Convergence Towards World-Models: A Gears-Level Model
post by Thane Ruthenis · 2022-08-04T23:31:33.448Z · LW · GW · 1 commentsContents
1. Intuitions 2. Formalisms 2.1. The Setup 2.2. Ideal Actions 2.3. Heuristics 2.4. The Need for World-Models 3. Extending the Framework 3.1. Incrementalism 3.2. The Planning Loop 3.3. The Mesa-Optimizer Pipeline Acknowledgements None 1 comment
1. Intuitions
One of the more solid results in agency theory is the generalized definition of power-seeking [? · GW]. Power-seeking is the tendency of agents to move towards states with the potential to achieve the best average outcome across some distribution of reward functions. In other words, looking at an agent whose values we do not know, we can a priori expect it to pursue "power", because it's trying to navigate to some specific end-state, and the path to it likely routes through environment-states in which it can choose from the largest variety of end-states. For example: take over the world so it can do whatever it wants.
Can we derive a similar definition for the convergent development of world-models?
I believe so, and it feels surprisingly simple in retrospect.
"World-models" are sets of statistical correlations across input-data. Every next correlation you notice — like object permanence, or the laws of gravity, or that your friend saying "I've ordered pizza" correlates with the image of a pizza entering your visual feed half an hour later — is another building block of your world-model.
A particularly important kind of statistical correlations are those that constitute selection pressures. When some system experiences selection pressure — be that an NN trained via the SGD, an animal species optimized by evolution, or a corporation shaped by market forces — it's receiving positive or negative feedback from the environment in a statistically predictable manner. The strength of such pressures increases or decreases according to certain correspondences between environment-states and the system's actions, and by definition of being optimized/selected, the system is gradually adjusted to minimize the pressure.
To do that, the system needs to (be made to) recognize the statistical correlations around it, pick out the ones related to the selection pressure, and enforce such correspondences between them and its actions as to minimize loss/survive/maximize revenue.
In turn, every bit of feedback from the selection pressure gives the system information about that pressure (somehow [LW · GW]). It builds into the system some understanding of the causal structure of the environment, by the very nature of selecting it.
When the system can only myopically respond to the input-data, when it can only uncover correlations on the level of e. g. pixels, its repository of statistical correlations is poor. As that repository grows, as its world-model develops, it starts being able to imagine more complex correlations:
"If the world is currently in this state, and I enforce such correlation between some elements of that state and my actions, it will correlate with me receiving such feedback."
And since any given system starts out not knowing what statistical correlations its selection pressure depends on, it's convergent to try to derive every statistical correlation it can — build a complete world-model, then search it for the sources of feedback it receives.
Thus: Any system subjected to some selection pressure the strength of which depends on some correlations between that system's actions and some features of the environment would converge towards discovering as many environmental statistical correlations as possible, in order to be more well-positioned to "guess" what correlation between the environment and its actions it needs to enforce in order to minimize that pressure.
The system doesn't know what the world wants of it, so it'll learn everything about the world in order to reverse-engineer that want.
Now let's try to show all of that in a toy mathematical environment.
2. Formalisms
2.1. The Setup
Suppose that we have some environment represented as a causal (not necessarily acyclic) graph , with nodes . The environment is dynamic: every time-step , the value of every child-node is updated by its parent-nodes, as in , where is the set of parental nodes of .
An intervention function sets the value of every node to some corresponding value for the time-step . This function will be used to model actions.
The System, every time-step, takes in the values of some set of observables , and runs on some set of actionables . After that, it receives from the Selection Pressure.
The Selection Pressure, every time-step, takes in the values of some set of reward nodes , and outputs a score. That is, .
Sidebar: Technically, and the System can be made parts of the environment as well. With , it's trivial — just imagine that every is a parent of the actual node, and is the update function of that node.
With the System, it's a bit more difficult. You can imagine that every observable plus has a node as its child-node, every actionable has as its only parental node, and that somehow controls the update functions from itself to the actionables. Alternatively, you might imagine to be a special node that represents a black-boxed cluster of nodes, to explain its ability to uniquely specify the value of each actionable. You may also imagine that the internals of this node perform at a much faster speed than the environment, so all of its computations happen in a single time-step. Or you may not [? · GW].
Postulating all of this is a needless complication for the purposes of this post, though, so I won't be doing this. But you can, if you want to expand on it while getting rid of Cartesianism.
Given this setup, what internal mechanisms would you need to put in the System to improve its ability to maximize across time, given that it would start from a place of total ignorance with regards to the environment structure, the current environment-state, and the nature of ?
2.2. Ideal Actions
Buuut first let's consider the environment from the position of omniscience. Given full knowledge of the environment structure, its current state, and the reward nodes, what can we say about the optimal policy?
Let's imagine a toy environment where is a function of the value of just one node, . The actionables, likewise, are a singular other node . Suppose the reward function wants the value of to equal at every time-step.
If , the optimal policy at the time-step is simple: .
If is adjacent to , then we'll only be able to act on it on the time-step following the current one, and we'll do it through the update function between and , whose output also depends on the values of 's parents. I. e., the optimal action is a function of , , and .
If is separated by some node from , we'll only affect two time-steps later, and the value we send will be interfered with by the parents of at and the parents of at and at .
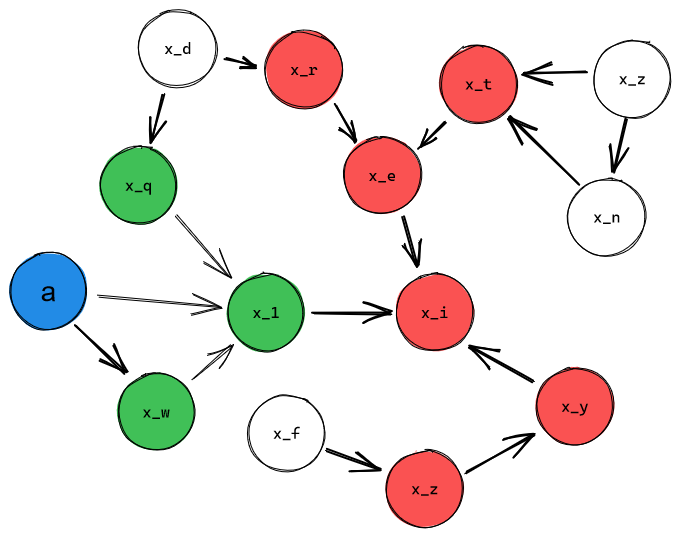
The optimal action, thus, is a function of , , , , , and . Note that is additionally a function of and , and is additionally a function of the update functions for all members of that set, and the values of every parent of every member of that set.
Generally, if the shortest path from to the reward-node consists of nodes , we'll only be able to affect it time-steps later, and the optimal action will be a function of , , .
Thus, the farther away the node we want to affect, the broader the "causality cone" of nodes we'll need to take into consideration. Or, equivalently, the current action is a function of further-in-time environment-states.
That complexity is not necessarily irreducible. Certain combinations of environment structure and update functions can result in some of the parents reliably cancelling each other out, such that the actual function for computing the most optimal action is a lower-dimensional one. If the environment is a well-abstracting one [? · GW], such dynamics might be ubiquitous, such that only a higher-level model of it suffices.
But in general, even taking such techniques into account, the "farther" the target node is, the more other nodes you'd need to take into account.
2.3. Heuristics
Some definitions:
- An idealized model is the probability distribution over the environment-state given some information . That is:
- A cross-temporal model of the environment is some set containing all values of nodes across some time period: .
- A cross-temporal slice of the environment is some subset .
- Similarly, we have a cross-temporal slice of the action-space: , where all nodes whose values are in are actionables.
In relation to this, given the current time-step , we can define a heuristic as follows:
A heuristic uses some function to look at some cross-temporal slice and judge whether some conditions it wants are met. If not (), it executes the part.
In English: given a model of the environment, a heuristic recommends taking certain action at present or at particular future points given certain beliefs about current, future, or past environment-states. A heuristic does not necessarily have a recommended action for every intermediate time-step, or a recommendation for every actionable. Several heuristics can be ran in the same time-step, in fact, if their action-slices aren't overlapping.
(Note that the cross-temporal actions slice is a subset of , because you can't take actions in the past.)
Intuitively, heuristics are likely defined over natural abstractions [? · GW], or some high-level environment-models wholly build out of them. would look for a particular object — a cluster of individual nodes whose internal complexity can be reduced to a high-level summary — and check its high-level state, possibly across time. For certain "undesirable" states or dynamics, it would attempt to intervene, correcting them.
As an example, consider a grandmaster playing a game of chess. They've developed a lot of chess-specific heuristics. These heuristics look exclusively at the cross-temporal slice of the world-model that has to do with the current game. What moves the grandmaster made, what moves their opponent made, and what moves both of them may make in the future. One of these heuristics may recognize a cross-temporal pattern — a particular sequence of moves the opponent made, perhaps, plus the moves they may be planning to make — and map that pattern to the memorized correct response to it, countering the tactic the opponent is trying.
Caveats: That function is technically incoherent, since , which it takes as an input, can presumably only be computed with the knowledge of the actions the System will take in the future, and these actions are what the heuristic computes as an output. There's a couple of ways around that: might be a "placeholder future", computed under the assumption that the System takes some default actions/null action. Or it might be the output of some other heuristic, passed to this one for potential correction.
The degenerate case of a heuristic, of course, is and :
This is an "instinctive reaction", an instant response to some stimuli.
Another simplified, but interestingly different case, is , but with being a few steps removed from the observations. Intuitively, this is how CNN image classifiers work: they take in a bunch of pixels, then extrapolate the environment-state these pixels are a snapshot of, and back out the values of "is the node dog = 1?", "is the node cat = 1?".
Okay, now let's try to answer the question.
2.4. The Need for World-Models
The System starts from a place of complete ignorance about the environment. It doesn't know its structure, its state, what nodes is defined over, or even that there is an outside world. All information it has access to are observations and the scores it receives for taking actions .
Any heuristic it can implement would follow the algorithm of, "IF (some set of observables has certain values) THEN (set some actionables to certain values)". Thus, its set of heuristics is defined over the power sets of observables and actionables . Heuristics, thus, would have a type signature , where , .
From a state of total ignorance, there's no strategy better than guessing blindly. So suppose the System samples a few random heuristics and runs them in a few episodes. Upon receiving , it would get some information about their effectiveness, and would ideally keep effective heuristics and improve on them while discarding bad ones. But how?
Well, any solution would need to solve the credit assignment problem [LW · GW] somehow.
So suppose it is solved, somehow. What properties would the solution have?
Whatever it is, it would establish a causal connection between observations, actions, and the feedback: , and also , since if it's possible to derive actionable information about from , they have to be somehow causally connected.
In other words: whatever the credit assignment mechanism, whether it's external (as in ML) or purely internal [LW · GW], it would convey information about the structure of the environment.
Thus, even as the System is blindly guessing shallow heuristics, it's learning a world-model. Even if only implicitly.
And acting on observables can only get us so far. Literally: as per 2.2, the farther away from our action-nodes the reward-node is, the more intermediate nodes we have to take into account to compute the correct action to take. Turning it around, the farther from the reward-node the observation-nodes are, the more "diffuse" the information about the reward-node they contain. In all probability, all individual have to be calculated as a function of all observables, to maximize our ability to map out the surrounding environment.
And this is where the world-models come in.
Let's assume that world-models can be incomplete — as in, contain only some part of the environment graph . For simplicity, let's assume that over time, it's expanded by one degree of separation in every direction, denoted as . So contains only the observables and the actionables, also contains all of their parents and children, contains parents and children of all nodes in , and so on.
Knowing the partial structure of the environment and the values of some of its variables (the observables) at allows us to reconstruct its state: , where and is some internal state (including the knowledge of the environment structure and likely a history of previous observations and the actions taken).
Further, knowing the environment structure, the state at , and what actions we plan to take, lets us compute the model of the next environment state, but at a one less degree of separation: .
Likewise, under some assumptions about the transition functions , we can often model the environment backwards: .
Let's denote the cross-temporal model we get from that as .
The main effect of all of this is that it greatly expands the space of heuristics: they're now defined over the power sets of actionables and all modelable nodes:
At the limit of infinite time, the System may expand the world-model to cover the entire environment. That would allow it to design optimal heuristics for controlling every reward-node , akin to the functions mentioned in 2.2, regardless of the specific environment-structure it's facing.
3. Extending the Framework
I believe the main point is made now, but the model could be extended to formalize a few more intuitions.
3.1. Incrementalism
The System won't start knowing the entire world-model, however. Conversely, it would start generating heuristics from the get-go. In theory, once the world-model is fully learned, there's nothing preventing the System from deriving and maximizing .
But what if we add friction?
The credit-assignment mechanism needs to know how to deal with imperfect heuristics, if it's to be useful before the world-model is complete. A generally good heuristic making a mistake shouldn't be grounds for immediately deleting it. We'd also need to know how to resolve heuristics conflicts: situations when the cross-temporal model conditioned on the System running some heuristic makes some other heuristic try to correct it, which causes try to re-correct it, and so on. Which one should be allowed to win?
The notion of a "weight" seems the natural answer to that need. Heuristics to which credit is assigned more often and in greater quantities shall have more weight than the less well-performing ones, and in case of a heuristics conflict, the priority shall be more often given to the weightier one.
Suppose that the individual reward-nodes aren't sitting in a cluster. They're scattered across the graph, such that you can often affect one of them without affecting the others. That will likely give rise to specialized heuristics, which focus on optimizing the state of just one or several such reward-node. Only the full heuristical ensemble would be optimizing directly.
Now consider the following structure:
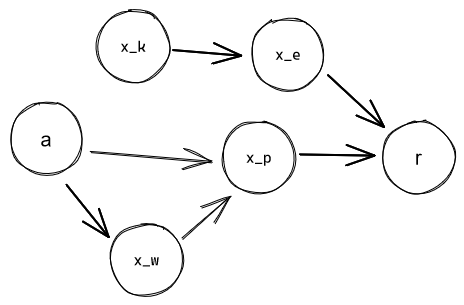
Suppose that we have some heuristic that's greatly specialized in optimizing . (I. e., it models the graph up to and picks actions that set to some value that the heuristic prefers. And it prefers it because setting to it has historically correlated with high .) Once the environment is mapped out up to , that heuristic can be replaced by one focusing on directly. But what if has a lot of weight by this point? The hypothetical would not have that much to contribute — controlling is a good proxy for controlling , and if don't have a very large effect, probably captures most of the reward that can be squeezed out of without taking them into account.
The better-performing would simply never be able to edge the older out, then.
Thus, the System would be optimized for a reward proxy.
And this is likely to be an ubiquitous outcome. The world-model is being developed in lockstep with new heuristics, and if the reward-nodes are sufficiently conceptually-far from the actionables, it'll find good reward-proxies well before it discovers the actual reward-nodes. And at that point, the proxy-controlling heuristics will be impossible to depose.
3.2. The Planning Loop
The definition of a heuristic has a free parameter: the mysterious function , which somehow calculates what actions to take given the world-model.
Its internals can have different contents:
- It may output a constant value, discarding .
- It may be a lookup table, taking some members of as input.
- It may run a somewhat more sophisticated algorithm, looking at the values of some nodes and "extracting" the answer from the world-model.
But most salient are algorithms of the following kind:
This process searches the world-model for a series of actions that will cause some set of nodes in it to assume certain values at certain times. I. e., "how do I make X happen?".
That is the planning loop/inner optimization. Since we expect heuristics to be defined in relation to some natural abstractions — i. e., the condition is looking for is some coherent high-level concept — we can assume that implicitly includes some mesa-objective. (Returning to the chess-game example, the heuristic with a planning loop would be searching the world-model for actions that lead to the condition "the grandmaster wins the game", or maybe "the opponent's tactic is countered".)
The planning loop may be niche. Instead of the entire , it may search over some . I. e., a given implemented in a given heuristic may only know how to optimize over a particular cluster of nodes in the world-model — the cluster the heuristic is specialized in. (E. g., the model of chess.)
Sidenote: Similar analysis can be made with regards to the function . The environment conditions for firing a heuristic can also be incredibly complex, so complex as to require intelligent analysis. I suspect there may be something interesting to be found in this direction as well. Consider, e. g., a heuristic with a very complex but a lookup table for ? I think we see some examples of that in humans...
Sidenote #2: A lot of complexity is still hidden in and . A mesa-optimizer would not perform blind search — it has some heuristics/mechanisms for efficiently guessing what actions it makes sense to try running the world-model on, before it actually performs search. I suspect it's some set of "advanced cognitive functions", and that complex likely share it with complex .
3.3. The Mesa-Optimizer Pipeline
So how does all of that grow into a terrifying lightcone-eating utility-maximizer? There's a few paths.
First, may be shared across all heuristics. As per the Orthogonality Thesis [? · GW], intelligence is orthogonal to values: a good optimization algorithm can be used to optimize any objective. This model concretizes this intuition somewhat. If can perform search in the entire world-model, there's no reason to replicate its functionality, and every reason to hook all the heuristics up to the same algorithm — to minimize memory expenditure.
In this scenario, the resultant AGI would be optimizing a mix of mesa-objectives, a weighted sum of the heuristics it developed. Possibly inconsistently, as different heuristics grab control at different times. Possibly unstably, if new heuristics are still being derived. Humans may work like this, see Why Subagents? [LW · GW] and the Shard Theory [? · GW].
Second, a more nuanced version of the above. The AGI may develop a sort of meta-heuristic, which would explicitly derive the weighted average of the extant heuristics, then set that as its primary mesa-objective, and pursue it consistently. There's probably a pressure to do that, as to do otherwise is a dominated strategy [? · GW]. It may also be required depending on the specifications of — if getting it to hit high values requires high coordination[1].
I suspect humans work like this some of the time — when we're consciously optimizing or performing value reflection, instead of acting on autopilot.
Third, one of the heuristics may take over. Suppose that isn't shared after all; every heuristic uses some specialized search algorithm. Then, the heuristic with the most advanced one starts to expand, gradually encroaching on others' territory. It should be pretty heavily weighted, probably heavier than any of the others, so that's not inconceivable. In time, it may take over others' roles, and the entire system would become a wrapper-mind [LW · GW] optimizing some simple mesa-objective.
That heuristic would probably need to do it deliberately. As in, it'd need to become an advanced enough agent to model this entire dynamic, and purposefully take over the mind it's running in, for instrumental power-seeking reasons, while actively preventing its mesa-objective from changing. It'd need to model the base objective instead of internalizing it [? · GW].
It feels like this scenario is relatively unlikely: that heuristics are unlikely to be this lopsided in their capabilities. On the other hand, what do I know about how that works in neural networks trained by the SGD the specific way we're doing it now?
Fourth, given some advanced heuristic management algorithms, we may reduce the friction described at the beginning of 3.1. If heuristics don't ossify, and are frequently replaced by marginally-better-performing alternatives, the inner alignment failures the three previous scenarios represent won't happen. The AGI would grow to optimize the outer reward function it's been optimized by.
(Edit: Correction, it will probably wirehead instead. If, as per the sidebar in 2.1, we view itself as a node on the graph, then a frictionless setup would allow the AGI navigate to it directly, not to the in-environment variables it's defined over. To fix this, we'd need to set up some special "Cartesian boundary" over the node, ensuring it doesn't make that final jump.)
This scenario seems unlikely without some advanced, probably intelligent oversight. E. g., very advanced interpretability and manual-editing tools under the control of humans/another ML model.
Acknowledgements
Thanks to Quintin Pope, TurnTrout, Logan Riggs, and others working on the Shard Theory [? · GW]: the thinking behind this post has been heavily inspired by it.
(In fact, I suspect that the concept I'm referring to by "heuristic" in this post is synonymous with their "shards". Subjective opinion, though, I haven't run it by the ST folks.)
- ^
E. g., if , we can have separate heuristics for maximizing the values of all of these nodes, operating mostly independently. On the other hand, if , that'd require tighter coordination to ensure the product approximates .
1 comments
Comments sorted by top scores.
comment by johnswentworth · 2022-08-04T23:52:17.295Z · LW(p) · GW(p)
Another excellent post! Building up from heuristics is a particularly novel piece - it's something other work has done, but usually not at the same time as anything else. You're integrating things together into a single coherent model.
One thing you kinda skipped over which I'd highlight:
And since any given system starts out not knowing what statistical correlations its selection pressure depends on, it's convergent to try to derive every statistical correlation it can — build a complete world-model, then search it for the sources of feedback it receives.
This applies mainly when the system doesn't know, in advance, which information it will need later on. If the system always needs the same bit, and can ignore everything else, then the argument doesn't work so well. (I see this as a core idea of the Gooder Regulator Theorem [LW · GW].)
Other than that, the main next question I'd suggest is: how can you take this model, and turn it into a world-model-detector/extractor which we could point at some system in practice? What other pieces are missing?