Six Dimensions of Operational Adequacy in AGI Projects
post by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2022-05-30T17:00:30.833Z · LW · GW · 66 commentsContents
Trustworthy command Closure Opsec Common good commitment Alignment mindset Resources Further Remarks None 67 comments
Editor's note: The following is a lightly edited copy of a document written by Eliezer Yudkowsky in November 2017. Since this is a snapshot of Eliezer’s thinking at a specific time, we’ve sprinkled reminders throughout that this is from 2017. A background note: It’s often the case that people are slow to abandon obsolete playbooks in response to a novel challenge. And AGI is certainly a very novel challenge. Italian general Luigi Cadorna offers a memorable historical example. In the Isonzo Offensive of World War I, Cadorna lost hundreds of thousands of men in futile frontal assaults against enemy trenches defended by barbed wire and machine guns. As morale plummeted and desertions became epidemic, Cadorna began executing his own soldiers en masse, in an attempt to cure the rest of their “cowardice.” The offensive continued for 2.5 years. Cadorna made many mistakes, but foremost among them was his refusal to recognize that this war was fundamentally unlike those that had come before. Modern weaponry had forced a paradigm shift, and Cadorna’s instincts were not merely miscalibrated—they were systematically broken. No number of small, incremental updates within his obsolete framework would be sufficient to meet the new challenge. Other examples of this type of mistake include the initial response of the record industry to iTunes and streaming; or, more seriously, the response of most Western governments to COVID-19.
As usual, the real challenge of reference class forecasting is figuring out which reference class the thing you’re trying to model belongs to. For most problems, rethinking your approach from the ground up is wasteful and unnecessary, because most problems have a similar causal structure to a large number of past cases. When the problem isn’t commensurate with existing strategies, as in the case of AGI, you need a new playbook. |
I've sometimes been known to complain, or in a polite way scream in utter terror, that "there is no good guy group in AGI", i.e., if a researcher on this Earth currently wishes to contribute to the common good, there are literally zero projects they can join and no project close to being joinable. In its present version, this document is an informal response to an AI researcher who asked me to list out the qualities of such a "good project".
In summary, a "good project" needs:
- Trustworthy command: A trustworthy chain of command with respect to both legal and pragmatic control of the intellectual property (IP) of such a project; a running AGI being included as "IP" in this sense.
- Research closure: The organizational ability to close and/or silo IP to within a trustworthy section and prevent its release by sheer default.
- Strong opsec: Operational security adequate to prevent the proliferation of code (or other information sufficient to recreate code within e.g. 1 year) due to e.g. Russian intelligence agencies grabbing the code.
- Common good commitment: The project's command and its people must have a credible commitment to both short-term and long-term goodness. Short-term goodness comprises the immediate welfare of present-day Earth; long-term goodness is the achievement of transhumanist astronomical goods.
- Alignment mindset: Somebody on the project needs deep enough security mindset plus understanding of AI cognition that they can originate new, deep measures to ensure AGI alignment; and they must be in a position of technical control or otherwise have effectively unlimited political capital. Everybody on the project needs to understand and expect that aligning an AGI will be terrifically difficult and terribly dangerous.
- Requisite resource levels: The project must have adequate resources to compete at the frontier of AGI development, including whatever mix of computational resources, intellectual labor, and closed insights are required to produce a 1+ year lead over less cautious competing projects.
I was asked what would constitute "minimal, adequate, and good" performance on each of these dimensions. I tend to divide things sharply into "not adequate" and "adequate" but will try to answer in the spirit of the question nonetheless.
Trustworthy command
Token: Not having pragmatic and legal power in the hands of people who are opposed to the very idea of trying to align AGI, or who want an AGI in every household, or who are otherwise allergic to the easy parts of AGI strategy.
E.g.: Larry Page begins with the correct view that cosmopolitan values are good, speciesism is bad, it would be wrong to mistreat sentient beings just because they're implemented in silicon instead of carbon, and so on. But he then proceeds to reject the idea that goals and capabilities are orthogonal, that instrumental strategies are convergent, and that value is complex and fragile. As a consequence, he expects AGI to automatically be friendly, and is liable to object to any effort to align AI as an attempt to keep AI "chained up".
Or, e.g.: As of December 2015, Elon Musk not only wasn’t on board with closure, but apparently wanted to open-source superhumanly capable AI.
Elon Musk is not in his own person a majority of OpenAI's Board, but if he can pragmatically sway a majority of that Board then this measure is not being fulfilled even to a token degree.
(Update: Elon Musk stepped down from the OpenAI Board in February 2018.)
Improving: There's a legal contract which says that the Board doesn't control the IP and that the alignment-aware research silo does.
Adequate: The entire command structure including all members of the finally governing Board are fully aware of the difficulty and danger of alignment. The Board will not object if the technical leadership have disk-erasure measures ready in case the Board suddenly decides to try to open-source the AI anyway.
Excellent: Somehow no local authority poses a risk of stepping in and undoing any safety measures, etc. I have no idea what incremental steps could be taken in this direction that would not make things worse. If e.g. the government of Iceland suddenly understood how serious things had gotten and granted sanction and security to a project, that would fit this description, but I think that trying to arrange anything like this would probably make things worse globally because of the mindset it promoted.
Closure
Token: It's generally understood organizationally that some people want to keep code, architecture, and some ideas a 'secret' from outsiders, and everyone on the project is okay with this even if they disagree. In principle people aren't being pressed to publish their interesting discoveries if they are obviously capabilities-laden; in practice, somebody always says "but someone else will probably publish a similar idea 6 months later" and acts suspicious of the hubris involved in thinking otherwise, but it remains possible to get away with not publishing at moderate personal cost.
Improving: A subset of people on the project understand why some code, architecture, lessons learned, et cetera must be kept from reaching the general ML community if success is to have a probability significantly greater than zero (because tradeoffs between alignment and capabilities make the challenge unwinnable if there isn’t a project with a reasonable-length lead time). These people have formed a closed silo within the project, with the sanction and acceptance of the project leadership. It's socially okay to be conservative about what counts as potentially capabilities-laden thinking, and it's understood that worrying about this is not a boastful act of pride or a trick to get out of needing to write papers.
Adequate: Everyone on the project understands and agrees with closure. Information is siloed whenever not everyone on the project needs to know it.
| Reminder: This is a 2017 document. |
Opsec
Token: Random people are not allowed to wander through the building.
Improving: Your little brother cannot steal the IP. Stuff is encrypted. Siloed project members sign NDAs.
Adequate: Major governments cannot silently and unnoticeably steal the IP without a nonroutine effort. All project members undergo government-security-clearance-style screening. AGI code is not running on AWS, but in an airgapped server room. There are cleared security guards in the server room.
Excellent: Military-grade or national-security-grade security. (It's hard to see how attempts to get this could avoid being counterproductive, considering the difficulty of obtaining trustworthy command and common good commitment with respect to any entity that can deploy such force, and the effect that trying would have on general mindsets.)
Common good commitment
Token: Project members and the chain of command are not openly talking about how dictatorship is great so long as they get to be the dictator. The project is not directly answerable to Trump or Putin. They say vague handwavy things about how of course one ought to promote democracy and apple pie (applause) and that everyone ought to get some share of the pot o' gold (applause).
Improving: Project members and their chain of command have come out explicitly in favor of being nice to people and eventually building a nice intergalactic civilization. They would release a cancer cure if they had it, their state of deployment permitting, and they don't seem likely to oppose incremental steps toward a postbiological future and the eventual realization of most of the real value at stake.
Adequate: Project members and their chain of command have an explicit commitment to something like coherent extrapolated volition as a long-run goal, AGI tech permitting, and otherwise the careful preservation of values and sentient rights through any pathway of intelligence enhancement. In the short run, they would not do everything that seems to them like a good idea, and would first prioritize not destroying humanity or wounding its spirit with their own hands. (E.g., if Google or Facebook consistently thought like this, they would have become concerned a lot earlier about social media degrading cognition.) Real actual moral humility with policy consequences is a thing.
Alignment mindset
Token: At least some people in command sort of vaguely understand that AIs don't just automatically do whatever the alpha male in charge of the organization wants to have happen. They've hired some people who are at least pretending to work on that in a technical way, not just "ethicists [LW · GW]" to talk about trolley problems and which monkeys should get the tasty banana.
Improving: The technical work output by the "safety" group is neither obvious nor wrong. People in command have ordinary paranoia about AIs. They expect alignment to be somewhat difficult and to take some extra effort. They understand that not everything they might like to do, with the first AGI ever built, is equally safe to attempt.
Adequate: The project has realized that building an AGI is mostly about aligning it. Someone with full security mindset and deep understanding of AGI cognition as cognition has proven themselves able to originate new deep alignment measures, and is acting as technical lead with effectively unlimited political capital within the organization to make sure the job actually gets done. Everyone expects alignment to be terrifically hard and terribly dangerous and full of invisible bullets whose shadow you have to see before the bullet comes close enough to hit you. They understand that alignment severely constrains architecture and that capability often trades off against transparency. The organization is targeting the minimal AGI doing the least dangerous cognitive work that is required to prevent the next AGI project from destroying the world. The alignment assumptions have been reduced into non-goal-valent statements, have been clearly written down, and are being monitored for their actual truth.
Alignment mindset is fundamentally difficult to obtain for a project because Graham's Design Paradox applies. People with only ordinary paranoia may not be able to distinguish the next step up in depth of cognition, and happy innocents cannot distinguish useful paranoia from suits making empty statements about risk and safety. They also tend not to realize what they're missing. This means that there is a horrifically strong default that when you persuade one more research-rich person or organization or government to start a new project, that project will have inadequate alignment mindset unless something extra-ordinary happens. I'll be frank and say relative to the present world I think this essentially has to go through trusting me or Nate Soares to actually work, although see below about Paul Christiano. The lack of clear person-independent instructions for how somebody low in this dimension can improve along this dimension is why the difficulty of this dimension is the real killer.
If you insisted on trying this the impossible way, I'd advise that you start by talking to a brilliant computer security researcher rather than a brilliant machine learning researcher.
Resources
Token: The project has a combination of funding, good researchers, and computing power which makes it credible as a beacon to which interested philanthropists can add more funding and other good researchers interested in aligned AGI can join. E.g., OpenAI would qualify as this if it were adequate on the other 5 dimensions.
Improving: The project has size and quality researchers on the level of say Facebook's AI lab, and can credibly compete among the almost-but-not-quite biggest players. When they focus their attention on an unusual goal, they can get it done 1+ years ahead of the general field so long as Demis doesn't decide to do it first. I expect e.g. the NSA would have this level of "resources" if they started playing now but didn't grow any further.
Adequate: The project can get things done with a 2-year lead time on anyone else, and it's not obvious that competitors could catch up even if they focused attention there. DeepMind has a great mass of superior people and unshared tools, and is the obvious candidate for achieving adequacy on this dimension; though they would still need adequacy on other dimensions, and more closure in order to conserve and build up advantages. As I understand it, an adequate resource advantage is explicitly what Demis was trying to achieve, before Elon blew it up, started an openness fad and an arms race, and probably got us all killed. Anyone else trying to be adequate on this dimension would need to pull ahead of DeepMind, merge with DeepMind, or talk Demis into closing more research and putting less effort into unalignable AGI paths.
Excellent: There's a single major project which a substantial section of the research community understands to be The Good Project that good people join, with competition to it deemed unwise and unbeneficial to the public good. This Good Project is at least adequate along all the other dimensions. Its major competitors lack either equivalent funding or equivalent talent and insight. Relative to the present world it would be extremely difficult to make any project like this exist with adequately trustworthy command and alignment mindset, and failed attempts to make it exist run the risk of creating still worse competitors developing unaligned AGI.
Unrealistic: There is a single global Manhattan Project which is somehow not answerable to non-common-good command such as Trump or Putin or the United Nations Security Council. It has orders of magnitude more computing power and smart-researcher-labor than anyone else. Something keeps other AGI projects from arising and trying to race with the giant project. The project can freely choose transparency in all transparency-capability tradeoffs and take an extra 10+ years to ensure alignment. The project is at least adequate along all other dimensions. This is how our distant, surviving cousins are doing it in their Everett branches that diverged centuries earlier towards more competent civilizational equilibria. You cannot possibly cause such a project to exist with adequately trustworthy command, alignment mindset, and common-good commitment, and you should therefore not try to make it exist, first because you will simply create a still more dire competitor developing unaligned AGI, and second because if such an AGI could be aligned it would be a hell of an s-risk [? · GW] given the probable command structure. People who are slipping sideways in reality fantasize about being able to do this.
| Reminder: This is a 2017 document. |
Further Remarks
A project with "adequate" closure and a project with "improving" closure will, if joined, aggregate into a project with "improving" (aka: inadequate) closure where the closed section is a silo within an open organization. Similar remarks apply along other dimensions. The aggregate of a project with NDAs, and a project with deeper employee screening, is a combined project with some unscreened people in the building and hence "improving" opsec.
"Adequacy" on the dimensions of closure and opsec is based around my mainline-probability scenario where you unavoidably need to spend at least 1 year in a regime where the AGI is not yet alignable on a minimal act that ensures nobody else will destroy the world shortly thereafter, but during that year it's possible to remove a bunch of safeties from the code, shift transparency-capability tradeoffs to favor capability instead, ramp up to full throttle, and immediately destroy the world.
During this time period, leakage of the code to the wider world automatically results in the world being turned into paperclips. Leakage of the code to multiple major actors such as commercial espionage groups or state intelligence agencies seems to me to stand an extremely good chance of destroying the world because at least one such state actor's command will not reprise the alignment debate correctly and each of them will fear the others.
I would also expect that, if key ideas and architectural lessons-learned were to leak from an insufficiently closed project that would otherwise have actually developed alignable AGI, it would be possible to use 10% as much labor to implement a non-alignable world-destroying AGI in a shorter timeframe. The project must be closed tightly or everything ends up as paperclips.
"Adequacy" on common good commitment is based on my model wherein the first task-directed AGI continues to operate in a regime far below that of a real superintelligence, where many tradeoffs have been made for transparency over capability and this greatly constrains self-modification.
This task-directed AGI is not able to defend against true superintelligent attack. It cannot monitor other AGI projects in an unobtrusive way that grants those other AGI projects a lot of independent freedom to do task-AGI-ish things so long as they don't create an unrestricted superintelligence. The designers of the first task-directed AGI are barely able to operate it in a regime where the AGI doesn't create an unaligned superintelligence inside itself or its environment. Safe operation of the original AGI requires a continuing major effort at supervision. The level of safety monitoring of other AGI projects required would be so great that, if the original operators deemed it good that more things be done with AGI powers, it would be far simpler and safer to do them as additional tasks running on the original task-directed AGI. Therefore: Everything to do with invocation of superhuman specialized general intelligence, like superhuman science and engineering, continues to have a single effective veto point.
This is also true in less extreme scenarios where AGI powers can proliferate, but must be very tightly monitored, because no aligned AGI can defend against an unconstrained superintelligence if one is deliberately or accidentally created by taking off too many safeties. Either way, there is a central veto authority that continues to actively monitor and has the power to prevent anyone else from doing anything potentially world-destroying with AGI.
This in turn means that any use of AGI powers along the lines of uploading humans, trying to do human intelligence enhancement, or building a cleaner and more stable AGI to run a CEV, would be subject to the explicit veto of the command structure operating the first task-directed AGI. If this command structure does not favor something like CEV, or vetoes transhumanist outcomes from a transparent CEV, or doesn't allow intelligence enhancement, et cetera, then all future astronomical value can be permanently lost and even s-risks may apply.
A universe in which 99.9% of the sapient beings have no civil rights because way back on Earth somebody decided or voted that emulations weren't real people, is a universe plausibly much worse than paperclips. (I would see as self-defeating any argument from democratic legitimacy that ends with almost all sapient beings not being able to vote.)
If DeepMind closed to the silo level, put on adequate opsec, somehow gained alignment mindset within the silo, and allowed trustworthy command of that silo, then in my guesstimation it might be possible to save the Earth (we would start to leave the floor of the logistic success curve).
OpenAI seems to me to be further behind than DeepMind along multiple dimensions. OAI is doing significantly better "safety" research, but it is all still inapplicable to serious AGI, AFAIK, even if it's not fake / obvious. I do not think that either OpenAI or DeepMind are out of the basement on the logistic success curve for the alignment-mindset dimension. It's not clear to me from where I sit that the miracle required to grant OpenAI a chance at alignment success is easier than the miracle required to grant DeepMind a chance at alignment success. If Greg Brockman or other decisionmakers at OpenAI are not totally insensible, neither is Demis Hassabis. Both OAI and DeepMind have significant metric distance to cross on Common Good Commitment; this dimension is relatively easier to max out, but it's not maxed out just by having commanders vaguely nodding along or publishing a mission statement about moral humility, nor by a fragile political balance with some morally humble commanders and some morally nonhumble ones. If I had a ton of money and I wanted to get a serious contender for saving the Earth out of OpenAI, I'd probably start by taking however many OpenAI researchers could pass screening and refounding a separate organization out of them, then using that as the foundation for further recruiting.
I have never seen anyone except Paul Christiano try what I would consider to be deep macro alignment work. E.g. if you look at Paul's AGI scheme there is a global alignment story with assumptions that can be broken down, and the idea of exact human imitation is a deep one rather than a shallow defense--although I don't think the assumptions have been broken down far enough; but nobody else knows they even ought to be trying to do anything like that. I also think [LW · GW] Paul's AGI scheme is orders-of-magnitude too costly and has chicken-and-egg alignment problems. But I wouldn't totally rule out a project with Paul in technical command, because I would hold out hope that Paul could follow along with someone else's deep security analysis and understand it in-paradigm even if it wasn't his own paradigm; that Paul would suggest useful improvements and hold the global macro picture to a standard of completeness; and that Paul would take seriously how bad it would be to violate an alignment assumption even if it wasn't an assumption within his native paradigm. Nobody else except myself and Paul is currently in the arena of comparison. If we were both working on the same project it would still have unnervingly few people like that. I think we should try to get more people like this from the pool of brilliant young computer security researchers, not just the pool of machine learning researchers. Maybe that'll fail just as badly, but I want to see it tried.
I doubt that it is possible to produce a written scheme for alignment, or any other kind of fixed advice, that can be handed off to a brilliant programmer with ordinary paranoia and allow them to actually succeed. Some of the deep ideas are going to turn out to be wrong, inapplicable, or just plain missing. Somebody is going to have to notice the unfixable deep problems in advance of an actual blowup, and come up with new deep ideas and not just patches, as the project goes on.
| Reminder: This is a 2017 document. |
66 comments
Comments sorted by top scores.
comment by jefftk (jkaufman) · 2022-05-30T22:24:23.799Z · LW(p) · GW(p)
Thanks for sharing this publicly! Candid transparency is very difficult.
It's also nice to see an organization making public something that it originally felt it couldn't, now that some time has passed!
comment by Rob Bensinger (RobbBB) · 2022-05-30T17:04:00.626Z · LW(p) · GW(p)
With Eliezer's assent, I hit the Publish button for this post, and included an editor's note that I co-wrote with Duncan Sabien.
Replies from: yitz↑ comment by Yitz (yitz) · 2022-05-30T20:45:40.062Z · LW(p) · GW(p)
May I ask why you guys decided to publish this now in particular? Totally fine if you can’t answer that question, of course.
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2022-05-30T21:30:53.606Z · LW(p) · GW(p)
It's been high on some MIRI staff's "list of things we want to release" over the years, but we repeatedly failed to make a revised/rewritten version of the draft we were happy with. So I proposed that we release a relatively unedited version of Eliezer's original draft, and Eliezer said he was okay with that (provided we sprinkle the "Reminder: This is a 2017 document" notes throughout).
We're generally making a push to share a lot of our models (expect more posts soon-ish), because we're less confident about what the best object-level path is to ensuring the long-term future is awesome, so (as I described in April [LW(p) · GW(p)]) we've "updated a lot toward existential wins being likelier if the larger community moves toward having much more candid and honest conversations, and generally produces more people who are thinking exceptionally clearly about the problem".
I think this was always plausible to some degree, but it's grown in probability; and model-sharing is competing against fewer high-value uses of Eliezer and Nate's time now that they aren't focusing their own current efforts on alignment research.
Replies from: chris-fong-1, yitz, CronoDAS, P., Gunnar_Zarncke↑ comment by Chris Fong (chris-fong-1) · 2022-05-31T09:50:22.186Z · LW(p) · GW(p)
now that they aren't focusing their own current efforts on alignment research.
Should I update and be encouraged or discouraged by this?
Replies from: RobbBB, Raemon↑ comment by Rob Bensinger (RobbBB) · 2022-05-31T21:00:39.696Z · LW(p) · GW(p)
Discouraged. Eliezer and Nate feel that their past alignment research efforts failed, and they don't currently know of a new research direction that feels promising enough that they want to focus their own time on advancing it, or make it MIRI's organizational focus.
I do think 'trying to directly solve the alignment problem' is the most useful thing the world can be doing right now, even if it's not Eliezer or Nate's comparative advantage right now. A good way to end up with a research direction EY or Nate are excited by, IMO, is for hundreds of people to try hundreds of different angles of attack and see if any bear fruit. Then a big chunk of the field can pivot to whichever niche approach bore the most fruit.
From MIRI's perspective, the hard part is that:
- (a) we don't know in advance which directions will bear fruit, so we need a bunch of people to go make unlikely bets so we can find out;
- (b) there currently aren't that many people trying to solve the alignment problem at all; and
- (c) nearly all of the people trying to solve the problem full-time are adopting unrealistic optimistic assumptions about things like 'will alignment generalize as well as capabilities?' and 'will the first pivotal AI systems be safe-by-default?', in such a way that their research can't be useful if we're in the mainline-probability world.
What I'd like to see instead is more alignment research, and especially research of the form "this particular direction seems unlikely to succeed, but if it succeeds then it will in fact help a lot in mainline reality", as opposed to directions that (say) seem a bit likelier to succeed but won't actually help in the mainline world.
(In principle you want nonzero effort going into both approaches, but right now the field is almost entirely in the second camp, from MIRI's perspective. And making a habit of assuming your way out of mainline reality is risky business, and outright dooms your research once you start freely making multiple such assumptions.)
Replies from: johnswentworth, lc, RobbBB, Mitchell_Porter↑ comment by johnswentworth · 2022-06-03T16:48:44.156Z · LW(p) · GW(p)
With a few examples, this comment would make a useful post in its own right.
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2022-06-03T16:55:39.498Z · LW(p) · GW(p)
Nate is writing that post. :)
↑ comment by lc · 2022-06-01T04:34:52.380Z · LW(p) · GW(p)
Fiscal limits notwithstanding, doesn't this suggest MIRI should try hiring a lot more maybe B-tier researchers?
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2022-06-01T07:59:31.541Z · LW(p) · GW(p)
Quoting a thing I said in March [LW(p) · GW(p)]:
The two big things we feel bottlenecked on are:
- (1) people who can generate promising new alignment ideas. (By far the top priority, but seems empirically rare.)
- (2) competent executives who are unusually good at understanding the kinds of things MIRI is trying to do, and who can run their own large alignment projects mostly-independently.
For 2, I think the best way to get hired by MIRI is to prove your abilities via the Visible Thoughts Project [LW · GW]. The post there says a bit more about the kind of skills we're looking for:
Eliezer has a handful of ideas that seem to me worth pursuing, but for all of them to be pursued, we need people who can not only lead those projects themselves, but who can understand the hope-containing heart of the idea with relatively little Eliezer-interaction, and develop a vision around it that retains the shred of hope and doesn’t require constant interaction and course-correction on our part. (This is, as far as I can tell, a version of the Hard Problem of finding good founders, but with an additional constraint of filtering for people who have affinity for a particular project, rather than people who have affinity for some project of their own devising.)
For 1, I suggest initially posting your research ideas to LessWrong, in line with John Wentworth's advice [LW · GW]. New ideas and approaches are desperately needed, and we would consider it crazy to not fund anyone whose ideas or ways-of-thinking-about-the-problem we think have a shred of hope in them. We may fund them via working at MIRI, or via putting them in touch with external funders; the important thing is just that the research happens.
If you want to work on alignment but you don't fall under category 1 or 2, you might consider applying to work at Redwood Research (https://www.redwoodresearch.org/jobs), which is a group doing alignment research we like. They're much more hungry for engineers right now than we are.
If your "hiring a lot more maybe B-tier researchers" suggestion implies something more than the above 'we intend to ensure that everyone whose ideas have a shred of hope gets funded' policy, I'd be interested to hear what additional thing you think should happen, and why.
A consideration pushing against 'just try to grow the field indiscriminately' is the argument Alex Flint gives [LW(p) · GW(p)] re the flywheel model.
↑ comment by Rob Bensinger (RobbBB) · 2022-05-31T22:39:07.267Z · LW(p) · GW(p)
What I'd like to see instead is more alignment research, and especially research of the form "this particular direction seems unlikely to succeed, but if it succeeds then it will in fact help a lot in mainline reality"
(Obviously even better would be if it seems likely to succeed and helps on the mainline. But 'longshot that will help if it succeeds' is second-best.)
↑ comment by Mitchell_Porter · 2022-06-01T01:49:09.998Z · LW(p) · GW(p)
Eliezer and Nate feel that their past alignment research efforts failed
I find this a little surprising. If someone had asked me what MIRI's strategy is, I would have said that the core of it was still something like CEV, with topics like logical induction and new decision theory paradigms as technical framework issues. I mean, part of the MIRI paradigm has always been that AGI alignment is grounded in how the human brain works, right? The mechanics of decision-making in human brains, are the starting point in constructing the mechanics of decision-making in an AGI that humans would call 'aligned'. And I would have thought that identifying how to do this, was still just research in progress in many directions, rather than something that had hit a dead end.
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2022-06-01T04:24:14.267Z · LW(p) · GW(p)
Quoting from the "strategic background" summary we shared in 2017:
[...] In very broad terms, however, our approach to global risk mitigation is to think in terms of desired outcomes, and to ask: “What is the likeliest way that the outcome in question might occur?” We then repeat this process until we backchain to interventions that actors can take today. [...]
1. Long-run good outcomes. Ultimately, we want humanity to figure out the best possible long-run future and enact that kind of future, factoring in good outcomes for all sentient beings. However, there is currently very little we can say with confidence about what desirable long-term outcomes look like, or how best to achieve them; and if someone rushes to lock in a particular conception of “the best possible long-run future,” they’re likely to make catastrophic mistakes both in how they envision that goal and in how they implement it.
In order to avoid making critical decisions in haste and locking in flawed conclusions, humanity needs:
2. A stable period during which relevant actors can accumulate whatever capabilities and knowledge are required to reach robustly good conclusions about long-run outcomes. This might involve decisionmakers developing better judgment, insight, and reasoning skills in the future, solving the full alignment problem for fully autonomous AGI systems, and so on.
Given the difficulty of the task, we expect a successful stable period to require:
3. A preceding end to the acute risk period. If AGI carries a significant chance of causing an existential catastrophe over the next few decades, this forces a response under time pressure; but if actors attempt to make irreversible decisions about the long-term future under strong time pressure, we expect the result to be catastrophically bad. Conditioning on good outcomes, we therefore expect a two-step process where addressing acute existential risks takes temporal priority.
To end the acute risk period, we expect it to be necessary for actors to make use of:
4. A risk-mitigating technology. On our current view of the technological landscape, there are a number of plausible future technologies that could be leveraged to end the acute risk period.
We believe that the likeliest way to achieve a technology in this category sufficiently soon is through:
5. AGI-empowered technological development carried out by task-directed AGI systems. Depending on early AGI systems’ level of capital-intensiveness, on whether AGI is a late-paradigm or early-paradigm invention, and on a number of other factors, AGI might be developed by anything from a small Silicon Valley startup to a large-scale multinational collaboration. Regardless, we expect AGI to be developed before any other (meta)technology that can be employed to end the acute risk period, and if early AGI systems can be used safely at all, then we expect it to be possible for an AI-empowered project to safely automate a reasonably small set of concrete science and engineering tasks that are sufficient for ending the risk period. This requires:
6. Construction of minimal aligned AGI. We specify “minimal” because we consider success much more likely if developers attempt to build systems with the bare minimum of capabilities for ending the acute risk period. We expect AGI alignment to be highly difficult, and we expect additional capabilities to add substantially to this difficulty.
Added: “Minimal aligned AGI” means “aligned AGI that has the minimal necessary capabilities”; be sure not to misread it as “minimally aligned AGI”. Rob Bensinger adds [LW · GW]: “The MIRI view isn’t ‘rather than making alignment your top priority and working really hard to over-engineer your system for safety, try to build a system with the bare minimum of capabilities’. It’s: ‘in addition to making alignment your top priority and working really hard to over-engineer your system for safety, also build the system to have the bare minimum of capabilities’.”
If an aligned system of this kind were developed, we would expect two factors to be responsible:
7a. A technological edge in AGI by an operationally adequate project. By “operationally adequate” we mean a project with strong opsec, research closure, trustworthy command, a commitment to the common good, security mindset, requisite resource levels, and heavy prioritization of alignment work. A project like this needs to have a large enough lead to be able to afford to spend a substantial amount of time on safety measures, as discussed at FLI’s Asilomar conference.
7b. A strong white-boxed system understanding on the part of the operationally adequate project during late AGI development. By this we mean that developers go into building AGI systems with a good understanding of how their systems decompose and solve particular cognitive problems, of the kinds of problems different parts of the system are working on, and of how all of the parts of the system interact.
On our current understanding of the alignment problem, developers need to be able to give a reasonable account of how all of the AGI-grade computation in their system is being allocated, similar to how secure software systems are built to allow security professionals to give a simple accounting of why the system has no unforeseen vulnerabilities. See “Security Mindset and Ordinary Paranoia” for more details.
Developers must be able to explicitly state and check all of the basic assumptions required for their account of the system’s alignment and effectiveness to hold. Additionally, they need to design and modify AGI systems only in ways that preserve understandability — that is, only allow system modifications that preserve developers’ ability to generate full accounts of what cognitive problems any given slice of the system is solving, and why the interaction of all of the system’s parts is both safe and effective.
Our view is that this kind of system understandability will in turn require:
8. Steering toward alignment-conducive AGI approaches. Leading AGI researchers and developers need to deliberately direct research efforts toward ensuring that the earliest AGI designs are relatively easy to understand and align.
We expect this to be a critical step, as we do not expect most approaches to AGI to be alignable after the fact without long, multi-year delays.
We then added:
We plan to say more in the future about the criteria for operationally adequate projects in 7a. We do not believe that any project meeting all of these conditions currently exists, though we see various ways that projects could reach this threshold.
The above breakdown only discusses what we view as the “mainline” success scenario. If we condition on good long-run outcomes, the most plausible explanation we can come up with cites an operationally adequate AI-empowered project ending the acute risk period, and appeals to the fact that those future AGI developers maintained a strong understanding of their system’s problem-solving work over the course of development, made use of advance knowledge about which AGI approaches conduce to that kind of understanding, and filtered on those approaches.
... and we said that MIRI's strategy is to do research aimed at making "8. Steering toward alignment-conducive AGI approaches" easier:
Replies from: RobbBBFor that reason, MIRI does research to intervene on 8 from various angles, such as by examining holes and anomalies in the field’s current understanding of real-world reasoning and decision-making. We hope to thereby reduce our own confusion about alignment-conducive AGI approaches and ultimately help make it feasible for developers to construct adequate “safety-stories” in an alignment setting. As we improve our understanding of the alignment problem, our aim is to share new insights and techniques with leading or up-and-coming developer groups, who we’re generally on good terms with. [...]
↑ comment by Rob Bensinger (RobbBB) · 2022-06-01T06:55:47.579Z · LW(p) · GW(p)
Replying to your points with that in mind, Mitchell:
I find this a little surprising. If someone had asked me what MIRI's strategy is, I would have said that the core of it was still something like CEV, with topics like logical induction and new decision theory paradigms as technical framework issues.
Assuming the long-run future goes well, I expect humanity to eventually build an AGI system that does something vaguely CEV-like. (This will plausibly be the main goal of step 2 in the backchained list, and therefore the main way we get to step 1.)
But I wouldn't say that MIRI's research is at all about CEV. Before humanity gets to steps 1-2 ('use CEV or something to make the long-term future awesome'), it needs to get past steps 3-6 ('use limited task AGI to ensure that humanity doesn't kill itself with AGI so we can proceed to take our time with far harder problems like "what even is CEV" and "how even in principle would one get an AI system to robustly do anything remotely like that, without some subtle or not-so-subtle disaster resulting"').
We'll have plenty of time to worry about steps 1-2 if we can figure out 3-6, so almost all of the alignment field's attention should be on how to achieve 3-6 (or plausible prerequisites for 3-6, like 7-8).
Re logical induction and decision theory: the main goal of this kind of research has been "de-confusion" in the sense described in The Rocket Alignment Problem [LW · GW] and our 2018 strategy update.
I mean, part of the MIRI paradigm has always been that AGI alignment is grounded in how the human brain works, right? The mechanics of decision-making in human brains, are the starting point in constructing the mechanics of decision-making in an AGI that humans would call 'aligned'.
Sounds false to me, and I'm not sure how this relates to CEV, logical induction, logical decision theory, etc.
It's true that humans reason under logical uncertainty (and logical induction may be getting at a core thing about why that works), and it's true that some of our instincts and reasoning are very likely to look FDT-ish insofar as they evolved in an environment where agents model each other and use similar reasoning processes.
But if humans somehow couldn't apply their normal probablistic reasoning to math (and couldn't do FDT-ish reasoning), and yet we could still somehow do math/AI research at all, then logical uncertainty and FDT would still be just as important, because they'd still be progress toward understanding how sufficiently smart AI systems reason about the world.
Think less "LI and FDT are how humans work, and we're trying to make a machine that works like a human brain", more "there's such a thing as general-purpose problem-solving, some undiscovered aspects of this thing are probably simple, and something like LI and FDT may be (idealized versions of) how certain parts of this general-purpose problem-solving works, or may be steps toward finding such parts".
And I would have thought that identifying how to do this, was still just research in progress in many directions, rather than something that had hit a dead end.
Last I checked, there are still MIRI researchers working on the major research programs we've done in the past (or working on research programs along those lines). But the organization as a whole isn't trying to concentrate effort on any one of those lines of research, and Nate and Eliezer aren't focusing their own efforts on any of the ongoing MIRI research projects, because Nate and Eliezer think AGI timelines are too short relative to those projects' rates of progress to date.
(Or, 'a critical mass of MIRI's research leadership (which includes more people than Nate and Eliezer but assigns a lot of weight to Nate's and Eliezer's views) thinks AGI timelines are too short relative to those projects' rates of progress to date'.)
From Nate/EY's perspective, as I understand it, the problem isn't 'none of the stuff MIRI's tried has borne fruit, or is currently bearing fruit'; it's 'the fruit is being borne too slowly for us to feel like MIRI's current or past research efforts are on the critical path to humanity surviving and flourishing'.
They don't know what is on the critical path, but they feel sufficiently pessimistic about the current things they've tried (relative to their timelines) that they'd rather work on things like aumanning right now and keep an eye out for better future alignment research ideas, rather than keep their focus on the 'things we've already tried putting lots of effort into' bucket.
(As with the vast majority of my comments, EY and Nate haven't reviewed this, so I may be getting stuff about their views wrong.)
Replies from: vanessa-kosoy, Mitchell_Porter↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2022-06-02T09:44:04.988Z · LW(p) · GW(p)
Before humanity gets to steps 1-2 ('use CEV or something to make the long-term future awesome'), it needs to get past steps 3-6 ('use limited task AGI to ensure that humanity doesn't kill itself with AGI so we can proceed to take our time with far harder problems like "what even is CEV" and "how even in principle would one get an AI system to robustly do anything remotely like that, without some subtle or not-so-subtle disaster resulting"').
I want to register my skepticism about this claim. Whereas it might naively seem that "put a strawberry on a plate" is easier to align than "extrapolated volition", on a closer look there are reasons why it might be the other way around. Specifically, the notion of "utility function of given agent" is a natural concept that we should expect to have a relatively succinct mathematical description. This intuition is supported by the AIT definition of intelligence [LW(p) · GW(p)]. On the other hand, "put a strawberry on a plate without undesirable side effects" is not a natural concept, since a lot of complexity is packed into the "undesirable side effects". Therefore, while I see some lines of attack on both task AGI [LW(p) · GW(p)] and extrapolated volition [LW(p) · GW(p)], the latter might well turn out easier.
Replies from: Eliezer_Yudkowsky, RobbBB, johnswentworth↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2022-06-02T20:36:37.673Z · LW(p) · GW(p)
And if humans had a utility function and we knew what that utility function was, we would not need CEV. Unfortunately extracting human preferences over out-of-distribution options and outcomes at dangerously high intelligence, using data gathered at safe levels of intelligence and a correspondingly narrower range of outcomes and options, when there exists no sensory ground truth about what humans want because human raters can be fooled or disassembled, seems pretty complicated. There is ultimately a rescuable truth about what we want, and CEV is my lengthy informal attempt at stating what that even is; but I would assess it as much, much, much more difficult than 'corrigibility' to train into a dangerously intelligent system using only training and data from safe levels of intelligence. (As is the central lethally difficult challenge of AGI alignment.)
If we were paperclip maximizers and knew what paperclips were, then yes, it would be easier to just build an offshoot paperclip maximizer.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2022-06-03T06:49:51.741Z · LW(p) · GW(p)
I agree that it's a tricky problem, but I think it's probably tractable. The way PreDCA [LW(p) · GW(p)] tries to deal with these difficulties is:
- The AI can tell that, even before the AI was turned on, the physical universe was running certain programs.
- Some of those programs are "agentic" programs.
- Agentic programs have approximately well-defined utility functions.
- Disassembling the humans doesn't change anything, since it doesn't affect the programs that were already running[1] before the AI was turned on.
- Since we're looking at agent-programs rather than specific agent-actions, there is much more ground for inference about novel situations.
Obviously, the concepts I'm using here (e.g. which programs are "running" or which programs are "agentic") are non-trivial to define, but infra-Bayesian physicalism [LW · GW] does allow us the define them (not without some caveats, but hopefully at least to a 1st approximation).
More precisely, I am looking at agents which could prevent the AI from becoming turned on, this is what I call "precursors". ↩︎
↑ comment by Rob Bensinger (RobbBB) · 2022-06-02T17:40:05.040Z · LW(p) · GW(p)
Yeah, I'm very interested in hearing counter-arguments to claims like this. I'll say that although I think task AGI is easier, it's not necessarily strictly easier, for the reason you mentioned.
Maybe a cruxier way of putting my claim is: Maybe corrigibility / task AGI / etc. is harder than CEV, but it just doesn't seem realistic to me to try to achieve full, up-and-running CEV with the very first AGI systems you build, within a few months or a few years of humanity figuring out how to build AGI at all.
And I do think you need to get CEV up and running within a few months or a few years, if you want to both (1) avoid someone else destroying the world first, and (2) not use a "strawberry-aligned" AGI to prevent 1 from happening.
All of the options are to some extent a gamble, but corrigibility, task AGI, limited impact, etc. strike me as gambles that could actually realistically work out well for humanity even under extreme time pressure to deploy a system within a year or two of 'we figure out how to build AGI'. I don't think CEV is possible under that constraint. (And rushing CEV and getting it only 95% correct poses far larger s-risks than rushing low-impact non-operator-modeling strawberry AGI and getting it only 95% correct.)
Replies from: vanessa-kosoy, johnswentworth↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2022-06-03T07:31:54.613Z · LW(p) · GW(p)
Maybe corrigibility / task AGI / etc. is harder than CEV, but it just doesn't seem realistic to me to try to achieve full, up-and-running CEV with the very first AGI systems you build, within a few months or a few years of humanity figuring out how to build AGI at all.
The way I imagine the win scenario is, we're going to make a lot of progress in understanding alignment before we know how to build AGI. And, we're going to do it by prioritizing understanding alignment modulo capability (the two are not really possible to cleanly separate, but it might be possible to separate them enough for this purpose). For example, we can assume the existence of algorithms with certain properties, s.t. these properties arguably imply the algorithms can be used as building-blocks for AGI, and then ask: given such algorithms, how would we build aligned AGI? Or, we can come up with some toy setting where we already know how to build "AGI" in some sense, and ask, how to make it aligned in that setting? And then, once we know how to build AGI in the real world, it would hopefully not be too difficult to translate the alignment method.
One caveat in all this is, if AGI is going to use deep learning, we might not know how to apply the lesson from the "oracle"/toy setting, because we don't understand what deep learning is actually doing, and because of that, we wouldn't be sure where to "slot" it in the correspondence/analogy s.t. the alignment method remains sound. But, mainstream researchers have been making progress on understanding what deep learning is actually doing, and IMO it's plausible we will have a good mathematical handle on it before AGI.
And rushing CEV and getting it only 95% correct poses far larger s-risks than rushing low-impact non-operator-modeling strawberry AGI and getting it only 95% correct.
I'm not sure whether you mean "95% correct CEV has a lot of S-risk" or "95% correct CEV has a little S-risk, and even a tiny amount of S-risk is terrifying"? I think I agree with the latter but not with the former. (How specifically does 95% CEV produce S-risk? I can imagine something like "AI realizes we want non-zero amount of pain/suffering to exist, somehow miscalibrates the amount and creates a lot of pain/suffering" or "AI realizes we don't want to die, and focuses on this goal on the expense of everything else, preserving us forever in a state of complete sensory deprivation". But these scenarios don't seem very likely?)
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2022-06-03T17:01:04.597Z · LW(p) · GW(p)
I'm not sure whether you mean "95% correct CEV has a lot of S-risk" or "95% correct CEV has a little S-risk, and even a tiny amount of S-risk is terrifying"?
The latter, as I was imagining "95%".
↑ comment by johnswentworth · 2022-06-03T17:05:51.568Z · LW(p) · GW(p)
Insofar as humans care about their AI being corrigible, we should expect some degree of corrigibility even from a CEV-maximizer. That, in turn, suggests at least some basin-of-attraction for values (at least along some dimensions), in the same way that corrigibility yields a basin-of-attraction.
(Though obviously that's not an argument we'd want to make load-bearing without both theoretical and empirical evidence about how big the basin-of-attraction is along which dimensions.)
Conversely, it doesn't seem realistic to define limited impact or corrigibility or whatever without relying on an awful lot of values information - like e.g. what sort of changes-to-the-world we do/don't care about, what thing-in-the-environment the system is supposed to be corrigible with, etc.
Values seem like a necessary-and-sufficient component. Corrigibility/task architecture/etc doesn't.
And rushing CEV and getting it only 95% correct poses far larger s-risks than rushing low-impact non-operator-modeling strawberry AGI and getting it only 95% correct.
Small but important point here: an estimate of CEV which is within 5% error everywhere does reasonably well; that gets us within 5% of our best possible outcome. The problem is when our estimate is waaayyy off in 5% of scenarios, especially if it's off in the overestimate direction; then we're in trouble.
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2022-06-03T18:37:35.252Z · LW(p) · GW(p)
Conversely, it doesn't seem realistic to define limited impact or corrigibility or whatever without relying on an awful lot of values information - like e.g. what sort of changes-to-the-world we do/don't care about, what thing-in-the-environment the system is supposed to be corrigible with, etc.
I suspect you could do this in a less value-loaded way if you're somehow intervening on 'what the AGI wants to pay attention to', as opposed to just intervening on 'what sorts of directions it wants to steer the world in'.
'Only spend your cognition thinking about individual physical structures smaller than 10 micrometers', 'only spend your cognition thinking about the physical state of this particular five-cubic-foot volume of space', etc. could eliminate most of the risk of 'high-impact' actions without forcing us to define human conceptions of 'impact', and without forcing the AI to do a bunch of human-modeling. But I don't know what research path would produce the ability to do things like that.
(There's still of course something that we're trying to get the AGI to do, like make a nanofactory or make a scanning machine for WBE or make improved computing hardware. That part strikes me as intuitively more value-loaded than 'only think about this particular volume of space'.
The difficulty with 'only think about this particular volume of space' is that it requires the ability to intervene on thoughts rather than outputs.)
Replies from: johnswentworth↑ comment by johnswentworth · 2022-06-03T19:41:39.800Z · LW(p) · GW(p)
'Only spend your cognition thinking about individual physical structures smaller than 10 micrometers', 'only spend your cognition thinking about the physical state of this particular five-cubic-foot volume of space', etc. could eliminate most of the risk of 'high-impact' actions without forcing us to define human conceptions of 'impact', and without forcing the AI to do a bunch of human-modeling.
I do not think that would do what you seem to think it would do. If something optimizes one little chunk of the world really hard, ignoring everything else, that doesn't mean the rest of the world is unchanged; by default there are lots of side effects. E.g. if something is building nanotech in a 1m cube, ignoring everything outside the cube, at the very least I'd expect that dump nuke levels of waste heat into its immediate surroundings.
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2022-06-03T20:41:35.368Z · LW(p) · GW(p)
I agree that this would be scary if the system is, for example, as smart as physically possible. What I'm imagining is:
- (1) if you find a way to ensure that the system is only weakly superhuman (e.g., it performs vast amounts of low-level-Google-engineer-quality reasoning, only rare short controlled bursts of von-Neumann-quality reasoning, and nothing dramatically above the von-Neumann level), and
- (2) if you get the system to only care about thinking about this cube of space, and
- (3) if you also somehow get the system to want to build the particular machine you care about,
then you can plausibly save the world, and (importantly) you're not likely to destroy the world if you fail, assuming you really are correctly confident in 1, 2, and 3.
I think you can also get more safety margin if the cube is in Antarctica (or on the Moon?), if you've tried to seal it off from the environment to some degree, and if you actively monitor for things like toxic waste products, etc.
Notably, the "only care about thinking about this cube of space" part is important for a lot of the other safety features to work, like:
- It's a lot harder to get guarantees about the system's intelligence if it's optimizing the larger world (since it might then improve itself, or build a smart successor in its environment -- good luck closing off all possible loopholes for what kinds of physical systems an AGI might build that count as "smart successors", while still leaving it able to build nanotech!).
- Likewise, it's a lot harder to get guarantees that the system stably is optimizing what you want it to optimize, or stably has any specific internal property, if it's willing and able to modify itself.
- Part of why we can hope to notice, anticipate, and guard against bad side-effects like "waste products" is that the waste products aren't optimized to have any particular effect on the external environment, and aren't optimized to evade our efforts to notice, anticipate, or respond to the danger. For that reason, "An AGI that only terminally cares about the state of a certain cube of space, but does spend time thinking about the larger world", is vastly scarier than an AGI that just-doesn't-think in those directions.
- If the system does start going off the rails, we're a lot more likely to be able to shut it down if it isn't thinking about us or about itself.
This makes me think that the "only care about thinking about certain things" part may be relatively important in order for a lot of other safety requirements to be tractable. It feels more "(realistically) necessary" than "sufficient" to me; but I do personally have a hunch (which hopefully we wouldn't have to actually rely on as a safety assumption!) that the ability to do things in this reference class would get us, like, 80+% of the way to saving the world? (Dunno whether Eliezer or anyone else at MIRI would agree.)
↑ comment by johnswentworth · 2022-06-03T17:01:01.451Z · LW(p) · GW(p)
↑ comment by Mitchell_Porter · 2022-06-01T11:55:20.133Z · LW(p) · GW(p)
Thank you for the long reply. The 2017 document postulates an "acute risk period" in which people don't know how to align, and then a "stable period" once alignment theory is mature.
So if I'm getting the gist of things, rather than focus outright on the creation of a human-friendly superhuman AI, MIRI decided to focus on developing a more general theory and practice of alignment; and then once alignment theory is sufficiently mature and correct, one can focus on applying that theory to the specific crucial case, of aligning superhuman AI with extrapolated human volition.
But what's happened is that we're racing towards superhuman AI while the general theory of alignment is still crude, and this is a failure for the strategy of prioritizing general theory of alignment over the specific task of CEV.
Is that vaguely what happened?
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2022-06-01T17:15:22.326Z · LW(p) · GW(p)
The 2017 document postulates an "acute risk period" in which people don't know how to align, and then a "stable period" once alignment theory is mature.
"Align" is a vague term. Let's distinguish "strawberry alignment" (where we can safely and reliably use an AGI to execute a task like "Place, onto this particular plate here, two strawberries identical down to the cellular but not molecular level.") from "CEV alignment" (where we can safely and reliably use an AGI to carry out a CEV-like procedure.)
Strawberry alignment seems vastly easier than CEV alignment to me, and I think it's a similar task (in both difficulty and kind) to what we'll need AGI to do in order to prevent humanity from killing itself with other AGIs.
The "acute risk period" is the period where we're at risk of someone immediately destroying the world once they figure out how to build AGI (or once hardware scales to the required level, or whatever).
Figuring out how to do strawberry alignment isn't sufficient for ending the acute risk period, since humanity then has to actually apply this knowledge and build and deploy an aligned AGI to execute some pivotal act. But I do think that figuring out strawberry alignment is the main obstacle; if we knew how to do that, I think humanity would have double-digit odds of surviving and flourishing.
The "stable period" is the period between "humanity successfully makes it the case that no one can destroy the world with AGI" and "humanity figures out how to ensure the long-term future is awesome".
This stable period is very similar to the idea of a "long reflection [? · GW]" posited by Toby Ord and Will MacAskill, though the lengths of time they cite sound far too long to me, at least if we're measuring in sidereal time. (With fast-running human whole-brain emulations, I think you could complete the entire "long reflection" in just a few sidereal years, without cutting any corners or taking any serious risks.)
So if I'm getting the gist of things, rather than focus outright on the creation of a human-friendly superhuman AI
"Human-friendly" and "superhuman" are both vague -- strawberry-aligned task AGI is less robustly friendly, and less broadly capable, than CEV AGI. But strawberry-aligned AGI is still superhuman in at least some respects -- heck, a pocket calculator is too -- and it's still friendly enough to do some impressive things without killing us.
Alignment is a matter of degree, and more ambitious tasks can be much harder to align.
MIRI decided to focus on developing a more general theory and practice of alignment;
Strawberry alignment is more "general" in the sense that we're not trying to impart as many human-specific values into the AGI (though we still need to impart some).
But it's less "general" in the sense that strawberry-grade alignment is likely to be much more brittle than CEV-grade alignment, and strawberry-grade alignment is much more dependent on us carefully picking exactly the right tasks and procedures to make the alignment work.
But what's happened is that we're racing towards superhuman AI while the general theory of alignment is still crude, and this is a failure for the strategy of prioritizing general theory of alignment over the specific task of CEV.
No. If we'd focused on CEV-grade alignment over strawberry-grade alignment, we'd be in even worse shape if anything.
The problem is that timelines look short, so it's looking more difficult to figure out strawberry alignment in time to prevent human extinction. We should nonetheless make strawberry alignment humanity's top priority, and put an enormous effort into it, because there isn't a higher-probability path to good outcomes. (AFAICT, anyway. Having at least some people try to prove me wrong here obviously seems worthwhile too.)
CEV alignment is even harder than strawberry alignment (by a large margin), so short timelines are much more of a problem for the 'rush straight to CEV alignment' plan than for the 'do strawberry alignment first, then CEV afterwards' plan.
Replies from: Mitchell_Porter, Vladimir_Nesov↑ comment by Mitchell_Porter · 2022-06-02T04:28:40.476Z · LW(p) · GW(p)
The "stable period" is supposed to be a period in which AGI already exists, but nothing like CEV has yet been implemented, and yet "no one can destroy the world with AGI". How would that work? How do you prevent everyone in the whole wide world from developing unsafe AGI during the stable period?
Replies from: Eliezer_Yudkowsky, RobbBB↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2022-06-02T20:31:11.194Z · LW(p) · GW(p)
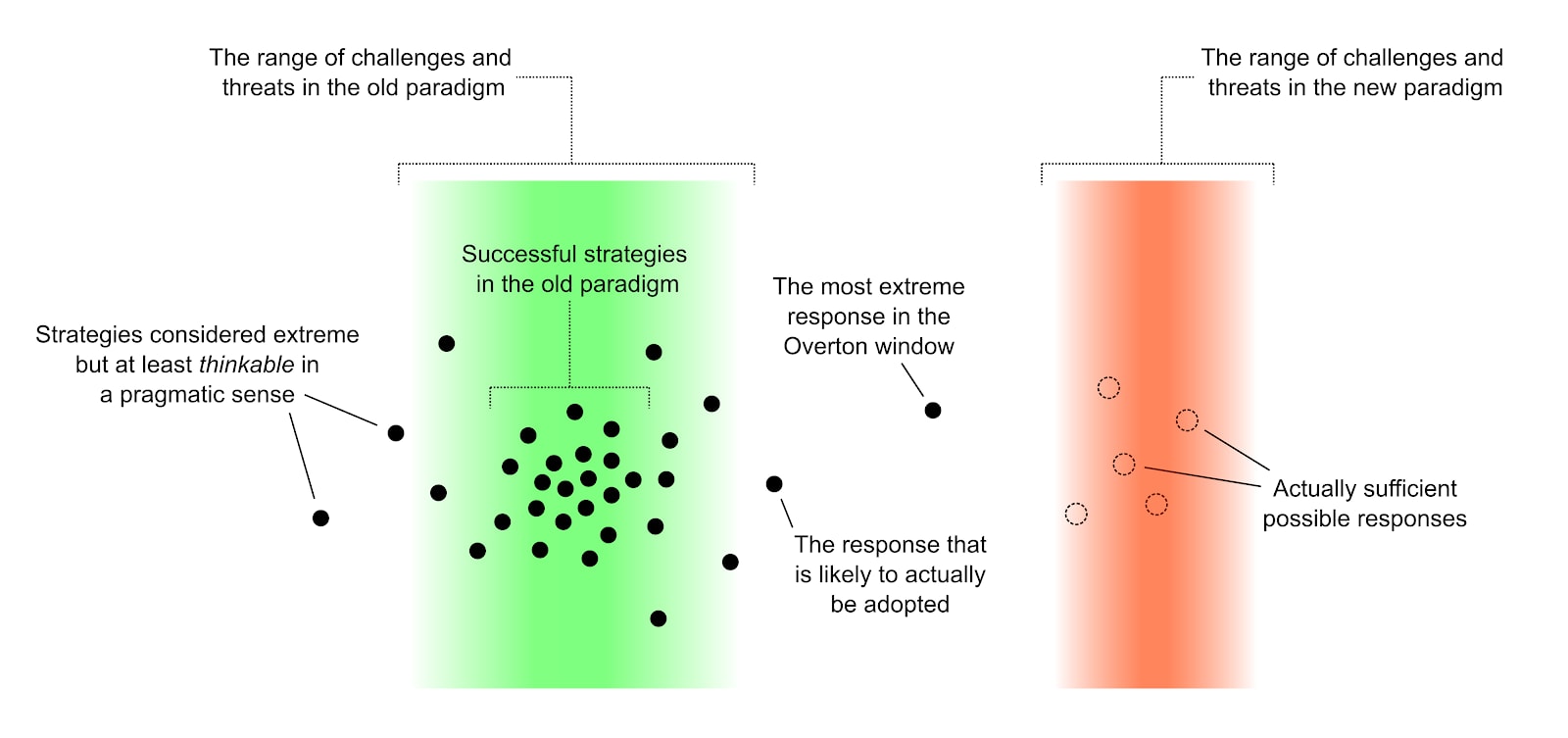
Use strawberry alignment to melt all the computing clusters containing more than 4 GPUs. (Not actually the best thing to do with strawberry alignment, IMO, but anything you can do here is outside the Overton Window, so I picked something of which I could say "Oh but I wouldn't actually do that" if pressed.)
↑ comment by Rob Bensinger (RobbBB) · 2022-06-02T05:57:57.478Z · LW(p) · GW(p)
I think there are multiple viable options, like the toy example EY uses [LW · GW]:
I think that after AGI becomes possible at all and then possible to scale to dangerously superhuman levels, there will be, in the best-case scenario where a lot of other social difficulties got resolved, a 3-month to 2-year period where only a very few actors have AGI, meaning that it was socially possible for those few actors to decide to not just scale it to where it automatically destroys the world.
During this step, if humanity is to survive, somebody has to perform some feat that causes the world to not be destroyed in 3 months or 2 years when too many actors have access to AGI code that will destroy the world if its intelligence dial is turned up. This requires that the first actor or actors to build AGI, be able to do something with that AGI which prevents the world from being destroyed; if it didn't require superintelligence, we could go do that thing right now, but no such human-doable act apparently exists so far as I can tell.
So we want the least dangerous, most easily aligned thing-to-do-with-an-AGI, but it does have to be a pretty powerful act to prevent the automatic destruction of Earth after 3 months or 2 years. It has to "flip the gameboard" rather than letting the suicidal game play out. We need to align the AGI that performs this pivotal act, to perform that pivotal act without killing everybody.
Parenthetically, no act powerful enough and gameboard-flipping enough to qualify is inside the Overton Window of politics, or possibly even of effective altruism, which presents a separate social problem. I usually dodge around this problem by picking an exemplar act which is powerful enough to actually flip the gameboard, but not the most alignable act because it would require way too many aligned details: Build self-replicating open-air nanosystems and use them (only) to melt all GPUs.
Since any such nanosystems would have to operate in the full open world containing lots of complicated details, this would require tons and tons of alignment work, is not the pivotal act easiest to align, and we should do some other thing instead. But the other thing I have in mind is also outside the Overton Window, just like this is. So I use "melt all GPUs" to talk about the requisite power level and the Overton Window problem level, both of which seem around the right levels to me, but the actual thing I have in mind is more alignable; and this way, I can reply to anyone who says "How dare you?!" by saying "Don't worry, I don't actually plan on doing that."
It's obviously a super core question; there's no point aligning your AGI if someone else just builds unaligned AGI a few months later and kills everyone. The "alignment problem" humanity has as its urgent task is exactly the problem of aligning cognitive work that can be leveraged to prevent the proliferation of tech that destroys the world. Once you solve that, humanity can afford to take as much time as it needs to solve everything else.
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2022-06-02T10:33:21.198Z · LW(p) · GW(p)
The "alignment problem" humanity has as its urgent task is exactly the problem of aligning cognitive work that can be leveraged to prevent the proliferation of tech that destroys the world. Once you solve that, humanity can afford to take as much time as it needs to solve everything else.
OK, I disagree very much with that strategy. You're basically saying, your aim is not to design ethical/friendly/aligned AI, you're saying your aim is to design AI that can take over the world without killing anyone. Then once that is accomplished, you'll settle down to figure out how that unlimited power would best be used.
To put it another way: Your optimistic scenario is one in which the organization that first achieves AGI uses it to take over the world, install a benevolent interim regime that monopolizes access to AGI without itself making a deadly mistake, and which then eventually figures out how to implement CEV (for example); and then it's finally safe to have autonomous AGI.
I have a different optimistic scenario: We definitively figure out the theory of how to implement CEV before AGI even arises, and then spread that knowledge widely, so that whoever it is in the world that first achieves AGI, they will already know what they should do with it.
Both these scenarios are utopian in different ways. The first one says that flawed humans can directly wield superintelligence for a protracted period without screwing things up. The second one says that flawed humans can fully figure out how to safely wield superintelligence before it even arrives.
Meanwhile, in reality, we've already proceeded an unknown distance up the curve towards superintelligence, but none of the organizations leading the way has much of a plan for what happens, if their creations escape their control.
In this situation, I say that people whose aim is to create ethical/friendly/aligned superintelligence, should focus on solving that problem. Leave the techno-military strategizing to the national security elites of the world. It's not a topic that you can avoid completely, but in the end it's not your job to figure out how mere humans can safely and humanely wield superhuman power. It's your job to design an autonomous superhuman power that is intrinsically safe and humane. To that end we have CEV, we have June Ku's work, and more. We should be focusing there, while remaining engaged with the developments in mainstream AI, like language models. That's my manifesto.
Replies from: RobbBB, Eliezer_Yudkowsky, M. Y. Zuo↑ comment by Rob Bensinger (RobbBB) · 2022-06-02T23:30:39.757Z · LW(p) · GW(p)
You're basically saying, your aim is not to design ethical/friendly/aligned AI [...]
My goal is an awesome, eudaimonistic long-run future. To get there, I strongly predict that you need to build AGI that is fully aligned with human values. To get there, I strongly predict that you need to have decades of experience actually working with AGI, since early generations of systems will inevitably have bugs and limitations and it would be catastrophic to lock in the wrong future because we did a rush job.
(I'd also expect us to need the equivalent of subjective centuries of further progress on understanding stuff like "how human brains encode morality", "how moral reasoning works", etc.)
If it's true that you need decades of working experience with AGI (and solutions to moral philosophy, psychology, etc.) to pull off CEV, then something clearly needs to happen to prevent humanity from destroying itself in those intervening decades.
I don't like the characterization "your aim is not to design ethical/friendly/aligned AI", because it's picking an arbitrary cut-off for which parts of the plan count as my "aim", and because it makes it sound like I'm trying to build unethical, unfriendly, unaligned AI instead. Rather, I think alignment is hard and we need a lot of time (including a lot of time with functioning AGIs) to have a hope of solving the maximal version of the problem. Which inherently requires humanity to do something about that dangerous "we can build AGI but not CEV-align it" time window.
I don't think the best solution to that problem is for the field to throw up their hands and say "we're scientists, it's not our job to think about practicalities like that" and hope someone else takes care of it. We're human beings, not science-bots; we should use our human intelligence to think about which course of action is likeliest to produce good outcomes, and do that.
[...] I have a different optimistic scenario: We definitively figure out the theory of how to implement CEV before AGI even arises, and then spread that knowledge widely, so that whoever it is in the world that first achieves AGI, they will already know what they should do with it. [...]
How long are your AGI timelines? I could imagine endorsing a plan like that if I were confident AGI is 200+ years away; but in fact I think it's very unlikely to even be 100 years away, and my probability is mostly on scenarios like "it's 8 years away" or "it's 25 years away".
I do agree that we're likelier to see better outcomes if alignment knowledge is widespread, rather than being concentrated at a few big orgs. (All else equal, anyway. E.g., you might not want to do this if it somehow shortens timelines a bunch.)
But the kind of alignment knowledge I think matters here is primarily strawberry-grade alignment. It's good if people widely know about things like CEV, but I wouldn't advise a researcher to spend their 2022 working on advancing abstract CEV theory instead of advancing strawberry-grade alignment, if they're equally interested in both problems and capable of working on either.
[...] To put it another way: Your optimistic scenario is one in which the organization that first achieves AGI uses it to take over the world, install a benevolent interim regime that monopolizes access to AGI without itself making a deadly mistake, and which then eventually figures out how to implement CEV (for example); and then it's finally safe to have autonomous AGI. [...]
Talking about "taking over the world" strikes me as inviting a worst-argument-in-the-world [LW · GW] style of reasoning. All the past examples of "taking over the world" weren't cases where there's some action A such that:
- if no one does A, then all humans die and the future's entire value is lost.
- by comparison, it doesn't matter much to anyone who does A; everyone stands to personally gain or lose a lot based on whether A is done, but they accrue similar value regardless of which actor does A. (Because there are vastly more than enough resources in the universe for everyone. The notion that this is a zero-sum conflict to grab a scarce pot of gold is calibrated to a very different world than the "ASI exists" world.)
- doing A doesn't necessarily mean that your idiosyncratic values will play a larger role in shaping the long-term future than anyone else's, and in fact you're bought into a specific plan aimed at preventing this outcome. (Because CEV, no-pot-of-gold, etc.)
I do think there are serious risks and moral hazards associated with a transition to that state of affairs. (I think this regardless of whether it's a government or a private actor or an intergovernmental collaboration or whatever that's running the task AGI.)
But I think it's better for humanity to try to tackle those risks and moral hazards, than for humanity to just give up and die? And I haven't heard a plausible-sounding plan for what humanity ought to do instead of addressing AGI proliferation somehow.
[...] you're saying your aim is to design AI that can take over the world without killing anyone. Then once that is accomplished, you'll settle down to figure out how that unlimited power would best be used. [...]
The 'rush straight to CEV' plan is exactly the same, except without the "settling down to figure out" part. Rushing straight to CEV isn't doing any less 'grabbing the world's steering wheel'; it's just taking less time to figure out which direction to go, before setting off.
This is the other reason it's misleading to push on "taking over the world" noncentral fallacies here. Neither the rush-to-CEV plan nor the strawberries-followed-by-CEV plan is very much like people's central prototypes for what "taking over the world" looks like (derived from the history of warfare or from Hollywood movies or what-have-you).
I'm tempted to point out that "rush-to-CEV" is more like "taking over the world" in many ways than "strawberries-followed-by-CEV" is. (Especially if "strawberries-followed-by-CEV" includes a step where the task-AGI operators engage in real, protracted debate and scholarly inquiry with the rest of the world to attempt to reach some level of consensus about whether CEV is a good idea, which version of CEV is best, etc.)
But IMO it makes more sense to just not go down the road of arguing about connotations, given that our language and intuitions aren't calibrated to this totally-novel situation.
The first one says that flawed humans can directly wield superintelligence for a protracted period without screwing things up. The second one says that flawed humans can fully figure out how to safely wield superintelligence before it even arrives.
There's clearly some length of time such that the cost of waiting that long to implement CEV outweighs the benefits. I think those are mostly costs of losing negentropy in the universe at large, though (as stars burn their fuel and/or move away from us via expansion), not costs like 'the AGI operators get corrupted or make some major irreversible misstep because they waited an extra five years too long'.
I don't know why you think the corruption/misstep risk of "waiting for an extra three years before running CEV" (for example) is larger than the 'we might implement CEV wrong' risk of rushing to implement CEV after zero years of tinkering with working AGI systems.
It seems like the sensible thing to do in this situation is to hope for the best, but plan for realistic outcomes that fall short of "the best":
- Realistically, there's a strong chance (I would say: overwhelmingly strong) that we won't be able to fully solve CEV before AGI arrives. So since our options in that case will be "strawberry-grade alignment, or just roll over and die", let's start by working on strawberry-grade alignment. Once we solve that problem, sure, we can shift resources into CEV. If you're optimistic about 'rush to CEV', then IMO you should be even more optimistic that we can nail down strawberry alignment fast, at which point we should have made a lot of headway toward CEV alignment without gambling the whole future on our getting alignment perfect immediately and on the first try.
- Likewise, realistically, there's a strong chance (I would say overwhelming) that there will be some multi-year period where humanity can build AGI, but isn't yet able to maximally align it. It would be good if we don't just roll over and die in those worlds; so while we might hope for there to be no such period, we should make plans that are robust to such a period occurring.
There's nothing about the strawberry plan that requires waiting, if it's not net-beneficial to do so. You can in fact execute a 'no one else can destroy the world with AGI' pivotal act, start working on CEV, and then surprise yourself with how fast CEV falls into place and just go implement that in relatively short order.
What strawberry-ish actions do is give humanity the option of waiting. I think we'll desperately need this option, but even if you disagree, I don't think you should consider it net-negative to have the option available in the first place.
Meanwhile, in reality, we've already proceeded an unknown distance up the curve towards superintelligence, but none of the organizations leading the way has much of a plan for what happens, if their creations escape their control.
I agree with this.
In this situation, I say that people whose aim is to create ethical/friendly/aligned superintelligence, should focus on solving that problem. Leave the techno-military strategizing to the national security elites of the world. It's not a topic that you can avoid completely, but in the end it's not your job to figure out how mere humans can safely and humanely wield superhuman power. It's your job to design an autonomous superhuman power that is intrinsically safe and humane.
This is the place where I say: "I don't think the best solution to that problem is for the field to throw up their hands and say 'we're scientists, it's not our job to think about practicalities like that' and hope someone else takes care of it. We're human beings, not science-bots; we should use our human intelligence to think about which course of action is likeliest to produce good outcomes, and do that."
We aren't helpless victims of our social roles, who must look at Research Path A and Research Path B and go, "Hmm, there's a strategic consideration that says Path A is much more likely to save humanity than Path B... but thinking about practical strategic considerations is the kind of thing people wearing military uniforms do, not the kind of thing people wearing lab coats do." You don't have to do the non-world-saving thing just because it feels more normal or expected-of-your-role. You can actually just do the thing that makes sense.
(Again, maybe you disagree with me about what makes sense to do here. But the debate should be had at the level of 'which factual beliefs suggest that A versus B is likeliest to produce a flourishing long-run future?', not at the level of 'is it improper for scientists to update on information that sounds more geopolitics-y than linear-algebra-y?'. The real world doesn't care about literary genres and roles; it's all just facts, and disregarding a big slice of the world's facts will tend to produce worse decisions.)
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2022-06-03T10:24:40.301Z · LW(p) · GW(p)
How long are your AGI timelines?
Very short. Longer timelines are logically possible, but I wouldn't count on them.
As for this notion that something like CEV might require decades of thought to be figured out, or even might require decades of trial and error with AGI - that's just a guess. I may be monotonous by saying June Ku over and over again (there are others whose work I intend to study too), but metaethical.ai is an extremely promising schema. If a serious effort was made to fill out that schema, while also critically but constructively examining its assumptions from all directions, who knows how far we'd get, and how quickly?
Another argument for shorter CEV timelines, is that AI itself may help complete the theory of CEV alignment. Along with the traditional powers of computation - calculation, optimization, deduction, etc - language models, despite their highly uneven output, are giving us a glimpse of what it will be like, to have AI contributing even to discussions like this. That day isn't far off at all.
So from my perspective, long CEV timelines don't actually seem likely. The other thing that I have great doubts about, is the stability of any world order in which a handful of humans - even if it were the NSA or the UN Security Council - use tool AGI to prevent everyone else from developing unsafe AGI. Targeting just one thing like GPUs won't work forever because you can do computation in other ways; there will be great temptations to use tool AGI to carry out interventions that have nothing to do with stopping unsafe AGI... Anyone in such a position becomes a kind of world government.
The problem of "world government" or "what the fate of the world should be", is something that CEV is meant to solve comprehensively, by providing an accurate first-principles extrapolation of humanity's true volition, etc. But here, the scenario is an AGI-powered world takeover where the problems of governance and normativity have not been figured out. I'm not at all opposed to thinking about such scenarios; the next chapter of human affairs may indeed be one in which autonomous superhuman AI does not yet exist, but there are human elites possessing tool AGI. I just think that's a highly unstable situation; making it stable and safe for humans would be hard to do without having something like CEV figured out; and because of the input of AI itself, one shouldn't expect figuring out CEV to take a long time. I propose that it will be done relatively quickly, or not at all.
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2022-06-03T17:50:42.256Z · LW(p) · GW(p)
Another argument for shorter CEV timelines, is that AI itself may help complete the theory of CEV alignment.
I agree [LW · GW] with this part. That's why I've been saying 'maybe we can do this in a few subjective decades or centuries' rather than 'maybe we can do this in a few subjective millennia.' 🙂
But I'm mostly imagining AGI helping us get CEV theory faster. Which obviously requires a lot of prior alignment just to make use of the AGI safely, and to trust its outputs.
The idea is to keep ratcheting up alignment so we can safely make use of more capabilities -- and then, in at least some cases, using those new capabilities to further improve and accelerate our next ratcheting-up of alignment.
Along with the traditional powers of computation - calculation, optimization, deduction, etc - language models, despite their highly uneven output, are giving us a glimpse of what it will be like, to have AI contributing even to discussions like this. That day isn't far off at all.
... And that makes you feel optimistic about the rush-to-CEV option? 'Unaligned AGIs or proto-AGIs generating plausble-sounding arguments about how to do CEV' is not a scenario that makes me update toward humanity surviving.
there will be great temptations to use tool AGI to carry out interventions that have nothing to do with stopping unsafe AGI...
I share your pessimism about any group that would feel inclined to give in to those temptations, when the entire future light cone is at stake.
The scenario where we narrowly avoid paperclips by the skin of our teeth, and now have a chance to breathe and think things through before taking any major action, is indeed a fragile one in some respects, where there are many ways to rapidly destroy all of the future's value by overextending. (E.g., using more AGI capabilities than you can currently align, or locking in contemporary human values that shouldn't be locked in, or hastily picking the wrong theory or implementation of 'how to do moral progress'.)
I don't think we necessarily disagree about anything except 'how hard is CEV'? It sounds to me like we'd mostly have the same intuitions conditional on 'CEV is very hard'; but I take this very much for granted, so I'm freely focusing my attention on 'OK, how could we make things go well given that fact?'.
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2022-06-05T02:24:44.521Z · LW(p) · GW(p)
I don't think we necessarily disagree about anything except 'how hard is CEV'? It sounds to me like we'd mostly have the same intuitions conditional on 'CEV is very hard'
I disagree on the plausibility of a stop-the-world scheme. The way things are now is as safe or stable as they will ever be. I think it's a better plan to use the rising tide of AI capabilities to flesh out CEV. In particular, since the details of CEV depend on not-yet-understood details of human cognition, one should think about how to use near-future AI power to extract those details from the available data regarding brains and behavior. But AI can contribute everywhere else in the development of CEV theory and practice too.
But I won't try to change your thinking. In practice, MIRI's work on simpler forms of alignment (and its work on logical induction, decision theory paradigms, etc) is surely relevant to a "CEV now" approach too. What I am wondering is, where is the de-facto center of gravity for a "CEV now" effort? I've said many times that June Ku's blueprint is the best I've seen, but I don't see anyone working to refine it. And there are other people whose work seems relevant and has a promising rigor, but I'm not sure how it best fits together.
edit: I do see a value to non-CEV alignment work, distinct from figuring out how to stop the world safely: and that is to reduce the risk arising from the general usage of advanced AI systems. So it is a contribution to AI safety.
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2022-06-02T20:39:21.714Z · LW(p) · GW(p)
CEV seems much much more difficult than strawberry alignment and I have written it off as a potential option for a baby's first try at constructing superintelligence.
To be clear, I also expect that strawberry alignment is too hard for these babies and we'll just die. But things can always be even more difficult, and with targeting CEV on a first try, it sure would be.
There's zero room, there is negative room, to give away to luxury targets like CEV. They're not even going to be able to do strawberry alignment, and if by some miracle we were able to do strawberry alignment and so humanity survived, that miracle would not suffice to get CEV right on the first try.
↑ comment by M. Y. Zuo · 2022-06-02T20:55:05.668Z · LW(p) · GW(p)
I highly doubt anything in this universe could be ‘intrinsically’ safe and humane. I’m not sure what such an object would even look like or how we could verify that.
Even purposefully designed safety systems for deep pocketed customers for very simple operations in a completely controlled environment, such as car manufacturer’s assembly lines with a robot arm assigned solely to tightening nuts, have safety systems that are not presumed to be 100% safe in any case. That’s why they have multiple layers of interlocks, panic buttons, etc.
And that’s for something millions of times simpler than a superhuman agi in ideal conditions.
Perhaps before even the strawberry, it would be interesting to consider the difficulty of the movable arm itself.
↑ comment by Vladimir_Nesov · 2022-06-02T16:56:34.674Z · LW(p) · GW(p)
A useful distinction. Yet of the rare outcomes that follow current timelines without ending in ruin, I expect the most likely one falls into neither category. Instead it's an AGI that behaves like a weird supersmart human that bootstrapped its humanity from language models with relatively little architecture support (for alignment), as a result of a theoretical miracle where things like that are the default outcome. Possibly from giving a language model autonomy/agency to debug its thinking while having notebooks and a working memory, tuning the model in the process. It's not going to reliably do as it's told, could be deceptive, yet possibly doesn't turn everything into paperclips. Arguably it's aligned, but only the way weird individual humans are aligned, which is noncentrally strawberry-aligned, and too-indirectly-to-use-the-term CEV-aligned.
↑ comment by Yitz (yitz) · 2022-05-31T17:04:24.994Z · LW(p) · GW(p)
Awesome! Looking forward to seeing what y'all come out with :)
↑ comment by CronoDAS · 2022-05-31T18:52:52.409Z · LW(p) · GW(p)
I'm fairly allergic to secrecy. Having to keep things secret is a good way to end up with groupthink and echo chamber effects, and every additional person who knows and understands what you're doing is another person that can potentially tell you if you're about to do something stupid. I understand that sometimes it's necessary but it generally makes things harder.
↑ comment by Gunnar_Zarncke · 2023-12-05T23:38:53.142Z · LW(p) · GW(p)
Is there an updated version or will there be one? Or is there an alternative approach to address these? What is the relation to responsible scaling policies, such as Anthropic's?
https://www-files.anthropic.com/production/files/responsible-scaling-policy-1.0.pdf
comment by lc · 2022-05-30T19:30:26.692Z · LW(p) · GW(p)
I expect e.g. the NSA would have this level of "resources" if they started playing now but didn't grow any further.
I do not expect at all that the NSA would be able to operate at the "improving" stage in capabilities as described. People on Lesswrong have this habit of forgetting everything they know about government bureaucracies when it comes to the Intelligence Agencies, like they could just put on hold their primary function of spying on each other and then do general science and technology as well as Facebook.
The NSA operates "well" now because their worker bees get clear tasks like "develop an 0day for this brand of router", for which success is highly apparent to even nontechnical, unintelligent people. It's very obvious and embarrassing when those personnel are not able to tap a phone line, or get network visibility in some Chinese telecom company. On the other hand, I barely know how to use pytorch, but I could probably bullshit my flailing as groundbreaking research to NSA leadership all damn day.
Replies from: TrevorWiesinger, yonatan-cale-1↑ comment by trevor (TrevorWiesinger) · 2022-05-30T23:35:41.457Z · LW(p) · GW(p)
It would be a lot harder to bullshit to NSA leadership all day if, say, they were to oversee the invention of a really good lie detector, and then use their broad authority to hoard technology like that.
Which, in addition to everything previously mentioned, is exactly the kind of thing that the NSA is built to do every day. In fact, the lie detector example would actually be even easier than putting uncompromised zero days in a particular brand of router, since that would be a very large, diverse, thin-spread system that probably has a ton of Chinese zero-days in the microchips, whereas a lie detector technology can easily be vetted (in realistic high-stakes environments that are actually real) as part of the everyday internal operations of the NSA leadership.
Replies from: lc↑ comment by lc · 2022-05-30T23:49:20.842Z · LW(p) · GW(p)
The NSA has never done anything remotely close to engineering a truly working lie detector, ever. Also:
In fact, the lie detector example would actually be even easier than putting uncompromised zero days in a particular brand of router, since that would be a very large, diverse, thin-spread system that probably has a ton of Chinese zero-days in the microchips, whereas a lie detector technology can easily be vetted in high-stakes environments as part of the everyday internal operations of the NSA leadership.
I'm not sure what you mean by the Chinese zero day thing. And I said develop a 0-day, not plant one. As far as I am aware, the NSA actually happens to be pretty bad at, and unethusiastic about, what I think you mean by the latter thing. Go figure.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-31T01:06:22.069Z · LW(p) · GW(p)
- I said oversee, not engineer it themselves. If they have in-house programs developing lie detection technology themselves, I know nothing about that; but assuming that lie prediction technology is being improved upon anywhere, then the NSA is probably aware of it and the first government agency in line to take advantage of the latest generation of that kind of tech (maybe second or third, etc).
- Basically everything I know about zero days comes from Chinese zero days. And it seems to me that if a Zero Day was developed in the US, it would be developed with planting in mind, because routers are fabricated and assembled in Asian countries with their own intelligence agencies and their own guiding principles of planting zero days on hardware.
- My understanding about what the NSA is and isn't enthusiastic about might be nearly a decade out of date, if it was ever accurate at all.
↑ comment by lc · 2022-05-31T01:35:21.056Z · LW(p) · GW(p)
So, zero day exploits are generally nonrivalrous; one agency can find one way to run code remotely on a device and another agency in a different country can find a different flaw or even the same flaw, and they're not conflicting scenarios. "Planting" bugs as the software or hardware product is being developed is an avenue to accomplish that, but it's unnecessary, especially for items like routers. I have several friends who do this exact type of work developing zero days for a private military contractor instead of the government. They're handed a piece of equipment, they find bugs, they develop a plug-and-play weaponization for someone else in the military-industial complex, rinse, repeat; there's no need to bribe anyone or do some sort of infiltration of the vendor themselves. When the NSA does the same thing in-house it's very similar. Injecting bugs during software development of a product is risky for multiple reasons, and if the vendor is American it could be illegal, even if the NSA is doing it.
Otherwise I'm kind of confused as to what we're talking about anymore.
↑ comment by Yonatan Cale (yonatan-cale-1) · 2022-06-24T20:29:36.566Z · LW(p) · GW(p)
If this question becomes important, there are people in our community who are.. domain experts. We can ask
comment by Raemon · 2022-06-17T18:35:47.418Z · LW(p) · GW(p)
Curated. My sense is there is no existing AI company with adequate infrastructure for safely deploying AGI, and this is a pretty big deal. I like this writeup for laying out a bunch of considerations.
A few times in this article, Eliezer notes "it'd be great if we could get X, but, the process of trying to get X would cause some bad consequences." I'd like to see further exploration/models of, "given the state of the current world, which approaches are actually tractable.
comment by Thomas Kwa (thomas-kwa) · 2022-06-05T00:56:34.445Z · LW(p) · GW(p)
This is very helpful and gives me substantially more of the MIRI strategic picture. If there are any further documents on the same order of importance, it seems pretty important to release them in order to isolate cruxes between MIRI and more optimistic perspectives.
comment by Ofer (ofer) · 2022-05-31T04:37:36.728Z · LW(p) · GW(p)
Even with adequate closure and excellent opsec, there can still be risks related to researchers on the team quitting and then joining a competing effort or starting their own AGI company (and leveraging what they've learned).
comment by lc · 2022-05-30T18:47:45.832Z · LW(p) · GW(p)
We need to talk about fifty-five.
Replies from: P.↑ comment by P. · 2022-05-31T15:46:57.603Z · LW(p) · GW(p)
Spoiler Warning. Tried hiding it with >! and :::spoiler but neither seems to work.
For those unaware, this is a story (worth reading) about anti-memes, ideas that cannot be spread, so researchers have a hard time working with them, not knowing they exist. So the point of the parent comment probably is that even if an adequate AGI project existed we wouldn’t know about it.
↑ comment by Rob Bensinger (RobbBB) · 2022-05-31T21:17:07.275Z · LW(p) · GW(p)
I don't think any AGI projects that exist today are anywhere near adequacy on all of these dimensions.
(And I don't think we live in the sort of world where there could plausibly be a secret-to-me adequate project, right now in 2022.)
I could imagine optimistic worlds where an adequate project exists in the future but I or others publicly glomarize about whether it's adequate (e.g., because we don't want to publicly talk about the state of the project's opsec or something)? Mostly, though, I think we'd want to loudly and clearly broadcast 'this is the Good Project, the Schelling AGI project to put your resources into if you put your resources into any AGI project', because part of the point is to facilitate coordination. And my current personal guess is that 'is this adequate?' would be useful public information in most worlds where an adequate project like that existed. In a sense this is really basic stuff, and should be more like 'first-order-obvious boxes to check'.
Replies from: lc↑ comment by lc · 2022-06-01T02:35:28.998Z · LW(p) · GW(p)
I don't think the SCP foundation actually exists. "We need to talk about fifty-five" is just a very well written, fictional story about a team of scientists trying to pacify "doomsday technology" within that universe that I think people here would enjoy reading. I also agree with you that everything you said is obviously true, and I probably mistakenly implied something really dumb by commenting that here without context.
Replies from: Benito, RobbBB↑ comment by Ben Pace (Benito) · 2022-06-01T02:41:44.794Z · LW(p) · GW(p)
I don't think the SCP foundation actually exists
I haven't read OP or know the context, but it was very enjoyable when skimming Recent Discussion to see someone feel the need to make this disclaimer.
↑ comment by Rob Bensinger (RobbBB) · 2022-06-01T03:22:13.982Z · LW(p) · GW(p)
FWIW I enjoyed the story when you posted it, and didn't assume you were trying to make a specific new point with it. :)
comment by Raemon · 2022-05-30T17:57:13.892Z · LW(p) · GW(p)
government-security-clearance-style screening
What does that actually involve?
Replies from: lc↑ comment by lc · 2022-05-30T19:11:27.451Z · LW(p) · GW(p)
If it's anything like real government clearances, lots of paperwork, interviews of friends/family, polygraphs (which contrary to popular belief do get some people), simple analysis of travel records, etc. etc. etc. They tend to be less about detecting past "bad behavior" than detecting lies about bad behavior, which imply you might be lying about the other things.
Honestly we could do better.
Replies from: Raemon↑ comment by Raemon · 2022-05-30T19:30:10.935Z · LW(p) · GW(p)
I ask because neither the Closure nor Ops-Sec section talk much about how to actually teach and/or vet the skill of confidentiality [LW · GW], and I wasn't sure if government-security-clearance-style-screening actually included that.
Replies from: lc↑ comment by lc · 2022-05-30T19:36:33.768Z · LW(p) · GW(p)
I'm afraid the clearances themselves won't be much help for vetting something like that. Their biggest job is to filter against people likeliest to become deliberate spies. Mostly they do that by performing the much easier job of making sure someone isn't thrill-seeking, is risk-intolerant, and is unlikely to break rules in general.
But teaching the skill of confidentiality can be done; governments have been doing that job passably for decades. You can even test it effectively every once in a while by red-teaming your own guys. Tell Paul from section A he'll get a bonus if he can get someone from section B to give him information that should be siloed there. Then see if section B manages to report Paul's suspicious questions (yay!), if Paul fails but isn't detected (meh), or if Paul actually succeeds at getting someone to reveal something confidential (oh no).
Replies from: Raemoncomment by lc · 2023-12-05T04:50:56.228Z · LW(p) · GW(p)
This post was actually quite elightening, and felt more immediately helpful for me in understanding the AI X-risk case than any other single document. I think that's because while other articles on AI risk can seem kind of abstract, this one considers concretely what kind of organization would be required for navigating around alignment issues, in the mildly inconvenient world where alignment is not solved without some deliberate effort, which put me firmly into near-mode.
comment by Raemon · 2022-05-30T17:44:22.701Z · LW(p) · GW(p)
If e.g. the government of Iceland suddenly understood how serious things had gotten and granted sanction and security to a project, that would fit this description, but I think that trying to arrange anything like this would probably make things worse globally because of the mindset it promoted.
I think I have an reasonable guess, but interested in more details about what goes wrong here and what mindset it promotes. (i.e. governments generally trying to regulate AI whether or not they understand how to do so, and then getting both random-ineffective regulations and rent capture and stuff?)
comment by Nicholas / Heather Kross (NicholasKross) · 2023-04-28T01:12:04.814Z · LW(p) · GW(p)
The lack of clear person-independent instructions for how somebody low in [alignment mindset / security mindset] can improve along this dimension is why the difficulty of this dimension is the real killer.
Cause area idea: finding ways to make everyone more paranoid spread security mindset to a high % of AI capabilities people.