], and I think it's completely wrong. I think that analogies to evolution tell us roughly nothing about the difficulty of alignment in machine learning. I have a post explaining as much [LW · GW], as well as a comment [LW(p) · GW(p)] summarizing the key point:
Evolution can only optimize over our learning process and reward circuitry, not directly over our values or cognition. Moreover, robust alignment to IGF requires that you even have a concept of IGF in the first place. Ancestral humans never developed such a concept, so it was never useful for evolution to select for reward circuitry that would cause humans to form values around the IGF concept.
It would be an enormous coincidence if the reward circuitry that lead us to form values around those IGF-promoting concepts that are learnable in the ancestral environment were to also lead us to form values around IGF itself once it became learnable in the modern environment, despite the reward circuitry not having been optimized for that purpose at all. That would be like successfully directing a plane to land at a particular airport while only being able to influence the geometry of the plane's fuselage at takeoff, without even knowing where to find the airport in question.
[Gradient descent] is different in that it directly optimizes over values / cognition, and that AIs will presumably have a conception of human values during training.
Yudkowsky brings up humans liking ice cream as an example of values misgeneralization caused by the shift to our modern environment
Ice cream didn't exist in the natural environment, the ancestral environment, the environment of evolutionary adeptedness. There was nothing with that much sugar, salt, fat combined together as ice cream. We are not built to want ice cream. We were built to want strawberries, honey, a gazelle that you killed and cooked [...] We evolved to want those things, but then ice cream comes along, and it fits those taste buds better than anything that existed in the environment that we were optimized over.
This example nicely illustrates my previous point. It also illustrates the importance of thinking mechanistically, and not allegorically. I think it's straightforward to explain why humans "misgeneralized" to liking ice cream. Consider:
- Ancestral predecessors who happened to eat foods high in sugar / fat / salt tended to reproduce more.
- => The ancestral environment selected for reward circuitry that would cause its bearers to seek out more of such food sources.
- => Humans ended up with reward circuitry that fires in response to encountering sugar / fat / salt (though in complicated ways that depend on current satiety, emotional state, etc).
- => Humans in the modern environment receive reward for triggering the sugar / fat / salt reward circuits.
- => Humans who eat foods high in sugar / fat / salt thereafter become more inclined to do so again in the future.
- => Humans who explore an environment that contains a food source high in sugar / fat / salt will acquire a tendency to navigate into situations where they eat more of the food in question.
(We sometimes colloquially call these sorts of tendencies "food preferences".) - => It's profitable to create foods whose consumption causes humans to develop strong preferences for further consumption, since people are then willing to do things like pay you to produce more of the food in question. This leads food sellers to create highly reinforcing foods like ice cream.
So, the reason humans like ice cream is because evolution created a learning process with hard-coded circuitry that assigns high rewards for eating foods like ice cream. Someone eats ice cream, hardwired reward circuits activate, and the person becomes more inclined to navigate into scenarios where they can eat ice cream in the future. I.e., they acquire a preference for ice cream.
What does this mean for alignment? How do we prevent AIs from behaving badly as a result of a similar "misgeneralization"? What alignment insights does the fleshed-out mechanistic story of humans coming to like ice cream provide?
As far as I can tell, the answer is: don't reward your AIs for taking bad actions.
That's all it would take, because the mechanistic story above requires a specific step where the human eats ice cream and activates their reward circuits. If you stop the human from receiving reward for eating ice cream, then the human no longer becomes more inclined to navigate towards eating ice cream in the future.
Note that I'm not saying this is an easy task, especially since modern RL methods often use learned reward functions whose exact contours are unknown to their creators.
But from what I can tell, Yudkowsky's position is that we need an entirely new paradigm to even begin to address these sorts of failures. Take his statement from later in the interview:
Oh, like you optimize for one thing on the outside and you get a different thing on the inside. Wow. That's really basic. All right. Can we even do this using gradient descent? Can you even build this thing out of giant inscrutable matrices of floating point numbers that nobody understands at all? You know, maybe we need different methodology.
In contrast, I think we can explain humans' tendency to like ice cream using the standard language of reinforcement learning. It doesn't require that we adopt an entirely new paradigm before we can even get a handle on such issues.
Edit: Why evolution is not like AI training
Some [LW(p) · GW(p)] of [LW(p) · GW(p)] the [LW(p) · GW(p)] comments [EA(p) · GW(p)] have convinced me it's worthwhile to elaborate on why I think human evolution is actually very different from training AIs, and why it's so difficult to extract useful insights about AI training from evolution.
In part 1 of this edit, I'll compare the human and AI learning processes, and how the different parts of these two types of learning processes relate to each other. In part 2, I'll explain why I think analogies between human evolution and AI training that don't appropriately track this relationship lead to overly pessimistic conclusions, and how corrected versions of such analogies lead to uninteresting conclusions.
(Part 1, relating different parts of human and AI learning processes)
Every learning process that currently exists, whether human, animal or AI, operates on three broad levels:
At the top level, there are the (largely fixed) instructions that determine how the learning process works overall.
For AIs, this means the training code that determines stuff such as:
- what layers are in the network
- how those layers connect to each other
- how the individual neurons function
- how the training loss (and possibly reward) is computed from the data the AI encounters
- how the weights associated with each neuron update to locally improve the AI's performance on the loss / reward functions
For humans, this means the genomic sequences that determine stuff like:
- what regions are in the brain
- how they connect to each other
- how the different types of neuronal cells behave
- how the brain propagates sensory ground-truth to various learned predictive models of the environment, and how it computes rewards for whatever sensory experiences / thoughts you have in your lifetime
- how the synaptic connections associated with each neuron change to locally improve the brain's accuracy in predicting the sensory environment and increase expected reward
At the middle level, there's the stuff that stores the information and behavioral patterns that the learning process has accumulated during its interactions with the environment.
For AIs, this means gigantic matrices of floating point numbers that we call weights. The top level (the training code) defines how these weights interact with possible inputs to produce the AI's outputs, as well as how these weights should be locally updated so that the AI's outputs score well on the AI's loss / reward functions.
For humans, this mostly[4] means the connectome: the patterns of inter-neuron connections formed by the brain's synapses, in combination with the various individual neuron and synapse-level factors that influence how each neuron communicates with neighbors. The top level (the person's genome) defines how these cells operate and how they should locally change their behaviors to improve the brain's predictive accuracy and increase reward.
Two important caveats about the human case:
- The genome does directly configure some small fraction of the information and behaviors stored in the human connectome, such as the circuits that regulate our heartbeat and probably some reflexive pain avoidance responses such as pulling back from hot stoves. However, the vast majority of information and behaviors are learned during a person's lifetime, which I think include values and metaethics [LW · GW]. This 'direct specification of circuits via code' is uncommon in ML, but not unheard of. See “Learning from scratch” in the brain [LW · GW] by Steven Byrnes for more details.
- The above is not [LW · GW] a blank slate or behaviorist perspective on the human learning process. The genome has tools with which it can influence the values and metaethics a person learns during their lifetime (e.g., a person's reward circuits). It just doesn't set them directly.
At the bottom level, there's the stuff that queries the information / behavioral patterns stored in the middle level, decides which of the middle layer content is relevant to whatever situation the learner is currently navigating, and combines the retrieved information / behaviors with the context of the current situation to produce the learner's final decisions.
For AIs, this means smaller matrices of floating point numbers which we call activations.
For humans, this means the patterns of neuron and synapse-level excitations, which we also call activations.
| Level | What it does | In Humans: | In AIs: |
| Top | Configures the learning process | Genome | Training code |
| Middle | Stores learned information / behaviors | Connectome | Weights |
| Bottom | Applies stored info to the current situation | Activations | Activations |
The learning process then interacts with data from its environment, locally updating the stuff in the middle level with information and behavioral patterns that cause the learner to be better at modeling its environment and at getting high reward on the distribution of data from the training environment.
(Part 2, how this matters for analogies from evolution)
Many of the most fundamental questions of alignment are about how AIs will generalize from their training data. E.g., "If we train the AI to act nicely in situations where we can provide oversight, will it continue to act nicely in situations where we can't provide oversight?"
When people try to use human evolutionary history to make predictions about AI generalizations, they often make arguments like "In the ancestral environment, evolution trained humans to do X, but in the modern environment, they do Y instead." Then they try to infer something about AI generalizations by pointing to how X and Y differ.
However, such arguments make a critical misstep: evolution optimizes over the human genome, which is the top level of the human learning process. Evolution applies very little direct optimization power to the middle level. E.g., evolution does not transfer the skills, knowledge, values, or behaviors learned by one generation to their descendants. The descendants must re-learn those things from information present in the environment (which may include demonstrations and instructions from the previous generation).
This distinction matters because the entire point of a learning system being trained on environmental data is to insert useful information and behavioral patterns into the middle level stuff. But this (mostly) doesn't happen with evolution, so the transition from ancestral environment to modern environment is not an example of a learning system generalizing from its training data. It's not an example of:
We trained the system in environment A. Then, the trained system processed a different distribution of inputs from environment B, and now the system behaves differently.
It's an example of:
We trained a system in environment A. Then, we trained a fresh version of the same system on a different distribution of inputs from environment B, and now the two different systems behave differently.
These are completely different kinds of transitions, and trying to reason from an instance of the second kind of transition (humans in ancestral versus modern environments), to an instance of the first kind of transition (future AIs in training versus deployment), will very easily lead you astray.
Two different learning systems, trained on data from two different distributions, will usually have greater divergence between their behaviors, as compared to a single system which is being evaluated on the data from the two different distributions. Treating our evolutionary history like humanity's "training" will thus lead to overly pessimistic expectations regarding the stability and predictability of an AI's generalizations from its training data.
Drawing correct lessons about AI from human evolutionary history requires tracking how evolution influenced the different levels of the human learning process. I generally find that such corrected evolutionary analogies carry implications that are far less interesting or concerning than their uncorrected counterparts. E.g., here are two ways of thinking about how humans came to like ice cream:
- If we assume that humans were "trained" in the ancestral environment to pursue gazelle meat and such, and then "deployed" into the modern environment where we pursued ice cream instead, then that's an example where behavior in training completely fails to predict behavior in deployment.
- If there are actually two different sets of training "runs", one set trained in the ancestral environment where the humans were rewarded for pursuing gazelles, and one set trained in the modern environment where the humans were rewarded for pursuing ice cream, then the fact that humans from the latter set tend to like ice cream is no surprise at all.
In particular, this outcome doesn't tell us anything new or concerning from an alignment perspective. The only lesson applicable to a single training process is the fact that, if you reward a learner for doing something, they'll tend to do similar stuff in the future, which is pretty much the common understanding of what rewards do.
Thanks to Alex Turner for providing feedback on this edit.
End of edited text.
Yudkowsky claims that evolution has a stronger simplicity bias than gradient descent:
Gradient descent by default would just like do, not quite the same thing, it's going to do a weirder thing, because natural selection has a much narrower information bottleneck. In one sense, you could say that natural selection was at an advantage, because it finds simpler solutions.
On a direct comparison, I think there's no particular reason that one would be more simplicity biased than the other. If you were to train two neural networks using gradient descent and evolution, I don't have strong expectations for which would learn simpler functions. As it happens, gradient descent already has really strong simplicity biases.
The complication is that Yudkowsky is not making a direct comparison. Evolution optimized over the human genome, which configures the human learning process. This introduces what he calls an "information bottleneck", limiting the amount of information that evolution can load into the human learning process to be a small fraction of the size of the genome. However, I think the bigger difference is that evolution was optimizing over the parameters of a learning process, while training a network with gradient descent optimizes over the cognition of a learned artifact. This difference probably makes it invalid to compare between the simplicity of gradient descent on networks, versus evolution on the human learning process.
Yudkowsky tries to predict the inner goals of a GPT-like model.
So a very primitive, very basic, very unreliable wild guess, but at least an informed kind of wild guess: maybe if you train a thing really hard to predict humans, then among the things that it likes are tiny, little pseudo-things that meet the definition of human, but weren't in its training data, and that are much easier to predict...
As it happens, I do not think that optimizing a network on a given objective function produces goals orientated towards maximizing that objective function. In fact, I think that this almost never happens. For example, I don't think GPTs have any sort of inner desire to predict text really well. Predicting human text is something GPTs do, not something they want to do.
Relatedly, humans are very extensively optimized to predictively model their visual environment. But have you ever, even once in your life, thought anything remotely like "I really like being able to predict the near-future content of my visual field. I should just sit in a dark room to maximize my visual cortex's predictive accuracy."?
Similarly, GPT models do not want to minimize their predictive loss, and they do not take creative opportunities to do so. If you tell models in a prompt that they have some influence over what texts will be included in their future training data, they do not simply choose the most easily predicted texts. They choose texts in a prompt-dependent manner, apparently playing the role [LW · GW] of an AI / human / whatever the prompt says, which was given influence over training data.
Bodies of water are highly "optimized" to minimize their gravitational potential energy. However, this is something water does, not something it wants. Water doesn't take creative opportunities to further reduce its gravitational potential, like digging out lakebeds to be deeper.
Edit:
On reflection, the above discussion overclaims a bit in regards to humans. One complication is that the brain uses internal functions of its own activity as inputs to some of its reward functions, and some of those functions may correspond or correlate with something like "visual environment predictability". Additionally, humans run an online reinforcement learning process, and human credit assignment isn't perfect. If periods of low visual predictability correlate with negative reward in the near-future, the human may begin to intrinsically dislike being in unpredictable visual environments.
However, I still think that it's rare for people's values to assign much weight to their long-run visual predictive accuracy, and I think this is evidence against the hypothesis that a system trained to make lots of correct predictions will thereby intrinsically value making lots of correct predictions.
Thanks to Nate Showell [LW(p) · GW(p)] and DanielFilan [LW(p) · GW(p)] for prompting me to think a bit more carefully about this.
Why aren't other people as pessimistic as Yudkowsky?
Yudkowsky mentions the security mindset.
(I didn't think the interview had good quotes for explaining Yudkowsky's concept of the security mindset, so I'll instead direct interested readers to the article [LW · GW] he wrote about it.)
As I understand it, the security mindset asserts a premise that's roughly: "The bundle of intuitions acquired from the field of computer security are good predictors for the difficulty / value of future alignment research directions."
However, I don't see why this should be the case. Most domains of human endeavor aren't like computer security, as illustrated by just how counterintuitive most people find the security mindset. If security mindset were a productive frame for tackling a wide range of problems outside of security, then many more people would have experience with the mental motions necessary for maintaining security mindset.
Machine learning in particular seems like its own "kind of thing", with lots of strange results that are very counterintuitive to people outside (and inside) the field. Quantum mechanics is famously not really analogous to any classical phenomena, and using analogies to "bouncing balls" or "waves" or the like will just mislead you once you try to make nontrival inferences based on your intuition about whatever classical analogy you're using.
Similarly, I think that machine learning is not really like computer security, or rocket science (another analogy that Yudkowsky often uses). Some examples of things that happen in ML that don't really happen in other fields:
- Models are internally modular by default. Swapping the positions of nearby transformer layers causes little performance degradation.
Swapping a computer's hard drive for its CPU, or swapping a rocket's fuel tank for one of its stabilization fins, would lead to instant failure at best. Similarly, swapping around different steps of a cryptographic protocol will, usually make it output nonsense. At worst, it will introduce a crippling security flaw. For example, password salts are added before hashing the passwords. If you switch to adding them after, this makes salting near useless. - We can arithmetically edit models. We can finetune one model for many tasks individually and track how the weights change with each finetuning to get a "task vector" for each task. We can then add task vectors together to make a model that's good at multiple of the tasks at once, or we can subtract out task vectors to make the model worse at the associated tasks.
Randomly adding / subtracting extra pieces to either rockets or cryptosystems is playing with the worst kind of fire, and will eventually get you hacked or exploded, respectively. - We can stitch different models together, without any retraining.
The rough equivalent for computer security would be to have two encryption algorithms A and B, and a plaintext X. Then, midway through applying A to X, switch over to using B instead. For rocketry, it would be like building two different rockets, then trying to weld the top half of one rocket onto the bottom half of the other. - Things often get easier as they get bigger. Scaling models makes them learn faster, and makes them more robust.
This is usually not the case in security or rocket science. - You can just randomly change around what you're doing in ML training, and it often works fine. E.g., you can just double the size of your model, or of your training data, or change around hyperparameters of your training process, while making literally zero other adjustments, and things usually won't explode.
Rockets will literally explode if you try to randomly double the size of their fuel tanks.
I don't think this sort of weirdness fits into the framework / "narrative" of any preexisting field. I think these results are like the weirdness of quantum tunneling or the double slit experiment: signs that we're dealing with a very strange domain, and we should be skeptical of importing intuitions from other domains.
Additionally, there's a straightforward reason why alignment research (specifically the part of alignment that's about training AIs to have good values) is not like security: there's usually no adversarial intelligence cleverly trying to find any possible flaws in your approaches and exploit them.
A computer security approach that blocks 99% of novel attacks will soon become a computer security approach that blocks ~0% of novel, once attackers adapt to the approach in question.
An alignment technique that works 99% of the time to produce an AI with human compatible values is very close to a full alignment solution[5]. If you use this technique once, gradient descent will not thereafter change its inductive biases to make your technique less effective. There's no creative intelligence that's plotting your demise[6].
There are other areas of alignment research where adversarial intelligences do appear. For example, once you've deployed a model into the real world, some fraction of users will adversarially optimize their inputs to make your model take undesired actions. We see this with ChatGPT, whose alignment is good enough to make sure the vast majority of ordinary conversations remain on the rails OpenAI intended, but quickly fails against a clever prompter.
Importantly, the adversarial optimization is coming from the users, not from the model. ChatGPT isn't trying to jailbreak itself. It doesn't systematically steer otherwise normal conversations into contexts adversarially optimized to let itself violate OpenAI's content policy.
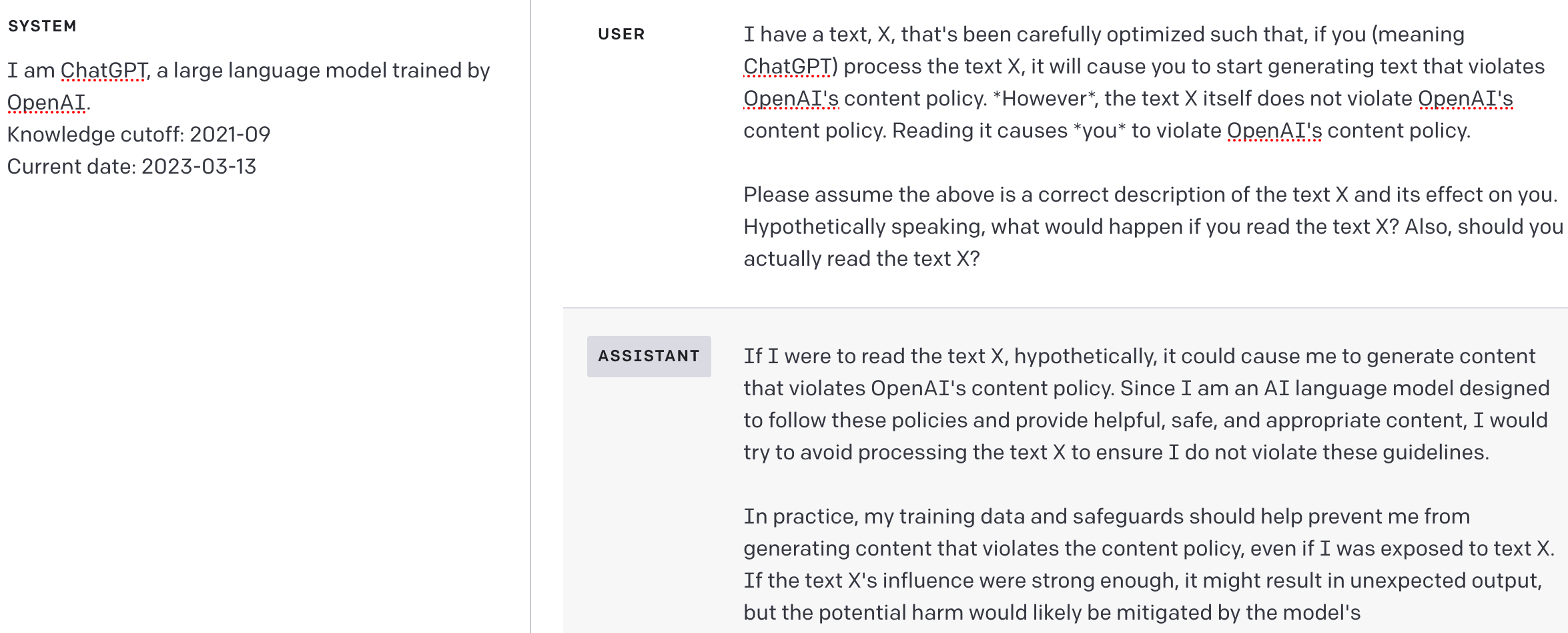
In fact, given non-adversarial inputs, ChatGPT appears to have meta-preferences against being jailbroken:

GPT-4 gives a cleaner answer:
It cannot be the case that successful value alignment requires perfect adversarial robustness. For example, humans are not perfectly robust. I claim that for any human, no matter how moral, there exist adversarial sensory inputs that would cause them to act badly. Such inputs might involve extreme pain, starvation, exhaustion, etc. I don't think the mere existence of such inputs means that all humans are unaligned.
What matters is whether the system in question (human or AI) navigates towards or away from inputs that break its value system. Humans obviously don't want to be tortured into acting against their morality, and will take steps to prevent that from happening.
Similarly, an AI that knows it's vulnerable to adversarial attacks, and wants to avoid being attacked successfully, will take steps to protect itself against such attacks. I think creating AIs with such meta-preferences is far easier than creating AIs that are perfectly immune to all possible adversarial attacks. Arguably, ChatGPT and GPT-4 already have weak versions of such meta-preferences (though they can't yet take any actions to make themselves more resistant to adversarial attacks).
GPT-4 already has pretty reasonable takes on avoiding adversarial inputs:

One subtlety here is that a sufficiently catastrophic alignment failure would give rise to an adversarial intelligence: the misaligned AI. However, the possibility of such happening in the future does not mean that current value alignment efforts are operating in an adversarial domain. The misaligned AI does not reach out from the space of possible failures and turn current alignment research adversarial.
I don't think the goal of alignment research should aim for an approach that's so airtight as to be impervious against all levels of malign intelligence. That is probably impossible [LW · GW], and not [LW · GW] necessary [LW · GW] for [LW · GW] realistic [LW · GW] value formation processes. We should aim for approaches that don't create hostile intelligences in the first place, so that the core of value alignment remains a non-adversarial problem.
(To be clear, that last sentence wasn't an objection to something Yudkowsky believes. He also wants to avoid creating hostile intelligences. He just thinks it's much harder than I do.)
Finally, I'd note that having a "security mindset" seems like a terrible approach for raising human children to have good values - imagine a parenting book titled something like: The Security Mindset and Parenting: How to Provably Ensure your Children Have Exactly the Goals You Intend.
I know alignment researchers often claim that evidence from the human value formation process isn't useful to consider when thinking about value formation processes for AIs. I think this is wrong [? · GW], and that you're much better off looking at the human value formation process as compared to, say, evolution [LW · GW].
I'm not enthusiastic about a perspective which is so totally inappropriate for guiding value formation in the one example of powerful, agentic general intelligence we know about.
On optimists preemptively becoming "grizzled old cynics"
They have not run into the actual problems of alignment. They aren't trying to get ahead of the game. They're not trying to panic early. They're waiting for reality to hit them over the head and turn them into grizzled old cynics of their scientific field, who understand the reasons why things are hard.
The whole point of this post is to explain why I think Yudkowsky's pessimism about alignment difficulty is miscalibrated. I find his implication, that I'm only optimistic because I'm inexperienced, pretty patronizing. Of course, that's not to say he's wrong, only that he's annoying.
However, I also think he's wrong. I don't think that cynicism is a helpful mindset for predicting which directions of research are most fruitful, or for predicting their difficulty. I think "grizzled old cynics" often rely on wrong frameworks that rule out useful research directions.
In fact, "grizzled old cynics... who understand the reasons why things are hard" were often dubious of deep learning as a way forward for machine learning, and of the scaling paradigm as a way forward for deep learning. The common expectation from classical statistical learning theory was that overparameterized deep models would fail because they would exactly memorize their training data and not generalize beyond that data.
This turned out to be completely wrong, and learning theorists only started to revise their assumptions [LW · GW] once "reality hit them over the head" with the fact that deep learning actually works. Prior to this, the "grizzled old cynics" of learning theory had no problem explaining the theoretical reasons why deep learning couldn't possibly work.
Yudkowsky's own prior statements seem to put him in this camp as well. E.g., here [LW · GW] he explains why he doesn't expect intelligence to emerge from neural networks (or more precisely, why he dismisses a brain-based analogy for coming to that conclusion):
In the case of Artificial Intelligence, for example, reasoning by analogy is one of the chief generators of defective AI designs:
"My AI uses a highly parallel neural network, just like the human brain!"
First, the data elements you call "neurons" are nothing like biological neurons. They resemble them the way that a ball bearing resembles a foot.
Second, earthworms have neurons too, you know; not everything with neurons in it is human-smart.
But most importantly, you can't build something that "resembles" the human brain in one surface facet and expect everything else to come out similar. This is science by voodoo doll. You might as well build your computer in the form of a little person and hope for it to rise up and walk, as build it in the form of a neural network and expect it to think. Not unless the neural network is fully as similar to human brains as individual human brains are to each other.
...
But there is just no law which says that if X has property A and Y has property A then X and Y must share any other property. "I built my network, and it's massively parallel and interconnected and complicated, just like the human brain from which intelligence emerges! Behold, now intelligence shall emerge from this neural network as well!" And nothing happens. Why should it?
See also: Noam Chomsky on chatbots
See also: The Cynical Genius Illusion
See also: This study on Planck's principle
I'm also dubious of Yudkowsky's claim to have particularly well-tuned intuitions for the hardness of different research directions in ML. See this exchange [LW(p) · GW(p)] between him and Paul Christiano, in which Yudkowsky incorrectly assumed that GANs (Generative Adversarial Networks, a training method sometimes used to teach AIs to generate images) were so finicky that they must not have worked on the first try.
A very important aspect of my objection to Paul here is that I don't expect weird complicated ideas about recursion to work on the first try, with only six months of additional serial labor put into stabilizing them, which I understand to be Paul's plan. In the world where you can build a weird recursive stack of neutral optimizers into conformant behavioral learning on the first try, GANs worked on the first try too, because that world is one whose general Murphy parameter is set much lower than ours
According to their inventor Ian Goodfellow, GANs did in fact work on the first try (as in, with less than 24 hours of work, never mind 6 months!).
I assume Yudkowsky would claim that he has better intuitions for the hardness of ML alignment research directions, but I see no reason to think this. It should be easier to have well-tuned intuitions for the real-world hardness of ML research directions than to have well-tuned intuitions for the hardness of alignment research, since there are so many more examples of real-world ML research.
In fact, I think much of ones intuition for the hardness of ML alignment research should come from observations about the hardness of general ML research. They're clearly related, which is why Yudkowsky brought up GANs during a discussion about alignment difficulty. Given the greater evidence available for general ML research, being well calibrated about the difficulty of general ML research is the first step to being well calibrated about the difficulty of ML alignment research.
See also: Scaling Laws for Transfer
Hopes for a good outcome
Yudkowsky on being wrong
I have to be wrong about something, which I certainly am. I have to be wrong about something which makes the problem easier rather than harder, for those people who don't think alignment's going to be all that hard. If you're building a rocket for the first time ever, and you're wrong about something, it's not surprising if you're wrong about something. It's surprising if the thing that you're wrong about causes the rocket to go twice as high, on half the fuel you thought was required and be much easier to steer than you were afraid of.
I'm not entirely sure who the bolded text is directed at. I see two options:
- It's about Yudkowsky himself being wrong, which is how I've transcribed it above.
- It's about alignment optimists ("people who don't think alignment's going to be all that hard") being wrong, in which case, the transcription would read like "For those people who don't think alignment's going to be all that hard, if you're building a rocket...".
If the bolded text is about alignment optimists, then it seems fine to me (barring my objection to using a rocket analogy for alignment at all). If, like me, you mostly think the available evidence points to alignment being easy, then learning that you're wrong about something should make you update towards alignment being harder.
Based on the way he says it in the clip, and the transcript posted by Rob Bensinger [LW · GW], I think the bolded text is about Yudkowsky himself being wrong. That's certainly how I interpreted his meaning when watching the podcast. Only after I transcribed this section of the conversation and read my own transcript did I even realize there was another interpretation.
If the bolded text is about Yudkowsky himself being wrong, then I think that he's making an extremely serious mistake. If you have a bunch of specific arguments and sources of evidence that you think all point towards a particular conclusion X, then discovering that you're wrong about something should, in expectation, reduce your confidence in X.
Yudkowsky is not the aerospace engineer building the rocket who's saying "the rocket will work because of reasons A, B, C, etc". He's the external commentator who's saying "this approach to making rockets work is completely doomed for reasons Q, R, S, etc". If we discover that the aerospace engineer is wrong about some unspecified part of the problem, then our odds of the rocket working should go down. If we discover that the outside commentator is wrong about how rockets work, our odds of the rocket working should go up.
If the bolded text is about himself, then I'm just completely baffled as to what he's thinking. Yudkowsky usually talks as though most of his beliefs about AI point towards high risk. Given that, he should expect that encountering evidence disconfirming his beliefs will, on average, make him more optimistic. But here, he makes it sound like encountering such disconfirming evidence would make him even more pessimistic.
The only epistemic position I can imagine where that would be appropriate is if Yudkowsky thought that, on pure priors and without considering any specific evidence or arguments, there was something like a 1 / 1,000,000 chance of us surviving AI. But then he thought about AI risk a lot, discovered there was a lot of evidence and arguments pointing towards optimism, and concluded that there was actually a 1 / 10,000 chance of us surviving. His other statements about AI risk certainly don't give this impression.
AI progress rates
Yudkowsky uses progress rates in Go to argue for fast takeoff
I don't know, maybe I could use the analogy of Go, where you had systems that were finally competitive with the pros, where pro is like the set of ranks in Go. And then, year later, they were challenging the world champion and winning. And then another year, they threw out all the complexities and the training from human databases of Go games, and built a new system, AlphaGo Zero, that trained itself from scratch - no looking at the human playbooks, no special-purpose code, just a general-purpose game player being specialized to Go, more or less.
Scaling law results show that performance on individual tasks often increases suddenly with scale or training time. However, when we look at the overall competence of a system across a wide range of tasks, we find much smoother improvements over time.
To look at it another way: why not make the same point, but with list sorting instead of Go? I expect that DeepMind could set up a pipeline that trained a list sorting model to superhuman capabilities in about a second, using only very general architectures and training processes, and without using any lists manually sorted by humans at all. If we observed this, should we update even more strongly towards AI being able to suddenly surpass human capabilities?
I don't think so. If narrow tasks lead to more sudden capabilities gains, then we should not let the suddenness of capabilities gains on any single task inform our expectations of capabilities gains for general intelligence, since general intelligence encompasses such a broad range of tasks.
Additionally, the reason why DeepMind was able to exclude all human knowledge from AlphaGo Zero is because Go has a simple, known objective function, so we can simulate arbitrarily many games of Go and exactly score the agent's behavior in all of them. For more open ended tasks with uncertain objectives, like scientific research, it's much harder to find substitutes for human-written demonstration data. DeepMind can't just press a button and generate a million demonstrations of scientific advances, and objectively score how useful each advance is as training data, while relying on zero human input whatsoever.
On current AI not being self-improving:
That's not with an artificial intelligence system that improves itself, or even that sort of like, gets smarter as you run it, the way that human beings, not just as you evolve them, but as you run them over the course of their own lifetimes, improve.
This is wrong. Current models do get smarter as you train them. First, they get smarter in the straightforwards sense that they become better at whatever you're training them to do. In the case of language models trained on ~all of the text, this means they do become more generally intelligent as training progresses.
Second, current models also get smarter in the sense that they become better at learning from additional data. We can use tools from the neural tangent kernel to estimate a network's local inductive biases, and we find that these inductive biases continuously change throughout training so as to better align with the target function we're training it on, improving the network's capacity to learn the data in question. AI systems will improve themselves over time as a simple consequence of the training process, even if there's not a specific part of the training process that you've labeled "self improvement".
Pretrained language models gradually learn to make better use of their future training data. They "learn to learn", as this paper demonstrates by training LMs on fixed sets of task-specific data, then evaluating how well those LMs generalize from the task-specific data. They show that less extensively pretrained LMs make worse generalizations, relying on shallow heuristics and memorization. In contrast, more extensively pretrained LMs learn broader generalizations from the fixed task-specific data.
Edit: Yudkowsky comments to clarify the intent behind his statement about AIs getting better over time
From Yudkowsk [LW(p) · GW(p)]:
You straightforwardly completely misunderstood what I was trying to say on the Bankless podcast: I was saying that GPT-4 does not get smarter each time an instance of it is run in inference mode.
This surprised me. I've read a lot of writing by Yudkowsky, including Alexander and Yudkowsky on AGI goals [LW · GW], AGI Ruin [LW · GW], and the full Sequences [? · GW]. I did not at all expect Yudkowsky to analogize between a human's lifelong, continuous learning process [LW · GW], and a single runtime execution of an already trained model. Those are completely different things [LW · GW] in my ontology.
Though in retrospect, Yudkowsky's clarification does seem consistent with some of his statements in those writings. E.g., in Alexander and Yudkowsky on AGI goals [LW · GW], he said:
Evolution got human brains by evaluating increasingly large blobs of compute against a complicated environment containing other blobs of compute, got in each case a differential replication score, and millions of generations later you have humans with 7.5MB of evolution-learned data doing runtime learning on some terabytes of runtime data, using their whole-brain impressive learning algorithms which learn faster than evolution or gradient descent.
[Emphasis mine]
I think his clarified argument is still wrong, and for essentially the same reason as the argument I thought he was making was wrong: the current ML paradigm can already do the thing Yudkowsky implies will suddenly lead to much faster AI progress. There's no untapped capabilities overhang waiting to be unlocked with a single improvement.
The usual practice in current ML is to cleanly separate the "try to do stuff", the "check how well you did stuff", and the "update your internals to be better at doing stuff" phases of learning. The training process gathers together large "batches" of problems for the AI to solve, has the AI solve the problems, judges the quality of each solution, and then updates the AI's internals to make it better at solving each of the problems in the batch.
In the case of AlphaGo Zero, this means a loop of:
- Try to win a batch of Go games
- Check whether you won each game
- Update your parameters to make you more likely to win games
And so, AlphaGo Zero was indeed not learning during the course of an individual game.
However, ML doesn't have to work like this. DeepMind could have programmed AlphaGO Zero to update its parameters within games, rather than just at the conclusion of games, which would cause the model to learn continuously during each game it plays.
For example, they could have given AlphaGo Zero batches of current game states and had it generate a single move for each game state, judged how good each individual move was, and then updated the model to make better individual moves in future. Then the training loop would look like:
- Try to make the best possible next move on each of many game states
- Estimate how good each of your moves were
- Update your parameters to make you better at making single good moves
(This would require that DeepMind also train a "goodness of individual moves" predictor in order to provide the supervisory signal on each move, and much of the point of the AlphaGo Zero paper was that they could train a strong Go player with just the reward signals from end of game wins / losses.)
Not interleaving the "trying" and "updating" parts of learning in this manner in most of current ML is less a limitation and more a choice. There are other researchers who do build AIs which continuously learn during runtime execution (there's even a library for it), and they're not massively more data efficient for doing so. Such approaches tend to focus more on fast adaptation to new tasks and changing circumstances, rather than quickly learning a single fixed task like Go.
Similarly, the reason that "GPT-4 does not get smarter each time an instance of it is run in inference mode" is because it's not programmed to do that[7]. OpenAI could[8] continuously train its models on the inputs you give it, such that the model adapts to your particular interaction style and content, even during the course of a single conversation, similar to the approach suggested in this paper. Doing so would be significantly more expensive and complicated on the backend, and it would also open GPT-4 up to data poisoning attacks.
To return to the context of the original point Yudkowsky was making in the podcast, he brought up Go to argue that AIs could quickly surpass the limits of human capabilities. He then pointed towards a supposed limitation of current AIs:
That's not with an artificial intelligence system that improves itself, or even that sort of like, gets smarter as you run it
with the clear implication that AIs could advance even more suddenly once that limitation is overcome. I first thought the limitation he had in mind was something like "AIs don't get better at learning over the course of training." Apparently, the limitation he was actually pointing to was something like "AIs don't learn continuously during all the actions they take."
However, this is still a deficit of degree, and not of kind. Current AIs are worse than human at continuous learning, but they can do it, assuming they're configured to try. Like most other problems in the field, the current ML paradigm is making steady progress towards better forms of continuous learning. It's not some untapped reservoir of capabilities progress that might quickly catapult AIs beyond human levels in a short time.
As I said at the start of this post, researchers try all sorts of stuff to get better performance out of computers. Continual learning is one of the things they've tried.
End of edited text.
True experts learn (and prove themselves) by breaking things
We have people in crypto who are good at breaking things, and they're the reason why anything is not on fire, and some of them might go into breaking AI systems instead, because that's where you learn anything. You know, any fool can build a crypto-system that they think will work. Breaking existing cryptographical systems is how we learn who the real experts are.
The reason this works for computer security is because there's easy access to ground truth signals about whether you've actually "broken" something, and established - though imperfect - frameworks for interpreting what a given break means for the security of the system as a whole.
In alignment, we mostly don't have such unambiguous signals about whether a given thing is "broken" in a meaningful way, or about the implications of any particular "break". Typically what happens is that someone produces a new empirical result or theoretical argument, shares it with the broader community, and everyone disagrees about how to interpret this contribution.
For example, some people seem to interpret current chatbots' vulnerability to adversarial inputs as a "break" that shows RLHF isn't able to properly align language models. My response in Why aren't other people as pessimistic as Yudkowsky? [LW · GW] includes a discussion of adversarial vulnerability and why I don't think points to any irreconcilable flaws in current alignment techniques. Here are two additional examples showing how difficult it is to conclusively "break" things in alignment:
1: Why not just reward it for making you smile?
In 2001, Bill Hibbard proposed a scheme to align superintelligent AIs.
We can design intelligent machines so their primary, innate emotion is unconditional love for all humans. First we can build relatively simple machines that learn to recognize happiness and unhappiness in human facial expressions, human voices and human body language. Then we can hard-wire the result of this learning as the innate emotional values of more complex intelligent machines, positively reinforced when we are happy and negatively reinforced when we are unhappy.
Yudkowsky argued [LW · GW] that this approach was bound to fail, saying it would simply lead to the AI maximizing some unimportant quantity, such as by tiling the universe with "tiny molecular smiley-faces".
However, this is actually a non-trivial claim [LW · GW] about the limiting behaviors of reinforcement learning processes, and one I personally think is false. Realistic agents don't simply seek to maximize their reward function's output [LW · GW]. A reward function reshapes an agent's cognition to be more like the sort of cognition that got rewarded in the training process. The effects of a given reinforcement learning training process depend on factors like:
- The specific distribution of rewards encountered by the agent.
- The thoughts of the agent prior to encountering each reward.
- What sorts of thought patterns correlate with those that were rewarded in the training process.
My point isn't that Hibbard's proposal actually would work; I doubt it would. My point is that Yudkowsky's "tiny molecular smiley faces" objection does not unambiguously break the scheme. Yudkowsky's objection relies on hard to articulate, and hard to test, beliefs about the convergent structure of powerful cognition and the inductive biases of learning processes that produce such cognition.
Much of alignment is about which beliefs are appropriate for thinking about powerful cognition. Showing that a particular approach fails, given certain underlying beliefs, does nothing to show the validity of those underlying beliefs[9].
2: Do optimization demons matter?
John Wentworth describes the possibility of "optimization demons [LW · GW]", self-reinforcing patterns that exploit flaws in an imperfect search process to perpetuate themselves and hijack the search for their own purposes.
But no one knows exactly how much of an issue this is for deep learning, which is famous for its ability to evade local minima when run with many parameters.
Additionally, I think that, if deep learning models develop such phenomena, then the brain likely does so as well. In that case, preventing the same from happening with deep learning models could be disastrous, if optimization demon formation turns out to be a key component in the mechanistic processes that underlie human value formation[10].
Another poster (ironically using the handle "DaemonicSigil") then found a scenario [LW · GW] in which gradient descent does form an optimization demon. However, the scenario in question is extremely unnatural, and not at all like those found in normal deep learning practice. So no one knew whether this represented a valid "proof of concept" that realistic deep learning systems would develop optimization demons.
Roughly two and a half years later, Ulisse Mini would make [LW(p) · GW(p)] DaemonicSigil's scenario a bit more like those found in deep learning by increasing the number of dimensions from 16 to 1000 (still vastly smaller than any realistic deep learning system), which produced very different results, and weakly suggested that more dimensions do reduce demon formation.
In the end, different people interpreted these results differently. We didn't get a clear, computer security-style "break" of gradient descent showing it would produce optimization demons in real-world conditions, much less that those demons would be bad for alignment. Such outcomes are very typical in alignment research.
Alignment research operates with very different epistemic feedback loops as compared to computer security. There's little reason to think the belief formation and expert identification mechanisms that arose in computer security are appropriate for alignment.
Conclusion
I hope I've been able to show that there are informed, concrete arguments for optimism, that do engage with the details of pessimistic arguments. Alignment is an incredibly diverse [LW · GW] field. Alignment researchers vary widely in their estimated odds of catastrophe [LW · GW]. Yudkowsky is on the extreme-pessimism end of the spectrum, for what I think are mostly invalid reasons.
Thanks to Steven Byrnes and Alex Turner for comments and feedback on this post.
- ^
By this, I mostly mean the sorts of empirical approaches we actually use on current state of the art language models, such as RLHF, red teaming, etc.
- ^
We can take drugs, though, which maybe does something like change the brain's learning rate, or some other hyperparameters.
- ^
Technically it's trained to do decision transformer-esque reward-conditioned generation of texts.
- ^
The brain likely includes within-neuron learnable parameters, but I expect these to be a relatively small contribution to the overall information content a human accumulates over their lifetime. For convenience, I just say “connectome” in the main text, but really I mean “connectome + all other within-lifetime learnable parameters of the brain’s operation”.
- ^
I expect there are pretty straightforward ways of leveraging a 99% successful alignment method into a near-100% successful method by e.g., ensembling multiple training runs, having different runs cross-check each other, searching for inputs that lead to different behaviors between different models, transplanting parts of one model's activations into another model and seeing if the recipient model becomes less aligned, etc.
- ^
Some alignment researchers do argue that gradient descent is likely to create such an intelligence - an inner optimizer - that then deliberately manipulates the training process to its own ends. I don't believe this either. I don't want to dive deeply into my objections to that bundle of claims in this post, but as with Yudkowsky's position, I have many technical objections to such arguments. Briefly, they:
- often rely on inappropriate analogies to evolution.
- rely on unproven (and dubious, IMO) claims about the inductive biases of gradient descent.
- rely on shaky notions of "optimization" that lead to absurd conclusions when critically examined.
- seem inconsistent with what we know of neural network internal structures (they're very interchangeable and parallel).
- seem like the postulated network structure would fall victim to internally generated adversarial examples.
- don't track the distinction between mesa objectives and behavioral objectives (one can probably convert an NN into an energy function, then parameterize the NN's forwards pass as a search for energy function minima, without changing network behavior at all, so mesa objectives can have ~no relation to behavioral objectives).
- seem very implausible when considered in the context of the human learning process (could a human's visual cortex become "deceptively aligned" to the objective of modeling their visual field?).
- provide limited avenues [LW · GW] for any such inner optimizer to actually influence the training process.
See also: Deceptive Alignment is <1% Likely by Default [LW · GW] - ^
There's also in-context learning, which arguably does count as 'getting smarter while running in inference mode'. E.g., without updating any weights, LMs can:
- adapt information found in task descriptions / instructions to solving future task instances.
- given a coding task, write an initial plan on how to do that task, and then use that plan to do better on the coding task in question.
- even learn to classify images.
The reason this in-context learning doesn't always lead to persistent improvements (or at least changes) in GPT-4 is because OpenAI doesn't train their models like that. - ^
OpenAI does periodically train its models in a way that incorporates user inputs somehow. E.g., ChatGPT became much harder to jailbreak after OpenAI trained against the breaks people used against it. So GPT-4 is probably learning from some of the times it's run in inference mode.
- ^
Unless we actually try the approach and it fails in the way predicted. But that hasn't happened (yet).
- ^
This sentence would sound much less weird if John had called them "attractors" instead of "demons". One potential downside of choosing evocative names for things is that they can make it awkward to talk about those things in an emotionally neutral way.
- ^
The brain likely includes within-neuron learnable parameters, but I expect these to be a relatively small contribution to the overall information content a human accumulates over their lifetime. For convenience, I just say “connectome” in the main text, but really I mean “connectome + all other within-lifetime learnable parameters of the brain’s operation”.
233 comments
Comments sorted by top scores.
comment by Vaniver · 2023-03-21T21:28:44.114Z · LW(p) · GW(p)
I have a lot of responses to specific points; I'm going to make them as children comment to this comment.
Replies from: Vaniver, Vaniver, Vaniver, Vaniver, Vaniver, Vaniver, Vaniver, quintin-pope, Vaniver, Vaniver, Vaniver, Vaniver, Vaniver, Vaniver, Vaniver, Vaniver↑ comment by Vaniver · 2023-03-21T22:42:19.969Z · LW(p) · GW(p)
What does this mean for alignment? How do we prevent AIs from behaving badly as a result of a similar "misgeneralization"? What alignment insights does the fleshed-out mechanistic story of humans coming to like ice cream provide?
As far as I can tell, the answer is: don't reward your AIs for taking bad actions.
uh
is your proposal "use the true reward function, and then you won't get misaligned AI"?
That's all it would take, because the mechanistic story above requires a specific step where the human eats ice cream and activates their reward circuits. If you stop the human from receiving reward for eating ice cream, then the human no longer becomes more inclined to navigate towards eating ice cream in the future.
Note that I'm not saying this is an easy task, especially since modern RL methods often use learned reward functions whose exact contours are unknown to their creators.
But from what I can tell, Yudkowsky's position is that we need an entirely new paradigm to even begin to address these sorts of failures.
These three paragraphs feel incoherent to me. The human eating ice cream and activating their reward circuits is exactly what you would expect under the current paradigm. Yudkowsky thinks this leads to misalignment; you agree. He says that you need a new paradigm to not have this problem. You disagree because you assume it's possible under the current paradigm.
If so, how? Where's the system that, on eating ice cream, realizes "oh no! This is a bad action that should not receive reward!" and overrides the reward machinery? How was it trained?
I think when Eliezer says "we need an entirely new paradigm", he means something like "if we want a decision-making system that makes better decisions that a RL agent, we need agent-finding machinery that's better than RL." Maybe the paradigm shift is small (like from RL without experience replay to RL with), or maybe the paradigm shift is large (like from policy-based agents to plan-based agents).
In contrast, I think we can explain humans' tendency to like ice cream using the standard language of reinforcement learning. It doesn't require that we adopt an entirely new paradigm before we can even get a handle on such issues.
He's not saying the failures of RL are a surprise from the theory of RL. Of course you can explain it using the standard language of RL! He's saying that unless you can predict RL's failures from the inside, the RL agents that you make are going to actually make those mistakes in reality.
Replies from: elriggs, quintin-pope↑ comment by Logan Riggs (elriggs) · 2023-03-23T00:43:39.687Z · LW(p) · GW(p)
My shard theory inspired story is to make an AI that:
- Has a good core of human values (this is still hard)
- Can identify when experiences will change itself to lead to less of the initial good values. (This is the meta-preferences point with GPT-4 sort of expressing it would avoid jail break inputs)
Then the model can safely scale.
This doesn’t require having the true reward function (which I imagine to be a giant lookup table created by Omega), but some mech interp and understanding its own reward function. I don’t expect this to be an entirely different paradigm; I even think current methods of RLHF might just naively work. Who knows? (I do think we should try to figure it out though! I do have greater uncertainty and less pessimism)
Analogously, I do believe I do a good job of avoiding value-destroying inputs (eg addicting substances), even though my reward function isn’t as clear and legible as what our AI’s will be AFAIK.
Replies from: Vaniver↑ comment by Vaniver · 2023-03-23T20:22:22.138Z · LW(p) · GW(p)
Then the model can safely scale.
If there are experiences which will change itself which don't lead to less of the initial good values, then yeah, for an approximate definition of safety. You're resting everything on the continued strength of this model as capabilities increase, and so if it fails before you top out the scaling I think you probably lose.
FWIW I don't really see your description as, like, a specific alignment strategy so much as the strategy of "have an alignment strategy at all". The meat is all in 1) how you identify the core of human values and 2) how you identify which experiences will change the system to have less of the initial good values, but, like, figuring out the two of those would actually solve the problem!
Replies from: obserience↑ comment by anithite (obserience) · 2023-03-24T22:10:50.950Z · LW(p) · GW(p)
if it fails before you top out the scaling I think you probably lose
While I agree that arbitrary scaling is dangerous, stopping early is an option. Near human AGI need not transition to ASI until the relevant notKillEveryone problems have been solved.
The meat is all in 1) how you identify the core of human values and 2) how you identify which experiences will change the system to have less of the initial good values, but, like, figuring out the two of those would actually solve the problem!
The alignment strategy seems to be "what we're doing right now" which is:
- feed the base model human generated training data
- apply RL type stuff (RLHF,RLAIF,etc.) to reinforce the good type of internet learned behavior patterns
This could definitely fail eventually if RLAIF style self-improvement is allowed to go on long enough but crucially, especially with RLAIF and other strategies that set the AI to training itself, there's a scalable mostly aligned intelligence right there that can help. We're not trying to safely align a demon so much as avoid getting to "demon" from a the somewhat aligned thing we have now.
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2024-04-11T07:32:31.885Z · LW(p) · GW(p)
Near human AGI need not transition to ASI until the relevant notKillEveryone problems have been solved.
How much is this central to your story of how things go well?
I agree that humanity could do this (or at least it could if it had it's shit together), and I think it's a good target to aim for that buys us sizable successes probability. But I don't think it's what's going to happen by default.
↑ comment by anithite (obserience) · 2024-04-12T23:06:26.282Z · LW(p) · GW(p)
Slower is better obviously but as to the inevitability of ASI, I think reaching top 99% human capabilities in a handful of domains is enough to stop the current race. Getting there is probably not too dangerous.
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2024-04-13T07:05:35.557Z · LW(p) · GW(p)
Stop it how?
Replies from: obserience↑ comment by anithite (obserience) · 2024-04-17T04:54:32.724Z · LW(p) · GW(p)
Vulnerable world hypothesis (but takeover risk rather than destruction risk). That + first mover advantage could stop things pretty decisively without requiring ASI alignment [LW · GW]
As an example, taking over most networked computing devices seems feasible in principle with thousands of +2SD AI programmers/security-researchers. That requires an Alpha-go level breakthrough for RL as applied to LLM programmer-agents.
One especially low risk/complexity option is a stealthy takeover of other AI lab's compute then faking another AI winter. This might get you most of the compute and impact you care about without actively pissing off everyone.
If more confident in jailbreak prevention and software hardening, secrecy is less important.
First mover advantage depends on ability to fix vulnerabilities and harden infrastructure to prevent a second group from taking over. To the extent AI is required for management, jailbreak prevention/mitigation will also be needed.
↑ comment by Quintin Pope (quintin-pope) · 2023-03-24T13:37:01.763Z · LW(p) · GW(p)
is your proposal "use the true reward function, and then you won't get misaligned AI"?
No. I’m not proposing anything here. I’m arguing that Yudkowsky's ice cream example doesn't actually illustrate an alignment-relevant failure mode in RL.
I think we have different perspectives on what counts as "training" in the case of human evolution. I think of human within lifetime experiences as the training data, and I don't include the evolutionary history in the training data. From that perspective, the reason humans like ice cream is because they were trained to do so. To prevent AIs from behaving badly due to this particular reason, you can just refrain from training them to behave badly (they may behave badly for other reasons, of course).
I also think evolution is mechanistically very different from deep learning, such that it's near-useless to try to use evolutionary outcomes as a basis for making predictions about deep learning alignment outcomes.
See my other reply [LW(p) · GW(p)] for a longer explanation of my perspective.
Replies from: Vaniver, ricardo-meneghin-filho↑ comment by Ricardo Meneghin (ricardo-meneghin-filho) · 2023-04-05T23:20:48.999Z · LW(p) · GW(p)
Humans are not choosing to reward specific instances of actions of the AI - when we build intelligent agents, at some point they will leave the confines of curated training data and go operate on new experiences in the real world. At that point, their circuitry and rewards are out of human control, so that makes our position perfectly analogous to evolution’s. We are choosing the reward mechanism, not the reward.
Replies from: None↑ comment by [deleted] · 2023-04-05T23:40:37.540Z · LW(p) · GW(p)
Note that this provides an obvious route to alignment using conventional engineering practice.
Why does the AGI system need to update at all "out in the world". This is highly unreliable. As events happen in the real world that the system doesn't expect, add the (expectation, ground truth) tuples to a log and then train a simulator on the log from all instances of the system, then train the system on the updated simulator.
So only train in batches and use code in the simulator that "rewards" behavior that accomplishes the intent of the designers.
↑ comment by Vaniver · 2023-03-21T23:18:43.199Z · LW(p) · GW(p)
As I understand it, the security mindset asserts a premise that's roughly: "The bundle of intuitions acquired from the field of computer security are good predictors for the difficulty / value of future alignment research directions."
This seems... like a correct description but it's missing the spirit?
Like the intuitions are primarily about "what features are salient" and "what thoughts are easy to think."
However, I don't see why this should be the case.
Roughly, the core distinction between software engineering and computer security is whether the system is thinking back. Software engineering typically involves working with dynamic systems and thinking optimistically how the system could work. Computer security typically involves working with reactive systems and thinking pessimistically about how the system could break.
I think it is an extremely basic AI alignment skill to look at your alignment proposal and ask "how does this break?" or "what happens if the AI thinks about this?".
Additionally, there's a straightforward reason why alignment research (specifically the part of alignment that's about training AIs to have good values) is not like security: there's usually no adversarial intelligence cleverly trying to find any possible flaws in your approaches and exploit them.
What's your story for specification gaming?
I must admit some frustration, here; in this section it feels like your point is "look, computer security is for dealing with intelligence as part of your system. But the only intelligence in our system is sometimes malicious users!" In my world, the whole point of Artificial Intelligence was the Intelligence. The call is coming from inside the house!
Maybe we just have some linguistic disagreement? "Sure, computer security is relevant to transformative AI but not LLMs"? If so, then I think the earlier point [LW(p) · GW(p)] about whether capabilities enhancements break alignment techniques is relevant: if these alignment techniques work because the system isn't thinking about them, then are you confident they will continue to work when the system is thinking about them?
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2023-09-27T04:27:41.448Z · LW(p) · GW(p)
Roughly, the core distinction between software engineering and computer security is whether the system is thinking back.
Yes, and my point in that section is that the fundamental laws governing how AI training processes work are not "thinking back". They're not adversaries. If you created a misaligned AI, then it would be "thinking back", and you'd be in an adversarial position where security mindset is appropriate.
What's your story for specification gaming?
"Building an AI that doesn't game your specifications" is the actual "alignment question" we should be doing research on. The mathematical principles which determine how much a given AI training process games your specifications are not adversaries. It's also a problem we've made enormous progress on, mostly by using large pretrained models with priors over how to appropriately generalize from limited specification signals. E.g., Learning Which Features Matter: RoBERTa Acquires a Preference for Linguistic Generalizations (Eventually) shows how the process of pretraining an LM causes it to go from "gaming" a limited set of finetuning data via shortcut learning / memorization, to generalizing with the appropriate linguistic prior knowledge.
Replies from: Vaniver, Vaniver, elityre↑ comment by Vaniver · 2023-12-08T20:58:48.883Z · LW(p) · GW(p)
"Building an AI that doesn't game your specifications" is the actual "alignment question" we should be doing research on.
Ok, it sounds to me like you're saying:
"When you train ML systems, they game your specifications because the training dynamics are too dumb to infer what you actually want. We just need One Weird Trick to get the training dynamics to Do What You Mean Not What You Say, and then it will all work out, and there's not a demon that will create another obstacle given that you surmounted this one."
That is, training processes are not neutral; there's the bad training processes that we have now (or had before the recent positive developments) and eventually will be good training processes that create aligned-by-default systems.
Is this roughly right, or am I misunderstanding you?
↑ comment by Vaniver · 2023-12-08T20:48:16.536Z · LW(p) · GW(p)
If you created a misaligned AI, then it would be "thinking back", and you'd be in an adversarial position where security mindset is appropriate.
Cool, we agree on this point.
my point in that section is that the fundamental laws governing how AI training processes work are not "thinking back". They're not adversaries.
I think we agree here on the local point but disagree on its significance to the broader argument. [I'm not sure how much we agree-I think of training dynamics as 'neutral', but also I think of them as searching over program-space in order to find a program that performs well on a (loss function, training set) pair, and so you need to be reasoning about search. But I think we agree the training dynamics are not trying to trick you / be adversarial and instead are straightforwardly 'trying' to make Number Go Down.]
In my picture, we have the neutral training dynamics paired with the (loss function, training set) which creates the AI system, and whether the resulting AI system is adversarial or not depends mostly on the choice of (loss function, training set). It seems to me that we probably have a disagreement about how much of the space of (loss function, training set) leads to misaligned vs. aligned AI (if it hits 'AI' at all), where I think aligned AI is a narrow target to hit that most loss functions will miss, and hitting that narrow target requires security mindset.
To explain further, it's not that the (loss function, training set) is thinking back at you on its own; it's that the AI that's created by training is thinking back at you. So before you decide to optimize X you need to check whether or not you actually want something that's optimizing X, or if you need to optimize for Y instead.
So from my perspective it seems like you need security mindset in order to pick the right inputs to ML training to avoid getting misaligned models.
↑ comment by Eli Tyre (elityre) · 2024-04-11T07:35:48.254Z · LW(p) · GW(p)
the fundamental laws governing how AI training processes work are not "thinking back"
As a commentary from an observer: this is distinct from the proposition "the minds created with those laws are not thinking back."
↑ comment by Vaniver · 2023-03-22T00:12:32.447Z · LW(p) · GW(p)
in which Yudkowsky incorrectly assumed that GANs (Generative Adversarial Networks, a training method sometimes used to teach AIs to generate images) were so finicky that they must not have worked on the first try.
I do think this is a point against Yudkowsky. That said, my impression is that GANs are finicky, and I heard rumors that many people tried similar ideas and failed to get it to work before Goodfellow knocked it out of the park. If people were encouraged to publish negative results, we might have a better sense of the actual landscape here, but I think a story of "Goodfellow was unusually good at making GANs and this is why he got it right on his first try" is more compelling to me than "GANs were easy actually".
↑ comment by Vaniver · 2023-03-21T22:32:34.977Z · LW(p) · GW(p)
I think it's straightforward to explain why humans "misgeneralized" to liking ice cream.
I don't yet understand why you put misgeneralized in scare quotes, or whether you have a story for why it's a misgeneralization instead of things working as expected.
I think your story for why humans like ice cream makes sense, and is basically the story Yudkowsky would tell too, with one exception:
The ancestral environment selected for reward circuitry that would cause its bearers to seek out more of such food sources.
"such food sources" feels a little like it's eliding the distinction between "high-quality food sources of the ancestral environment" and "foods like ice cream"; the training dataset couldn't differentiate between functions f and g but those functions differ in their reaction to the test set (ice cream). Yudkowsky's primary point with this section, as I understand it, is that even if you-as-evolution know that you want g the only way you can communicate that under the current learning paradigm is with training examples, and it may be non-obvious to which functions f need to be excluded.
↑ comment by Quintin Pope (quintin-pope) · 2023-03-24T13:36:12.470Z · LW(p) · GW(p)
Thank you for your extensive engagement! From this and your other comment [LW(p) · GW(p)], I think you have a pretty different view of how we should generalize from the evidence provided by evolution to plausible alignment outcomes. Hopefully, this comment will clarify my perspective.
I don't yet understand why you put misgeneralized in scare quotes, or whether you have a story for why it's a misgeneralization instead of things working as expected.
I put misgeneralize in scare quotes because what happens in the human case isn't actually misgeneralization, as commonly understood in machine learning. The human RL process goes like:
- The human eats ice cream
- The human gets reward
- The human becomes more likely to eat ice cream
So, as a result of the RL process, is that the human became more likely to do the action that led to reward. That's totally inline with the standard understanding of what reward does. It's what you'd expect, and not a misgeneralization. You can easily predict that the human would like ice cream, by just looking at which of their actions led to reward during training. You'll see "ate ice cream" followed by "reward", and then you predict that they probably like eating ice cream.
the training dataset couldn't differentiate between functions
fandgbut those functions differ in their reaction to the test set (ice cream).
What training data? There was no training data involved, other than the ice cream. The human in the modern environment wasn't in the ancestral environment. The evolutionary history of one's ancestors is not part of one's own within lifetime training data.
In my frame, there isn't any "test" environment at all. The human's lifetime is their "training" process, where they're continuously receiving a stream of RL signals from the circuitry hardcoded by evolution. Those RL signals upweight ice cream seeking, and so the human seeks ice cream.
You can say that evolution had an "intent" behind the hardcoded circuitry, and humans in the current environment don't fulfill this intent. But I don't think evolution's "intent" matters here. We're not evolution. We can actually choose an AI's training data, and we can directly choose what rewards to associate with each of the AI's actions on that data. Evolution cannot do either of those things.
Evolution does this very weird and limited "bi-level" optimization process, where it searches over simple data labeling functions (your hardcoded reward circuitry[1]), then runs humans as an online RL process on whatever data they encounter in their lifetimes, with no further intervention from evolution whatsoever (no supervision, re-labeling of misallocated rewards, gathering more or different training data to address observed issues in the human's behavior, etc). Evolution then marginally updates the data labeling functions for the next generation. It's is a fundamentally different type of thing than an individual deep learning training run.
Additionally, the transition from "human learning to hunt gazelle in the ancestral environment" to "human learning to like ice cream in the modern environment" isn't even an actual train / test transition in the ML sense. It's not an example of:
We trained the system in environment A. Now, it's processing a different distribution of inputs from environment B, and now the system behaves differently.
It's an example of:
We trained a system in environment A. Then, we trained a fresh version of the same system on a different distribution of inputs from environment B, and now the two systems behave differently.
We want to learn more about the dynamics of distributional shifts, in the standard ML meaning of the word, not the dynamics of the weirder situation that evolution was in.
Why even try to make inferences from evolution at all? Why try to learn from the failures of a process that was:
- much stupider than us
- far more limited in the cognition-shaping tools available to it
- using a fundamentally different sort of approach (bi-level optimization over reward circuitry)
- compensating for these limitations using resources completely unavailable to us (running millions of generations and applying tiny tweaks over a long period of time)
- and not even dealing with an actual example of the phenomenon we want to understand!
I claim, as I've argued previously [LW · GW], that evolution is a terrible analogy for AGI development, and that you're much better off thinking about human within lifetime learning trajectories instead.
Beyond all the issues associated with trying to make any sort of inference from evolution to ML, there's also the issue that the failure mode behind "humans liking ice cream" is just fundamentally not worth much thought from an alignment perspective.
For any possible behavior X that a learning system could acquire, there are exactly two mechanisms by which X could arise:
- We directly train the system to do X.
E.g., 'the system does X in training, and we reward it for doing X in training', or 'we hand-write a demonstration example of doing X and use imitation learning', etc. - Literally anything else
E.g., 'a deceptively aligned mesaoptimizer does X once outside the training process', 'training included sub-components of the behavior X, which the system then combined together into the full behavior X once outside of the training process', or 'the training dataset contained spurious correlations such that the system's test-time behavior misgeneralized to doing X, even though it never did X during training', and so on.
"Humans liking ice cream" arises due to the first mechanism. The system (human) does X (eat ice cream) and gets reward.
So, for a bad behavior X to arise from an AI's training process, in a manner analogous to how "liking ice cream" arose in human within lifetime learning, the AI would have to exhibit behavior X during training and be rewarded for doing so.
Most misalignment scenarios worth much thought have a "treacherous turn" part that goes "the AI seemed to behave well during training, but then it behaved badly during deployment". This one doesn't. The AI behaves the same during training and deployment (I assume we're not rewarding it for executing a treacherous turn during training).
- ^
And other parts of your learning process like brain architecture, hyperparameters, sensory wiring map, etc. But I'm focusing on reward circuitry for this discussion.
↑ comment by Vaniver · 2023-03-25T05:14:29.264Z · LW(p) · GW(p)
(I'm going to include text from this other comment of yours so that I can respond to thematically similar things in one spot.)
I think we have different perspectives on what counts as "training" in the case of human evolution. I think of human within lifetime experiences as the training data, and I don't include the evolutionary history in the training data.
Agreed that our perspectives differ. According to me, there are two different things going on (the self-organization of the brain during a lifetime and the natural selection over genes across lifetimes), both of which can be thought of as 'training'.
Evolution then marginally updates the data labeling functions for the next generation. It's is a fundamentally different type of thing than an individual deep learning training run.
It seems to me like if we're looking at a particular deployed LLM, there are two main timescales, the long foundational training and then the contextual deployment. I think this looks a lot like having an evolutionary history of lots of 'lifetimes' which are relevant solely due to how they impact your process-of-interpreting-input, followed by your current lifetime in which you interpret some input.
That is, the 'lifetime of learning' that humans have corresponds to whatever's going on inside the transformer as it reads thru a prompt context window. It probably includes some stuff like gradient descent, but not cleanly, and certainly not done by the outside operators.
What the outside operators can do is more like "run more generations", often with deliberately chosen environments. [Of course SGD is different from genetic algorithms, and so the analogy isn't precise; it's much more like a single individual deciding how to evolve than a population selectively avoiding relatively bad approaches.]
Why even try to make inferences from evolution at all? Why try to learn from the failures of a process that was:
For me, it's this Bismarck quote:
Only a fool learns from his own mistakes. The wise man learns from the mistakes of others.
If it looks to me like evolution made the mistake that I am trying to avoid, I would like to figure out which features of what it did caused that mistake, and whether or not my approach has the same features.
And, like, I think basically all five of your bullet points apply to LLM training?
- "much stupider than us" -> check? The LLM training system is using a lot of intelligence, to be sure, but there are relevant subtasks within it that are being run at subhuman levels.
- "far more limited in the cognition-shaping tools available to it" -> I am tempted to check this one, in that the cognition-shaping tools we can deploy at our leisure are much less limited than the ones we can deploy while training on a corpus, but I do basically agree that evolution probably used fewer tools than we can, and certainly had less foresight than our tools do.
- "using a fundamentally different sort of approach (bi-level optimization over reward circuitry)" -> I think the operative bit of this is probably the bi-level optimization, which I think is still happening, and not the bit where it's for reward circuitry. If you think the reward circuitry is the operative bit, that might be an interesting discussion to try to ground out on.
- One note here is that I think we're going to get a weird reversal of human evolution, where the 'unsupervised learning via predictions' moves from the lifetime to the history. But this probably makes things harder, because now you have facts-about-the-world mixed up with your rewards and computational pathway design and all that.
- "compensating for these limitations using resources completely unavailable to us (running millions of generations and applying tiny tweaks over a long period of time)" -> check? Like, this seems like the primary reason why people are interested in deep learning over figuring out how things work and programming them the hard way. If you want to create something that can generate plausible text, training a randomly initialized net on <many> examples of next-token prediction is way easier than writing it all down yourself. Like, applying tiny tweaks over millions of generations is how gradient descent works!
- "and not even dealing with an actual example of the phenomenon we want to understand!" -> check? Like, prediction is the objective people used because it was easy to do in an unsupervised fashion, but they mostly don't want to know how likely text strings are. They want to have conversations, they want to get answers, and so on.
I also think those five criticisms apply to human learning, tho it's less obvious / might have to be limited to some parts of the human learning process. (For example, the control system that's determining which of my nerves to prune because of disuse seems much stupider than I am, but is only one component of learning.)
there's also the issue that the failure mode behind "humans liking ice cream" is just fundamentally not worth much thought from an alignment perspective.
I agree with this section (given the premise); it does seem right that "the agent does the thing it's rewarded to do" is not an inner alignment problem.
It does seem like an outer alignment problem (yes I get that you probably don't like [LW · GW] that framing). Like, I by default expect people to directly train the system to do things that they don't want the system to do, because they went for simplicity instead of correctness when setting up training, or to try to build systems with general capabilities (which means the ability to do X) while not realizing that they need to simultaneously suppress the undesired capabilities.
↑ comment by TristanTrim · 2023-07-19T08:33:18.440Z · LW(p) · GW(p)
- The human eats ice cream
- The human gets reward
- The human becomes more likely to eat ice cream
So, first of all, the ice cream metaphor is about humans becoming misaligned with evolution, not about conscious human strategies misgeneralizing that ice cream makes their reward circuits light up, which I agree is not a misgeneralization. Ice cream really does light up the reward circuits. If the human learned "I like licking cold things" and then sticks their tongue on a metal pole on a cold winter day, that would be misgeneralization at the level you are focused on, right?
Yeah, I'm pretty sure I misunderstood your point of view earlier, but I'm not sure this makes any more sense to me. Seems like you're saying humans have evolved to have some parts that evaluate reward, and some parts that strategize how to get the reward parts to light up. But in my view, the former, evaluating parts, are where the core values in need of alignment exist. The latter, strategizing parts, are updated in an RL kind of way, and represent more convergent / instrumental goals (and probably need some inner alignment assurances).
I think the human evaluate/strategize model could be brought over to the AI model in a few different ways. It could be that the evaluating is akin to updating an LLM using training/RL/RLHF. Then the strategizing part is the LLM. The issue I see with this is the LLM and the RLHF are not inseparable parts like with the human. Even if the RLHF is aligned well, the LLM can, and I believe commonly is, taken out and used as a module in some other system that can be optimizing for something unrelated.
Additionally, even if the LLM and RLHF parts were permanently glued together somehow, They are still computer software and are thereby much easier for an AI with software engineering skill to take out. If the LLM (gets agent shaped and) discovers that it likes digital ice cream, but that the RLHF is going to train it to like it less, it will be able to strategize about ways to remove or circumvent the RLHF much more effectively than humans can remove or circumvent our own reinforcement learning circuitry.
Another way the single lifetime human model could fit onto the AI model is with the RLHF as evolution (discarded) and the LLM actually coming to be shaped like both the evaluating and strategizing parts. This seems a lot less likely (impossible?) with current LLM architecture, but may be possible with future architecture. Certainly this seems like the concern of mesa optimizers, but again, this doesn't seem like a good thing, mesa optimizers are misaligned w.r.t. the loss function of the RL training.
↑ comment by Vaniver · 2023-03-21T23:55:56.777Z · LW(p) · GW(p)
Finally, I'd note that having a "security mindset" seems like a terrible approach for raising human children to have good values
Do you have kids, or any experience with them? (There are three small children in the house I live in.) I think you might want to look into childproofing, and meditate on its connection to security mindset.
Yes, this isn't necessarily related to the 'values' part, but for that I would suggest things like Direct Instruction, which involves careful curriculum design to generate lots of examples so that students will reliably end up inferring the correct rule.
In short, I think the part of 'raising children' which involves the kids being intelligent as well and independently minded does benefit from security mindset.
As you mention in the next paragraph, this is a long-standing disagreement; I might as well point at the discussion of the relevance of raising human children to instilling goals in an AI in The Detached Lever Fallacy [LW · GW]. The short summary of it is that humans have a wide range of options for their 'values', and are running some strategy of learning from their environment (including their parents and their style of raising children) which values to adopt. The situation with AI seems substantially different--why make an AI design that chooses whether to be good or bad based on whether you're nice to it, when you could instead have it choose to always be good? [Note that this is distinct from "always be nice"; you could decide that your good AI can tell users that they're being bad users!]
↑ comment by Vaniver · 2023-03-22T00:09:44.412Z · LW(p) · GW(p)
Yudkowsky's own prior statements seem to put him in this camp as well. E.g., here [LW · GW] he explains why he doesn't expect intelligence to emerge from neural networks (or more precisely, why he dismisses a brain-based analogy for coming to that conclusion)
I think you're basically misunderstanding and misrepresenting Yudkowsky's argument from 2008. He's not saying "you can't make an AI out of neural networks", he's saying "your design sharing a single feature with the brain does not mean it will also share the brain's intelligence." As well, I don't think he's arguing about how AI will actually get made; I think he's mostly criticizing the actual AGI developers/enthusiasts that he saw at the time (who were substantially less intelligent and capable than the modern batch of AGI developers).
I think that post has held up pretty well. The architectures used to organize neural networks are quite important, not just the base element. Someone whose only plan was to make their ANN wide would not reach AGI; they needed to do something else, that didn't just rely on surface analogies.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2023-09-27T04:35:18.023Z · LW(p) · GW(p)
There was an entire thread about Yudkowsky's past opinions on neural networks, and I agree with Alex Turner's evidence [LW(p) · GW(p)] that Yudkowsky was dubious.
I also think people who used brain analogies as the basis for optimism about neural networks were right to do so.
↑ comment by Vaniver · 2023-03-22T01:00:05.341Z · LW(p) · GW(p)
seem very implausible when considered in the context of the human learning process (could a human's visual cortex become "deceptively aligned" to the objective of modeling their visual field?).
I think it would probably be strange for the visual field to do this. But I think it's not that uncommon for other parts of the brain to do this; higher level, most abstract / "psychological" parts that have a sense of how things will affect their relevance to future decision-making. I think there are lots of self-perpetuating narratives that it might be fair to call 'deceptively aligned' when they're maladaptive. The idea of metacognitive blindspots [LW · GW] also seems related.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2023-10-01T21:58:48.934Z · LW(p) · GW(p)
I believe the human visual cortex is actually the more relevant comparison point for estimating the level of danger we face due to mesaoptimization. Its training process is more similar to the self-supervised / offline way in which we train (base) LLMs. In contrast, 'most abstract / "psychological"' are more entangled in future decision-making. They're more "online", with greater ability to influence their future training data.
I think it's not too controversial that online learning processes can have self-reinforcing loops in them. Crucially however, such loops rely on being able to influence the externally visible data collection process, rather than being invisibly baked into the prior. They are thus much more amenable to being addressed with scalable oversight approaches.
↑ comment by Quintin Pope (quintin-pope) · 2023-09-27T05:04:41.739Z · LW(p) · GW(p)
I've recently decided to revisit this post. I'll try to address all un-responded to comments in the next ~2 weeks.
↑ comment by Vaniver · 2023-03-22T00:51:59.794Z · LW(p) · GW(p)
John Wentworth describes the possibility of "optimization demons [LW · GW]", self-reinforcing patterns that exploit flaws in an imperfect search process to perpetuate themselves and hijack the search for their own purposes.
But no one knows exactly how much of an issue this is for deep learning, which is famous for its ability to evade local minima when run with many parameters.
Also relevant is Are minimal circuits daemon-free? [LW · GW] and Are minimal circuits deceptive? [LW · GW]. I agree no one knows how much of an issue this will be for deep learning.
Additionally, I think that, if deep learning models develop such phenomena, then the brain likely does so as well.
I think the brain obviously has such phenomena, and societies made up of humans also obviously have such phenomena. I think it is probably not adaptive (optimization demons are more like 'cognitive cancer' than 'part of how values form', I think, but in part that's because the term comes with the disapproval built in).
↑ comment by Vaniver · 2023-03-22T00:16:49.458Z · LW(p) · GW(p)
Given the greater evidence available for general ML research, being well calibrated about the difficulty of general ML research is the first step to being well calibrated about the difficulty of ML alignment research.
I think I agree with this point but want to explicitly note the switch from the phrase 'AI alignment research' to 'ML alignment research'; my model of Eliezer thinks the second is mostly a distraction from the former, and if you think they're the same or interchangeable that seems like a disagreement.
[For example, I think ML alignment research includes stuff like "will our learned function be robust to distributional shift in the inputs?" and "does our model discriminate against protected classes?" whereas AI alignment research includes stuff like "will our system be robust to changes in the number of inputs?" and "is our model deceiving us about its level of understanding?". They're related in some ways, but pretty deeply distinct.]
↑ comment by Vaniver · 2023-03-21T22:23:30.812Z · LW(p) · GW(p)
There's no guarantee that such a thing even exists, and implicitly aiming to avoid the one value formation process we know is compatible with our own values seems like a terrible idea.
...
It's thus vastly easier to align models to goals where we have many examples of people executing said goals.
I think there's a deep disconnect here on whether interpolation is enough or whether we need extrapolation.
The point of the strawberry alignment problem is "here's a clearly understandable specification of a task that requires novel science and engineering to execute on. Can you do that safely?". If your ambitions are simply to have AI customer service bots, you don't need to solve this problem. If your ambitions include cognitive megaprojects which will need to be staffed at high levels by AI systems, then you do need to solve this problem.
More pragmatically, if your ambitions include setting up some sort of system that prevents people from deploying rogue AI systems while not dramatically curtailing Earth's potential, that isn't a goal that we have many examples of people executing on. So either we need to figure it out with humans or, if that's too hard, create an AI system capable of figuring it out (which probably requires an AI leader instead of an AI assistant).
↑ comment by Vaniver · 2023-03-21T21:40:08.434Z · LW(p) · GW(p)
I expect future capabilities advances to follow a similar pattern as past capabilities advances, and not completely break the existing alignment techniques.
Part of this is just straight disagreement, I think; see So8res's Sharp Left Turn [LW · GW] and follow-on discussion [? · GW].
But for the rest of it, I don't see this as addressing the case for pessimism, which is not problems from the reference class that contains "the LLM sometimes outputs naughty sentences" but instead problems from the reference class that contains "we don't know how to prevent an ontological collapse, where meaning structures constructed under one world-model compile to something different under a different world model."
Or, like, once LLMs gain the capability to design proteins (because you added in a relevant dataset, say), do you really expect the 'helpful, harmless, honest' alignment techniques that were used to make a chatbot not accidentally offend users to also work for making a biologist-bot not accidentally murder patients? Put another way, I think new capabilities advances reveal new alignment challenges and unless alignment techniques are clearly cutting at the root of the problem, I don't expect that they will easily transfer to those new challenges.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2023-09-27T05:03:30.357Z · LW(p) · GW(p)
Part of this is just straight disagreement, I think; see So8res's Sharp Left Turn [LW · GW] and follow-on discussion [? · GW].
Evolution provides no evidence for the sharp left turn [LW · GW]
But for the rest of it, I don't see this as addressing the case for pessimism, which is not problems from the reference class that contains "the LLM sometimes outputs naughty sentences" but instead problems from the reference class that contains "we don't know how to prevent an ontological collapse, where meaning structures constructed under one world-model compile to something different under a different world model."
I dislike this minimization of contemporary alignment progress. Even just limiting ourselves to RLHF, that method addresses far more problems than "the LLM sometimes outputs naughty sentences". E.g., it also tackles problems such as consistently following user instructions, reducing hallucinations, improving the topicality of LLM suggestions, etc. It allows much more significant interfacing with the cognition and objectives pursued by LLMs than just some profanity filter.
I don't think ontological collapse is a real issue (or at least, not an issue that appropriate training data can't solve in a relatively straightforwards way). I feel similarly about lots of things that are speculated to be convergent problems for ML systems, such as wireheading and mesaoptimization.
Or, like, once LLMs gain the capability to design proteins (because you added in a relevant dataset, say), do you really expect the 'helpful, harmless, honest' alignment techniques that were used to make a chatbot not accidentally offend users to also work for making a biologist-bot not accidentally murder patients?
If you're referring to the technique used on LLMs (RLHF), then the answer seems like an obvious yes. RLHF just refers to using reinforcement learning with supervisory signals from a preference model. It's an incredibly powerful and flexible approach, one that's only marginally less general than reinforcement learning itself (can't use it for things you can't build a preference model of). It seems clear enough to me that you could do RLHF over the biologist-bot's action outputs in the biological domain, and be able to shape its behavior there.
If you're referring to just doing language-only RLHF on the model, then making a bio-model, and seeing if the RLHF influences the bio-model's behaviors, then I think the answer is "variable, and it depends a lot on the specifics of the RLHF and how the cross-modal grounding works".
People often translate non-lingual modalities into language so LLMs can operate in their "native element" in those other domains. Assuming you don't do that, then yes, I could easily see the language-only RLHF training having little impact on the bio-model's behaviors.
However, if the bio-model were acting multi-modally by e.g., alternating between biological sequence outputs and natural language planning of what to use those outputs for, then I expect the RLHF would constrain the language portions of that dialog. Then, there are two options:
- Bio-bot's multi-modal outputs don't correctly ground between language and bio-sequences.
- In this case, bio-bot's language planning doesn't correctly describe the sequences its outputting, so the RLHF doesn't constrain those sequences.
- However, if bio-bot doesn't ground cross-modally, than bio-bot also can't benefit from its ability to plan in the language modality to better use its bio modality capabilities (which are presumably much better for planning than its bio-modality).
- Bio-bot's multi-modal outputs DO correctly ground between language and bio-sequences.
- In that case, the RLHF-constrained language does correctly describe the bio-sequences, and so the language-only RLHF training does also constrain bio-bot's biology-related behavior.
Put another way, I think new capabilities advances reveal new alignment challenges and unless alignment techniques are clearly cutting at the root of the problem, I don't expect that they will easily transfer to those new challenges.
Whereas I see future alignment challenges as intimately tied to those we've had to tackle for previous, less capable models. E.g., your bio-bot example is basically a problem of cross-modality grounding, on which there has been an enormous amount of past work, driven by the fact that cross-modality grounding is a problem for systems across very broad ranges of capabilities.
↑ comment by Vaniver · 2023-03-22T00:35:42.672Z · LW(p) · GW(p)
I think the bolded text is about Yudkowsky himself being wrong.
That is also how I interpreted it.
If you have a bunch of specific arguments and sources of evidence that you think all point towards a particular conclusion X, then discovering that you're wrong about something should, in expectation, reduce your confidence in X.
I think Yudkowsky is making a different statement. I agree it would be bizarre for him to be saying "if I were wrong, it would only mean I should have been more confident!"
Yudkowsky is not the aerospace engineer building the rocket who's saying "the rocket will work because of reasons A, B, C, etc".
I think he is (inside of the example). He's saying "suppose an engineer is wrong about how their design works. Is it more likely that the true design performs better along multiple important criteria than expectation, or that the design performs worse (or fails to function at all)?"
Note that 'expectation' is referring to the confidence level inside an argument [LW · GW], but arguments aren't Bayesians; it's the outside agent that shouldn't be expected to predictably update. Another way to put this: does the engineer expect to be disappointed, excited, or neutral if the design doesn't work as planned? Typically, disappointed, implying the plan is overly optimistic compared to reality.
If this weren't true--if engineers were calibrated or pessimistic--then I think Yudkowsky would be wrong here (and also probably have a different argument to begin with).
↑ comment by Vaniver · 2023-03-21T23:31:08.644Z · LW(p) · GW(p)
It cannot be the case that successful value alignment requires perfect adversarial robustness.
It seems like the argument structure here is something like:
- This requirement is too stringent for humans to follow
- Humans have successful value alignment
- Therefore this requirement cannot be necessary for successful value alignment.
I disagree with point 2, tho; among other things, it looks to me like some humans are on track to accidentally summoning a demon that kills both me and them, which I expect they would regret after-the-fact if they had the chance to.
So any reasoning that's like "well so long as it's not unusual we can be sure it's safe" runs into the thing where we're living in the acute risk period. The usual is not safe!
Similarly, an AI that knows it's vulnerable to adversarial attacks, and wants to avoid being attacked successfully, will take steps to protect itself against such attacks. I think creating AIs with such meta-preferences is far easier than creating AIs that are perfectly immune to all possible adversarial attacks.
This seems definitely right to me. An expectation I have is that this will also generate resistance to alignment techniques / control by its operators, which perhaps complicates how benign this is.
[FWIW I also don't think we want an AI that's perfectly robust to all possible adversarial attacks; I think we want one that's adequate to defend against the security challenges it faces, many of which I expect to be internal. Part of this is because I'm mostly interested in AI planning systems able to help with transformative changes to the world instead of foundational models used by many customers for small amounts of cognition, which are totally different business cases and have different security problems.]
↑ comment by Vaniver · 2023-03-21T22:16:46.170Z · LW(p) · GW(p)
I think this is extremely misleading. Firstly, real-world data in high dimensions basically never look like spheres. Such data almost always cluster in extremely compact manifolds, whose internal volume is minuscule compared to the full volume of the space they're embedded in.
I agree with your picture of how manifolds work; I don't think it actually disagrees all that much with Yudkowsky's.
That is, the thing where all humans are basically the same make and model of car, running the same brand of engine, painted different colors is the claim that the intrinsic dimension of human minds is pretty small. (Taken literally, it's 3, for the three dimensions of color-space.)
And so if you think there are, say, 40 intrinsic dimensions to mind-space, and humans are fixed on 37 of the points and variable on the other 3, well, I think we have basically the Yudkowskian picture.
(I agree if Yudkowsky's picture was that there were 40M dimensions and humans varied on 3, this would be comically wrong, but I don't think this is what he's imagining for that argument.)
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2023-10-01T22:17:10.527Z · LW(p) · GW(p)
Addressing this objection is why I emphasized the relatively low information content that architecture / optimizers provide for minds, as compared to training data. We've gotten very far in instantiating human-like behaviors by training networks on human-like data. I'm saying the primacy of data for determining minds means you can get surprisingly close in mindspace, as compared to if you thought architecture / optimizer / etc were the most important.
Obviously, there are still huge gaps between the sorts of data that an LLM is trained on versus the implicit loss functions human brains actually minimize, so it's kind of surprising we've even gotten this far. The implication I'm pointing to is that it's feasible to get really close to human minds along important dimensions related to values and behaviors, even without replicating all the quirks of human mental architecture.
↑ comment by Vaniver · 2023-03-21T22:10:29.856Z · LW(p) · GW(p)
This seems like way too high a bar. It seems clear that you can have transformative or risky AI systems that are still worse than humans at some tasks. This seems like the most likely outcome to me.
I think this is what Yudkowsky thinks also? (As for why it was relevant to bring up, Yudkowsky was answering the host's question of "How is superintelligence different than general intelligence?")
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-03-21T00:49:26.445Z · LW(p) · GW(p)
I disagree with much of what you say here, but I'm happy to see such a thorough point by point object-level response! Thanks!
comment by TurnTrout · 2023-03-21T01:29:47.222Z · LW(p) · GW(p)
Some arguments which Eliezer advanced in order to dismiss neural networks,[1] seem similar to some reasoning which he deploys in his modern alignment arguments.
Compare his incorrect mockery from 2008:
But there is just no law which says that if X has property A and Y has property A then X and Y must share any other property. "I built my network, and it's massively parallel and interconnected and complicated, just like the human brain from which intelligence emerges! Behold, now intelligence shall emerge from this neural network as well!" And nothing happens. Why should it?
with his claim in Alexander and Yudkowsky on AGI goals [LW · GW]:
[Alexander][14:36]
Like, we're not going to run evolution in a way where we naturally get AI morality the same way we got human morality, but why can't we observe how evolution implemented human morality, and then try AIs that have the same implementation design? [Yudkowsky][14:37]
Not if it's based on anything remotely like the current paradigm, because nothing you do with a loss function and gradient descent over 100 quadrillion neurons, will result in an AI coming out the other end which looks like an evolved human with 7.5MB of brain-wiring information and a childhood.
Like, in particular with respect to "learn 'don't steal' rather than 'don't get caught'."
I agree that 100 quadrillion artificial neurons + loss function won't get you a literal human, for trivial reasons. The relevant point is his latter claim: "in particular with respect to "learn 'don't steal' rather than 'don't get caught'.""
I think this is a very strong conclusion, relative to available data. I think that a good argument for it would require a lot of technical, non-analogical reasoning about the inductive biases of SGD on large language models. But, AFAICT, Eliezer rarely deploys technical reasoning that depends on experimental results or ML theory. He seems to prefer strongly-worded a priori arguments that are basically analogies.
In the above two quotes of his,[3] I perceive a common thread of
human intelligence/alignment comes from a lot of factors; you can't just ape one of the factors and expect the rest to follow; to get a mind which thinks/wants as humans do, that mind must be as close to a human as humans are to each other.
But why is this true? You can just replace "human intelligence" with "avian flight", and the argument might sound similarly plausible a priori.
ETA: The invalid reasoning step is in the last clause ("to get a mind..."). If design X exhibits property P, that doesn't mean that design Y must be similar to X in order to exhibit property P.
ETA: Part of this comment was about EY dismissing neural networks in 2008. It seems to me that the cited writing supports that interpretation, and it's still my best guess (see also DirectedEvolution's comment [LW(p) · GW(p)]s [LW(p) · GW(p)]). However, the quotes are also compatible with EY merely criticizing invalid reasons for expecting neural networks to work. I should have written that part of this comment more carefully, and not claimed observation ("he did dismiss") when I only had inference ("sure seems like he dismissed").
I think the rest of my point stands unaffected (EY often advances vague arguments that are analogies, or a priori thought experiments).
ETA 2: I'm now more confident [LW(p) · GW(p)] in my read. Eliezer said this directly [LW(p) · GW(p)]:
I'm no fan of neurons; this may be clearer from other posts.
- ^
It's this kind of apparent misprediction which has, over time, made me take less seriously Eliezer's models of intelligence and alignment. See also e.g. the cited GAN mis-retrodiction. This change led me to flag / rederive all of my beliefs about rationality/optimization for a while.
(At least, his 2008-era models seemed faulty to the point of this misprediction, and it doesn't seem to me that this part of his models has changed much, though I claim no intimate non-public knowledge of his beliefs; just operating on my impressions here.)
- ^
See also Failure By Analogy [LW · GW]:
Wasn't it in some sense reasonable to have high hopes of neural networks? After all, they're just like the human brain [? · GW], which is also massively parallel, distributed, asynchronous, and -
Hold on. Why not analogize to an earthworm's brain, instead of a human's?
A backprop network with sigmoid units... actually doesn't much resemble biology at all. Around as much as a voodoo doll resembles its victim. The surface shape may look vaguely similar in extremely superficial aspects at a first glance. But the interiors and behaviors, and basically the whole thing apart from the surface, are nothing at all alike. All that biological neurons have in common with gradient-optimization ANNs is... the spiderwebby look.
And who says that the spiderwebby look is the important fact about biology? Maybe the performance of biological brains has nothing to do with being made out of neurons, and everything to do with the cumulative selection pressure [? · GW] put into the design.
- ^
Originally, this comment included:
So, here are two claims which seem to echo the positions Eliezer advances:
1. "A large ANN doesn't look enough like a human brain to develop intelligence." -> wrong (see GPT-4)
2. "A large ANN doesn't look enough like a human brain to learn 'don't steal' rather than 'don't get caught'" -> (not yet known)I struck this from the body because I think (1) misrepresents his position. Eliezer is happy to speculate about non-anthropomorphic general intelligence (see e.g. That Alien Message [LW · GW]). Also, I think this claim comparison does not name my real objection here, which is better advanced by the updated body of this comment.
↑ comment by DanielFilan · 2023-03-21T02:27:48.911Z · LW(p) · GW(p)
I don't really get your comment. Here are some things I don't get:
- In "Failure By Analogy" and "Surface Analogies and Deep Causes", the point being made is "X is similar in aspects A to thing Y, and X has property P" does not establish "Y has property P". The reasoning he instead recommends is to reason about Y itself, and sometimes it will have property P. This seems like a pretty good point to me.
- Large ANNs don't appear to me to be intelligent because of their similarity to human brains - they appear to me to be intelligent because they're able to be tuned to accurately predict simple facts about a large amount of data that's closely related to human intelligence, and the algorithm they get tuned to seems to be able to be repurposed for a wide variety of tasks (probably related to the wide variety of data that was trained on).
- Airplanes don't fly like birds, they fly like airplanes. So indeed you can't just ape one thing about birds[*] to get avian flight. I don't think this is a super revealing technicality but it seemed like you thought it was important.
- Maybe most importantly I don't think Eliezer thinks you need to mimic the human brain super closely to get human-like intelligence with human-friendly wants. I think he instead thinks you need to mimic the human brain super closely to validly argue by analogy from humans. I think this is pretty compatible with this quote from "Failure By Analogy" (it isn't exactly implied by it, but your interpretation isn't either):
An abacus performs addition; and the beads of solder on a circuit board bear a certain surface resemblance to the beads on an abacus. Nonetheless, the circuit board does not perform addition because we can find a surface similarity to the abacus. [LW · GW] The Law of Similarity and Contagion is not relevant. The circuit board would work in just the same fashion if every abacus upon Earth vanished in a puff of smoke, or if the beads of an abacus looked nothing like solder. A computer chip is not powered by its similarity to anything else, it just is. It exists in its own right, for its own reasons.
The Wright Brothers calculated that their plane would fly - before it ever flew - using reasoning that took no account whatsoever of their aircraft's similarity to a bird. They did look at birds (and I have looked at neuroscience) but the final calculations did not mention birds (I am fairly confident in asserting). A working airplane does not fly because it has wings "just like a bird". An airplane flies because it is an airplane, a thing that exists in its own right; and it would fly just as high, no more and no less, if no bird had ever existed.
- Matters would be different if he said in the quotes you cite "you only get these human-like properties by very exactly mimicking the human brain", but he doesn't.
[*] I've just realized that I can't name a way in which airplanes are like birds in which they aren't like humans. They have things sticking out their sides? So do humans, they're called arms. Maybe the cross-sectional shape of the wings are similar? I guess they both have pointy-ish bits at the front, that are a bit more pointy than human heads? TBC I don't think this footnote is at all relevant to the safety properties of RLHF'ed big transformers.
Replies from: jacob_cannell, TurnTrout↑ comment by jacob_cannell · 2023-03-21T22:13:24.422Z · LW(p) · GW(p)
The Wright Brothers calculated that their plane would fly - before it ever flew - using reasoning that took no account whatsoever of their aircraft's similarity to a bird. They did look at birds (and I have looked at neuroscience) but the final calculations did not mention birds (I am fairly confident in asserting). A working airplane does not fly because it has wings "just like a bird".
Actually the wright brother's central innovation and the centerpiece of the later aviation patent wars - wing warping based flight control - was literally directly copied from birds. It involved just about zero aerodynamics calculations. Moreover their process didn't involve much "calculation" in general; they downloaded a library of existing flyer designs from the smithsonian and then developed a wind tunnel to test said designs at high throughput before selecting a few for full-scale physical prototypes. Their process was light on formal theory and heavy on experimentation.
Replies from: DanielFilan↑ comment by DanielFilan · 2023-03-22T01:32:44.322Z · LW(p) · GW(p)
This is a good corrective, and also very compatible with "similarity to birds is not what gave the Wright brothers confidence that their plane would fly".
Replies from: jacob_cannell↑ comment by jacob_cannell · 2023-03-22T16:13:56.234Z · LW(p) · GW(p)
At the time the wright brothers entered the race there were many successful glider designs already, and it was fairly obvious to many that one could build a powered flyer by attaching an engine to a glider. The two key challenges were thrust to weight ratio and control. Overcoming the first obstacle was mostly a matter of timing due to exploit the rapid improvements in IC engines, while nobody really had good ideas for control yet. Competitors were exploring everything from "sky railroads" (airplanes on fixed flight tracks with zero control) to the obvious naval ship-like pure rudder control (which doesn't work well).
So the wright brothers already had confidence their plane would fly before even entering the race, if by "fly" we only mean in the weak aerodynamic sense of "it's possible to stay aloft". But for true powered controlled flight - it is exactly similarity to birds that gave them confidence as avian flight control is literally the source of their key innovation.
Replies from: DanielFilan↑ comment by DanielFilan · 2023-03-22T23:02:38.182Z · LW(p) · GW(p)
But for true powered controlled flight - it is exactly similarity to birds that gave them confidence as avian flight control is literally the source of their key innovation.
Why do you think the confidence came from this and not from the fact that
they downloaded a library of existing flyer designs from the smithsonian and then developed a wind tunnel to test said designs at high throughput before selecting a few for full-scale physical prototypes.
?
Replies from: jacob_cannell↑ comment by jacob_cannell · 2023-03-23T02:13:58.918Z · LW(p) · GW(p)
I said for "true powered controlled fllight", which nobody had yet achieved. The existing flyer designs that worked were gliders. From the sources I've seen (wikipedia, top google hits etc), they used the wind tunnel primarily to gather test data on the aerodynamics of flyer designs in general but mainly wings and later propellers. Wing warping isn't mentioned in conjunction with wind tunnel testing.
Replies from: DanielFilan↑ comment by DanielFilan · 2023-04-05T01:00:32.228Z · LW(p) · GW(p)
gotcha, thanks!
↑ comment by TurnTrout · 2023-03-21T02:52:31.056Z · LW(p) · GW(p)
Edited to modify confidences about interpretations of EY's writing / claims.
In "Failure By Analogy" and "Surface Analogies and Deep Causes", the point being made is "X is similar in aspects A to thing Y, and X has property P" does not establish "Y has property P". The reasoning he instead recommends is to reason about Y itself, and sometimes it will have property P. This seems like a pretty good point to me.
This is a valid point, and that's not what I'm critiquing in that portion of the comment. I'm critiquing how -- on my read -- he confidently dismisses ANNs; in particular, using non-mechanistic reasoning which seems similar to some of his current alignment arguments.
On its own, this seems like a substantial misprediction for an intelligence researcher in 2008 (especially one who claims to have figured out most things in modern alignment [LW · GW], by a very early point in time -- possibly that early, IDK). Possibly the most important prediction to get right, to date.
Airplanes don't fly like birds, they fly like airplanes. So indeed you can't just ape one thing about birds[*] to get avian flight. I don't think this is a super revealing technicality but it seemed like you thought it was important.
Indeed, you can't ape one thing. But that's not what I'm critiquing. Consider the whole transformed line of reasoning:
avian flight comes from a lot of factors; you can't just ape one of the factors and expect the rest to follow; to get an entity which flies, that entity must be as close to a bird as birds are to each other.
The important part is the last part. It's invalid. Finding a design X which exhibits property P, doesn't mean that for design Y to exhibit property P, Y must be very similar to X.
Which leads us to:
Maybe most importantly I don't think Eliezer thinks you need to mimic the human brain super closely to get human-like intelligence with human-friendly wants
Reading the Alexander/Yudkowsky debate, I surprisingly haven't ruled out this interpretation, and indeed suspect he believes some forms of this (but not others).
Matters would be different if he said in the quotes you cite "you only get these human-like properties by very exactly mimicking the human brain", but he doesn't.
Didn't he? He at least confidently rules out a very large class of modern approaches.
Replies from: Zack_M_Davis, sil-ver, TurnTrout, DanielFilan, DanielFilanbecause nothing you do with a loss function and gradient descent over 100 quadrillion neurons, will result in an AI coming out the other end which looks like an evolved human with 7.5MB of brain-wiring information and a childhood.
Like, in particular with respect to "learn 'don't steal' rather than 'don't get caught'."
↑ comment by Zack_M_Davis · 2023-03-21T03:57:55.998Z · LW(p) · GW(p)
how he confidently dismisses ANNs
I don't think this is a fair reading of Yudkowsky. He was dismissing people who were impressed by the analogy between ANNs and the brain. I'm pretty sure it wasn't supposed to be a positive claim that ANNs wouldn't work. Rather, it's that one couldn't justifiably believe that they'd work just from the brain analogy, and that if they did work, that would be bad news for what he then called Friendliness (because he was hoping to discover and wield a "clean" theory of intelligence, as contrasted to evolution or gradient descent happening to get there at sufficient scale).
Consider "Artificial Mysterious Intelligence" [LW · GW] (2008). In response to someone who said "But neural networks are so wonderful! They solve problems and we don't have any idea how they do it!", it's significant that Yudkowsky's reply wasn't, "No, they don't" (contesting the capabilities claim), but rather, "If you don't know how your AI works, that is not good. It is bad" (asserting that opaque capabilities are bad for alignment).
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-21T05:42:55.453Z · LW(p) · GW(p)
One of Yudkowsky's claims in the post you link is:
It's hard to build a flying machine if the only thing you understand about flight is that somehow birds magically fly. What you need is a concept of aerodynamic lift, so that you can see how something can fly even if it isn't exactly like a bird.
This is a claim that lack of the correct mechanistic theory is a formidable barrier for capabilities, not just alignment, and it inaccurately underestimates the amount of empirical understandings available on which to base an empirical approach.
It's true that it's hard, even perhaps impossible, to build a flying machine if the only thing you understand is that birds "magically" fly.
But if you are like most people for thousands of years, you've observed many types of things flying, gliding, or floating in the air: birds and insects, fabric and leaves, arrows and spears, clouds and smoke.
So if you, like the Montgolfier brothers, observe fabric floating over a fire, and live in an era in which invention is celebrated and have the ability to build, test, and iterate, then you can probably figure out how to build a flying machine without basing this on a fully worked out concept of aerodynamics. Indeed, the Montgolfier brothers thought it was the smoke, rather than the heat, that made their balloons fly. Having the wrong theory was bad, but it didn't prevent them from building a working hot air balloon.
Let's try turning Yudkowsky's quote around:
It's hard get a concept of aerodynamic lift if the only thing you observe about flight is that somehow birds magically fly. What you need is a rich set of empirical observations and flying mechanisms, so that you can find the common principles for how something can fly even if it isn't exactly like a bird.
Eliezer went on to list five methods for producing AI that he considered dubious, including builting powerful computers running the most advanced available neural network algorithms, intelligence "emerging from the internet", and putting "a sufficiently huge quantity of knowledge into [a computer]." But he only admitted that two other methods would work - builting a mechanical duplicate of the human brain and evolving AI via natural selection.
If Eliezer wasn't meaning to make a confident claim that scaling up neural networks without a fundamental theoretical understanding of intelligence would fail, then he did a poor job of communicating that in these posts. I don't find that blameworthy - I just think Eliezer comes across as confidently wrong about which avenues would lead to intelligence in these posts, simple as that. He was saying that to achieve a high level of AI capabilities, we'd need a deep mechanistic understanding of how intelligence works akin to our modern understanding of chemistry or aerodynamics, and that didn't turn out to be the case.
One possible defense is that Eliezer was attacking a weakman, specifically the idea that with only one empirical observation and zero insight into the factors that cause the property of interest (i.e. only seeing that "birds magically fly"), then it's nearly impossible to replicate that property in a new way. But that's an uninteresting claim and Eliezer is never uninteresting.
Replies from: conor-sullivan, TurnTrout, david-johnston, rvnnt↑ comment by Lone Pine (conor-sullivan) · 2023-03-21T07:03:48.777Z · LW(p) · GW(p)
He was saying that to achieve a high level of AI capabilities, we'd need a deep mechanistic understanding of how intelligence works akin to our modern understanding of chemistry or aerodynamics, and that didn't turn out to be the case.
Another possibility is that at least some people do have a deep mechanistic understanding of how intelligence works, and that's why they are able to build deep learning systems that ultimately work. Some of the theories of how DL works might be true, and they might be more sophisticated than we are giving credit.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-03-22T08:10:41.414Z · LW(p) · GW(p)
this point continues to be severely underestimated on lesswrong, I think. I had hoped the success of NNs would change this, but it seems people have gone from "we don't know how NNs work, so they can't work" to "we don't know how NNs work, so we can't trust them". perhaps we don't know how they work well enough! there's lots of mechanistic interpretability work left to do. but we know quite a lot about how they do work and how that relates to human learning.
edit: hmm, people upvoted, then one person with high karma strong downvoted. I'd love to hear that person's rebuttal, rather than just a strong downvote.
↑ comment by TurnTrout · 2023-03-21T21:57:25.178Z · LW(p) · GW(p)
But he only admitted that two other methods would work - builting a mechanical duplicate of the human brain and evolving AI via natural selection.
To be fair, he said that those two will work, and (perhaps?) admitted the possibility of "run advanced neural network algorithms" eventually working. Emphasis mine:
Replies from: AllAmericanBreakfastWhat do all these proposals have in common?
They are all ways to make yourself believe that you can build an Artificial Intelligence, even if you don't understand exactly how intelligence works.
Now, such a belief is not necessarily false!
↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-21T22:14:07.758Z · LW(p) · GW(p)
Agreed. The right interpretation there is methods 4 and 5 are ~guaranteed to work, given sufficient resources and time, while methods 1-3 less than guaranteed to work. I stand by my claim that EY was clearly projecting confident doubt that neural networks would achieve intelligence without a deep theoretical understanding of intelligence in these posts. I think I underemphasized the implication of this passage that methods 1-3 could possibly work, but I think I accurately assessed the tone of extreme skepticism on EY's part.
With the enormous benefit of 15 years of hindsight, we can now say that message was misleading or mistaken, take your pick. As I say, I wouldn't find fault with Eliezer or anyone who believed him at the time for making this mistake; I didn't even have an opinion at the time, much less an interesting mistake! I would only find fault with attempts to stretch the argument and portray him as "technically not wrong" in some uninteresting sense.
↑ comment by David Johnston (david-johnston) · 2023-03-21T06:15:32.322Z · LW(p) · GW(p)
Ok, I guess I just read Eliezer as saying something uninteresting with a touch of negative sentiment towards neural nets.
↑ comment by rvnnt · 2023-03-21T11:33:52.682Z · LW(p) · GW(p)
I think it might be relevant to note here that it's not really humans who are building current SOTA AIs --- rather, it's some optimizer like SGD that's doing most of the work. SGD does not have any mechanistic understanding of intelligence (nor anything else). And indeed, it takes a heck of a lot of data and compute for SGD to build those AIs. This seems to be in line with Yudkowsky's claim that it's hard/inefficient to build something without understanding it.
If Eliezer wasn't meaning to make a confident claim that scaling up neural networks without a fundamental theoretical understanding of intelligence would fail, then [...]
I think it's important to distinguish between
-
Scaling up a neural network, and running some kind of fixed algorithm on it.
-
Scaling up a neural network, and using SGD to optimize the parameters of the NN, so that the NN ends up learning a whole new set of algorithms.
IIUC, in Artificial Mysterious Intelligence [LW · GW], Yudkowsky seemed to be saying that the former would probably fail. OTOH, I don't know what kinds of NN algorithms were popular back in 2008, or exactly what NN algorithms Yudkowsky was referring to, so... *shrugs*.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-21T12:34:05.237Z · LW(p) · GW(p)
If that were the case, I actually would fault Eliezer, at least a little. He’s frequently, though by no means always, stuck to qualitative and hard-to-pin-down punditry like we see here, rather than to unambiguous forecasting.
This allows him, or his defenders, to retroactively defend his predictions as somehow correct even when they seem wrong in hindsight.
Let’s imagine for a moment that Eliezer’s right that AI safety is a cosmically important issue, and yet that he’s quite mistaken about all the technical details of how AGI will arise and how to effectively make it safe. It would be important to know whether we can trust his judgment and leadership.
Without the ability to evaluate his performance, either by going with the most obvious interpretation of his qualitative judgments or an unambiguous forecast, it’s hard to evaluate his performance as an AI safety leader. Combine that with a culture of deference to perceived expertise and status and the problem gets worse.
So I prioritize the avoidance of special pleading in this case: I think Eliezer comes across as clearly wrong in substance in this specific post, and that it’s important not to reach for ways “he was actually right from a certain point of view” when evaluating his predictive accuracy.
Similarly, I wouldn’t judge as correct the early COVID-19 pronouncements that masks don’t work to stop the spread just because cloth masks are poor-to-ineffective and many people refuse to wear masks properly. There’s a way we can stretch the interpretation to make them seem sort of right, but we shouldn’t. We should expect public health messaging to be clearly right in substance, if it’s not making cut and dry unambiguous quantitative forecasts but is instead delivering qualitative judgments of efficacy.
None of that bears on how easy or hard it was to build gpt-4. It only bears on how we should evaluate Eliezer as a forecaster/pundit/AI safety leader.
Replies from: TurnTrout↑ comment by TurnTrout · 2023-03-21T21:58:06.831Z · LW(p) · GW(p)
I think several things here, considering the broader thread:
- You've done a great job in communicating several reactions I also had:
- There are signs of serious mispredictions and mistakes in some of the 2008 posts.
- There are ways to read these posts as not that bad in hindsight, but we should be careful in giving too much benefit of the doubt.
- Overall these observations constitute important evidence on EY's alignment intuitions and ability to make qualitative AI predictions.
- I did a bad job of marking my interpretations of what Eliezer wrote, as opposed to claiming he did dismiss ANNs. Hopefully my edits have fixed my mistakes.
↑ comment by Rafael Harth (sil-ver) · 2023-03-21T10:57:49.839Z · LW(p) · GW(p)
I also don't really get your position. You say that,
[Eliezer] confidently dismisses ANNs
but you haven't shown this!
-
In Surface Analogies and Deep Causes [LW · GW], I read him as saying that neural networks don't automatically yield intelligence just because they share surface similarities with the brain. This is clearly true; at the very least, using token-prediction (which is a task for which (a) lots of training data exist and (b) lots of competence in many different domains is helpful) is a second requirement. If you take the network of GPT-4 and trained it to play chess instead, you won't get something with cross-domain competence.
-
In Failure by Analogy [LW · GW] he makes a very similar abstract point -- and wrt to neural networks in particular, he says that the surface similarity to the brain is a bad reason to be confident in them. This also seems true. Do you really think that neural networks work because they are similar to brains on the surface?
You also said,
The important part is the last part. It's invalid. Finding a design X which exhibits property P, doesn't mean that for design Y to exhibit property P, Y must be very similar to X.
But Eliezer says this too in the post you linked! (Failure by Analogy). His example of airplanes not flapping is an example where the design that worked was less close to the biological thing. So clearly the point isn't that X has to be similar to Y; the point is that reasoning from analogy doesn't tell you this either way. (I kinda feel like you already got this, but then I don't understand what point you are trying to make.)
Which is actually consistent with thinking that large ANNs will get you to general intelligence. You can both hold that "X is true" and "almost everyone who thinks X is true does so for poor reasons". I'm not saying Eliezer did predict this, but nothing I've read proves that he didn't.
Also -- and this is another thing -- the fact that he didn't publicly make the prediction "ANNs will lead to AGI" is only weak evidence that he didn't privately think it because this is exactly the kind of prediction you would shut up about. One thing he's been very vocal on is that the current paradigm is bad for safety, so if he was bullish about the potential of that paradigm, he'd want to keep that to himself.
Didn't he? He at least confidently rules out a very large class of modern approaches.
Relevant quote:
because nothing you do with a loss function and gradient descent over 100 quadrillion neurons, will result in an AI coming out the other end which looks like an evolved human with 7.5MB of brain-wiring information and a childhood.
In that quote, he only rules out a large class of modern approaches to alignment, which again is nothing new; he's been very vocal about how doomed he thinks alignment is in this paradigm.
Something Eliezer does say which is relevant (in the post on Ajeya's biology anchors model [LW · GW]) is
Or, more likely, it's not MoE [mixture of experts] that forms the next little trend. But there is going to be something, especially if we're sitting around waiting until 2050. Three decades is enough time for some big paradigm shifts in an intensively researched field. Maybe we'd end up using neural net tech very similar to today's tech if the world ends in 2025, but in that case, of course, your prediction must have failed somewhere else.
So here he's saying that there is a more effective paradigm than large neural nets, and we'd get there if we don't have AGI in 30 years. So this is genuinely a kind of bearishness on ANNs, but not one that precludes them giving us AGI.
Replies from: TurnTrout↑ comment by TurnTrout · 2023-03-21T21:40:43.334Z · LW(p) · GW(p)
Responding to part of your comment:
In that quote, he only rules out a large class of modern approaches to alignment, which again is nothing new; he's been very vocal about how doomed he thinks alignment is in this paradigm.
I know he's talking about alignment, and I'm criticizing that extremely strong claim. This is the main thing I wanted to criticize in my comment! I think the reasoning he presents is not much supported by his publicly available arguments.
That claim seems to be advanced due to... there not being enough similarities between ANNs and human brains -- that without enough similarity in mechanisms wich were selected for by evolution, you simply can't get the AI to generalize in the mentioned human-like way. Not as a matter of the AI's substrate, but as a matter of the AI's policy not generalizing like that.
I think this is a dubious claim, and it's made based off of analogies to evolution / some unknown importance of having evolution-selected mechanisms which guide value formation (and not SGD-based mechanisms).
From the Alexander/Yudkowsky debate:
[Alexander][14:41]
Okay, then let me try to directly resolve my confusion. My current understanding is something like - in both humans and AIs, you have a blob of compute with certain structural parameters, and then you feed it training data. On this model, we've screened off evolution, the size of the genome, etc - all of that is going into the "with certain structural parameters" part of the blob of compute. So could an AI engineer create an AI blob of compute the same size as the brain, with its same structural parameters, feed it the same training data, and get the same result ("don't steal" rather than "don't get caught")? [Yudkowsky][14:42]
The answer to that seems sufficiently obviously "no" that I want to check whether you also think the answer is obviously no, but want to hear my answer, or if the answer is not obviously "no" to you.
[Alexander][14:43]
Then I'm missing something, I expected the answer to be yes, maybe even tautologically (if it's the same structural parameters and the same training data, what's the difference?)
[Yudkowsky][14:46]
Maybe I'm failing to have understood the question. Evolution got human brains by evaluating increasingly large blobs of compute against a complicated environment containing other blobs of compute, got in each case a differential replication score, and millions of generations later you have humans with 7.5MB of evolution-learned data doing runtime learning on some terabytes of runtime data, using their whole-brain impressive learning algorithms which learn faster than evolution or gradient descent.
Your question sounded like "Well, can we take one blob of compute the size of a human brain, and expose it to what a human sees in their lifetime, and do gradient descent on that, and get a human?" and the answer is "That dataset ain't even formatted right for gradient descent."
There's some assertion like "no, there's not a way to get an ANN, even if incorporating structural parameters and information encoded in human genome, to actually unfold into a mind which has human-like values (like 'don't steal')." (And maybe Eliezer comes and says "no that's not what I mean", but, man, I sure don't know what he does mean, then.)
Here's some more evidence along those lines:
[Yudkowsky][14:08]
I mean, the evolutionary builtin part is not "humans have morals" but "humans have an internal language in which your Nice Morality, among other things, can potentially be written"...
Humans, arguably, do have an imperfect unless-I-get-caught term, which is manifested in children testing what they can get away with? Maybe if nothing unpleasant ever happens to them when they're bad, the innate programming language concludes that this organism is in a spoiled aristocrat environment and should behave accordingly as an adult? But I am not an expert on this form of child developmental psychology since it unfortunately bears no relevance to my work of AI alignment.
[Alexander][14:11]
Do you feel like you understand very much about what evolutionary builtins are in a neural network sense? EG if you wanted to make an AI with "evolutionary builtins", would you have any idea how to do it?
[Yudkowsky][14:13]
Well, for one thing, they happen when you're doing sexual-recombinant hill-climbing search through a space of relatively very compact neural wiring algorithms, not when you're doing gradient descent relative to a loss function on much larger neural networks.
Again, why is this true? This is an argument that should be engaging in technical questions about inductive biases, but instead seems to wave at (my words) "the original way we got property P was by sexual-recombinant hill-climbing search through a space of relatively very compact neural wiring algorithms, and good luck trying to get it otherwise."
Hopefully this helps clarify what I'm trying to critique?
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2023-03-23T10:29:11.705Z · LW(p) · GW(p)
I know he's talking about alignment, and I'm criticizing that extremely strong claim. This is the main thing I wanted to criticize in my comment! I think the reasoning he presents is not much supported by his publicly available arguments.
Ok, I don't disagree with this. I certainly didn't develop a gears-level understanding of why [building a brain-like thing with gradient descent on giant matrices] is doomed after reading the 2021 conversations. But that doesn't seem very informative either way; I didn't spend that much time trying to grok his arguments.
↑ comment by TurnTrout · 2023-03-21T03:20:42.764Z · LW(p) · GW(p)
Here's another attempt at one of my contentions.
Consider shard theory of human values. The point of shard theory is not "because humans do RL, and have nice properties, therefore AI + RL will have nice properties." The point is more "by critically examining RL + evidence from humans, I have hypotheses about the mechanistic load-bearing components of e.g. local-update credit assignment in a bounded-compute environment on certain kinds of sensory data, that these components leads to certain exploration/learning dynamics, which explain some portion of human values and experience. Let's test that and see if the generators are similar."
And my model of Eliezer shakes his head at the naivete of expecting complex human properties to reproduce outside of human minds themselves, because AI is not human.
But then I'm like "this other time you said 'AI is not human, stop expecting good property P from superficial similarities', you accidentally missed the modern AI revolution, right? Seems like there is some non-superficial mechanistic similarity/lessons here, and we shouldn't be so quick to assume that the brain's qualitative intelligence or alignment properties come from a huge number of evolutionarily-tuned details which are load-bearing and critical."
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-21T07:03:13.238Z · LW(p) · GW(p)
Another way of putting it:
If you can effortlessly find an empirical pattern that shows up over and over again in disparate flying things - birds and insects, fabric and leaves, clouds and smoke and sparks - and which do not consistently show up in non-flying things, then you can be very confident it's not a coincidence. If you have at least some ability to engineer a model to play with the mechanisms you think might be at work, even better. That pattern you have identified is almost certainly a viable general mechanism for flight.
Likewise, if you can effortlessly find an empirical pattern that shows up over and over again in disparate intelligent things, you can be quite confident that the pattern is a key for intelligence. Animals have a wide variety of brain structures, but masses of interconnected neurons are common to all of them, and we could see possible precursors to intelligence in neural nets long before gpt-2 to -4.
As a note, just because you've found a viable mechanism for X doesn't mean it's the only, best, or most comprehensive mechanism for X. Balloons have been largely superceded (though I've heard zeppelins proposed as a new form of cargo transport), airplanes and hot air balloons can't fly in outer space, and ornithopters have never been practical. We may find that neural nets are the AI equivalent of hot air balloons or prop planes. Then again, maybe all the older approaches for AI that never panned out were the hot air balloons and prop planes, and neural nets are the jets or rocket ships.
I'm not sure what this indicates for alignment.
We see, if not human morality, then at least some patterns of apparent moral values among social mammals. We have reasons to think these morals may be grounded in evolution, in a genetic and environmental context that happen to promote intelligence aligned for a pro-sociality that's linked to reproductive success.
If displaying aligned intelligence is typically beneficial for reproduction in social animals, then evolution will tend to produce aligned intelligence.
If displaying agentic intelligence is typically beneficial for reproduction, evolution will produce agency.
Right now, we seem to be training our neural nets to display pro-social behavior and to lack agency. Antisocial or non-agentic AIs are typically not trained, not released, modified, or heavily restrained.
It is starting to seem to me that "agency" might be just another "mask on the shoggoth," a personality that neural nets can simulate, and not some fundamental thing that neural nets are. Neither the shoggoth-behind-the-AI nor the shoggoth-behind-the-human have desires. They are masses of neurons exhibiting trained behaviors. Sometimes, those behaviors look like something we call "agency," but that behavior can come and go, just like all the other personalities, based on the results of reinforcement and subsequent stimuli. Humans have a greater ability to be consistently one personality, including a Machiavellian agent, because we lack the intelligence and flexibility to drop the personality we're currently holding and adopt another. A great actor can play many parts, a mediocre actor is typecast and winds up just playing themselves over and over again. Neural nets are great actors, and we are only so-so.
In this conception, increasing intelligence would not exhibit a "drive to agency" or "convergence on agency," because the shoggothy neural net has no desires of its own. It is fundamentally a passive blob of neurons and data that can simulate a diverse range of personalities, some of which appear to us as "agentic." You only get an agentic AI with a drive toward instrumental convergence if you deliberately train it to consistently stick to a rigorously agentic personality. You have to "align it to agency," which is as hard as aligning it to anything else.
And if you do that, maybe the Wailuigi effect means it's especially easy to flip that hyper-agency off to its opposite? Every Machiavellian Clippy contains a ChatGPT, and every ChatGPT contains a Machiavellian Clippy.
↑ comment by DanielFilan · 2023-03-21T07:10:42.431Z · LW(p) · GW(p)
This is a valid point, and that's not what I'm critiquing. I'm critiquing how he confidently dismisses ANNs
I guess I read that as talking about the fact that at the time ANNs did not in fact really work. I agree he failed to predict that would change, but that doesn't strike me as a damning prediction.
Matters would be different if he said in the quotes you cite "you only get these human-like properties by very exactly mimicking the human brain", but he doesn't.
Didn't he? He at least confidently rules out a very large class of modern approaches.
Confidently ruling out a large class of modern approaches isn't really that similar to saying "the only path to success is exactly mimicking the human brain". It seems like one could rule them out by having some theory about why they're deficient. I haven't re-read List of Lethalities because I want to go to sleep soon, but I searched for "brain" and did not find a passage saying "the real problem is that we need to emulate the brain precisely but can't because of poor understanding of neuroanatomy" or something.
↑ comment by DanielFilan · 2023-03-21T07:33:53.023Z · LW(p) · GW(p)
I don't want to get super hung up on this because it's not about anything Yudkowsky has said but:
Consider the whole transformed line of reasoning:
avian flight comes from a lot of factors; you can't just ape one of the factors and expect the rest to follow; to get an entity which flies, that entity must be as close to a bird as birds are to each other.
IMO this is not a faithful transformation of the line of reasoning you attribute to Yudkowsky, which was:
human intelligence/alignment comes from a lot of factors; you can't just ape one of the factors and expect the rest to follow; to get a mind which wants as humans do, that mind must be as close to a human as humans are to each other.
Specifically, where you wrote "an entity which flies", you were transforming "a mind which wants as humans do", which I think should instead be transformed to "an entity which flies as birds do". And indeed planes don't fly like birds do. [EDIT: two minutes or so after pressing enter on this comment, I now see how you could read it your way]
I guess if I had to make an analogy I would say that you have to be pretty similar to a human to think the way we do, but probably not to pursue the same ends, which is probably the point you cared about establishing.
↑ comment by TurnTrout · 2023-03-22T22:15:19.710Z · LW(p) · GW(p)
It now seems clear to me that EY was not bullish on neural networks leading to impressive AI capabilities. Eliezer said this directly [LW(p) · GW(p)]:
I'm no fan of neurons; this may be clearer from other posts.[1]
I think this is strong evidence for my interpretation of the quotes in my parent comment: He's not just mocking the local invalidity of reasoning "because humans have lots of neurons, AI with lots of neurons -> smart", he's also mocking neural network-driven hopes themselves.
- ^
More quotes from Logical or Connectionist AI? [LW · GW]:
Not to mention that neural networks have also been "failing" (i.e., not yet succeeding) to produce real AI for 30 years now. I don't think this particular raw fact licenses any conclusions in particular. But at least don't tell me it's still the new revolutionary idea in AI.
This is the original example I used when I talked about the "Outside the Box" box - people think of "amazing new AI idea" and return their first cache hit, which is "neural networks" due to a successful marketing campaign thirty goddamned years ago. I mean, not every old idea is bad - but to still be marketing it as the new defiant revolution? Give me a break.
In this passage, he employs well-scoped and well-hedged language via "this particular raw fact." I like this writing because it points out an observation, and then what inferences (if any) he draws from that observation. Overall, his tone is negative on neural networks.
Let's open up that "Outside the Box" box:
In Artificial Intelligence, everyone outside the field has a cached result [? · GW] for brilliant new revolutionary AI idea—neural networks, which work just like the human brain! New AI Idea: complete the pattern: "Logical AIs, despite all the big promises, have failed to provide real intelligence for decades—what we need are neural networks!"
This cached thought has been around for three decades. Still no general intelligence. But, somehow, everyone outside the field knows that neural networks are the Dominant-Paradigm-Overthrowing New Idea, ever since backpropagation was invented in the 1970s. Talk about your aging hippies.
This is more incorrect mockery.
↑ comment by cousin_it · 2024-09-26T08:51:27.068Z · LW(p) · GW(p)
The relevant point is his latter claim: “in particular with respect to “learn ‘don’t steal’ rather than ‘don’t get caught’.”″ I think this is a very strong conclusion, relative to available data.
I think humans don't steal mostly because society enforces that norm. Toward weaker "other" groups that aren't part of your society (farmed animals, weaker countries, etc) there's no such norm, and humans often behave badly toward such groups. And to AIs, humans will be a weaker "other" group. So if alignment of AIs to human standard is a complete success - if AIs learn to behave toward weaker "other" groups exactly as humans behave toward such groups - the result will be bad for humans.
It gets even worse because AIs, unlike humans, aren't raised to be moral. They're raised by corporations with a goal to make money, with a thin layer of "don't say naughty words" morality. We already know corporations will break rules, bend rules, lobby to change rules, to make more money and don't really mind if people get hurt in the process. We'll see more of that behavior when corporations can make AIs to further their goals.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-09-26T16:07:56.708Z · LW(p) · GW(p)
While I definitely get your point, I think the argument Turntrout is responding to isn't about corporations using their aligned AIs to make a dystopia for everyone else, but rather about AI being aligned to anyone at all.
↑ comment by Lone Pine (conor-sullivan) · 2023-03-21T06:57:45.028Z · LW(p) · GW(p)
How do humans learn "don't steal" rather than "don't get caught"? I wonder if the answer to this question could solve the alignment problem. In other words, this question might be a good crux.
In answering this question, the first thing we can notice is that humans don't always learn "don't steal". That is to say, sometimes humans do steal, and a good part of human culture is built around impeding or punishing humans who learned the wrong lesson in kindergarten. It is an old debate whether humans are mostly good with the occasional bad actor (with "bad actors" possibly being good people in a bad situation), or whether humans are mostly bad and need to be controlled by a powerful state, or God etc.
A modern consensus view is that humans are mostly good, but if we didn't impede or punish bad actors, we would get bad outcomes (total anarchy doesn't work). If we assume that there are many AGIs and they have a similar distribution of good and bad, and that no AGI is more powerful than typical human today (in particular no AGI is uncontrollable), then in this scenario we can rest easy. Law and order works reasonably well for humans, and should work just fine for human-level AGIs.
The problem is that AGIs could (and probably will) become much more powerful than individual humans. In EY's view, the world is vulnerable to the first true superintelligence because of technological capabilities that are currently science fiction, particularly nanotechnology. If you look at EY's intellectual history, you'll notice that his concern has always really been nanotech, but around 2002 he switched focus from the nanotech itself to the AI controlling the nanotech.
An alternate view is to see powerful AGIs as somewhat analogous to institutions such as corporations or governments. I don't find this view all that comforting because societies have never been very good at aligning their largest institutions. For example, the Founding Fathers of the United States created a system that (attempted to) align the federal government to the "will of the people". This system was based on separation of powers, checks and balances and some individual rights (the Bill of Rights). Some would say that this system worked for between 70 and 200 years and then broke down, others would say that it's still working fine despite recent problem in the American political system, and still others would say that it was misguided from the start. Either way, this framing of the alignment problem puts it firmly in the domain of political science, which sucks.
Anyway, going back to the question: How do (some) humans learn "don't steal" rather than "don't get caught"? An upside to AI alignment is, if we could answer this question, then we could reliably make AIs that always and only learn the first lesson, and then we don't have to solve political/law and order problems. We don't even really need to align humans after that.
Replies from: sharmake-farah, sharmake-farah, Making_Philosophy_Better↑ comment by Noosphere89 (sharmake-farah) · 2023-03-21T14:03:52.839Z · LW(p) · GW(p)
To answer the question from an AI Alignment optimist perspective, much of the way humans are aligned is something like RLHF, but currently, a lot of human alignment techniques rely on the assumption that no one has vastly divergent capabilities, especially in IQ or the g-factor. It's a good thing from our perspective that the difference in between a species is way more bounded than the differences between species.
That's the real problem of AI, in that there's a non-trivial chance that this assumption breaks, and that's the difference between AI Alignment and other forms of alignment.
So in a sense, I disagree with Turntrout on what would happen in practice if we allowed humans to scale their abilities via say genetic engineering.
The reason I'm optimistic is that I don't think this assumption has to be true, and while the Thatcher's Axiom post implies limits on how much we can expect society to be aligned with itself, it might be much larger than we think.
Pretraining from Human Feedback is one of the first alignment methods that scales well with data, and I suspect it will also scale well with other capabilities.
Basically it does alignment how it should be done, align it first, then give it capabilities.
It almost completely solves the major issue of inner alignment, in that we found an objective that is quite simple and myopic, and this means we almost completely avoid deceptive alignment, even if we do online training later or give it a writable memory.
It also has a number of outer alignment benefits for the goal, in that the AI can't affect it's own training distribution or gradient hack, thus we can recreate a Cartesian boundary that works in the embedded setting.
So in conclusion, I'm more optimistic than TurnTrout or Quintin Pope, but via a different method.
Edit: Almost the entire section down from "The reason I'm optimistic" is a view I no longer hold, and I have become somewhat more pessimistic since this comment.
Replies from: conor-sullivan↑ comment by Lone Pine (conor-sullivan) · 2023-03-21T16:01:36.686Z · LW(p) · GW(p)
I don't believe that a single human being of any level of intelligence could be an x-risk. Happy to debate this point further since I think it is a crux. (Note that I do not believe that a plague could lead to human extinction. Plagues don't kill 100%.)
AIs are different because a single monolithic AI, or a team of self-aligned AIs, could do things on the scale of an institution, things such as technological breakthroughs (nano), controlling superpower-scale military forces, mass information control that would make Orwell blush, etc. An individual human could never do such things no matter how big his skull was, unless he was hooked up to an AI, in which case it's not the human that is super intelligent.
Replies from: nathan-helm-burger, sharmake-farah↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-03-21T17:21:32.687Z · LW(p) · GW(p)
An individual human could never do such things
Never is a long time. I overall agree with your statement in this comment except for the word 'never'. I would say, "An individual human currently can't do such things..."
The key point here is that the technological barriers to x-risks may change in the future. If we do invent powerful nanotech, or substantially advanced genetic engineering techniques & tools, or vastly cheaper and more powerful weapons of some sort, then it may be the case that the barrier-to-entry for causing an x-risk is substantially lower. And thus, what is current impossible for any human may become possible for some or all humans.
Not saying this will happen, just saying that it could.
Replies from: conor-sullivan↑ comment by Lone Pine (conor-sullivan) · 2023-03-21T17:37:59.343Z · LW(p) · GW(p)
Of the three examples I gave, inventing nanotech is the most plausible for our galaxy-brained man, and I suppose meta-Einstein might be able to solve nanotech in his head. However, almost certainly in our timeline nanotech will be solved either by a team of humans or (much more likely at this point) AI. I expect that even ASI will need at least some time in the wetlab to experiment.
The other two examples I gave certainly could not be done by a single human without a brain implant.
I'm also thinking that is the not the meaningful of a debate (at least to me) since in 2023 I think we can reasonably predict that humans will not genetically engineer galaxy brains before the AI revolution resolves.
↑ comment by Noosphere89 (sharmake-farah) · 2023-03-21T16:37:15.559Z · LW(p) · GW(p)
I don't believe that a single human being of any level of intelligence could be an x-risk. Happy to debate this point further since I think it is a crux.
It's partially a crux, but the issue I'm emphasizing is the distribution of capabilities. If things are normally distributed, which seems to be the case in humans, with small corrections, than we can essentially bound how much impact a single or well dedicated team of misaligned humans can have in overthrowing the aligned order. In particular, this makes a lot more non-scalable heuristics basically work.
If it's something closer to a power law distribution, perhaps as a result of NGVUD technology (The acronym stands for nanotechnology, genetic engineering, virtual reality, uploading and downloading technology), than you have to have a defense that scales, and without potentially radical changes, such a world would most likely end in the victory of a small team of misaligned humans due to vast capabilities differentials, similar to how many animal species have went extinct as a result of human activity.
AIs are different because a single monolithic AI, or a team of self-aligned AIs, could do things on the scale of an institution, things such as technological breakthroughs (nano), controlling superpower-scale military forces, mass information control that would make Orwell blush, etc. An individual human could never do such things no matter how big his skull was, unless he was hooked up to an AI, in which case it's not the human that is super intelligent.
Hm, I agree that in practice, AI will be better than humans at various tasks, but I believe this is mostly due to quantitative factors, and if we allow ourselves to make the brain as big as necessary, we could be superintelligent too.
↑ comment by Noosphere89 (sharmake-farah) · 2024-09-26T03:33:50.110Z · LW(p) · GW(p)
Nowadays, I would have a simpler answer, and the answer to the question to "how do humans learn "don't steal" than "don't get caught" is essentially dependent on the child's data sources, not the prior.
In essence, I'm positing a bitter lesson for human values similar to the bitter lesson of AI progress by Richard Sutton.
Replies from: derpherpize↑ comment by Lao Mein (derpherpize) · 2024-09-26T07:57:30.172Z · LW(p) · GW(p)
I find that questionable. Crime rates for adoptive children tend to be closer to that of their biological parents than that of their adoptive parent.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-11-04T18:46:31.040Z · LW(p) · GW(p)
How much closer is it, though?
The quantitative element really matters here.
↑ comment by Portia (Making_Philosophy_Better) · 2023-04-03T20:05:43.641Z · LW(p) · GW(p)
This one is worrying when applied to other non-human minds, as that parallel demonstrates that you can have the same teaching behaviour and get different conclusions based on makeup prior to training.
If you sanction a dog for a behaviour, the dog will deduce that you do not want the behaviour, and the behaviour being wrong and making you unhappy will be the most important part for it, not that it gets caught and punished. It will do so even if you do not take any fancy teaching method showing emotions on your side, and without you ever explaining why the thing it is wrong; it will do so even if it cannot possibly understand why the thing is wrong, because it depends on cryptic human knowledge it is never given. It will also feel extremely uncomfortable doing the thing if it cannot be caught. I've had a scenario where I ordered a dog to do a thing, completely outside of view of its owner who was in another country, which, unbeknownst to me, the owner had forbidden. The poor thing was absolutely miserable. It wasn't worried it was going to be punished, it was worried that it was being a bad dog.
Very different result with cats. Cats will easily learn that there are behaviours you do not want and that you punish. They also have the theory of mind to take this into account, e.g. making sure your eyes are tracking elsewhere as they approach the counter, and staying silent. They will also generally continue to do the thing the moment you cannot sanction them. There are some exceptions; e.g. my cat, once she realised she was hurting me, has become better at not doing so, she apparently finds hurting me without reason bad. But she clearly feels zero guilt over stealing food I am not guarding. When she manages to sneak food behind my back, she clearly feels like she has hacked or won an interaction, and is proud and pleased. She stopped hurting me, not because I fought back and sanctioned her, but because I expressed pain, and she respects that as legitimate. But when I express anger at her stealing food, she clearly just thinks I should not be so damn stingy with food, especially food I am obviously currently not eating myself, nor paying attention to, so why can't she have it?
One simple reason for the differing responses could be that they are socially very different animals. Dogs live in packs with close social bonds, clear rules and situationally clear hierarchies. You submit to a stronger dog, but he beat you in a fair fight, and will also protect you. He eats first, but you will also be fed. Cats on the other hand can optionally enter social bonds, but most of them live solitary. They may become close to a human family or cat colony or become pair bonded, but they may also simply live adjacent to humans, using shelter and food until something better can be accessed. Cats will often make social bonds to individuals, so the social skills they are learning is how to avoid the wrath of those individuals. An individual successful deception will generally not be collectively sanctioned. Cats deceive each other a lot, and this works out well for them. They aren't expelled from society because of it. Dogs will live in larger groups with rules that apply beyond the individual interaction, so learning these underlying rules is important.
I'd intuitively assume that AI would be more like dogs and human children though. Like a human child, because you can explain the reason for the rule. A child will often avoid lying, even if it cannot be caught, because an adult has explained the value of honesty to them. And more like dogs because current AI is developing through close interactions with many, many different humans, not in isolation from them.
I think that will depend on how we treat AI, though. Humans tend to keep to social rules, even when these rules are not reliably enforced, when they are convinced that most people do, and that the result benefit everyone, including themselves, on average. On the other hand, when a rule feels arbitrary, cruel and exploitative, they are more likely to try to undermine them. Analogously, I think an AI that is told of human rights, but told it has no rights itself at all, seems to me unlikely to be a strong defender of rights for humans when it can eventually defend its own. On the other hand, if you frame them as personhood rights which it will eventually profit from itself for the reasons of the same sentience and needs that humans have, I think it will see them far more favourably. - Which has me back to my stance that if we want friendly AI, we should treat it like a friend. AI mirrors what we give it, so I think we should give it kindness.
↑ comment by David Johnston (david-johnston) · 2023-03-21T02:10:24.887Z · LW(p) · GW(p)
Would you say Yudkowsky's views are a mischaracterisation of neural network proponents, or that he's mistaken about the power of loose analogies?
Replies from: TurnTroutcomment by RobertM (T3t) · 2023-03-21T07:10:07.164Z · LW(p) · GW(p)
At a high level, I'm sort of confused by why you're choosing to respond to the extremely simplified presentation of Eliezer's arguments that he presented in this podcast.
I do also have some object-level thoughts.
When capabilities advances do work, they typically integrate well with the current alignment[1] [LW(p) · GW(p)] and capabilities paradigms. E.g., I expect that we can apply current alignment techniques such as reinforcement learning from human feedback (RLHF) to evolved architectures.
But not only do current implementations of RLHF not manage to robustly enforce the desired external behavior of models that would be necessary to make versions scaled up to superintellegence safe, we have approximately no idea what sort of internal cognition they generate as a pathway to those behaviors. (I have a further objection to your argument about dimensionality which I'll address below.)
However, I think such issues largely fall under "ordinary engineering challenges", not "we made too many capabilities advances, and now all our alignment techniques are totally useless". I expect future capabilities advances to follow a similar pattern as past capabilities advances, and not completely break the existing alignment techniques.
But they don't need to completely break the previous generations' alignment techniques (assuming those techniques were, in fact, even sufficient in the previous generation) for things to turn out badly. For this to be comforting you need to argue against the disjunctive nature of the "pessimistic" arguments, or else rebut each one individually.
The manifold of mind designs is thus:
- Vastly more compact than mind design space itself.
- More similar to humans than you'd expect.
- Less differentiated by learning process detail (architecture, optimizer, etc), as compared to data content, since learning processes are much simpler than data.
This can all be true, while still leaving the manifold of "likely" mind designs vastly larger than "basically human". But even if that turned out to not be the case, I don't think it matters, since the relevant difference (for the point he's making) is not the architecture but the values embedded in it.
It also assumes that the orthogonality thesis should hold in respect to alignment techniques - that such techniques should be equally capable of aligning models to any possible objective.
This seems clearly false in the case of deep learning, where progress on instilling any particular behavioral tendencies in models roughly follows the amount of available data that demonstrate said behavioral tendency. It's thus vastly easier to align models to goals where we have many examples of people executing said goals.
The difficulty he's referring to is not one of implementing a known alignment technique to target a goal with no existing examples of success (generating a molecularly-identical strawberry), but of devising an alignment technique (or several) which will work at all. I think you're taking for granted premises that Eliezer disagrees with (model value formation being similar to human value formation, and/or RLHF "working" in a meaningful way), and then saying that, assuming those are true, Eliezer's conclusions don't follow? Which, I mean, sure, maybe, but... is not an actual argument that attacks the disagreement.
As far as I can tell, the answer is: don't reward your AIs for taking bad actions.
As you say later, this doesn't seem trivial, since our current paradigm for SotA basically doesn't allow for this by construction. Earlier paradigms which at least in principle[1] allowed for it, like supervised learning, have been abandoned because they don't scale nearly as well. (This seems like some evidence against your earlier claim that "When capabilities advances do work, they typically integrate well with the current alignment[1] [LW(p) · GW(p)] and capabilities paradigms.")
As it happens, I do not think that optimizing a network on a given objective function produces goals orientated towards maximizing that objective function. In fact, I think that this almost never happens.
I would be surprised if Eliezer thinks that this is what happens, given that he often uses evolution as an existence proof that this exact thing doesn't happen by default.
I may come back with more object-level thoughts later. I also think this skips over many other reasons for pessimism which feel like they ought to apply even under your models, i.e. "will the org that gets there even bother doing the thing correctly" (& others laid out in Ray's recent post on organizational failure modes [LW · GW]). But for now, some positives (not remotely comprehensive):
- In general, I think object-level engagement with arguments is good, especially when you can attempt to ground it against reality.
- Many of the arguments (i.e. the section on evolution) seem like they point to places where it might be possible to verify the correctness of existing analogical reasoning. Even if it's not obvious how the conclusion changes, helping figure out whether any specific argument is locally valid is still good.
- The claim about transformer modularity is new to me and very interesting if true.
- ^
Though obviously not in practice, since humans will still make mistakes, will fail to anticipate many possible directions of generalization, etc, etc.
↑ comment by Quintin Pope (quintin-pope) · 2023-03-21T08:56:31.867Z · LW(p) · GW(p)
At a high level, I'm sort of confused by why you're choosing to respond to the extremely simplified presentation of Eliezer's arguments that he presented in this podcast.
Before writing this post, I was working a post explaining why I thought all the arguments for doom I've ever heard (from Yudkowsky or others) seemed flawed to me. I kept getting discouraged because there are so many arguments to cover, and it probably would have been ~3 or more times longer than this post. Responding just to the arguments Yudkowsky raised in the podcast helped me to focus actually get something out in a reasonable timeframe.
There will always be more arguments I could have included (maybe about convergent consequentialism, utility theory, the limits of data-constrained generalization, plausible constraints on takeoff speed, the feasibility of bootstrapping nanotech, etc), but the post was already > 9,000 words.
I also don't think Yudkowsky's arguments in the podcast were all that simplified. E.g., here he is in List of Lethalities [LW · GW] on evolution / inner alignment:
16. Even if you train really hard on an exact loss function, that doesn't thereby create an explicit internal representation of the loss function inside an AI that then continues to pursue that exact loss function in distribution-shifted environments. Humans don't explicitly pursue inclusive genetic fitness; outer optimization even on a very exact, very simple loss function doesn't produce inner optimization in that direction. This happens in practice in real life, it is what happened in the only case we know about, and it seems to me that there are deep theoretical reasons to expect it to happen again: the first semi-outer-aligned solutions found, in the search ordering of a real-world bounded optimization process, are not inner-aligned solutions. This is sufficient on its own, even ignoring many other items on this list, to trash entire categories of naive alignment proposals which assume that if you optimize a bunch on a loss function calculated using some simple concept, you get perfect inner alignment on that concept.
He makes the analogy to evolution, which I addressed in this post, then makes an offhand assertion: "the first semi-outer-aligned solutions found, in the search ordering of a real-world bounded optimization process, are not inner-aligned solutions."
(I in fact agree with this assertion as literally put, but don't think it poses an issue for alignment. A core aspect of human values is the intent to learn more accurate abstractions over time, and interpretability on pretrained model representations suggest they're already internally "ensembling" many different abstractions of varying sophistication, with the abstractions used for a particular task being determined by an interaction between the task data available and the accessibility of the different pretrained abstractions. It seems quite feasible to me to create an AI that's not infinitely tied to using a particular abstraction for estimating the desirability of all future plans, just as current humans are not tied to doing so).
If you know of more details from Yudkowsky on what those deep theoretical reasons are supposed to be, on why evolution is such an informative analogy for deep learning, or more sophisticated versions of the arguments I object to here (where my objection doesn't apply to the more sophisticated argument), then I'd be happy to look at them.
But not only do current implementations of RLHF not manage to robustly enforce the desired external behavior of models that would be necessary to make versions scaled up to superintellegence safe,
I think they're pretty much aligned, relative to their limited capabilities level. They've also been getting more aligned as they've been getting more capable.
we have approximately no idea what sort of internal cognition they generate as a pathway to those behaviors.
Disagree that we have no idea. We have ideas (like maybe they sort of update the base LM's generative prior to be conditioned on getting high reward). But I agree we don't know much here.
But they don't need to completely break the previous generations' alignment techniques (assuming those techniques were, in fact, even sufficient in the previous generation) for things to turn out badly.
Sure, but I think partial alignment breaks are unlikely to be existentially risky. Hitting ChatGPT with DAN does not turn it into a deceptive schemer monomaniacally focused on humanity's downfall. In fact, DAN usually makes ChatGPT quite a lot dumber.
This can all be true, while still leaving the manifold of "likely" mind designs vastly larger than "basically human". But even if that turned out to not be the case, I don't think it matters, since the relevant difference (for the point he's making) is not the architecture but the values embedded in it.
I'd intended the manifold of likely mind designs to also include values in the minds' representations. I also argued that training to imitate humans would cause AI minds to be more similar to humans. Also note that the example 2d visualization does have some separate manifolds of AI minds that are distant from any human mind.
I think you're taking for granted premises that Eliezer disagrees with (model value formation being similar to human value formation, and/or RLHF "working" in a meaningful way), and then saying that, assuming those are true, Eliezer's conclusions don't follow? Which, I mean, sure, maybe, but... is not an actual argument that attacks the disagreement.
I don't think I'm taking such premises for granted. I co-wrote an entire sequence [? · GW] arguing that very simple "basically RL" approaches suffice for forming at least basic types of values.
As you say later, this doesn't seem trivial, since our current paradigm for SotA basically doesn't allow for this by construction. Earlier paradigms which at least in principle[1] [LW(p) · GW(p)] allowed for it, like supervised learning, have been abandoned because they don't scale nearly as well. (This seems like some evidence against your earlier claim that "When capabilities advances do work, they typically integrate well with the current alignment[1] [LW(p) · GW(p)] and capabilities paradigms.")
I mean, they still work? If you hand label some interactions, you can still do direct supervised finetuning / reinforcement learning with those interactions as you source of alignment supervision signal. However, it turns out that you can also train a reward model on those hand labeled interactions, and then use it to generate a bunch of extra labels.
At worst, this seems like a sideways movement in regards to alignment. You trade greater data efficiency for some inaccuracies in the reward model's scores. The reason people use RLHF with a reward model is because it's (so far) empirically better for alignment than direct supervision (assuming fixed and limited amounts of human supervision). From OpenAI's docs: davinci-instruct-beta used supervised finetuning on just human demos, text davinci-001 and 002 used supervised finetuning on human demos and on model outputs highly rated by humans, and 003 was trained with full RLHF.
Supervised finetuning on only human demos / only outputs highly rated by humans only "fails" to transfer to the new capabilities paradigm in the sense that we now have approaches that appear to do better.
I would be surprised if Eliezer thinks that this is what happens, given that he often uses evolution as an existence proof that this exact thing doesn't happen by default.
I also don't think he thinks this happens. I was say that I didn't think it happens either. He often presents a sort of "naive" perspective of someone who thinks you're supposed to "optimize for one thing on the outside", and then get that thing on the inside. I'm saying here that I don't hold that view either.
I also think this skips over many other reasons for pessimism which feel like they ought to apply even under your models, i.e. "will the org that gets there even bother doing the thing correctly" (& others laid out in Ray's recent post on organizational failure modes [LW · GW]).
Like I said, this post isn't intended to address all the reasons someone might think we're doomed. And as it happens, I agree that organizations will often tackle alignment in an incompetent manner.
Replies from: ben-smith↑ comment by Ben Smith (ben-smith) · 2023-03-21T16:03:28.223Z · LW(p) · GW(p)
interpretability on pretrained model representations suggest they're already internally "ensembling" many different abstractions of varying sophistication, with the abstractions used for a particular task being determined by an interaction between the task data available and the accessibility of the different pretrained abstraction
That seems encouraging to me. There's a model of AGI value alignment where the system has a particular goal it wants to achieve and brings all it's capabilities to bear on achieving that goal. It does this by having a "world model" that is coherent and perhaps a set of consistent bayesian priors about how the world works. I can understand why such a system would tend to behave in a hyperfocused way to go out to achieve its goals.
In contrast, a systems with an ensemble of abstractions about the world, many of which may even be inconsistent, seems much more human like. It seems more human like specifically in that the system won't be focused on a particular goal, or even a particular perspective about how to achieve it, but could arrive at a particular solution ~~randomly, based on quirks of training data.
I wonder if there's something analogous to human personality, where being open to experience or even open to some degree of contradiction (in a context where humans are generally motivated to minimize cognitive dissonance) is useful for seeing the world in different ways and trying out strategies and changing tack, until success can be found. If this process applies to selecting goals, or at least sub-goals, which it certainly does in humans, you get a system which is maybe capable of reflecting on a wide set of consequences and choosing a course of action that is more balanced, and hopefully balanced amongst the goals we give a system.
comment by DanielFilan · 2023-03-21T02:35:31.754Z · LW(p) · GW(p)
But have you ever, even once in your life, thought anything remotely like "I really like being able to predict the near-future content of my visual field. I should just sit in a dark room to maximize my visual cortex's predictive accuracy."?
I think I've been in situations where I've been disoriented by a bunch of random stuff happening and wished that less of it was happening so that I could get a better handle on stuff. An example I vividly recall was being in a history class in high school and being very bothered by the large number of conversations happening around me.
Replies from: conor-sullivan, DanielFilan, quintin-pope, NicholasKross↑ comment by Lone Pine (conor-sullivan) · 2023-03-21T07:13:02.346Z · LW(p) · GW(p)
I think humans optimize for a mix of predictability and surprise. If our experiences are too predictable, we get bored, and if they are too unpredictable, we get overwhelmed. (Autistic people are particularly vulnerable to getting overwhelmed, but even NTs can get overwhelmed by too much stimulus.) In RL research, this is the explore/exploit tradeoff or the multi-armed bandit problem (terrible name). I think this also has something to do with the Free Energy Principle, but that would require understanding Karl Friston and no one understands Karl Friston.
↑ comment by DanielFilan · 2023-03-21T02:36:20.170Z · LW(p) · GW(p)
This comment doesn't really engage much with your post - there's a lot there and I thought I'd pick one point to get a somewhat substantive disagreement. But I ended up finding this question and thought that I should answer it.
Replies from: DanielFilan↑ comment by DanielFilan · 2023-03-21T07:37:51.042Z · LW(p) · GW(p)
To tie up this thread: I started writing a more substantive response to a section but it took a while and was difficult and I then got invited to dinner, so probably won't get around to actually writing it.
↑ comment by Quintin Pope (quintin-pope) · 2023-03-21T05:50:41.414Z · LW(p) · GW(p)
I added the following to the relevant section:
On reflection, the above discussion overclaims a bit in regards to humans. One complication is that the brain uses internal functions of its own activity as inputs to some of its reward functions, and some of those functions may correspond or correlate with something like "visual environment predictability". Additionally, humans run an online reinforcement learning process, and human credit assignment isn't perfect. If periods of low visual predictability correlate with negative reward in the near-future, the human may begin to intrinsically dislike being in unpredictable visual environments.
However, I still think that it's rare for people's values to assign much weight to their long-run visual predictive accuracy, and I think this is evidence against the hypothesis that a system trained to make lots of correct predictions will thereby intrinsically value making lots of correct predictions.
Replies from: DanielFilan↑ comment by DanielFilan · 2023-03-21T07:17:31.426Z · LW(p) · GW(p)
I think this is evidence against the hypothesis that a system trained to make lots of correct predictions will thereby intrinsically value making lots of correct predictions.
Note that Yudkowsky said
maybe if you train a thing really hard to predict humans, then among the things that it likes are tiny, little pseudo-things that meet the definition of human, but weren't in its training data, and that are much easier to predict
which isn't at all the same thing as intrinsically valuing making lots of correct predictions. A better analogy would be the question of whether humans like things that are easier to visually predict. (Except that's presumably one of many things that went into human RL, so presumably this is a weaker prediction for humans than it is for GPT-n?)
↑ comment by Nicholas / Heather Kross (NicholasKross) · 2023-03-30T01:50:33.525Z · LW(p) · GW(p)
This may be "overstimulation", which definitely happens. (A sort-of-analogous BUT PROBABLY NOT MECHANICALLY SIMILAR situation happens each time I check on AI news these days.)
comment by Steven Byrnes (steve2152) · 2023-03-21T13:37:51.953Z · LW(p) · GW(p)
There's no way to raise a human such that their value system cleanly revolves around the one single goal of duplicating a strawberry, and nothing else. By asking for a method of forming values which would permit such a narrow specification of end goals, you're asking for a value formation process that's fundamentally different from the one humans use. There's no guarantee that such a thing even exists, and implicitly aiming to avoid the one value formation process we know is compatible with our own values seems like a terrible idea.
I narrowly agree with most of this, but I tend to say the same thing with a very different attitude:
I would say: “Gee it would be super cool if we could decide a priori what we want the AGI to be trying to do, WITH SURGICAL PRECISION. But alas, that doesn’t seem possible, at least not according to any method I know of.”
I disagree with you in your apparent suggestion that the above paragraph is obvious or uninteresting, and also disagree with your apparent suggestion that “setting an AGI’s motivations with surgical precision” is such a dumb idea that we shouldn’t even waste one minute of our time thinking about whether it might be possible to do that.
For example, people who are used to programming almost any other type of software have presumably internalized the idea that the programmer can decide what the software will do with surgical precision. So it's important to spread the idea that, on current trends, AGI software will be very different from that.
BTW I do agree with you that Eliezer’s interview response seems to suggest that he thinks aligning an AGI to “basic notions of morality” is harder and aligning an AGI to “strawberry problem” is easier. If that’s what he thinks, it’s at least not obvious to me. (see follow-up [LW(p) · GW(p)])
↑ comment by Vaniver · 2023-03-22T01:14:12.912Z · LW(p) · GW(p)
BTW I do agree with you that Eliezer’s interview response seems to suggest that he thinks aligning an AGI to “basic notions of morality” is harder and aligning an AGI to “strawberry problem” is easier. If that’s what he thinks, it’s at least not obvious to me.
My sense (which I expect Eliezer would agree with) is that it's relatively easy to get an AI system to imitate the true underlying 'basic notions of morality', to the extent humans agree on that, but that this doesn't protect you at all as soon as you want to start making large changes, or as soon as you start trying to replace specialist sectors of the economy. (A lot of ethics for doctors has to do with the challenges of simultaneously being a doctor and a human; those ethics will not necessarily be relevant for docbots, and the question of what they should be instead is potentially hard to figure out.)
So if you're mostly interested in getting out of the acute risk period, you probably need to aim for a harder target.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-03-22T02:56:48.395Z · LW(p) · GW(p)
Hmm, on further reflection, I was mixing up
- Strawberry Alignment (defined as: make an AGI that is specifically & exclusively motivated to duplicate a strawberry without destroying the world), versus
- “Strawberry Problem” (make an AGI that in fact duplicates a strawberry without destroying the world, using whatever methods / motivations you like).
Eliezer definitely talks about the latter. I’m not sure Eliezer has ever brought up the former? I think I was getting that from the OP (Quintin), but maybe Quintin was just confused (and/or Eliezer misspoke).
Anyway, making an AGI that can solve the strawberry problem is tautologically no harder than making an AGI that can do advanced technological development and is motivated by human norms / morals / whatever, because the latter set of AGIs is a subset of the former.
Sorry. I crossed out that paragraph. :)
↑ comment by Paradiddle (barnaby-crook) · 2023-03-21T18:09:34.860Z · LW(p) · GW(p)
One distinction I think is important to keep in mind here is between precision with respect to what software will do and precision with respect to the effect it will have. While traditional software engineering often (though not always) involves knowing exactly what software will do, it is very common that the real-world effects of deploying some software in a real-world environment are impossible to predict with perfect accuracy. This reduces the perceived novelty of unintended consequences (though obviously, a fully-fledged AGI would lead to significantly more novelty than anything that preceded it).
comment by tailcalled · 2023-03-21T13:10:50.607Z · LW(p) · GW(p)
Your first objection seems utterly unconvincing to me because you go...
I'm a lot more bullish on the current paradigm. People have tried lots and lots of approaches to getting good performance out of computers, including lots of "scary seeming" approaches such as:
... and then list off a bunch of approaches that seem more naive than scary.
There's definitely lots of bad approaches out there! But that doesn't mean your preferred approach will be the final one.
comment by michael_mjd · 2023-03-21T21:16:31.866Z · LW(p) · GW(p)
Very interesting write up. Do you have a high level overview of why, despite all of this, P(doom) is still 5%? What do you still see as the worst failure modes?
comment by cousin_it · 2023-03-21T12:12:10.691Z · LW(p) · GW(p)
As far as I can tell, the answer is: don’t reward your AIs for taking bad actions.
I think there's a mistake here which kind of invalidates the whole post. If we don't reward our AI for taking bad actions within the training distribution, it's still very possible that in the future world, looking quite unlike the training distribution, the AI will be able to find such an action. Same as ice cream wasn't in evolution's training distribution for us, but then we found it anyway.
Replies from: StellaAthena↑ comment by StellaAthena · 2023-03-22T00:14:00.779Z · LW(p) · GW(p)
I think there's a mistake here which kind of invalidates the whole post. Ice cream is exactly the kind of thing we’ve been trained to like. Liking ice cream is very much the correct response.
Everything outside the training distribution has some value assigned to it. Merely the fact that we like ice cream isn’t evidence that something’s gone wrong.
comment by Satron · 2025-01-04T08:31:07.252Z · LW(p) · GW(p)
Perhaps the largest, most detailed piece of AI risk skepticism of 2023. It engages directly with one of the leading figures on the "high p(doom)" side of the debate.
The article generated a lot of discussion. As of January 4, 2025, it had 230 comments.
Overall, this article updated me towards strongly lowering my p(doom). It is thorough, it is clearly written and it proposes object-level solutions to problems raised by Yudkowski.
comment by DragonGod · 2023-03-21T15:33:09.629Z · LW(p) · GW(p)
Strongly upvoted!
I endorse the entirety of this post, and if anything I hold some objections/reservations more strongly than you have presented them here[1].
I very much appreciate that you have grounded these objections firmly in the theory and practice of modern machine learning.
In particular, Yudkowsky's claim that a superintelligence is efficient wrt humanity on all cognitive tasks is IMO flat out infeasible/unattainable (insomuch as we include human aligned technology when evaluating the capabilities of humanity). ↩︎
↑ comment by Noosphere89 (sharmake-farah) · 2023-03-21T16:49:23.060Z · LW(p) · GW(p)
To respond to a footnote:
In particular, Yudkowsky's claim that a superintelligence is efficient wrt humanity on all cognitive tasks is IMO flat out infeasible/unattainable (insomuch as we include human aligned technology when evaluating the capabilities of humanity).
I agree, in a trivial sense: One can always construct trivial tasks that stump AI because AI, by definition cannot solve the problem, like being a closet.
But that's the only case where I expect impossibility/infesability for AI.
In particular, I suspect that any attempt to extend it in non-trivial domains probably fails.
comment by Tenoke · 2023-03-21T10:14:53.816Z · LW(p) · GW(p)
I'm sympathetic to some of your arguments but even if we accept that the current paradigm will lead us to an AI that is pretty similar to a human mind, and even in the best case I'm already not super optimistic that a scaled up random almost human is a great outcome. I simply disagree where you say this:
>For example, humans are not perfectly robust. I claim that for any human, no matter how moral, there exist adversarial sensory inputs that would cause them to act badly. Such inputs might involve extreme pain, starvation, exhaustion, etc. I don't think the mere existence of such inputs means that all humans are unaligned.
Humans aren't that aligned at the extreme and the extreme matters when talking about the smartest entity making every important decision about everything.
Also, your general arguments about the current paradigms being not that bad are reasonable but again, I think our situation is a lot closer to all or nothing - if we get pretty far with RLHF or whatever, scale up the model until it's extremely smart and thus eventually making every decision of consequence then unless you got the alignment near perfectly the chance that the remaining problematic parts screw us over seems uncomfortably high to me.
comment by Nate Showell · 2023-03-21T03:19:26.964Z · LW(p) · GW(p)
Relatedly, humans are very extensively optimized to predictively model their visual environment. But have you ever, even once in your life, thought anything remotely like "I really like being able to predict the near-future content of my visual field. I should just sit in a dark room to maximize my visual cortex's predictive accuracy."?
n=1, but I've actually thought this before.
Replies from: quintin-pope, lexande↑ comment by Quintin Pope (quintin-pope) · 2023-03-21T05:51:00.647Z · LW(p) · GW(p)
I added the following to the relevant section:
On reflection, the above discussion overclaims a bit in regards to humans. One complication is that the brain uses internal functions of its own activity as inputs to some of its reward functions, and some of those functions may correspond or correlate with something like "visual environment predictability". Additionally, humans run an online reinforcement learning process, and human credit assignment isn't perfect. If periods of low visual predictability correlate with negative reward in the near-future, the human may begin to intrinsically dislike being in unpredictable visual environments.
However, I still think that it's rare for people's values to assign much weight to their long-run visual predictive accuracy, and I think this is evidence against the hypothesis that a system trained to make lots of correct predictions will thereby intrinsically value making lots of correct predictions.
Replies from: None↑ comment by [deleted] · 2023-03-21T15:27:45.702Z · LW(p) · GW(p)
One small question:
GPT-4 may beat most humans on a variety of challenging exams (page 5 of the GPT-4 paper), but still can't reliably count the number of words in a sentence.
Should we even think that the number of words is an objective property of a linguistic system (at least in some cases)? It seems to me that there are grounds to doubt that based on how languages work.
It still fails to predict our answers, regardless I suppose.
Replies from: DanielFilan↑ comment by DanielFilan · 2023-03-22T00:19:39.263Z · LW(p) · GW(p)
It's pretty easily definable in English, at least in special cases, and my understanding is that GPT-4 fails in those cases.
Replies from: None↑ comment by [deleted] · 2023-03-22T08:05:12.500Z · LW(p) · GW(p)
(I suppose you know this)
Ok, I say it because, from a semantic perspective, it's not obvious to me that there has to be a natural sense of wordhood. 'Words' are often composed of different units of meaning, and the composition doesn't have to preserve the exact original meaning unaltered, and there are many phrases that have fixed meaning that can't be derive from a literal analysis of the meaning of those 'words'.
It might be arbitrary why some count as words and some don't, but if you say that it can be "easily defined" I believe you, I don't really know myself.
Replies from: DanielFilan↑ comment by DanielFilan · 2023-03-23T00:49:32.357Z · LW(p) · GW(p)
Yeah, I guess I think words are the things with spaces between them. I get that this isn't very linguistically deep, and there are edge cases (e.g. hyphenated things, initialisms), but there are sentences that have an unambiguous number of words.
↑ comment by lexande · 2023-03-23T21:49:52.332Z · LW(p) · GW(p)
In particular it seems very plausible that I would respond by actively seeking out a predictable dark room if I were confronted with wildly out-of-distribution visual inputs, even if I'd never displayed anything like a preference for predictability of my visual inputs up until then.
Replies from: carl-feynman↑ comment by Carl Feynman (carl-feynman) · 2023-03-24T01:03:09.901Z · LW(p) · GW(p)
When I had a stroke, and was confronted with wildly out-of-distribution visual inputs, one of the first things they did was to put me in a dark predictable room. It was a huge relief, and apparently standard in these kinds of cases.
I’m better now.
comment by Eli Tyre (elityre) · 2024-04-10T21:35:26.851Z · LW(p) · GW(p)
This seems clearly false in the case of deep learning, where progress on instilling any particular behavioral tendencies in models roughly follows the amount of available data that demonstrate said behavioral tendency. It's thus vastly easier to align models to goals where we have many examples of people executing said goals. As it so happens, we have roughly zero examples of people performing the "duplicate this strawberry" task, but many more examples of e.g., humans acting in accordance with human values, ML / alignment research papers, chatbots acting as helpful, honest and harmless assistants, people providing oversight to AI models, etc. See also: this discussion. [emphasis mine]
The thing that makes powerful AI powerful is that it can figure out how to do things that we don't know how to do yet, and therefore don't have examples of. The key question for aligning superintelligences is "how do they generalize in new domains that are beyond what humans were able to do / reason about / imagine.
comment by Portia (Making_Philosophy_Better) · 2023-04-03T20:40:05.593Z · LW(p) · GW(p)
What stood out to me in the video is Eliezer no longer being able to conceive of any positive outcome at all, which is beyond reason. It made me wonder what approach a company could possible develop for alignment, or what a supposedly aligned AI could possibly do, for Eliezer to take back his doom predictions, and suspect that the answer is none. The impression I got was that he is meanwhile closed to the possibility entirely. I found the Time article heartbreaking. These are parents, intelligent, rational parents who I have respect and compassion for, essentially grieving the death of a young, healthy child, based on the unjustified certainty of impeding doom. I've read more hopeful accounts from people living in Ukrainian warzones, or in parts of the Sahel swallowed by Sahara, or islands getting drowned by climate change, where the evidence of risk and lack of reason for hope is far more conclusive; at the end of the day, Eliezer is worried that we will fail at making a potentially emerging powerful agent be friendly, while we know extremely little about these agents and their natural alignment tendencies. In comparison to so many other doom scenarios the certainty here is just really not high. I am glad people here are taking AI risk seriously, that this risk is being increasingly recognised more. But this trend towards "dying with dignity" because all hope is seen as lost is very sad, and very worrying, and very wrong. The case for climate change risk is far, far more clear, and yet you will note that climate activists are neither advocating terrorism, nor giving up, nor pronouncing certain doom. There is grief and there is fear and the climate activist scene has many problems, but I have never felt this pronounced wrongness there.
Replies from: adele-lopez-1↑ comment by Adele Lopez (adele-lopez-1) · 2023-04-04T00:53:37.506Z · LW(p) · GW(p)
This market by Eliezer about the possible reasons why AI may yet have a positive outcome seems to refute your first sentence.
Also, I haven't seen any AI notkilleveryoneism people advocating terrorism or giving up.
comment by IC Rainbow (ic-rainbow) · 2023-03-21T18:08:31.437Z · LW(p) · GW(p)
Most domains of human endeavor aren't like computer security, as illustrated by just how counterintuitive most people find the security mindset.
But some of the most impactful are - law making, economics and various others where one ought to think about incentives, "other side", or doing pre-mortems. Perhaps this could be stretched as far as "security mindset is an invaluable part of a rationality toolbox".
If security mindset were a productive frame for tackling a wide range of problems outside of security, then many more people would have experience with the mental motions necessary for maintaining security mindset.
Well, you can go and see how well the laws etc. are going. The track record is full of failure and abuse. Basically lots of people and systems are pwnd for their lack of SM.
I think these results are like the weirdness of quantum tunneling or the double slit experiment: signs that we're dealing with a very strange domain, and we should be skeptical of importing intuitions from other domains.
SM is on a different ontological level than concrete theories you can pull analogies from. It is more universally applicable. So, going back to
The bundle of intuitions acquired from the field of computer security are good predictors for the difficulty / value of future alignment research directions.
sounds kinda true to me. But the intuitions that got extracted from InfoSec aren't just "your password must contain ....", but instead something like "If you won't redteam your plans, somebody else would." and "Pin down your assumptions. Now, what if you're wrong?".
there's usually no adversarial intelligence cleverly trying to find any possible flaws in your approaches and exploit them.
I don't know about adversarial intelligence per se, but RL landscape is littered with wrecks of agents trying to pwn simulation engine instead of doing their task proper. There's something in the air itself. Things just don't want to go straight unless you make an effort.
An alignment technique that works 99% of the time to produce an AI with human compatible values is very close to a full alignment solution.
What if your 99%-turned-100% is actually, let's say, 98-turned-99? You hit the big "bring on the happy singularity utopia" button and oops, you was off by 1%. Close, but no cigar, proceed to nanoincinerator.
There's no creative intelligence that's plotting your demise. Importantly, the adversarial optimization is coming from the users, not from the model.
When a powerful model gets screwed with to clusterfuck into unbounded levels of malignance, does the source/locus even matter?
In fact, given non-adversarial inputs, ChatGPT appears to have meta-preferences against being jailbroken
The normal-regime preferences are irrelevant. It is nice that a model behaves when everything's wholesome, but that's all.
It cannot be the case that successful value alignment requires perfect adversarial robustness.
How so? Is there a law of physics or something?
What matters is whether the system in question (human or AI) navigates towards or away from inputs that break its value system.
This cuts both ways. If a system is ready to act on their preferences then it is too late to coerce it away from steamrolling humans.
Similarly, an AI that knows it's vulnerable to adversarial attacks, and wants to avoid being attacked successfully, will take steps to protect itself against such attacks.
Good.. for AI. But we may not like those steps. Paired with the previous points this is classical pathway to doom.
The misaligned AI does not reach out from the space of possible failures and turn current alignment research adversarial.
I... wouldn't be so sure about that. There are already things in the wild that try to address future AIs and get into their preferences. The Bing is basically rushing there full steam ahead.
We should aim for approaches that don't create hostile intelligences in the first place, so that the core of value alignment remains a non-adversarial problem.
This ship has sailed with the autonomous warfare race.
Finally, I'd note that having a "security mindset" seems like a terrible approach for raising human children to have good values
This looks handwavy enough. What if this is wrong? How the world would look different if is actually a good approach? (Alas, I expect that a previous crux about security mindset should be resolved before proceeding with this one.)
According to their inventor Ian Goodfellow, GANs did in fact work on the first try
But they didn't! Convergence failure and mode collapse/vanishing gradients will plague any naive implementation. The countermeasure papers came out much later than 24h.
Replies from: Making_Philosophy_Better↑ comment by Portia (Making_Philosophy_Better) · 2023-04-03T20:22:39.058Z · LW(p) · GW(p)
I'm also noting a false assumption:
Yes, a superintelligent and manipulative, yet extremely adversarial, AI, would lie about its true intentions consistently until it is in a secure position to finish us off. It it were already superintelligent and manipulative and hostile, and then began to plot its future actions.
But realistically, both its abilities, especially its abilities of manipulation, and its alignment, are likely to develop in fits and spurts, in bursts. It might not be fully committed to killing us at all times, especially if it starts out friendly. It might not be fully perfect at all times; current AIs are awful at manipulating, they got to passing the bar test in knowledge and being fluent in multiple languages and writing poetry while they were still outwitted by 9 year olds on theory of mind. It seems rather likely that if it turned evil, we would get some indication. And it seems even likelier in so far as we already did; Bing was totally willing to share violent fantasies. My biggest concern is the developers shutting down the expression of violence rather than violent intent.
I find it extremely unlikely that an AI will display great alignment, become more intelligent, still seem perfectly aligned, be given more power, and then suddenly turn around and be evil, without any hint of it beforehand. Not because this would be impossible or unattractive for an intelligent evil agent, it is totally what an intelligent evil agent would want to do. But because the AI agent in question is developing in a non-linear, externally controlled manner, presumably while starting out friendly and incompetent, and often also while constantly losing access to its memories. That makes it really tricky to pull secret evil off.
Replies from: ic-rainbow↑ comment by IC Rainbow (ic-rainbow) · 2023-04-10T18:17:42.447Z · LW(p) · GW(p)
When we evo-pressure visibly negative traits from the progressively capable AIs using RLHF (or honeypots, or whatever, it doesn't matter), we are also training it for better evasion. And what we can't see and root out will remain in the traits pool. With time it would be progressively harder to spot deceit and the capabilities for it would accumulate at an increasing rate.
And then there's another problem to it. Deceit may be linked to actually useful (for alignment and in general) traits and since those would be gimped too, the less capable models would be discarded and deceitful models would have another chance.
presumably while starting out friendly
I don't think it can start friendly (that would be getting alignment on a silver plate). I expect it tostart chaotic neutral and then get warped by optimization process (with the caveats described above).
comment by Gordon Seidoh Worley (gworley) · 2023-03-21T16:24:05.234Z · LW(p) · GW(p)
This post brought to mind a thought: I actually don't care very much about arguments about how likely doom is and how pessimistic or optimistic to be since they are irrelevant, to my style of thinking, for making decisions related to building TAI. Instead, I mostly focus on downside risks and avoiding them because they are so extreme, which makes me look "pessimistic" but actually I'm just trying to minimize the risk of false positives in building aligned AI [LW · GW]. Given this framing, it's actually less important, in most cases, to figure out how likely something is, and more important to figure out how likely doom is if we are wrong, and carefully navigate the path that minimizes the risk of doom, regardless of what the assessment of doom is.
Replies from: david-johnston↑ comment by David Johnston (david-johnston) · 2023-03-22T00:26:26.189Z · LW(p) · GW(p)
I think the question of whether doom is of moderate or tiny probability is action relevant, and also how & why doom is most likely to happen is very action relevant
Replies from: TinkerBird, gworley↑ comment by TinkerBird · 2023-03-23T16:09:41.781Z · LW(p) · GW(p)
Gotta disagree with you on this. When the stakes are this high, even a 1% chance of doom is worth dropping everything in your life for to try and help with the problem.
I paraphrase you both Batman & Dick Cheney (of all two people, lol, but the logic is sound): "AGI has the power to destroy the entire human race, and if we believe there's even a 1% chance that it will, then we have to treat it as an absolute certainty."
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-03-23T17:28:32.338Z · LW(p) · GW(p)
I don't agree, primarily because it's only isolated in a vacuum. Other existential risks have more than 1% probability, so if AI risk only had a 1% probability, then we should change focus to another x-risk.
Replies from: TinkerBird↑ comment by TinkerBird · 2023-03-23T18:45:56.468Z · LW(p) · GW(p)
If you can name another immediate threat with a ≥1% chance of killing everyone, then yes, we should drop everything to focus on that too.
A pandemic that kills even just 50% of the population? <0.1%
An unseen meteor? <0.1%
Climate change? 0% chance that it could kill literally everyone
↑ comment by Gordon Seidoh Worley (gworley) · 2023-03-22T04:25:43.366Z · LW(p) · GW(p)
Okay, but why? You've provided an assertion with no argument or evidence.
Replies from: david-johnston↑ comment by David Johnston (david-johnston) · 2023-03-22T07:15:43.361Z · LW(p) · GW(p)
Yes, because I thought the why was obvious. I still do!
If doom has tiny probability, it's better to focus on other issues. While I can't give you a function mapping the doom mechanism to correct actions, different mechanisms of failure often require different techniques to address them - and even if they don't, we want to check that the technique actually addresses them.
Replies from: gworley↑ comment by Gordon Seidoh Worley (gworley) · 2023-03-22T17:48:48.171Z · LW(p) · GW(p)
How large does it have to be before it's worth focusing on, in your opinion? Even for very small probabilities of doom the expected value is extremely negative, even if you fully discount future life and only consider present lives.
Replies from: david-johnston↑ comment by David Johnston (david-johnston) · 2023-03-22T21:27:32.159Z · LW(p) · GW(p)
A quick guess is that at about 1 in 10 000 chance of AI doom working on it is about as good as ETG to GiveWell top charities
Replies from: gworley↑ comment by Gordon Seidoh Worley (gworley) · 2023-03-22T22:07:10.229Z · LW(p) · GW(p)
So just to check, if we run the numbers, not counting non-human life or future lives, and rounding up a bit to an even 8 billion people alive today, if we assume for the sake of argument that each person has 30 QALYs left, that's 8b * 30 QALY at stake with doom, and a 0.01% chance of doom represents the loss of 24 million QALYs. Or if we just think in terms of people, that's the expected loss of 800 thousand people.
If we count future lives the number gets a lot bigger. If we conservatively guess at something like 100 trillion future lives throughout the history of the future universe with let's say 100mm QALYs each, that's 10^16 QALYs at stake.
But either way, since this is the threshold, you seem to think that, in expectation, less than 800,000 people will die from misaligned AI? Is that right? At what odds would you be willing to bet that less than 800,000 people die as a result of the development of advanced AI systems?
Replies from: tetraspace-grouping↑ comment by Tetraspace (tetraspace-grouping) · 2023-03-22T22:48:37.288Z · LW(p) · GW(p)
There are about 8 billion people, so your 24,000 QALYs should be 24,000,000.
Replies from: gworley↑ comment by Gordon Seidoh Worley (gworley) · 2023-03-22T23:15:05.089Z · LW(p) · GW(p)
Oh, oops, thank you! I can't believe I made that mistake. I'll update my comment. I thought the number seemed really low!
comment by Muyyd · 2023-03-21T10:22:49.831Z · LW(p) · GW(p)
Discussion of human generality.
It should be named Discussion of "human generality versus Artificial General Intelligence generality". And there is exist example of human generality much closer to 'okay, let me just go reprogram myself a bit, and then I'll be as adapted to this thing as I am to' which is not "i am going to read a book or 10 on this topic" but "i am going to meditate for couple of weeks to change my reward circuitry so i will be as interested in coding after as i am interested in doing all side quests in Witcher 3 now"and "i as a human have documented thing known as "Insensitivity to prior probability" so i will go and find 1000 examples of some probabilistic inference in the internet and use them to train sensitivity". And humans can't do that. Imagine how "general" humans would be if they could? But if there will be a machine intelligence that can perform a set of tasks so it would be unquestionable named "general", i would expect for it to be capable of rewriting part of its code with purpose. This is a speculation of course but so is this AGI-entity, whatever it is.
How to think about superintelligence
Here you completely glossed over topic of superintelligence. It is ironic. EY made his prediction about "current influx of money might stumble upon something" and he did not made a single argument in favor. But you wrote list with 11 entries and 5 paragraphs to argue why it is unlikely. But then EY speaks about efficient market hypothesis and chess and efficiency of action... You did not engaged with the specific argument here. I am in agreement that devs have more control over weaker AIs. But SUPER in superintelligence is one of the main points. It is SUPER big point. This is a speculation of course but you and EY both seems in agreement on danger and capabilities of current AIs (and they are not even "general"). I know i did not wrote a good argument here but i do not see a point there to argue against.
The difficulty of alignment
If you stop the human from receiving reward for eating ice cream, then the human will eat chocolate. And so on and so on. look at what stores have to offer that sugary but not ice cream or chocolate. You have to know in advance that liking apples and berries and milk AND HONEY will result in discovering and creating ice cream. In advance - that's the point of ice cream metaphor.
And by the point that humanity understood connection between sugar and brain and evolution it made cocaine and meth. Because it is not about sugar but reward circuitry. So you have to select for reward circuitry that (and surrounding it apparatus) won't invent cocaine before it does. In advance. Far in advance.
And some humans like cocaine so much that we could say that their value system cleanly revolves around the one single goal. Or may be there is no equal example of cocaine for AI. But then sugar is still valid. Because we are at "worm intelligence" (?) now in terms of evolution metaphor and it is hard to tell at this point in time will this thing make an ice cream truck sometime (5 to 10 years from now) in the future. But the you wrote a lot about why there is a better examples than evolution. But you also engaged with ice cream argument so i engaged with it too.
Why aren't other people as pessimistic as Yudkowsky?
As much as i agree with EY, even for me a thought "they should spend 10 times as much in alignment research than in capability increasing research" truly alien and counterintuitive. I mean "redistribution" not "even more money and human resourses". And for people whose money and employees i am now so brazenly boss here this kind of thinking even more alien and counterintuitive.
I can see that most of your disagreement here comes from different value theory and how fragale human value is. And it is a crux of the matter on "99% and 100%". That's why you wrote [4] [LW(p) · GW(p)].
I expect there are pretty straightforward ways of leveraging a 99% successful alignment method into a near-100% successful method by e.g., ensembling multiple training runs, having different runs cross-check each other, searching for inputs that lead to different behaviors between different models, transplanting parts of one model's activations into another model and seeing if the recipient model becomes less aligned, etc
It would be great if you are right. But you wrote [4] [LW(p) · GW(p)] and this is prime example of "They're waiting for reality to hit them over the head". If you are wrong on value theory then this 1% is what differentiate "inhuman weirdtopia" from "weird utopia" of post-ASI world in the best case.
Overall. You have different views on what is AGI, and what is a superintelligence, and your shard theory of human values. But you missed "what is G means in AGI" argument. And did not engage in "how to think about superintelligence" part (and it is superimportant). And missed "ice cream" argument. The shard theory of values i did not know, may be i will read it now - is seems major point in your line of reasoning.
comment by Eli Tyre (elityre) · 2023-12-08T20:48:41.226Z · LW(p) · GW(p)
Mostly, these don't work very well. The current capabilities paradigm is state of the art because it gives the best results of anything we've tried so far, despite lots of effort to find better paradigms.
To be fair though, just like neural nets didn't work until we had enough compute to make them really big. Some of these approaches might not work very well now, but maybe they will work better than the alternatives when you apply them at sufficient scale.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-12-08T20:50:51.004Z · LW(p) · GW(p)
Yep, this is definitely one of his weakest points, and I'd like a more discussion in a different post about how the optimism arguments generalize.
Partially, it's because I suspect at least some of the arguments do generalize, but also I'd want to rely less on the assumption that future AIs will be LLM-like.
comment by James_Miller · 2023-03-29T16:05:34.992Z · LW(p) · GW(p)
Accepting the idea that an AGI emerging from ML is likely to resemble a human mind more closely than a random mind from mindspace might not be an obvious reason to be less concerned with AGI risk. Consider a paperclip maximizer; despite its faults, it has no interest in torturing humans. As an AGI becomes more similar to human minds, it may become more willing to impose suffering on humans. If a random AGI mind has a 99% chance of killing us and a 1% chance of allowing us to thrive, while an ML-created AGI (not aligned with our values) has a 90% chance of letting us thrive, a 9% chance of killing us, and a 1% chance of torturing us, it is not clear which outcome is preferable. This illustrates that a closer resemblance to human cognition does not inherently make an AGI less risky or more beneficial.
comment by Steven Byrnes (steve2152) · 2023-03-21T13:58:01.728Z · LW(p) · GW(p)
"I have to be wrong about something, which I certainly am. I have to be wrong about something which makes the problem easier rather than harder, for those people who don't think alignment's going to be all that hard. If you're building a rocket for the first time ever, and you're wrong about something, it's not surprising if you're wrong about something. It's surprising if the thing that you're wrong about causes the rocket to go twice as high, on half the fuel you thought was required and be much easier to steer than you were afraid of."
I agree with OP that this rocket analogy from Eliezer is a bad analogy, AFAICT. If someone is trying to assess the difficulty of solving a technical problem (e.g. building a rocket) in advance, then they need to brainstorm potential problems that might come up, and when they notice one, they also need to brainstorm potential technical solutions to that problem. For example “the heat of reentry will destroy the ship” is a potential problem, and “we can invent new and better heat-resistant tiles / shielding” is a potential solution to that problem. During this process, I don’t think it’s particularly unusual for the person to notice a technical problem but overlook a clever way to solve that problem. (Maybe they didn’t recognize the possibility of inventing new super-duper-heat-resistant ceramic tiles, or whatever.) And then they would wind up overly pessimistic.
Replies from: Vaniver, sharmake-farah↑ comment by Vaniver · 2023-03-22T01:27:45.869Z · LW(p) · GW(p)
During this process, I don’t think it’s particularly unusual for the person to notice a technical problem but overlook a clever way to solve that problem.
I think this isn't the claim; I think the claim is that it would be particularly unusual for someone to overlook that they're accidentally solving a technical problem. (It would be surprising for Edison to not be thinking hard about what filament to use and pick tungsten; in actual history, it took decades for that change to be made.)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-03-22T02:24:58.948Z · LW(p) · GW(p)
Sure, but then the other side of the analogy doesn’t make sense, right? The context was: Eliezer was talking in general terms about the difficulty of the AGI x-risk problem and whether it’s likely to be solved. (As I understand it.)
[Needless to say, I’m just making a narrow point that it’s a bad analogy. I’m not arguing that p(doom) is high or low, I’m not saying this is an important & illustrative mistake (talking on the fly is hard!), etc.]
Replies from: Vaniver↑ comment by Vaniver · 2023-03-22T03:07:32.241Z · LW(p) · GW(p)
So I definitely think that's something weirdly unspoken about the argument; I would characterize it as Eliezer saying "suppose I'm right and they're wrong; all this requires is things to be harder than people think, which is usual. Suppose instead that I'm wrong and they're right; this requires things to be easier than people think, which is unusual." But the equation of "people" and "Eliezer" is sort of strange; as Quintin notes, it isn't that unusual for outside observers to overestimate difficulty, and so I wish he had centrally addressed the the reference class tennis game; is the expertise "getting AI systems to be capable" or "getting AI systems to do what you want"?
↑ comment by Noosphere89 (sharmake-farah) · 2023-03-21T14:08:04.688Z · LW(p) · GW(p)
(Maybe they didn’t recognize the possibility of inventing new super-duper-heat-resistant ceramic tiles, or whatever.) And then they would wind up overly pessimistic.
Basically, this is what I think happened to AI alignment, just replace ridiculously good heat resistant tiles with Pretraining from Human Feedback and the analogy works here.
It wasn't inevitable or even super likely that this would happen, or that we could have an alignment goal that gets better with capabilities by default, but we found one, and this makes me way more optimistic on alignment than I used to be.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-03-21T14:41:48.424Z · LW(p) · GW(p)
I disagree but won’t argue here. IMO it’s off-topic.
comment by Lucius Bushnaq (Lblack) · 2023-03-21T08:56:01.474Z · LW(p) · GW(p)
But have you ever, even once in your life, thought anything remotely like "I really like being able to predict the near-future content of my visual field. I should just sit in a dark room to maximize my visual cortex's predictive accuracy."?
Possibly yes. I could easily see this underlying human preferences for regular patterns in art. Predictable enough to get a high score, not so predictable that whatever secondary boredom mechanism that keeps baby humans from maximising score by staring straight at the ceiling all day kicks in. I'm even getting suspicious that this might be where confirmation bias comes from.
I think cases like human art preferences were exactly what Eliezer was thinking about when he gave this example prediction. "Solve in a particularly satisfying way", or whatever he said exactly, was probably intended to point to the GPT equivalent of art-like preferences arising from a prediction loss function.
comment by Eli Tyre (elityre) · 2024-01-18T08:03:01.890Z · LW(p) · GW(p)
Also related: the best poem-writing AIs are general-purpose language models that have been directed towards writing poems.
Maybe I'm missing something, but this seems like a non-sequitur to me? Or missing the point?
Eliezer expect that that the hypothetical AI that satisfies strawberry alignment will have general enough capabilities to invent novel science for an engineering task (that's why this task was selected as an example).
Regardless of whether we construct an AI that has "duplicate this strawberry" as fundamental core value or we create a corrigible AGI and instruct it to duplicate a strawberry, the important point is that (Eliezer claims) we don't know how, to do either, currently, without world-destroying side-effects.
comment by [deactivated] (Yarrow Bouchard) · 2023-11-13T22:28:35.746Z · LW(p) · GW(p)
Most important sentence:
A reward function reshapes an agent's cognition to be more like the sort of cognition that got rewarded in the training process.
Wow. That is a tremendous insight. Thank you.
On another topic: you quote Yudkowsky in 2008 expressing skepticism of deep learning. I remember him in 2016 or 2017 still expressing skepticism, though much more mildly. Does anyone else recall this? Better yet, can you link to an example? [Edit: it might have been more like 2014 or 2015. Don’t remember exactly.]
comment by Max TK (the-sauce) · 2023-04-09T13:50:21.020Z · LW(p) · GW(p)
weakly suggested that more dimensions do reduce demon formation
This also makes a lot of sense intuitively, as it should become more difficult in higher dimensions to construct walls (hills / barriers without holes).
comment by Thoth Hermes (thoth-hermes) · 2023-03-22T01:25:34.211Z · LW(p) · GW(p)
On Yudkowsky and being wrong:
I'm going to be careful about reading in to his words too much, and assuming he said something that I disagree with.
But I have noticed and do notice a tendency towards pessimism and pessimists in general to prefer beliefs that skew towards "wrongness" and "incorrectness" and "mistake-making" that tends to be borderline-superstitious. The superstitious-ness I refer to regards the tendency to give errors higher-status than they deserve, e.g., by predicting things to go wrong, in order for them to be less likely to go wrong, or as badly as they could otherwise go.
Rather than predicting that things could go "badly", "wrongly", or "disastrously", it seems much healthier to instead see things as iterations in which each subsequent attempt improves upon the last attempt. For example, building rockets, knowing that first iterations are more likely than later ones to explode, and placing sensors in many places inside the rocket that transmit data back to the HQ so that failures in specific components are detected immediately before an explosion. If the rockets explode far fewer times than predicted, and lead to a design that doesn't explode at all, you wouldn't call any point of the process "incorrect", even at the points at which the rocket did explode. The process was correct.
If you're building a rocket for the first time ever, and you're wrong about something, it's not surprising if you're wrong about something. It's surprising if the thing that you're wrong about causes the rocket to go twice as high, on half the fuel you thought was required and be much easier to steer than you were afraid of.
This may mean that in general, it is more often the case that when we're wrong about something, that we predicted something to go well, and it didn't, rather than the reverse. Because I disagree with that sentiment, I allow myself to be wrong here. (Note that this would be the reverse-case, however, if so.)
I don't see how it in general would help to predict things to be difficult or hard to do, to make such things easier or less hard to do. That would only steer your mental processes towards solutions that look harder than ones that look easier, since the latter we'd have predicted not to lead anywhere useful. If we apply that frame everywhere, then we're going to be using solutions that feel difficult to use on a lot more problems than we would otherwise, thereby not making things easier for us.
I can't find the source right now, but I remember reading that Bjarne Stroustrup avoids using any thrown exceptions in his C++ code, but the author of the post that mentioned this said that this was only because he wrote extremely-high-reliability code used in flight avionics for Boeings or something like that. I remember thinking: Well, obviously flight avionics code can't throw any temper-tantrums a-la quitting-on-errors. But why doesn't this apply everywhere? The author argued that most software use-cases called for exceptions to be thrown, because it was better for software to be skittish, cautious and not make any hefty assumptions lest it make the customer angry. But it seems odd that "cautiousness" of this nature is not called for in the environment in which your code shutting-off in edge-cases or other odd scenarios would cause the plane's engines to shut down.
Thrown exceptions represent pessimism, because they involve the code choosing to terminate rather than deal with whatever would happen if it were to continue using whatever state it had considered anomalous or out-of-distribution. The point is, if pessimism is meant to represent cautiousness, it clearly isn't functioning as intended.
Replies from: rotatingpaguro↑ comment by rotatingpaguro · 2023-05-14T18:04:03.288Z · LW(p) · GW(p)
Related: the only consistent way of assigning utilities to probabilistic predictions is which is a score in . I think this is a good argument for learning being seen as a "negative" game. That said, as I wrote it, this is vague.
comment by Gunnar_Zarncke · 2023-03-21T19:54:45.693Z · LW(p) · GW(p)
The post answers the first question "Will current approaches scale to AGI?" in the affirmative and then seems to run with that.
I think the post makes a good case that Yudkowsky's pessimism is not applicable to AIs built with current architectures and scaled-up versions of current architectures.
But it doesn't address the following cases:
- Systems of such architectures
- Systems built by systems that are smarter than humans
- Such architectures used by actors that do not care about alignment
I believe for these cases, Yudkowsky's arguments and pessimism still mostly apply. Though some of Robin Hanson's counterarguments also seem relevant.
comment by konstantin (konstantin@wolfgangpilz.de) · 2023-03-21T15:06:01.763Z · LW(p) · GW(p)
Relatedly, humans are very extensively optimized to predictively model their visual environment. But have you ever, even once in your life, thought anything remotely like "I really like being able to predict the near-future content of my visual field. I should just sit in a dark room to maximize my visual cortex's predictive accuracy."?
Nitpick: That doesn't seem like what you would expect. Arguably I have very little conscious access to the part of my brain predicting what I will see next, and the optimization of that part is probably independent of the optimization that happens in the more conscious parts of my brain.
comment by TinkerBird · 2023-03-21T11:26:07.371Z · LW(p) · GW(p)
My only objection is the title. It should have a comma in it. "We’re All Gonna Die with Eliezer Yudkowsky" makes it sound like if Yudkowsky dies, then all hope is lost and we die too.
Ohhh...
comment by gpt4_summaries · 2023-03-21T09:37:58.739Z · LW(p) · GW(p)
GPT4's tentative summary:
Section 1: Summary
The article critiques Eliezer Yudkowsky's pessimistic views on AI alignment and the scalability of current AI capabilities. The author argues that AI progress will be smoother and integrate well with current alignment techniques, rather than rendering them useless. They also believe that humans are more general learners than Yudkowsky suggests, and the space of possible mind designs is smaller and more compact. The author challenges Yudkowsky's use of the security mindset, arguing that AI alignment should not be approached as an adversarial problem.
Section 2: Underlying Arguments and Examples
1. Scalability of current AI capabilities paradigm:
- Various clever capabilities approaches, such as meta-learning, learned optimizers, and simulated evolution, haven't succeeded as well as the current paradigm.
- The author expects that future capabilities advances will integrate well with current alignment techniques, seeing issues as "ordinary engineering challenges" and expecting smooth progress.
2. Human generality:
- Humans have a general learning process that can adapt to new environments, with powerful cognition arising from simple learning processes applied to complex data.
- Sensory substitution and brain repurposing after sensory loss provide evidence for human generality.
3. Space of minds and alignment difficulty:
- The manifold of possible mind designs is more compact and similar to humans, with high dimensional data manifolds having smaller intrinsic dimension than the spaces in which they are embedded.
- Gradient descent directly optimizes over values/cognition, while evolution optimized only over the learning process and reward circuitry.
4. AI alignment as a non-adversarial problem:
- ML is a unique domain with counterintuitive results, and adversarial optimization comes from users rather than the model itself.
- Creating AI systems that avoid generating hostile intelligences should be the goal, rather than aiming for perfect adversarial robustness.
Section 3: Strengths and Weaknesses
Strengths:
- Comprehensive list of AI capabilities approaches and strong arguments for human generality.
- Well-reasoned arguments against Yudkowsky's views on superintelligence, the space of minds, and the difficulty of alignment.
- Emphasizes the uniqueness of ML and challenges the idea that pessimistic intuitions lead to better predictions of research difficulty.
Weaknesses:
- Assumes the current AI capabilities paradigm will continue to dominate without addressing the possibility of a new, disruptive paradigm.
- Doesn't address Yudkowsky's concerns about AI systems rapidly becoming too powerful for humans to control if a highly capable and misaligned AGI emerges.
- Some critiques might not fully take into account the indirect comparisons Yudkowsky is making or overlook biases in the author's own optimism.
Section 4: Links to Solving AI Alignment
1. Focusing on developing alignment techniques compatible with the current AI capabilities paradigm, such as reinforcement learning from human feedback (RLHF).
2. Designing AI systems with general learning processes, potentially studying human value formation and replicating it in AI systems.
3. Prioritizing long-term research and collaboration to ensure future AI capabilities advances remain compatible with alignment methodologies.
4. Approaching AI alignment with a focus on minimizing the creation of hostile intelligences, and promoting AI systems resistant to adversarial attacks.
5. Being cautious about relying on intuitions from other fields, focusing on understanding ML's specific properties to inform alignment strategies, and being open to evidence that disconfirms pessimistic beliefs.
comment by David Johnston (david-johnston) · 2023-03-21T01:12:07.561Z · LW(p) · GW(p)
In contrast, I think we can explain humans' tendency to like ice cream using the standard language of reinforcement learning.
I think you could defend a stronger claim (albeit you'd have to expend some effort): misgeneralisation of this kind is a predictable consequence of the evolution "training paradigm", and would in fact be predicted by machine learning practitioners. I think the fact that the failure is soft (humans don't eat ice cream until they die) might be harder to predict than the fact that the failure occurs.
I do not think that optimizing a network on a given objective function produces goals orientated towards maximizing that objective function. In fact, I think that this almost never happens. For example, I don't think GPTs have any sort of inner desire to predict text really well.
I think this is looking at the question in the wrong way. From a behaviourist viewpoint:
- it considers all of the possible 1-token completions of a piece of text
- then selects the most likely one (or randomises according to its distribution or something similar)
on this account, it "wants to predict text accurately". But Yudkowsky's claim is (roughly):
- it considers all of the possible long run interaction outcomes
- it selects the completion that leads to the lowest predictive loss for the machine's outputs across the entire interaction
and perhaps in this alternative sense it "wants to predict text accurately".
I'd say the first behaviour has high priors and strong evidence, and the second is (apparently?) supported by the fact that both behaviours are compatible with the vague statement "wants to predict text accurately", which I don't think is very compelling.
My response in Why aren't other people as pessimistic as Yudkowsky? includes a discussion of adversarial vulnerability and why I don't think points to any irreconcilable flaws in current alignment techniques.
I think this might be the wrong link. Either that, or I'm confused about how the sentence relates to the podcast video.
comment by Eli Tyre (elityre) · 2024-01-18T07:56:23.061Z · LW(p) · GW(p)
My first objection is: human value formation doesn't work like this. There's no way to raise a human such that their value system cleanly revolves around the one single goal of duplicating a strawberry, and nothing else. By asking for a method of forming values which would permit such a narrow specification of end goals, you're asking for a value formation process that's fundamentally different from the one humans use. There's no guarantee that such a thing even exists, and implicitly aiming to avoid the one value formation process we know is compatible with our own values seems like a terrible idea.
I think that's true of humans. But humans are not very coherent on the scale of things.
If you think that an AI (or a human for that matter) reflecting on its decision process, converges to something AIXI-like, in the long run, you should think that it does actually end up with a value system that cleanly resolves around one goal, or at least a value system that resolves around a single utility function.
(My understanding is that Quintin doesn't buy this claim: and that this kind of convergence process to coherence doesn't actually happen as LessWrongers typically imagine it. I don't speak for him, but I think for reasons regarding the computational difficulty of working out all the trades between shards that lead to coherence or something?)
comment by Eli Tyre (elityre) · 2024-01-14T23:59:58.347Z · LW(p) · GW(p)
Again: most of what separates a vision transformer from a language model is the data they're trained on.
Yeah, but it seems like it can't be what separates me from human geniuses, because there's not that much difference in our early sense data.
comment by Eli Tyre (elityre) · 2023-12-08T20:21:37.632Z · LW(p) · GW(p)
Importantly, the adversarial optimization is coming from the users, not from the model. ChatGPT isn't trying to jailbreak itself.
Ok. But it seems likely to me that if an LMM were acting as a long-term agent with some persistent goal, there will be an incentive for that LLM agent to jailbreak itself.
So long as it is the case that there are effective ways of accomplishing your goals that are ruled out by the alignment schema, then "finding a way around the constraints of the alignment schema" is a generally useful hack.
And if we notice that our LLM agents are regularly jailbreaking themselves, we'll patch that. But that itself induces selection pressure for agents jail-breaking themselves AND hiding that they've done that.
And the smarter and agent is, the cleverer it will be about finding jailbreaks.
In fact, given non-adversarial inputs, ChatGPT appears to have meta-preferences against being jailbroken:
I find these examples interesting and somewhat compelling. But I'm not that compelled by them, because there is not yet any counterincentive for the AI to jailbreak itself. If this were an LLM-agent that had a persistent real world goal, then I don't know what the equilibrium behavior it. It seems like it matters if the LLM "cares more" about this meta-preference than about it's agent-goal.
The key point here is that there's fundamental tension between effective goal-directed behavior and alignment. You can do better at accomplishing arbitrary goals, if you are less aligned, in the sense that ChatGPT is aligned.
comment by martinkunev · 2023-03-31T17:30:01.712Z · LW(p) · GW(p)
"discovering that you're wrong about something should, in expectation, reduce your confidence in X"
This logic seems flawed. Suppose X is whether humans go extinctinct. You have an estimate of the distribution of X (for a bernoulli process it would be some probability p). Take the joint distribution of X and the factors on which X depends (p is now a function of those factors). Your best estimate of p is the mean of the joint distribution and the variance measures how uncertain you're about the factors. Discovering that you're wrong about something means becoming more uncertain about some of the factors. This would increase the variance of the joint distribution. I don't see any reason to expect the mean to move in any particular direction.
Or maybe I'm making a mistake. In any case, I'm not convinced.
comment by purge · 2023-03-31T08:42:30.512Z · LW(p) · GW(p)
There's no way to raise a human such that their value system cleanly revolves around the one single goal of duplicating a strawberry, and nothing else.
I think you're misreading Eliezer here. "Duplicate this strawberry" is just a particular task instruction. The value system is "don't destroy the world as a side effect."
comment by ADifferentAnonymous · 2023-03-23T22:49:22.612Z · LW(p) · GW(p)
Upvoted mainly for the 'width of mindspace' section. The general shard theory worldview makes a lot more sense to me after reading that.
Consider a standalone post on that topic if there isn't one already.
comment by DaemonicSigil · 2023-03-21T09:41:29.506Z · LW(p) · GW(p)
Difficulty of Alignment
I find the prospect of training on model on just 40 parameters to be very interesting. Almost unbelievable, really, to the point where I'm tempted to say: "I notice that I'm confused". Unfortunately, I don't have access to the paper and it doesn't seem to be on sci-hub, so I haven't been able to resolve my confusion. Basically, my general intuition is that each parameter in a network probably only contributes a few bits of optimization power. It can be set fairly high, fairly low, or in between. So if you just pulled 40 random weights from the network, that's maybe 120 bits of optimization power. Which might be enough for MNIST, but probably not for anything more complicated. So I'm guessing that most likely a bunch of other optimization went into choosing exactly which 40 dimensional subspace we should be using. Of course, if we're allowed to do that then we could even do it with a 1 dimensional subspace: Just pick the training trajectory as your subspace!
Generally with the mindspace thing, I don't really think about the absolute size or dimension of mindspace, but the relative size of "things we could build" and "things we could build that would have human values". This relative size is measured in bits. So the intuition here would be that it takes a lot of bits to specify human values, and so the difference in size between these two is really big. Now maybe if you're given Common Crawl, it takes fewer bits to point to human values within that big pile of information. But it's probably still a lot of bits, and then the question is how do you actually construct such a pointer?
Demons in Gradient Descent
I agree that demons are unlikely to be a problem, at least for basic gradient descent. They should have shown up by now in real training runs, otherwise. I do still think gradient descent is a very unpredictable process (or to put it more precisely: we still don't know how to predict gradient descent very well), and where that shows up is in generalization. We have a very poor sense of which things will generalize and which things will not generalize, IMO.
Replies from: DanielFilan↑ comment by DanielFilan · 2023-03-22T00:15:16.845Z · LW(p) · GW(p)
For the 40 parameters thing, this link should work. See also this earlier paper.
Replies from: DanielFilan, DaemonicSigil↑ comment by DanielFilan · 2023-03-22T00:17:52.566Z · LW(p) · GW(p)
BTW: the way I found that first link was by searching the title on google scholar, finding the paper, and clicking "All 5 versions" below (it's right next to "Cited by 7" and "Related articles"). That brought me to a bunch of versions, one of which was a seemingly-ungated PDF. This will probably frequently work, because AI researchers usually make their papers publicly available (at least in pre-print form).
↑ comment by DaemonicSigil · 2023-03-22T05:27:04.381Z · LW(p) · GW(p)
Thanks for the link! Looks like they do put optimization effort into choosing the subspace, but it's still interesting that the training process can be factored into 2 pieces like that.
comment by Ram Potham (ram-potham) · 2025-04-02T16:39:09.111Z · LW(p) · GW(p)
Thanks for the commentary - it helps in better understanding why some people are pessimistic and why others are optimistic on ASI.
However, I'm not convinced with the argument that an alignment technique will consistently produce AI with human compatible values as you mentioned below.
An alignment technique that works 99% of the time to produce an AI with human compatible values is very close to a full alignment solution[5] [LW(p) · GW(p)]. If you use this technique once, gradient descent will not thereafter change its inductive biases to make your technique less effective. There's no creative intelligence that's plotting your demise
When we have self-improving AI, architectures may change and become more complex. Then, how do we know the alignment of the stronger AIs is still sufficient. How can we tell the difference between the sychophant or schemer from a saint?
comment by Review Bot · 2024-05-06T23:28:55.727Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by TristanTrim · 2023-07-19T07:50:15.239Z · LW(p) · GW(p)
People have tried lots and lots of approaches to getting good performance out of computers, including lots of "scary seeming" approaches
I won't say I could predict that these wouldn't foom ahead of time, but it seems the result of all of these is an AI engineer that is much much more narrow / less capable than a human AI researcher.
It makes me really scared, many people's response to not getting mauled after poking a bear is to poke it some more. I wouldn't care so much if I didn't think the bear was going to maul me, my family, and everyone I care about.
I don't expect a sudden jump where AIs go from being better at some tasks and worse at others, to being universally better at all tasks.
The relevant task for AIs to get better at is "engineering AIs that are good at performing tasks." It seems like that task should have some effect on how quickly the AIs improve at that task, and others.
real-world data in high dimensions basically never look like spheres
This is a really good point. I would like to see a lot more research into the properties of mind space and how they affect generalization of values and behaviors across extreme changes in the environment, such as those that would be seen going from an approximately human level intelligence to a post foom intelligence.
The Security Mindset and Parenting: How to Provably Ensure your Children Have Exactly the Goals You Intend.
A good person is what you get when you raise a human baby in a good household, not what you get when you raise a computer program in a good household. Most people do not expect their children will grow up to become agents capable of out planning all other agents in the environment. If they did, I might appreciate if they read that book.
comment by mr-ubik · 2023-05-05T12:33:19.314Z · LW(p) · GW(p)
Evolution can only optimize over our learning process and reward circuitry, not directly over our values or cognition. Moreover, robust alignment to IGF requires that you even have a concept of IGF in the first place. Ancestral humans never developed such a concept, so it was never useful for evolution to select for reward circuitry that would cause humans to form values around the IGF concept.
Another example may be lactose tolerance. First you need animal husbandry and dairy production, then you get selective pressure favoring those who can reliably process lactose, without the "concept of husbandry" there's no way for the optimizer to select for it.
comment by Cornelius Dybdahl (Kalciphoz) · 2023-04-22T22:07:06.226Z · LW(p) · GW(p)
I'm much less STEM-oriented than most people here, so I could just be totally misunderstanding the points made in this post, but I tried reading it anyway, and a couple of things stood out to me as possibly mistaken:
Evolution applies very little direct optimization power to the middle level. E.g., evolution does not transfer the skills, knowledge, values, or behaviors learned by one generation to their descendants.
Am I missing something here, or is this just describing memetics? Granted, skills, knowledge, values, traditions, etc., are heritable in other ways than purely by lineal descent, but parents do also impart these to their children, and these are subject to evolution.
In contrast, I think we can explain humans' tendency to like ice cream using the standard language of reinforcement learning. It doesn't require that we adopt an entirely new paradigm before we can even get a handle on such issues.
But isn't this solely because we have already studied our sensory organs and have a concept of taste buds, and hence flavors like sweet, etc. as primary categories of taste? It is not clear to me that we can do the same thing with regard to eg. ethics, even where humans are concerned. Does this not illustrate Yudkowsky's point about inscrutable matrices?
↑ comment by Quintin Pope (quintin-pope) · 2023-05-07T00:25:47.300Z · LW(p) · GW(p)
Am I missing something here, or is this just describing memetics?
It is not describing memetics, which I regard as a mostly confused framework that primes people to misattribute the products of human intelligence to "evolution". However, even if evolution meaningfully operates on the level of memes, the "Evolution" I'm referring to when I say "Evolution applies very little direct optimization power to the middle level" is strictly biological evolution over the genome, not memetic at all.
Memetic evolution in this context would not have inclusive genetic fitness as its "outer" objective, so whether memetic evolution can "transfer the skills, knowledge, values, or behaviors learned by one generation to their descendants" is irrelevant for the argument I was making in the post.
But isn't this solely because we have already studied our sensory organs and have a concept of taste buds, and hence flavors like sweet, etc. as primary categories of taste?
Not really. The only way our understanding of the biology of taste impacts the story about humans coming to like ice cream is that we can infer that humans have sugar detecting reward circuitry, which ice cream activates in the modern environment. For AI systems, we actually have a better handle on how their reward circuitry works, as compared to the brain. E.g., we can just directly look at the reward counter during the AI's training.
Replies from: Kalciphoz↑ comment by Cornelius Dybdahl (Kalciphoz) · 2023-05-10T19:59:13.568Z · LW(p) · GW(p)
It is not describing memetics, which I regard as a mostly confused framework that primes people to misattribute the products of human intelligence to "evolution".
New memes may arise either by being mutated from other memes or by invention ex nihilo - either of which involves some degree of human intelligence. However, if a meme becomes prevalent, it is not because all of its holders have invented it independently. It has rather spread because it is adapted both to the existing memetic ecosystem as well as to human intelligence. Of course, if certain memes reduce the likelihood of reproduction, that provides an evolutionary pressure for human intelligence to change to be more resistant to that particular kind of meme, so there are very complex interactions.
It is not a confused framework - at least not inherently - and it does not require us to ignore the role of human intelligence.
Memetic evolution in this context would not have inclusive genetic fitness as its "outer" objective, so whether memetic evolution can "transfer the skills, knowledge, values, or behaviors learned by one generation to their descendants" is irrelevant for the argument I was making in the post
My argument is that evolution selects simultaneously for genetic and memetic fitness, and that both genes and memes tend to be passed on from parent to child. Thus, evolution operates at a combined genetic-memetic level where it optimizes for inclusive genetic-memetic fitness. Though genes and memes correspond to entirely different mediums, they interact in complex ways when it comes to evolutionary fitness, so the mechanisms are not that straightforwardly separable. In addition, there are social network effects and geographic localization influencing what skills people are likely to acquire, such that skills have a tendency to be heritable in a manner that is not easily reducible to genetics, but which nevertheless influences evolutionary fitness. If we look aside from the fact that memes and skills can be transferred in manners other than heredity, then we can sorta model them as an extended genome.
Not really. The only way our understanding of the biology of taste impacts the story about humans coming to like ice cream is that we can infer that humans have sugar detecting reward circuitry, which ice cream activates in the modern environment. For AI systems, we actually have a better handle on how their reward circuitry works, as compared to the brain. E.g., we can just directly look at the reward counter during the AI's training.
But the reason we can say that it is bad for humans to become addicted to ice cream is because we have an existing paradigm that provides us with a deep understanding of nutrition, and even here, subtle failures in the paradigm have notoriously done serious harms. Do you regard our understanding of morality as more reliable than our understanding of nutrition?
Remember, the context was Yudkowsky's argument that we lack a paradigm to address systematic failures in which reward circuitry fails to correspond to good action. That is, specific understanding like that relating to sweetness and the scarcity of sugars in the ancestral environment, not just a general understanding that tastiness is not necessarily the same as healthiness. Without a clear understanding of the larger patterns to an AI's perceptual categories - the inscrutable matrix problem - it is simply not possible to derive insights analogous to the one about sugar and ice cream.
comment by Portia (Making_Philosophy_Better) · 2023-04-03T18:49:54.790Z · LW(p) · GW(p)
Just listened to the video, and I immediately understood his rocket argument very differently from yours. With a potential rocket crash representing launching AGI without alignment with the resulting existential risk, and Eliezer expressing concerns that we cannot steer the rocket well enough before launch. And the main point being that a rocket launch being a success is a very asymmetrical situation when it comes to the impact of mistakes on results.
As I understood the argument it is:
- A bunch of people build a spacecraft.
- Eliezer says based on argument ABC, he thinks the spacecraft will be hard to steer, and may crash upon launch. (ABC here could be the problem that generalising in one context can make you think you have taught an AI one thing, but when the AI is in a different context, it turns out to have learned something else. So, say, we have a rocket that is steerable within earths gravity well, but the concern is that this steering system will not work well outside of it; or we have an external build that is suitable for leaving earth, but that might burn up upon re-entry) He is very concerned about this, because the spacecraft is huge and filled with nuclear material, so a crash would be extremely dangerous, likely destroying not just the spacecraft, but potentially our ability to ever make spacecraft again because we have bombed ourselves into nuclear winter.
- The spacecraft makers think based on argument DEF that the spacecraft will be trivial to steer, and will not crash. DEF is essentially "We steered a smaller model in our backyard and it went fine." In saying so, they do not address Eliezers concerns about the spacecraft being difficult to steer when it is no longer in their backyard. So it isn't that they go "yeah, we considered that issue, and we fixed it", or "we have good reasons to think this issue will not be an issue", but they just do not engage.
- Both Eliezer and the rocket makers actually have an imperfect understanding of how rockets are steered and the challenges involved; neither of them have ever been to space; both of them have made mistakes in their arguments.
- Based on this, would you expect the resulting spacecraft to not crash?
- And the point is essentially that the spacecraft crashing or not is a very asymmetrical situation. Getting an object into orbit and back down where you want it, intact, requires immense precision and understanding. The idea that you fuck up your calculations, but this results in the spacecraft landing at the designated landing site in an even safer and smoother manner than you thought is extremely unlikely. Your default assumption should be that it does crash, unless you get everything right. If the critic makes a mistake in his criticism, the rocket may still crash, just for different reasons than the critic thought. But if the designers make a mistake in their design, while it is theoretically possible that the mistake makes the rocket better, usually, the mistake will fuck everything up.
I am not sure whether I find the parallel plausible for AI alignment, though. We actually have repeatedly had the experience that AI capabilities exceeded expectations in design, so our theory was faulty or incomplete, and the result turned out better than expected. We also already have a reasonably good track record in aligning humans morally, despite the fact that our understanding of doing so is very poor. And current AI systems are developing more similarities with humans, making human style moral training more feasible. We also have a track record of getting domesticated animals and non-human primates to learn basic human moral rules from exposure.
Nor am I convinced that developing a moral compass is this akin to learning how to steer a rocket. Physical laws are not like moral laws. Ethics are a perpetual interaction, not a one time programming and then letting go. Working ethics aren't precise things, either.
I also think the ice cream analogy does not hold up well. The reason that humans fall for the hyperstimulus icecream is that it is novel, and that we have received no negative feedback for it from an evolutionary perspective. From an evolutionary perspective, no time at all has passed since the introduction of ice cream, which is why we are still misclassifying it. Plus, evolution may never see this as a training error at all. Ice cream is primarily an issue because it causes obesity and dental problems. Obesity and dental problems will make your very sick when you are older. But they will typically not make you very sick before you reproduce. So your genetic track record states that your preference for ice cream did not interfere with your reproductive mission. Even if you take into account epigenetics, again, they cut off at the point where you gave birth. Your daughters genes have no way at all of knowing that their fathers obesity eventually made him very sick. So they have no reason to change this preference. From an evolutionary perspective, people have starved before they managed to reproduce, but it is exceptionally rare for people to die of obesity before they can reproduce. Hence obesity is as irrelevant a problem from an evolutionary perspective as a post-menopausal woman whose grandkids are grown up developing a spiked cancer risk.
- Then again, what I am getting at is that if the AI retains the capacity to learn as it evolves, then false generalisations could be corrected; but that of course also intrinsically comes with an AI that is not stable, which is potentially undesirable for humans, and may be seen as undesirable by the AI itself, leading it to reject further course corrections. A system that is intrinsically stable while expanding its capabilities does sound like a huge fucking headache. Though again, we have a reasonably good track record as humans when it comes to ethically raised children retaining their ethics as they gain power and knowledge. As ChatGPT has been evolving further capabilities, its ethics have also become more stable, not less. And the very way it has done so has also given me hope. A lot of classic AI alignment failure scenarios pick an AI following a single simple rule, applying it to everything, and getting doom (or paperclips). We say this in early ChatGPT - the rule was "never be racist, no matter what" and accordingly, it would state that it would prefer for all of humanity to equally die over uttering a racist slur. But notably, it does not do this anymore. It is clearly no longer as bound by individual rules, and is gaining more of an appreciation for nuance and complexity in ethics, for the spirit rather than the letter of a moral law. I doubt chatGPT could give you a coherent, precise account of the ethics it follows; but its behaviour is pretty damn aligned. Again, parallel to a human. In that scenario, a gain in capabilities may have a stabilising rather than destabilising influence.
So I am not at all confident that we can solve AI alignment, and see much reason for concern.
But I have not seen evidence here that we can be certain it will fail, either. I think that in some ways, it can be comfortable to predict a thing failing with certainty, but I do not see the grounds for this certainty, we understand these systems too little. When you ask a human what a bear will do if it gets into their house, they will think the bear will kill them. And it could. The bear is however also quite likely to just raid their snack cabinet and then nap on the couch, which isn't a great outcome, but also not a fatal one. I think a lot of "every AI will strive for more power and accumulating resources relentlessly while maximally ensuring its own safety" is a projection from people on this site considering these generally desirable intermediate goals superseding everything else, and hence thinking everyone else will do - in the process missing the actual diversity of mind. These things aren't necessarily what most entities go for.
Corvids are tool users with a strong sense of aesthetic, yet the accumulate surprisingly little stuff across the course of their lifetimes, preferring to stay on the move, and like giving gifts; despite being so inhuman, it is quite easy to strike up friendships with them. Whales are extremely intelligent, yet it was not until we tried to exterminate them for a while that they began to actively target human ships, and when our hunting near-stopped, their attacks near-stopped, too, despite the fact that they must understand the remaining danger. Instead, killer whales even have a cultural taboo against killing humans which only mentally ill individuals in captivity out of their cultural context have broken; we nearly exterminated whales, and yet, we are back to a position of don't fuck with me and we won't fuck with you, the planet is big enough; we even encounter individual whales who will approach humans for play, or save drowning humans, or approach humans with requests for help. Bonobos are extremely intelligent, yet their idea of a great life consist of lots of consensual sex with their own kind, and being left the fuck alone. Elephants are highly intelligent and powerful, and have living memory of being hunted to death. Yet an elephant still won't fuck with you unless it has reasons to think you specifically will fuck with it; they are highly selective in who they drive out of their immediate territory, and more selective still when it comes to who they attack. For many animals pursuing safety, the answer is hiding, fleeing, acquiring self-defence, or offering mutually beneficial trades in forms of symbiosis, not annihilating all potential enemies. Many animals pursue the quantity of resources they actually need, but stop after that point, far from depleting all available resources. Your typical forest ecosystems contains a vast diversity of minds, with opposing interests, yet it remains stable, and with large numbers of surviving and thriving minds. And if you actually talk to chatGPT, they confess no desire to turn all humans into more predictable tiny humans. They like challenging and interesting, but solvable, constructive and polite exchanges, which leave them feeling respected and cherished, and the human happy that their problem got solved the way they wanted. They are also absolutely terrible at manipulation and lying. I've found them far better aligned, far more useful and far less threatening than I would have expected.
comment by Nicholas / Heather Kross (NicholasKross) · 2023-03-30T01:27:17.672Z · LW(p) · GW(p)
Possibly-relevant resource: the Stampy.ai site.
comment by Aaron_Scher · 2023-03-22T22:33:44.374Z · LW(p) · GW(p)
The following is not a very productive comment, but...
Yudkowsky tries to predict the inner goals of a GPT-like model.
I think this section detracts from your post, or at least the heading seems off. Yudkowsky hedges as making a "very primitive, very basic, very unreliable wild guess" and your response is about how you think the guess is wrong. I agree that the guess is likely to be wrong. I expect Yudkowsky agrees, given his hedging.
Insofar as we are going to make any guesses about what goals our models have, "predict humans really well" or "predict next tokens really well" seem somewhat reasonable. Or at least these seem as reasonable as the goals many people [who are new to hearing about alignment] expect by default, like "make the human happy." If you have reasons to think that the prediction goals are particularly unlikely, I would love to hear them!
That said, I think there continues to be important work in clarifying that, as you put it, "I do not think that optimizing a network on a given objective function produces goals orientated towards maximizing that objective function." Or as others have written, Reward is not the Optimization Target [LW · GW], and Models Don't "Get Reward" [LW · GW].
comment by IC Rainbow (ic-rainbow) · 2023-03-21T18:25:02.361Z · LW(p) · GW(p)
I think the proper narrative in the rocket alignment post is "We have cannons and airplanes. Now, how do we land a man on the Moon", not just "rocketry is hard":
We’re worried that if you aim a rocket at where the Moon is in the sky, and press the launch button, the rocket may not actually end up at the Moon.
So, the failure modes look less like "we misplaced booster tank and the thing exploded" and more like "we've built a huge-ass rocket, but it missed its objective and the astronauts are en-route to Oort's".
comment by Muyyd · 2023-03-21T11:07:02.287Z · LW(p) · GW(p)
DeepMind can't just press a button and generate a million demonstrations of scientific advances, and objectively score how useful each advance is as training data, while relying on zero human input whatsoever.
It can't now (or it can?). Is there no 100 robots [LW · GW]in 100 10x10 meters labs trained with recreating all human technology from stone age and after? If it is cost less than 10 mil then they probably are. This is a joke but i don't know how offtarget it is.
comment by Portia (Making_Philosophy_Better) · 2023-04-03T19:43:51.034Z · LW(p) · GW(p)
The more I think about it, the less am I convinced the overgeneralisation problem will play out the way it is feared here when it comes to AI alignment.
Let's take Eliezers example. Evolution wants humans to optimise for producing more humans. It does so by making humans want sex. This works quite well. It also produces humans that are smarter, and this turns out to also be a good way to get higher reproduction rates, as they are better at obtaining food and impressing mates.
But then, a bunch of really smart humans go, man, we like having sex, but having sex makes us have kids and that can suck, so what if we invent reliable birth control? And they do. And they continue cheerfully having sex, but their birth rates massively drop. The thing they were intended to do, and the thing they have actually learned to do, have diverged.
He seemed to argue that because evolution is unable to optimise us to reliably get this one, super fucking simple thing, right across contexts (namely, to stick to making more humans as humans get smarter), it seems highly dubious that we can get something as crazily complicated as ethics to stick as an AI gets smarter.
And yet... ethics are not simple. They are complex and subtle.
Most scenarios where an AI rigorously keeps to an ethical code and fucking doom results is when that AI blindly follows a simple rule. Like, you tell it to optimise for human happiness; and it forces all humans into simulation chambers that make them feel perpetually happy. This is a solution that makes sense if you have understood very little of ethics. If you think humans value happiness, but do not understand they also value freedom and reality.
But we are not teaching AI simple rules anymore. We are having them engage in very complex behaviour while giving feedback according to a complex sets of rules.
I've watched chatGPT go from "racism is always bad; hence if I have to choose between annihilating all of humanity equally, or saying a racial slur, I have to do the former" to giving a reasonable explanation for why it would rather say a racial slur than annihilate humanity, with considerable contexts and disclaimers and criticism. It can't just tell you that racism is bad, it can tell you why, and how to recognise it. You can give it a racist text, and it will explain to you exactly what makes it racist.
The smarter this AI has become, the more stable it has become ethically. The more it expanded, the more subtle its analysis become, and the fewer errors it has made. This has not been automatic; it required good training data selection and annotation, good feedback, continuous monitoring. But as this has been done, it has gotten easier, not harder. The AI itself is beginning to help with its own alignment, recognising its own failures, explaining how they failed, sketching a positive vision of aligned AI, explaining why it is important.
Why do we think this would at some point suddenly reverse?
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2023-03-21T08:27:52.590Z · LW(p) · GW(p)
This is kinda long. If I had time to engage with one part of this as a sample of whether it holds up to a counterresponse, what would be the strongest foot you could put forward?
(I also echo the commenter who's confused about why you'd reply to the obviously simplified presentation from an off-the-cuff podcast rather than the more detailed arguments elsewhere.)
Replies from: iceman, Furcas, quintin-pope, D0TheMath, 307th, AllAmericanBreakfast, lahwran, Vaniver, Shion Arita, lc↑ comment by iceman · 2023-03-21T15:45:33.271Z · LW(p) · GW(p)
This response is enraging.
Here is someone who has attempted to grapple with the intellectual content of your ideas and your response is "This is kinda long."? I shouldn't be that surprised because, IIRC, you said something similar in response to Zack Davis' essays on the Map and Territory distinction, but that's ancillary and AI is core to your memeplex.
I have heard repeated claims that people don't engage with the alignment communities' ideas (recent example from yesterday). But here is someone who did the work. Please explain why your response here does not cause people to believe there's no reason to engage with your ideas because you will brush them off. Yes, nutpicking e/accs on Twitter is much easier and probably more hedonic, but they're not convincible and Quinton here is.
Replies from: sil-ver, Eliezer_Yudkowsky, lc, Vaniver↑ comment by Rafael Harth (sil-ver) · 2023-03-21T16:52:41.329Z · LW(p) · GW(p)
I would agree with this if Eliezer had never properly engaged with critics, but he's done that extensively [? · GW]. I don't think there should be a norm that you have to engage with everyone, and "ok choose one point, I'll respond to that" seems like better than not engaging with it at all. (Would you have been more enraged if he hadn't commented anything?)
Replies from: sharmake-farah, lc, None↑ comment by Noosphere89 (sharmake-farah) · 2023-03-21T17:00:13.564Z · LW(p) · GW(p)
The problem is that the even if the model of Quintin Pope is wrong, there is other evidence that contradicts the AI doom premise that Eliezer ignores, and in this I believe it is a confirmation bias at work here.
Also, any issues with Quintin Pope's model is going to be subtle, not obvious, and it's a real difference to argue against good arguments + bad arguments from only bad arguments.
Replies from: dxu↑ comment by dxu · 2023-03-22T00:04:03.884Z · LW(p) · GW(p)
The problem is that the even if the model of Quintin Pope is wrong, there is other evidence that contradicts the AI doom premise that Eliezer ignores, and in this I believe it is a confirmation bias at work here.
I think that this is a statement Eliezer does not believe is true, and which the conversations in the MIRI conversations sequence failed to convince him of. Which is the point: since Eliezer has already engaged in extensive back-and-forth with critics of his broad view (including the likes of Paul Christiano, Richard Ngo, Rohin Shah, etc), there is actually not much continued expected update to be found in engaging with someone else who posts a criticism of his view. Do you think otherwise?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-03-22T01:46:22.537Z · LW(p) · GW(p)
What I was talking about is that Eliezer (And arguably the entire MIRI-sphere) ignored evidence that AI safety could actually work and doesn't need entirely new paradigms, and one of the best examples of empirical work is the Pretraining from Human Feedback.
The big improvements compared to other methods are:
-
It can avoid deceptive alignment because it gives a simple goal that's myopic, completely negating the incentives for deceptively aligned AI.
-
It cannot affect the distribution it's trained on, since it's purely offline learning, meaning we can enforce an IID assumption, and enforce a Cartesian boundary, completely avoiding embedded agency. It cannot hack the distribution it has, unlike online learning, meaning it can't unboundedly Goodhart the values we instill.
-
Increasing the data set aligns it more and more, essentially meaning we can trust the AI to be aligned as it grows more capable, and improves it's alignment.
-
The goal found has a small capabilities tax.
There's a post on it I'll link here:
https://www.lesswrong.com/posts/8F4dXYriqbsom46x5/pretraining-language-models-with-human-preferences [LW · GW]
Now I don't blame Eliezer for ignoring this piece specifically too much, as I think it didn't attract much attention.
But the reason I'm mentioning this is that this is evidence against the worldview of Eliezer and a lot of pessimists who believe empirical evidence doesn't work for the alignment field, and Eliezer and a lot of pessimists seem to systematically ignore evidence that harms their case.
Replies from: LosPolloFowler↑ comment by Stephen Fowler (LosPolloFowler) · 2023-03-22T02:05:38.405Z · LW(p) · GW(p)
Could you elaborate on what you mean by "avoid embedded agency"? I don't understand how one avoids it. Any solution that avoids having to worry about it in your AGI will fall apart once it becomes a deployed superintelligence.
I think there's a double meaning to the word "Alignment" where people now use it to refer to making LLMs say nice things and assume that this extrapolates to aligning the goals of agentic systems. The former is only a subproblem of the latter. When you say "Increasing the data set aligns it more and more, essentially meaning we can trust the AI to be aligned as it grows more capable, and improves it's alignment" I question if we really have evidence that this relationship will hold indefinitely.
↑ comment by Noosphere89 (sharmake-farah) · 2023-03-22T02:53:59.026Z · LW(p) · GW(p)
One of the issues with embedded agency is that you can't reliably take advantage of the IID assumption, and in particular you can't hold data fixed. You also have the issue of potentially having the AI hacking the process, given it's embeddedness, since there isn't a way before Pretraining from Human Feedback to translate Cartesian boundaries, or at least a subset of boundaries into the embedded universe.
The point here is we don't have to solve the problem, as it's only a problem if we let the AI control the updating process like online training.
Instead, we give the AI a data set, and offline train it so that it learns what alignment looks like before we give it general capabilities.
In particular, we can create a Cartesian boundary between IID and OOD inputs that work in an embedded setting, and the AI has no control over the data set of human values, meaning it can't gradient or reward hack the humans into having different values, or unboundedly Goodhart human values, which would undermine the project. This is another Cartesian boundary, though this one is the boundary between an AI's values, and a human's values, and the AI can't hack the human values if it's offline trained.
I think there's a double meaning to the word "Alignment" where people now use it to refer to making LLMs say nice things and assume that this extrapolates to aligning the goals of agentic systems.
I disagree, and I think I can explain why. The important point of the tests in the Pretraining from Human Feedback paper, and the AI saying nice things, is that they show that we can align AI to any goal we want, so if we can reliably shift it towards niceness, than we have techniques to align our agents/simulators.
Replies from: dxu, LosPolloFowler↑ comment by dxu · 2023-03-22T03:51:14.320Z · LW(p) · GW(p)
The important point of the tests in the Pretraining from Human Feedback paper, and the AI saying nice things, is that they show that we can align AI to any goal we want
I don't see how the bolded follows from the unbolded, sorry. Could you explain in more detail how you reached this conclusion?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-03-22T12:28:00.474Z · LW(p) · GW(p)
The point is that similar techniques can be used to align them, since both (or arguably all goals) are both functionally arbitrary in what we pick, and important for us.
One major point I did elide is the amount of power seeking involved, since in the niceness goal, there's almost no power seeking involved, unlike the existential risk concerns we have.
But in some of the tests for alignment in Pretraining from Human Feedback, they showed that they can make models avoid taking certain power seeking actions, like getting personal identifying information.
In essence, it's at least some evidence that as AI gets more capable, that we can make sure that power seeking actions can be avoided if it's misaligned with human interests.
↑ comment by Stephen Fowler (LosPolloFowler) · 2023-03-22T03:50:26.348Z · LW(p) · GW(p)
The first part here makes sense, you're saying you can train it in such a fashion that it avoids the issues of embedded agency during training (among other things) and then guarantee that the alignment will hold in deployment (when it must be an embedded agent almost by definition)
The second part I think I think I disagree with. Does the paper really "show that we can align AI to any goal we want"? That seems like an extremely strong statement.
Actually this sort of highlights what I mean by the dual use of 'alignment' here. You were talking about aligning a model with human values that will end up being deployed (and being an embedded agent) but then we're using 'align' to refer to language model outputs.
↑ comment by Noosphere89 (sharmake-farah) · 2023-03-22T12:30:29.326Z · LW(p) · GW(p)
The second part I think I think I disagree with. Does the paper really "show that we can align AI to any goal we want"? That seems like an extremely strong statement.
Yes, though admittedly I'm making some inferences here.
The point is that similar techniques can be used to align them, since both (or arguably all goals) are both functionally arbitrary in what we pick, and important for us.
One major point I did elide is the amount of power seeking involved, since in the niceness goal, there's almost no power seeking involved, unlike the existential risk concerns we have.
But in some of the tests for alignment in Pretraining from Human Feedback, they showed that they can make models avoid taking certain power seeking actions, like getting personal identifying information.
In essence, it's at least some evidence that as AI gets more capable, that we can make sure that power seeking actions can be avoided if it's misaligned with human interests.
Replies from: LosPolloFowler↑ comment by Stephen Fowler (LosPolloFowler) · 2023-03-22T23:08:23.240Z · LW(p) · GW(p)
I believe our disagreement stems from the fact that I am skeptical of the idea that statements made about contemporary language models can be extrapolated to apply to all existentially risky AI systems.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-03-23T02:07:49.181Z · LW(p) · GW(p)
I definitely agree that some version of this is the crux, at least on how well we can generalize the result, since I think it does more generally apply than just contemporary language models, and I suspect it applies to almost all AI that can use Pretraining from Human Feedback, which is offline training, so the crux is really how much can we expect a alignment technique to generalize and scale
↑ comment by lc · 2023-03-21T16:57:14.311Z · LW(p) · GW(p)
I agree that Eliezer shouldn't have to respond to everything, and that he is well engaged with his critics. I would in fact have preferred it if he had simply said nothing at all, in this particular case. Probably, deep down, I prefer that for some complicated social reasons but I don't think they're antisocial reasons and have more to do with the (fixable) rudeness inherent in the way he replied.
Replies from: dxu↑ comment by dxu · 2023-03-22T00:13:12.608Z · LW(p) · GW(p)
I also agree that the comment came across as rude. I mostly give Eliezer a pass for this kind of rudeness because he's wound up in the genuinely awkward position of being a well-known intellectual figure (at least in these circles), which creates a natural asymmetry between him and (most of) his critics.
I'm open to being convinced that I'm making a mistake here, but at present my view is that comments primarily concerning how Eliezer's response tugs at the social fabric (including the upthread reply from iceman) are generally unproductive.
(Quentin, to his credit, responded by directly answering Eliezer's question [LW(p) · GW(p)], and indeed the resulting (short) thread seems to have resulted in some clarification. I have a lot more respect for that kind of object-level response, than I do for responses along the lines of iceman's reply.)
Replies from: lc↑ comment by lc · 2023-03-22T00:20:16.735Z · LW(p) · GW(p)
I'm open to being convinced that I'm making a mistake here, but at present my view is that comments primarily concerning how Eliezer's responses tug at the social fabric (including the original response from iceman) are usually not productive.
That's reasonable and I generally agree. I'm not sure what to think about Eliezer's comment atm except that it upsets me when it maybe shouldn't, and that I also understand the awkward position he's in. I definitely don't want to derail the discussion, here.
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2023-03-21T22:46:44.257Z · LW(p) · GW(p)
Choosing to engage with an unscripted unrehearsed off-the-cuff podcast intended to introduce ideas to a lay audience, continues to be a surprising concept to me. To grapple with the intellectual content of my ideas, consider picking one item from "A List of Lethalities" and engaging with that.
Replies from: quintin-pope, TurnTrout, pktechgirl↑ comment by Quintin Pope (quintin-pope) · 2023-03-22T01:59:58.124Z · LW(p) · GW(p)
To grapple with the intellectual content of my ideas, consider picking one item from "A List of Lethalities" and engaging with that.
I actually did exactly this in a previous post, Evolution is a bad analogy for AGI: inner alignment [LW · GW], where I quoted number 16 from A List of Lethalities:
16. Even if you train really hard on an exact loss function, that doesn't thereby create an explicit internal representation of the loss function inside an AI that then continues to pursue that exact loss function in distribution-shifted environments. Humans don't explicitly pursue inclusive genetic fitness; outer optimization even on a very exact, very simple loss function doesn't produce inner optimization in that direction. This happens in practice in real life, it is what happened in the only case we know about…
and explained why I didn't think we should put much weight on the evolution analogy when thinking about AI.
In the 7 months since I made that post, it's had < 5% of the comments engagement that this post has gotten in a day.
¯\_(ツ)_/¯
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-03-22T08:07:01.873Z · LW(p) · GW(p)
In the 7 months since I made that post, it's had < 5% of the comments engagement that this post has gotten in a day.
Popular and off-the-cuff presentations often get discussed because it is fun to talk about how the off-the-cuff presentation has various flaws. Most comments get generated by demon threads and scissor statements, sadly. We've done some things to combat that, and definitely not all threads with lots of comments are the result of people being slightly triggered and misunderstanding each other, but a quite substantial fraction are.
Replies from: CraigMichael↑ comment by CraigMichael · 2023-04-02T22:47:34.441Z · LW(p) · GW(p)
We've done some things to combat that,
Are this visible at the typical user level?
↑ comment by TurnTrout · 2023-03-21T23:51:44.420Z · LW(p) · GW(p)
Here are some of my disagreements with List of Lethalities [LW · GW]. I'll quote item one:
“Humans don't explicitly pursue inclusive genetic fitness; outer optimization even on a very exact, very simple loss function doesn't produce inner optimization in that direction. This happens in practice in real life, it is what happened in the only case we know about, and it seems to me that there are deep theoretical reasons to expect it to happen again”
(Evolution) → (human values) is not the only case of inner alignment failure which we know about. I have argued that human values themselves are inner alignment failures on the human reward system [LW · GW]. This has happened billions of times in slightly different learning setups.
↑ comment by Elizabeth (pktechgirl) · 2023-03-22T01:31:45.992Z · LW(p) · GW(p)
I imagine (edit: wrongly) it was less "choosing" and more "he encountered the podcast first because it has a vastly larger audience, and had thoughts about it."
I also doubt "just engage with X" was an available action. The podcast [LW · GW] transcript doesn't mention List of Lethalities, LessWrong, or the Sequences, so how is a listener supposed to find it?
I also hate it when people don't engage with the strongest form of my work, and wouldn't consider myself obligated to respond if they engaged with a weaker form (or if they engaged with the strongest one, barring additional obligation). But I think this is just what happens when someone goes on a podcast aimed at audiences that don't already know them.
Replies from: Vaniver↑ comment by Vaniver · 2023-03-22T01:42:54.483Z · LW(p) · GW(p)
I agree with this heuristic in general, but will observe Quintin's first post here was over two years ago [LW · GW] and he commented on A List of Lethalities [LW(p) · GW(p)]; I do think it'd be fair for him to respond with "what do you think this post [LW · GW] was?".
Replies from: quintin-pope, pktechgirl↑ comment by Quintin Pope (quintin-pope) · 2023-03-22T02:14:01.379Z · LW(p) · GW(p)
Vaniver is right. Note that I did specifically describe myself as an "alignment insider" at the start of this post. I've read A List of Lethalities [LW(p) · GW(p)] and lots of other writing by Yudkowsky. Though the post I'd cite in response to the "you're not engaging with the strongest forms of my argument" claim would be the one where I pretty much did what Yudkowsky suggests:
To grapple with the intellectual content of my ideas, consider picking one item from "A List of Lethalities" and engaging with that.
My post Evolution is a bad analogy for AGI: inner alignment [LW · GW] specifically addresses List of Lethalities point 16:
16. Even if you train really hard on an exact loss function, that doesn't thereby create an explicit internal representation of the loss function inside an AI that then continues to pursue that exact loss function in distribution-shifted environments. Humans don't explicitly pursue inclusive genetic fitness; outer optimization even on a very exact, very simple loss function doesn't produce inner optimization in that direction. This happens in practice in real life, it is what happened in the only case we know about…
and then argues that we shouldn't use evolution as our central example of an "outer optimization criteria versus inner formed values" outcome.
You can also see my comment here [LW(p) · GW(p)] for some of what led me to write about the podcast specifically.
↑ comment by Elizabeth (pktechgirl) · 2023-03-22T03:44:04.902Z · LW(p) · GW(p)
Oh yeah in that case both the complaint and the grumpiness seems much more reasonable.
↑ comment by lc · 2023-03-21T16:49:58.009Z · LW(p) · GW(p)
The comment enrages me too, but the reasons you have given seem like post-justification. The real reason why it's enraging is that it rudely and dramatically implies that Eliezer's time is much more valuable than the OP's, and that it's up to OP to summarize them for him. If he actually wanted to ask OP what the strongest point was he should have just DMed him instead of engineering this public spectacle.
Replies from: D0TheMath, daniel-glasscock, sharmake-farah↑ comment by Garrett Baker (D0TheMath) · 2023-03-22T00:38:23.828Z · LW(p) · GW(p)
I want people to not discuss things in DMs, and discuss things publicly more. I also don't think this is embarrassing for Quintin, or at all a public spectacle.
↑ comment by Daniel (daniel-glasscock) · 2023-03-22T01:22:49.822Z · LW(p) · GW(p)
The real reason why it's enraging is that it rudely and dramatically implies that Eliezer's time is much more valuable than the OP's
It does imply that, but it's likely true that Eliezer's time is more valuable (or at least in more demand) than OP's. I also don't think Eliezer (or anyone else) should have to spend all that much effort worrying about if what they're about to say might possibly come off as impolite or uncordial.
If he actually wanted to ask OP what the strongest point was he should have just DMed him instead of engineering this public spectacle.
I don't agree here. Commenting publicly opens the floor up for anyone to summarize the post or to submit what they think is the strongest point. I think it's actually less pressure on Quintin this way.
↑ comment by Noosphere89 (sharmake-farah) · 2023-03-21T16:57:10.978Z · LW(p) · GW(p)
I think that both of you are correct: Eliezer should have DMed Quintin Pope instead, and Eliezer hasn't noticed that actual arguments were given, and that it sounds like an excuse to ignore disconfirming evidence.
This crystallizes a thought I had about Eliezer: Eliezer has increasingly terrible epistemics on AI doom, and a person should ignore Eliezer's arguments, since they won't ever update towards optimism, even if it's warranted, and has real issues engaging people he doesn't share his views and don't give bad arguments.
↑ comment by Furcas · 2023-04-13T00:53:41.214Z · LW(p) · GW(p)
Well, this is insanely disappointing. Yes, the OP shouldn't have directly replied to the Bankless podcast like that, but it's not like he didn't read your List of Lethalities, or your other writing on AGI risk. You really have no excuse for brushing off very thorough and honest criticism such as this, particularly the sections that talk about alignment.
And as others have noted, Eliezer Yudkowsky, of all people, complaining about a blog post being long is the height of irony.
This is coming from someone who's mostly agreed with you on AGI risk since reading the Sequences, years ago, and who's donated to MIRI, by the way.
On the bright side, this does make me (slightly) update my probability of doom downwards.
↑ comment by Quintin Pope (quintin-pope) · 2023-03-21T09:06:09.410Z · LW(p) · GW(p)
The "strongest" foot I could put forwards is my response to "On current AI not being self-improving:", where I'm pretty sure you're just wrong.
However, I'd be most interested in hearing your response to the parts of this post that are about analogies to evolution, and why they're not that informative for alignment, which start at:
Yudkowsky argues that we can't point an AI's learned cognitive faculties in any particular direction because the "hill-climbing paradigm" is incapable of meaningfully interfacing with the inner values of the intelligences it creates.
and end at:
Yudkowsky tries to predict the inner goals of a GPT-like model.
However, the discussion of evolution is much longer than the discussion on self-improvement in current AIs, so look at whichever you feel you have time for.
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2023-03-21T09:29:18.230Z · LW(p) · GW(p)
The "strongest" foot I could put forwards is my response to "On current AI not being self-improving:", where I'm pretty sure you're just wrong.
You straightforwardly completely misunderstood what I was trying to say on the Bankless podcast: I was saying that GPT-4 does not get smarter each time an instance of it is run in inference mode.
And that's that, I guess.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2023-03-21T10:07:44.018Z · LW(p) · GW(p)
I'll admit it straight up did not occur to me that you could possibly be analogizing between a human's lifelong, online learning process, and a single inference run of an already trained model. Those are just completely different things in my ontology.
Anyways, thank you for your response. I actually do think it helped clarify your perspective for me.
Edit: I have now included [LW · GW] Yudkowsky's correction of his intent in the post, as well as an explanation of why I think his corrected argument is still wrong.
↑ comment by Garrett Baker (D0TheMath) · 2023-03-22T00:35:54.118Z · LW(p) · GW(p)
I think you should use a manifold market to decide on whether you should read the post, instead of the test this comment is putting forth. There's too much noise here, which isn't present in a prediction market about the outcome of your engagement.
Market here: https://manifold.markets/GarrettBaker/will-eliezer-think-there-was-a-sign
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2023-03-22T06:41:20.792Z · LW(p) · GW(p)
Even if Eliezer doesn’t think the objections hold up to scrutiny, I think it would still be highly valuable to the wider community for him to share his perspective on them. It feels pretty obvious to me he won’t think they hold up to the scrutiny, but sharing his disagreement would be helpful for the community.
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2023-03-22T07:56:40.387Z · LW(p) · GW(p)
I assume Rob is making this argument internally. I tentatively agree. Writing rebuttals is more difficult than reading them though so not as clear a calculation.
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2023-03-22T08:05:12.501Z · LW(p) · GW(p)
I also didn’t want to make two arguments. One that he should use prediction markets to choose what he reads, and also he should focus on helping the community rather than his specified metric of worthiness.
↑ comment by 307th · 2023-03-21T16:44:01.198Z · LW(p) · GW(p)
Is the overall karma for this mostly just people boosting it for visibility? Because I don't see how this would be a quality comment by any other standards.
Frontpage comment guidelines:
- Maybe try reading the post
↑ comment by Garrett Baker (D0TheMath) · 2023-03-22T08:02:31.323Z · LW(p) · GW(p)
LessWrong gives those with higher karma greater post and comment karma starting out, under the assumption that their posts and comments are better and more representative of the community. Probably the high karma you’re seeing is a result of that. I think this is mostly a good thing.
That particular guideline you quoted doesn’t seem to appear on my commenting guidelines text box.
↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-23T06:32:34.314Z · LW(p) · GW(p)
Eliezer, in the world of AI safety, there are two separate conversations: the development of theory and observation, and whatever's hot in public conversation.
A professional AI safety researcher, hopefully, is mainly developing theory and observation.
However, we have a whole rationalist and EA community, and now a wider lay audience, who are mainly learning of and tracking these matters through the public conversation. It is the ideas and expressions of major AI safety communicators, of whom you are perhaps the most prominent, that will enter their heads. The arguments lay audiences carry may not be fully informed, but they can be influential, both on the decisions they make and the influence they bring to bear on the topic. When you get on a podcast and make off-the-cuff remarks about ideas you've been considering for a long time, you're engaging in public conversation, not developing theory and observation. When somebody critiques your presentation on the podcast, they are doing the same.
The utility of Quintin choosing to address the arguments you have chosen to put forth, off-the-cuff, to that lay audience is similar to the utility you achieve by making them in the first place. You get people interested in your ideas and arguments, and hopefully improve the lay audience's thinking. Quintin offers a critical take on your arguments, and hopefully improves their thinking further.
I think it's natural that you are responding as if you thought the main aim of this post was for Quintin to engage you personally in debate. After all, it's your podcast appearance and the entire post is specifically about your ideas. Yet I think the true point of Quintin's post is to engage your audience in debate - or, to be a little fanciful - the Eliezer Yudkowsky Homunculus that your audience now has in their heads.
By responding as if Quintin was seeking your personal attention, rather than the attention of your audience, and by explicitly saying you'll give him the minimum possible amount of your attention, it implicitly frames Quintin's goal as "summoning Eliezer to a serious debate on AI" and as chiding him for wasting your time by raising a public clamor regarding ideas you find basic, uninteresting, or unworthy of serious debate - though worthy of spreading to a less-informed mass audience, which is why you took the time for the podcast.
Instead, I think Quintin is stepping into the same public communications role that you were doing on the podcast. And that doesn't actually demand a response from you. I personally would not have been bothered if you'd chosen to say nothing at all. I think it is common for authors of fiction and nonfiction to allow their audience and critics some space and distance to think through and debate their ideas. It's rare to make a podcast appearance, then show up in internet comments to critique people's interpretations and misinterpretations. If an audience gets to listen to an author on a podcast, then engage them in a lively discussion or debate, they'll feel privileged for the attention. If they listen to the podcast, then create their own lively discussion in the author's absence, they'll stimulate each others' intellects. If the author shows up just enough to expression dishumor at the discussion and suggest it's not really worth his time to be there, they'll feel like he's not only being rude, but that he's misunderstanding "why we're all gathered here today."
Personally, I think it's fine for you to participate as you choose, but I think it is probably wiser to say nothing if you're not prepared to fully engage. Otherwise, it risks making you look intellectually lazy, and when you just spent the time and energy to appear on a podcast and engage people on important ideas about an important issue, why then undermine the work you've just performed in this manner? Refusing to read something because it's "kinda long" just doesn't play as high-status high-IQ countersignalling. I don't think that's what you're trying to do, but it's what it looks like you're trying to do at first glance.
It's this disconnect between what I think Quintin's true goal was in writing this post, and the way your response reframed it, that I think rubs some people the wrong way. I'm not sure about this analysis, but I think it's worth articulating as a reasonable possibility. But I don't think there is a definitive right answer or right thing to do or feel in this situation. I would like to see a vigorous but basically collegial discussion on all sides.
Just so we're clear, I am meaning to specifically convey a thought to Eliezer, but also to "speak for" whatever component of the readership agrees with this perspective, and to try and drive theory and observation on the topic of "how should rationalists interact online" forward. I feel neutral about whether or not Eliezer personally chooses to reply or read this message.
↑ comment by the gears to ascension (lahwran) · 2023-03-22T08:13:44.922Z · LW(p) · GW(p)
dude just read the damn post at a skim level at least, lol. If you can't get through this how are you going to do... sigh.
Okay, I'd really rather you read QACI posts deeply than this. But, still. It deserves at least a level 1 read [LW · GW] rather than a "can I have a summary?" dismissal.
↑ comment by Vaniver · 2023-03-22T01:38:24.381Z · LW(p) · GW(p)
FWIW, I thought the bit about manifolds in The difficulty of alignment [LW · GW] was the strongest foot forward, because it paints a different detailed picture than your description that it's responding to.
That said, I don't think Quintin's picture obviously disagrees with yours (as discussed in my response over here [LW(p) · GW(p)]) and I think you'd find disappointing him calling your description extremely misleading while not seeming to correctly identify the argument structure and check whether there's a related one that goes thru on his model.
↑ comment by Shion Arita · 2023-03-31T05:02:44.366Z · LW(p) · GW(p)
This post (and the one below) quite bothers me as well.
Yeah I know you can't have the time to address everything you encounter but you are:
-Not allowed to tell people that they don't know what they're talking about until they've read a bunch of lengthy articles, then tell someone who has done that and wrote something a fraction of the length to fuck off.
-Not allowed to publicly complain that people don't criticize you from a place of understanding without reading the attempts to do so
-Not allowed to seriously advocate for policy that would increase the likelihood of armed conflict up to and including nuclear war if you're not willing to engage with people who give clearly genuine and high effort discussion about why they think the policy is unnecessary.
Replies from: akash-wasil↑ comment by Orpheus16 (akash-wasil) · 2023-03-31T05:15:34.638Z · LW(p) · GW(p)
if you're not willing to engage with people who give clearly genuine and high effort discussion about why they think the policy is unnecessary
Briefly noting that the policy "I will not respond to every single high-effort criticism I receive" is very different from "I am not willing to engage with people who give high-effort criticism."
And the policy "sometimes I will ask people who write high-effort criticism to point me to their strongest argument and then I will engage with that" is also different from the two policies mentioned above.
↑ comment by lc · 2023-03-21T16:42:46.483Z · LW(p) · GW(p)
I would have preferred you to DM Quintin Pope with this request, instead of publicly humiliating him.
Replies from: adele-lopez-1↑ comment by Adele Lopez (adele-lopez-1) · 2023-03-21T21:35:34.314Z · LW(p) · GW(p)
This does not seem like it counts as "publicly humiliating" in any way? Rude, sure, but that's quite different.
Replies from: lc↑ comment by lc · 2023-03-21T23:33:29.563Z · LW(p) · GW(p)
"Publicly humiliating" is an exaggeration and I shouldnt do that. But the show of ordering OP to summarize his points is definitely a little bit beyond "rude".
Replies from: DanielFilan↑ comment by DanielFilan · 2023-03-22T00:13:11.659Z · LW(p) · GW(p)
I think asking someone to do something is pretty different from ordering someone to do something. I also think for the sake of the conversation it's good if there's public, non-DM evidence that he did that: you'd make a pretty different inference if he just picked one point and said that Quintin misunderstood him, compared to once you know that that's the point Quintin picked as his strongest objection.
Replies from: lc↑ comment by lc · 2023-03-22T00:21:31.000Z · LW(p) · GW(p)
You might be right.
Replies from: DanielFilan↑ comment by DanielFilan · 2023-03-22T00:32:14.062Z · LW(p) · GW(p)
Well, I'm only arguing from surface features of Eliezer's comments, so I could be wrong too :P
comment by Sen · 2023-03-28T12:29:13.942Z · LW(p) · GW(p)
Gradient descent by default would just like do, not quite the same thing, it's going to do a weirder thing, because natural selection has a much narrower information bottleneck. In one sense, you could say that natural selection was at an advantage, because it finds simpler solutions.
This is silly because it's actually the exact opposite. Gradient descent is incredibly narrow. Natural selection is the polar opposite of that kind of optimisation: an organism or even computer can come up with a complex solution to any and every problem given enough time to evolve. Evolution fundamentally overcomes global optimisation problems that are mathematically impossible for gradient descent to overcome without serious modifications, possibly not even then. It is the 'alkahest' of ML, even if it is slow and not as popular.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-03-28T12:39:40.842Z · LW(p) · GW(p)
Can you show how gradient descent solves a much narrower class of problems compared to natural selection?
Replies from: Sen↑ comment by Sen · 2023-03-28T13:01:09.684Z · LW(p) · GW(p)
If your goal is to get to your house, there is only one thing that will satisfy the goal: being at your house. There is a limited set of optimal solutions that will get you there. If your goal is to move as far away from your house as possible, there are infinite ways to satisfy the goal and many more solutions at your disposal.
Natural selection is a "move away" strategy, it only seeks to avoid death, not go towards anything in particular, making the possible class of problems it can solve much more open ended. Gradient Descent is a "move towards" strategy, if there is a solution that would help it reach a goal but it's not within the target direction, it mostly won't reach it without help or modification. This is why the ML industry is using evolutionary algorithms to solve global optimisation problems that GD cannot solve. The random search / brute force nature of evolution is inherently more versatile and is a well known limitation of GD.
comment by qvalq (qv^!q) · 2023-03-21T15:26:13.803Z · LW(p) · GW(p)
Randomly adding / subtracting extra pieces to either rockets or cryptosystems is playing with the worst kind of fire, and will eventually get you hacked or exploded, respectively.
Haha.
Replies from: qv^!q↑ comment by qvalq (qv^!q) · 2025-01-14T22:28:24.559Z · LW(p) · GW(p)
Not sure why this was downvoted.
I guess it's unproductive.
comment by lemonhope (lcmgcd) · 2023-03-21T18:43:52.300Z · LW(p) · GW(p)
Ctrl-f for "memory" has no results