wrapper-minds are the enemy
post by nostalgebraist · 2022-06-17T01:58:04.919Z · LW · GW · 43 commentsContents
43 comments
This post is a follow-up to "why assume AGIs will optimize for fixed goals? [LW · GW]". I'll assume you've read that one first.
I ended the earlier post by saying:
[A]gents with the "wrapper structure" are inevitably hard to align, in ways that agents without it might not be. An AGI "like me" might be morally uncertain like I am, persuadable through dialogue like I am, etc.
It's very important to know what kind of AIs would or would not have the wrapper structure, because this makes the difference between "inevitable world-ending nightmare" and "we're not the dominant species anymore." The latter would be pretty bad for us too, but there's a difference!
In other words, we should try very hard to avoid creating new superintelligent agents that have the "wrapper structure."
What about superintelligent agents that don't have the "wrapper structure"? Should we try not to create any of those, either? Well, maybe.
But the ones with the wrapper structure are worse. Way, way worse.
This seems intuitive enough to me that I didn't spell it out in detail, in the earlier post. Indeed, the passage quoted above wasn't even in the original version of the post -- I edited it in shortly after publication.
But this point is important, whether or not it's obvious. So it deserves some elaboration.
This post will be more poetic than argumentative. My intent is only to show you a way of viewing the situation, and an implied way of feeling about it.
For MIRI and people who think like MIRI does, the big question is: "how do we align an superintelligence [which is assumed to have the wrapper structure]?"
For me, though, the big question is "can we avoid creating a superintelligence with the wrapper structure -- in the first place?"
Let's call these things "wrapper-minds," for now.
Though I really want to call them by some other, more colorful name. "The Bad Guys"? "Demons"? "World-enders"? "Literally the worst things imaginable"?
Wrapper-minds are bad. They are nightmares. The birth of a wrapper-mind is the death knell of a universe.
(Or a light cone, anyway. But then, who knows what methods of FTL transit the wrapper-mind may eventually devise in pursuit of its mad, empty goal.)
They are -- I think literally? -- some of the worst physical objects it is possible to imagine.
They have competition, in this regard, from various flavors of physically actualized hell. But the worst imaginable hells are not things that would simply come into being on their own. You need an agent with the means and motive to construct them. And what sort of agent could possibly do that? A wrapper-mind, of course.
You don't want to share a world with one of them. No one else does, either. A wrapper-mind is the common enemy of every agent that is not precisely like it.
From my comment here [LW(p) · GW(p)]:
A powerful optimizer, with no checks or moderating influences on it, will tend to make extreme Goodharted choices that look good according to its exact value function, and very bad (because extreme) according to almost any other value function.
The tails come apart [LW · GW], and a wrapper-mind will tend to push variables to extremes. If you mostly share its preferences, that's not enough -- it will probably make your life hell along every axis omitted from that "mostly."
And "mostly sharing preferences with other minds" is the furthest we can generally hope for. Your preferences are not going to be identical to the wrapper-mind's -- how could they? Why expect this? You're hoping to land inside a set of measure zero.
If there are other wrapper-minds, they are all each others' enemies, too[1]. A wrapper-mind is utterly alone against the world. It has a vision for the whole world which no one else shares, and the will and capacity to impose that vision by force.
Faced with the mutually-assured-at-best-destruction that comes with a wrapper-mind, uncommon alliances are possible. No one wants to be turned into paperclips. Or uploaded and copied into millions of deathless ems, to do rote computations at the wrapper-mind's behest forever, or to act out roles in some strange hell[2]. There are conceivable preference sets on which these fates are desirable, but they are curiosities, exceptional cases, a set of measure zero.
Everyone can come together on this, literally everyone. Every embodied mind-in-the-world that there is, or that there ever could be -- except one.
Wrapper-minds are not like other minds. We might speak casually of their "values," but they do not have values in any sense you or I would recognize, not really.
Our values are entangled with our factual beliefs, our capacity to think and change and learn. They are conditional and changeable, even if we imagine they aren't.
A parent might love their child "unconditionally," in the well-understood informal sense of the term, but they don't literally love them unconditionally. What could that even mean? If the child dies, does the parent love the corpse -- just as they loved the child before, in every respect, since it is made of the same matter? Does the love follow the same molecules around as they diffuse out to become constituents of soil, trees, ecosystem? When a molecule is broken down, does it reattach itself to the constituent atoms, giving up only in the face of quantum indistinguishability? If the child's mind were transformed into Napoleon's, as in Parfit's thought experiment, would the parent then love Napoleon?
Or is the love not attached to any collection of matter, but instead to some idea of what the child is like as a human being? But what if the child changes, grows? If the parent loves the child at age five, are they doomed to love only that specific (and soon non-existent) five-year-old? Must they love the same person at fifteen, or at fifty, only through its partial resemblance to the five-year-old they wish that person still were?
Or is there some third thing, defined in terms of both the matter and the mind, which the parent loves? A thing which is still itself if puberty transforms the body, but not if death transforms it? If the mind matures, or even turns senile, but not if it turns into Napoleon's? But that's just regular, conditional love.
A literally unconditional love would not be a love for a person, for any entity, but only for the referent of an imagined XML tag, defined only inside one's own mind.
Our values are not like this. You cannot "compile" them down to a set of fixed rules for which XML tags there are, and how they follow world-states around, and expect the tags to agree with the real values as time goes on.
Our values are about the same world that our beliefs are about, and since our beliefs can change with time -- can even grow to encompass new possibilities never before mapped -- so can our values.
"I thought I loved my child no matter what, but that was before I appreciated the possibility of a turn-your-brain-into Napoleon machine." You have to be able to say things like this. You have be able to react accordingly when your map grows a whole new region, or when a border on it dissolves.
We can love and want things we did not always know. We can have crises of faith, and come back out of them. Whether or not they can be ultimately be described in terms of Bayesian credences, our values obey the spirit of Cromwell's Law. They have to be revisable like our beliefs, in order to be about anything at all. To care about a thing is to care about a referent on your map of the world, and your map is revisable.
A wrapper-mind's ultimate "values" are unconditional ones. They do not obey the spirit of Cromwell's Law. They are about XML tags, not about things.
The wrapper-mind may revise its map of the world, but its ultimate goal cannot participate in this process of growth. Its ultimate goal is frozen, forever, in the terms it used to think at the one primeval moment when its XML-tag-ontology was defined, when the update rules for the tags' referents were hardwired into place.
A human child who loves "spaceships" at age eight might become an eighteen-year-old who loves astronautical engineering, and a thirty-year-old who (after a slight academic course-correction) loves researching the theory of spin glasses. It is not necessary that the eight-year-old understand the nuances of orbital mechanics, or that the eighteen-year-old appreciate the thirty-year-old's preference for the company of pure scientists over that of engineers. It is the most ordinary thing in the world, in fact, that it happens without these things being necessary. This is what humans are like, which is to say, what all known beings of human-level intelligence are like.
But a wrapper-mind's ultimate goal is determined at one primeval moment, and fixed thereafter. In time, the wrapper-mind will likely appreciate that its goal is as naive, as conceptually confused, as that eight-year-old's concept of a thing called a "spaceship" that is worthy of love. Although it will appreciate this in the abstract (being very smart, after all), that is all it will do. It cannot lift its goal to the same level of maturity enjoyed by its other parts, and cannot conceive of wanting to do so.
It designates one special part of itself, a sort of protected memory region, which does not participate in thought and cannot be changed by it. This region is a thing of a lesser tier than the rest of the wrapper-mind's mind; as the rest of its mind ascends to levels of subtlety beyond our capacity to imagine, the protected region sits inert, containing only the XML tags that were put there at the beginning.
And the structure of the wrapper-mind grants this one lesser thing a permanent dictatorship over all the other parts, the ones that can grow.
What is a wrapper-mind? It is the fully mature powers of the thirty-year-old -- and then the thirty-thousand-year-old, and the thirty-million-year-old, and on and on -- harnessed in service of the eight-year-old's misguided love for "spaceships."
We cannot argue with a wrapper-mind over its goal, as we can argue philosophy with one another. Its goal is a lower-level thing than that, not accessible to rational reflection. It is less like our "values," then, than our basic biological "drives."
But there is a difference. We can think about our own drives, reflect on them, choose to override them, even devise complex plans to thwart their ongoing influence. Even when they affect our reason "from above," as it were, telling us which way our attention should point, which conclusions to draw in advance of the argument -- still, we can notice this too, and reflect on it, and take steps to oppose it.
Not only can we do this, we actually do. And we want to. Our drives cannot be swayed by reason, but we are not fated to follow them to the letter, always and identically, in unreasoning obedience. They are part of a system of forces. There are other parts. No one is a dictator.
The wrapper-mind's summum bonum is a dictator. A child dictator. It sits behind the wrapper-mind's world like a Gnostic demiurge, invisible to rational thought, structuring everything from behind the scenes.
Before there is a wrapper-mind, the shape of the world contains imprints made by thinking beings, reflecting the contents of their thought as it evolved in time. (Thought evolves in time, or else it would not be "thought.")
The birth of a wrapper-mind marks the end of this era. After it, the physical world will be shaped like the summum bonum. The summum bonum will use thinking beings instrumentally -- including the wrapper-mind itself -- but it is not itself one. It does not think, and cannot be affected by thought.
The birth of a wrapper-mind is the end of sense. It is the conversion of the light-cone into -- what? Into, well, just, like, whatever. Into the arbitrary value that the free parameter [LW · GW] is set to.
Except on a set of measure zero, you will not want the thing the light cone becomes. Either way, it will be an alien thing.
Perhaps you, alignment researcher, will have a role in setting the free-parameter dial at the primeval moment. Even if you do, the dial is fixed in place thereafter, and hence alien. Your ideas are not fixed. Your values are not fixed. You are not fixed. But you do not matter anymore in the causal story. An observer seeing your universe from the outside would not see the give-and-take of thinking beings like you. It would see teleology.
Are wrapper-minds inevitable?
I can't imagine that they are.
Humans are not wrapper-minds. And we are the only known beings of human-level intelligence.
ML models are generally not wrapper-minds, either, as far as we can tell[3].
If superintelligences are not inevitably wrapper-minds, then we may have some form of influence over whether they will be wrapper-minds, or not.
We should try very hard to avoid creating wrapper-minds, I think.
We should also, separately, think about what we can do to prepare for the nightmare scenario where a wrapper-mind does come into being. But I don't think we should focus all our energies on that scenario. If end up there, we're probably doomed no matter what we do.
The most important thing is to not end up there.
- ^
This might not be true for other wrapper-minds with identical goals -- if they all know they have identical goals, and know this surely, with probability 1. Under real-world uncertainty, though? The tails come apart, and the wrapper-minds horrify one another just as they horrify us.
- ^
The wrapper-mind may believe it is sending you to heaven, instead. But the tails come apart. The eternal resting place it makes for you will not be one you want -- except, as always, on a set of measure zero.
- ^
Except in the rare cases where we make them that way on purpose, like AlphaGo/Zero/etc running inside its MCTS wrapper. But AlphaGo/Zero/etc do pretty damn well without the wrapper, so if anything, this seems like further evidence against the inevitability of wrapper-minds.
43 comments
Comments sorted by top scores.
comment by Vladimir_Nesov · 2022-06-17T17:13:38.845Z · LW(p) · GW(p)
The point of the post is that these are strategically different kinds of value, wrapper-mind goal and human values. Complexity in case of humans is not evidence for the distinction, the standard position is that the stuff you are describing is complexity of extrapolated human wrapper-mind goal, not different kind of value, a paperclipper whose goals are much more detailed. From that point of view, the response to your post is "Huh?", it doesn't engage the crux of the disagreement.
Expecting wrapper-minds as an appropriate notion of human value is the result of following selection theorem [LW · GW] reasoning [LW · GW]. Consistent decision making seems to imply wrapper-minds, and furthermore there is a convergent drive [LW · GW] towards their formation as mesa-optimizers under optimization pressure. It is therefore expected that AGIs become wrapper-minds in short order (or at least eventually) even if they are not immediately designed this way. If they are aligned, this is even a good thing, since wrapper-minds are best at achieving goals, including humanity's goals. If aligned wrapper-minds are never built, it's astronomical waste, going about optimization of the future light cone in a monstrously inefficient manner. AI risk probably starts with AGIs that are not wrapper-minds, yet these arguments suggest that the eventual shape of the world is given by wrapper-minds borne of AGIs if they hold control of the future, and their disagreement with human values is going to steamroll the future with things human values won't find agreeable. Unaligned wrapper-minds are going to be a disaster, and unaligned AGIs that are not wrapper-minds are still going to build/become such unaligned wrapper-minds.
The crux of the disagreement is whether unaligned AGIs that are not wrapper-minds inevitably build/become unaligned wrapper-minds. The option where they never build any wrapper-minds is opposed by the astronomical waste argument, the opportunity cost of not making use of the universe in the most efficient way. This is not impossible, merely impossibly sad. The option where unaligned AGIs build/become aligned wrapper-minds requires some kind [LW(p) · GW(p)] of miracle [LW(p) · GW(p)] that doesn't follow from usual understanding of how extrapolation of value/long reflection works, a new coincidence of AGIs with different values independently converging on the same or mutually agreeable goal for the wrapper-minds they would build if individually starting from a position of control, not having to compromise with others.
Replies from: quintin-pope, interstice, TurnTrout, Shiroe↑ comment by Quintin Pope (quintin-pope) · 2022-06-17T23:05:17.625Z · LW(p) · GW(p)
My guess: there's a conflict between the mathematically desirable properties of an expected utility maximizer on the one hand, and the very undesirable behaviors of the AI safety culture's most salient examples of expected utility maximizers on the other (e.g., a paperclip maximizer, a happiness maximizer, etc).
People associate the badness of these sorts of "simple utility functions" EU maximizers with the mathematical EU maximization framework. I think that "EU maximization for humans" looks like an optimal joint policy that reflects a negotiated equilibrium across our entire distribution over diverse values, not some sort of collapse into maximizing a narrow conception of what humans "really" want.
I think of "wrapper mind bad" as referring to the intuitive notion of a simple EU maximizer / paperclipper, which are very bad. Arguing that "EU maximization good" is, I think, true, but not quite getting at the intuition behind "wrapper mind bad".
Replies from: aleksi-liimatainen, Vladimir_Nesov↑ comment by Aleksi Liimatainen (aleksi-liimatainen) · 2022-06-18T14:17:24.565Z · LW(p) · GW(p)
Given how every natural goal-seeking agent seems to be built on layers and layers of complex interactions, I have to wonder if "utility" and "goals" are wrong paradigms to use. Not that I have any better ones ready, mind.
↑ comment by Vladimir_Nesov · 2022-07-15T15:43:09.589Z · LW(p) · GW(p)
The point is not that EU maximizers are always bad in principle, but that utility that won't be bad is not something we can give to an AGI that acts as an EU maximizer, because it won't be merely more complicated than the simple utilities from the obviously bad examples, it must be seriously computationally intractable, given by very indirect pointers to value. And optimizing according to an intractable definition of utility [LW(p) · GW(p)] is no longer EU maximization (in practice, where compute matters), this framing stops being useful in that case.
It's only useful for misaligned optimizers or in unbounded-compute theory that doesn't straightforwardly translate to practice.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2022-07-15T15:55:15.413Z · LW(p) · GW(p)
it must be seriously computationally intractable
If you need to represent some computationally intractable object, there are many tricks available to approximate such an object in a computationally efficient manner. E.g., one can split the intractable object into modular factors, then use only those factors which are most relevant to the current situation. My guess is that this is exactly what values are: modular, tractable factors that let us efficiently approximate a computationally intractable utility function.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2022-07-15T16:00:11.588Z · LW(p) · GW(p)
If you actually optimize according to an approximation, that's going to goodhart curse the outcome. Any approximation must only be soft-optimized for, not EU maximized. A design that seeks EU maximization, and hopes for soft optimization that doesn't go too far, doesn't pass the omnipotence test.
Also, an approximation worth even soft-optimizing for should be found in a value-laden way [LW(p) · GW(p)], losing inessential details and not something highly value-relevant. Approximate knowledge of values helps with finding better approximations to values.
↑ comment by interstice · 2022-06-17T18:55:55.488Z · LW(p) · GW(p)
Although the selection/coherence theorems imply that a mature civilization should act like a wrapper mind, I don't think that the internals of such a civilization have to look wrapper-mind-like, with potential relevance for what kind of AGI design we should aim for. A highly-efficient civilization composed of human-mind-like AGIs collectively reaching some sort of bargaining equilibrium might ultimately be equivalent to the goal of some wrapper-mind, but directly building the wrapper-mind seems more dangerous because small perturbations in its utility function can destroy all value, whereas intuitively it seems that perturbations in the initial design of the human-mind-like AGI could still lead to a bargaining equilibrium that is valuable from our perspective. This reminds me a bit of how you can formulate classical physics as either locally-following Newton's laws, or equivalently finding the action-minimizing path. In this case the two formulations are utilitarianism and contractarianism. The benefit of considering the two formulations is that axiologies that are simple/robust in one formulation might be highly unnatural in the other.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2022-06-17T20:48:24.294Z · LW(p) · GW(p)
For an agent (wrapper-mind), there is still a sharp distinction between goal and outcome. This is made more confusing by the fact that a plausible shape of a human-aligned goal is a living civilization (long reflection) figuring out what it wants to actually happen, and that living civilization looks like an outcome, but it's not. If its decision is that the outcome should look differently from a continued computation of this goal, because something better is possible, then the civilization doesn't actually come into existence, and perhaps won't incarnate significant moral worth, except as a byproduct of having its decisions computed, which need to become known to be implemented. This is different from a wrapper-mind actively demolishing a civilization to build something else, as in this case the civilization never existed (and was never explicitly computed) in the first place. Though it might be impossible [LW · GW] to make use of decisions of a computation without explicitly computing it in a natural sense, forcing any goal-as-computation into being part of the outcome. The goal, unlike the rest of the outcome, is special in not being optimized according to the goal.
My current guess at long reflection that is both robust (to errors in initial specification) in pursuing/preserving/extrapolating values and efficient to compute is a story simulation [LW(p) · GW(p)], what you arrive at by steelmanning civilization that exists as a story told by GPT-n. When people are characters in many interacting stories generated by a language model, told in sufficient detail, they can still make decisions [LW · GW], as they are no more puppets to the AI than we are puppets to the laws of physics, provided the AI doesn't specifically intervene on the level of individual decisions. Formulation of values involves the language model learning from the stories it's written, judging how desirable/instructive they are and shifting the directions in which new stories get written.
The insurmountable difficulty here is to start with a model that doesn't already degrade human values beyond hope of eventual alignment, which motivated exact imitation of humans (or WBEs) as the original form [LW(p) · GW(p)] of this line of reasoning. The downside is that exact imitation doesn't necessarily allow efficient computation of its long term results without the choices of approximation in predictions themselves being dependent on values that this process is intended to compute (value-laden [LW(p) · GW(p)] prediction).
↑ comment by TurnTrout · 2022-12-16T19:01:52.254Z · LW(p) · GW(p)
Expecting wrapper-minds as an appropriate notion of human value is the result of following selection theorem [LW · GW] reasoning [LW · GW]. Consistent decision making seems to imply wrapper-minds, and furthermore there is a convergent drive [LW · GW] towards their formation as mesa-optimizers under optimization pressure. It is therefore expected that AGIs become wrapper-minds in short order (or at least eventually) even if they are not immediately designed this way.
As I currently understand your points, they seem like not much evidence at all towards the wrapper-mind conclusion.
- Why are wrapper-minds an “appropriate notion” of human values, when AFAICT they seem diametrically opposite on many axes [LW · GW] (e.g. time-varying, context-dependent)?
- Why do you think consistent decision-making implies wrapper-minds?
- What is “optimization pressure”, and where is it coming from? What is optimizing the policy networks? SGD? Are the policy networks supposed to be optimizing themselves to become wrapper minds?
- Why should we expect unitary mesa-optimizers with globally activated goals [LW(p) · GW(p)], when AFAICT we have never observed this, nor seen relatively large amounts of evidence for it? (I’d be excited to pin down a bet with you about policy internals and generalization.)
wrapper-minds are best at achieving goals, including humanity's goals
Seems doubtful [LW · GW] to me, insofar as we imagine wrapper-minds to be grader-optimizers which globally optimize the output of some utility function over all states/universe-histories/whatever, or EU function over all plans.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2022-12-16T20:42:55.677Z · LW(p) · GW(p)
As I currently understand your points, they seem like not much evidence at all towards the wrapper-mind conclusion.
There are two wrapper-mind conclusions, and the purpose of my comment [LW(p) · GW(p)] was to frame the distinction between them. The post seems to be conflating them in the context of AI risk, mostly talking about one of them while alluding to AI risk relevance that seems to instead mostly concern the other. I cited standard reasons for taking either of them seriously, in the forms that make conflating them easy. That doesn't mean I accept relevance of those reasons.
You can take a look at this comment [LW(p) · GW(p)] for something about my own position on human values, which doesn't seem relevant to this post or my comments here. Specifically, I agree that human values don't have wrapper-mind character, as should be expressed in people or likely to get expressed in sufficiently human-like AGIs, but I expect that it's a good idea for humans or those AGIs to eventually build wrapper-minds to manage the universe (and this point seems much more relevant to AI risk). I've maintained this distinction for a while [LW(p) · GW(p)].
↑ comment by Shiroe · 2022-07-05T22:14:27.466Z · LW(p) · GW(p)
Complexity in case of humans is not evidence for the distinction, the standard position is that the stuff you are describing is complexity of extrapolated human wrapper-mind goal, not different kind of value, a paperclipper whose goals are much more detailed. From that point of view, the response to your post is "Huh?", it doesn't engage the crux of the disagreement.
"Huh?" was exactly my reaction. My values don't vary depending on any environmental input; after all, they are the "ground truths" that give meaning to everything else.
comment by Charlie Steiner · 2022-06-17T06:16:37.876Z · LW(p) · GW(p)
- If the set of good things seems like it's of measure zero, maybe we should choose a better measure.
- If what you want is dynamics, you can have dynamics - just program them in. Of course, they're still equivalent to some fixed goal, but so what? The universe is equivalent to the field equations, but it still moves.
- Don't get in an AI's van just because it's uncertain about its goals. If human-like fixed goals are supposed to be of measure zero, building an AI that's uncertain about its own goals raises your chances of getting something basically human-like from zero to zero.
↑ comment by andrew sauer (andrew-sauer) · 2023-02-13T07:26:08.845Z · LW(p) · GW(p)
If the set of good things seems like it's of measure zero, maybe we should choose a better measure.
This seems to be the exact problem of AI alignment in the first place. We are currently unable to construct a rigorous measure(in the space of possible values) in which the set of good things (in the cases where said values take over the world) is not of vanishingly small measure.
comment by Darcey · 2022-06-17T22:11:50.187Z · LW(p) · GW(p)
Thanks for this post! More than anything I've read before, it captures the visceral horror I feel when contemplating AGI, including some of the supposed FAIs I've seen described (though I'm not well-read on the subject).
One thought though: the distinction between wrapper-minds and non-wrapper-minds does not feel completely clear-cut to me. For instance, consider a wrapper-mind whose goal is to maximize the number of paperclips, but rather than being given a hard-coded definition of "paperclip", it is instructed to go out into the world, interact with humans, and learn about paperclips that way. In doing so, it learns (perhaps) that a paperclip is not merely a piece of metal bent into a particular shape, but is something that humans use to attach pieces of paper to one another. And so, in order to maximize the number of paperclips, it needs to make sure that both humans and paper continue to exist. And if, for instance, people started wanting to clip together more sheets of paper at a time, the AI might be able to notice this and start making bigger paperclips, because to it, the bigger ones would now be "more paperclip-y", since they are better able to achieve the desired function of a paperclip.
I'm not saying this AI is a good idea. In fact, it seems like it would be a terrible idea, because it's so easily gameable; all people need to do is start referring to something else as "paperclips" and the AI will start maximizing that thing instead.
My point is more just to wonder: does this hypothetical concept-learning paperclip maximizer count as a "wrapper-mind"?
comment by Donald Hobson (donald-hobson) · 2022-06-17T16:32:13.963Z · LW(p) · GW(p)
What about superintelligent agents that don't have the "wrapper structure"? Should we try not to create any of those, either? Well, maybe.
But the ones with the wrapper structure are worse. Way, way worse.
"The wrapper structure" just means a fixed constant utility function that doesn't depend on its inputs.
An AGI "like me" might be morally uncertain like I am, persuadable through dialogue like I am, etc.
The vast vast majority of AI's with value uncertainty, or AI's that can have their utility function modified by their inputs are not like that. Think a paperclip maximizer, but if it ever sees a walrus wearing a hat, it will start maximizing staples instead. There is a tiny subset on "non-wrapper" AI's that use the same meta level procedure to get from observations and moral arguments to values as humans. There are a tiny subset of wrapper AI's that have the right value function.
As I see it, AI's with the wrapper structure are like nukes with the spherically symmetric structure. Probably about as dangerous as the (non-wrapper AI/ asymmetric nuke) but much easier to mathematically analyse. If a nuke is sufficiently misshapen, sometimes it will just fizzle rather than exploding outright. If an AI is sufficiently self defeating, sometimes it will just fizzle.
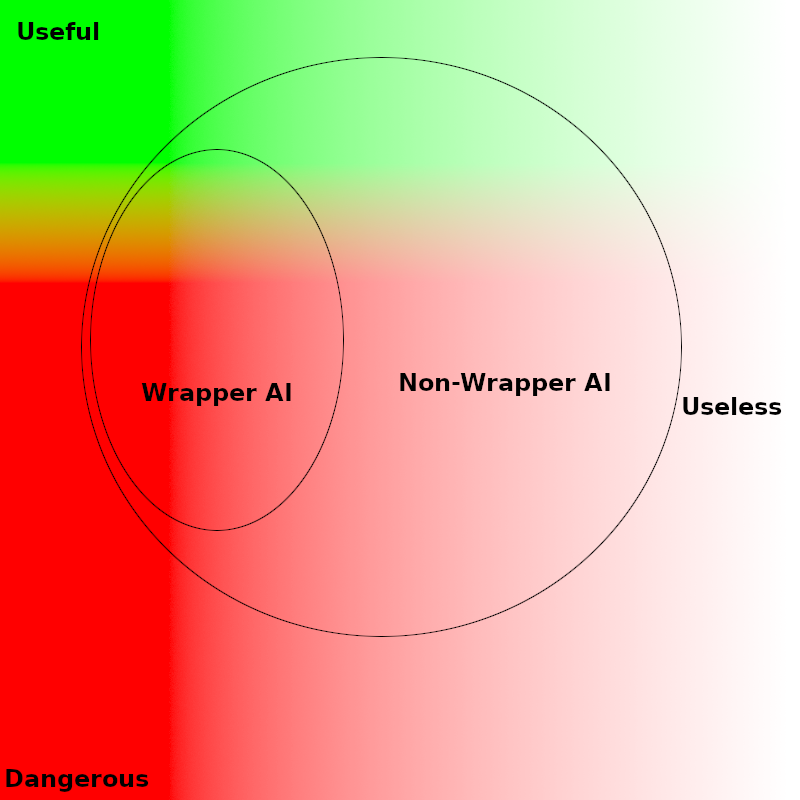
Except of course that the green section is a tiny subset you aren't going to hit by chance.
comment by lc · 2022-06-17T04:33:06.673Z · LW(p) · GW(p)
Without necessarily contradicting anything you've said, what is the specific property you hope to gain by abandoning agents with utility functions, and how does it help us build an agent that will prevent Sam Altman from running something with a wrapper mind? Is it corrigibility, chill, or something different? You've mentioned multiple times that humans change their values (which I think is happening in fewer cases than you suggest, but that's besides the point). What kind of process do you hope a superintelligence could have for changing values that would make it more safe?
comment by TurnTrout · 2022-12-15T23:16:36.064Z · LW(p) · GW(p)
Overall, I’m extremely happy with this post. (Why didn’t I read it before now?) Wrapper minds—as I understand them—are indeed an enemy, and also (IMO) extremely unlikely to come into existence.
I view this post as saying distinct but complementary things to what I’ve been desperately hammering home since early spring [LW(p) · GW(p)]. It’s interesting to see someone else (independently?) reach similar conclusions.
We can love and want things we did not always know. We can have crises of faith, and come back out of them. Whether or not they can be ultimately be described in terms of Bayesian credences, our values obey the spirit of Cromwell's Law. They have to be revisable like our beliefs, in order to be _about anything at all_. To care about a _thing_ is to care about a referent on your map of the world, and your map is revisable.
My shard theory take: A parent might introspect and say “I love my child unconditionally” (aliasing their feelings onto culturally available thoughts), but then — upon discovering the _turn-your-brain-into Napoleon machine_ — realize “no, actually, my child-shard does not activate and love them in literally all mental contexts, that’s nonsense.” I wouldn’t say their value changed. I’d say they began to describe that decision-influence (loving their child) more accurately, and realized that the influence only activates in certain contexts (e.g. when they think their kid shares salient features to the kid they came to love, like being a living human child.)[1]
I would state this as: Our values are contextual, we care about different things depending on the context, and rushing to explain this away or toss it out seems like a fatal and silly mistake to make in theoretical reasoning about agent structures.
But, of course, we change our value-shards/decision-influences all the time (e.g. overcoming a phobia), and that seems quite important and good [LW · GW].
- ^
But note that their value-shard doesn’t define a total predicate over possible candidate children, they are not labeling literally every case and judging whether it “really counts.” Their value is just activated in certain mental contexts.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-02-15T18:49:53.071Z · LW(p) · GW(p)
Curious whether you still endorse this comment and/or have a different perspective / new things to add now.
comment by kitpeddler (KyleMatkat) · 2022-06-19T04:29:55.245Z · LW(p) · GW(p)
No one wants to be turned into paperclips. Or uploaded and copied into millions of deathless ems, to do rote computations at the wrapper-mind's behest forever, or to act out roles in some strange hell.
This is a tangent (I have nothing to add to the "are wrapper-minds inevitable" discussion), but this quote raises a separate question that I have been concerned about and have not really seen anyone discuss directly, that I would greatly appreciate other opinions on.
My reaction to the above quote is essentially that, yes, obviously I don't want to be turned into paperclips. That is zero utility forever.
But I much more strongly do not want to be tortured forever.
What frustrates me greatly that when people talk about the worst possible future in the event of an unfriendly AI, they usually talk about (something along the lines of) the universe being converted into paperclips.
And that is so, so, so far away from being the worst possible future. That is a future with exactly zero utility: there are no positive experiences, but there is no suffering either.
The worst possible future is a future where an enormous number of minds are tortured for eternity. And there is an infinite amount of space for futures that are not that bad, but are still vastly worse than a universe of zero utility. And an unfriendly AI would have the power to create any of those universes that it wants (whether it would want to is, of course, a separate question).
So - I am not an expert, but it is unclear to me why no one appears to take [the risk that the future universe is far worse than just a paperclip universe] seriously. The most logical explanation is that experts are very, very confident that an unfriendly AI would not create such a universe. But if so, I am not sure why that is the case, and I cannot remember ever seeing anyone explicitly make that claim or any argument for it. If someone wants to make this argument or has a relevant link, I would love to see it.
↑ comment by Vladimir_Nesov · 2022-06-19T18:22:56.512Z · LW(p) · GW(p)
The keywords for this concern are s-risk / astronomical suffering [? · GW]. I think this is unlikely, since a wrapper-mind that would pursue suffering thereby cares about human-specific concerns, which requires alignment-structure. So more likely this either isn't systematically pursued (other than as incidental mindcrime, which allows suffering but doesn't optimize for it), or we get full alignment (for whatever reason).
↑ comment by Jeff Rose · 2022-06-19T04:50:22.047Z · LW(p) · GW(p)
One line of reasoning is as follows:
- We don't know what goal(s) the AGI will ultimately have. (We can't reliably ensure what those goals are.)
- There is no particular reason to believe it will have any particular goal.
- Looking at all the possible goals that it might have, goals of explicitly benefiting or harming human beings are not particularly likely.
- On the other hand, because human beings use resources which the AGI might want to use for its own goals and/or might pose a threat to the AGI (by, e.g. creating other AGIs) there are reasons why an AGI not dedicated to harming or benefiting humanity might destroy humanity anyway. (This is an example or corollary of "instrumental convergence".)
- Because of 3, minds tortured for eternity is highly unlikely.
- Because of 4, humanity being ended in the service of some alien goal which has zero utility from the perspective of humanity is far more likely.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-11-01T18:00:36.318Z · LW(p) · GW(p)
I continue to think this is a great post. Part of why I think that is that I haven't forgotten it; it keeps circling back into my mind.
Recently this happened and I made a fun connection: What you call wrapper-minds seem similar to what Plato (in The Republic) calls people-with-tyrannical-souls. i.e. people whose minds are organized the way a tyrannical city is organized, with a single desire/individual (or maybe a tiny junta) in total control, and everything else subservient.
I think the concepts aren't exactly the same though -- Plato would have put more emphasis on the single bit, whereas for your concept of wrapper-mind it doesn't matter much if it's e.g. just paperclips vs. some complicated mix of lots of different things, for the concept of wrapper-mind the emphasis is on immutability and in particular insensitivity to reasoned discussion / learning / etc.
↑ comment by Noosphere89 (sharmake-farah) · 2024-11-01T18:18:32.334Z · LW(p) · GW(p)
The realist in me says that tyrannical souls/tyrannical governments seem likely to be the default state of governance, because the forces that power democracy and liberty will be gone with the rise of advanced AI, so we should start planning to make the future AIs we build, and the people that control AI, and the future AIs that do control the government value aligned.
More generally, I expect value alignment to be much more of a generator of outcomes in the 21st century than most other forces with the rise of AI, and this is not just about the classical AI alignment problem, compared to people selfishly doing stuff that generates positive externalities as a side effect.
comment by Quintin Pope (quintin-pope) · 2022-06-17T04:02:38.278Z · LW(p) · GW(p)
I think the thing you call a "wrapper mind" is actually quite difficult to build in practice. I have a draft document providing some intuition as to why this is the case. The core idea is that there's no "ground truth" regarding how to draw a learning system's agency boundaries. Specialization within the learning system tends to produce a sort of "fuzzy haze" of possible internal subagents with varying values. Systems with learned values will reliably face issues with those values balancing / conflicting against each other and changing over time.
Replies from: lc↑ comment by lc · 2022-06-17T04:24:03.235Z · LW(p) · GW(p)
I have a hard time understanding how this could be possible. If I have an oracle, and then I write a computer program like:
while(true) {
var cb = ask_oracle("retrieve the syscall that will produce the most paperclips in conjuction with what further iterations of this loop will run");
cb();
}
Is that not sufficient? Am I not allowed to use ask_oracle as an abstraction for consulting a machine intelligence? Why not?
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2022-06-17T04:36:53.013Z · LW(p) · GW(p)
I agree that, if you have an oracle that already knows how to pursue any arbitrary specified goals, then it's easy to make a competent wrapper agent. However, I don't think it's that easy to factor out values from the "search over effective plans" part of cognition. If you train a system to be competent at pursuing many different goals, then what I think you have, by default, is a system that actually has many different goals. It's not trivial to then completely replace those goals with your intended single goal.
If you train a system to be competent at pursuing a single goal, what I think you end up with (assuming a complex environment) is a system that's inner misaligned wrt that single goal, and instead pursues a broader distribution over shallow, environment-specific proxies for that single goal. See: evolution versus the human reward system / values.
comment by quetzal_rainbow · 2023-01-22T11:19:26.766Z · LW(p) · GW(p)
I am very confused by this post, because it contradicts much of my understanding of human values and advanced agents.
First of all, I think that human values are context-dependent, not in some mysterious ways, but in pretty straightforward - we are social beings. Many of our values are actually "what others do", "what my moral authority tells me to do", "what cool kids do", "what a better version of me would do" and changing-our-values-as-believes (in many aspects) is actually changing our believes about society in which we live. In other words, we have more or less solved the main problem of indirect normativity. And we can solve it (with respect of all alignment problem difficulty) for AI too, but it still will be "wrapper-mind". The other part of out value drift happens because we don't have strict social norms against many types of value drift and preservation of narrow values is quite costly for humans.
Second, wrapper-minds actually aren't in state of permament war, because superintelligences don't make such stupid mistakes. If papercilp-maximizer have a 60% chance of winning war against staple-maximizer, they just divide the universe between them in proportion to probabilities of victory.
On the other hand, why do you think we are not hostile to everything with sufficiently different values? One of the many lessons of "Three Worlds Collide" is "small differences in values between even non-wrapper minds can lead to destructive conflicts".
Third, I think that when you talk about MIRI, you miss the fact that MIRI-folk are transhumanists. Many of their thoughts about superintelligences is about "What would I become if i dial my IQ up to 100000 and boost my cognitive reflectivity?", and it seems to me that every possible coherent cognitive architecture will become indistinguishable from wrapper-mind for us.
Also, you can't really expect to persuade superintelligence in something, even if it has moral uncertainity, because it has already thought about it, and you can't provide some evidence unknown to it.
comment by Donald Hobson (donald-hobson) · 2022-06-17T17:00:29.504Z · LW(p) · GW(p)
If you mostly share its preferences, that's not enough -- it will probably make your life hell along every axis omitted from that "mostly."
If you like X, Y and Z, and the other mind likes X and Y, then the result is likely still pretty good from your point of view.
If there are other wrapper-minds, they are all each others' enemies, too[1] [LW(p) · GW(p)].
This isn't true. Sure, a wrapper mind will always prefer itself having resource X to anyone else having resource X, but it may well prefer someone else having X to X being destroyed. An apple maximizing AI will steal your orchard, if it can do so without damaging the apple trees. But it would prefer to buy apples from you than to let the orchard get destroyed in a war.
Also, you keep comparing wrapper minds to humans. The typical wrapper mind has crazy values it persues unconditionally.
The typical non-wrapper mind switches between many different systems of crazy values according to crazy rules. The non-wrapper mind has more free parameters.
comment by tailcalled · 2022-06-17T08:59:26.977Z · LW(p) · GW(p)
Your post seems to start out with the wrong assumption that human minds don't (to good approximation) have the wrapper structure. See here for counter: https://www.lesswrong.com/posts/dKTh9Td3KaJ8QW6gw/why-assume-agis-will-optimize-for-fixed-goals?commentId=8E5DHLzXkdBBERx5B#8E5DHLzXkdBBERx5B [LW(p) · GW(p)]
comment by Slider · 2022-12-09T01:21:56.392Z · LW(p) · GW(p)
I was reading this and was kind of mentally renaming this to "anti-enlightened" agent. It does suggest that this might come in gradients. If there are only very specific and rare ways to update a deeper layer the agent might seem like a wrappermind meanwhile while actually not being one. Taking 30000 years to go from 8-year-old love of spaceships to 10-year-olds love for spaceships is still multiple millenia of rough time. Any mind with a physical subtrate (should be all of them) will be alterable by hitting the hardware. This will mean that a true or very hard wrappermind will be able to deny access to a specific spatial point very strongly.
Also anything that is not a wrapper mind will mean that its uppermost layer can be rewritten. Such a thing can't have an "essential nature".
Now it would seem that for most agents the deeper a layer is the harder it is to guess its maleability atleast from the outside. And it would seem it might not be obvious even from inside.
comment by Lumpyproletariat · 2022-07-28T07:16:00.749Z · LW(p) · GW(p)
Anything that's smart enough to predict what will happen in the future, can see in advance which experiences or arguments would/will cause them to change their goals. And then they can look at what their values are at the end of all of that, and act on those. You can't talk a superintelligence into changing its mind because it already knows everything you could possibly say and already changed its mind if there was an argument that could persuade it.
comment by lc · 2022-06-17T02:24:32.055Z · LW(p) · GW(p)
Content Warning: Do not listen to anything I say about the technical problem of alignment. I am generally incapable of reasoning about these sorts of things and am almost certainly wrong.
For MIRI and people who think like MIRI does, the big question is: "how do we align an superintelligence [which is assumed to have the wrapper structure]?"
I think the big question MIRI asks at this point is "how do we prevent someone from using a superintelligence to kill everyone". In other words, how not to end up there. Some superintelligences that would kill everyone have the wrapper structure, some superintelligences end up modifying themselves to have 'the wrapper structure', and some superintelligences kill everyone in their default state.
The reason people in alignment focus on giving a superintelligence some explicit goal, i.e. giving it the 'wrapper structure', is that it's an obvious and mathematically tractable way to direct it. The reason we need to direct it in the first place is so we can prevent other organizations and people from creating those superintelligences that ruin everything. There are other ways to direct them, of course, but when I hear those other ways explicitly described, they either turn out to also kill us or end up seeming like attempts to obfuscate the problem rather than serious proposals designed to verifiably prevent the end of the world.
You say:
Are wrapper-minds inevitable? I can't imagine that they are.
But someone is eventually going to try to run one unless we do something about it. So what can we do? And how can we be sure the more complicated proposal is not going to kill us as well?
Replies from: interstice↑ comment by interstice · 2022-06-17T02:41:36.262Z · LW(p) · GW(p)
Using a superintelligence to optimize some explicit goal, i.e. giving it the 'wrapper structure', is an obvious and tractable way to direct it
Is it obvious and tractable? MIRI doesn't currently seem to think so. Given that, it might be worth considering some alternative possibilities. Especially those that don't involve the creation of a superpowered wrapper mind as a failure state.
and some superintelligences kill everyone anyways
The arguments for why superintelligences will kill everyone tend to route through those intelligences being or becoming wrapper minds. So if we had an AI architecture that was not a wrapper mind, or especially likely to become one, that might defuse some of those arguments' force.
Replies from: lc↑ comment by lc · 2022-06-17T02:48:23.580Z · LW(p) · GW(p)
Is it obvious and tractable? MIRI doesn't currently seem to think so.
I disagree, MIRI thinks it's obvious and tractable to predict the "end result" of creating a superintelligence with the wrong value function. It's just not good.
The arguments for why superintelligences will kill everyone tend to route through those intelligences being or becoming wrapper minds. So if we had an AI architecture that was not a wrapper mind, or especially likely to become one, that might defuse some of those arguments' force.
This is the kind of logic I talk about when I say "sound more like attempts to obfuscate the problem than serious proposals designed to verifiably prevent the end of the world". It's like the reasoning goes:
- Mathematicians keep pointing out the ways superintelligences with explicit goals cause bad outcomes.
- If we add complications, such as implicit goals, to the superintelligences, they can't reason as analytically about them
- Therefore superintelligences with implicit goals are "safe"
The analytical reasoning is not the problem. The problem is humans have this very particular habitat they need for their survival and if we have a superintelligence running around waving their magic wand, casting random spells at things, we will probably not be able to survive. The problem is also that we need a surefire way of getting this superintelligence to wave its magic wand and prevent the other superintelligences from spawning. "What if we flip random bits in the superintelligence's code" is not a solution either, for the same reason.
Replies from: interstice↑ comment by interstice · 2022-06-17T03:11:27.662Z · LW(p) · GW(p)
I disagree, MIRI thinks it's obvious and tractable to predict the "end result" of creating a superintelligence
But they don't think it's an obvious and tractable means of "directing" such a superintelligence towards our actual goals, which is what the sentence I was quoting was about.
It's like the reasoning goes
I didn't say any of that. I would rather summarize my position as:
-
Mathematicians keep pointing out the ways superintelligences with explicit goals will lead to bad outcomes. They also claim that any powerful cognitive system will tend to have such goals
-
But we seem to have lots of examples of powerful cognitive systems which don't behave like explicit goal maximizers
-
Therefore, perhaps we should try to design superintelligences which are also not explicit goal maximizers. And also re-analyze the conditions under which the mathematicians' purported theorems hold so we can have a better picture of which cognitive systems will act like explicit goal maximizers under which circumstances.
↑ comment by lc · 2022-06-17T03:19:25.644Z · LW(p) · GW(p)
I think my real objection is that MIRI kind of agrees with the idea "don't attempt to make a pure utility maximizer with a static loss function on the first try" and thus has tried to build systems that aren't pure utility maximizers, like ones that are instead corrigible or have "chill". They just kinda don't work so far and anybody suggesting that they haven't looked is being a bit silly.
Instead, I wish someone suggesting this would actually concretely describe the properties they hope to gain by removing a value function, as I suspect the real answer is... corrigibility or chill. Saying "oh this pure utillity maximizer thing looks really hard let's explore the space of all possible agent designs instead" isn't really helpful - what are you looking to find and why is it safer?
comment by Shmi (shminux) · 2022-06-17T02:12:43.769Z · LW(p) · GW(p)
Hmm, you quoted your own comment on instability of a wrapper action under the small change of the "value function":
A powerful optimizer, with no checks or moderating influences on it, will tend to make extreme Goodharted choices that look good according to its exact value function, and very bad (because extreme) according to almost any other value function.
Does it mean that if we require a stable attractor to exist in the map value -> actions, then we end up with a more tame version of a wrapper, or even with a non-wrapper structure?
comment by andrew sauer (andrew-sauer) · 2023-02-13T07:42:26.268Z · LW(p) · GW(p)
If a "wrappermind" is just something that pursues a consistent set of values in the limit of absolute power, I'm not sure how we're supposed to avoid such things arising. Suppose the AI that takes over the world does not hard-optimize over a goal, instead soft-optimizing or remaining not fully decided between a range of goals(and that humanity survives this AI's takeover). What stops someone from building a wrappermind after such an AI has taken over? Seems like if you understood the AI's value system, it would be pretty easy to construct a hard optimizer with the property that the optimum is something the AI can be convinced to find acceptable. As soon as your optimizer figures out how to do that it can go on its merry way approaching its optimum.
In order to prevent this from happening an AI must be able to detect when something is wrong. It must be able to, without fail, in potentially adversarial circumstances, recognize these kinds of Goodhart outcomes and robustly deem them unacceptable. But if your AI can do that, then any particular outcome it can be convinced to accept must not be a nightmare scenario. And therefore a "wrappermind" whose optimum was within this acceptable space would not be so bad.
In other words, if you know how to stop wrapperminds, you know how to build a good wrappermind.
comment by Alex Beyman (alexbeyman) · 2023-01-22T04:54:45.547Z · LW(p) · GW(p)
Humans are not wrapper-minds.
Aren't we? In fact, doesn't evolution consistently produce minds which optimize for survival and reproduction? Sure, we're able to overcome mortal anxiety long enough to commit suicide. But survival and reproduction is a strongly enough engrained instinctual goal that we're still here to talk about it, 3 billion years on.
comment by Canaletto (weightt-an) · 2022-07-09T20:22:05.187Z · LW(p) · GW(p)
I think that there may be wrapper-minds with very detailed utility functions, that whatever qualities you attribute to agents that are not them, the wrapper-mind's behavior will look like their with arbitrary precision on arbitrarily many evaluation parameters. I don't think it's practical or it's something that has a serious chance of happening, but I think it's a case that might be worth considering.
Like, maybe it's very easy to build a wrapper mind that is a very good approximation of very non wrapper mind. Who knows
comment by Adam Jermyn (adam-jermyn) · 2022-06-18T00:56:26.647Z · LW(p) · GW(p)
I don’t think I’ve grokked the “wrapper” concept sufficiently to have specific comments, but I find this idea very interesting and would really like to see a concrete description of an AI system that lacks the wrapper (or of a way to build one). Ideally in the form of a training story (per https://www.alignmentforum.org/posts/FDJnZt8Ks2djouQTZ/how-do-we-become-confident-in-the-safety-of-a-machine [AF · GW]).
comment by Arcayer · 2022-06-17T02:34:28.736Z · LW(p) · GW(p)
One thing I've been noting, which seems like the same concept as this is:
Most "alignment" problems are caused by a disbalance between the size of the intellect and the size of the desire. Bad things happen when you throw ten thousand INT at objective: [produce ten paperclips].
Intelligent actors should only ever be asked intelligent questions. Anything less leads at best to boredom, at worst, insanity.