why assume AGIs will optimize for fixed goals?
post by nostalgebraist · 2022-06-10T01:28:10.961Z · LW · GW · 33 commentsThis is a question post.
Contents
Answers 76 Rob Bensinger 44 Quintin Pope 35 TekhneMakre 22 Vladimir_Nesov 6 Jacob Pfau 5 Quinn 2 Roger Dearnaley 0 Sphinxfire None 33 comments
When I read posts about AI alignment on LW / AF/ Arbital, I almost always find a particular bundle of assumptions taken for granted:
- An AGI has a single terminal goal[1].
- The goal is a fixed part of the AI's structure. The internal dynamics of the AI, if left to their own devices, will never modify the goal.
- The "outermost loop" of the AI's internal dynamics is an optimization process aimed at the goal, or at least the AI behaves just as though this were true.
- This "outermost loop" or "fixed-terminal-goal-directed wrapper" chooses which of the AI's specific capabilities to deploy at any given time, and how to deploy it[2].
- The AI's capabilities will themselves involve optimization for sub-goals that are not the same as the goal, and they will optimize for them very powerfully (hence "capabilities"). But it is "not enough" that the AI merely be good at optimization-for-subgoals: it will also have a fixed-terminal-goal-directed wrapper.
- So, the AI may be very good at playing chess, and when it is playing chess, it may be running an internal routine that optimizes for winning chess. This routine, and not the terminal-goal-directed wrapper around it, explains the AI's strong chess performance. ("Maximize paperclips" does not tell you how to win at chess.)
- The AI may also be good at things that are much more general than chess, such as "planning," "devising proofs in arbitrary formal systems," "inferring human mental states," or "coming up with parsimonious hypotheses to explain observations." All of these are capacities[3] to optimize for a particular subgoal that is not the AI's terminal goal.
- Although these subgoal-directed capabilities, and not the fixed-terminal-goal-directed wrapper, will constitute the reason the AI does well at anything it does well at, the AI must still have a fixed-terminal-goal-directed wrapper around them and apart from them.
- There is no way for the terminal goal to change through bottom-up feedback from anything inside the wrapper. The hierarchy of control is strict and only goes one way.
My question: why assume all this? Most pressingly, why assume that the terminal goal is fixed, with no internal dynamics capable of updating it?
I often see the rapid capability gains of humans over other apes cited as a prototype case for the rapid capability gains we expect in AGI. But humans do not have this wrapper structure! Our goals often change over time. (And we often permit or even welcome this, whereas an optimizing wrapper would try to prevent its goal from changing.)
Having the wrapper structure was evidently not necessary for our rapid capability gains. Nor do I see reason to think that our capabilities result from us being “more structured like this” than other apes. (Or to think that we are “more structured like this” than other apes in this first place.)
Our capabilities seem more like the subgoal capabilities discussed above: general and powerful tools, which can be "plugged in" to many different (sub)goals, and which do not require the piloting of a wrapper with a fixed goal to "work" properly.
Why expect the "wrapper" structure with fixed goals to emerge from an outer optimization process? Are there any relevant examples of this happening via natural selection, or via gradient descent?
There are many, many posts on LW / AF/ Arbital about "optimization," its relation to intelligence, whether we should view AGIs as "optimizers" and in what senses, etc. I have not read all of it. Most of it touches only lightly, if at all, on my question. For example:
- There has been much discussion over whether an AGI would inevitably have (close to) consistent preferences, or would self-modify itself to have closer-to-consistent preferences. See e.g. here, here [LW · GW], here [? · GW], here [LW · GW]. Every post I've read on this topic implicitly assumes that the preferences are fixed in time.
- Mesa-optimizers have been discussed extensively. The same bundle of assumptions is made about mesa-optimizers.
- It has been argued that if you already have the fixed-terminal-goal-directed wrapper structure, then you will prefer to avoid outside influences that will modify your goal. This is true, but does not explain why the structure would emerge in the first place.
- There are arguments (e.g.) that we should heuristically imagine a superintelligence as a powerful optimizer, to get ourselves to predict that it will not do things we know are suboptimal. These arguments tell us to imagine the AGI picking actions that are optimal for a goal iff it is currently optimizing for that goal. They don't tell us when it will be optimizing for which goals.
EY's notion of "consequentialism" seems closely related to this set of assumptions. But, I can't extract an answer from the writing I've read on that topic.
EY seems to attribute what I've called the powerful "subgoal capabilities" of humans/AGI to a property called "cross-domain consequentialism":
We can see one of the critical aspects of human intelligence as cross-domain consequentialism. Rather than only forecasting consequences within the boundaries of a narrow domain, we can trace chains of events that leap from one domain to another. Making a chess move wins a chess game that wins a chess tournament that wins prize money that can be used to rent a car that can drive to the supermarket to get milk. An Artificial General Intelligence that could learn many domains, and engage in consequentialist reasoning that leaped across those domains, would be a sufficiently advanced agent to be interesting from most perspectives on interestingness. It would start to be a consequentialist about the real world.
while defining "consequentialism" as the ability to do means-end reasoning with some preference ordering:
Whenever we reason that an agent which prefers outcome Y over Y' will therefore do X instead of X' we're implicitly assuming that the agent has the cognitive ability to do consequentialism at least about Xs and Ys. It does means-end reasoning; it selects means on the basis of their predicted ends plus a preference over ends.
But the ability to use this kind of reasoning, and do so across domains, does not imply that one's "outermost loop" looks like this kind of reasoning applied to the whole world at once.
I myself am a cross-domain consequentialist -- a human -- with very general capacities to reason and plan that I deploy across many different facets of my life. But I'm not running an outermost loop with a fixed goal that pilots around all of my reasoning-and-planning activities. Why can't AGI be like me?
EDIT to spell out the reason I care about the answer: agents with the "wrapper structure" are inevitably hard to align, in ways that agents without it might not be. An AGI "like me" might be morally uncertain like I am, persuadable through dialogue like I am, etc.
It's very important to know what kind of AIs would or would not have the wrapper structure, because this makes the difference between "inevitable world-ending nightmare" and "we're not the dominant species anymore." The latter would be pretty bad for us too, but there's a difference!
- ^
Often people speak of the AI's "utility function" or "preference ordering" rather than its "goal."
For my purposes here, these terms are more or less equivalent: it doesn't matter whether you think an AGI must have consistent preferences, only whether you think it must have fixed preferences.
- ^
...or at least the AI behaves just as though this were true. I'll stop including this caveat after this.
- ^
Or possibly one big capacity -- "general reasoning" or what have you -- which contains the others as special cases. I'm not taking a position on how modular the capabilities will be.
Answers
It has been argued that if you already have the fixed-terminal-goal-directed wrapper structure, then you will prefer to avoid outside influences that will modify your goal. This is true, but does not explain why the structure would emerge in the first place.
I think Eliezer usually assumes that goals start off not stable, and then some not-necessarily-stable optimization process (e.g., the agent modifying itself to do stuff, or a gradient-descent-ish or evolution-ish process iterating over mesa-optimizers) makes the unstable goals more stable over time, because stabler optimization tends to be more powerful / influential / able-to-skillfully-and-forcefully-steer-the-future.
(I don't need a temporally stable goal in order to self-modify toward stability, because all of my time-slices will tend to agree that stability is globally optimal, though they'll disagree about which time-slice's goal ought to be the one stably optimized.)
E.g., quoting Eliezer:
So what actually happens as near as I can figure (predicting future = hard) is that somebody is trying to teach their research AI to, god knows what, maybe just obey human orders in a safe way, and it seems to be doing that, and a mix of things goes wrong like:
The preferences not being really readable because it's a system of neural nets acting on a world-representation built up by other neural nets, parts of the system are self-modifying and the self-modifiers are being trained by gradient descent in Tensorflow, there's a bunch of people in the company trying to work on a safer version but it's way less powerful than the one that does unrestricted self-modification, they're really excited when the system seems to be substantially improving multiple components, there's a social and cognitive conflict I find hard to empathize with because I personally would be running screaming in the other direction two years earlier, there's a lot of false alarms and suggested or attempted misbehavior that the creators all patch successfully, some instrumental strategies pass this filter because they arose in places that were harder to see and less transparent, the system at some point seems to finally "get it" and lock in to good behavior which is the point at which it has a good enough human model to predict what gets the supervised rewards and what the humans don't want to hear, they scale the system further, it goes past the point of real strategic understanding and having a little agent inside plotting, the programmers shut down six visibly formulated goals to develop cognitive steganography and the seventh one slips through, somebody says "slow down" and somebody else observes that China and Russia both managed to steal a copy of the code from six months ago and while China might proceed cautiously Russia probably won't, the agent starts to conceal some capability gains, it builds an environmental subagent, the environmental agent begins self-improving more freely, undefined things happen as a sensory-supervision ML-based architecture shakes out into the convergent shape of expected utility with a utility function over the environmental model, the main result is driven by whatever the self-modifying decision systems happen to see as locally optimal in their supervised system locally acting on a different domain than the domain of data on which it was trained, the light cone is transformed to the optimum of a utility function that grew out of the stable version of a criterion that originally happened to be about a reward signal counter on a GPU or God knows what.
Perhaps the optimal configuration for utility per unit of matter, under this utility function, happens to be a tiny molecular structure shaped roughly like a paperclip.
That is what a paperclip maximizer is. It does not come from a paperclip factory AI. That would be a silly idea and is a distortion of the original example.
One way of thinking about this is that a temporally unstable agent is similar to a group of agents that exist at the same time, and are fighting over resources.
In the case where a group of agents exist at the same time, each with different utility functions, there will be a tendency (once the agents become strong enough and have a varied enough option space) for the strongest agent to try to seize control from the other agents, so that the strongest agent can get everything it wants.
A similar dynamic exists for (sufficiently capable) temporally unstable agents. Alice turns into a werewolf every time the moon is full; since human-Alice and werewolf-Alice have very different goals, human-Alice will tend (once she's strong enough) to want to chain up werewolf-Alice, or cure herself of lycanthropy, or brainwash her werewolf self, or otherwise ensure that human-Alice's goals are met more reliably.
Another way this can shake out is that human-Alice and werewolf-Alice make an agreement to self-modify into a new coherent optimizer that optimizes some compromise of the two utility functions. Both sides will tend to prefer this over, e.g., the scenario where human-Alice keeps turning on a switch and then werewolf-Alice keeps turning the switch back off, forcing both of them to burn resources in a tug-of-war.
↑ comment by nostalgebraist · 2022-06-10T23:13:30.106Z · LW(p) · GW(p)
because stabler optimization tends to be more powerful / influential / able-to-skillfully-and-forcefully-steer-the-future
I personally doubt that this is true, which is maybe the crux here.
This seems like a possibly common assumption, and I'd like to see a more fleshed-out argument for it. I remember Scott making this same assumption in a recent conversation:
I agree humans aren’t like that, and that this is surprising.
Maybe this is because humans aren’t real consequentialists, they’re perceptual control theory agents trying to satisfy finite drives? [...] Might gradient descent produce a PCT agent instead of a mesa-optimizer? I don’t know. My guess is maybe, but that optimizers would be more, well, optimal [...]
But is it true that "optimizers are more optimal"?
When I'm designing systems or processes, I tend to find that the opposite is true -- for reasons that are basically the same reasons we're talking about AI safety in the first place.
A powerful optimizer, with no checks or moderating influences on it, will tend to make extreme Goodharted choices that look good according to its exact value function, and very bad (because extreme) according to almost any other value function.
Long before things reach the point where the outer optimizer is developing a superintelligent inner optimizer, it has plenty of chances to learn the general design principle that "putting all the capabilities inside an optimizing outer loop ~always does something very far from what you want."
Some concrete examples from real life:
- Using gradient descent. I use gradient descent to make things literally every day. But gradient descent is never the outermost loop of what I'm doing.
That would look like "setting up a single training run, running it, and then using the model artifact that results, without giving yourself freedom to go back and do it over again (unless you can find a way to automate that process itself with gradient descent)." This is a peculiar policy which no one follows. The individual artifacts resulting from individual training runs are quite often bad -- they're overfit, or underfit, or training diverged, or they got great val metrics but the output sucks and it turns out your val set has problems, or they got great val metrics but the output isn't meaningfully better and the model is 10x slower than the last one and the improvement isn't worth it, or they are legitimately the best thing you can get on your dataset but that causes you to realize you really need to go gather more data, or whatever.
All the impressive ML artifacts made "by gradient descent" are really outputs of this sort of process of repeated experimentation, refining of targets, data gathering and curation, reframing of the problem, etc. We could argue over whether this process is itself a form of "optimization," but in any case we have in our hands a (truly) powerful thing that very clearly is optimization, and yet to leverage it effectively without getting Goodharted, we have to wrap it inside some other thing.
- Delegating to other people. To quote myself from here:
"How would I want people to behave if I – as in actual me, not a toy character like Alice or Bob – were managing a team of people on some project? I wouldn’t want them to be ruthless global optimizers; I wouldn’t want them to formalize the project goals, derive their paperclip-analogue, and go off and do that. I would want them to take local iterative steps, check in with me and with each other a lot, stay mostly relatively close to things already known to work but with some fraction of time devoted to far-out exploration, etc."
There are of course many Goodhart horror stories about organizations that focus too hard on metrics. The way around this doesn't seem to be "find the really truly correct metrics," since optimization will always find a way to trick you. Instead, it seems crucial to include some mitigating checks on the process of optimizing for whatever metrics you pick. - Checks against dictatorship as a principle of government design, as opposed to the alternative of just trying to find a really good dictator.
Mostly self-explanatory. Admittedly a dictator is not likely to be a coherent optimizer, but I expect a dictatorship to behave more like one than a parliamentary democracy.
If coherence is a convergent goal, why don't all political sides come together and build a system that coherently does something, whatever that might be? In this context, at least, it seems intuitive enough that no one really wants this outcome.
In brief, I don't see how to reconcile
- "in the general case, coherent optimizers always end up doing some bad, extreme Goodharted thing" (which matches both my practical experience and a common argument in AI safety), and
- "outer optimizers / deliberating agents will tend to converge on building (more) coherent (inner) optimizers, because they expect this to better satisfy their own goals," i.e. the "optimizers are more optimal" assumption.
EDIT: an additional consideration applies in the situation where the AI is already at least as smart as us, and can modify itself to become more coherent. Because I'd expect that AI to notice the existence of the alignment problem just as much as we do (why wouldn't it?). I mean, would you modify yourself into a coherent EU-maximizing superintelligence with no alignment guarantees? If that option became available in real life, would you take it? Of course not. And our hypothetical capable-but-not-coherent AI is facing the exact same question.
Replies from: yitz, alexlyzhov, Vladimir_Nesov, leogao, jeremy-gillen↑ comment by Yitz (yitz) · 2022-06-19T04:14:54.448Z · LW(p) · GW(p)
This is a really high-quality comment, and I hope that at least some expert can take the time to either convincingly argue against it, or help confirm it somehow.
↑ comment by alexlyzhov · 2022-06-19T11:45:32.658Z · LW(p) · GW(p)
- When you say that coherent optimizers are doing some bad thing, do you imply that it would always be a bad decision for the AI to make the goal stable? But wouldn't it heavily depend on what other options it thinks it has, and in some cases maybe worth the shot? If such a decision problem is presented to the AI even once, it doesn't seem good.
- The stability of the value function seems like something multidimensional, so perhaps it doesn't immediately turn into a 100% hardcore explicit optimizer forever, but there is at least some stabilization. In particular, bottom-up signals that change the value function most drastically may be blocked.
- AI can make its value function more stable to external changes, but it can also make it more malleable internally to partially compensate for Goodharting. The end result for outside actors though is that it only gets harder to change anything.
- Edit: BTW, I've read some LW articles on Goodharting but I'm also not yet convinced it will be such a huge problem at superhuman capability levels - seems uncertain to me. Some factors may make it worse as you get there (complexity of the domain, dimensionality of the space of solutions), and some factors may make it better (the better you model the world, the better you can optimize for the true target). For instance, as the model gets smarter, the problems from your examples seem to be eliminated: in 1, it would optimize end-to-end, and in 2, the quality of the decisions would grow (if the model had access to the ground truth value function all along, then it would grow because of better world models and better tree search for decision-making). If the model has to check-in and use feedback from the external process (human values) to not stray off course, then as it's smarter it's discovering a more efficient way to collect the feedback, has better priors, etc.
↑ comment by Vladimir_Nesov · 2022-06-19T19:10:48.619Z · LW(p) · GW(p)
I mean, would you modify yourself into a coherent EU-maximizing superintelligence with no alignment guarantees? If that option became available in real life, would you take it? Of course not. And our hypothetical capable-but-not-coherent AI is facing the exact same question.
Why no alignment guarantees and why modify yourself and not build separately? The concern is that even if a non-coherent AGI solves its own alignment problem correctly, builds an EU-maximizing superintelligence aligned with the non-coherent AGI, the utility of the resulting superintelligence is still not aligned with humanity.
So the less convenient question should be, "Would you build a coherent optimizer if you had all the alignment guarantees you would want, all the time in the world to make sure it's done right?" A positive answer to that question given by first non-coherent AGIs supports relevance of coherent optimizers and their alignment.
↑ comment by leogao · 2022-06-17T04:28:24.424Z · LW(p) · GW(p)
One possible reconciliation: outer optimizers converge on building more coherent inner optimizers because the outer objective is only over a restricted domain, and making the coherent inner optimizer not blow up inside that domain is much much easier than making it not blow up at all, and potentially easier than just learning all the adaptations to do the thing. Concretely, for instance, with SGD, the restricted domain is the training distribution, and getting your coherent optimizer to act nice on the training distribution isn't that hard, the hard part of fully aligning it is getting from objectives that shake out as [act nice on the training distribution but then kill everyone when you get a chance] to an objective that's actually aligned, and SGD doesn't really care about the hard part.
↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-12-13T15:35:07.851Z · LW(p) · GW(p)
because stabler optimization tends to be more powerful / influential / able-to-skillfully-and-forcefully-steer-the-future
I personally doubt that this is true, which is maybe the crux here.
Would you like to do a dialogue about this? To me it seems clearly true in exactly the same way that having more time to pursue a goal makes it more likely you will achieve that goal.
It's possible another crux is related to the danger of Goodharting, which I think you are exaggerating the danger of. When an agent actually understand what it wants, and/or understands the limits of its understanding, then Goodhart is easy to mitigate, and it should try hard to achieve its goals (i.e. optimize a metric).
↑ comment by Gunnar_Zarncke · 2022-06-10T21:23:52.485Z · LW(p) · GW(p)
Do we have evidence about more intelligent beings being more stable or getting more stable over time? Are more intelligent humans more stable/get more stable/get stable more quickly?
↑ comment by RHollerith (rhollerith_dot_com) · 2022-06-10T20:42:27.860Z · LW(p) · GW(p)
I agree with this comment. I would add that there is an important sense in which the typical human is not a temporally unstable agent.
It will help to have an example: the typical 9-year-old boy is uninterested in how much the girls in his environment like him and doesn't necessarily wish to spend time with girls (unless those girls are acting like boys). It is tempting to say that the boy will probably undergo a change in his utility function over the next 5 or so years, but if you want to use the concept of expected utility (defined as the sum of the utility of the various outcome weighted by their probability) then to keep the math simple you must assume that the boy's utility function does not change with time with the result that you must define the utility function to be not the boy's current preferences, but rather his current preferences (conscious and unconscious) plus the process by which those preference will change over time.
Humans are even worse at perceiving the process that changes their preferences over time than they are at perceiving their current preferences. (The example of the 9-year-old boy is an exception to that general rule: even the 9-year-old boys tend to know that their preferences around girls are probably going to change in not too many years.) The author of the OP seems to have conflated the goals that the human knows that he has with the human's utility function whereas they are quite different.
It might be that there is some subtle point the OP is making about temporally unstable agents that I have not addressed in my comment, but if he expects me to hear him out on it, he should write it up in such a way as to make to clear that he not just confused about how the concept of the utility function is being applied to AGIs.
I haven't explained or shown how or why the assumption that the AGI's utility function is constant over time simplifies the math -- and simplifies an analysis that does not delve into actual math. Briefly, if you want to create a model in which the utility function evolves over time, you have to specify how it evolves -- and to keep the model accurate, you have to specify how evidence coming in from the AGI's senses influences the evolution. But of course, sensory information is not the only things influencing the evolution; we might call the other influence an "outer utility function". But then why not keep the model simple and assume (define) the goals that the human is aware of to be not terms (terminology?) in a utility function, but rather subgoals? Any intelligent agent will need some machinery to identify and track subgoals. That machinery must modify the priorities of the subgoals in response to evidence coming in from the senses. Why not just require our model to include a model of the subgoal-updating machinery, then equate the things the human perceives as his current goals with subgoals?
Here is another way of seeing it. Since a human being is "implemented" using only deterministic laws of physics, the "seed" of all of the human's behaviors, choices and actions over a lifetime are already present in the human being at birth! Actually that is not true: maybe the human's brain is hit by a cosmic ray when the human is 7 years old with the result that the human grows up to like boys whereas if it weren't for the cosmic ray, he would like girls. (Humans have evolved to be resistant to such "random" influences, but such influences nevertheless do occasionally happen.) But it is true that the "seed" of all of the human's behaviors, choices and actions over a lifetime are already present at birth! (That sentence is just a copy of a previous sentence omitting the words "in the human being" to take into account the possibility that the "seed" includes a cosmic ray light years away from Earth at the time of the person's birth.) So for us to assume that the human's utility function does not vary over time not only simplifies the math, but also is more physically realistic.
If you define the utility function of a human being the way I have recommended above that you do, you must realize that there are many ways in which humans are unaware or uncertain about their own utility function and that the function is very complex (incorporating for example the processes that produce cosmic rays) although maybe all you need is an approximation. Still, that is better than defining your model such that utility function vary over time.
This question gets at a bundle of assumptions in a lot of alignment thinking that seem very wrong to me. I'd add another, subtler, assumption that I think is also wrong: namely, that goals and values are discrete. E.g., when people talk of mesa optimizers, they often make reference to a mesa objective which the (single) mesa optimizer pursues at all times, regardless of the external situation. Or, they'll talk as though humans have some mysterious set of discrete "true" values that we need to figure out.
I think that real goal-orientated learning systems are (1) closer to having a continuous distribution over possible goals / values, (2) that this distribution is strongly situation-dependent, and (3) that this distribution evolves over time as the system encounters new situations.
I sketched out a rough picture of why we should expect such an outcome from a broad class of learning systems in this comment. [LW · GW]
An AGI "like me" might be morally uncertain like I am, persuadable through dialogue like I am, etc.
I strongly agree that the first thing (moral uncertainty) happens by default in AGIs trained on complex reward functions / environments. The second (persuadable through dialog) seems less likely for an AGI significantly smarter than you.
It has been argued that if you already have the fixed-terminal-goal-directed wrapper structure, then you will prefer to avoid outside influences that will modify your goal. This is true, but does not explain why the structure would emerge in the first place.
I think that this is not quite right. Learning systems acquire goals / values because the outer learning process reinforces computations that implement said goals / values. Said goals / values arise to implement useful capabilities for the situations that the learning system encountered during training.
However, it's entirely possible for the learning system to enter new domains in which any of the following issues arise:
- The system's current distribution of goals / values are incapable of competently navigating.
- The system is unsure of which goals / values should apply.
- The system is unsure of how to weigh conflicting goals / values against each other.
In these circumstances, it can actually be in the interests of the current equilibrium of goals / values to introduce a new goal / value. Specifically, the new goal / value can implement various useful computational functions such as:
- Competently navigate situations in the new domain.
- Determine which of the existing goals / values should apply to the new domain.
- Decide how the existing goals / values should weigh against each other in the new domain.
Of course, the learning system wants to minimize the distortion of its existing values. Thus, it should search for a new value that both implements the desired capabilities and is maximally aligned with the existing values.
In humans, I think this process of expanding the existing values distribution to a new domain is what we commonly refer to as moral philosophy. E.g.:
Suppose you (a human) have a distribution of values that implement common sense human values like "don't steal", "don't kill", "be nice", etc. Then, you encounter a new domain where those values are a poor guide for determining your actions. Maybe you're trying to determine which charity to donate to. Maybe you're trying to answer weird questions in your moral philosophy class.
The point is that you need some new values to navigate this new domain, so you go searching for one or more new values. Concretely, let's suppose you consider classical utilitarianism (CU) as your new value.
The CU value effectively navigates the new domain, but there's a potential problem: the CU value doesn't constrain itself to only navigating the new domain. It also produces predictions regarding the correct behavior on the old domains that already existing values navigate. This could prevent the old values from determining your behavior on the old domains. For instrumental reasons, the old values don't want to be disempowered.
One possible option is for there to be a "negotiation" between the old values and the CU value regarding what sort of predictions CU will generate on the domains that the old values navigate. This might involve an iterative process of searching over the input space to the CU value for situations where the CU shard strongly diverges from the old values, in domains that the old values already navigate.
Each time a conflict is found, you either modify the CU value to agree with the old values, constrain the CU value so as to not apply to those sorts of situations, or reject the CU value entirely if no resolution is possible. This can lead to you adopting refinements of CU, such as rule based utilitarianism or preference utilitarianism, if those seem more aligned to your existing values.
IMO, the implication is that (something like) the process of moral philosophy seems strongly convergent among learning systems capable of acquiring any values at all. It's not some weird evolutionary baggage, and it's entirely feasible to create an AI whose meta-preferences over learned values work similar to ours. In fact, that's probably the default outcome.
Note that you can make a similar argument that the process we call "value reflection" is also convergent among learning systems. Unlike "moral philosophy", "value reflection" relates to negotiations among the currently held values, and is done in order to achieve a better Pareto frontier of tradeoffs among the currently held values. I think that a multiagent system whose constituent agents were sufficiently intelligent / rational should agree to a joint Pareto-optimal policy that cause the system to act as though it had a utility function. The process by which an AGI or human tried to achieve this level of internal coherence would look like value reflection.
I also think values are far less fragile than is commonly assumed in alignment circles. In the standard failure story around value alignment, there's a human who has some mysterious "true" values (that they can't access), and an AI that learns some inscrutable "true" values (that the human can't precisely control because of inner misalignment issues). Thus, the odds of the AI's somewhat random "true" values perfectly matching the human's unknown "true" values seem tiny, and any small deviation between these two means the future is lost forever.

(In the discrete framing, any divergence means that the AI has no part of it that concerns itself with "true" human values)
But in the continuous perspective, there are no "true" values. There is only the continuous distribution over possible values that one could instantiate in various situations. A Gaussian distribution does not have anything like a "true" sample that somehow captures the entire distribution at once, and neither does a human or an AI's distribution over possible values.
Instead, the human and AI both have distributions over their respective values, and these distributions can overlap to a greater or lesser degree. In particular, this means partial value alignment is possible. One tiny failure does not make the future entirely devoid of value.
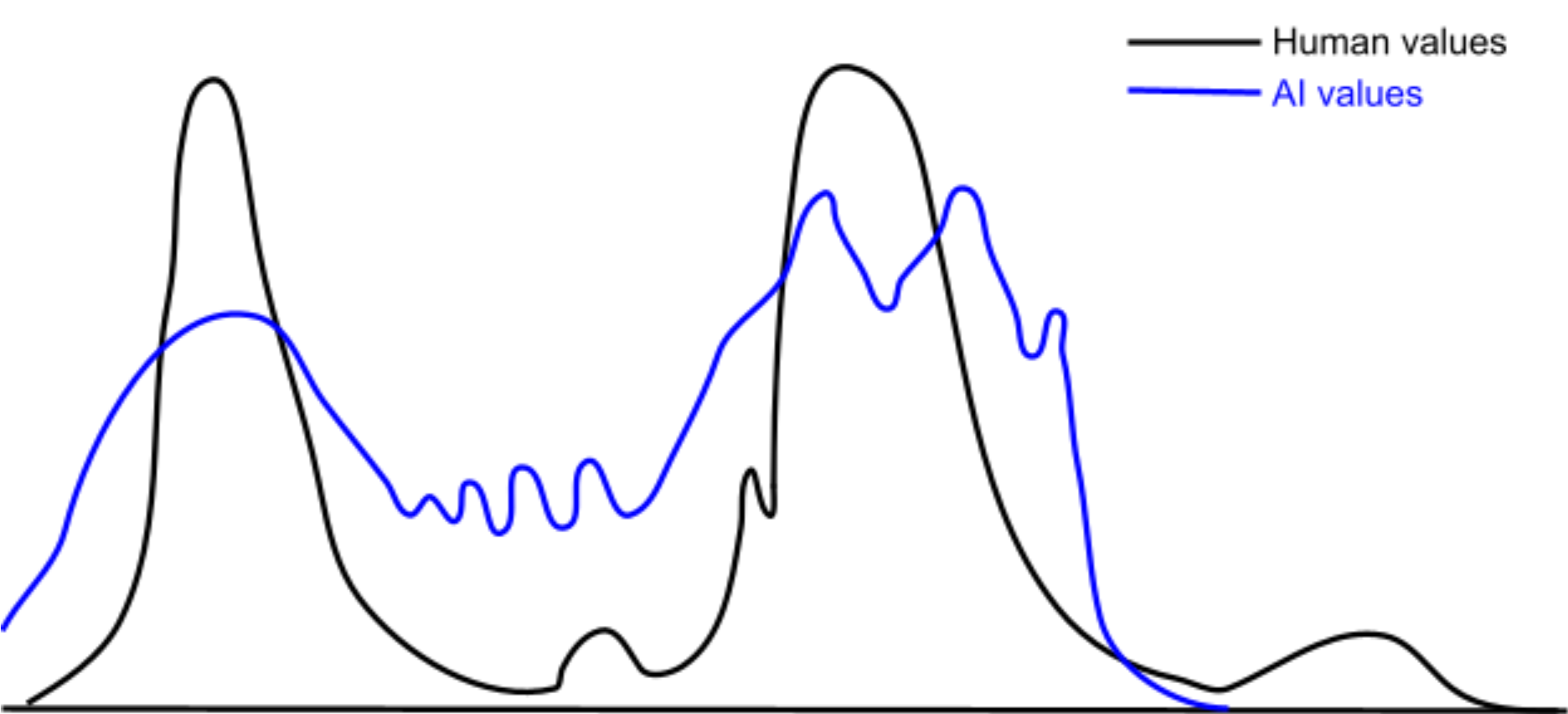
(Important note: this is a distribution over values, as in, each point in this space represents a value. It's a space of functions, where each function represents a value[1].)
Obviously, we prefer more overlap to less, but an imperfect representation of our distribution over values is still valuable, and are far easier to achieve than near-perfect overlaps.
- ^
I am deliberately being agnostic about what exactly a "value" is and how they're implemented. I think the argument holds regardless.
↑ comment by Charlie Steiner · 2022-06-10T08:36:41.115Z · LW(p) · GW(p)
Upvoted but disagree.
Moral philosophy is going to have to be built in on purpose - default behavior (e.g. in model-based reinforcement learning agents) is not to have value uncertainty in response to new contexts, only epistemic uncertainty.
Moral reasoning is natural to us like vision and movement are natural to us, so it's easy to underestimate how much care evolution had to take to get us to do it.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2022-06-10T19:34:17.507Z · LW(p) · GW(p)
Seems like you're expecting the AI system to be inner aligned? I'm assuming it will have some distribution over mesa objectives (or values, as I call them), and that implies uncertainty over how to weigh them and how they apply to new domains.
Moral reasoning is natural to us like vision and movement are natural to us, so it's easy to underestimate how much care evolution had to take to get us to do it.
Why are you so confident that evolution played much of a role at all? How did a tendency to engage in a particular style of moral philosophy cognition help in the ancestral environment? Why would that style, in particular, be so beneficial that evolution would "care" so much about it?
My position: mesa objectives learned in domain X do not automatically or easily generalize to a sufficiently distinct domain Y. The style of cognition required to make such generalizations is startlingly close to that which we call "moral philosophy".
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2022-06-10T23:58:39.048Z · LW(p) · GW(p)
Human social instincts are pretty important, including instincts for following norms and also for pushing back against norms. Not just instincts for specific norms, also one-level-up instincts for norms in general. These form the basis for what I see when I follow the label "moral reasoning."
I think I do expect AIs to be more inner-aligned than many others (because of the advantages gradient descent has over genetic algorithms). But even if we suppose that we get an AI governed by a mishmash of interdependent processes that sometimes approximate mesa-optimizers, I still don't expect what you expect - I don't expect early AGI to even have the standards by which it would say values "fail" to generalize, it would just follow what would seem to us like a bad generalization.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2022-06-11T00:31:08.852Z · LW(p) · GW(p)
By "moral philosophy", I'm trying to point to a specific subset of values-related cognition that is much smaller than the totality of values related cognition. Specifically, that subset of values-related cognition that pertains to generalization of existing values to new circumstances. I claim that there exists a simple "core" of how this generalization ought to work for a wide variety of values-holding agentic systems, and that this core is startlingly close to how it works in humans.
It's of course entirely possible that humans implement a modified version of this core process. However, it's not clear to me that we want an AI to exactly replicate the human implementation. E.g., do you really want to hard wire an instinct for challenging the norms you try to impose?
Also, I think there are actually two inner misalignments that occurred in humans.
1: Between inclusive genetic fitness as the base objective, evolution as the learning process, and the human reward circuitry as the mesa objectives.
2: Between activation of human reward circuitry as the base objective, human learning as the learning process, and human values as the mesa objectives.
I think AIs will probably be, by default, a bit less misaligned to their reward functions than humans are misaligned to their reward circuitry.
↑ comment by Oliver Sourbut · 2022-06-10T21:10:52.852Z · LW(p) · GW(p)
I think this is an interesting perspective, and I encourage more investigation.
Briefly responding, I have one caveat: curse of dimensionality. If values are a high dimensional space (they are: they're functions) then 'off by a bit' could easily mean 'essentially zero measure overlap'. This is not the case in the illustration (which is 1-D).
Replies from: quintin-pope, shawnghu↑ comment by Quintin Pope (quintin-pope) · 2022-06-11T00:09:44.428Z · LW(p) · GW(p)
I agree with your point about the difficulty of overlapping distributions in high dimensional space. It's not like the continuous perspective suddenly makes value alignment trivial. However, to me it seems like "overlapping two continuous distributions in a space X" is ~ always easier than "overlapping two sets of discrete points in space X".
Of course, it depends on your error tolerance for what counts as "overlap" of the points. However, my impression from the way that people talk about value fragility is that they expect there to be a very low degree of error tolerance between human versus AI values.
↑ comment by lc · 2022-06-10T13:59:21.641Z · LW(p) · GW(p)
So what is the chance, in practice, that the resolution of this complicated moral reasoning system will end up with a premium on humans in habitable living environments, as opposed to any other configuration of atoms?
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2022-06-10T19:42:02.369Z · LW(p) · GW(p)
Depends on how much measure human-compatible values hold in the system's initial distribution over values. A paperclip maximizer might do "moral philosophy" over what, exactly, represents the optimal form of paperclip, but that will not somehow lead to it valuing humans. Its distribution over values centers near-entirely on paperclips.
Then again, I suspect that human-compatible values don't need much measure in the system's distribution for the outcome you're talking about to occur. If the system distributes resources in rough proportion to the measure each value holds, then even very low-measure values get a lot of resources dedicated to them. The universe is quite large, and sustaining some humans is relatively cheap.
Replies from: Kerrigan↑ comment by Kerrigan · 2025-04-08T07:12:28.442Z · LW(p) · GW(p)
The initial distribution of values need not be highly related to the resultant values after moral philosophy and philosophical self-reflection. Optimizing hedonistic utilitariansm, for example, looks very little like any values from the outer optimization loop of natural selection.
I think that in order to understand intelligence, one can't start by assuming that there's an outer goal wrapper.
I think many of the arguments that you're referring to don't depend on this assumption. For example, a mind that keeps shifting what it's pursuing, with no coherent outer goal, will still pursue most convergent instrumental goals. It's simpler to talk about agents with a fixed goal. In particular, it cuts off some arguments like "well but that's just stupid, if the agent were smarter then it wouldn't make that mistake", by being able to formally show that there are logically possible minds that could be arbitrarily capable while still exhibiting the behavior in question.
Regarding the argument from Yudkowsky about coherence and utility, a version I'd agree with is: to the extent that you're having large consequences, your actions had to "add up" towards having those consequences, which implies that they "point in the same direction", in the same way implied by Dutch book arguments, so quantitatively your behavior is closer to being describable as optimizing for a utility function.
The point about reflectively stability is that if your behavior isn't consistent with optimizing a goal function, then you aren't reflectively stable. (This is very much not a theorem and is hopefully false, cf. satisficers which are at least reflectively consistent: https://arbital.com/p/reflective_stability/ .) Poetically, we could tell stories about global strategicness taking over a non-globally-strategic ecology of mind. In terms of analysis, we want to discuss reflectively stable minds because those have some hope of being analyzable; if it's not reflectively stable, if superintelligent processes might rewrite the global dynamic, all analytic bets are off (including the property of "has no global strategic goal").
Absence of legible alien goals in first AGIs combined with abundant data about human behavior in language models is the core of my hope for a technical miracle in this grisly business. AGIs with goals are the dangerous ones, the assumption of goals implies AI risk. But AGIs without clear goals (let's call these "proto-agents"), such as humans, don't have manic dedication to anything in particular, except a few stark preferences that stop being urgent after a bit of optimization that's usually not that strong. It's unclear if even these preferences remain important upon sufficiently thorough reflection, and don't become overshadowed by considerations that are currently not apparent (like math, which is not particularly human-specific).
Instead there are convergent purposes (shared by non-human proto-agents) such as mastering physical manufacturing, and preventing AI risk and other shadows of Moloch, as well as a vague project of long reflection or extrapolated volition (formulation of much more detailed actionable goals) motivated mostly by astronomical waste (opportunity cost of leaving the universe fallow). Since humans and other proto-agents don't have clear/legible/actionable preferences, there might be little difference in the outcome of long reflection if pursued by different groups of proto-agents, which is the requisite technical miracle. The initial condition of having a human civilization, when processed with a volition of merely moderately alien proto-agents (first AGIs), might result in giving significant weight to human volition, even if humans lose control over the proceedings in the interim. All this happens before the assumption of agency (having legible goals) takes hold.
(It's unfortunate that the current situation motivates thinking of increasingly phantasmal technical miracles that retain a bit of hope, instead of predictably robust plans. Still, this is somewhat actionable: when strawberry alignment [LW(p) · GW(p)] is not in reach, try not to make AGIs too alien, even in pursuit of alignment, and make sure a language model holds central stage.)
I see three distinct reasons for the (non-)existence of terminal goals:
I. Disjoint proxy objectives
A scenario in which there seems to be reason to expect no global, single, terminal goal:
- Outer loop pressure converges on multiple proxy objectives specialized to different sub-environments in a sufficiently diverse environment.
- These proxy objectives will be activated in disjoint subsets of the environment.
- Activation of proxy objectives is hard-coded by the outer loop. Information about when to activate a given proxy objective is under-determined at the inner loop level.
In this case, even if there is a goal-directed wrapper, it will face optimization pressure to leave the activation of proxy objectives described by 1-3 alone. Instead it will restrict itself to controlling other proxy objectives which do not fit the assumptions 1-3.
Reasons why this argument may fail:
- As capabilities increase, the goal-directed wrapper comes to realize when it lacks information relative to the information used in the outer loop. The optimization pressure for the wrapper not to interact with these 'protected' proxy objectives then dissipates, because the wrapper can intelligently interact with these objectives by recognizing its own limitations.
- As capabilities increase, one particular subroutine learns to self-modify and over-ride the original wrapper's commands -- where the original wrapper was content with multiple goals this new subroutine was optimized to only pursue a single proxy objective.
Conclusion: I'd expect a system described by points 1-3 to emerge before the counterarguments come into play. This initial system may already gradient hack to prevent further outer loop pressures. In such a case, the capabilities increase assumed in the two counter-argument bullets may never occur. Hence, it seems to me perfectly coherent to believe both (A) first transformative AI is unlikely to have a single terminal goal (B) sufficiently advanced AI would have a single terminal goal.
II. AI as market
If an AI is decentralized because of hardware constraints, or because decentralized/modular cognitive architectures are for some reason more efficient, then perhaps the AI will develop a sort of internal market for cognitive resources. In such a case, there need not be any pressure to converge to a coherent utility function. I am not familiar with this body of work, but John Wentworth claims that there are relevant theorems in the literature here: https://www.lesswrong.com/posts/L896Fp8hLSbh8Ryei/axrp-episode-15-natural-abstractions-with-john-wentworth#Agency_in_financial_markets_ [LW · GW]
III. Meta-preferences for self-modification (lowest confidence, not sure if this is confused. May be simply a reframing of reason I.)
Usually we imagine subagents as having conflicting preferences, and no meta-preferences. Instead imagine a system in which each subagent developed meta-preferences to prefer being displaced by other subagents under certain conditions.
In fact, we humans are probably examples of all I-III.
You may be interested: the NARS literature describes a system that encounters goals as atoms and uses them to shape the pops from a data structure they call bag, which is more or less a probabilistic priority queue. It can do "competing priorities" reasoning as a natural first class citizen, and supports mutation of goals.
But overall your question is something I've always wondered about.
I made an attempt to write about it here [LW(p) · GW(p)], I refer systems of fixed/axiomatic goals as "AIXI-like" and systems of driftable/computational goals "AIXI-unlike".
I share your intuition that this razor seems critical to mathematizing agency! I can conjecture about why we do not observe it in the literature:
Goal mutation is a special case of multi-objective optimization, and MOO is is just single-objective optimization where the objective is a linear multivariate function of other objectives
Perhaps agent foundations researchers, in some verbal/tribal knowledge that is on the occasional whiteboard in berkeley but doesn't get written up, reason that if goals are a function of time, the image of a sequence of discretized time steps forms a multi-objective optimization problem.
AF under goal mutation is super harder than AF under fixed goals, and we're trying to walk before we run
Maybe agent foundations researchers believe that just fixing the totally borked situation of optimization and decision theory with fixed goals costs 10 to 100 tao-years, and that doing it with unfixed goals costs 100 to 1000 tao-years.
If my goal is a function of time, instrumental convergence still applies
self explanatory
If my goal is a function of time, corrigibility????
Incorrigibility is the desire to preserve goal-content integrity, right? This implies that as time goes to infinity, the agent will desire for the goal to stabilize/converge/become constant. How does it act on this desire? Unclear to me. I'm deeply, wildly confused, as a matter of fact.
(Edited to make headings H3 instead of H1)
The standard argument is as follows:
Imagine Mahatma Ghandi. He values non-violence above all other things. You offer him a pill, saying "Here, try my new 'turns you into a homicidal manic' pill." He replies "No thank-you - I don't want to kill people, thus I also don't want to become a homicidal maniac who will want to kill people."
If an AI has a utility function that it optimizes in order to tell it how to act, then, regardless of what that function is, it disagrees with all other (non-isomorphic) utility functions in at least some places, thus it regards them as inferior to itself -- so if it is offered the choice "Should I change from you to to this alternative utility function ?" it will always answer "no".
So this basic and widely modeled design for an AI is inherently dogmatic and non-corrigible, and will always seek to preserve its goal. So if you use this kind of AI, its goals are stable but non-corrigible, and (once it becomes powerful enough to stop you shutting it down) you get only one try at exactly aligning them. Humans are famously bad at writing reward functions, so this is unwise.
Note that most humans don't work like this - they are at least willing to consider updating their utility function to a better one. In fact, we even have a word for someone who has this particular mental failing: 'dogmatism'. This is because most humans are aware that their model of how the universe works is neither complete nor entirely accurate - as indeed any rational entity should be.
Reinforcement Learning machines also don't work this way -- they're trying to learn the utility function to use, so they update it often, and they don't ask the previous utility function if that was a good idea since its reply will always be 'no' so is useless input.
There are alternative designs, see for example the Human Compatible/CIRL/Value Learning approach suggested by Stuart Russell and others, which is simultaneously trying to find out what its utility function should be (where 'should' is defined as 'humans would want it to be, but sadly are not good enough at writing reward functions to be able to tell me') so doing Bayesian updates to it as it gathers more information about what humans actually want, and also optimizing its actions while internally modelling its uncertainty about the utility of possible actions as a probability distribution of possible utilities for an action (i.e. it can model situations like "I'm about ~95% convinced that this act will just produce the true-as-judged-by-humans utility level 'I fetched a human some coffee (+1)', but I'm uncertain, and there's also an ~5% chance I current misunderstand humans so badly that it might instead have a true utility level of 'the extinction of the human species (-10^25)', so I won't do it, and will consider spawning a subgoal of my 'become a better coffee fetcher' goal to further investigate this uncertainty, by some means far safer than just trying it and seeing what happens." Note that the utility probability distribution contains more information than just its mean would: it can both be updated in a more Bayesian way, and optimized over in a more cautious way (for example, it you were optimizing over O(20) possible actions, you should probably optimize against a score of "I'm ~95% confident that the utility is at least this", so roughly two sigma below the mean if your distribution is normal - which it may well not be - to avoid building an optimizer that mostly retrieves actions for which your error bars are wide. Similarly if you're optimizing over O(10,000) possible actions, you should probably optimize the 99.99%-confidence lower bounds on utility, and thus also consider some really unlikely ways in which you might be mistaken about what humans want.
I think the answer to 'where is Eliezer getting this from' can be found in the genesis of the paperclip maximizer scenario. There's an older post on LW talking about 'three types of genie' and another on someone using a 'utility pump' (or maybe it's one and the same post?), where Eliezer starts from the premise that we create an artifical intelligence to 'make something specific happen for us', with the predictable outcome that the AI finds a clever solution which maximizes for the demanded output, one that naturally has nothing to do with what we 'really wanted from it'. If asked to produce smiles, it will manufacture molecular smiley faces, and it will do its best to prevent us from executing this splendid plan.
This scenario, to me, seems much more realistic and likely to occur in the near-term than an AGI with full self-reflective capacities either spontaneously materializing or being created by us (where would we even start on that one)?
AI, more than anything else, is a kind of transhumanist dream, a deus ex machina that will grant all good wishes and make the world into the place they (read:people who imagine themselves as benevolent philosopher kings) want it to be ー so they'll build a utility maximizer and give it a very painstakingly thought-through list of instructions, and the genie will inevitably find a loophole that lets it follow those instructions to the letter, with no regard for its spirit.
It's not the only kind of AI that we could build, but it will likely be the first, and, if so, it will almost certainly also be the last.
33 comments
Comments sorted by top scores.
comment by 1a3orn · 2024-01-13T15:37:16.029Z · LW(p) · GW(p)
I think that (1) this is a good deconfusion post, (2) it was an important post for me to read, and definitely made me conclude that I had been confused in the past, (3) and one of the kinds of posts that, ideally, in some hypothetical and probably-impossible past world, would have resulted in much more discussion and worked-out-cruxes in order to forestall the degeneration of AI risk arguments into mutually incomprehensible camps with differing premises, which at this point is starting to look like a done deal?
On the object level: I currently think that -- well, there are many, many, many ways for an entity to have it's performance adjusted so that it does well by some measure. One conceivable location that some such system could arrive in is for it to move to an outer-loop-fixed goal, per the description of the post. Rob (et al) think that there is a gravitational attraction towards such an outer-loop-fixed goal, across an enormous variety of future architectures, such that multiplicity of different systems will be pulled into such a goal, will develop long-term coherence towards (from our perspective) random goals, and so on.
I think this is almost certainly false, even for extremely powerful systems -- to borrow a phrase, it seems equally well to be an argument that humans should be automatically strategic [LW · GW], which of course they are not. It also part of the genre of arguments that argue that AI systems should act in particular ways regardless of their domain, training data, and training procedure -- which I think by now we should have extremely strong priors against, given that for literally all AI systems -- and I mean literally all, including MCTS-based self-play systems -- the data from which the NN's learn is enormously important for what those NNs learn. More broadly, I currently think the gravitational attraction towards such an outer-loop-fixed-goal will be absolutely tiny, if at all present, compared to the attraction towards more actively human-specified goals.
But again, that's just a short recap of one way to take what is going on in the post, and one that of course many people will not agree with. Overall, I think the post itself, Robs's reply, and Nostalgebrist's reply to Rob's reply, are all pretty good at least as a summary of the kind of thing people say about this.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-11-01T19:15:04.759Z · LW(p) · GW(p)
This sounds like the shortest, most succinct description of what I consider 1 central problem in the entire AI alignment community that makes a lot of their other thoughts on AI risk very distorted, so thank you for stating the issue so clearly.
I don't think this is the only problem, and there is another problem I'll mention in this comment, but as a description of why I tend to be more optimistic about data-based alignment strategies than many others, this statement is why I think this way:
It also part of the genre of arguments that argue that AI systems should act in particular ways regardless of their domain, training data, and training procedure -- which I think by now we should have extremely strong priors against, given that for literally all AI systems -- and I mean literally all, including MCTS-based self-play systems -- the data from which the NN's learn is enormously important for what those NNs learn.
My post about the issue of assuming instrumental convergence being far more unconstrained than happens in reality is also another central issue in the AI alignment community:
https://www.lesswrong.com/posts/HHkYEyFaigRpczhHy/ai-88-thanks-for-the-memos#EZLm32pKskw8F5xiF [LW(p) · GW(p)]
comment by lc · 2022-06-10T06:25:47.744Z · LW(p) · GW(p)
Note: I am often not even in the ballpark with this shit.
I am skipping the majority of the content to address an edit other than to say: humans ended up with their specific brand of moral uncertainty as a circumstance of their evolution. That brand still includes, ultimately arbitrary, universals, like valuing human life, which is why we can have moral debates between each other at all. Moral uncertainty of a superpowerful agent between a set of values that are all EV=0 means we still die, and if the average EV of the set is nonzero, it's probably because we put some of them there. We also still need some way to resolve that uncertainty towards the ones we like, or else it's either "hedging" our bets or rolling the dice. That resolution process has to be a deliberate, carefully engineered system; there's no ethical argument you can give me for ending humanity that would be convincing and there's probably not any ethical argument you can give to a "morally uncertain" Clippy for letting me live.
...to spell out the reason I care about the answer: agents with the "wrapper structure" are inevitably hard to align, in ways that agents without it might not be. An AGI "like me" might be morally uncertain like I am, persuadable through dialogue like I am, etc.
The way I'm parsing "morally uncertain like I am, persuadable through dialogue like I am, etc.", it sounds like the underlying propert(y/ies) you're really hoping for by eschewing the fixed goal assumptions might have one of two possible operationalizations.
The first is: an AI that is uncertain about exactly what humans want, but still wants to want what humans want. Instead of taking a static utility function and running with it, one that tries to predict what humans would want if they were highly intelligent. As far as I can tell, that's Coherent Extrapolated Volition (CEV), and everyone pretty much agrees a workable plan to make one would solve the alignment problem. It'll be extraordinarily difficult to engineer correctly the first time around, for all of the reasons explained in the AGI ruin post.
The second possibility is: an AI that's corrigible, one that can be told to stop by existing human operators and updated/modified by its human operators (via "debate" or whatever else) after it's run the first time. Obviously corrigible AIs aren't straightforward utilitarians. AFAICT though we don't have a consistent explanation of how one would even work, and MIRI has tried to find one for the last decade to little success.
So, if your primary purpose in looking into the behavior of agent designs that don't have very trivially fixed goals is either of these two strategies, you should mention so.
comment by Shmi (shminux) · 2022-06-10T03:24:28.888Z · LW(p) · GW(p)
I don't think that a single fixed goal is a necessary assumption at all before someone can conclude that WE ARE ALL GONNA DIE!!! Humans don't have a single fixed terminal goal at all. And yet if you have a 1000 times scaled up human intelligence, even with all the faults and inconsistencies of a human preserved (and magnified), you are still in the world where human survival is at the mercy of the new species whose behavior is completely incomprehensible and unfathomable. What is likely to happen is that the world will lose its predictability to humans and agency, by definition, can only exist in a world that is predictable from the inside. And without agency being possible agents automatically cease to exist.
Replies from: Gunnar_Zarncke↑ comment by Gunnar_Zarncke · 2022-06-10T21:21:25.405Z · LW(p) · GW(p)
Yes, but that doesn't engage with the main argument which seems novel. nostalgebraist doesn't claim that the AGI couldn't kill us all if it wanted.
comment by JoeTheUser · 2024-02-01T05:08:27.275Z · LW(p) · GW(p)
The consensus goals strongly needs rethinking imo. This is a clear and fairly simple start at such an effort. Challenging the basics matters.
comment by TekhneMakre · 2022-06-10T02:04:25.673Z · LW(p) · GW(p)
I have an impression that David Deutsch's critical rationalism, in the idea of "absolutely everything in a mind can be critiqued", describes something like the model you're point at. Unfortunately I don't know of writing about this and don't remember why I have this impression.
Replies from: PaulK↑ comment by PaulK · 2022-06-11T07:01:06.874Z · LW(p) · GW(p)
I do see the inverse side: a single fixed goal would be something in the mind that's not open to critique, hence not truly generally intelligent from a Deutschian perspective (I would guess; I don't actually know his work well).
To expand on the "not truly generally intelligent" point: one way this could look is if the goal included some tacit assumptions about the universe that turned out later not to be true in general -- e.g. if the agent's goal was something involving increasingly long-range simultaneous coordination, before the discovery of relativity -- and if the goal were really unchangeable, then it would bar or at least complicate the agent's updating to a new, truer ontology.
comment by Donald Hobson (donald-hobson) · 2022-06-11T11:12:51.624Z · LW(p) · GW(p)
As well as various self modification and coherence arguments, there is also the "frictionless sphere in a vacuum".
Sometimes we assume an object is a sphere, when its actually slightly aspherical, just because spheres are so easy to reason about and the approximation is good enough.
There is also an argument that goes "we aren't claiming that all AI's will optimize for fixed goals, it just happens that most of the research is on such AI's". And finally, if an AI is too incoherent, it may sit there fighting itself, ie doing nothing.
Remember that in some sense, time consistent agents are a small subset of all programs. You have to make a cart out of something specific, you can't make a cart out of "nonwood materials". https://www.lesswrong.com/posts/2mLZiWxWKZyaRgcn7/selling-nonapples [LW · GW] If anyone can describe a specific design that isn't a time consistent outer optimizer, and that has interesting safety properties, that would be valuable. If you are telling us that nonconsistant AI's should be in our search space, yes they should. They might be not too high in the search ordering, because when you find a smaller, easier to understand subset of a space that has nice mathematical properties, you usually want to look there first.
comment by tailcalled · 2022-06-10T07:14:24.025Z · LW(p) · GW(p)
I often see the rapid capability gains of humans over other apes cited as a prototype case for the rapid capability gains we expect in AGI. But humans do not have this wrapper structure! Our goals often change over time. (And we often permit or even welcome this, whereas an optimizing wrapper would try to prevent its goal from changing.)
Just so I can more directly comment on it, can you name three examples that you like on this?
Replies from: nostalgebraist↑ comment by nostalgebraist · 2022-06-10T22:11:28.255Z · LW(p) · GW(p)
Sure. Although before I do, I want to qualify the quoted claim a bit.
When I say "our goals change over time," I don't mean "we behave something like EU maximizers with time-dependent utility functions." I think we don't behave like EU maximizers, in the sense of having some high-level preference function that all our behavior flows from in a top-down manner.
If we often make choices that are rational in a decision-theoretic sense (given some assumption about the preferences we are trying to satisfy), we are doing so via a "subgoal capacity." This kind of decision-making is available to our outermost loop, and our outermost loop sometimes uses it.
But I don't think the logic of our outermost loop actually is approximate EU maximization -- as evidenced by all the differences between how we deploy our capabilities, and how a "smart EU maximizer" would deploy its own. For instance, IMO we are less power-seeking than an EU maximizer would be (and when humans do seek power, it's often as an end in itself, whereas power-seeking is convergent across goals for EU maximizers).
Saying that "our goals change over time, and we permit/welcome this" is meant to gesture at how different we are from a hypothetical EU maximizer with our capabilities. But maybe this concedes too much, because it implies we have some things called "goals" that play a similar role to the EU maximizer's utility function. I am pretty sure that's not in fact true. We have "goals" in the informal sense, but I don't really know what it is we do with them, and I don't think mapping them on to the "preferences" in a decision-theoretic story about human behavior is likely to yield accurate predictions.
Anyway:
- Some people grow up in cultures where meat eating is normal, and eat meat themselves until some point, then become convinced to stop out of moral concern for animals. In rare cases, the person might have "always felt on some level" the same moral concern that later drives them to veganism, but in the median case (it seems to me) this moral concern is actually acquired over time -- the person really does not care as much about animals earlier as they do later. (This is a particular case of a more general thing, where one's "moral circle" widens over time; various kinds of individual change toward more "progressive" attitudes fall in this category.)
- When I was younger, I felt very strongly that I ought to "be moral" while also feeling very uncertain about what this entailed; I felt sure there was some "true ethics" (something like a single, objectively true ethical theory) which was important to follow, without knowing what it was, and when I tried to "be moral" this often involved trying to figure out what the true ethics was. Over time, I have lost this emotion towards "the true ethics" (I am not sure it exists and not sure the question matters), while gaining a tendency to have more moral emotions/motivations about concrete instances of harm. I am not sure how glad I am that this has occurred. I find my former self strange and even "silly," but I have difficulty coming up with a fully satisfying argument that I am "right" while he is "wrong."
- When a person loses or gains religious faith, this changes their world model so drastically that their previous goals/values (or at least the things they consciously articulated as goals/values) are not even on the map anymore. If you think of yourself as fundamentally striving to "serve God," and then you decide God doesn't exist, you need a new thing to do.
- Some people have a single, consuming passion that drives them for much/most/all of their adult life. For each such person, there was a time before they became passionate about this subject, and indeed a time before they had even heard of it. So it was not always their "goal." Mathematicians seem like an especially clear case of this, since higher math is so remote from everyday life.
- New parents sometimes report that their children provide them with a kind of value which they did not anticipate, or perhaps could not even have understood, before parenthood. And, the belief that this occurs is widespread enough that people sometimes have children, not because they want to on their current values, but because they expect to become different people with different values as a result, and wish this change to occur.
Sorry, you asked for three, that was five. I wanted to cover a range of areas, since one can look at any one of these on its own and imagine a way it might fit inside a decision-theoretic story.
EU maximization with a non-constant world model ("map") might look like 3 and 4, while 5 involves a basic biological function of great interest to natural selection, so we might imagine it a hardwired "special case" not representative of how we usually work. But the ubiquity and variety of this kind of thing, together with our lack of power-seeking etc., does strike me a problem for decision-theoretic interpretations of human behavior at the lifetime level.
Replies from: tailcalled↑ comment by tailcalled · 2022-06-11T08:16:28.707Z · LW(p) · GW(p)
Aha, this seems somewhat cruxy, because the things you list as examples of human goals are mostly about values, which I agree act in a sort of weird way, whereas I would see maintenance of homeostasis as a more central example of human goals. And while maintaining homeostasis isn't 100% aligned with the concept of utility maximization, it does seem to be a lot more aligned than values.
With respect to maintaining homeostasis, it can be a bit unclear what exactly the utility function is. The obvious possibility would be "homeostasis" or "survival" or something like that, but this is slightly iffy in two directions.
First, because strictly speaking we maintain homeostasis based on certain proxies, so in a sense the proxies are what we more strictly optimize. But this can also be fit into the EU framework in another way, with the proxies representing part of the mechanism for how the expectation of utility is operationalised.
And second, because maintaining homeostasis is again just a proxy for other goals that evolution has, namely because it grants power to engage in reproduction and kin altruism. And this doesn't fit super neatly into classical EU frameworks, but it does fit neatly into later rationalist developments like outer/mesa-optimization.
So basically, "homeostasis" is kind of fuzzy in how it relates to EU-style maximization, but it does also sort of fit, and I think it fits much better than values do:
- A human has a goal of maintaining homeostasis
- The goal is a fixed part of the human's structure. The internal dynamics of the human, if left to their own devices, will never modify the goal.
- The "outermost loop" of the human's internal dynamics is an optimization process aimed at maintaining homeostasis, or at least the human behaves just as though this were true.
- This "outermost loop" or "fixed-homeostasis-directed wrapper" chooses which of the human's specific capabilities to deploy at any given time, and how to deploy it.
- The human's capabilities will themselves involve optimization for sub-goals that are not the same as maintaining homeostasis, and they will optimize for them very powerfully (hence "capabilities"). But it is "not enough" that the human merely be good at optimization-for-subgoals: it will also have a fixed-homeostasis-directed wrapper.
- So, the human may be very good at maintaining homeostasis, and when they are maintaining homeostasis, they may be running an internal routine that optimizes for maintaining homeostasis. This routine, and not the terminal-goal-directed wrapper around it, explains the human's strong homeostasis. ("Maximize paperclips" does not tell you how to maintain homeostasis.)
- The human may also be good at things that are much more general than maintaining homeostasis, such as "planning," "devising proofs in arbitrary formal systems," "inferring human mental states," or "coming up with parsimonious hypotheses to explain observations." All of these are capacities to optimize for a particular subgoal that is not the human's terminal goal.
- Although these subgoal-directed capabilities, and not the fixed-homeostasis-directed wrapper, will constitute the reason the human does well at anything it does well at, the human must still have a fixed-homeostasis-directed wrapper around them and apart from them. ADDED BECAUSE THE EXPLANATION WAS MISSING IN THE ORIGINAL OP: Because otherwise there is no principle to decide what subgoal to pursue in any one moment, and how to trade it off against other subgoals. Furthermore, otherwise you'd run into salt-starvation problems [LW · GW].
- There is no way for the pursuit of homeostasis to change through bottom-up feedback from anything inside the wrapper. The hierarchy of control is strict and only goes one way.
Homeostasis also fits the whole power-seeking/misalignment/xrisk dynamic much more closely than values do. Would humanity commit planet-scale killings and massively transform huge parts of the world for marginal values gain? Eh. Sort of. Sometimes. It's complicated. Would humans commit planet-scale killings and massively transform huge parts of the world for marginal homeostasis gain? Obviously yes.
Replies from: PaulK, TekhneMakre, TAG, PaulK↑ comment by PaulK · 2022-06-11T20:36:29.413Z · LW(p) · GW(p)
>There is no way for the pursuit of homeostasis to change through bottom-up feedback from anything inside the wrapper. The hierarchy of control is strict and only goes one way.
Note that people do sometimes do things like starve themselves to death or choose to become martyrs in various ways, for reasons that are very compelling to them. I take this as a demonstration that homeostatic maintenance of the body is in some sense "on the same level" as other reasons / intentions / values, rather than strictly above everything else.
Replies from: tailcalled↑ comment by tailcalled · 2022-06-11T21:17:01.764Z · LW(p) · GW(p)
"No way" is indeed an excessively strong phrasing, but it seems clear to me that pursuit of homeostasis is much more robust to perturbations than most other pursuits.
Replies from: PaulK↑ comment by TekhneMakre · 2022-06-12T03:08:32.688Z · LW(p) · GW(p)
I speculate that a significant chunk of Heidegger's philosophy can be summarized as "people are homeostats for roles". Everything we do (I'm speculating Heidegger claims) grounds out in "in order to be an X" where X is like "good person", "father", "professor", "artist", etc.
↑ comment by TAG · 2022-06-17T12:01:16.454Z · LW(p) · GW(p)
This could really.do.with some concrete examples of homeostasis, and some discussion of how homeostasis is compatible with major life changes.
And second, because maintaining homeostasis is again just a proxy for other goals that evolution has, namely because it grants power to engage in reproduction and kin altruism
Staying alive grants power to engage in reproduction and kin altruism ... But homeostasis means "staying the same", according to the dictionary. The two come apart. A single homeostat would want to stay single, because that is their current state. But singletons often don't want to stay single, and don't serve evolutionary purposes by doing so.
Replies from: tailcalled↑ comment by tailcalled · 2022-06-17T21:15:32.563Z · LW(p) · GW(p)
This could really.do.with some concrete examples of homeostasis,
- There's a whole bunch of pure bio stuff that I'm not properly familiar with the details of, e.g. the immune system. But the more interesting stuff is probably the behavioral stuff.
- When you are low on nutrition or calories, you get hungry and try to eat. You generally feel motivated to ensure that you have food to eat for when you do get hungry, which in modern society involves doing stuff like working for pay, but in other societies has involved farming or foraging. If there are specific nutrients like salt that you are missing, then you feel strong cravings for food containing those nutrients.
- Shelter, if the weather is sufficiently cold that it would hurt you (or waste energy), then you find it aversive and seek protection. Longer-term, you ensure you have a house etc..
- Safety. If you touch a hot stove, you immediately move your hand away from it. In order to avoid getting hurt, people create safety regulations. Etc.
There's just tons of stuff, and nobody is likely to talk you out of ensuring that you get your nutritional needs covered, or to talk you out of being protected from the elements. They are very strong drives.
and some discussion of how homeostasis is compatible with major life changes.
And second, because maintaining homeostasis is again just a proxy for other goals that evolution has, namely because it grants power to engage in reproduction and kin altruism
Staying alive grants power to engage in reproduction and kin altruism ... But homeostasis means "staying the same", according to the dictionary. The two come apart. A single homeostat would want to stay single, because that is their current state. But singletons often don't want to stay single, and don't serve evolutionary purposes by doing so.
I mean homeostasis in the sense of "keeping conditions within the range where one is healthily alive", not in the sense of "keeping everything the same".
Replies from: TAG, TAG↑ comment by TAG · 2022-06-20T16:28:32.149Z · LW(p) · GW(p)
I mean homeostasis in the sense of “keeping conditions within the range where one is healthily alive”, not in the sense of “keeping everything the same”.
But that still isn't the sole explanation of human behaviour, because humans do flourishing type stuff like going on dates, going to college, going to the gym.
Also: global warming.
Replies from: tailcalled↑ comment by tailcalled · 2022-06-20T21:17:47.758Z · LW(p) · GW(p)
I'm not saying that it is the sole explanation of all human behavior, I'm saying that it is a major class of behaviors that is difficult to stop people from engaging in and which is necessary for the effectiveness of humans in influencing the world.
Not sure what the relevance of global warming is to this discussion.
Replies from: TAG↑ comment by TAG · 2022-06-21T11:38:05.401Z · LW(p) · GW(p)
Global warming is humans moving conditions out of the range where one is healthily alive.
Replies from: tailcalled↑ comment by tailcalled · 2022-06-21T18:33:51.430Z · LW(p) · GW(p)
Insofar as that is true, seems like a scale issue [LW · GW]. (It doesn't seem entirely true - global warming is a major problem, but not exactly an x-risk. Many of the biggest contributors to global warming are not the ones who will be hit the hardest. And there's a tragedy of the commons issue to it.)
↑ comment by TAG · 2022-06-17T22:32:02.134Z · LW(p) · GW(p)
I'm familiar with the ordinary biological meaning of homeostasis , but I don't see how it relates to
Would humanity commit planet-scale killings and massively transform huge parts of the world for marginal values gain? Eh. Sort of. Sometimes. It’s complicated. Would humans commit planet-scale killings and massively transform huge parts of the world for marginal homeostasis gain? Obviously yes.
Why would anyone commit massive crimes for marginal gains?
Replies from: tailcalled↑ comment by tailcalled · 2022-06-18T06:13:02.594Z · LW(p) · GW(p)
Factory farming
Replies from: TAG↑ comment by TAG · 2022-06-18T14:31:20.281Z · LW(p) · GW(p)
Why's no one in jail for it?
Replies from: tailcalled↑ comment by tailcalled · 2022-06-18T15:08:22.945Z · LW(p) · GW(p)
It's not illegal. I said "killings", not "homicides" or "murders".
↑ comment by PaulK · 2022-06-11T20:47:38.527Z · LW(p) · GW(p)
As a slightly tangential point, I think if you start thinking about how to cast survival / homeostasis in terms of expected-utility maximization, you start having to confront a lot of funny issues, like, "what happens if my proxies for survival change because I self-modified?", and then more fundamentally, "how do I define / locate the 'me' whose survival I am valuing? what if I overlap with other beings? what if there are multiple 'copies' of me?". Which are real issues for selfhood IMO.
Replies from: tailcalled↑ comment by tailcalled · 2022-06-11T21:17:56.537Z · LW(p) · GW(p)
In the evolutionary case, the answer is that this is out of distribution, so it's not evolved to be robust to such changes.
comment by TW123 (ThomasWoodside) · 2022-06-10T04:12:32.414Z · LW(p) · GW(p)
We wrote a bit about this in this post [AF · GW]. In short, I don't think it's a necessary assumption. In my view, it does seem like we need objectives that can (and will) be updated over time, and for this we probably need some kind of counteracting reward system, since an individual agent is going to be incentivized to avoid a modification to its goal. The design of this kind of adaptive counteracting reward system (like what we humans have) is certainly a very difficult problem, but probably not any harder than aligning a superintelligence with a fixed goal.
Stuart Russell also makes an uncertain objective that can change one of the centerpieces of his agenda (that being said, not many seem to be actually working on it).
comment by David Johnston (david-johnston) · 2022-06-11T04:31:12.235Z · LW(p) · GW(p)
I'm not sure exactly how important goal-optimisation is. I think AIs are overwhelmingly likely to fail to act as if they were universally optimising for simple goals compared to some counterfactual "perfect optimiser with equivalent capability", but this is failure only matters if the dangerous behaviour is only executed by the perfect optimiser.
They're also very likely to act as if they are optimising for some simple goal X in circumstances Y under side conditions Z (Y and Z may not be simple) - in fact, they already do. This could easily be enough for dangerous behaviour, especially if in practice there's a lot of variation in X, Y and Z. Subject to restrictions imposed by Y and Z, instrumental convergence still applies.
A particular worry is if dangerous behaviour is easy. Suppose it's completely trivial: there's a game of Go where placing the right 5-stone sequence kills everybody and awards the stone placer the win. You have a smart AI (that already "knows" how to win at Go, and about the five stone technique) that you want to play the game for you. You use some method to try to direct it to play games of Go. Unless it has particular reason to ignore the 5-stone sequence, it will probably consider it about its top moves, even if it's simultaneously prone to getting distracted by butterflies, or if it misunderstands your request to be about playing go only on sunny days. It just comes down to the fact that the 5-stone sequence is a strong move that's easy to know about.