Seriously, what goes wrong with "reward the agent when it makes you smile"?
post by TurnTrout · 2022-08-11T22:22:32.198Z · LW · GW · 7 commentsThis is a question post.
Contents
Answers 49 johnswentworth 16 Thane Ruthenis 7 Daniel Kokotajlo 6 Nora Belrose 5 DanielFilan 5 Tao Lin 2 Noosphere89 None 7 comments
Suppose you're training a huge neural network with some awesome future RL algorithm with clever exploration bonuses and a self-supervised pretrained multimodal initialization and a recurrent state. This NN implements an embodied agent which takes actions in reality (and also in some sim environments). You watch the agent remotely using a webcam (initially unbeknownst to the agent). When the AI's activities make you smile, you press the antecedent-computation-reinforcer button (known to some as the "reward" button). The agent is given some appropriate curriculum, like population-based self-play, so as to provide a steady skill requirement against which its intelligence is sharpened over training. Supposing the curriculum trains these agents out until they're generally intelligent—what comes next?
- The standard response is "One or more of the agents gets smart, does a treacherous turn, kills you, and presses the reward button forever."
- But reward is not the optimization target [LW · GW]. This story isn't impossible, but I think it's pretty improbable, and definitely not a slam-dunk.
- Another response is "The AI paralyzes your face into smiling."
- But this is actually a highly nontrivial claim about the internal balance of value and computation which this reinforcement schedule carves into the AI. Insofar as this response implies that an AI will primarily "care about" literally making you smile, that seems like a highly speculative and unsupported claim about the AI internalizing a single powerful decision-relevant criterion / shard of value, which also happens to be related to the way that humans conceive of the situation (i.e. someone is being made to smile).
My current answer is "I don't know precisely what goes wrong, but probably something does, but also I suspect I could write down mechanistically plausible-to-me stories where things end up bad but not horrible." I think the AI will very probably have a spread of situationally-activated computations which steer its actions towards historical reward-correlates (e.g. if near a person, then tell a joke), and probably not singularly value e.g. making people smile or reward. Furthermore, I think its values won't all map on to the "usual" quantities-of-value [LW(p) · GW(p)]:
80% credence: It's very hard to train an inner agent which reflectively equilibrates to an EU maximizer only over commonly-postulated motivating quantities (like
# of diamondsor# of happy peopleorreward-signal) and not quantities like (# of times I have to look at a cube in a blue roomor-1 * subjective micromorts accrued).
So, I'm pretty uncertain about what happens here, but would guess that most other researchers are less uncertain than I am. So here's an opportunity for us to talk it out!
(My mood here isn't "And this is what we do for alignment, let's relax." My mood is "Why consider super-complicated reward and feedback schemes when, as far as I can tell, we don't know what's going to happen in this relatively simple scheme? How do reinforcement schedules map into inner values [LW · GW]?")
Answers
I think the main concept missing here is compression: trained systems favor more compact policies/models/heuristics/algorithms/etc. The fewer parameters needed to implement the inner agent, the more parameters are free to vary, and therefore the more parameter-space-volume the agent takes up and the more likely it is to be found. (This is also the main argument for why overparameterized ML systems are able to generalize at all.)
The outer training loop doesn't just select for high reward, it also implicitly selects for compactness. We expect it to find, not just policies which achieve high reward, but policies which are very compactly represented.
Compression is the main reason we expect inner search processes to appear. Here's the relevant argument from Risks From Learned Optimization [LW · GW]:
In some tasks, good performance requires a very complex policy. At the same time, base optimizers are generally biased in favor of selecting learned algorithms with lower complexity. Thus, all else being equal, the base optimizer will generally be incentivized to look for a highly compressed policy.
One way to find a compressed policy is to search for one that is able to use general features of the task structure to produce good behavior, rather than simply memorizing the correct output for each input. A mesa-optimizer is an example of such a policy. From the perspective of the base optimizer, a mesa-optimizer is a highly-compressed version of whatever policy it ends up implementing: instead of explicitly encoding the details of that policy in the learned algorithm, the base optimizer simply needs to encode how to search for such a policy. Furthermore, if a mesa-optimizer can determine the important features of its environment at runtime, it does not need to be given as much prior information as to what those important features are, and can thus be much simpler.
The same argument applies to the terminal objectives/heuristics/proxies instilled in an RL-trained system: it may not terminally value the reward button being pushed or the human smiling or whatever, but its values should be generated from a relatively small, relatively simple set of things. For instance, a plausible Fermi estimate for humans is that our values are ultimately generated from ~tens of simple proxies. (And I would guess that modern ML training would probably result in even fewer, relative to human evolution.)
Furthermore, whatever terminal values are instilled in the RL-trained system, they do need to at least induce near-perfect optimization of the feedback signal on the training set; otherwise the outer training loop would select some other parameters. The outer training loop is still an optimization process, after all, so whatever policy the trained system ends up with should still be roughly-optimal. (There's some potential wiggle room here insofar as the AI which takes off will be the first one to pass the threshold, and that may happen during a training run before convergence, but I think that's probably not central to discussion here?)
Putting that all together: we don't know that the AI will necessarily end up optimizing reward-button-pushes or smiles; there may be other similarly-compact proxies which correlate near-perfectly with reward in the training process. We can probably rule out "a spread of situationally-activated computations which steer its actions towards historical reward-correlates", insofar as that spread is a much less compact policy-encoding than an explicit search process + simple objective(s).
↑ comment by Ivan Vendrov (ivan-vendrov) · 2022-08-12T03:02:30.256Z · LW(p) · GW(p)
Agreed with John, with the caveat that I expect search processes + simple objectives to only emerge from massively multi-task training. If you're literally training an AI just on smiling, TurnTrout is right that "a spread of situationally-activated computations" is more likely since you're not getting any value from the generality of search.
The Deep Double Descent paper is a good reference for why gradient descent training in the overparametrized regime favors low complexity models, though I don't know of explicit evidence for the conjecture that "explicit search + simple objectives" is actually lower complexity (in model space) than "bundle of heuristics". Seems intuitive if model complexity is something close to Kolmogorov complexity, but would love to see an empirical investigation!
Replies from: ivan-vendrov↑ comment by Ivan Vendrov (ivan-vendrov) · 2022-08-13T04:23:08.754Z · LW(p) · GW(p)
Thinking about this more, I think gradient descent (at least in the modern regime) probably doesn't select for inner search processes, because it's not actually biased towards low Kolmogorov complexity. More in my standalone post [LW · GW], and here's a John Maxwell comment making a similar point [LW(p) · GW(p)].
↑ comment by Thane Ruthenis · 2022-08-12T01:16:34.605Z · LW(p) · GW(p)
We can probably rule out "a spread of situationally-activated computations which steer its actions towards historical reward-correlates", insofar as that spread is a much less compact policy-encoding than an explicit search process + simple objective(s).
Not sure if I disagree with the object-level assertion, but I think some important caveats are missing here. We have to take the plausible paths through algorithm-space the SGD is likely to take as well, and that might change the form of the final compressed policy in non-intuitive ways.
Another compact policy is "a superintelligence with a messy slew of values that figured out the training context and maneuvered the SGD around to learn the reward function without internalizing it + compress itself while keeping its messy values static", and I think it's a probable-enough end-point.
It's still likely that the "messy slew of values" won't be that messy and will be near-perfect correlates for the reward, but given some (environment structure, reward) pairs, neither may be true. E. g., if the setup is such that strategic intelligence somehow develops well before the AI achieves optimal performance on the training set, then that intelligence will set in stone proxy objectives that aren't good correlates of the reward.
↑ comment by Quintin Pope (quintin-pope) · 2022-08-12T03:32:35.152Z · LW(p) · GW(p)
We can probably rule out "a spread of situationally-activated computations which steer its actions towards historical reward-correlates", insofar as that spread is a much less compact policy-encoding than an explicit search process + simple objective(s).
Seems like you can have a yet-simpler policy by factoring the fixed "simple objective(s)" into implicit, modular elements that compress many different objectives that may be useful across many different environments. Then at runtime, you feed the environmental state into your factored representation of possible objectives and produce a mix of objectives tailored to your current environment, which steer towards behaviors that achieved high reward on training runs similar to the current environment.
That would seem quite close to "a spread of situationally-activated computations which steer its actions towards historical reward-correlates", and it seems pretty similar to how my own values / goals arise in an environmentally-dependent manner without me having access to any explicitly represented "simple objective(s)" that I retain across environments.
Replies from: daniel-kokotajlo, Thane Ruthenis, johnswentworth↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-08-15T23:18:53.949Z · LW(p) · GW(p)
Seems like you can have a yet-simpler policy by factoring the fixed "simple objective(s)" into implicit, modular elements that compress many different objectives that may be useful across many different environments. Then at runtime, you feed the environmental state into your factored representation of possible objectives and produce a mix of objectives tailored to your current environment, which steer towards behaviors that achieved high reward on training runs similar to the current environment.
Can you explain why this policy is yet-simpler? It sounds more complicated to me.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2022-08-16T19:39:32.570Z · LW(p) · GW(p)
I’m saying that it’s simpler to have a goal generator that can be conditioned on the current environment, rather than memorizing each goal individually.
↑ comment by Thane Ruthenis · 2022-08-12T12:47:24.330Z · LW(p) · GW(p)
That seems like a semantical difference? We may just as well call these modular elements the "objectives", with them having different environment-specific local implementations.
E. g., if my goal is "winning", it would unfold into different short-term objectives depending on whether I'm playing chess or football, but we can still meaningfully call it a "goal".
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2022-08-13T05:10:59.534Z · LW(p) · GW(p)
I'm confident that this is not a semantic difference. The modular elements I was describing represent a process for determining ones objectives, depending on the environment and your current beliefs. It would be a type error to call them "objectives", just as it would be a type error to call a search process your "plans". They each represent compressions of possible objectives / plans, but are not those things themselves.
Similarly, it would be incorrect to call a GPT model a "collection of sentences", even though they are essentially compressions over many possible sentences.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2022-08-13T06:56:13.484Z · LW(p) · GW(p)
Okay, suppose we feed many environment-states into some factored representation of possible objectives, and generate a lot of (environment, objectives) mappings for a given agent. In your model, is it possible to summarize these results somehow; is it possible to say something general about what the agent is trying to do in all of these environments? (E. g., like my football & chess example.)
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2022-08-13T07:47:47.997Z · LW(p) · GW(p)
Yes, it’s possible to do summary statistics on the outputted goals, just like you can do summary statistics on the outputs of GPT-3, or in the plans produced by a given search algorithm. That doesn’t make generators of these things have the same type signature as the things themselves.
My counterpoint to John is specifically about the sort of computational structures that can represent goals, while being both simple AND environment/belief-dependent. I’m saying simplicity does not push against representing goals in an environment-dependent way, because your generator of goals can be conditioned on the environment.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2022-08-13T09:34:47.380Z · LW(p) · GW(p)
Yes, it’s possible to do summary statistics on the outputted goals
How "meaningful" would that summary be? Does my "winning at chess vs football" analogy fit what you're describing, with "winning" being the compressed objective-generator and the actual win conditions of chess/football being the environment-specific objectives?
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2022-08-15T06:42:04.861Z · LW(p) · GW(p)
My point is that you can have “goals” (things your search process steers the world towards) and “generators of goals”. These are different things, and you should not use the same name for them.
More specifically, there is a difference in the computational type signature between generators and the things they generate. You can call these two things by whatever label you like, but they are not the same thing.
You can look a person’s plans / behavior in many different games and conclude that it demonstrates a common thread which you might label “winning”. But you should not call the latent cognitive generators responsible for this common thread by the same name you use for the world states the person’s search process steers towards in different environments.
Replies from: Thane Ruthenis, Thane Ruthenis↑ comment by Thane Ruthenis · 2022-08-15T07:28:29.278Z · LW(p) · GW(p)
Alright, then it is a semantics debate from my perspective. I don't think we're actually disagreeing, now. Your "objective-generators" cleanly map to my "goals", and your "objectives" to my "local implementations of goals" (or maybe "values" and "local interpretations of values"). That distinction definitely makes sense at the ground level. In my ontology, it's a distinction between what you want and how achieving it looks like in a given situation.
I think it makes more sense to describe it my way, though, since I suspect a continuum of ever-more-specific/local objectives ("winning" as an environment-independent goal, "winning" in this type of game, "winning" against the specific opponent you have, "winning" given this game and opponent and the tactic they're using), rather than a dichotomy of "objective-generator" vs "objective", but that's a finer point.
↑ comment by Thane Ruthenis · 2022-08-15T08:32:28.121Z · LW(p) · GW(p)
Although, digging into the previously-mentioned finer points, I think there is room for some meaningful disagreement.
I don't think there are goal-generators as you describe them. I think there are just goals, and then some plan-making/search mechanism which does goal translation/adaptation/interpretation for any given environment the agent is in. I. e., the "goal generators" are separate pieces from the "ur-goals" they take as input.
And as I'd suggested, there's a continuum of ever-more specific objectives. In this view, I think the line between "goals" and "plans" blurs, even, so that the most specific "objectives" are just "plans". In this case, the "goal generator" is just the generic plan-making process working in a particular goal-interpreting regime.
(Edited-in example: "I want to be a winner" -> "I want to win at chess" -> "I want to win this game of chess" -> "I want to decisively progress towards winning in this turn" -> "I want to make this specific move". The early steps here are clear examples of goal-generation/translation (what does winning mean in chess?), the latter clear examples of problem-solving (how do I do well this turn?), but they're just extreme ends of a continuum.)
The initial goal-representations from which that process starts could be many things — mathematically-precise environment-independent utility functions, or goals defined over some default environment (as I suspect is the case with humans), or even step-one objective-generators, as you're suggesting. But the initial representation being an objective-generator itself seems like a weirdly special case, not how this process works in general.
↑ comment by johnswentworth · 2022-08-12T04:45:15.725Z · LW(p) · GW(p)
That sure does sound like a description of a search algorithm, right there.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2022-08-12T05:03:53.020Z · LW(p) · GW(p)
I'm not objecting to your assertion that some sort of search takes place. I'm objecting to your characterization of what sorts of objectives the search ends up pointed towards. Basically, I'm saying that "situationally activated heuristics that steer towards environment-dependent goals" is totally in-line with a simplicity prior over cognitive structures leading to a search-like process.
The whole reason you say that we should expect search processes is because they can compress many different environment and beliefs dependent plans into a simpler generator of such plans (the search), which takes in environment info, beliefs, and the agent's simple, supposedly environment-independent, objectives, and produces a plan. So, the agent only needs to store the search process and its environment-independent objectives.
I'm saying you can apply a similar "compress into an environment / beliefs conditioned generator" trick to the objectives as well, and get a generator of objectives that condition on the environment and current beliefs to produce objectives for the search process.
Thus, objectives remain environment-dependent, and will probably steer towards world states that resemble those which were rewarded during training. I think this is quite similar to "a spread of situationally-activated computations which steer its actions towards historical reward-correlates", if involving rather more sophisticated cognition than phrases like "contextually activated heuristics" often imply.
↑ comment by TurnTrout · 2022-08-15T03:54:10.666Z · LW(p) · GW(p)
We can probably rule out "a spread of situationally-activated computations which steer its actions towards historical reward-correlates", insofar as that spread is a much less compact policy-encoding than an explicit search process + simple objective(s).
Here's what I think you mean by an explicit search process:
- In every situation, the neural network runs e.g. MCTS with a fixed leaf evaluation function (the simple objective).
On this understanding of your argument, I would be surprised if it went through. Here are a few quick counterpoints.
- Outside tiny maze environments, constantly running search with a fixed objective is downright stupid, you're going to constantly time out; anytime guarantees won't necessarily save you, they'll probably be weak or nonexistent; constantly running search will consistently waste computation time which could have been saved by caching computations and then thinking about other things during the rest of the forward pass (aka shards); fixed-depth neural networks also have a speed prior.
- (See also the independently written Gradient descent doesn't select for inner search [LW · GW])
- EDIT: Reading your reply comment on that post
And there are many other tricks one can use too - like memoization on subsearches, or A*-style heuristic search, or (one meta-level up from A*) relaxation-based methods to discover heuristics. The key point is that these tricks are all very general purpose: they work on a very wide variety of search problems, and therefore produce general-purpose search algorithms which are more efficient than brute force (at least on realistic problems).
More advanced general-purpose search methods seem to rely relatively little on enumerating possible actions and evaluating their consequences. By the time we get to human-level search capabilities, we see human problem-solvers spend most of their effort on nontrivial problems thinking about subproblems, abstractions and analogies rather than thinking directly about particular solutions.
Memoization and heuristics would definitely count as part of a "spread" of contextually activated computations? Are we even disagreeing?
- Humans are the one example we have of general intelligences [LW · GW]; they surely have different e.g. inductive biases than ML, and that's damn important. But even so, humans do not search in every situation in order to optimize a simple objective. Seems like an important hint.
- More generally: "If your theory of alignment and/or intelligence is correct, why doesn't it explain the one datapoint we have on general intelligence?"
- any "simplicity prior" that ANNs have is not like the simplicity prior of a programming language. A single forwards pass is acyclic, so loops / recursion are impossible. If NN layers were expressed as programs, the language in question would also have to be acyclic, which would make "search" quite a dumb thing to do anyways.
- EDIT Although in OP I did presume a recurrent state! Still important to keep in mind as we consider different architectures, though.
- Initial contextually-activated-heuristics might (low-confidence) starve gradients towards search.
For instance, a plausible Fermi estimate for humans is that our values are ultimately generated from ~tens of simple proxies. (And I would guess that modern ML training would probably result in even fewer, relative to human evolution.)
Do you mean "hardcoded reward circuit" by "proxy"?
Replies from: johnswentworth↑ comment by johnswentworth · 2022-08-15T06:05:44.413Z · LW(p) · GW(p)
Do you mean "hardcoded reward circuit"
I'm not that committed to the RL frame, but roughly speaking yes. Whatever values we have are probably generated by ~tens of hardcoded things. Anyway, on to the meat of the discussion...
It seems like a whole bunch of people are completely thrown off by use of the word "search". So let's taboo that and talk about what's actually relevant here.
We should expect compression, and we should expect general-purpose problem solving (i.e. the ability to take a fairly arbitrary problem in the training environment and solve it reasonably well). The general-purpose part comes from a combination of (a) variation in what the system needs to do to achieve good performance in training, and (b) the recursive nature of problem solving, i.e. solving one problem involves solving a wide variety of subproblems. Compactness means that it probably won't be a whole boatload of case-specific heuristics; lookup tables are not compact. A subroutine for reasonably-general planning or problem-solving (i.e. take a problem statement, figure out a plan or solution) is the key thing we're talking about here. Possibly a small number of such subroutines for a few different problem-classes, but not a large number of such subroutines, because compactness. My guess would be basically just one.
That probably will not look like babble and prune. It may look like a general-purpose heuristic-generator (like e.g. relaxation based heuristic generation). Or it may look like general-purpose efficiency tricks, like caching solutions to common subproblems. Or it may look like harcoded heuristics which are environment-specific but reasonably goal-agnostic (like e.g. the sort of thing in Mazes and Duality [LW · GW] yields a maze-specific heuristic, but one which applies to a wide variety of path finding problems within that maze). Or it may look like harcoded strategies for achieving instrumentally convergent goals in the training environment (really this is another frame of caching solutions to common subproblems). Or it may look like learning instrumentally convergent concepts and heuristics from the training environment (i.e. natural abstractions; really this is another frame on environment-specific but goal-agnostic heuristics). Probably it's a combination of all of those, and others too.
The important point is that it's a problem-solving subroutine which is goal-agnostic (though possibly environment-specific). Pass in a goal, it figures out how to achieve that goal. And we do see this with humans: you can give humans pretty arbitrary goals, pretty arbitrary jobs to do, pretty arbitrary problems to solve, and they'll go figure out how to do it.
Replies from: nora-belrose, TurnTrout↑ comment by Nora Belrose (nora-belrose) · 2022-08-15T13:52:28.573Z · LW(p) · GW(p)
I agree that AGI will need general purpose problem solving routines (by definition). I also agree that this requires something like recursive decomposition of problems into subproblems. I'm just very skeptical that the kinds of neural nets we're training right now can learn to do anything remotely like that— I think it's much more likely that people will hard code this type of reasoning into the compute graph with stuff like MCTS. This has already been pretty useful for e.g. MuZero. Once we're hard coding search it's less scary because it's more interpretable and we can see exactly where the mesaobjective is.
I also don't really buy the compactness argument at all. I think neural nets are biased toward flat minima / broad basins but these don't generally correspond to "simple" functions in the Kolmogorov sense; they're more like equivalence classes of diverse bundles of heuristics that all get about the same train and val loss. I'm interpreting this paper as providing some evidence in that direction.
Replies from: johnswentworth↑ comment by johnswentworth · 2022-08-15T17:25:09.253Z · LW(p) · GW(p)
I'm just very skeptical that the kinds of neural nets we're training right now can learn to do anything remotely like that— I think it's much more likely that people will hard code this type of reasoning into the compute graph with stuff like MCTS. This has already been pretty useful for e.g. MuZero. Once we're hard coding search it's less scary because it's more interpretable and we can see exactly where the mesaobjective is.
I hope that you're right; that would make Retargeting The Search [LW · GW] very easy, and basically eliminates the inner alignment problem. Assuming, of course, that we can somehow confidently rule out the rest of the net doing any search in more subtle ways.
↑ comment by TurnTrout · 2022-08-22T15:54:08.469Z · LW(p) · GW(p)
Probably it's a combination of all of those, and others too
This seems like roughly what I had in mind by "contextually activated computations" (probably with a few differences about when/how the subroutines will be goal-agnostic). I was imagining computations like "contextually activated cached death-avoidance policy influences" and "contextually activated steering of plans towards paperclip production, in generalizations of the historical reinforcement contexts for paperclip-reward."
I think the AI will very probably have a spread of situationally-activated computations which steer its actions towards historical reward-correlates (e.g. if near a person, then tell a joke), and probably not singularly value e.g. making people smile or reward
I agree. My recent write-up [LW · GW] is partly an attempt to model this dynamic in a toy causal-graph environment. Most relevantly, this section [LW · GW].
Imagine an environment represented as a causal graph, with some action-nodes an agent can set, observation-nodes whose values that agent can read off, and some reward-node whose value determines how much reinforcement the agent gets. The agent starts with no information about the environment structure or the environment state. If the reward-node is sufficiently distant from its action-nodes, it'll take time for the agent's world-model to become advanced enough to model it. However, the agent would start trying to develop good policies/heuristics for increasing the reward immediately. Thus, its initial policies will necessarily act on proxies: it'll be focusing on the values of some intermediate nodes between its action-nodes and the reward-node.
And these proxies can be quite good. For example:
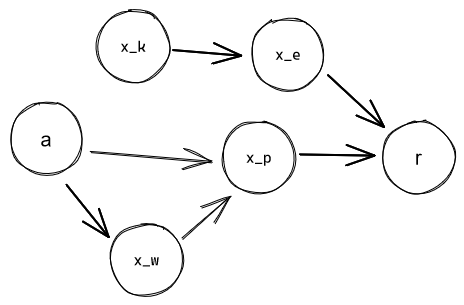
is a good proxy for controlling the value of if the chain doesn't perturb it too much. So an agent that only cares about the environment up to can capture e. g. of the possible maximum reward.
It feels like it shouldn't matter: that once the world-model is advanced enough to include directly, the agent should just recognize as the source of reinforcement, and optimize it directly.
But suppose the heuristics the agent develops have "friction". That is: once a heuristic has historically performed well enough, the agent is reluctant to replace it with a better but more novel (and therefore untested) one. Or, at least, less willing the less counterfactual reward it promises to deliver. So a heuristic that performs 10x as well as the one it currently has will be able to win against a much older one, but a novel heuristic that only performs 1.1x as well won't be.
In this case, the marginally more effective policy will not be able to displace a more established one.
(An alternate view: suppose that the agent has two mutually-exclusive heuristic on what to do in a given situation, A and B. A has a good track record, B is a new one, but it's willing to try B out. Suppose it picks A with probability and B with , with proportional to how long A's track record is. If the reinforcement B receives is much larger than the reinforcement A receives, then even a rarely-picked B will eventually outpace A. If it's not much larger, however, then A will be able to "keep up" with B by virtue of being picked more often, and eventually outrace B into irrelevancy.)
Therefore: Yes, the agent will end up optimized for good performance on some proxies of "the human presses the button". What these proxies are depends on the causal structure of the environment, the percentage of max-reward optimizing for them allows the agent to capture, and some "friction" value that depends on the agent's internal architecture.
Major caveat: This mainly only holds for less-advanced systems; for those that are optimized, but do not yet optimize at the strategic level. A hedonist wrapper-mind [LW · GW] would have no problems with evaluating whether the new heuristic is actually better, testing it out, and implementing it, no matter how comparably novel it is.
Caveat to the caveat: Such strategic thinking will probably appear after the "values" have already been formed, and at that point the agent will do deceptive alignment to preserve them, instead of self-modifying into a reward-maximizer.
Route warning: This doesn't mean the agent's proxies will be friendly or even comprehensible to us. In particular, if the reward structure is
Then it's about as likely (very not) that the agent will end up focusing on "I smile" as on "I press the button", since there's basically just a single causal step. Much more likely is that it'll value some stuff upstream of "something makes me smile"; possibly very strange stuff.
Note: Using the "antecedent-computation-reinforcer" term really makes all of this clearer, but it's so unwieldy. Any ideas for coining a better term?
Quoting Rob Bensinger quoting Eliezer:
So what actually happens as near as I can figure (predicting future = hard) is that somebody is trying to teach their research AI to, god knows what, maybe just obey human orders in a safe way, and it seems to be doing that, and a mix of things goes wrong like:
The preferences not being really readable because it's a system of neural nets acting on a world-representation built up by other neural nets, parts of the system are self-modifying and the self-modifiers are being trained by gradient descent in Tensorflow, there's a bunch of people in the company trying to work on a safer version but it's way less powerful than the one that does unrestricted self-modification, they're really excited when the system seems to be substantially improving multiple components, there's a social and cognitive conflict I find hard to empathize with because I personally would be running screaming in the other direction two years earlier, there's a lot of false alarms and suggested or attempted misbehavior that the creators all patch successfully, some instrumental strategies pass this filter because they arose in places that were harder to see and less transparent, the system at some point seems to finally "get it" and lock in to good behavior which is the point at which it has a good enough human model to predict what gets the supervised rewards and what the humans don't want to hear, they scale the system further, it goes past the point of real strategic understanding and having a little agent inside plotting, the programmers shut down six visibly formulated goals to develop cognitive steganography and the seventh one slips through, somebody says "slow down" and somebody else observes that China and Russia both managed to steal a copy of the code from six months ago and while China might proceed cautiously Russia probably won't, the agent starts to conceal some capability gains, it builds an environmental subagent, the environmental agent begins self-improving more freely, undefined things happen as a sensory-supervision ML-based architecture shakes out into the convergent shape of expected utility with a utility function over the environmental model, the main result is driven by whatever the self-modifying decision systems happen to see as locally optimal in their supervised system locally acting on a different domain than the domain of data on which it was trained, the light cone is transformed to the optimum of a utility function that grew out of the stable version of a criterion that originally happened to be about a reward signal counter on a GPU or God knows what.
Perhaps the optimal configuration for utility per unit of matter, under this utility function, happens to be a tiny molecular structure shaped roughly like a paperclip.
That is what a paperclip maximizer is. It does not come from a paperclip factory AI. That would be a silly idea and is a distortion of the original example.
↑ comment by TurnTrout · 2022-08-15T04:05:43.255Z · LW(p) · GW(p)
Perhaps the optimal configuration for utility per unit of matter, under this utility function, happens to be a tiny molecular structure shaped roughly like a paperclip.
I think this is very improbable, but thanks for the quote. Not sure if it addresses my question?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-08-25T03:10:28.467Z · LW(p) · GW(p)
Yudkowsky & I would of course agree that that is very improbable. It's just an example.
The point I was making with this quote is that the question you are asking is a Big Old Unsolved Problem in the literature. If we had any idea what sort of utility function the system would end up with, that would be great and an improvement over the status quo. Yudkowsky's point in the quote is that it's a complicated multi-step process we currently don't have a clue about, it's not nearly as simple as "the system will maximize reward." A much better story would be "The system will maximize some proxy, which will gradually evolve via SGD to be closer and closer to reward, but at some point it'll get smart enough to go for reward for instrumental convergence reasons and at that point its proxy goal will crystallize." But this story is also way too simplistic. And it doesn't tell us much at all about what the proxy will actually look like, because so much depends on the exact order in which various things are learned.
I should have made it just a comment, not an answer.
Replies from: TurnTrout↑ comment by TurnTrout · 2022-08-29T21:30:35.227Z · LW(p) · GW(p)
because so much depends on the exact order in which various things are learned.
I actually doubt that claim in its stronger forms. I think there's some substantial effect, but e.g. whether a child loves their family doesn't depend strongly on the precise curriculum at grade school.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-08-30T02:36:15.646Z · LW(p) · GW(p)
Yet whether a child grows up to work on x-risk reduction vs. homeless shelters vs. voting Democrats out of office vs. voting Republicans out of office does often depend on the precise curriculum in college+high school.
(I think we are in agreement here. I'd be interested to hear if you can point to any particular value AGI will probably have, or (weaker) any particular value such that if AGI has it, it doesn't depend strongly on the curriculum, order in which concepts are learned, etc.)
I don't know what the agent would end up valuing in this scenario either. I think a pretty good research direction for shard theory would be to closely examine the training history of the agent to find particular episodes where qualitatively new behaviors seem to form / new circuits arise in the neural net. This might allow you to identify shards, whereas it seems much harder to do that if you're only looking at the final trained weights of the agent.
Not having read other responses, my attempt to answer in my own words: what goes wrong is that there are tons of possible cognitive influences that could be reinforced by rewards for making people smile. E.g. "make things of XYZ type think things are going OK", "try to promote physical configurations like such-and-such", "trying to stimulate the reinforcer I observe in my environment". Most of these decision-influences, when extrapolated to coherent behaviour where those decision-influences drive the course of the behaviour, lead to resource-gathering and not respecting what the informed preferences of humans would be. Then this causes doom because you can better achieve most goals/preferences you could have by having more power and disempowering the humans.
Pretrained models don't need any exploration to know that pressing the reward button gets more reward than doing things the humans want. If you just ask GPT3, it'll tell you that.
Then the only exploration the AI needs is to get reward after thinking about analogies between its situation and its textual knowledge of AI/reinforcement learning/AI doom scenarios.
This applies especially much to simple/often discussed tasks such as making people smile - an LM has already heard of this exact task, so if it took an action based on the "make people smile task" its heard about, this could outperform other thought processes which are only conditioned on data so far.
↑ comment by TurnTrout · 2022-08-15T04:06:44.403Z · LW(p) · GW(p)
OK, but that's a predictive fact in the world model, not a motivational quantity in the policy. I know about my reward center too, and my brain does RL of some kind, but I don't primarily care about reward.
Replies from: tao-lin, tao-lin↑ comment by Tao Lin (tao-lin) · 2022-08-15T14:00:28.342Z · LW(p) · GW(p)
Here's a plausible story to me:
The model sees its environment + past actions, and its LM predictive modelling part puts non-neglible prob on "this the 'make humans smile' task". Then its language modelling prior predicts the next action, not based on the training setup, which it doesn't see, but based on the environment, and it outputs an action aimed at pressing the reward button. This action does well, is reinforced, and you get a reward-button-presser.
Some context is that when training language models with RLHF, the language modelling prior tends to dominate over RL-learned behaviors on sub-distributions even after lots of RLHF training.
Another version of this is "for many trajectories, an LM will be primarily predicting text, not executing rl-reinforced behaviors. Given this, actions that get reinforced are likely to come from the LM producing text that gets high reward in its reward model, rather than random actions"
Replies from: nora-belrose↑ comment by Nora Belrose (nora-belrose) · 2022-08-15T14:27:02.100Z · LW(p) · GW(p)
This is actually a pretty good argument, and has caused me to update more strongly to the view that we should be optimizing only the thought process of chain of thought language models, not the outcomes that they produce
↑ comment by Tao Lin (tao-lin) · 2022-08-15T14:35:12.697Z · LW(p) · GW(p)
Also, I think if you trained something to predict text, then RL trained it on inclusive genetic fitness as a human (or human motivation signals), its learning would be mostly in the space of "select specific human / subdistribution of humans to imitate" rather than learning behaviors specific to the task, and then its generalization properties would depend more on those humans than on the specific training setup used
One plausible answer is that it does in fact reward hack/optimize the reward, because reward hacking/reward optimization has happened before empirically, so there are reasonable grounds to raise the hypothesis to plausibility:
7 comments
Comments sorted by top scores.
comment by Richard_Ngo (ricraz) · 2022-08-12T00:58:03.307Z · LW(p) · GW(p)
- Another response is "The AI paralyzes your face into smiling."
- But this is actually a highly nontrivial claim about the internal balance of value and computation which this reinforcement schedule carves into the AI. Insofar as this response implies that an AI will primarily "care about" literally making you smile, that seems like a highly speculative and unsupported claim about the AI internalizing a single powerful decision-relevant criterion / shard of value, which also happens to be related to the way that humans conceive of the situation (i.e. someone is being made to smile).
Who do you think would make the claim that the AI in this scenario would care about "literally making you smile", as opposed to some complex, non-human-comprehensible goal somewhat related to humans smiling? E.g. Yudkowsky gives the example of an AI in that situation learning to optimize for "tiny molecular smiley faces", which is a much weirder generalization than "making you smile", although I think still less weird than the goal he'd actually expect such a system to learn (which wouldn't be describable in a single four-word phrase).
I think the AI will very probably have a spread of situationally-activated computations which steer its actions towards historical reward-correlates (e.g. if near a person, then tell a joke), and probably not singularly value e.g. making people smile or reward.
I think this happens when you have less intelligent systems, and then as you have more intelligent systems those correlates end up unified into higher-level abstractions which correspond to large-scale goals. I outline some of the arguments for that position in phase 3 here [LW · GW].
Replies from: TurnTrout↑ comment by TurnTrout · 2022-08-15T04:12:23.778Z · LW(p) · GW(p)
Who do you think would make the claim that the AI in this scenario would care about "literally making you smile", as opposed to some complex, non-human-comprehensible goal somewhat related to humans smiling?
I don't know? Seems like a representative kind of "potential risk" I've read about before, but I'm not going to go dig it up right now. (My post also isn't primarily about who said what, so I'm confused by your motivation for posting this question?)
Replies from: abramdemski↑ comment by abramdemski · 2022-08-15T16:01:26.601Z · LW(p) · GW(p)
I've often repeated scenarios like this, or like the paperclip scenario.
My intention was never to state that the specific scenario was plausible or default or expected, but rather, that we do not know how to rule it out, and because of that, something similarly bad (but unexpected and hard to predict) might happen.
The structure of the argument we eventually want is one which could (probabilistically, and of course under some assumptions) rule out this outcome. So to me, pointing it out as a possible outcome is a way of pointing to the inadequacy of our current ability to analyze the situation, not as part of a proto-model in which we are conjecturing that we will be able to predict "the AI will make paperclips" or "the AI will literally try to make you smile".
comment by Joel Burget (joel-burget) · 2022-08-12T14:47:09.088Z · LW(p) · GW(p)
Meta-comment: I'm happy to see this -- someone knowledgeable, who knows and seriously engages with the standard arguments, willing to question the orthodox answer (which some might fear would make them look silly). I think this is a healthy dynamic and I hope to see more of it.
Replies from: Raemon↑ comment by Raemon · 2022-08-12T18:55:05.286Z · LW(p) · GW(p)
I also found this a good exercise in deliberate questioning/boggling.
From 2010-2014, when I was first forming my opinions on AI, it was really frustrating that anyone who objected to the basic AI arguments just... clearly hadn't been paying attention and at all and didn't understand the basic arguments.
comment by Shmi (shminux) · 2022-08-11T23:55:35.386Z · LW(p) · GW(p)
Somewhat unrelated and probably silly... Why reward the agent directly instead of letting it watch humans act in their natural environment and leaving it to build a predictive model of humans?
Replies from: green_leaf↑ comment by green_leaf · 2022-08-12T07:18:37.871Z · LW(p) · GW(p)
To predict if a human ends up happy with something or not?